
Identification, Authentication, Authorization, and Accountability
For a user to be able to access a resource, he first must prove he is who he claims to be, has the necessary credentials, and has been given the necessary rights or privileges to perform the actions he is requesting. Once these steps are completed successfully, the user can access and use network resources; however, it is necessary to track the user’s activities and enforce accountability for his actions. Identification describes a method of ensuring that a subject (user, program, or process) is the entity it claims to be. Identification can be provided with the use of a username or account number. To be properly authenticated, the subject is usually required to provide a second piece to the credential set. This piece could be a password, passphrase, cryptographic key, personal identification number (PIN), anatomical attribute, or token. These two credential items are compared to information that has been previously stored for this subject. If these credentials match the stored information, the subject is authenticated. But we are not done yet.
Once the subject provides its credentials and is properly identified, the system it is trying to access needs to determine if this subject has been given the necessary rights and privileges to carry out the requested actions. The system will look at some type of access control matrix or compare security labels to verify that this subject may indeed access the requested resource and perform the actions it is attempting. If the system determines that the subject may access the resource, it authorizes the subject.
Although identification, authentication, authorization, and accountability have close and complementary definitions, each has distinct functions that fulfill a specific requirement in the process of access control. A user may be properly identified and authenticated to the network, but he may not have the authorization to access the files on the file server. On the other hand, a user may be authorized to access the files on the file server, but until she is properly identified and authenticated, those resources are out of reach. Figure 4-2 illustrates the four steps that must happen for a subject to access an object.
Figure 4-2. Four steps must happen for a subject to access an object: identification, authentication, authorization, and accountability.
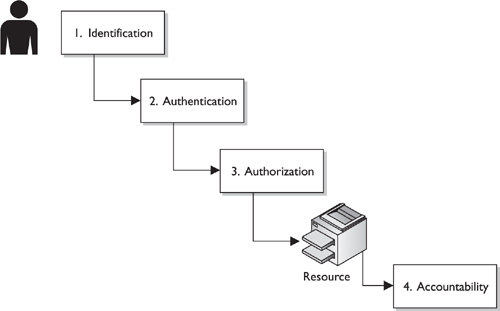
The subject needs to be held accountable for the actions taken within a system or domain. The only way to ensure accountability is if the subject is uniquely identified and the subject’s actions are recorded.
Logical access controls are tools used for identification, authentication, authorization, and accountability. They are software components that enforce access control measures for systems, programs, processes, and information. The logical access controls can be embedded within operating systems, applications, add-on security packages, or database and telecommunication management systems. It can be challenging to synchronize all access controls and ensure all vulnerabilities are covered without producing overlaps of functionality. However, if it were easy, security professionals would not be getting paid the big bucks!
Note

| The words “logical” and “technical” can be used interchangeably in this context. It is conceivable that the CISSP exam would refer to logical and technical controls interchangeably. |
An individual’s identity must be verified during the authentication process. Authentication usually involves a two-step process: entering public information (a username, employee number, account number, or department ID), and then entering private information (a static password, smart token, cognitive password, one-time password, PIN, or digital signature). Entering public information is the identification step, while entering private information is the authentication step of the two-step process. Each technique used for identification and authentication has its pros and cons. Each should be properly evaluated to determine the right mechanism for the correct environment.
Note

| A cognitive password is based on a user’s opinion or life experience. The password could be a mother’s maiden name, a favorite color, or a dog’s name. |
References
FWPro Secure Coding Standards http://pageblocks.org/refc/refc_security
“What Are Race Conditions and Deadlocks?” Microsoft Knowledge Base Article 317723 http://support.microsoft.com/kb/317723
Identification and Authentication
Now, who are you again?
Once a person has been identified, through the user ID or a similar value, she must be authenticated, which means she must prove she is who she says she is. Three general factors can be used for authentication: something a person knows, something a person has, and something a person is. They are also commonly called authentication by knowledge, authentication by ownership, and authentication by characteristic.
Verification 1:1 is the measurement of an identity against a single claimed identity. The conceptual question is, “Is this person who he claims to be?” So if Bob provides his identity and credential set, this information is compared to the data kept in an authentication database. If they match, we know that it is really Bob. If the identification is 1: N (many), the measurement of a single identity is compared against multiple identities. The conceptual question is, “Who is this person?” An example is if fingerprints were found at a crime scene, the cops would run them through their database to identify the suspect.
Something a person knows (authentication by knowledge) can be, for example, a password, PIN, mother’s maiden name, or the combination to a lock. Authenticating a person by something that she knows is usually the least expensive to implement. The downside to this method is that another person may acquire this knowledge and gain unauthorized access to a system or facility.
Something a person has (authentication by ownership) can be a key, swipe card, access card, or badge. This method is common for accessing facilities, but could also be used to access sensitive areas or to authenticate systems. A downside to this method is that the item can be lost or stolen, which could result in unauthorized access.
Something specific to a person (authentication by characteristic) becomes a bit more interesting. This is not based on whether the person is a Republican, a Martian, or a moron—it is based on a physical attribute. Authenticating a person’s identity based on a unique physical attribute is referred to as biometrics. (For more information, see the upcoming section, “Biometrics.”)
Strong authentication contains two out of these three methods: something a person knows, has, or is. Using a biometric system by itself does not provide strong authentication because it provides only one out of the three methods. Biometrics supplies what a person is, not what a person knows or has. For a strong authentication process to be in place, a biometric system needs to be coupled with a mechanism that checks for one of the other two methods. For example, many times the person has to type a PIN number into a keypad before the biometric scan is performed. This satisfies the “what the person knows” category. Conversely, the person could be required to swipe a magnetic card through a reader prior to the biometric scan. This would satisfy the “what the person has” category. Whatever identification system is used, for strong authentication to be in the process, it must include two out of the three categories. This is also referred to as two-factor authentication.
Identity is a complicated concept with many varied nuances, ranging from the philosophical to the practical. A person can have multiple digital identities. For example, a user can be JPublic in a Windows domain environment, JohnP on a Unix server, JohnPublic on the mainframe, JJP in instant messaging, JohnCPublic in the certification authority, and IWearPanties at myspace.com. If a company would want to centralize all of its access control, these various identity names for the same person may put the security administrator into a mental health institution.
Determining identity in security has three key aspects: uniqueness, nondescriptive, and issuance. The first, uniqueness, refers to the identifiers that are specific to an individual, meaning every user must have a unique ID for accountability. Things like fingerprints and retina scans can be considered unique elements in determining identity. Nondescriptive means that neither piece of the credential set should indicate the purpose of that account. For example, a user ID should not be “administrator,” “backup_ operator,” or “CEO.” The third key aspect in determining identity is issuance. These elements are the ones that have been provided by another authority as a means of proving identity. ID cards are a kind of security element that would be considered an issuance form of identification.
Access Control ReviewThe following is a review of the basic concepts in access control:
|
Identity Management
There are too many of you who want to access too much stuff. Everyone just go away!
Identity management is a broad and loaded term that encompasses the use of different products to identify, authenticate, and authorize users through automated means. To many people, the term also includes user account management, access control, password management, single sign-on functionality, managing rights and permissions for user accounts, and auditing and monitoring of all of these items. The reason that individuals, and companies, have different definitions and perspectives of identity management (IdM) is because it is so large and encompasses so many different technologies and processes. Remember the story of the four blind men who are trying to describe an elephant? One blind man feels the tail and announces, “It’s a tail.” Another blind man feels the trunk and announces, “It’s a trunk.” Another announces it’s a leg, and another announces it’s an ear. This is because each man cannot see or comprehend the whole of the large creature—just the piece he is familiar with and knows about. This analogy can be applied to IdM because it is large and contains many components and many people may not comprehend the whole—only the component they work with and understand.
It is important for security professionals to understand not only the whole of IdM, but understand the technologies that make up a full enterprise IdM solution. IdM requires management of uniquely identified entities, their attributes, credentials, and entitlements. IdM allows organizations to create and manage digital identities’ life cycles (create, maintain, terminate) in a timely and automated fashion. The enterprise IdM must meet business needs and scale from internally facing systems to externally facing systems. In this section, we will be covering many of these technologies and how they work together.
Selling identity management products is now a flourishing market that focuses on reducing administrative costs, increasing security, meeting regulatory compliance, and improving upon service levels throughout enterprises. The continual increase in complexity and diversity of networked environments only increases the complexity of keeping track of who can access what and when. Organizations have different types of applications, network operating systems, databases, enterprise resource management (ERP) systems, customer relationship management (CRM) systems, directories, main-frames—all used for different business purposes. Then the organizations have partners, contractors, consultants, employees, and temporary employees. (Figure 4-3 actually provides the simplest view of most environments.) Users usually access several different types of systems throughout their daily tasks, which makes controlling access and providing the necessary level of protection on different data types difficult and full of obstacles. This complexity usually results in unforeseen and unidentified holes in asset protection, overlapping and contradictory controls, and policy and regulation non-compliance. It is the goal of identity management technologies to simplify the administration of these tasks and bring order to chaos.

The following are many of the common questions enterprises deal with today in controlling access to assets:
What should each user have access to?
Who approves and allows access?
How do the access decisions map to policies?
Do former employees still have access?
How do we keep up with our dynamic and ever-changing environment?
What is the process of revoking access?
How is access controlled and monitored centrally?
Why do employees have eight passwords to remember?
We have five different operating platforms. How do we centralize access when each platform (and application) requires its own type of credential set?
How do we control access for our employees, customers, and partners?
How do we make sure we are compliant with the necessary regulations?
Where do I send in my resignation? I quit.
The traditional identity management process has been manual, using directory services with permissions, access control lists (ACLs), and profiles. This approach has proven incapable of keeping up with complex demands and thus has been replaced with automated applications rich in functionality that work together to create an identity management infrastructure. The main goals of identity management (IdM) technologies are to streamline the management of identity, authentication, authorization, and the auditing of subjects on multiple systems throughout the enterprise. The sheer diversity of a heterogonous enterprise makes proper implementation of IdM a huge undertaking.
Many identity management solutions and products are available in the marketplace. For the CISSP exam, the following are the types of technologies you should be aware of:
Directories
Web access management
Password management
Legacy single sign-on
Profile update
Directories
Most enterprises have some type of directory that contains information pertaining to the company’s network resources and users. Most directories follow a hierarchical database format, based on the X.500 standard, and a type of protocol, as in Lightweight Directory Access Protocol (LDAP), that allows subjects and applications to interact with the directory. Applications can request information about a particular user by making an LDAP request to the directory, and users can request information about a specific resource by using a similar request.
The objects within the directory are managed by a directory service. The directory service allows an administrator to configure and manage how identification, authentication, authorization, and access control take place within the network. The objects within the directory are labeled and identified with namespaces.
In a Windows environment when you log in, you are logging in to a domain controller (DC), which has a hierarchical directory in its database. The database is running a directory service (Active Directory), which organizes the network resources and carries out user access control functionality. So once you successfully log in to the DC, certain network resources will be available to you (the print service, file server, e-mail server, and so on) as dictated by the configuration of AD.
How does the directory service keep all of these entities organized? By using namespaces. Each directory service has a way of identifying and naming the objects they will manage. In databases based on the X.500 standard that are accessed by LDAP, the directory service assigns distinguished names (DNs) to each object. Each DN represents a collection of attributes about a specific object, and is stored in the directory as an entry. In the following example, the DN is made up of a common name (cn) and domain components (dc). Since this is a hierarchical directory, .com is the top, LogicalSecurity is one step down from .com, and Shon is at the bottom (where she belongs).
dn: cn=Shon Harris,dc=LogicalSecurity,dc=com cn: Shon Harris

This is a very simplistic example. Companies usually have large trees (directories) containing many levels and objects to represent different departments, roles, users, and resources.
A directory service manages the entries and data in the directory and also enforces the configured security policy by carrying out access control and identity management functions. For example, when you log in to the DC, the directory service (AD) will determine what resources you can and cannot access on the network.
Organizing All of This StuffIn a database directory based on the X.500 standard, the following rules are used for object organization;
The schema describes the directory structure and what names can be used within the directory, among other things. (Schema and database components are covered more in-depth in Chapter 11.) The following diagram shows how an object (Kathy Conlon) can have the attributes of ou=General ou=NCTSW ou=pentagon ou=locations ou=Navy ou=DoD ou=U.S. Government C=US. 
Note that OU stands for organizational unit. They are used as containers of other similar OUs, users, and resources. They provide the parent-child (sometimes called tree-leaf) organization structure. |

So are there any problems with using a directory product for identity management and access control? Yes, there’s always something. Many legacy devices and applications cannot be managed by the directory service because they were not built with the necessary client software. The legacy entities must be managed through their inherited management software. This means that most networks have subjects, services, and resources that can be listed in a directory and controlled centrally by an administrator through the use of a directory service. Then there are legacy applications and devices that the administrator must configure and manage individually.
The Directories’ Role in Identity Management
A directory used for IdM is specialized database software that has been optimized for reading and searching operations. It is the main component of an identity management solution. This is because all resource information, users’ attributes, authorization profiles, roles, potential access control policies, and more are stored in this one location. When other IdM software applications need to carry out their functions (authorization, access control, assigning permissions), they now have a centralized location for all of the information they need.
As an analogy, let’s say I’m a store clerk and you enter my store to purchase alcohol. Instead of me having to find a picture of you somewhere to validate your identity, go to another place to find your birth certificate to obtain your true birth date, and find proof of which state you are registered in, I can look in one place—your driver’s license. The directory works in the same way. Some IdM application may need to know a user’s authorization rights, role, employee status, or clearance level, so instead of this application having to make requests to several databases and other applications, it makes its request to this one directory.
A lot of the information stored in an IdM directory is scattered throughout the enterprise. User attribute information (employee status, job description, department, and so on) is usually stored in the HR database, authentication information could be in a Kerberos server, role and group identification information might be in a SQL database, and resource-oriented authentication information is stored in Active Directory on a domain controller. These are commonly referred to as identity stores and are located in different places on the network. Something nifty that many identity management products do is create meta-directories or virtual directories. A meta-directory gathers the necessary information from multiple sources and stores them in one central directory. This provides a unified view of all users’ digital identity information throughout the enterprise. The meta-directory synchronizes itself with all of the identity stores periodically to ensure the most up-to-date information is being used by all applications and IdM components within the enterprise.
A virtual directory plays the same role and can be used instead of a meta-directory. The difference between the two is that the meta-directory physically has the identity data in its directory, whereas a virtual directory does not and points to where the actual data resides. When an IdM component makes a call to a virtual directory to gather identity information on a user, the virtual directory will point to where the information actually lives.
Figure 4-4 illustrates a central LDAP directory that is used by the IdM services: access management, provisioning, and identity management. When one of these services accepts a request from a user or application, it pulls the necessary data from the directory to be able to fulfill the request. Since the data needed to properly fulfill these requests are stored in different locations, the metadata directory pulls the data from these other sources and updates the LDAP directory.
Figure 4-4. Meta-directories pull data from other sources to populate the IdM directory.

Web Access Management
Web access management (WAM) software controls what users can access when using a web browser to interact with web-based enterprise assets. This type of technology is continually becoming more robust and experiencing increased deployment. This is because of the increased use of e-commerce, online banking, content providing, web services, and more. The Internet only continues to grow and its importance to businesses and individuals increases as more and more functionality is provided. We just can’t seem to get enough of it.
Figure 4-5 shows the basic components and activities in a web access control management process.

User sends in credentials to web server.
Web server validates user’s credentials.
User requests to access a resource (object).
Web server verifies with the security policy to determine if the user is allowed to carry out this operation.
Web server allows access to the requested resource.
This is a simple example. More complexity comes in with all the different ways a user can authenticate (password, digital certificate, token, and others), the resources and services that may be available to the user (transfer funds, purchase product, update profile, and so forth) and the necessary infrastructure components. The infrastructure is usually made up of a web server farm (many servers), a directory that contains the users’ accounts and attributes, a database, a couple of firewalls, and some routers, all laid out in a tiered architecture. But let’s keep it simple right now.
The WAM software is the main gate between users and the corporate web-based resources. It is commonly a plug-in for a web server, so it works as a front-end process. When a user makes a request for access, the web server software will query a directory (described in the last section), an authentication server, and potentially a back-end database before serving up the resource the user requested. The WAM console allows the administrator to configure access levels, authentication requirements, and account setup workflow steps, and to perform overall maintenance.
WAM tools usually also provide a single sign-on capability so that once a user is authenticated at a web site, she can access different web-based applications and resources without having to log in multiple times. When a product provides a single sign-on capability in a web environment, the product must keep track of the user’s authentication state and security context as the user moves from one resource to the next.
For example, if Kathy logs on to her online bank web site, the communication is taking place over the HTTP protocol. This protocol itself is stateless, which means it will allow a web server to pass the user a web page and then the connection is closed and the user is forgotten about. Many web servers work in a stateless mode because they have so many requests to fulfill and they are just providing users with web pages. Keeping a constant connection with each and every user who is requesting to see a web page would exhaust the web server’s resources. When a user has to log on to a web site is when “keeping the user’s state” is required and a continuous connection is needed.
When Kathy first goes to her bank’s web site, she is viewing publicly available data that do not require her to authenticate before viewing. A constant connection is not being kept by the web server, thus it is working in a stateless manner. Once she clicks Access My Account, the web server sets up a secure connection (SSL) with her browser and requests her credentials. After she is authenticated, the web server sends a cookie (small text file) that indicates she has authenticated properly and the type of access she should be allowed. When Kathy requests to move from her savings account to her checking account, the web server will assess the cookie on Kathy’s web browser to see if she has the rights to access this new resource. The web server continues to check this cookie during Kathy’s session to ensure no one has hijacked the session and that the web server is continually communicating with Kathy’s system and not someone else’s.
The web server continually asks Kathy’s web browser to prove she has been authenticated, which the browser does by providing the cookie information. (The cookie information could include her password, account number, security level, browsing habits, and/or personalization information.) As long as Kathy is authenticated, the web server software will keep track of each of her requests, log her events, and make changes that she requests that can take place in her security context. Security context is the authorization level she is assigned based on her permissions, entitlements, and access rights.
Once Kathy ends the session, the cookie is usually erased from the web browser’s memory and the web server no longer keeps this connection open or collects session state information on this user.
Note

| A cookie can be in the format of a text file stored on the user’s hard drive (permanent) or it can be only held in memory (session). If the cookie contains any type of sensitive information, then it should only be held in memory and be erased once the session has completed. |
As an analogy, let’s say I am following you in a mall as you are shopping. I am marking down what you purchase, where you go, and the requests you make. I know everything about your actions; I document them in a log, and remember them as you continue. (I am keeping state information on you and your activities.) You can have access to all of these stores if you show me a piece of paper that I gave you every 15 minutes. If you fail to show me the piece of paper at the necessary interval, I will push a button and all stores will be locked—you no longer have access to the stores, I no longer collect information about you, and I leave and forget all about you. Since you are no longer able to access any sensitive objects (store merchandise), I don’t need to keep track of you and what you are doing.
As long as the web browser serves up the cookie to the web browser, Kathy does not have to provide credentials as she asks for different resources. This is what single sign-on is. You only have to provide your credentials once and the continual validation that you have the necessary cookie will allow you to go from one resource to another. If you end your session with the web server and need to interact with it again, you must re-authenticate and a new cookie will be sent to your browser and it starts all over again.
Note

| We will cover specific single sign-on technologies later in this chapter along with their security issues. |
So the WAM product allows an administrator to configure and control access to internal resources. This type of access control is commonly put in place to control external entities requesting access. The product may work on a single web server or a server farm.
Password Management
Wouldn’t it be easier for everyone to just use the value “password” for their password?
Response: Yes! Let’s do that, and then no password management will ever be needed.
We cover password requirements, security issues, and best practices later in this chapter. At this point, we need to understand how password management can work within an IdM environment.
Help-desk workers and administrators commonly complain about the amount of time they have to spend resetting passwords when users forget them. Another issue is the amount of different passwords the users are required to remember for the different platforms within the network. When a password changes, an administrator must connect directly to that management software of the specific platform and change the password value. This may not seem like much of a hassle, but if an organization has 4000 users and seven different platforms, and 35 different applications, it could require a full-time person to continually make these password modifications. And who would really want that job?
Different types of password management technologies have been developed to get these pesky users off the backs of IT and the help desk by providing a more secure and automated password management system. The most common password management approaches are listed next.
Password Synchronization Reduces the complexity of keeping up with different passwords for different systems.
Self-Service Password Reset Reduces help-desk call volumes by allowing users to reset their own passwords.
Assisted Password Reset Reduces the resolution process for password issues for the help desk. This may include authentication with other types of authentication mechanisms (biometrics, tokens).
Password Synchronization
If users have too many passwords they need to keep track of, they will write the passwords down on a sticky note and cleverly hide this under their keyboard or just stick it on the side of their monitor. This is certainly easier for the user, but not so great for security.
Password synchronization technologies can allow a user to maintain just one password across multiple systems. The product will synchronize the password to other systems and applications, which happens transparently to the user.
The goal is to require the user to memorize only one password and have the ability to enforce more robust and secure password requirements. If a user only needs to remember one password, he is more likely to not have a problem with longer, more complex strings of values. This reduces help-desk call volume and allows the administrator to keep her sanity for just a little bit longer.
One criticism of this approach is that since only one password is used to access different resources, now the hacker only has to figure out one credential set to gain unauthorized access to all resources. But if the password requirements are more demanding (12 characters, no dictionary words, three symbols, upper and lower letters, and so on) and the password is changed out regularly, the balance between security and usability can be acceptable.
Self-Service Password Reset
Some products are implemented to allow users to reset their own passwords. This does not mean that the users have any type of privileged permissions on the systems to allow them to change their own credentials. Instead, during the registration of a user account, the user can be asked to provide several personal questions (school graduated from, favorite teacher, favorite color, and so on) in a question and answer form. When the user forgets his password, he may be required to provide another authentication mechanism (smart card, token) and to answer these previously answered questions to prove his identity. If he does this properly, he is allowed to change his password. If he does not do this properly, he is fired because he is an idiot.
Products are available that allow users to change their passwords through other means. For example, if you forgot your password, you may be asked to answer some of the questions answered during the registration process of your account. If you do this correctly, an e-mail is sent to you with a link you must click. The password management product has your identity tied to the answers you gave to the questions during your account registration process and to your e-mail address. If the user does everything correctly, he is given a screen that allows him to reset his password.
Caution
|
| The product should not ask for information that is publicly available, as in your mother’s maiden name, because anyone can find that out and attempt to identify himself as you. |
Assisted Password Reset
Some products are created for help-desk employees who need to work with individuals when they forget their password. The help-desk employee should not know or ask the individual for her password. This would be a security risk since only the owner of the password should know the value. The help-desk employee also should not just change a password for someone calling in without authenticating that person first. This can allow social engineering attacks where an attacker calls the help desk and indicates she is someone who she is not. If this took place, then an attacker would have a valid employee password and can gain unauthorized access to the company’s jewels.
The products that provide assisted password reset functionality allow the help-desk individual to authenticate the caller before resetting the password. This authentication process is commonly performed through the question and answer process described in the previous section. The help-desk individual and the caller must be identified and authenticated through the password management tool before the password can be changed. Once the password is updated, the system that the user is authenticating to should require the user to change her password again. This would ensure that only she (and not she and the help-desk person) knows her password. The goal of an assisted password reset product is to reduce the cost of support calls and ensure all calls are processed in a uniform, consistent, and secure fashion.
Various password management products on the market provide one or all of these functionalities. Since IdM is about streamlining identification, authentication, and access control, one of these products is typically integrated into the enterprise IdM solution.
Legacy Single Sign-On
We will cover specific single sign-on (SSO) technologies later in this chapter, but at this point we want to understand how SSO products are commonly used as an IdM solution, or part of a larger IdM enterprise-wide solution.
An SSO technology allows a user to authenticate one time and then access resources in the environment without needing to re-authenticate. This may sound the same as password synchronization, but it is not. With password synchronization, a product takes the user’s password and updates each user account on each different system and application with that one password. If Tom’s password is iwearpanties, then this is the value he must type into each and every application and system he must access. In an SSO situation, Tom would send his password to one authentication system. When Tom requests to access a network application, the application will send over a request for credentials, but the SSO software will respond to the application for Tom. So in SSO environments, the SSO software intercepts the login prompts from network systems and applications and fills in the necessary identification and authentication information (that is, the username and password) for the user.
Even though password synchronization and single sign-on are different technologies, they still have the same vulnerability. If an attacker uncovers a user’s credential set, she can have access to all the resources that the legitimate user may have access to.
An SSO solution may also provide a bottleneck or single point of failure. If the SSO server goes down, users are unable to access network resources. This is why it’s a good idea to have some type of redundancy or fail-over technology in place.
Most environments are not homogeneous in devices and applications, which makes it more difficult to have a true enterprise SSO solution. Legacy systems many times require a different type of authentication process than the SSO software can provide. So potentially 80 percent of the devices and applications may be able to interact with the SSO software and the other 20 percent will require users to authenticate to them directly. In many of these situations, the IT department may come up with their own homemade solutions, such as using login batch scripts for the legacy systems.
Are there any other downfalls with SSO we should be aware of? Well, it can be expensive to implement, especially in larger environments. Many times companies evaluate purchasing this type of solution and find out it is too cost prohibitive. The other issue is that it would mean all of the users’ credentials for the company’s resources are stored in one location. If an attacker was able to break in to this storehouse, she could access whatever she wanted, and do whatever she wanted, with the company’s assets.
As always, security, functionality, and cost must be properly weighed to determine the best solution for the company.
Account Management
Account management is often not performed efficiently and effectively in companies today. Account management deals with creating user accounts on all systems, modifying the account privileges when necessary, and decommissioning the accounts when they are no longer needed. Most environments have their IT department create accounts manually on the different systems, users are given excessive rights and permissions, and when an employee leaves the company, many or all of the accounts stay active. This is because a centralized account management technology has not been put into place.
Account management products attempt to attack these issues by allowing an administrator to manage user accounts across multiple systems. When there are multiple directories containing user profiles or access information, the account management software allows for replication between the directories to ensure each contains the same up-to-date information.
Now let’s think about how accounts are set up. In many environments, when a new user needs an account, a network administrator will set up the account(s) and provide some type of privileges and permissions. But how would the network administrator know what resources this new user should have access to and what permissions should be assigned to the new account? In most situations, he doesn’t—he just wings it. This is how users end up with too much access to too much stuff. What should take place instead is implementing a workflow process that allows for a request for a new user account. This request is approved, usually, by the employee’s manager, and the accounts are automatically set up on the systems, or a ticket is generated for the technical staff to set up the account(s). If there is a request for a change to the permissions on the account or if an account needs to be decommissioned, it goes through the same process. The request goes to a manager (or whoever is delegated with this approval task), the manager approves it, and the changes to the various accounts take place.
The automated workflow component is common in account management products that provide IdM solutions. Not only does this reduce the potential errors that can take place in account management, each step (including account approval) is logged and tracked. This allows for accountability and provides documentation for use in backtracking if something goes wrong. It also helps ensure that only the necessary amount of access is provided to the account and that there are no “orphaned” accounts still active when employees leave the company. In addition, these types of processes are the kind your auditors will be looking for—and we always want to make the auditors happy!
Note

| These types of account management products are commonly used to set up and maintain internal accounts. Web access control management is used mainly for external users. |
As with SSO products, enterprise account management products are usually expensive and can take years to properly roll out across the enterprise. Regulatory requirements, however, are making more and more companies spend the money for these types of solutions—which the vendors love!
Provisioning
Let’s review what we know, and then build upon these concepts.
Most IdM solutions pull user information from the HR database, because this data are already collected and held in one place and are constantly updated as employee or contractors’ statuses change. So user information will be copied from the HR database (referred to as the authoritative source) into a directory, which we covered in an early section.
When a new employee is hired, the employee’s information, along with his manager’s name, is pulled from the HR database into the directory. The employee’s manager is automatically sent an e-mail asking for approval of this new account. After the manager approves, the necessary accounts are set up on the required systems.
Over time, this new user will commonly have different identity attributes, which will be used for authentication purposes, stored in different systems in the network. When a user requests access to a resource, all of his identity data has already been copied from other identity stores and the HR database and held in this centralized directory (sometimes called the identity repository). This may be a meta-directory or a virtual directory. The access control component of the IdM system will compare the user’s request to the IdM access control policy and ensure the user has the necessary identification and authentication pieces in place before allowing access to the resource.
When this employee is fired, this new information goes from the HR database to the directory. An e-mail is automatically generated and sent to the manager to allow this account to be decommissioned. Once this is approved, the account management software disables all of the accounts that had been set up for this user.
This example illustrates user account management and provisioning, which is the life-cycle management of identity components.
Why do we have to worry about all of this identification and authentication stuff? Because users always want something—they are very selfish. Okay, users actually need access to resources to carry out their jobs. But what do they need access to, and what level of access? This question is actually a very difficult one in our distributed, heterogeneous, and somewhat chaotic environments today. Too much access to resources opens the company up to potential fraud and other risks. Too little access means the user cannot do his job. So we are required to get it just right.
User provisioning refers to the creation, maintenance, and deactivation of user objects and attributes as they exist in one or more systems, directories, or applications, in response to business processes. User provisioning software may include one or more of the following components: change propagation, self-service workflow, consolidated user administration, delegated user administration, and federated change control. User objects may represent employees, contractors, vendors, partners, customers, or other recipients of a service. Services may include electronic mail, access to a database, access to a file server or mainframe, and so on.
Great. So we create, maintain, and deactivate accounts as required based on business needs. What else does this mean? The creation of the account also is the creation of the access rights to company assets. It is through provisioning that users are given access, or access is taken away. Throughout the life cycle of a user identity, access rights, permissions, and privileges should change as needed in a clearly understood, automated, and audited process.
By now, you should be able to connect how these different technologies work together to provide an organization with streamlined IdM. Directories are built to contain user and resource information. A metadata directory pulls identity information that resides in different places within the network to allow IdM processes to only have to get the needed data for their tasks from this one location. User management tools allow for automated control of user identities through their lifetimes and can provide provisioning. A password management tool is in place so that productivity is not slowed down by a forgotten password. A single sign-on technology requires internal users to only authenticate once for enterprise access. Web access management tools provide a single sign-on service to external users and controls access to web-based resources. Figure 4-6 provides a visual example of how many of these components work together.

Profile Update
Most companies do not just contain the information “Bob Smith” for a user and make all access decisions based off of this data. There can be a plethora of information on a user that is captured (e-mail address, home address, phone number, panty size, and so on). When this collection of data is associated with the identity of a user, we call it a profile.
The profile should be centrally located for easier management. IdM enterprise solutions have profile update technology that allows an administrator to create, make changes, or delete these profiles in an automated fashion when necessary. Many user profiles contain nonsensitive data that the user can update himself (called self service). So if George moved to a new house, there should be a profile update tool that allows him to go into his profile and change his address information. Now, his profile may also contain sensitive data that should not be available to George—for example, his access rights to resources or information that he is going to get laid off on Friday.
You have interacted with a profile update technology if you have requested to update your personal information on a web site, as in Orbitz, Amazon, or Expedia. These companies provide you with the capability to sign in and update the information they allow you to access. This could be your contact information, home address, purchasing preferences, or credit card data. This information is then used to update their customer relationship management (CRM) system so they know where to send you their junk mail advertisements or spam messages.
Digital IdentityAn interesting little fact that not many people are aware of is that a digital identity is made up of attributes, entitlements, and traits. Many of us just think of identity as a user ID that is mapped to an individual. The truth is that it is usually more complicated than that. A user’s identity can be a collection of her attributes (department, role in company, shift time, clearance, and others), her entitlements (resources available to her, authoritative rights in the company, and so on) and her traits (biometric information, height, sex, and so forth). So if a user requests access to a database that contains sensitive employee information, the IdM solution would need to pull together the necessary identity information and her supplied credentials before she is authorized access. If the user is a senior manager (attribute), with a Secret clearance (attribute), and has access to the database (entitlement)—she is granted the permissions Read and Write to certain records in the database Monday through Friday, 8 A.M. to 5 P.M. (attribute). Another example is if a soldier requests to be assigned an M-16 firearm. She must be in the 34th division (attribute), have a Top Secret clearance (attribute), her supervisor must have approved this (entitlement), and her physical features (traits) must match the ID card she presents to the firearm depot clerk. The directory (or meta-directory) of the IdM system has all of this identity information centralized, which is why it is so important. Many people think that just logging in to a domain controller or a network access server is all that is involved in identity management. But if you peek under the covers, you can find an array of complex processes and technologies working together. The CISSP exam is not currently getting into this level of detail (entitlement, attribute, traits) pertaining to IdM, but in the real world there are many facets to identification, authentication, authorization, and auditing that make it a complex beast. |
Federation
The world continually gets smaller as technology brings people and companies closer together. Many times, when we are interacting with just one web site, we are actually interacting with several different companies—we just don’t know it. The reason we don’t know it is because these companies are sharing our identity and authentication information behind the scenes. This is not done for nefarious purposes necessarily, but to make our lives easier and to allow merchants to sell their goods without much effort on our part.
For example, a person wants to book an airline flight and a hotel room. If the airline company and hotel company use a federated identity management system, this means they have set up a trust relationship between the two companies and will share customer identification and, potentially, authentication information. So when I book my flight on Southwest, the web site asks me if I want to also book a hotel room. If I click “Yes,” I could then be brought to the Hilton web site, which provides me with information on the closest hotel to the airport I’m flying into. Now, to book a room I don’t have to log in again. I logged in on the Southwest web site, and that web site sent my information over to the Hilton web site, all of which happened transparently to me.
A federated identity is a portable identity, and its associated entitlements, that can be used across business boundaries. It allows a user to be authenticated across multiple IT systems and enterprises. Identity federation is based upon linking a user’s otherwise distinct identities at two or more locations without the need to synchronize or consolidate directory information. Federated identity offers businesses and consumers a more convenient way of accessing distributed resources and is a key component of e-commerce.
Note

| Federation identity and all of the IdM technologies we have discussed so far are usually more complex than what has been presented in this text. This is just the “one-inch deep” overview that the CISSP exam expects of test takers. To get more in-depth information on IdM, visit the author’s web site at www.logicalsecurity.com/IdentityManagement. |
Who Needs Identity Management?The following are good indications that an identity management solution might be right for your company:
|
The following sections explain the various types of authentication methods commonly used and integrated in many identity management processes and products today.
References
Identity Management www.opengroup.org/projects/idm/uploads/40/9784/idm_wp.pdf
Work Papers www.ec3.org/Pubs/PubWGPapersYr.htm
Identity Management http://en.wikipedia.org/wiki/Identity_management
EDUCASE Core Content www.educause.edu/content.asp?page_id=645&PARENT_ID=679&bhcp=1
Biometrics
I would like to prove who I am. Please look at the blood vessels at the back of my eyeball.
Response: Gross.
Biometrics verifies an individual’s identity by analyzing a unique personal attribute or behavior, which is one of the most effective and accurate methods of verifying identification. Biometrics is a very sophisticated technology; thus, it is much more expensive and complex than the other types of identity verification processes. A biometric system can make authentication decisions based on an individual’s behavior, as in signature dynamics, but these can change over time and possibly be forged. Biometric systems that base authentication decisions on physical attributes (such as iris, retina, or fingerprint) provide more accuracy, because physical attributes typically don’t change, absent of some disfiguring injury, and are harder to impersonate.
Biometrics is typically broken up into two different categories. The first is the physiological. These are traits that are physical attributes unique to a specific individual. Fingerprints are a common example of a physiological trait used in biometric systems.
The second category of biometrics is known as behavioral. This is based on a characteristic of an individual to confirm his identity. An example is signature dynamics. Physiological is “what you are” and behavioral is “what you do.”
A biometric system scans a person’s physiological attribute or behavioral trait and compares it to a record created in an earlier enrollment process. Because this system inspects the grooves of a person’s fingerprint, the pattern of someone’s retina, or the pitches of someone’s voice, it must be extremely sensitive. The system must perform accurate and repeatable measurements of anatomical or behavioral characteristics. This type of sensitivity can easily cause false positives or false negatives. The system must be calibrated so these false positives and false negatives occur infrequently and the results are as accurate as possible.
When a biometric system rejects an authorized individual, it is called a Type I error (false rejection rate). When the system accepts impostors who should be rejected, it is called a Type II error (false acceptance rate). The goal is to obtain low numbers for each type of error, but Type II errors are the most dangerous and thus the most important to avoid.
When comparing different biometric systems, many different variables are used, but one of the most important metrics is the crossover error rate (CER). This rating is stated as a percentage and represents the point at which the false rejection rate equals the false acceptance rate. This rating is the most important measurement when determining the system’s accuracy. A biometric system that delivers a CER of 3 will be more accurate than a system that delivers a CER of 4.

What is the purpose of this CER value anyway? Using the CER as an impartial judgment of a biometric system helps create standards by which products from different vendors can be fairly judged and evaluated. If you are going to buy a biometric system, you need a way to compare the accuracy between different systems. You can just go by the different vendors’ marketing material (they all say they are the best), or you can compare the different CER values of the products to see which one really is more accurate than the others. It is also a way to keep the vendors honest. One vendor may tell you, “We have absolutely no Type II errors.” This would mean that their product would not allow any imposters to be improperly authenticated. But what if you asked the vendor how many Type I errors their product had and she sheepishly replied, “We average around 90 percent of Type I errors.” That would mean that 90 percent of the authentication attempts would be rejected, which would negatively affect your employees’ productivity. So you can ask about their CER value, which represents when the Type I and Type II errors are equal, to give you a better understanding of the product’s overall accuracy.
Individual environments have specific security level requirements, which will dictate how many Type I and Type II errors are acceptable. For example, a military institution that is very concerned about confidentiality would be prepared to accept a certain number of Type I errors, but would absolutely not accept any false accepts (Type II errors). Because all biometric systems can be calibrated, if you lower the Type II error rate by adjusting the system’s sensitivity, it will result in an increase in Type I errors. The military institution would obviously calibrate the biometric system to lower the Type II errors to zero, but that would mean it would have to accept a higher rate of Type I errors.
Biometrics is the most expensive method of verifying a person’s identity, and it faces other barriers to becoming widely accepted. These include user acceptance, enrollment timeframe, and throughput. Many times, people are reluctant to let a machine read the pattern of their retina or scan the geometry of their hand. This lack of enthusiasm has slowed down the widespread use of biometric systems within our society. The enrollment phase requires an action to be performed several times to capture a clear and distinctive reference record. People are not particularly fond of expending this time and energy when they are used to just picking a password and quickly typing it into their console. When a person attempts to be authenticated by a biometric system, sometimes the system will request an action to be completed several times. If the system was unable to get a clear reading of an iris scan or could not capture a full voice verification print, the individual may have to repeat the action. This causes low throughput, stretches the individual’s patience, and reduces acceptability.
During enrollment, the user provides the biometric data (fingerprint, voice print) and the biometric reader converts this data into binary values. Depending on the system, the reader may create a hash value of the biometric data, or it may encrypt the data, or do both. The biometric data then goes from the reader to a back-end authentication database where her user account has been created. When the user needs to later authenticate to a system, she will provide the necessary biometric data (fingerprint, voice print) and the binary format of this information is compared to what is in the authentication database. If they match, then the user is authenticated.
In Figure 4-7, we see that biometric data can be stored on a smart card and used for authentication. Also, you might notice that the match is 95 percent instead of 100 percent. Obtaining a 100 percent match each and every time is very difficult because of the level of sensitivity of the biometric systems. A smudge on the reader, oil on the person’s finger, and other small environmental issues can stand in the way of matching 100 percent. If your biometric system was calibrated so it required 100 percent matches, this would mean you would not allow any Type II errors and that users would commonly not be authenticated in a timely manner.
Figure 4-7. Biometric data is turned into binary data and compared for identity validation.

Processing SpeedWhen reviewing biometric devices for purchase, one component to take into consideration is the length of time it takes to actually authenticate users. From the time a user inserts data until she receives an accept or reject response should take five to ten seconds. |
The following is an overview of the different types of biometric systems and the physiological or behavioral characteristics they examine.
Fingerprint
Fingerprints are made up of ridge endings and bifurcations exhibited by friction ridges and other detailed characteristics called minutiae. It is the distinctiveness of these minutiae that gives each individual a unique fingerprint. An individual places his finger on a device that reads the details of the fingerprint and compares this to a reference file. If the two match, the individual’s identity has been verified.
Note

| Fingerprint systems store the full fingerprint, which is actually a lot of information that takes up hard drive space and resources. The finger-scan technology extracts specific features from the fingerprint and stores just that information, which takes up less hard drive space and allows for quicker database lookups and comparisons. |
Palm Scan
The palm holds a wealth of information and has many aspects that are used to identify an individual. The palm has creases, ridges, and grooves throughout that are unique to a specific person. The palm scan also includes the fingerprints of each finger. An individual places his hand on the biometric device, which scans and captures this information. This information is compared to a reference file and the identity is either verified or rejected.
Hand Geometry
The shape of a person’s hand (the length and width of the hand and fingers) defines hand geometry. This trait differs significantly between people and is used in some biometric systems to verify identity. A person places her hand on a device that has grooves for each finger. The system compares the geometry of each finger, and the hand as a whole, to the information in a reference file to verify that person’s identity.
Retina Scan
A system that reads a person’s retina scans the blood-vessel pattern of the retina on the backside of the eyeball. This pattern has shown to be extremely unique between different people. A camera is used to project a beam inside the eye and capture the pattern and compare it to a reference file recorded previously.
Iris Scan
The iris is the colored portion of the eye that surrounds the pupil. The iris has unique patterns, rifts, colors, rings, coronas, and furrows. The uniqueness of each of these characteristics within the iris is captured by a camera and compared with the information gathered during the enrollment phase. Of the biometric systems, iris scans are the most accurate. The iris remains constant through adulthood, which reduces the type of errors that can happen during the authentication process. Sampling the iris offers more reference coordinates than any other type of biometric. Mathematically, this means it has a higher accuracy potential than any other type of biometric.
Note

| When using an iris pattern biometric system, the optical unit must be positioned so the sun does not shine into the aperture; thus, when implemented, it must have proper placement within the facility. |
Signature Dynamics
When a person signs a signature, usually they do so in the same manner and speed each time. Signing a signature produces electrical signals that can be captured by a biometric system. The physical motions performed when someone is signing a document create these electrical signals. The signals provide unique characteristics that can be used to distinguish one individual from another. Signature dynamics provides more information than a static signature, so there are more variables to verify when confirming an individual’s identity and more assurance that this person is who he claims to be.
Signature dynamics is different from a digitized signature. A digitized signature is just an electronic copy of someone’s signature and is not a biometric system that captures the speed of signing, the way the person holds the pen, and the pressure the signer exerts to generate the signature.
Keyboard Dynamics
Whereas signature dynamics is a method that captures the electrical signals when a person signs a name, keyboard dynamics captures electrical signals when a person types a certain phrase. As a person types a specified phrase, the biometric system captures the speed and motions of this action. Each individual has a certain style and speed, which translate into unique signals. This type of authentication is more effective than typing in a password, because a password is easily obtainable. It is much harder to repeat a person’s typing style than it is to acquire a password.
Voice Print
People’s speech sounds and patterns have many subtle distinguishing differences. A biometric system that is programmed to capture a voice print and compare it to the information held in a reference file can differentiate one individual from another. During the enrollment process, an individual is asked to say several different words. Later, when this individual needs to be authenticated, the biometric system jumbles these words and presents them to the individual. The individual then repeats the sequence of words given. This technique is used so others cannot attempt to record the session and play it back in hopes of obtaining unauthorized access.
Facial Scan
A system that scans a person’s face takes many attributes and characteristics into account. People have different bone structures, nose ridges, eye widths, forehead sizes, and chin shapes. These are all captured during a facial scan and compared to an earlier captured scan held within a reference record. If the information is a match, the person is positively identified.
Hand Topography
Whereas hand geometry looks at the size and width of an individual’s hand and fingers, hand topology looks at the different peaks and valleys of the hand, along with its overall shape and curvature. When an individual wants to be authenticated, she places her hand on the system. Off to one side of the system, a camera snaps a side-view picture of the hand from a different view and angle than that of systems that target hand geometry, and thus captures different data. This attribute is not unique enough to authenticate individuals by itself and is commonly used in conjunction with hand geometry.
Biometrics are not without their own sets of issues and concerns. Because they depend upon the specific and unique traits of living things there can be problems that arise. Living things are notorious for not remaining the same, which means they won’t present static biometric information for each and every login attempt. Voice recognition can be hampered by a user with a cold. Pregnancy can change the patterns of the retina. Someone could lose a finger. Or all three could happen. You just never know in this crazy world.
Some biometric systems actually check for the pulsation and/or heat of a body part to make sure it is alive. So if you are planning to cut someone’s finger off or pluck out someone’s eyeball so you can authenticate yourself as a legitimate user, it may not work. Although not specifically stated, I am pretty sure this type of activity falls outside the bounds of the CISSP ethics you will be responsible for upholding once you receive your certification.
References
Michigan State University Biometrics Research web site biometrics.cse.msu.edu
The Biometric Consortium home page www.biometrics.org
Passwords
User identification coupled with a reusable password is the most common form of system identification and authorization mechanisms. A password is a protected string of characters that is used to authenticate an individual. As stated previously, authentication factors are based on what a person knows, has, or is. A password is something the user knows.
Passwords are one of the most often used authentication mechanisms employed today. It is important the passwords are strong and properly managed.
Password Management
Although passwords are the most commonly used authentication mechanisms, they are also considered one of the weakest security mechanisms available. Why? Users usually choose passwords that are easily guessed (a spouse’s name, a user’s birth date, or a dog’s name), or tell others their passwords, and many times write the passwords down on a sticky note and cleverly hide it under the keyboard. To most users, security is usually not the most important or interesting part of using their computers—except when someone hacks into their computer and steals confidential information, that is. Then security is all the rage.
This is where password management steps in. If passwords are properly generated, updated, and kept secret, they can provide effective security. Password generators can be used to create passwords for users. This ensures that a user will not be using “Bob” or “Spot” for a password, but if the generator spits out “kdjasijew284802h,” the user will surely scribble it down on a piece of paper and safely stick it to the monitor, which defeats the whole purpose. If a password generator is going to be used, the tools should create uncomplicated, pronounceable, nondictionary words to help users remember them so they aren’t tempted to write them down.
If the users can choose their own passwords, the operating system should enforce certain password requirements. The operating system can require that a password contain a certain number of characters, unrelated to the user ID, include special characters, include upper- and lowercase letters, and not be easily guessable. The operating system can keep track of the passwords a specific user generates so as to ensure no passwords are reused. The users should also be forced to change their passwords periodically. All of these factors make it harder for an attacker to guess or obtain passwords within the environment.
If an attacker is after a password, she can try a few different techniques:
Electronic monitoring Listening to network traffic to capture information, especially when a user is sending her password to an authentication server. The password can be copied and reused by the attacker at another time, which is called a replay attack.
Access the password file Usually done on the authentication server. The password file contains many users’ passwords and, if compromised, can be the source of a lot of damage. This file should be protected with access control mechanisms and encryption.
Brute force attacks Performed with tools that cycle through many possible character, number, and symbol combinations to uncover a password.
Dictionary attacks Files of thousands of words are compared to the user’s password until a match is found.
Social engineering An attacker falsely convinces an individual that she has the necessary authorization to access specific resources.
Rainbow tables An attacker uses a table that contains all possible passwords already in a hash format.
Certain techniques can be implemented to provide another layer of security for passwords and their use. After each successful logon, a message can be presented to a user indicating the date and time of the last successful logon, the location of this logon, and whether there were any unsuccessful logon attempts. This alerts the user to any suspicious activity, and whether anyone has attempted to log on using his credentials. An administrator can set operating parameters that allow a certain number of failed logon attempts to be accepted before a user is locked out; this is a type of clipping level. The user can be locked out for five minutes or a full day after the threshold (or clipping level) has been exceeded. It depends on how the administrator configures this mechanism. An audit trail can also be used to track password usage and both successful and unsuccessful logon attempts. This audit information should include the date, time, user ID, and workstation the user logged in from.
A password’s lifetime should be short but practical. Forcing a user to change a password on a more frequent basis provides more assurance that the password will not be guessed by an intruder. If the lifetime is too short, however, it causes unnecessary management overhead and users may forget which password is active. A balance between protection and practicality must be decided upon and enforced.
As with many things in life, education is the key. Password requirements, protection, and generation should be addressed in security-awareness programs so users understand what is expected of them, why they should protect their passwords, and how passwords can be stolen. Users should be an extension to a security team, not the opposition.
Note

| Rainbow tables contain passwords already in their hashed format. The attacker just compares a captured hashed password with one that is listed in the table to uncover the plaintext password. This takes much less time than carrying out a dictionary or brute force attack. |
Password Checkers
Several organizations test user-chosen passwords using tools that perform dictionary and/or brute force attacks to detect the weak passwords. This helps make the environment as a whole less susceptible to dictionary and exhaustive attacks used to discover users’ passwords. Many times the same tools employed by an attacker to crack a password are used by a network administrator to make sure the password is strong enough. Most security tools have this dual nature. They are used by security professionals and IT staff to test for vulnerabilities within their environment in the hope of uncovering and fixing them before an attacker finds the vulnerabilities. An attacker uses the same tools to uncover vulnerabilities to exploit before the security professional can fix them. It is the never-ending cat-and-mouse game.
If a tool is called a password checker, it is a tool used by a security professional to test the strength of a password. If a tool is called a password cracker, it is usually used by a hacker; however, most of the time, these tools are one and the same.
You need to obtain management’s approval before attempting to test (break) employees’ passwords with the intent of identifying weak passwords. Explaining you are trying to help the situation, not hurt it, after you have uncovered the CEO’s password is not a good situation to be in.
Password Hashing and Encryption
In most situations, if an attacker sniffs your password from the network wire, she still has some work to do before she actually knows your password value, because most systems hash the password with a hashing algorithm, commonly MD4 or MD5, to ensure passwords are not sent in cleartext.
In a Windows environment, the passwords are stored in a Security Accounts Management (SAM) database in their hashed version. For extra protection, administrators can use the Syskey utility, which encrypts the database that stores the passwords with a locally stored system key. Syskey can work in three modes, each one increasing the protection provided:
Mode 1 A system key is generated, encrypted, and stored locally. The computer can restart and work normally with no user interaction.
Mode 2 A system key is generated, encrypted, and stored locally, but is password protected. When the computer restarts, the administrator must enter the password to “unlock Syskey,” and this password is not stored locally.
Mode 3 A system key is generated, encrypted, and stored on a floppy disk or CD-ROM. The computer cannot start up properly without a user providing the floppy disk.
Although some people think the world is run by Microsoft, other types of operating systems are out there, such as Unix and Linux. These systems do not use registries and SAM databases, but contain their user passwords in a file cleverly called passwd. Now, this passwd file does not contain passwords in cleartext; instead, your password is run through a hashing algorithm, and the resulting value is stored in this file. Unix-type systems zest things up by using salts in this process. Salts are random values added to the encryption process to add more complexity. The more randomness entered into the encryption process, the harder it is for the bad guy to decrypt and uncover your password. The use of a salt means that the same password can be encrypted into 4096 different formats, which makes it much more difficult for an attacker to uncover the right format for your system.
Password Aging
Many systems enable administrators to set expiration dates for passwords, forcing users to change them at regular intervals. The system may also keep a list of the last five to ten passwords (password history) and not let the users revert back to previously used passwords.
Limit Logon Attempts
A threshold can be set to allow only a certain number of unsuccessful logon attempts. After the threshold is met, the user’s account can be locked for a period of time or indefinitely, which requires an administrator to manually unlock the account. This protects against dictionary and other exhaustive attacks that continually submit credentials until the right combination of username and password is discovered.
Cognitive Password
What is your mother’s name?
Response: Shucks, I don’t remember. I have it written down somewhere.
Cognitive passwords are fact- or opinion-based information used to verify an individual’s identity. A user is enrolled by answering several questions based on her life experiences. Passwords can be hard for people to remember, but that same person will not likely forget her mother’s maiden name, favorite color, dog’s name, or the school she graduated from. After the enrollment process, the user can answer the questions asked of her to be authenticated, instead of having to remember a password. This authentication process is best for a service the user does not use on a daily basis because it takes longer than other authentication mechanisms. This can work well for help-desk services. The user can be authenticated via cognitive means. This way, the person at the help desk can be sure he is talking to the right person, and the user in need of help does not need to remember a password that may be used once every three months.
One-Time Password
A one-time password is also called a dynamic password. It is used for authentication purposes and is only good once. After the password is used, it is no longer valid; thus, if a hacker obtained this password, it could not be reused. This type of authentication mechanism is used in environments that require a higher level of security than static passwords provide. One-time password generating tokens come in two general types: synchronous and asynchronous. The token device generates the one-time password for the user to submit to an authentication server. The following sections explain these concepts.
The Token Device
The token device, or password generator, is usually a handheld device that has an LCD display and possibly a keypad. This hardware is separate from the computer the user is attempting to access. The token device and authentication service must be synchronized in some manner to be able to authenticate a user. The token device presents the user with a list of characters to be entered as a password when logging on to a computer. Only the token device and authentication service know the meaning of these characters. Because the two are synchronized, the token device will present the exact password the authentication service is expecting. This is a one-time password, also called a token, and is no longer valid after initial use.
SecureIDSecureID, from RSA Security, Inc., is one of the most widely used time-based tokens. One version of the product generates the one-time password by using a mathematical function on the time, date, and ID of the token card. Another version of the product requires a PIN to be entered into the token device. 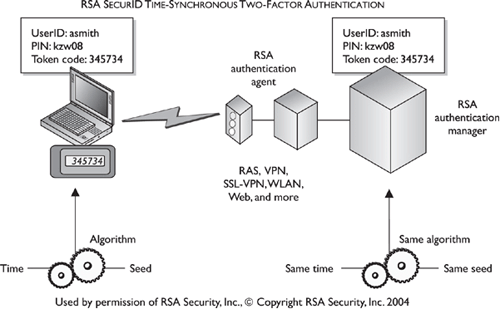
|
Synchronous
A synchronous token device synchronizes with the authentication service by using time or a counter as the core piece of the authentication process. If the synchronization is time-based, the token device and the authentication service must hold the same time within their internal clocks. The time value on the token device and a secret key are used to create the one-time password, which is displayed to the user. The user enters this value and a user ID into the computer, which then passes them to the server running the authentication service. The authentication service decrypts this value and compares it to the value it expected. If the two match, the user is authenticated and allowed to use the computer and resources.
If the token device and authentication service use counter-synchronization, the user will need to initiate the creation of the one-time password by pushing a button on the token device. This causes the token device and the authentication service to advance to the next authentication value. This value and a base secret are hashed and displayed to the user. The user enters this resulting value along with a user ID to be authenticated. In either time- or counter-based synchronization, the token device and authentication service must share the same secret base key used for encryption and decryption.
Asynchronous
A token device using an asynchronous token–generating method employs a challenge/response scheme to authenticate the user. In this situation, the authentication server sends the user a challenge, a random value also called a nonce. The user enters this random value into the token device, which encrypts it and returns a value the user uses as a one-time password. The user sends this value, along with a user-name, to the authentication server. If the authentication server can decrypt the value and it is the same challenge value sent earlier, the user is authenticated, as shown in Figure 4-8.
Figure 4-8. Authentication using an asynchronous token device includes a workstation, token device, and authentication service.

Note

| The actual implementation and process that these devices follow can differ between different vendors. What is important to know is that asynchronous is based on challenge/response mechanisms, while synchronous is based on time-or counter-driven mechanisms. |
Both token systems can fall prey to masquerading if a user shares his identification information (ID or username) and the token device is shared or stolen. The token device can also have battery failure or other malfunctions that would stand in the way of a successful authentication. However, this type of system is not vulnerable to electronic eavesdropping, sniffing, or password guessing.
If the user has to enter a password or PIN into the token device before it provides a one-time password, then strong authentication is in effect because it is using two factors—something the user knows (PIN) and something the user has (the token device).
Note

| One-time passwords can also be generated in software, in which case a piece of hardware such as a token device is not required. These are referred to as soft tokens and require that the authentication service and application contain the same base secrets, which are used to generate the one-time passwords. |
References
RFC 2289 - A One-Time Password System www.faqs.org/rfcs/rfc2289.html
RFC 2444 - The One-Time-Password SASL Mechanism www.faqs.org/rfcs/rfc2444.html
One-Time Password http://en.wikipedia.org/wiki/One-time_password
RSA SecureID Authentication home page www.rsasecurity.com/node.asp?id=1156
Cryptographic Keys
Another way to prove one’s identity is to use a private key by generating a digital signature. A digital signature could be used in place of a password. Passwords are the weakest form of authentication and can be easily sniffed as they travel over a network. Digital signatures are forms of authentication used in environments that require higher security protection than what is provided by passwords.
A private key is a secret value that should be in the possession of one person, and one person only. It should never be disclosed to an outside party. A digital signature is a technology that uses a private key to encrypt a hash value (message digest). The act of encrypting this hash value with a private key is called digitally signing a message. A digital signature attached to a message proves the message originated from a specific source, and that the message itself was not changed while in transit.
A public key can be made available to anyone without compromising the associated private key; this is why it is called a public key. We explore private keys, public keys, digital signatures, and public key infrastructure (PKI) in Chapter 8, but for now, understand that a private key and digital signatures are other mechanisms that can be used to authenticate an individual.
Passphrase
A passphrase is a sequence of characters that is longer than a password (thus a “phrase”) and, in some cases, takes the place of a password during an authentication process. The user enters this phrase into an application and the application transforms the value into a virtual password, making the passphrase the length and format that is required by the application. (For example, an application may require your virtual password to be 128 bits to be used as a key with the AES algorithm.) If a user wants to authenticate to an application, such as Pretty Good Privacy (PGP), he types in a passphrase, let’s say StickWithMeKidAndYouWillWearDiamonds. The application converts this phrase into a virtual password that is used for the actual authentication. The user usually generates the passphrase in the same way a user creates a password the first time he logs on to a computer. A passphrase is more secure than a password because it is longer, and thus harder to obtain by an attacker. In many cases, the user is more likely to remember a passphrase than a password.
Memory Cards
The main difference between memory cards and smart cards is their capacity to process information. A memory card holds information but cannot process information. A smart card holds information and has the necessary hardware and software to actually process that information. A memory card can hold a user’s authentication information so the user only needs to type in a user ID or PIN and present the memory card, and if the data that the user entered matches the data on the memory card, the user is successfully authenticated. If the user presents a PIN value, then this is an example of two-factor authentication—something the user knows, and something the user has. A memory card can also hold identification data that are pulled from the memory card by a reader. It travels with the PIN to a back-end authentication server. An example of a memory card is a swipe card that must be used for an individual to be able to enter a building. The user enters a PIN and swipes the memory card through a card reader. If this is the correct combination, the reader flashes green and the individual can open the door and enter the building. Another example is an ATM card. If Buffy wants to withdraw $40 from her checking account, she needs to enter the correct PIN and slide the ATM card (or memory card) through the reader.
Memory cards can be used with computers, but they require a reader to process the information. The reader adds cost to the process, especially when one is needed per computer, and card generation adds additional cost and effort to the whole authentication process. Using a memory card provides a more secure authentication method than using a password because the attacker would need to obtain the card and know the correct PIN. Administrators and management must weigh the costs and benefits of a memory token–based card implementation to determine if it is the right authentication mechanism for their environment.
Smart Card
My smart card is smarter than your memory card.
A smart card has the capability of processing information because it has a microprocessor and integrated circuits incorporated into the card itself. Memory cards do not have this type of hardware and lack this type of functionality. The only function they can perform is simple storage. A smart card, which adds the capability to process information stored on it, can also provide a two-factor authentication method because the user may have to enter a PIN to unlock the smart card. This means the user must provide something she knows (PIN) and something she has (smart card).
Two general categories of smart cards are the contact and the contactless types. The contact smart card has a gold seal on the face of the card. When this card is fully inserted into a card reader, electrical fingers wipe against the card in the exact position that the chip contacts are located. This will supply power and data I/O to the chip for authentication purposes. The contactless smart card has an antenna wire that surrounds the perimeter of the card. When this card comes within an electromagnetic field of the reader, the antenna within the card generates enough energy to power the internal chip. Now, the results of the smart card processing can be broadcast through the same antenna, and the conversation of authentication can take place. The authentication can be completed by using a one-time password, by employing a challenge/response value, or by providing the user’s private key if it is used within a PKI environment.

Note

| Two types of contactless smart cards are available: hybrid and combi. The hybrid card has two chips, with the capability of utilizing both the contact and contactless formats. A combi card has one microprocessor chip that can communicate to contact or contactless readers. |
The information held within the memory of a smart card is not readable until the correct PIN is entered. This fact and the complexity of the smart token make these cards resistant to reverse-engineering and tampering methods. If George loses the smart card he uses to authenticate to the domain at work, the person who finds the card would need to know his PIN to do any real damage. The smart card can also be programmed to store information in an encrypted fashion, as well as detect any tampering with the card itself. In the event that tampering is detected, the information stored on the smart card can be automatically wiped.
The drawbacks to using a smart card are the extra cost of the readers and the overhead of card generation, as with memory cards, although this cost is decreasing. The smart cards themselves are more expensive than memory cards because of the extra integrated circuits and microprocessor. Essentially, a smart card is a kind of computer, and because of that it has many of the operational challenges and risks that can affect a computer.
Smart cards have several different capabilities, and as the technology develops and memory capacities increase for storage, they will gain even more. They can store personal information in a storage manner that is tamper resistant. This also allows them to have the ability to isolate security-critical computations within themselves. They can be used in encryption systems in order to store keys and have a high level of portability as well as security. The memory and integrated circuit also allow for the capacity to use encryption algorithms on the actual card and use them for secure authorization that can be utilized throughout an entire organization.
Smart Card Attacks
Smart cards are more tamperproof than memory cards, but where there is sensitive data there are individuals who are motivated to circumvent any countermeasure the industry throws at them.
Over the years, people have become very inventive in the development of various ways to attack smart cards. For example, individuals have introduced computational errors into smart cards with the goal of uncovering the encryption keys used and stored on the cards. These “errors” are introduced by manipulating some environmental component of the card (changing input voltage, clock rate, temperature fluctuations). The attacker reviews the result of an encryption function after introducing an error to the card, and also reviews the correct result, which the card performs when no errors are introduced. Analysis of these different results may allow an attacker to reverse-engineer the encryption process, with the hope of uncovering the encryption key. This type of attack is referred to as fault generation.
Side-channel attacks are nonintrusive and are used to uncover sensitive information about how a component works, without trying to compromise any type of flaw or weakness. As an analogy, suppose you want to figure out what your boss does each day at lunch time but you feel too uncomfortable to ask her. So you follow her, and you see she enters a building holding a small black bag and exits exactly 45 minutes later with the same bag and her hair not looking as great as when she went in. You keep doing this day after day and come to the conclusion that she must be working out. Now you could have simply read the sign on the building that said “Gym,” but we will give you the benefit of the doubt here and just not call you for any further private investigator work.
So a noninvasive attack is one in which the attacker watches how something works and how it reacts in different situations instead of trying to “invade” it with more intrusive measures. Some examples of side-channel attacks that have been carried out on smart cards are differential power analysis (examining the power emissions released during processing), electromagnetic analysis (examining the frequencies emitted), and timing (how long a specific process takes to complete). These types of attacks are used to uncover sensitive information about how a component works without trying to compromise any type of flaw or weakness. They are commonly used for data collection. Attackers monitor and capture the analog characteristics of all supply and interface connections and any other electromagnetic radiation produced by the processor during normal operation. They can also collect the time it takes for the smart card to carry out its function. From the collected data, the attacker can deduce specific information she is after, which could be a private key, sensitive financial data, or an encryption key stored on the card.
InteroperabilityAn ISO/IEC standard, 14443, outlines the following items for smart card standardization:
|
In the industry today, lack of interoperability is a big problem. Although vendors claim to be “compliant with ISO/IEC 14443,” many have developed technologies and methods in a more proprietary fashion. The lack of true standardization has caused some large problems because smart cards are being used for so many different applications. In the United States, the DoD is rolling out smart cards across all of their agencies, and NIST is developing a framework and conformance testing programs specifically for interoperability issues.
Software attacks are also considered noninvasive attacks. A smart card has software just like any other device that does data processing, and anywhere there is software there is the possibility of software flaws that can be exploited. The main goal of this type of attack is to input instructions into the card that will allow the attacker to extract account information, which he can use to make fraudulent purchases. Many of these types of attacks can be disguised by using equipment that looks just like the legitimate reader.
If you would like to be more intrusive in your smart card attack, give microprobing a try. Microprobing uses needles and ultrasonic vibration to remove the outer protective material on the card’s circuits. Once this is completed, data can be accessed and manipulated by directly tapping into the card’s ROM chips.
References
NIST Smart Card Standards and Research web page http://smartcard.nist.gov/
Smart Card Alliance home page www.smartcardalliance.org
“Smart Cards: A Primer,” by Rinaldo Di Giorgio, JavaWorld (Dec. 1997) www.javaworld.com/javaworld/jw-12-1997/jw-12-javadev.html
“What Is a Smart Card?” HowStuffWorks.com http://electronics.howstuffworks.com/question332.htm
Authorization
Now that I know who you are, let’s see if I will let you do what you want.
Although authentication and authorization are quite different, together they comprise a two-step process that determines whether an individual is allowed to access a particular resource. In the first step, authentication, the individual must prove to the system that he is who he claims to be—a permitted system user. After successful authentication, the system must establish whether the user is authorized to access the particular resource and what actions he is permitted to perform on that resource.
Authorization is a core component of every operating system, but applications, security add-on packages, and resources themselves can also provide this functionality. For example, suppose Marge has been authenticated through the authentication server and now wants to view a spreadsheet that resides on a file server. When she finds this spreadsheet and double-clicks the icon, she will see an hourglass instead of a mouse pointer. At this stage, the file server is seeing if Marge has the rights and permissions to view the requested spreadsheet. It also checks to see if Marge can modify, delete, move, or copy the file. Once the file server searches through an access matrix and finds that Marge does indeed have the necessary rights to view this file, the file opens up on Marge’s desktop. The decision of whether or not to allow Marge to see this file was based on access criteria. Access criteria are the crux of authentication.
Access Criteria
You can perform that action only because we like you, and you wear a funny hat.
We have gone over the basics of access control. This subject can get very granular in its level of detail when it comes to dictating what a subject can or cannot do to an object or resource. This is a good thing for network administrators and security professionals, because they want to have as much control as possible over the resources they have been put in charge of protecting, and a fine level of detail enables them to give individuals just the precise level of access they need. It would be frustrating if access control permissions were based only on full control or no access. These choices are very limiting, and an administrator would end up giving everyone full control, which would provide no protection. Instead, different ways of limiting access to resources exist, and if they are understood and used properly, they can give just the right level of access desired.
Granting access rights to subjects should be based on the level of trust a company has in a subject and the subject’s need to know. Just because a company completely trusts Joyce with its files and resources does not mean she fulfills the need-to-know criteria to access the company’s tax returns and profit margins. If Maynard fulfills the need-to-know criteria to access employees’ work histories, it does not mean the company trusts him to access all of the company’s other files. These issues must be identified and integrated into the access criteria. The different access criteria can be enforced by roles, groups, location, time, and transaction types.
Using roles is an efficient way to assign rights to a type of user who performs a certain task. This role is based on a job assignment or function. If there is a position within a company for a person to audit transactions and audit logs, the role this person fills would only need a read function to those types of files. This role would not need full control, modify, or delete privileges.
Using groups is another effective way of assigning access control rights. If several users require the same type of access to information and resources, putting them into a group and then assigning rights and permissions to that group is easier to manage than assigning rights and permissions to each and every individual separately. If a specific printer is available only to the accounting group, when a user attempts to print to it, the group membership of the user will be checked to see if she is indeed in the accounting group. This is one way that access control is enforced through a logical access control mechanism.
Physical or logical location can also be used to restrict access to resources. Some files may be available only to users who can log on interactively to a computer. This means the user must be physically at the computer and enter the credentials locally versus logging on remotely from another computer. This restriction is implemented on several server configurations to restrict unauthorized individuals from being able to get in and reconfigure the server remotely.
Logical location restrictions are usually done through network address restrictions. If a network administrator wants to ensure that status requests of an intrusion detection management console are accepted only from certain computers on the network, the network administrator can configure this within the software.
Time of day, or temporal isolation, is another access control mechanism that can be used. If a security professional wants to ensure no one is accessing payroll files between the hours of 8:00 P.M. and 4:00 A.M., that configuration can be implemented to ensure access at these times is restricted. If the same security professional wants to ensure no bank account transactions happen during days on which the bank is not open, she can indicate in the logical access control mechanism this type of action is prohibited on Sundays.
Temporal access can also be based on the creation date of a resource. Let’s say Russell started working for his company in March of 2007. There may be a business need to allow Russell to only access files that have been created after this date and not before.
Transaction-type restrictions can be used to control what data is accessed during certain types of functions and what commands can be carried out on the data. An online banking program may allow a customer to view his account balance, but may not allow the customer to transfer money until he has a certain security level or access right. A bank teller may be able to cash checks of up to $2000, but would need a supervisor’s access code to retrieve more funds for a customer. A database administrator may be able to build a database for the human resources department, but may not be able to read certain confidential files within that database. These are all examples of transaction-type restrictions to control the access to data and resources.
Default to No Access
If you’re unsure, just say no.
Access control mechanisms should default to no access so as to provide the necessary level of security and ensure no security holes go unnoticed. A wide range of access levels is available to assign to individuals and groups, depending on the application and/or operating system. A user can have read, change, delete, full control, or no access permissions. The statement that security mechanisms should default to no access means that if nothing has been specifically configured for an individual or the group she belongs to, that user should not be able to access that resource. If access is not explicitly allowed, it should be implicitly denied. Security is all about being safe, and this is the safest approach to practice when dealing with access control methods and mechanisms. In other words, all access controls should be based on the concept of starting with zero access, and building on top of that. Instead of giving access to everything, and then taking away privileges based on need to know, the better approach is to start with nothing and add privileges based on need to know.
Authorization CreepI think Mike’s a creep. Let’s not give him any authorization to access company stuff. Response: Sounds like a great criterion. All creeps—no access. As employees work at a company over time and move from one department to another, they often are assigned more and more access rights and permissions. This is commonly referred to as authorization creep. It can be a large risk for a company, because too many users have too much privileged access to company assets. In the past, it has usually been easier for network administrators to give more access than less, because then the user would not come back and require more work to be done on her profile. It is also difficult to know the exact access levels different individuals require. This is why user management and user provisioning are becoming more prevalent in identity management products today and why companies are moving more towards role-based access control implementation. Enforcing least privilege on user accounts should be an ongoing job, which means each user’s rights are permissions that should be reviewed to ensure the company is not putting itself at risk. Note: Rights and permission reviews have been incorporated into many regulatory induced processes. As part of the SOX regulations, managers have to review their employees’ permissions to data on an annual basis. |
Most access control lists (ACLs) that work on routers and packet-filtering firewalls default to no access. Figure 4-9 shows that traffic from Subnet A is allowed to access Subnet B, traffic from Subnet D is not allowed to access Subnet A, and Subnet B is allowed to talk to Subnet A. All other traffic transmission paths not listed here are not allowed by default. Subnet D cannot talk to Subnet B because such access is not explicitly indicated in the router’s ACL.

Need to Know
If you need to know, I will tell you. If you don’t need to know, leave me alone.
The need-to-know principle is similar to the least-privilege principle. It is based on the concept that individuals should be given access only to the information they absolutely require in order to perform their job duties. Giving any more rights to a user just asks for headaches and the possibility of that user abusing the permissions assigned to him. An administrator wants to give a user the least amount of privileges she can, but just enough for that user to be productive when carrying out tasks. Management will decide what a user needs to know, or what access rights are necessary, and the administrator will configure the access control mechanisms to allow this user to have that level of access and no more, and thus the least privilege.
For example, if management has decided that Dan, the copy boy, needs to know where the files he needs to copy are located and needs to be able to print them, this fulfills Dan’s need-to-know criteria. Now, an administrator could give Dan full control of all the files he needs to copy, but that would not be practicing the least-privilege principle. The administrator should restrict Dan’s rights and permissions to only allow him to read and print the necessary files, and no more. Besides, if Dan accidentally deletes all the files on the whole file server, whom do you think management will hold ultimately responsible? Yep, the administrator.
It is important to understand that it is management’s job to determine the security requirements of individuals and how access is authorized. The security administrator configures the security mechanisms to fulfill these requirements, but it is not her job to determine security requirements of users. Those should be left to the owners. If there is a security breach, management will ultimately be held responsible, so it should make these decisions in the first place.
Single Sign-On
I only want to have to remember one username and one password for everything in the world!
Many times employees need to access many different computers, servers, databases, and other resources in the course of a day to complete their tasks. This often requires the employees to remember multiple user IDs and passwords for these different computers. In a utopia, a user would need to enter only one user ID and one password to be able to access all resources in all the networks this user is working in. In the real world, this is hard to accomplish for all system types.
Because of the proliferation of client/server technologies, networks have migrated from centrally controlled networks to heterogeneous, distributed environments. The propagation of open systems and the increased diversity of applications, platforms, and operating systems have caused the end user to have to remember several user IDs and passwords just to be able to access and use the different resources within his own network. Although the different IDs and passwords are supposed to provide a greater level of security, they often end up compromising security (because users write them down) and causing more effort and overhead for the staff that manages and maintains the network.
As any network staff member or administrator can attest to, too much time is devoted to resetting passwords for users who have forgotten them. More than one employee’s productivity is affected when forgotten passwords have to be reassigned. The network staff member who has to reset the password could be working on other tasks, and the user who forgot the password cannot complete his task until the network staff member is finished resetting the password. Many help-desk employees report that a majority of their time is spent on users forgetting their passwords. System administrators have to manage multiple user accounts on different platforms, which all need to be coordinated in a manner that maintains the integrity of the security policy. At times the complexity can be overwhelming, which results in poor access control management and the generation of many security vulnerabilities. A lot of time is spent on multiple passwords, and in the end they do not provide us with more security.
The increased cost of managing a diverse environment, security concerns, and user habits, coupled with the users’ overwhelming desire to remember one set of credentials, has brought about the idea of single sign-on (SSO) capabilities. These capabilities would allow a user to enter credentials one time and be able to access all resources in primary and secondary network domains. This reduces the amount of time users spend authenticating to resources and enables the administrator to streamline user accounts and better control access rights. It improves security by reducing the probability that users will write down passwords and also reduces the administrator’s time spent on adding and removing user accounts and modifying access permissions. If an administrator needs to disable or suspend a specific account, she can do it uniformly instead of having to alter configurations on each and every platform.
So that is our utopia: log on once and you are good to go. What bursts this bubble? Mainly interoperability issues. For SSO to actually work, every platform, application, and resource needs to accept the same type of credentials, in the same format, and interpret their meanings the same. When Steve logs on to his Windows XP workstation and gets authenticated by a mixed-mode Windows 2000 domain controller, it must authenticate him to the resources he needs to access on the Apple computer, the Unix server running NIS, the mainframe host server, the MICR print server, and the Windows XP computer in the secondary domain that has the plotter connected to it. A nice idea, until reality hits.
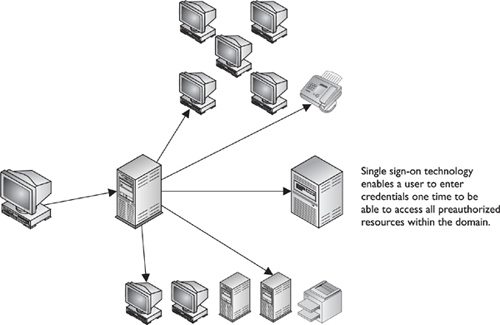
There is also a security issue to consider in an SSO environment. Once an individual is in, he is in. If an attacker was able to uncover one credential set, he would have There is also a security issue to consider in an SSO environment. Once an individual is in, he is in. If an attacker was able to uncover one credential set, he would have access to every resource within the environment that the compromised account has access to. This is certainly true, but one of the goals is that if a user only has to remember one password, and not ten, then a more robust password policy can be enforced. If the user has just one password to remember, then it can be more complicated and secure because he does not have nine other ones to remember also.
SSO technologies come in different types. Each has its own advantages and disadvantages, shortcomings, and quality features. It is rare to see a real SSO environment; rather, you will see a cluster of computers and resources that accept the same credentials. Other resources, however, still require more work by the administrator or user side to access the systems. The SSO technologies that may be addressed in the CISSP exam are described in the next sections.
Kerberos
Sam, there is a three-headed dog in front of the server!
Kerberos is the name of a three-headed dog that guards the entrance to the underworld in Greek mythology. This is a great name for a security technology that provides authentication functionality, with the purpose of protecting a company’s assets. Kerberos is an authentication protocol and was designed in the mid-1980s as part of MIT’s Project Athena. It works in a client/server model and is based on symmetric key cryptography. The protocol has been used for years in Unix systems and is currently the default authentication method for Windows 2000 and 2003 operating systems. Commercial products supporting Kerberos are becoming more frequent, so this one might be a keeper.
Kerberos is an example of a single sign-on system for distributed environments, and is a de facto standard for heterogeneous networks. Kerberos incorporates a wide range of security capabilities, which gives companies much more flexibility and scalability when they need to provide an encompassing security architecture. It has four elements necessary for enterprise access control: scalability, transparency, reliability, and security. However, this open architecture also invites interoperability issues. When vendors have a lot of freedom to customize a protocol, it usually means no two vendors will customize it in the same fashion. This creates interoperability and incompatibility issues.
Kerberos uses symmetric key cryptography and provides end-to-end security. Although it allows the use of passwords for authentication, it was designed specifically to eliminate the need to transmit passwords over the network. Most Kerberos implementations work with shared secret keys.
Main Components in Kerberos
The Key Distribution Center (KDC) is the most important component within a Kerberos environment. The KDC holds all users’ and services’ secret keys. It provides an authentication service, as well as key distribution functionality. The clients and services trust the integrity of the KDC, and this trust is the foundation of Kerberos security.
The KDC provides security services to principals, which can be users, applications, or network services. The KDC must have an account for, and share a secret key with, each principal. For users, a password is transformed into a secret key value. The secret key is used to send sensitive data back and forth between the principal and the KDC, and is used for user authentication purposes.
A ticket is generated by the ticket granting service (TGS) on the KDC and given to a principal when that principal, let’s say a user, needs to authenticate to another principal, let’s say a print server. The ticket enables one principal to authenticate to another principal. If Emily needs to use the print server, she must prove to the print server she is who she claims to be and that she is authorized to use the printing service. So Emily requests a ticket from the TGS. The TGS gives Emily the ticket, and in turn, Emily passes this ticket on to the print server. If the print server approves this ticket, Emily is allowed to use the print service.
A KDC provides security services for a set of principals. This set is called a realm in Kerberos. The KDC is the trusted authentication server for all users, applications, and services within a realm. One KDC can be responsible for one realm or several realms. Realms are used to allow an administrator to logically group resources and users.
So far, we know that principals (users and services) require the KDC’s services to authenticate to each other; that the KDC has a database filled with information about each and every principal within its realm; that the KDC holds and delivers cryptographic keys and tickets; and that tickets are used for principals to authenticate to each other. So how does this process work?
The Kerberos Authentication Process
The user and the KDC share a secret key, while the service and the KDC share a different secret key. The user and the requested service do not share a symmetric key in the beginning. The user trusts the KDC because they share a secret key. They can encrypt and decrypt data they pass between each other, and thus have a protected communication path. Once the user authenticates to the service, they too will share a symmetric key (session key) that will enable them to encrypt and decrypt the information they need to pass to each other. This is how Kerberos provides data transmission protection.
Here are the exact steps:
1. | Emily comes in to work and enters her username and password into her workstation at 8 A.M. |
2. | The Kerberos software on Emily’s computer sends the username to the authentication service (AS) on the KDC, which in turn sends Emily a ticket granting ticket (TGT) that is encrypted with Emily’s password (secret key). |
3. | If Emily has entered her correct password, then this TGT is decrypted and Emily gains access to her local workstation desktop. |
4. | When Emily needs to send a print job to the print server, her system sends the TGT to the ticket granting service (TGS), which runs on the KDC. (This allows Emily to prove she has been authenticated and allows her to request access to the print server.) |
5. | The TGS creates and sends a second ticket to Emily, which she will use to authenticate to the print server. This second ticket contains two instances of the same session key, one encrypted with Emily’s secret key and the other encrypted with the print server’s secret key. The second ticket also contains an authenticator, which contains identification information on Emily, her system’s IP address, sequence number, and a timestamp. |
6. | Emily’s system receives the second ticket, decrypts and extracts the session key, adds a second authenticator set of identification information to the ticket, and sends the ticket onto the print server. |
7. | The print server receives the ticket, decrypts and extracts the session key, and decrypts and extracts the two authenticators in the ticket. If the printer server can decrypt and extract the session key, it knows the KDC created the ticket, because only the KDC has the secret key used to encrypt the session key. If the authenticator information that the KDC and the user put into the ticket matches, then the print server knows it received the ticket from the correct principal. |
8. | Once this is completed, it means Emily has been properly authenticated to the print server and the server prints her document. |
This is an extremely simplistic overview of what is going on in any Kerberos exchange, but it gives you an idea of the dance taking place behind the scenes whenever you interact with any network service in an environment that uses Kerberos. Figure 4-10 provides a simplistic view of this process.
Figure 4-10. The user must receive a ticket from the KDC before being able to use the requested resource.

The authentication service is the part of the KDC that authenticates a principal, and the TGS is the part of the KDC that makes the tickets and hands them out to the principals. TGTs are used so the user does not have to enter his password each time he needs to communicate with another principal. After the user enters his password, it is temporarily stored on his system, and any time the user needs to communicate with another principal, he just reuses the TGT.
Be sure you understand that a session key is different from a secret key. A secret key is shared between the KDC and a principal and is static in nature. A session key is shared between two principals and is generated when needed and destroyed after the session is completed.
If a Kerberos implementation is configured to use an authenticator, the user sends to the printer server her identification information and a timestamp and sequence number encrypted with the session key they share. The printer server decrypts this information and compares it with the identification data the KDC sent to it about this requesting user. If the data is the same, the printer server allows the user to send print jobs. The timestamp is used to help fight against replay attacks. The printer server compares the sent timestamp with its own internal time, which helps determine if the ticket has been sniffed and copied by an attacker, and then submitted at a later time in hopes of impersonating the legitimate user and gaining unauthorized access. The printer server checks the sequence number to make sure that this ticket has not been submitted previously. This is another countermeasure to protect against replay attacks.
The primary reason to use Kerberos is that the principals do not trust each other enough to communicate directly. In our example, the print server will not print anyone’s print job without that entity authenticating itself. So none of the principals trust each other directly; they only trust the KDC. The KDC creates tickets to vouch for the individual principals when they need to communicate. Suppose I need to communicate directly with you, but you do not trust me enough to listen and accept what I am saying. If I first give you a ticket from something you do trust (KDC), this basically says, “Look, the KDC says I am a trustworthy person. The KDC asked me to give this ticket to you to prove it.” Once that happens, then you will communicate directly with me.
The same type of trust model is used in PKI environments. (More information on PKI is presented in Chapter 8.) In a PKI environment, users do not trust each other directly, but they all trust the certificate authority (CA). The CA vouches for the individuals’ identities by using digital certificates, the same as the KDC vouches for the individuals’ identities by using tickets.
So why are we talking about Kerberos? Because it is one example of a single sign-on technology. The user enters a user ID and password one time and one time only. The tickets have time limits on them that administrators can configure. Many times, the lifetime of a TGT is eight to ten hours, so when the user comes in the next day, he will have to present his credentials again.
Note

| Walking through these steps for the first time can be confusing. You can review a free animated overview of Kerberos at www.logicalsecurity.com/kerberos. |
Weaknesses of Kerberos
The following are some of the potential weaknesses of Kerberos:
The KDC can be a single point of failure. If the KDC goes down, no one can access needed resources. Redundancy is necessary for the KDC.
The KDC must be able to handle the number of requests it receives in a timely manner. It must be scalable.
Secret keys are temporarily stored on the users’ workstations, which means it is possible for an intruder to obtain these cryptographic keys.
Session keys are decrypted and reside on the users’ workstations, either in a cache or in a key table. Again, an intruder can capture these keys.
Kerberos is vulnerable to password guessing. The KDC does not know if a dictionary attack is taking place.
Network traffic is not protected by Kerberos if encryption is not enabled.
If the keys are too short, they can be vulnerable to brute force attacks.
Kerberos must be transparent (work in the background without the user needing to understand it), scalable (work in large, heterogeneous environments), reliable (use distributed server architecture to ensure there is no single point of failure), and secure (provide authentication and confidentiality).
References
Kerberos FAQ www.nrl.navy.mil/CCS/people/kenh/kerberos-faq.html
MIT Kerberos Papers and Documentation web page www.mit.edu/afs/athena.mit.edu/astaff/project/kerberos/www/papers.html
SESAME
The Secure European System for Applications in a Multi-vendor Environment (SESAME) project is a single sign-on technology developed to extend Kerberos functionality and improve upon its weaknesses. SESAME uses symmetric and asymmetric cryptographic techniques to authenticate subjects to network resources.
Note

| Kerberos is a strictly symmetric key–based technology, whereas SESAME is based on both asymmetric and symmetric key cryptography. |
Kerberos uses tickets to authenticate subjects to objects, whereas SESAME uses Privileged Attribute Certificates (PACs), which contain the subject’s identity, access capabilities for the object, access time period, and lifetime of the PAC. The PAC is digitally signed so the object can validate it came from the trusted authentication server, which is referred to as the Privileged Attribute Server (PAS). The PAS holds a similar role to that of the KDC within Kerberos. After a user successfully authenticates to the authentication service (AS), he is presented with a token to give to the PAS. The PAS then creates a PAC for the user to present to the resource he is trying to access. Figure 4-11 shows a basic overview of the SESAME process.

Note

| Kerberos and SESAME can be accessed through the Generic Security Services Application Programming Interface (GSS-API), which is a generic API for client-to-server authentication. Using standard APIs enables vendors to communicate with and use each other’s functionality and security. Kerberos Version 5 and SESAME implementations allow any application to use their authentication functionality as long as the application knows how to communicate via GSS-API. |
References
SESAME in a Nutshell www.cosic.esat.kuleuven.be/sesame/html/sesame_what.html
SESAME links www.cosic.esat.kuleuven.ac.be/sesame/html/sesame_links.html
Security Domains
I am highly trusted and have access to many resources.
Response: So what.
The term “domain” has been around a lot longer than Microsoft, but when people hear this term, they often think of a set of computers and devices on a network segment being controlled by a server that runs Microsoft software, referred to as a domain controller. A domain is really just a set of resources available to a subject. Remember that a subject can be a user, process, or application. Within an operating system, a process has a domain, which is the set of system resources available to the process to carry out its tasks. These resources can be memory segments, hard drive space, operating system services, and other processes. In a network environment, a domain is a set of physical and logical resources that is available, which can include routers, file servers, FTP service, web servers, and so forth.
The term security domain just builds upon the definition of domain by adding the fact that resources within this logical structure (domain) are working under the same security policy and managed by the same group. So, a network administrator may put all of the accounting personnel, computers, and network resources in Domain 1 and all of the management personnel, computers, and network resources in Domain 2. These items fall into these individual containers because they not only carry out similar types of business functions, but also, and more importantly, have the same type of trust level. It is this common trust level that allows entities to be managed by one single security policy.
The different domains are separated by logical boundaries, such as firewalls with ACLs, directory services making access decisions, and objects that have their own ACLs indicating which individuals and groups can carry out operations on them. All of these security mechanisms are examples of components that enforce the security policy for each domain.
Domains can be architected in a hierarchical manner that dictates the relationship between the different domains and the ways in which subjects within the different domains can communicate. Subjects can access resources in domains of equal or lower trust levels. Figure 4-12 shows an example of hierarchical network domains. Their communication channels are controlled by security agents (firewalls, router ACLs, directory services), and the individual domains are isolated by using specific subnet mask addresses.
Figure 4-12. Network domains are used to separate different network segments.

Remember that a domain does not necessarily pertain only to network devices and segmentations, but can also apply to users and processes. Figure 4-13 shows how users and processes can have more granular domains assigned to them individually based on their trust level. Group 1 has a high trust level and can access both a domain of its own trust level (Domain 1) and a domain of a lower trust level (Domain 2). User 1, who has a lower trust level, can access only the domain at his trust level and nothing higher. The system enforces these domains with access privileges and rights provided by the file system and operating system security kernel.
Figure 4-13. Subjects can access specific domains based on their trust levels.

So why are domains in the “Single Sign-On” section? Because several different types of technologies available today are used to define and enforce these domains and security policies mapped to them: domain controllers in a Windows environment, enterprise resource management (ERM) products, Microsoft Passport, and the various products that provide SSO functionality. The goal of each of them is to allow a user (subject) to sign in one time and be able to access the different domains available without having to reenter any other credentials.
References
Underlining Technical Models for Information Technology Security, Recommendations of the National Institute of Standards and Technology, by Gary Stoneburner, NIST Special Publication 800-33 (Dec. 2001) http://csrc.nist.gov/publications/nistpubs/800-33/sp800-33.pdf
“New Thinking About Information Technology Security,” by Marshall Abrams, PhD and Michael Joyce (first published in Computers & Security, Vol. 14, No. 1, pp. 57–68) www.acsac.org/secshelf/papers/new_thinking.pdf
Directory Services
A network service is a mechanism that identifies resources (printers, file servers, domain controllers, and peripheral devices) on a network. A network directory service contains information about these different resources, and the subjects that need to access them, and carries out access control activities. If the directory service is working in a database based on the X.500 standard, it works in hierarchical schema that outlines the resources’ attributes, such as name, logical and physical location, subjects that can access them, and the operations that can be carried out on them.
In a database based on the X.500 standard, access requests are made from users and other systems using the LDAP protocol. This type of database provides a hierarchical structure for the organization of objects (subjects and resources). The directory service develops unique distinguished names for each object and appends the corresponding attribute to each object as needed. The directory service enforces a security policy (configured by the administrator) to control how subjects and objects interact.
Network directory services provide users access to network resources transparently, meaning that users don’t need to know the exact location of the resources or the steps required to access them. The network directory services handle these issues for the user in the background. Some examples of directory services are Lightweight Directory Access Protocol (LDAP), Novell NetWare Directory Service (NDS), and Microsoft Active Directory (AD). Note: Directory services were also covered in the “Identity Management” section, earlier in this chapter.
Thin Clients
Hey, where’s my operating system?
Response: You don’t deserve one.
Diskless computers, sometimes thin clients, cannot store much information because of their lack of onboard storage space and necessary resources. This type of client/server technology forces users to log on to a central server just to use the computer and access network resources. When the user starts the computer, it runs a short list of instructions and then points itself to a server that will actually download the operating system, or interactive operating software, to the terminal. This enforces a strict type of access control, because the computer cannot do anything on its own until it authenticates to a centralized server, and then the server gives the computer its operating system, profile, and functionality. Thin-client technology provides another type of SSO access for users because users authenticate only to the central server or mainframe, which then provides them access to all authorized and necessary resources.
In addition to providing an SSO solution, a thin-client technology offers several other advantages. A company can save money by purchasing thin clients instead of powerful and expensive PCs. The central server handles all application execution, processing, and data storage. The thin client displays the graphical representation and sends mouse clicks and keystroke inputs to the central server. Having all of the software in one location, instead of distributed throughout the environment, allows for easier administration, centralized access control, easier updates, and standardized configurations. It is also easier to control malware infestations and the theft of confidential data because the thin clients often do not have CD-ROM, DVD, or USB ports.
Note

| The technology industry came from a centralized model, with the use of mainframes and dumb terminals, and is in some ways moving back towards this model with the use of terminal services, Citrix, Service Oriented Architecture, and so on. |
Examples of Single Sign-On Technologies
|