
Appendix A
VLC Construction Algorithms
A.1 First RVLC Construction Algorithm
We now introduce the MRG-based algorithm proposed in [21] by slightly paraphrasing it as follows. Continuing the list of definitions in Section 3.3.1, we add:
Definition 12 (Minimum Repetition Gap (MRG) [21]) A codeword c having k bits is represented as c1c2 ... ck. We form a new bit pattern b by concatenating c with a k-bit pattern x yielding the pattern b = cx. Every bit in x can be viewed as ‘0’ or ‘1’ in the following calculation. The minimum repetition gap g of c may be defined as the minimal-length interval that can be created for which it is valid that all the bits in b are repeated every g bits, ie. appear to be repeated every g bits. This may be formulated mathematically as:
![]()
For example, given a codeword c = 010, we have k = 3. The resultant 2k-bit long concatenated pattern is formulated as b = 010x1x2x3. We can opt, for example, for setting x = 101, resulting in b1 = b3 = b5 (i.e. x2) = 0 and b2 = b4(x1) = b6(x3) = 1. Therefore, by observing the resultant six-bit pattern of 010101 we infer that the two-bit pattern of 01 repeats itself. Hence we conclude that g is equal to 2 in this case. Alternatively, we may opt for x = 010, in which case we have a six-bit pattern of 010010 emerging, and hence we infer that the three-bit pattern of 010 repeats itself. Therefore we conclude that g is equal to 3 in this case. Thus we have MRG = min {2, 3} = 2.
The RVLC construction method of [21] is based on the following conjecture. For any two candidate codewords c1 and c2 at level l, let g1 and g2 denote the MRGs of c1 and c2, respectively. V(c1, k) and V(c2, k) denote the sets of candidate codewords at level k that violate the affix condition for c1 and c2. If g1 ≤ g2, then |V (c1, k)|≤|V (c2, k)| for k ≥ l.
Therefore, if we always choose codewords with the smallest MRGs while satisfying the affix condition, we can make the set of usable candidate codewords for the next levels as large as possible.
Let U = {u1, ..., uM} be a M-ary i.i.d. information source with the probability mass function Pu = {p1, ..., pM}, p1 ≥ · · · ≥ pM. The RVLC construction algorithm of [21] is then summarized as Algorithm A.1.
|
Step 1: Construct a Huffman code CH, which maps the source symbols into binary codewords w1,.. ., wM of length l1, ..., lM, Lmin = l1, ≤ · · · ≤ lM = Lmax. Denote the bit length vector of CH by (nH(1), ..., nH(Lmax)), where nH(i) represents the number of Huffman codewords having length i. Initialize the bit length vector of the target asymmetrical RVLC, n(i), by nH(i). Step 2: Calculate the total number of available candidate codewords of a full binary tree at level i, denoted by na(i), and the MRG for each candidate codeword, and then arrange these codewords based on the increasing order of MRGs. If n(i) ≤ na(i), assign n(i) codewords. Otherwise, assign all the available codewords, and the remaining (n(i) − na(i)) codewords are added to n(i + 1) so as to be assigned at the next stage, i.e. n(i + 1):=n(i + 1) + n(i) − na(i), n(i):=na(i). Step 3: Step 2 is repeated until every source symbol has been assigned a codeword. |
A.2 Second RVLC Construction Algorithm
In [23] Lakovic and Villasenor improved the above algorithm by establishing the formal relationship between the number of available RVLC codewords of any length and the structure of shorter RVLC codewords that had been selected, and pointed out that the MRG metric was a special case of this relationship. We now re-derive this relationship.
Let a binary codeword w of length i be denoted as w = (w1w2 · · · wi). Define the prefix set Pj(w) as the set of length-j codewords, j > i, which are prefixed by w, and define the suffix set Sj(w) as the set of length-j codewords, j > i, which are suffixed by w. It is obvious that
|Pj(w)| = |Sj(w)| = 2(j−i).
Assume that W = {w1, w2, ..., wm} is a set of RVLC codewords of lengths l1 ≤ l2 ≤ · · · ≤ lm. Denote with na(j) the number of codewords of length j, j > lm, which are neither prefixed nor suffixed by any codeword from W. Since the total number of length-j codewords is equal to 2j, it holds that
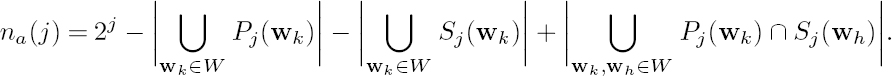
For RVLCs all the prefix sets, as well as all the suffix sets, are disjoint, and therefore

Now define the affix set Aj(wk, wh) as the set of codewords of length j, j > max(lk, lh), prefixed by wk and suffixed by wh:
Aj(wk, wh) = Pj(wk) ∩ Sj(wh).
Obviously, na(j) depends on the cardinalities of affix sets Aj(wk, wh), i.e., on the affix index of the set W, defined as
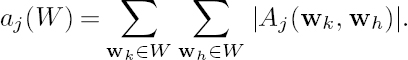
The cardinalities of affix sets Aj(wk, wh) are given as follows [27]. For max(lk, lh) < j < lk + lh,
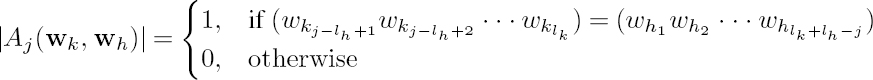
while for lk + lh ≤ j,
|Aj(wk, wh)| = 2j−lk−lh.
With the above formulas, the MRG can be interpreted as follows. The MRG of a length-i codeword w, denoted as g(w), is equal to the minimal positive integer g such that |Ai+g(w, w)| > 0. Algorithm A.1 [21] selects the codewords with the lowest g(w), which contributes to the increase in na(i + g), with the lowest g first, because na(i + g) depends on |Ai + g(w, w)|. However, this algorithm does not consider the elements |Ai + g(wk, wh)|, wk ≠ wh, which have a significant impact on na(i + g), and consequently on the coding efficiency. Therefore, Lajovic and Villasenor [23] proposed a new construction algorithm, shown here as Algorithm A.2, that differed from Algorithm A.1
Algorithm A.2 can generate RVLCs with smaller average code lengths than Algorithm A.1; however, the complexity is much higher. At each level i, with na(i) ≥ n(i), Algorithm A.1 considers na(i) MRGs, while Algorithm A.2 considers ![]() affix indices.
affix indices.
A.3 Greedy Algorithm and Majority Voting Algorithm (MVA)
Both the greedy algorithm and the MVA may be applied for the construction of a fixed-length code of length n having a given block distance of d from a given set of codewords that may not necessarily contain all possible n tuples. Given a set of codewords W, the greedy algorithm initialises the target codeword set C with an arbitrary codeword in W, and then selects the first available codeword in W that is at a distance of at least d from all the existing codewords in the set C. This procedure is repeated until no more legitimate codewords are available in the set W. This algorithm is easy to implement; however, the number of codewords in the resultant codeword set may be far from the maximum achievable value, since it ignores the effect that the codewords selected at the current stage will limit the number of legitimate codewords at the next stage. By contrast, the MVA is usually capable of generating larger codeword sets by ‘looking’ a step forward. Its procedure can be described as in Algorithm A.3 [30].
|
Step 1 and Step 3: Same as Step 1 and Step 3 of Algorithm A.1. Step 2: If n(i) ≤ na(i), n(i) codewords should be assigned. There are n(i + 1) = n(i + 1) + n(i) − na(i), n(i) = na(i). |
|
Step 1: Initialize the target code C to the null code (i.e. no codewords selected). Step 2: For each codeword in W determine the number of remaining codewords in W that are at least distance d from the given codeword. Step 3: Choose the codeword that has got the maximum number of other codewords that satisfy the minimum distance requirement. If there is more than one such codeword, then choose an arbitrary one. Add this codeword to the target code C. Step 4: Remove from W all those codewords that do not satisfy the minimum distance requirement to the chosen codeword. Step 5: Repeat Steps 2–4 with the new set W. Each time, the selected codeword is added to the code C. The algorithm ends when W is empty. |
The main disadvantage of Algorithm A.3 is that as the number of codewords in W increases it becomes too computationally expensive, and the greedy algorithm will then be preferred.