
Chapter 4. Understanding the Technology
Introduction
In Chapter 3, we mentioned that, in addition to traditional investigative skills, a good cybercrime investigator needs a thorough understanding of the technology that is used to commit these crimes. Just as a homicide investigator must know something about basic human pathology to understand the significance of evidence provided by dead bodies—rigor mortis, lividity, blood-spatter patterns, and so forth—a cybercrime investigator needs to know how computers operate so as to recognize and preserve the evidence they offer.
A basic tenet of criminal investigation is that there is no “perfect crime.” No matter how careful, a criminal always leaves something of him- or herself at the crime scene and/or takes something away from the scene. These clues can be obvious, or they can be well hidden or very subtle. Even though a cybercriminal usually never physically visits the location where the crime occurs (the destination computer or network), the same rule of thumb as for physical crimes applies: Everyone who accesses a network, a system, or a file leaves a track behind. Technically sophisticated criminals might be able to cover those tracks, just as sophisticated and careful criminals are able to do in the physical world. But in many cases, they don't completely destroy the evidence; they only make the evidence more difficult to find.
For example, a burglar might take care to wipe all fingerprints off everything he's touched while inside a residence, removing the most obvious evidence (and often the evidence that's the most helpful to police) that proves he was there. But if as he does so, tiny bits of fabric from the rag that he uses adhere to some of the surfaces, and if he takes that rag with him and it is later found in his possession, police could still have a way to link him to the crime scene. Likewise, the cybercriminal may take care to delete incriminating files from his hard disk, even going so far as to reformat the disk. It will appear to those who aren't technically savvy that the data is gone, but an investigator who understands how information is stored on disk will realize that evidence could still be on the disk, even though it's not immediately visible (much like latent fingerprints), and will take the proper steps to recover and preserve that evidence.
Information technology (IT) professionals who are reading this book and who already have a good understanding of technology might wonder whether they can skip this chapter. We recommend that they read the chapter. It might be useful for those who anticipate working with law enforcement officers and crime scene technicians to see computer technology from a new perspective: how it can serve as evidence and which technological details are most important to understand from the investigative point of view. Most IT professionals are used to looking at computer and networking hardware, software, and protocols in terms of making things work. Investigators see these items in terms of what they can reveal that is competent, relevant, and material to the case. A network administrator familiar with the Windows operating system, for example, knows that it can be made to display file modification dates, but he or she might not have considered how crucial this information could be in an investigation. Similarly, a police investigator who is not trained in the technology might realize the importance of the information but not realize that such information is available, because it isn't obvious when the operating system is using default settings. Once again, each side has only half of the pieces to the puzzle. If the two sides work together, the puzzle falls into place that much more quickly.
In this chapter, we provide an overview of how computers process and store information. First we look at the hardware, then we discuss the software (particularly the operating system) on which personal computers run. We will also discuss some basic issues of networks, and introduce you to some of the other devices that may be a source of evidence in an investigation. By introducing you to these technologies, we will be better able to expand on them in later chapters, where we discuss acquiring evidence from them.
Understanding Computer Hardware
It's commonplace for people who operate in the business world or in any administrative or clerical capacity in the public sector to have exposure to computers. The fact that they use computers every day doesn't mean that they understand them, however. This makes sense. Most of us drive cars every day without necessarily knowing anything about mechanics. Even people with enough mechanical aptitude to change their own car's oil and spark plugs might not really understand how an internal combustion engine works. Similarly, we can turn on our televisions and change the channels without really knowing how programs are broadcast over the airwaves or via cable.
Most casual users take it for granted that if they put gas in a car, it takes them where they want to go, and if they pay the cable bill, the show goes on. Even though we don't understand these technologies, they've been around long enough that we're comfortable with them. To “first-generation” users, though, the old Model T Ford must have seemed like quite a mysterious and scary machine, and pictures that somehow invisibly flew through the air and landed inside a little box in people's living rooms seemed nothing short of magic to early TV owners.
We must remember that many of the people using computers today are members of the “first generation” of computer users—people who didn't grow up with computers in every office, much less in almost every home. To them, computers still retain the flavor of something magical, something unexplainable. Some skilled crime investigators fit into this category. Just as effective cybercrime fighting requires that we acquaint IT professionals with the legal process, it also requires that we acquaint law enforcement personnel with computer processing—how the machines work “under the hood.”
The first step toward this enlightenment is to open the case and look inside at all the computer's parts and pieces and what they do so that we can understand the role that each plays in creating and retaining electronic evidence.
Note
Police colleges and other training opportunities that provide courses on electronic search and seizure or computer forensics may have prerequisites that require a person to understand some of the specifics of how computers function and store information. Having a basic understanding of the topics covered in this chapter will be useful to officers or other individuals who plan to attend such courses.
Looking Inside the Machine
At its most basic level, all a computer really does is crunch numbers. As explained later in this chapter, all data—text, pictures, sounds, programs—must be reduced to numbers for the computer to “understand” it. According to the Merriam-Webster Online Dictionary (http://www.merriam-webster.com/dictionary/computer), a computer is “a programmable usually electronic device that can store, retrieve, and process data.” To a allow a person to enter this data so that it can be processed, saved, and retrieved according to preprogrammed instructions, a combination of different kinds of hardware is required. Although we commonly think of the computer as a box with a keyboard, monitor, and mouse attached to it, it is actually an assembly of different parts.
Regardless of whether it is a tiny handheld model or a big mainframe system, computers consist of the same basic components:
▪ A control unit
▪ A processing unit
▪ A memory unit
▪ Input/output units
Of course, there must be a way for all these components to communicate with one another. PC architecture is fairly standardized, which makes it easy to interchange parts between different computers. The foundation of the system is a main circuit board, fondly referred to as the motherboard.
The Role of the Motherboard
As shown in Figure 4.1, most of the computer's components plug into the main board, and they all communicate via the electronic paths (circuits) that are imprinted into the board. Additional circuit boards can be added via expansion slots. The electronic interface between the motherboard and these additional boards, cards, and connectors is called the bus. The bus is the pathway on the motherboard that connects the components and allows them to interact with the processor.
 |
| Figure 4.1 Motherboard and Computer Components inside a Computer Case |
The motherboard is the PC's control unit. The motherboard is actually made up of many subcomponents:
▪ The printed circuit board (PCB) itself, which may be made of several thin layers or a single planar surface onto which the circuitry is affixed
▪ Voltage regulators, which reduce the 5V signal from the power supply to the voltage needed by the processor (typically 3.3V or less)
▪ Capacitors that filter the signals
▪ The integrated chipset that controls the interface between the processor and all the other components
▪ Controllers for the keyboard and I/O devices (integrated SCSI, onboard sound and video, and so on)
▪ An erasable programmable read-only memory (EPROM) chip that contains the core software that directly drives the system hardware
▪ A battery-operated CMOS chip that contains the Basic Input Output System (BIOS) settings and the real-time clock that maintains the time and date
▪ Sockets and slots for attaching other components (processor, main memory, cache memory, expansion cards, power supply)
The layout and organization of the components on the motherboard is called its form factor. The form factor determines the size and shape of the board and where its integrated ports are located, as well as the type of power supply it is designed to use. The computer case type must match the motherboard form factor or the openings in the back of the case won't line up correctly with the slots and ports on the motherboard. Typical motherboard form factors include:
▪ ATX/mini ATX/microATX Currently the most popular form factors; all current Intel motherboards are ATX or microATX. Port connectors and PS/2 mouse connectors are built in; access to components is generally more convenient, and the ATX power supply provides better air flow to reduce overheating problems. microATX provides a smaller motherboard size and smaller power supply, and supports AGP high-performance graphics. A subset of the microATX form factor is the FlexATX, which is a flexible form factor that allows various custom designs of the motherboard's shape.
▪ AT/Baby AT The most common PC motherboard form factor prior to 1997. The power supply connects to the board with two connectors labeled P8 and P9; reversing them can destroy the motherboard.
▪ LPX/Mini LPX Used by big brand-name computer manufacturers to save space in small cases. This form factor uses a “daughterboard” or riser card that plugs into the main board. Expansion cards then plug into the riser card.
▪ NLX A modernized and improved version of LPX. This form factor is also used by name-brand vendors.
Note
For additional information and specifications of various form factors, you can visit http://www.formfactors.org.
The Roles of the Processor and Memory
Two of the most important components in a computer are the processor and memory. Let's take a brief look at what these components do.
The Processor
The processor (short for microprocessor) is an integrated circuit on a single chip that performs the basic computations in a computer. The processor is sometimes called the CPU (for central processing unit), although many computer users use that term to refer to the PC “box”—the case and its contents—without monitor, keyboard, and other external peripherals.
The processor is the part of the computer that does all the work of processing data. Processors receive input in the form of strings of 1s and 0s (called binary communication, which we discuss later in this chapter) and use logic circuits, or formulas, to create output (also in the form of 1s and 0s). This system is implemented via digital switches. In early computers, vacuum tubes were used as switches; they were later replaced by transistors, which were much smaller and faster and had no moving parts (making them solid-state switches). Transistors were then grouped together to form integrated circuit chips, made of materials (particularly silicon) that conduct electricity only under specific conditions (in other words, a semiconductor). As more and more transistors were included on a single chip, the chips became increasingly smaller and less expensive to make. In 1971, Intel was the first to use this technology to incorporate several separate logic components into one chip and call it a microprocessor.
Processors are able to perform different tasks using programmed instructions. Modern operating systems allow multiple applications to share the processor using a method known as time slicing, in which the processor works on data from one application, then switches to the next (and the next and the next) so quickly that it appears to the user as though all the applications are being processed simultaneously. This method is called multitasking, and there are a couple of different ways it can be accomplished. Some computers have more than one processor. To take advantage of multiple processors, the computer must run an operating system that supports multiprocessing. We discuss multitasking and multiprocessing in more depth later in this chapter.
The processor chip itself is an ultra-thin piece of silicon crystal, less than a single millimeter in thickness, that has millions of tiny electronic switches (transistors) embedded in it. This embedding is done via photolithography, which involves photographing the circuit pattern and chemically etching away the background. The chip is part of a wafer, which is a round piece of silicon substrate, on which 16 to 256 individual chips are etched (depending on wafer size). The chips are then packaged, which is the process of matching up the tiny connection points on the chip with the pins that will connect the processor to the motherboard socket and encasing the fragile chip in an outer cover.
Before they're packaged, the chips are tested to ensure that they perform their tasks properly and to determine their rated speed. Processor speed is dependent on the production quality, the processor design, the process technology, and the size of the circuit and die. Smaller chips generally can run faster because they generate less heat and use less power. As processor chips have shrunk in size, they've gotten faster. The circuit size of the original 8088 processor chip was 3 microns; modern Pentium chips are 0.25 microns or less. Overheating decreases performance, and the more power is used, the hotter the chip gets. For this reason, new processors run at lower voltages than older ones. They also are designed as dual voltage chips, in which the core voltage (the internal voltage) is lower than the I/O voltage (the external voltage). The same motherboard can support processors that use different voltages, because they have voltage regulators that convert the power supply voltage to the voltage needed by the processor that is installed.
Even running at lower voltages, modern high-speed processors get very hot. Heat sinks and processor fans help keep the temperature down. A practice popular with hackers and hardware aficionados—called overclocking (setting the processor to run faster than its rating)—causes processors to overheat easily. Elaborate—and expensive—water-cooling systems and Peltier coolers that work like tiny solid-state air conditioners are available to address this problem.
The System Memory
The term memory refers to a chip on which data is stored. Some novice computer users might confuse the terms disk space and memory; thus, you hear the question, “How much memory do I have left on my hard drive?” In one sense, the disk does indeed “remember” data. However, the term memory is more accurately used to describe a chip that stores data temporarily and is most commonly used to refer to the system memory or random access memory (RAM) that stores the instructions with which the processor is currently working and the data is currently being processed. Memory chips of various types are used in other parts of the computer; there's cache memory, video memory, and so on. It is called random access memory because data can be read from any location in memory, in any order.
The amount of RAM installed in your computer affects how many programs can run simultaneously and the speed of the computer's performance. Memory is a common system bottleneck (that is, the slowest component in the system that causes other components to work at less than their potential performance speed). The data that is stored in RAM, unlike data stored on disks or in some other types of memory, is volatile. That means the data is lost when the system is shut down or the power is lost.
Each RAM chip has a large number of memory addresses or cells, organized in rows and columns. A single chip can have millions of cells. Dynamic random access memory (DRAM) pairs a transistor and capacitor together to create a memory cell, which represents a single bit of data. Each address holds a specified number of bits of data. Multiple chips are combined on a memory module, which is a small circuit board that you insert in a memory slot on the computer's motherboard. The memory controller, which is part of the motherboard chipset, is the “traffic cop” that controls which memory chip is written to or read at a given time. How does the data get from the memory to the processor? It takes the bus—the memory bus (or data bus), that is. As mentioned earlier, a bus is a channel that carries the electronic signals representing the data within the PC from one component to another.
RAM can be both read and written. Computers use another type of memory, read-only memory (ROM), for storing important programs that need to be permanently available. A special type of ROM mentioned earlier, erasable programmable ROM (EPROM), is used in situations in which you might need to occasionally, but not often, change the data. A common function of EPROM (or EEPROM, which is electrically erasable PROM) is to store “flashable” BIOS programs, which generally stay the same but might need to be updated occasionally. Technically, EPROM is not “read-only” 100 percent of the time, because it can be erased and rewritten, but most of the time it is only read, not written. The data stored in ROM (including EPROM) is not lost when the system is shut down.
Yet another type of memory used in PCs is cache memory. Cache memory is much faster than RAM but also much more expensive, so there is less of it. Cache memory holds recently accessed data. The cache is arranged in layers between the RAM and the processor. Primary, or Level 1 (L1), cache is fastest; when the processor needs a particular piece of data, the cache controller looks for it first in L1 cache. If it's not there, the controller moves on to the secondary, or L2, cache. If the controller still doesn't find the data, the controller looks to RAM for it. At this writing, L1 cache memory costs approximately 100 times as much as normal RAM or SDRAM, whereas L2 cache memory costs four to eight times the price of the most expensive available RAM. Cache speeds processing considerably because statistically, the data that is most recently used is likely to be needed again. Getting it from the faster cache memory instead of the slower RAM increases overall performance.
Note
There are other types of cache in addition to the processor's cache memory. For example, Web browsers create a cache on the hard disk where they store recently accessed Web pages, so if those same pages are requested again, the browser can access them from the local hard disk. This system is faster than going out over the Internet to download the same pages again. The word cache (pronounced “cash”) originally meant “a secret page where things are stored,” and appropriately, the Web cache can provide a treasure trove of information that might be useful to investigators, as we discuss in Chapter 15.
Cache memory uses static RAM (SRAM) instead of the dynamic RAM (DRAM) that is used for system memory. The difference is that SRAM doesn't require a periodic refresh to hold the data that is stored there, as DRAM does. This makes SRAM faster. Like DRAM, though, SRAM loses its data when the computer's power is turned off.
Storage Media
The term storage media is usually used to refer to a means of storing data permanently, and numerous media types can be used to store data more or less permanently, including those storing data magnetically or using optical disks. In this section, we'll look at a number of different digital media devices, as well as the most common method of storing data: hard disks.
Hard Disks
Hard disks are nonvolatile storage devices that are used to store and retrieve data quickly. Nonvolatile storage is physical media that retains data without electrical power. This means that no data is lost when the computer is powered off, making hard disks suitable for permanent storage of information. As we'll discuss in the sections that follow, hard disk drives write the digital data as magnetic patterns to rigid disks that are stored inside the hard disk drive (HDD). Because the HDD is installed in the computer, it is able to access and process the data faster than removable media such as floppy disks.
Although hard disks have been used for decades in computers, the use of them has expanded to other forms of technology. Today, you can find camcorders, game systems, and Digital Video Recorders that use hard disks to store data instead of magnetic tapes or other media. Regardless of their use, the hard disks and their related file systems all perform the same tasks of storing data so that it can be retrieved, processed, and viewed at a later time.
Overview of a Hard Disk
Although removable hard disks exist, most HDDs are designed for installation inside a computer, and for that reason were referred to as fixed disks. To avoid custom or proprietary hard disks needing to be purchased to fit inside different brands of computer, standards were developed early in the personal computer's history. These standards dictate the size and shape of the hard disk, as well as the interfaces used to attach them to the computer. As we saw when discussing motherboards, these standards are called form factors, and they refer to the physical external dimensions of the disk drive. The most common form factors that have been used over the past few decades are:
▪ 5.25-inch, which were the first hard drives that were used on PCs and were commonly installed in machines during the 1980s
▪ 3.5-inch, which is the common size form factor used in modern PCs
▪ 2.5-inch, which is the common size form factor used in laptop/notebook computers
Note
The two most common sizes of hard disk are the 2.5-inch form factor (used for laptops) and the 3.5-inch form factor (used for PCs). Although the numbers are generally associated with the width of the drive's platter (or sometimes the drive itself), this isn't necessarily the case. The 3.5-inch drives are generally 4 inches wide and use a platter that's 3.74 inches in width. They're called 3.5-inch form factor drives because they fit in the bay for a 3.5-inch floppy drive. Similarly, the obsolete 5.25-inch form factor was named as such because it fit in the 5.25-inch floppy drive bay.
The 5.25-inch disk drive is obsolete, although you may still find some in legacy machines. The first of these drives appeared on the market in 1980, but were succeeded in 1983 when the 3.5-inch drives appeared. When these became available, they were either mounted into the computer case's 3.5-inch floppy drive bays, or screwed into frames that allowed the 3.5-inch form factor to fit into the larger 5.25-inch bays.
Even though the 3.5-inch form factor has been around for more than two decades, it continues to be the common size used in modern desktop computers. The other most popular form factor is the 2.5-inch disk, which is used in laptop computers. Figure 4.2 shows a 3.5-inch form factor hard disk on the left, and a 2.5-inch form factor drive on the right. When comparing the two, you can immediately see the difference in size between them, and see that both encase the internal mechanisms of the disk drive inside a sturdy metal case. This is to prevent dust and other foreign elements from coming into contact with the internal components, which (as we'll see later) would cause the disk to cease functioning.
 |
| Figure 4.2 Hard Disks |
In looking at the 3.5-inch hard disk depicted on the left of Figure 4.2, you will see that the HDD has several connections that allow it to be installed in a computer. The 2.5-inch hard disk doesn't have these same components because it is installed differently in a laptop; a cover is removed from the laptop (generally on the back of the computer), where the 2.5-inch HDD is inserted into a slot. The 3.5-inch HDD needs to be installed in the computer using several different components outside the HDD:
▪ Jumpers
▪ Hard disk interface
▪ Power connector
Jumpers are a connector that works as an on/off switch for the hard disk. A small piece of plastic with metal connectors inside is placed over two of the metal pins to create an electrical circuit. The existence of the circuit lets the computer know whether the hard disk is configured in one of the following two roles:
▪ Master The primary hard disk that is installed on a computer. The master is the first hard disk that the computer will attempt to access when booting up (that is, starting), and it generally contains the operating system that will be loaded. If only one hard disk is installed on a machine, that hard disk is the master drive.
▪ Slave The secondary hard disk that is installed on a computer. Slave drives are generally used for additional data storage, and as a location where additional software is installed.
The power connector on a hard disk used to plug the hard disk into the computer's power supply. A power cable running from the power supply is attached to the hard disk, allowing it to receive power when the computer is started.
The hard disk interface is used to attach the hard disk to the computer so that data can be accessed from the HDD. Although we'll discuss hard disk interfaces in greater detail later in this chapter, the one shown in Figure 4.2 is an IDE hard disk interface, which is one of the most popular interfaces used on HDDs. A thin, flat cable containing parallel wires called a ribbon cable is inserted into the interface on the HDD, while the other end of the ribbon cable is plugged into the disk drive controller. As a result of this configuration, the computer can communicate with the HDD and access its data.
The Evolution of Hard Disks
The hard disk is usually the primary permanent storage medium in a PC. However, the earliest PCs didn't have hard disks. In fact, early computers (prior to the PC) didn't have any sort of data storage medium. You had to type in every program that you wanted to run, each time you ran it. Later, punched cards or tape was used to store programs and data. The next advancement in technology brought us magnetic tape storage; large mainframes used big reels of tape, whereas early microcomputers used audiocassette tapes to store programs and data. By the time the IBM PC and its clones appeared, computers were using floppy disks (the 5.25-inch type that really was floppy). More expensive models had two floppy drives (which we'll discuss later in this chapter), one for loading programs and a second for saving data—but still no hard disk.
The first hard disks that came with PCs provided 5 megabytes (MB) of storage space—a huge amount, compared to floppies. The IBM PC XT came with a gigantic 10MB hard disk. Today's hard disks are generally measured in hundreds of gigabytes (GB), at prices far lower than those first comparatively tiny disks, with arrays of them measured in terabytes (TB). Despite the fact that they're much bigger, much faster, less fragile, and more reliable, the hard disks of today are designed basically the same way as those of years ago.
Disk Platter
Although there are a number of external elements to a hard disk, the major components are inside the HDD. As shown in Figure 4.3, hard disks comprise from one to several platters, which are flat, round disks that are mounted inside the disk. The platters are stacked one on top of another on a spindle that runs through a hole in the middle of each platter, like LPs on an old-time record player. A motor is attached to the spindle that rotates the platters, which are made of some rigid material (often aluminum alloy, glass, or a glass composite) and are coated with a magnetic substance. Electromagnetic heads write information onto the disks in the form of magnetic impulses and read the recorded information from them.
 |
| Figure 4.3 Inside Components of a Hard Disk |
Data can be written to both sides of each platter. The information is recorded in tracks, which are concentric circles in which the data is written. The tracks are divided into sectors (smaller units). Thus, a particular bit of data resides in a specific sector of a specific track on a specific platter. Later in this chapter, when we discuss computer operating systems and file systems, you will see how the data is organized so that users can locate it on the disk.
The spindles of a hard disk spin the platters at high speeds, with the spindles on most IDE hard disks spinning platters at thousands of revolutions per minute (rpm). The read/write head moves over the platter and reads or writes data to the platter. When there is more than one platter in the hard disk, each platter usually has a read/write head on each of its sides. Smaller platter sizes do more than save space inside the computer; they also improve disk performance (seek time) because the heads don't have to move as far.
To read and write the magnetic information on the hard disk, the read/write head of the HDD is positioned incredibly close to the platter. It floats less than 0.1 micron over the surface of the platter. A micron (or micrometer) is one one-millionth of a meter, meaning that the read/write is less than one-tenth of one one-millionth of a meter from the platter's surface. To illustrate this, Figure 4.4 compares the sizes of a read/write head and the sizes of an average dust particle (which is 2.5 microns) and an average human hair (which is 50 microns). In looking at the differences in size, it is easy to see how a simple piece of dust or hair on a platter could cause the hard disk to crash, and why the internal components are sealed inside the hard disk assembly.
Hard Disk Sizes
IBM introduced its first hard disk in 1956, but the real “grandfather” of today's hard disks was the Winchester drive, which wasn't introduced until the 1970s. The standard physical size of disks at that time was 14 inches (the size of the platters that are stacked to make up the disk). In 1979, IBM made an 8-inch disk, and Seagate followed that in 1980 with the first 5.25-inch hard disk, which was used in early PCs. Three years later, disks got even smaller; the 3.5-inch disk was introduced. This became a standard for PCs. Much smaller disks (2.5 inches) were later developed for use in laptop and notebook computers. The IBM “microdrive” shrunk the diameter of the platter to 1 inch, connecting to a laptop computer via a PC Card (also called PCMCIA, for the Personal Computer Memory Card International Association that created the standard).
 |
| Figure 4.4 Comparison of Objects to a Read/Write Head's Distance from the Platter |
Tracks
While the platters in a hard disk spin, the read/write head moves into a position on the platter where it can read data. The part of the platter passing under the read/write head is called a track. Tracks are concentric circles on the disk where data is saved on the magnetic surface of the platter. These thin concentric rings or bands are shown in Figure 4.5 and although a full number of tracks aren't shown in this figure, a single 3.5-inch hard disk can have thousands of tracks. The tracks hold data, and pass beneath the stationary read/write head as the platter rotates.
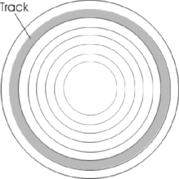 |
| Figure 4.5 Tracks on a Hard Disk |
Tracks and sectors (which we'll discuss in the next section) are physically defined through the process of low-level formatting (LLF), which designates where the tracks and sectors are located on each disk. Although in the 1980s people would perform an LLF on their hard disk themselves, typically this is done at the factory where the hard disk is made. It is necessary for the tracks and sectors to be present so that the areas where data is written to are visible to the disk controller, and the operating system can perform a high-level format and generate the file structure.
Because there are so many tracks on a platter, they are numbered so that the computer can reference the correct one when reading and writing data. The tracks are numbered from zero to the highest numbered track (which is typically 1,023), starting from the outermost edge of the disk to the track nearest the center of the platter. In other words, the first track on the disk is the track on the outer edge of the platter, and the highest numbered disk is close to the center.
Note
Although we discuss tracks and sectors on hard disks here, other media also use these methods of formatting the surface of a disk to store data. For example, a 1.44MB floppy disk has 160 tracks.
Sectors
Sectors are segments of a track, and are the smallest physical storage unit on a disk. As mentioned, the hard disk comprises predefined tracks that form concentric rings on the disk. As seen in Figure 4.6, the disk is further organized by dividing the platter into pie slices, which also divide the tracks into smaller segments. These segments are called sectors, and are typically 512 bytes (0.5KB) in size. By knowing the track number and particular sector in which a piece of data is stored, a computer is able to locate where data is physically stored on the disk.
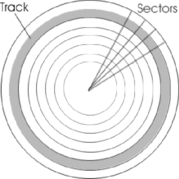 |
| Figure 4.6 Sectors on a Hard Disk |
Just as tracks on a hard disk are numbered, an addressing scheme is also associated with sectors. When a low-level format is performed at the factory, a number is assigned to the sector by writing a number immediately before the sector's contents. This number in this header identifies the sector address, so it can be located on the disk.
Bad Sectors
At times, areas of a hard disk can be damaged, making them unusable. Bad sectors are sectors of a hard disk that cannot store data due to a manufacturing defect or accidental damage. When sectors become unusable, it only means that those areas of the disk cannot be used, not the entire disk itself. When you consider that an average 3.5-inch disk will have more than 1,000 tracks that are further segmented into millions of sectors, it isn't surprising that over the lifetime of a disk, a few sectors will eventually go bad.
Because bad sectors mean that damage has occurred at the surface of the disk, it cannot be repaired, and any data stored in that area of the hard disk is lost. It can, however, be marked as bad so that the operating system or other software doesn't write to this area again. To check and mark sectors as being unusable, special utilities are used. Programs such as Scandisk and Checkdisk (CHKDSK in DOS 8.3 notation) have been available under versions of Windows, and badblocks is a tool used on Linux systems. Each can detect a sector that has been damaged and mark it as bad.
Disk Partitions
Before a hard disk can be formatted to use a particular file system (which we'll discuss later in this chapter), the HDD needs to be partitioned. A partition is a logical division of the hard disk, allowing a single hard disk to function as though it were one or more hard disks on the computer. Even if different partitions aren't used, and the entire disk is set up as a single partition, a partition must be set so that the operating system knows the disk is going to be used in its entirety. Once a partition is set, it can be given a drive letter (such as C:, D:, and so on) and formatted to use a file system. When an area of the hard disk is formatted and issued a drive letter, it is referred to as a volume.
If more than one partition is set, multiple file systems supported by the operating system can be used on a single HDD. For example, on one volume of a Windows computer, you could have C: formatted as a FAT32 file system and D: formatted as a New Technology File System (NTFS). This allows you to use features unique to different file systems on the same computer.
On computers running Linux, DOS, or Windows operating systems, you can use different kinds of partitions. The two types of partitions are:
▪ Primary partition
▪ Extended partition
A primary partition is a partition on which you can install an operating system. A primary partition with an operating system installed on it is used when the computer starts to load the OS. Although a primary partition can exist without an operating system, on older Windows and DOS operating systems, the first partition installed had to be a primary partition. Modern versions of Windows allow up to four primary, or three primary and one extended partition (which we'll discuss next) on a single disk.
An extended partition is a partition that can be divided into additional logical drives. Unlike a primary partition, you don't need to assign it a drive letter and install a file system. Instead, you can use the operating system to create an additional number of logical drives within the extended partition. Each logical drive has its own drive letter and appears as a separate drive. Your only limitations to how many logical drives you create are the amount of free space available on the extended partition and the number of available drive letters you have left on your system.
System and Boot Partitions
When a partition is created, it can be designated as the boot partition, system partition, or both. A system partition stores files that are used to boot (start) the computer. These are used whenever a computer is powered on (cold boot) or restarted from within the operating system (warm boot). A boot partition is a volume of the computer that contains the system files used to start the operating system. Once the boot files on the system partition have been accessed and have started the computer, the system files on the boot partition are accessed to start the operating system. The system partition is where the operating system is installed. The system and boot partitions can exist as separate partitions on the same computer, or on separate volumes.
Note
Don't get too confused about the purposes of the boot and system partitions. The names are self-explanatory if you reverse their actual purposes. Remember that the system partition is used to store boot files, and the boot partition is used to store system files (that is, the operating system). On many machines, both of these are on the same volume of the computer.
Boot Sectors and the Master Boot Record
Although many sectors may exist on an HDD, the first sector (sector 0) on a hard disk is always the boot sector. This sector contains codes that the computer uses to start the machine. The boot sector is also referred to as the Master Boot Record (MBR). The MBR contains a partition table, which stores information on which primary partitions have be created on the hard disk so that it can then use this information to start the machine. By using the partition table in the MBR, the computer can understand how the hard disk is organized before actually starting the operating system that will interact with it. Once it determines how partitions are set up on the machine, it can then provide this information to the operating system.
Note
At times, you'll hear about boot viruses that infect your computer when it's started, which is why users have been warned never to leave a floppy disk or other media in a bootable drive when starting a machine. Because the MBR briefly has control of the computer when it starts, a boot virus will attempt to infect the boot sector to infect the machine immediately after it's started, and before any antivirus (AV) software is started.
NTFS Partition Boot Sector
One of the many file systems we'll discuss later in this chapter is NTFS, which is used on many computers running Windows. Because NTFS uses a Master File Table (MFT) that's used to store important information about the file system, information on the location of the MFT and MFT mirror file is stored in the boot sector. To prevent this information from being lost, a duplicate of the boot sector is stored at the disk's logical center, allowing it to be recovered if the original information in the boot sector was corrupted.
Clusters
Clusters are groups of two or more consecutive sectors on a hard disk, and they are the smallest amount of disk space that can be allocated to store a file. As we've mentioned, a sector is typically 512 bytes in size, but data saved to a hard disk is generally larger than this. As such, more than one sector is required to save the data to the disk. To access the data quickly, the computer will attempt to keep this data together by writing the data to a contiguous series of sectors on the disk. In doing so, the read/write head can access the data on a single track of the hard disk. As such, the head doesn't need to move from track to track, increasing the time it takes to read and write data.
Unlike tracks and sectors of the hard disk, clusters are logical units of file storage. Clusters are managed by the operating system, which assigns a unique number to each cluster so that it can keep track of files according to the clusters they use. Although the computer will try to store files in contiguous clusters on the disk, this isn't always possible, and so data belonging to a single file may be split across the disk in different clusters. This is invisible to the user of the computer, who will open the file without any knowledge of whether the data is stored in clusters that are scattered across various areas of the disk.
Cluster Size
Because clusters are controlled by the operating system, the size of the cluster is determined by a number of factors, including the file system being used. When a disk is formatted, the option may exist to specify the size of the cluster being used. For example, in Windows XP, right-clicking on a drive in Windows Explorer displays a context menu that provides a Format menu item. When you click on this menu item the screen shown in Figure 4.7 is displayed. As shown in this figure, the dialog box provides the ability to choose the file system in which the disk will be formatted, and it provides a drop-down list called Allocation unit size. This drop-down list is where you choose what size clusters will be created when the disk is formatted.
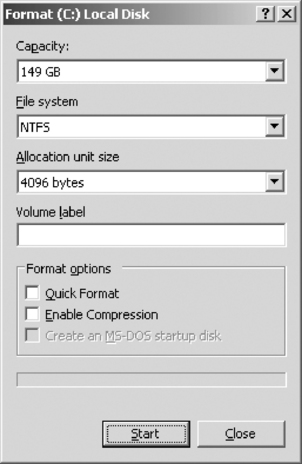 |
| Figure 4.7 Specifying Cluster Size When Formatting a Disk |
The dialog box in Figure 4.7 provides options to allocate clusters in sizes of 512 bytes, 1,024 bytes, 2,048 bytes, and 4,096 bytes. If a cluster size isn't specified, Windows will use the other option to use a default allocation size. On computers running Windows 2003 Server, the default cluster sizes are those shown in Table 4.1.
Slack Space
Because clusters are a fixed size, the data stored in a cluster will use the entire space, regardless of whether it needs the entire cluster. For example, if you allocated a cluster size of 4,096 bytes, and saved a 10-byte file to the disk, the entire 4KB cluster would be used even though 4,086 bytes of space are wasted. This wasted space is called slack space or file slack. Slack space is the area of space between the end of a file and the end of the last cluster used by that data.
Because an operating system will track where a file is located using the clusters used to store the data, clusters will always be used and potential storage space will always be wasted. Essentially, slack space is the same as pouring a bottle of cola into a series of glasses. As the bottle is emptied, the first glasses are filled to the top, but the final glass will be only partially filled. Because the glass has already been used, it can't be filled with something else as well. In the same way, once a cluster has been allocated to store a file, it can't be used to store data associated with other files.
Because extra space must be allocated to hold a file, it is better that the sizes of the clusters are lower. When clusters are smaller, the amount of space in the final cluster used to store a file will have less space that is unused. Smaller clusters will limit the amount of wasted space and will utilize disk space more effectively.
On any system, there will always be a certain amount of disk space that's wasted. You can calculate the amount of wasted space using the following formula: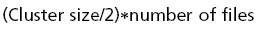
Although this formula isn't exact, it does give an estimate of how much disk space is wasted on a particular hard disk. The number of files includes the number of directories, and this amount is multiplied by half of the allocated cluster size. Therefore, if you had a cluster size of 2,048 bytes, you would divide this in half to make it 1,024 bytes (or 1KB). If there were 10,000 files on the hard disk, this would be multiplied by 1KB, making the amount of wasted space 10MB; that is, (2,048/2) * 10,000 = 10,000KB or 10MB.
Any tool used to acquire and analyze data on a hard disk should also examine the slack space. When a file is deleted from the disk, data will continue to reside in the unallocated disk space. Even if parts of the file are overwritten on the disk, data may be acquired from the slack space that could be crucial to your investigation.
Lost Clusters
As we mentioned, each cluster is given a unique number, and the operating system uses these to keep track of which files are stored in particular clusters on the hard disk. When you consider the thousands of files stored on a hard disk, and that each may be assigned to one or more clusters, it isn't surprising that occasionally a cluster gets mismarked. From time to time, an operating system will mark a cluster as being used, even though it hasn't been assigned to a file. This is known as a lost cluster.
Lost clusters are also known as lost allocation units or lost file fragments. In UNIX or Linux machines that refer to clusters as blocks, they are referred to as lost blocks or orphans. According to the operating system, these clusters don't belong to any particular file. They generally result from improperly shutting down the computer, loss of power, shutting down the computer without closing applications first, files not being closed properly, or ejecting removable storage such as floppy disks while the drive is reading or writing to the media. When these things occur, data in the cache may have been assigned a cluster, but it was never written because the machine lost power or shut down unexpectedly. Even though the cluster isn't actually used by a file, it isn't listed as being free to use by the operating system.
Although lost clusters are generally empty, such as when a cluster is allocated to a program but never released, lost clusters may contain data. If the system was incorrectly shut down (or some other activity occurred), the cluster may have had data written to it before the event occurred. This data may be a fragment of the file or other corrupted data.
Just as bad sectors can be marked as unusable using programs such as Scandisk or Checkdisk, these same programs can be used to identify lost clusters. These tools will find lost clusters, and can recover data that may have been stored in the cluster. The data is stored as files named file####.chk, and although most of the time they are empty and can be deleted, viewing the contents using Notepad or other tools to view text may reveal missing data that is important. In UNIX, you can use another program called Filesystem Check (fsck) to identify and fix orphans. With this tool, the lost blocks of data are saved in a directory called lost+found. If the data contained in these files doesn't have any useful information, it can simply be deleted. In doing so, the lost cluster is reassigned and disk space is freed up.
Disk Capacity
Disk capacity is the amount of data that a hard disk is capable of holding. The capacity is measured in bytes, which is 7 or 8 bits (depending on whether error correction is used). Bit is short for binary digit, and it is the smallest unit of measurement for data. It can have a value of 1 or 0, which respectively indicates on or off. A bit is abbreviated as b, whereas a byte is abbreviated as B. Because bits and bytes are incredibly small measurements of data, and the capacity of an HDD or other media is considerably larger, capacity is measured in increments of these values.
A kilobyte is abbreviated as KB, and although you might expect this to equal 1,000 bytes, it actually equals 1,024 bytes. This is because a kilobyte is calculated using binary (base 2) math instead of decimal (base 10) math. Because computers use this function to calculate the number of bytes used, a kilobyte is calculated as 210 or 1,024. These values increase proportionally, but to make it easier for laypeople to understand, the terms associated with the number of bytes are incremented by thousands, millions, and larger amounts of bytes. The various units used to describe the capacity of disks are as follows:
▪ Kilobyte (KB), which is actually 1,024 bytes
▪ Megabyte (MB), which is 1,024KB or 1,048,576 bytes
▪ Gigabyte (GB), which is 1,024MB or 1,073,741,824 bytes
▪ Terabyte (TB), which is 1,024GB or 1,099,511,627,776 bytes
▪ Petabyte (PB), which is 1,024TB or 1,125,899,906,842,624 bytes
▪ Exabyte (EB), which is 1,024PB or 1,152,921,504,606,846,976 bytes
▪ Zettabyte (ZB), which is 1,024EB or 1,180,591,620,717,411,303,424 bytes
▪ Yottabyte (YB), which is 1,024 ZB or 1,208,925,819,614,629,174,706,176 bytes
To put these monumental sizes in terms that are fathomable, consider that a single terabyte can hold roughly the equivalent of 1,610 CDs of data, or approximately the same amount of data stored in all the books of a large library.
Hard Disk Interfaces
The hard disk interface is one of several standard technologies used to connect the hard disk to the computer so that the machine can then access data stored on the hard disk. The interface used by an HDD serves as a communication channel, allowing data to flow between the computer and the HDD. Over the years, a number of different interfaces have been developed, allowing the hard disk to be connected to a disk controller that's usually mounted directly on the computer's motherboard. The most common hard disk interfaces include:
▪ IDE/EIDE/ATA
▪ SATA
▪ SCSI
▪ USB
▪ Fibre Channel
IDE/EIDE/ATA
IDE is an acronym for Integrated Drive Electronics, and EIDE is an acronym for Enhanced IDE. Integrated Drive Electronics is so named because the disk controller is built into, or integrated with, the disk drive's logic board. It is also referred to as Advanced Technology Attachment (ATA), a standard of the American National Standards Institute (ANSI). Almost all modern PC motherboards include two EIDE connectors. Up to two ATA devices (hard disks or CD-ROM drives) can be connected to each connector, in a master/slave configuration. One drive functions as the “master,” which responds first to probes or signals on the interrupt (a signal from a device or program to the operating system that causes the OS to stop briefly to determine what task to do next) that is shared with the other, “slave” drive that shares the same cable. User-configurable settings on the drives determine which will act as master and which as slave. Most drives have three settings: master, slave, and cable-controlled. If the latter is selected for both drives, the first drive in the chain will be the master drive.
SATA
SATA is an acronym for Serial Advanced Technology Attachment, and is the next generation that will probably replace ATA. It provides high data transfer rates between the motherboard and storage device, and uses thinner cables that can be used to hot-swap devices (plug in or unplug the devices while they're still operating). The ability to hot-swap devices has made SATA a possible successor to USB connections used with such things as external hard disks, which can be plugged into the computer to provide large removable storage or data.
SCSI
SCSI (pronounced “skuzzy”) is an acronym for Small Computer System Interface. SCSI is another ANSI standard that provides faster data transfer than IDE/EIDE. Some motherboards have SCSI connectors and controllers built in; for those that don't, you can add SCSI disks by installing a SCSI controller card in one of the expansion slots. There are a number of different versions of SCSI; later forms provide faster transfer rates and other improvements. Devices can be “chained” on a SCSI bus, each with a different SCSI ID number. Depending on the SCSI version, either eight or 16 SCSI IDs can be attached to one controller (with the controller using one ID, thus allowing seven or 15 SCSI peripherals).
USB
USB is an acronym for Universal Serial Bus. As we'll discuss later in this chapter, USB is used for a variety of different peripherals, including keyboards, mice, and other devices that previously required serial and parallel ports, as well as newer technologies such as digital cameras and digital audio devices. Because USB uses a bus topology, the devices can be daisy-chained together or connected to a USB hub, allowing up to 127 devices to be connected to the computer at one time.
In addition to peripherals, USB provides an interface for external hard disks. Hard disks can be mounted in cases that provide a USB connection that plugs into a USB port on the computer. Once plugged into the port, the computer then detects the device and installs it, allowing you to access any data on the external hard disk. The current standard for USB is USB 2.0, which is backward compatible to earlier 1.0 and 1.1 standards, and supports bandwidths of 1.5Mbps (megabits per second), 12.5Mbps, and 480Mbps. Using an external USB hard disk that supports USB 2.0 provides a fast exchange of data between the computer and the HDD.
Fibre Channel
Fibre Channel is another ANSI standard that provides fast data transfer, and uses optical fiber to connect devices. Several different standards apply to fiber channels, but the one that primarily applies to storage is Fibre Channel Arbitrated Loop (FC-AL). FC-AL is designed for mass storage devices, and is used for storage area networks (SANs). A SAN is a network architecture in which computers attach to remote storage devices such as optical jukeboxes, disk arrays, tape libraries, and other mass storage devices. Because optical fiber is used to connect devices, FC-AL supports transfer rates of 100Mbps, and is expected to replace SCSI for network storage systems.
Hard Disk Sizes
There are ways to completely erase the data on a disk, but the average user (and the average cybercriminal) will not usually take these measures. Software programs that “zero out” the disk do so by overwriting all the 1s and 0s that make up the data on the disk, replacing them with 0s. These programs are often called “wiping” programs. Some of these programs make several passes, overwriting what was already overwritten in the previous pass, for added security. However, in some cases, the data tracks on the disk are wider than the data stream that is written on them. This means that some of the original data might still be visible and recoverable with sophisticated techniques.
A strong magnet can also erase or scramble the data on magnetic media. This process is called degaussing. It generally makes the disk unusable without restoring the factory-installed timing tracks. The platters might have to be disassembled to completely erase all the data on all of them, but equipment is available that will degauss all the platters while they remain intact.
In very high-security environments such as sensitive government operations, disks that have contained classified information are usually physically destroyed (pulverized, incinerated, or exposed to an abrasive or acid) to prevent recovery of the data.
Digital Media Devices
Although to this point we've focused on the most common method of storing data, it is important to realize there are other data storage methods besides hard disks. There are several popular types of removable media, so called because the disk itself is separate from the drive, the device that reads and writes to it. There are also devices that attach to a computer through a port, allowing data to be transferred between the machine and storage device. In the sections that follow, we'll look at a number of different digital media devices, including:
Magnetic Tape
In the early days of computing, magnetic tapes were one of the few methods used to store data. Magnetic tapes consist of a thin plastic strip that has a magnetic coating, on which data can be stored. Early systems throughout the 1950s to the 1970s used magnetic tape on 10.5-inch tape, whereas home computers in the early 1980s used audiocassette tapes for storing programs and data. Today, magnetic tape is still commonly used to back up data on network servers and individual computers.
Magnetic tape is a relatively inexpensive form of removable storage, especially for backing up data. It is less useful for data that needs to be accessed frequently, because it is a sequential access medium. You have to move back and forth through the tape to locate the particular data you want. In other words, to get from file 1 to file 20, you have to go through files 2 through 19. This is in contrast to direct access media such as disks, in which the heads can be moved directly to the location of the data you want to access without progressing in sequence through all the other files.
Floppy Disks
In the early days of personal computing, floppy disks were large (first 8 inches, then 5.25 inches in diameter), thin, and flexible. Today's “floppies,” often and more accurately called diskettes, are smaller (3.5 inches), rigid, and less fragile. The disk inside the diskette housing is plastic and is coated with magnetic material. The drive into which you insert the diskette contains a motor to rotate the diskette so that the drive heads, made of tiny electromagnets, can read and write to different locations on the diskette. Standard diskettes today hold 1.44MB of data; SuperDisk technology (developed by Imation Corporation) provides for storing either 120MB or 240MB on diskettes of the same size. Although diskettes are still used, larger file sizes have created the need for removable media that store greater amounts of data.
Compact Discs and DVDs
CDs and DVDs are rigid disks a little less than 5 inches in diameter, made of hard plastic with a thin layer of coating. CDs and DVDs are called optical media because CD and DVD drives use a laser beam, along with an optoelectronic sensor, to write to and read the data that is “burned” into the coating material (a compound that changes from reflective to nonreflective when heated by the laser). The data is encoded in the form of incredibly tiny pits or bumps on the surface of the disc. CDs and DVDs work similarly, but the latter can store more data because the pits and tracks are smaller, because DVDs use a more efficient error correction method (that uses less space), and because DVDs can have two layers of storage on each side instead of just one.
CDs
The term CD originates from “Compact Disc” under which audio discs were marketed. Philips and Sony still hold the trademark to this name. Several different types of CDs have been developed over the years, with the first being CD Audio or Compact Disc Digital Audio (CDDA).
CD Audio discs are the first CDs that were used to record audio discs. Little has changed in CD physics since the origin of CD Audio discs in 1980. This is due in part to the desire to maintain physical compatibility with an established base of installed units, and because the structure of CD media was both groundbreaking and nearly ideal for this function.
CD-ROM
Until 1985, CDs were used only for audio. Then Philips and Sony introduced the CD-ROM standard. CD-ROM is an acronym for Compact Disc – Read Only Memory, and it refers to any data CD. However, the term has grown to refer to the CD-ROM drive used to read this optical storage medium. For example, when you buy software, the disc used to install the program is called an installation CD. Such a disc is capable of holding up to 700MB of data, and remains a common method of storing data.
DVDs
Originally, DVD was an acronym for Digital Video Disc and then later Digital Versatile Disc. Today it is generally agreed that DVD is not an acronym for anything. However, although these discs were originally meant to store video, they have become a common method of storing data. In fact, DVD-ROM drives are not only able to copy (rip) or create (burn) data on DVD discs, but also they are backward compatible and can copy and create CDs as well.
DVDs represent an evolutionary growth of CDs, with slight changes. Considering that the development of DVD follows the CD by 14 years, you can see that the CD was truly a revolutionary creation in its time. It is important to understand that both CDs and DVDs are electro optical devices, as opposed to nearly all other computer peripherals which are electromagnetic. No magnetic fields are involved in the reading or recording of these discs; therefore, they are immune to magnetic fields of any strength, unlike hard drives.
Due to their immunity to magnetic fields, CD and DVD media are unaffected by Electromagnetic Pulse (EMP) effects, X-rays, and other sources of electromagnetic radiation. The primary consideration with recordable CD media (and to a lesser extent, manufactured media) is energy transfer. It takes a significant amount of energy to affect the media that the writing laser transfers to the disc. Rewritable discs (which we'll discuss later) require even more energy to erase or rewrite data.
This is in direct contrast to floppy discs and hard drives, which can be affected by electromagnetic devices such as Magnetic Resonance Imaging (MRI) machines, some airport X-ray scanners, and other devices that create a strong magnetic field. CDs and DVDs are also immune to EMPs from nuclear detonations.
It is important to understand that CD and DVD media are read with light and that recordable discs are written with heat. Using an infrared (IR) laser, data is transferred to a CD or DVD onto a small, focused area that places all of the laser energy onto the target for transfer. It should be noted that all CD and DVD media are sensitive to heat (that is, higher than 120°F/49°C), and recordable media are sensitive to IR, ultraviolet (UV), and other potential intense light sources. Some rewritable media are affected by EPROM erasers, which use an intense UV light source. Various forensic alternative light sources can provide sufficient energy to affect optical media, especially if it is focused on a small area. It is not necessarily a question of heat but one of total energy transfer, which can result in heating.
Both CD and DVD media are organized as a single line of data in a spiral pattern. This spiral is more than 3.7 miles (or 6 kilometers [km]) in length on a CD, and 7.8 miles (or 12.5 km) for a DVD. The starting point for the spiral is toward the center of the disc, with the spiral extending outward. This means that the disc is read and written from the inside out, which is the opposite of how hard drives organize data.
With this spiral organization, there are no cylinders or tracks like those on a hard drive. The term track refers to a grouping of data for optical media. The information along the spiral is spaced linearly, thus following a predictable timing. This means that the spiral contains more information at the outer edge of the disc than at the beginning. It also means that if this information is to be read at a constant speed, the rotation of the disc must change between different points along the spiral.
As shown in Figure 4.8, all optical media are constructed of layers of different materials. This is similar to how all optical media discs are constructed. The differences between different types of discs are as follows:
▪ CD-R The dye layer can be written to once.
▪ CD-ROM The reflector has the information manufactured into it and there is no dye layer.
▪ CD-RW The dye is replaced with multiple layers of different metallic alloys. The alloy is bi-stable and can be changed many times between different states.
▪ DVD DVDs are constructed of two half-thickness discs bonded together, even when only one surface contains information. Each half disc contains the information layer 0.6 millimeters (mm) from the surface of the disc.
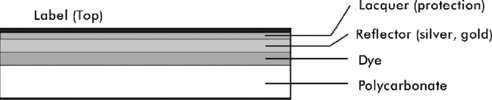 |
| Figure 4.8 CD-R Construction |
DVD media consist of two half-thickness polycarbonate discs; each half contains information and is constructed similarly to CD media. DVD write-once recordable media use a dye layer with slightly different dyes than those used for CD-R media, but otherwise they are very similar physically. Manufactured DVD media have the information manufactured into the reflector and no dye layer is present. Rewritable DVD media use bi-stable alloy layers similar to those for CD rewritable media. The differences between manufactured, write-once, and rewritable media are physically similar between CD and DVD media.
The key to all recordable media types is the presence of a reflector with the ability to reflect laser energy. Data is represented by blocking the path to the reflector either by dye or by a bi-stable metallic alloy. The bottom of a CD is made of a relatively thick piece of polycarbonate plastic. Alternatively, the top is protected by a thin coat of lacquer. Scratches on the polycarbonate are out of focus when the disc is read, and minor scratches are ignored completely. It takes a deep scratch in the polycarbonate to affect the readability of a disc. However, even a small scratch in the lacquer can damage the reflector. Scratching the top of a disc can render it unreadable, which is something to consider the next time you place a disc on your desk top-down “to protect it.” A DVD has polycarbonate on both sides; therefore, it is difficult to scratch the reflector.
Types of DVDs
Just as several types of CDs are available for a variety of uses, a wide variety of DVDs are available as well. As mentioned previously, the storage capacity of a DVD is immense compared to that of a CD, and can range from 4.5GB on a single-layer, single-sided DVD to 17GB on a dual-layer, double-sided DVD. The various types of DVDs on the market include the following:
▪ DVD-R Stands for DVD minus Recordable. A DVD-R disc will hold up to 4.5GB of data, and is a write once-read many (WORM) medium. In other words, once it is written to, the data on the DVD cannot be modified.
▪ DVD+R Stands for DVD plus Recordable. A DVD+R disc will also hold up to 4.5GB of data, and is similar to the DVD-R. You should choose between DVD-R and DVD+R discs based on how you intend to use the disc. There is some evidence that DVD-R discs are more compatible with consumer DVD recorders than DVD+R discs; however, some consumer players that will only read DVD+R discs. DVD-R discs are often the best choice for compatibility if the disc being produced contains data files. Early DVD-ROM drives can generally read DVD-R discs but are incapable of reading DVD+R discs. DVD writers that only write DVD+R/RW discs will read DVD-R discs.
▪ DVD-RW Stands for DVD minus Read Write. This, like CD-RW discs, allows an average of 1,000 writes in each location on the disc before failing. A DVD-RW disc will hold up to 4.5GB of data and is recordable.
▪ DVD+R DL (dual-layer) Is an extension of the DVD standard to allow for dual-layer recording. Previously the only dual-layer discs were those manufactured that way. This allows up to 8.5GB of data to be written to a disc. Most current DVD drives support reading and writing DVD+R DL discs.
▪ DVD+RW Stands for DVD plus Read Write. This, like CD-RW discs, allows an average of 1,000 writes in each location on the disc before failing. A DVD+RW disc will hold up to 4.5GB of data and is recordable.
▪ DVD-RAM Is a relatively obsolete media format, which emphasized rewritable discs that could be written to more than 10,000 times. There were considerable interoperability issues with these discs and they never really caught on.
HD-DVD and Blu-ray
HD-DVD is an acronym for High Definition DVD, and is the high-density successor to DVD and a method of recording high-definition video to disc. Developed by Toshiba and NEC, a single-layer HD-DVD is capable of storing up to 15GB of data, whereas a dual-layer disc can store up to 30GB of data. Although developed for high-definition video, HD-DVD ROM drives for computers were released in 2006, allowing HD-DVD to be used as an optical storage medium for computers.
HD-DVDs require so much storage space because of the amount of data required to record high-definition television (HDTV) and video. A dual-layer HD-DVD can record eight hours of HDTV or 48 hours of standard video. The difference between the two is that that HDTV uses 1,125 lines of digital video, which requires considerably more storage space. HD-DVD ROM drives are used much the same way that VCRs were used to record video onto VHS tapes, and have a transfer rate of 36Mbps, which is 12Mbps more than the rate at which HDTV signals are transmitted. Similar to the format wars between Betamax and VHS, HD-DVD has been less popular than Blu-ray.
Like HD-DVD, Blu-ray is a high-density optical storage method that was designed for recording high-definition video. The name of this technology comes from the blue-violet laser that is used to read and write to the discs. A single-layer Blu-ray disc can store up to 25GB of data, whereas a dual-layer Blu-ray disc can store up to 50GB of data.
Although stand-alone Blu-ray and HD-DVD players and recorders are available, ones that will play either technology are also available. Also, certain Blu-ray drives allow users to record and play data on computers. In 2007, Pioneer announced the release of a Blu-ray drive that can record data to Blu-ray discs, as well as DVDs and CDs. In addition to this, Sony has also released its own rewritable drive for computers.
iPod and Zune
iPod is the brand name of portable media players developed by Apple in 2001. iPods were originally designed to play audio files, with capability to play media files added in 2005. Apple has introduced variations of the iPod, with different capabilities. For example, the full-size iPod stores data on an internal hard disk, whereas the iPod Nano and iPod Shuffle both use flash memory, which we'll discuss later in this chapter. Although iPod is a device created by Apple, the term has come to apply in popular culture to any portable media player.
iPods store music and video by transferring the files from a computer. Audio and video files can be purchased from iTunes, or can be acquired illegally by downloading them from the Internet using peer-to-peer (P2P) software or other Internet sites and applications, or sharing them between devices.
Unless you're investigating the illegal download of music or video files, where iPods become an issue during an investigation is through their ability to store other data. iPods can be used to store and transfer photos, video files, calendars, and other data. As such, they can be used as storage devices to store any file that may be pertinent to an investigation. Using the Enable Disk Use option in iTunes activates this function, and allows you to transfer files to the iPod. Because any media files are stored in a hidden folder on the iPod, you will need to enable your computer to view hidden files to browse any files stored on the iPod.
iPods use a file system that is based on the computer formatting the iPod. When you plug an iPod into a computer, it will use the file system corresponding to the type of machine to which it's connecting. If you were formatting it on Windows XP, it would use a FAT32 file system format, but if you were formatting it on a machine running Macintosh OS X, it would be formatted to use the HFS Plus file system. The exception to this is the iPod Shuffle, which uses only the FAT32 file system.
Entering late in the portable digital media market is Microsoft, which developed its own version of the iPod in 2006. Zune is a portable media player that allows you to play both audio and video, as well as store images and other data. Another feature of this device is that you can share files wirelessly with others who use Zune. In addition to connecting to a computer, it can also be connected to an Xbox using USB. Ironically, although it is compatible with only Xbox 360 and Windows, it was incompatible with Windows Vista until late 2006.
Flash Memory Cards
Flash memory cards and sticks are popular for storing and transferring varying amounts of data. Memory cards have typically ranged from 8MB to 512MB, but new cards are capable of storing upward of 8GB of data. They are commonly used for storing photos in digital cameras (and transferring them to PCs) and for storing and transferring programs and data between handheld computers (Pocket PCs and Palm OS devices). Although called “memory,” unlike RAM, flash media is nonvolatile storage; that means the data is retained until it is deliberately erased or overwritten. PC Card (PCMCIA) flash memory cards are also available. Flash memory readers/writers come in many handheld and some laptop/notebook computers, and external readers can be attached to PCs via USB or serial port. Flash memory cards include:
▪ Secure Digital (SD) Memory Card
▪ CompactFlash (CF) Memory Card
▪ Memory Stick (MS) Memory Card
▪ Multi Media Memory Card (MMC)
▪ xD-Picture Card (xD)
▪ SmartMedia (SM) Memory Card
USB Flash Drives
USB flash drives are small, portable storage devices that use a USB interface to connect to a computer. Like flash memory cards, they are removable and rewritable, and have become a common method of storing data. However, whereas flash memory cards require a reader to be installed, USB flash drives can be inserted into the USB ports found on most modern computers. The storage capacity of these drives ranges from 32MB to 64GB.
USB flash drives are constructed of a circuit board inside a plastic or metal casing, with a USB male connector protruding from one end. The connector is then covered with a cap that slips over it, allowing the device to be carried in a pocket or on a key fob without worry of damage. When you need it, you can insert the USB flash drive into the USB port on a computer, or into a USB hub that allows multiple devices to be connected to one machine.
USB flash drives often provide a switch that will set write protection on the device. In doing so, any data on the device cannot be modified, allowing it to be easily analyzed. This is similar to the write protection that could be used on floppy disks, making it impossible to modify or delete any existing data, or add additional files to the device.
Although USB flash drives offer limited options in terms of their hardware, a number of flash drives will come with software that you can use for additional features. Encryption may be used, protecting anyone from accessing data on the device without first entering a password. Compression may also be used, allowing more data to be stored on the device. Also, a number of programs are specifically designed to run from a USB flash drive rather than a hard disk. For example, Internet browsers may be used that will store any history and temporary files on the flash drive. This makes it more difficult to identify a person's browsing habits.
USB flash drives have been known by many other names over the years, including thumb drive and USB pen drive. Because these devices are so small, they can be packaged in almost any shape or item. Some USB flash drives are hidden in pens, making them unidentifiable as a flash drive, unless one pulled each end of the pen to pop it open and saw the USB connector. The pen itself is completely usable, but contains a small flash drive that is fully functional. This allows the device to be hidden, and can be useful for carrying the drive around with you…unless you tend to forget your pen in places, or work in a place where others walk off with your pens.
Understanding Why These Technical Details Matter to the Investigator
Why does the cybercrime investigator need to know the difference between RAM and disk space, what a microprocessor does, or the function of cache memory? Understanding what each part of a computer does will ensure that you also understand where in the machine the evidence (data) you need might be—and where not to waste your time looking for it.
For example, if you know that information in RAM is lost when the machine is shut down, you'll be more careful about immediately turning off a computer being seized pursuant to warrant. You'll want to evaluate the situation; was the suspect “caught in the act” while at the computer? The information that the suspect is currently working on will not necessarily be saved if you shut down the system. The contents of open chat sessions, for example, could be lost forever if they're not automatically being logged. You will want to consider the best way to preserve this volatile data without compromising the integrity of the evidence. You might be able to save the current data, print current screens, or even have your crime scene photographer take photos of the screens to prevent information in RAM from being lost.
Understanding how data is stored on and accessed from hard disks and removable media will help you recognize why data can often be recovered even though the cybercriminal thinks he or she has “erased” it, either by merely deleting the files or by formatting the disk.
Investigators should also be aware of the many existing removable media options that allow cybercriminals to store evidentiary data in a location separate from the computer, easily transfer that data to another computer, or make copies of the data that can be used in case the original data on the computer's hard disk is destroyed. The presence of any removable media drive (diskette drive, CD-R, tape drive, or the like) means that there is definitely a possibility that data has been saved and taken away. Unfortunately, the absence of such a drive does not negate that possibility, because many removable media drives are external and portable; they can be quickly and easily moved from one computer to another, attaching to the machine by way of a serial, parallel, USB, or other port.
The Language of the Machine
Computer hardware and accessories, such as hard disks and removable media, might provide the physical evidence of cybercrime. However, in most cases the hardware itself is not really the evidence; it merely contains the evidence. Similarly, a letter written by a criminal might be entered into evidence, but it is not the physical page and ink that provide proof of guilt, it is the words written on the page that indicate the criminal's culpable mental state or that provide a written confession of the criminal's actions. If those words are in a language that the police, prosecutors, and jury can understand, using them as evidence is easy. On the other hand, if the words are written in a foreign language, using them as evidence might be more difficult because they will have to be interpreted by someone who understands both languages.
In a sense, most computer data is written in a foreign language. The data stored in computers is written in the “language” of 1s and 0s, or binary language (also called machine language or machine code). Although relatively few humans can program in pure machine language and few cybercrime investigators or programmers learn to translate the magnetic encoding representing 1s and 0s on a disk into “real” (understandable) data, it is helpful for investigators to understand how binary language works to anticipate questions that the defense can raise in a case that relies on computer data as evidence.
Getting Down to the Lowest Level
Machine language is the lowest level of programming language. The next step up is assembly language, which allows programmers to use names (or mnemonics) represented by ASCII characters, rather than just numbers. Code written in assembly language is translated into machine language by a program called an assembler.
Most programmers, however, write their code in high-level languages (for example, BASIC, C++, and so on). High-level languages are “friendlier” than other languages in that they are more like the languages that humans write and speak to communicate with one another and are less like the machine language that computers “understand.” Although easier for people to work with, high-level languages must be converted into machine language for the computer to use the program. This is done by a program called a compiler, which reorganizes the instructions in the source code, or an interpreter, which immediately executes the source code. Because different computing platforms use different machine languages, there are different compilers for a single high-level language to enable the code to run on different platforms.
Wandering through a World of Numbers
Working with numbers, beyond the primitive method of simply representing each item counted as a one (for example, carving one notch on the investigator's wooden desktop for each case solved), requires that we use a base system to group items in an ordered fashion, making it easier for us to keep count.
Who's on Which Base?
Most of us are most familiar with the base-10 numbering system, also called the decimal numbering system. Many sources credit early Indian cultures with creating this numbering system approximately 5,000 years ago; it was later refined in the Arab world. This system uses 10 digits (0 through 9) to represent all possible numbers. Each digit's value depends on its place; as you move left in reading a number, each place represents 10 times the value to its right. Thus, the digit 1 can represent 1, 10, 100, 1,000, and so on, depending on its place as defined by the number of digits to its right. A decimal point is used to allow numbers less than 1 to be represented.
We use base 10 all the time; it is our day-to-day numbering system. When we see a decimal number such as 168, we understand that the 1 represents one hundred, the 6 represents six tens, and the 8 represents eight ones, based on the place occupied by each digit in relation to the others.
Base 10 works great for human counting because we have 10 fingers (also called digits) that we can use to count on. Historians believe this explains the development and popularity of decimal numbering; primitive people found it easy to count to 10 on their fingers and then make a mark in the sand or on stone to represent each group of 10.
Computers, however, work with electrical impulses that have two discrete states. You can visualize this system by thinking of a standard light switch. The bulb can be in one of two possible states at a given time; it is either on or off. This is a digital signal. We don't have 10 different states to represent the 10 digits of the decimal system to the computer, but we can still represent all possible numbers using the base-2 numbering system, also called the binary numbering system.
Understanding the Binary Numbering System
Binary numbering uses only two digits, 0 and 1. Each binary digit (each 0 or 1) is called a bit. In binary numbering, as in decimal, the value of a digit is determined by its place. However, in binary, each place represents two times the value of the place to its right (instead of 10 times, as in base 10).
This means the binary number 1000 does not represent one thousand; instead, it represents eight (its decimal equivalent) because that's the value of the fourth place to the left. A zero is a placeholder that indicates that a place has no value, and a one indicates that a place has the value assigned to it. Thus, 1111 represents 15 in decimal, because each place (starting from the right) has a value of 1, 2, 4, and 8. Adding these values together gives us 15.
Converting between Binary and Decimal
Although computer processors must work with binary numbering, humans prefer to work with numbering systems that use more digits, because it is less confusing for us to deal with a number that looks like 139 than its binary equivalent of 10001011.
Table 4.2 shows the place values of the first 12 places of a binary number, starting from the right. If the binary digit is a 1, the value shown is assigned to it; if it's a 0, no value is assigned. The second line of the table shows the digits of a typical binary number.
Looking at this binary number, 110100011001, we see that the bits that are “on” (represented by 1s) have values of 1, 8, 16, 256, 1,024, and 2,048. If we add those values together, we get 3,353. This is the decimal equivalent of the binary number.
Converting between Binary and Hexadecimal
Another numbering system that is sometimes used to make binary more palatable for humans is the hexadecimal, or hex, system, or base 16. Why not just use our familiar decimal system and convert it to binary instead of learning yet another numbering system? Hex is useful because it is easier to convert hex to binary. Because hex uses 16 digits, each byte (eight binary digits) can be represented by two hex digits. Hex also produces shorter numbers to work with than decimal.
Hex needs six more symbols than decimal to represent all its digits, so it uses the standard decimal digits 0 to 9 to represent the first 10 digits and then uses the first six letters of the alphabet, A to F, to represent the remaining six digits. Table 4.3 shows the hexadecimal digits and their decimal equivalents.
| Hexadecimal | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
| Decimal | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
Using this system, for example, the decimal number 11,085 is equivalent to the hex number 2B4D, and the decimal number 1,409 is equivalent to the hex number 581. In the first case, it's obvious that we're dealing with a hexadecimal number, but if we see the number 581, how do we know whether it's a decimal or a hexadecimal number? To solve this problem, hex numbers are indicated by either a prefix of 0x or a suffix of H. Thus, our hex equivalent of 1,409 would be written as either 0x581 or 581H.
In the computer world, you'll find that some numbers (such as Internet Protocol [IP] addresses) are traditionally represented by their decimal equivalents, whereas others (such as memory addresses and Media Access Control [MAC] addresses) are traditionally represented by their hexadecimal equivalents. We will discuss IP addresses and MAC addresses later in this chapter.
Converting Text to Binary
Computers “think” in binary, but people (aside from the rare mathematical genius) don't. We tend to work with words, and much of the data that we input to our computers is in the form of text. How does the computer process this data? Ultimately, it must be converted to the binary “language” that the computer understands.
Text files are commonly encoded in either ASCII (in UNIX and MS-DOS-based operating systems) or Unicode (in Windows). ASCII stands for American Standard Code for Information Interchange, which represents binary numbers as text. Assembly language uses ASCII characters for programming. Each character of the alphabet, numeric digit, or symbol is represented by a specific 1-byte string of binary digits. (In a binary file, there is no one-to-one correlation between characters and bytes.)
ASCII characters are used by text-based operating systems and programs such as MS-DOS and WordPerfect versions prior to 5.0. By contrast, graphical programs use bitmaps or geometrical shapes instead of characters to create display objects.
Note
The extended ASCII character set includes additional characters, such as shapes for drawing pictures so that graphics objects can be simulated. MS-DOS uses extended ASCII to display menus, bar charts, and other shapes that are based on straight lines.
Encoding Nontext Files
The original ASCII encoding scheme used 7-bit characters and is designed to handle plain text only. Then along came the Internet, and people wanted to send files to one another via e-mail. E-mail server software was designed to handle the ASCII character set and another 7-bit encoding scheme, Extended Binary Coded Decimal Interchange Code (EBCDIC), which IBM developed for its minicomputers and mainframes. This worked fine as long as everyone was sending plain text files. However, it was a problem if you wanted to send pictures, audio, programs, or files created in applications that did not produce plain text, because most nontext files use 8-bit characters. Even the documents created by word processors are usually not saved as ASCII files but as binary files (to preserve formatting information).
The answer to this problem was to use an encoding scheme that could represent nontext files as text. Programmers came up with solutions such as uuencode and Multipurpose Internet Mail Extensions (MIME) to convert nontext files into ASCII text. Thus, a photo or other nontext file could be sent across the Internet without a problem. An encoded file looks like a mass of meaningless ASCII characters to the human eye, but when it is decoded by software at the recipient's end, it is converted back into its original form. MIME provided a number of advantages over uuencode in that it supported sending multiple attachments and interactive multimedia content. Perhaps most important, it supports languages such as Japanese, Chinese, and Hebrew that don't use the Roman alphabet.
Another encoding scheme, called BinHex, is often used by Apple Macintosh software. Mac files differ from those created by Windows and some other operating systems in that Mac files consist of two parts, called forks—one that contains the actual data and one that contains attribute information and parametric values. Programs are available to convert the files into a single byte stream for sending over a network. Macintosh files can be sent via MIME, using the MIME encapsulation specifications outlined in RFC 1740.
Web browsers also support MIME so that they can display files that are not in Hypertext Markup Language (HTML) format. There is also a version of MIME called S/MIME that supports encryption of messages.
Understanding Why These Technical Details Matter to the Investigator
Investigators might not be capable of interpreting machine language, but they should understand what it is when they see it. The 1s and 0s of binary computation, the odd-looking hexadecimal numbers used in some types of addressing, and the indecipherable “gibberish” of MIME-encoded files might look meaningless, but when properly translated they can contain valuable evidence.
Just as an investigator should not throw away a letter found at the scene of a crime just because it happens to be written in Chinese, neither should computer data be dismissed as useless just because the investigators can't understand it. Pure binary data, or data that has been encoded for sending across a network, might be less convenient to work with than text or unencoded pictures, but often it can be converted to a readable form by the proper software.
It is also important for investigators to understand the difference between the type of encoding we are discussing here—which is done to make data recognizable and usable by a computer—and encryption, the purpose of which is to make data unrecognizable and unusable by unauthorized humans. Encoded data is intended to be easily decoded, and the software for doing so is widely available; encrypted data is intended to be difficult or impossible to decrypt without the proper key.
The very fact that a file has been encrypted can in some cases be a red flag that arouses suspicion or a building block of the probable cause needed to get a warrant or effect an arrest. Thus, knowing the difference between an encoded file and an encrypted file will save investigators time and strengthen their credibility before a judge.
Does File Encryption Create Probable Cause?
Investigators know that probable cause is usually not based on one fact or piece of evidence, but rather comprises multiple building blocks that, when taken together, would cause a reasonable and prudent person to believe that a crime has been committed by the suspect. Law enforcement professionals sometimes refer to these building blocks collectively as the totality of the circumstances. The Fourth Amendment to the U.S. Constitution requires that probable cause, based on the totality of the circumstances, be shown before a search warrant can be issued.
Does the existence of an encrypted file (or files) on a computer establish probable cause to seize that computer and examine the files, going on the theory that “only guilty people have something to hide”? In other words, if the girlfriend of a child-pornography suspect tells you that files on the family computer are encrypted so that she can't open them, is that enough cause for a search warrant? Given the nature of probable cause, the answer is no—at least, not by itself. Encryption alone generally would not be enough to satisfy the definition of probable cause. Use of encryption is not illegal in the United States (it is in some countries), and many people concerned with privacy use encryption to protect data that has nothing to do with criminal activity.
However, the fact that data is encrypted can be used as one of your building blocks of probable cause. If you have other evidence that indicates, for example, that a suspect regularly downloads pornographic photos of children (such as testimony of a known child pornographer that the suspect requested such photos from him, intercepted e-mail messages, or the like), the existence of encrypted files on the suspect's hard disk would add to the suspicion that illicit photos were stored there.
Other considerations include whether all the files on the disk are encrypted or only some select ones. The former situation is more indicative of someone who is just generally concerned about privacy, whereas the latter situation serves as a red flag that those particular files could contain something of interest to law enforcement. We'll discuss encryption more in this chapter, when we discuss file systems. We also discuss encryption in greater detail in Chapter 12, in the section on cryptography.
Understanding Computer Operating Systems
As a computer starts, the operating system is loaded into its memory and provides the foundation or platform on which application programs run. Although the vast majority of today's personal computers run some version of one of the three most popular PC operating systems (Windows, UNIX/Linux, or Macintosh OS), thousands of different computer operating systems exist. Some of these are network operating systems such as NetWare that run servers but don't function as desktop/client operating systems. Some run on mainframe or mini-mainframe computers, and some are designed for high-end workstations, such as Sun's Solaris. Others are proprietary operating systems used for specific devices, such as Cisco's Internet Operating System (IOS) that runs on Cisco routers, or SCOUT, which runs network appliances, whereas others are experimental operating systems such as GNU HURD and SkyOS. Some are used as embedded operating systems in a variety of devices, such as Windows Embedded CE or Windows XP Embedded, which is used in such devices as personal digital assistants (PDAs), Voice over IP (VoIP) phones, navigational devices, medical devices, and so on.
Understanding the Role of the Operating System Software
The operating system acts as a sort of liaison between the computer hardware and the application programs that are used to perform specific tasks (such as word processing or downloading and sending e-mail). It also provides file management, security, and coordination of application and utility programs that are running simultaneously. Operating systems can be classified in a number of different ways:
▪ Text-based (or character-based) operating systems such as MS-DOS and UNIX/Linux are faster performers because they don't have the overhead required to display complex graphics, but many people find them to be less user-friendly than graphical user interface (GUI) operating systems because you must learn and type commands to perform tasks. Most text-based operating systems can run shell programs to give them a graphical interface. Examples include Windows 3.x for MS-DOS and KDE for Linux.
▪ Multiuser operating systems generally run on mainframe systems and allow more than one user to log on, through terminals, and run programs simultaneously. The term is sometimes also used to refer to operating systems (such as Windows XP or Vista) that allow only one user at a time to log on but identify different users by a user account that is assigned a profile that defines settings, preferences, and documents that are specific to that user. Server operating systems (such as Windows Server 200x, Novell NetWare, and UNIX) allow multiple users to log on to the server over the network and access its resources, although only one user is logged on interactively (at the local machine).
▪ Multitasking operating systems are those that allow you to run more than one program at a time. MS-DOS is a single-tasking operating system; in other words, you have to close one application before you can start another. Shell programs (such as the Windows 3.1 shell) running on top of DOS allowed it to multitask. UNIX, and Windows 9x/ME/NT/2000, XP, and Vista are all true multitasking operating systems.
▪ Multiprocessing operating systems are able to use the capabilities of more than one microprocessor installed in the system, either by assigning different programs to run on different processors or by allowing different parts of a single program to run on different processors. For example, Windows 9x and ME operating systems do not recognize or use multiple processors, but Windows NT, 2000, XP, and Vista do. (The number of processors depends on the OS version.) UNIX and Macintosh also support multiple processors.
Differentiating between Multitasking and Multiprocessing Types
Different operating systems support such features as multitasking and multiprocessing in different ways. The type of multitasking or multiprocessing that a particular operating system uses depends on its architecture—that is, its design and structure.
Multitasking
Multitasking works by time slicing—that is, allowing multiple programs to use tiny slices of the processor's time, one after the other. PC operating systems use two basic types of multitasking: cooperative and preemptive. Cooperative multitasking was used by Windows 3.x and earlier, running on top of MS-DOS, as well as Macintosh operating systems prior to OS X. In this type of multitasking environment, each program must be written so that its processes (tasks or executing programs) use the processor for a short amount of time and then give up control of the processor to other processes. As long as the programs are written to cooperate, this system works. However, poorly written programs can take over the processor and refuse to relinquish control. When this happens, the system can freeze or crash.
Preemptive multitasking is more efficient. This method puts the operating system itself in charge of the processor. This way, a badly written program can't hog control of the processor; if it tries to do so, the operating system preempts its use of the processor and gives it to another process. A component in the operating system's kernel called the scheduler is responsible for allotting use of the processor to each process in turn. Some operating systems allow you to assign priorities to certain processes so that they come first when they need to use the processor. Preemptive processing is used by Windows 9x and later, UNIX, and Macintosh OS X.
Multiprocessing
Even if a computer has more than one processor physically installed, it might not be able to perform multiprocessing. To perform multiprocessing, the operating system must be capable of recognizing the presence of multiple processors and be able to use them. Some operating systems—such as Windows 9x—do not support multiprocessing. Even among those that do, not all multiprocessing operating systems are created equal.
There are three methods of supporting multiple processing:
▪ Asymmetric multiprocessing (AMP or ASMP)
▪ Symmetric multiprocessing (SMP)
▪ Massively parallel processing (MPP)
With asymmetric multiprocessing, each processor is assigned specific tasks. One primary processor acts as the “master” and controls the actions of the other, secondary processors.
Symmetric multiprocessing makes all the processors available to all individual processes. The processors share the workload, distributed more or less equally, thus increasing performance. Symmetric multiprocessing is also called tightly coupled multiprocessing because the multiple processors still use just one instance of the operating system and share the computer's memory and I/O resources.
Massively parallel processing is a means of crunching huge amounts of data by distributing the processing over hundreds or thousands of processors, which might be running in the same box or in separate, distantly located computers. Each processor in an MPP system has its own memory, disks, applications, and instances of the operating system. The problem being worked on is divided into many pieces, which are processed simultaneously by the multiple systems.
Note
MMP is generally used in research, academic, and government environments running large, complex computer systems. It is seldom used on desktop machines or typical business servers, although there is a type of parallel processing called distributed computing that uses large numbers of ordinary PCs on a network to work together on a problem, dividing the task among multiple machines. One of the best-known examples of this type of processing is done on Berkeley Open Infrastructure for Network Computing (BOINC), which expanded from the original Search for Extraterrestrial Intelligence (SETI) project called SETI@Home. BOINC recruits volunteers across the Internet who install software on their home computers that allows their systems, during idle time, to process a portion of the massive amount of data used for analyzing data from projects chosen by the user, which research such areas as biology, earth sciences, physics, and so on.
A paper that outlines the advantages of the distributed computing model of parallel processing used in SETI and other projects is available at http://roland.grc.nasa.gov/~mallman/papers/prime-delay.pdf.
Symmetric multiprocessing is the type supported by mainstream operating systems, including Windows XP and Vista, Linux, BSD, and other UNIX versions. To take advantage of the multiprocessing capabilities, the programs running on multiprocessor machines and operating systems must be multithreaded—that is, they must be written in a way that allows them to execute tasks in small executable parts called threads. Windows 2000/XP and later also support a feature called processor affinity that provides AMP-like functionality.
Differentiating between Proprietary and Open Source Operating Systems
Most commercial operating systems are proprietary—that is, the vendors keep the source code (the programming instructions) secret, and the licensing agreements prohibit “reverse engineering” (that is, dismantling the software's components and replicating them). However, some operating systems are distributed as open source products, meaning that the source code is made available to the public and developers at no cost. Anyone is free to modify the code to improve it. The only “catch” is that the license, although free, usually obligates programmers to disclose their improvements or even to make them available to the public at no cost.
The most notable (though not the only) open source operating system is Linux, which is based on the UNIX operating system. Many versions of UNIX, such as FreeBSD, are open source, with some such as HP-UX and Solaris originating as proprietary systems but moving to support open source. To confuse matters more, although the source code for Linux is free, vendors such as Red Hat market their own “distros” (Linux-speak for distributions) commercially. The term open source doesn't necessarily mean that the compiled version is free—only the source code is.
Linux was developed by and is named after Linus Torvalds, under the GNU General Public License (GPL). The licensing agreement makes it clear that developers who modify or distribute the software can charge for the service if they like; what they can't do is keep the source code secret or patent the products (unless the patent is licensed for everyone's free use).
Note
You can read all the terms of the entire GNU GPL on the GNU Web site, at http://www.gnu.org/licenses/gpl.html#SEC1. For information about the Open Source Initiative (OSI), visit http://www.opensource.org.
If open source software is free—or at least the source code is—why doesn't everyone use it instead of proprietary commercial software that costs big bucks? There are several reasons:
▪ There are dozens of different versions or distros of each open source operating system or application. This can be confusing to users, who don't know which one to select.
▪ Because anyone and everyone can make modifications to the operating system, you don't have the standardization that you have with proprietary software. In other words, one version of Linux might work fine with your hardware configuration, but another distro might not.
▪ Often, device drivers are not readily available for open source operating systems, so you must write your own. This is beyond the capabilities of many consumers and business users.
▪ Generally, no warranty is included with open source software, and no technical support is available (although some companies, such as Red Hat, package their distros of Linux and in essence sell the warranty/tech support services accompanied by the “free” software). This is especially important to business users, who generally will not use software that doesn't include tech support from the vendor.
An Overview of Commonly Used Operating Systems
The most commonly used operating systems for computers include those made by Microsoft, Apple's Macintosh operating systems, and the various distros of Linux and other UNIX-based operating systems. In this section, we look briefly at these operating systems. In doing so, we'll see how some of these systems have evolved over the years, and we'll introduce you to some features that we'll discuss later in this chapter and expand upon in future chapters.
Understanding DOS
DOS is the Disk Operating System, which was the operating system first used on the original IBM PCs. Today, few computers still run some form of DOS. The most popular “flavor” of DOS is Microsoft's version, MS-DOS. IBM licensed DOS from Microsoft and marketed a version called PC-DOS that was bundled with its early PCs. Digital Research sold a version called DR-DOS that was later marketed by Caldera as DR-OpenDOS. There is also an open source version of DOS called FreeDOS; for more information on this product, see the FreeDOS Web site, at http://www.freedos.org.
The earliest versions of DOS used a file system called FAT12 (we'll discuss file systems in more detail in the next section). MS-DOS versions 3.x through 6.x supported the FAT16 file system along with the FAT12 file system and were used both as stand-alone operating systems and as the operating system on which Windows (through Version 3.11) was loaded, because early versions of Windows were not full-fledged operating systems, only graphical shells that required DOS underneath. MS-DOS Version 7.0, which also supported the FAT12 and FAT16 file systems, was part of the Windows 95 operating system. At that point in the evolution of Microsoft operating systems, the shell was integrated with the operating system, and users no longer installed MS-DOS and Windows as two separate products. Windows 95b (also called OEM Service Release 2, or OSR 2) was integrated with a new version of MS-DOS, Version 7.1, which supported the FAT32 file system.
MS-DOS as a stand-alone operating system is text-based and is not capable of multitasking. It has several limitations, such as the inability to work with disk partitions larger than 2GB or memory greater than 1MB (unless you use the Expanded Memory Scheme, or EMS, software). Windows 3.x used EMS to provide multitasking. DOS was built on the BASIC programming language, and most versions included a version of BASIC. The MS-DOS interface appears in Figure 4.9.
 |
| Figure 4.9 The Text-Based MS-DOS Interface |
Windows 1.x through 3.x
Not really operating systems in their own right, but rather add-ons to MS-DOS, Windows versions 1.x through 3.x were designed to bring a graphical environment to the Microsoft computing environment. Versions 1 and 2 were not very popular, but as the old adage says, the third time is a charm, and Windows 3.0, released in 1990, was the beginning of Microsoft's dominance in the operating system market.
Who “Stole” What from Whom?
It is a popular truism in the PC community that Microsoft “stole” (or at least derived) the idea of a graphical interface for Windows from its chief competitor at the time, Apple. Like most truisms, it is only partially true. It is true that Apple did develop a graphical operating system for its Local Integrated Software Architecture (LISA) computer, which it officially released in 1983, just prior to Microsoft's announcement of Windows and almost two years before Windows 1.0 actually became available to the public. However, Apple didn't “invent” the idea of the mouse-driven GUI, as many people believe. The Xerox Alto (named after the Palo Alto Research Center, where it was developed) and Star computers were actually the first PCs to use these features, way back in the 1970s. Both Steve Jobs (of Apple) and Bill Gates (of Microsoft) visited Palo Alto and “borrowed” the ideas from Xerox, which later showed up in the Lisa (and later the Macintosh) and in Windows.
For more information about the Alto, see http://www.fortunecity.com/marina/reach/435/. To view the Lisa interface, see http://members.fortunecity.com/pcmuseum/lisadsk.htm. For a look at the interface on Windows 1.0 and subsequent versions of Windows (up through XP), visit http://www.infosatellite.com/news/2001/10/a251001windowshistory_screenshots.html#win101.
Like DOS, you would be hard-pressed to find a computer running Windows 3.x in the world today. Like MS-DOS alone, it will run on older hardware, and many applications were made for it. Windows 3.x over MS-DOS is known as a 16-bit operating system, meaning that it can process two bytes (which equals 16 bits) at a time. One of its limitations was the inability to handle filenames that have more than eight characters (with a three-character extension).
Note
The first microcomputer operating systems, used by the Commodore PET, Tandy TRS-80, Texas Instruments TI/99, and Apple II, were 8-bit operating systems.
Windows 3.11 added 32-bit file access (a new way of accessing the disk), updated device drivers, and bug fixes. Another popular version of Windows 3.1 and 3.11 was called Windows for Workgroups, which included integrated networking components for the first time. It included Microsoft Mail support and remote access services, and it claimed 50 percent to 150 percent faster disk I/O performance. Windows for Workgroups made peer-to-peer networking much easier and more convenient than earlier Microsoft operating systems and became very popular in small-business environments. Figure 4.10 shows the Windows 3.11 interface.
 |
| Figure 4.10 Windows 3.x Running on Top of MS-DOS, Providing a Graphical Interface |
Windows 9x (95, 95b, 95c, 98, 98SE, and ME)
Windows 95 was a major new operating system release that was accompanied by heavy fanfare from Microsoft and the computing community. Released in August 1995, Windows 95 was Microsoft's first 32-bit consumer operating system; however, it is a hybrid operating system rather than a true 32-bit OS. For backward compatibility with older programs written for Windows 3.x, there was still a good deal of 16-bit code in Windows 95.
Windows 95 was designed to provide users with an entirely new interface (doing away with the old Program Manager and incorporating the now-familiar Start button and taskbar) and many enhanced features, such as:
▪ Preemptive multitasking (for 32-bit programs only)
▪ Support for long filenames (up to 256 characters) through the VFAT file system
▪ Plug and Play (which makes hardware installation easier)
▪ The Recycle Bin (which makes it easier to recover deleted files)
▪ Dial-up networking support built into the operating system
Although many computer enthusiasts were disappointed with the loss of DOS and changes to the Windows GUI, Windows 95 became tremendously popular and was the beginning of the Windows 9x family tree, which includes Windows 98 and ME. The Windows 95 interface appears in Figure 4.11.
 |
| Figure 4.11 The Windows 95 Interface |
The second release of Windows 95, popularly called 95b and officially referred to as OSR 2, was not available to consumers on the shelves. It was released to original equipment manufacturers (OEMs, or PC hardware vendors) to install on the machines they sold. Version 95b added support for the FAT32 file system. A variant of 95b, called OSR 2.1, added rudimentary USB support. Another variant, OSR 2.5, which is often called Windows 95c, added the Internet Explorer 4.0 Web browser as an integrated component.
The next upgrade to Microsoft's 9x line of consumer operating systems was Windows 98, released, appropriately enough, in June 1998. This was the first version available as packaged software to consumers that supported the FAT32 file system (in addition to the “old” file systems FAT12 and FAT16). Windows 98 also added networking and dial-up enhancements, better hardware support, infrared (IrDA) support, and Advanced Configuration and Power Interface (ACPI) technology. It also included the Active Desktop (which you could add to Windows 95 by installing the Internet Explorer 4.0 browser) and provided for multiple-monitor support. Windows 98 replaced the old Help files with an indexed, searchable HTML system that is far more functional and added a number of interactive Troubleshooting Wizards, along with the Windows Update online driver/component update feature. Windows 98SE (second edition) added a few new features such as Internet Connection Sharing (ICS) and DVD-ROM support.
Next in the Windows 9x line was Windows ME, short for Millennium Edition, released in September 2000. ME added several multimedia features such as a video-editing program, and included better home networking support, but it was not a major upgrade. ME was presumably the last of the Windows operating systems exclusively geared to home users. The Windows 9x/ME line and the Windows NT/2000 line, geared toward businesses, were merged into one with the advent of Windows XP.
Windows NT
Microsoft designed Windows NT for the corporate desktop and server market. NT came in two versions: Workstation for desktops and Server for servers. NT was released in 1993 and was based in part on the work done jointly by Microsoft and IBM, before they parted ways, on OS/2. Thus, many of NT's features, such as its pure 32-bit code and its high-performance, secure file system, are similar to features in OS/2. NT was Microsoft's first operating system that was not based on MS-DOS. However, it could run MS-DOS programs by creating a virtual machine that emulated the DOS environment on which DOS applications can run.
Note
What does NT stand for? In its early days, Microsoft said the letters stood for New Technology. Later (when the technology could no longer be called “new”), Microsoft changed its story and said it doesn't stand for anything. David Cutler was the driving force behind the development of Windows NT.
The primary differences between Windows 9x and Windows NT were stability and security. The business environment requires an operating system that does not crash frequently, one that is secure enough to protect the sensitive data often stored on corporate computers. The architecture of Windows NT incorporated a hardware abstraction layer (referred to fondly as HAL) that prevented software applications from making direct calls to the hardware. This made NT more stable and less crash-prone but also meant that some applications written for Windows 9x wouldn't run on Windows NT.
NT 3.1 was released in 1993, a year prior to the release of Windows 95. The interface resembled Windows 3.x, but the kernel was completely different. A significant factor was the way NT handled memory. Unlike with Windows 3.x before it, each program ran in its own separate memory address. This meant that if one program crashed, it would not bring down with it the remaining programs that were currently running. Security features included mandatory logon (a user must have an account name and password to log on to the computer). NT also introduced support for a new file system, NTFS, which offers better performance as well as the ability to set permissions (called NTFS permissions or file-level permissions) on individual files and folders. NT 3.51 and earlier versions also included support for the native file system of IBM's OS/2, High Performance File System (HPFS).
NT 4.0 was a major upgrade released in 1996. The interface resembled that of Windows 95, and it included advanced user administration tools, wizards, a network monitor (a built-in protocol analyzer or “sniffer” software), a task manager (a tool that provides information on running applications and processes), and support for system policies and user profiles to allow administrators to more easily control the users' desktop environment. Remote access services and built-in virtual private network (VPN) support via Point-to-Point Tunneling Protocol (PPTP) were other improvements. NT 4.0 dropped support for HPFS. Figure 4.12 shows the Windows NT 4.0 interface.
 |
| Figure 4.12 The Windows NT 4.0 Interface |
Although Windows NT Workstation had many advantages over the Windows 9x operating systems, it never became popular for home computing, for several reasons:
▪ NT was not optimized for gaming; many popular Windows 9x and DOS games wouldn't run on NT, because the game software needs direct access to the hardware, which NT doesn't allow.
▪ NT Workstation cost about twice as much as Windows 9x.
▪ NT was more complex and less “user-friendly.” Many home users considered its extra security measures unnecessary and inconvenient.
Despite its lack of popularity in the consumer market, Windows NT—both the Workstation and Server versions—became immensely popular in the business environment, with Microsoft's server product eventually overtaking and surpassing Novell's NetWare as a network authentication server. Windows NT made huge inroads into the Internet mail and Web server markets, which were previously dominated by UNIX.
Os/2
Operating System 2 (OS/2) began as a joint effort between IBM and Microsoft in the 1980s to replace DOS. The original OS/2 (Version 1) was text-based but was a 16-bit operating system, unlike the then-current version of DOS (Version 3.0), which was 8-bit. Version 2.0 included a graphical interface and was a true 32-bit operating system. OS/2 was designed to feature stability and multitasking capabilities that DOS didn't have.
After Microsoft's Windows 3.0 started to become popular, Microsoft dropped its support for OS/2, although it based the Windows NT kernel on the OS/2 kernel. IBM was really a hardware company rather than a software company, so when Microsoft left the project, IBM contracted with Commodore and borrowed from the Amiga for OS/2's object-oriented GUI. Version 2.11 added support for symmetric multiprocessing and was able to run Windows 3.x programs as well as applications written for OS/2. In 1994, IBM released OS/2 Warp 3.0. It included built-in Internet support (the first consumer OS to do so), and its successor, OS/2 Warp Connect, supported all the major networking protocols: Transmission Control Protocol/Internet Protocol (TCP/IP), Internetwork Packet Exchange (IPX), and NetBIOS.
In 1996, “Merlin” (OS/2 4.0) was released, with a more attractive interface and support for OpenGL and the Java virtual machine. Unfortunately for IBM, by this time Windows had gained momentum and most applications were written for it. OS/2 was unable to run 32-bit Windows applications, a limitation that severely hurt its popularity. Despite this, OS/2 continued to be popular in certain industries such as banking and IBM continued to support it while also marketing OS/2 Warp Server for e-business. IBM's long fight to keep OS/2 as a marketable product ended December 23, 2005, when IBM withdrew all of its OS/2 products from the market, and stopped standard support of the product December 31, 2006.
If you think that OS/2 is gone forever, though, you're wrong. Serenity Systems manufactures an OEM upgrade to OS/2 called eComStation, which is available from http://www.ecomstation.com.
Windows 2000
Although Windows NT provided significantly more stability and security than the 9x operating systems, to continue to grow in market share among business customers, especially when competing with UNIX, Microsoft needed something better. Windows 2000 was released in February 2000, and although the interface hadn't really changed from NT, it represented at least as many changes as the upgrade from Windows 3.x to 95. Like NT, Windows 2000 is really a family of products: Professional (the desktop/client operating system that replaces NT Workstation) and three versions of the server software (Server, Advanced Server, and Datacenter Server).
The Windows 2000 operating systems are built on the NT kernel but with the Windows 98 interface and literally hundreds of enhancements and improvements. Many features that were missing in NT (although some of them could be added via third-party add-on software) such as file encryption, disk quotas, and—finally!—Plug and Play are included in Windows 2000. New security features included support for the Internet-standard Kerberos authentication protocol, IP Security (IPSec) for encrypting data that travels over the network, Group Policy (a much more robust and powerful replacement for system policies), and the Layer 2 Tunneling Protocol (L2TP) for more secure VPNs. The biggest difference between NT and Windows 2000 networking is the addition of Active Directory, a directory service similar in some ways to Novell's eDirectory, which was known as Novell Directory Services (NDS) at the time. Both Active Directory and eDirectory are used to provide a centralized database for managing security, user data, and distributed resources.
Windows XP
In October 2001, Microsoft released another semimajor desktop upgrade, this one called Windows XP. One thing that makes XP special is the fact that it is an upgrade to both the Windows 9x/ME line and the Windows NT/2000 line of desktop operating systems, which have been merged back together into one product line—sort of. Although both are based on the more stable NT kernel, XP comes in two different versions: XP Home Edition for consumers and XP Professional for business users.
The Home Edition of XP focuses on entertainment (digital photography, music, and video), gaming, and other consumer-oriented activities, along with features that make Internet connectivity and home networking easier than ever. The Professional Edition includes all the features of XP Home plus additional features that are geared toward the corporate user, such as Remote Desktop (a “lite” terminal server application that allows you to access your XP desktop from anywhere across the network), file encryption, support for multiple-processor systems, and advanced networking features. The Windows XP Professional interface is shown in Figure 4.13 and features increased use of themes to change the appearance of the taskbar, windows, and other objects running in the Windows environment.
 |
| Figure 4.13 Windows XP, Which Combines the Best of the 9x and NT/2000 Worlds |
A Windows XP Pro computer, like NT Workstation and Windows 2000 Pro, can be a member of a Windows domain (a server-based network), whereas XP Home computers, like Windows 9x systems, can be used to access domain resources but cannot belong to the domain. Useful features included in both versions of XP are:
▪ A built-in Internet firewall for better security
▪ A Windows file protection feature that prevents accidentally changing the core operating system files
▪ Fast user switching that allows users to change the currently logged-on user account without closing applications (on nondomain computers)
▪ A number of new wizards that walk you through commonly performed tasks such as transferring files and settings from one computer to another, setting up a network, publishing to the Web, and so on
Note
You can find additional information on Windows XP at http://www.microsoft.com/windows/products/windowsxp.
Windows Server 2003
Windows XP is a desktop/client operating system only. In the first few years after XP's release, Windows 2000 Server continued to be used as the server operating system on most Microsoft networks. Its successor, Windows Server 2003, was released in April 2003.
Like its predecessor, Windows Server 2003 comes in several different editions that are designed for different purposes on a network. These editions included Standard, Enterprise, Datacenter, Web, Storage, Small Business Server, and Cluster. Windows Server 2003 boasts a number of advancements over previous versions, including enhanced security, changes in Active Directory (such as the ability to run multiple instances of the directory server), and improvements in Group Policy and Internet Information Server (IIS). A major difference from previous Microsoft server operating systems was that the default installation of Windows Server 2003 doesn't have any server components enabled. This allows network administrators to choose and configure only the services they need, thereby reducing the possibility of attacks that exploit unnecessary services running on the server.
Note
Additional information on Windows Server 2003 is available at http://www.microsoft.com/windowsserver2003.
Windows Vista
In January 2007, the successor to Windows XP was released, to lackluster results. According to ZDNet (http://news.zdnet.com/2100-9593_22-6159700.html), the first week's sales of boxed copies of Vista were 59 percent lower than the first week's sales of XP sales. Added to this, PC World dubbed Windows Vista number 1 in “The 15 Biggest Tech Disappointments of 2007” (http://www.pcworld.com/article/id,140583-page,5-c,techindustrytrends/article.html). The complaints weren't exactly unmerited, as people found their existing hardware and software incompatible, and many manufacturers hadn't upgraded their products to work with Vista. The funny thing was, a number of Microsoft products were also incompatible with the new system.
Despite this, Vista does offer a number of improvements. It includes a new GUI, named Aero, that looks sleek and allows you to flip through the windows that you have open. It also provides improved security features, improvements in searching, speech recognition, and more efficient networking capabilities. Also new is the Windows Sidebar, which is used to access gadgets that allow you to access weather, a calculator, and other tools. For parents, one of the best features would probably be the parental control features, which you can use to control what Web sites and programs can be viewed and installed (a feature that isn't included in the Business or Enterprise edition of Vista).
Some of the security features available in Vista are directly related to cybercrime issues that we'll discuss in this book. Windows Defender is incorporated into Vista to provide protection against malware (malicious programs), which is software that can be installed without a person's knowledge and can damage systems. This antispyware product was previously available only as a download for Windows XP and Windows Server 2003.
Another new feature is BitLocker Drive Encryption, which you can use to encrypt entire volumes on machines running the Vista Enterprise or Ultimate edition or Windows Server 2008. Encrypting the data makes it unlikely that others will be able to access it if the computer is lost, stolen, or decommissioned (and the drive isn't properly wiped), or if someone attempts to steal data by accessing the files using hacking tools. We will discuss encryption further in Chapter 12.
Note
Additional information on Vista is available at http://www.microsoft.com/windows/products/windowsvista.
Windows Server 2008
In February 2008, Windows Server 2008 was released as the successor to Windows Server 2003. It comes in a number of different editions, including Standard, Enterprise, Web, and Datacenter. Unlike the release of Vista one year previous, there were no changes to the GUI, although there were a number of significant features, including:
▪ A scaled-back installation option called Server Core, which allows you to install a GUI-less version of the server. The “componentized” Server Core installation allows only the server roles and features that are necessary for a particular server. Because unnecessary services aren't installed, attackers can't use them to compromise a system.
▪ A Security Configuration Wizard that makes it easier for network administrators to properly configure security on servers.
▪ New cryptography features. A new cryptographic API called Cryptography Next Generation (CNG) is used for creation, storage, and retrieval of cryptographic keys, and the BitLocker Drive Encryption feature mentioned previously is used to encrypt volumes of data.
▪ The introduction of a new command-line shell and scripting language called Windows PowerShell.
▪ A self-healing feature to the NTFS file system. A service checks the file system for errors, and when one is found, it attempts to fix the error (meaning you don't have to take the system down to run CHKDSK).
Note
Additional information on Windows Server 2008 is available at http://www.microsoft.com/windowsserver2008.
Linux/UNIX
UNIX has been around since the 1960s, when it was developed at Bell Labs in conjunction with MIT computer scientists and thus has a “head start” on most of the competition in the PC operating system market. Generally used for servers rather than desktop machines, UNIX is a very powerful operating system that runs many of the mail, Web, and other servers on the Internet. Traditionally, it has been a complex text-based operating system, although it has become more user-friendly with the addition of interfaces.
UNIX grew out of the Multiplexed Information and Computing Service (Multics) mainframe system developed at MIT but was a completely new operating system designed to create a multiuser computing environment that would support a large number of users. It originally ran on the huge PDP timesharing machines in use at universities and government facilities in the 1960s and 1970s. The first versions of UNIX were written in assembler language, but later versions were written in the high-level C programming language. In the late 1970s, the popularity of UNIX began to spread beyond the academic world, and in the early days of the Internet, it ran on most of the VAX computers that were connected to the internetwork. In the 1980s, more versions of UNIX were developed, and its use spread throughout the business world.
Today there are still a large number of different versions of UNIX, including IBM's AIX, Sun Microsystems' Solaris, Hewlett-Packard's HP-UX, Santa Cruz Operations' SCO OpenServer (which that company bought from Novell in 1995), and others. The X Window system was developed to add a graphical shell to UNIX and make it more user-friendly. It's not really a GUI but is instead a protocol that can be used to build a GUI, such as Common Desktop Environment (CDE). However, UNIX graphical interfaces tend to be somewhat clunky and ugly compared to Windows interfaces, and UNIX purists shun the GUI, preferring the higher-performance command-line environment.
In 1991, Finnish student Linus Torvalds wrote a UNIX-based operating system that he called Linux (mentioned briefly earlier in this chapter) and that he distributed free through Internet newsgroups. Linux caught on with programmers and then with users who were looking for an alternative to Microsoft Windows. Although Linux is often used to run servers (especially Web servers running the open source Apache Web server software), it is more suitable for the desktop than UNIX. Linux is a text-based operating system like UNIX, but when it became popular as a desktop operating system, developers soon created a variety of graphical shells that ran on top of it, much as Windows 3.x ran on MS-DOS.
In 1994, Red Hat released a commercial version of Linux, which was followed by a release from Caldera in 1997 called OpenLinux. A large number of versions of Linux are available today, with some of the most popular being:
▪ Red Hat (http://www.redhat.com)
▪ SUSE (http://www.novell.com/linux/)
▪ Ubuntu (http://www.ubuntu.com)
▪ openSUSE (http://www.opensuse.org)
▪ Debian (http://www.debian.org)
▪ Slackware (http://www.slackware.com)
▪ Turbolinux (http://www.turbolinux.com)
Dozens of distributions are available; you can find information and comparisons at the Linux Distrowatch Web site at http://www.distrowatch.com.
Apple
The Apple Macintosh computers differ from Intel-compatible PCs in many ways, one of which is the fact that they are proprietary. Until recently, Apple made both the hardware and the operating system software. In other words, Mac operating systems wouldn't run on PCs, and PC operating systems wouldn't run on Macs. The Apple–Intel architecture changed this, however, when computers developed by Apple began to use the Intel x86 processors that allowed multiple operating systems to run on a single Apple computer. Prior to this, running multiple operating systems on a Mac was limited to using software such as VMware (http://www.vmware.com), which is third-party software used to run other operating systems in a virtual machine. Using VMware allows you to run a PC operating system in a window on top of your Mac OS, or vice versa.
The latest version of the Mac OS, called OS X, is a big departure from prior versions because it is based on a version of UNIX called Darwin. Macintosh OS X combines the power of underlying UNIX code with a beautiful, user-friendly GUI called Aqua. The Mac has always been popular with educational institutions and graphic designers, but OS X gained popularity among both traditional UNIX users and die-hard Windows fans. A Mac OS X interface is shown in Figure 4.14.
 |
| Figure 4.14 The Macintosh OS X Interface on a UNIX OS |
Unlike other operating systems that primarily use version numbers to designate new releases of the operating system, OS X uses the names of big cats for each new version. To date, these include:
▪ Puma (Version 10.1; released September 2001), which features support for writing CDs and DVDs, the ability to easily connect to a local area network (LAN) or the Internet, and built-in support to access files on Windows PCs across a network. It also includes software such as SAMBA, to allow you to share your Mac files with networked Windows machines. With OS X, the Mac finally added such advanced features as preemptive multitasking and protected memory and includes support for symmetric multiprocessing, USB, and FireWire (IEEE 1394).
▪ Jaguar (Version 10.2; released August 2002), which provides network support for Microsoft networks and iChat (instant messaging [IM]).
▪ Panther (Version 10.3; released October 2003), which provides the ability to switch between users (so that one user remains logged on while another user logs on), as well as improvements to iChat that allow audio and videoconferencing.
▪ Tiger (Version 10.4; released April 2005), which provides such new features as the Dashboard, which is used to run widgets (small applications that provide such functions as weather forecasts, a world clock, a calculator, calendars, and so on). This was the first release to run on Apple machines that used x86 processors.
▪ Leopard (Version 10.5; released October 2007), which provides a feature called Back to My Mac that allows remote access over the Internet to files on the computer, an automated backup utility called Time Machine, and the ability for Macs using Intel processors to install other operating systems such as Windows on separate partitions.
Apple also markets a server version, OS X Server, which supports clients running Mac, Windows, UNIX, and Linux. For more information about OS X, see the Apple Web site (http://www.apple.com).
File Systems
File systems or file management systems are systems that the operating system uses to organize and locate data stored on a hard disk. File systems can manage storage media such as hard disks, and control how sectors on the drive are used to store and access files. In doing so, a file system will keep track of which sectors are used to store files, and which are empty and available for use. In the complex world of networks, however, this isn't always the case. Network file systems aren't used to manage the HDD, but instead provide a way to present a client with access to data on a remote server.
Many file systems are hierarchical file systems in which the data is organized as a tree structure. As shown in Figure 4.15, a hierarchical file system looks like an inverted tree. At the base of the structure is a root directory, and directories (or folders as they're now called in Windows) branch out from the root. These directories are containers that can be used to store files or other directories. These directories within directories are called subdirectories (or subfolders). As we'll see later in this chapter, the file system will keep track of how this organization translates to directories and files that are stored on the disk so that when a particular directory is opened, the files in that directory are displayed properly and can be located on the hard disk.
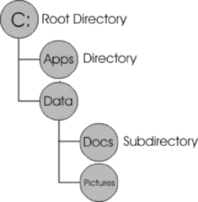 |
| Figure 4.15 A Hierarchical Directory Structure |
File systems will keep track of this structure (the directories and the files contained within those directories) using different methods. As we'll discuss in the next section, the FAT file system uses a File Allocation Table that will manage where the file is stored on the hard disk, and will also manage other aspects of how you name and can access the file. In earlier operating systems such as MS-DOS, the FAT file system only allowed files to be named with eight characters, with a period separating the name from a three-character extension. For example, a document might be named DOCUMENT.DOC using this 8.3 notation. When Windows 95 was developed, long file names (LFNs) were supported that allowed filenames to comprise up to 255 characters. This and other information is stored within the file by the file system, along with properties identifying the owner of a file, when it was created, and attributes that control access to the file (such as whether it is read-only or can be modified).
Microsoft File Systems
Different operating systems use different file systems, and some operating systems support more than one file system. The most familiar are those used by the Microsoft operating systems:
▪ FAT12
▪ FAT16
▪ VFAT
▪ FAT32
▪ NTFS
In the following sections, we look at some of the characteristics of each file system, along with some less commonly encountered file systems used by networks and non-Microsoft operating systems.
FAT12
FAT stands for File Allocation Table; the FAT file system was developed for use by the DOS operating systems. The first version of the FAT file system was called FAT12 because its allocation tables used a 12-digit binary number (12 bits) for cluster information (which we'll discuss later in this chapter). The FAT12 file system was useful for the very small hard disks that came with the original IBM PC (less than 16MB in size). It is also used to format floppy diskettes.
FAT16
The FAT16 file system was developed for disks larger than 16 MB, and for a long time it was the standard file system for formatting hard disks. As you can probably guess, it uses 16-bit allocation table entries. The FAT16 file system (often referred to as just the FAT file system) is supported by all Microsoft operating systems, from MS-DOS to Windows Vista. It is also supported by some non-Microsoft operating systems, such as Linux.
This support makes it the most universally compatible file system. However, it has many drawbacks, including the following:
▪ It doesn't scale well to large disks; because the cluster size increases as the disk partition size increases, a large disk (larger than about 2 GB) formatted with the FAT16 file system will have a lot of wasted space.
▪ It doesn't support file-level compression; the compression scheme that is used with the FAT16 file system, such as that implemented by DriveSpace, requires that the entire logical drive be compressed.
▪ It doesn't support file-level security (assignment of permissions to individual files and folders).
Note
You may read in some sources that the FAT16 file system is limited to 2 GB in size, but that's not really the case (although it does become inefficient at larger disk sizes). MS-DOS will not allow you to create a FAT16 partition larger than 2 GB, but you can create larger FAT16 partitions (up to 4 GB) in Windows NT/2000, XP, and Vista. These larger FAT16 partitions are not supported and recognized by MS-DOS or Windows 9x.
VFAT
Virtual FAT, or VFAT, is a file system driver that was introduced in Windows for Workgroups 3.11 and supported by Windows 95. Its advantages are that it operates in protected mode and provides the capability for using long filenames with the FAT16 file system. VFAT is not a file system; rather, it is a program extension that handles filenames over the 8.3 limitation imposed by the original FAT16 file system.
FAT32
The FAT32 file system uses a 32-bit allocation table. It was first supported by the OSR 2 version of Windows 95 (95b) and was designed to improve on the functionality of the FAT16 file system by adding such features as:
▪ Support for larger partitions, up to 2 TB in size, in theory (Windows supports FAT32 partitions of up to 32 GB)
▪ Greater reliability, due to the inclusion of a backup copy of important data structure information in the boot record
The FAT32 file system also has its disadvantages, including the fact that it is incompatible with older Microsoft operating systems (for example, MS-DOS, Windows 3.x, Windows 95a, Windows NT), and some non-Microsoft operating systems (although FAT32 drivers are available from third-party vendors for Windows 95, NT, and even non-Microsoft operating systems such as Linux). Additionally, the overhead used by the FAT32 file system can slow performance slightly.
NTFS
NTFS is the most secure file system offered for computers running Microsoft Windows operating systems. NTFS was designed as a replacement for the FAT file system on Windows NT operating systems, including successive releases such as Windows 2000, Windows Server 2003, XP, and Vista. It was designed to be more robust and secure than other Microsoft file systems. Part of these features can be seen in how it handles partitions. As we'll see later in this chapter, partitions are logical divisions of a hard disk, allowing you to divide the space on a hard disk so that it functions as separate drives. For example, you could partition a hard disk to appear as C: or D: on the computer. NTFS supports very large partition sizes (up to 16EB, in theory) and allows you to create volumes that span two or more partitions.
NTFS is also more reliable because it supports a feature called hot fixing, a process by which the operating system detects a bad sector on the disk and automatically relocates the data stored on that sector to a good sector, and then marks the bad sector so that the system won't use it. This process is done on the fly, without the awareness or intervention of the user or applications.
Metadata and the Master File Table
Metadata is information about a particular set of data, and can include such information as who created a file, its size, and other technical information hidden from the common user. In other words, metadata is data about data. It can be used to describe a file, its format, when it was created, and other information. NTFS stores data about files, users, and other information the system uses in the form of special files that are hidden on the system. When a disk is formatted to use NTFS, these files are created, and their locations are stored in one of these files, called the Master File Table (MFT). The special system files that NTFS creates to store metadata, and their location in the MFT, are listed in Table 4.4.
Whereas the FAT file system uses a File Allocation Table to keep track of files, NTFS uses an MFT to perform similar (albeit more complex) functions. When a disk is formatted to use the NTFS file system, an MFT is created to keep track of each file on the volume. As shown in Table 4.4, the first record of the table describes the MFT itself, while a mirror of this information is stored in the second record in case the first record is corrupted. The third record in the MFT is a log that is used to recover files, while the bulk of the remaining records are used to keep track of each file and folder, the NTFS volume, and the attributes of those files. Keeping track of the files in a table allows them to be accessed quickly from the hard disk.
NTFS Attributes
One of the records stored in the MFT deals with NTFS attributes. NTFS views each file and directory as a set of file attributes, consisting of such information as its name, data, and security information. Attributes are data that define a file, and are used by the operating system and other software to determine how a file is accessed and used. In the MFT, a code is associated with each attribute, and may contain information on the attribute's name and description. In NTFS, two different kinds of attributes can be used:
▪ Resident attributes Attributes that can fit in an MFT record. The name of the file and timestamp are always included as a resident attribute.
▪ Nonresident attributes Allocated to one or more clusters elsewhere on the disk. These are used when information about a file is too large to fit in the MFT.
As shown in Table 4.5, a number of attributes can be associated with files and directories stored on an NTFS volume. To identify the location of all of the records associated with file attributes, NTFS uses an attribute list. The list contains attributes defined by NTFS, and also allows additional attributes to be added later.
From the administrator's and user's point of view, these attributes can be modified on the file or folder by using the file or accessing its properties. For example, by modifying the filename, you are modifying the Filename attribute. Similarly, opening a file will change timestamp information regarding when the file was last accessed. By accessing the properties of a file, you can set access permissions at the file level to control who can read, change, or otherwise access a file. This applies to users accessing the file from the local machine as well as over the network and is in addition to network share permissions that are set at the folder/directory level.
NTFS Compressed Files
NTFS allows files to be compressed to save space either by compressing an entire NTFS volume, or on a file-by-file basis. Using NTFS compression, you can compress individual folders or files, or everything on a particular drive using the NTFS file system. In doing so, a file is decompressed automatically when it is read, and compressed when it is saved or closed. Compressing data allows you to save disk space and archive folders, without having to rely on additional software to compress and decompress files.
When data is compressed on an NTFS drive, only the file system can read it. When a program attempts to open a file that's been compressed, the file system's compression drive must first decompress the file before making it available.
NTFS Encrypting File Systems
Encryption is the process of encoding a file so that it can't be read by anyone other than those who are authorized to open and view the data. Users who aren't authorized will be denied access to the file, and will be unable to open, copy, move, or rename a file or folder that's been encrypted. Encryption may be used on a single file or an entire disk.
Disk encryption refers to encrypting the entire contents of a hard disk, diskette, or removable disk. File encryption refers to encrypting data stored on disk on a file-by-file basis. In either case, the goal is to prevent unauthorized persons from opening and reading files that are stored on the disk. Support for disk/file encryption can be built into an operating system or file system. NTFS v5, the native file system for Windows 2000, Server 2003, XP, and Vista, includes the Encrypting File System (EFS), which can be used to protect data on a hard disk or large removable disk. EFS can't be used to protect data on floppy diskettes because they cannot be formatted in NTFS format, but it does allow encryption of individual files and/or folders. Because EFS is integrated with the operating system, the process of encryption and decryption is invisible to the user.
EFS relies on public key cryptography and digital certificates. Public key cryptography involves two mathematically related keys, one called the public key and another called the private key, which are generated to be used together. The private key is never shared; it is kept secret and used only by its owner. The public key is made available to anyone who wants it. Because of the time and amount of computer processing power required, it is considered “mathematically unfeasible” for anyone to be able to use the public key to re-create the private key, so this form of encryption is considered very secure.
Each file has a unique file encryption key, which is used to decrypt the file's data. Like the encrypted file or folder, the key is also encrypted, and must be decrypted by the user who has a private key that matches the public key. Because these keys match, the system can then determine that the person is authorized to view the data, and can then open the file.
Whether a person is permitted to access the data is based on the user account that is being used when opening the file. A digital certificate is used to identify the person logged on to the computer, and to provide credentials showing that the person is authorized to access certain data. EFS uses digital certificates that are associated with the user account. Although this requires less user interaction, it does have its drawbacks. It might not be possible to share encrypted files with others without decrypting them in cases where only one particular account is allowed access. In addition, there is a security risk if the user leaves the computer while logged on; then anyone who sits down at the machine can access the encrypted data.
Linux File Systems
Linux supports multiple file systems through the use of a virtual file system (VFS). VFS works as an abstract layer between the kernel and lower-level file systems. For a file system to work on Linux, it has to conform and provide an interface to VFS so that the upper levels of the operating system can communicate with the file systems used on the machine. Using VFS, Linux has been able to support a number of file systems, including the following:
▪ ext The first version of EFS, and the first file system created specifically for Linux. It was also the first file system to use the VFS that was added to the Linux kernel. It was replaced by ext2 and xiafs, which was based on the older Minix system and is not found in current systems due to its obsolescence. Minix was a file system originally used by Linux but was replaced by ext due to shortcomings such as a 14-character limit in naming files, and a 64 MB limitation on partition sizes.
▪ ext2 Stands for Second Extended File System, and offers greater performance and support for up to 2 TB file sizes, and which continues to be a file system used on many Linux machines. This file system implemented a data structure that includes inodes, which store information about files, directories, and other system objects. ext2 stores files as blocks of data on the hard disk. As we'll see when we discuss clusters later in this chapter, blocks are the smallest unit of data used by the file system, and data is stored to one or more blocks on the HDD. A group of blocks containing information used by the operating system (which can contain such data as how to boot the system) is called a superblock.
▪ ext3Stands for Third Extended File System, and supersedes ext2. A major improvement to previous versions is that ext3 is a journaled file system, which makes it easier to recover. A journal is similar to transaction logs used in databases, where data is logged before being written. On ext3, the journal is updated before blocks of data are updated. If the computer crashed, the journal could be used to restore the file system by ensuring that any data that wasn't written to blocks before the crash are resolved so that the blocks are marked as being used when they are actually free (a concept we'll discuss later when we talk about clusters). On ext2, if a problem occurred, you would need to run Filesystem Check (fsck) to resolve issues with files and metadata on the system.
▪ ext4 Short for Fourth Extended File System. In addition to improvements in performance, this version of the file system supports volumes of up to 1EB.
Mac OS X File System
Over the years, Macs have used several different file systems. When the original Macintosh computer was released January 24, 1984, it used the Macintosh File System (MFS), which was used to store data on 400KB floppy disks. Although archaic by today's standards, MFS offered a number of innovations, as is common with technology developed by Apple.
MFS saved files to hard disks in two parts. A resource fork was used to store structured information, and a data fork was used to store unstructured data. Whereas data used in a file would be stored in the data fork, information related to the file (including icons, menus and menu items, and other aspects of the file) would be stored in the resource fork. The resource fork allowed files to be opened by the correct application, without the need for a file extension, and could also be used to store metadata.
A year after MFS was released, the Hierarchical File System (HFS) replaced it. HFS continued to use multiple forks when storing data, but was designed to organize and manage data on both floppy disks and hard disks. Like its predecessor, it also supported filenames that were 255 characters in length, but where it was exceptional over MFS was in performance. MFS was designed for use on floppy disks, so it performed slowly on larger media. HFS was designed to perform well with hard disks, and it used a hierarchical design through a Catalog File to replace the flat table structure used by MFS.
In 1998, Apple introduced a new version of HFS called HFS Plus. In addition to better performance, improvements were made in how HFS Plus handled data. Like Linux machines, HFS and HFS Plus both store data in blocks on the hard disk, with volumes divided into logical blocks that are 512 bytes in size. HFS used 16-bit block addresses, but this was improved in HFS Plus, where 32-bit block addresses were supported. The 16-bit blocks used in HFS meant that only 65,536 blocks could be allocated to files on a volume. Although this wasn't an issue when hard disks were smaller, it resulted in a considerable amount of wasted space on larger volumes.
Mac OS X computers also support a number of other file systems, including the FAT16 and FAT32 file systems mentioned previously, and the UNIX File System (UFS) that's a variant of the BSD Fast File System.
CD-ROM/DVD File System
Not all file systems are developed for hard disks or accessing data over a network (as we'll discuss later in this chapter). File systems also exist that are specifically designed for organizing and accessing files stored on CDs and DVDs. As we discussed earlier in this chapter, although both are 5-inch optical discs that visually appear identical, CDs can contain up to 700MB of data whereas DVDs are able to store from 4.7GB to 17GB of data. Although CDs were designed to store an entire album of music and DVDs were designed to store an entire movie on one disc, both CDs and DVDs are capable of storing various kinds of data.
Universal Disk Format (UDF) is a file system that is used by both CDs and DVDs, and is a standard format the Optical Storage Technology Association (OSTA). UDF is based on the International Organization for Standardization (ISO) 13346 standard, and uses a file structure that's accessible by any computer or CD/DVD system. UDF was not initially supported by Microsoft operating systems, which was why Microsoft released a format called UDF Bridge with Windows 95 to provide support until the next release of Windows. Although UDF is compatible with ISO 9660 (which we'll discuss next), UDF was developed as a hybrid of both UDF and ISO 9660 standards. To allow DVDs to be played and burned (that is, recorded) on Windows computers, DVD-ROM vendors had to include support for both UDF and UDF Bridge.
ISO 9660 was introduced as a standard for CD-ROM media in 1988, and is commonly referred to as CDFS (Compact Disc File System). It allows CDs created on different operating systems to be accessed by other operating systems. Using this standard, CD data is stored as frames on the disc, with each frame being 24 bytes in length. Using ISO 9660 for recording, three different modes may be available in disc creation software:
▪ CD-ROM Mode 1 Generally used to record computer data. Filenames are limited to eight characters with three additional characters for the extension (the standard 8.3 format).
▪ CD-ROM Mode 2 Form 1 Also generally used for recording computer data. Although it uses the same format as Mode 1, it isn't compatible across all systems. It allows filenames of up to 180 characters (depending on how many extended attributes are used).
▪ CD-ROM Mode 2 Form 2 Allows data to be fragmented so that data can be written in increments to the CD. It is commonly used for video CDs, and other fault-tolerant data, where any errors that occur would happen so fast that a person viewing the media would generally not detect it.
Because technology changed, extensions to the ISO 9660 standard were developed to address issues that the initial standard didn't address. These extensions include:
▪ Joliet Addresses limitations in the filenames as ISO 9660 didn't support long filenames. Joliet is still supported by disc creation software and all Windows operating systems since Windows 95, and allows filenames that are 64 characters in length.
▪ Apple ISO9660 Extensions Developed by Apple to address limitations in the properties of files stored on CDs. Because HFS supports more properties than the FAT file system and uses a resource fork and data fork to save files, Apple developed an extension that allows non-Macintosh systems to access data saved by Macintosh computers and view the properties of these files.
▪ Rock Ridge Interchange Protocol Abbreviated as RRIP and corresponds to IEEE P1282. RRIP is used for storing information that's specific to UNIX machines, and supports filenames that are up to 255 characters in length.
▪ El Torito Developed by Phoenix Technologies (which manufactured the BIOS of computers) and IBM to allow computers to be booted from a CD. If a CD has already been inserted in a CD-ROM when the computer starts up and has a boot code on it, the BIOS assigns a drive number to the CD-ROM and allows the computer to boot from that device.
Understanding Network Basics
It wasn't so long ago that most computers were stand-alone, meaning they weren't connected to any type of network. If you wanted to share programs, pictures, or other data, you would copy it to a floppy disk and use sneakernet (put on your sneakers and walk it to another computer). Today that isn't the case. As we saw earlier in this chapter, operating systems over the past few years have added features that make it increasingly easier to connect to networks.
A network is two or more computers that are connected together so that they can share data and other resources. A network can be as small as a couple of computers connected with a hub in a home network, to a corporate network made up of thousands of computers, to the largest network on the planet—the Internet. From this, you can see that networks can be defined by their scale, as follows:
▪ Personal area network (PAN) A network of two or more devices that exchange data within a few yards or so of one another. An example is a cell phone or PDA that is uses Bluetooth technology to exchange pictures or an address book with another laptop, cell phone, or PDA.
▪ Local area network (LAN) A network of computers in a small geographic area, such as the computers networked together in a department, a floor of a building, an entire building, and so on.
▪ Metropolitan area network (MAN) A network made up of smaller networks across the geographical span of a city. It may consist of several blocks of buildings, or smaller LANs that are connected across a city.
▪ Campus area network (CAN) A network made up of several interconnected LANs, such as several buildings on a university campus. A CAN is a subset of a MAN, and the term is usually limited to describing the MAN of an educational institution.
▪ Wide area network (WAN) A network that is spread across a large geographical area, such as in different cities, states, or countries. he largest (and best known) WAN is the Internet.
As we've already discussed in previous chapters, network connectivity opens up new opportunities for criminals as well as for legitimate computer users. Even for crimes that are less technical in nature, the network gives criminals an infinite number of additional locations for storing files that provide evidence of the crime. Investigators must be aware of this fact or they could overlook crucial pieces of evidence. For example, a child pornographer might be careful to upload all his illegal graphics files to a location someplace geographically far away from his home computer, deleting the originals from his hard disk. Examination of the suspect's own computer might reveal nothing incriminating. However, network logs could show when and to where the transmissions were made. The logs of File Transfer Protocol (FTP) clients or other programs used to transfer the data could reveal the site to which uploads were made. An investigator who doesn't understand how data is sent across networks or who is not aware of the existence of log files or the significance of program settings would not even know how to begin to look for this evidence.
Network Operating Systems
Modern operating systems have networking capabilities built in. Early PC operating systems such as DOS (and the Windows shell that ran on it) did not; it wasn't until Version 3.11, with Windows for Workgroups, that Microsoft included networking components. As the name implied, that version of Windows was designed to function in a small peer-to-peer local network. Windows NT added authentication server functionality (Microsoft called the authentication server a domain controller), but with the early versions of NT, the focus was still on the LAN, not the WAN. At that time, Microsoft operating systems were not considered scalable enough for enterprise networking, and most Web servers on the Internet were UNIX machines. With Windows 95, it became easier for users to connect to the Internet, and NT 4.0 supported Web services (IIS) that made it easy to host Web sites on the Internet or intranets. Windows 2000 built more heavily on Internet connectivity and added features to the server products that made it more suitable for enterprise-level computing, including a robust directory service (Active Directory), industry-standard security protocols such as Kerberos and IPSec, and load-balancing and clustering support. The next generation of Windows servers, 2003 and 2008, continued this trend and embrace the idea that “the network is the computer” to a larger extent than ever.
The term network operating system (NOS) is used in three different ways:
▪ It is sometimes used to refer to any computer operating system that has built-in networking components, as do all of today's popular PC operating systems. Thus, Windows 9x, NT, 200x, XP, and Vista, along with most distros of Linux, UNIX, and Macintosh, are considered NOSes, whereas MS-DOS and Windows 3.1 and earlier are not.
▪ It is sometimes used to refer to the components of the operating system that make networking possible. For example, today's Windows operating systems include file and print sharing services, which allow the computer to act as a server and share its resources with other systems, and the Client for Microsoft Networks (known as the Workstation service in NT) which allows the computer to connect to and access the shared resources of other systems. These components, along with the protocol stacks on which the network operates, are sometimes referred to as the NOS.
▪ It is sometimes used to refer to the server operating system software—such as Windows NT Server, Windows 200x Server, UNIX, Apple OS X Server, or NetWare—especially when functioning as an authentication server that maintains a security accounts database for the network.
In the following sections, we look at how client/server computing works and discuss both the server software and the client software that work together to enable network communications. We will also take a look at network file systems and how they differ from local file systems as well as the protocols that govern the network communication process.
Understanding Client/Server Computing
The term client/server computing has different meanings, depending on the context in which it is used. Some documentation uses the term narrowly, to refer to applications in which the bulk of the processing is performed on a server. For example, SQL Server is a database application that uses the server's power to sort the data in response to a query and then returns only the results to the client. Contrast this system with Microsoft's Access, in which database files are stored on a server, but a client query results in the entire file being transferred to the client machine, where the sorting takes place.
Using this meaning of the term, thin client computing is the ultimate form of client/server computing. With thin client software such as Microsoft's terminal services, the operating system runs on the server, and all applications run there; only the graphical representation of the desktop screen runs on the client machine. This means client machines can be low-power systems with modest processors and small amounts of RAM—machines that are not capable of running the operating system themselves. Thus, a user can work in Windows XP using an old 80486 system that has only 16MB of RAM, because the operating system isn't really running on that old system—it's being used only as a terminal to access the OS on the server.
Authentication Server-Based Networks
A second, broader meaning of the term client/server computing refers to a network that is based on an authentication server. This is a server that controls access to the network, storing a security accounts database that holds users' network-wide account information. When a user wants to log on to the network the client computer contacts this authentication server. The server checks its database to ensure that the user is authorized and to determine the level of access allowed to that user (usually based on security groups to which the user belongs). The authentication server is a centralized point of security and network resource management and must run special (and usually expensive) server software. In Microsoft networking, this type of network is called a domain and the authentication server is called a domain controller. UNIX and NetWare servers also provide network authentication services.
Note
We discuss authentication, which refers to the verification of a user's or computer's identity, in much more detail in Chapter 12, when we discuss security concepts.
Authentication server operating systems such as NT Server used a flat accounts database, but the trend quickly changed toward the use of hierarchical databases called directory services, such as Novell's eDirectory, Apple's Open Directory implantation, and Microsoft's Active Directory. All these services have something in common: They are compatible with the Lightweight Directory Access Protocol (LDAP) standards. This is an industry standard based on the ISO's X.500 specifications, and adherence to the standards allows directory services from different vendors to interoperate on a network.
These client/server (or server-based) networks provide many advantages, especially for large networks. Because security and management are centralized, this type of network can be more easily secured and managed than the alternative network model.
Peer-to-Peer Networks
Networks without an authentication server are called workgroups or peer-to-peer networks. This model is appropriate for small networks with only a few computers, in environments where high security is not required. They are common to small offices or home networks. In a workgroup, all computers can provide both client and server services.
Note
In this context, the term server services means only that the computers make their resources accessible to (share them with) other computers on the network. The computers in a workgroup do not have to run expensive server software, although a workgroup can have machines running such software as Windows Server 2008, operating as member servers instead of domain controllers. The key differentiating factor is that in a workgroup, there is no authentication server, although there can be other types of servers (file and print servers, remote access servers, fax servers, and the like).
Workgroups are less expensive to implement than server-based networks, for several reasons:
▪ Server operating system software is costly, and must be purchased to implement a server-based network.
▪ Server software generally requires more powerful hardware than do desktop operating systems, so you might need to purchase more expensive machinery to run it.
▪ Server-based networks generally require a dedicated network administrator to perform the many tasks involved in network administration and maintenance, necessitating hiring additional personnel or extra work on the part of an existing employee.
Despite the cost advantage of workgroups, they are less secure, because the user of each computer must manage its resources. To access resources on any other computer in the workgroup, a user must have a local account created on that machine, or alternatively, each individual shared resource can be protected by a password. Either of these methods gets very cumbersome when there are more than a handful of users and/or more than a few shared resources.
With the first method, a user might need accounts on a dozen or more computers; with the second method, that user would have to keep track of dozens or even hundreds of different passwords to access different shared folders or printers. Contrast this scenario with the authentication server-based network, where each user has a single username and password for logging on to the entire network. The user can then access any resource on any machine in the network for which the appropriate permissions have been assigned. Although administrators do have to assign permissions to each shared resource, from the user's point of view this is a much simpler system. When workgroups grow beyond 20 or 25 computers, it is usually advantageous to convert to a centralized (server-based) model.
Server Software
Remember that all modern operating systems, even consumer and home editions, have a server component (such as file and print sharing for Microsoft Networks) that allows them to share their resources. When we refer to server software here, we're talking about operating systems capable of providing network authentication services (as well as other server services such as domain name system [DNS], Web services, or remote access services). There are also many server applications (such as the SQL database server, the ISA proxy/firewall server, the Exchange mail server, and the like) that can be installed only on a system running a server operating system.
Earlier in this chapter, we discussed the major computer operating systems, as well as a number of the major server operating systems. Windows NT and Windows Server 200x are higher-level products that provide services on most corporate networks. Previous to Windows NT 4.0, the major network operating system was Novell NetWare, which is still used on many networks. However, when Windows 2000 was released, Novell lost significant ground to Microsoft. As we mentioned previously, Windows 2000 Server provided a directory service called Active Directory that was similar to Novell's NDS (later called eDirectory). Using the directory service, user accounts and access to resources could be easily managed, controlling who had access to what.
Active Directory (AD) catalogs information about the network as objects. These objects include the users (people who use the network), computers, printers, and other resources that make up the network. Each object has attributes associated with it, such as a person's attributes including his or her first and last names, logon name, and other information. To organize the objects, network administrators can arrange them into containers, much in the same way that you might organize files into folders on your hard disk. When a person logs on to the network, Active Directory compares the logon information to the password associated with that user account. After authenticating the user, appropriate access is given.
Another popular server is UNIX, which has been around since the beginning of networking and the Internet. UNIX is a very powerful server operating system, but it is considered to have a steep learning curve. It is a character-based OS, but GUI interfaces are available. There are dozens of different popular commercial and free distributions of UNIX.
Apple also makes its OS X in a server version, which supports Macintosh, Windows, UNIX, and Linux clients and includes Apache Web server, Post Office Protocol (POP) and Internet Message Access Protocol (IMAP) mail, and DNS and Dynamic Host Configuration Protocol (DHCP) services. OS X Server runs only on Macintosh systems, and isn't widely implemented. The server version of OS X is less costly than Microsoft's and Novell's products and much more user-friendly than other versions of UNIX.
Client Software
Most modern operating systems can also function as network clients. For example, if you were running Windows 2008 on your computer, you could log on to the network as a user, run programs, and use it as you would Windows Vista. With the exception of NetWare, this is common among many server operating systems. However, it would be inefficient and costly to run Windows Server 2008, for example, as a desktop client as it costs considerably more than the desktop operating system. UNIX is most often used as a server, but Linux has grown in popularity as a desktop/client OS. Mac OS X comes in both client and server forms. Novell doesn't make a client OS of its own; NetWare clients generally run Windows or UNIX operating systems with NetWare client software installed.
This brings up an important point: Client machines don't necessarily have to run an operating system made by the vendor of the network's server software. Macintosh and UNIX-based clients can access Windows servers, Windows and Macintosh clients can access UNIX servers, and so forth. As shown in the Figure 4.16, the Novell client for Windows is used to supply a username and password, which is then sent to a Novell server. The Novell server then uses eDirectory to authenticate the user and to determine what the user is permitted to access, and may access a script to map drives to locations on the network. As a result, the user will see a variety of new drive letters, which allow the user to store files on network servers.
 |
| Figure 4.16 The Novell Client |
Understanding Network Hardware
Just as operating systems commonly have the features necessary to connect to a network easily, so do computers. Although a person used to have to buy and install a network card in his or her computer to connect to an existing network, laptops and desktops are now sold with Ethernet cards included as a basic feature. Even if the computer isn't used for a home or organization's network, manufacturers know that they will still be used to connect to the Internet, as in the case of users who use Digital Subscriber Line (DSL) technology.
Just as you need a working knowledge of the hardware that makes up a PC to understand how a computer works, you need to be familiar with the hardware that enables network communication to understand how that communication process works. Networks range from very small (two directly linked computers) to very large (WANs that rely on complex hardware devices to link entire local networks in distant locations). Thus, the number and types of network hardware devices on a network will vary. However, all computer networking begins with an interface connecting each networked computer to the network.
The Role of the NIC
The network interface card (NIC) or network card is the hardware device most essential to establishing communication between computers. Although there are ways to connect computers without a NIC (by modem over phone lines or via a serial “null modem” cable, for instance), in most cases where there is a network, there is a NIC for each participating computer.
The NIC is responsible for preparing the data to be sent over the network medium. Exactly how that preparation is done depends on the medium being used. Most networks today use Ethernet. Ethernet was developed in the 1960s with specifications developed by Digital, Intel, and Xerox (governed by IEEE 802.3 standards). It uses a method of accessing the network called Carrier Sense Multiple Access/Collision Detection (CSMA/CD), in which each computer monitors the network to ensure that no one else is sending data along the same line of cabling. If two computers send data at the same time, it causes a collision that's detected by the other workstations, and the computers will wait a random time interval to send the data again.
Understanding How Data Is Sent across a Network
On a network, data is sent across the cables as signals that represent the binary 1s and 0s that represent the data. Signals represent individual bits, and those bits are often grouped together in bytes for convenience, but computers send data across the network in larger units: packets, segments, datagrams, or frames. A packet is a generic term, generally defined as a “chunk” of data of a size that is convenient for transmitting. Rather than sending an entire, large file as one long stream of bits, the system divides the file into blocks, and each block is transmitted individually. This system allows for more efficient network communications, because one computer doesn't “hog” the network bandwidth while sending a large amount of data. On an internetwork, where there are multiple routes from a particular sender to a particular destination, this system also allows the separate blocks of data to take different routes.
Most networks, including the Internet, run on the TCP/IP protocols. At the transport level, a unit of data is called a segment when TCP is the transport layer protocol. To further confuse an already confusing issue, it's called a user datagram when User Datagram Protocol (UDP) is used. One step down, at the network (IP) level, the chunks of data that are routed across the network are called datagrams. When we move down to the data link level (at which Ethernet and other link layer protocols operate), the unit of data we work with is called a frame.
The Internet uses packet-switching technology to most effectively move large amounts of data being transmitted by multiple computers along the best pathways toward their destinations. Each packet travels independently; when all the packets that make up a communication arrive at the destination computer, they are reassembled in proper order using information contained in their headers. You can think of a packet as an electronic envelope that contains the data as well as addressing and other relevant information (such as sequencing and checksum information).
The Role of the Network Media
The network media are the cable or wireless technologies on which the signal is sent. Cable types include thin and thick coaxial cable (similar to but not the same as cable TV media), twisted-pair cable (such as that used for modern telephone lines, available in both shielded and unshielded types), and fiber optic cable, which sends pulses of light through thin strands of glass or plastic for fast, reliable communication but is expensive and difficult to work with. Wireless media include radio waves, laser, infrared, and microwave.
Unauthorized people can capture data directly from the media, by “tapping into” the cable and using a protocol analyzer to open packets and view the data inside. Copper cables are especially easy to compromise in this way, but data can also be intercepted on fiber optic cabling using a device called an optical splitter. Wireless transmissions are also easy to intercept; the practice of “war driving” is popular with hackers, who set up laptop systems with wireless network cards and then drive around looking for open wireless networks to connect to. Because many businesses leave the default settings on their wireless access points and don't elect to use wireless encryption protocols, their networks are wide open to anyone with a portable computer, a wireless NIC, and a small amount of technical knowledge. We address wireless security in detail in Chapter 10, when we discuss network intrusions and attacks, and again in Chapter 13.
The Roles of Network Connectivity Devices
Network connectivity devices do exactly what the name implies: They connect two or more segments of cable. Complex connectivity devices can serve two seemingly opposite purposes: They are used to divide large networks into smaller parts (called subnets or segments, depending on the device type), and they are used to combine small networks into a larger network called an internetwork or internet. Less complex connectivity devices do neither; they are used merely as connection points for the computers on a network (or network segment) or to amplify the signals of networked computers, which extends the distance over which transmissions can be sent. They can also:
▪ Connect network segments that use different media types (for instance, thin coax and unshielded twisted pair [UTP])
▪ Segment the network to reduce traffic without dividing the network into separate IP subnets
We look briefly at some of these devices in the following subsections. In looking at these various devices, it is important to realize that newer corporate networks use switches that combine many of the features of different devices into a single device. This isn't uncommon, as network devices commonly incorporate many features that were previously available only in separate network components.
Repeaters and Hubs
Repeaters and hubs are connection devices. We discuss them together because, in many cases, they are the same thing. In fact, you will hear hubs referred to as multiport repeaters. Repeaters connect two network segments (usually thin or thick coax) and boost the signal so that the distance of the cabling can be extended past the normal limits at which attenuation, or weakening, interferes with the reliable transmission of the data.
A repeater is used to extend the usable length of a given type of cable. For instance, a 10Base5 Ethernet network, using thick coax cable, has a maximum cable segment length of 500 meters, or 1,640 feet. At that distance, attenuation (signal loss due to distance) begins to take place. But when you place a repeater at the end of the cable and attach another length to the repeater's second port, the signal is boosted and the data can travel farther without damage or loss.
Hubs are different from basic repeaters in that the repeater generally has only two ports, whereas the hub can have many more (typically from five to 64 or more). Hubs can also be connected to one another and stacked, providing even more ports. Hubs are generally used with Ethernet twisted-pair cable, and most modern hubs are repeaters with multiple ports; they also strengthen the signal before passing it back to the computers attached to it. Hubs can be categorized as follows:
▪ Passive hubs These hubs serve as connection points only; they do not boost the signal. Passive hubs do not require electricity and thus don't use a power cord as active hubs do.
▪ Active hubs These hubs serve as both a connection point and a signal booster. Data that comes in is passed back out on all ports. Active hubs require electrical power.
Another type of hub, called a switching hub and is more commonly called simply a switch.
Bridges
Bridges can separate a network into segments, but they don't subnet the network as routers do. In other words, if you use a bridge to physically separate two areas of the network, it still appears to higher-level protocols to be one network.
A bridge monitors the data frames it receives to construct a table of MAC addresses, which are unique addresses that are assigned to the NIC to identify it on the network. The bridge determines which NIC sent the data using the source addresses on the frames. This is a simple table that tells the bridge on which side a particular address resides. Then the bridge can look at the destination address on a frame and, if it is in the table, determine whether to let it cross the bridge (if the address is on the other side) or not (if the address is on the side from which it was received).
In this way, less unnecessary traffic is generated. Let's say a computer in the HR department sends a message to another computer that is also in that department, and the signal goes only to those computers on that side of the bridge. The computers in Finance, on the other side of the bridge, go blithely on with their business and never have to deal with the message. Bridges can cut network congestion because they can do some basic filtering of data traffic based on the destination computer's MAC address. When a transmission reaches the bridge, the bridge will not pass it to the other side of the network if the destination computer's MAC address is known to be on the same side of the network as the sending computer.
Switches
Switching hubs are installed in place of the active hubs that have been more typically used to connect computers on a UTP-cabled network. Switches cost a bit more than hubs, but offer several important advantages.
A switch combines the characteristics of hubs and bridges. Like a bridge, a switch constructs a table of MAC addresses. The switch knows which computer network interface (identified by its physical address) is attached to which of its ports. It can then determine the destination address for a particular packet and route it only to the port to which that NIC is attached. Obviously, this system cuts down a great deal on unnecessary bandwidth usage because the packet is not sent out to all the remaining ports, where it will be disregarded when those computers determine that it is not intended for them. Figure 4.17 illustrates this process.
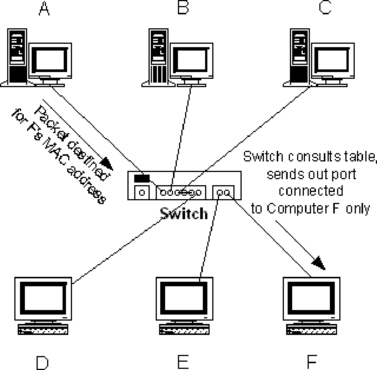 |
| Figure 4.17 Switches Reducing Traffic by Sending Data Out the Port with Which the Destination MAC Address Is Associated |
Using switches instead of hubs creates individual “collision domains” for each segment (the cable length between the switch and each node). This means a particular computer receives only the packets addressed to it, or to a multicast address to which it belongs, or to the broadcast address (when messages are being sent to every computer). You increase potential bandwidth in this way by the number of devices connected to the switch, because each computer can send and receive at the same time that one or more other nodes are doing so.
Switches can forward data frames more quickly than bridges because instead of reading the entire incoming Ethernet frame before forwarding it to the destination segment, the switch typically reads only the destination address in the frame, then retransmits it to the correct segment. This is why switches can offer fewer and shorter delays throughout the network, resulting in better performance.
A type of switch that operates at the network layer, or on Layer 3 of the Open Systems Interconnection model (OSI model), has become a popular connectivity option. A Layer 3 switch, sometimes referred to as a switch router, is in fact a type of router. Although a Layer 2 switch (switching hub) is unable to distinguish between protocols, a Layer 3 switch actually performs the functions of a router. A Layer 3 switch can filter the packets of a particular protocol to allow you to further reduce network traffic.
Layer 3 switches perform the same tasks as routers and can be deployed in the same locations in which a router is traditionally used. Yet the Layer 3 switch overcomes the performance disadvantage of routers, layering routing on top of switching technology. Layer 3 switches have become the solution of choice for enterprise network connectivity.
Routers
Routers are multiport connectivity devices that are used on large, complex networks because they are able to use the logical IP address to determine where packets need to go. How does using the IP address help to simplify the routing process? s we'll discuss later in this chapter, an IP address is used to identify each computer on a network. The IP address is divided into two parts: the network ID and the host ID. The network ID is a group of numbers that identifies which network the computer is on, and the host ID is used to identify which of the computers (or host as it's called on TCP/IP networks) sent or is meant to receive a particular message. The network ID is the key here because it “narrows down” the location of the particular destination computer by acting somewhat the way a ZIP Code does for the post office.
Routers are used to handle complex routing tasks. Routers also reduce network congestion by confining broadcast messages to a single subnet. A router can be either a dedicated device or a computer running an operating system that is capable of acting as a router. A Windows server can function as a router when two network cards are installed and IP forwarding is enabled.
Routers are capable of filtering so that you can, for instance, block inbound traffic. This capability allows the router to act as a firewall, creating a barrier that prevents undesirable packets from either entering or leaving a particular designated area of the network. However, in general, the more filtering a router is configured to do, the slower its performance.
Gateways
Gateways are usually not implemented as “devices” (although they can be). Rather, they are implemented as software programs running on servers. However, because they are also used to connect disparate networks, we touch briefly on what they are and why they are implemented in many networks.
Gateways can be used to connect two networks that use entirely different protocols. For instance, Microsoft's Host Integration Server allows PCs running Windows to communicate with an IBM mainframe computer, even though the two systems are “alien” to one another. There are many other different types of gateways, such as e-mail gateways, which translate between e-mail protocols.
Note
Additional information on Microsoft's Host Integration Servers is available at http://www.microsoft.com/hiserver/default.mspx.
Protocols
A protocol is a set of rules that determine how computers connect, communicate, and exchange data over a network. To illustrate how a protocol works, consider what happens when you make a phone call. You dial a number that identifies the person being called. When the phone rings and the person answers, he or she says “Hello”; when one person finishes talking the other can begin; and when communication terminates, you say “Goodbye.” These rules serve as a protocol for communications between two people, just as network protocols dictate how computers communicate.
Many different kinds of protocols are available, each providing different functions on a network. In some cases, these protocols are combined into a protocol suite, as in the case of TCP/IP. The TCP/IP protocol suite includes such individual protocols as the following:
▪ TCP (Transmission Control Protocol) Used to coordinate the transmission, reception, and retransmission (if necessary) of packets of data on a network. It is a connection-oriented protocol that provides reliable communication between two hosts on a network so that transmission of data between them is guaranteed.
▪ IP (Internet Protocol) Used to specify the format of packets and provides connectionless delivery of packets.
▪ UDP (User Datagram Protocol) Used for one-way transmission of data, and doesn't guarantee that every bit of data will make it to its destination. This is used for streaming video or other media being sent that doesn't require every bit of data to display the information.
▪ HTTP (Hypertext Transfer Protocol) Used to transfer data over a TCP/IP network, and primarily used by Internet browsers to access HTML files (also known as Web pages) on intranets and the Internet.
▪ FTP (File Transfer Protocol) Commonly used to transfer files over a TCP/IP network.
Although numerous individual protocols are installed with TCP/IP, which protocol a particular program uses is often invisible to the user. For example, someone sending a video message over the Internet wouldn't know whether UDP was the protocol being used, whereas the average person wouldn't care that HTTP was a protocol being used to access a Web page.
Understanding IP Addresses
All law enforcement investigators need to understand the basics of IP addressing to trace users of the Internet to a physical location. Much like a phone number that shows up on a caller ID box from a threatening phone call can provide an investigator with a specific starting location for his or her investigation, an IP address can provide that same type of lead. By understanding what IP addresses are, how they're assigned, and who has control over them, an investigator can develop workable case leads.
IP addresses provide a connection point through which communication can occur between two computers. Without getting into too much detail about them, it is important that you understand how to identify an IP address when you see one. These addresses are made up of four 8-bit numbers divided by a dot (.), much like this one: 155.212.56.73. Currently, the Internet operates under the Internet Protocol Version 4 (IPv4) standard. In IPv4, approximately 4 billion IP addresses are available for use over the Internet. That number will be expanding in the near future to about 16 billion times that number when transition is made to IPv6.
During the birth and initial development of today's Internet, IP addresses primarily were assigned to computers for them to pass network traffic over the Internet. Computers were physically very large, extremely expensive, and pretty much limited to the organizations that controlled the primary networks that were part of the primordial Internet. During this time, an IP address most likely could be traced back to a specific computer. A limited number of large organizations own and control most of the IP addresses available with IPv4. Therefore, if an investigator has been able to ascertain the IP address of an illegal communication, he or she will also be able to determine which organization owns the network space within which that address is contained. That information in and of itself will often not be enough because many of these organizations sublease blocks of the IP addresses they own to smaller companies, such as Internet service providers (ISPs). The investigative follow-up with the ISP is therefore likely to provide the best results. Using an analogy, we can think about IP addresses much like phone numbers, where the major corporations are states and ISPs are towns or calling districts. If an investigator was following up on a case involving a phone number, the area code would narrow down the search to a particular state, and the remaining numbers would identify a particular account.
Remember that for Internet traffic to occur, an external IP address must be available to the device. An ISP provides access to an external IP address. ISPs sublease blocks of IP addresses from one or more of the larger corporations that control address space, and in return they will in essence sublease one of those addresses to the individual customer. This connection to the Internet is most often done through a modem. Modems come in varying configurations, such as dial-up, cable, and DSL. Depending on when you began to use the Internet, you may already be familiar with these devices. The older of the three listed is the dial-up modem, which required the use of a telephone line. When users wanted to connect to the Internet, they would plug the modem installed in their computer to their phone line and then dial one of the access numbers provided by the ISP. The dial-up modem is the slowest of the available devices and can make the transfer of large files a painful process. Therefore, when dealing with cases that require large file transfers such as child pornography, it is less likely that a dial-up connection would be used. A distinct advantage of the dial-up modem, though, is portability, because the connection can be made on any phone line by dialing an appropriate access number and providing valid account information.
More common today is Internet service provided through TV cable or through DSL; both of these services provide higher connection speeds, making the transfer of large files relatively easy. When a consumer contacts an ISP about Internet access, typically the consumer is assigned an installation date when a technician comes to the residence to connect the necessary wiring to the home through either the consumer's cable provider (cable modem) or phone provider (DSL). With the appropriate wiring in place, an external modem is connected to the line provided through which the computer in the home will connect. The modem provides the interface through which the home computer can be physically connected to the Internet.
When the home user is connected to the ISP's physical connection to the Internet, the ISP must still assign the home user's computer an IP address for the computer to communicate over the Internet. IP addresses are assigned in two ways: statically and dynamically. If static addressing was to be used, the install technician would configure the computer's NIC with the specific IP address during install. Static assignment by an ISP would limit the total number of customers an ISP could have by the total number of external addresses it controls. Let's say that XYZ ISP had subleased a block of 1,000 unique and valid IP addresses from a large corporation. If that ISP statically assigned addresses to its customers, the total number of customers it could have on the Internet would be limited to 1,000. Leasing blocks of external IP addresses is very expensive as the demand is high compared to availability. ISPs realize that it is unlikely that all of their customers will be on the Internet at the same time, so to get the largest return on their investment, they use an addressing scheme called dynamic addressing, which allows for computers that are actively connected to the Internet to be assigned an unused IP address.
Here's how dynamic addressing works. XYZ ISP has 1,000 addresses available to its customers. It sets up a server, referred to as a DHCP server, which maintains a list of the available addresses. At installation, the technician sets the consumer's computer NIC to get an address assignment through DHCP. When the consumer's computer is turned on and connected to the network, the NIC puts out a broadcast requesting an IP address assignment. The DHCP server responsible for the assignment responds to the request by providing an IP address from the pool of available addresses to the computer's NIC. The length of time that the computer will use that assigned address is based on the “lease” time set by the DHCP server. Remember that the ISP wants to have the maximum number of customers using the smallest number of addresses, so the ISP wants to ensure that any unused addresses are made available to other computers. The lease time determines how long that address will be used before the NIC will be required to send out another broadcast for an IP address. The IP address returned after the reassignment could be the same address used previously or an entirely new address, depending on what's available in the server pool.
You can determine a number of details about the configuration of a computer's NIC(s) in Windows by using a tool called ipconfig. As shown in Figure 4.18, when you enter the command ipconfig /all at a computer's command prompt, the IP address assigned to different NICs on the computer is displayed with other networking information.
 |
| Figure 4.18 The ipconfig /all Command |
Note that this example provides details on several different NICs; a physical Ethernet port is identified by the Local Area Connection designation, a wireless network connection, virtual network adapters used by VMware, and a dial-up connection to the Internet that is associated with a modem. Each NIC can possess a different IP address. IP addresses are important because each device that communicates over a TPC/IP network and the Internet must have an address. In a computer crime investigation involving the Internet, it is very likely that the investigator will need to track an IP address to a location—preferably a person. As discussed earlier, ISPs control the assignment of IP addresses, and ISPs can provide the link between the IP address and the account holder. Understanding the distinction between static and dynamic IP assignment is very important because the investigator must record the date/time that IP address was captured. If the ISP uses DHCP, the IP address assignments can change—investigators need to be sure that the account holder identified by the ISP was actually assigned the IP address in question when the illicit activity occurred.
Let's take a moment and think about this. You're investigating an e-mail-based criminal threatening case where you were able to determine the originating IP address of the illegal communication. You were able to determine which ISP controls the address space that includes the IP address in question. If ISPs use dynamic addressing, how are you going to be able to determine which subscriber account used that address if any of a thousand or more could have been assigned to the suspect's computer? In this case, it would be extremely important for you to also record and note the date and time of the originating communication. The date/timestamp can be matched against the logs for the DHCP server to determine which subscriber account was assigned the IP address in question at that time.
Summary
Cybercrime investigators need to be as intimately familiar with the internal workings of computers and the software that runs on them as homicide investigators must be with basic human pathology. That includes understanding the function of all the hardware components that go together to make up a computer and how these components interact with one another.
It would be difficult for an investigator to conduct a proper investigation in a foreign country where he or she does not speak the local language, because many clues might go unnoticed if the investigator cannot understand the information being collected. Likewise, a cybercrime investigator must have a basic understanding of the “language” used by the machines to process data and communicate with each another. Even though an investigator in the field might not be able to speak all human languages, it is helpful to at least be able to recognize what language written evidence is in, because this evidence might be significant and will certainly help the investigator find someone who can translate it. Similarly, even though a cybercrime investigator is not expected to be able to program in binary, it helps to recognize the significance of data that is in binary or hexadecimal format and when it can or can't be valuable as evidence.
Computers today run a variety of operating systems and file systems, and the investigator's job of locating evidence will be performed differently depending on the system being used. A good cybercrime investigator is familiar with the most common operating systems and how their file systems organize the data on disk.
Regardless of operating system or hardware platform, the majority of networks today run on the TCP/IP protocols. TCP/IP is the most routable protocol stack and thus the most appropriate for large routed networks; it is required for connecting to the Internet. This chapter provided a basic overview of networking hardware and software and how TCP/IP communications are accomplished.
Frequently Asked Questions
A These are ways to measure the performance of a hard disk. The data transfer rate refers to the number of bytes per second (bps) that the disk drive is able to transfer to the processor. This is usually measured for today's disks in megabytes per second, and rates between 5 and 40 are common. The higher this number is, the better the disk performance. Seek time refers to the time interval between the time the processor makes a request for a file from disk and the time at which the first byte of that file is received by the processor. This time is measured in milliseconds (typically between 7 and 20), and the lower this number is, the better the performance.
Q How does a CD-R drive write data on a CD?
A CD-Recordable, or CD-R, discs, unlike regular read-only CDs, have a layer of dye (usually a greenish color) on the disk that is then covered with a reflective gold layer. Both of these thin layers sit on top of a rigid piece of plastic called the substrate. The CD-R drive has a writing laser that is more powerful than the reading laser in a regular CD-ROM drive. This more powerful laser heats the layer of dye from the bottom, going through the substrate. The heating process changes the transparency of the dye at that spot, creating a “bump” that is not reflective. This bump forms a readable mark that is then read by the CD drive as data. The same encoding scheme is used as for regular CDs; that's why a regular CD-ROM drive can read CD-R discs.
Q How does virtual memory work?
A When an operating system supports the use of virtual memory, it creates a file on the hard disk (called a swap file or a page file) in which it can “swap out” data between the RAM and the disk. The system detects which areas of the physical memory (RAM) haven't been used recently. Then it copies the data from that location in memory to the file on the hard disk. This means there will be more free space in RAM, which allows you to run additional applications or speed the performance of applications that are currently running. When the processor needs the data stored in the swap/page file, it can be loaded from the hard disk back to RAM. The data is stored in units called pages. Using virtual memory can degrade performance if the system has to frequently swap the data in and out of RAM. This is because the hard disk is much slower than the RAM. Frequent swapping results in disk thrashing, which is usually a sign that you need to add more physical memory to the computer.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.