
13. Rule Review and Prioritization
In addition to being a handy aggregation of the rules for future reference, this chapter introduces a method by which these rules may be analyzed for application in your architecture. If you are building something from scratch, we highly recommend the inclusion of as many of the 50 rules as makes sense in your product. If you are attempting to redesign your existing system in an evolutionary fashion for greater scale, the method of risk-benefit analysis represented herein may help you prioritize the application of these rules in your reengineering efforts.
A Risk–Benefit Model for Evaluating Scalability Projects and Initiatives
Before we begin describing a risk-benefit model, let’s first review why we are interested in scalability. The desire to have a highly available and usable (to some specified or implied quality of service metric) product or service, even under conditions of moderate to extreme growth, is why we invest in making our product scalable. If we weren’t interested in what would happen to our product’s availability or quality of service as demand increased on our site, we wouldn’t be interested in attempting to scale it. This is the approach we think that most state governments take in implementing their Department of Motor Vehicles services. The government simply doesn’t appear to care that people will line up and wait for hours during periods of peak demand. Nor do they care that the individuals providing service couldn’t care less about the customer. The government knows it offers a service that customers must use if they want to drive and any customers who are dissatisfied and leave will simply come back another day. But most of the products that we build won’t have this state sanctioned and protected monopoly. As a result, we must be concerned about our availability and hence our scalability.
It is within this context of concern over availability and scalability that we represent our concept of risk. The risk of an incident caused by the inability to scale manifests itself as a threat to our quality of service or availability. One method of calculating risk is to look at the probability that a problem will happen multiplied by its impact should it happen (or move from risk to issue). Figure 13.1 shows this method of risk decomposition.
Figure 13.1. Scalability and availability risk composition

The impact might be further broken down into components of the percentage impact to your user base and the actual impact such as downtime (the amount of time your service is unavailable), data loss, and response time degradation. Percentage impact might be further broken down into the percentage of the customers impacted and the percentage of the functionality impacted. There is certainly further decomposition possible; for instance, some customers may represent significantly greater value on either a license or transaction fee basis. Furthermore, downtime may have a different multiplier applied to it than response time; data loss may trump both of these.
This model isn’t meant to hold true for all businesses. Rather it is meant to demonstrate a way in which you can build a model to help determine which things you should focus on in your business. One quick note before we proceed with how to use the model: We highly recommend that businesses calculate actual impact to revenue when determining the system’s actual availability rather than attempting to model it as we’ve done here. For instance, if you can show or believe that you lost 10% of your expected revenue in a given day you should say your availability was 90%. Wall clock time is a terrible measure of availability as it treats every hour of every day equivalently, and most businesses don’t have an equal distribution of traffic or revenue producing transactions. Now back to our regularly scheduled show.
The terminal nodes (nodes without children) of the decomposition graph of Figure 13.1 are leaves within our risk tree: Probability of a Problem, % Customers Impacted, % Functionality Impacted, Downtime, % Data Loss, and Response time Impact. Looking at these leaves, we can see that many of our rules map to these leaves. For instance, Rule 1 is really about decreasing the probability of a problem happening by ensuring that the system is easily understood and therefore less likely to be problematic. It may also decrease downtime as the solution is likely to be easier to troubleshoot and resolve. Using a bit of subjective analysis, we may decide that this rule has a small (or low) benefit to impact and a medium change to the probability of a problem happening. The result of this may be that the rule has an overall medium impact to risk (low + medium = ~medium).
We want to take just a minute and discuss how we arrived at this conclusion. The answer is that we used a simple High (H), Medium (M), and Low (L) analysis. There’s no rocket science here (nor “rocket surgery” depending on how you prefer to coin a phrase); we simply used our experiences on how the rule might apply to the tree we developed for our particular view of risk and scalability. So while the answer was largely subjective, it was informed by 70 years of combined experience within our partnership. While you can certainly invest in creating a more deterministic model, we are not convinced that it will yield significantly better results than having a team of smart people determine how these rules impact your risk.
We are now going to assume that a change in risk serves as a proxy for benefit. This is a fairly well understood concept within business, so we won’t spend a great deal of time explaining it. Suffice it to say that if you can reduce your risk, you reduce the likelihood of a negative impact to your business and therefore increase the probability of achieving your goals. What we need to do now is determine the cost of this risk reduction. Once we know that, we can take our benefit (risk reduction) and subtract our costs to develop the solution. This combination creates a prioritization of work. We suggest a simple High, Medium, and Low for cost. High cost might be anything more than $10M for a very large company to more than $10K for a very small company. Low cost could be anything less than $1M for a very large company or verging on zero for a very small company. This is often derived from the cost of developer days. For example if your average developer’s salary and benefits cost the business $100,000 per year, then each day a developer needs to work on a project, assuming ~250 days of work per year, you add $400 to the cost.
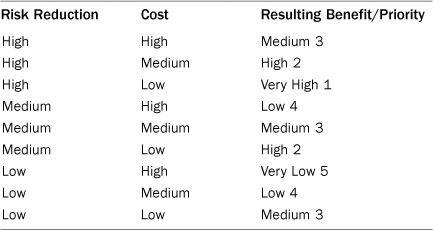
Our prioritization equation then becomes risk reduction minus cost equals priority or (R – C = P). Table 13.1 shows how we computed the nine permutations of risk and cost and the resulting priority. The method we chose was simple. The benefit for any equation where risk and cost were equivalent was set to medium and the priority set to the midrange of 3. Where risk reduction was two levels higher than cost, the benefit was set to Very High, and the Priority set to 1. Where risk reduction was two levels lower than cost (Low Risk, High Cost) the benefit was set to Very Low, and priority set to 5. Differences of one were either Low (Risk Reduction Low and Cost Medium) with a priority score of 4or High (Risk Reduction Medium and Cost Low) with a priority score of 2. The projects with the lowest priority score have the highest benefit and are the first things we will do.
Table 13.1. Risk Reduction, Cost, and Benefit Calculation
Using the previous approach, we now rate each of our 50 rules. The sidebars from each chapter for each rule are repeated in the following sections with the addition of our estimation of risk reduction, cost, and the calculated benefit/priority. As we mentioned earlier the way we arrived at these values was the result of our experience of more than 70 years (combined) with more than 150 companies and growing. Your particular risk reduction, cost, and benefit may vary, and we encourage you to calculate and prioritize these yourselves. Our estimates should be good for smaller action-oriented companies that simply want to know what to do today. Note that these estimates are to “rework” an existing solution. The cost of designing something from scratch will be significantly different—typically a lower cost but with equivalent benefit.
For the sake of completeness, there are many other approaches to determining cost and benefit. You may, for instance, replace our notion of risk reduction with the ability to achieve specific KPIs (Key Performance Indicators) within your company. The previous method would be appropriate if you had a KPI regarding the scalability and availability of your product (something all Web-enabled businesses should have). If you are a business with contractual obligations another approach might be to determine the risk reduction of not meeting specific SLAs (Service Level Agreements) outlined within your contracts. Many other possibilities exist. Just choose the right approach to prioritize for your business and get going!
Rule 1—Don’t Overengineer the Solution
What: Guard against complex solutions during design.
When to use: Can be used for any project and should be used for all large or complex systems or projects.
How to use: Resist the urge to overengineer solutions by testing ease of understanding with fellow engineers.
Why: Complex solutions are costly to implement and have excessive long-term costs.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Systems that are overly complex limit your ability to scale. Simple systems are more easily and cost effectively maintained and scaled.
Rule 2—Design Scale into the Solution (D-I-D Process)
What: An approach to provide JIT (Just In Time) Scalability.
When to use: On all projects; this approach is the most cost-effective (resources and time) to ensure scalability.
How to use:
• Design for 20x capacity.
• Implement for 3x capacity.
• Deploy for ~1.5x capacity.
Why: D-I-D provides a cost-effective, JIT method of scaling your product.
Risk reduction: L
Cost: L
Benefit and priority: Medium - 3
Key takeaways: Teams can save a lot of money and time by thinking of how to scale solutions early, implementing (coding) them a month or so before they are needed, and implementing them days before the customer rush or demand.
Rule 3—Simplify the Solution 3 Times Over
What: Used when designing complex systems, this rule simplifies the scope, design, and implementation.
When to use: When designing complex systems or products where resources (engineering or computational) are limited.
How to use:
• Simplify scope using the Pareto principle.
• Simplify design by thinking about cost-effectiveness and scalability.
• Simplify implementation by leveraging the experience of others.
Why: Focusing just on “not being complex” doesn’t address the issues created in requirements or story and epoch development or the actual implementation.
Risk reduction: L
Cost: L
Benefit and priority: Medium - 3
Key takeaways: Simplification needs to happen during every aspect of product development.
Rule 4—Reduce DNS Lookups
What: Reduce the number of DNS lookups from a user perspective.
When to use: On all Web pages where performance matters.
How to use: Minimize the number of DNS lookups required to download pages, but balance this with the browser’s limitation for simultaneous connections.
Why: DNS lookups take a great deal of time, and large numbers of them can amount to a large portion of your user experience.
Risk reduction: L
Cost: L
Benefit and priority: Medium - 3
Key takeaways: Reduction of objects, tasks, computation, and so on is a great way of speeding up page load time, but division of labor must be considered as well.
Rule 5—Reduce Objects Where Possible
What: Reduce the number of objects on a page where possible.
When to use: On all Web pages where performance matters.
How to use:
• Reduce or combine objects, but balance this with maximizing simultaneous connections.
• Test changes to ensure performance improvements.
Why: The number of objects impacts page download times.
Risk reduction: L
Cost: L
Benefit and priority: Medium - 3
Key takeaways: The balance between objects and methods that serve them is a science that requires constant measurement and adjustment; it’s a balance between customer usability, usefulness, and performance.
Rule 6—Use Homogenous Networks
What: Don’t mix the vendor networking gear.
When to use: When designing or expanding your network.
How to use:
• Do not mix different vendors’ networking gear (switches and routers).
• Buy best of breed for other networking gear (firewalls, load balancers, and so on).
Why: Intermittent interoperability and availability issues simply aren’t worth the potential cost savings.
Risk reduction: H
Cost: H
Benefit and priority: Medium - 3
Key takeaways: Heterogeneous networking gear tends to cause availability and scalability problems. Choose a single provider.
Rule 7—Design to Clone Things (X Axis)
What: Typically called horizontal scale, this is the duplication of services or databases to spread transaction load.
• Databases with a very high read to write ratio (5:1 or greater—the higher the better).
• Any system where transaction growth exceeds data growth.
How to use:
• Simply clone services and implement a load balancer.
• For databases, ensure the accessing code understands the difference between a read and a write.
Why: Allows for fast scale of transactions at the cost of duplicated data and functionality.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: X axis splits are fast to implement and can allow for transaction but not data scalability.
Rule 8—Design to Split Different Things (Y Axis)
What: Sometimes referred to as scale through services or resources, this rule focuses on scaling data sets, transactions, and engineering teams.
When to use:
• Very large data sets where relations between data are not necessary.
• Large, complex systems where scaling engineering resources require specialization.
How to use:
• Split up actions by using verbs or resources by using nouns or use a mix.
• Split both the services and the data along the lines defined by the verb/noun approach.
Why: Allows for efficient scaling of not only transactions but also very large data sets associated with those transactions.
Cost: M
Benefit and priority: Medium - 3
Key takeaways: Y axis or data/service-oriented splits, allow for efficient scaling of transactions, large data sets, and can help with fault isolation.
Rule 9—Design to Split Similar Things (Z Axis)
What: This is often a split by some unique aspect of the customer such as customer ID, name, geography, and so on.
When to use: Very large, similar data sets such as large and rapidly growing customer bases.
How to use: Identify something you know about the customer, such as customer ID, last name, geography, or device and split or partition both data and services based on that attribute.
Why: Rapid customer growth exceeds other forms of data growth or you have the need to perform “fault isolation” between certain customer groups as you scale.
Risk reduction: H
Cost: H
Benefit and priority: Medium - 3
Key takeaways: Z axis splits are effective at helping you to scale customer bases but can also be applied to other very large data sets that can’t be pulled apart using the Y axis methodology.
Rule 10—Design Your Solution to Scale Out—Not Just Up
What: Scaling out is the duplication of services or databases to spread transaction load and is the alternative to buying larger hardware, known as scaling up.
When to use: Any system, service, or database expected to grow rapidly.
How to use: Use the AKF Scale Cube to determine the correct split for your environment. Usually the horizontal split (cloning) is the easiest.
Why: Allows for fast scale of transactions at the cost of duplicated data and functionality.
Cost: L
Benefit and priority: High - 2
Key takeaways: Plan for success and design your systems to scale out. Don’t get caught in the trap of expecting to scale up only to find out that you’ve run out of faster and larger systems to purchase.
Rule 11—Use Commodity Systems (Goldfish Not Thoroughbreds)
What: Use small, inexpensive systems where possible.
When to use: Use this approach in your production environment when going through hyper growth.
How to use: Stay away from very large systems in your production environment.
Why: Allows for fast, cost-effective growth.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Build your systems to be capable of relying on commodity hardware and don’t get caught in the trap of using high margin, high end servers.
Rule 12—Scale Out Your Data Centers
What: Design your systems to have three or more live data centers to reduce overall cost, increase availability, and implement disaster recovery.
When to use: Any rapidly growing business that is considering adding a disaster recovery (cold site) data center.
How to use: Split up your data to spread across data centers and spread transaction load across those data centers in a “multiple live” configuration. Use spare capacity for peak periods of the year.
Why: The cost of data center failure can be disastrous to your business. Design to have three or more as the cost is often less than having two data centers. Make use of idle capacity for peak periods rather than slowing down your transactions.
Cost: H
Benefit and priority: Medium - 3
Key takeaways: When implementing DR, lower your cost of disaster recovery by designing your systems to leverage three or more live data centers. Use the spare capacity for spiky demand when necessary.
Rule 13—Design to Leverage the Cloud
What: This is the purposeful utilization of cloud technologies to scale on demand.
When to use: When demand is temporary, spiky, and inconsistent and when response time is not a core issue in the product.
How to use:
• Make use of third-party cloud environments for temporary demands, such as large batch jobs or QA environments during testing cycles.
• Design your application to service some requests from a third-party cloud when demand exceeds a certain peak level.
Why: Provisioning of hardware in a cloud environment takes a few minutes as compared to days or weeks for physical servers in your own collocation facility. When utilized temporarily this is also very cost effective.
Risk reduction: L
Cost: M
Benefit and priority: Low - 4
Key takeaways: Design to leverage virtualization and the cloud to meet unexpected spiky demand.
Rule 14—Use Databases Appropriately
What: Use relational databases when you need ACID properties to maintain relationships between your data. For other data storage needs consider more appropriate tools.
When to use: When you are introducing new data or data structures into the architecture of a system.
How to use: Consider the data volume, amount of storage, response time requirements, relationships, and other factors to choose the most appropriate storage tool.
Why: RDBMSs provide great transactional integrity but are more difficult to scale, cost more, and have lower availability than many other storage options.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Use the right storage tool for your data. Don’t get lured into sticking everything in a relational database just because you are comfortable accessing data in a database.
Rule 15—Firewalls, Firewalls Everywhere!
What: Use firewalls only when they significantly reduce risk and recognize that they cause issues with scalability and availability.
When to use: Always.
How to use: Employ firewalls for critical PII, PCI compliance, and so on. Don’t use them for low-value static content.
Why: Firewalls can lower availability and cause unnecessary scalability chokepoints.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: While firewalls are useful, they are often overused and represent both an availability and a scalability concern if not designed and implemented properly.
Rule 16—Actively Use Log Files
What: Use your application’s log files to diagnose and prevent problems.
When to use: Put a process in place that monitors log files and forces people to take action on issues identified.
How to use: Use any number of monitoring tools from custom scripts to Splunk to watch your application logs for errors. Export these and assign resources for identifying and solving the issue.
Why: The log files are excellent sources of information about how your application is performing for your users; don’t throw this resource away without using it.
Risk reduction: L
Cost: L
Benefit and priority: Medium - 3
Key takeaways: Make good use of your log files and you will have fewer production issues with your system.
Rule 17—Don’t Check Your Work
What: Avoid checking things you just did or reading things you just wrote within your products.
When to use: Always (see rule conflict discussion in Rule 17 in Chapter 5).
How to use: Never read what you just wrote for the purpose of validation. Store data in a local or distributed cache if it is required for operations in the near future.
Why: The cost of validating your work is high relative to the unlikely cost of failure. Such activities run counter to cost-effective scaling.
Risk reduction: L
Cost: M
Benefit and priority: Low - 4
Key takeaways: Never justify reading something you just wrote for the purposes of validating the data. Read and act upon errors associated with the write activity instead. Avoid other types of reads of recently written data by storing that data locally.
Rule 18—Stop Redirecting Traffic
What: Avoid redirects when possible; use the right method when they are necessary.
When to use: Use redirects as little as possible.
How to use: If you must have them, consider server configurations instead of HTML or other code-based solutions.
Why: Redirects in general delay the user, consume computation resources, and are prone to errors.
Risk reduction: L
Cost: L
Benefit and priority: Medium - 3
Key Takeaways: Use redirect correctly and only when necessary.
Rule 19—Relax Temporal Constraints
What: Alleviate temporal constraints in your system whenever possible.
When to use: Anytime you are considering adding a constraint that an item or object maintains a certain state between a user’s actions.
How to use: Relax constraints in the business rules.
Why: The difficulty in scaling systems with temporal constraints is significant because of the ACID properties of most RDMSs.
Risk reduction: H
Cost: L
Benefit and priority: Very High - 1
Key takeaways: Carefully consider the need for constraints such as items being available from the time a user views them until the user purchases them. Some possible edge cases where users are disappointed are much easier to compensate for than not being able to scale.
Rule 20—Leverage CDNs
What: Use CDNs to offload traffic from your site.
When to use: Ensure it is cost justified and then choose which content is most suitable.
How to use: Most CDNs leverage DNS to serve content on your site’s behalf.
Why: CDNs help offload traffic spikes and are often economical ways to scale parts of a site’s traffic.
Risk reduction: M
Cost: M
Benefit and priority: Medium - 3
Key takeaways: CDNs are a fast and simple way to offset spikiness of traffic as well as traffic growth in general. Ensure you perform a cost-benefit analysis and monitor the CDN usage.
Rule 21—Use Expires Headers
What: Use Expires headers to reduce requests and improve the scalability and performance of your system.
When to use: All object types need to be considered.
How to use: Headers can be set on Web servers or through application code.
Why: The reduction of object requests increases the page performance for the user and decreases the number of requests your system must handle per user.
Risk reduction: L
Cost: L
Benefit and priority: Medium - 3
Key takeaways: For each object type (image, html, css, php, and so on) consider how long the object can be cached for and implement the appropriate header for that timeframe.
Rule 22—Cache Ajax Calls
What: Use appropriate HTTP response headers to ensure cacheability of Ajax calls.
When to use: Every Ajax call but those absolutely requiring real time data that is likely to have been recently updated.
How to use: Modify Last-Modified, Cache-Control, and Expires headers appropriately.
Why: Decrease user-perceived response time, increase user satisfaction, and increase the scalability of your platform or solution.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Leverage Ajax and cache Ajax calls as much as possible to increase user satisfaction and increase scalability.
Rule 23—Leverage Page Caches
What: Deploy Page Caches in front of your Web services.
When to use: Always.
How to use: Choose a caching system and deploy.
Why: Decrease load on Web servers by caching and delivering previously generated dynamic requests and quickly answering calls for static objects.
Cost: M
Benefit and priority: Medium - 3
Key takeaways: Page caches are a great way to offload dynamic requests and to scale cost effectively.
Rule 24—Utilize Application Caches
What: Make use of application caching to scale cost effectively.
When to use: Whenever there is a need to improve scalability and reduce costs.
How to use: Maximize the impact of application caching by analyzing how to split the architecture first.
Why: Application caching provides the ability to scale cost effectively, but should be complmentary to the architecture of the system.
Risk reduction: M
Cost: M
Benefit and priority: Medium - 3
Key takeaways: Consider how to split the application by Y Axis—Rule 8 or Z Axis—Rule 9 before applying application caching in order to maximize the effectiveness from both cost and scalability perspectives.
Rule 25—Make Use of Object Caches
What: Implement object caches to help your system scale.
When to use: Anytime you have repetitive queries or computations.
How to use: Select any one of the many open source or vendor supported solutions and implement the calls in your application code.
Why: A fairly straightforward object cache implementation can save a lot of computational resources on application servers or database servers.
Risk reduction: H
Cost: L
Benefit and priority: Very High - 1
Key takeaways: Consider implementing an object cache anywhere computations are performed repeatedly, but primarily this is done between the database and application tiers.
Rule 26—Put Object Caches on Their Own “Tier”
What: Use a separate tier in your architecture for object caches.
When to use: Anytime you have implemented object caches.
How to use: Move object caches onto their own servers.
Why: The benefits of a separate tier are better utilization of memory and CPU resources and having the ability to scale the object cache independently of other tiers.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: When implementing an object cache it is simplest to put the service on an existing tier such as the application servers. Consider implementing or moving the object cache to its own tier for better performance and scalability.
Rule 27—Learn Aggressively
What: Take every opportunity to learn.
When to use: Be constantly learning from your mistakes as well as successes.
How to use: Watch your customers or use A/B testing to determine what works. Use postmortems to learn from incidents and problems in production.
Why: Doing something without measuring the results or having an incident without learning from it are wasted opportunities that your competitors are taking advantage of.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Be constantly and aggressively learning. The companies that do this best are the ones that grow the fastest and are the most scalable.
Rule 28—Don’t Rely on QA to Find Mistakes
What: Use QA to lower cost of delivered products, increase engineering throughput, identify quality trends, and decrease defects—not to increase quality.
When to use: Whenever you can get greater throughput by hiring someone focused on testing rather than writing code. Use QA to learn from past mistakes—always.
How to use: Hire a QA person anytime you get greater than one engineer’s worth of output with the hiring of a single QA person.
Why: Reduce cost, increase delivery volume/velocity, and decrease the number of repeated defects.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: QA doesn’t increase the quality of your system, as you can’t test quality into a system. If used properly, it can increase your productivity while decreasing cost, and most importantly it can keep you from increasing defect rates faster than your rate of organization growth during periods of rapid hiring.
Rule 29—Failing to Design for Rollback Is Designing for Failure
What: Always have the ability to roll back code.
When to use: Ensure all releases have the ability to roll back, practice it in a staging or QA environment, and use it in production when necessary to resolve customer incidents.
How to use: Clean up your code and follow a few simple procedures to ensure you can roll back your code.
Why: If you haven’t experienced the pain of not being able to roll back, you likely will at some point if you keep playing with the “fix-forward” fire.
Risk reduction: H
Cost: L
Benefit and priority: Very High - 1
Key takeaways: Don’t accept that the application is too complex or that you release code too often as excuses that you can’t roll back. No sane pilot would take off in an airplane without the ability to land, and no sane engineer would roll code that they could not pull back off in an emergency.
Rule 30—Discuss and Learn from Failures
What: Leverage every failure to learn and teach important lessons.
When to use: Always.
How to use: Employ a postmortem process and hypothesize failures in low failure environments.
Why: We learn best from our mistakes—not our successes.
Risk reduction: H
Cost: L
Benefit and priority: Very High - 1
Key takeaways: Never let a good failure go to waste. Learn from every one and identify the technology, people, and process issues that need to be corrected.
Rule 31—Be Aware of Costly Relationships
What: Be aware of relationships in the data model.
When to use: When designing the data model, adding tables/columns, or writing queries consider how the relationships between entities will affect performance and scalability in the long run.
How to use: Think about database splits and possible future data needs as you design the data model.
Why: The cost of fixing a broken data model after it has been implemented is likely 100x as much as fixing it during the design phase.
Risk reduction: L
Cost: L
Benefit and priority: Medium - 3
Key takeaways: Think ahead and plan the data model carefully. Consider normalized forms, how you will likely split the database in the future, and possible data needs of the application.
Rule 32—Use the Right Type of Database Lock
What: Be cognizant of the use of explicit locks and monitor implicit locks.
When to use: Anytime you employ relational databases for your solution.
How to use: Monitor explicit locks in code reviews. Monitor databases for implicit locks and adjust explicitly as necessary to moderate throughput. Choose a database and storage engine that allows flexibility in types and granularity of locking.
Why: Maximize concurrency and throughput in databases within your environment.
Risk reduction: H
Cost: L
Benefit and priority: Very High - 1
Key takeaways: Understand the types of locks and manage their usage to maximize database throughput and concurrency. Change lock types to get better utilization of databases and look to split schemas or distribute databases as you grow. When choosing databases, ensure you choose one that allows multiple lock types and granularity to maximize concurrency.
Rule 33—Pass on Using Multiphase Commits
What: Do not use a multiphase commit protocol to store or process transactions.
When to use: Always pass, or alternatively never use multiphase commits.
How to use: Don’t use it; split your data storage and processing systems with Y or Z axis splits.
Why: Multiphase commits are blocking protocols that do not permit other transactions from occurring until it is complete.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Do not use multiphase commit protocols as a simple way to extend the life of your monolithic database. It will likely cause it to scale even less and result in an even earlier demise of your system.
Rule 34—Try Not to Use “Select For Update”
What: Minimize the use of the FOR UPDATE clause in a SELECT statement when declaring cursors.
When to use: Always.
How to use: Review cursor development and question every SELECT FOR UPDATE usage.
Why: Use of FOR UPDATE causes locks on rows and may slow down transactions.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Cursors are powerful constructs that when properly used can actually make programming faster and easier while speeding up transactions. But FOR UPDATE cursors may cause long held locks and slow transactions. Refer to your database documentation for whether you need to use the FOR READ ONLY clause to minimize locks.
Rule 35—Don’t Select Everything
What: Don’t use Select * in queries.
When to use: Never select everything (unless of course you are going to use everything).
How to use: Always declare what columns of data you are selecting or inserting in a query.
Why: Selecting everything in a query is prone to break things when the table structure changes and it transfers unneeded data.
Risk reduction: H
Cost: L
Benefit and priority: Very High - 1
Key takeaways: Don’t use wildcards when selecting or inserting data.
Rule 36—Design Using Fault Isolative “Swimlanes”
What: Implement fault isolation or “swimlanes” in your designs.
When to use: Whenever you are beginning to split up databases to scale.
How to use: Split up databases and services along the Y or Z axis and disallow synchronous communication or access between services.
Why: Increase availability, scalability, and reduce incident identification and resolution as well as time to market and cost.
Risk reduction: H
Cost: H
Benefit and priority: Medium - 3
Key takeaways: Fault isolation consists of eliminating synchronous calls between fault isolation domains, limiting asynchronous calls and handling synchronous call failure, and eliminating the sharing of services and data between swimlanes.
Rule 37—Never Trust Single Points of Failure
What: Never implement and always eliminate single points of failure.
When to use: During architecture reviews and new designs.
How to use: Identify single instances on architectural diagrams. Strive for active/active configurations.
Why: Maximize availability through multiple instances.
Risk reduction: H
Cost: M
Benefit and priority: High - 2
Key takeaways: Strive for active/active rather than active/passive solutions. Use load balancers to balance traffic across instances of a service. Use control services with active/passive instances for patterns that require singletons.
Rule 38—Avoid Putting Systems in Series
What: Reduce the number of components that are connected in series.
When to use: Anytime you are considering adding components.
How to use: Remove unnecessary components or add multiple versions of them to minimize the impact.
Why: Components in series have a multiplicative effect of failure.
Risk reduction: M
Benefit and priority: Medium - 3
Key takeaways: Avoid adding components to your system that are connected in series. When necessary to do so add multiple versions of that component so that if one fails others are available to take its place.
Rule 39—Ensure You Can Wire On and Off Functions
What: Create a framework to disable and enable features of your product.
When to use: Risky, very high use, or shared services that might otherwise cause site failures when slow to respond or unavailable.
How to use: Develop shared libraries to allow automatic or on-demand enabling and disabling of services. See Table 9.4 for recommendations.
Why: Graceful failure (or handling failures) of transactions can keep you in business while you recover from the incident and problem that caused it.
Risk reduction: M
Cost: H
Benefit and priority: Low - 4
Key takeaways: Implement Wire On/Wire Off frameworks whenever the cost of implementation is less than the risk and associated cost of failure. Work to develop shared libraries that can be reused to lower the cost of future implementation.
Rule 40—Strive for Statelessness
What: Design and implement stateless systems.
When to use: During design of new systems and redesign of existing systems.
How to use: Choose stateless implementations whenever possible. If stateful implementations are warranted for business reasons, refer to Rules 41 and 42.
Why: The implementation of state limits scalability and increases cost.
Risk reduction: H
Benefit and priority: Medium - 3
Key takeaways: Always push back on the need for state in any system. Use business metrics and multivariate (or A/B) testing to determine whether state in an application truly results in the expected user behavior and business value.
Rule 41—Maintain Sessions in the Browser When Possible
What: Try to avoid session data completely, but when needed, consider putting the data in users’ browsers.
When to use: Anytime that you need session data for the best user experience.
How to use: Use cookies to store session data on the users’ browsers.
Why: Keeping session data on the users’ browsers allows the user request to be served by any Web server in the pool and takes the storage requirement away from your system.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Using cookies to store session data is a common approach and has advantages in terms of ease of scale but also has some drawbacks. One of the most critical cons is that unsecured cookies can easily be captured and used to log into people’s accounts.
Rule 42—Make Use of a Distributed Cache for States
What: Use a distributed cache when storing session data in your system.
When to use: Anytime you need to store session data and cannot do so in users’ browsers.
How to use: Watch for some common mistakes such as a session management system that requires affinity of a user to a Web server.
Why: Careful consideration of how to store session data can help ensure your system will continue to scale.
Cost: L
Benefit and priority: High - 2
Key takeaways: Many Web servers or languages offer simple server-based session management, but these are often fraught with problems such as user affiliation with specific servers. Implementing a distributed cache will allow you to store session data in your system and continue to scale.
Rule 43—Communicate Asynchronously As Much As Possible
What: Use asynchronous instead of synchronous communication as often as possible.
When to use: Consider for all calls between services and tiers.
How to use: Use language-specific calls to ensure the requests are made and not waited on.
Why: Synchronous calls stop the entire program’s execution waiting for a response, which ties all the services and tiers together resulting in cascading failures.
Risk reduction: H
Cost: M
Benefit and priority: High - 2
Key takeaways: Use asynchronous communication techniques to ensure that each service and tier is as independent as possible. This allows the system to scale much farther than if all components are closely coupled together.
Rule 44—Ensure Your Message Bus Can Scale
What: Message buses can fail from demand like any other physical or logical system. They need to be scaled.
When to use: Anytime a message bus is part of your architecture.
How to use: Employ the Y and Z AKF axes of scale.
Why: To ensure your bus scales to demand.
Risk reduction: H
Cost: M
Benefit and priority: High - 2
Key takeaways: Treat message buses like any other critical component of your system. Scale them ahead of demand using either the Y or Z axes of scale.
Rule 45—Avoid Overcrowding Your Message Bus
What: Limit bus traffic to items of higher value than the cost to handle them.
When to use: On any message bus.
How to use: Value and cost justify message traffic. Eliminate low value, high cost traffic. Sample low value/low cost and high value/high cost traffic to reduce the cost.
Why: Message traffic isn’t “free” and presents costly demand on your system.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Don’t publish everything. Sample traffic to ensure alignment between cost and value.
Rule 46—Be Wary of Scaling Through Third Parties
What: Scale your own system; don’t rely on vendor solutions to achieve scalability.
When to use: When considering whether to use a new feature or product from a vendor.
How to use: Rely on the rules of this book for understanding how to scale and use vendor provided products and services in the most simplistic manner possible.
Why: Three reasons for following this rule: Own your destiny, keep your architecture simple, and reduce your total cost of ownership.
Risk reduction: H
Cost: L
Benefit and priority: Very High - 1
Key takeaways: Do not rely on vendor products, services, or features to scale your system. Keep your architecture simple, keep your destiny in your own hands, and keep your costs in control. All three of these can be violated by using a vendor’s proprietary scaling solution.
Rule 47—Purge, Archive, and Cost-Justify Storage
What: Match storage cost to data value, including removing data of value lower than the costs to store it.
When to use: Apply to data and its underlying storage infrastructure during design discussions and throughout the lifecycle of the data in question.
How to use: Apply recency, frequency, and monetization analysis to determine the value of the data. Match storage costs to data value.
Why: Not all data is created equal (that is, of the same value) and in fact it often changes in value over time. Why then should we have a single storage solution with equivalent cost for that data?
Risk reduction: M
Cost: M
Benefit and priority: Medium - 3
Key takeaways: It is important to understand and calculate the value of your data and to match storage costs to that value. Don’t pay for data that doesn’t have a stakeholder return.
Rule 48—Remove Business Intelligence from Transaction Processing
What: Separate business systems from product systems and product intelligence from database systems.
When to use: Anytime you are considering internal company needs and data transfer within, to, or from your product.
How to use: Remove stored procedures from the database and put them in your application logic. Do not make synchronous calls between corporate and product systems.
Why: Putting application logic in databases is costly and represents scale challenges. Tying corporate systems and product systems together is also costly and represents similar scale challenges as well as availability concerns.
Risk reduction: H
Cost: M
Benefit and priority: High - 2
Key takeaways: Databases and internal corporate systems can be costly to scale due to license and unique system characteristics. As such, we want them dedicated to their specific tasks. In the cases of databases, we want them focused on transactions rather than product intelligence. In the case of back office systems (business intelligence), we do not want our product tied to their capabilities to scale. Use asynchronous transfer of data for business systems.
Rule 49—Design Your Application to Be Monitored
What: Think about how you will need to monitor your application as you are designing it.
When to use: Anytime you are adding or changing modules of your code base.
How to use: Build hooks into your system to record transaction times.
Why: Having insight into how your application is performing will help answer many questions when there is a problem.
Risk reduction: M
Cost: L
Benefit and priority: High - 2
Key takeaways: Adopt as an architectural principle that your application must be monitored. Additionally, look at your overall monitoring strategy to make sure you are first answering the question of “Is there a problem?” and then the “Where” and “What.”
Rule 50—Be Competent
What: Be competent, or buy competency in/for each component of your architecture.
When to use: For any Internet service or commerce solution.
How to use: For each component of your infrastructure, identify the team responsible and level of competency with that component.
Why: To a customer, every problem is your problem. You can’t blame suppliers or providers. You provide a service—not software.
Risk reduction: H
Cost: L
Benefit and priority: Very High - 1
Key takeaways: Don’t confuse competence with build versus buy or core versus context decisions. You can buy solutions and still be competent in their deployment and maintenance. In fact, your customers demand that you do so.
A Benefit/Priority Ranking of the Scalability Rules
As you would expect the distribution of rules is fairly normal but shifted toward the high end of benefit and priority. There are of course no rules that were ranked Very Low since they would not have made the cut for inclusion in the list. The following sections group the 50 rules by Benefit/Priority for ease of reference.
Very High – 1

High – 2

Medium – 3


Low – 4

Very Low – 5
N/A
Summary
This chapter was a summary of the 50 rules in this book. Additionally we provided a method by which these rules can be prioritized for a generic Web-based business looking to re-architect its platform in an evolutionary fashion. The prioritization does not mean as much for a business just starting to build its product or platform because it is much easier to build in many of these rules at relatively low cost when you are building something from scratch.
As with any rule there are exceptions, and not all of these rules will apply to your specific technology endeavors. For instance, you may not employ traditional relational databases in which case our database rules will not apply to you. In some cases, it does not make sense to implement or employ a rule due to cost constraints and the uncertainty of your business. After all, as many of our rules imply, you don’t want to overcomplicate your solution, and you want to incur costs at an appropriate time so as to maintain profitability. Rule 2 is a recognition of this need to scale cost effectively; where you can’t afford the time or money to implement a solution today, at least spend some amount of comparatively cheap time deciding how the solution will look when you do implement it. One example might be to wait to implement a scalable (fault isolated and Y or Z axis scaled) message bus. If you don’t implement the solution in code and systems infrastructure, you should at least discuss how you will make such an implementation in the future if your business becomes successful.
Similarly there are exceptions with our method of prioritizing these rules. We have applied a repeatable model that encapsulates our collective learning across many companies. Because the result is, in a fashion, an average, it is subject to the same problem as all averages: In attempting to describe an entire population it is going to be wrong for many specific data points. Feel free to modify our mechanism to fit your specific needs.
A great use for this chapter is to select a number of rules that fit your specific needs and codify them as architectural principles within your organization. Use these principles as the standards employed within software and infrastructure reviews. The exit criteria for these meetings can be complete adherence to the set of rules that you develop. Architectural reviews and joint architectural development sessions can similarly employ these rules to ensure adherence to principles of scalability and availability.
Whether your system is still in the design phase on the whiteboard or ten years old with millions of lines of code, incorporating these rules into your architecture will help improve its scalability. If you’re an engineer or an architect, make use of these rules in your designs. If you are a manager or an executive, share these rules with your teams. We wish you the best of luck with all your scalability projects.