
12. Miscellaneous Rules
We’re not going to lie to you—we ran out of themes and catchy titles for the rules in this chapter. But even without a theme these rules are important. Two of these rules deal with the competencies of your team; one cautions you not to over-rely on third-party solutions for scale, and the other urges you to build the necessary competencies to be world class for each portion of your technology architecture and infrastructure. One rule outlines the foolishness of relying on stored procedures for business logic, including the hazards to scale and long-term costs to your company. Yet another rule examines the need for products to be designed from day one with monitoring in mind.
Rule 46—Be Wary of Scaling Through Third Parties
As you climb the management track in technology organizations you invariably start to attend vendor meetings and eventually get solicited by vendors almost constantly. In a world where global IT spending of over $781 billion fell 6.9% in 2009,1 you can safely bet that vendors are recruiting the best salespeople possible and are working their hardest to sell you their products and services. These vendors are often sophisticated in their approaches and truly consider it a long-term relationship with clients. Unfortunately, this long-term relationship is actively managed for the clients to end up spending more and more with the vendor. This is all great business and we don’t fault the vendors for trying, but we do want to caution you as a technologist or business leader to be aware of the pros and cons of relying on vendors to help you scale. We’re going to cover three reasons that you should avoid relying on vendors to scale.
First, we believe that you should want the fate of your company, your team, and your career in your own hands. Looking for vendors to relieve you of this burden will likely result in a poor outcome because to the vendor you’re just one of many customers so they are not going to respond to your crisis like you will respond. As a CTO or technology leader, if the vendor you vetted and selected fails, causing downtime for your business, you are just as responsible as if you had written every line of code. All code has bugs, even vendor provided code, and if you don’t believe this ask the vendor for how many patches they’ve produced for a specific version. Just like all code the patches are 99% bug fixes with the major versions reserved for new features. We would rather have the source code to fix a problem than have to rely on a vendor to find the problem and provide you with a patch, which often takes days if it ever occurs. This should not be taken to imply that you should do everything yourself such as writing your own database or firewall. Use vendors for things that they can do better than you and that are not part of your core competency. Ultimately we are talking about ensuring that you can split up your application and product to allow it to scale as scaling should be a core competency of yours.
Second, with scalability, as with most things in life, simple is better. We teach a simple cube (see Chapter 2, “Distribute Your Work”) to understand how to build scalable architectures. The more complex you make your system the more you are likely to suffer from availability issues. More complex systems are more difficult and more costly to maintain. Clustering technologies are much more complex than straightforward log shipping for creating read replicas. Recall Rules 1 and 3 from this book: Do not overengineer the solution and simplify the solution three times over.
Third, let’s talk about the real total cost of trying to scale with vendors. One of our architectural principles, and should be one of yours as well, is that the most cost-effective way to scale is to be vendor neutral. Locking yourself into a single vendor gives them the upper hand in negotiations. We’re going to pick on database vendors for a bit, but this discussion applies to almost all technology vendors. The reason database companies build additional features into their systems is that their revenue streams faster than just the adoption of new customers would normally allow. The way to achieve this is through a technique called up-selling and involves getting existing customers to purchase more or additional features or services.
One of the most prevalent add-on features for databases is clustering. It’s a perfect feature in that it supposedly solves a problem that customers who are growing rapidly need solving—scalability of the customer’s platform. Additionally, it is proprietary, meaning that once you start using one vendor’s clustering service you can’t just switch to another’s solution. If you’re a CTO of a hyper growth company that needs to continue producing new features for your customers and might not be that familiar with scaling architectures, when a vendor waltzes in and tells you that they have a solution to your biggest, scariest problem, you’re anxious to jump on board with them. And, often the vendor will make the jump very easy by throwing in this additional feature for the first year contract. The reason they do this is that they know this is the hook. If you start scaling with their technology solution you’ll be reluctant to switch, and they can increase prices dramatically with you having very few alternatives.
For these three reasons, control of your own destiny, additional complexity, and total cost of ownership, we implore you to consider scaling without relying on vendors. The rules in this book should more than adequately arm you and your team with the knowledge to get started scaling in a simple but effective manner.
Rule 47—Purge, Archive, and Cost-Justify Storage
Storage has been getting cheaper, faster, and denser just as processors have been getting faster and cheaper. As a result, some companies and many organizations within companies just assume that storage is virtually free. In fact, a marketing professional asked us in 2002 why we were implementing mail file size maximum constraints while companies like Google and Yahoo! were touting free unlimited personal e-mail products. Our answer was twofold and forms the basis for this rule. First, the companies offering these solutions expected to make money off their products through advertising, whereas it was unclear how much additional revenue the marketing person was committing to while asking for more storage. Second, and most importantly, while the marketing professional considered a decrease in cost to be virtually “free,” the storage in fact still costs money in at least three ways: The storage itself costs money to purchase, the space it occupied costs us money (or lost opportunity relative to higher value services where we owned the space), and the power and HVAC to spin and cool the drives was increasing rather than decreasing in cost on a per-unit basis.
Discussing this point with our marketing colleague, we came upon a shared realization and a solution to the problem. The realization was that not every piece of data (or e-mail), whether it be used for a product or to run an IT back office system, is of equivalent value. We hinted at this concept in Chapter 11, “Asynchronous Communication and Message Buses,” Rule 44, while discussing message buses and asynchronous communication. Order history in commerce systems provides a great example of this concept; the older the data the less meaningful it is to our business and our customer. Our customers aren’t likely to go back and view purchase data that is ten years, five years, or possibly even two years old, and even if they are the frequency of that viewing is likely to decay over time. Furthermore, that data isn’t likely as meaningful to our business in determining product recommendations as more recent purchase information (except in the case of certain durable goods that get replaced in those intervals like vehicles). Given this reduction in value both to the customer and to our business, why would we possibly want to store it on systems that cost us the same as more recent data?
The solution was to apply a marketing concept known as RFM, which stands for recency, frequency, and monetization analysis. Marketing gurus use this technique to make recommendations to people or send special offers to keep high value customers happy or to “reactivate” those who haven’t been active recently. The concept is extensible to our storage needs (or as the case may be our storage woes). Many of our clients tell us that the largest growing portion of their budget and in some cases the largest single component of their budget is storage. We’ve applied this RFM technique within their businesses to help both mature their understanding of the data residing on their storage subsystems and ultimately solve the problem through a tiered storage archival and purge strategy.
First we need an understanding of the meaning of the terms within RFM analysis. Recency accounts for how recently the data item in question has been accessed. This might be a file in your storage system or rows within a database. Frequency speaks to how frequently that data is accessed. Sometimes this is captured as the mean period between access and the rough inverse of this—the number of accesses over some time interval. Monetization is the value that a specific piece of data has to your business in general. When applied to data, these three terms help us calculate overall business value and access speeds. As you might expect, we are moving toward applying our proprietary cube to yet another problem! By matching the type of storage to the value of the data in an RFM-like approach, we might have a cube that has high cost storage mapped to high value data in the upper right and an approach to delete and/or archive data in the bottom left. The resulting cube is shown in Figure 12.1.
Figure 12.1. AKF Scale Cube applied to RFM storage analysis
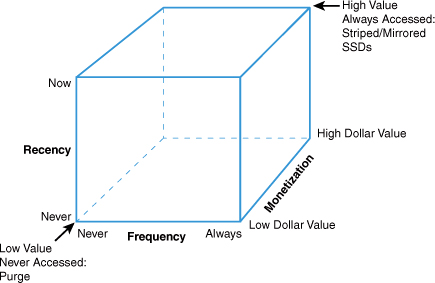
The X axis of our repurposed cube addresses the frequency of access. The axis moves from data that is “never” (or very infrequently) accessed to that which is accessed constantly or always. The Y axis of the cube identifies recency of access and has low values of never to high values of the data being accessed right now. The Z axis of the cube deals with monetization, from values of no value to very high value. Using the cube as a method of analysis, one could plot potential solutions along the multiple dimensions of the cube. Data in the lower left and front portion of the cube has no value and was never accessed, meaning that we should purge this data if regulatory conditions allow us to do so. Why would we incur a cost for data that won’t return value to our business? The upper right and back portion of our three-dimensional cube identifies the most valuable pieces of business data. We strive to store these on the solutions with the highest reliability and fastest access times such that the transactions that use them can happen quickly for our clients. Ideally we would cache this data somewhere as well as having it on a stable storage solution, but the underlying storage solution might be the fastest solid state disks that current technology supports. These disks might be striped and mirrored for access speed and high availability.
The product of our RFM analysis might yield a score for the value of the data overall. Maybe it’s as simple as a product or maybe you’ll add some magic of your own that actually applies some dollar value to the resulting score. If we employed this dollar value score to a value curve that matched the resulting RFM value to the cost of a solution to support it we might end up with a diagram similar to that of Figure 12.2.
Figure 12.2. RFM value, cost, and solution curve
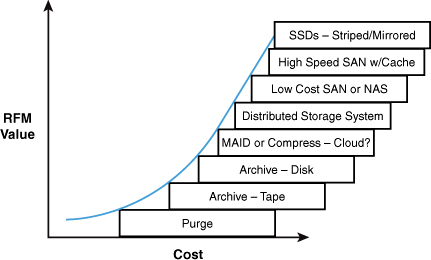
We purge very low value data, just as we did in our analysis of the cube of Figure 12.1. Low value data goes on low cost systems with slow access times. If you need to access it, you can always do it offline and e-mail a report or whatever to the requester. High value systems might go on very fast but relatively costly SSDs or some storage area network equivalent. The curve of Figure 12.2 is purely illustrative and was not developed with actual data. Because data varies in value across businesses, and because the cost of the solutions to support this data change over time, you should develop your own solution. Some data might need to be kept for some period of time due to regulatory or legal reasons. In these cases we look to put the data on the cheapest solution possible to meet our legal/regulatory requirements while not making the data dilutive in terms of shareholder value.
It is important to keep in mind that data ages, and the RFM cube recognizes this fact. As a result, it isn’t a one-time analysis but rather a living process. As datum ages and decays in value, so too do we want to move it to storage cost consistent with that declining value. As such, we need to have processes and procedures to “archive” data or to move it to lower cost systems. In rare cases, data may actually increase in value with age and so we may also need systems to move data to higher cost (more reliable and faster) storage over time. Make sure you address these needs in your architecture.
Rule 48—Remove Business Intelligence from Transaction Processing
We often tell our clients to steer clear of stored procedures within relational databases. One of their first questions is typically “Why do you hate stored procedures so much?” The truth is that we don’t dislike stored procedures. In fact, we’ve used them with great effect on many occasions. The problem is that stored procedures are often overused within solutions, and this overuse sometimes causes scalability bottlenecks in systems that would otherwise scale efficiently and almost always results in a very high cost of scale. Given the emphasis on databases, why didn’t we put this rule in the chapter on databases? The answer is that the drivers of our concerns over stored procedures are really driven by the need to separate business intelligence and product intelligence from transaction processing. In general, this concept can be further abstracted to “Keep like transactions together (or alternatively separate unlike transactions) for the highest possible availability and scalability and best possible cost.” Those are a lot of words for a principle, so let’s first return to our concern over stored procedures and databases as an illustration as to why this separation should occur.
Databases tend to be one of the most expensive systems or services within your architecture. Even in the case where you are using an open source database, in most cases the servers upon which these systems exist are attached to a relatively high cost storage solution (compared to other solutions you might own), have the fastest and largest number of processors, and have the greatest amount of memory. Often, in mature environments, these systems are tuned to do one thing well—perform relational operations and commit transactions to a stable storage engine as quickly as possible. The cost per compute cycle on these systems tends to be higher than the remainder of the solutions or services within a product’s architecture (for example, application servers or Web servers). These systems also tend to be the points at which certain services converge and the defining points for a swimlane. In the most extreme sense, such as in a young product, they might be monolithic in nature and as a result the clear governor of scale for the environment.
For all these reasons, using this expensive compute resource for business logic makes very little sense. Each transaction will only cost us more as the system is more expensive to operate. The system is likely also a governor to our scale, so why would we want to steal capacity by running other than relational transactions on it? For all these reasons, we should limit these systems to database (or storage related or NoSQL) transactions to allow the systems to do what they do best. In so doing we can both increase our scalability and reduce our cost for scale.
Using the database as a metaphor, we can apply this separation of dissimilar services to other pieces of our architecture. We very likely have back office systems that perform functions like e-mail sending and receiving (nonplatform related), general ledger and other accounting activities, marketing segmentation, customer support operations, and so on. In each of these cases, we may be enticed to simply bolt these things onto our platform. Perhaps we want a transaction purchased in our ecommerce system to immediately show up in our CFO’s Enterprise Resource Planning system. Or maybe we want it to be immediately available to our customer support representatives in case something goes wrong with the transaction. Similarly, if we are running an advertising platform we might want to analyze data from our data warehouse in real time to suggest even better advertising. There are a number of reasons why we might want to mix our business process related systems with our product platform. We have a simple answer: Don’t do it.
Ideally we want these systems to scale independently relative to their individual needs. By tying these systems together, each of them needs to scale at the same rate as the system making requests of them. In some cases, as was the case with our database performing business logic, the systems may be more costly to scale. This is often the case with ERP systems that have licenses associated with CPUs to run them. Why would we possibly want to increase our cost of scale by making a synchronous call to the ERP system for each transaction? Moreover, why would we want to reduce the availability of our product platform by adding yet another system in series as we discussed in Chapter 9, “Design for Fault Tolerance and Graceful Failure,” Rule 38?
Just as product intelligence should not be placed on databases, business intelligence should not be tied to product transactions. There are many cases where we need that data resident within our product, and in those cases we should do just that—make it resident within the product. We can select data sets from these other systems and represent them appropriately within our product offering. Often this data will be best served with a new or different representation—sometimes of a different normal form. Very often we need to move data from our product back to our business systems such as in the case of customer support systems, marketing systems, data warehouses, and ERP systems. In these cases, we will also likely want to summarize and/or represent the data differently. Furthermore, to increase our availability we will want these pieces of data moved asynchronously back and forth between the systems. ETL, or extract, transform, and load, systems are widely available for such purposes, and there are even open source tools available to allow you to build your own ETL processes.
And remember that asynchronous does not mean “old” or “stale” data. There is little reason why you can select elements of data over small time periods and move them around between systems. Additionally, you can always publish the data on some sort of message bus for use on these other systems. The lowest cost solution will be batch extraction, but if temporal constraints don’t allow such cost-efficient movement then message buses are absolutely an appropriate solution. Just remember to revisit our rules on message buses and asynchronous transactions in Chapter 11.
Rule 49—Design Your Application to Be Monitored
When it comes to monitoring, most SaaS companies start by installing one of the open source monitoring tools such as Cacti, Ntop, or Nagios, just to name a few. This is a great way to check in on network traffic or the servers’ CPU and memory but requires someone to pay attention to the monitors. The next step for most companies is to set up an automatic alerting system, which is a nice step forward. The problem with this scenario is that if you follow these steps by now you’re at a point where you are paging out at least one person in the middle of the night when a server starts consuming too much memory. If your reaction is “great!” then let me ask the question “Is there a problem with your site?” The reality is that you don’t know.
Just because a server has a high CPU or memory utilization does not mean that your customers are having any issue with your site at all. And while reacting to every bump in the night on your system is better than ignoring them, the best solution is to actually know the impact of that bump on your customers to determine the most appropriate response. The way to achieve this is to monitor your system from the perspective of a business metric. For example, if you have an ecommerce site you might want to monitor the number of items put into shopping carts or the total value of purchases per time period (sec, minute, 10 mins, and so on). For an auction site you might want to monitor the number of items listed or the number of searches performed per time period. The correct time period is the one that smoothes out the data points enough that the normal variation doesn’t obscure real issues. When you plot these business metrics on a graph against the data from a week ago (week-over-week) you can start to easily see when there is a problem.
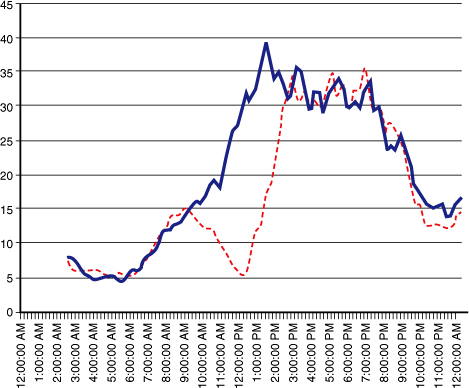
Figure 12.3 shows a graph of new account signups for a site. The solid line represents data from last week, and the dotted line represents data from this week. Notice the drop starting around 9:00 a.m. and lasting until 3:00 p.m. From this graph it is obvious that there was a problem. If the cause of this problem had been a network issue with your ISP, monitoring your servers would not have caught this. Their CPU and memory would have been fine during these six hours because very little processing was taking place on them. The next step after plotting this data is to put an automated check that compares today’s values against last week’s and alerts when it is out of statistical significance.2
Figure 12.3. Monitoring business metrics
Once you know there is a problem affecting your customers, you can react appropriately and start asking the other questions that monitoring is designed to answer. These questions include “Where is the problem?” and “What is the problem?” Figure 12.4 shows two triangles. The one on the left represents the scope of the question being asked, and the one on the right represents how much data is required to answer that question. Answering the question “Is there a problem?” doesn’t require much data but is very large in terms of scope. This as we previously discussed is best answered by monitoring business metrics. The next question “Where is the problem?” requires more data, but the scope is smaller. This is the level at which monitoring of the application will help answer this question. We cover this in more detail later in the chapter. The last question “What is the problem?” requires the most data but is the most narrow in scope. This is where the Nagios, Cacti, and so on can be used to answer the question.
Figure 12.4. Monitoring scope versus amount of data

Rule 16 covered the importance of trapping exceptions, logging them, and monitoring the logs. We’re going to expand on the concept by discussing how you not only should catch errors and exceptions but also should adopt as an architectural principle the concept of “design to be monitored.” This simply stated is the idea that your application code should make it easy to place hooks in for watching the execution of transactions such as SQL, API, RPC, or method calls. Some of the best monitored systems have asynchronous calls before and after a transaction to record the start time, transaction type, and end time. These are then posted on a bus or queue to be processed by a monitoring system. Tracking and plotting this data can yield all types of insights into answering the question of “Where is the problem?”
Once you’ve mastered answering these three questions of “Is there a problem?”; “Where is the problem?”; and “What is the problem?” there are a couple of advanced monitoring questions that you can start to ask. The first is “Why is there a problem?” This question usually gets asked during the postmortem process as discussed in Rule 30. When performing continuous deployments, answering this problem requires a much faster cycle than a typical postmortem. Your organization must integrate learning from answering “Why” into the next hour’s code release. Insights from answering this question might include adding another test to the smoke or regression test to ensure future bugs similar to this one get caught before being deployed.
A final question that monitoring can help answer is “Will there be a problem?” This type of monitoring requires the combination of business monitoring data, application monitoring data, and hardware monitoring data. Using statistical tools such as control charts or machine learning algorithms such as neural nets or Bayesian belief networks, this data can be analyzed to predict whether a problem is likely to occur. A final step to this and perhaps the holy grail of monitoring would be for the system to take action when it thinks a problem will occur and fix itself. Considering that today most automatic failover monitors mess up and failover inappropriately we know automatic or self-healing systems are a long way off.
While predicting problems sounds like a fun computer science project, don’t even think about it until you have all the other steps of monitoring in place and working well. Start monitoring from the customer’s perspective by using business metrics. This will start you off on the appropriate level of response to all the other monitoring.
Rule 50—Be Competent
Maybe you think that this particular rule goes without saying. “Of course we are competent in what we do—how else could we remain in business?” For the purpose of this rule, we are going to assume that you have an Internet offering—some sort of SaaS platform, ecommerce offering, or some other solution delivered over the Internet.
How well does your team really understand the load balancers that you use? How often are you required to get outside help to resolve problems or figure out how to implement something on those load balancers? What about your databases? Do your developers or DBAs know how to identify which tables need indices and which queries are running slowly? Do you know how to move tables around on file systems to reduce contention and increase overall capacity? How about your application servers? Who is your expert with those?
Perhaps your answer to all these questions is that you don’t really need to do those things. Maybe you’ve read books, including at least one other that these authors have written, that indicate you should identify the things in which you have value producing differentiation capabilities and specialize in those areas. The decision that something is “non-core” or that one should buy versus build (as in the case of a build versus buy decision) should not be confused with whether your team should be competent in the technology that you buy. It absolutely makes sense for you to use a third-party or open source database, but that doesn’t mean that you don’t have to understand and be capable of operating and troubleshooting that database.
Your customers expect you to deliver a service to them. To that end, the development of unique software to create that service is a means to an end. You are, at the end of the day, in the service business. Make no mistake about that. It is a mindset requirement that when not met has resulted in the deterioration and even death of companies. Friendster’s focus on the “F-graph,” the complex solution that calculated relationships within the social network, was at least one of the reasons Facebook won the private social network race. At the heart of this focus was an attitude held within many software shops—a focus that the challenging problem of the F-graph needed to be solved. This focus led to a number of outages within the site, or very slow response times as systems ground to a halt while attempting to compute relationships in near real time. Contrast this with a focus on a service, where availability and response time are more important than any particular feature. Software is just a means for providing that service.
But in our world you also need more than just software. Infrastructure is also important to help us get transactions processed on time and in a highly available manner. Just as we might focus too much on the solution to a single problem, so might we overlook the other components within our architecture that deliver that service. If we must be competent in our software to deliver a service, so must we be competent in everything else that we employ to deliver that service. Our customers expect superior service delivery. They don’t understand and don’t care that you didn’t develop and aren’t an expert in the particular component of your architecture that is failing.
So it is that while we don’t need to develop every piece of our solution (in fact we should not develop every piece), we do need to understand each piece. For anything we employ, we need to know that we are using it correctly, maintaining it properly, and restoring it to service promptly when it fails. We can do this by developing those skills within our own team or by entering into relationships to help us. The larger our team and the more we rely on the component in question, the more likely it is that we should have some in-house expertise. The smaller our team and the less important the component, the more willing we should be to outsource the expertise. But in relying on partners for help, the relationship needs to go beyond that provided by most suppliers of equipment. The provider of the service needs to have “skin in the game.” Put another way, they need to feel your pain and the pain of the customer when your service fails. You can’t be caught in a wait queue for second level support while your customers scream at you for service restoration.
Summary
This chapter is a mix of rules that don’t fit well in other chapters but are extremely important. Starting with a warning to avoid letting vendors provide scalability solutions through their products and continuing with advice about keeping business logic in the most appropriate place, monitoring appropriately, and finally being competent, we covered a wide variety of topics. While all of these rules are important perhaps no other rule than Rule 50, “Be Competent,” brings it all together. Understanding and implementing these 50 rules is a great way to ensure that you and your team are competent when it comes to ensuring that your systems will scale.
Endnotes
1 “Gartner: Global Technology Spending Likely to Increase 33% in 2010,” TOPNEWS, http://topnews.us/content/27798-gartner-global-technology-spending-likely-increase-33-2010.
2 That the data is unlikely to have occurred because of chance. Wikipedia, “Statistical significance,” http://en.wikipedia.org/wiki/Statistical_significance.