
Math Library
Math libraries offer a very attractive option for using the power of Intel® Xeon Phi™ coprocessors quickly and effectively, often as easy as swapping out a processor optimized library for compatible library that uses the combined capabilities of the processor and Intel Xeon Phi coprocessors. Intel has done a great job giving several powerful options for programs that utilize the Intel® Math Kernel Library (Intel® MKL) already, or use industry standard interfaces like BLAS, CBLAS, LAPACK, LAPACKE, FFTW, and ScaLAPACK, to have access to the power of Intel processors and the Intel Xeon Phi coprocessor.
Table 11.1 lists the three programming models for using Intel MKL with Intel Xeon Phi coprocessors. These programming models are simply different interfaces to the same underlying performance capabilities of the processors and coprocessors. Multiple models can easily be utilized in the same program to meet your needs. The library does not operate in different modes; these models are just different interfaces to the same underlying performance capabilities in processors and coprocessors. The key choice is native versus offload, based on the same logic covered in Chapter 7: use native for highly parallel workloads and use offload when it is beneficial for parts of your program run specifically on a processor or coprocessor at the right time.
Table 11.1
Intel® MKL: Programming Models for Intel® Xeon Phi™ Coprocessors
| Model | Description |
| Native | Intel MKL functions called from within an application executing natively on an Intel Xeon Phi coprocessor run on the coprocessor. Calling Intel MKL from C/C++ and Fortran is supported. |
| Offload, Automatic | Select Intel MKL functions are automatically distributed to run across the processor(s) and Intel Xeon Phi coprocessor(s) when present including the automatic control of data movement to/from the coprocessor(s). This mode is enabled and more finely controlled where desirable with simple service functions (or environment variables) and supports calling from both C/C++ and Fortran. |
| Offload, Compiler Assisted | Intel MKL functions called from within compiler offload regions (see Chapter 7) run on the Xeon Phi coprocessor(s) when present (or on the processor(s) otherwise). Compiler offload pragmas (C/C++) and directives (Fortran) control data movement to/from the coprocessor(s). This approach supports offloading regions of code potentially comprising numerous calls to Intel MKL functions, thereby amortizing the data movement over multiple computation operations. |
Math libraries from other vendors, such as IMSL Numerical Libraries from Rogue Wave software and the NAG Library from The Numerical Algorithms Group Ltd. also provide support for Intel Xeon Phi coprocessors. Both of these libraries integrate portions of the Intel MKL as well to provide optimizations of highly computationally intensive functions. If your program uses any of these interfaces, or could use them, then you should definitely look at library solutions. The rest of this chapter provides further details on how to use Intel MKL for the Intel Xeon Phi coprocessor.
Intel Math Kernel Library overview
The Intel MKL includes routines and functions optimized for Intel and compatible processor-based computers running operating systems that support multiprocessing. In addition to Fortran interfaces, Intel MKL includes C-language interfaces for the BLAS1 (called CBLAS) and LINPACK with C interfaces known as LINPACKE, Discrete Fourier transform functions, Vector Math and Vector Statistical Library functions. Intel MKL includes the following groups of routines:
• Basic Linear Algebra Subprograms (BLAS):
− level 1 BLAS: vector operations
− level 2 BLAS: matrix-vector operations
− level 3 BLAS: matrix-matrix operations
• Sparse BLAS Level 1, 2, and 3 (basic operations on sparse vectors and matrices)
• LAPACK2 routines for solving systems of linear equations, least squares problems, eigenvalue and singular value problems, Sylvester’s equations and auxiliary and utility LAPACK routines
• ScaLAPACK3 computational, driver, and auxiliary routines for solving systems of linear equations across a compute cluster
• PBLAS routines for distributed vector, matrix-vector, and matrix-matrix operation
• Direct Sparse Solver routines (PARDISO)
• Iterative Sparse Solver routines
• Vector math functions for computing core mathematical functions on vector arguments
• Vector statistical functions for generating vectors of pseudorandom numbers with different types of statistical distributions and for performing convolution and correlation computations. VSL also includes summary statistics functions. Used to accurately estimate, for example, central moments, skewness, kurtosis, variance, quantiles, and to compute variance-covariance matrices and correlation matrices.
• General Fast Fourier Transform (FFT) functions, providing fast computation of Discrete Fourier Transforms via the FFT algorithms (using the FFTW interface)
• Cluster FFT functions4 for solving FFTs across a compute cluster
• Tools for solving partial differential equations—trigonometric transform routines and Poisson solver
• Optimization Solver routines for solving nonlinear least squares problems through the Trust-Region (TR) algorithms and computing Jacobi matrix by central differences
• Data Fitting functions for spline-based approximation of functions, derivatives and integrals of functions, and cell search
The Intel Math Kernel Library Reference Manual is the definitive resource for learning more about the many functions available in Intel MKL. A very large number of the routines have industry standard interfaces that are used to access the Intel optimized implementations.
Intel MKL provides both static and dynamic libraries for Intel Xeon Phi coprocessors. However, the Single Dynamic Library (SDL) capability is unavailable for coprocessors as the resulting library is too large for use on a coprocessor. If you are using SDL, refer to the Intel MKL User’s Guide section “Linking on Intel Xeon Phi Coprocessors” to understand your linking options. The Intel MKL product includes a “Link Line Advisor” to help suggest the right linkage commands to meet your needs (see http://tinyurl.com/Link-MKL). The Advisor requests information about your system and on how you intend to use the library and then the tool automatically generates the appropriate link line for specified application configuration.
The focus for the remainder of this chapter is on how to use Intel MKL with an Intel Xeon Phi coprocessor, and not about the details of the functions within Intel MKL. You are encouraged to read the Intel Math Kernel Library Reference Manual in order to explore the many functions in Intel MKL and refer to the Intel Math Kernel Library User’s Guide for usage details such as linking options.
Intel MKL differences on the coprocessor
In general, the Intel Math Kernel Library (Intel MKL) supports an Intel Xeon Phi coprocessor equivalently to a processor, with only one key difference:
Intel MKL and Intel compiler
The Intel compiler has an option –mkl as a convenience option, but does not indicate dependence between the library and compiler as they can be used separately. The mkl=lib option indicates the part of the MKL library that the compiler should link to. Possible values are:
• parallel: Tells the compiler to link using the threaded part of the Intel® MKL. This is the default if the option is specified with no lib.
• sequential: Tells the compiler to link using the non-threaded part of the Intel® MKL.
• cluster: Tells the compiler to link using the cluster part and the sequential part of the Intel® MKL.
Coprocessor support overview
Intel MKL supports Intel Xeon Phi coprocessors in two major ways, from routines called on processors and versions of the routines for calling directly from code running on the coprocessor. The first way utilizes the coprocessor via offload and the second is simply native execution.
The offloading of computations to Intel Xeon Phi coprocessors can be done without requiring any change to source code with automatic offload or using pragmas or directives in the source code in what is called compiler-assisted offload.
The automatic offload capability automatically detects the presence of coprocessors and automatically offloads computations that may benefit from additional computational resources available. To use this capability, you simply link with a recent version of Intel MKL (which includes Intel Xeon Phi coprocessor support) and set an environment variable (MKL_MIC_ENABLE=1). Alternately, a single function call (mkl_mic_enable) can be inserted to activate this capability for your program as an alternative to using an environment variable. The function call takes priority over the environment variable when used.
The compiler-assisted offload offers the convenience of pragmas or directives for detailed control with the assistance of the compiler. This capability enables you to use the Intel compiler and its offload support to manage the functions and data offloaded to a coprocessor. Within an offload region, you should specify both the input and output data for the Intel MKL functions to be offloaded. Data can be reused between calls to optimize performance by reducing unnecessary back and forth data copies and allocation. After linking with the Intel MKL libraries for Intel MIC Architecture, the compiler provided runtime libraries transfer the functions along with their data to a coprocessor to carry out the computations.
In addition to offloading computations to coprocessors, you can call Intel MKL functions from an application that runs natively on a coprocessor. Native execution occurs when an application runs entirely on the coprocessor. Native mode simply uses versions of Intel MKL routines that have been tuned for Intel Xeon Phi coprocessor features including the 512-bit wide vector instructions and fused multiply add instructions. The library used on the coprocessor is identical whether invoked via offload, automatic offload, or via native usage.
Control functions for automatic offload
C and Fortran functions, and corresponding environment variable alternatives, to support the use of Intel Xeon Phi coprocessors are shown in Table 11.2 with some example usages shown in Figures 11.1 and 11.2.
Table 11.2
MKL Support Functions and Environment Variables Specifically for Intel® Xeon Phi™ Coprocessors
| Function {environment variable} | Description |
| mkl_mic_enable {MKL_MIC_ENABLE=1} | Enables Automatic Offload mode. |
| mkl_mic_disable {MKL_MIC_ENABLE=0} | Disables Automatic Offload mode. |
| {OFFLOAD_DEVICES} | This environment variable control offloading constructs from the compiler as well as Intel® MKL. This environment variable specifies a list of coprocessors to be used for Automatic Offload. There is no function call for this control. Should be a comma-separated list of integers, each ranging from 0 to the largest number of an Intel® Xeon Phi™ coprocessor on the system. If the list contains any non-integer data, the list is ignored completely as if the environment variable were not set at all. If this variable is not set, all the coprocessors available on the system are used for Automatic Offload. |
| mkl_mic_get_device_count | Returns the number of Intel Xeon Phi coprocessors on the system when called on processors. |
| mkl_mic_set_workdivision {MKL_MIC_WORKDIVISION or MKL_MIC_num_WORKDIVISION or MKL_HOST_WORKDIVISION} | For computations in the Automatic Offload mode, sets the fraction of the work for the coprocessors, all or specified by num to do. Values of 0.0 to 1.0, or “MKL_MIC_AUTO_WORKDIVISION” to decide the best division of work at runtime. Intel MKL interprets the values of these as guidance toward dividing work between coprocessors, but the library may choose a different work division. For LAPACK routines, setting the fraction of work to any value other than 0.0 enables the specified processor for Automatic Offload mode but does not use the value specified to divide the workload. |
| mkl_mic_get_workdivision | For computations in the Automatic Offload mode, retrieves the fraction of the work for the specified target (processor or coprocessor) to do. |
| mkl_mic_set_max_memory {MKL_MIC_MAX_MEMORY or MKL_MIC_num_MAX_MEMORY} | Sets the maximum amount of coprocessor memory reserved for Automatic Offload computations. Can be set for all coprocessors or a specific num coprocessor. Memory size in Kilobytes (K), megabytes (M), gigabytes (G), or terabytes (T). For example, a value of 4096M is the same as a value of 4G. |
| mkl_mic_free_memory | Frees the coprocessor memory reserved for Automatic Offload computations. |
| mkl_mic_set_offload_report {OFFLOAD_REPORT} | The Intel compilers and Intel MKL share the offload report capability, and reports will contain information about offload from both sources. Turns on/off reporting of Automatic Offload profiling. Values of 0 (off), 1 (essential information) or 2 (everything/verbose). |

Figure 11.1 Intel® MKL Support Function Examples for Fortran.

Figure 11.2 Intel® MKL Support Function Examples for C/C++.
The mkl_mic_enable function enables Intel MKL to offload computations to Intel Xeon Phi coprocessors automatically, while the mkl_mic_disable function disables automatic offloading.
Optional work-division control functions enable you to specify the fractional amount of work of a function to distribute between processors and the coprocessors on a single computer (node in a cluster). Work division is a fractional measure ranging from 0.0 to 1.0. For example, setting work division for processors to 0.5 means to keep half of the computational work of a function on processors and move half to the coprocessor(s). Setting work division to 0.25 for a coprocessor means to offload a quarter of the computational work to this coprocessor while leaving the rest on processors and any additional coprocessors.
Use of these support functions inside a program will take precedence over the respective environment variables. Fortran programs use include file mkl.fi, while C/C++ programs use include file mkl.h.
Examples of how to set the environment variables
The environment variables for Intel MKL need to be set precisely and exported (bash shell). Here are some actual examples to help learn the syntax properly.
For the bash shell, set the appropriate environment variable(s) as shown in Figure 11.3.

Figure 11.3 Setting Environment Variables in the Bash Shell.
For the C shell (csh or tcsh), set the appropriate environment variable(s) as shown in Figure 11.4.
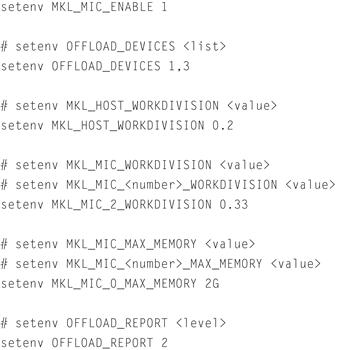
Figure 11.4 Setting Environment Variables in the C Shell (csh or tcsh).
Using the coprocessor in native mode
Building to run on an Intel Xeon Phi coprocessor in native mode can be done with little or no change to source code, compiling with the –mmic option and simply linking with the Intel Xeon Phi coprocessor version of the library. The dynamic libraries should be transferred, along with the program, to the coprocessor. In particular, the Intel MKL libraries are available in the <mkl directory>/lib/mic directory and libiomp5.so is available in the <Composer XE directory>/lib/mic directory. The paths to the dynamic libraries transferred on the coprocessor should be added to the LD_LIBRARY_PATH environment variable. You will also likely want to set OpenMP thread affinity and the OMP_NUM_THREADS environment variable (as discussed in the OpenMP section of Chapter 6). You run the program just as you would on a Linux system.
Tips for using native mode
A few tips have proven valuable for many users in their usage of Intel MKL natively (without offload):
• Use all the threads to get best performance. You do not need to avoid the core where the OS resides, as you should when using offload, because the OS is much less likely to be using significant computational resources. For examples, on a 60-core Intel Xeon Phi coprocessor use the following:
OMP_NUM_THREADS=240
• Use thread affinity to avoid thread migration. For examples, on a 60-core Intel Xeon Phi coprocessor use the following:
KMP_AFFINITY=explicit,granularity=fine,proclist=[1-239:1,0]
• Consider enabling huge paging for memory allocation by using libhugetlbfs.so or using the mmap() system call (see Chapter 9).
Using automatic offload mode
Automatic offload is a unique feature that enables selected Intel MKL functions called in user code to take advantages of Intel Xeon Phi coprocessors automatically and transparently. With this feature, code that calls Intel MKL functions does not need any change in order to execute these functions on Intel coprocessors. There is no need to modify the process for compiling and linking your application other than to be using the latest Intel MKL. Automatic offload provides great ease-of-use for Intel MKL on coprocessor systems, allowing programmers to use the same usage model they are familiar with, while enjoying performance scaling across multicore to many core.
Automatic offload is not available for all Intel MKL functions; for those functions for which automatic offload is not an option, consider using the compiler-assisted offload, which can be used with all Intel MKL functions available for use on Intel Xeon Phi coprocessors. Consult the most recent Intel MKL documentation for a current list of functions that have automatic offload. As of the end of 2012, the list of functions with automatic offload capabilities included select routines in BLAS (?GEMM, ?TRSM, and ?TRMM) and ?GETRF, ?GEQRF, and ?POTRF in LAPACK. You can check the documentation to see if this list is expanded in the future.
How to enable automatic offload
Automatic offload can be enabled using a single call of a support function (mkl_mic_enable()) or setting an environment variable (MKL_MIC_ENABLE=1). Compiler pragmas are not needed. Users compile and link the code the usual way.
There are also environment variables that are generally needed for MKL that you should make sure are set:
export MIC_LD_LIBRARY_PATH=$COMPOSER_ROOT/compiler/lib/mic:/opt/intel/mic/coi/device-linux-release/lib:/opt/intel/mic/myo/lib:$MKLROOT/lib/mic
export LD_LIBRARY_PATH=$COMPOSER_ROOT/compiler/lib/intel64:/opt/intel/mic/coi/host-linux-release/lib:/opt/intel/mic/myo/lib:$MKLRO
In Fortran or C, the function returns zero if successful:
rc = mkl_mic_enable( ) ! Fortran
#include “mkl.h” /* C */
rc = mkl_mic_enable( );
Alternatively, setting an environment variable MKL_MIC_ENABLE=1 does the same thing without changing source code.
Once Automatic Offload is enabled, Intel MKL may automatically offload parts of computations within Intel MKL to one or more Intel coprocessors. Automatic offloading is transparent to the user in the sense that the Intel MKL runtime decides how much work to offload. Depending on the problem size and the current status of coprocessors, it may decide to run the whole work, part of the work, or nothing on coprocessors. It may decide to use all coprocessors available or to use only one coprocessor. For users who would like to have some control over offloading, Intel MKL provides mechanisms to fine-tune how the work should be divided between processors and coprocessors. See the “How to Control Work Division” below for the information.
Offloading is transparent also in the sense that if no coprocessor is present, the same executable still works. It simply runs all the computation on the processors as usual without any penalty.
Examples of using control work division
As we’ve seen, on Intel MIC architecture, Intel MKL provides a few support functions to allow users to substitute alternate guidance instead of the default work division guidance for the Intel MKL runtime as well as to query the current work division settings and the number of available coprocessors. Table 11.2 summarizes mkl_mic_set_workdivision, mkl_mic_get_workdivision, and mkl_mic_get_device_count. Note that these functions take effect only when automatic offload is enabled. Examples in Figures 11.5 and 11.6 illustrate their usage.

Figure 11.5 Fortran: Work Division Control Using Support Functions.

Figure 11.6 C: Work Division Control Using Support Functions.
Tips for effective use of automatic offload
We can share a few tips to help better understand automatic offload and to get the most out of it.
Automatic offload works better when matrix size is right
Matrix size is critical for automatic offload to get good performance. In fact, automatic offload does not even start when matrices are too small (generally this is when row or column size is smaller than 2048). This is because in this situation the overhead of data transferring overshadows any performance benefit offloading can bring. If matrices are sufficiently large, then the best performance is typically achieved when the matrices are square. The MKL environment variable MKL_MIC_MAX_MEMORY may be valuable to guide MKL on memory usage to best suit your application and system.
Debug or test by forcing execution to exit if offload fails
By default, if offload does not occur either because the runtime cannot find a coprocessor or because it cannot be properly initialized, then the runtime will automatically do all the work on the processors. This behavior is part of the transparent execution model provided by automatic offload. There is an environment variable OFFLOAD_REPORT to set to have an offloading report dumped out during runtime for seeing what is being offloaded. Users can also override the default fallback behavior by setting the environment variable (MKL_MIC_DISABLE_HOST_FALLBACK=1). Then, if offload cannot take place the program will exit with an error message indicating that the automatic offload could not be initialized or otherwise performed.
When not to use automatic offload
There are situations where compiler-assisted offload is more appropriate:
How to disable and re-enable automatic offload
Automatic offload only needs to be enabled once and its effect lasts until the end of the execution for all automatic offload-aware functions (excluding those explicitly offloaded using compiler-assisted offload). To disable automatic offload in the middle of a program, user code should call the support function mkl_mic_disable(). Alternatively, user code can call mkl_mic_set_workdivision() to set 100 percent of work to be done on the processors:
rc = mkl_mic_set_workdivision(MKL_TARGET_HOST,
coprocessor_number, 1.0);
Later on, automatic offload can be re-enabled by calling mkl_mic_enable() or the workdivision function again to specify a different percentage for the processors or for a coprocessor. The environment variable OFFLOAD_DEVICES can be used to regulate the compiler and MKL library usage of devices as well.
Use automatic and compiler-assisted offload together
In addition to automatic offload, Intel MKL supports compiler-assisted offload. That is, offload can be explicitly specified using compiler pragmas provided in Intel® Fortran Compiler XE and Intel® C/C++ Compiler XE. Compiler-assisted offload requires more effort from programmers, but it provides more control and is more flexible. In sophisticated applications, cases may exist where mixing automatic offload and compiler-assisted offloading in one application is necessary. Intel MKL does allow this usage model. However, when automatic offload and compiler-assisted offload are used in the same program, and you may need to explicitly specify work division for automatic offload-aware functions using support functions but not via environment variables. The default work division setting is to run all the work on the processors.
Avoid oversubscription
To help avoid performance drops caused by oversubscribing Intel Xeon Phi coprocessors, Intel MKL limits the number of threads it uses to parallelize computations:
• For native runs on coprocessors, Intel MKL uses 4×Number-of-Cores threads by default and scales down the number of threads back to this value if you request more threads and MKL_DYNAMIC is true.
• For runs that offload computations, Intel MKL uses 4×(Number-of-Cores −1) threads by default and scales down the number of threads back to this value if you request more threads and MKL_DYNAMIC is true.
• If you request fewer threads than the default number, Intel MKL will use the requested number but never more than the number in the system (MKL will not oversubscribe).
In these, Number-of-Cores is the number of core in an Intel Xeon Phi coprocessor.
Some tips for effective use of Intel MKL with or without offload
Optimize openMP and threading settings
To improve performance of Intel MKL routines, use the following OpenMP and threading settings:
Data alignment and leading dimensions
Additionally, for data issues, to improve performance of Intel MKL you may wish to:
• For other Intel MKL function domains, use the general recommendations for data alignment.
• To improve performance of your application that calls Intel MKL, align your arrays on 64-byte boundaries and ensure that the leading dimensions of the arrays are divisible by 64.
Specifically for FFT functions, follow these additional recommendations:
• Align the first element of the input data on 64-byte boundaries.
• For two- or higher-dimensional single-precision transforms, use leading dimensions (strides) divisible by 8 but not divisible by 16.
• For two- or higher-dimensional double-precision transforms, use leading dimensions divisible by 4 but not divisible by 8.
Favor LAPACK unpacked routines
The routines with the names that contain the letters HP, OP, PP, SP, TP, or UP in the matrix type and storage position (the second and third letters respectively) operate on the matrices in the packed format (see LAPACK “Routine Naming Conventions” sections in the Intel MKL Reference Manual). Their functionality is equivalent to the functionality of the unpacked routines with the names containing the letters HE, OR, PO, SY, TR, or UN in the same positions, but the performance is significantly lower.
If the memory restriction is not too tight, use an unpacked routine for better performance. In this case, you need to allocate N2/2 more memory than the memory required by a respective packed routine, where N is the problem size (the number of equations).
For example (Fortran code shown), to speed up solving a symmetric eigenproblem with an expert driver, use the unpacked routine:
call dsyevx(jobz, range, uplo, n, a, lda, vl, vu, il, iu, abstol, m, w, z, ldz, work, lwork, iwork, ifail, info)
where a is the dimension lda-by-N, which is at least N2 elements, instead of the packed routine use this:
call dspevx(jobz, range, uplo, n, ap, vl, vu, il, iu, abstol, m, w, z, ldz, work, iwork, ifail, info)
where ap is an array with size of N×(N+1)/2 holding the triangular part of a symmetric matrix.
Using compiler-assisted offload
Compiler-assisted offload gives more control over data movement and therefore is more powerful than automatic offload. The largest advantage is data persistence so that data can be reused on the coprocessors instead of making a round trip more often. Compiler assisted offload will require some program modifications, but the compiler offers syntax for pragmas and directives that limit the amount of work for us to do. Generally we just tell the compiler what to do and it does much of the work for us. Figures 11.7 and 11.8 have code examples showing use of compiler-assisted offload. The offload pragmas or directives are the same as we cover in Chapter 7. All the same explicit copy modifiers and modifier options are available for compiler-assisted offload with Intel MKL as are available for general code offload.

Figure 11.7 Fortran Example of Compiler-Assisted Offload.
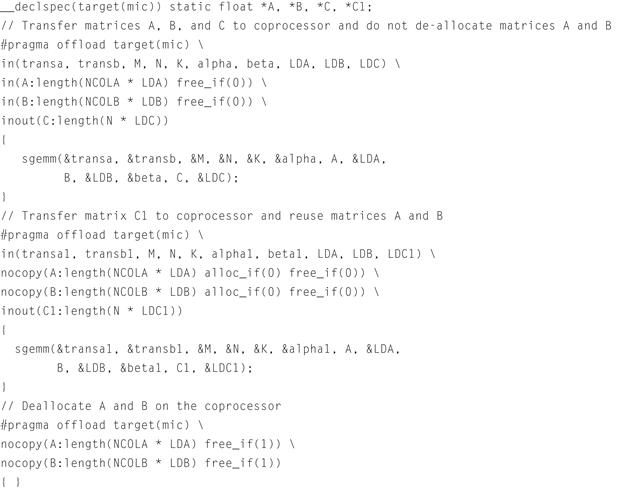
Figure 11.8 C Example of Data Persistence with Compiler-Assisted Offload.
Tips for using compiler assisted offload
A few tips have proven valuable for many users in their usage of compiler assisted offload:
• Use data persistence to avoid unnecessary data copying and memory allocations and deallocations.
• Use thread affinity and avoid using the core where the OS is doing its work when using offload. For examples, on a 60-core Intel Xeon Phi coprocessor use the following:
MIC_KMP_AFFINITY=explicit,granularity=fine,proclist=[1-235:1,0]
• Consider using larger pages by setting MIC_USE_2MB_BUFFERS=64K
Precision choices and variations
Floating point numbers have limited precision which give rise to question on both how we might speed up computation by selecting less precision or how we might make results more predictable. This section gives some of the most used options for both. The Intel compiler has many more controls for those with very precise needs, so the compiler documentation is worth reading through if you want much finer controls.
Fast transcendentals and mathematics
While a topic that is generally useful on processors and coprocessors, the existence of special 512-bit vector operations on Intel Xeon Phi coprocessors makes this topic of special interest. To use the lower accuracy vectorizable math functions with –fp–model precise, you would specify:
• –fast–transcendentals for transcendentals (sin, log, pow, …)
• –no–prec–sqrt for square roots
• –fimf–precision set desired accuracy to high, medium or low
These are compiler options, and not an MKL library capability (libraries supplied by the Intel compiler including the math library (libm) and the Short Vector Math Library, or SVML). Many algorithms find the performance of certain mathematics to be valuable and higher precision to be not required, hence the Intel compilers offers a rich set of options. Searching on these in the Intel Compiler documentation will give more details, and also links to additional related options.
Understanding the potential for floating-point arithmetic variations
The floating-point model used by the Intel® Compiler and its application to Intel® Xeon® processors is described in the online article “Consistency of Floating-Point Results using the Intel® Compiler.” For a suitable choice of settings, the compiler generates code that is fully compliant with the ANSI language standards and the IEEE-754 standard for binary floating-point arithmetic. Compiler options give the user control over the tradeoffs between optimizations for performance, accuracy, reproducibility of results, and strict conformance with these standards.
The same floating-point model applies to the Intel® Xeon Phi™ coprocessor, but the architectural differences compared to Intel Xeon processors lead to a few small differences in implementation. Those differences are the subject of this section.
Basics
The Intel Xeon Phi coprocessor supports the same floating-point data types as the Intel Xeon processor. Single (32 bit) and double (64 bit) precision are supported in hardware; quadruple (128 bit) precision is supported through software. Extended (80 bit) precision is supported through the x87 instruction set. Denormalized numbers and gradual underflow are supported, but abrupt underflow is the default at all optimization levels except –O0. The same set of rounding modes is supported as for Intel Xeon processors.
Floating-point exceptions
The biggest differences arise in the treatment of floating-point exceptions. The vector floating-point unit on the Intel Xeon Phi coprocessor flags but does not support trapping of floating-point exceptions. The corresponding bit in the VXCSR register is protected; attempts to modify it result in a segmentation fault. Some compiler options such as –fp–trap (C/C++) or –fpe0 (Fortran) that would unmask floating-point exceptions on Intel Xeon processors are unsupported on Intel® MIC architecture. The options –fp–model except or –fp–model strict still request strict, standard-conforming semantics for floating-point exceptions. This is achieved by generating x87 code for floating-point operations instead of code that makes use of Intel Xeon Phi coprocessor vector instructions. Because such code cannot be vectorized, this may have a substantial impact on performance. Nevertheless, these options may be useful for application debugging. For similar reasons, the options –ansi and –fmath–errno may result in calls to math functions that are implemented in x87 rather than the vector instructions.
In the Intel Fortran compiler version 13.0, the IEEE_FEATURES, IEEE_ARITHMETIC and IEEE_EXCEPTIONS modules are not yet updated for the properties of the Intel Xeon Phi coprocessor.
The –fp–model switch
The same settings of the –fp–model switch are supported as for Intel Xeon processors. The default setting is –fp–model fast=1 for both. The behavior of the –fp–model precise option is the same, though the impact on performance may be somewhat greater for Intel Xeon Phi coprocessors, because of the larger vector width on Intel MIC architecture and larger potential performance gain from the vectorization of reduction loops and loops containing transcendental math functions, square roots or division. The impact of –fp–model except and –fp–model strict on performance may be greater, for the reasons noted above.
The setting –fp–model fast=2 sets the –fimf–domain–exclusion switch and enables faster, inlined versions of some math functions for the Intel Xeon Phi Coprocessor, see the section “Precision of Math Functions” below.
The –fp–model precise switch enables arithmetic using denormalized numbers and disables abrupt underflow; abrupt [gradual] underflow can be enabled (but not required) explicitly using –[no–]ftz. This behavior is the same as on Intel Xeon processors.
Fused multiply-add
Intel Xeon processors up to and including Intel® 3rd Generation Core™ processors do not have a fused multiply-add (FMA) instruction. The FMA instruction on Intel Xeon Phi coprocessors only performs a single rounding on the final result, so can yield results that differ very slightly from separate addition and multiplication instructions.
In principle, the –fp–model strict switch would disable fused multiply-add (FMA) instructions. But since, as noted above, –fp–model strict suppresses vector instructions in favor of legacy x87 floating-point instructions, this additional behavior is moot. FMA operations are enabled by default, but may be disabled directly by the switch –no–fma. FMA operations are not disabled by –fp–model precise.
Precision of math functions
In the Intel® Composer XE 2013 product, the compiler for Intel Xeon Phi coprocessors invokes medium accuracy (< 4 ulp) transcendental functions for both scalar and vector code by default, mostly as calls to libsvml. For Intel Xeon processors, the default is libm (< 0.55 ulp) for scalar code and medium accuracy libsvml (< 4 ulp) for vector code. On Intel Xeon Phi coprocessors, division defaults to medium accuracy inlined code that uses a reciprocal instruction, whereas in the initial 13.0 compiler release, square roots call a medium accuracy SVML function by default (this will change to inlined code in a forthcoming update). An inlined version of square root may be obtained with –fimf–domain–exclusion=15:sqrt (double precision) or –fimf–domain–exclusion=15:sqrtf (single precision). See compiler documentation for details of the excluded domains. The –fimf–domain–exclusion switch may also be used to obtain inlined versions of certain other math functions. High accuracy (typically 0.6 ulp) vectorizable SVML versions of divide, square root, and transcendental functions may be obtained with –fimf–precision=high.
Using –fp–model precise results in high accuracy (<0.55 ulp), scalar calls to libm for transcendentals and to libsvml for square roots. For division, it results in an x87 division instruction. The switches –no–fast–transcendentals, –prec–sqrt, and –prec–div respectively have the same effect. In forthcoming updates, vectorizable inlined code sequences using Intel Xeon Phi coprocessor vector instructions may be used for division and square roots in preference to x87 instructions for these switches and for –fp–model precise. x87 instructions will continue to be generated for –fp–model strict.
Medium accuracy, vectorizable math functions can still be obtained in conjunction with –fp–model precise by specifying –fp–model precise –fast–transcendentals –no–prec–sqrt –no–prec–div. Higher accuracy, vectorizable versions are obtained by adding –fimf–precision=high.
Comparing floating-point results between Intel Xeon Phi coprocessors and Intel Xeon processors
In general, floating-point computations on an Intel Xeon Phi coprocessor may not give bit-for-bit identical results to the equivalent computations on an Intel Xeon processor, even though underlying hardware instructions conform to the same standards. Compiler optimizations may be implemented differently, math functions may be implemented differently, and so on. The fused multiply-add (FMA) instruction available on the Intel Xeon Phi coprocessor is a common source of differences. Nevertheless, the following guidelines may help to minimize differences between results obtained on different platforms, at a cost in performance:
• Build your application on both platforms using –fp–model precise –fp–model source
• Build your application on the Intel Xeon Phi coprocessor with –no–fma, to disable the use of FMA instructions. (Alternatively, for Fortran applications only, you may inhibit the use of fma instructions in individual expressions by the use of parentheses, in conjunction with the command line switch –assume protect_parens, for example: X = (A + (B*C))]. For C or C++ applications, you may disable FMA generation for individual functions by using #pragma fp_contract (off | on).
• Select high accuracy math functions on both platforms, such as using –fimf–precision=high.
• For OpenMP applications that perform reductions in parallel, set the environment variable KMP_DETERMINISTIC_REDUCTIONS=yes, use static scheduling, and use OMP_NUM_THREADS to set the same number of threads on each platform.
• For C++ applications making use of Intel® Threading Building Blocks, (TBB), the parallel_deterministic_reduction() function may help to obtain more consistent results on both platforms, even for differing numbers of threads.
These guidelines are intended to help enhance reproducibility and minimize variations in floating-point results between different platforms. The observed variations do not represent the true numerical uncertainty in your result, which may be much greater.
Summary
Automatic offload is the simplest way of using Intel MKL on Intel MIC–enabled systems and works best when calls to Intel MKL are significant and largely unrelated to each other. When data persistence is important, use of compiler-assisted offload or native mode will give more control and performance but require code changes and additional work.
In the advanced usage models of automatic offload, programmers can control work divisions between processors and coprocessors. It is also possible to use both automatic offload and compiler-assisted offload for Intel MKL functions in one application.
Intel MKL brings breakthrough performance for highly parallel applications on Intel Xeon processors and Intel Xeon Phi coprocessors.
For some complete examples to study or use as starting points, you should take a look at the example codes available in the examples/mic_samples directory installed with Intel MKL.
For more information
Here are some additional reading materials we recommend related to this chapter.
• Intel tools documentation including MKL reference manuals: http://software.intel.com/en-us/articles/intel-parallel-studio-xe-for-linux-documentation/
• Article titles “Consistency of Floating-Point Results using the Intel® Compiler,” http://software.intel.com/en-us/articles/consistency-of-floating-point-results-using-the-intel-compiler/
• MKL Link Advisor tool, http://tinyurl.com/Link-MKL
1Basic Linear Algebra Subprograms, www.netlib.org/blas
2Linear Algebra PACKage
3supported only on Linux† and Windows† versions, not supported on Mac† OS systems
4supported only on Linux and Windows versions, not supported on Mac OS systems