
Chapter 5. Object-Oriented Fundamentals
FAQ 5.01 What is the purpose of this chapter?
![]()
To explain fundamental OO concepts.
C++ is a huge language that can be used in many ways. The preceding chapters on management and architectural perspectives limit the ways the language is used, which makes life simpler for developers and maintainers. This chapter further limits the ways in which the language can be (mis)used.
In this book, we assume an OO approach and the C++ presentation reflects this bias. Some readers will need a refresher on OO concepts, and others need to become familiar with our terminology. Hence this chapter presents the basic OO ideas and philosophies that are used throughout the book. Don't take this to mean that all programs must use OO (they don't) or that “C++ as a better C” has no place in life (it does).
FAQ 5.02 Why is the world adopting OO technology?
Because OO can handle change more effectively than its predecessors.
The former paradigm (structured analysis, design, and programming) enabled the design and construction of huge software systems. However, these systems lack the flexibility required to meet the demands placed on software in today's rapidly changing business environment. Thus, the old paradigm died from its own success: it created demand that it couldn't satisfy.
As users demanded more from software, economics dictated a better paradigm, and object-oriented technology is that better approach. This book is not just about technology; it also focuses on how to apply technology in a practical way to achieve the goals of the organization.
A cynic might note that the world is adopting OO technology whether it makes sense or not, because most of the software tools being built today assume OO orientation. The conviction of the early pioneers that OO was the best approach was a self-fulfilling prophecy.
FAQ 5.03 What are some of the benefits of using C++ for OO programming?
Large user community, multiparadigm language, performance, and legacy code access.
C++ is an object-oriented programming language with a very broad base of users. This large and thriving user community has led to high-quality compilers and other development tools for a wide range of systems. It has also led to the availability of learning aids, such as books, conferences, bulletin boards, and organizations that specialize in training and consulting. With that much support, investing in C++ is a relatively safe undertaking.
C++ is a multiparadigm language. This allows developers to choose the programming style that is right for the task at hand. For example, a traditional procedural style may be appropriate for performing a simple task such as writing the code within a small member function.
C++ software can be performance and memory efficient, provided it is designed properly. For example, well-designed, object-oriented software is normally comprehensible and therefore amenable to performance tuning. In addition, C++ has low-level—and often dangerous—facilities that allow a skilled C++ developer to obtain appropriate levels of performance.
C++ is (mostly) backward compatible with C. This is useful in very large legacy systems where the migration to OO normally occurs a few subsystems at a time rather than all at once. In particular, C++'s backward compatibility makes it relatively inexpensive to compile legacy C code with a C++ compiler, allowing the old, non-OO subsystems to coexist with the new OO subsystems. Furthermore, simply compiling the legacy C code with a C++ compiler subjects the non-OO subsystems to the relatively stronger type-safety checks of a C++ compiler. In today's quality-sensitive culture, this makes good business sense.
FAQ 5.04 What are the fundamental concepts of object-oriented technology?
Objects, classes, and inheritance.
By definition, object-oriented programming languages must provide objects, classes, and inheritance. In addition, polymorphism and dynamic binding are also required for all but the most trivial applications. Together, these five features provide the tools for fulfilling the goals of OO: abstraction, encapsulation, comprehensibility, changeability, and reusability.
An object is a software entity that combines state and behavior. A class is a programming construct that defines the common state and behavior of a group of similar objects; that is, a class has a name, and it describes the state (member data) and services (member functions) provided by objects that are instances of that class. The runtime system creates each object based on a class definition.
As an analogy, consider a home. A home is like an object since it has state (whether the lights are on, ambient temperature, and so on) and it provides services (a button that opens the garage door, a thermostat that controls the temperature, an alarm system that detects intruders, and so on). To carry the home metaphor a bit further, a blueprint for a home is like a class since a blueprint defines the characteristics of a group of similar homes.
Simple data types as int and float can be thought of as classes; variables of these types can be thought of as objects of the associated class.
Classes can be related by inheritance. In C++, inheritance facilitates polymorphism and dynamic binding. Polymorphism allows objects of one class to be used as if they were objects of another, related class. Dynamic binding ensures that the code that is executed is always consistent with the type of the object. Rather than selecting the proper code fragment by some ad hoc technique such as complex decision logic, the proper code fragment is automatically selected in a manner that is both extensible and always correct. Together, these allow old code to call new code; new classes can be added to a working system without affecting existing code.
FAQ 5.05 Why are classes important?
![]()
Classes are the fundamental packaging unit of OO technology.
Classes are a way to localize all the state (data) and services (typically member functions) associated with a cohesive concept. The main idea is to organize things so that when changes to the concept or abstraction occur (as is inevitable), it will be possible to go to one place to make the necessary modifications. We have seen examples in the procedural world where a simple change required modifying dozens of source code files. This shouldn't happen with a proper OO class definition, but we recall one C++ project where a simple change required modifying 46 different files. Obviously, the people responsible for this failure didn't “get it”; they may have been using C++, but they weren't using it properly. It's easy for beginners, no matter how much experience they have, to fall into this trap.
Here is the skeletal syntax for a typical class definition:

Here is the UML representation of a class.

FAQ 5.06 What is an object?
![]()
It depends on who you are.
To a programmer, an object is a region of storage with associated semantics. To a designer, an object is any identifiable component in the problem domain. In the following diagram recRoomTV is an object of class TV.
After a declaration such as int i;, i is said to be an object of type int. In OO/C++, an object is usually an instance of a class.
Here is the UML notation for an object:

FAQ 5.07 What are the desirable qualities of an object?
An ideal object is a service provider that is alive, responsible, and intelligent.
Each object is an independent entity with its own lifetime, internal state, and set of services. Objects should be alive, responsible, and intelligent agents. Objects are not simply a convenient way to package data structures and functions together. The fundamental purpose of an object is to provide services.
Ideal objects should be alive so that they can take care of themselves. They are born (constructed), live a full and productive life, and die (destroyed). Objects are expected to do something useful and maintain themselves in a coherent state. The opposite of “alive objects” is “dead data.” Most data structures in procedural programs are dead in the sense that they just lie there in memory and wait for the functions to manipulate them.
Ideal objects should be responsible so that you can delegate to them. Since they are alive, they have rights and responsibilities. They have the right to look after their own affairs—programmers do not reach into their innards and manipulate them, and they are responsible for providing one or more services. This means that other objects (“users”) can delegate work to them instead of having to do everything for themselves. This helps produce more modular and reusable software that consists of many objects, each of which does one thing.
Ideal objects should be intelligent so that they can provide services to their users, thus simplifying user code. For example, the knowledge of how to do some task (whether it is simple or complex) resides in only one place, inside the object. Users simply request the service; they concentrate on what needs to be done rather than how it's done. Effectively this moves complexity from the many to the few.
The benefits of moving complexity from the many to the few are all around us. As an analogy, consider how airlines might consider getting rid of all those expensive pilots and let the customers fly the airplanes for a rental fee like the car rental companies do. However, this would require, among other things, that every traveler be trained as a pilot, making air travel both more complicated and more accident prone. Instead, airlines move the intelligence regarding cockpit controls from the many to the few—from every traveler using the airlines to the pilots. The result is simpler and safer for travelers (users) and cheaper for the airlines (servers).
As a practical matter, this means that the first step for a new class is to write down its roles and responsibilities. This helps clarify why the class exists, whether or not it is needed, and what services it should provide. Defining the responsibilities of all objects prevents confusion and simplifies the design process.
FAQ 5.08 How are classes better than the three basic building blocks of procedural software?
A class is better than a C-style struct, better than a module, and better than a C-style function.
A class can be thought of as a C-style struct that is also alive and intelligent. Take away all the member functions from a class, make everything public:, eliminate inheritance, and remove all the static member data and functions; the result is a traditional C-style struct. A C-style struct supports multiple instances, but it is difficult to encapsulate its implementations properly. Classes support both multiple instances and encapsulation. When a C-style struct dreams about growing up, it dreams of being a class.
A class can be thought of as a module that also provides natural support for multiple instances and inline functions. Take away from a class all the non-static member data and the non-static member functions and force all remaining static member functions to be non-inline, and the result is a traditional module. Modules support encapsulation, but creating multiple instances of a module is cumbersome. Classes support both encapsulation and multiple instances. When a module dreams about growing up, it dreams of being a class.
A class can be thought of as a C-style function that can maintain state between invocations in a thread-safe manner and can also provide multiple services. If there were exactly one instance of a class, and all its member functions except for exactly one public: member function were removed, the result would be a C-style function (the object's member data would correspond to static data that is local to the function). C-style functions support computation, but it's cumbersome to maintain state between calls in a thread-safe manner (using static local data is not immediately thread safe). However, classes support computation and can maintain state between calls in a thread-safe manner (each thread can make a separate local object of the class, so there is no conflict when multiple threads are accessing their own independent data). When a C-style function dreams about growing up, it dreams of being a class.
FAQ 5.09 What is the purpose of composition?
Composition allows software to be developed by assembling existing components rather than crafting new ones.
Composition (sometimes called aggregation) is the process of putting an object (a part) inside another object (the composite). It models the has-a relationship. For example, a FordTaurus can be composed of, among other things, an Engine, Transmission, InstrumentPanel, and so on. In other words, a FordTaurus has an Engine (equivalently, an Engine is part-of a FordTaurus):
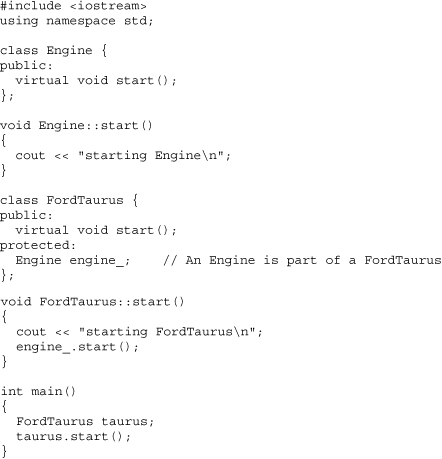
Sometimes developers incorrectly use inheritance (kind-of) when they should use composition. For example, they might make FordTaurus inherit from Engine, which confuses kind-of with part-of.
FAQ 5.10 What is the purpose of inheritance?
In C++, inheritance is for subtyping. It lets developers model the kind-of relationship.
Inheritance allows developers to make one class a kind-of another class. In an inheritance relationship, the new class is called the derived class and the original class from which the new class is being derived is called the base class. All the data structures and member functions that belong to the base class automatically become part of the derived class.
For example, suppose the class Stack has member functions push() and pop(), and there is a need for a class PrintableStack. PrintableStack is exactly like Stack except PrintableStack also provides the member function print(). Class PrintableStack can be built by inheriting from Stack—Stack would be the base class and PrintableStack would be the derived class. The member functions push() and pop() and any others that belong to Stack automatically become part of PrintableStack, so the only requirement for building PrintableStack is adding the print() member function to it.
To do something similar in C, the existing Stack source file would be modified (which is trouble if Stack is being used by other source files and they rely on the exact layout of Stack) or copied into another file that would then be tweaked. However, code copying is the least desirable form of reuse: it doubles the maintenance costs and duplicates any bugs in the original source file. Using C++ and inheritance, Stack remains unmodified, yet PrintableStack doesn't need to duplicate the code for the inherited member functions.
FAQ 5.11 What are the advantages of polymorphism and dynamic binding?
They allow old code to call new code in a substitutable fashion.
The real power of object-oriented programming isn't just inheritance; it's the ability to treat objects of derived classes as if they were objects of the base class. The mechanisms that support this are polymorphism and dynamic binding.
Polymorphism allows an object of a derived class to be passed to a function that accepts a reference or a pointer to a base class. A function that receives such objects is a polymorphic function.
When a polymorphic function invokes a member function using a base class reference or pointer, dynamic binding executes the code from the derived class even though the polymorphic function may be unaware that the derived class exists. The code that is executed depends on the type of the object rather than on the type of the reference or pointer. In this way, objects of a derived class can be substituted for objects of a base class without requiring any changes in the polymorphic functions that use the objects.
FAQ 5.12 How does OO help produce flexible and extensible software?
By minimizing the ripple effect of enhancements.
Even in well-designed structured systems, enhancements often require modifications to significant portions of existing design and code. OO achieves flexibility by (1) allowing the past to make use of the future, and (2) designing for comprehensibility.
The past can make use of the future when old user code (the past) can reliably and predictably call new server code (the future) without any modifications to the old user code. Inheritance, polymorphism, and dynamic binding are used to achieve this lofty goal.
Comprehensibility allows software to be understood not only by the original development team, but also by the team making the enhancements. Abstraction and specification are used to achieve this lofty goal.
This approach can be contrasted with software developed using the traditional, structured approach, where enhancements or modifications often lead to a seemingly endless cycle of random modifications (a.k.a. hacks) until the system appears to work.
FAQ 5.13 How can old code call new code?
![]()
Through the magic of polymorphism, inheritance, and dynamic binding.
In the traditional software paradigm, it is easy for new code to call old code using subroutine libraries. However, it is difficult for old code to call new code (unless the old code is modified so that it knows about the new code, in which case the old code is no longer old).
With object orientation, old polymorphic functions can dynamically bind to new server code. An object of a derived class can be passed to and used by an existing polymorphic function without modifying the polymorphic function.
When compiling a polymorphic function, it is as if the compiler looks forward in time and generates code that will bind to all the classes that will ever be added. For example, a graphical drawing package might deal with squares, circles, polygons, and various other shapes. Most of the drawing package's services deal with generic shapes rather than a particular kind of shape, like a square (for example, “if a shape is selected by the mouse, the shape is dragged across the screen and placed in a new location”). Polymorphism and dynamic binding allow the drag-and-drop code to work correctly regardless of the kind of shape being manipulated. To implement this approach, class Shape would declare virtual functions for drawing and moving. The derived classes would represent the various kinds of shapes: Square, Circle, and so forth.




This dragAndDrop(Shape&) function properly invokes the right member functions from class Square and Circle, even though the compiler didn't know about Square or Circle when it was compiling dragAndDrop(Shape&). Here is the output of this program.
Square::move
Square::draw
Circle::move
Circle::draw
Suppose the function dragAndDrop(Shape&) is compiled on Tuesday, and a new kind of shape—say a Hexagon—is created on Wednesday. dragAndDrop(Shape&) works with a Hexagon even though the Hexagon class didn't exist when dragAndDrop(Shape&) was compiled.
FAQ 5.14 What is an abstraction and why is it important?
An abstraction is a simplified view of an object in the user's own vocabulary.
In OO and C++, an abstraction is the simplest interface to an object that provides all the features and services the intended users expect.
An abstraction tells users everything they need to know about an object but nothing else. It is the well-defined, unambiguously specified interface. For example, on a vending machine, the abstraction is formed by the buttons and their meanings; users don't have to know about levers, internal counters, or other parts that are needed for the machine to operate. Furthermore the vending machine's price list implies a legally binding promise to users: if users put in the right amount of money, the machine promises to dispense the desired item.
The key to a good abstraction is deep knowledge of the problem domain. A good abstraction allows users to use an object in a relatively safe and predictable manner. It reduces the learning curve by providing a simple interface described in terms of the user's own vocabulary.
A good abstraction separates specification from implementation. It doesn't expose too much nor does it hide features that users need to know about. If an abstraction is good, users aren't tempted to peek at the object's implementation. The net result is simpler, more stable user code.
FAQ 5.15 Should abstractions be user-centric or developer-centric?
User-centric.
New object-oriented programmers commonly make the mistake of thinking that inheritance, objects, and so on exist to make it easier to build a class. Although this developer-centric view of OO software provides a short burst of improved productivity; it fails to produce a software development culture that has “sustainable effectiveness.” In other words, a flash in the pan, then nothing.
The only way to achieve long-term success with OO is for developers to focus on their users instead of on themselves. Ironically, most developers eventually become users of their own abstractions, so they can help themselves through their efforts to help others.
Abstractions that involve technology, such as “database” or “communications link,” are probably developer-centric. The best abstractions use terminology from the language of the user, such as “general ledger account” or “customer.”
FAQ 5.16 What's the difference between encapsulation and abstraction?
Encapsulation protects abstractions. Encapsulation is the bodyguard; abstraction is the VIP.
Encapsulation provides the explicit boundary between an object's abstract interface (its abstraction) and its internal implementation details. Encapsulation puts the implementation details “in a capsule.” Encapsulation tells users which features are stable, permanent services of the object and which features are implementation details that are subject to change without notice.
Encapsulation helps the developers of an abstraction: it provides the freedom to implement the abstraction in any way consistent with the interface. (Encapsulation tells developers exactly what users can and cannot access.) Encapsulation also helps the users of an abstraction: it provides protection by preventing dependence on volatile implementation details.
Abstraction provides business value; encapsulation “protects” these abstractions. If a developer provides a good abstraction, users won't be tempted to peek at the object's internal mechanisms. Encapsulation is simply a safety feature that reminds users not to stray over the line inadvertently.
FAQ 5.17 What are the consequences of encapsulating a bad abstraction?
Wasted money. Lots of wasted money.
There's nothing more frustrating than a lousy abstraction that is encapsulated. When a developer encapsulates a bad abstraction, users continually attempt to violate the abstraction's encapsulation barrier. When that happens, don't waste time trying to make it even harder for users to access the object's internals; fix the abstraction instead.
Don't think of encapsulation as a club with which the good guys (the class's authors) prevent the bad guys (the class's users) from looking inside an object. Object-oriented design and programming is not a contest between developers and users.
FAQ 5.18 What's the value of separating interface from implementation?
![]()
It's a key to eliminating the ripple effect when a change is made.
Interfaces are a company's most valuable asset. Maintaining interface consistency across implementation changes is a priority for many companies. Keeping the interface separate from the implementation allows interface consistency. It also produces software that is cheaper to design, write, debug, test, and maintain than other software.
Separating the interface from the implementation makes a system easier to understand by reducing its overall complexity. Each object needs to know only about the interfaces—not about the implementations—of the objects with which it collaborates. This is in stark contrast to most systems, in which it seems as if every source file knows about the implementation of every other source file. In one extreme case, 157 different source files had direct access to a data structure in some other source file (we're not making this up). Imagine how expensive it would be to change that data structure in response to a new customer requirement.
Separating the interface from the implementation also makes a system more flexible by reducing coupling between components. A high incidence of coupling between components is a major factor in systems becoming brittle and makes it difficult to accommodate new customer requirements in a cost-effective manner. When coupling is strong, a change to one source file affects other source files, so they require changes as well. This produces a ripple effect that eventually cascades through a large part of the system. Since separating the interface from the implementation reduces coupling, it also reduces ripples. The result is a more flexible software product and an organization that is better equipped to keep up with market changes.
Separating the interface from the implementation also simplifies debugging and testing. The software that provides the interface is the only software that directly touches the implementation, and therefore is the only software that can cause nonsensical, incoherent, or inconsistent behavior by the implementation. For example, if a linked list caches its length and the length counter doesn't match the number of links in the list, finding the code that caused this error is vastly simpler if only a small number of routines can directly access the nodes and the length counter.
Finally, separating the interface from the implementation encourages software reuse by reducing education costs for those who want to reuse an object. The reusers of an object need learn about only the interface rather than the (normally vastly more complicated) implementation.
FAQ 5.19 How can separating interface from implementation improve performance as well as flexibility?
![]()
Late life-cycle performance tuning.
Fact 1: The only objects worth tuning are the ones that create performance bottlenecks, and the only way to know which objects are the bottlenecks is to measure the behavior of a running system (profiling). Developers sometimes think they can predict where the bottlenecks will be, but studies have shown that they often guess wrong—they cannot reliably predict where the application's bottlenecks will be. Therefore, don't waste time tuning the performance of a piece of code until actual measurements have shown that it is a bottleneck.
Fact 2: The most potent means of improving performance is changing algorithms and data structures. Hand tuning the wrong algorithm or data structure has very little benefit compared to finding an algorithm or data structure that is a better match for the problem being solved. This is especially true for large problems where algorithms and data structures must be scalable.
These two facts lead to an undeniable conclusion: the most effective performance tuning occurs when the product's fundamental data structures and algorithms can be changed late in the product's life cycle. This can be accomplished only if there is adequate separation of interface from implementation.
For example, it would be expensive to change a sorted array to a binary search tree in a typical non-OO software product today, because all the places that use integer indices to access entries would need to be modified to use node pointers. In other words, the interface is the implementation in typical software today. The key to solving this problem is to focus on the similarity in the abstractions rather than the differences in the data structures: sorted arrays and binary trees are both containers that keep their entries in sorted order. In this light they are merely alternate implementations of the same abstraction and they should have the same interface.
The key to late life-cycle performance tuning is to hide performance differences behind a uniform interface. Thus users code to the abstraction rather than to the data structure. This allows the data structure and the algorithm to be replaced at any time.
Ultimately the key is to ask the right questions at the right time. This lofty goal is achieved by a good software development process (SDP). Unfortunately, many SDPs cause developers to ask the wrong questions at the wrong time, often resulting in a premature commitment to an implementation technique. Even if an SDP uses OO terminology (for example, by using the term object diagram rather than data structure), the software will be inflexible if the bulk of its code is aware of relationships that may need to change.
The first programming technique that exploited these ideas was based on abstract data types. The OO paradigm is built on top of the abstract data type technique: OO adds the ability for the user code to work with all implementations of an abstraction simultaneously. That is, among other things, OO allows the data structures to be interchanged dynamically on a case-by-case basis, which is an improvement over a statically chosen, one-size-fits-all approach.
FAQ 5.20 What is the best way to create a good interface to an abstraction?
Design the interface from the user's point of view (i.e., design the interface from the outside in). In other words, start by writing some sample user code.
Interface design decisions should be based primarily on the users' external perspective. In contrast, when the implementation is built before the interface is designed, the interface inevitably smells like the implementation. If the interface has to be explained to its users in terms of the implementation, then the implementation becomes cast in concrete.
For example, consider a member function that tells whether a particular integer is in a set-of-int. This is a boolean inspector: it inspects (versus mutates) the set object and it returns a boolean value. A naive name for such a member function might be Set::isElemOf(int) const. However, putting this name in an if statement shows that the name gives the wrong connotation, since the user code reads “if mySet is an element of x”:
if (mySet.isElemOf(x)) ...
A much better sentence structure would be “if mySet contains x,” which means the member function would be named contains:
if (mySet.contains(x)) ...
Note that the names of boolean inspectors should imply the meaning of the true response. For example, File::isOpen() const is better than File::status() const.
FAQ 5.21 How are get/set member functions related to poorly designed interfaces?
Get/set member functions are often used as Band-Aids to patch broken interfaces.
Get/set member functions provide users with access to an object's internal data structures. Although get/set member functions appear to encapsulate the object's implementation, all they really do is hide the name of a data member while exposing the data member's existence, as well as the relationships between the data member and all the other data members. In other words, they expose the implementation technique. Ultimately, the resultant interface makes the user code dependent on the implementation technique, and changing the implementation technique breaks user code—the ripple effect.
If a Container class exports information about the binary tree that implements it (for example, if it exports member functions getLeftChild() and getRightChild()), the users will be forced to think in terms of binary trees rather than containers. The result is a cluttered interface in the implementer's vocabulary instead of a simple interface defined in the user's vocabulary.
When an interface is cluttered, the resultant user code is more complicated. When an interface is defined in the implementer's vocabulary, implementation details will show through, and changing the implementation technique breaks user code. Either way, the users lose.
Please don't think that we are saying that get and set member functions are always bad. They aren't, and frameworks such as CORBA automatically provide get and set member functions for all attributes. The real issue is that a good object will always have a secret, something that it encapsulates and the interface hides, and get and set member functions can sometimes undermine the object's secrets.
FAQ 5.22 Should there be a get and a set member function for each member datum?
Not necessarily.
Some data members are a legitimate part of an object's interface. Having a get or set member function for such a datum is appropriate because the datum represents something that is part of the user's vocabulary.
One way to tell which data members are a legitimate part of an object's interface is by asking a typical user to describe the class in implementation-independent terms. The words used to describe the class form the user's vocabulary. The interface should be expressed in the user's vocabulary.
FAQ 5.23 Is the real purpose of a class to export data?
No, the real purpose of a class is to provide services.
A class is a way to abstract behavior, not just a way to encapsulate bits. A class's interface must make sense from the outside. If a user expects member functions to access an attribute, the member functions should exist. But remember: the member functions to access an attribute exist because their existence makes sense in the user's vocabulary (that is, for outside reasons), not because there are bits in the object (that is, not for inside reasons).
A class's interface should be designed from the outside in. It takes a little while for this to feel comfortable to newcomers, but it is the only right way to do the job.
This FAQ and the next one reflect a really important lesson learned from the OO modeling wars in the early 1990s: objects should reflect behaviors and services. Data modeling per se is inappropriate as an OO technique. There is still a limited place for data modeling because most object persistence schemes still end up invoking relational databases as an implementation technique, but this fact of life doesn't mean that the data model should bleed through to the user.
FAQ 5.24 Should OO be viewed as data-centric?
No, OO should be viewed as behavior-centric.
The data-centric view of OO (the wrong approach) says that objects are fundamentally buckets of bits and that the primary purpose of a class is to export attributes.
The behavior-centric view of OO (the right approach) sees objects as intelligent agents that export useful services. The behavior-centric view of OO produces more cost-effective systems that are easier to adapt to changing requirements, are easier to tune for performance, and tend to have fewer defects. The reason for these benefits is simple: behavior-centric systems move common code from a class's users into the class itself, from the many to the few. Coalescing snippets of code that show up in several users reduces maintenance costs (by reducing code bulk) and avoids duplicating defects.