
Chapter 9
Audio Coding
U. Zölzer and P. Bhattacharya
For transmission and storage of audio signals, different methods for compressing data have been investigated in addition to the pulse‐code modulation (PCM) representation. The requirements of different applications have resulted in a variety of audio coding methods which have become international standards. In this chapter, the basic principles of audio coding will be introduced and then the most important audio coding standards will be discussed. Audio coding can be divided into two types: lossless and lossy audio coding. Lossless audio coding is based on a statistical model of the signal amplitudes and coding of the audio signal (audio coder). The reconstruction of the audio signal at the receiver allows a lossless resynthesis of the signal amplitudes of the original audio signal (audio decoder). Alternatively, lossy audio coding makes use of a psychoacoustic model of the human acoustic perception for quantizing and coding the audio signal. In this case, only the acoustic relevant parts of the signal are coded and reconstructed at the receiver. The samples of the original audio signal are not exactly reconstructed. The objective of both audio coding methods is a data rate reduction or data compression for transmission or storage compared with the original PCM signal.
9.1 Lossless Audio Coding
Lossless audio coding is based on linear prediction followed by entropy coding [Jay84], as shown in Fig. 9.1.
- Linear Prediction. A quantized set of coefficients
 for a block of
for a block of  samples is determined, which leads to an estimate
samples is determined, which leads to an estimate  of the input sequence
of the input sequence  . The aim is to minimize the power of the difference signal
. The aim is to minimize the power of the difference signal  without any additional quantization errors, i.e. the word length of the signal
without any additional quantization errors, i.e. the word length of the signal  must be equal to the word length of the input. An alternative approach [Han98, Han01] quantizes the prediction signal
must be equal to the word length of the input. An alternative approach [Han98, Han01] quantizes the prediction signal  such that the word length of the difference signals
such that the word length of the difference signals  remains the same as the input signal word length. Figure 9.2 shows a signal block
remains the same as the input signal word length. Figure 9.2 shows a signal block  and the corresponding spectrum
and the corresponding spectrum 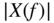 . Filtering the input signal with the predictor filter transfer function
. Filtering the input signal with the predictor filter transfer function  delivers the estimate
delivers the estimate 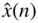 . Subtracting input and prediction signals yields the prediction error
. Subtracting input and prediction signals yields the prediction error  , which is also shown in Fig. 9.2 and which has a considerably lower power compared with the input power. The spectrum of this prediction error is nearly white (see Fig. 9.2 bottom right figure). The prediction can be represented as a filter operation with an analysis transfer function
, which is also shown in Fig. 9.2 and which has a considerably lower power compared with the input power. The spectrum of this prediction error is nearly white (see Fig. 9.2 bottom right figure). The prediction can be represented as a filter operation with an analysis transfer function  on the coder side.
on the coder side. - Entropy Coding. Quantization of signal
 arising from the probability density function of the block. Samples
arising from the probability density function of the block. Samples  of higher probability are coded with shorter data words whereas samples
of higher probability are coded with shorter data words whereas samples  of lower probability are coded with longer data words [Huf52].
of lower probability are coded with longer data words [Huf52]. - Frame Packing. The frame packing uses the quantized and coded difference signal and the coding of the
 coefficients of the predictor filter
coefficients of the predictor filter  of order
of order  .
.

Figure 9.1 Lossless audio coding based on linear prediction and entropy coding.

Figure 9.2 Signals and spectra for linear prediction.
- Decoder. On the decoder side, the inverse synthesis transfer function
 reconstructs the input signal with the coded difference samples and the
reconstructs the input signal with the coded difference samples and the  filter coefficients. The frequency response of this synthesis filter represents the spectral envelope shown in the top right part of Fig. 9.2. The synthesis filter shapes the white spectrum of the difference (prediction error) signal with the spectral envelope of the input spectrum.
filter coefficients. The frequency response of this synthesis filter represents the spectral envelope shown in the top right part of Fig. 9.2. The synthesis filter shapes the white spectrum of the difference (prediction error) signal with the spectral envelope of the input spectrum.
The attainable compression rates depend on the statistics of the audio signal and allow a compression rate of up to two [Bra92, Cel93, Rob94, Cra96, Cra97, Pur97, Han98, Han01, Lie02, Raa02, Sch02]. Figure 9.3 illustrates examples of the necessary word length for lossless audio coding [Blo95, Sqa88]. In addition to the local entropy of the signal (entropy computed over a block length of 256), results for linear prediction followed by Huffman coding [Huf52] are presented. Huffman coding is carried out with a fixed code table [Pen93] and a power‐controlled choice of adapted code tables. It is observed from Fig. 9.3 that for high signal powers, a reduction of word length is possible if the choice is made from several adapted code tables. Lossless compression methods are used for storage media with limited word length (16 bit), which are used for recording audio signals of higher word lengths (![]() 16 bit). Further applications are in the transmission and archiving of audio signals.
16 bit). Further applications are in the transmission and archiving of audio signals.

Figure 9.3 Lossless audio coding (Mozart, Stravinsky): word length in bits versus time (entropy ‐ ‐, linear prediction with Huffman coding —).
9.2 Lossy Audio Coding
Significantly higher compression rates (of factor four to eight) can be obtained with lossy coding methods. Psychoacoustic phenomena of human hearing are used for signal compression. The fields of application have a wide range, from professional audio like source coding for audio transmission to home entertainment applications.
An outline of the coding methods [Bra94] is standardized in an international specification ISO/IEC 11172‐3 [ISO92], which is based on the following processing (see Fig. 9.4) steps.
- Sub‐band decomposition with filter banks of short latency time.
- Calculation of psychoacoustic model parameters based on
short‐time fast Fourier transform (FFT).
- Dynamic bit allocation owing to psychoacoustic model parameters
(signal‐to‐mask ratio
 ).
). - Quantization and coding of sub‐band signals.
- Multiplex and frame packing.

Figure 9.4 Lossy audio coding based on sub‐band coding and psychoacoustic models.
Owing to lossy audio coding, post‐processing of such signals or several coding and decoding steps is associated with some additional problems. The high compression rates justify the use of lossy audio coding techniques in applications like transmission.
9.3 Psychoacoustics
In this section, the basic principles of psychoacoustics are presented. The results of psychoacoustic investigations by Zwicker [Zwi82, Zwi90] form the basis for audio coding based on models of human perception. These coded audio signals have a significantly reduced data rate compared with the linearly quantized PCM representation. The human auditory system analyzes broadband signals in so‐called critical bands. The aim of psychoacoustic coding of audio signals is to decompose the broadband audio signal into sub‐bands, which are matched to the critical bands, and then perform quantization and coding of these sub‐band signals [Joh88a, Joh88b, Thei88]. Because the perception of sound below the absolute threshold of hearing is not possible, sub‐band signals below this threshold need neither to be coded nor transmitted. In addition to the perception in critical bands and the absolute threshold, the effects of signal masking in human perception play an important role in signal coding. These will be explained in the following and their application to psychoacoustic coding will be discussed.
9.3.1 Critical Bands and Absolute Threshold
Critical Bands. Critical bands, as investigated by Zwicker [Zwi82], are listed in Table 9.1.
Table 9.1 Critical bands as given by Zwicker. Modified from [Zwi82].
| 0 | 0 | 100 | 100 | 50 |
| 1 | 100 | 200 | 100 | 150 |
| 2 | 200 | 300 | 100 | 250 |
| 3 | 300 | 400 | 100 | 350 |
| 4 | 400 | 510 | 110 | 450 |
| 5 | 510 | 630 | 120 | 570 |
| 6 | 630 | 770 | 140 | 700 |
| 7 | 770 | 920 | 150 | 840 |
| 8 | 920 | 1080 | 160 | 1000 |
| 9 | 1080 | 1270 | 190 | 1170 |
| 10 | 1270 | 1480 | 210 | 1370 |
| 11 | 1480 | 1720 | 240 | 1600 |
| 12 | 1720 | 2000 | 280 | 1850 |
| 13 | 2000 | 2320 | 320 | 2150 |
| 14 | 2320 | 2700 | 380 | 2500 |
| 15 | 2700 | 3150 | 450 | 2900 |
| 16 | 3150 | 3700 | 550 | 3400 |
| 17 | 3700 | 4400 | 700 | 4000 |
| 18 | 4400 | 5300 | 900 | 4800 |
| 19 | 5300 | 6400 | 1100 | 5800 |
| 20 | 6400 | 7700 | 1300 | 7000 |
| 21 | 7700 | 9500 | 1800 | 8500 |
| 22 | 9500 | 1200 | 2500 | 10500 |
| 23 | 12000 | 15500 | 3500 | 13500 |
| 24 | 15500 |
A transformation of the linear frequency scale into a hearing adapted scale is given by Zwicker [Zwi90] (units of ![]() in Bark)
in Bark)

The individual critical bands have the following bandwidths:

Absolute Threshold. The absolute threshold ![]() (threshold in quiet) denotes the curve of sound pressure level
(threshold in quiet) denotes the curve of sound pressure level ![]() [Zwi82] versus frequency, which leads to the perception of a sinusoidal tone. The absolute threshold is given by [Ter79]
[Zwi82] versus frequency, which leads to the perception of a sinusoidal tone. The absolute threshold is given by [Ter79]

Below the absolute threshold, no perception of signals is possible. Figure 9.5 shows the absolute threshold versus frequency. Band splitting in critical bands and the absolute threshold allow for the calculation of an offset between the signal level and the absolute threshold for every critical band. This offset is responsible for choosing appropriate quantization steps per critical band.

Figure 9.5 Absolute threshold (threshold in quiet).
9.3.2 Masking
For audio coding, the use of sound perception in critical bands and absolute threshold only is not sufficient for high compression rates. The bases for further data reduction are the masking effects investigated by Zwicker [Zwi82, Zwi90]. For band‐limited noise or a sinusoidal signal, frequency‐dependent masking thresholds can be given. These thresholds perform masking of frequency components if these components are below a masking threshold (see Fig. 9.6). The application of masking for perceptual coding is described in the following.

Figure 9.6 Masking threshold of band‐limited noise.
Calculation of Signal Power in Band ![]() . First, the sound pressure level within a critical band is calculated. The short‐time spectrum
. First, the sound pressure level within a critical band is calculated. The short‐time spectrum ![]() is used to calculate the power density spectrum
is used to calculate the power density spectrum
with the help of an ![]() ‐point FFT. The signal power in band
‐point FFT. The signal power in band ![]() is calculated by the sum
is calculated by the sum

from the lower frequency up to the upper frequency of critical band ![]() . The sound pressure level in band
. The sound pressure level in band ![]() is given by
is given by ![]() .
.
Absolute Threshold. The absolute threshold is set such that a 4‐kHz signal with peak amplitude ![]() LSB for a 16‐bit representation lies at the lower limit of the absolute threshold curve. Every masking threshold calculated in individual critical bands, which lies below the absolute threshold, is set to a value equal to the absolute threshold in the corresponding band. Because the absolute threshold within a critical band varies for low and high frequencies, it is necessary to make use of the mean absolute threshold within a band.
LSB for a 16‐bit representation lies at the lower limit of the absolute threshold curve. Every masking threshold calculated in individual critical bands, which lies below the absolute threshold, is set to a value equal to the absolute threshold in the corresponding band. Because the absolute threshold within a critical band varies for low and high frequencies, it is necessary to make use of the mean absolute threshold within a band.
Masking Threshold. The offset between signal level and the masking threshold in critical band ![]() (see Fig. 9.7) is given by [Hel72]
(see Fig. 9.7) is given by [Hel72]

Figure 9.7 Offset between signal level and masking threshold.
where ![]() denotes the tonality index and
denotes the tonality index and ![]() is the masking index. The masking index [Kap92] is given by
is the masking index. The masking index [Kap92] is given by

As an approximation,
can be used [Joh88a, Joh88b]. If a tone is masking a noise‐like signal (![]() ), the threshold is set
), the threshold is set ![]() dB below the value of
dB below the value of ![]() . If a noise‐like signal is masking a tone (
. If a noise‐like signal is masking a tone (![]() ), the threshold is set
), the threshold is set ![]() dB below
dB below ![]() . To recognize a tonal or noise‐like signal within a certain number of samples, the spectral flatness measure (SFM) is estimated. The SFM is defined by the ratio of the geometric to arithmetic mean value of
. To recognize a tonal or noise‐like signal within a certain number of samples, the spectral flatness measure (SFM) is estimated. The SFM is defined by the ratio of the geometric to arithmetic mean value of ![]() according to
according to

The SFM is compared with the SFM of a sinusoidal signal (definition ![]() dB) and the tonality index is calculated [Joh88a, Joh88b] by
dB) and the tonality index is calculated [Joh88a, Joh88b] by

An SFM = 0 dB corresponds to a noise‐like signal and leads to ![]() , whereas an SFM = 75 dB gives a tone‐like signal (
, whereas an SFM = 75 dB gives a tone‐like signal (![]() ). With the sound pressure level
). With the sound pressure level ![]() and the offset
and the offset ![]() , the masking threshold is given by
, the masking threshold is given by
Masking Across Critical Bands. Masking across critical bands can be carried out with the help of the Bark scale. The masking threshold is of a triangular form which decreases with ![]() dB per Bark for the lower slope and with
dB per Bark for the lower slope and with ![]() dB per Bark for the upper slope, depending on the sound pressure level
dB per Bark for the upper slope, depending on the sound pressure level ![]() and the center frequency
and the center frequency ![]() in band
in band ![]() (see [Ter79]), according to
(see [Ter79]), according to

An approximation of the minimum masking within a critical band can be made using Fig. 9.8 [Thei88, Sauv90]. Masking at the upper frequency ![]() in the critical band
in the critical band ![]() is responsible for masking the quantization noise with approximately 32 dB using the lower masking threshold that decreases by 27 dB/Bark. The upper slope has a steepness which depends on the sound pressure level. This steepness is lower than the steepness of the lower slope. Masking across critical bands is presented in Fig. 9.9. The masking signal in critical band
is responsible for masking the quantization noise with approximately 32 dB using the lower masking threshold that decreases by 27 dB/Bark. The upper slope has a steepness which depends on the sound pressure level. This steepness is lower than the steepness of the lower slope. Masking across critical bands is presented in Fig. 9.9. The masking signal in critical band ![]() is responsible for masking the quantization noise in critical band
is responsible for masking the quantization noise in critical band ![]() as well as the masking signal in critical band
as well as the masking signal in critical band ![]() . This kind of masking across critical bands further reduces the number of quantization steps within critical bands.
. This kind of masking across critical bands further reduces the number of quantization steps within critical bands.
![Schematic illustration of masking within a critical band. Based on [Thei88] and [Sauv90].](https://imgdetail.ebookreading.net/2023/10/9781119832676/9781119832676__9781119832676__files__images__c09f008.png)
Figure 9.8 Masking within a critical band. Based on [Thei88] and [Sauv90].

Figure 9.9 Masking across critical bands.
An analytical expression for masking across critical bands [Schr79] is given by
Here, ![]() denotes the distance between two critical bands in Bark. Expression (9.15) is called the spreading function. With the help of this spreading function, masking of critical band
denotes the distance between two critical bands in Bark. Expression (9.15) is called the spreading function. With the help of this spreading function, masking of critical band ![]() by critical band
by critical band ![]() can be calculated [Joh88a, Joh88b] with
can be calculated [Joh88a, Joh88b] with ![]() such that
such that


Figure 9.10 Stepwise calculation of psychoacoustic model.
The masking across critical bands can therefore be expressed as a matrix operation given by
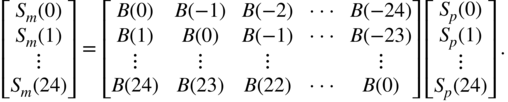
A renewed calculation of the masking threshold with Eq. (9.16) leads to the global masking threshold
For a clarification of the single steps for a psychoacoustic‐based audio coding, we will summarize the operations with exemplified analysis results.
- Calculation of the signal power
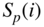 in critical bands
in critical bands
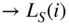 in dB (Fig. 9.10a).
in dB (Fig. 9.10a). - Calculation of masking across critical bands

 in dB (Fig. 9.10b).
in dB (Fig. 9.10b). - Masking with tonality index
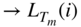 in dB (Fig. 9.10c).
in dB (Fig. 9.10c). - Calculation of global masking threshold with respect to threshold in quiet

 in dB (Fig. 9.10d).
in dB (Fig. 9.10d).
With the help of the global masking threshold ![]() , we calculate the signal‐to‐mask ratio (SMR)
, we calculate the signal‐to‐mask ratio (SMR)
per Bark band. This SMR defines the necessary number of bits per critical band, such that masking of quantization noise is achieved. For the given example, the signal power and the global masking threshold are shown in Fig. 9.11a. The resulting signal‐to‐mask ratio ![]() is shown in Fig. 9.11b. As soon as
is shown in Fig. 9.11b. As soon as ![]() , one has to allocate bits to the critical band
, one has to allocate bits to the critical band ![]() . For
. For ![]() , the corresponding critical band will not be transmitted. Figure 9.12 shows the masking thresholds in critical bands for a sinusoid of 440 Hz. Compared to the first example, the influence of masking thresholds across critical bands is easier to note and to interpret.
, the corresponding critical band will not be transmitted. Figure 9.12 shows the masking thresholds in critical bands for a sinusoid of 440 Hz. Compared to the first example, the influence of masking thresholds across critical bands is easier to note and to interpret.

Figure 9.11 Calculation of the signal‐to‐mask ratio SMR.

Figure 9.12 Calculation of psychoacoustic model for a pure sinusoid with 440 Hz.
9.4 ISO‐MPEG1 Audio Coding
In this section, the coding method for digital audio signals is described, which is specified in the standard ISO/IEC 11172‐3 [ISO92]. The filter banks used for sub‐band decomposition, the psychoacoustic models, dynamic bit allocation, and coding are discussed. A simplified block diagram of the coder for implementing layers I and II of the standard is shown in Fig. 9.13. The corresponding decoder is shown in Fig. 9.14. It uses the information from the ISO‐MPEG1 frame and feeds the decoded sub‐band signals to a synthesis filter bank for reconstructing the broadband PCM signal. The complexity of the decoder is significantly lower compared with that of the coder. Prospective improvements of the coding method are being made entirely for the coder.

Figure 9.13 Simplified block diagram of an ISO‐MPEG1 coder.

Figure 9.14 Simplified block diagram of an ISO‐MPEG1 decoder.
9.4.1 Filter Banks
The sub‐band decomposition is done with a pseudo‐quadrature mirror filter (QMF) bank (see Fig. 9.15). The theoretical background is found in the related literature [Rot83, Mas85, Vai93]. The decomposition of the broadband signal is made into ![]() uniformly spaced sub‐bands. The sub‐bands are processed further after a sampling rate reduction by a factor of
uniformly spaced sub‐bands. The sub‐bands are processed further after a sampling rate reduction by a factor of ![]() . The implementation of an ISO‐MPEG1 coder is based on
. The implementation of an ISO‐MPEG1 coder is based on ![]() frequency bands. The individual bandpass filters
frequency bands. The individual bandpass filters ![]() are designed using a prototype lowpass filter
are designed using a prototype lowpass filter ![]() and frequency‐shifted versions. The frequency shifting of the prototype with cutoff frequency
and frequency‐shifted versions. The frequency shifting of the prototype with cutoff frequency ![]() is done by modulating the impulse response
is done by modulating the impulse response ![]() with a cosine term [Bos02] according to
with a cosine term [Bos02] according to
with ![]() and
and ![]() . The bandpass filters have bandwidth
. The bandpass filters have bandwidth ![]() . For the synthesis filter bank, corresponding filters
. For the synthesis filter bank, corresponding filters ![]() give outputs which are added together resulting in a broadband PCM signal. The prototype impulse response with 512 taps, the modulated bandpass impulse responses, and the corresponding magnitude responses are shown in Fig. 9.16. The magnitude responses of all 32 bandpass filters are also shown. The overlap of neighboring bandpass filters is limited to the lower and upper filter bands. This overlap reaches up to the center frequency of the neighboring bands. The resulting aliasing after downsampling in each sub‐band will be canceled in the synthesis filter bank. The pseudo‐QMF bank can be implemented by the combination of a polyphase filter structure followed by a discrete cosine transform [Rot83, Vai93, Kon94].
give outputs which are added together resulting in a broadband PCM signal. The prototype impulse response with 512 taps, the modulated bandpass impulse responses, and the corresponding magnitude responses are shown in Fig. 9.16. The magnitude responses of all 32 bandpass filters are also shown. The overlap of neighboring bandpass filters is limited to the lower and upper filter bands. This overlap reaches up to the center frequency of the neighboring bands. The resulting aliasing after downsampling in each sub‐band will be canceled in the synthesis filter bank. The pseudo‐QMF bank can be implemented by the combination of a polyphase filter structure followed by a discrete cosine transform [Rot83, Vai93, Kon94].

Figure 9.15 Pseudo‐QMF bank.

Figure 9.16 Impulse responses and magnitude responses of pseudo‐QMF bank.
For increasing the frequency resolution, layer III of the standard decomposes each of the 32 sub‐bands further into a maximum of 18 uniformly spaced sub‐bands (see Fig. 9.17). The decomposition is carried out with the help of an overlapped transform of windowed sub‐band samples. The method is based on a modified discrete cosine transform (MDCT), also known as the TDAC filter bank (time domain aliasing cancellation) and MLT (modulated lapped transform). An exact description is found in [Pri87, Mal92]. This extended filter bank is denoted as the polyphase/MDCT hybrid filter bank [Bra94]. The higher frequency resolution enables a higher coding gain but has the disadvantage of having a worse time resolution. This is observed for impulse‐like signals. To minimize these artifacts, the number of sub‐bands per sub‐band can be altered from 18 down to 6. Sub‐band decompositions that are matched to the signal can be obtained by specially designed window functions with overlapping transforms [Edl89, Edl95]. The equivalence of overlapped transforms and filter banks is found in [Mal92, Glu93, Vai93, Edl95, Vet95].

Figure 9.17 Polyphase/MDCT hybrid filter bank.
9.4.2 Psychoacoustic Models
Two psychoacoustic models have been developed for layers I to III of the ISO‐MPEG1 standard. Both models can be used independently of each other for all three layers. Psychoacoustic model 1 is used for layers I and II whereas model 2 is used for layer III. Owing to the numerous applications of layers I and II, we will discuss psychoacoustic model 1 in the following.
Psychoacoustic Model 1. Bit allocation in each of the 32 sub‐bands is carried out using the signal‐to‐mask ratio ![]() . This is based on the minimum masking threshold and the maximum signal level within a sub‐band. To calculate this ratio, the power density spectrum is estimated with the help of a short‐time FFT in parallel with the analysis filter bank. As a consequence, a higher frequency resolution is obtained to estimate the power density spectrum in contrast to the frequency resolution of the 32‐band analysis filter bank. The signal‐to‐mask ratio for every sub‐band is determined as follows.
. This is based on the minimum masking threshold and the maximum signal level within a sub‐band. To calculate this ratio, the power density spectrum is estimated with the help of a short‐time FFT in parallel with the analysis filter bank. As a consequence, a higher frequency resolution is obtained to estimate the power density spectrum in contrast to the frequency resolution of the 32‐band analysis filter bank. The signal‐to‐mask ratio for every sub‐band is determined as follows.
- Calculating the power density spectrum of a block of
 samples using FFT. After windowing a block of
samples using FFT. After windowing a block of  (
(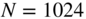 for layer II) input samples, the power density spectrum
(9.22)is calculated. After this, the window
for layer II) input samples, the power density spectrum
(9.22)is calculated. After this, the window
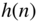 is displaced by 384 (
is displaced by 384 ( ) samples and the next block is processed.
) samples and the next block is processed. - Determination of sound pressure level in every sub‐band. The sound pressure level is derived from the calculated power density spectrum and by calculating a scaling factor in the corresponding sub‐band, as given by
(9.23)

For
 , the maximum of the spectral lines in a sub‐band is used. The scaling factor
, the maximum of the spectral lines in a sub‐band is used. The scaling factor 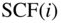 for sub‐band
for sub‐band  is calculated from the absolute value of the maximum of 12 consecutive sub‐band samples. A nonlinear quantization to 64 levels is carried out (layer I). For layer II, the sound pressure level is determined by choosing the largest of the three scaling factors from
is calculated from the absolute value of the maximum of 12 consecutive sub‐band samples. A nonlinear quantization to 64 levels is carried out (layer I). For layer II, the sound pressure level is determined by choosing the largest of the three scaling factors from  sub‐band samples.
sub‐band samples. - Considering the absolute threshold. The absolute threshold
 is specified for different sampling rates in [ISO92]. The frequency index
is specified for different sampling rates in [ISO92]. The frequency index  is based on a reduction of
is based on a reduction of  relevant frequencies with the FFT of index
relevant frequencies with the FFT of index  (see Fig. 9.18). The sub‐band index is still
(see Fig. 9.18). The sub‐band index is still  .
.

Figure 9.18 Nomenclature of frequency indices.
- Calculating tonal
 or non‐tonal
or non‐tonal  masking components and determining relevant masking components (for details, see [ISO92]). These masking components are denoted as
masking components and determining relevant masking components (for details, see [ISO92]). These masking components are denoted as  and
and  . With the index
. With the index  , tonal and non‐tonal masking components are labeled. The variable
, tonal and non‐tonal masking components are labeled. The variable  is listed for reduced frequency indices
is listed for reduced frequency indices  in [ISO92]. It allows a finer resolution of the 24 critical bands with the frequency group index
in [ISO92]. It allows a finer resolution of the 24 critical bands with the frequency group index  .
. - Calculating the individual masking thresholds. For masking thresholds of tonal and non‐tonal masking components
 and
and  , the following calculation is performed:
(9.24)
, the following calculation is performed:
(9.24) (9.25)
(9.25)
The masking index for tonal masking components is given by
(9.26)
and the masking index for non‐tonal masking components is
(9.27)
The masking function
 with distance
with distance  is given by
is given by
This masking function
 describes the masking of the frequency index
describes the masking of the frequency index  by the masking component
by the masking component  .
. - Calculating the global masking threshold. For frequency index
 , the global masking threshold is calculated as the sum of all contributing masking components according to
(9.28)
, the global masking threshold is calculated as the sum of all contributing masking components according to
(9.28)
The total number of tonal and non‐tonal masking components are denoted as
 and
and  , respectively. For a given sub‐band
, respectively. For a given sub‐band  , only masking components that lie in the range
, only masking components that lie in the range  to +3 Bark will be considered. Masking components outside this range are neglected.
to +3 Bark will be considered. Masking components outside this range are neglected. - Determination of the minimum masking threshold in every sub‐band:
(9.29)

Several masking thresholds
 can occur in a sub‐band as long as
can occur in a sub‐band as long as  lies within the sub‐band
lies within the sub‐band  .
. - Calculation of the signal‐to‐mask ratio
 in every sub‐band:
(9.30)
in every sub‐band:
(9.30)
The signal‐to‐mask ratio determines the dynamic range that has to be quantized in the particular sub‐band so that the level of quantization noise lies below the masking threshold. The signal‐to‐mask ratio is the basis for the bit allocation procedure for quantizing the sub‐band signals.
9.4.3 Dynamic Bit Allocation and Coding
Dynamic Bit Allocation. Dynamic bit allocation is used to determine the number of bits that are necessary for the individual sub‐bands so that a transparent perception is possible. The minimum number of bits in sub‐band ![]() can be determined from the difference between scaling factor
can be determined from the difference between scaling factor ![]() and the absolute threshold
and the absolute threshold ![]() as
as ![]() . With this, quantization noise remains under the masking threshold. Masking across critical bands is used for the implementation of the ISO‐MPEG1 coding method.
. With this, quantization noise remains under the masking threshold. Masking across critical bands is used for the implementation of the ISO‐MPEG1 coding method.
For a given transmission rate, the maximum possible number of bits ![]() for coding sub‐band signals and scaling factors is calculated as
for coding sub‐band signals and scaling factors is calculated as

The bit allocation is performed within an allocation frame consisting of 12 sub‐band samples (![]() PCM samples) for layer I and 36 sub‐band samples (
PCM samples) for layer I and 36 sub‐band samples (![]() PCM samples) for layer II.
PCM samples) for layer II.
The dynamic bit allocation for the sub‐band signals is carried out as an iterative procedure. At the beginning, the number of bits per sub‐band is set to zero. First, the mask‐to‐noise ratio,
is determined for every sub‐band. The signal‐to‐mask ratio ![]() is the result of the psychoacoustic model. The signal‐to‐noise ratio
is the result of the psychoacoustic model. The signal‐to‐noise ratio ![]() is defined by a table in [ISO92], in which for every number of bits, a corresponding signal‐to‐noise ratio is specified. The number of bits must be increased as long as the mask‐to‐noise ratio MNR is less than zero.
is defined by a table in [ISO92], in which for every number of bits, a corresponding signal‐to‐noise ratio is specified. The number of bits must be increased as long as the mask‐to‐noise ratio MNR is less than zero.
The iterative bit allocation is performed by the following steps.
- Determination of the minimum
 of all sub‐bands.
of all sub‐bands. - Increasing the number of bits of these sub‐bands on to the next stage of the MPEG1 standard. Allocation of 6 bits for the scaling factor of the MPEG1 standard when the number of bits is increased for the first time.
- New calculation of
 in this sub‐band.
in this sub‐band. - Calculation of the number of bits for all sub‐bands and scaling factors and comparison with the maximum number
 . If the number of bits is smaller than the maximum number, the iteration starts again with step 1.
. If the number of bits is smaller than the maximum number, the iteration starts again with step 1.
Quantization and Coding of Sub‐band Signals. The quantization of the sub‐band signals is done with the allocated bits for the corresponding sub‐band. The 12 (36) sub‐band samples are divided by the corresponding scaling factor and then linearly quantized and coded (for details see [ISO92]). This is followed by a frame packing. In the decoder, the procedure is reversed. The decoded sub‐band signals with different word lengths are reconstructed to a broadband PCM signal with a synthesis filter bank (see Fig. 9.14). MPEG‐1 audio coding has a one or a two channel stereo mode with sampling frequencies of 32, 44.1, and 48 kHz and a bit rate of 128 kbit/s per channel.
9.5 MPEG‐2 Audio Coding
The aim of the introduction of MPEG‐2 audio coding was the extension of MPEG‐1 to lower sampling frequencies and multichannel coding [Bos97]. Backward compatibility to existing MPEG‐1 systems is achieved through the version MPEG‐2 BC (Backward Compatible) and the introduction toward lower sampling frequencies of 32, 22.05, 24 kHz with version MPEG‐2 LSF (Lower Sampling Frequencies). The bit rate for a five‐channel MPEG‐2 BC coding with full bandwidth of all channels is 640–896 kBit/s.
9.6 MPEG‐2 Advanced Audio Coding
To improve the coding of mono, stereo, and multichannel audio signals, the MPEG‐2 AAC (Advanced Audio Coding) standard is specified. This coding standard is not backward compatible with the MPEG‐1 standard and forms the kernel for new extended coding standards such as MPEG‐4. The achievable bit rate for a five‐channel coding is 320 kBit/s. In the following, the main signal processing steps for MPEG‐2 AAC will be introduced and the principle functionalities will be explained. An extensive explanation can be found in [Bos97, Bra98, Bos02]. An MPEG‐2 AAC coder is shown in Fig. 9.19. The corresponding decoder performs the functional units in reverse order with corresponding decoder functionalities.

Figure 9.19 MPEG‐2 AAC coder and decoder.
Pre‐processing: the input signal will be band limited according to the sampling frequency. This step is used only in the scalable sampling rate profile [Bos97, Bra98, Bos02].
Filter bank: the time‐frequency decomposition into ![]() sub‐bands with an overlapped MDCT [Pri86, Pri87] is based on blocks of
sub‐bands with an overlapped MDCT [Pri86, Pri87] is based on blocks of ![]() input samples. A step‐wise explanation of the implementation will be introduced. A graphical representation of the single steps is depicted in Fig. 9.20. The single steps are as follows.
input samples. A step‐wise explanation of the implementation will be introduced. A graphical representation of the single steps is depicted in Fig. 9.20. The single steps are as follows.
- Partitioning of the input signal
 with time index
with time index  into overlapped blocks
(9.33)of length
into overlapped blocks
(9.33)of length
 with an overlap (hop size) of
with an overlap (hop size) of  . The time index inside a block is denoted by
. The time index inside a block is denoted by  . The variable
. The variable  denotes the block index.
denotes the block index. - Windowing of blocks with window function
 .
. - MDCT
(9.34)
 (9.35)yields every
(9.35)yields every
 input samples
input samples  spectral coefficients from
spectral coefficients from  windowed input samples.
windowed input samples. - Quantization of spectral coefficients
 leads to quantized spectral coefficients
leads to quantized spectral coefficients  based on a psychoacoustic model.
based on a psychoacoustic model. - IMDCT
(9.35)
 (9.36)yields every
(9.36)yields every
 input samples
input samples  output samples in block
output samples in block  .
. - Windowing of inverse transformed block
 with window function
with window function  .
. - Reconstruction of output signal
 by overlap and add operation according to
(9.36)with overlap
by overlap and add operation according to
(9.36)with overlap
 .
.

Figure 9.20 Time‐frequency decompostion with MDCT/inverse modified discrete cosine transform (IMDCT).

Figure 9.21 Signals of MDCT/IMDCT.
To explain the procedural steps, we consider the MDCT/IMDCT of a sine pulse shown in Fig. 9.21. The left column shows top down the input signal and partitions of the input signal of block length ![]() . The window function is a sine window. The corresponding MDCT coefficients of length
. The window function is a sine window. The corresponding MDCT coefficients of length ![]() are shown in the middle column. The IMDCT delivers the signals in the right column. One can notice that the inverse transforms with the IMDCT do not exactly reconstruct the single input blocks. Moreover, each output block consists of an input block and a special superposition of a time‐reversed and circular shifted by
are shown in the middle column. The IMDCT delivers the signals in the right column. One can notice that the inverse transforms with the IMDCT do not exactly reconstruct the single input blocks. Moreover, each output block consists of an input block and a special superposition of a time‐reversed and circular shifted by ![]() input block, which is denoted by time domain aliasing [Pri86, Pri87, Edl89]. The overlap and add operation of the single output blocks perfectly recovers the input signal, which is shown in the top signal of the right column (Fig. 9.21). For a perfect reconstruction of the output signal, the window function of the analysis and synthesis step has to fulfill the condition
input block, which is denoted by time domain aliasing [Pri86, Pri87, Edl89]. The overlap and add operation of the single output blocks perfectly recovers the input signal, which is shown in the top signal of the right column (Fig. 9.21). For a perfect reconstruction of the output signal, the window function of the analysis and synthesis step has to fulfill the condition ![]() . The Kaiser–Bessel‐derived window [Bos02] and a sine window
. The Kaiser–Bessel‐derived window [Bos02] and a sine window ![]() with
with ![]() [Mal92] are applied. Figure 9.22 shows both window functions with
[Mal92] are applied. Figure 9.22 shows both window functions with ![]() and the corresponding magnitude responses for a sampling frequency of
and the corresponding magnitude responses for a sampling frequency of ![]() Hz. The sine window has a smaller passband width but slower falling side lobes. In contrast, the Kaiser–Bessel‐derived window shows a wider passband and a faster decay of the side lobes. To demonstrate the filter bank properties and, in particular, the frequency decomposition of MDCT, we derive the modulated bandpass impulse responses of the window functions (prototype impulse response
Hz. The sine window has a smaller passband width but slower falling side lobes. In contrast, the Kaiser–Bessel‐derived window shows a wider passband and a faster decay of the side lobes. To demonstrate the filter bank properties and, in particular, the frequency decomposition of MDCT, we derive the modulated bandpass impulse responses of the window functions (prototype impulse response ![]() ) according to
) according to
Figure 9.23 shows the normalized prototype impulse response of the sine window and the first two modulated bandpass impulse responses ![]() and
and ![]() , and accordingly, the corresponding magnitude responses are depicted. In addition to the increased frequency resolution with
, and accordingly, the corresponding magnitude responses are depicted. In addition to the increased frequency resolution with ![]() bandpass filters, a reduced stopband attenuation can be observed. A comparison of this magnitude responses of the MDCT with the frequency resolution of the pseudo‐QMF bank with
bandpass filters, a reduced stopband attenuation can be observed. A comparison of this magnitude responses of the MDCT with the frequency resolution of the pseudo‐QMF bank with ![]() in Fig. 9.16 points out the different properties of both sub‐band decompositions.
in Fig. 9.16 points out the different properties of both sub‐band decompositions.

Figure 9.22 Kaiser–Bessel‐derived window and sine window for  and magnitude responses of the normalized window functions.
and magnitude responses of the normalized window functions.

Figure 9.23 Normalized impulse responses of sine window for  , modulated bandpass impulse responses, and magnitude responses.
, modulated bandpass impulse responses, and magnitude responses.
To adjust the time and frequency resolution to the properties of an audio signal, several methods have been investigated. Signal‐adaptive audio coding based on the wavelet transform can be found in [Sin93, Ern00]. Window switching can be applied to achieve a time‐variant time‐frequency resolution for MDCT and IMDCT applications. For stationary signals, a high frequency resolution and a low time resolution are necessary. This leads to long windows with ![]() . Coding of attacks of instruments needs a high time resolution (reduction of window length to
. Coding of attacks of instruments needs a high time resolution (reduction of window length to ![]() ) and thus reduces the frequency resolution (reduction of number of spectral coefficients). A detailed description of switching between time–frequency resolution with the MDCT/IMDCT can be found in [Edl89, Bos97, Bos02]. Examples of switching between different window functions and windows of different length are shown in Fig. 9.24.
) and thus reduces the frequency resolution (reduction of number of spectral coefficients). A detailed description of switching between time–frequency resolution with the MDCT/IMDCT can be found in [Edl89, Bos97, Bos02]. Examples of switching between different window functions and windows of different length are shown in Fig. 9.24.

Figure 9.24 Switching of window functions.
Temporal Noise Shaping. A further method for adapting the time–frequency resolution of a filter bank and here a MDCT/IMDCT to the signal characteristic is based on linear prediction along the spectral coefficients in the frequency domain [Her96, Her99]. This method is called temporal noise shaping (TNS) and is a weighting of the temporal envelope of the time domain signal. Such weighting of the temporal envelope is demonstrated in Fig. 9.25.

Figure 9.25 Attack of castanet and spectrum.
Figure 9.25a shows a signal from a castanet attack. Making use of the discrete cosine transform (DCT, [Rao90]),

and the IDCT,

the spectral coefficients of the DCT of this castanet attack are represented in Fig. 9.25b. After quantization of these spectral coefficients ![]() to 4 bit (Fig. 9.25d) and IDCT of the quantized spectral coefficients, the time‐domain signal in Fig. 9.25c and the difference signal in Fig. 9.25e between input and output results. One can notice in the output and difference signal that the error is spread along the entire block length. This means that before the attack of the castanet happens, the error signal of the block is perceptible. The time‐domain masking, the so‐called pre‐masking [Zwi90], is not sufficient. Ideally, the spreading of the error signal should follow the time‐domain envelope of the signal itself. From the forward linear prediction in the time domain, it is known that the power spectral density of the error signal after coding and decoding is weighted by the envelope of the power spectral density of the input signal [Var06]. Performing a forward linear prediction along the frequency axis in the frequency domain and quantization and coding leads to an error signal in the time domain where the temporal envelope of the error signal follows the time‐domain envelope of the input signal [Her96]. To point out the temporal weighting of the error signal, we consider the forward prediction in the time domain using Fig. 9.26a. For coding the input signal,
to 4 bit (Fig. 9.25d) and IDCT of the quantized spectral coefficients, the time‐domain signal in Fig. 9.25c and the difference signal in Fig. 9.25e between input and output results. One can notice in the output and difference signal that the error is spread along the entire block length. This means that before the attack of the castanet happens, the error signal of the block is perceptible. The time‐domain masking, the so‐called pre‐masking [Zwi90], is not sufficient. Ideally, the spreading of the error signal should follow the time‐domain envelope of the signal itself. From the forward linear prediction in the time domain, it is known that the power spectral density of the error signal after coding and decoding is weighted by the envelope of the power spectral density of the input signal [Var06]. Performing a forward linear prediction along the frequency axis in the frequency domain and quantization and coding leads to an error signal in the time domain where the temporal envelope of the error signal follows the time‐domain envelope of the input signal [Her96]. To point out the temporal weighting of the error signal, we consider the forward prediction in the time domain using Fig. 9.26a. For coding the input signal, ![]() is predicted by an impulse response
is predicted by an impulse response ![]() . The output of the predictor is subtracted from the input signal
. The output of the predictor is subtracted from the input signal ![]() and delivers the signal
and delivers the signal ![]() , which is then quantized to a reduced word length. The quantized signal
, which is then quantized to a reduced word length. The quantized signal ![]() is the sum of the convolution of
is the sum of the convolution of ![]() with the impulse response
with the impulse response ![]() and the additive quantization error
and the additive quantization error ![]() . The power spectral density of the coder output is
. The power spectral density of the coder output is ![]() . The decoding operation performs the convolution of
. The decoding operation performs the convolution of ![]() with the impulse response
with the impulse response ![]() of the inverse system to the coder. Therefore,
of the inverse system to the coder. Therefore, ![]() must hold and thus
must hold and thus ![]() . Hereby, the output signal
. Hereby, the output signal ![]() is derived with the corresponding discrete Fourier transform
is derived with the corresponding discrete Fourier transform ![]() . The power spectral density of the decoder out signal is given by
. The power spectral density of the decoder out signal is given by ![]() . Herein, one can notice the spectral weighting of the quantization error with the spectral envelope of the input signal which is represented by
. Herein, one can notice the spectral weighting of the quantization error with the spectral envelope of the input signal which is represented by ![]() . The same kind of forward prediction will now be applied in the frequency domain to the spectral coefficients
. The same kind of forward prediction will now be applied in the frequency domain to the spectral coefficients ![]() for a block of input samples
for a block of input samples ![]() shown in Fig. 9.26b. The output of the decoder is then given by
shown in Fig. 9.26b. The output of the decoder is then given by ![]() with
with ![]() . Thus, the corresponding time‐domain signal is
. Thus, the corresponding time‐domain signal is ![]() , where the temporal weighting of the quantization error with the temporal envelope of the input signal is clearly evident. The temporal envelope is represented by the absolute value
, where the temporal weighting of the quantization error with the temporal envelope of the input signal is clearly evident. The temporal envelope is represented by the absolute value ![]() of the impulse response
of the impulse response ![]() . The relation between the temporal signal envelope (absolute value of the analytical signal) and the auto‐correlation function of the analytical spectrum is discussed in [Her96]. The dualities between forward linear predictions in the time and frequency domains are summarized in Table 9.2. Figure 9.27 demonstrates the operations for temporal noise shaping in the coder, where the prediction is performed along the spectral coefficients. The coefficients of the forward predictor have to be transmitted to the decoder, where inverse filtering is performed along the spectral coefficients.
. The relation between the temporal signal envelope (absolute value of the analytical signal) and the auto‐correlation function of the analytical spectrum is discussed in [Her96]. The dualities between forward linear predictions in the time and frequency domains are summarized in Table 9.2. Figure 9.27 demonstrates the operations for temporal noise shaping in the coder, where the prediction is performed along the spectral coefficients. The coefficients of the forward predictor have to be transmitted to the decoder, where inverse filtering is performed along the spectral coefficients.

Figure 9.26 Forward prediction in time and frequency domains.
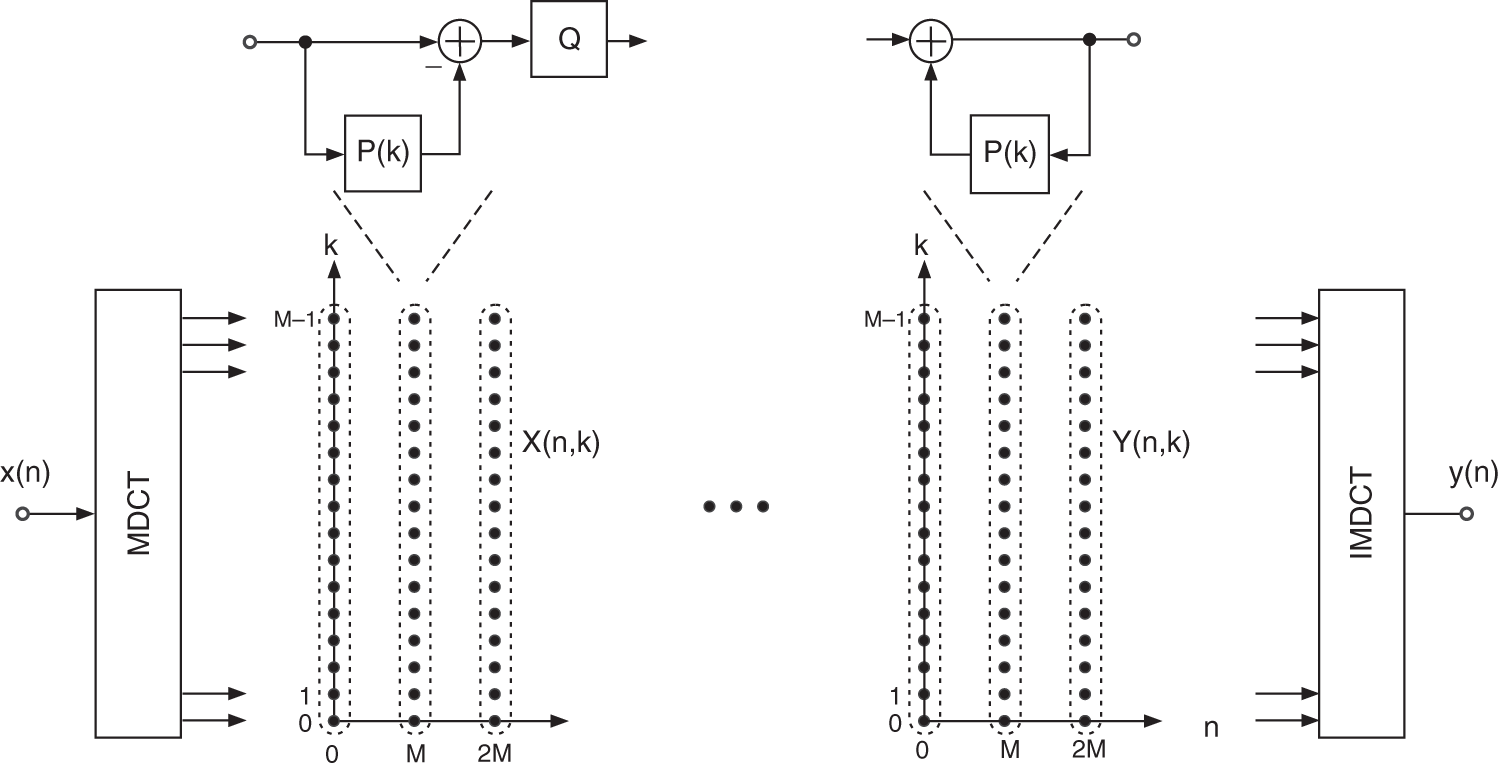
Figure 9.27 Temporal noise shaping with forward prediction in the frequency domain.
Table 9.2 Forward prediction in the time and frequency domains.
| Prediction in time domain | Prediction in frequency domain |
|---|---|
The temporal weighting is finally demonstrated in Fig. 9.28, where the corresponding signals with the forward prediction in the frequency domain are shown. Figure 9.28a/b shows the castanet signal ![]() and its corresponding spectral coefficients
and its corresponding spectral coefficients ![]() of the applied DCT. The forward prediction delivers
of the applied DCT. The forward prediction delivers ![]() in Fig. 9.28d and the quantized signal
in Fig. 9.28d and the quantized signal ![]() in Fig. 9.28f. After the decoder, the signal
in Fig. 9.28f. After the decoder, the signal ![]() in Fig. 9.28h is reconstructed by the inverse transfer function. The IDCT of
in Fig. 9.28h is reconstructed by the inverse transfer function. The IDCT of ![]() finally results in the output signal
finally results in the output signal ![]() in Fig. 9.28e. The difference signal
in Fig. 9.28e. The difference signal ![]() in Fig. 9.28g demonstrates the temporal weighting of the error signal with the temporal envelope from Fig. 9.28c. For this example, the order of the predictor is chosen to be 20 [Bos97] and the prediction along the spectral coefficients
in Fig. 9.28g demonstrates the temporal weighting of the error signal with the temporal envelope from Fig. 9.28c. For this example, the order of the predictor is chosen to be 20 [Bos97] and the prediction along the spectral coefficients ![]() is performed by the Burg method. The prediction gain for this signal in the frequency domain is
is performed by the Burg method. The prediction gain for this signal in the frequency domain is ![]() dB (see Fig. 9.28d).
dB (see Fig. 9.28d).

Figure 9.28 Temporal noise shaping: attack of castanet and spectrum.
Frequency Domain Prediction. A further compression of the bandpass signals is possible by using linear prediction. A backward prediction [Var06] of the bandpass signals is applied on the coder side (see Fig. 9.29). In using a backward prediction, the predictor coefficients need not be coded and transmitted to the decoder, because the estimate of the input sample is based on the quantized signal. The decoder derives the predictor coefficients ![]() in the same way from the quantized input. A second‐order predictor is sufficient, because the bandwidth of the bandpass signals is very low [Bos97].
in the same way from the quantized input. A second‐order predictor is sufficient, because the bandwidth of the bandpass signals is very low [Bos97].

Figure 9.29 Backward prediction of bandpass signals.
Mono/Side Coding. Coding of stereo signals with left and right signals ![]() and
and ![]() can be achieved by coding a mono signal (M)
can be achieved by coding a mono signal (M) ![]() and a side (S, difference) signal
and a side (S, difference) signal ![]() (M/S coding). Because the power of the side signal is reduced for highly correlated left and right signals, a reduction of the bit rate for this signal can be achieved. The decoder can reconstruct the left signal
(M/S coding). Because the power of the side signal is reduced for highly correlated left and right signals, a reduction of the bit rate for this signal can be achieved. The decoder can reconstruct the left signal ![]() and the right signal
and the right signal ![]() , if no quantization and coding is applied to the mono and side signals. This M/S coding is carried out for MPEG‐2 AAC [Bra98, Bos02] with the spectral coefficients of a stereo signal (see Fig. 9.30).
, if no quantization and coding is applied to the mono and side signals. This M/S coding is carried out for MPEG‐2 AAC [Bra98, Bos02] with the spectral coefficients of a stereo signal (see Fig. 9.30).

Figure 9.30 M/S coding in the frequency domain.
Intensity Stereo Coding. For intensity stereo (IS) coding, a mono signal ![]() and two temporal envelopes
and two temporal envelopes ![]() and
and ![]() of the left and right signals are coded and transmitted. On the decoding side, the left signal is reconstructed by
of the left and right signals are coded and transmitted. On the decoding side, the left signal is reconstructed by ![]() and the right signal by
and the right signal by ![]() . This reconstruction is lossy. The intensity stereo coding of MPEG‐2 AAC [Bra98] is performed by the summation of spectral coefficients of both signals and by coding of scale factors which represent the temporal envelope of both signals (see Fig. 9.31). This type of stereo coding is only useful for higher frequency bands, because the human perception for phase shifts is non‐sensitive for frequencies above 2 kHz.
. This reconstruction is lossy. The intensity stereo coding of MPEG‐2 AAC [Bra98] is performed by the summation of spectral coefficients of both signals and by coding of scale factors which represent the temporal envelope of both signals (see Fig. 9.31). This type of stereo coding is only useful for higher frequency bands, because the human perception for phase shifts is non‐sensitive for frequencies above 2 kHz.
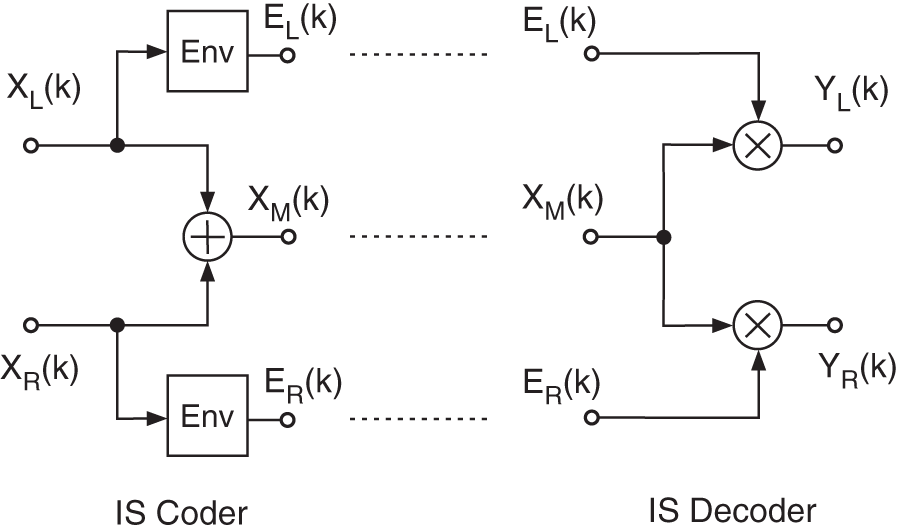
Figure 9.31 Intensity stereo coding in the frequency domain.
Quantization and Coding. During the last coding step, the quantization and coding of the spectral coefficients take place. The quantizers, which are used in the figures for prediction along spectral coefficients in the frequency direction (Fig. 9.27) and prediction in the frequency domain along bandpass signals (Fig. 9.29), are now combined to a single quantizer per spectral coefficient. This quantizer performs nonlinear quantization similar to a floating‐point quantizer presented in Chapter 2, such that a nearly constant SNR over a wide amplitude range is achieved. This floating‐point quantization with a so‐called scale factor is applied to several frequency bands, in which several spectral coefficients use a common scale factor derived from an iteration loop (see Fig. 9.19). Finally, a Huffman coding of the quantized spectral coefficients is performed. An extensive presentation can be found in [Bos97, Bra98, Bos02].
9.7 MPEG‐4 Audio Coding
The MPEG‐4 audio coding standard consists of a family of audio and speech coding methods for different bit rates and a variety of multimedia applications [Bos02, Her02]. In addition to a higher coding efficiency, new functionalities such as scalability, object‐oriented representation of signals, and interactive synthesis of signals at the decoder are integrated. The MPEG‐4 coding standard is based on the following speech and audio coders.
- Speech coders
- – CELP: Code‐excited linear prediction (bit rate 4–24 kBit/s).
- – HVXC: Harmonic vector excitation coding (bit rate 1.4–4 kBit/s).
- Audio coders
- – Parametric audio: representation of a signal as a sum of sinusoids, harmonic components, and residual components (bit rate 4–16 kBit/s).
- – Structured audio: synthetic signal generation at decoder (extension of the MIDI standard1 (0.2–4 kBit/s).
- – Generalized audio: extension of MPEG‐2 AAC with additional methods in the time‐frequency domain. The basic structure is depicted in Fig. 9.19 (bit rate 6–64 kBit/s).
The basics of speech coders can found in [Var06]. The specified audio coders allow coding with lower bit rates (parametric audio and structured audio) and coding with higher quality at lower bit rates compared with MPEG‐2 AAC.

Figure 9.32 MPEG‐4 parametric coder.
Compared with the so far introduced coding methods, such as MPEG‐1 and MPEG‐2, parametric audio coding is of special interest as an extension to the filter bank methods [Pur99, Edl00]. A parametric audio coder is shown in Fig. 9.32. The analysis of the audio signal leads to a decomposition into sinusoidal, harmonic, and noise‐like signal components and the quantization and coding of these signal components is based on psychoacoustics [Pur02a]. According to an analysis/synthesis approach [McA86, Ser89, Smi90, Geo92, Geo97, Rod97, Mar00a] shown in Fig. 9.33, the audio signal is represented in a parametric form given by

The first term describes a sum of sinusoids with time‐varying amplitudes ![]() , frequencies
, frequencies ![]() , and phases
, and phases ![]() . The second term consists of a noise‐like component
. The second term consists of a noise‐like component ![]() with a time‐varying temporal envelope. This noise‐like component
with a time‐varying temporal envelope. This noise‐like component ![]() is derived by subtracting the synthesized sinusoidal components from the input signal. With the help of a further analysis step, harmonic components with a fundamental frequency and multiples of this fundamental frequency are identified and grouped to harmonic components. The extraction of deterministic and stochastic components from an audio signal can be found in [Alt99, Hai03, Kei01, Kei02, Mar00a, Mar00b, Lag02, Lev98, Lev99, Pur02b]. In addition to the extraction of sinusoidal components, the modeling of noise‐like components and transient components is of specific importance [Lev98, Lev99]. Figure 9.34 exemplifies the decomposition of an audio signal into a sum of sinusoids
is derived by subtracting the synthesized sinusoidal components from the input signal. With the help of a further analysis step, harmonic components with a fundamental frequency and multiples of this fundamental frequency are identified and grouped to harmonic components. The extraction of deterministic and stochastic components from an audio signal can be found in [Alt99, Hai03, Kei01, Kei02, Mar00a, Mar00b, Lag02, Lev98, Lev99, Pur02b]. In addition to the extraction of sinusoidal components, the modeling of noise‐like components and transient components is of specific importance [Lev98, Lev99]. Figure 9.34 exemplifies the decomposition of an audio signal into a sum of sinusoids ![]() and a noise‐like signal
and a noise‐like signal ![]() . The spectrogram shown in Fig. 9.35 represents the short‐time spectra of the sinusoidal components. The extraction of the sinusoids has been achieved by a modified FFT method [Mar00a] with an FFT length of
. The spectrogram shown in Fig. 9.35 represents the short‐time spectra of the sinusoidal components. The extraction of the sinusoids has been achieved by a modified FFT method [Mar00a] with an FFT length of ![]() and an analysis hop size of
and an analysis hop size of ![]() .
.

Figure 9.33 Parameter extraction with analysis/synthesis.

Figure 9.34 Original signal, sum of sinusoids, and noise‐like signal.

Figure 9.35 Spectrogram of sinusoidal components.
The corresponding parametric MPEG‐4 decoder is shown in Fig. 9.36 [Edl00, Mei02]. The synthesis of the three signal components can be achieved by inverse FFT and overlap and add methods or can be directly performed by time‐domain methods [Rod97, Mei02]. A significant advantage of parametric audio coding is the direct access at the decoder to the three main signal components which allows effective post‐processing for the generation of a variety of audio effects [Zöl11]. Effects such as time and pitch scaling, virtual sources in three‐dimensional spaces, and cross‐synthesis of signals (karaoke) are just a few examples for interactive sound design on the decoding side.

Figure 9.36 MPEG‐4 parametric decoder.
9.8 Spectral Band Replication
To further reduce the bit rate, an extension of MPEG‐1 layer 3 with the name MP3pro was introduced [Die02, Zie02]. The underlying method, called spectral band replication (SBR) performs a lowpass and highpass decomposition of the audio signal, where the lowpass filtered part is coded by a standard coding method (e.g. MPEG‐1 Layer 3) and the highpass part is represented by a spectral envelope and a difference signal [Eks02, Zie03]. Figure 9.37 shows the functional units of an SBR coder. For the analysis of the difference signal, the highpass part (HP generator) is reconstructed from the lowpass part and compared with the actual highpass part. The difference is coded and transmitted. For decoding (see Fig. 9.38), the decoded lowpass part of a standard decoder is used by the HP generator to reconstruct the highpass part. An additional coded difference signal is added at the decoder. An equalizer provides the spectral envelope shaping for the highpass part. The spectral envelope of the highpass signal can be achieved by a filter bank and computing the root‐mean‐square values of each bandpass signal [Eks02, Zie03]. The reconstruction of the highpass part (HP generator) can also be achieved by a filter bank and substituting the bandpass signals by using the lowpass parts [Schu96, Her98]. To code the difference signal of the highpass part, additive sinusoidal models can be applied such as the parametric methods of the MPEG‐4 coding approach.

Figure 9.37 SBR coder.
Figure 9.38 SBR decoder. Based on [Edl00] and [Mei02].

Figure 9.39 Functional units of the SBR method.
Figure 9.39 shows the functional units of the SBR method in the frequency domain. First, the short‐time spectrum is used to calculate the spectral envelope (Fig. 9.39a). The spectral envelope can be derived from an FFT, a filter bank, the cepstrum, or by linear prediction [Zöl11]. The band‐limited lowpass signal can be downsampled and coded by a standard coder which operates at a reduced sampling rate. In addition, the spectral envelope has to be coded (Fig. 9.39b). On the decoding side, the reconstruction of the upper spectrum is achieved by frequency shifting of the lowpass part, or even specific lowpass parts, and applying the spectral envelope onto this artificial highpass spectrum (Fig. 9.39c). An efficient implementation of a time‐varying spectral envelope computation (at the coder side) and spectral weighting of the highpass signal (at the decoder side) with a complex‐valued QMF bank is described in [Eks02].
9.9 Constrained Energy Lapped Transform – Gain and Shape Coding
Another audio coding system using overlapped MDCT and a gain‐shape quantization scheme in the frequency domain was introduced in [Val09, Val10], which is lossy in nature. The block diagram in Fig. 9.40 shows a simple version of the so‐called constrained energy lapped transform (CELT) encoder and decoder. In this section, a simplified version of the CELT codec is described that excludes some refinements such as pre‐ and post‐filtering, bit allocation for pitch period filter, and filter gain, which are described in [Val13].

Figure 9.40 A simplified illustration of the CELT codec.
In the CELT codec, the MDCT with a given window length ![]() is performed on a pre‐processed audio input to generate the coefficients
is performed on a pre‐processed audio input to generate the coefficients ![]() . From the coefficients, the energies in 20 Bark bands are computed as
. From the coefficients, the energies in 20 Bark bands are computed as
where ![]() denote the band indices. These band energies are called gain coefficients and they are given by
denote the band indices. These band energies are called gain coefficients and they are given by ![]() . Division of the Bark band coefficient vectors
. Division of the Bark band coefficient vectors ![]() by these gain coefficients
by these gain coefficients ![]() leads to the shape coefficient vectors given by
leads to the shape coefficient vectors given by

The mapping from DCT coefficients ![]() to Bark bands
to Bark bands ![]() is described in Table IV of [Val10]. The corresponding frequency for each DCT coefficient
is described in Table IV of [Val10]. The corresponding frequency for each DCT coefficient ![]() is given by
is given by ![]() in Hz with
in Hz with ![]() . The sequential operations for computing gain and shape are given by
. The sequential operations for computing gain and shape are given by

Figure 9.41 shows the individual spectrograms representing the energies per Bark band in dB, the corresponding gain coefficients in dB, and the shape coefficient vectors. The values of elements in each shape vector lie between ![]() and 1. In the next step, quantization of the gain and shape coefficients takes place. The gain coefficients use scalar quantization and the shape coefficients use a form of vector quantization, which usually performs a dimension reduction and leads to compression.
and 1. In the next step, quantization of the gain and shape coefficients takes place. The gain coefficients use scalar quantization and the shape coefficients use a form of vector quantization, which usually performs a dimension reduction and leads to compression.
Figure 9.41 CELT spectrograms for a) energies per Bark band, b) gain coefficients in dB, and c) shape coefficients.
9.9.1 Gain Quantization
CELT uses a strategy to quantize the gain in the log2 domain that includes two steps – coarse and fine quantization. For coarse quantization, gain coefficients from each band can be directly quantized with a pre‐defined resolution. However, direct quantization of the coefficients will result in the usage of a high number of bits during encoding if the variance among the coefficients or the entropy of their distribution is high. When CELT is used for real‐time audio coding over a network as part of the OPUS codec [Val12], the available bandwidth governs the bit allocation. Hence, the CELT encoder eliminates the redundancy between the gain coefficients across time and frequency by performing a prediction. The corresponding details of the predictive method are provided in [Val10]. The method leads to a set of predictive gain coefficients, denoted by ![]() , with lower variance or entropy than the original gain coefficients. Figure 9.42 shows the mean gain vector compared with the mean predictive gain vector, averaged across all bands for 100 overlapping frames of an audio signal. The variance of the mean gain vector is 0.088 while the variance of the average predictive gain vector is 0.017. The coarse quantization (CQ) is then performed as
, with lower variance or entropy than the original gain coefficients. Figure 9.42 shows the mean gain vector compared with the mean predictive gain vector, averaged across all bands for 100 overlapping frames of an audio signal. The variance of the mean gain vector is 0.088 while the variance of the average predictive gain vector is 0.017. The coarse quantization (CQ) is then performed as

and the fine quantization (FQ) is performed as
where ![]() denote the predictive gain coefficients expressed in decibels and
denote the predictive gain coefficients expressed in decibels and ![]() denotes the coarse quantization error. The range of the rounded values after coarse quantization varies between frames and depends on the quantization resolution
denotes the coarse quantization error. The range of the rounded values after coarse quantization varies between frames and depends on the quantization resolution ![]() . The quantized values or indices are transformed into positive integers for encoding. The coarse quantization symbols are usually distributed in such a way that it can be modeled by a generalized Gaussian or Laplace distribution. An example of the real symbol distribution over 100 overlapping frames is provided in Fig. 9.43 along with the ideal Laplace distribution that can be used during entropy coding. The coarse quantization error usually lies between
. The quantized values or indices are transformed into positive integers for encoding. The coarse quantization symbols are usually distributed in such a way that it can be modeled by a generalized Gaussian or Laplace distribution. An example of the real symbol distribution over 100 overlapping frames is provided in Fig. 9.43 along with the ideal Laplace distribution that can be used during entropy coding. The coarse quantization error usually lies between ![]() and
and ![]() . Fine quantization maps the error value to an integral symbol which represents a sub‐interval of the error range. The resolution for fine quantization depends on its bit allocation. The fine quantization symbols per frame are usually not distributed well enough to be modeled by any standard distribution. However, if many frames are taken into account, its distribution approaches a uniform distribution, as shown in Fig. 9.44.
. Fine quantization maps the error value to an integral symbol which represents a sub‐interval of the error range. The resolution for fine quantization depends on its bit allocation. The fine quantization symbols per frame are usually not distributed well enough to be modeled by any standard distribution. However, if many frames are taken into account, its distribution approaches a uniform distribution, as shown in Fig. 9.44.

Figure 9.42 Mean gain and mean predictive gain coefficients, averaged over all bands.

Figure 9.43 Actual and ideal distribution of the coarse quantization symbols for  frames.
frames.

Figure 9.44 Distribution of the fine quantization symbols for  frames.
frames.
9.9.2 Shape Quantization
Quantization of the shape vectors is performed by pyramid vector quantization (PVQ) [Fis86, Say12, Val13]. In PVQ, a codebook containing reference vectors of length ![]() is created, where
is created, where ![]() denotes the length of the shape vector to be quantized. The codebook is made of integers, whose absolute values add up to a predefined constant
denotes the length of the shape vector to be quantized. The codebook is made of integers, whose absolute values add up to a predefined constant ![]() referred to as the number of pulses. The codebook vectors are normalized to produce unit vectors which are ordered and assigned with numeric indices. The shape vector to be encoded receives the index that corresponds to its nearest unit vector in the codebook. The
referred to as the number of pulses. The codebook vectors are normalized to produce unit vectors which are ordered and assigned with numeric indices. The shape vector to be encoded receives the index that corresponds to its nearest unit vector in the codebook. The ![]() distance is used to find the appropriate unit vector in a codebook search. Each band is uniquely encoded based on its bit allocation and the low‐ and mid‐frequency bands usually have a better bit resolution. A shape vector
distance is used to find the appropriate unit vector in a codebook search. Each band is uniquely encoded based on its bit allocation and the low‐ and mid‐frequency bands usually have a better bit resolution. A shape vector ![]() of the
of the ![]() th band is mapped to a codebook index
th band is mapped to a codebook index ![]() according to
according to

The distribution of the shape quantization symbols per frame is usually sparse and similar to the fine quantization symbols, it cannot be modeled by any standard distribution. When many frames are considered, it approaches a uniform distribution for each band. The inverse operation maps the codebook index ![]() to a codebook vector
to a codebook vector ![]() as given by
as given by

9.9.3 Range Coding
Range coding [Nig79, Say12] is an entropy coding method that performs a progressive encoding of symbols by narrowing down an initial range, based on the probability distribution of the symbols, until the final range and codeword are determined. The final codeword is decoded with the help of the probability distribution of the symbols as well. It is very similar to arithmetic encoding, except that the encoding is done with digits in any base instead of with bits. However, CELT uses range coding as a bit packer. It performs an iterative compression of a sequence of 20 symbols corresponding to 20 bands with a pre‐defined probability density function and outputs a single codeword. From this codeword, the iterative decompression delivers the 20 input symbols. This range coding and decoding is usually performed for the course gain symbols only while the shape and fine quantization symbols are encoded as raw and decoded directly. However, if the standalone CELT codec is used for non‐real‐time compression of audio after a look‐ahead of multiple frames, entropy coding is able to compress the shape and fine quantization symbols as well with the use of a uniform distribution function.
9.9.4 CELT Decoding
Figure 9.40 shows a simplified operation of the CELT decoder. Once the bit streams are available to the decoder, range decoding is applied to retrieve the coarse quantization symbols while the raw bits are decoded to retrieve the fine and shape quantization symbols. The inverse quantization of the symbols takes place in the next step as denoted by ![]() ,
, ![]() , and
, and ![]() to get the respective coefficients. The reconstructed gain error is added to the reconstructed predictive gain coefficients and subsequently the reconstructed gain coefficients
to get the respective coefficients. The reconstructed gain error is added to the reconstructed predictive gain coefficients and subsequently the reconstructed gain coefficients ![]() are calculated based on the inverse prediction method. The gain coefficients are transformed to the linear domain as
are calculated based on the inverse prediction method. The gain coefficients are transformed to the linear domain as ![]() and the frequency domain coefficients are reconstructed as
and the frequency domain coefficients are reconstructed as
The coefficients are transformed using IMDCT to get the reconstructed time‐domain signal. Figure 9.45 shows an original and reconstructed signal along with the reconstruction error for 100 frames of a test audio file using a quantization resolution of 6 dB. For the above example, CELT encoding results in an average rate of 348 bits per frame while the average rate for coarse quantization after entropy coding is nearly 26 bits per frame. The overall compression achieved for the corresponding audio snippet is nearly 25 % of the original.

Figure 9.45 Performance of the CELT codec on an audio snippet.
9.10 JS Applet – Psychoacoustics
The applet shown in Fig. 9.46 demonstrates psychoacoustic audio masking effects [Gui05]. It is designed for a first insight into the perceptual experience of masking a sinusoidal signal with band‐limited noise.
You can choose between two predefined audio files from our web server (“Audio1.wav” or “Audio2.wav”). These are band‐limited noise signals with different frequency ranges. A sinusoidal signal is generated by the applet, and two sliders can be used to control its frequency and magnitude values.
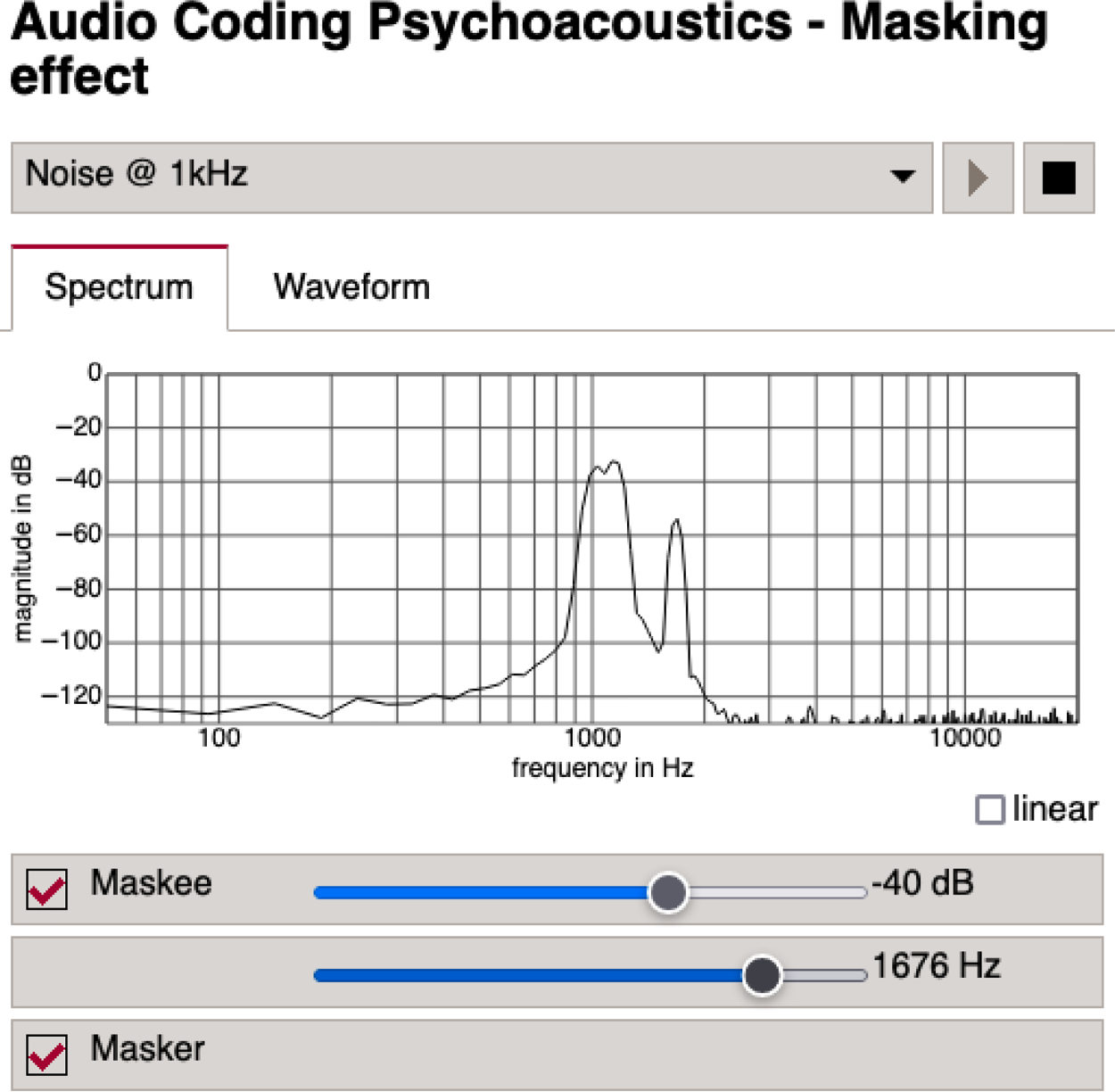
Figure 9.46 JS applet – psychoacoustics.
9.11 Exercises
1. Psychoacoustics
- Human hearing
- In which frequency range is a human able to perceive sounds?
- What is the frequency range of speech?
- In the above specified range, where is human hearing most sensitive?
- How is the absolute threshold of hearing determined?
- Masking
- What is frequency‐domain masking?
- What is a critical band and why is it needed for frequency masking phenomena?
- Consider
 and
and  to be respectively the amplitude and the frequency of a partial at index
to be respectively the amplitude and the frequency of a partial at index  and
and  to be the corresponding volume in dB. The difference between the level of the masker and the masking threshold is
to be the corresponding volume in dB. The difference between the level of the masker and the masking threshold is  dB. The masking curves toward lower and higher frequencies are described respectively by a left slope (27 dB/Bark) and a right slope (15 dB/Bark). Explain the main steps of frequency masking in this case and show with plots how this masking phenomena is achieved.
dB. The masking curves toward lower and higher frequencies are described respectively by a left slope (27 dB/Bark) and a right slope (15 dB/Bark). Explain the main steps of frequency masking in this case and show with plots how this masking phenomena is achieved. - What are the psychoacoustic parameters used for lossy audio coding?
- How can we explain temporal masking and what is its duration after stopping the active masker?
2. Audio coding
- How do a lossless coder and decoder work.
- What is the achievable compression factor for lossless coding?
- How do an MPEG‐1 Layer 3 coder and decoder work.
- How do an MPEG‐2 AAC coder and decoder work.
- What is temporal noise shaping?
- How do an MPEG‐4 coder and decoder work.
- What is the benefit of SBR?
References
- [Alt99] R. Althoff, F. Keiler, U. Zölzer: Extracting Sinusoids from Harmonic Signals, Proc. DAFX‐99 Workshop on Digital Audio Effects, pp. 97–100, Trondheim, Norway, 1999.
- [Blo95] T. Block: Untersuchung von Verfahren zur verlustlosen Datenkompression von digitalen Audiosignalen, Studienarbeit, TU Hamburg‐Harburg, 1995.
- [Bos97] M. Bosi, K. Brandenburg, S. Quackenbush, L. Fielder, K. Akagiri, H. Fuchs, M. Dietz, J. Herre, G. Davidson, Y. Oikawa: ISO/IEC MPEG‐2 Advanced Audio Coding, J. Aud. Eng. Soc., Vol. 45, No. 10, pp. 789–814, October 1997.
- [Bos02] M. Bosi, R.E. Goldberg: Introduction to Digital Audio Coding and Standards, Kluwer Academic Publishers, 2002.
- [Bra92] K. Brandenburg, J. Herre: Digital Audio Compression for Professional Applications, Proc. 92nd AES Convention, Preprint No. 3330, Vienna 1992.
- [Bra94] K. Brandenburg, G. Stoll: The ISO‐MPEG‐1 Audio: A Generic Standard for Coding of High Quality Digital Audio, J. Aud. Eng. Soc., Vol. 42, No. 10, pp. 780–792, October 1994.
- [Bra98] K. Brandenburg: Perceptual Coding of High Quality Digital Audio, in M. Kahrs, K. Brandenburg: Applications of Digital Signal Processing to Audio and Acoustics, Kluwer Academic Publishers, 1998.
- [Cel93] C. Cellier, P. Chenes, M. Rossi: Lossless Audio Data Compression for Real‐Time Applications, Proc. 95th AES Convention, Preprint No. 3780, New York 1993.
- [Cra96] P. Craven, M. Gerzon: Lossless coding for audio discs, J. Audio Eng. Soc., Vol. 44, No. 9, pp.706–720, 1996.
- [Cra97] P. Craven, M. Law, and J. Stuart: Lossless compression using IIR prediction, Proc. 102nd AES Convention, Preprint No. 4415, Munich, Germany, 1997.
- [Die02] M. Dietz, L. Liljeryd, K. Kjörling, O. Kunz: Spectral Band Replication: A Novel Approach in Audio Coding Proc. 112th AES Convention, Preprint No. 5553, Munich 2002.
- [Edl89] B. Edler: Codierung von Audiosignalen mit überlappender Transformation und adaptiven Fensterfunktionen, Frequenz, Vol. 43, pp. 252–256, 1989.
- [Edl00] B. Edler, H. Purnhagen: Parametric Audio Coding, 5th International Conference on Signal Processing (ICSP 2000), Beijing, August 2000.
- [Edl95] B. Edler: Äquivalenz von Transformation und Teilbandzerlegung in der Quellencodierung, Dissertation, Universität Hannover, 1995.
- [Eks02] P. Ekstrand: Bandwidth Extension of Audio Signals by Spectral Band Replication, Proc. 1st IEEE Benelux Workshop on Model‐based Processing and Coding of Audio (MPCA‐2002), Leuven, Belgium, 2002.
- [Ern00] M. Erne: Signal Adpative Audio Coding Using Wavelets and Rate Optimization, Dissertation, ETH Zrich, 2000.
- [Fis86] T.H. Fischer: A pyramid vector quantizer. IEEE Trans. on Information Theory, 32:56–583, 1986.
- [Geo92] E.B. George, M.J.T. Smith: Analysis‐by‐Synthesis/Overlap‐Add Sinusoidal Modeling applied to the Analysis and Synthesis of Musical Tones, Journal of the Audio Engineering Society, Vol. 40, No. 6, pp. 497–516, June 1992.
- [Geo97] E.B. George, M.J.T. Smith: Speech Analysis/Synthesis and Modification using an Analysis‐by‐Synthesis/Overlap‐Add Sinusoidal Model, IEEE Transactions on Speech and Audio Processing, Vol. 5, No. 5, pp.389–406, September 1997.
- [Glu93] R. Gluth: Beiträge zur Beschreibung und Realisierung digitaler, nichtrekursiver Filterbänke auf der Grundlage linearer diskreter Transformationen, Dissertation, Ruhr‐Universität Bochum, 1993.
- [Gui05] M. Guillemard, C. Ruwwe, U. Zölzer: J‐DAFx ‐ Digital Audio Effects in Java, Proc. 8th Int. Conference on Digital Audio Effects (DAFx‐05), Madrid, Spain, pp.161–166, 2005.
- [Hai03] S. Hainsworth, M. Macleod: On Sinusoidal Parameter Estimation, Proc. DAFX‐03 Conference on Digital Audio Effects, London, UK, September 2003.
- [Han98] M. Hans: Optimization of Digital Audio for Internet Transmission, PhD Thesis, Georgia Inst. Technol., Atlanta, 1998.
- [Han01] M. Hans, R.W. Schafer: Lossless Compression of Digital Audio, IEEE Signal Processing Magazine, Vol. 18, No. 4, pp. 21–32, July 2001.
- [Hel72] R.P. Hellman: Asymmetry in Masking Between Noise and Tone, Perception and Psychophys., Vol. 11, pp. 241–246, 1972.
- [Her96] J. Herre, J.D. Johnston: Enhancing the Performance of Perceptual Audio Coders by Using Temporal Noise Shaping (TNS), Proc. 101st AES Convention, Preprint No. 4384, Los Angeles, 1996.
- [Her98] J. Herre, D. Schultz: Extending the MPEG‐4 AAC Codec by Perceptual Noise Substitution, Proc. 104th AES Convention, Preprint No. 4720, Amsterdam, 1998.
- [Her99] J. Herre: Temporal Noise Shaping, Quantization and Coding Methods In Perceptual Audio Coding: A Tutorial Introduction, Proc. AES 17th International Conference on High Quality Audio Coding, Florence, September 1999.
- [Her02] J. Herre, B. Grill: Overview of MPEG‐4 Audio and its Applications in Mobile Communications, Proc. 112th AES Convention, Preprint No. 5553, Munich 2002.
- [Huf52] D.A. Huffman: A Method for the Construction of Minimum‐”‐Redundancy Codes, Proc. of the IRE, pp. 1098–1101, 1952.
- [ISO92]ISO/IEC 11172‐3: Coding of Moving Pictures and Associated Audio for Digital Storage Media at up to 1.5 Mbits/s ‐ Audio Part, International Standard, 1992.
- [Jay84] N.S. Jayant, P. Noll: Digital Coding of Waveforms, Prentice‐Hall, New Jersey, 1984.
- [Joh88a] J.D. Johnston: Transform Coding af Audio Signals Using Perceptual Noise Criteria, IEEE Journal on Selected Areas in Communications, Vol. 6, No. 2, pp. 314–323, February 1988.
- [Joh88b] J.D. Johnston: Estimation of Perceptual Entropy Using Noise Masking Criteria, Proc. ICASSP‐88, pp. 2524–2527, 1988.
- [Kap92] R. Kapust: A Human Ear Related Objective Measurement Technique Yields Audible Error and Error Margin, Proc. 11th Int. AES Conference ‐ Test&Measurement, Portland, pp. 191–202, 1992.
- [Kei01] F. Keiler, U. Zölzer: Extracting Sinusoids from Harmonic Signals, Journal of New Music Research, Special Issue: “Musical Applications of Digital Signal Processing”, Guest Editor: Mark Sandler, Vol. 30, No. 3, pp. 243–258, September 2001.
- [Kei02] F. Keiler, S. Marchand: Survey on Extraction of Sinusoids in Stationary Sounds, Proc. DAFX‐02 Conference on Digital Audio Effects, pp. 51–58, Hamburg, 2002.
- [Kon94] K. Konstantinides: Fast Subband Filtering in MPEG Audio Coding, IEEE Signal Processing Letters, Vol. 1, No. 2, pp. 26–28, February 1994.
- [Lag02] M. Lagrange, S. Marchand, J.‐B. Rault: Sinusoidal Parameter Extraction and Component Selection in a Non Stationary Model, Proc. DAFX‐02 Conference on Digital Audio Effects, pp. 59–64, Hamburg, 2002.
- [Lev98] S. Levine: Audio Representations for Data Compression and Compressed Domain Processing, PhD Thesis, Stanford University, 1998.
- [Lev99] S. Levine, J.O. Smith: Improvements to the Switched Parametric & Transform Audio Coder, Proc. 1999 IEEE Workshop on Applicatrions of Signal Proceassing to Audio and Acoustics, New Paltz, October 1999.
- [Lie02] T. Liebchen: Lossless Audio Coding Using Adaptive Multichannel Prediction, Proc. 113th AES Convention, Preprint No. 5680, Los Angeles, 2002.
- [Mar00a] S. Marchand: Sound Models for Computer Music, PhD Thesis, University of Bordeaux, October 2000.
- [Mar00b] S. Marchand: Compression of Sinusoidal Modeling Parameters, Proc. DAFX‐00 Conference on Digital Audio Effects, pp. 273–276, Verona, Italy, December 2000.
- [Mal92] H.S. Malvar: Signal Processing with Lapped Transforms, Artech House, Norwood, 1992.
- [McA86] R. McAulay, T. Quatieri: Speech Transformations Based in a Sinusoidal Representation, IEEE Trans. Acoustics, Speech, Signal Processing, Vol. 34, No. 4, pp. 744–754, 1989.
- [Mas85] J. Masson, Z. Picel: Flexible Design of Computationally Efficient Nearly Perfect QMF Filter Banks, Proc. ICASSP‐85, pp. 541–544, 1985.
- [Mei02] N. Meine, H. Purnhagen: Fast Sinusoid Synthesis For MPEG‐4 HILN Parametric Audio Decoding, Proc. DAFX‐02 Conference on Digital Audio Effects, pp. 239–244, Hamburg, September 2002.
- [Nig79] G. Nigel and N. Martin: Range encoding: An algorithm for removing redundancy from a digitized message. In Proc. Video and Data Recording Conference, Oct 1979.
- [Pen93] W.B. Pennebaker, J.L. Mitchell: JPEG Still Image Data Compression Standard, Van Nostrand Reinhold, New York, 1993.
- [Pri86] J.P. Princen, A.B. Bradley: Analysis/Synthesis Filter Bank Design Based on Time Domain Aliasing Cancellation, IEEE Trans. on Acoustics, Speech, and Signal Processing, Vol. 34, No. 5, pp. 1153–1161, October 1986.
- [Pri87] J.P. Princen, A.W. Johnston, A.B. Bradley: Subband/Transform Coding Using Filter Bank Designs Based on Time Domain Aliasing Cancellation, Proc. ICASSP‐87, pp. 2161–2164, 1987.
- [Pur97] M. Purat, T. Liebchen, and P. Noll: Lossless Transform Coding of Audio Signals, Proc. 102nd AES Convention, Preprint No. 4414, Munich, Germany, 1997.
- [Pur99] H. Purnhagen: Advances in Parametric Audio Coding, Proc. 1999 IEEE Workshop on Applicatrions of Signal Proceassing to Audio and Acoustics, New Paltz, October 1999.
- [Pur02a] H. Purnhagen, N. Meine, B. Edler: Sinusoidal Coding Using Loudness‐Based Component Selection, Proc. ICASSP‐2002, May 13‐17, Orlando, USA, 2002.
- [Pur02b] H. Purnhagen: Parameter Estimation and Tracking For Time‐Varying Sinusoids, Proc. 1st IEEE Benelux Workshop on Model Based Processing and Coding of Audio, Leuven, Belgium, November 2002.
- [Raa02] M. Raad, A. Mertins: From Lossy to Lossless Audio Coding Using SPIHT, Proc. DAFX‐02 Conference on Digital Audio Effects, pp. 245–250, Hamburg, 2002.
- [Rao90] K.R. Rao, P. Yip: Discrete Cosine Transform – Algorithms, Advantages, Applications, Academic Press, Inc., San Diego, 1990.
- [Rob94] T. Robinson: SHORTEN: Simple lossless and near‐lossless waveform compression, Technical Report CUED/F‐INFENG/TR.156, Cambridge University Engineering Department, Cambridge, UK, December 1994.
- [Rod97] X. Rodet: Musical Sound Signals Analysis/Synthesis: Sinusoidal+Residual and Elementary Waveform Models, Proceedings of the IEEE Time‐Frequency and Time‐Scale Workshop (TFTS‐97), University of Warwick, Coventry, UK, August 1997.
- [Rot83] J.H. Rothweiler: Polyphase Quadrature Filters ‐ A New Subband Coding Technique, Proc. ICASSP‐87, pp. 1280–1283, 1983.
- [Sauv90] U. Sauvagerd: Bitratenreduktion hochwertiger Musiksignale unter Verwendung von Wellendigitalfiltern, VDI‐Verlag, Düsseldorf 1990.
- [Say12] K. Sayood: Introduction to Data Compression. Morgan Kaufmann, 2012.
- [Schr79] M.R. Schroeder, B.S. Atal, J.L. Hall: Optimizing Digital Speech Coders by Exploiting Masking Properties of the Human Ear, J. Acoust. Soc. Am., Vol. 66, No. 6, pp. 1647–1652, December 1979.
- [Sch02] G.D.T. Schuller, Bin Yu, Dawei Huang, B. Edler: Perceptual Audio Coding Using Adaptive Pre‐ and Post‐Filters and Lossless Compression, IEEE Transactions on Speech and Audio Processing, Vol. 10, No. 6, pp. 379–390, Sept. 2002.
- [Schu96] D. Schulz: Improving Audio Codecs by Noise Substitution, J. Aud. Eng. Soc., Vol. 44, No. 7/8, pp. 593–598, July/August 1996.
- [Ser89] X. Serra: A System for Sound Analysis/Transformation/Synthesis based on a Deterministic plus Stochastic Decomposition, PhD Thesis, Stanford University, 1989.
- [Sin93] D. Sinha, A.H. Tewfik: Low bit rate Transparent Audio Compression Using Adapted Wavelets, IEEE Transactions on Signal Processing, Vol. 41, pp.3463–3479, 1993.
- [Smi90] J.O. Smith, X. Serra: Spectral Modeling Synthesis: A Sound Analysis/Synthesis System based on a Deterministic plus Stochastic Decomposition, Computer Music Journal, Vol. 14, No. 4, pp. 12–24, 1990.
- [Sqa88]EBU‐SQAM: Sound Quality Assessment Material, Recordings for Subjective Tests, CompactDisc, 1988.
- [Ter79] E. Terhardt: Calculating Virtual Pitch, Hearing Res., Vol. 1, pp. 155–182, 1979.
- [Thei88] G. Theile, G. Stoll, M. Link: Low Bit‐Rate Coding of High‐quality Audio Signals, EBU Review, No. 230, pp. 158–181, August 1988.
- [Vai93] P.P. Vaidyanathan: Multirate Systems and Filter Banks, Prentice‐Hall, Englewood Cliffs, 1993.
- [Val09] J.‐M. Valin, T.B. Terriberry, and G. Maxwell: A full‐bandwidth audio codec with low complexity and very low delay. In Proc. EUSIPCO 2009, pages 125–1258, 2009.
- [Val10] J.‐M. Valin, T. B. Terriberry, C. Montgomery, and G. Maxwell: A high‐quality speech and audio codec with less than 10 ms delay. IEEE Trans. Audio, Speech and Language Processing, 18(1):5–67, 2010.
- [Val12] J.‐M. Valin, K. Vos, and T. Terriberry: Definition of the Opus Audio Codec. RFC 6716, Sep 2012.
- [Val13] J.‐M. Valin, T. B. Terriberry, C. Montgomery, and K. Vos: Highquality, low‐delay coding in the opus codec. In Audio Engineering Society Convention 135, Oct 2013.
- [Var06] P. Vary, R. Martin: Digital Speech Transmission. Enhancement, Coding and Error Concealment, J. Wiley & Sons, Chichester, 2006.
- [Vet95] M. Vetterli, J. Kovacevic: Wavelets and Subband Coding, Prentice‐Hall, Englewood Cliffs, 1995.
- [Zie02] T. Ziegler, A. Ehret, P. Ekstrand, M. Lutzky: Enhancing mp3 with SBR: Features and Capabilities of the new mp3PRO Algorithm, Proc. 112th AES Convention, Preprint No. 5560, Munich 2002.
- [Zie03] T. Ziegler, M. Dietz, K. Kjörling, A. Ehret: aacPlus‐Full Bandwidth Audio Coding for Broadcast and Mobile Applications, International Signal Processing Conference, Dallas, 2003.
- [Zöl11] U. Zölzer (Ed.): DAFX ‐ Digital Audio Effects, 2nd edition, J. Wiley & Sons, Chichester, 2011.
- [Zwi82] E. Zwicker: Psychoakustik, Springer‐Verlag, Berlin, 1982.
- [Zwi90] E. Zwicker, H. Fastl: Psychoacoustics, Springer‐Verlag, Berlin, 1990.
Note
- 1
http://www.midi.org/