
4. Use the Right Tools
You may never have heard of Abraham Maslow, but there is a good chance that you know of his “law of the instrument,” otherwise known as Maslow’s hammer. Paraphrased, it goes something like “When all you have is a hammer, everything looks like a nail.” There are at least two important implications of this “law.”
The first is that we all tend to use instruments or tools with which we are familiar in solving the problems before us. If you are a C programmer, you will likely try to solve a problem or implement requirements within C. If you are a DBA, there is a good chance that you’ll think in terms of how to use a database to solve a given problem. If your job is to maintain a third-party ecommerce package, you might try to solve nearly any problem using that package rather than simpler solutions that might require a two to three line interpreted shell script.
The second implication of this law really builds on the first. If, within our organizations we consistently bring in people of similar skill sets to solve problems or implement new products, we will very likely get consistent answers built with similar tools and third-party products. The problem with such an approach is that while it has the benefit of predictability and consistency, it may very well drive us to use tools or solutions that are inappropriate or suboptimal for our task. Let’s imagine we have a broken sink. Given Maslow’s hammer, we would beat on it with our hammer and likely cause further damage. Extending this to our topic of scalability, why would we want to use a database when just writing to a file might be a better solution? Why would we want to implement a firewall if we are only going to block certain ports and we have that ability within our routers? Let’s look at a few scalability related “tools rules.”
Rule 14—Use Databases Appropriately
Relational database management systems (RDBMSs), such as Oracle and MySQL, are based on the relational model introduced by Edgar F. Codd in his 1970 paper “A Relational Model of Data for Large Shared Data Banks.” Most RDBMSs provide two huge benefits for storing data. The first is the guarantee of transactional integrity through ACID properties, see Table 2.1 in Chapter 2, “Distribute Your Work,” for definitions. The second is the relational structure within and between tables. To minimize data redundancy and improve transaction processing, the tables of most Online Transaction Processing databases (OLTP) are normalized to Third Normal Form, where all records of a table have the same fields, nonkey fields cannot be described by only one of the keys in a composite key, and all nonkey fields must be described by the key. Within the table each piece of data is highly related to other pieces of data. Between tables there are often relationships known as foreign keys. While these are two of the major benefits of using an RDBMS, these are also the reason for their limitations in terms of scalability.
Because of this guarantee of ACID properties, an RDBMS can be more challenging to scale than other data stores. When you guarantee consistency of data and you have multiple nodes in your RDBMS cluster, such as with MySQL NDB, synchronous replication is used to guarantee that data is written to multiple nodes upon committing the data. With Oracle RAC there is a central database, but ownership of areas of the DB are shared among the nodes so write requests have to transfer ownership to that node and reads have to hop from requestor to master to owner and back. Eventually you are limited by the number of nodes that data can be synchronously replicated to or by their physical geographical location.
The relational structure within and between tables in the RDBMS makes it difficult to split the database through such actions as sharding or partitioning. See Chapter 2 for rules related to distributing work across multiple machines. A simple query that joined two tables in a single database must be converted into two separate queries with the joining of the data taking place in the application to split tables into different databases.
The bottom line is that data that requires transactional integrity or relationships with other data are likely ideal for an RDBMS. Data that requires neither relationships with other data nor transactional integrity might be better suited for other storage systems. Let’s talk briefly about a few of the alternative storage solutions and how they might be used in place of a database for some purposes to achieve better, more cost-effective, and more scalable results.
One often overlooked storage system is a file system. Perhaps this is thought of as unsophisticated because most of us started programming by accessing data in files rather than databases. Once we graduated to storing and retrieving data from a database we never looked back. File systems have come a long way, and many are specifically designed to handle very large amounts of files and data. Some of these include Google File System (GFS), MogileFS, and Ceph. File systems are great alternatives when you have a “write once-read many” system. Put another way, if you don’t expect to have conflicting reads and writes over time on a structure or object and you don’t need to maintain a great deal of relationships, you don’t really need the transactional overhead of a database; file systems are a great choice for this kind of work.
The next set of alternative storage strategies is termed NoSQL. Technologies that fall into this category are often subdivided into key-value stores, extensible record stores, and document stores. There is no universally agreed classification of technologies, and many of them could accurately be placed in multiple categories. We’ve included some example technologies in the following descriptions, but this is not to be considered gospel. Given the speed of development on many of these projects, the classifications are likely to become even more blurred in the future.
Key-value stores include technologies such as Memcached, Tokyo Tyrant, and Voldemort. These products have a single key-value index for data and that is stored in memory. Some have the capability to write to disk for persistent storage. Some products in this subcategory use synchronous replication across nodes while others are asynchronous. These offer significant scaling and performance by utilizing a simplistic data store model, the key-value pair, but this is also a significant limitation in terms of what data can be stored. Additionally, the key-value stores that rely on synchronous replication still face the limitations that RDBMS clusters do, which are a limit on the number of nodes and their geographical locations.
Extensible record stores include technologies such as Google’s proprietary BigTable and Facebook’s, now open source, Cassandra. These products use a row and column data model that can be split across nodes. Rows are split or sharded on primary keys, and columns are broken into groups and placed on different nodes. This method of scaling is similar to the X and Y axes in the AKF Scale Cube, shown in Figure 2.1 in Chapter 2, where the X axis split is read replicas, and the Y axis is separating the tables by services supported. In these products row sharding is done automatically, but column splitting requires user definitions, similar to how it is performed in an RDBMS. These products utilize an asynchronous replication providing eventual consistency. This means that eventually, which may take milliseconds or hours, the data will become consistent across all nodes.
Document stores include technologies such as CouchDB, Amazon’s SimpleDB, and Yahoo’s PNUTS. The data model used in this category is called a “document” but is more accurately described as a multi-indexed object model. The multi-indexed object (or “document”) can be aggregated into collections of multi-indexed objects (typically called “domains”). These collections or “domains” in turn can be queried on many different attributes. Document store technologies do not support ACID properties; instead, they utilize asynchronous replication, providing an eventually consistent model.
NoSQL solutions limit the number of relationships between objects or entities to a small number. It is this reduction of relationships that allows for the systems to be distributed across many nodes and achieve greater scalability while maintaining transactional integrity and read-write conflict resolution.
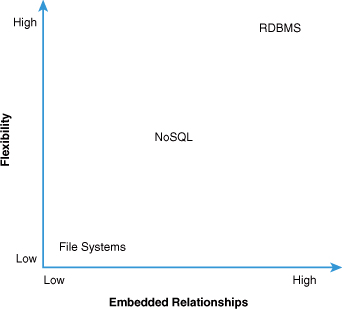
As is so often the case, and as you’ve probably determined reading the preceding text, there is a tradeoff between scalability and flexibility within these systems. The degree of relationship between data entities ultimately drives this tradeoff; as relationships increase, flexibility also increases. This flexibility comes at an increase in cost and a decrease in the ability to easily scale the system. Figure 4.1 plots RDBMS, NoSQL, and file systems solutions against both the costs (and limits) to scale the system and the degree to which relationships are used between data entities. Figure 4.2 plots flexibility against the degree of relationships allowed within the system. The result is clear: Relationships engender flexibility but also create limits to our scale. As such, we do not want to overuse relational databases but rather choose a tool appropriate to the task at hand to engender greater scalability of our system.
Figure 4.1. Cost and limits to scale versus relationships

Figure 4.2. Flexibility versus relationships
Another data storage alternative that we are going to cover in this rule is Google’s MapReduce.1 At a high level, MapReduce has both a Map and a Reduce function. The Map function takes a key-value pair as input and produces an intermediate key-value pair. The input key might be the name of a document or pointer to a piece of a document. The value could be content consisting of all the words within the document itself. This output is fed into a reducer function that uses a program that groups the words or parts and appends the values for each into a list. This is a rather trivial program that sorts and groups the functions by key. The huge benefit of this technology is the support of distributed computing of very large data sets across many servers.
An example technology that combines two of our data storage alternatives is Apache’s Hadoop. This was inspired by Google’s MapReduce and Google File System, both of which are described previously. Hadoop provides benefits of both a highly scalable file system with distributed processing for storage and retrieval of the data.
So now that we’ve covered a few of the many options that might be preferable to a database when storing data, what data characteristics should you consider when making this decision? As with the myriad of options available for storage, there are numerous characteristics that should be considered. A few of the most important ones are the number of degree of relationships needed between elements, the rate of growth of the solution, and the ratio of reads to writes of the data (and potentially whether data is updated). Finally we are interested in how well the data monetizes (that is, is it profitable?) as we don’t want our cost of the system to exceed the value we expect to achieve from it.
The degree of relationships between data is important as it drives flexibility, cost, and time of development of a solution. As an example, imagine the difficulty of storing a transaction involving a user’s profile, payment, purchase, and so on, in a key-value store and then retrieving the information piecemeal such as through a report of purchased items. While you can certainly do this with a file system or NoSQL alternative, it may be costly to develop and time consuming in delivering results back to a user.
The expected rate of growth is important for a number of reasons. Ultimately this rate impacts the cost of the system and the response times we would expect for some users. If a high degree of relationships are required between data entities, at some point we will run out of hardware and processing capacity to support a single integrated database, driving us to split the databases into multiple instances.
Read and write ratios are important as they help drive an understanding of what kind of system we need. Data that is written once and read many times can easily be put on a file system coupled with some sort of application, file, or object cache. Images are great examples of systems that typically can be put on file systems. Data that is written and then updated, or with high write to read ratios, are better off within NoSQL or RDBMS solutions.
These considerations bring us to another cube, Figure 4.3, where we’ve plotted the three considerations against each other. Note that as the X, Y, and Z axes increase in value, so does the cost of the ultimate solution increase. Where we require a high degree of relationships between systems (upper right and back portion of Figure 4.3), rapid growth, and resolution of read and write conflicts we are likely tied to several smaller RDBMS systems at relatively high cost in both our development and the systems, maintenance, and possibly licenses for the databases. If growth and size are small but relationships remain high and we need to resolve read and write conflict, we can use a single monolithic database (with high availability clustering).
Figure 4.3. Solution decision cube

Relaxing relationships slightly allows us to use NoSQL alternatives at any level of reads and writes and with nearly any level of growth. Here again we see the degree to which relationships drive our cost and complexity, a topic we explore later in Chapter 8, “Database Rules.” Cost is lower for these NoSQL alternatives. Finally, where relationship needs are low and read-write conflict is not a concern we can get into low-cost file systems to provide our solutions.
Monetization value of the data is critical to understand because as many struggling startups have experienced, storing terabytes of user data for free on class A storage is a quick way to run out of capital. A much better approach might be using tiers of data storage; as the data ages in terms of access date, continue to push it off to cheaper and slower access storage media. We call this the Cost-Value Data Dilemma, which is where the value of data decreases over time and the cost of keeping it increases over time. We discuss this dilemma more in Rule 47 and describe how to solve the dilemma cost effectively.
Rule 15—Firewalls, Firewalls Everywhere!
The decision to employ security measures should ultimately be viewed from the lens of profit maximization. Security in general is an approach to reduce risk. Risk in turn is a function of both the probability that an action will happen and the impact or damage the action causes should it happen. Firewalls help to manage risk in some cases by reducing the probability that an event happens. They do so at some additional capital expense, some impact to availability (and hence either transaction revenue or customer satisfaction), and often an additional area of concern for scalability: the creation of a difficult to scale chokepoint in either network traffic or transaction volume. Unfortunately, far too many companies view firewalls as an all or nothing approach to security. They overuse firewalls and underuse other security approaches that would otherwise make them even more secure. We can’t understate the impact of firewalls to availability. In our experience, failed firewalls are the number two driver of site downtime next to failed databases. As such, this rule is about reducing them in number. Remember, however, that there are many other things that you should be doing for security while you look to eliminate any firewalls that are unnecessary or simply burdensome.
In our practice, we view firewalls as perimeter security devices meant to increase both the perceived and actual cost of gaining entry to a product. In this regard, they serve a similar purpose as the locks you have on the doors to your house. In fact, we believe that the house analogy is appropriate to how one should view firewalls, so we’ll build on that analogy here.
There are several areas of your house that you don’t likely lock up—for example, you probably don’t lock up your front yard. You probably also leave certain items of relatively low value in front of your house, such as hoses and gardening implements. You may also leave your vehicle outside even though you know it is more secure in your garage given how quickly most thieves can bypass vehicle security systems. More than likely you have locks and maybe deadbolts on your exterior doors and potentially smaller privacy locks on your bathrooms and bedrooms. Other rooms of your house, including your closets, probably don’t have locks on them. Why the differences in our approaches?
Certain areas outside your house, while valuable to you, simply aren’t of significant value for someone else to steal them. You really value your front yard but probably don’t think someone’s going to come with a shovel and dig it up to replant elsewhere. You might be concerned with someone riding a bicycle across it and destroying the grass or the sprinkler head, but that concern probably doesn’t drive you to incur the additional cost of fencing it (other than a decorative picket fence) and destroying the view for both you and others within the neighborhood.
Your interior doors really only have locks for the purpose of privacy. Most of the interior doors don’t have locks meant to keep out an interested and motivated intruder. We don’t lock and deadbolt most of our interior doors because these locks present more of a hassle to us as occupants of the house, and the additional hassle really isn’t worth the additional security provided by such locks.
Now consider your product. Several aspects, such as static images, .css files, JavaScript, and so on, are important to you but don’t really need high-end security. In many cases, you likely look to deliver these attributes via an edge-cache (or content delivery network) outside your network anyway (see Chapter 6, “Use Caching Aggressively”). As such, we shouldn’t subject these objects to an additional network hop (the firewall), the associated lower overall availability, and its scale limiting attributes of an additional network chokepoint. We can save some money and reduce the load on our firewalls simply by ensuring that these objects are delivered from private IP addresses and only have access via port 80 and 443.
Returning to the value and costs of firewalls, let’s explore a framework by which we might decide when and where to implement firewalls. We’ve indicated that firewalls cost us in the following ways: There is a capital cost to purchase the firewall, they create an additional item that needs to be scaled, and they represent an impact to our availability as it is one more device on the critical route of any transaction that can fail and cause problems. We’ve also indicated that they add value when they are used to deter or hinder the efforts of those who would want to steal from us or harm our product. Table 4.1 shows a matrix indicating some of the key decision criteria for us in implementing firewalls.
Table 4.1. Firewall Implementation Matrix

The first thing that you might notice is that we’ve represented value to the bad guy and cost to firewall as having a near inverse relationship. While this relationship won’t always be true, in many of our clients’ products it is the case. Static object references tend to represent a majority of object requests on a page and often are the heaviest elements of the pages. As such they tend to be costly to firewall given the transaction rate and throughput requirements. They are even more costly when you consider that they hold very little value to a potential bad guy. Given the high cost in terms of potential availability impact and capital relative to the likelihood that they are the focus of a bad guy’s intentions, it makes little sense for us to invest in their protection. We’ll just ensure that they are on private IP space (for example, 10.X.Y.Z addresses or the like) and that the only traffic that gets to them are requests for ports 80 and 443.
On the flip side we have items like credit cards, bank account information, and social security numbers. These items have a high perceived value to our bad guy. They are also less costly to protect relative to other objects as they tend to be requested less frequently than many of our objects. We absolutely should lock these things away!
In the middle are all the other requests that we service within our platform. It probably doesn’t make a lot of sense to ensure that every search a user performs goes through a firewall. What are we protecting? The actual servers themselves? We can protect our assets well against attacks such as distributed denial of service attacks with packet filters, routers, and carrier relationships. Other compromises can be thwarted by limiting the ports that access these systems. If there isn’t a huge motivation for a bad guy to go after the services, let’s not spend a lot of money and decrease our availability by pretending that they are the crown jewels.
In summation, don’t assume that everything deserves the same level of protection. The decision to employ firewalls is a business decision focused on decreasing risk at the cost of decreasing availability and increasing capital costs. Too many companies view firewalls as a unary decision—if it exists within our site it must be firewalled when in fact firewalls are just one of many tools you might employ to help decrease your risk. Not everything in your product is likely deserving of the cost and impact to availability that a firewall represents. As with any other business decision, this one should be considered in the light of these tradeoffs, rather than just assuming a cookie-cutter approach to your implementation. Given the nature of firewalls, they can easily become the biggest bottleneck from a scale perspective for your product.
Rule 16—Actively Use Log Files
In the spirit of using the right tools for the job, one of the tools that is likely in all our toolboxes but often gets overlooked are log files. Unless you’ve purposely turned off logging on your Web or application servers almost all varieties come with error and access logs. Apache has error and access logs, Tomcat has java.util.logging or Log4j logs, and Websphere has SystemErr and SystemOut logs. These logs can be incredibly valuable tools for providing insights into the performance and problems occurring within your application that might prevent it from scaling. To best use this tool there are a few simple but important steps to follow.
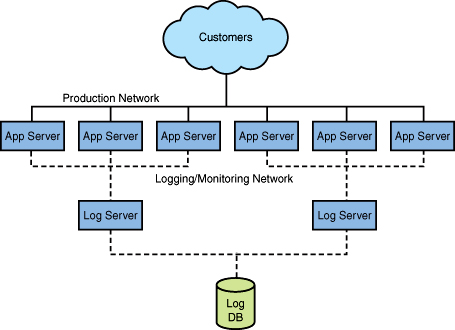
The first step in using log files is to aggregate them. As you probably have dozens or perhaps even hundreds of servers, you need to pull this data together to use it. If the amount of data is too large to pull together there are strategies such as sampling, pulling data from every nth server, which can be implemented. Another strategy is to aggregate the logs from a few servers onto a log server that can then transmit the semi-aggregated logs into the final aggregation location. As shown in Figure 4.4, dedicated log servers can aggregate the log data to then be sent to a data store. This aggregation is generally done through an out-of-band network that is not the same network used for production traffic. What we want to avoid is impacting production traffic from logging, monitoring, or aggregating data.
The next step is to monitor these logs. Surprisingly many companies spend the time and computational resources to log and aggregate but then ignore the data. While you can just use log files during incidents to help restore service, this isn’t optimal. A preferred use is to monitor these files with automated tools. This monitoring can be done through custom scripts such as a simple shell script that greps the files, counting errors and alerting when a threshold is exceeded. More sophisticated tools such as Cricket or Cacti include graphing capabilities. A tool that combines the aggregation and monitoring of log files is Splunk.
Once you’ve aggregated the logs and monitored them for errors, the last step is to take action to fix the problems. This requires assigning engineering and QA resources to identify common errors as being related to individual problems. It is often the case that one bug in an application flow can result in many different error manifestations. The same engineers who identified the bug might also get assigned to fix it, or other engineers might get assigned the task.
We’d like to have the log files completely free of errors, but we know that’s not always possible. While it’s not uncommon to have some errors in application log files you should establish a process that doesn’t allow them to get out of control or ignored. Some teams periodically, every third or fourth release, clean up all miscellaneous errors that don’t require immediate actions. These errors might be something as simple as missing redirect configurations or not handling known error conditions in the application.
We must also remember that logging comes at some cost. Not only is there a cost in keeping additional data, but very often there is a cost in terms of transaction response times. We can help mitigate the former by summarizing logs over time and archiving and purging them as their value decreases (see Rule 47). We can help minimize the former by logging in an asynchronous fashion. Ultimately we must pay attention to our costs for logging and make a cost-effective decision of both how much to log and how much data to keep.
Hopefully we’ve convinced you that log files are an important tool in your arsenal of debugging and monitoring your application. By simply using a tool that you likely already have, you can greatly improve your customer experience and scalability of your application.
Summary
Using the right tool for the job is important in any discipline. Just as you wouldn’t want your plumber to bring only a hammer into your house to fix your pipes, your customers and investors don’t want you to bring a single tool to solve problems with diverse characteristics and requirements. Avoid falling prey to Maslow’s hammer and bring together diverse teams capable of thinking of different solutions to problems. A final word of caution on this topic is that each new technology introduced requires another skill set to support. While the right tool for the job is important, don’t overspecialize to the point that you have no depth of skills to support your systems.
Endnotes
1 Jeffrey Dean and Sanjay Ghernawat, “Map Reduce: Simplified Data Processing on Large Clusters,” Google Research Publications, http://labs.google.com/papers/mapreduce.html.