
Lots of Data (Vectors)
The Intel® Xeon Phi™ coprocessor is designed with strong support for vector level parallelism with features such as 512-bit vector math operations, hardware prefetching, software prefetch instructions, caches, and high aggregate memory bandwidth. This rich support in hardware coupled with numerous software options may seem overwhelming at first glance, but the richness available offers many solutions for diverse needs. Processors and coprocessors benefit from vectorization. Exposing opportunities to use vector instructions for vector parallel portions of algorithms is the first programming effort. Even then, the layout of data, alignment of data, and the effectiveness of prefetching into caches can affect vectorization. This chapter covers the rich set of options available for processors and Intel Xeon Phi coprocessors with little specific Intel Xeon Phi knowledge required.
The best software options are using functions in the Intel® Math Kernel Library (MKL), or programming using the vector support from any of SIMD directives, prefetching, or Intel® Cilk™ Plus. Alternatives such as intrinsics and compilers auto-vectorization can deliver excellent performance results, but the limitations in portability and future maintenance can be substantial. All together, the numerous methods to achieve vector performance on Intel Xeon Phi coprocessors are plentiful enough to help you use this important capability. In the first chapter we explained how you should aim to have at a high usage of vector instructions on Intel Xeon Phi coprocessors. These vector instructions are critical to keeping the coprocessor busy.
We break down our discussion in this chapter as follows: we start by explaining why vectorization matters, and then we give an overview of five approaches to vectorization. We introduce a six-step methodology for looking for important and easy places where a few changes might improve vectorization. The rest of the chapter then walks through the key topics for writing vectorizable code:
• Streaming through caches: data layout, alignment, prefetching, streaming stores
• Compiler tips, options, and directives
Why vectorize?
Performance! Full use of the vector instructions means being able to do 16 single-precision or 8 double-precision mathematical operations at once instead of one. The performance boost that offers is substantial, and is a key to the performance we should expect from an Intel Xeon Phi coprocessor. Until a couple years ago, with SSE, processors could only offer four single-precision or two double-precision operations per instruction. The advent of AVX has make that eight and four, respectively, but still half what is found in Intel Xeon Phi coprocessors.
How to vectorize
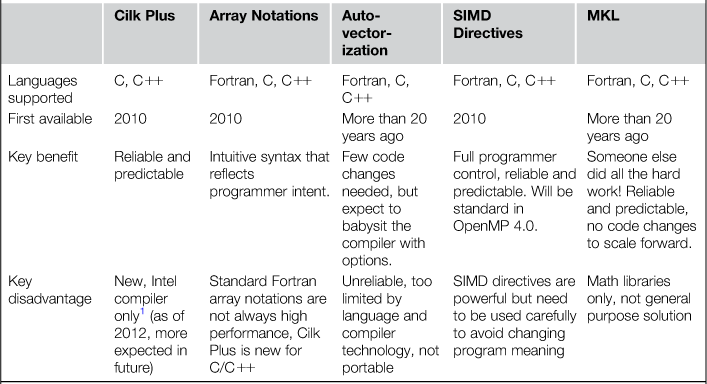
Effective vectorization comes from a combination of efficient data movement and recognition of vectorization opportunities in the program itself. Many things get in the way of vectorization: poor data layout, C/C++ language limitations, required compiler conservatism, and poor program structure. We’ll start with the five approaches to vectorization that should be of most interest, then look at a six-step method that may help you, and finally we’ll review the multiple obstacles and solutions such as data layout and compiler options, in order to vectorize your code! Table 5.1 summarizes techniques for achieving vectorization.
Table 5.1
Techniques to Achieve Vectorization
1There has been work on the gcc compiler in an experiment branch to support this specification too.
Five approaches to achieving vectorization
Vectorization occurs when code makes use of vector instructions effectively. We encourage finding a method that has the compiler generate the instructions as opposed to manually writing in assembly code or with explicit intrinsics. The compiler can do everything automatically for a very small number of examples, but usually does much better with some help from programmers to overcome limitations in the programming language or algorithm implementation. As listed in Table 5.1, five approaches to consider are:
• Math library. See Chapter 11. The Intel Math Kernel library has been tuned to use vectorization when possible within the library routines in Intel MKL.
• Auto vectorization. Count on the compiler to figure it all out. This works for only the simplest loops, and usually only with a little help overcoming programming language limitations (for instance, using the –ansi-alias compiler option). Figure 5.1 shows the C code for a simple add of two vectors (we illustrate later in Figure 5.6). We have inserted an alignment directive, which is important. We saw alignment directives in Chapters 2 through 4 for the same reason. There are additional tips for compiler vectorization in an upcoming section, General Compiler Tips and Comments for Vectorization, in this chapter.
![]()
Figure 5.1 Vector Addition Using Standard C, Similar Programming Can Be Done in Fortran.
• Directives/pragmas to assist or require vectorization. See Figure 5.2. The SIMD directives (expected to be standard in OpenMP 4.0 in 2013, probably with slightly different syntax) give simple and effective controls to mandate vectorization. These are much more powerful than “IVDEP” directives that did not mandate vectorization. The catch in using these directives is that the vectorization of arbitrary loops is generally unsafe or will change the meaning of the program. Use of these directives has been very popular, but requires a firm understanding of their meaning and their dangers. SIMD directives are covered in an upcoming section, SIMD Directives, in this chapter.

Figure 5.2 Vector Addition Using Standard C, Similar Programming Can Be Done in Fortran.
• Array notations. See Figure 5.3 and Figure 5.4. Array notations convey programmer intent in an intuitive notation that reflects the array operations within an algorithm. The concise semantics of array notations match vector execution, thereby naturally avoiding unintended barriers to vectorization. Fortran has array notations in the standard, whereas array notations in C/C++ are extensions support by compilers with support for Cilk Plus.
![]()
Figure 5.3 Vector Addition Using Cilk Plus Array Notation, Similar Programming Can Be Done in Fortran.

Figure 5.4 Vector Addition Using Cilk Plus Array Notation, with “Short Vector” Syntax.. Similar Programming Can Be Done in Fortran.
• Elemental functions. See Figure 5.5. Elemental functions are very useful when a program has an existing function that does one operation at a time that could be done in parallel with vector operations. This elemental function capability of Cilk Plus allows programs to maintain their current modularity but benefit from vectorization. Another advantage is that the simple code can be inlined but more complex operations may be left as functions for efficiency.

Figure 5.5 Vector Addition Using a Cilk Plus Elemental Function, No Fortran Equivalent Exists.
Six step vectorization methodology
Intel has published an interesting article suggesting a six-step process for vectorizing an application. It is not specific to Intel Xeon Phi coprocessors, but rather a general methodology designed for processors that is equally appropriate for Intel Xeon Phi coprocessors. It is neatly documented in an online Vectorization Toolkit that includes links to additional resources for each step. The URL is given at the end of this chapter. This section is a brief overview suitable to give a taste of some interesting tools Intel has to help evaluate and guide vectorization work.
This approach is very useful in cases where incremental work can yield strong results. Scientific codes that have successfully used vector supercomputers previously, or made use of SIMD instructions such as SSE or AVX, are easily the best candidates for this approach. This six-step methodology is no panacea because it can completely miss a bigger picture of overall algorithm redesign when that might be most appropriate. Parallelism may not be easily exposed. An effective parallel program may require a more holistic approach involving restructuring (refactoring) of the algorithm and data layout to get significant gains. Whether parallelism is easily exposed, or with great difficulty, it is wise to start by looking for the easiest opportunities to expose. These six steps help explain how to look for the most accessible and easiest opportunities.
Step 1. Measure baseline release build performance
We should start with a baseline for performance so we know if changes to introduce vectorization are effective. In addition, setting a goal can be useful at this point so we can celebrate later when we achieve it. A release build should be used instead of a debug build. A release build will contain all the optimizations for our final application and may alter the hotspots or even the code that is executed. For instance a release build may optimize away a loop in a hotspot that otherwise would be a candidate for vectorization. Using a debug build would be a mistake when working to optimize. A release build is the default in the Intel Compiler. We have to specifically turn off optimizations by doing a DEBUG build on Windows (or using the -Zi switch) or using the -Od switch on Linux or OS X. If using the Intel Compiler, ensure you are using optimization levels 2 or 3 (−O2 or –O3) to enable the auto-vectorizer.
Step 2. Determine hotspots using Intel® VTune™ Amplifier XE
We can use Intel® VTune™ Amplifier XE, our performance profiler, to find the most time-consuming functions in your application. The Hotspots analysis type is recommended; although Lightweight Hotspots would work as well (it will profile the whole system as opposed to just your application).
Identifying which areas of the code are taking the most time will allow us to focus on optimization efforts in the areas where performance improvements will have the most effect. Generally we want to focus on only the top few hotspots, or functions taking at least 10 percent of the application’s total time. Make note of the hotspots we want to focus on for the next step.
Step 3. Determine loop candidates using Intel Compiler vec-report
The vectorization report (or vec-report) of the Intel Compiler can tell us whether or not each loop in our code was vectorized. We should ensure that we are using Compiler optimization level 2 or 3 (–O2 or –O3) to enable the auto-vectorizer, then run the vec-report and look at the output for the hotspots we determined in Step 2. If there are loops in the hotspots that did not vectorize, we can check whether they have math, data processing, or string calculations on data in parallel (for instance in an array). If they do, they might benefit from vectorization. Continue to Step 4 if any candidates are found. To run the vec-report, use the -vec-report2 or /Qvec-report2 option. The vec-report option, when used with offloading, can be easier to read if the reports for the host and the coprocessor are not interspersed. The section “Vec-report Option Used with Offloads” in Chapter 7 explains how to do this.
Step 4. Get advice using the Intel Compiler GAP report and toolkit resources
Run the Intel Compiler Guided Auto-parallelization (or GAP) report to see suggestions from the compiler on how to vectorize the loop candidates from Step 3. (Note: Intel named it guided auto-parallelization because it helps with task and data (vector) parallelism, vectorization is really just a special type of parallel processing.) Examine the advice and refer to additional toolkit resources as needed. Run the GAP-report using the -guide or /Qguide options for the Intel Compiler.
Step 5. Implement GAP advice and other suggestions (such as using elemental functions and/or array notations)
Now that we know the GAP report suggestions for the loop, it is time to implement them if possible. The report may suggest making a code change. Make sure the change would be “safe” to do. In other words, we must make sure the change does not affect the semantics or safety of the loop. The tool can definitely suggest changes that will yield vectorization but will change the program and get the wrong answer (but it will be faster!). One way to ensure that the loop has no dependencies that may be affected is to consider if executing the loop in backwards order would change the results. Another is to think about the calculations in the loop being in a scrambled order. If the results would be changed, the loop has dependencies and vectorization would not be “safe.” We may still be able to vectorize by eliminating dependencies in this case. We could modify the source to give additional information to the compiler or optimize a loop for better vectorization. At this point we may introduce some of the high-level constructs provided by Cilk Plus or Fortran to better expose the vector parallelism.
Step 6: Repeat!
Iterate through the process as needed until performance is achieved or there are no good candidates left in the identified hotspots. Please bear in mind that this six-step process does not consider opportunities that may be possible if algorithm and data restructuring are considered. This six-step approach does not attempt to identify such opportunities.
Streaming through caches: data layout, alignment, prefetching, and so on
In order for vectorization to occur efficiently, data needs to flow to and from the vector instructions without excessive overhead. Efficiency in data movement depends on data layout, alignment, prefetching and efficient store operations. Some investigation into the code produced by the compiler can be done by anyone, and is discussed in a later section in this chapter titled “Looking at What the Compiler Created.”
Why data layout affects vectorization performance
Vector parallelism comes from performing the same operation on multiple pairs (or triplets with FMA) of data elements simultaneously. Figure 5.6 illustrates the concept using the same vector registers we first showed in Figure 2.1. Figure 5.6 is not particular to Intel Xeon Phi coprocessors, other than the exact width of the registers. In fact, the optimizations discussed in the chapter are essentially the same as we would do for any modern microprocessors. The Intel Xeon Phi coprocessor does offer more vector level parallelism by having wider registers and more aggregate memory bandwidth, but with the correct programming methods an application can be written to map to processors or coprocessors through use of Intel MKL or the compiler without requiring different approaches in programming.
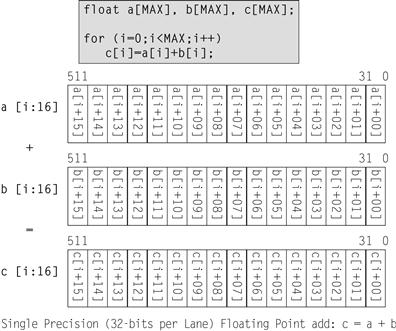
Figure 5.6 Vector Addition.
Figure 5.6 illustrates a vector addition of two registers, each holding 16 single-precision floating-point values yielding 16 single precision sums. In general, this math is done by loading the two input registers from data in memory and then performing the addition operation. There are several issues that need to be understood and optimized to make this possible:
• Data layout in memory, aligned and packed. Sixteen values have to be collected into each input register. If the data is laid out in memory in the same linear order and aligned on 512-bit (64 bytes) boundary, then a simple high performance vector load will suffice. If not, the first consideration should be whether data could be laid out in order and alignment. Data that is not packed and aligned optimally will require more instructions and cache or memory accesses to collect and organize in registers in order to use the vector operations. The extra instructions and data accesses reduce performance. The compilers offer alignment directives and command line options, covered later in this chapter, to force or specify alignment of variables.
− Fetch data from cache not memory. Data eventually comes from memory, but at the time a vector load instruction is issued it is much faster if the data has been fetched into the closest (level 1, known as L1 cache) prior to the load instruction. On an Intel Xeon Phi coprocessor data actually travels from memory to L2 cache to L1 cache. Optimally this can be done by a prefetch of data from memory to L2, later followed by a prefetch from L2 to L1 cache, and later by the load instruction from L1 cache. The prefetches can be initiated by hardware or by software prefetches specified by the compiler automatically or manually by the programmer. L1 Prefetch instructions can ask for memory data to L1, but there are far fewer L1 prefetch operations allowed to be outstanding at the same time than the capacity for L2 prefetches to be outstanding. The compiler inserts prefetches automatically, and there are directives to help the compiler with hints and there are mm_prefetch intrinsics to do the prefetching manually. These are covered in a later section in this chapter.
− Data reuse. If a program is fetching data into the cache that will be accessed more than once, then those accesses should occur close together. This is called temporal locality of reference. Ensuring that data is reused quickly helps reduce the chance that data will be evicted before it is needed again—resulting in a new fetch. Rearranging a program to increase temporal reuse is often a rewarding optimization. Intel MKL (Chapter 11) uses blocking in the library routines, which is a big help. For code we write explicitly, the challenge of blocking generally falls to the programmer. The good news is that cache blocking has been studied for decades for processors, and Intel Xeon Phi coprocessor relies on the same programming techniques. Before we decide to curse caches, it is worth noting that caches exist to lower power consumption and increase performance. The fact that our programming style can align with the cache designs to maximize performance is the price we pay to have more performance and power efficiency than would be possible without caches.
− Streaming stores. If a program is writing data out that it will not use again, and that occupies memory linearly without gaps, then making sure streaming stores are being generated is important. Streaming stores increase cache utilization for data that matters by preventing the data being written from needlessly using up cache space.
Data alignment
If poor vectorization is detected via compiler vectorization report or assembler inspection, we may decide to improve data alignment to increase vectorization opportunities. For alignment, what is important is often the relative alignment of one array compared to another, or of one row of a matrix compared to the next. The compiler can often compensate for an overall offset in absolute alignment. Though of course, absolute alignment of everything is one way of getting relative alignment. For matrices, we may want to pad the row length (or column length, for Fortran) to be a multiple of the alignment factor. For Intel Xeon Phi coprocessors, alignment to 64-byte boundaries of all data (usually arrays) is very important in order to reach maximum performance. Aligned heap memory allocation can be achieved with calls to:
Void* _mm_malloc (int size, int base)
Alignment assertion align(base) can be used on statically allocated variables:
__attribute__((align(64))) float temp[SIZE]; /* array temp: 64byte aligned */
or
__declspec(align(64)) float temp[SIZE]; /* array temp: 64byte aligned */
Note: The Intel compilers accept either __attribute__() or __declspec() spellings to contain the directives for alignment. The __attribute() spelling is associated with gcc and Linux generally whereas __declspec() originated with Microsoft compilers and Windows. The Intel compiler allows source code to be used on Linux, Windows, or Mac OS X systems without changing the spelling, allowing either to be used.
The equivalent Fortran directive is
!DIR$ ATTRIBUTES ALIGN: base :: variable
Alignment assertion __assume_aligned(pointer, base) can be used on pointers:
__assume_aligned(ptr, 64); /* ptr is 64B aligned */
Fortran programmers would use the following to assert that the address of A(1) is 64B aligned:
!DIR$ ASSUME_ALIGNED A(1): 64
Additionally, there are compiler command line options (“align”) to specify alignment of data. The Fortran compiler support variations to force alignment of arrays and COMMON blocks. C/C++ programs generally use only the __attribute() or __declspec() source code directives, whereas Fortran programmers often use the command line options as an alternative to the directives.
Some examples of alignment directives (shown in Fortran) include:
!dir$ attributes align : 32 :: A, B
• Directs compiler to align the start of objects A, B to 32 bytes
• Does not work for objects inside common blocks or derived types with sequence attribute; can be used to align start of common block itself
!dir$ assume_aligned A:32, B:32
!dir$ vector aligned
• Invites the compiler to vectorize a loop using aligned loads for all arrays, ignoring efficiency heuristics, provided that it is safe to do so.
!dir$ attributes align
and
!dir$ assume_aligned
!dir$ assume_aligned
• Most obvious use is for an incoming subroutine argument
• Cannot be used for global objects declared elsewhere or sequential objects (risk of conflicts) such as within common blocks or within modules or within structures
!dir$ vector aligned
Prefetching
The best performing applications will have well laid out data ready to be streamed to the math units to be processed. Moving the data from its tidy layout in memory to the math units is done using prefetching to avoid delays that occur as a mathematical operation has to wait for input data.
Prefetching is an important topic to consider regardless of what coding method we use to write an algorithm. To avoid having a vector load operation request data that is not in cache, we can make sure prefetch operations are happening. Any time a load requests data not in the L1 cache, a delay occurs to fetch the data from an L2 cache. If data is not in any L2 cache, an even longer delay occurs to fetch data from memory. The lengths of these delays are nontrivial, and avoiding the delays can greatly enhance the performance of an application. Optimized libraries such as Intel MKL will already utilize prefetches, so we will focus on controlling prefetches for code we are writing.
There are four sources of prefetches: automatic prefetching by the hardware to L2 caches (see Chapter 8), automatic software prefetch instructions by the compiler to L1 cache, compiler-generated prefetches (which were assisted by information from the programmer), and manual prefetch instructions by the programmer with both L2 and L1 fetch capabilities. The hardware prefetching is automatic and will automatically give way to software prefetches because they have higher priority. Figure 5.7 shows usage of prefetch directives. Figure 5.8 demonstrates the roughly equivalent using manual prefetches. It’s easy to see that pragmas are far simpler to use. We recommend starting by working with the compiler, and moving to coding of manual prefetches only if required.

Figure 5.7 Examples of Prefetching Directives.
Figure 5.8 Roughly the “Manual Prefetches” that Are Generated from the Example in Figure 5.7 by the Compiler.
Compiler prefetches
When using the Intel compiler with normal or elevated optimization levels (-O2 or greater) then prefetching is automatically set to opt-prefetch=3. Compiler prefetching is enabled with the -opt-prefetch=n option with n being a value 1 to 4 on Linux (Windows: /Qopt-prefetch:n). The higher the value, the more aggressive the compiler is with issuing prefetch instructions. If algorithm is well blocked to fit in L2 cache, prefetching is less critical but generally still useful for Intel Xeon Phi coprocessors.
In general, we recommend using the compiler to issue prefetches. If this is not perfect, there are a number of ways to give the compiler additional hints or refinements but still have the compiler generate the prefetches. We consider manual insertion of prefetch directives to be a last resort if compiler prefetching cannot be utilized for a particular need.
The first tuning to try is to use different second-level prefetch (vprefetch0) distances. We recommend trying n=1,2,4,8 with -mP2OPT_hlo_use_const_second_pref_dist=n. In this case, n=2 means use a prefetch distance of two vectorized iterations ahead (if the loop is vectorized). Instead of the compiler option, prefetch pragmas can be utilized in the source code.
Compiler prefetch controls (prefetching via pragmas/directives)
Instead of relying only on the compiler option, prefetch pragmas can be utilized in the source code. The compiler can be given prefetch directives to modify default behavior. The passing of addition information through directives can improve the performance of an application. The format for C/C++ and Fortran are respectively:
#pragma prefetch var:hint:distance
!DIR$ prefetch var:hint:distance
The hint value can be 0 (L1 cache [and L2 due to inclusion]), 1 (L2 cache, not L1). Figure 5.7 shows usage of prefetch directives and Figure 5.8 shows the roughly equivalent manual prefetches that we get from the compiler automatically with the simpler Figure 5.7 example syntax. Figures 5.9, 5.10A, 5.10B, and 5.11 give additional usage examples to examine.

Figure 5.9 A Prefetch Directive Example in Fortran.

Figure 5.10a Another Prefetch Directive Example in Fortran.

Figure 5.10b A Prefetch Directive Example in C.

Figure 5.11 C Prefetch Examples Illustrating Interoperation with Vector Intrinsics.
Manual prefetches (using vprefetch0 and vprefetch1)
Figures 5.12 and 5.13 show examples of using manual prefetch directives. We recommend only doing this if the compiler cannot generate prefetches sufficiently even with hint covered in the prior section. These intrinsics work on processors and coprocessors both and are not specific to Intel Xeon Phi coprocessors. The intrinsics for Fortran and C/C++, respectively, are:

Figure 5.12 C Prefetch Intrinsics Example, Manual Prefetching.

Figure 5.13 Fortran Prefetch Intrinsics Example, Manual Prefetching.
MM_PREFETCH (address [, hint])
void _mm_prefetch(char const*address, int hint)
The intrinsic issues a software prefetch to load one cache line of data located at address. The value hint specifies the type of prefetch operation. Values of _MM_HINT_T0 or 0 (for L1 prefetches) and _MM_HINT_T1 or 1 (for L2 prefetches) are most common and are the interesting ones for use with Intel Xeon Phi coprocessors.
If we do decide to insert prefetches manually, we will want to disable automatic compiler insertion of prefetch instructions. Doing both will generally create competition for the limited prefetch capabilities of the hardware, and will result in reduced performance. If we are going through the effort to control prefetching manually, we should have already determined the compiler prefetching was not optimal. This generally happens for more complex data processing than the compiler can determine automatically.
Compiler prefetching is disabled with the -opt-prefetch=0 or -no-opt-prefetch option on Linux (Windows: /Qopt-prefetch:0 or /Qopt-prefetch-).
Streaming stores
Streaming stores are a special consideration in vectorization. Streaming stores are instructions especially designed for a continuous stream of output data that fills in a section of memory with no gaps between data items. They are supported by many processors, including Intel Xeon processors, as well as Intel Xeon Phi coprocessors. An interesting property of an output stream is that the result in memory does not require knowledge of the prior memory content. This means that the original data does not need to be fetched from memory. This is the problem that streaming stores solve—the ability to output a data stream but not use memory bandwidth to read data needlessly.
Having the compiler generate streaming stores can improve performance by not having the processor or coprocessor fetch caches lines from memory that will be completely overwritten. This method stores data with instructions that use a nontemporal buffer, which minimizes memory hierarchy pollution. This optimization helps with memory bandwidth utilization and is present for processors and Intel Xeon Phi coprocessors and may improve performance for both.
Use of the compiler option -opt-streaming-stores keyword (Linux and OS X) or /Qopt-streaming-stores:keyword (Windows) controls the compilers generation of streaming stores. The keyword can be always, never or auto. The default is auto. It is useful to know how to help the compiler understand an application enough to use streaming stores effectively.
When streaming stores will be generated for Intel® Xeon Phi™ coprocessors
The compiler is smart enough not to generate prefetches for lines for the streaming store, so as to avoid negating the value of the streaming stores. The compiler will also inject L2 cache line eviction instructions when using streaming stores. The Intel compiler generates streaming store instructions for an Intel Xeon Phi coprocessor only when:
1. It is able to vectorize the loop and generate an aligned unit-strided vector unmasked store:
• If the store accesses in the loop are aligned properly, user can convey alignment information using pragmas/clauses
− Suggestion: Use vector aligned directive before loop to convey alignment of all memory references inside loop including the stores.
• In some cases, even when there is no directive to align the store-access, the compiler may align the store-access at runtime using a dynamic peel-loop based on its own heuristics.
• Based on alignment analysis, compiler could prove that the store accesses are aligned (at 64 bytes)
• Store has to be aligned and be writing to a full cache line (vstore – 64 bytes, no masks)
− Suggestion: it is the responsibility of the programmer to align the data appropriately at allocation time using align clauses, aligned_malloc, -align array64byte option on Fortran, and so on.
2. Vector-stores are classified as nontemporal using one of:
• We have specified a nontemporal pragma on the loop to mark the vector-stores as streaming
− Suggestion: Use vector nontemporal directive before loop to mark aligned stores, or communicate nontemporal-property of store using a vector nontemporal A directive where an assignment into array A is the store inside the loop.
• We have specified the compiler option -opt-streaming-stores always to force marking all aligned vector-stores as nontemporal.
− This has the implicit effect of adding the nontemporal pragma to all loops that are vectorized by the compiler in the compilation scope
− Using this option has few negative consequences even if used incorrectly for Intel Xeon Phi coprocessor since the data remains in the L2 cache (just not in the L1 cache)—so this option can be used if most aligned vector-stores are nontemporal. However, using this option on processors for cases where some accesses actually are temporal can cause significant performance losses since the streaming-store instructions on Intel Xeon bypass the cache altogether.
Compiler generation of clevicts
On streaming operations, the use of clevicts instructions allows the compiler to tell the hardware to not fetch data that will entirely be discarded (overwritten). This effectively avoids wasted prefetching efforts. Compiler has heuristics that determine whether a store is streaming. Usually this heuristic will kick in only when the loop has a large number of iterations specified and that is known at compile time. This is very limiting, so for applications where the calculation for the number of iterations is symbolic, there is a nontemporal pragma that allows us to mark streaming stores:
#pragma vector nontemporal
For processors, this pragma generates the nontemporal hints on stores. For Intel Xeon Phi coprocessors the compiler generates clevicts instead when the compiler knows the store addresses are aligned. Feature is controlled via the option:
-mGLOB_default_function_attrs=”clevict_level=N”
where N=0, 1, 2 or 3 (default is 3)
Compiler tips
There are a number of tips we can offer on how to get the most of the ability for the compiler to help with vectorization.
Avoid manual loop unrolling
The Intel® Compiler can typically generate efficient vectorized code if a loop structure is not manually unrolled. Unrolling means duplicating the loop body as many times as needed to operate on data using full vectors. For single precision on Intel Xeon Phi coprocessors, this commonly means unrolling 16-times. This means the loop body would do 16 iterations at once and the loop itself would need to skip ahead 16 per iteration of the new loop.
It is better to let the compiler do the unrolls, and we can control unrolling using #pragma unroll N (C/C++) or !DIR$ UNROLL N (Fortran). If N is specified, the optimizer unrolls the loop N times. If N is omitted, or if it is outside the allowed range, the optimizer picks the number of times to unroll the loop. Manual unrolling will generally interfere with the compiler optimizations enough to hurt performance.
To add to this, manual loop unrolling tends to tune a loop for a particular processor or architecture, making it less than optimal for some future port of the application. Generally, it is good advice to write code in the most readable, straightforward manner. This gives the compiler the best chance of optimizing a given loop structure. Here is a Fortran example where manual unrolling is done in the source:
m = MOD(N,4)
if ( m /= 0 ) THEN
do i = 1 , m
Dy(i) = Dy(i) + Da*Dx(i)
end do
end if
if (mp1 = m +1) then
do i = mp1 , N , 4
Dy(i) = Dy(i) + Da*Dx(i)
Dy(i+1) = Dy(i+1) + Da*Dx(i+1)
Dy(i+2) = Dy(i+2) + Da*Dx(i+2)
Dy(i+3) = Dy(i+3) + Da*Dx(i+3)
end do
end if
It is better to express this in the simple form of:
do i=1,N
Dy(i)=Dy(i) + Da*Dx(i)
end do
This allows the compiler to generate efficient vector-code for the entire computation and also improves code readability. Here is a C/C++ example where manual unrolling is done in the source:
double accu1 = 0, accu2 = 0, accu3 = 0, accu4 = 0;
double accu5 = 0, accu6 = 0, accu7 = 0, accu8 = 0;
for (i = 0; i < NUM; i += 8) {
accu1 = src1[i+0]*src2 + accu1;
accu2 = src1[i+1]*src2 + accu2;
accu3 = src1[i+2]*src2 + accu3;
accu4 = src1[i+3]*src2 + accu4;
accu5 = src1[i+4]*src2 + accu5;
accu6 = src1[i+5]*src2 + accu6;
accu7 = src1[i+6]*src2 + accu7;
accu8 = src1[i+7]*src2 + accu8;
}
accu = accu1 + accu2 + accu3 + accu4
+ accu5 + accu6 + accu7 + accu8;
It is better to express this in the simple form of:
double accu = 0;
for (i = 0; i < NUM; i++ ) {
accu = src1[i]*src2 + accu;
}
Requirements for a loop to vectorize (Intel® Compiler)
Since a single iteration of a loop generally operates on one element of array, but use of vector instruction depends on operating on multiple elements of an array at once (see Figure 5.6), the “vectorization” of a loop essentially requires unrolling the loop so that it can take advantage of packed SIMD instructions to perform the same operation on multiple data elements in a single instruction.
The Intel compilers may be among the most capable and aggressive at vectorizing programs, but they still have limitations. In the most recent Intel compilers, vectorization is one of many optimizations enabled by default. Here is a list of requirements in order for a loop to potentially vectorize:
• If a loop is part of a loop nest, it must be the inner loop. Outer loops can be parallelized using OpenMP or autoparallelization (-parallel), but they cannot be vectorized unless the compiler is able either to fully unroll the inner loop, or to interchange the inner and outer loops. Additional high level loop transformations such as these may require -O3.
• The loop must contain straight-line code (a single basic block). There should be no jumps or branches, but masked assignments are allowed. A “masked assignment” simply means an assignment controlled by a conditional (such as an IF statement).
• The loop must be countable, which means that the number of iterations must be known before the loop starts to execute although it need not be known at compile time. Consequently, there must be no data-dependent exit conditions.
• There should be no backward loop-carried dependencies. For example, the loop must not require statement 2 of iteration 1 to be executed before statement 1 of iteration 2 for correct results. This allows consecutive iterations of the original loop to be executed simultaneously in a single iteration of the unrolled, vectorized loop. Figures 5.14 and 5.15 illustrate this requirement. The examples only make sense when thinking of doing multiple iterations at once due to vectorization. That is what would make Figure 5.15 illustrate a barrier to vectorization.
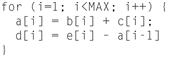
Figure 5.14 Vectorizable: a[i-1] Is Always Computed Before It Is Used.

Figure 5.15 Not Vectorizable: a[i-1] Might Be Needed Before It Has Been Computed (if Vectorized).
There should be no special operators and no function or subroutine calls, unless these are inlined, either manually or automatically by the compiler. Intrinsic math functions such as sin(), log(), and fmax() are allowed, since the compiler runtime library contains vectorized versions of these functions. The following math functions may be vectorized by the Intel C/C++ compiler: sin, cos, tan, asin, acos, atan, log, log2, log10, exp, exp2, sinh, cosh, tanh, asinh, acosh, atanh, erf, erfc, erfinv, sqrt, cbrt, trunk, round, ceil, floor, fabs, fmin, fmax, pow, and atan2. The list may not be exhaustive. Single precision versions such as sinf may also vectorize. The Fortran equivalents, where available, should also vectorize.
Some additional advice on how to have a loop vectorize:
• Both reductions and vector assignments to arrays are allowed.
• Try to avoid mixing vectorizable data types in the same loop (except for integer arithmetic on array subscripts). Vectorization of type conversions may be either unsupported or inefficient. Support for the vectorization of loops containing mixed data types may be extended in a future version of the Intel compiler.
• Try to access contiguous memory locations. (So loop over the first array index in Fortran, or the last array index in C). While the compiler may sometimes be able to vectorize loops with indirect or non-unit stride memory addressing, the cost of gathering data from or scattering back to memory is often too great to make vectorization worthwhile.
• The ivdep pragma or directive may be used to advise the compiler that there are no loop-carried dependencies that would make vectorization unsafe.
• The vector always pragma or directive may be used to override the compiler’s heuristics that determine whether vectorization of a loop is likely to yield a performance benefit.
• To see whether a loop was or was not vectorized, and why, look at the vectorization report. This may be enabled by the command line switch /Qvec-report3 (Windows) or -vec-report3 (Linux or Mac OS X).
• The vec-report option, when used with offloading, can be easier to read if the reports for the host and the coprocessor are not interspersed. The section “Vec-report Option Used with Offloads” in Chapter 7 explains how to do this.
Importance of inlining, interference with simple profiling
Because vectorization happens on innermost loops consisting of straight line code (see actual rules in the prior section), inlining of functions within the loop is critical. Turning off optimizations (the default is ON) will stop automatic inlining, and that will affect the ability of loops to vectorize if they contain function calls. Instrumenting for profiling using the –pg option will generally do the same, and stop optimization. Better profiling can be done using the less intrusive Intel VTune Amplifier XE (see Chapter 13). Because it requires no instrumentation that will defeat inlining, we can do profiling on the release version of an application. The -opt-report-phase-ipo_inl option can show which functions are inlined.
Compiler options
There are many ways to share information that we know about out program that is not captured purely in the existing language. We selected a few of the most used and most effective compiler options to consider in order to boost the performance of an application:
• Use the ANSI aliasing option for C++ programs; this is not ON by default due to potential compatibility issues with older programs. This enables compiler to do type-based disambiguation (asserts that pointers and floats do not overlap). Without the flag, the compiler may assume that the count for the number of iterations is changing inside the loop if the upper bound is an object-field access. Obeying strict ANSI aliasing rules provides more room for optimization. Hence, it is highly recommended to enable for ANSI-conforming code via -ansi-alias (Linux and OS ) or /Qansi-alias (Windows). This is already the default for the Intel Fortran Compiler. See an example coming up next in the section titled “Memory Disambiguation Inside Vector-Loops.”
• No aliasing of arguments: on Linux and Mac OS X the option -fargument-noalias acts in the same way as applying the keyword restrict to all pointers of all function parameters throughout a compilation unit. This option is not available on Windows.
Use optimization reports to understand what the compiler is doing:
-opt-report-phase hlo –opt-report-phase hpo –opt-report 2
This lets us check whether a loop of interest is properly vectorized. The “Loop Vectorized” message is the first step. We can get extra information using –vec-report 6.
• Use loop count directives to give hints to compiler; this affects prefetch distance calculation, use #pragma loop count (200), before a loop.
• The restrict keyword is a feature of the C99 standard that can be useful to C/C++ programmers. It can be attributed to pointers to guarantee that no other pointer overlaps the referenced memory location. Using the Intel C++ compiler does not only limit it to C99. It makes the keyword available for C89 and even for C++, simply by enabling a dedicated option: -restrict (Linux and Mac OS X) or /Qrestrict (Windows).
• In order to allow vectorization to happen, we need to avoid converting 64-bit integers to/from floating point. Use of 32-bit integers, preferable signed integers (most efficient).
Memory disambiguation inside vector-loops
Consider vectorization for a simple loop:
void vectorize(float *a, float *b, float *c, float *d, int n) {
int i;
for (i=0; i<n; i++) {
a[i] = c[i] * d[i];
b[i] = a[i] + c[i]−d[i];
}
}
Here, the compiler has no idea as to where those four pointers are pointing. As programmers, we may know they point to totally independent locations. The compiler thinks differently. Unless the programmer explicitly tells the compiler that they point to independent locations, the compiler has to assume the worst case aliasing is happening. For example, c[1] and a[0] may be at the same address and thus the loop cannot be vectorized at all.
When the number of unknown pointers are very small, the compiler can generate a runtime check and generate optimized and unoptimized versions of the loops (with overhead in compile time, code size, and also runtime testing). Since the overhead grows quickly, that very small number has to be really small—like two—and even then we are paying the price for not telling the compiler that “pointers are independent.”
So, the better thing to do is to tell the compiler that “pointers are independent.” One way to do it is to use C99 restrict pointer keyword. Even if we are not compiling with C99 standard, we can use -restrict (Linux) and -Qrestrict (Windows) flag to let the Intel compilers to accept restrict as a keyword. In the following example, we tell the compiler that a isn’t aliased with anything else, and b isn’t aliased with anything else:
void vectorize(float *restrict a, float *restrict b, float *c, float *d, int n) {
int i;
for (i=0; i<n; i++) {
a[i] = c[i] * d[i];
b[i] = a[i] + c[i]−d[i];
}
}
Another way is to use IVDEP pragma. Semantics of IVDEP is different from the restrict pointer, but it allows the compiler to eliminate some of the assumed dependencies—just enough to let the compiler think vectorization is safe.
void vectorize(float *a, float *b,
float *c, float *d, int n) {
int i;
#pragma ivdep
for (i=0; i<n; i++) {
a[i] = c[i] * d[i];
b[i] = a[i] + c[i]−d[i];
}
}
Compiler directives
When we work to get the key part of an algorithm (usually a loop) to vectorize, we may quickly realize that there are two barriers: (1) getting the code to be vectorizable, (2) expressing the algorithm so the compiler accepts that it is vectorizable. The former is our responsibility as programmers. The nuisances of programming languages complicate the latter so that even the most brilliant compiler cannot auto-vectorize most loops written with no hints at all. In general, the presence of pointers that are too flexible in the C/C++ languages tend to make this problem most significant in C/C++ code and less for Fortran. Nevertheless, the challenge to completely specify our intent so that a compiler will vectorize is why we have directives. In a later section, we will review array notation and elemental functions as more elegant coding styles that can do much the same thing if we rewrite our code using a better notation. The directive is a bit more like a hammer—we use directives to force our current program to vectorize assuming it should. Code transformations to make the code vectorize is a prerequisite, the directive simply finishes reassuring the compiler so that it does the vectorization.
Traditionally, directives have been hints to the compiler to remove certain restrictions it may enforces. Assuming the concerns that blocked vectorization were removed, then the compiler will vectorize the code. These offer safety, but can be less portable and less predictable, even from release to release, as the heuristics in a compiler shift and change. The VECTOR and IVDEP directives are examples—they give the compiler hints but still rely on the compiler checking and approving all concerns for which the hints do not apply.
The SIMD directives are a different approach; they force the compiler to vectorize and essentially place all the burden on the programmer to ensure correctness. Gone are the days of fighting the compiler? Perhaps, but the programmer has to do the work and ensure correctness. For many, it is a dream come true: no compiler to fight. For many others, it is difficult without the compiler to help verify correctness.
SIMD directives
The SIMD directives enforce vectorization of loops. SIMD directives are an important capability to understand for vectorization work. SIMD directives come in two forms for C/C++ and Fortran, respectively:
#pragma simd [clause[ [,] clause]…]
!DIR$ SIMD [clause[[,] clause]…]
Analogously to how cilk_for gives permission to parallelize a loop (see Chapter 6), but does not require it, marking a for loop with #pragma simd similarly gives a compiler permission to execute a loop with vectorization. Usually this vectorization will be performed in small chunks whose size will depend on the vector width of the machine. For example, writing:
extern float a[];
#pragma simd
for ( int i=0; i<1000; ++i ) {
a[i] = 2 * a[i+1];
}
grants the compiler permission to transform the code equivalently into:
extern float a[];
#pragma simd
for ( int i=0; i<1000; i+=4 ) {
float tmp[4];
tmp[0:4] = 2 * a[i+1:4];
a[i:4] = tmp[0:4];
}
The original loop in our example would not be legal to parallelize with cilk_for, because of the dependence between iterations. A #pragma simd is okay in the example because the chunked reads of locations still precede chunked writes of those locations. However, if the original loop body reversed the subscripts and assigned a[i+1] = 2 * a[i], then the chunked loop would not preserve the original semantics, because each iteration needs the value of the previous iteration.
In general, #pragma simd is legal on any loop for which cilk_for is legal, but not vice versa. In cases where only #pragma simd appears to be legal, study dependences carefully to be sure that it is really legal.
Note that #pragma simd is not restricted to inner loops. For example, the following code grants the compiler permission to vectorize the outer loop:
#pragma simd
for ( int i=1; i<1000000; ++i ) {
while ( a[i]>1 )
a[i] *= 0.5f;
}
In theory, a compiler can vectorize the outer loop by using masking to emulate the control flow of the inner while loop. Whether a compiler actually does so depends on the implementation. The Intel compiler detects and handles many forms of masking.
Requirements to vectorize with SIMD directives (Intel® Compiler)
The SIMD directives ask the compiler to relax some of its requirements and to make every possible effort to vectorize a loop. If an ASSERT clause is present, the compilation will fail if the loop is not successfully vectorized. This has led it to be sometimes called the “vectorize or die” directive.
The directive (#pragma simd in C/C++, or !DIR$ SIMD in Fortran) behaves somewhat like a combination of #pragma vector always and #pragma ivdep, but is more powerful. The compiler does not try to assess whether vectorization is likely to lead to performance gain, it does not check for aliasing or dependencies that might cause incorrect results after vectorization, and it does not protect against illegal memory references. #pragma ivdep overrides potential dependencies, but the compiler still performs a dependency analysis, and will not vectorize if it finds a proven dependency that would affect results. With #pragma simd, the compiler does no such analysis, and tries to vectorize regardless. It is the programmer’s responsibility to ensure that there are no backward dependencies that might impact correctness. The semantics of #pragma simd are rather similar to those of the OpenMP #pragma omp parallel for. It accepts optional clauses such as REDUCTION, PRIVATE, FIRSTPRIVATE, and LASTPRIVATE. SIMD-specific clauses are VECTORLENGTH (implies the loop unroll factor), and LINEAR, which can specify different strides for different variables. Pragma SIMD allows a wider variety of loops to be vectorized, including loops containing multiple branches or function calls. It is particularly powerful in conjunction with the vector functions of Intel Cilk Plus.
Nevertheless, the technology underlying the SIMD directives is still that of the compiler vectorizer, and some restrictions remain on what types of loop can be vectorized:
• The loop must be countable. This means that the number of iterations must be known before the loop starts to execute, although it need not be known at compile time. Consequently, there must be no data-dependent exit conditions, such as break (C/C++) or EXIT (Fortran) statements. This also excludes most while loops. Typical diagnostic messages for incorrect application are similar to
error: invalid simd pragma // warning #8410: Directive SIMD must be followed by counted DO loop.
• Certain special, nonmathematical operators are not supported, and also certain combinations of operators and of data types, with diagnostic messages such as “operation not supported,” “unsupported reduction,” and “unsupported data type.”
• Very complex array subscripts or pointer arithmetic may not be vectorized, a typical diagnostic message is “dereference too complex.”
• Loops with very low number of iterations (also referred to as a low trip count) may not be vectorized. Typical diagnostic: “remark: loop was not vectorized: low trip count.”
• Extremely large loop bodies (very many lines and symbols) may not be vectorized. The compiler has internal limits that prevent it from vectorizing loops that would require a very large number of vector registers, with many spills and restores to and from memory.
• SIMD directives may not be applied to Fortran array assignments or to Intel Cilk Plus array notation.
• SIMD directives may not be applied to loops containing C++ exception handling code.
A number of the requirements detailed in the prior section “Requirements for a Loop to Vectorize (Intel® Compiler)” are relaxed for SIMD directives, in addition to the above-mentioned ones relating to dependencies and performance estimates. Loops that are not the innermost loop may be vectorized in certain cases; more mixing of different data types is allowed; function calls are possible and more complex control flow is supported. Nevertheless, the advice in the prior section should be followed where possible, since it is likely to improve performance.
It is worth noting that with SIMD directives, loops are vectorized under the “fast” floating-point model, corresponding to /fp:fast (-fp-model=fast). The command line option /fp:precise (-fp-model precise) is not respected by a loop vectorized with a SIMD directive; such a loop might not give identical results to a loop without the directive. For further information about the floating-point model, see “Consistency of Floating-Point Results using the Intel® Compiler” (listed in additional reading at the end of the chapter).
SIMD directive clauses
A SIMD directive can be modified by additional clauses, which control chunk size or allow for some C/C++ programmers’ fondness for bumping pointers or indices inside the loop. The SIMD directives come in two forms for C/C++ and Fortran, respectively:
#pragma simd [clause[ [,] clause]…]
!DIR$ SIMD [clause[[,] clause]…]
If we specify the SIMD directive with no clause, default rules are in effect for variable attributes, vector length, and so forth. The VECTORLENGTH and VECTORLENGTHFOR clauses are mutually exclusive. We cannot use the VECTORLENGTH clause with the VECTORLENGTHFOR clause, and vice versa.
If we do not explicitly specify a VECTORLENGTH or VECTORLENGTHFOR clause, the compiler will choose a VECTORLENGTH using its own cost model. Misclassification of variables into PRIVATE, FIRSTPRIVATE, LASTPRIVATE, LINEAR, and REDUCTION, or the lack of appropriate classification of variables, may lead to unintended consequences such as runtime failures and/or incorrect results.
We can only specify a particular variable in at most one instance of a PRIVATE, LINEAR, or REDUCTION clause. If the compiler is unable to vectorize a loop, a warning occurs by default. However, if ASSERT is specified, an error occurs instead. If the vectorizer has to stop vectorizing a loop for some reason, the fast floating-point model is used for the SIMD loop. A SIMD loop may contain one or more nested loops or be contained in a loop nest. Only the loop preceded by the SIMD directive is processed for SIMD vectorization.
The vectorization performed on this loop by the SIMD directive overrides any setting we may specify for options -fp-model (Linux OS and OS X) and /fp (Windows) for this loop.
VECTORLENGTH (n1 [, n2]…)
n is a vector length (VL). It must be an integer that is a power of 2 (16 or less for C/C++); the value must be 2, 4, 8, or 16. If we specify more than one n, the vectorizor will choose the VL from the values specified. This clause causes each iteration in the vector loop to execute the computation equivalent to n iterations of scalar loop execution. Multiple VECTORLENGTH clauses will cause a syntax error.
VECTORLENGTHFOR (data-type)
data-type is one of the following intrinsic data types in Fortran or built-in integer, pointer, float, double or complex types in C/C++. This clause causes each iteration in the vector loop to execute the computation equivalent to n iterations of scalar loop execution where n is computed from size_of_vector_register/sizeof(data_type).
For example, VECTORLENGTHFOR (REAL (KIND=4)) or vectorlengthfor(float) results in n=4 for SSE2 to SSE4.2 targets (packed float operations available on 128-bit XMM registers) and n=8 for AVX target (packed float operations available on 256-bit YMM registers) and n=16 for Intel Xeon Phi coprocessors. The VECTORLENGTHFOR and VECTORLENGTH clauses are mutually exclusive. We cannot use the VECTORLENGTHFOR clause with the VECTORLENGTH clause, and vice versa. Multiple VECTORLENGTHFOR clauses cause a syntax error.
LINEAR (var1:step1 [, var2:step2]…)
var is a scalar variable; step is a compile-time positive, integer constant expression. For each iteration of a scalar loop, var1 is incremented by step1, var2 is incremented by step2, and so on. Therefore, every iteration of the vector loop increments the variables by VL*step1, VL*step2, …, to VL*stepN, respectively. If more than one step is specified for a var, a compile-time error occurs. Multiple LINEAR clauses are merged as a union. A variable in a LINEAR clause cannot appear in a REDUCTION, PRIVATE, FIRSTPRIVATE, or LASTPRIVATE clause.
REDUCTION (oper:var1[, var2]…)
oper is a reduction operator (+, *,−, .AND., .OR., .EQV., or .NEQV.); var is a scalar variable. Applies the vector reduction indicated by oper to var1, var2, …, varN. A SIMD directive can have multiple reduction clauses using the same or different operators. If more than one reduction operator is associated with a var, a compile-time error occurs. A variable in a REDUCTION clause cannot appear in a LINEAR, PRIVATE, FIRSTPRIVATE, or LASTPRIVATE clause.
[NO]ASSERT
Directs the compiler to assert (produce an error) or not to assert (produce a warning) when the vectorization fails. The default is NOASSERT. If this clause is specified more than once, a compile-time error occurs.
PRIVATE (var1 [, var2]…)
var is a scalar variable. Causes each variable to be private to each iteration of a loop. Its initial and last values are undefined upon entering and exiting the SIMD loop. Multiple PRIVATE clauses are merged as a union. A variable that is part of another variable (for example, as an array or structure element) cannot appear in a PRIVATE clause. A variable in a PRIVATE clause cannot appear in a LINEAR, REDUCTION, FIRSTPRIVATE, or LASTPRIVATE clause.
FIRSTPRIVATE (var1 [, var2]…)
var is a scalar variable. Provides a superset of the functionality provided by the PRIVATE clause. Variables that appear in a FIRSTPRIVATE list are subject to PRIVATE clause semantics. In addition, its initial value is broadcast to all private instances for each iteration upon entering the SIMD loop. A variable in a FIRSTPRIVATE clause can appear in a LASTPRIVATE clause. A variable in a FIRSTPRIVATE clause cannot appear in a LINEAR, REDUCTION, or PRIVATE clause.
LASTPRIVATE (var1 [, var2]…)
var is a scalar variable. Provides a superset of the functionality provided by the PRIVATE clause. Variables that appear in a LASTPRIVATE list are subject to PRIVATE clause semantics. In addition, when the SIMD loop is exited, each variable has the value that resulted from the sequentially last iteration of the SIMD loop (which may be undefined if the last iteration does not assign to the variable). A variable in a LASTPRIVATE clause can appear in a FIRSTPRIVATE clause. A variable in a LASTPRIVATE clause cannot appear in a LINEAR, REDUCTION, or PRIVATE clause.
[NO]VECREMAINDER
Directs the compiler to vectorize (or not to vectorize) the remainder loop when the original loop is vectorized. If !DIR$ VECTOR ALWAYS is specified, the following occurs: if neither the VECREMAINDER or NOVECREMAINDER clause is specified, the compiler overrides efficiency heuristics of the vectorizer and it determines whether the loop can be vectorized. If VECREMAINDER is specified, the compiler vectorizes remainder loops when the original main loop is vectorized. If NOVECREMAINDER is specified, the compiler does not vectorize the remainder loop when the original main loop is vectorized.
Use SIMD directives with care
The SIMD directives are most powerful in forcing vectorization, but come with the danger that the implications of vectorization need to be understood to avoid changing the program behavior in unexpected ways. They should be used with care. First-time users generally make mistakes and learn from them. We advise working on loops where the output values can be tested during development to provide rapid feedback. Some instructors advise “stick in SIMD directives and start debugging.” We find that suggestion a little scary, but it seems to work with many developers quite well. Just be advised that it is hard to see the changes in a loop that are unexpected and problematic. On the other hand, SIMD directives free us from another evil: everything looks good, but we cannot figure out how to get the compiler to do the vectorization. Take your pick: SIMD to force the compiler to vectorize but we have to be careful, or auto-vectorization where the burden is on the compiler to keep things correct to the limits of its ability to analyze an application. The VECTOR and IVDEP directives give us some “in between” options, which share the burden by retaining some compiler checking but giving us more control.
The VECTOR and NOVECTOR directives
Unlike SIMD directives, VECTOR and NOVECTOR are generally hints to modify compiler heuristics. The VECTOR and NOVECTOR overrides the default heuristics for vectorization of FORTRAN DO loops and C/C++ for loops. They can also affect certain optimizations. Their format is:
!DIR$ VECTOR [clause[[,] clause]…]
!DIR$ NOVECTOR
#pragma vector [clause[[,] clause]…]
#pragma vector nontemporal[(var1[, var2, …])]
clause is an optional vectorization or optimizer clause. It can be one or more of the following:
ALWAYS [ASSERT]
Enables or disables vectorization of a loop. The ALWAYS clause overrides efficiency heuristics of the vectorizer, but it only works if the loop can actually be vectorized. If the ASSERT keyword is added, the compiler will generate an error-level assertion message saying that the compiler efficiency heuristics indicate that the loop cannot be vectorized. We should use the IVDEP directive to ignore assumed dependences or SIMD directive to ignore virtually everything. This makes VECTOR ALWAYS safer for the programmer in a way but leaves room for the compiler to be more conservative than might be strictly necessary. IVDEP and SIMD all shift more burden to the programmer to check that the vectorization is safe (preserves the programmer’s intent).
ALIGNED | UNALIGNED
Specifies that all data is aligned or no data is aligned in a loop. These clauses override efficiency heuristics in the optimizer. The clauses ALIGNED and UNALIGNED instruct the compiler to use, respectively, aligned and unaligned data movement instructions for all array references. These clauses disable all the advanced alignment optimizations of the compiler, such as determining alignment properties from the program context or using dynamic loop peeling to make references aligned.
Be careful when using the ALIGNED clause. Instructing the compiler to implement all array references with aligned data movement instructions will cause a runtime exception if some of the access patterns are actually unaligned.
TEMPORAL | NONTEMPORAL [(var1 [, var2]…)]
var is an optional memory reference in the form of a variable name. This controls how the “stores” of register contents to storage are performed (streaming versus non-streaming). The TEMPORAL clause directs the compiler to use temporal (that is, non-streaming) stores. The NONTEMPORAL clause directs the compiler to use non-temporal (that is, streaming) stores. For Intel Xeon Phi coprocessors, the compiler generates clevict (cache-line-evict) instructions after the stores based on the non-temporal directive when the compiler knows that the store addresses are aligned.
By default, the compiler automatically determines whether a streaming store should be used for each variable. Streaming stores may enable significant performance improvements over non-streaming stores for large numbers on certain processors. However, the misuse of streaming stores can significantly degrade performance.
VECREMAINDER | NOVECREMAINDER
Same as the [NO]VECREMAINDER clause for SIMD directives (see above).
Use VECTOR directives with care
The VECTOR directive should be used with care. Overriding the efficiency heuristics of the compiler should only be done if we are absolutely sure the vectorization will improve performance.
For instance, the compiler normally does not vectorize loops that have a large number of non-unit stride references (compared to the number of unit stride references). In the following example, vectorization would be disabled by default, but the directive overrides this behavior:
!DIR$ VECTOR ALWAYS
do i = 1, 100, 2
! two references with stride 2 follow
a(i) = b(i)
enddo
There may be cases where we want to explicitly avoid vectorization of a loop; for example, if vectorization would result in a performance regression rather than an improvement. In these cases, we can use the NOVECTOR directive to disable vectorization of the loop.
In the following example, vectorization would be performed by default, but the directive overrides this behavior:
!DIR$ NOVECTOR
do i = 1, 100
a(i) = b(i) + c(i)
enddo
The IVDEP directive
Unlike SIMD directives, IVDEP gives specific hints to modify compiler heuristics about dependencies. Specifically, the compiler will assume dependencies between loops when it cannot prove they do not exist. The IVDEP directive instructs the compiler to ignore assumed vector dependencies. The format for C/C++ and Fortran, respectively, is:
#pragma ivdep
!DIR$ IVDEP [: option]
!DIR$ IVDEP with no option can also be spelled !DIR$ INIT_DEP_FWD (INITialize DEPendences ForWarD)
To ensure correct code, the compiler will prevents vectorization in the presence of assumed dependencies. This pragma overrides that decision. Use this pragma only when we know that the assumed loop dependencies are safe to ignore.
In Fortran, the option LOOP implies no loop-carried dependencies and the option BACK implies no backward dependencies. When no option is specified, the compiler begins dependence analysis by assuming all dependences occur in the same forward direction as their appearance in the normal scalar execution order. This contrasts with normal compiler behavior, which is for the dependence analysis to make no initial assumptions about the direction of dependence.
IVDEP example in fortran
In the following example, the IVDEP directive provides more information about the dependences within the loop, which may enable loop transformations to occur:
!DIR$ IVDEP
DO I=1, N
A(INDARR(I)) = A(INDARR(I)) + B(I)
END DO
In this case, the scalar execution order follows:
4. Use the result from step 1 to retrieve A(INDARR(I)).
6. Add the results from steps 2 and 3.
7. Store the results from step 4 into the location indicated by A(INDARR(I)) from step 1.
IVDEP directs the compiler to initially assume that when steps 1 and 5 access a common memory location, step 1 always accesses the location first because step 1 occurs earlier in the execution sequence. This approach lets the compiler reorder instructions, as long as it chooses an instruction schedule that maintains the relative order of the array references.
IVDEP examples in C
The loop in this example will not vectorize without the ivdep pragma, since the value of k is not known; vectorization would be illegal if k<0:
void ignore_vec_dep(int *a, int k, int c, int m)
{
#pragma ivdep
for (int i = 0; i < m; i++)
a[i] = a[i + k] * c;
}
The pragma binds only the for loop contained in current function. This includes a for loop contained in a sub-function called by the current function.
The following loop requires the parallel option in addition to the ivdep pragma to indicate there are no loop-carried dependencies:
#pragma ivdep
for (i=1; i<n; i++)
{
e[ix[2][i]] = e[ix[2][i]]+1.0;
e[ix[3][i]] = e[ix[3][i]]+2.0;
}
The following loop requires the parallel option in addition to the ivdep pragma to ensure there is no loop-carried dependency for the store into a():
#pragma ivdep
for (j=0; j<n; j++)
{
a[b[j]] = a[b[j]] + 1;
Random number function vectorization
The Intel Compiler supports a vectorized version of the random number function. This is the drand48 family of random number functions in C/C++ and RANF and Random_Number functions (single and double precision) in Fortran. Figure 5.16 shows the list of supported C/C++ functions and Figures 5.17 through 5.22 show examples using them.

Figure 5.16 Supported C/C++ Functions.

Figure 5.17 Example of drand48 Vectorization.

Figure 5.18 erand38 Vectorization; Seed Value Is Passed as an Argument.

Figure 5.19 lrand38 Vectorization.

Figure 5.20 nrand48 Vectorization; Seed Value ID Passed as an Argument.

Figure 5.21 mrand48 Vectorization.

Figure 5.22 jrand48 Vectorization; Seed Value Is Passed as an Argument.
Utilizing full vectors, -opt-assume-safe-padding
Efficient vectorization involves making full use of the vector hardware. This implies that users should strive to get most code to be executed in the kernel-vector loop as opposed to peel loop and/or remainder loop.
Remainder loop
A remainder loop is created to execute the remaining iterations when the number of loop iterations (trip count) for a vectorized loop is not a multiple of the vector length. While this is unavoidable in many cases, having a large amount of time spent in remainder loops will lead to performance inefficiencies. For example, if the vectorized loop trip count is 20 and the vector length is 16, it means every time the kernel loop gets executed once, the remainder 4 iterations have to be executed in the remainder-loop. Though the Intel Xeon Phi compiler may vectorize the remainder-loop (as reported by -vec-report6), it won’t be as efficient as the kernel loop. For example, the remainder-loop will use masks, and may have to use gathers/scatters instead of unit-strided loads/stores (due to memory-fault-protection issues). The best way to address this is to refactor the algorithm/code in such a way that the remainder-loop is not executed at runtime (by making trip counts a multiple of vector length) and/or making the trip count large compared to the vector length (so that the overhead of any execution in the remainder loop is low).
The compiler optimizations also take into account any knowledge of actual trip count values. So if the trip count is 20, compiler usually makes better decisions if it knows that the trip count is 20 (trip count is a constant known statically to the compiler) as opposed to a trip count of n (symbolic value) that happens to have a value of 20 at runtime (maybe it is an input value read in from a file). In the latter case, we can help the compiler by using a #pragma loop_count (20) in C/C++, or CDEC$ LOOP COUNT (20) in Fortran, before the loop.
Also take into account any unrolling of the vector-loop done by the compiler (by studying output from -vec-report6 option). For example, if the compiler vectorizes a loop (of trip count n and vector length 16) and unrolls the loop by 2 (after vectorization), each kernel loop is designed to execute 32 iterations of the original src loop. If the dynamic trip count happens to be 20, the kernel loop gets skipped completely and all execution will happen in the remainder loop. If we encounter this issue, we can use the #pragma nounroll in C/C++ or CDEC$ NOUNROLL in Fortran to turn off the unrolling of the vector loop. (We can also use the loop_count pragma described earlier instead to influence the compiler heuristics).
If we want to disable vectorization of the remainder loop generated by the compiler, use #pragma vector novecremainder in C/C++ or CDEC$ vector noremainder in Fortran pragma/directive before the loop (using this also disables vectorization of any peel loop generated by the compiler for this loop). We can also use the compiler internal option -mP2OPT_hpo_vec_remainder=F to disable remainder loop vectorization (for all loops in the scope of the compilation). This is typically useful if we are analyzing the assembly code of the vector loop, and we want to identify clearly the vector-kernel loop from the line numbers (otherwise we have to carefully sift through multiple versions of the loop in the assembly—kernel/remainder/peel to identify which one we are looking at).
Peel loop
The compiler generates dynamic peel loops typically to align one of the memory accesses inside the loop. The peel loop peels a few iterations of the original src loop until the candidate memory access gets aligned. The peel loop is guaranteed to have a trip count that is smaller than the vector length. This optimization is done so that the kernel vector loop can utilize more aligned load/store instructions—thus increasing the performance efficiency of the kernel loop. But the peel loop itself (even though it may be vectorized by the compiler) is less efficient (study the-vec-report6 output from the compiler). The best way to address this is to refactor the algorithm/code in such a way that the accesses are aligned and the compiler knows about the alignment following the vectorizer alignment BKMs. If the compiler knows that all accesses are aligned (say if the user correctly uses #pragma vector aligned before the loop so that the compiler can safely assume all memory accesses inside the loop are aligned), then there will be no peel loop generated by the compiler.
We can also use the loop_count pragma described earlier to influence the compiler decision of whether or not to create a peel loop.
We can instruct the compiler to not generate a dynamic peel loop by adding #pragma vector unaligned in C/C++ or CDEC$ vector unaligned in Fortran pragma/directive before the loop in the source.
We can use the vector pragma/directive with the novecremainder clause (as mentioned above) to disable vectorization of the peel loop generated by the compiler. We can also use the compiler internal option -mP2OPT_hpo_vec_peel=F to disable peel-loop vectorization (for all loops in the scope of the compilation).
% cat -n t2.c
#include <stdio.h>
void foo1(float *a, float *b, float *c, int n)
{
int i;
#pragma ivdep
for (i=0; i<n; i++) {
a[i] *= b[i] + c[i];
}
}
void foo2(float *a, float *b, float *c, int n)
{
int i;
#pragma ivdep
for (i=0; i<20; i++) {
a[i] *= b[i] - c[i];
}
}
For the loop in function foo1, the compiler generates a kernel-vector loop (unrolled after vectorization by a factor of 2), a peel loop and remainder loop, both of which are vectorized. For the loop in function foo2, the compiler takes advantage of the fact that the trip count is a constant (20) and generates a kernel loop that is vectorized (and not unrolled). The remainder loop (of 4 iterations) is completely unrolled by the compiler (and not vectorized). There is no peel loop generated.
Option -opt-assume-safe-padding
We can increase the size of arrays by using the compiler option -opt-assume-safe-padding, which can improve performance. This option determines whether the compiler assumes that variables and dynamically allocated memory are padded past the end of the object.
When -opt-assume-safe-padding is specified, the compiler assumes that variables and dynamically allocated memory are padded. This means that code can access up to 64 bytes beyond what is specified in our program. The compiler does not add any padding for static and automatic objects when this option is used, but it assumes that code can access up to 64 bytes beyond the end of the object, wherever the object appears in the program. To satisfy this assumption, we must increase the size of static and automatic objects in our programs when we use this option.
One example of where this option can help is in the sequences generated by the compiler for vector-remainder and vector-peel loops. This option may improve performance of memory operations in such loops. If this option is used in the compilation above, the compiler will assume that the arrays a, b, and c have a padding of at least 64 bytes beyond n. If these arrays were allocated using malloc, such as:
ptr = (float *)malloc(sizeof(float) * n);
then they should be changed by the user to say:
ptr = (float *)malloc(sizeof(float) * n + 64);
After making such changes (to satisfy the legality requirements for using this option), we get a higher-performing sequence for the peel loop generated for loop at line 7.
Data alignment to assist vectorization
Data alignment is a method to force the compiler to create data objects in memory on specific byte boundaries. This is done to increase efficiency of data loads and stores to and from the processor. Without going into great detail, processors are designed to efficiently move data when that data can be moved to and from memory addresses that are on specific byte boundaries. For the Intel Xeon Phi coprocessor, memory movement is optimal when the data starting address lies on 64-byte boundaries. Thus, it is desired to force the compiler to create data objects with starting addresses that are modulo 64 bytes.
In addition to creating the data on aligned boundaries, the compiler is able to make optimizations when the data is known to be aligned by 64 bytes. By default, the compiler cannot know and cannot assume data alignment when that data is created outside of the current scope. Thus, we must also inform the compiler of this alignment via pragmas (C/C++) or directives (Fortran) so that the compiler can generate optimal code. The one exception is that Fortran module data receives alignment information at USE sites. To summarize, two steps are needed:
2. Use pragmas/directives in performance critical regions where the data is used to tell the compiler that the arguments are aligned
Step 1: Aligning the data
It is important for performance to align data. It is also important for optimization to inform the compiler of the alignment information in critical regions of the code. If we align data but do not tell the compiler, we can end up getting less optimal code and/or longer compilation time.
How to define aligned STATIC arrays
Here is an example for statically declaring a 1000-element single-precision floating-point array A on a 64-byte boundary, optimal on Windows C/C++:
__declspec(align(64)) float A[1000];
on Linux or OS X C/C++:
float A[1000] __attribute__((aligned(64)));
For Fortran simple arrays, the easiest way to get array data aligned is to use compiler option -align array64byte to get all arrays, static or dynamic, aligned on a 64-byte boundary. This option does not align data in COMMON blocks, nor elements within derived types. We can also align arrays with a directive. Directives in our code remove the need to remember the -align array64byte compiler option by explicitly calling out the alignment in our code where the variable is declared. Here is an example:
real :: A(1000)
!dir$ attributes align: 64:: A
For Fortran COMMON data, use -align zcommons to align all common block entities on 32-byte boundaries by adding padding bytes as needed. This is not the ideal data alignment for Intel Xeon Phi coprocessors, but is ideal for AVX. For the coprocessor, we have a 50/50 chance of full 64-byte alignment. Note: padding bytes may break many legacy applications that assume COMMON entities are packed and have no padding. So be sure to check results from our application to insure correctness with this compiler option.
For a Fortran derived-type data element, use -align recnbyte. To align data elements contained within a derived type on the 64-byte boundary optimal for the coprocessor, use the compiler option -align rec64byte. This option aligns components of derived types and fields within record structures on the boundary specified by (n). Each derived type element after the first is stored on either the size of the member type or n-byte boundaries, whichever is smaller. Fortran module data:
module mymod
real, allocatable :: a(:), b(:)
!dir$ attributes align:64 :: a
!dir$ attributes align:64 :: b
…
end module mymod
For alignment of dynamic data in C/C++ we replace malloc() and free() with alignment-specified replacements _mm_malloc() and _mm_free(). The arguments are identical. These _mm_ replacements provided by the Intel C++ Composer XE use the same argument and return types as malloc() and free(). The returned data from _mm_malloc() will be 64-byte aligned.
_aligned_malloc()
_mm_malloc() and _mm_free()
For alignment of dynamic data in Fortran we use the -align arraynbyte and -align recnbyte compiler options as discussed previously.
Step 2: Inform the compiler of the alignment
Now that we have aligned our data, it is necessary to inform the compiler that this data is aligned where that data is actually used in the program. For example, when we pass data as arguments to a performance-critical function or subroutine, how does the compiler know if the arguments are aligned or unaligned? This information must be provided by us since the compiler has no information on the arguments.
Here’s an example in C/C++: for a specific variable, use the __assume_aligned macro to inform the compiler that a particular variable or argument is aligned. For example, to inform the compiler that an array passed in as an argument or in global data is aligned we would do the following:
void myfunc( double p[] ) {
__assume_aligned(p, 64);
for (int i=0; i<N; i++){
p[i]++;
}
}
void myfunc2( double *p2, double *p3, double *p4, int n) {
for (int j=0; j<n; j+=8) {
__assume_aligned(p2, 64);
__assume_aligned(p3, 64);
__assume_aligned(p4, 64);
p2[j:8] = p3[j:8] * p4[j:8];
}
}
Here’s an example in Fortran: use the directive ASSUME_ALIGNED. The general syntax is:
cDEC$ ASSUME_ALIGNED address1:n1 [, address2:n2]…
If we specify more than one address:n item, they must be separated by a comma. If address is a Cray POINTER or it has the POINTER attribute, it is the POINTER and not the pointee or the TARGET that is assumed aligned. If we specify an invalid value for n, an error message is displayed.
!DIR$ ASSUME_ALIGNED A: 64
do i=1, N
A(I) = A(I) + 1
end do
!DIR$ ASSUME_ALIGNED A: 64
How to tell the vectorizer all memory references are nicely aligned for the target
A more general pragma or directive can be put in front of a loop to tell the compiler that all data in the loop is aligned. In this way, we do not have to specify each variable using the methods above.
Example in C/C++
#pragma vector aligned
for (i=0; i<n; i++){
A[i] = B[i] * C[i] + D[i];
}
//Add pragma just before an array-notation stmt to
//specify alignment for arrays used
#pragma vector aligned
A[0:n] = B[0:n] * C[0:n] + D[0:n];
Examples in Fortran:
!DIR$ VECTOR ALIGNED
do I=1, N
A(I) = B(I) * C(I) + D(I)
end do
!DIR$ VECTOR ALIGNED
A = B * C + D
Some notes: these clauses override the efficiency heuristics in the compiler vectorizer. These clauses cause the compiler to use aligned data movement instructions for all array references. These clauses disable all the advanced alignment optimizations of the compiler, such as determining alignment properties from the program context or using dynamic loop peeling to make references aligned. Be careful when using these clauses. Instructing the compiler to implement all array references with aligned data movement instructions will cause a runtime exception if some of the access patterns are actually unaligned.
Mixing aligned and unaligned accesses: how to tell the vectorizer all RHS memory references are 64-Byte aligned
Data alignment is a method to force the compiler to create data objects in memory on specific byte boundaries. This is done to increase efficiency of data loads and stores to and from the processor. For The Intel® Many Integrated Core Architecture (Intel® MIC Architecture) products such as the Intel Xeon Phi coprocessor, memory movement is optimal when the data starting address lies on 64-byte boundaries.
In addition to creating the data on aligned boundaries, the compiler is able to make optimizations when the data is known to be aligned by 64 bytes. Thus, we must also inform the compiler of this alignment via pragmas (C/C++) or directives (Fortran) so that the compiler can generate optimal code. The one exception is that Fortran module data receives alignment information at USE sites.
This example shows alignment being asserted to help the compiler optimize as much as possible:
float *p, *p1;
__assume_aligned(p1,64);
__assume(n1%16==0);
__assume(n2%16==0);
__assume(n3%16==0);
__assume(n4%16==0);
__assume(n5%16==0);
for(i=0;i<n;i++){
q[i] = p[i]+p[i+n1]+p[i+n2]+p[i+n3]+p[i+n4]+p[i+n5];
}
for(i=0;i<n;i++){
q1[i] =
p1[i]+p1[i+n1]+p1[i+n2]+p1[i+n3]+p1[i+n4]+p1[i+n5];
}
Tradeoffs in array notations due to vector lengths
When converting code to array notation, it is useful to keep in mind what operations are directly supported by the target hardware. Consider this scalar code:
void scalar(T *R, T *A, T *B, int S, T k) {
// S is size __assume_aligned(R,64);
__assume_aligned(A,64);
__assume_aligned(B,64);
for (int i = 0; i < S; i++) {
T tmp = A[i] * k - B[i];
if (tmp > 5.0f) {
tmp = tmp * sin(B[i]);
}
A[i] = tmp;
}
}
If the scalar code were converted directly to array notation using the basic technique of replacing loop-index-subscripts [i] with array notation [0:S], this code would be the result:
void longvector(T *R, T *A, T *B, int S, T k) {
__assume_aligned(R,64);
__assume_aligned(A,64);
__assume_aligned(B,64);
T tmp[S];
tmp[0:S] = A[0:S] * k - B[0:S];
if (tmp[0:S] > 5.0f) {
tmp[0:S] = tmp[0:S] * sin(B[0:S]);
}
A[0:S] = tmp[0:S];
}
If the array size S is large (larger than L2 cache size), the above code may not perform optimally because the array sections are very large. Specifically:
1. The temporary array tmp, which was a single scalar value in the original code, is now a large array. This data is reused several times in the algorithm, but does not fit in the cache and must be reloaded from memory. It may even lead to stack allocation problems.
2. The array B has the same problem: it is reused but does not fit in the cache.
3. The size S array section operations are much larger than hardware vector length. The compiler must decide how to break them up for efficient vectorization.
The compiler may be able to “fuse” all the code together, which will improve reuse, but it may be hampered by the unknown size S and the generic declaration of the arrays as kpointers to T.
A way to write the above code that relies less on aggressive compiler analysis is:
void shortvector(T *R, T *A, T *B, int S, T k) {
__assume_aligned(R,64);
__assume_aligned(A,64);
__assume_aligned(B,64);
for (int i = 0; i < S; i += VLEN) {
T tmp[VLEN];
tmp[:] = A[i:VLEN] * k - B[i:VLEN];
if (tmp[:] > 5.0f) {
tmp[:] = tmp[:] * sin(B[i:VLEN]);
}
A[i:VLEN] = tmp[:];
}
}
This “short vector” style reintroduces the for loop and iterates through the loop in groups of VLEN elements. Within the loop, the compiler will generate operations that handle VLEN elements at a time. If VLEN is chosen to match the target hardware vector length, these operations can map directly into vector instructions and register operations.
The obvious question to ask is: isn’t the short vector style more complicated to read than the original for loop? Wouldn’t it be better to use a scalar for loop and rely on compiler vectorization and other optimizations? The answer is “it depends.” The advantage of the short vector style is that it tells the compiler exactly what is expected and assists with dependency analysis due to the array notation semantics (array notation implies no dependencies within a statement). If the scalar for loop performs optimally, of course there is no reason to use this style. But if the compiler is not providing the desired code generation with the scalar for loop, then short vectors are a good way to tune the loop without unnatural looking constructions like strip-mining.
Another natural question is: “What is the optimal value of VLEN?” A good rule of thumb is to start with the target hardware vector size and try multiplying or dividing by 2. Increasing the size will increase the number of vector registers that are needed to compute the loop, but may increase performance by reducing trip count and exposing more optimization opportunities. Decreasing the size will increase trip count, but may be needed if the loop operations require more vector registers than are available (it is a good idea to reduce VLEN when mixing floats and doubles, for instance). For the Intel Xeon Phi coprocessor, 16 seems to be the optimal VLEN for the above routine.
On the Intel Xeon Phi coprocessor, the short vector code above ran 25 percent faster in our tests than the native scalar code. Here is the full code:
// Example of short vector style coding vs. scalar.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define S 8192*4
#define T float
#define ITERS 100
#define VLEN 16
// Reduce for AVX,SSE,etc.
__declspec(noinline) void scalar(T *R,T *A, T *B, T k) {
__assume_aligned(R,64);
__assume_aligned(A,64);
__assume_aligned(B,64);
for (int i = 0; i < S; i++) {
T tmp = A[i] * k - B[i];
if (tmp > 5.0f) {
tmp = tmp * sin(B[i]);
}
A[i] = tmp;
}
}
// NOT EXECUTED; CAUSES STACK OVERFLOW DUE TO LARGE stack allocation
__declspec(noinline) void longvector(T *R,T *A, T *B, T k) {
//__declspec(noinline) void longvector(T R[S],T A[S], T B[S], T k) {
__assume_aligned(R,64);
__assume_aligned(A,64);
__assume_aligned(B,64);
T tmp[S];
tmp[0:S] = A[0:S] * k - B[0:S];
if (tmp[0:S] > 5.0f) {
tmp[0:S] = tmp[0:S] * sin(B[0:S]);
} A[0:S] = tmp[0:S];
__declspec(noinline) void shortvector(T *R,T *A, T *B, T k) {
__assume_aligned(R,64);
__assume_aligned(A,64);
__assume_aligned(B,64);
for (int i = 0; i < S; i += VLEN) {
T tmp[VLEN];
tmp[:] = A[i:VLEN] * k - B[i:VLEN];
if (tmp[:] > 5.0f) {
tmp[:] = tmp[:] * sin(B[i:VLEN]);
} A[i:VLEN] = tmp[:];
}
}
bool compare(T ref, T cean) {
return (fabs(ref - cean) < 0.00001);
}
//__declspec(align(64)) T A[S],B[S],C[S]; int main() {
volatile __int64 start=0, end=0, perf_ref=0, perf_short=0, max, tmpdiff;
T *A,*B,*C;
posix_memalign((void **)&A, 64, sizeof(T)*S);
posix_memalign((void **)&B, 64, sizeof(T)*S);
posix_memalign((void **)&C, 64, sizeof(T)*S);
//__declspec(align(64)) T A[S],B[S],C[S];
int short_vs_ref;
T ref_result, short_result;
float k = 0.5;
max = 0;
for (int i = 0; i < ITERS; i++) {
A[0:S] = __sec_implicit_index(0);
B[0:S] = __sec_implicit_index(0);
C[0:S] = __sec_implicit_index(0);
start = __rdtsc();
scalar(A,B,C,k);
tmpdiff = __rdtsc() - start;
perf_ref += tmpdiff;
if (max < tmpdiff) max = tmpdiff;
ref_result = __sec_reduce_add(A[0:S]);
}
perf_ref -= max;
tmpdiff = (perf_ref - perf_short) * 100 / perf_ref;
short_vs_ref = (int)tmpdiff;
if (!compare(ref_result, short_result)) {
printf("MISCOMPARE SHORT: FAILEDn");
} else if (short_vs_ref < 15) {
printf("SHORT VECTOR IS < 15%% FASTER THAN SCALAR : %d%%n", short_vs_ref);
printf(“FAILEDn”); return −2;
}
printf(“SHORT VS SCALAR SPEEDUP >= 15%%: %d%%n”, short_vs_ref);
printf(“PASSEDn”);
return 0;
}
C++ Array Notation is part of Intel Cilk Plus, which is a feature of the Intel® C++ Composer XE. Array Notation is one way to express parallelism. Array Notation helps the compiler with vectorization. However, one has to be careful in its use. Array expressions often require creation of temporary copies of the intermediate arrays used in evaluation of the expression. A side effect could be that these temporary vectors spill out of cache, eliminating reuse and causing a performance loss compared to the original loop equivalent. Rewriting the array syntax in shorter vectors can avoid this cache overflow.
Use array sections to encourage vectorization
Use of array sections in Fortran or C/C++ are better at explaining our intent as programmers. This in turn helps the compiler have the information it needs to vectorize the loop because it is has less of the implied dependencies that creep up from the use of loops.
Fortran array sections
An array section is a portion of an array that is an array itself. It is an array sub-object. A section subscript list (appended to the array or array component) determines which portion is being referred to. A reference to an array section takes the following form array(sect-subscript-list), where array is the name of the array, sect-subscript-list is a list of one or more section subscripts (subscripts, subscript triplets, or vector subscripts) indicating a set of elements along a particular dimension. At least one of the items in the section subscript list must be a subscript triplet or vector subscript. A subscript triplet specifies array elements in increasing or decreasing order at a given stride. A vector subscript specifies elements in any order. Each subscript and subscript triplet must be a scalar integer (or other numeric) expression. Each vector subscript must be a rank-one integer expression.
If no section subscript list is specified, the rank and shape of the array section is the same as the parent array. Otherwise, the rank of the array section is the number of vector subscripts and subscript triplets that appear in the list. Its shape is a rank-one array where each element is the number of integer values in the sequence indicated by the corresponding subscript triplet or vector subscript.
If any of these sequences is empty, the array section has a size of zero. The subscript order of the elements of an array section is that of the array object that the array section represents.
Each array section inherits the type, kind type parameter, and certain attributes (INTENT, PARAMETER, and TARGET) of the parent array. An array section cannot inherit the POINTER attribute. If an array (or array component) is of type character, it can be followed by a substring range in parentheses.
Subscript triplets
A subscript triplet is a set of three values representing the lower bound of the array section, the upper bound of the array section, and the increment (stride) between them. It takes the following form [first-bound] : [last-bound] [:stride], where first-bound is a scalar integer (or other numeric) expression representing the first value in the subscript sequence. If omitted, the declared lower bound of the dimension is used, last-bound is a scalar integer (or other numeric) expression representing the last value in the subscript sequence. If omitted, the declared upper bound of the dimension is used. When indicating sections of an assumed-size array, this subscript must be specified. Here stride is a scalar integer (or other numeric) expression representing the increment between successive subscripts in the sequence. It must have a nonzero value. If it is omitted, it is assumed to be 1.
If the stride is positive, the subscript range starts with the first subscript and is incremented by the value of the stride, until the largest value less than or equal to the second subscript is attained. If the first subscript is greater than the second subscript, the range is empty. If the stride is negative, the subscript range starts with the value of the first subscript and is decremented by the absolute value of the stride, until the smallest value greater than or equal to the second subscript is attained. If the second subscript is greater than the first subscript, the range is empty. If a range specified by the stride is empty, the array section has a size of zero.
A subscript in a subscript triplet need not be within the declared bounds for that dimension if all values used to select the array elements are within the declared bounds. For example, if an array has been declared as A(15), the array section specified as A(4:16:10) is valid. The section is a rank-one array with shape (2) and size 2. It consists of elements A(4) and A(14).
If the subscript triplet does not specify bounds or stride, but only a colon (:), the entire declared range for the dimension is used. If all subscripts are omitted, the section defaults to the entire extent in that dimension.
Vector subscripts
A vector subscript is a one-dimensional (rank one) array of integer values (within the declared bounds for the dimension) that selects a section of a whole (parent) array. The elements in the section do not have to be in order and the section can contain duplicate values. An array section with a vector subscript that has two or more elements with the same value is called a many-one array section. A many-one section must not appear on the left of the equal sign in an assignment statement, or as an input item in a READ statement.
Implications for array copies, efficiency issues
Unlike the array section definition for C/C++ with Cilk Plus, the Fortran language semantics sometimes require the compiler to make a temporary copy of an array or array slice. Situations where this can occur include:
• Passing a noncontiguous array to a procedure that does not declare it as assumed-shape
• Array expressions, especially those involving RESHAPE, PACK, and MERGE
• Assignments of arrays where the array appears on both the left- and right-hand sides of the assignment
By default, these temporary values are created on the stack and, if large, may result in a “stack overflow” error at runtime. The size of the stack can be increased, but with limitations dependent on the operating system. Use of the /heap-arrays (Windows) or -heap-arrays (Linux) compiler option tells the compiler to use heap allocation, rather than the stack, for such temporary copies. Heap allocation adds a small amount of overhead when creating and removing the temporary values, but this is usually inconsequential in comparison to the rest of the code.
Performance can be further improved by eliminating the need for a temporary copy entirely. For the first case above, passing a noncontiguous array to a procedure expecting a contiguous array, enabling the /check: arg_temp_created (Windows OS) or -check arg_temp_created (Linux OS) compiler option, will produce a runtime informational message when the compiler determines that the argument being passed is not contiguous. A runtime test is made and, if the argument is contiguous, no copy is made. However, this option will not issue a diagnostic for other uses of temporary copies.
One way to avoid temporary copies for array arguments is to change the called procedure to declare the array as assumed-shape, with the DIMENSION(:) attribute. Such procedures require an explicit interface to be visible to the caller. This is best provided by placing the called procedure in a module or a CONTAINS section. As an alternative, an INTERFACE block can be declared.
Use of POINTER arrays makes it difficult for the compiler to know if a temporary value can be avoided. Where possible, replace POINTER with ALLOCATABLE, especially as components of derived types. The language definition allows the compiler to assume that ALLOCATABLE arrays are contiguous and that they do not overlap other variables, unlike POINTERs.
Another situation where the temporary values can be created is for automatic arrays, where an array’s bounds are dependent on a routine argument, use or host associated variable, or COMMON variable, and the array is a local variable in the procedure. As above, these automatic arrays are created on the stack by default; the /heap-arrays (Windows) or -heap-arrays (Linux) compiler option will create them on the heap. Consider making such arrays ALLOCATABLE instead; local ALLOCATABLE variables that do not have the SAVE attribute are automatically deallocated when the routine exits. For example, replace:
SUBROUTINE SUB (N)
INTEGER, INTENT(IN) :: N
REAL :: A(N)
with:
SUBROUTINE SUB(N)
INTEGER, INTENT(IN) :: N
REAL, ALLOCATABLE :: A(:)
ALLOCATE (A(N))
Cilk Plus array sections and elemental functions
Cilk Plus extends C and C++ with array notation and elemental functions, which lets the programmer specify array sections, operations on array sections, and scalar operations to be applied on vectors. These are the parts of Cilk Plus that enable vector programming and are therefore covered in this chapter. The task-oriented features of Cilk Plus are covered in Chapter 6.
Programming with array notation achieves predictable performance based on mapping parallel constructs to the underlying hardware vector parallelism, and possibly thread parallelism in the future. The notation is explicit, easy to understand, and enables compilers to exploit vector and thread parallelism with less reliance on alias and dependence analysis. For example:
a[0:n] = b[10:n] * c[20:n];
is an unordered equivalent of:
for ( int i=0; i<n; ++i )
a[i] = b[10+i] + c[20+i];
Use array notation where our operations on arrays do not require a specific order of operations among elements of the arrays.
Specifying array sections
An array section operator is written as one of the following:
[first:length:stride]
[first:length]
[:]
where:
• first is the index of the first element in the section.
• length is the number of elements in the section.
• stride is the difference between successive indices. The stride is optional, and if omitted is implicitly 1. The stride can be positive, zero, or negative.
All three of these values must be integers, but they can be computed at runtime (they do not need to be known at compile time). The notation expr[:] is a shorthand for a whole array dimension if expr has array type before decay (conversion to pointer type) and the size of the array is known. If either first or length is specified, then both must be specified.
Operations on array sections
Most C and C++ scalar operations act element-wise on array sections and return an element-wise result. For example, a[10:n]-b[20:n] returns an array section of length n where the j element is a[10+j]-b[20+j]. Each operand must have the same shape, unless it is a scalar operand. Scalar operands are reshaped by replication to match the shape of the non-scalar operands. Function calls are also applied element-wise. The few operators that are not applied element-wise or have peculiar rank rules are:
• Comma operator. The rank of x, y is the rank of y.
• Array section operator. As described earlier, the rank of a[i : n : k] is one more than the rank of a.
• Subscript operator. As described earlier, the rank of the result of a[i] is the sum of the ranks of a and i. The j element of a[k[0 : n]] is a[k[j]]. Trickier is the second subscript in b[0 : m][k[0 : n]]. Both b[0 : m] and k[0 : n] have rank 1, so the result is a rank-two section where the element at subscript i, j is b[i][k[j]].
Note that pointer arithmetic follows the element-wise rule just like other arithmetic. A consequence is that a[i] is not always the same as *(a+i) when array sections are involved. For example, if both a and i have rank one, then a[i] has rank two, but *(a+i) has rank one, because it is element-wise unary * applied to the result of element-wise addition.
Historical note: In the design of array notation, an alternative was explored that preserved the identity ∗(a + i) ≡ a[i], but it broke the identity (a + i) + j ≡ a + (i + j) when a is a pointer type, and made the rank of a+i dependent on the type (not just the rank) of a. It turns out that array notation must break one of the two identities, and breaking associativity was deemed the worse of two evils.
Reductions on array sections
There are built-in operations for efficient reductions of array sections. For example, _sec_reduce_add(a[0:n]) sums the values of array section a[0:n]. Table 5.2 is a summary of the built-in operations. The last column shows the result of reducing a zero-length section.
Table 5.2
Built-in Operations
| Operation | Result | If Empty |
| sec_reduce_add | Σi ai | 0 |
| sec_reduce_mul | Πi ai | 1 |
| sec_reduce_max | maxi ai | “−∞” |
| sec_reduce_min | mini ai | “∞” |
| sec_reduce_max_ind | j such that ∀i : ai≥aj | unspecified |
| sec_reduce_min_ind | j such that ∀i : ai≤aj | unspecified |
| sec_reduce_all_zero | ∀i : ai=0 ? 1 : 0 | 1 |
| sec_reduce_all_nonzero | ∀i : ai /= 0 ? 1 : 0 | 0 |
| sec_reduce_any_zero | ∃i : ai=0 ? 1 : 0 | 1 |
| sec_reduce_any_nonzero | ∃i : ai /= 0 ? 1 : 0 | 0 |
The “−∞” and “∞” are shorthand for the minimum and maximum representable values of the type. The result of a reduction is always a scalar. For most of these reductions, the rank of a can be one or greater. The exception is that the rank of a must be one for _sec_reduce_max_ind and _sec_reduce_min_ind.
Avoid partial overlap of array sections
In C and C++, the effect of a structure assignment *p=*q is undefined if *p and *q point to structures that partially overlap in memory. The assignment is well defined if *p and *q are either completely disjoint or are aliases for exactly the same structure. Cilk Plus extends this rule to array sections. Examples:
extern float a[15];
a[0:4] = a[5:4]; // Okay, disjoint
a[0:5] = a[4:5]; // WRONG! Partial overlap
a[0:5] = a[0:5]+1; // Okay, exact overlap
a[0:5:2] = a[1:5:2]; // Okay, disjoint, no locations shared
a[0:5:2] = a[1:5:3]; // WRONG! Partial overlap (both share a [4])
a[0:5] = a[5:5]+a[6:5]; // Okay, reads can partially overlap
The last example shows how partial overlap of reads is okay. It is partial overlap of a write with another read or write that is undefined. This definition for array notation, which makes partial overlap ill defined, is different from the “well-defined but inefficient” choice made by APL and Fortran. Experience showed that doing so required a compiler to often generate temporary arrays, so it could fully evaluate the right side of a statement before doing an assignment. These temporary arrays hurt performance and caused unpredictable space consumption, both at odds with the C++ philosophy of providing abstractions with minimal performance penalty. So the specification was changed to match the rules for structure assignment in C/C++. Perhaps future compilers will offer to insert partial overlap checks into code for debugging.
Elemental functions
An elemental function is a scalar function with markup that tells the compiler to generate extra versions of it optimized to evaluate multiple iterations in parallel. These are well-suited to converting legacy code where such functions already exist and can be converted without changing the rest of the program. It is a convenient notation that is useful to consider in writing new code as well because it holds up well over time as hardware vector lengths change.
When we call an elemental function from a parallel context, the compiler can call the parallel version instead of the serial version, even if the function is defined in a different source file than the calling context. The steps for using an elemental function are:
1. Write a function in scalar form using standard C/C++.
2. Add __declspec(vector), and perhaps with optional control clauses, to the function declaration so that the compiler understands the intended parallel context(s) for calling it. Use additional clauses let you tell the compiler the expected nature of the parameters:
• uniform(b) indicates that parameter b will be the same for all invocations from a parallel loop.
• linear(a:k) indicates that parameter a will step by k in each successive invocation from the original serial loop. For example, linear(p:4) says that parameter p steps by 4 on each invocation. Omitting :k is the same as using :1.
3. Invoke the function from a loop marked with #pragma simd or with array section arguments.
The examples in Figures 5.23 and 5.24 show definition and use respectively of an elemental function. This code will likely perform better than a program where the function is not marked as elemental, particularly when the function is defined in a separate file. Writing in this manner exposes the opportunity explicitly instead of hoping that a super-optimizing compiler will discover the opportunity, which is particularly important in examples less trivial than this one.

Figure 5.23 Defining an elemental function. The declspec tells the compiler to generate, in addition to the usual code, a specialized version for efficiently handling vectorized chunks where a has unit stride and b is invariant.

Figure 5.24 Calling an elemental function from a vectorizable loop. The declspec on the prototype tells the compiler that the specialized version from the prior example exists. As usual in C/C++, a separate prototype is unnecessary if the function is defined first in the same file.
Specifying unit-stride accesses inside elemental functions
If an elemental function accesses memory in unit-stride, these are the two ways we can write the function to achieve good performance, as shown in Figure 5.25.

Figure 5.25 Two ways to promise unit-stride for vector (elemental) functions.
Look at what the compiler created: assembly code inspection
There are several ways to gain insight into how well applications were vectorized for the Intel® MIC architecture. The Vectorization Intensity performance metric, discussed in Chapter 13, quantifies the efficiency of an application’s vectorization in terms of how many elements operations applied to. The Vectorization report (-vec-report) compiler option, introduced in this chapter, gives detailed information on which loops vectorized. Another handy tool for judging vectorization is assembly code inspection.
Visual inspection of assembly code can help identify performance problems that may merit further investigation. Understanding generated assembly code and its impact on application execution is a complex subject that can require years of study. We don’t attempt to tackle that whole subject in this chapter. Instead we will share possible signs of trouble that anyone can look for in generated assembly for the Intel Xeon Phi coprocessor.
How to find the assembly code
There are two methods for obtaining the assembly code for your coprocessor application. The first is by using the -S option (Linux) for the Intel Compiler. This will produce an assembly file instead of a typical executable, and it will end in .s unless otherwise specified. If an offload application is being compiled to assembly, two files will be generated: one with a .s and the other ending in MIC.s, which will contain the specific binary to be run on the coprocessor. When using the -S option, we recommend removing -g (debug information) as it will remove a great deal of extra symbolic labeling in the assembly file and make it easier to read. Looking at an assembly listing presents several challenges though. The sheer length of most assembly listings can be intimidating. A trick for finding relevant code regions in an Intel Compiler assembly file is to search for ‘#linenumber’ in the file (for example, ‘#206’ for line 206). Even after doing this, however, you will often see hundreds of lines of assembly corresponding to one or two lines of source. For example, the compiler will typically try to align one or more memory references in a for loop dynamically. If, for example, a loop is accessing floats in an array and the first reference happens to be to a piece of data that is the eleventh element in a cacheline, the compiler will generate three loops. The first is a “peel” loop, which will perform the first five iterations of the loop (accessing the last five elements in the first cacheline). Then will be the main loop, accessing elements aligned to cachelines (16 elements per line). Then will be a remainder loop, to access any remaining elements in the final cacheline. Many other types of performance enhancements the compiler performs have the effect of making the assembly language very different from a straightline interpretation of the original source. Another source of confusion in assembly files can come from parallelism libraries like OpenMP, which create a function for the parallel region and result in loop code being found in a different location than expected.
Given the challenges outlined above, many people prefer to use the second method for viewing assembly, which is the source/assembly viewer in Intel® VTune™ Amplifier XE. VTune Amplifier XE can display the assembly for an application you are analyzing without needing any special compilation options. If symbolic information is available, the assembly code can be displayed side-by-side with the original source code. When a line of source code is selected, the corresponding assembly lines are displayed. This makes it easier to locate the assembly code of interest, but doesn’t completely solve the issue of sorting out things like where the body of a loop that has been parallelized will appear in the assembly. Another way that the Intel VTune Amplifier XE can make things easier: loop analysis. Using loop analysis mode (Figure 5.26), VTune Amplifier XE will display hot information for the loops in your code instead of the functions. This makes it even easier to select a loop to focus on, and then view the source just for that loop and the corresponding lines of assembly (Figure 5.27). When looking at the assembly, you can using the line-by-line event count information to see how much time each instruction took to execute, allowing you to focus on the main loop body (higher execution times) instead of peel/remainder loops.

Figure 5.26 Loop Analysis, using VTune.

Figure 5.27 Assembly Code View Selected, using VTune.
Quick inspection of assembly code
After determining which assembly code is relevant to look at for your loop or function, the next thing to understand is what it means. Understanding the instruction set for the Intel Xeon Phi coprocessor is beyond the scope of this book and is covered in the Intel Xeon Phi Coprocessor Instruction Set Architecture Reference Manual (see “For More Information” at the end of this chapter). This section focuses on spotting potential performance issues with a quick inspection. Since vectorization is so important to performance on the Intel Xeon Phi coprocessor, all of the assembly language issues that we cover here will pertain to vectorization.
Symptom 1: usage of unaligned loads and stores
Loading or storing unaligned data in a loop can result in the compiler using two instructions for each memory access. Generally, the compiler will try to dynamically align accesses using peel/remainder loops as discussed above, but in some situations this may not be possible. If the vloadunpackld/hd (low data/high data) or vstoreunpackld/hd instruction pairs are observed in a main loop body (not a peel or remainder loop), it indicates compiler was not able to enforce alignment dynamically and this is likely impacting performance. To address this issue, you should both align your data accesses and tell the compiler they are aligned. Both are important. Alignment is discussed in the section “Data Layout, Alignment, Prefetching, and So On” earlier in this chapter. In an illustrative example, a simple for loop (Figure 5.28) results in unaligned loads and stores (Figure 5.29). After telling the compiler that alignment is enforced using the #pragma vector aligned, the vmovaps instruction can be used just once for each data access (Figure 5.30) for a much more efficient loop.
![]()
Figure 5.28 Source Code for the Loop.

Figure 5.29 Unaligned Version of the Loop.

Figure 5.30 Aligned Version of the Loop.
Symptom 2: usage of %k1 mask
If the vector instructions for the Xeon Phi coprocessor are all masked, this may indicate inefficiencies. Masks are used for marking which elements in a vector register to which to apply the operation. Instructions that are generated by the compiler with a %k0 mask apply to every element in a vector register – mask %k0 is automatically all 1 s. The compiler can use a different mask with an instruction to indicate that it should apply to less than a full vector (to fewer than all elements in a 512bit vector register). For a thorough explanation of how the masks are used, see section 2.1.2 of the Intel® Xeon Phi™ Coprocessor Instruction Set Architecture Reference Manual.
If scalar code (not vectorized) is being generated, typically the compiler will still use a vector instruction with a mask of %k1. Earlier in the code the compiler will have set %k1 to have a value of 1 – so, the vector instruction being used will only apply to 1 element in the vector register. Seeing the %k1 mask being used is not a definite sign of an issue – but, it is likely that less than full registers are being operated on and so vectorization is not as efficient as it could be. Again, this is something to be concerned about when looking at the assembly code for the main loop body, which should have aligned memory accesses and operate on full vector registers. Peel and remainder loops will have instructions operation on fewer elements and so may use masking effectively.
If this symptom is present, examine the compiler vectorization report for the loops in question. Using the highest level of diagnostic information (level 6) gives information on which loops were not vectorized and why. Figure 5.31 shows instructions not operating on full vectors. Instructions operating on full vectors are shown in Figure 5.32. Or, depending on the format, the %k0 mask may be left out to indicate no mask is being given as shown in Figure 5.33.

Figure 5.31 Instructions using %k1 Mask.
![]()
Figure 5.32 Full Vectors Being Operated On.
![]()
Figure 5.33 Full Vectors: No Mask Being Used At All.
Symptom 3: usage of scatters or gathers
Like symptoms 1 and 2, usage of scatter or gather instructions, see Figure 5.34, should cause concern only if observed in a main loop body and not a peel or remainder loop. Scatter and gather instructions are used to load or store multiple elements at a time. Gathers load elements into a vector register to be operated on, and scatters store elements back to multiple memory locations (cachelines) at once. They are useful instructions in the case where the application code is performing true indirect memory accesses, such as in a sparse data structure. However, due to their nature of loading/storing many elements they can have a long execution latency. In some cases, such as strided accesses, the application code can be restructured to have stride 1 access and avoid long latency scatter/gather operations. (When memory is accessed with a stride of 1, a single cacheline can hold a full vector register’s worth of data to be operated on.)
![]()
Figure 5.34 Example Scatter/Gather Instructions.
A typical case of strided accesses is an array of structures, often seen in molecular dynamics codes. These arrays holding structs (X, Y, and Z coordinates for example) are usually accessed in a strided fashion—moving through memory accessing all the X elements for example. Restructuring the code to access a structure of arrays—with all the Xs in one array, the Ys in another array, and so on, can change the access pattern to stride 1, which is far more beneficial. Section 5 of the Guide to Vectorization with Intel C++ Compilers (see “For More Information” at end of this chapter) discusses the structure of arrays concept with an example.
Symptom 4: lack of prefetch instructions
Software prefetch is an important strategy for improving performance on the Intel Xeon Phi coprocessor. Within loops, the compiler will usually insert prefetch instructions into code for you. One prefetch methodology used by the compiler is to prefetch data first into the local L2 cache with a vprefetch1 instruction, and then into the L1 cache with a vprefetch0 instruction. Typically you will see 1 or 2 prefetch instructions prior to each data load in a loop, as in Figure 5.35, and these could be a mixture of vprefetch0 and vprefetch1, and sometimes vprefetche1 or 2 (for stores). The absence of these prefetch instructions could indicate that the compiler is using an alternate prefetching methodology. If you see few or no prefetch instructions, and are seeing a poor L1 hit rate (see Chapter 13), it may be worth trying some of the compiler pragmas governing prefetch. A number of prefetch options are configurable and may yield better performance. The earlier section “Prefetching” in this chapter discusses these options.

Figure 5.35 Example: 6 Prefetches Followed by 6 Loads.
Symptoms: quick inspections
The quick inspections we have shown give some things to look for in assembly code that may point to less than optimal code being generated for the Intel Xeon Phi coprocessor. These inspections can be useful tool in searching for top performance, and do not require great expertise in assembly language code.
Numerical result variations with vectorization
Generally vectorized reductions do not produce numerically identical results to scalar loops. Additionally, sometimes they may not be reproducible from one run to the next due to concurrency, even for identical executables running on identical data on the identical processor or coprocessor. If this is an issue, we can try the –fp-model precise, which, amongst other things, disables vectorization of reductions. Performance will be reduced by such an option.
Summary
The vector parallel capabilities of the Intel Xeon Phi coprocessor are utilized in the same manner as vectorization for processors. The big difference being that the level of performance possible due to the extra wide vectors makes it more important than for processors with smaller vector capabilities. Best use of the vector capability requires vectorization to create the vector instructions and good data layout and streaming to enable efficient movement of data to and from the vector instructions. This gives rise to many models to expose the vector parallelism so vectorization occurs, as well as influencing prefetching of data into levels of the data cache. This chapter gave the fundamentals, which are the same techniques we’d find in most any tutorial or reference on vectorization for processors. The Intel compiler documentation has more examples and options for advanced usage.
For more information
Here are some additional reading materials we recommend related to this chapter.
• Intel documentation including compiler reference manuals: http://software.intel.com/en-us/articles/intel-parallel-studio-xe-for-linux-documentation/
• Vectorization Toolkit. The toolkit also includes links to additional resources for a step-by-step vectorization methodology. http://tinyurl.com/intelveckit
• Guide to Vectorization with Intel C++ Compilers, http://tinyurl.com/intelautovec
• The article “Cache Blocking Techniques” provides more background on this general purpose technique that helps processor and coprocessor performance http://tinyurl.com/intelcacheblock
• The article “Memory Layout Transformations” provides more background the “array of structures” vs. “structures of array” topic. Understanding this general-purpose transformation can motivate changes to benefit processor and coprocessor performance. http://tinyurl.com/intelmemlayout
• In the article “Fortran Array Data and Arguments and Vectorization,” various Fortran array data types and arguments are vectorized by the Intel compiler. This information may be helpful in generating effective vectorized programs. http://tinyurl.com/intelfortranarrays
• Article titled “Consistency of Floating-Point Results using the Intel® Compiler,” http://tinyurl.com/intelfpconsist
• Reference material titled “Quick-Reference Guide to Optimization with Intel® Compilers,” http://software.intel.com/en-us/intel-composer-xe/
• Intel Xeon Phi Coprocessor Instruction Set Architecture Reference Manual, http://intel.com/software/mic