
2
Data Management and Transfer
In Chapter 1, High-Performance Computing Fundamentals, we introduced the concepts of HPC applications, why we need HPC, and its use cases across different industries. Before we begin developing HPC applications, we need to migrate the required data into the cloud. In this chapter, we will uncover some of the challenges in managing and transferring data to the cloud and the ways to mitigate them. We will dive deeper into the services in AWS online and offline data transfer services using which you can securely transfer data to the AWS cloud, while maintaining data integrity and consistency. We will cover different data transfer scenarios and provide guidance on how to select the right service for each one.
We will cover the following topics in this chapter:
- Importance of data management
- Challenges of moving data into the cloud
- How to securely transfer large amounts of data into the cloud
- AWS online data transfer services
- AWS offline data transfer services
These topics will help you understand how you can transfer Gigabytes (GB), Terabytes (TB), or Petabytes (PB) of data onto the cloud with minimal disruption, cost, and time involved.
Let’s get started with data management and its role in HPC applications.
Importance of data management
Data management is the process of effectively capturing, storing, and collating data created by different applications in your company to make sure it’s accurate, consistent, and available when needed. It includes developing policies and procedures for managing your end-to-end data life cycle. The following are some of the elements of the data life cycle specific to HPC applications, due to which it’s important to have data management policies in place:
- Cleaning and transforming raw data to perform detailed faultless analysis.
- Designing and building data pipelines to automatically transfer data from one system to another.
- Extracting, Transforming, and Loading (ETL) data into appropriate data storage systems such as databases, data warehouses, and object storage or filesystems from disparate data sources.
- Building data catalogs for storing metadata to make it easier to find and track the data lineage.
- Following policies and procedures as outlined by your data governance model. This also involves conforming to the compliance requirements of the federal and regional authorities of the country where data is being captured and stored. For example, if you are a healthcare organization in California, United States, you would need to follow both federal and state data privacy laws, including the Health Insurance Portability and Accountability Act (HIPAA) and California’s health data privacy law, the Confidentiality of Medical Information Act (CMIA). Additionally, you would also need to follow the California Consumer Privacy Act (CCPA), which came into effect starting January 1, 2020, as it relates to healthcare data. If you are in Europe, you would have to follow the data guidelines governed by the European Union’s General Data Protection Regulation (GDPR).
- Protecting your data from unauthorized access, while at rest or in transit.
Now that we have understood the significance of data management in HPC applications, let’s see some of the challenges of transferring large amounts of data into the cloud.
Challenges of moving data into the cloud
In order to start building HPC applications on the cloud, you need to have data on the cloud, and also think about the various elements of your data life cycle in order to be able to manage data effectively. One way is to write custom code for transferring data, which will be time-consuming and might involve the following challenges:
- Preserving the permissions and metadata of files.
- Making sure that data transfer does not impact other existing applications in terms of performance, availability, and scalability, especially in the case of online data transfer (transferring data over the network).
- Scheduling data transfer for non-business hours to ensure other applications are not impeded.
- In terms of structured data, you might have to think about schema conversion and database migration.
- Maintaining data integrity and validating the transfer.
- Monitoring the status of the data transfer, having the ability to look up the history of previous transfers, and having a retry mechanism in place to ensure successful transfers.
- Making sure there are no duplicates – once the data has been transferred, the system should not trigger the transfer again.
- Protecting data during the transfer, which will include encrypting data both in transit and at rest.
- Ensuring data arrives intact and is not corrupted. You would need a mechanism to check that the data arriving at the destination matches the data read from the source to validate data consistency.
- Last but not least, you would have to manage, version-control, and optimize your data-copying scripts.
The data transfer and migration services offered by AWS can assist you in securely transferring data to the cloud without you having to write and manage code, helping you overcome these aforementioned challenges. In order to select the right service based on your business requirement, you first need to build a data transfer strategy. We will discuss the AWS data transfer services in a subsequent section of this chapter. Let’s first understand the items that you need to consider while building your strategy.
In a nutshell, your data transfer strategy needs to take the following into account in order to move data with minimal disruption, time, and cost:
- What kind of data do you need for developing your HPC application – for example, structured data, unstructured data (such as images and PDF documents), or a combination of both?
- For unstructured data, which filesystem do you use for storing your files currently? Is it on Network Attached Storage (NAS) or Storage Area Network (SAN)?
- How much purchased storage is available right now, and for how long will it last based on the rate of growth of your data, before you plan to buy more storage?
- For structured data, which database do you use?
- Are you tied up in database licenses? If yes, when are they due for renewal, and what are the costs of the licenses?
- What is the volume of data that you need to transfer to the cloud?
- What are the other applications that are using this data?
- Do these applications require local access to data? Will there be any performance impact on the existing applications if the data is moved to the cloud?
- What is your network bandwidth? Is it good enough to transfer data over the network?
- How quickly do you need to move your data to the cloud?
Based on the answers to these questions, you can create your data strategy and select appropriate AWS services that will help you to transfer data with ease and mitigate the challenges mentioned in the preceding list. To understand it better, let’s move to the next topic and see how to securely transfer large amounts of data into the cloud with a simple example.
How to securely transfer large amounts of data into the cloud
To understand this topic, let’s start with a simple example where you want to build and train a computer vision deep learning model to detect product defects in your manufacturing production line. You have cameras installed on each production line, which capture hundreds of images each day. Each image can be up to 5 MB in size, and you have about 1 TB of data, which is currently stored on-premises in a NAS filesystem that you want to use to train your machine learning model. You have about 1 Gbps of network bandwidth and need to start training your model in 2-4 weeks. There is no impact on other applications if the data is moved to the cloud and no structured data is needed for building the computer vision model. Let’s rearrange this information into the following structure, which will become part of your data strategy document:
- Objective: To transfer 1 TB of image data to the cloud, where the file size can be up to 5 MB. Need to automate the data transfer to copy about 10 GB of images every night to the cloud. Additionally, need to preserve the metadata and file permissions while copying data to the cloud.
- Timeline: 2-4 weeks
- Data type: Unstructured data – JPG or PNG format image files
- Dependency: None
- Impact on existing applications: None
- Network bandwidth: 1 Gbps
- Existing storage type: Network attached storage
- Purpose of data transfer: To perform distributed training on a computer vision deep learning model using multiple GPUs
- Data destination: Amazon S3, which is secure, durable, and the most cost-effective object storage on AWS for storing large amounts of data
- Sensitive data: None, but data should not be available for public access
- Local data access: Not required
Since you have 5 TB of data with a maximum file size of 5 MB to transfer securely to Amazon S3, you can use the AWS DataSync service. It is an AWS online data transfer service to migrate data securely using a Virtual Private Cloud (VPC) endpoint to avoid your data going through the open internet. We will discuss all the AWS data transfer services in detail in the later sections of this chapter.
The following architecture visually depicts how the transfer will take place:

Figure 2.1 – Data transfer using AWS DataSync with a VPC endpoint
The AWS DataSync agent transfers the data between your local storage, NAS in this case, and AWS. You deploy the agent in a Virtual Machine (VM) in your on-premises network, where your data source resides. With this approach, you can minimize the network overhead while transferring data using the Network File System (NFS) and Server Message Block (SMB) protocols.
Let’s take a deeper look into AWS DataSync in the next section.
AWS online data transfer services
Online data transfer services are out-of-the-box solutions built by AWS for transferring data between on-premises systems and the AWS cloud via the internet. They include the following services:
- AWS DataSync
- AWS Transfer Family
- Amazon S3 Transfer Acceleration
- Amazon Kinesis
- AWS Snowcone
Let’s look at each of these services in detail to understand the scenarios in which we can use the relevant services.
AWS DataSync
AWS DataSync helps you overcome the challenges of transferring data from on-premises to AWS storage services and between AWS storage services in a fast and secure fashion. It also enables you to automate or schedule the data transfer to optimize your use of network bandwidth, which might be shared with other applications. You can monitor the data transfer task, add data integrity checks to make sure that the data transfer was successful, and validate that data was not corrupted during the transfer, while preserving the file permissions and associated metadata. DataSync offers integration with multiple filesystems and enables you to transfer data between the following resources:
- On-premises file servers and object storage:
- AWS storage services:
- Snow Family Devices
- Amazon Simple Storage Service (Amazon S3) buckets
- Amazon Elastic File System (EFS)
- Amazon FSx for Windows File Server
- Amazon FSx for Lustre filesystems
Important note
We will discuss AWS storage services in detail in Chapter 4, Data Storage.
Use cases
As discussed, AWS DataSync is used for transferring data to the cloud over the network. Let’s now see some of the specific use cases for which you can use DataSync:
- Hybrid cloud workloads, where data is generated by on-premises applications and needs to be moved to and from the AWS cloud for processing. This can include HPC applications in healthcare, manufacturing, life sciences, big data analytics in financial services, and research purposes.
- Migrate data rapidly over the network into AWS storage services such as Amazon S3, where you need to make sure that data arrives securely and completely. DataSync has encryption and data integrity during transfer enabled by default. You can also choose to enable additional data verification checks to compare the source and destination data.
- Data archiving, where you want to archive the infrequently accessed data (cold data) directly into durable and long-term storage in the AWS cloud, such as Amazon S3 Glacier or S3 Glacier Deep Archive. This helps you to free up your on-premises storage capacity and reduce costs.
- Scheduling a data transfer job to automatically start on a recurring basis at a particular time of the day to optimize network bandwidth usage, which might be shared with other applications. For example, in the life sciences domain, you may want to upload genomic data generated by on-premises applications for processing and training machine learning models on a daily basis. You can both schedule data transfer tasks and monitor them as required using DataSync.
Workings of AWS DataSync
We will use an architecture diagram to show how DataSync can transfer data between on-premises self-managed storage systems to AWS storage services and between AWS storage resources.
We will start with on-premises storage to AWS storage services.
Data transfer from on-premises to AWS storage services
The architecture in Figure 2.2 depicts the data transfer from on-premises to AWS storage resources:

Figure 2.2 – Data transfer from on-premises to AWS storage services using AWS DataSync
The DataSync agent is a VM that reads from and writes the data to the on-premises storage. You can configure and activate your agent using the DataSync console or API. This process associates your agent with your AWS account. Once the agent is activated, you can create the data transfer task from the console or API to kick start the data transfer. DataSync encrypts and performs a data integrity check during transfer to make sure that data is transferred securely. You can enable additional checks as well to verify the data copied to the destination is the same as that read at the source. Additionally, you can also monitor your data transfer task. The time that DataSync takes to transfer depends on your network bandwidth, the amount of data, and the network traffic. However, a single data transfer task is capable of utilizing a 10-Gbps network link.
Data transfer between AWS storage resources
Let’s take a deeper look to understand the data transfer between AWS storage resources using AWS DataSync.
The architecture in Figure 2.3 depicts the data transfer between AWS storage resources using DataSync in the same AWS account. The same architecture applies for data transfers within the same region as well as cross-region:

Figure 2.3 – Data transfer between AWS storage resources using AWS DataSync
As shown in the architecture, DataSync does not use the agent for transferring data between AWS resources in the same account. However, if you want to transfer data between different AWS accounts, then you need to set up and activate the DataSync Amazon EC2 agent in an AWS Region.
In summary, you can use AWS DataSync for online data transfer from on-premises to AWS storage services, and between AWS storage resources. AWS DataSync transfers data quickly, safely, and in a cost-effective manner while ensuring data integrity and consistency, without the need to write and manage data-copy scripts.
Now, let’s move on to another AWS data transfer service, AWS Transfer Family, which is used for scaling your recurring business-to-business file transfers to Amazon S3 and Amazon EFS.
AWS Transfer Family
File transfer protocols such as File Transfer Protocol (FTP), Secure File Transfer Protocol (SFTP), and File Transfer Protocol Secure (FTPS) are commonly used in business-to-business data exchange workflows across different industries including financial services, healthcare, manufacturing, and retail. AWS Transfer Family helps in scaling and migrating these file workflows to the AWS cloud. It uses the FTP, SFTP, and FTPS protocols for data transfer. It enables you to transfer files to and from Amazon EFS and Amazon S3.
Use cases
As discussed, AWS Transfer Family uses protocols such as FTP, SFTP, and FTPS for data exchange workflows in business-to-business contexts. So, let’s understand some of the common use cases for transferring data to and from Amazon S3 and Amazon EFS using AWS Transfer Family:
- Securely transfer files internally within your organization or with third-party vendors. Some industries, including financial services, life sciences, and healthcare, have to make sure to have a secure file transfer workflow in place due to the sensitive nature of the data and to comply with regulations such as Payment Card Industry Data Security Standard (PCI DSS), HIPPA, or GDPR, depending on their location.
- To distribute subscription-based content to your customers. For example, BluTV is a famous subscription-based video-on-demand service in Turkey, which is available globally and caters to Turkish and Arabic speaking viewers. Previously, they self-managed their SFTP setup on the cloud, and ran into a lot of problems such as managing open source projects for mounting S3 to Amazon EC2 and scaling issues when additional resources were required. After moving their setup to the fully managed AWS Transfer Family for SFTP, they no longer have to monitor their file transfers, manage open source projects, or pay for unused resources.
- For building a central repository of data (also known as a data lake) on AWS for storing both structured and unstructured data coming from disparate data sources and third parties such as vendors or partners. For example, FINRA, a government-authorized non-profit organization that oversees US stockbrokers, has a data lake on Amazon S3 as its central source of data. FINRA uses the AWS Transfer Family for SFTP service to alleviate operational overheads while maintaining a connection to their existing authentication systems for external users to avoid any disruption while migrating their SFTP services to AWS.
Now that we have gone over some of the use cases for AWS Transfer Family, let’s see how it works.
Workings of AWS Transfer Family
The architecture in Figure 2.4 shows how files are transferred using AWS Transfer Family from on-premises file servers to Amazon S3 or Amazon EFS, which can then be used for downstream file processing workflows such as content distribution, machine learning, and data analysis:

Figure 2.4 – File transfer workflow using AWS Transfer Family
You can configure any standard file transfer protocol client such as WinSCP, FileZilla, or OpenSSH to initially transfer to Amazon S3 or EFS using AWS Transfer Family. It will first authenticate the user based on the identity provider type that you have configured, and once the user is authenticated, it will initiate the file transfer.
So far, we have seen how we can transfer data using AWS DataSync and AWS Transfer Family over the network and understood their use cases and how these services work to transfer data securely while reducing the operational burden in a cost-effective manner. Let’s now see how we can accelerate the data transfer to S3 using Amazon S3 Transfer Acceleration.
Amazon S3 Transfer Acceleration
Amazon S3 Transfer Acceleration (S3TA) is a feature in Amazon S3 buckets that lets you speed up your data transfer to a S3 bucket over long distances, regardless of internet traffic and without the need for any special clients or proprietary network protocols. You can speed up transfers to and from Amazon S3 by 50-500% using the transfer acceleration feature.
Some of the use cases include the following:
- Time-sensitive transfers of large files, such as lab imagery or media, from distributed locations to your data lake built on Amazon S3 (centralized data repository).
- Web or mobile applications with a file upload or download feature where users are geographically distributed and are far from the destination S3 bucket. S3TA can accelerate this long-distance transfer of files and helps you provide a better user experience.
It uses Amazon CloudFront’s globally distributed edge locations, AWS backbone networks, and network protocol optimizations to route traffic, which speeds up the transfer, reduces the internet traffic variability, and helps in logically shortening the distance to S3 for remote applications.
Important note
There is an additional charge to use Amazon S3 Transfer Acceleration.
We have discussed using online data transfer services such as AWS DataSync, AWS Transfer Family, and S3TA for moving data from on-premises storage to AWS storage resources over the network. There might be scenarios where you want to transfer streaming data in real time to the AWS cloud, for example, telemetry data from IoT sensors, video for online streaming applications, and so on. For this, we will go deeper into Amazon Kinesis, which is a fully managed streaming service built by AWS.
Amazon Kinesis
Amazon Kinesis is a fully managed service used to collect, process, and analyze streaming data in real time at any scale. Streaming data can include ingesting application logs, audio, video, website clickstreams, or IoT sensor data for deep learning, machine learning, analytics, and other applications. It allows you to perform data analysis as the data arrives in real time, instead of waiting for all the data to be transferred before processing.
Amazon Kinesis includes the following services:
- Kinesis Video Streams: This is used when you have to securely stream video from connected devices to AWS for applications such as processing, analytics, or machine learning to drive insights in real time. It has a built-in autoscaling mechanism to provision the infrastructure required for ingesting video streams coming from millions of devices. It automatically encrypts the data at rest as well as in transit. It uses Amazon S3 as its underlying storage, allowing you to store and retrieve data reliably. This helps you to develop real-time computer vision applications by integrating it with other fully managed AWS services or using popular open source machine learning frameworks on AWS. Figure 2.5 shows how Kinesis video streams can be used to collect, process, and store video streams coming from media devices for machine learning, analytics, and playback with integration with other media applications:

Figure 2.5 – Capture, process, and store video streams for machine learning, analytics, and playback
- Kinesis Data Streams: This is a fully managed serverless service used for securely streaming data at any scale in a cost-effective manner. You can stream gigabytes of data per second by adjusting your capacity or use it in on-demand mode for automatic scaling and provisioning the underlying infrastructure based on the capacity required by your application. It has built-in integration with other AWS services, and you only pay for what you use. Figure 2.6 shows how Kinesis Data Streams can be used to ingest, process, and store streaming data generated by different sources to other AWS services to gain insights in real time:

Figure 2.6 – Capture data from different sources into Amazon Kinesis Data Streams
- Kinesis Data Firehose: This is used to securely stream data into data lakes built on Amazon S3, or data warehouses such as Amazon Redshift, into the required formats for further processing or analysis without the need to build data processing pipelines. Let’s look at some of the benefits of using Kinesis Data Firehose:
- It enables you to create your delivery stream easily by extracting, transforming, and loading streaming data securely at scale, without the need to manage the underlying infrastructure.
- It has built-in autoscaling to provision the resources required by your streaming application, without any continuous management.
- It enables you to transform raw streaming data using either built-in or custom transformations. It supports converting data into different formats such as Apache Parquet and can dynamically partition data without building any custom processing logic.
- You can enhance your data streams using machine learning models within Kinesis Firehose to analyze and perform inference as the data travels to the destination. It provides enhanced network security by monitoring and creating alerts in real time when there is a potential threat using Security Information and Event Management (SIEM) tools.
- You can connect with 30+ AWS services and streaming destinations, which are fully integrated with Kinesis Data Firehose.
Figure 2.7 shows how Amazon Kinesis Data Firehose can be used for ETL use cases without having to write long lines of code or managing your own infrastructure at scale:
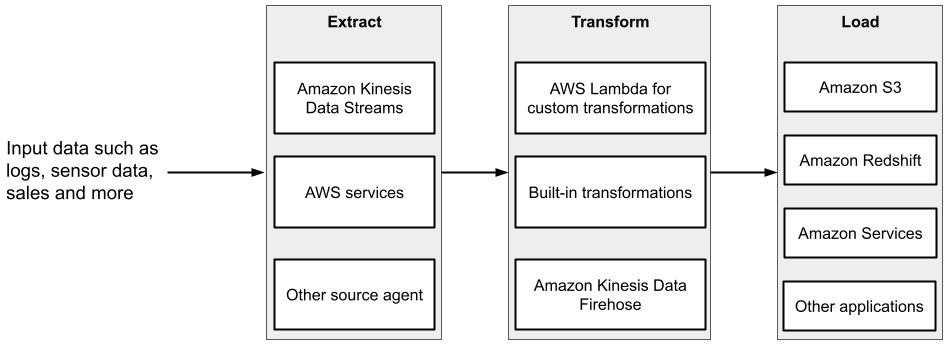
Figure 2.7 – ETL using Amazon Kinesis Data Firehose
- Kinesis Data Analytics: This is used to process data streams in real time with serverless and fully managed Apache Flink or SQL, from data sources such as Amazon S3, Amazon Kinesis Data Streams, and Amazon Managed Apache Kafka (MSK) (used to ingest and process streaming data). It can also be used to trigger real-time actions such as anomaly detection from long-running stateful computations based on past data trends. It has a built-in autoscaling mechanism to match the volume and throughput of your input data stream. You only pay for what you use; there is no minimum fee or set-up cost associated with it. It helps you to understand your data in real time, for example, by building a leaderboard for your gaming application, analyzing sensor data, log analytics, web clickstream analytics, building a streaming ETL application, or continuously generating metrics for understanding data trends.
Figure 2.8 shows how a typical Kinesis Data Analytics application works. It has three main components:
- An input data streaming source on which to perform real-time analytics
- Amazon Kinesis Data Analytics Studio Notebook to analyze streaming data using SQL queries and Python or Scala programs
- Finally, it stores processed results on a destination service or application, such as Amazon Redshift or Amazon DynamoDB (NoSQL database) and Amazon Kinesis Data Streams:

Figure 2.8 – Real-time processing of streaming data using Amazon Kinesis Data Analytics
In this section, we discussed how to transfer and process streaming data to AWS Storage, using Amazon Kinesis. There are some use cases, such as edge computing and edge storage, for which you can use AWS Snowcone, a portable, rugged, and secure device for edge computing, storage, and data transfer. Next, let’s see how we can transfer data online from AWS Snowcone to AWS.
AWS Snowcone
AWS Snowcone is a small, rugged, and portable device, used for running edge computing workloads, edge storage, and data transfer. The device weighs about 4.5 lbs (2.1 kg) and has multiple layers of security and encryption. It has 8 TB of storage, while the AWS Snowcone Solid State Drive (SSD) version provides 14 TB. Some of the common use cases for Snowcone are as follows:
- Healthcare IoT, for transferring critical and sensitive data from emergency medical vehicles to hospitals for processing data faster and reducing the response time to serve the patients in a better way. You can then transfer the data securely to the AWS cloud.
- Industrial IoT, for capturing sensor or machine data, as it can withstand extreme temperatures, vibrations, and humidity found on factory floors where traditional edge devices might not work.
- Capturing and storing sensor data from autonomous vehicles and drones.
You can transfer terabytes of data from various AWS Snowcone devices over the network using AWS DataSync, as discussed in the AWS DataSync section.
AWS online data transfer services are helpful when you have to transfer up to terabytes of data over the network to AWS. The time taken to transfer data is dependent on your available network bandwidth and internet traffic. When you have to transfer data from remote locations, or when your network bandwidth is heavily used by existing applications, you would need an alternative mechanism to transfer data offline. Let’s discuss the AWS offline data transfer services in the next section.
AWS offline data transfer services
For transferring up to petabytes of data via offline methods, in a secure and cost-effective fashion, you can use AWS Snow Family devices. Sometimes, your applications may require enhanced performance at the edge, where you want to process and analyze your data close to the source in order to deliver real-time meaningful insights. This would mean having AWS-managed hardware and software services beyond the AWS cloud. AWS Snow Family can help you to run operations outside of your data center, as well as in remote locations with limited network connectivity.
It consists of the following devices:
- AWS Snowcone: In the AWS online data transfer services section, we introduced and discussed how Snowcone can be used for collecting and storing data at the edge and then transferring it to the AWS cloud using AWS DataSync. In cases of limited network bandwidth, you can also use it for offline data transfer by sending the device to an AWS facility. It includes an E Ink shipping label, which also aids in tracking.
- AWS Snowball: This is used for migrating data and performing edge computing. It comes with two options:
- Snowball Edge Compute Optimized has 42 TB of block or Amazon S3-compatible storage with 52 vCPUs and an optional GPU for edge computing use cases such as machine learning, video analysis, and big data processing in environments with intermittent network connectivity, such as industrial and transportation use cases, or extremely remote locations found in defense or military applications.
- Snowball Edge Storage Optimized has 80 TB of usable block or Amazon S3-compatible object storage, with 40 vCPUs for performing computing at the edge. It is primarily used for either local storage or large-scale offline data transfers to the AWS cloud.
- AWS Snowmobile is used to migrate up to 100 PB of data in a 45-foot-long shipping container, which is tamper resistant, waterproof, and temperature controlled with multiple layers of logical and physical security. It is ideal for use cases where you have to transfer exabytes or hundreds of petabytes of data, which might occur due to data center shutdowns. You need to order it from the AWS Snow Family console, and it arrives at your site as a network-attached data store that connects to your local network to perform high-speed data transfers. Once the data is moved to the device, it is driven back to the AWS facility where the data is then uploaded to the specified Amazon S3 bucket. To ensure data security in transit and the successful delivery of data to the AWS facility, it comes with fire suppression, encryption, dedicated security personnel, GPS tracking, alarm monitoring, 24/7 video surveillance, and an escort security vehicle.
Now that we understand the various offline data transfer options offered by AWS, let’s understand the process for ordering the device.
Process for ordering a device from AWS Snow Family
To order AWS Snowmobile, you need to contact AWS sales support. For Snowcone or Snowball devices, you can follow these steps:
- Log in to the AWS Console and type AWS Snow Family in the search bar. Click on AWS Snow Family, which will take you to the AWS Snow Family console as shown in Figure 2.9:

Figure 2.9 – AWS Snow Family console
- Click on the orange button reading Order an AWS Snow Family device, which opens another screen, as shown in Figure 2.10. This will provide you with steps to create a job for ordering the device:

Figure 2.10 – AWS Snow Family – Create new job
- Click on Next to go to Step 2, Get started with import to S3 job, as shown in Figure 2.11:
Figure 2.11 – Getting started with import to S3 job
- Read the instructions carefully, check the acknowledgment checkbox, and click Next to go to Step 3, Choose your shipping preferences, as shown in Figure 2.12:

Figure 2.12 – Choose your shipping preferences
- Fill in your shipping details, select your preferred shipping speed, and click Next to go to Step 4, Choose your job details, as shown in Figure 2.13. Make sure to enter a valid address as it will give you an error message if your address is incorrect:
Figure 2.13 – Choose your job details
On this screen, you can select your Snow device, power supply, wireless options for Snowcone, S3 bucket, compute using EC2 instances, and the option to install the AWS IoT Greengrass validated AMI.
Please note that the S3 bucket will appear as directories on your device, and the data in those directories will be transferred back to S3. If you have selected the AWS IoT Greengrass AMI to run IoT workloads on the device, you also need to select the Remote device management option to open and manage the device remotely with OpsHub or Snowball Client.
Important note
All the options as mentioned in step 4 are not shown in Figure 2.13 – Choose your job details, but will be present on your console screen.
- After you have filled out the job details, click on the Next button to go to Step 5, Choose your security preferences, as shown in Figure 2.14:

Figure 2.14 – Choose your security preferences
- Select the permission and encryption settings for your job on this screen, which will help you to protect your data while in transit, and then click on Next to go to Step 6, Choose your notification preferences, as shown in Figure 2.15:

Figure 2.15 – Choose your notification preferences
- To receive email notifications of your job status changes, you can choose either an existing Simple Notification Service (SNS) topic or create a new SNS topic. Click on Next to go to Step 7, Review and create your job, as shown in Figure 2.16:

Figure 2.16 – Review and create your job
- You can review all the details that you have entered from Step 1 through Step 7 and then click on the Create job button.
- Once the job is created, it will take you to the Jobs screen, as shown in Figure 2.17, where you can see details of your job including the status:

Figure 2.17 – Snow Family jobs
Important note
On the Actions drop-down menu, you also have options to cancel a job, edit a job name, and clone a job.
In this section, we learned about AWS Snow Family devices to transfer data offline based on our application requirements, network connectivity, available bandwidth, and the location of our data sources. We also discussed how we can use these devices not only for transferring data but also for edge computing.
One of the most frequently asked questions on this topic is, how do we calculate the time taken to move data to the cloud based on the network speed and available bandwidth? For this, AWS provides a simple formula based on the best-case scenario, which is given as follows:

For example, if we have a network connection of 1.544 Mbps, and we want to move 1 TB of data into and out of the AWS cloud, then theoretically the minimum time that it would take to transfer over your network connection at 80% network utilization is 82 days.
Important note
Please note that this formula only gives a high-level estimate; the actual time taken might differ based on the variability of network traffic and available bandwidth.
Let’s now take a brief look at all the topics that we have covered in this chapter.
Summary
In this chapter, we talked about various aspects of data management, including data governance and compliance with the legal requirements of federal and regional authorities of the country where the data resides. We also discussed that in order to build HPC applications on the cloud, we need to have data on the cloud, and looked at the challenges of transferring this data to the cloud. In order to mitigate these challenges, we can use the managed AWS data transfer services, and in order to select which service to use for your application, we then discussed the elements of building a data strategy.
We then took an example of how we can transfer petabyte-scale data to the cloud in order to understand the concepts involved in a data transfer strategy. Finally, we did a deep dive on various AWS data transfer services for both online and offline data transfer based on your network bandwidth, connectivity, type of application, speed of data transfer, and location of your data source.Now that we understand the mechanisms for transferring data to the cloud, the challenges involved, and how to mitigate them, in the next chapter, we will focus on understanding the various compute options provided by AWS for running HPC applications, and how to optimize these based on the application requirements.
Further reading
The following are some additional resources for this chapter:
- Migrate Petabyte Scale Data: https://aws.amazon.com/getting-started/projects/migrate-petabyte-scale-data/
- Introduction to HPC on AWS: https://d1.awsstatic.com/whitepapers/Intro_to_HPC_on_AWS.pdf
- Data management versus data governance: https://www.tableau.com/learn/articles/data-management-vs-data-governance
- What is DataSync?: https://docs.aws.amazon.com/datasync/latest/userguide/what-is-datasync.html
- S3 Transfer Acceleration: https://aws.amazon.com/s3/transfer-acceleration/
- AWS Transfer Family Customers: https://aws.amazon.com/aws-transfer-family/customers/
- Kinesis Data Streams: https://aws.amazon.com/kinesis/data-streams/
- Kinesis Video Streams: https://aws.amazon.com/kinesis/video-streams/
- Kinesis Data Analytics: https://aws.amazon.com/kinesis/data-analytics/
- AWS Snowcone: https://aws.amazon.com/snowcone
- AWS Snow Family: https://aws.amazon.com/snow/
- Cloud Data Migration: https://aws.amazon.com/cloud-data-migration/