
6. Use Caching Aggressively
It is often said in the world of business that “Cash is King.” In the technology world, a close parallel to this saying is the homophone “cache,” as in “Cache is King.” While we typically tell our clients that there is a difference between tuning and scaling, and while we often indicate that caching is more of a tuning activity than a scaling activity, there is no doubt that the application of caches “in depth” throughout one’s platform architecture has significant impact to the scalability of one’s site. By caching at every level from the browser through the cloud, your network, application servers, and even databases, one can significantly increase one’s ability to scale. Similar to the theme of Chapter 5, “Don’t Duplicate Your Work,” caching is also about how to minimize the amount of work your system does. Caching allows you to not look up, create, or serve the same data over and over again. This chapter covers seven rules that will help guide you on the appropriate type and amount of caching for your application.
A word of caution is warranted here before we get into these rules. As with any system implementation or major modification, the addition of caching, while often warranted, will create complexity within your system. Multiple levels of caching can make it more difficult to troubleshoot problems in your product. As such, you should design the caching to be monitored as we discuss in Rule 49. While caching is a mechanism that often engenders greater scalability, it also needs to be engineered to scale well. Developing a caching solution that doesn’t scale well will create a scalability chokepoint within your system and lead to lower availability down the road. The failure of caches can have catastrophic impact to the availability of your site as services soon get overloaded. As such, you should ensure that you’ve designed the caches to be highly available and easily maintained. Finally, caching is a bit of an art that is performed best with deep experience. Look to hire engineers with past experience to help you with your caching initiatives.
Rule 20—Leverage Content Delivery Networks
The easiest way to handle a huge amount of user traffic is to avoid it. Now there are two ways in which you can do this. The first is by failing to scale, and having your site crash and all the users leave. A better way to avoid the traffic is to get someone else to handle as many of the requests as possible. This is where the content delivery networks (CDNs) come in.
CDNs are a collection of computers, called nodes or edge servers, connected via a network, called a backbone, that have duplicate copies of their customers’ data or content (images, Web pages, and so on) on them. By strategically placing edge servers on different Tier 1 networks and employing a myriad of technologies and algorithms the CDN can direct requests to nodes that are optimally suited to respond. This optimization could be based on such things as the fewest network hops, highest availability, or fewest requests. The focus of this optimization is most often the reduction of response times as perceived by the end user, requesting person, or service.
How this works in practice can be demonstrated best by an example, see Figure 6.1. Let’s say the AKF blog was getting so much traffic that we decided to employ a CDN. We would set up a CNAME in DNS that pointed users requesting www.akfpartners.com/techblog to 1107.c.cdn_vendor.net (see the DNS table in Figure 6.1). The user’s browser would then query DNS for akfpartners.com (step 1), receive the CDN domain name back (step 2), perform another DNS lookup on the CDN domain (step 3), receive IPs associated with 1107.c.cdn_vendor.net (step 4), and route and receive the request for our blog content to one of those IPs (steps 5-6). The content of our blog would be cached on the CDN servers, and periodically it would query the origin or originating server, in this case our server hosting our blog, for updates.
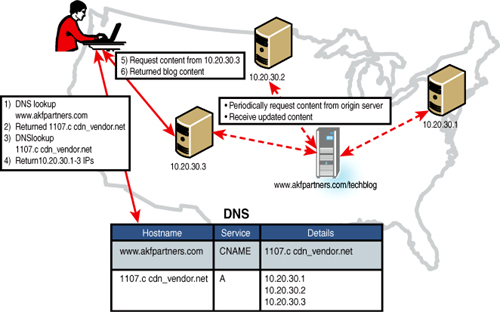
As you can see in our example, the benefit of using a CDN in front of our own blog server is that the CDN takes all the requests (possibly hundreds or thousands per hour) and only requests from our server when checking for updated cache. This requires you to purchase fewer servers, less power, and smaller amounts of bandwidth, as well as fewer people required to maintain that infrastructure. This aid in scale, availability, and response time isn’t free—it typically comes at a premium to your public peering (Internet peering) traffic costs. Often CDN providers price on either the 95th percentile of peak traffic (like many transit providers) or total traffic delivered. Rates drop on a per traffic delivered basis as the traffic increases. As a result, the analysis of when to convert to a CDN almost never works on a cost-only basis. You need to factor in the reduction in response time to end users, the likely resulting increase in user activity (faster response often elicits more transactions), the increase in availability of your site, and the reduction in server, power, and associated infrastructure costs. In most cases, we’ve found that clients with greater than 10M of avenue revenues are better served by implementing CDNs than continuing to serve that traffic themselves.
You might be thinking that all this caching sounds great for static Web sites but how does this help your dynamic pages? To start with even dynamic pages have static content. Images, JavaScript, CSS, and so on, are all usually static, which means they can be cached in a CDN. The actual text or content generated dynamically is usually the smallest portion of the page. Second, CDNs are starting to enable dynamic page support. Akamai offers a service called Dynamic Site Accelerator1 that is used to accelerate and cache dynamic pages. Akamai was one of the companies, along with Oracle, Vignette, and others, who developed Edge Side Includes,2 which is a markup language for assembling dynamic Web content on edge servers.
Whether you have dynamic or static pages on your site, consider adding a CDN into the mix of caches. This layer provides the benefit of faster delivery, typically very high availability, and less traffic on your site’s servers.
Rule 21—Use Expires Headers
It is a common misconception that pages can control how they are cached by placing meta tags, such as Pragma, Expires, or Cache-Control, in the <HEAD> element of the page. See the following code for examples. Unfortunately, meta tags in HTML are recommendations of how a page should be treated by the browser, but many browsers do not pay attention to these tags. Even worse, because proxy caches don’t inspect the HTML, they do not abide by these tags at all.
<META HTTP-EQUIV="EXPIRES" CONTENT="Mon, 22 Aug 2011
11:12:01 GMT">
<META HTTP-EQUIV="Cache-Control" CONTENT="NO-CACHE">
HTTP headers, unlike meta tags, provide much more control over caching. This is especially true with regard to proxy caches because they do pay attention to headers. These headers cannot be seen in the HTML and are generated dynamically by the Web server or the code that builds the page. You can control them by configurations on the server or in code. A typical HTTP response header could look like this:
HTTP Status Code: HTTP/1.1 200 OK
Date: Thu, 21 Oct 2010 20:03:38 GMT
Server: Apache/2.2.9 (Fedora)
X-Powered-By: PHP/5.2.6
Expires: Mon, 26 Jul 2011 05:00:00 GMT
Last-Modified: Thu, 21 Oct 2010 20:03:38 GMT
Cache-Control: no-cache
Vary: Accept-Encoding, User-Agent
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8
A couple of the most pertinent headers for caching are the Expires and Cache-Control. The Expires entity-header field provides the date and time after which the response is considered stale. To mark a response as “never expires,” the origin server should send a date one year from the time of response. In the preceding example, notice the Expires header identifies the date 26 July 2011 with a time of 05:00 GMT. If today’s date was 26 June 2011, then the page requested would expire in approximately one month and should be refreshed from the server at that time.
The Cache-Control general-header field is used to specify directives that, in accordance with the Request For Comments (RFC) 2616 Section 14 defining the HTTP 1.1 protocol, must be obeyed by all caching mechanisms along the request/response chain.3 There are many directives that can be issued under the header, including public, private, no-cache, and max-age. If a response includes both an Expires header and a max-age directive, the max-age directive overrides the Expires header, even if the Expires header is more restrictive. Following are the definitions of a few of the Cache-Control directives:
• public— The response may be cached by any cache, shared or nonshared.
• private— The response message is intended for a single user and must not be cached by a shared cache.
• no-cache— A cache must not use the response to satisfy a subsequent request without revalidation with the origin server.
• max-age— The response is stale if its current age is greater than the value given (in seconds) at the time of a request.
There are several ways to set HTTP headers, including through a Web server and through code. In Apache 2.2 the configurations are set in the httpd.conf file. Expires headers require the mod_expires module to be added to Apache.4 There are three basic directives for the expires module. The first tells the server to activate the module, ExpiresActive. The next directive is to set the Expires header for a specific type of object such as images or text, ExpiresByType. The last directive is a default for how to handle all objects not specified by a type, ExpiresDefault. See the following code for an example:
ExpiresActive On
ExpiresByType image/png "access plus 1 day"
ExpiresByType image/gif "modification plus 5 hours"
ExpiresByType text/html "access plus 1 month 15 days 2 hours"
ExpiresDefault "access plus 1 month"
The other way to set HTTP Expires as well as Cache-Control and other headers is in code. In PHP this is pretty straightforward by using the header() command to send a raw HTTP header. This header() command must be called before any output is sent, either by HTML tags or from PHP. See the following sample PHP code for setting headers. Other languages have similar methods of setting headers.
<?php
header("Expires: 0");
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");
header("cache-control: no-store, no-cache, must-revalidate");
header("Pragma: no-cache");
?>
The last topic for this rule actually has nothing to do with headers but has to deal with configuring Web servers for optimization of performance and scale, so this is a good place to talk about it. Keep-alives, or HTTP persistent connections, allow for the reuse of TCP connections for multiple HTTP requests. In HTTP/1.1 all connections are considered persistent, and most Web servers default to allow keep-alives. According to the Apache documentation the use of keep-alives has resulted in a 50% reduction in latency for HTML pages.5 The default setting in Apache’s httpd.conf file is KeepAlive On, but the default KeepAliveTimeOut is set at only 5 seconds. The benefit of longer timeout periods is that more HTTP requests do not have to establish, use, and break down TCP connections, but the benefit of short timeout periods is that the Web server threads will not be tied up for servicing other requests. A balance between the two based on the specifics of your application or site is important.
As a practical example, we ran a test on one of our sites using webpagetest.org, the open-source tool developed by AOL for testing Web pages. The configuration was a simple MediaWiki running on an Apache HTTP Server v 2.2. In Figure 6.2, the results from the test on the wiki page with the keep-alives turned off and the Expires headers not set are shown. The initial page load was 3.8 seconds, and the repeat view as 2.3 seconds.
Figure 6.2. Wiki page test (keep-alives off and no Expires headers)
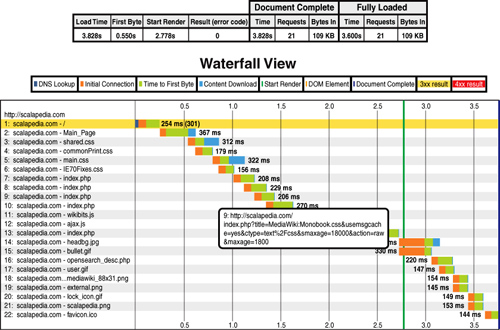
In Figure 6.3, the results are shown from the test on the wiki page with the keep-alives turned on and the Expires headers set. The initial page load was 2.6 seconds, and the repeat view as 1.4 seconds. This is a reduction in page load time of 32% for the initial page load and 37% for the repeat page load.
Figure 6.3. Wiki page test (keep-alives on and Expires headers set)

Rule 22—Cache Ajax Calls
For newcomers or those unfamiliar with some fairly common Internet terms, think of Ajax as one of the “approaches” behind some of those drop-down menus that start to offer suggestions as you type, or the map services that allow you to zoom in and out of maps without making additional round-trip calls to a distant server. If handled properly, Ajax not only makes for wonderfully interactive user interfaces, it helps us in our scalability endeavors by allowing the client to handle and interact with data and objects without requiring additional server side work. But if not handled properly, Ajax can actually create some unique scalability constraints by significantly increasing the number of requests our servers need to handle. And make no mistake about it, while these requests might be asynchronous from the perspective of the browser, a huge burst in a short period of time may very well flood our server farms and cause them to fail.
Ajax is an acronym for Asynchronous JavaScript and XML. While often referred to as a technology, it’s perhaps best described as a group of techniques, languages, approaches, and technologies employed on the browser (or client side) to help create richer and more interactive Web applications. While the items within this acronym are descriptive of many Ajax implementations, the actual interactions need not be asynchronous and need not make use of XML only as a data interchange format. JSON may take the place of XML for instance. JavaScript, however, is almost always used.
Jesse James Garrett is widely cited as coining the term Ajax in 2005 in his article “Ajax: A New Approach to Web Applications.”6 In a loose sense of the term, Ajax consists of standards-based presentation leveraging CSS and DHTML, interaction and dynamic display capabilities facilitated by the Document Object Model (or DOM), a data interchange and manipulation mechanism such as XML with XSLT or JSON, and a data retrieval mechanism. Data retrieval is often (but not absolutely necessarily) asynchronous from the end user perspective. JavaScript is the language used to allow everything to interact within the client browser. When asynchronous data transfer is used, the XMLHttpRequest object is used. The purpose of Ajax is to put an end to the herky-jerky interactions described by our first experiences with the Internet, where everything was a request and reply interaction. With this background behind us, we move on to some of the scalability concerns associated with Ajax and finally discuss how our friend caching might help us solve some of these concerns.
Clearly we all strive to create interfaces that increase user interaction and satisfaction and hopefully in so doing increase revenues, profits, and stakeholder wealth. Ajax is one method by which we might help facilitate a richer and more real time experience for our end users. Because it can help eliminate what would otherwise be unnecessary round-trips for interactions within our browser, user interactions can happen more quickly. Users can zoom in or zoom out without waiting for server responses, drop-down menus can be prepopulated based on previous entries, and users typing query strings into search bars can start to see potential search strings in which they might be interested to better guide their exploration. The asynchronous nature of Ajax can also help us load mail results into a client browser by repetitively fetching mail upon certain user actions without requiring the user to hit a “next page” button.
But some of these actions can also be detrimental to cost-effective scale of our platforms. Let’s take the case of a user entering a search term for a specific product on a Web site. We may want to query a product catalog to populate suggested search terms for a user as he types in search terms. Ajax could help with such an implementation by using each successive keystroke to send a request to our servers, return a result based on what was typed thus far, and populate that result in a drop-down menu without a browser refresh as the user types. Or the returned result may be the full search results of an as yet uncompleted string as the user types! Examples of both implementations can be found in many search engines and commerce sites today. But allowing each successive keystroke to ultimately result in a search query to a server is both costly for our backend systems and might be wasteful. A user typing “beanie baby” for instance may cause 11 successive searches to be performed where only one is absolutely necessary. The user experience might be fantastic, but if the user types quickly as many as 8 to 10 of those searches may never actually return results before he finishes typing.
There is another way to achieve your goals without a 10x increase in traffic while achieving the same result and as you might expect given the theme of this chapter; it involves caching. With a little work, we can cache the results of previous Ajax interactions within the client browser and potentially within our CDNs (Rule 20), page caches (Rule 23), and application caches (Rule 24). Let’s first look at how we can make sure that we leverage the cache in the browser.
Three key elements in ensuring that we can cache our content in the browser are the Cache-Control header, the Expires header, and the Last-Modified header of our HTTP response. Two of these we discussed in detail in Rule 21. For Cache-Control we want to avoid the no-store option and where possible we want to set the header to public so that any proxies and caches (such as a CDN) in between our end points (clients) and our servers can store result sets and serve them up to other requests. Of course we don’t want private data set to public, but where possible we certainly want to leverage the high degree of caching that “public” offers us.
Remember that our goal is to eliminate round-trips to both decrease user perceived response time and decrease server load. As such, the Expires header of our response should be set far enough out into the future that the browser will cache the first result locally and read from it with subsequent requests. For static or semistatic objects, such as profile images or company logos, this might be set days or more out into the future. Some objects might have greater temporal sensitivity, such as the reading of a feed of friends’ status updates. In these cases, we might set Expires headers out by seconds or maybe even minutes to both give the sense of real time behavior while reducing overall load.
The Last-Modified header helps us handle conditional GET requests. In these cases, consistent with the HTTP 1.1 protocol, the server should respond with a 304 status if the item in cache is appropriate or still valid. The key to all these points is, as the “Http” portion of the name XMLHttpRequest implies, that Ajax requests behave (or should behave) the same as any other HTTP request and response. Using our knowledge of these requests will aid us in ensuring that we increase the cacheability, usability, and scalability of all the systems that enable these requests.
While the previous approaches will help when we have content that we can modify in the browser, the problem becomes a bit more difficult when we use expanding search strings such as those we might find when a user interacts with a search page and starts typing a search string. There simply is no simple solution to this particular problem. But using public as the argument in the Cache-Control header will help to ensure that all similar search strings are cached in intermediate caches and proxies. Therefore common beginnings of search strings and common intermediate search strings have a good chance of being cached somewhere before we get them. This particular problem can be generalized to other specific objects within a page leveraging Ajax. For instance, systems that request specific objects such as an item for sale in an auction, a message in a social networking site, or an e-mail system should use specific message IDs rather than relative offsets when making requests. Relative names such as “page=3&item=2” that identify the second message in the third page of a system can change and cause coherency and consistency problems. Better terms would be “id=124556”, with this ID representing an atomic item that does not change and can be cached for this user or future users where the item is public.
Easier to solve are the cases where we know that we have a somewhat static set or even semidynamic set of items such as a limited or context-sensitive product catalog. We can fetch these results, asynchronously from the client perspective, and both cache them for later use by the same client or perhaps more importantly ensure they are cached by CDNs and intermediate caches or proxies for other clients performing similar searches.
We close this rule by giving an example of a bad response to an Ajax call and a good response. The bad response may look like this:
HTTP Status Code: HTTP/1.1 200 OK
Date: Thu, 21 Oct 2010 20:03:38 GMT
Server: Apache/2.2.9 (Fedora)
X-Powered-By: PHP/5.2.6
Expires: Mon, 26 Jul 1997 05:00:00 GMT
Last-Modified: Thu, 21 Oct 2010 20:03:38 GMT
Pragma: no-cache
Vary: Accept-Encoding,User-Agent
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8
Using our three topics, we notice that our Expires header occurs in the past. We are missing the Cache-Control header completely, and the last modified header is consistent with the date that the response was sent; together, these force all GETs to grab new content. A more easily cached Ajax result would look like this:
HTTP Status Code: HTTP/1.1 200 OK
Date: Thu, 21 Oct 2010 20:03:38 GMT
Server: Apache/2.2.9 (Fedora)
X-Powered-By: PHP/5.2.6
Expires: Sun, 26 Jul 2020 05:00:00 GMT
Last-Modified: Thu, 31 Dec 1970 20:03:38 GMT
Cache-Control: public
Pragma: no-cache
Vary: Accept-Encoding,User-Agent
Transfer-Encoding: chunked
Content-Type: text/html; charset=UTF-8
In this example, we set the Expires header out to be well into the future, set the Last-Modified header to be well into the past, and told intermediate proxies that they can cache and reuse the object for other systems through Cache-Control:public.
Rule 23—Leverage Page Caches
A page cache is a caching server you install in front of your Web servers to offload requests for both static and dynamic objects from those servers. Other common names for such a system or server are reverse proxy cache, reverse proxy server, and reverse proxy. We use the term page cache deliberately, because whereas a proxy might also be responsible for load balancing or SSL acceleration, we are simply focused on the impact that these caching servers have on our scalability. When implemented, the proxy cache looks like Figure 6.4.

Page caches handle some or all the requests until the pages or data that are stored in them is out of date or until the server receives a request for which it does not have the data. A failed request is known as a cache miss and might be a result of either a full cache with no room for the most recent request or an incompletely filled cache having either a low rate of requests or a recent restart. The cache miss is passed along to the Web server, which answers and populates the cache with the request, either replacing the least recently used record or taking up an unoccupied space.
There are three key arguments that we make in this rule. The first is that you should implement a page (or reverse proxy) cache in front of your Web servers and that in doing so you will get a significant scalability benefit. Web servers that generate dynamic content do significantly less work as calculated results (or responses) are appropriately cached for the appropriate time. Web servers that serve static content do not need to look up that content, and you can use fewer of them. We will, however, agree that the benefit of a page cache for static content isn’t nearly as great as the benefit for dynamic content.
The second point is that you need to use the appropriate HTTP headers to ensure the greatest (but also business appropriate) cache potential of your content and results. For this, refer to our brief discussion of the Cache-Control, Last-Modified, and Expires headers in Rules 21 and 22. Section 14 of RFC 2616 has a complete description of these headers, their associated arguments, and the expected results.7
Our third point is that where possible you should include another HTTP header from RFC 2616 to help maximize the cacheability of your content. This new header is known as the ETag. The ETag, or entity tag, was developed to facilitate the method of If-None-Match conditional get requests by clients of a server. ETags are unique identifiers issued by the server for an object at the time of first request by a browser. If the resource on the server side is changed, a new ETag is assigned to it. Assuming appropriate support by the browser (client), the object and its ETag are cached by the browser and subsequent If-None-Match requests by the browser to the Web server will include the tag. If the tag matches, the server may respond with an HTTP 304 Not Modified response. If the tag is inconsistent with that on the server, the server will issue the updated object and its associated ETag.
The use of an ETag is optional, but to help ensure greater cacheability within page caches as well as all other proxy caches throughout the network transit of any given page or object, we highly recommend their use.
Rule 24—Utilize Application Caches
This isn’t a section on how to develop an application cache. That’s a topic for which you can get incredible, and free, advice by performing a simple search on your favorite Internet search engine. Rather we are going to make two basic but important points:
• The first is that you absolutely must employ application level caching if you want to scale in a cost-effective manner.
• The second is that such caching must be developed from a systems architecture perspective to effective long term.
We’ll take it for granted that you agree wholeheartedly with our first point and spend the rest of this rule on our second point.
In both Rule 8 and Rule 9 (see Chapter 2), we hinted that the splitting of a platform (or an architecture) functionally by service or resource (Y Axis—Rule 8), or by something you knew about the requester or customer (Z Axis—Rule 9), could pay huge dividends in the cacheability of data to service requests. The question is which axis or rule to employ to gain what amount of benefit. The answer to that question likely changes over time as you develop new features or functions with new data requirements. The implementation approach, then, needs to change over time to accommodate the changing needs of your business. The process to identify these changing needs, however, remains the same. The learning organization needs to constantly analyze production traffic, costs per transaction, and user perceived response times to identify early indications of bottlenecks as they arise within the production environment and feed that data into the architecture team responsible for making changes.
The key question to answer here is what type of split, or refinement of a split, will gain the greatest benefit from a scalability and cost perspective? It is entirely possible that through an appropriate split implementation, and with the resulting cacheability of data within the application servers, that 100 or even 100,000 servers can handle double, triple, or even 10x the current production traffic. To illustrate this, let’s walk through a quick example of a common ecommerce site, a fairly typical SaaS site focused on servicing business needs and a social networking or social interaction site.
Our ecommerce site has a number of functions, including search, browse, image inspection (including zooming), account update, sign-in, shopping cart, checkout, suggested items, and so on. Analysis of current production traffic indicates that 80% of our transactions across many of our most heavily used functions, including searching, browsing, and suggested products, occur across less than 20% of our inventory. Here we can leverage the Pareto Principle and deploy a Y axis (functional) split for these types of services to leverage the combined high number of hits on a comparatively small number of objects by our entire user base. Cacheability will be high, and our dynamic systems can benefit from the results delivered pursuant to similar earlier requests.
We may also find out that we have a number of power users—users who are fairly frequent in their requests. For these user-specific functions, we can decide to employ a Z axis split for user-specific functionality such as sign-in, shopping cart, account update (or other account information), and so on. While we can probably hypothesize about these events, clearly it is valuable to get real production data from our existing revenue producing site to help inform our decisions.
As another example, let’s imagine that we have a SaaS business that helps companies handle customer support operations through hosted phone services, e-mail services, chat services, and a relationship management system. In this system, there are a great number of rules unique to any given business. On a per-business basis, these rules might require a great deal of memory to cache the rules and data necessary for a number of business operations. If you’ve immediately jumped to the conclusion that a customer-oriented or Z axis split is the right approach you are correct. But we also want to maintain some semblance of multitenancy both within the database and the application. How do we accomplish this and still cache our heaviest users to scale cost-effectively? Our answer, again, is the Pareto Principle. We can take the 20% of our largest businesses that might represent 80% of our total transaction volumes (such a situation exists with most of our customers) and spread them across several swimlanes of database splits. To gain cost leverage, we take the 80% of our smaller users and sprinkle them evenly across all these swimlanes. The theory here is that the companies with light utilization are going to experience low cache hit rates even if they exist among themselves. As such, we might as well take our larger customers and allow them to benefit from caching while gaining cost leverage from our smaller customers. Those smaller customer experiences aren’t going to be significantly different unless we host them on their own dedicated systems, which as we all know runs counter to the cost benefits we expect to receive in a SaaS environment.
Our last example deals with a social network or interaction site. As you might expect, we are again going to apply the Pareto Principle and information from our production environment to help guide our decisions. Social networks often involve a small number of users with an incredibly skewed percentage of traffic. Sometimes these users are active consumers, sometimes they are active producers (destinations where other people go), and sometimes they are both.
Our first step might be to identify whether there is a small percentage of information or subsites that have a disproportionately high percentage of the “read” traffic. Such nodes within our social network can help guide us in our architectural considerations and might lead us to perform Z axis splits for these producers such that their nodes of activity are highly cacheable from a read perspective. Assuming the Pareto Principle holds true (as it typically does), we’ve now serviced nearly 80% of our read traffic with a small number of servers (and potentially page/proxy caches—see Rule 23). Our shareholders are happy because we can service requests with very little capital intensity.
What about the very active producers of contents and/or updates within our social network? The answer may vary depending on whether their content also has a high rate of consumption (reads) or sits mostly dormant. In the case where these users have both high production (write/update) rates and high consumption (read) rates, we can just publish their content directly to the swimlane or node in which it is being read. If read and write conflicts start to become a concern as these “nodes” get hot, we can use read replication and horizontal scale techniques (the X axis or Rule 7), or we can start to think about how we order and asynchronously apply these updates over time (see Chapter 11, “Asynchronous Communication and Message Buses”). As we continue to grow, we can mix these techniques. If we still have troubles, after caching aggressively from the browser through CDNs to page and application caches (the rules in this chapter), we can continue to refine our splits. Maybe we enforce a hierarchy within a given user’s updates and start to split them along content boundaries (another type of Y axis split—Rule 8), or perhaps we just continue to create read replicas of data instances (X axis—Rule 7). Maybe we identify that the information that is being read has a unique geographic bias as is the case with some types of news and we begin to split the data along geolocation determined boundaries by request, which is something we know about the requester and therefore another type of Z axis split (Rule 9).
With any luck, you’ve identified a pattern in this rule. The first step is to hypothesize as to likely usage and determine ways to split to maximize cacheability. After implementing these splits in both the application and supporting persistent data stores, evaluate their effectiveness in production. Further refine your approach based on production data and iteratively apply the Pareto Principle and the AKF Scale Cube (Rules 7, 8, and 9) to refine and increase cache hit rates. Lather, rinse, repeat.
Rule 25—Make Use of Object Caches
Object caches are simply in-process data stores (usually in memory) that store a hashed summary of each item. These caches are used primarily for caching data that may be computationally expensive to regenerate, such as the result set of complex database queries. A hash function is a mathematical function that converts a large and variable-sized amount of data, into a small hash value.8 This hash value (also called a hash sum or checksum) is usually an integer that can be used as an index in an array. This is by no means a full explanation of hash algorithms as the design and implementation of them are a domain unto itself, but you can test several of these on Linux systems with cksum, md5sum, and sha1sum as shown in the following code. Notice how variable lengths of data result in consistent 128-bit hashes.
# echo 'AKF Partners' | md5sum
90c9e7fd09d67219b15e730402d092eb -
# echo 'Hyper Growth Scalability AKF Partners' | md5sum
faa216d21d711b81dfcddf3631cbe1ef -
There are many different varieties of object caches such as the popular Memcached, Apache’s OJB, and NCache just to name a few. As varied as the choice of tools are the implementations. Object caches are most often implemented between the database and the application to cache result sets from SQL queries. However, some people use object caches for results of complex application computations such as user recommendations, product prioritization, or reordering advertisements based on recent past performance. The object cache in front of a database tier is the most popular implementation because often the database is the most difficult and most expensive to scale. If you have the ability to postpone the split of a database or the purchase of a larger server, which is not a recommended approach to scaling, by implementing an object cache this is an easy decision. Let’s talk about how to decide when to pull the trigger and implement an object cache.
Besides the normal suspects of CPU and memory utilization by the database, one of the most telling pieces of data that indicates when your system is in need of an object cache is the Top SQL report. This is a generic name for any report or tool that is used to mean any report generated to show the most frequently and most resource-intensive queries run on the database. Oracle’s Enterprise Manager Grid Control has a Top SQL Assessment built in for identifying the most resource intensive SQL statements. Besides using this data to identify and prioritize the improvement of slow running queries, this data can also be used to show which queries could be eliminated from the database by adding caching. There are equivalent reports or tools either built in or offered as add-ons for all the popular databases.
Once you’ve decided you need an implementation of an object cache, you then need to choose one that best fits your needs and implement it. A word of caution for those engineering teams that at this point might be considering building a home-grown solution. There are more than enough production-grade object cache solutions to choose from. As an example, Facebook uses more than 800 servers supplying more than 28 terabytes of memory for its system.9 While there are possible reasons that might drive you to make a decision to build an object cache instead of buying/using an open source product this decision should be highly scrutinized.
The next step is to actually implement the object cache, which depending on the product selected is straightforward. Memcached supports clients for many different programming languages such as Java, Python, and PHP. In PHP the two primary commands are get and set. In the following example you can see that we connect to the memcached server. If that fails we just query the database through a function we call dbquery, not shown in the example. If the memcached connection succeeds we attempt to retrieve the $data that is associated with a particular $key. If that get fails, then we query the db and set the $data into memcached so that the next time we look for that data it is in memcached. The false flag in the set command is for compression and the 90 is for the expiration time in seconds.
$memcache = new Memcache;
If ($memcache->connect('127.0.0.1', 11211)) {
If ($data = $memcache->get('$key')) {
} else {
$data = dbquery($key);
$memcache->set('$key',$data, false, 90);
}
} else {
$data = dbquery($key);
}
The final step in implementing the object cache is to monitor it for the cache hit rate. This ratio is the number of times the system requests an object that is in the cache compared to the total number of requests. Ideally this ratio is 85% or better, meaning that the requests for objects is not in cache or expired in cache only 15% or less of the time. If the cache hit ratio drops, you need to consider adding more object cache servers.
Rule 26—Put Object Caches on Their Own “Tier”
In Rule 25 we covered the basics of implementing an object cache. We left off with you monitoring the object cache for cache hit ratio and when this dropped below ~85% we suggested that you consider expanding the object cache pool. In this rule, we’re going to discuss where to implement the object cache pool and whether it should reside on its own tier within your application architecture.
Many companies start with the object cache on the Web or application servers. This is a simple implementation that works well to get people up and running on an object cache without an investment in additional hardware or virtual instances if operating within a cloud. The downside to this is that the object cache takes up a lot of memory on the server, and it can’t be scaled independently of the application or Web tier when needed.
A better alternative is to put the object cache on its own tier of servers. This would be between the application servers and the database, if using the object cache to cache query result sets. If caching objects created in the application tier, this object cache tier would reside between the Web and application servers. See Figure 6.5 for a diagram of what this architecture would look like. This is a logic architecture in that the object cache tier could be a single physical tier of servers that are used for both database object caching as well as application object caching.
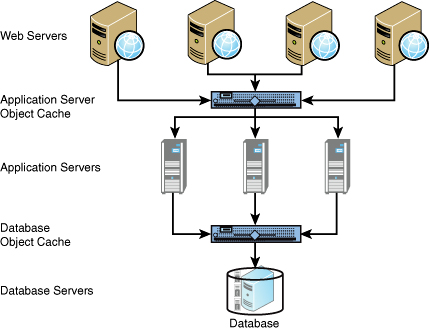
The advantage of separating these tiers is that you can size the servers appropriately in terms of how much memory and CPU are required, and you can scale the number of servers in this pool independently of other pools. Sizing the server correctly can save quite a bit of money since object caches typically require a lot of memory—most all store the objects and keys in memory—but require relatively low computational processing power. You can also add servers as necessary and have all the additional capacity utilized by the object cache rather than splitting it with an application or Web service.
Summary
In this chapter, we offered seven rules for caching. We have so many rules dedicated to this one subject because there are a myriad of caching options to consider but also because caching is a proven way to scale a system. By caching at every level from the browser through the network all the way through your application to the databases, you can achieve significant improvements in performance as well as scalability.
Endnotes
1 Akamai Solution, “Dynamic Site Accelerator,” 2008, http://www.akamai.com/dl/brochures/akamai_dsa_sb.pdf.
2 Mark Tsimelzon et al., W3C, “ESI Language Specification 1.0,” http://www.w3.org/TR/esi-lang.
3 R. Fielding et al., Networking Group Request for Comments 2616, June 1999, “Hypertext Transfer Protocol—HTTP/1.1,” http://www.ietf.org/rfc/rfc2616.txt.
4 Apache HTTP Server Version 2.0, “Apache Module mod_expires,” http://httpd.apache.org/docs/2.0/mod/mod_expires.html.
5 Apache HTTP Server Version 2.0, Apache Core Features, “KeepAlive Directive,” http://httpd.apache.org/docs/current/mod/core.html#keepalive.
6 Jesse James Garrett, “Ajax: A New Approach to Web Applications,” Adaptive Path.com, “Ideas: Essays and Newsletter,” February 18, 2005, http://www.adaptivepath.com/ideas/essays/archives/000385.php.
7 Fielding et al., Hypertext Transfer Protocol/1.1, “Header Field Definitions,” http://www.w3.org/Protocols/rfc2616/rfc2616-sec14.html.
8 Wikipedia, “Hash function,” http://en.wikipedia.org/wiki/Hash_function.
9 Paul Saab, “Scaling memcached at Facebook,” December 12, 2008, http://www.facebook.com/note.php?note_id=39391378919&ref=mf.