
Chapter 8: DevOps and MLOps for the Edge
The 21st century's flurry of connected devices has transformed the way we live. It can be hard to remember the days without the convenience of smartphones, smartwatches, personal digital assistants (such as Amazon Alexa), connected cars, smart thermostats, or other devices.
This adoption is not going to slow down anytime soon as the industry forecasts that there will be over 25 billion IoT devices globally in the next few years. With the increased adoption of connected technologies, the new normal is to have always-on devices. In other words, the devices should work all the time. Not only that, but we also expect these devices to continuously get smarter and stay secure throughout their life cycles with new features, enhancements, or bug fixes. But how do you make that happen reliably and at scale? Werner Vogels, Amazon's chief technology officer and vice president, often says that "Everything fails all the time." It's challenging to keep any technological solution up and running all the time.
With IoT, these challenges are elevated and more complicated as the edge devices are deployed in diverse operating conditions, exposed to environmental interferences, and have multiple layers of connectivity, communication, and latency. Thus, it's critical to build an edge-to-cloud continuum mechanism to collect feedback from the deployed fleet of edge devices and act on them quickly. This is where DevOps for IoT helps. DevOps is short for development and operations. It facilitates an agile approach to performing continuous integration and continuous deployment (CI/CD) from the cloud to the edge.
In this chapter, we will focus on how DevOps capabilities can be leveraged for IoT workloads. We will also expand our discussion to MLOps at the edge, which implies implementing agile practices for machine learning (ML) workloads. You learned about some of these concepts in the previous chapter when you built an ML pipeline. The focus of this chapter will be on deploying and operating those models efficiently.
You are already familiar with developing local processes on the edge or deploying components from the cloud in a decoupled way. In this chapter, we will explain how to stitch those pieces together using DevOps principles that will help automate the development, integration, and deployment workflow for a fleet of edge devices. This will allow you to efficiently operate an intelligent distributed architecture on the edge (that is, a Greengrass-enabled device) and help your organization achieve a faster time to market for rolling out different products and features.
In this chapter, we will be covering the following topics:
- Defining DevOps for IoT workloads
- Performing MLOps at the edge
- Hands-on with deploying containers at the edge
- Checking your knowledge
Technical requirements
- The technical requirements for this chapter are the same as those outlined in Chapter 2, Foundations of Edge Workloads. See the full requirements in that chapter.
Now, let's dive into this chapter.
Defining DevOps for IoT workloads
DevOps has transformed the way companies do business in today's world. Companies such as Amazon, Netflix, Google, and Facebook conduct hundreds or more deployments every week to push different features, enhancements, or bug fixes. The deployments themselves are typically transparent to the end customers in that they don't experience any downtime from these constant deployments.
DevOps is a methodology that brings developers and operations closer to infer quantifiable technical and business benefits with faster time to market through shorter development cycles and increased release frequency. A common misunderstanding is that DevOps is only a set of new technologies to build and deliver software faster. DevOps also represents a cultural shift to promote ownership, collaboration, and cohesiveness across different teams to foster innovation across the organization. DevOps has been adopted by organizations and companies of all sizes for distributed workloads to deliver innovation, enhancements, and operational efficiency faster. The following diagram shows the virtuous cycle of software delivery:
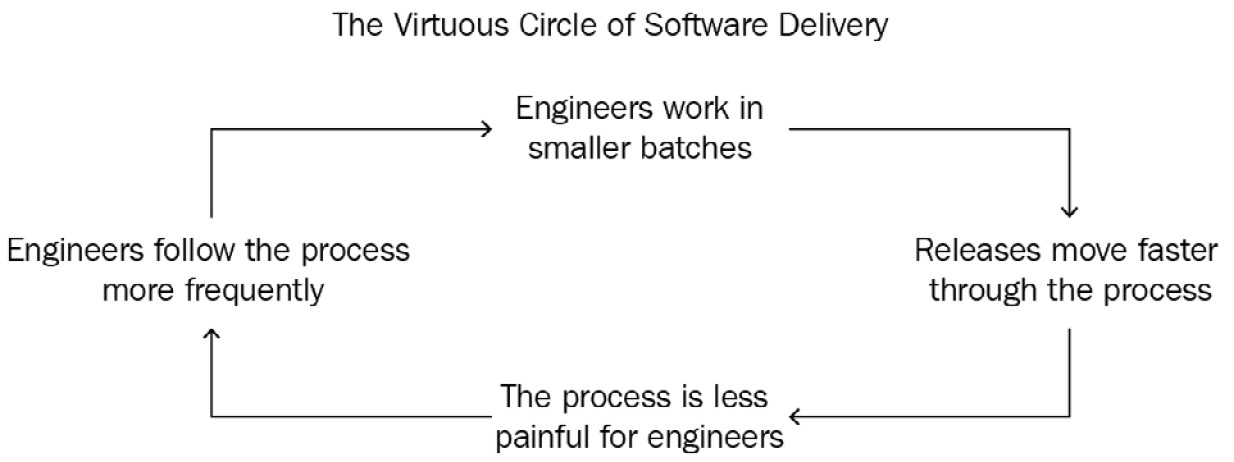
Figure 8.1 – The virtuous cycle of software delivery
For the sake of brevity, we are not going to dive deeper into the concepts of DevOps or Agile practices here. Instead, we will focus on introducing the high-level concepts surrounding DevOps and discuss its relevance for IoT workloads.
Fundamentals of DevOps
DevOps brings together different tools and best practices, as follows:
- Shared code repository: Using a version control system is a prerequisite and a best practice in the field of code development. All artifacts that are required in the deployment package need to be stored here. Examples include Bitbucket, Gitlab, and AWS CodeCommit.
- Continuous integration (CI): In this step, developers commit their code changes regularly in the code repository. Every revision that is committed will trigger an automated build process that performs code scanning, code reviews, compilation, and automated unit testing. This allows developers to identify and fix bugs quickly, allowing them to adhere to the best practices and deliver features faster. The output of this process includes build artifacts (such as binaries or executable programs) that comply with the organization's enforced practices. Examples of toolchains include Jenkins, Bamboo, GitLab CI, and AWS CodePipeline. For IoT workloads, similar toolchains can be used.
- Continuous delivery (CD): This step expands on the previous step of CI and deploys all the compiled binaries to the staging or test environment. Once deployed, automated tests related to integration, functional, or non-functional requirements are executed as part of the workflow. Examples of toolchains for testing include JMeter, Selenium, Jenkins, and Cucumber. This allows developers to thoroughly test changes and pre-emptively discover issues in the context of the overall application. The final step is deploying the validated code artifacts to the production environment (with or without manual approval).
- Continuous monitoring (CM): The core objective for DevOps is to remove silos between the development and operations teams. Thus, CM is a critical step if you wish to have a continuous feedback loop for observing, alerting, and mitigating issues related to infrastructure or hosted applications, as shown in the following diagram:
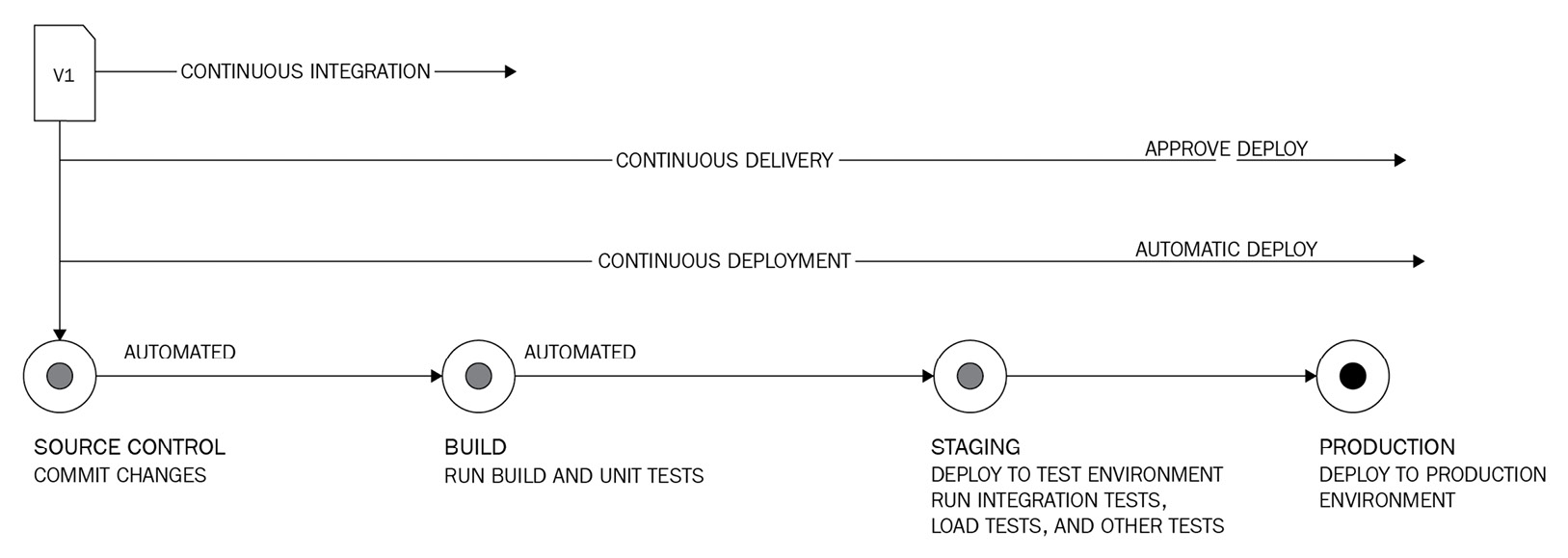
Figure 8.2 – DevOps life cycle
Common toolchains for monitoring include Amazon CloudWatch, Amazon X-Ray, Splunk, and New Relic.
- Infrastructure as Code (IaC): Adhering to the software development practices of CI/CD to expedite shipping code is a great first step, but it's not enough. Teams can develop and test their code using agile processes, but the final delivery to production still follows waterfall methods. This is often due to a lack of control regarding provisioning or scaling the infrastructure dynamically. Traditionally, organizations will have system admins to provision the required infrastructure resources manually, which can take days, weeks, or months. This is where IaC helps as it allows you to provision and manage the infrastructure, configurations, and policies using code (or APIs) in an automated fashion without requiring any manual interventions that might be error-prone or time-consuming. Common toolchains include Amazon CloudFormation, HashiCorp Terraform, and Ansible.
Now that we have covered the the basics of DevOps, let's understand its relevance to IoT and the edge.
Relevance of DevOps for IoT and the edge
The evolution of edge computing from simple radio frequency identification systems to the microcontrollers and microprocessors of today has opened up different use cases across industry segments that require building a distributed architecture on the edge. For example, the connected HBS hub has a diverse set of functionalities, such as the following:
- A gateway for backend sensors/actuators
- Runtime for local components
- Interface to the cloud
- Message broker
- Datastream processor
- ML inferencing engine
- Container orchestrator
That's a lot of work on the edge! Thus, the traditional ways of developing and delivering embedded software are not sustainable anymore. So, let's discuss the core activities in the life cycle of an IoT device, as depicted in the following table, to understand the relevance of DevOps:
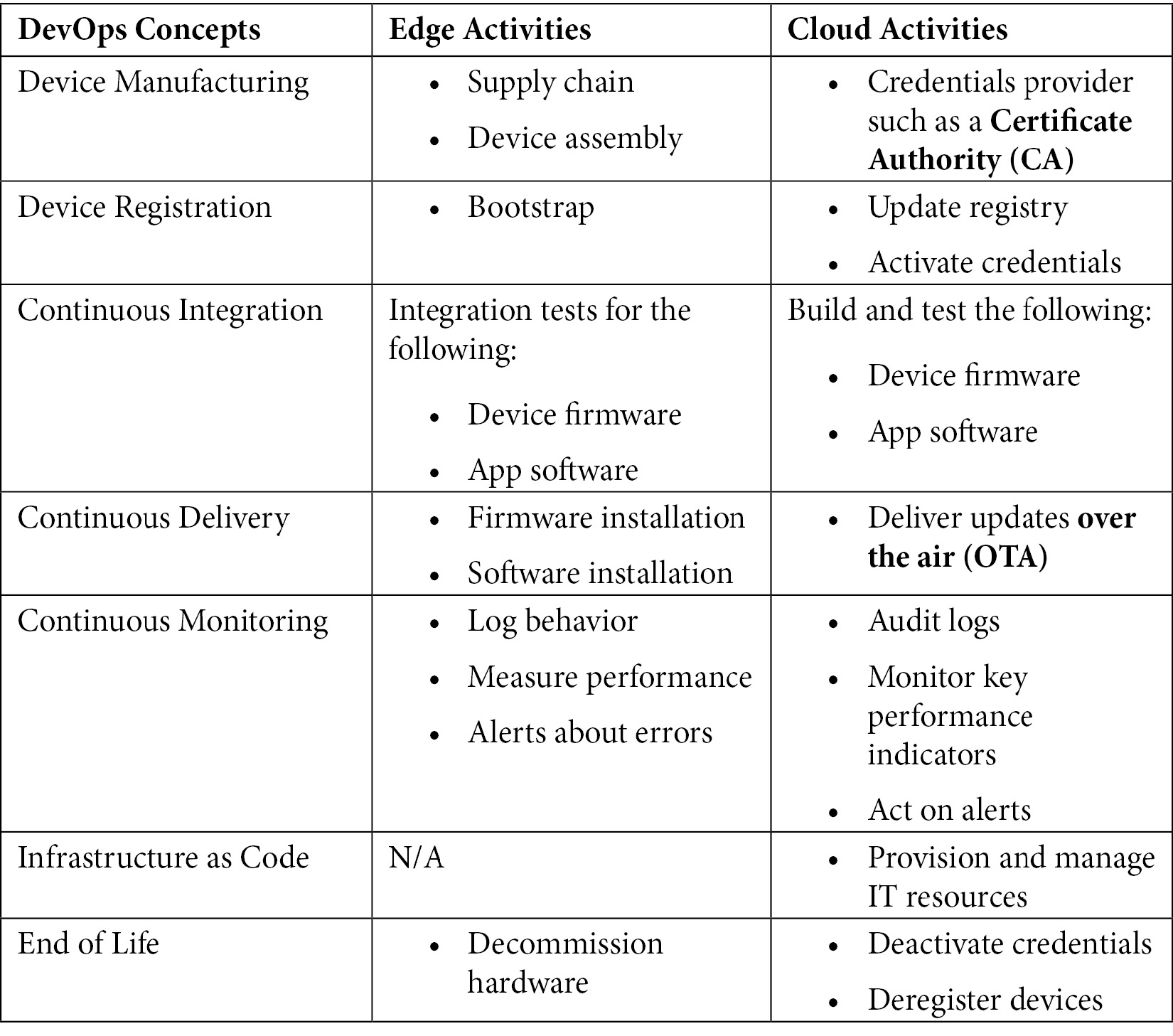
Figure 8.3 – Relevance of DevOps in IoT workloads
The key components of DevOps such as CI/CD/CM are equally relevant for IoT workloads. This set of activities is often referred to as EdgeOps and, as we observed earlier, they are applied differently between the edge and the cloud. For example, CI is different for the edge because we need to test device software on the same hardware that is deployed in the world. However, because of the higher costs and risks associated with edge deployments, it is common to reduce the frequency of updating devices at the edge. It is also common for organizations to have different sets of hardware for prototyping versus production runtimes.
DevOps challenges with IoT workloads
Now that you understand how to map DevOps phases to different IoT activities, let's expand on those a bit more. The following diagram shows the workflow that's typically involved in the life cycle of a device, from its creation to being decommissioned:
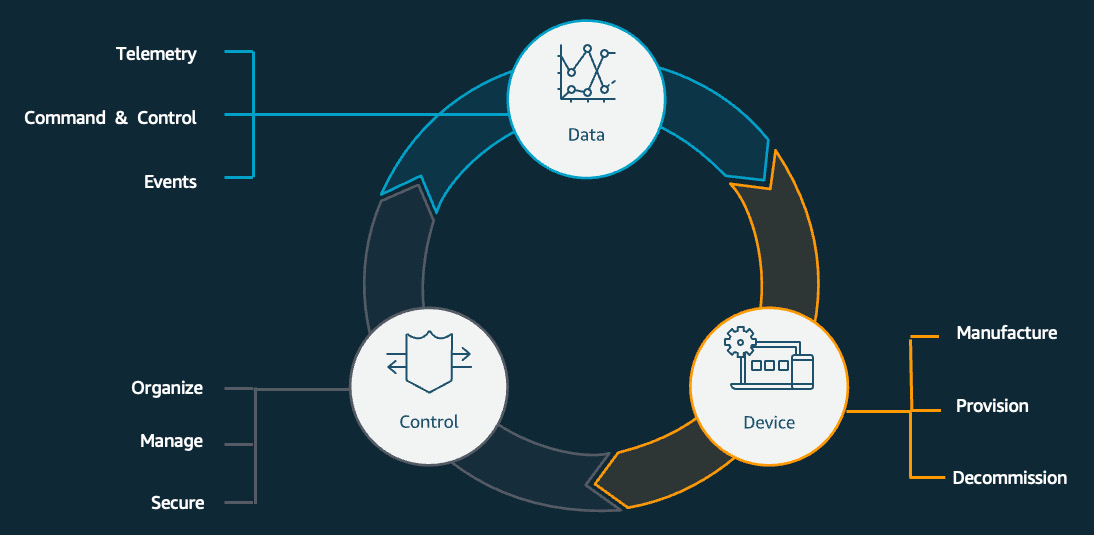
Figure 8.4 – DevOps workflow for IoT
Here, you can see some key differences between an IoT workload and other cloud-hosted workloads. Let's take a look.
The manufacturing process is involved:
Distributed workloads such as web apps, databases, and APIs use the underlying infrastructure provided by the cloud platform. Software developers can use IaC practices and integrate them with other CI/CD mechanisms to provision the cloud resources that are automatically required to host their workload. For edge workloads, the product lives beyond the boundaries of any data center. Although it's possible to run edge applications on virtual infrastructure provided by the cloud platform during the testing or prototyping phases, the real product is always hosted on hardware (such as a Raspberry Pi for this book's project). There is always a dependency on the contract manufacturer (or other vendors) in the supply chain for manufacturing the hardware, as per the required specifications that are followed for programming it with the device firmware. Although the firmware can be developed on the cloud using DevOps practices, flashing the firmware image is done at manufacturing time only. This hinders the end-to-end automation common in traditional DevOps workflows, where the infrastructure (such as an AWS EC2 instance) is readily imaged and available for application deployments. The following diagram shows the typical life cycle of device manufacturing and distribution:
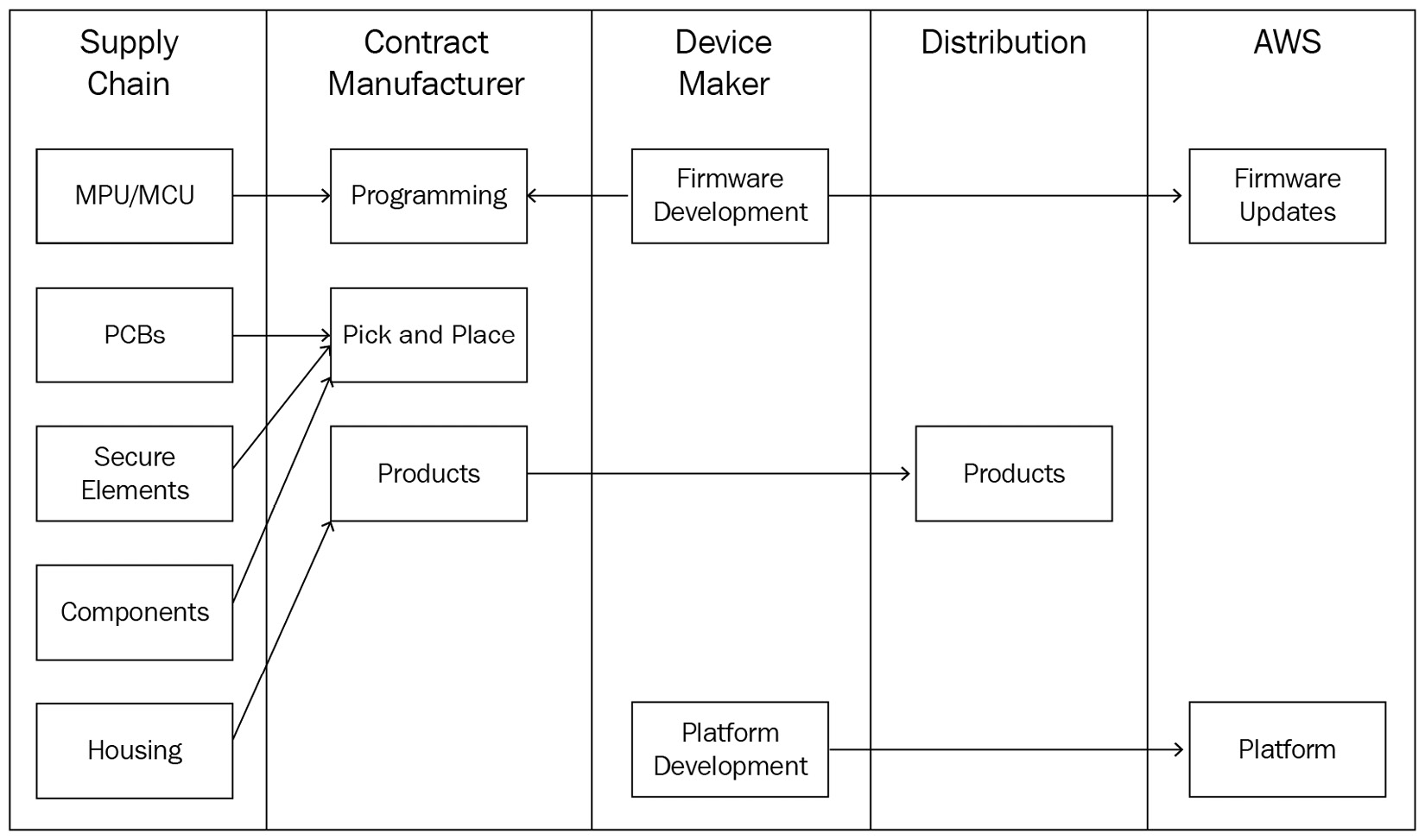
Figure 8.5 – IoT device manufacturing process
Securing the hardware is quintessential:
Some of the key vulnerabilities for edge workloads that are listed by The Open Web Application Security Project (OWASP) are as follows:
- Weak, guessable, or hardcoded passwords
- Lack of physical hardening
- Insecure data transfer and storage
- Insecure default settings
- Insecure ecosystem interfaces
Although distributed workloads may have similar challenges, mitigating them using cloud-native controls makes them easier to automate than IoT workloads. Using AWS as an example, all communications within AWS infrastructure (such as across data centers) are encrypted in transit by default and require no action. Data at rest can be encrypted with a one-click option (or automation) using the key management infrastructure provided by AWS (or customers can bring their own). Every service (or hosted workloads) needs to enable access controls for authentication and authorization through cloud-native Identity & Access Management services, which can be automated as well through IaC implementation. Every service (or hosted workload) can take advantage of observability and traceability through cloud-native monitoring services (such as Amazon CloudTrail or Amazon CloudWatch).
On the contrary, for edge workloads, all of the preceding requirements are required to be fulfilled during manufacturing, assembling, and registering the device, thus putting more onus on the supply chain to manually implement these over one-click or automated workflows. For example, as a best practice, edge devices should perform mutual authentication over TLS1.2 with the cloud using credentials such as X.509 certificates compared to using usernames and passwords or symmetric credentials. In addition, the credentials should have least-privileged access implemented using the right set of permissions (through policies). This can help ensure that the devices are implementing the required access controls to protect the device's identity and that the data in transit is fully encrypted. In addition, device credentials (such as X.509 certificates) on the edge must reside inside a secure element or trusted platform module (TPM) to reduce the risk of unauthorized access and identity compromise. Additionally, secure mechanisms are required to separate the filesystems on the device and encrypt the data at rest using different cryptographic utilities such as dm-crypt, GPG, and Bitlocker. Observability and traceability implementations for different edge components are left to the respective owners.
Lack of standardized frameworks for the edge:
Edge components are no longer limited to routers, switches, miniature servers, or workstations. Instead, the industry is moving toward building distributed architectures on the edge in different ways, as follows:
- Fog computing, which lets us shift more intelligence to the edge using a decentralized computing infrastructure of heterogeneous nodes
- Mobile/Multi-Access Computing (MEC), which incorporates next-generation radio spectrums (such as 5G) to enable a new generation of workloads possible for the edge
- Data center-in-a-box, which enables resource-intensive computing capabilities at the edge with integrations to the cloud
The following diagram shows an edge-to-cloud workflow that includes various technology capabilities that are common in distributed architectures:
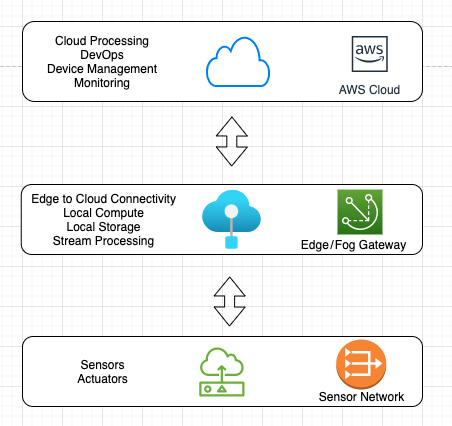
Figure 8.6 – Edge-to-cloud architecture
The edge architecture's standards are still evolving. Considering there are different connectivity interfaces, communication protocols, and topologies, there are heterogeneous ways of solving different use cases. For example, connectivity interfaces may include different short-range (such as BLE, Wi-Fi, and Ethernet) or long-range radio networks (such as cellular, NB-IoT, and LoRa). The connectivity interface that's used needs to be determined during the hardware designing phase and is implemented as a one-time process. Communication protocols may include different transport layer protocols over TCP (connection-oriented such as MQTT and HTTPS) or UDP (connectionless such as CoAP). Recall the layers of the Open System Interconnection (OSI) model, which we reviewed in Chapter 2, Foundations of Edge Workloads. The choice of communication interfaces can be flexible, so long as the underlying Layer 4 protocols are supported on the hardware. For example, if the hardware supports UDP, it can be activated with configuration changes, along with installing additional Layer 7 software (such as a COAP client) as required. Thus, this step can be performed through a cloud-to-edge DevOps workflow (that is, an OTA update). Bringing more intelligence to the edge requires dealing with the challenges of running distributed topologies on a computing infrastructure with low horsepower. Thus, it's necessary to define standards and design principles to design, deploy, and operate optimized software workloads on the edge (such as brokers, microservices, containers, caches, and lightweight databases).
Hopefully, this has helped you understand the unique challenges for edge workloads from a DevOps perspective. In the next section, you will understand how AWS IoT Greengrass can help you build and operate distributed workloads on the edge.
Understanding the DevOps toolchain for the edge
In the previous chapters, you learned how to develop and deploy native processes, data streams, and ML models on the edge locally and then deployed them at scale using Greengrass's built-in OTA mechanism. We will explain the reverse approach here; that is, building distributed applications on the cloud using DevOps practices and deploying them to the edge. The following diagram shows the approach to continuously build, test, integrate, and deploy workloads using the OTA update mechanism:

Figure 8.7 – A CI/CD view for Edge applications
The two most common ways to build a distributed architecture on the edge using AWS IoT Greengrass is by using AWS Lambda services or Docker containers.
AWS Lambda at the edge
I want to make it clear, to avoid any confusion, that the concept of Lambda design, which was introduced in Chapter 5, Ingesting and Streaming Data from the Edge, is an architectural pattern that's used to operate streaming and batch workflows on the edge. AWS Lambda, on the contrary, is a serverless compute service that offers a runtime for executing any type of application with no administration. It allows developers to focus on the business logic, write code in different programming languages (such as C, C++, Java, Node.js, and Go), and upload it as a ZIP file. The service takes it from there in provisioning the underlying infrastructure's resources and scales based on incoming requests or events.
AWS Lambda has been a popular compute choice in designing event-based architectures for real-time processing, batch, and API-driven workloads. Due to this, AWS has decided to extend the Lambda runtime support for edge processing through Amazon IoT Greengrass.
So, are you wondering what the value of implementing AWS Lambda at the edge is?
You are not alone! Considering automated hardware provisioning is not an option for the edge, as explained earlier in this chapter, the value here is around interoperability, consistency, and continuity from the cloud to the edge. It's very common for IoT workloads to have different code bases for the cloud (distributed stack) and the edge (embedded stack), which leads to additional complexity around code integration, testing, and deployment. This results in additional operational overhead and a delayed time to market.
AWS Lambda aimed to bridge this gap so that the cloud and embedded developers can use similar technology stacks for software development and have interoperable solutions. Therefore, building a DevOps pipeline from the cloud to the edge using a common toolchain becomes feasible.
Benefits of AWS Lambda on AWS IoT Greengrass
There are several benefits of running Lambda functions on the edge, as follows:
- Lambda functions that are deployed locally on the edge devices can connect to different physical interfaces such as CANBus, Modbus, or Ethernet to access different serial ports or GPIO on the hardware similar to embedded applications.
- Lambda functions can act as the glue between different edge components (such as Stream Manager) within AWS IoT Greengrass and the cloud resources.
- AWS IoT Greengrass also makes it easier to deploy different versions of Lambda functions by using an alias or a specific version for the edge. This helps in continuous delivery and is useful for scenarios such as blue/green deployments.
- Granular access control, including specifying configurations (run as root) or permissions (read/write) for different local resources (such as disk volumes, serial ports, or GPIOs), can be managed for Lambda functions.
- Lambda functions can be run in both containerized and non-containerized modes. Non-containerized mode removes the abstraction layer and allows Lambda to run as a regular process on the OS. This is useful for latency-sensitive applications such as ML inferencing.
- Finally, AWS IoT Greengrass allows you to manage the hardware resources (RAM) that can be used by the Lambda function on the edge.
The following diagram shows how an AWS Lambda function that's been deployed on the edge can interact with different components on the physical (such as the filesystem) or abstracted layer (such as stream manager on AWS IoT Greengrass):

Figure 8.8 – Lambda interactions on the edge
Here, you can see that Lambda provides some distinct value propositions out of the box that you have to build yourself with native processes.
Challenges with Lambda on the edge
As you have understood by now, every solution or architecture has a trade-off. AWS Lambda is not an exception either and can have the following challenges:
- Lambda functions can be resource-intensive compared to native processes. This is because they require additional libraries.
- Lambda functions are AWS only. Thus, if you are looking to develop a cloud-agnostic edge solution (to mitigate vendor lock-in concerns), you may need to stick to native processes or Docker containers. Although Greengrass v2, as an edge software, is open source, AWS Lambda functions are not.
Now, let's understand containers for the edge.
Containers for the edge
A container is a unit of software that packages the necessary code with the required dependencies for the application to run reliably across different computing environments. Essentially, a container provides an abstraction layer to its hosted applications from the underlying OS (such as Ubuntu, Linux, or Windows) or architecture (such as x86 or ARM). In addition, since containers are lightweight, a single server or a virtual machine can run multiple containers. For example, you can run a 3-tier architecture (web, app, and a database) on the same server (or VM) using their respective container images. The two most popular open source frameworks for container management are Docker and Kubernetes.
In this section, we will primarily discuss Docker as it's the only option that's supported natively by AWS IoT Greengrass at the time of writing. Similar to Lambda, Docker supports an exhaustive set of programming languages and toolchains for the developers to develop, operate, and deploy their applications in an agile fashion. The following diagram shows the reference architecture for a Docker-based workload deployed on AWS IoT Greengrass:
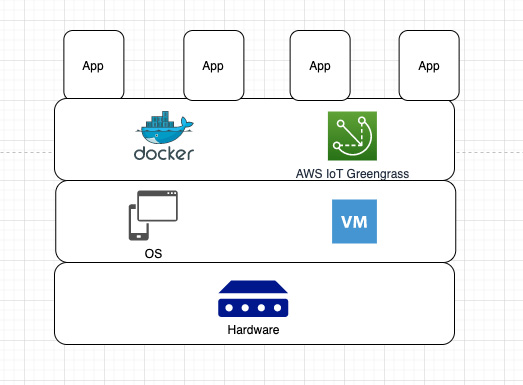
Figure 8.9 – Docker abstraction layers
So, why run containers over Lambda on the edge?
Containers can bring all of the benefits that Lambda does (and more), along with being heterogeneous (different platforms), open source, and better optimized for edge resources. Containers have a broader developer community as well. Since containers have an orchestration and abstraction layer, it's not dependent on other runtimes such as AWS IoT Greengrass. So, if your organization decides to move away to another edge solution, containers are more portable than Lambda functions.
Benefits of Docker containers on AWS IoT Greengrass
Running containers at the edge using Greengrass has the following benefits:
- Developers can continue to use their existing CI/CD pipelines and store artifacts (that is, Docker images) in different code repositories such as Amazon Elastic Container Registry (ECR), the public Docker Hub, the public Docker Trusted Registry, or an S3 bucket.
- Greengrass simplifies deploying to the edge, with the only dependency being having the Docker image URI in the configuration. In addition, Greengrass also offers a native Docker application manager component (aws.greengrass.DockerApplicationManager) that enables Greengrass to manage credentials and download images from the supported repositories.
- Greengrass offers first-class support for Docker utilities such as docker-compose, docker run, and docker load, all of which can be included as dependencies in the recipe file for the component or can be used separately for testing or monitoring purposes.
- Finally, Greengrass also supports inter-process communication between Docker-based applications and other components.
The following diagram shows how containerized applications can be developed using a CI/CD approach and be deployed on the edge while running AWS IoT Greengrass:

Figure 8.10 – CI/CD approach for Docker workloads
Next, let's learn about the challenges with Docker on the edge.
Challenges with Docker on the edge
Running containers on the edge has some tradeoffs that need to be considered, as follows:
- Managing containers at scale on the edge brings more operational overhead as it can become complex. Thus, it requires careful designing, planning, and monitoring.
- As you build sophisticated edge applications with private and public Docker images, you are increasing the surface area for attacks as well. Thus, adhering to various operational and security best practices at all times is quintessential.
- In addition to AWS IoT Greengrass-specific updates, you need to have a patching and maintenance routine for Docker-specific utilities as well, which, in turn, increases the operational overhead and network charges.
- An additional layer of abstraction with containers may not be a fit for latency-sensitive use cases. For example, performing ML inferencing on GPUs for time-sensitive actions such as detecting an intrusion in your home through computer vision may run better as a native process over a container.
In the lab section of this chapter, you will get your hands dirty by deploying a Docker-based application to the edge using AWS IoT Greengrass.
Additional toolsets for Greengrass deployments
Similar to other AWS services, AWS IoT Greengrass also supports integration with various IaC solutions such as CloudFormation, CDK, and Terraform. All these tools can help you create cloud-based resources and integrate with different CI/CD pipelines for supporting cloud-to-edge deployments.
Now that you are familiar with the benefits and tradeoffs of the DevOps toolchain, let's learn how that extends to machine learning.
MLOps at the edge
Machine Learning Operations (MLOps) aims to integrate agile methodologies into the end-to-end process of running machine learning workloads. MLOps brings together best practices from data science, data engineering, and DevOps to streamline model design, development, and delivery across the machine learning development life cycle (MLDLC).
As per MLOps special interest group (SIG), MLOps is defined as "The extension of the DevOps methodology to include machine learning and data science assets as first-class citizens within the DevOps ecology." MLOps has gained rapid momentum in the last few years from ML practitioners and is a language-, framework-, platform-, and infrastructure-agnostic practice.
The following diagram shows the virtuous cycle of the MLDLC:

Figure 8.11 – MLOps workflow
The preceding diagram shows how Operations is a fundamental block of the ML workflow. We introduced some of the concepts of ML design and development in Chapter 7, Machine Learning Workloads at the Edge, so in this section, we will primarily focus on the Operations layer.
There are several benefits of MLOps, as follows:
- Productive: Data, ML engineers, and data scientists can use self-service environments to iterate faster with curated datasets and integrated ML tools.
- Repeatable: Similar to DevOps, bringing automation to all aspects of the ML development life cycle (that is, MLDC) reduces human error and improves efficiency. MLOps helps ensure a repeatable process to help version, build, train, deploy, and operate ML models.
- Reliable: Incorporating CI/CD practices into the MLDC adds to the quality and consistency of the deployments.
- Auditable: Enabling capabilities such as versioning of all inputs and outputs, ranging from source data to trained models, allows for end-to-end traceability and observability of the ML workload.
- Governance: Implementing governance practices to enforce policies helps to guard against model bias and track changes to data lineage and model quality over time.
So, now that you understand what MLOps is, are you curious to know how it's related to IoT and the edge? Let's take a look.
Relevance of MLOps for IoT and the edge
As an IoT/edge SME, you will NOT be owning the MLOps process. Rather, you need to ensure that the dependencies are met on the edge (at the hardware and software layer) for the ML engineers to perform their due diligence in setting up and maintaining this workflow. Thus, don't be surprised by the brevity of this section, as our goal is to only introduce you to the fundamental concepts and the associated services available today on AWS for this subject area. We hope to give you a quick ramp-up so that you are adept at having better conversations with ML practitioners in your organization.
So, with that background, let's consider the scenario where the sensors from the connected HBS hub are reporting various anomalies from different customer installations. This is leading to multiple technician calls and thereby impacting the customer experience and bottom line. Thus, your CTO has decided to build a predictive maintenance solution using ML models to rapidly identify and fix faults through remote operations. The models should be able to identify data drift dynamically and collect additional information around the reported anomalies. Thus, the goal for ML practitioners here is to build an MLOps workflow so that models can be frequently and automatically trained on the collected data, followed by deploying it to the connected HBS hub.
In addition, it's essential to monitor the performance of the ML models that are deployed on the edge to understand their efficiency; for example, to see how many false positives are being generated. Similar to the DevOps workflow, the ML workflow includes different components such as source control for versioning, a training pipeline for CI/CD, testing for model validation, packaging for deployment, and monitoring for assessing efficiency. If this project is a success, it will help the company add more ML intelligence to the edge and mitigate issues predictively to improve customer experience and reduce costs. The following reference architecture depicts a workflow we can use to implement the predictive maintenance of ML models on AWS IoT Greengrass v2:
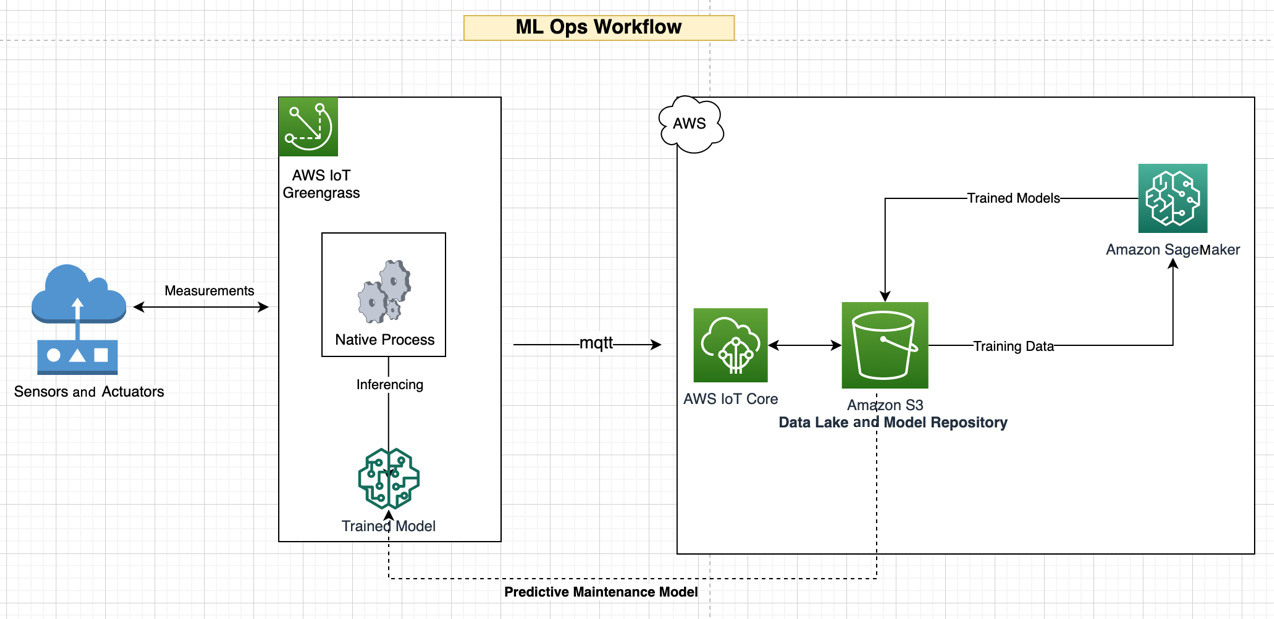
Figure 8.12 – Predictive maintenance of HBS sensors
If we want to implement the preceding architecture, we must try to foresee some common challenges.
MLOps challenges for the edge
Quite often, the most common questions that are asked by edge and ML practitioners related to MLOps are as follows:
- How do I prepare and deploy ML models to edge devices at scale?
- How do I secure the models (being intellectual property) once they've been deployed at the edge?
- How do I monitor the ML models operating at the edge and retrain them when needed?
- How do I eliminate the need for installing resource-intensive runtimes such as TensorFlow and PyTorch?
- How do I interface one or more models with my edge applications using a standard interface?
- How do I automate all these tasks so that there is a repeatable, efficient mechanism in place?
This is not an exhaustive list as it continues to expand with ML being adopted more and more on the edge. The answers to some of those questions are a mix of cultural and technical shifts within an organization. Let's look at some examples:
- Communication is key: For MLOps to generate the desired outcomes, communication and collaboration across different stakeholders are key. Considering ML projects involve a different dimension of technology related to algorithms and mathematical models, the ML practitioners often speak a different technical language than traditional IT (or IoT) folks.
Thus, becoming an ML organization requires time, training, and co-development exercises to be completed across different teams to produce fruitful results.
- Decoupling and recoupling: Machine learning models have life cycles that are generally independent of other distributed systems. This decoupling allows ML practitioners to focus on building their applications without being distracted by the rest.
At the same time, though, ML workflows have certain dependencies, such as on big data workflows or applications required for inferencing. This means that MLOps is a combination of a traditional CI/CD workflow and another workflow engine. This can often become tricky without a robust pipeline and the required toolsets.
- Deployment can be tricky: According to Algorithmia's report, 2020 State of Enterprise Machine Learning, "Bridging the gap between ML model building and practical deployments is a challenging task." There is a fundamental difference between building an ML model in a Jupyter notebook on a laptop or a cloud environment versus deploying that model into a production system that generates value.
With IoT, this problem acts as the force multiplier, as it's required to consider various optimization strategies for different hardware and runtimes before deploying the ML models. For example, in Chapter 7, Machine Learning Workloads at the Edge, you learned how to optimize ML models using Amazon SageMaker Neo so that they can run efficiently in your working environment.
- The environment matters: The ML models may need to run in offline conditions and thus are more susceptible to data drift due to the high rate of data from changing environments. For example, think of a scenario where your home has a power or water outage due to a natural disaster. Thus, your devices, such as the HVAC or water pumps, act in an anomalous way, leading to data drift for the locally deployed models. Thus, your locally deployed ML models need to be intelligent enough to handle different false positives in unexpected scenarios.
We have gone through the MLOps challenges for the edge in this section. In the next section, we will understand the MLOps toolchain for the edge.
Understanding the MLOps toolchain for the edge
In Chapter 7, Machine Learning Workloads at the Edge, you learned how to develop ML models using Amazon SageMaker, optimize them through SageMaker Neo, and deploy them on the edge using AWS IoT Greengrass v2. In this chapter, I would like to introduce you to another service in the SageMaker family called Edge Manager, which can help address some of the preceding MLOps challenges and which provides the following capabilities out of the box:
- The ability to automate the build-train-deploy workflow from cloud to edge devices and trace the life cycle of each model.
- Automatically optimize ML models for deployment on a wide variety of edge devices that are powered by CPUs, GPUs, and embedded ML accelerators.
- Supports model compilation from different frameworks such as DarkNet, Keras, MXNet, PyTorch, TensorFlow, TensorFlow-Lite, ONNX, and XGBoost.
- Supports multi-modal hosting of ML models, along with simple API interfaces, for performing common queries such as loading, unloading, and running inferences on the models on a device.
- Supports open source remote procedure protocols (using gRPC), which allow you to integrate with existing edge applications through APIs in common programming languages, such as Android Java, C#/.NET, Go, Java, Python, and C.
- Offers a dashboard to monitor the performance of models running on different devices across the fleet. So, in the scenario explained earlier with a connected HBS hub, if issues related to model drift, model quality, or predictions are identified, these issues can be quickly visualized in a dashboard or reported through configured alerts.
As you can see, Edge Manager brings robust capabilities to manage required capabilities for MLOps out of the box and brings native integrations with different AWS services, such as AWS IoT Greengrass. The following is a reference architecture for Edge Manager integrating with various other services that you were exposed to earlier in this book, such as SageMaker and S3:
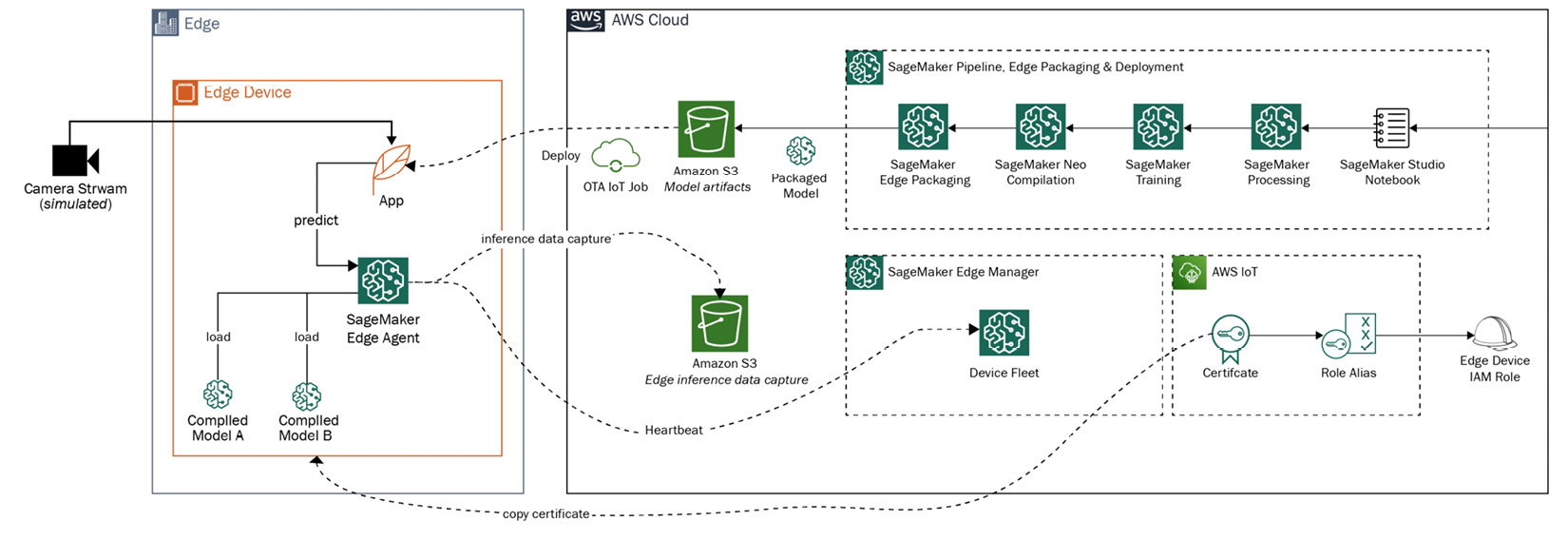
Figure 8.13 – Edge Manager reference architecture
Note
MLOps is still emerging and can be complicated to implement without the involvement of ML practitioners. If you would like to learn more about this subject, please refer to other books that have been published on this subject.
Now that you have learned the fundamentals of DevOps and MLOps, let's get our hands dirty so that we can apply some of these practices and operate edge workloads in an agile fashion.
Hands-on with the DevOps architecture
In this section, you will learn how to deploy multiple Docker applications to the edge that have already been developed using CI/CD best practices in the cloud. These container images are available in a Docker repository called Docker Hub. The following diagram shows the architecture for this hands-on exercise, where you will complete Steps 1 and 2 to integrate the HBS hub with an existing CI/CD pipeline (managed by your DevOps org), configure the Docker containers, and then deploy and validate them so that they can operate at the edge:
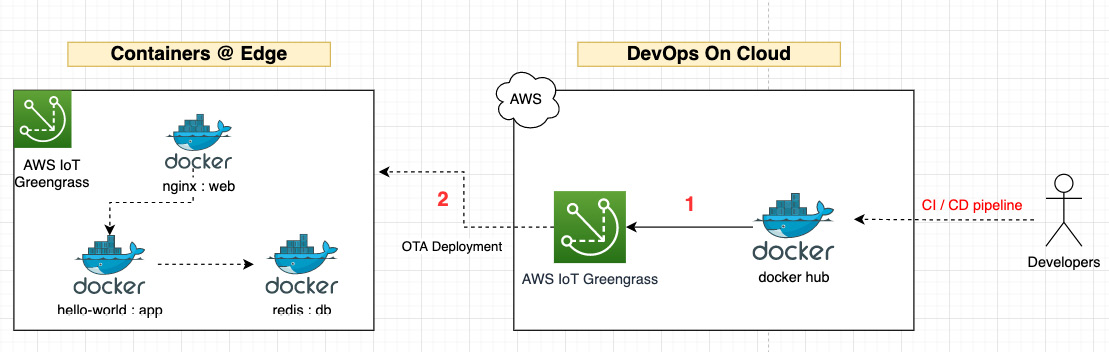
Figure 8.14 – Hands-on DevOps architecture
The following are the services you will use in this exercise:

Figure 8.15 – Services for this exercise
Your objectives for this hands-on section are as follows:
- Deploy container images from Docker Hub to AWS IoT Greengrass.
- Confirm that the containers are running.
Let's get started.
Deploying the container from the cloud to the edge
In this section, you will learn how to deploy a pre-built container from the cloud to the edge:
- Navigate to your device's terminal and confirm that Docker is installed:
cd hbshub/artifacts
docker –-version
docker-compose –-version
If Docker Engine and docker-compose are not installed, please refer to the documentation from Docker for your respective platform to complete this before proceeding.
- Now, let's review the docker-compose file. If you have not used docker-compose before, then note that it is a utility that's used for defining and running multi-container applications. This tool requires a file called docker-compose.yaml that lists the configuration details for application services to be installed and their dependencies.
- Please review the docker-compose.yaml file in the artifacts folder of this chapter. It includes three container images from Docker Hub corresponding to the web, application, and database tiers:
services:
web:
image: "nginx:latest"
app:
image: "hello-world:latest"
db:
image: "redis:latest"
- Navigate to the following working directory to review the Greengrass recipe file:
cd ~/hubsub/recipes
nano com.hbs.hub.Container-1.0.0.yaml
- Note that there is a dependency on the Greengrass-managed Docker application manager component. This component helps with retrieving container images from the respective repositories and executes Docker-related commands for installing and managing the life cycle of containers on the edge:
---
RecipeFormatVersion: '2020-01-25'
ComponentName: com.hbs.hub.Container
ComponentVersion: '1.0.0'
ComponentDescription: 'A component that uses Docker Compose to run images from Docker Hub.'
ComponentPublisher: Amazon
ComponentDependencies:
aws.greengrass.DockerApplicationManager:
VersionRequirement: ~2.0.0
Manifests:
- Platform:
os: all
Lifecycle:
Startup:
RequiresPrivilege: true
Script: |
cd {artifacts:path}
docker-compose up -d
Shutdown:
RequiresPrivilege: true
Script: |
cd {artifacts:path}
docker-compose down
- Now that we have the updated docker-compose file and the Greengrass component recipe, let's create a local deployment:
sudo /greengrass/v2/bin/greengrass-cli deployment create
--recipeDir ~/hbshub/recipes --artifactDir
~/hbshub/artifacts --merge "com.hbs.hub.Container=1.0.0"
- Verify that the component has been successfully deployed (and is running) using the following command:
sudo /greengrass/v2/bin/greengrass-cli component list
- To test which containers are currently running, run the following command:
docker container ls
You should see the following output:

Figure 8.16 – Running container processes
In our example here, the app (hello-world) is a one-time process, so it has already been completed. But the remaining two containers are still up and running. If you want to check all the container processes that have run so far, use the following command:
docker ps -a
You should see the following output:

Figure 8.17 – All container processes
Congratulations – you now have multiple containers successfully deployed on the edge from a Docker repository (Docker Hub). In the real world, if you want to run a local web application on the HBS hub, this pattern can be useful.
Challenge zone (Optional)
Can you figure out how to deploy a Docker image from Amazon ECR or Amazon S3? Although Docker Hub is useful for storing public container images, enterprises will often use a private repository for their home-grown applications.
Hint: You need to make changes to docker-compose with the appropriate URI for the container images and provide the required permissions to the Greengrass role.
With that, you've learned how to deploy any number of containers on the edge (so long as the hardware resource permits it) from heterogeneous sources to develop a multi-faceted architecture on the edge. Let's wrap up this chapter with a quick summary and a set of knowledge check questions.
Summary
In this chapter, you were introduced to the DevOps and MLOps concepts that are required to bring operational efficiency and agility to IoT and ML workloads at the edge. You also learned how to deploy containerized applications from the cloud to the edge. This functionality allowed you to build an intelligent, distributed, and heterogeneous architecture on the Greengrass-enabled HBS hub. With this foundation, your organization can continue to innovate with different kinds of workloads, as well as deliver features and functionalities to the end consumers throughout the life cycle of the product. In the next chapter, you will learn about the best practices of scaling IoT operations as your customer base grows from thousands to millions of devices globally. Specifically, you will learn about the different techniques surrounding fleet provisioning and fleet management that are supported by AWS IoT Greengrass.
Knowledge check
Before moving on to the next chapter, test your knowledge by answering these questions. The answers can be found at the end of the book:
- What strategy would you implement to bring agility in developing IoT workloads faster?
- True or false: DevOps is a set of tools to help developers and operations collaborate faster.
- Can you recall at least two challenges of implementing DevOps with IoT workloads?
- What services should you consider when designing a DevOps workflow from the cloud to the edge?
- True or false: Running native containers and AWS Lambda functions on the edge both offer similar benefits.
- Can you think of at least three benefits of using MLOps with IoT workloads?
- What are the different phases of an MLOps workflow?
- True or false: The MLOps toolchain for the edge is limited to a few frameworks and programming languages.
- What service is available from AWS for performing MLOps on the edge?
References
For more information regarding the topics that were covered in this chapter, take a look at the following resources:
- DevOps and AWS: https://aws.amazon.com/devops/
- Infrastructure as Code with AWS CloudFormation: https://aws.amazon.com/cloudformation/
- Developing an IoT-MLOps workflow on AWS Using Edge Manager: https://docs.aws.amazon.com/sagemaker/latest/dg/edge-greengrass.html
- CRISP-ML Methodology with Quality Assurance: https://arxiv.org/pdf/2003.05155.pdf
- Machine Learning Operations: https://ml-ops.org/
- Overview of Docker: https://docs.docker.com/get-started/overview/
- Different Ways of Running Dockerized Applications on AWS IoT Greengrass: https://docs.aws.amazon.com/greengrass/v2/developerguide/run-docker-container.html
- Special interest group: https://github.com/cdfoundation/sig-mlops