
![]()
Implementing a Database
Chapter 1 detailed how to efficiently install the Oracle binaries. After you’ve installed the Oracle software, the next logical task is creating a database. There are two standard ways for creating Oracle databases:
- Use the Database Configuration Assistant (dbca) utility
- Run a CREATE DATABASE statement from SQL*Plus
Oracle’s dbca utility has a graphical interface from which you can configure and create databases. This visual tool is easy to use and has a very intuitive interface. If you need to create a development database and get going quickly, then this tool is more than adequate. Having said that, I normally don’t use the dbca utility to create databases. In Linux/Unix environments the dbca tool depends on X software and an appropriate setting for the OS DISPLAY variable. The dbca utility therefore requires some setup and can perform poorly if you’re installing on remote servers when the network throughput is slow.
The dbca utility also allows you to create a database in silent mode, without the graphical component. Using dbca in silent mode with a response file is an efficient way to create databases in a consistent and repeatable manner. This approach also works well when you’re installing on remote servers, which could have a slow network connection or not have the appropriate X software installed.
When you’re creating databases on remote servers, it’s usually easier and more efficient to use SQL*Plus. The SQL*Plus approach is simple and inherently scriptable. In addition, SQL*Plus works no matter how slow the network connection is, and it isn’t dependent on a graphical component. Therefore, I almost always use the SQL*Plus technique to create databases.
This chapter starts by showing you how to quickly create a database using SQL*Plus, and also how to make your database remotely available by enabling a listener process. Later, the chapter demonstrates how to use the dbca utility in silent mode with a response file to create a database.
Before creating a database, you need to know a bit about OS variables, often called environment variables. Before you run SQL*Plus (or any other Oracle utility), you must set several OS variables:
- ORACLE_HOME
- ORACLE_SID
- LD_LIBRARY_PATH
- PATH
The ORACLE_HOME variable defines the starting point directory for the default location for the initialization file, which is ORACLE_HOME/dbs on Linux/Unix. On Windows this directory is usually ORACLE_HOMEdatabase. The ORACLE_HOME variable is also important because it defines the starting point directory for locating the Oracle binary files (such as sqlplus, dbca, netca, rman, and so on) that are in ORACLE_HOME/bin.
The ORACLE_SID variable defines the default name of the database you’re attempting to create. ORACLE_SID is also used as the default name for the parameter file, which is init<ORACLE_SID>.ora or spfile<ORACLE_SID>.ora.
The LD_LIBRARY_PATH variable is important because it specifies where to search for libraries on Linux/Unix boxes. The value of this variable is typically set to include ORACLE_HOME/lib.
The PATHvariable specifies which directories are looked in by default when you type a command from the OS prompt. In almost all situations, ORACLE_HOME/bin (the location of the Oracle binaries) must be included in your PATH variable.
You can take several different approaches to setting the prior variables. This chapter discusses three, beginning with a hard-coded manual approach and ending with the approach that I personally prefer.
In Linux/Unix, when you’re using the Bourne, Bash, or Korn shell, you can set OS variables manually from the OS command line with the export command::
$ export ORACLE_HOME=/u01/app/oracle/product/12.1.0.1/db_1
$ export ORACLE_SID=o12c
$ export LD_LIBRARY_PATH=/usr/lib:$ORACLE_HOME/lib
$ export PATH=$ORACLE_HOME/bin:$PATH
For the C or tcsh shell, use the setenv command to set variables:
$ setenv ORACLE_HOME <path>
$ setenv ORACLE_SID <sid>
$ setenv LD_LIBRARY_PATH <path>
$ setenv PATH <path>
Another way that DBAs set these variables is by placing the previous export or setenv commands into a Linux/Unix startup file, such as .bash_profile, .bashrc, or .profile. That way, the variables are automatically set upon login.
However, manually setting OS variables (either from the command line or by hard-coding values into a startup file) isn’t the optimal way to instantiate these variables. For example, if you have multiple databases with multiple Oracle homes on a box, manually setting these variables quickly becomes unwieldy and not very maintainable.
Oracle’s Approach to Setting OS Variables
A much better method for setting OS variables is use of a script that uses a file that contains the names of all Oracle databases on a server and their associated Oracle homes. This approach is flexible and maintainable. For instance, if a database’s Oracle home changes (e.g., after an upgrade), you only have to modify one file on the server and not hunt down where the Oracle home variables may be hard-coded into scripts.
Oracle provides a mechanism for automatically setting the required OS variables. Oracle’s approach relies on two files: oratab and oraenv.
You can think of the entries in the oratab file as a registry of what databases are installed on a box and their corresponding Oracle home directories. The oratab file is automatically created for you when you install the Oracle software. On Linux boxes, oratab is usually placed in the /etc directory. On Solaris servers the oratab file is placed in the /var/opt/oracle directory. If, for some reason, the oratab file isn’t automatically created, you can manually create the directory and file.
The oratab file is used in Linux/Unix environments for the following purposes:
- Automating the sourcing of required OS variables
- Automating the start and stop of Oracle databases on the server
The oratab file has three columns with this format:
<database_sid>:<oracle_home_dir>:Y|N
The Y or N indicates whether you want Oracle to restart automatically on reboot of the box; Y indicates yes, and N indicates no. Automating the startup and shutdown of your database is covered in detail in Chapter 21.
Comments in the oratab file start with a pound sign (#). Here is a typical oratab file entry:
o12c:/u01/app/oracle/product/12.1.0.1/db_1:N
rcat:/u01/app/oracle/product/12.1.0.1/db_1:N
The names of the databases on the previous lines are o12c and rcat. The path of each database’s Oracle home directory is next on the line (separated from the database name by a colon [:]).
Several Oracle-supplied utilities use the oratab file:
- oraenv uses oratab to set the OS variables.
- dbstart uses it to start the database automatically on server reboots (if the third field in oratab is Y).
- dbshut uses it to stop the database automatically on server reboots (if the third field in oratab is Y).
The oraenv tool is discussed in the following section.
If you don’t properly set the required OS variables for an Oracle environment, then utilities such as SQL*Plus, Oracle Recovery Manager (RMAN), Data Pump, and so on won’t work correctly. The oraenv utility automates the setting of required OS variables (such as ORACLE_HOME, ORACLE_SID, and PATH) on an Oracle database server. This utility is used in Bash, Korn, and Bourne shell environments (if you’re in a C shell environment, there is a corresponding coraenv utility).
The oraenv utility is located in the ORACLE_HOME/bin directory. You can run it manually, like this:
$ . oraenv
Note that the syntax to run this from the command line requires a space between the dot (.) and the oraenv tool. You’re prompted for ORACLE_SID and ORACLE_HOME values:
ORACLE_SID = [oracle] ?
ORACLE_HOME = [/home/oracle] ?
You can also run the oraenv utility in a noninteractive way by setting OS variables before you run it. This is useful for scripting when you don’t want to be prompted for input:
$ export ORACLE_SID=o12c
$ export ORAENV_ASK=NO
$ . oraenv
Keep in mind that if you set your ORACLE_SID to a value that isn’t found with the oratab file, then you may be prompted for values such as ORACLE_HOME.
My Approach to Setting OS Variables
I don’t use Oracle’s oraenvfile to set the OS variables (see the previous section, “Using oraenv,” for details of Oracle’s approach). Instead, I use a script named oraset. The oraset script depends on the oratab file’s being in the correct directory and expected format:
<database_sid>:<oracle_home_dir>:Y|N
As mentioned in the previous section, the Oracle installer should create an oratab file for you in the correct directory. If it doesn’t, then you can manually create and populate the file. In Linux the oratab file is usually created in the /etc directory. On Solaris servers the oratab file is located in the /var/opt/oracle directory.
Next, use a script that reads the oratab file and sets the OS variables. Here is an example of an oraset script that reads the oratab file and presents a menu of choices (based on the database names in the oratab file):
#!/bin/bash
# Sets Oracle environment variables.
# Setup: 1. Put oraset file in /etc (Linux), in /var/opt/oracle (Solaris)
# 2. Ensure /etc or /var/opt/oracle is in $PATH
# Usage: batch mode: . oraset <SID>
# menu mode: . oraset
#====================================================
if [ −f /etc/oratab ]; then
OTAB=/etc/oratab
elif [ −f /var/opt/oracle/oratab ]; then
OTAB=/var/opt/oracle/oratab
else
echo 'oratab file not found.'
exit
fi
#
if [ −z $1 ]; then
SIDLIST=$(egrep -v '#|*' ${OTAB} | cut -f1 -d:)
# PS3 indicates the prompt to be used for the Bash select command.
PS3='SID? '
select sid in ${SIDLIST}; do
if [ −n $sid ]; then
HOLD_SID=$sid
break
fi
done
else
if egrep -v '#|*' ${OTAB} | grep -w "${1}:">/dev/null; then
HOLD_SID=$1
else
echo "SID: $1 not found in $OTAB"
fi
shift
fi
#
export ORACLE_SID=$HOLD_SID
export ORACLE_HOME=$(egrep -v '#|*' $OTAB|grep -w $ORACLE_SID:|cut -f2 -d:)
export ORACLE_BASE=${ORACLE_HOME%%/product*}
export TNS_ADMIN=$ORACLE_HOME/network/admin
export ADR_BASE=$ORACLE_BASE/diag
export PATH=$ORACLE_HOME/bin:/usr/ccs/bin:/opt/SENSsshc/bin/
:/bin:/usr/bin:.:/var/opt/oracle:/usr/sbin
export LD_LIBRARY_PATH=/usr/lib:$ORACLE_HOME/lib
You can run the oraset script either from the command line or from a startup file (such as .profile, .bash_profile, or .bashrc). To run oraset from the command line, place the oraset file in a standard location, such as /var/opt/oracle (Solaris) or /etc (Linux), and run, as follows:
$ . /etc/oraset
Note that the syntax to run this from the command line requires a space between the dot (.) and the rest of the command. When you run oraset from the command line, you should be presented with a menu such as this:
1) o12c
2) rcat
SID?
In this example you can now enter 1 or 2 to set the OS variables required for whichever database you want to use. This allows you to set up OS variables interactively, regardless of the number of database installations on the server.
You can also call the oraset file from an OS startup file. Here is a sample entry in the .bashrc file:
. /etc/oraset
Now, every time you log in to the server, you’re presented with a menu of choices that you can use to indicate the database for which you want the OS variables set. If you want the OS variables automatically set to a particular database, then put an entry such as this in the .bashrc file:
. /etc/oraset o12c
The prior line will run the oraset file for the o12c database and set the OS variables appropriately.
Creating a Database
This section explains how to create an Oracle database manually with the SQL*Plus CREATE DATABASE statement. These are the steps required to create a database:
- Set the OS variables.
- Configure the initialization file.
- Create the required directories.
- Create the database.
- Create a data dictionary.
Each of these steps is covered in the following sections.
As mentioned previously, before you run SQL*Plus (or any other Oracle utility), you must set several OS variables. You can either manually set these variables or use a combination of files and scripts to set the variables. Here’s an example of setting these variables manually:
$ export ORACLE_HOME=/u01/app/oracle/product/12.1.0.1/db_1
$ export ORACLE_SID=o12c
$ export LD_LIBRARY_PATH=/usr/lib:$ORACLE_HOME/lib
$ export PATH=$ORACLE_HOME/bin:$PATH
See the section “Setting OS Variables,” earlier in this chapter, for a complete description of these variables and techniques for setting them.
Step 2: Configure the Initialization File
Oracle requires that you have an initialization file in place before you attempt to start the instance. The initialization file is used to configure features such as memory and to control file locations. You can use two types of initialization files:
- Server parameter binary file (spfile)
- init.ora text file
Oracle recommends that you use an spfile for reasons such as these:
- You can modify the contents of the spfile with the SQL ALTER SYSTEM statement.
- You can use remote-client SQL sessions to start the database without requiring a local (client) initialization file.
These are good reasons to use an spfile. However, some shops still use the traditional init.ora file. The init.ora file also has advantages:
- You can directly edit it with an OS text editor.
- You can place comments in it that detail a history of modifications.
When I first create a database, I find it easier to use an init.ora file. This file can be easily converted later to an spfile if required (via the CREATE SPFILE FROM PFILE statement). In this example my database name is o12c, so I place the following contents in a file named inito12c.ora and put the file in the ORACLE_HOME/dbs directory:
db_name=o12c
db_block_size=8192
memory_target=300M
memory_max_target=300M
processes=200
control_files=(/u01/dbfile/o12c/control01.ctl,/u02/dbfile/o12c/control02.ctl)
job_queue_processes=10
open_cursors=500
fast_start_mttr_target=500
undo_management=AUTO
undo_tablespace=UNDOTBS1
remote_login_passwordfile=EXCLUSIVE
Ensure that the initialization file is named correctly and located in the appropriate directory. This is critical because when starting your instance, Oracle first looks in the ORACLE_HOME/dbs directory for parameter files with specific formats, in this order:
- spfile<SID>.ora
- spfile.ora
- init<SID>.ora
In other words, Oracle first looks for a file named spfile<SID>.ora. If found, the instance is started; if not, Oracle looks for spfile.ora and then init<SID>.ora. If one of these files is not found, Oracle throws an error.
This may cause some confusion if you’re not aware of the files that Oracle looks for, and in what order. For example, you may make a change to an init<SID>.ora file and expect the parameter to be instantiated after stopping and starting your instance. If there is an spfile<SID>.ora in place, the init<SID>.ora is completely ignored.
![]() Note You can manually instruct Oracle to look for a text parameter file in a directory, using the pfile=<directory/filename> clause with the startup command; under normal circumstances, you shouldn’t need to do this. You want the default behavior, which is for Oracle to find a parameter file in the ORACLE_HOME/dbs directory (for Linux/Unix). The default directory on Windows is ORACLE_HOME/database.
Note You can manually instruct Oracle to look for a text parameter file in a directory, using the pfile=<directory/filename> clause with the startup command; under normal circumstances, you shouldn’t need to do this. You want the default behavior, which is for Oracle to find a parameter file in the ORACLE_HOME/dbs directory (for Linux/Unix). The default directory on Windows is ORACLE_HOME/database.
Table 2-1 lists best practices to consider when configuring an Oracle initialization file.
Table 2-1. Initialization File Best Practices
| Best Practice | Reasoning |
|---|---|
| Oracle recommends that you use a binary server parameter file (spfile). However, I still use the old text init.ora files in some cases. | Use whichever type of initialization parameter file you’re comfortable with. If you have a requirement to use an spfile, then by all means, implement one. |
| In general, don’t set initialization parameters if you’re not sure of their intended purpose. When in doubt, use the default. | Setting initialization parameters can have far-reaching consequences in terms of database performance. Only modify parameters if you know what the resulting behavior will be. |
| For 11g and higher, set the memory_target and memory_max_target initialization parameters. | Doing this allows Oracle to manage all memory components for you. |
| For 10g, set the sga_target and sga_target_max initialization parameters. | Doing this lets Oracle manage most memory components for you. |
| For 10g, set pga_aggregate_target and workarea_size_policy. | Doing this allows Oracle to manage the memory used for the sort space. |
| Starting with 10g, use the automatic UNDO feature. This is set using the undo_management and undo_tablespace parameters. | Doing this allows Oracle to manage most features of the UNDO tablespace. |
| Set open_cursors to a higher value than the default. I typically set it to 500. Active online transaction processing (OLTP) databases may need a much higher value. | The default value of 50 is almost never enough. Even a small, one-user application can exceed the default value of 50 open cursors. |
| Name the control files with the pattern /<mount_point>/dbfile/<database_name>/control0N.ctl. | This deviates slightly from the OFA standard. I find this location easier to navigate to, as opposed to being located under ORACLE_BASE. |
| Use at least two control files, preferably in different locations, using different disks. | If one control file becomes corrupt, it’s always a good idea to have at least one other control file available. |
Step 3: Create the Required Directories
Any OS directories referenced in the parameter file or CREATE DATABASE statement must be created on the server before you attempt to create a database. For instance, in the previous section’s initialization file, the control files are defined as
control_files=(/u01/dbfile/o12c/control01.ctl,/u02/dbfile/o12c/control02.ctl)
From the previous line, ensure that you’ve created the directories /u01/dbfile/o12c and /u02/dbfile/o12c (modify this according to your environment). In Linux/Unix you can create directories, including any parent directories required, by using the mkdir command with the p switch:
$ mkdir -p /u01/dbfile/o12c
$ mkdir -p /u02/dbfile/o12c
Also make sure you create any directories required for data files and online redo logs referenced in the CREATE DATABASE statement (see step 4). For this example, here are the additional directories required:
$ mkdir -p /u01/oraredo/o12c
$ mkdir -p /u02/oraredo/o12c
If you create the previous directories as the root user, ensure that the oracle user and dba groups are properly set to own the directories, subdirectories, and files. This example recursively changes the owner and group of the following directories:
# chown -R oracle:dba /u01
# chown -R oracle:dba /u02
Step 4: Create the Database
After you’ve established OS variables, configured an initialization file, and created any required directories, you can now create a database. This step explains how to use the CREATE DATABASE statement to create a database.
Before you can run the CREATE DATABASE statement, you must start the background processes and allocate memory via the STARTUP NOMOUNT statement:
$ sqlplus / as sysdba
SQL> startup nomount;
When you issue a STARTUP NOMOUNT statement, SQL*Plus attempts to read the initialization file in the ORACLE_HOME/dbs directory (see step 2). The STARTUP NOMOUNT statement instantiates the background processes and memory areas used by Oracle. At this point, you have an Oracle instance, but you have no database.
![]() Note An Oracle instance is defined as the background processes and memory areas. The Oracle database is defined as the physical files (data files, control files, online redo logs) on disk.
Note An Oracle instance is defined as the background processes and memory areas. The Oracle database is defined as the physical files (data files, control files, online redo logs) on disk.
Listed next is a typical Oracle CREATE DATABASE statement:
CREATE DATABASE o12c
MAXLOGFILES 16
MAXLOGMEMBERS 4
MAXDATAFILES 1024
MAXINSTANCES 1
MAXLOGHISTORY 680
CHARACTER SET AL32UTF8
DATAFILE
'/u01/dbfile/o12c/system01.dbf'
SIZE 500M REUSE
EXTENT MANAGEMENT LOCAL
UNDO TABLESPACE undotbs1 DATAFILE
'/u01/dbfile/o12c/undotbs01.dbf'
SIZE 800M
SYSAUX DATAFILE
'/u01/dbfile/o12c/sysaux01.dbf'
SIZE 500M
DEFAULT TEMPORARY TABLESPACE TEMP TEMPFILE
'/u01/dbfile/o12c/temp01.dbf'
SIZE 500M
DEFAULT TABLESPACE USERS DATAFILE
'/u01/dbfile/o12c/users01.dbf'
SIZE 20M
LOGFILE GROUP 1
('/u01/oraredo/o12c/redo01a.rdo',
'/u02/oraredo/o12c/redo01b.rdo') SIZE 50M,
GROUP 2
('/u01/oraredo/o12c/redo02a.rdo',
'/u02/oraredo/o12c/redo02b.rdo') SIZE 50M,
GROUP 3
('/u01/oraredo/o12c/redo03a.rdo',
'/u02/oraredo/o12c/redo03b.rdo') SIZE 50M
USER sys IDENTIFIED BY foo
USER system IDENTIFIED BY foo;
In this example the script is placed in a file named credb.sql and is run from the SQL*Plus prompt as the sys user:
SQL> @credb.sql
If it’s successful, you should see the following message:
Database created.
![]() Note See Chapter 23 for details on creating a pluggable database.
Note See Chapter 23 for details on creating a pluggable database.
If any errors are thrown while the CREATE DATABASE statement is running, check the alert log file. Typically, errors occur when required directories don’t exist, the memory allocation isn’t sufficient, or an OS limit has been exceeded. If you’re unsure of the location of your alert log, issue the following query:
SQL> select value from v$diag_info where name = 'Diag Trace';
The prior query should work even when your database is in the nomount state. Another way to quickly find the alert log file is from the OS:
$ cd $ORACLE_BASE
$ find . -name "alert*.log"
![]() Tip The default format for the name of the alert log file is alert_<SID>.log.
Tip The default format for the name of the alert log file is alert_<SID>.log.
There are few key things to point out about the prior CREATE DATABASE statement example. Note that the SYSTEM data file is defined as locally managed. This means that any tablespace created in this database must be locally managed (as opposed to dictionary managed). Oracle throws an error if you attempt to create a dictionary-managed tablespace in this database. This is the desired behavior.
A dictionary-managed tablespace uses the Oracle data dictionary to manage extents and free space, whereas a locally managed tablespace uses a bitmap in each data file to manage its extents and free space. Locally managed tablespaces have these advantages:
- Performance is increased.
- No coalescing is required.
- Contention for resources in the data dictionary is reduced.
- Recursive space management is reduced.
Also note that the TEMP tablespace is defined as the default temporary tablespace. This means that any user created in the database automatically has the TEMP tablespace assigned to him or her as the default temporary tablespace. After you create the data dictionary (see step 5), you can verify the default temporary tablespace with this query:
select *
from database_properties
where property_name = 'DEFAULT_TEMP_TABLESPACE';
Finally, note that the USERS tablespace is defined as the default permanent tablespace for any users created that don’t have a default tablespace defined in a CREATE USER statement. After you create the data dictionary (see step 5) you can run this query to determine the default temporary tablespace:
select *
from database_properties
where property_name = 'DEFAULT_PERMANENT_TABLESPACE';
Table 2-2 lists best practices to consider when you’re creating an Oracle database.
Table 2-2. Best Practices for Creating an Oracle Database
| Best Practice | Reasoning |
|---|---|
| Ensure that the SYSTEM tablespace is locally managed. | Doing this enforces that all tablespaces created in this database are locally managed. |
| Use the REUSE clause with caution. Normally, you should use it only when you’re re-creating a database. | The REUSE clause instructs Oracle to overwrite existing files, regardless of whether they’re in use. This is dangerous. |
| Create a default temporary tablespace with TEMP somewhere in the name. | Every user should be assigned a temporary tablespace of the type TEMP, including the SYS user. If you don’t specify a default temporary tablespace, then the SYSTEM tablespace is used. You never want a user to be assigned a temporary tablespace of SYSTEM. If your database doesn’t have a default temporary tablespace, use the ALTER DATABASE DEFAULT TEMPORARY TABLESPACE statement to assign one. |
| Create a default permanent tablespace named USERS. | This ensures that users are assigned a default permanent tablespace other than SYSTEM. If your database doesn’t have a default permanent tablespace, use the ALTER DATABASE DEFAULT TABLESPACE statement to assign one. |
| Use the USER SYS and USER SYSTEM clauses to specify nondefault passwords. | Doing this creates the database with nondefault passwords for database accounts that are usually the first targets for hackers. |
| Create at least three redo log groups, with two members each. | At least three redo log groups provides time for the archive process to write out archive redo logs between switches. Two members mirror the online redo log members, providing some fault tolerance. |
| Give the redo logs a name such as redoNA.rdo. | This deviates slightly from the OFA standard, but I’ve had files with the extension.log accidentally deleted more than once (it shouldn’t ever happen, but it has). |
| Make the database name somewhat intelligent, such as PAPRD, PADEV1, or PATST1. | This helps you determine what database you’re operating in and whether it’s a production, development, or test environment. |
| Use the ? variable when you’re creating the data dictionary (see step 5). Don’t hard-code the directory path. | SQL*Plus interprets the ? as the directory contained in the OS ORACLE_HOME variable. This prevents you from accidentally running scripts from the wrong version of ORACLE_HOME. |
Note that the CREATE DATABASE statement used in this step deviates slightly from the OFA standard in terms of the directory structure. I prefer not to place the Oracle data files, online redo logs, and control files under ORACLE_BASE (as specified by the OFA standard). I instead directly place files under directories named /<mount_point>/<file_type>/<database_name>, because the path names are much shorter. The shorter path names make command line navigation to directories easier, and the names fit more cleanly in the output of SQL SELECT statements. Figure 2-1 displays this deviation from the OFA standard.
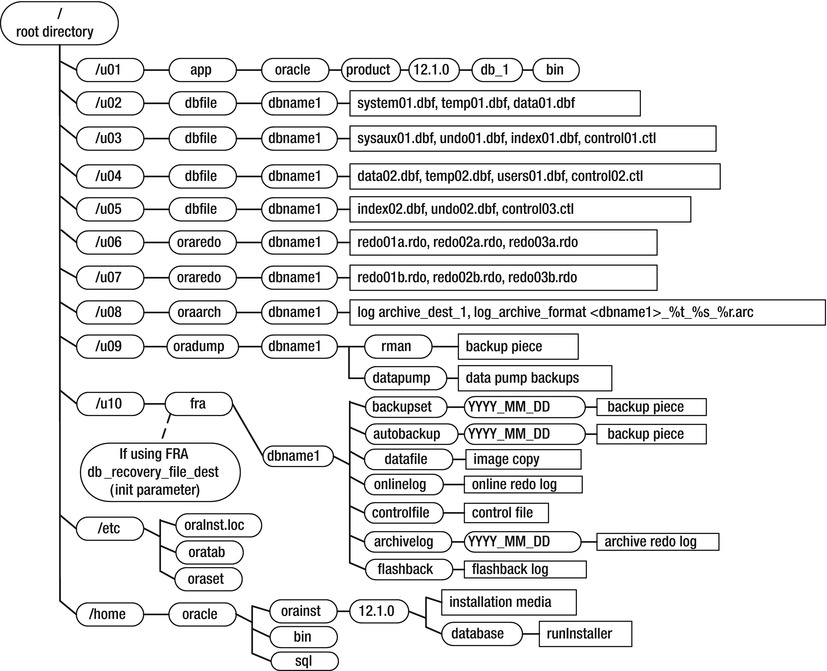
Figure 2-1. A slight deviation from the OFA standard for laying out database files
It’s not my intention to have you use nonstandard OFA structures. Rather, do what makes sense for your environment and requirements. Apply reasonable standards that foster manageability, maintainability, and scalability.
Step 5. Create a Data Dictionary
After your database is successfully created, you can instantiate the data dictionary by running two scripts. These scripts are created when you install the Oracle binaries. You must run these scripts as the SYS schema:
SQL> show user
USER is "SYS"
Before I create the data dictionary, I like to spool an output file that I can inspect in the event of unexpected errors:
SQL> spool create_dd.lis
Now, create the data dictionary:
SQL> @?/rdbms/admin/catalog.sql
SQL> @?/rdbms/admin/catproc.sql
After you successfully create the data dictionary, as the SYSTEM schema, create the product user profile tables:
SQL> connect system/<password>
SQL> @?/sqlplus/admin/pupbld
These tables allow SQL*Plus to disable commands on a user-by-user basis. If the pupbld.sql script isn’t run, then all non-sys users see the following warning when logging in to SQL*Plus:
Error accessing PRODUCT_USER_PROFILE
Warning: Product user profile information not loaded!
You may need to run PUPBLD.SQL as SYSTEM
These errors can be ignored. If you don’t want to see them when logging in to SQL*Plus, make sure you run the pupbld.sql script.
At this point, you should have a fully functional database. You next need to configure and implement your listener to enable remote connectivity and, optionally, set up a password file. These tasks are described in the next two sections.
Configuring and Implementing the Listener
After you’ve installed binaries and created a database, you need to make the database accessible to remote-client connections. You do this by configuring and starting the Oracle listener. Appropriately named, the listener is the process on the database server that “listens” for connection requests from remote clients. If you don’t have a listener started on the database server, then you can’t connect from a remote client. There are two methods for setting up a listener: manually and using the Oracle Net Configuration Assistant (netca).
Manually Configuring a Listener
When you’re setting up a new environment, manually configuring the listener is a two-step process:
- Configure the listener.ora file.
- Start the listener.
The listener.ora file is located by default in the ORACLE_HOME/network/admin directory. This is the same directory that the TNS_ADMIN OS variable should be set to. Here is a sample listener.ora file that contains network configuration information for one database:
LISTENER =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = oracle12c)(PORT = 1521))
)
)
)
SID_LIST_LISTENER =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = o12c)
(ORACLE_HOME = /u01/app/oracle/product/12.1.0.1/db_1)
(SID_NAME = o12c)
)
)
This code listing has two sections. The first defines the listener name; in this example the listener name is LISTENER. The second defines the list of SIDs for which the listener is listening for incoming connections (to the database). The format of the SID list name is SID_LIST_<name of listener>. The name of the listener must appear in the SID list name. The SID list name in this example is SID_LIST_LISTENER.
Also, you don’t have to explicitly specify the SID_LIST_LISTENER section (the second section) in the prior code listing. This is because the process monitor (PMON) background process will automatically register any running databases as a service with the listener; this is known as dynamic registration. However, some DBAs prefer to explicitly list which databases should be registered with the listener and therefore include the second section; this is known as static registration.
After you have a listener.ora file in place, you can start the listener background process with the lsnrctl utility:
$ lsnrctl start
You should see informational messages, such as the following:
Listening Endpoints Summary. . .
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=oracle12c)(PORT=1521)))
Services Summary. . .
Service "o12c" has 1 instance(s).
You can verify the services for which a listener is listening via
$ lsnrctl services
You can check the status of the listener with the following query:
$ lsnrctl status
For a complete listing of listener commands, issue this command:
$ lsnrctl help
![]() Tip Use the Linux/Unix ps -ef | grep tns command to view any listener processes running on a server.
Tip Use the Linux/Unix ps -ef | grep tns command to view any listener processes running on a server.
Implementing a Listener with the Net Configuration Assistant
The netca utility assists you with all aspects of implementing a listener. You can run the netca tool in either graphical or silent mode. Using the netca in graphical mode is easy and intuitive. To use the netca in graphical mode, ensure that you have the proper X software installed, then issue the xhost + command, and check that your DISPLAY variable is set; for example,
$ xhost +
$ echo $DISPLAY
:0.0
You can now run the netca utility:
$ netca
Next, you will be guided through several screens from which you can choose options such as name of the listener, desired port, and so on.
You can also run the netca utility in silent mode with a response file. This mode allows you to script the process and ensure repeatability when creating and implementing listeners. First, find the default listener response file within the directory structure that contains the Oracle install media:
$ find . -name "netca.rsp"
./12.1.0.1/database/response/netca.rsp
Now, make a copy of the file so that you can modify it:
$ cp 12.1.0.1/database/response/netca.rsp mynet.rsp
If you want to change the default name or other attributes, then edit the mynet.rsp file with an OS utility such as vi:
$ vi mynet.rsp
For this example I haven’t modified any values within the mynet.rsp file. In other words, I’m using all the default values already contained within the response file. Next, the netca utility is run in silent mode:
$ netca -silent -responsefile /home/oracle/orainst/mynet.rsp
The utility creates a listener.ora and sqlnet.ora file in the ORACLE_HOME/network/admin directory and starts a default listener.
Connecting to a Database through the Network
Once the listener has been configured and started, you can test remote connectivity from a SQL*Plus client, as follows:
$ sqlplus user/pass@'server:port/service_name'
In the next line of code, the user and password are system/foo, connecting the oracle12c server, port 1521, to a database named o12c:
$ sqlplus system/foo@'oracle12c:1521/o12c'
This example demonstrates what is known as the easy connect naming method of connecting to a database. It’s easy because it doesn’t rely on any setup files or utilities. The only information you need to know is username, password, server, port, and service name (SID).
Another common connection method is local naming. This method relies on connection information in the ORACLE_HOME/network/admin/tnsnames.ora file. In this example the tnsnames.ora file is edited, and the following Transparent Network Substrate (TNS) (Oracle’s network architecture) entry is added:
o12c =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = oracle12c)(PORT = 1521))
(CONNECT_DATA = (SERVICE_NAME = o12c)))
Now, from the OS command line, you establish a connection by referencing the o12c TNS information that was placed in the tnsnames.ora file:
$ sqlplus system/foo@o12c
This connection method is local because it relies on a local client copy of the tnsnames.ora file to determine the Oracle Net connection details. By default, SQL*Plus inspects the directory defined by the TNS_ADMIN variable for a file named tnsnames.ora. If not found, then the directory defined by ORACLE_HOME/network/admin is searched. If the tnsnames.ora file is found, and if it contains the alias specified in the SQL*Plus connection string (in this example, o12c), then the connection details are derived from the entry in the tnsnames.ora file.
The other connection-naming methods that Oracle uses are external naming and directory naming. See the Oracle Net Services Administrator’s Guide, which can be freely downloaded from the Technology Network area of the Oracle web site (http://otn.oracle.com), for further details.
![]() Tip You can use the netca utility to create a tnsnames.ora file. Start the utility, and choose the Local Net Service Name Configuration option. You will be prompted for input, such as the SID, hostname, and port.
Tip You can use the netca utility to create a tnsnames.ora file. Start the utility, and choose the Local Net Service Name Configuration option. You will be prompted for input, such as the SID, hostname, and port.
Creating a Password File
Creating a password file is optional. There are some good reasons for requiring a password file:
- You want to assign non-sys users sys* privileges (sysdba, sysoper, sysbackup, and so on).
- You want to connect remotely to your database via Oracle Net with sys* privileges.
- An Oracle feature or utility requires the use of a password file.
Perform the following steps to implement a password file:
- Create the password file with the orapwd utility.
- Set the initialization parameter REMOTE_LOGIN_PASSWORDFILE to EXCLUSIVE.
In a Linux/Unix environment, use the orapwd utility to create a password file, as follows:
$ cd $ORACLE_HOME/dbs
$ orapwd file=orapw<ORACLE_SID> password=<sys password>
In a Linux/Unix environment the password file is usually stored in ORACLE_HOME/dbs; in Windows it’s typically placed in the ORACLE_HOMEdatabase directory.
The format of the filename that you specify in the previous command may vary by OS. For instance, in Windows the format is PWD<ORACLE_SID>.ora. The following example shows the syntax in a Windows environment:
c:> cd %ORACLE_HOME%database
c:> orapwd file=PWD<ORACLE_SID>.ora password=<sys password>
To enable the use of the password file, set the initialization parameter REMOTE_LOGIN_PASSWORDFILE to EXCLUSIVE (this is the default value). If the parameter is not set to EXCLUSIVE, then you’ll have to modify your parameter file:
SQL> alter system set remote_login_passwordfile='EXCLUSIVE' scope=spfile;
You need to stop and start the instance to instantiate the prior setting.
You can add users to the password file via the GRANT <any SYS privilege> statement. The following example grants SYSDBA privileges to the heera user (and thus adds heera to the password file):
VSQL> grant sysdba to heera;
Grant succeeded.
Enabling a password file also allows you to connect to your database remotely with SYS*-level privileges via an Oracle Net connection. This example shows the syntax for a remote connection with SYSDBA-level privileges:
$ sqlplus <username>/<password>@<database connection string> as sysdba
This allows you to do remote maintenance with sys* privileges (sysdba, sysoper, sysbackup, and so on) that would otherwise require your logging in to the database server physically. You can verify which users have sys* privileges by querying the V$PWFILE_USERS view:
SQL> select * from v$pwfile_users;
Here is some sample output:
USERNAME SYSDB SYSOP SYSAS SYSBA SYSDG SYSKM CON_ID
------------------------------ ----- ----- ----- ----- ----- ----- ----------
SYS TRUE TRUE FALSE FALSE FALSE FALSE 0
The concept of a privileged user is also important to RMAN backup and recovery. Like SQL*Plus, RMAN uses OS authentication and password files to allow privileged users to connect to the database. Only a privileged account is allowed to back up, restore, and recover a database.
Starting and Stopping the Database
Before you can start and stop an Oracle instance, you must set the proper OS variables (previously covered in this chapter). You also need access to either a privileged OS account or a privileged database user account. Connecting as a privileged user allows you to perform administrative tasks, such as starting, stopping, and creating databases. You can use either OS authentication or a password file to connect to your database as a privileged user.
Understanding OS Authentication
OS authentication means that if you can log in to a database server via an authorized OS account, you’re allowed to connect to your database without the requirement of an additional password. A simple example demonstrates this concept. First, the id command is used to display the OS groups to which the oracle user belongs:
$ id
uid=500(oracle) gid=506(oinstall) groups=506(oinstall),507(dba),508(oper)
Next, a connection to the database is made with SYSDBA privileges, purposely using a bad (invalid) username and password:
$ sqlplus bad/notgood as sysdba
I can now verify that the connection as SYS was established:
SYS@o12c> show user
USER is "SYS"
How is it possible to connect to the database with an incorrect username and password? Actually, it’s not a bad thing (as you might initially think). The prior connection works because Oracle ignores the username/password provided, as the user was first verified via OS authentication. In that example the oracle OS user belongs to the dba OS group and is therefore allowed to make a local connection to the database with SYSDBA privileges without having to provide a correct username and password.
See Table 1-1, in Chapter 1, for a complete description of OS groups and the mapping to corresponding database privileges. Typical groups include dba and oper; these groups correspond to sysdba and sysoper database privileges, respectively. The sysdba and sysoper privileges allow you to perform administrative tasks, such as starting and stopping your database.
In a Windows environment an OS group is automatically created (typically named ora_dba) and assigned to the OS user that installs the Oracle software. You can verify which OS users belong to the ora_dba group as follows: select Start ➤ Control Panel ➤ Administrative Tools ➤ Computer Management ➤ Local Users and Groups ➤ Groups. You should see a group with a name such as ora_dba. You can click that group and view which OS users are assigned to it. In addition, for OS authentication to work in Windows environments, you must have the following entry in your sqlnet.ora file:
SQLNET.AUTHENTICATION_SERVICES=(NTS)
The sqlnet.ora file is usually located in the ORACLE_HOME/network/admin directory.
Starting the Database
Starting and stopping your database is a task that you perform frequently. To start/stop your database, connect with a sysdba- or sysoper- privileged user account, and issue the startup and shutdown statements. The following example uses OS authentication to connect to the database:
$ sqlplus / as sysdba
After you’re connected as a privileged account, you can start your database, as follows:
SQL> startup;
For the prior command to work, you need either an spfile or init.ora file in the ORACLE_HOME/dbs directory. See the section “Step 2: Configure the Initialization File,” earlier in this chapter, for details.
![]() Note Stopping and restarting your database in quick succession is known colloquially in the DBA world as bouncing your database.
Note Stopping and restarting your database in quick succession is known colloquially in the DBA world as bouncing your database.
When your instance starts successfully, you should see messages from Oracle indicating that the system global area (SGA) has been allocated. The database is mounted and then opened:
ORACLE instance started.
Total System Global Area 313159680 bytes
Fixed Size 2259912 bytes
Variable Size 230687800 bytes
Database Buffers 75497472 bytes
Redo Buffers 4714496 bytes
Database mounted.
Database opened.
From the prior output the database startup operation goes through three distinct phases in opening an Oracle database:
- Starting the instance
- Mounting the database
- Opening the database
You can step through these one at a time when you start your database. First, start the Oracle instance (background processes and memory structures):
SQL> startup nomount;
Next, mount the database. At this point, Oracle reads the control files:
SQL> alter database mount;
Finally, open the data files and online redo log files:
SQL> alter database open;
This startup process is depicted graphically in Figure 2-2.

Figure 2-2. Phases of Oracle startup
When you issue a STARTUP statement without any parameters, Oracle automatically steps through the three startup phases (nomount, mount, open). In most cases, you will issue a STARTUP statement with no parameters to start your database. Table 2-3 describes the meanings of parameters that you can use with the database STARTUP statement.
Table 2-3. Parameters Available with the startup Command
| Parameter | Meaning |
|---|---|
| FORCE | Shuts down the instance with ABORT before restarting it; useful for troubleshooting startup issues; not normally used |
| RESTRICT | Only allows users with the RESTRICTED SESSION privilege to connect to the database |
| PFILE | Specifies the client parameter file to be used when starting the instance |
| QUIET | Suppresses the display of SGA information when starting the instance |
| NOMOUNT | Starts background processes and allocates memory; doesn’t read control files |
| MOUNT | Starts background processes, allocates memory, and reads control files |
| OPEN | Starts background processes, allocates memory, reads control files, and opens online redo logs and data files |
| OPEN RECOVER | Attempts media recovery before opening the database |
| OPEN READ ONLY | Opens the database in read-only mode |
| UPGRADE | Used when upgrading a database |
| DOWNGRADE | Used when downgrading a database |
Normally, you use the SHUTDOWN IMMEDIATE statement to stop a database. The IMMEDIATE parameter instructs Oracle to halt database activity and roll back any open transactions:
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
Table 2-4 provides a detailed definition of the parameters available with the SHUTDOWN statement. In most cases, SHUTDOWN IMMEDIATE is an acceptable method of shutting down your database. If you issue the SHUTDOWN command with no parameters, it’s equivalent to issuing SHUTDOWN NORMAL.
Table 2-4. Parameters Available with the SHUTDOWN Command
| Parameter | Meaning |
|---|---|
| NORMAL | Wait for users to log out of active sessions before shutting down. |
| TRANSACTIONAL | Wait for transactions to finish, and then terminate the session. |
| TRANSACTIONAL LOCAL | Perform a transactional shutdown for local instance only. |
| IMMEDIATE | Terminate active sessions immediately. Open transactions are rolled back. |
| ABORT | Terminate the instance immediately. Transactions are terminated and aren’t rolled back. |
Starting and stopping your database is a fairly simple process. If the environment is set up correctly, you should be able to connect to your database and issue the appropriate STARTUP and SHUTDOWN statements.
![]() Tip If you experience any issues with starting or stopping your database, look in the alert log for details. The alert log usually has a pertinent message regarding any problems.
Tip If you experience any issues with starting or stopping your database, look in the alert log for details. The alert log usually has a pertinent message regarding any problems.
You should rarely need to use the SHUTDOWN ABORT statement. Usually, SHUTDOWN IMMEDIATE is sufficient. Having said that, there is nothing wrong with using SHUTDOWN ABORT. If SHUTDOWN IMMEDIATE isn’t working for any reason, then use SHUTDOWN ABORT.
On a few, rare occasions the SHUTDOWN ABORT will fail to work. In those situations, you can use ps -ef | grep smon to locate the Oracle system-monitor process and then use the Linux/Unix kill command to terminate the instance. When you kill a required Oracle background process, this causes the instance to abort. Obviously, you should use an OS kill command only as a last resort.
DATABASE VS. INSTANCE
Although DBAs often use the terms database and instance synonymously, these two terms refer to very different architectural components. In Oracle the term database denotes the physical files that make up a database: the data files, online redo log files, and control files. The term instance denotes the background processes and memory structures.
For instance, you can create an instance without having a database present. Before a database is physically created, you must start the instance with the STARTUP NOMOUNT statement. In this state you have background processes and memory structures without any associated data files, online redo logs, or control files. The database files aren’t created until you issue the CREATE DATABASE statement.
Another important point to remember is that an instance can only be associated with one database, whereas a database can be associated with many different instances (as with Oracle Real Application Clusters [RAC]). An instance can mount and open a database one time only. Each time you stop and start a database, a new instance is associated with it. Previously created background processes and memory structures are never associated with a database.
To demonstrate this concept, close a database with the ALTER DATABASE CLOSE statement:
SQL> alter database close;
If you attempt to restart the database, you receive an error:
SQL> alter database open;
ERROR at line 1:
ORA-16196: database has been previously opened and closed
This is because an instance can only ever mount and open one database. You must stop and start a new instance before you can mount and open the database.
Using the dbca to Create a Database
You can also use the dbca utility to create a database. This utility works in two modes: graphical and silent. To use the dbca in graphical mode, ensure you have the proper X software installed, then issue the xhost + command, and make certain your DISPLAY variable is set; for example,
$ xhost +
$ echo $DISPLAY
:0.0
To run the dbca in graphical mode, type in dbca from the OS command line:
$ dbca
The graphical mode is very intuitive and will walk you through all aspects of creating a database. You may prefer to use this mode if you are new to Oracle and want to be explicitly prompted with choices.
You can also run the dbca in silent mode with a response file. In some situations, using dbca in graphical mode isn’t feasible. This may be due to slow networks or the unavailability of X software. To create a database, using dbca in silent mode, perform the following steps:
- Locate the dbca.rsp file.
- Make a copy of the dbca.rsp file.
- Modify the copy of the dbca.rsp file for your environment.
- Run the dbca utility in silent mode.
First, navigate to the location in which you copied the Oracle database installation software, and use the find command to locate dbca.rsp:
$ find . -name dbca.rsp
./12.1.0.1/database/response/dbca.rsp
Copy the file so that you’re not modifying the original (in this way, you’ll always have a good, original file):
$ cp dbca.rsp mydb.rsp
Now, edit the mydb.rsp file. Minimally, you need to modify the following parameters: GDBNAME, SID, SYSPASSWORD, SYSTEMPASSWORD, SYSMANPASSWORD, DBSNMPPASSWORD, DATAFILEDESTINATION, STORAGETYPE, CHARACTERSET, and NATIONALCHARACTERSET. Following is an example of modified values in the mydb.rsp file:
[CREATEDATABASE]
GDBNAME = "O12DEV"
SID = "O12DEV"
TEMPLATENAME = "General_Purpose.dbc"
SYSPASSWORD = "foo"
SYSTEMPASSWORD = "foo"
SYSMANPASSWORD = "foo"
DBSNMPPASSWORD = "foo"
DATAFILEDESTINATION ="/u01/dbfile"
STORAGETYPE="FS"
CHARACTERSET = "AL32UTF8"
NATIONALCHARACTERSET= "UTF8"
Next, run the dbca utility in silent mode, using a response file:
$ dbca -silent -responseFile /home/oracle/orainst/mydb.rsp
You should see output such as
Copying database files
1% complete
. . .
Creating and starting Oracle instance
. . .
62% complete
Completing Database Creation
. . .
100% complete
Look at the log file . . . for further details.
If you look in the log files, note that the dbca utility uses the rman utility to restore the data files used for the database. Then, it creates the instance and performs postinstallation steps. On a Linux server you should also have an entry in the /etc/oratab file for your new database.
Many DBAs launch dbca and configure databases in the graphical mode, but a few exploit the options available to them using the response file. With effective utilization of the response file, you can consistently automate the database creation process. You can modify the response file to build databases on ASM and even create RAC databases. In addition, you can control just about every aspect of the response file, similar to launching the dbca in graphical mode.
![]() Tip You can view all options of the dbca via the help parameter: dbca -help
Tip You can view all options of the dbca via the help parameter: dbca -help
USING DBCA TO GENERATE A CREATE DATABASE STATEMENT
You can use the dbca utility to generate a CREATE DATABASE statement. You can perform this either interactively with the graphical interface or via silent mode. The key is to choose the “custom database template” and also specify the option to “generate database creation scripts.” This example uses the silent mode to generate a script that contains a CREATE DATABASE statement:
$ dbca -silent -generateScripts -customCreate -templateName New_Database.dbt
-gdbName DKDEV
The prior line of code instructs the dbca to create a script named CreateDB.sql and place it in the ORACLE_BASE/admin/DKDEV/scripts directory. The CreateDB.sql file contains a CREATE DATABASE statement within it. Also created is an init.ora file for initializing your instance.
In this example the scripts required to create a database are generated for you. No database is created until you manually run the scripts.
This technique gives you an automated method for generating a CREATE DATABASE statement. This is especially useful if you are new to Oracle and are unsure of how to construct a CREATE DATABASE statement or if you are using a new version of the database and want a valid CREATE DATABASE statement generated by an Oracle utility.
If you have an unused database that you need to drop, you can use the DROP DATABASE statement to accomplish this. Doing so removes all data files, control files, and online redo logs associated with the database.
Needless to say, use extreme caution when dropping a database. Before you drop a database, ensure that you’re on the correct server and are connected to the correct database. On a Linux/Unix system, issue the following OS command from the OS prompt:
$ uname -a
Next, connect to SQL*Plus, and be sure you’re connected to the database you want to drop:
SQL> select name from v$database;
After you’ve verified that you’re in the correct database environment, issue the following SQL commands from a SYSDBA-privileged account:
SQ> shutdown immediate;
SQL> startup mount exclusive restrict;
SQL> drop database;
![]() Caution Obviously, you should be careful when dropping a database. You aren’t prompted when dropping the database and, as of this writing, there is no UNDROP ACCIDENTALLY DROPPED DATABASE command. Use extreme caution when dropping a database, because this operation removes data files, control files, and online redo log files.
Caution Obviously, you should be careful when dropping a database. You aren’t prompted when dropping the database and, as of this writing, there is no UNDROP ACCIDENTALLY DROPPED DATABASE command. Use extreme caution when dropping a database, because this operation removes data files, control files, and online redo log files.
The DROP DATABASE command is useful when you have a database that needs to be removed. It may be a test database or an old database that is no longer used. The DROP DATABASE command doesn’t remove old archive redo log files. You must manually remove those files with an OS command (such as rm, in Linux/Unix, or del, at the Windows command prompt). You can also instruct RMAN to remove archive redo log files.
How Many Databases on One Server?
Sometimes, when you’re creating new databases, this question arises: How many databases should you put on one server? One extreme is to have only one database running on each database server. This architecture is illustrated in Figure 2-3, which shows two different database servers, each with its own installation of the Oracle binaries. This type of setup is profitable for the hardware vendor but in many environments isn’t an economical use of resources.

Figure 2-3. Architecture with one server per database
If you have enough memory, central processing unit (CPU), and disk resources, then you should consider creating multiple databases on one server. You can create a new installation of the Oracle binaries for each database or have multiple databases share one set of Oracle binaries. Figure 2-4 shows a configuration using one set of Oracle binaries that’s shared by multiple databases on one server. Of course, if you have requirements for different versions of the Oracle binaries, you must have multiple Oracle homes to house those installations.

Figure 2-4. Multiple databases sharing one set of Oracle binaries on a server
If you don’t have the CPU, memory, or disk resources to create multiple databases on one server, consider using one database to host multiple applications and users, as shown in Figure 2-5. In environments such as this, be careful not to use public synonyms, because there may be collisions between applications. It’s typical to create different schemas and tablespaces to be used by different applications in such environments.
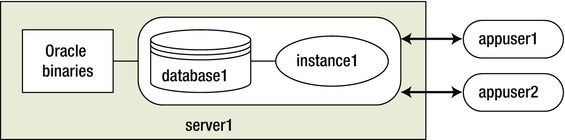
Figure 2-5. One database used by multiple applications and users
With Oracle Database 12c you have the option of using the pluggable database feature. This technology allows you to house several pluggable databases within one container database. The pluggable databases share the instance, background processes, undo, and Oracle binaries but function as completely separate databases. Each pluggable database has its own set of tablespaces (including SYSTEM) that are not visible to any other pluggable databases within the container database. This allows you to securely implement an isolated database that shares resources with other databases. Figure 2-6 depicts this architecture (see Chapter 23 for details on how to implement a pluggable database).

Figure 2-6. One container database with multiple pluggable databases
You must consider several architectural aspects when determining whether to use one database to host multiple applications and users:
- Do the applications generate vastly different amounts of redo, which may necessitate differently sized online redo logs?
- Are the queries used by applications dissimilar enough to require different amounts of undo, sorting space, and memory?
- Does the type of application require a different database block size, such as 8KB, for an OLTP database, or 32KB, for a data warehouse?
- Are there any security, availability, replication, or performance requirements that require an application to be isolated?
- Does an application require any features available only in the Enterprise Edition of Oracle?
- Does an application require the use of any special Oracle features, such as Data Guard, partitioning, Streams, or RAC?
- What are the backup and recovery requirements for each application? Does one application require online backups and the other application not? Does one application require tape backups?
- Is any application dependent on an Oracle database version? Will there be different database upgrade schedules and requirements?
Table 2-5 describes the advantages and disadvantages of these architectural considerations regarding how to use Oracle databases and applications.
Table 2-5. Oracle Database Configuration Advantages and Disadvantages
| Configuration | Advantages | Disadvantages |
|---|---|---|
| One database per server | Dedicated resources for the application using the database; completely isolates applications from each other; | Most expensive; requires more hardware |
| Multiple databases and Oracle homes per server | requires fewer servers | Multiple databases competing for disk, memory, and CPU resources |
| Multiple databases and one installation of Oracle binaries on the server | Requires fewer servers; doesn’t require multiple installations of the Oracle binaries | Multiple databases competing for disk, memory, and CPU resources |
| One database and one Oracle home serving multiple applications | Only requires one server and one database; inexpensive | Multiple databases competing for disk, memory, and CPU resources; multiple applications dependent on one database; one single point of failure |
| Container database containing multiple pluggable databases | Least expensive; allows multiple pluggable databases to use the infrastructure of one parent container database securely | Multiple databases competing for disk, memory, and CPU resources; multiple applications dependent on one database; one single point of failure |
Understanding Oracle Architecture
This chapter introduced concepts such as database (data files, online redo log files, control files), instance (background processes and memory structures), parameter file, password file, and listener. Now is a good time to present an Oracle architecture diagram that shows the various files and processes that constitute a database and instance. Some of the concepts depicted in Figure 2-7 have already been covered in detail, for example, database vs. instance. Other aspects of Figure 2-7 will be covered in future chapters. However, it’s appropriate to include a high-level diagram such as this in order to represent visually the concepts already discussed and to lay the foundation for understanding upcoming topics in this book.

Figure 2-7. Oracle database architecture
There are several aspects to note about Figure 2-7. Communication with the database is initiated through a sqlplus user process. Typically, the user process connects to the database over the network. This requires that you configure and start a listener process. The listener process hands off incoming connection requests to an Oracle server process, which handles all subsequent communication with the client process. If a remote connection is initiated as a sys*-level user, then a password file is required. A password file is also required for local sys* connections that don’t use OS authentication.
The instance consists of memory structures and background processes. When the instance starts, it reads the parameter file, which helps establish the size of the memory processes and other characteristics of the instance. When starting a database, the instance goes through three phases: nomount (instance started), mount (control files opened), and open (data files and online redo logs opened).
The number of background processes varies by database version (more than 300 in the latest version of Oracle). You can view the names and descriptions of the processes via this query:
SQL> select name, description from v$bgprocess;
The major background processes include
- DBWn: The database writer writes blocks from the database buffer cache to the data files.
- CKPT: The checkpoint process writes checkpoint information to the control files and data file headers.
- LGWR: The log writer writes redo information from the log buffer to the online redo logs.
- ARCn: The archiver copies the content of online redo logs to archive redo log files.
- RVWR: The recovery writer maintains before images of blocks in the fast recovery area.
- MMON: The manageability monitor process gathers automatic workload repository statistics.
- MMNL: The manageability monitor lite process writes statistics from the active session history buffer to disk.
- SMON: The system monitor performs system level clean-up operations, including instance recovery in the event of a failed instance, coalescing free space, and cleaning up temporary space.
- PMON: The process monitor cleans up abnormally terminated database connections and also automatically registers a database instance with the listener process.
- RECO: The recoverer process automatically resolves failed distributed transactions.
The structure of the SGA varies by Oracle release. You can view details for each component via this query:
SQL> select pool, name from v$sgastat;
The major SGA memory structures include
- SGA: The SGA is the main read/write memory area and is composed of several buffers, such as the database buffer cache, redo log buffer, shared pool, large pool, java pool, and streams pool.
- Database buffer cache: The buffer cache stores copies of blocks read from data files.
- Log buffer: The log buffer stores changes to modified data blocks.
- Shared pool: The shared pool contains library cache information regarding recently executed SQL and PL/SQL code. The shared pool also houses the data dictionary cache, which contains structural information about the database, objects, and users.
Finally, the program global area (PGA) is a memory area separate from the SGA. The PGA is a process-specific memory area that contains session-variable information.
Summary
After you’ve installed the Oracle binaries, you can create a database. Before creating a database, make sure you’ve correctly set the required OS variables. You also need an initialization file and to pre-create any necessary directories. You should carefully think about which initialization parameters should be set to a nondefault value. In general, I try to use as many default values as possible and only change an initialization parameter when there is a good reason.
This chapter focused on using SQL*Plus to create databases. This is an efficient and repeatable method for creating a database. When you’re crafting a CREATE DATABASE statement, consider the size of the data files and online redo logs. You should also put some thought into how many groups of online redo logs you require and how many members per group.
I’ve worked in some environments in which management dictated the requirement of one database per server. Usually that is overkill. A fast server with large memory areas and many CPUs should be capable of hosting several different databases. You have to determine what architecture meets your business requirements when deciding how many databases to place on one box.
After you’ve created a database, the next step is to configure the environment so that you can efficiently navigate, operate, and monitor the database. These tasks are described in the next chapter.