
Chapter 12
Building Enterprise Security Solutions for Hadoop Implementations
WHAT’S IN THIS CHAPTER?
- Understanding security concerns for enterprise applications
- Understanding what Hadoop security does not provide for enterprise applications
- Looking at approaches for building enterprise security solutions
Chapter 10 discussed Hadoop security and the mechanisms within Hadoop that are used to provide security controls. When building enterprise security solutions (which may encompass many applications and enterprise services that interact with Hadoop data sets), securing Hadoop itself is only one aspect of the security solution. Organizations struggle with applying consistent security mechanisms on data that is extracted from heterogeneous data sources with different security policies. When organizations take data from multiple sources, and then extract, transform, and load that data into Hadoop, the security challenges become even more complicated as the resulting data sets are imported into enterprise applications. For example, how do you enforce the access control policies from the initial data sets, when the data sets produced from Hadoop jobs represent a combination of multiple data sets?
To complicate matters, many organizations are finding that the level of security that Hadoop provides does not meet all of their security and compliance requirements, and they must complement Hadoop’s security model. For example, some organizations are required to encrypt data at rest in order to meet their compliance regulations — functionality that Hadoop does not natively provide. Still, other organizations require that Hadoop queries provide a level of granular, attribute-based access control for data scientists performing analytical queries. Although this is certainly on the road map and in Hadoop security’s future (as discussed in Chapter 10), such functionality currently requires more than what Hadoop itself can provide.
Because of these challenges, enterprise solutions must be developed with a holistic (and not an Hadoop-centric) security approach. Certainly, you can use native security mechanisms in Hadoop to satisfy some of your security requirements, but in many organizations, you will find that Hadoop’s security mechanisms will not solve all of them. Enterprise applications that make use of Hadoop must be planned for, designed, and complemented with other security mechanisms, looking at the enterprise “big picture.”
As discussed in Chapter 10, Hadoop was designed and developed without security in mind, and for quite a while there was little to no security for Hadoop implementations. An early assumption adopted by the community was that Hadoop clusters would consist of cooperating, trusted machines used by trusted users in a trusted environment. Since those early days, the Hadoop community adopted a new security architecture with new security controls (as discussed in Chapter 10), but many organizations with significant access control restrictions, confidentiality rules, privacy restrictions, and compliance mandates have still not been able to use the basic tools in the Hadoop ecosystem to meet their security requirements. Because they want to leverage Hadoop’s capabilities, they have had to build security into other tools, or design solutions using Hadoop in different ways.
This chapter is written for developers of enterprise applications who want to utilize Hadoop, but who also must “answer the mail” on security. It is important to understand that most enterprise applications are required to adhere to an organization’s security requirements. This may include integrating with identity and access management infrastructure, other network infrastructure, and it may also mean applying other security controls that are not integrated with Hadoop “out of the box.” This chapter provides a methodology and potential solutions for meeting such requirements.
This chapter begins with a brief overview of security concerns for developing enterprise applications that utilize Hadoop. It then discusses what Hadoop security does not provide out of the box, and provides a number of approaches for building enterprise security solutions with Hadoop, including real-world examples. Finally, this chapter briefly covers security provided by another tool that you can use with Hadoop distributions — Apache Accumulo, which is a highly secure data storage and retrieval system originally built on top of Hadoop by the National Security Agency (NSA) for the purpose of fine-grained access control.
SECURITY CONCERNS FOR ENTERPRISE APPLICATIONS
When building Hadoop solutions, it is not only important that you think about securing Hadoop itself (as discussed in Chapter 10), but it is also important that you understand the big picture from a security policy and a data-centric perspective.
As you can see in Figure 12-1, there is an Hadoop data life cycle that must be understood. When building Hadoop solutions, there is a process of retrieving data sets from information sources, loading them into an Hadoop cluster, running queries and analytics, and utilizing the result sets. As this data travels, it is the goal of the security architect to ensure that all policies are enforced throughout that life cycle.
FIGURE 12-1: Security concerns in the data life cycle of Hadoop

Regardless of the tools involved, data is extracted from a wide variety of data sources, transformed into a common format, and loaded into an Hadoop cluster onto HDFS, in what is typically referred to as an Extract, Transform, and Load (ETL) process. Data analysts then run a series of MapReduce jobs, and perform queries that produce result sets, which are, in turn, typically used by enterprise applications.
The challenge here is multifaceted. You must be able to protect the data as it transitions through this life cycle, adhering to the original security policies. As data is extracted, loaded, and combined with other data sets on a cluster of machines, and as result sets are used by other applications, this can be a challenge.
Figure 12-1 should provide a good overview of some of the concerns examined in this chapter. To build secure enterprise solutions that involve Hadoop, architects must have an understanding of information security fundamentals, and how they can be applied. Many security goals for solutions utilizing Hadoop require some explanation, and understanding best practices is dependent on understanding security concerns and the terminology associated with those terms. This discussion is not intended to be an exhaustive list or explanation of every security concern, but it provides a brief information security vocabulary for the security goals that enterprise architects need to know. For each goal the term is defined, and you learn why it is important in the Hadoop context.
Authentication
Authentication means validating the identity of a subject. A subject can be a user, an application, a task, or other “actor” in a system. As discussed in Chapter 10, Hadoop can be configured to use Kerberos to authenticate users, services, and servers in an Hadoop cluster. Authentication provides a certain amount of assurance that users and services are who they say they are, and thwarts the impersonation of users, tasks, and services by malicious systems.
It should also be mentioned that not every organization has an enterprise Kerberos deployment that is used for authentication outside of Hadoop. Enterprise applications may require the additional integration of other identity and access management infrastructure into their solutions.
Authorization
Authorization means determining what a subject has permission to do. After the subject’s identity is validated in authentication, systems must determine the subject’s authorization credentials, and must compare them with an expressed authorization policy to provide access to requested resources. As discussed in Chapter 10, Hadoop currently provides a certain level of access control by utilizing access control lists (ACLs) to express access control policy for certain aspects of Hadoop, and UNIX-like file permissions for owner and group user permissions.
In addition to what Hadoop provides, most enterprise organizations have additional controls for authorization. For example, an organization may have one or more of the following:
- Lightweight Directory Access Protocol (LDAP) directories or Active Directory (AD) instances that store groups, roles, and permissions for subjects
- Attribute Services that use attributes as authorization credentials for subjects
- Security Token Services (STS) that are used for issuing tokens related to a subject’s authorization credentials, and for issuing authorization decisions in transactions
- Policy Services that use standards such as the eXtensible Access Control Markup Language (XACML) and the Security Assertion Markup Language (SAML) to express access control policy for resources, and provide access control decisions for subjects
Enterprise solutions utilizing Hadoop may need to control access to data sets based on their organization’s enterprise access control policies, which typically means complementing Hadoop’s native authorization controls with other mechanisms.
Remember that it is important for authorization to be consistently addressed throughout the data life cycle. If your original data sources have access control policies on their data, it may be important for you to provide the same access control to the data scientists running queries on that data. It may be even more important for any result sets that are later imported into enterprise applications to also be properly controlled. This is indeed a challenge.
Confidentiality
Confidentiality is the security goal for restricting sensitive information so that only authorized parties can see it. When sensitive information is transmitted on the network, it may be a requirement that this information is not seen in transit by eavesdroppers. This is accomplished by network encryption. Some organizations require on-disk encryption, or “data at rest” encryption, where cryptography is used on the data where it is stored, reducing the risk of theft of unprotected data.
As you learned in Chapter 10, Hadoop provides the capability and the mechanisms for providing network encryption. However, it does not provide the capabilities for encrypting data at rest. You learn more about strategies for achieving this goal later in this chapter.
Integrity
Integrity means providing the assurance that data has not been altered in transit or at rest. This is typically achieved via cryptography through the use of message digests, hash codes, or as a side effect of a digital signature. When Hadoop is configured to implement network encryption, it applies data integrity in transit.
Integrity at rest is another matter, and luckily, much data integrity is built into Hadoop because of the duplication of data for reliability. An intended side effect of Hadoop’s robust, distributed architecture was data integrity and reliability. Because HDFS was designed to run on commodity hardware, it provides duplication of data onto multiple nodes to provide fault tolerance. Because of the amount of replication, and because of the mechanisms of checksum checking and corruption detection, it provides a robust mechanism for the integrity of data sets stored in HDFS.
However, security architects sometimes voice a concern that if a node in an Hadoop cluster is compromised, a malicious user could potentially modify the data, resulting in skewed data analysis. This is certainly a possibility, but by complementing Hadoop’s security mechanisms (server/service authentication, integrity checks, and so on) with a defense-in-depth strategy for security, enterprise solution architects can reduce such risks.
Auditing
Most companies rely on security auditing to provide assurance of compliance issues, and to identify potential security breaches. Hadoop can certainly be configured to log all access — the NameNode stores a local log, and an audit log can be configured to write to a secured volume to ensure log integrity. Organizations may have further audit requirements related to authentication and authorization.
WHAT HADOOP SECURITY DOESN’T NATIVELY PROVIDE FOR ENTERPRISE APPLICATIONS
With some context and security terminology now in place for the rest of this chapter, it is important that you understand some aspects of enterprise security that Hadoop doesn’t natively provide. Certainly, Hadoop does provide a level of authentication (Kerberos), a certain amount of authorization (ACLs and UNIX-level file permissions), and capabilities to support network encryption and integrity. However, there are some aspects of security that Hadoop simply does not provide.
Data-Oriented Access Control
Other than ACLs and POSIX-based file permissions (read and write) for users and groups on HDFS, Hadoop does not natively keep track of the access control policies for its data. As you have learned in this chapter, many organizations restrict access based on policies that may be quite complex. There could be situations in which an Hadoop implementation may contain data sets from data that must be protected from data analysts who may not have permission to see the results of MapReduce jobs and queries.
Following are a few good examples of this:
- A health care organization may have an access control requirement that a physician can only access data related to his own patients, during normal business hours (9 a.m. to 5 p.m.). This means that to provide access control to patient data, a system providing access to that data must restrict data based on the user’s role (physician), the time of day (normal business hours), and whether or not the data is a record belonging to the physician’s patient.
- A government document may restrict access based on a user’s citizenship and/or security clearance by requiring what is known as Mandatory Access Control (MAC).
- A financial advisor who advises a particular company should not have access to plans and advice for that company’s competitors. This is typically known as a “conflict of interest” or “Chinese wall” policy.
- A university may collect student data from all of its divisions and sub-organizations, ranging from finance, medical records, and campus police. The university may be required to control access to that data based on the division or role (medical, police, financial).
In each of these cases, Hadoop’s native security mechanisms cannot easily be used to enforce these access control policies. Some of these challenges are architectural, based on the way that the MapReduce algorithm was designed. Imported data may initially be associated with access control policies (in examples where data is “marked up” with the security policies). However, there is a split of this association between the policies and the data as the data is distributed over HDFS, and later combined with other data sets as jobs are run. This may result in new, combined data sets where access control policies are not completely clear.
This is a challenging problem for organizations needing to provide this level of access control, and one that will be examined later in this chapter.
Differential Privacy
For nearly 40 years, research has been conducted on the topic of unintentionally disclosing information from statistical databases, as well as security and privacy concerns related to data mining. In 2006, Dr. Cynthia Dwork of Microsoft Research defined this area of data science as differential privacy.
Differential privacy focuses on the protection against disclosure of information from multiple data sets and databases. As Hadoop and other data analytics platforms have brought together the capability to process multiple, large data sets with a large amount of computing power, differential privacy has become a very hot topic with serious privacy and legal implications. This has been especially true with regulations like the Health Insurance Portability and Accountability Act (HIPAA) and other privacy-preserving digital laws.
Even if it is “anonymized” with privacy information stripped out, an Hadoop data set may contain (or may be coupled with) other seemingly harmless information that may be used to disclose the identity of an individual or other sensitive information, resulting in a violation of privacy policies. It may be possible to combine information derived from multiple Hadoop jobs in such a way that the data scientist or the Hadoop user is not allowed to see the exposed information. However, Hadoop itself does not provide differential privacy. Certainly, this has access control implications for internal users, but also has serious implications for organizations sharing statistics and data sets with other organizations.
Because Hadoop is a powerful analytic platform used by many organizations, it can be used to discover information that you may not want discovered. An organization should think twice before releasing its data sets into the public or to its business partners. There may also be internal controls on your data — depending on your environment, be aware that some of your Hadoop users may not be authorized to see certain results of their analytical queries. This was one of the concerns of the NSA, which developed and later released Accumulo to Apache as open source, providing cell-level security.
Encrypted Data at Rest
Because of the many threats to the confidentiality of information stored on disks and end-user devices, many organizations with sensitive information have policies that require the encryption of data at rest. Many of the reasons for such a policy relate to the threat of malware, the sensitivity or confidentiality of the data, or legal regulations. HIPAA, for example, has guidance related to encrypting data at rest related to Electronic Protected Health Information (EPHI), and other laws protecting Personally Identifiable Information (PII) come into play.
Some organizations are pushing for encrypting data at rest on HDFS, which Hadoop does not natively provide. However, third-party libraries and other products can be used along with Hadoop to satisfy these requirements, and Project Rhino (as discussed in Chapter 10) is working to address this issue in Hadoop.
Enterprise Security Integration
Most businesses have all sorts of security infrastructure in their enterprises, ranging from Public Key Infrastructure (PKI) components for authentication, Active Directory instances, Security Token Services, Attribute Services, and Policy Servers used for authenticating users, providing authorization credentials, and making and enforcing access control decisions. Hadoop’s native security capabilities will not always allow you to “fit it” into or integrate with the security infrastructure of every organization. When security requirements dictate that enterprise applications integrate with an organization’s security infrastructure, it is therefore the security architect’s job to design a solution that uses other tools to integrate with that security infrastructure while utilizing Hadoop.
APPROACHES FOR SECURING ENTERPRISE APPLICATIONS USING HADOOP
Recently, a significant number of projects, Hadoop add-ons, and proprietary Hadoop distributions have promised to enhance the security of Hadoop. Hortonworks’ Knox Gateway, Intel’s security-enhanced distribution of Hadoop, and open source projects such as Project Rhino have been released and hold much promise for helping the enterprise application developer satisfy security requirements. Regardless, it is important to remember that every enterprise application is different, and requirements for security in every deployment will be different.
Before getting into the nuts and bolts, it is important that you understand some general basics and guidelines for providing secure enterprise applications that make use of Hadoop. A lot of projects run off the rails when they jump into focusing on specific security mechanisms and don’t follow some of these common-sense guidelines that apply to any project.
Each project’s enterprise security strategy may be different, based on the customer’s mission and requirements, but will follow these common-sense rules:
- Determine your security requirements — Understanding your security requirements is crucial. Requirements for authentication, access control, auditing, encryption, integrity, and privacy will be dictated by your organization. Some of the questions that you might have to ask may revolve around the security of the resulting data sets from Hadoop MapReduce jobs, versus the security of the Hadoop run time itself (providing access control to the applications/users doing the queries and running the jobs). Meet with the proper decision makers to understand what is needed, so that you can plan accordingly.
- Design for security from the beginning — One of the biggest problems with these types of projects is trying to retrofit security at the end — such practices lead to a short-lived and brittle architecture, and they typically leave a project doomed for failure. If your project has the security requirements discussed in this chapter, and you think you will focus only on data analytics and try to worry about securing the solution later, then you run a great risk of failure. Focus on developing an initial high-level security architecture that can be discussed with the proper authorities for concept approval.
- Don’t secure what you don’t need to — If you don’t have the security requirements to achieve some of the goals discussed in this chapter, then don’t! Don’t add the complexity or the performance overhead by implementing what you don’t need.
- Use a “defense-in-depth” approach — It should never be assumed that an individual security approach or mechanism that you employ will thwart or prevent an attack or a violation of security policy. A defense-in-depth strategy involves multiple layers of defense.
- Keep the big picture in mind — Understand your data’s life cycle, such as the one shown earlier in Figure 12-1. Understand that providing security may mean controlling access, as well as preserving and enforcing policies throughout this life cycle — from the data in the original data sources, to data loaded onto an Hadoop cluster, to the result set data.
The following sections delve into concrete approaches for meeting some of the security requirements, and complementing the security that Hadoop natively provides. The discussion focuses on three main approaches, which provide the building blocks of enterprise security when coupled with Hadoop’s native mechanisms. In these next sections, the discussion focuses on Apache Accumulo.
Access Control Protection with Accumulo
Apache Accumulo is a sparse, distributed, sorted, and multidimensional key/value store that has the property of fine-grained access control at the cell level. Developed by the NSA in 2008 and based on Google’s design of BigTable, it was released into the Apache open source community in 2011, and now it is a top-level Apache project. It is a highly scalable NoSQL database that is built on top of Hadoop and Zookeeper. Part of the reason that it was developed was to solve Big Data security problems.
Accumulo extended BigTable’s data model, but added an element that provided cell-level, mandatory Attribute-Based Access Control (ABAC). All data that is imported into Accumulo can be marked with visibility controls, and as data analysts query the data, they will see only what they are supposed to see, based on the visibility controls in the access control policy. Accumulo’s API provides the capability for you to write clients to authenticate users and integrate with enterprise attribute services to pull down authorization credentials of users to provide a level of access control. It also provides the capability for user and authorization information to be stored in Accumulo itself.
As you can see in Figure 12-2, Accumulo is a key/value store whose key is a 5-tuple. A key in Accumulo is a combination of a Row ID, Column Family, Column Qualifier, Column Visibility, and a Timestamp. This 5-element key is associated with a Value.
FIGURE 12-2: Accumulo data model

This 5-tuple key provides atomicity, locality, uniqueness, access control, and versioning. It is important to note that the Timestamp aspect of the key contains the capability to provide multiple versions of the same data, based on different times and days. For the most part, Accumulo’s data model borrowed much of the data model of BigTable, but added the Visibility element to provide data-oriented security — it will return only cells whose visibility labels are satisfied by the credentials of the user/application running a query.
Most developers who are more familiar with relational databases are typically used to seeing tables that look like Table 12-1, which is a two-dimensional model.
TABLE 12-1: Example Data in Relational Data Model

In Accumulo’s structure, the same data would look similar to Table 12-2, where data is stored with a fine degree of granularity, including visibility and a timestamp that enables you to track data that changes over time.
TABLE 12-2: Data in Accumulo Data Model

Note that in Table 12-2, visibility is marked up with security labels. These labels can be added to a record, using AND/OR boolean logic. For example, you can come up with authorization policies similar to Table 12-3, where authorization credentials can be created and associated with users, restricting access to each cell in the table.
TABLE 12-3: Example Security Policies and Their Security Label Syntax
| EXAMPLE POLICY FOR ACCESS TO A RECORD | SECURITY LABEL SYNTAX |
| Must be a Republican and a U.S. Citizen | Republican & USCitizen |
| Must either be a Police Officer, or must be both a U.S. Citizen and in the Armed Forces | Police Officer | (USCitizen & ArmedForces) |
| Must be a Project Manager and must be either in the FGM or White Oak organizations | ProjectManager & (FGM | White Oak) |
| Over 17 years old or parental consent | Over17 | parentalConsent |
In the security model for Accumulo, users authenticate to trusted clients (which you, as a developer, can write), and the clients have the responsibility of authenticating the users and passing the proper authorization credentials to Accumulo. You have the option of integrating with your own authentication and authorization system, or you can use Accumulo’s internal authentication/authorization component, where users and their authorization credentials can be stored. This section provides an example of each.
A Simple Example
Let’s consider a university database example, where a university collects data from various departments and sub-organizations about their students. In this example, you have data coming from campus medical centers, the finance center, university administration, the sports facility, and the campus police. A wide variety of information is collected, and can be queried by the entire organization. You have a requirement to protect certain information, such as the following:
- Student medical test records should be seen only by medical personnel or the university administration.
- Students in college athletics have records related to sports records that should be visible only to their coaches, and sometimes also medical personnel.
- Payment records, grades, and sensitive information such as Social Security numbers should be visible only to university administration.
- Campus police records for students should be visible only to campus police or university administration.
For this example, let’s load some sample data into an Accumulo database, as shown in Table 12-4. In this simple example, you have a student named Kirk Rest, who has a variety of information collected from a number of data sources in the university.
TABLE 12-4: Key/Values for University Data Example


Let’s say that this information is loaded into an Accumulo store that you have set up on a test Hadoop instance. To do this, you would use the Accumulo shell, which is a simple client that can be used to create and modify tables, as well as create users and assign authorization credentials to those users. Because this chapter is focused on security and not the finer details of Accumulo, this discussion won’t address the details of loading the data.
Accumulo is optimized to quickly retrieve values for keys. To do this, an Accumulo client that you develop (or, in this case, the client is the Accumulo shell) creates a scanner that iterates over values. As you can see in Listing 12-1, the scan command enables you to iterate over the values in the new table you created — universitydata (as root, who was assigned blanket access to everything in the table).
LISTING 12-1: Viewing the data
root@accumulo universitydata> scan
Kirk Rest Address:111 Carson Ave, Richmond VA [ADMIN]
Kirk Rest Grade:Calculus 1 [ADMIN] B
Kirk Rest Grade:Organic Chem [ADMIN] A
Kirk Rest Grade:Radical Presbyterianism [ADMIN] D
Kirk Rest Medical Test Report:Cholesterol [MEDICAL] 200
Kirk Rest Nedical Test Report:Biopsy [MEDICAL] Negative
Kirk Rest Payment:Semester Payment [ADMIN] 1000
Kirk Rest Phone:8045550005 [ADMIN]
Kirk Rest Police Charge:Curfew Violation [ADMIN|POLICE] Pending Hearing
Kirk Rest Police Charge:DUI Arrest [ADMIN|POLICE] Guilty
Kirk Rest Running Test:10K [COACH] 56
Kirk Rest Running Test:5K [COACH] 27
Kirk Rest SSN:99999999 [ADMIN]
Kirk Rest Weight:170 [MEDICAL|COACH]To demonstrate an example of cell visibility, you create the following users:
- A doctor (drhouse), to whom you assign the MEDICAL role
- An administrator (denyseAccountant), to whom you assign the ADMIN role
- A coach (coachTark), to whom you assign the COACH role
- A police chief (chiefDoug), to whom you assign the POLICE role
As shown in Listing 12-2, you use the shell to assign permissions for all of these users to be able to read the table (granting them each the Table.READ privilege), and assign them each the appropriate roles for visibility using the setauths command.
LISTING 12-2: Assigning permissions and user views
root@accumulo universitydata> grant Table.READ -t universitydata -u drhouse
root@accumulo universitydata> setauths -s MEDICAL -user drhouse
root@accumulo universitydata> grant Table.READ -t universitydata -u
denyseAccountant
root@accumulo universitydata> setauths -s ADMIN -user denyseAccountant
root@accumulo universitydata> grant Table.READ -t universitydata -u coachTark
root@accumulo universitydata> setauths -s COACH -user coachTark
root@accumulo universitydata> grant Table.READ -t universitydata -u chiefDoug
root@accumulo universitydata> setauths -s POLICE -user chiefDougFinally, to show that Accumulo will now protect access to the table, you log in as each user using the Accumulo shell. You scan (or iterate) over the universitydata table. Listing 12-3 shows how you might have logged in as the users coachTark, drHouse, denyseAccountant, and chiefDoug, iterated over the table, and the table provided access control based on the privileges of each user.
LISTING 12-3: Demonstrating roles and visibility for users
root@accumulo universitydata> user coachTark
Enter password for user coachTark: *********
coachTark@accumulo universitydata> scan
Kirk Rest Running Test:10K [COACH] 56
Kirk Rest Running Test:5K [COACH] 27
Kirk Rest Weight:170 [MEDICAL|COACH]
root@accumulo universitydata> user drhouse
Enter password for user drhouse: *******
drhouse@accumulo universitydata> scan
Kirk Rest Medical Test Report:Cholesterol [MEDICAL] 200
Kirk Rest Nedical Test Report:Biopsy [MEDICAL] Negative
Kirk Rest Weight:170 [MEDICAL|COACH]
drhouse@accumulo universitydata> user denyseAccountant
Enter password for user denyseAccountant: ******
denyseAccountant@accumulo universitydata> scan
Kirk Rest Address:111 Carson [ADMIN]
Kirk Rest Grade:Calculus 1 [ADMIN] B
Kirk Rest Grade:Organic Chem [ADMIN] A
Kirk Rest Grade:Radical Presbyterianism [ADMIN] D
Kirk Rest Payment:Semester Payment [ADMIN] 1000
Kirk Rest Phone:8045550005 [ADMIN]
Kirk Rest Police Charge:Curfew Violation [ADMIN|POLICE] Pending Hearing
Kirk Rest Police Charge:DUI Arrest [ADMIN|POLICE] Guilty
Kirk Rest SSN:999999999 [ADMIN]
denyseAccountant@accumulo universitydata> user chiefDoug
Enter password for user chiefDoug: *********
chiefDoug@accumulo universitydata> scan
Kirk Rest Police Charge:Curfew Violation [ADMIN|POLICE] Pending Hearing
Kirk Rest Police Charge:DUI Arrest [ADMIN|POLICE] GuiltyAs you can see from Listing 12-3, Accumulo is able to restrict access based on the authorization controls of each user, which has been demonstrated by using the Accumulo shell. Now, let’s build an Accumulo client in Java that will demonstrate the same level of access control for this example, integrating with identity and access management infrastructure in the enterprise.
As it pertains to integrating with enterprise infrastructure, Accumulo has a flexible model. As previously mentioned, it is the Accumulo client’s responsibility to authenticate the user and retrieve the authorization credentials of the users, presenting this to Accumulo for processing. As long as the visibility of the data in tables in Accumulo is marked with the same attributes or roles in your enterprise attribute store, it will work nicely. If not, you will most likely need to do some processing of the attributes you pull from your attribute store in your client to ensure that they are exactly the same characters.
To demonstrate this, let’s go through a simple example of how you would be able to write a very simple client that authenticates the user through the authentication mechanism of your choice, and pulls authorization credentials from the Attribute Service or LDAP directory of your choice.
Listing 12-4 shows an example of writing a Java class that connects to Accumulo. In order to connect, you must establish an Accumulo connection using the Connector class. To do that, you must first connect to the Zookeeper instance keeping track of Accumulo by instantiating a ZookeeperInstance class, which will return a connector.
LISTING 12-4: Example Accumulo client code
import java.util.Collection;
import java.util.Collections;
import java.util.Map.Entry;
import org.apache.accumulo.core.client.Connector;
import org.apache.accumulo.core.client.ZooKeeperInstance;
import org.apache.accumulo.core.client.Scanner;
import org.apache.accumulo.core.data.Key;
import org.apache.accumulo.core.data.Range;
import org.apache.accumulo.core.data.Value;
import org.apache.accumulo.core.security.Authorizations;
public class QueryExample
{
public static void main(String[] args) throws Exception
{
//Simple Example of the name of your accumulo instance & zookeeper
ZooKeeperInstance inst = new ZooKeeperInstance("accumulo", "localhost");
//Obviously this is just an example
Connector connector = inst.getConnector("root", "secret");
//Scan in the username and password for this simple example
java.util.Scanner in = new java.util.Scanner(System.in);
System.out.println("Username:");
String username = in.nextLine();
System.out.println("Password:");
String password = in.nextLine();
Authorizations auths = null;
try
{
//An example of how you can interact with other systems (LDAP,etc)
CustomAuthenticator authenticator = new CustomAuthenticator();
authenticator.authenticate(username,password);
//Retrieve credentials from external system
auths = authenticator.getAuthorizationInfo(username);
}
catch (Exception authenticationException)
{
System.out.println("Authentication Failure.");
System.exit(-1);
}
// Search our university data example & print out everything
Scanner scanner = connector.createScanner("universitydata", auths);
for (Entry<Key,Value> entry : scanner) {
System.out.println( entry.getKey().toString());
}
}
}Once you establish a connection, you want to authenticate the user. In this case, for such a simple example, you grab it from the command line, and pass it to an external class called CustomAuthenticator, written simply to show that you can use another authentication mechanism and authorization mechanism outside of Accumulo. In that class, you pass the username and password you scanned in from the command line in that class’s authenticate() method. If the user was successful in authenticating, you then pull the user’s authorization credentials from an external store, returning the value in Accumulo’s expected org.apache.accumulo.core.security.Authorizations class. Finally, you create a scanner to iterate over the values in the same table as shown in the earlier example, and simply print the results.
Listing 12-5 shows the results on the command line. In this example, you set up an external LDAP directory with a user called joeUser in the ADMIN role.
LISTING 12-5: Results of Accumulo client
Script started on Fri 03 May 2013 12:45:09 AM EDT
$ java QueryExample
13/05/03 00:45:16 INFO zookeeper.ZooKeeper:
Client environment:zookeeper.version=3.4.3--1,
built on 03/20/2012 16:15 GMT
13/05/03 00:45:16 INFO zookeeper.ZooKeeper: Client environment:host.name=ubuntu
13/05/03 00:45:16 INFO zookeeper.ZooKeeper:
Client environment:java.version=1.6.0_27
13/05/03 00:45:16 INFO zookeeper.ZooKeeper:
Client environment:java.vendor=Sun Microsystems Inc.
13/05/03 00:45:16 INFO zookeeper.ZooKeeper:
Client environment:java.home=/usr/lib/jvm/java-6-openjdk-amd64/jre
13/05/03 00:45:16 INFO zookeeper.ZooKeeper: Client environment:java.class.path=.
13/05/03 00:45:16 INFO zookeeper.ZooKeeper:
Client environment:java.library.path=/usr/lib/jvm/java-6-openjdk-
amd64/jre/lib/amd64/server:/usr/lib/jvm/java-6-openjdk-
amd64/jre/lib/amd64:/usr/lib/jvm/java-6-openjdk-
amd64/jre/../lib/amd64:/usr/java/packages/lib/amd64:/usr/lib/x86_64-linux-
gnu/jni:/lib/x86_64-linux-gnu:/usr/lib/x86_64-linux-
gnu:/usr/lib/jni:/lib:/usr/lib
13/05/03 00:45:16 INFO zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp
13/05/03 00:45:16 INFO zookeeper.ZooKeeper: Client environment:java.compiler=<NA>
13/05/03 00:45:16 INFO zookeeper.ZooKeeper: Client environment:os.name=Linux
13/05/03 00:45:16 INFO zookeeper.ZooKeeper: Client environment:os.arch=amd64
13/05/03 00:45:16 INFO zookeeper.ZooKeeper:
Client environment:os.version=3.2.0-29-generic
13/05/03 00:45:16 INFO zookeeper.ZooKeeper: Client environment:user.name=accumulo
13/05/03 00:45:16 INFO zookeeper.ZooKeeper:
Client environment:user.home=/usr/lib/accumulo
13/05/03 00:45:16 INFO zookeeper.ZooKeeper:
Client environment:user.dir=/usr/lib/accumulo/classes
13/05/03 00:45:16 INFO zookeeper.ZooKeeper: Initiating client connection,
connectString=localhost sessionTimeout=30000
watcher=org.apache.accumulo.core.zookeeper
.ZooSession$AccumuloWatcher@6791d8c1
13/05/03 00:45:16 INFO zookeeper.ClientCnxn:
Opening socket connection to server /127.0.0.1:2181
13/05/03 00:45:16 INFO client.ZooKeeperSaslClient:
Client will not SASL-authenticate because the default JAAS
configuration section 'Client' could not be found. If you are not
using SASL, you may ignore this. On the other hand,
if you expected SASL to work, please fix your JAAS configuration.
13/05/03 00:45:16 INFO zookeeper.ClientCnxn:
Socket connection established to localhost/127.0.0.1:2181,
initiating session
13/05/03 00:45:16 INFO zookeeper.ClientCnxn:
Session establishment complete on server localhost/127.0.0.1:2181,
sessionid = 0x13e6757677611f1, negotiated timeout = 30000
Username:
joeAdmin
Password:
******
Kirk Rest Address:111 Carson [ADMIN] 20050612 false
Kirk Rest Grade:Calculus 1 [ADMIN] 20111201 false
Kirk Rest Grade:Organic Chem [ADMIN] 20111201 false
Kirk Rest Grade:Radical Presbyterianism [ADMIN] 20100612 false
Kirk Rest Payment:Semester Payment [ADMIN] 20111223 false
Kirk Rest Phone:804 [ADMIN] 20050612 false
Kirk Rest Police Charge:Curfew Violation [ADMIN|POLICE] 20071103 false
Kirk Rest Police Charge:DUI Arrest [ADMIN|POLICE] 20091104 false
Kirk Rest SSN:99 [ADMIN] 20050612 falseThe user that authenticated in this example, joeAdmin, was not stored in Accumulo like the users in earlier examples. As shown here, you could write a Java client to authenticate a user, pull authorization credentials from an enterprise store, and query Accumulo.
There is much more to Apache Accumulo — much more than has been covered in this section of this chapter. However, it is important to realize that for organizations that use Accumulo for data security, Accumulo is only one aspect of an enterprise security solution. Enterprise security requires defense-in-depth, and must cover the security of the entire data life cycle — not just when the data is stored in Hadoop.
Encryption at Rest
Encrypted data at rest in Hadoop is a topic that is being worked on in many different projects — some open source, and some commercial. Hadoop does not natively provide such functionality. Currently, a number of companies are protecting sensitive data in different distributions of Hadoop not only to protect the sensitive information, but also to comply with laws such as HIPAA and other security regulations. Many organizations want to use encryption at rest to protect against malicious users who might attempt to obtain unauthorized access to DataNodes.
Some of the solutions currently provided include Gazzang zNcrypt, which provides data security for Cloudera CDH distributions. Intel’s distribution of Hadoop, released in early 2013, has been optimized to do encryption at rest when using their company’s Xeon processors. There seem to be new solutions coming out every day — but so far, all of them are currently proprietary, or promise to tie you to a particular distribution of Hadoop. As mentioned in Chapter 10, Project Rhino (contributed by Intel to Apache) contains enhancements that include distributed key management and the capability to do encryption at rest. The Hadoop developer community is currently reviewing this for the inclusion in a future Hadoop distribution.
Regardless of the mechanisms that you can use to achieve encryption at rest for Hadoop, it is very important to also understand the unintentional effects of such functionality. If you need a solution for encryption at rest, keep in mind the impact that encryption will have on your performance. If you think your MapReduce jobs might be slower than desired now, imagine what encryption at rest will do to your performance. Intel’s distribution of Hadoop is optimized to do encryption and decryption for use on machines with specific Intel processors that are optimized to do the encryption and decryption. Just as Intel’s distribution was developed with its hardware accelerators in mind, it is also important for enterprise architects to weigh the cost of encryption at rest for their applications — if you indeed need such functionality, plan accordingly for performance.
For now, unless you are in dire need of encryption at rest, at this point you may want to avoid it for a few reasons. First of all, this is a functionality area that is very complex because of the distributed data and key management challenges. Secondly, enhancements in this area from Project Rhino may be forthcoming, and until then, there is the potential for you to be locked into a particular distribution or vendor. Finally, as mentioned, there are performance ramifications related to encryption at rest. If your data is so sensitive that you are exploring the possibility of encryption at rest, the next section may be a potential solution.
Network Isolation and Separation Approaches
As mentioned previously, organizations with confidential and sensitive data have traditionally used network isolation of their Hadoop clusters as an approach for meeting their security requirements. These organizations often control access to the individual clusters based on the authorization levels of the user, often using physical security as one protection mechanism. Others utilize a less-restrictive approach, separating the network, but allowing some transmissions from trusted servers and workstations to travel between the two networks.
Such approaches are still very viable options for a number of reasons:
- Complexity of security integration — If your security policies are so strict and your data is so sensitive that you will have to integrate an immense amount of non-native security controls into your Hadoop cluster, consider using network isolation, separating it from your other networks, and restricting access to only authorized users. If you do that, you will only have to worry about the releasability of resulting Hadoop data sets — and not your runtime Hadoop security. This will minimize your overall risk, and will most likely reduce costs.
- Performance — It is often said that “security is the enemy of performance.” The more security mechanisms you throw at a solution, the slower it will often become. This is true with securing Hadoop, especially if you are considering using third-party tools to encrypt and decrypt data on HDFS at rest. Many people will choose a network isolation approach to simply avoid the performance penalty.
- Data levels of differing sensitivity — Some data in your organization may only be releasable to certain groups of people. If this is the case, the result sets of Hadoop jobs will be sensitive as well. Although some tools used with Hadoop (such as HBase and Accumulo) can provide a way of filtering access at the column level (HBase) and cell level (Accumulo), other tools used with Hadoop will not provide that level of security. If you are running Java MapReduce applications for building result sets, and are using a variety of different tools, it may be smart to consider separating clusters based on who can see them.
- The evolving Hadoop security landscape — A number of new products, releases, and distributions for Hadoop are providing new security features. As mentioned in Chapter 10, security enhancements for Hadoop may be forthcoming within the next year. These upcoming changes will affect enterprise applications using Hadoop, and so many organizations are choosing the network isolation model until they understand the ramifications of such changes.
- Data security review before integration — Because a network isolation approach does not provide real-time access to the data by enterprise applications on other networks, it would allow review and filtering of the material before it is used by enterprise applications, minimizing potential confidentiality and privacy breaches. (This is certainly a “double-edged sword” in that network isolation is typically a barrier to real-time Hadoop, and requires a process for releasing data sets for use by enterprise applications.)
Network isolation can be used in a number of ways in the security of enterprise applications. Figure 12-3 shows one way to achieve this. An organization creates a “data analytics” network, separate from the organization’s enterprise network with a physical “air gap” that prevents any data from being transferred between the two networks. Data scientists with the appropriate access controls perform queries and MapReduce operations on the Hadoop cluster(s) in the data analytics network, and access to this network is controlled by physical security and/or authentication to the client machines used to perform queries.
FIGURE 12-3: “Air gap” network isolation with import/export workflow

To support enterprise applications that utilize the results of these data sets, there is a significant workflow process that must be developed and utilized:
For many organizations, this is a cumbersome process because it involves a physical separation between the two networks, and it requires a workflow of exporting data from the original network, importing it into the data analytics network, and analyzing, filtering, and preparing the result set data for loading into an enterprise application. However, when the data is extremely sensitive, many organizations are taking this approach.
Because of the complexity involved, some organizations are moving to a similar model, but one that restricts traffic from trusted hosts in the enterprise network to the data analytics network, as shown in Figure 12-4. In this situation, the ETL process can be done over the network, removing the first step in the process described earlier.
FIGURE 12-4: Network isolation with one-way transmissions
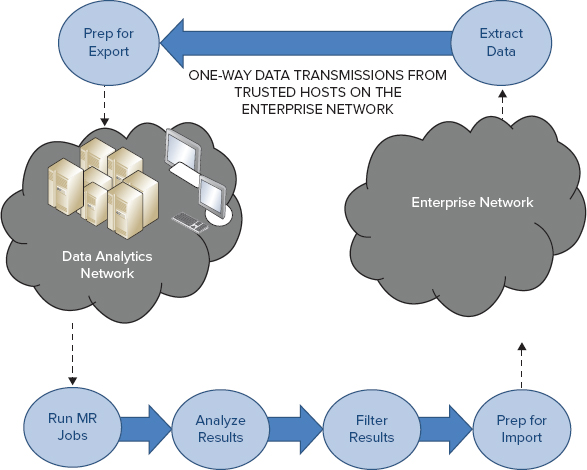
Some organizations that primarily utilize Apache Accumulo for controlling access to data perform the data-filtering results for the result sets that can be released to the enterprise network — for example, creating the “Enterprise Network User, who has credentials equal to the lowest authorization level of the network. Filtering data to be released based on such a user often makes the result set easier to post internally without fear of the unintentional release of information.
Network isolation can be used in countless other ways — these are just a few of them. Others involve isolating Hadoop clusters based on the type of data that they use, and some less-restrictive approaches involve allowing connections to and from machines in the enterprise network, utilizing ACLs to restrict access to only trusted hosts.
Each part of your solution for enterprise security will depend on your organization’s security requirements — two organizations are seldom the same. Regardless, the examples and the guidance provided in this chapter should help you as you build your enterprise security solution.
SUMMARY
This chapter provided you with an enterprise view of security, focusing on the data life cycle from a security-policy and a data-centric perspective. It is important that security architects understand this big picture, while being able to address different aspects of enterprise security that Hadoop and complementary security tools provide.
This chapter began with a brief overview of security concerns for developing enterprise applications that utilize Hadoop. You learned about some security challenges that Hadoop itself does not address — including data-oriented security, differential privacy, and encryption at rest. You saw a number of approaches for building enterprise security solutions with Hadoop, and worked through some guidance and examples. You learned how to use Apache Accumulo for cell-level security, and gained some insight into encryption at rest and some of the offerings that are currently available. You also learned about some approaches related to network isolation used by many organizations that are concerned with exposing sensitive data.
Security is certainly an evolving topic for Hadoop, and an area where Hadoop will be growing in the next few years. Chapter 13 focuses on some other enhancements that are forthcoming for Hadoop, and discusses trends that are emerging today, and will continue to grow in the future.