
Once you have identified opportunities to reuse content in your organization, you need to “model” the content you plan to reuse. Models formalize the structure of your content in guidelines, templates, and structured frameworks, such as DTDs or schemas. Through information modeling, you identify and document the framework upon which your reuse strategy is based.
Chapter 1 “Content: The lifeblood of an organization,” established that content is the life blood of an organization, and that content is created and used by many independent and often disparate areas of an organization. Walls are erected between content areas and even within content areas, which leads to content being created, and re-created, and re-created, often with permutations at each iteration. However, for content to be truly unified, it must follow a consistent approach in writing style and structure, and it must be stored so that whoever needs it can find it, access it, reuse or repurpose it, and deliver it (often dynamically) to everyone who needs it when and where it’s needed. The information model is your blueprint for the effective writing, structuring, and delivery of reusable content. As such, it’s important to start with strong analysis of your information and audiences to make sure the model reflects all potential uses and users of your content.
This chapter discusses the basics of information architecture, as well as structure, in relation to information models. It describes granularity, information product and element models, and components of information models, including examples. At the end of the chapter there is a discussion on buying versus building information models.
When you build a house, the builder doesn’t simply show up at the building site and start pouring the foundation and erecting the walls without having a building plan that shows how the house will be constructed and out of what materials. This is the architectural blueprint; it defines how many rooms are in the house, their dimensions, the building materials, and so on. It also defines which parts of the house should adhere to a standard, such as the width of doorways and the thickness of the insulation.
Likewise, software developers follow specifications when designing new software, and each developer or programmer who works on the project designs according to the specification.
Architecture also applies to information. Information architecture is the blueprint that defines how content will be organized and structured to make up the various “information products” in your organization. (An information product is any output consisting of content, such as user guides, catalogs, documents, brochures, press releases, annual reports, intranets, web sites, or technical specifications.) An effective information architecture helps people (both internal and external to your organization) find, manage, and continue to add to the existing information consistently, following defined rules for structure and semantics.
Information modeling is critical in a unified content strategy because it provides the blueprint upon which your information products are based. In a unified content strategy you break content down into objects, and rather than write documents, you write objects that are stored in your repository (often a database). Elements are then compiled into information products from that repository. The power of a unified strategy lies in effectively reusing content elements—whether they’re paragraphs, procedures, or sentences—over and over again, reducing costs and increasing productivity. Information models identify all the required elements and illustrate how to structure and reuse them. The goal of information modeling is a complete specification outlining how content is used—and reused—throughout your organization.
When you build information models that consider information requirements across an entire organization, you look beyond your own department to determine how other areas can use your information and how you can use theirs. An effective information model serves to identify all the knowledge within an organization, and to capture and reuse it effectively. The information modeling process forces you to consider all information requirements (either for a specific project or within an entire organization) and to assess what information is available to fulfill those requirements. In a unified content strategy, the information model becomes the “catalog” of all the information products, and it outlines the necessary information elements for each, based on thorough analysis of your audiences and their information needs.
Information modeling is a critical task in your unified content strategy and it can seem daunting. However, after you have done thorough information, audience, and process analyses, the modeling is the next logical step in implementing your findings.
Information modeling takes place after the analysis and recommendations are completed and signed off (see Chapter 6, “Performing a content audit”). Through your analysis, you develop an understanding of the types of information within your organization, who uses what information, and in what context. Most important, your analysis also helps you to see how information can be reused to support its various uses.
For example, you may have discovered that you have product descriptions published in 20 different places and written by 10 different people in 5 different groups (and translated into 7 different languages) within your organization. You may also have discovered that many product descriptions are inconsistent in meaning, contain different types of information (some contain costs, some do not), and are structured/written differently, so that users have trouble identifying them as product descriptions. In addition, each time authors update a description, they do it in isolation, so the other uses of that description are not updated concurrently and are thus inconsistent.
During information modeling, you form a strategy for unifying the product descriptions so that wherever they appear, they are consistent, contain the same types of information, and are structured and written the same. However, you must have completed the analysis and identified key areas to unify to make valuable modeling decisions, and to know which inconsistencies are valid and which are not. It’s also important to model what you want the structure of your information products to be, not what their structures currently are. This is your opportunity to make improvements in how your information products are structured, to improve their consistency and usability.
Models reflect the structure of information products, so it’s necessary to understand exactly what structure is. Information products such as product descriptions, press releases, letters, catalogs, and so on have a recognizable structure that is repeated every time the information product is created. For example, a letter has a repeatable structure, as shown in Figure 8.1.

Note that the letter has the following structural elements:
Date
Address
Salutation
Subject
Body
Closing
Notice that these elements can be broken down further:
Date
Month
Day
Year
Address
Salutation
Dear
First name
Subject
Re:
Topic
Body
Closing
Author
Title
However, it is much harder to break down the body of the letter because it is less structured. Authors can choose to structure the body of the letter in a number of ways depending upon their styles, the nature of the content, and the impact they want to have. The body of the letter can be broken down into only very generic elements that can be used in any order:
Structure is critical because it unifies the content, regardless of who is writing it. If the model is supported by a DTD (Document Type Definition), the DTD allows authors to create documents only according to the structure defined in the DTD. If the model is not supported by a DTD, authors may select from style tags or complete areas within a form, or they can enter text into a template that tells them what content must appear in the document. Authors rely on the model itself for the hierarchy.
The degree to which you break down the structure of your content depends upon the granularity of your material and your desire for consistency.
An information model reflects all the components that make up each information product; the level of detail in the model depends on the granularity. Granularity determines the smallest piece of information that is reusable. To identify granularity, you determine the smallest possible piece of content you plan to reuse. Although granularity must be reflected in the information model, the level of granularity can change throughout your content. In one instance you may reuse large sections of information unchanged; in others, you may reuse content at the sentence or even the word level.
You may have different levels of granularity for authoring, for reuse, and for delivery. You may want to break content down to a very granular level for authors so that they can see exactly what to include as they write, but you can reuse content at whatever level of granularity is appropriate for your reuse strategy. See Chapter 12, “Implementing your design,” for more information about granularity.
However, care should be exercised when determining the level of granularity. The more granular the content, the greater the complexity of modeling, authoring, and managing the content. Yet if the content is not granular enough, you compromise your ability to easily reuse information. After a reuse strategy is implemented, it may be difficult to increase the level of granularity later on. Weigh the benefits and reasons for very granular content before modeling and implementing it. You also need to consider that the meaning of a granule may change if it’s used out of context. If an element relies on surrounding information to make its meaning clear, the surrounding information may need to be included as part of the element. You may find it necessary to model very granular information at first, then before implementing it, review the model in the context of how information will actually be authored. Note, for example, that granularity at the word level is not recommended. It’s extremely difficult to model and maintain and can impede the writing process. In cases where word variations are required to make content reusable (for example, product name or version), you can use metadata to define variables that are inserted as required.
Keep in mind, too, that regardless of the level of granularity, authors still write complete documents, not elements. If your granularity is at the sentence level, authors don’t write a number of disparate sentences that are stored in a database to be compiled into documents. Rather, authors write documents, assigning the required granularity to elements (as defined by the information model) as they write. The main difference for authors is in following the assigned structure and in assigning or selecting metadata. The granularity defines how the completed document is broken down, tagged, and stored for reuse; it doesn’t define the authoring process. Chapter 12 provides more information on implementing your model.
After you’ve determined granularity, you’re ready to start building the model. There are two levels of modeling required: modeling at the information product level and modeling at the information element level. Modeling at the information product level is like determining the framework of a house; modeling at the information element level is like determining everything that goes into the house—the rooms as well as all the elements within the rooms.
When you design a house, you specify what all the components (for example, rooms) are as well as what the structure of each room is. You also ensure that repeated components, such as doorways, are structured consistently. The “product” model for a house specifies which rooms comprise the house. The “element” model tells you how each room is constructed and which elements are reused from room to room. Architects and builders follow the model to ensure the house is built according to specifications, and that wherever an element is reused, it is reused consistently and not redesigned from scratch.
Models also indicate which elements are mandatory and which are optional. For example, some elements are standard in a kitchen and others are optional. However, the contents of a kitchen would never be the same as the contents of a bathroom or a bedroom. A kitchen model might include
Windows
Sink
Butcher’s block island (optional)
Cabinets
Countertop
Door
And, the elements for the bedroom might include:
Closet
Windows
En suite bathroom (optional)
Door
For the purposes of this analogy, you can consider the door and window elements as reusable elements that are the same regardless of where they are used.
Just as you specify which rooms a house has and which elements each room contains, when you model an information product (such as a press release, a training manual, user guide, or brochure), you specify what its components are, as well as what the structure for each component is. The product model defines the content’s elements, attributes and metadata, as well as the relationship among elements. Authors follow the model to create and compile information products consistently.
The information product model also provides information on what type of information should be included in a particular information product. For example, an information product model for a press release may include the following elements:
In addition to product models, you need to create element models. An element model breaks the information product model down even further, describing the components that are assembled to create the information product. For example, the body element of the press release might include:
Building on the house analogy, you can think of each information element as a “container.” The house is a container element for each room, and each room is a container element for all the components that make up each room. In this way, there can be containers within containers.
The same applies to information. Elements are containers of information, for example, Date = Month + Day + Year and may contain additional containers, for example, Contact = (First Name + Last Name) + (Area Code + Local Number). An information product model is a container for its elements and each element may also be a container for subelements.
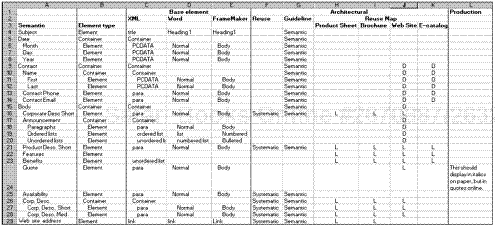
Figure 8.2 shows which elements are complete on their own and which are containers for other elements, using the press release information product model as an example.
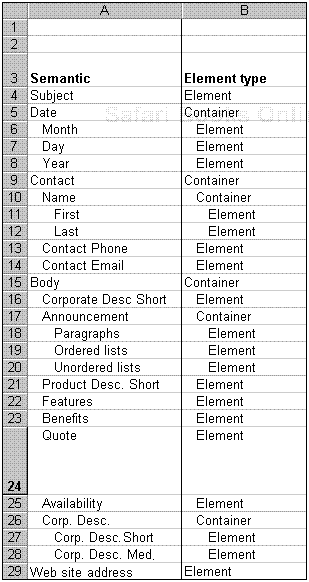
An information model comprises a number of components, which describe the semantic information, the base information, the metadata, the architectural information, and the production information for each element.
Semantic information uses semantic tags to describe what goes into each element, that is, tags that have a specific meaning. The press release information product model (shown previously) identifies semantically what goes in the press release. Instead of referring to the structure generically, it uses semantic tags to describe the structure. For example, the element <Website address> explicitly identifies that the content to be included within this element is the web site address. The opposite of a semantic tag is a generic tag (for example, <paragraph>). If you use a generic tag such as <paragraph> for the web site address or the product features, it is not clear what content is to be included in the paragraph.
Semantic information is extremely valuable in guiding authors as they create content. Semantic information explicitly defines the structure of the information. However, you may not want to use semantic tags when you implement your model. You may choose to use metadata instead because using a semantic tag may limit your ability to reuse content. The semantic tag <Features> may contain information required in another information product, but in the other information product, the information has a different semantic structure. Thus, the reuse is not identifiable from the semantic tag. See Chapter 12, for more information about semantic tags and metadata.
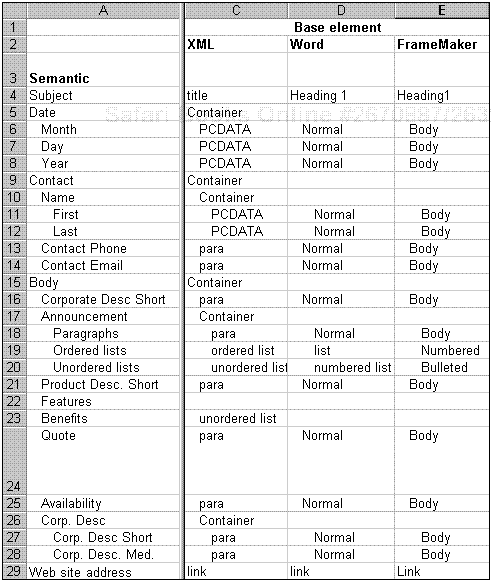
Base information describes the common naming of each element within a container and uses generic tags or “base elements.” Base elements guide information technologists as they implement the models (see Chapter 21, “Managing change”). Base elements help them to understand what underlying structure your elements should include. They also indicate what generic tag your elements should use if you choose not to use semantic tags. If you are using a traditional authoring tool, base elements guide authors in selecting the correct tag for the model. Figure 8.3 shows semantic tags and their corresponding base elements for the press release model. You would typically only have one column of base elements. For the purpose of this example, base elements are shown for XML, Microsoft Word, and Adobe FrameMaker to provide multiple examples of base elements.
Within your model, you also need to indicate what metadata applies to which elements. Metadata provides data about data, or information about your information. While semantic tags help to direct the authoring of the text and the reuse, metadata provides search criteria, similar to index entries. Metadata is required to uniquely identify content so that authors can find it, reuse it, and move it. Depending on the authoring tool, some metadata can be automatically applied to the elements that require them (as defined by the model), whereas some are selected by authors as they create content. Again, depending on the authoring tool, authors are shown the available metadata for the particular element they are authoring. The element is then stored with its associated metadata, so if people are looking for everything written for a particular audience, for a particular product, for a particular version, or by a particular author, they can find it in the database, then reuse it if necessary.
Refer to Chapter 9, “Defining metadata,” for a further discussion of metadata and its role in a unified content strategy.
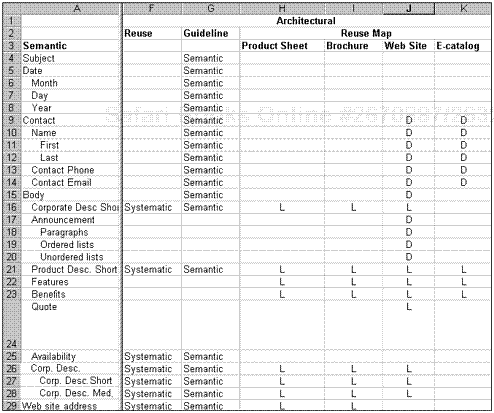
Architectural information provides details on the type of reuse (for example, systematic), guidelines for how you want the content formalized in your DTD or templates (for example, use semantic tags or not), where content is reused, and how it is reused (for example, Locked [L] or Derivative [D]). Figure 8.4 illustrates the architectural information for the press release.
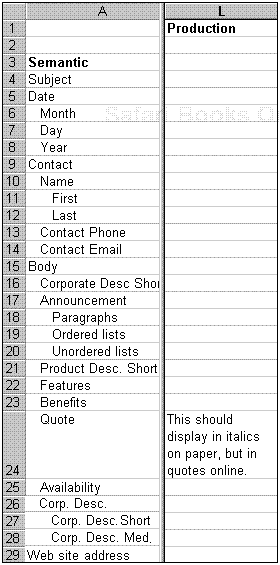
Further adding to the model, production information guides the information technologist in creating the stylesheets or templates. Figure 8.5 shows production information added to the press release model.
Figures 8.2 through 8.5 show you various parts of the model, hiding certain columns to focus on the components relevant to the point being illustrated. Figure 8.6 shows the complete model.
Once models are developed, they need to be implemented throughout your organization, so that all authors and reviewers can use them as they create, edit, and review content. Authors use information models to determine what information goes in which information product, as well as how to structure each element. Referring to the information model, they can determine, for example, that an information product requires an overview, and then they can determine the structure of the overview and get hints or rules (writing notes) about how to write certain components. Depending on the type of reuse (that is, opportunistic, systematic, derivative, locked, or nested), authors may select elements from the content management system based on what the model tells them they have to include. Or systematic reuse may automatically populate a document with some elements, guide authors on how to write or structure the other elements, and show them in what order elements appear.
Content reviewers use information models to review authors’ drafts. Reviewers compare drafts against the information model to ensure that they contain all the necessary elements. They also review the models to ensure that they contain all the necessary elements for each information product.
Information technologists use models to guide them in creating authoring templates or DTDs, implementing the content management system, and developing delivery stylesheets.
Information modeling is one of the most critical phases of designing your reuse strategy. Information models specify how information is reused and how it must be written and structured to support reuse. Information models provide the framework that guides authors, reviewers, and architects in creating, reviewing, managing, and publishing content. A good information model also improves the usability of your information products; your analyses of information and audiences may turn up usability issues that your models can address.
The level of detail in your information model depends on the level of reuse you are trying to achieve. The more granular the reuse, the more detail you need in the model; each element of information must be defined. The level of detail in the model also depends on the level of guidance your authors need and how much control you want them to have over authoring. For example, if you write regulatory documents with strictly defined components, you should include more guidance in your model. Authors need to know exactly how each element of content is used and how it is structured.
Accordingly, the information model should include
Which information products the model supports.
Which elements (based on granularity) are used for which product; which information containers the information product must contain.
The type of reuse or architecture that applies to the model, for example,
Opportunistic
Systematic
Derivative
Locked
Nested
The semantic structure of each element, a tagging structure that uniquely identifies the element’s content. Semantic tags are based on content (as opposed to format), helping authors to identify elements for reuse and to structure them consistently.
The metatags that apply to each element.
The base structure (common naming) of each element (for example, paragraph, unordered list, ordered list, title, and so on). The base structure identifies more clearly what kind of text the element comprises.
Any production notes, such as instructions to information technologists to autopopulate an element with pre-defined data.