
10. Avoid or Distribute State
The state that we hate the most can’t be found on a map of the United States or any other country for that matter. The state we hate most is persistent state (and session information) held within the application of an Internet site. And why, you might ask, do we hate state so? Session and state destroy the ultimate value promised by multitenancy within Internet (SaaS, commerce, and so on) applications. If we must keep great amounts of data associated with a user’s interactions at any given time, then we can house fewer users on any given system at any given time. In the desktop world, we rarely needed to be concerned with this as we often had a lot of power and memory available for a single user at any given time. In the multitenant world, our goal is to house as many users as possible on a single system while still delivering a stellar user experience. As such, we strive to eliminate any approach that will limit the degree of tenancy on any system. State and session cost us both in terms of memory and processing power, and as a result is an enemy to our cost-effective scale goals.
While we would prefer to avoid state at all cost, it is sometimes valuable to the business. Indeed, the very nature of some applications (such as some workflow systems) requires us to model a state machine, which in turn requires some notion of state. If state is necessary, we need to implement it in a fault-tolerant, highly available, and cost-effective way such as distributing it to our end users (Rule 41) or positioning it on a special service within our infrastructure (Rule 42).
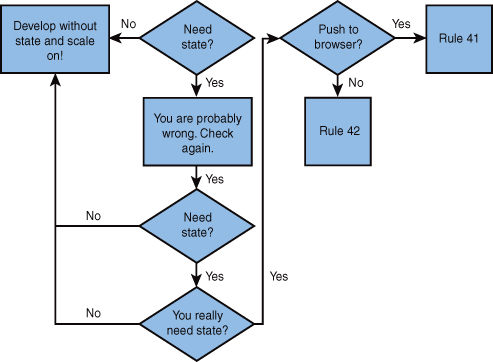
Figure 10.1 depicts, diagrammatically both our feelings on state and how to approach decisions on how to implement state.
Figure 10.1. Decision flowchart for implementing state in a Web application
Rule 40—Strive for Statelessness
Paradoxically it is both a sad and exciting day when our applications grow beyond the ability of a single server to meet the transaction processing needs of our product. It is exciting because our business is growing and sad because we embark upon a new era of development requiring new skills to scale our systems. Depending on our implementation, we can sometimes rely on clustering software with state or session replication to help us scale, but such an approach only delays the inevitable if our business continues to experience power-curve or even linear but aggressive growth. If your company is successful you will quickly grow out of this rather costly session synchronization method. As we describe in Chapter 2, “Distribute Your Work,” you will soon find yourself replicating too much information in memory across too many application servers. Very likely you will need to perform a Y or Z axis split.
Many of our clients simply stop at these splits and rely on affinity maintained through a load balancer to handle session and state needs. Once a user logs in, or starts some flow specific to a pool of application servers, she maintains affinity to that application server until the function (in the case of Y axis splits where different pools provide different functions) or session (in the case of a Z axis split where customers are segmented into pools) is complete. This is an adequate approach for many products where growth has slowed or where customers have more relaxed availability requirements.
Maintaining affinity comes with some fairly high costs hinted at previously; capacity planning can become troublesome when several high volume or long running sessions become bound to a handful of servers, and availability for certain customers will be impacted when the application server on which they are running fails. While we can rely on session replication to create another host to which we might move in the event of a system failure, as described previously this approach is costly in terms of duplicated memory consumption and system capacity.
Ultimately, the solution that serves a majority of our hyper growth clients the best is to eliminate the notion of state wherever possible. We prefer to start discussions on the topic of state with “Why do you need it at all?” Our clients are often taken aback, and the typical response is “Well, that’s the way it’s always been and we need to know what just happened to make the next move.” When pressed to back up their responses with data showing the efficacy of state in terms of revenue, increased transaction volume, and so on they are often at a loss. Granted there are certain solutions that probably need state, such as solutions that implement state machines like workflow processes. But more often than not, state is a luxury and a costly one at that.
Never underestimate the power of “simple and easy” in an application as an effective weapon against “rich and complex.” Craigslist won the local classifieds war against eBay with a largely text-based and stateless application. eBay, while always attempting to stay as stateless as possible had a competing classifieds product with a significantly greater number of features and “richness” years ahead of rival Craigslist. Yet simple won the day in the local classifieds war. Not convinced? How about Google against all comers in the search market? While others invested in rich interfaces, Google at least initially built on the concept that your last search was the only thing that mattered, and what you really want is good search results. No state, no session, no nonsense.
The point is that session and state cost money and you should only implement them where there is a clear competitive advantage displayed in key operating metrics determined through A/B or multivariate analysis. Session (and state) require memory and imply greater complexity in code, which means at least slightly longer running transactions. This reduces the number of transactions we can handle per second per server, which increases the number of systems that we need. The systems may also need to be larger and more costly given the memory requirements to house state on or off the systems. Potentially we need to develop “state farms” as we describe later in this chapter, which means more devices. And of course more devices mean more space, power, and cooling or in the virtual world more cloud resources for which we are paying. Remember that every server (or virtual machine) we need costs us three times over as we need to provide space for it, cool it, and power it. Cloud resources have the same costs; they are just passed on to us in a bundle.
You are best served to have a principle that always questions the need for state in any application or service. State this principle strongly—something along the lines of “We develop stateless applications.” Be clear that state distribution (the movement of state to the browser or distributed state server or cache) is not the same as stateless. Rules 41 and 42 exist to allow us to create rich business functionality where there is a clear competitive advantage, displayed through operating metrics that drive revenue and transactions, not as an alternative to this rule.
Rule 41—Maintain Sessions in the Browser When Possible
If you have to keep sessions for your users, one way to do so is in the users’ browsers. We’ll talk about how to do this but first let’s talk about the pros and cons of this approach. One benefit of putting the session data in a browser is that your system doesn’t have to store the data. As we explain in Rule 42, keeping session data within the system can amount to a large overhead of storage and retrieval. Not having to do this relieves the system of a large burden in terms of storage and workload. A second benefit of this approach is that the browser’s request can be serviced by any server in the pool. As you scale your Web servers along the X axis (horizontally) with the session data in the browser, any server in the pool can handle the request.
Of course since everything has its tradeoffs, one of the cons of this approach is that the data must be transferred back and forth between the browser and the servers that need this data. Moving this data back and forth for every request can be expensive, especially if the amount of data starts to become significant. Be careful not to dismiss this last statement too quickly. While your session data might not be too large now, let a couple dozen developers have access to storing data in cookies and after a couple code releases you will be wondering why the pages are loading so slowly. Another very serious con that was brought to light by the Firefox plug-in Firesheep is that session data can be easily captured on an open WiFi network and used to nefariously log in to someone else’s account. With the aforementioned plug-in, session cookies from most of the popular sites such as Google, Facebook, Twitter, and Amazon, just to name a few, can be compromised. We suggest a way to protect your users’ cookies against this type of hack or attack, commonly called sidejacking, but first let’s talk about storing session data in browser cookies.
Storing cookies in browsers is simple and straightforward. In PHP, as shown in the following example, it is as simple as calling setcookie with the parameters of the cookie name, value, expiration, path, domain, and secure (whether it should be set only over HTTPS). To destroy the cookie when you’re done with it just set the same cookie but with the expire to time()-3600, which sets the expiration time to one hour ago.
setcookie("SessionCookie", $value, time()+3600, '/', '.akf-
partners.com', true);
Some sessions are stored in multiple cookies, and other session data is stored in a single cookie. One factor to consider is the maximum size of cookies. According to RFC2965 browsers should support cookies at least up to 4KB in size and up to 20 cookies from the same domain.1 Most browsers, however, support these as maximums. To our earlier point, the larger the cookie the slower your pages will load since this data has to be transmitted back and forth with each request.
Now that we’re using cookies to support our sessions and we’re keeping them as small as possible so that our system can scale, the next question is how do we protect them from being sidejacked? Obviously you can transmit your pages and cookies all in HTTPS. The Secure Socket Layer (SSL) protocol used for HTTPS requires encrypting and decrypting all communication and requests. While this might be a requirement for a banking site, this doesn’t make sense for a news or social networking site. Instead we recommend a method using at least two cookies. One cookie is an authorization cookie that is requested via HTTPS on each HTTP page using a JavaScript call such as the following. This allows the bulk of the page (content, CSS, scripts, and so on) to be transferred by unsecure HTTP but a single authorization cookie to be transferred via HTTPS.2
<script type="text/javascript" src="https://verify.akfdemo.
com/authenticate.php"></script>
For ultimate scalability we recommend avoiding sessions all together. However, we understand that this isn’t always the case. In these cases we recommend storing the session data on the user’s browser. When implementing this it is critical to maintain control of the size of the cookie data. Excessive amounts of data slow the performance of the page load as well as the Web servers on the system.
Rule 42—Make Use of a Distributed Cache for States
Per our recommendations in Figure 10.1, we hope that you’ve taken your time in arriving at the conclusion to maintain state in your application or system and in deciding that you cannot push that state out to the end user. It is a sad, sad day that you’ve come this far and you should hang your head in shame that you were not enough of an engineer to figure out how to develop the system without state or without the ability to allow the end users to maintain state.
Of course we are kidding as we have already acknowledged that there are some systems that must maintain state and even a small number where that state is best maintained within the service, application, or infrastructure of your product. Granting that point, let’s move on to a few rules on what not to do when you maintain state within your application.
First and foremost, stay away from state systems that require affinity to an application or Web server. It goes without saying that these implementations will have lower availability than those that allow remote access of state from any of a number of servers. If the server dies, all of the session information (including state) on that server will likely go away as well requiring those customers (potentially numbering into the thousands) to restart whatever process they were in. Even if you persist the data in some local or network enabled storage, the user will need to start again on another server, and there will be some interruption of service.
Second, don’t use state or session replication services such as those within some application servers or third-party “clustering” servers. As stated previously in this chapter, such systems simply don’t scale well as modifications to session need to be propagated to multiple nodes. Furthermore, in choosing to do this type of implementation we are creating a new concern for scalability in how much memory we use on our systems.
Third, when choosing a session or state cache or persistence engine, locate that cache away from the servers performing the actual work. While this is a bit of a nit, it does help with availability as when you lose a server you either lose the cache associated with that server or the service running on it and not both. Creating a cache (or persistent) tier also allows us to scale that tier based on the cache accesses alone rather than needing to accommodate both the application service and the internal and remote cache services.
If you abide by the rules governing what not to do, the choice of what to do becomes pretty easy. We strive to be agnostic in our approaches to such matters, and as such we care more about designs and less about the implementation details such as which open source caching or database solution you might want to implement. We do feel strongly that there is rarely a need to develop the caching solution yourself. With all of the options from distributed object caches like memcached to open source and third-party databases, it seems ludicrous that one would implement their own caching solution for session information.
This brings us to the question of what we should use for a cache. To us, the question really comes down to reliability and persistence versus cost. If you expect to keep session or state information for quite some time such as in the case of a shopping cart, you may decide that for some or all of your session information you are going to rely on a solution that allows lengthy and durable persistence. In many cases we’ve seen databases used for these implementations. Clearly, however, a database will cost you more per transaction than a simpler solution such as a nonpersisting distributed object cache.
If you don’t need persistence and durability, you can choose from one of many object caches. Refer to Chapter 6, “Use Caching Aggressively,” for a discussion on object caches and their uses. In some cases, you may decide that you want both the persistence of a database and the relative low cost for performance of a cache in front of that database. Such an implementation gives you the persistence of a database while allowing to scale the transactions more cost effectively through a cache that front ends that database.
Summary
Our first recommendation is to avoid state at all cost, but we understand that session data is sometimes a necessity. If state is necessary, we first recommend trying to store the session data in the users’ browsers (Rule 41). Doing so eliminates the need to store data in your system and allows for the servicing of requests by any Web server in the pool. If not possible we recommend making use of a distributed caching system for session data (Rule 42). Following these rules will help ensure your system continues to scale.
Endnotes
1 D. Kristol and L. Montulli, Networking Working Group Request for Comments 2965, “HTTP State Management Mechanism,” October 2000, http://www.ietf.org/rfc/rfc2965.txt.
2 This solution was developed by Randy Wigginton, as explained and demonstrated on our blog, http://akfpartners.com/techblog/2010/11/20/slaying-firesheep/.