
Chapter 9. Error Handling Strategies
FAQ 9.01 Is error handling a major source of fundamental mistakes?
![]()
Yes.
Unfortunately, error handling is usually not considered during the design process in most systems, and instead it is allowed to evolve chaotically and in an ad hoc manner. Part of this is the old-dog-new-trick problem: many programmers' instincts about error handling are based on outdated technology, which tends to lead them in the wrong direction. The purpose of this chapter is to present a sound strategy for modern error handling.
A software application's error-handling strategy must be designed as carefully as the rest of the system. Without a careful design, error handling will be applied inconsistently and will create more problems than it solves. Typically, half of a system's code is dedicated to handling errors in one way or another, and systems that attempt to survive faults, as opposed to simply crashing, have even more to gain from good error-handling strategies.
FAQ 9.02 How should runtime errors be handled in C++?
![]()
Use C++ exceptions.
The purpose of the C++ exception-handling mechanism is to handle errors in software composed of independently developed components operating in a single process and under synchronous control.
In C++, a routine that cannot fulfill its promises should throw an exception. The caller that knows how to handle this unusual situation can catch the thrown exception. Callers can specify the types of exceptions they are willing to handle; exceptions that don't match the specified types are automatically propagated to the caller's caller. Thus intermediate callers (between the thrower and the catcher) can simply ignore the exception. Only the original thrower and the ultimate catcher need to know about the unusual situation.
This is illustrated in the following call graph. In the diagram, main() calls f(), which calls g(), and so forth. Typically these routines are member functions on objects, but they may also be non-member (“top-level”) functions. Eventually routine i() detects an erroneous situation such as an invalid parameter, an invalid return value from another object, an invalid entry in a file, a network outage, or insufficient memory, and i() throws an exception. The thrown exception is caught by f(), meaning control is transferred from i() to f(). Routines g(), h(), and i() are removed from the runtime stack and their local variables are destructed.
The effect is to separate policy from mechanism. Objects at low levels (such as i()) have the mechanism to detect and throw exceptions, and objects at higher levels, such as f(), specify the policy of how exceptions are to be handled.

FAQ 9.03 What happens to objects in stack frames that become unwound during the throw / catch process?
![]()
They are properly destructed.
Local objects that reside on the stack between the throw and the catch are properly destructed in stack order; last constructed, first destructed. The result is an extension of the C++ destructor discipline, and allocated resources can be safely kept in an object whose destructor releases the resource. This resource is often memory, but it could also be files that need to be closed, semaphores that need to be unlocked, and so on. For example, a local auto_ptr should be used to hold the pointer to an allocated object, as shown in FAQ 2.07.
FAQ 9.04 What is an exception specification?
![]()
A specification indicating which exception objects a function expects to throw.
For example, in FAQ 2.23, routine fileExists() is decorated with the specification throw(), indicating that fileExists() never throws any exceptions, and routine processFile() is decorated with the specification throw(BadfileName, FileNotFound), indicating that processFile() expects to throw BadFileName or FileNotFound (or some object derived from those classes) but nothing else.
If a function throws an exception other than those listed in the exception specification, the unexpected() function is called, which (by default) calls terminate(), which (by default) calls abort(). See FAQ 26.11 for how to change this default behavior.
In general, exception specifications should be used. One place where they are contraindicated, however, is where bug fixes for very large systems are shipped to customers in small binary pieces that are “patched” into the original binary. This is because exception specifications can unnecessarily increase the number of source files that must be shipped with such a bug fix. However for those systems that ship bug fixes as a complete executable, exception specifications should be used.
FAQ 9.05 What are the disadvantages of using return codes for error handling?
They don't separate exceptional logic from normal logic as well as exceptions do, they impose avoidable overhead, and they can't be used in constructors.
Return codes are a nice-guy approach; they allow the caller to do something when an error occurs but they don't require the caller to do anything or even notice that the error has occurred.
Return codes require an explicit if-check after every function call. This spreads the error-handling code into every caller of every function rather than focusing it on the relatively few routines that can actually correct the problem. Return codes therefore create a complex chain that is hard to test and maintain—everyone percolates the error information backward until finally someone is capable of handling it.
Since testing for return codes requires a conditional branch in the normal execution path, it imposes runtime costs for situations that rarely occur. When functions were hundreds of lines long, checking for return codes was a small percentage of the executable code. But with OO, where member functions often have less than ten lines of code, return codes would impose an unnecessary performance penalty.
Return codes can't be returned from constructors. Fortunately constructors can (and should) throw exceptions. So using return codes with constructors can be disastrous since return codes allow errors to remain uncorrected. For example, if a hash table can't allocate memory for its hash buckets, it might set an error flag within its object, hoping the caller will check this flag and do the right thing. Thus all the object's callers are expected to check this flag (presumably another member function that would have to be added), and all the object's member functions would also have to check the flag. This adds a lot of unnecessary decision logic as well as overhead.
FAQ 9.06 What are the advantages of throw...catch?
Clarity, compiler support, and runtime support.
The most important advantage is that throw...catch clearly separates normal logic from exception-handling logic. In contrast, when a function call uses return codes to signal exceptions, the caller must check the return code with control flow logic (if). This mingles normal logic with exception-handling logic, increasing the complexity of both paths.
A second advantage is that throw...catch can transmit an arbitrarily large amount of information from the throw point to the catch point. This is because C++ allows arbitrary objects, as opposed to just simple data types, to be thrown, and these objects can carry behavior as well as data from where the error is detected to where the error is handled. In contrast return codes are almost always simple data types such as int.
Also, throw...catch allows different error handlers to be defined for different types of objects and automatically transfers control to the correct error handler.
Finally, throw...catch is suited for OO programming. In contrast, return codes are ill suited for OO: since many member functions tend to be short, return codes would overwhelm the routine's normal logic with error-handling logic.
FAQ 9.07 Why is it helpful to separate normal logic from exception handling logic?
The program is easier to read because normal logic doesn't get lost in the error-handling code.
Consider the following Matrix class.

Suppose the goal is to create a routine that will add, subtract, multiply, and divide two matrices (assuming a suitable definition for matrix division). The routine is supposed to handle any overflow condition by printing a message to cout, but it is supposed to report any underflow condition back to the caller. Two solutions are presented here: the first uses C++ exceptions and the second uses return codes.
The following low-level routines that perform the arithmetic would be an ideal example for operator overloading, but in an effort to keep the two solutions as similar as possible, normal named functions are used instead. The header <stdexcept> declares the standard C++ exceptions overflow_error and underflow_error.
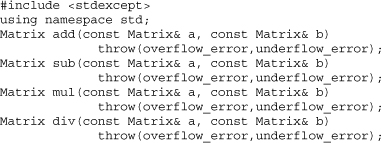
The routine that does the actual work, solutionA(), is defined as follows. As specified, the routine handles overflow errors by printing a message but doesn't handle underflow errors, instead (implicitly) passing the underflow exception back to its caller.

Now consider the same situation using return codes. First the four arithmetic routines are declared, as before. However, this time two separate return values are needed: the Matrix result and the return code that indicates whether there is an error. In this case the Matrix result is passed by reference and the return code is returned, but these could be reversed easily. The return code has three potential values: OK, OVERFLOW_ERROR, and UNDERFLOW_ERROR:

Up until this point the return code technique is not substantially more (or less) complex than the technique that uses C++ exceptions. However, the code that uses the arithmetic routines is much more complex when return codes are used. This routine needs to explicitly check the return code from each of the arithmetic calls. This tends to mix the normal logic with the error handling logic:


In this case, the normal algorithm gets lost in the code for error detection and error recovery.
FAQ 9.08 What is the hardest part of using exception handling?
![]()
Deciding what is an error and when an exception should be thrown.
One of the hardest parts of using exception handling is deciding when to throw an exception. Without proper guidelines, programmers spend endless hours discussing “Should this function throw an exception when X happens? What about when Y happens? Or how about when Z happens?” Often these discussions go in circles with no clear resolution. Usually this happens when the programmers have not been given any guidelines for deciding what is and is not an exception. Even worse are situations where exception handling is added to the system as an afterthought, usually just before it ships, and every programmer makes up and follows a unique set of ad hoc rules.
A useful guideline is “A function should throw an exception when anything occurs that prevents it from fulfilling its promises (a.k.a. its contract).” One advantage of this approach is that it ties exception handling to the functional specification of a class and its member functions—that is, it gives a rational basis for deciding what is and what is not an exception. Obviously this means that a function's promises must be clearly defined before a decision can be made about whether something is an error (see FAQ 6.04).
Another advantage of this approach is that it clearly separates errors—things that require an exception to be thrown—from unusual cases, which should not cause an exception to be thrown. The point is that a function should not throw an exception just because something unusual happens. Specifically, if a function detects a situation that happens rarely but that doesn't prohibit the function from fulfilling its promises, then it needs to handle the case and should not throw an exception.
Although it sounds trite, exception handling is for handling errors, not for handling unusual situations. For example, assume that one of the member functions of class Gardener is mowing the lawn.

Is it an error if mac the Gardener is asked to mow the lawn and the lawn mower runs out of gas? Or if the lawn mower breaks and cannot be fixed until a new part arrives? Or if mac has taken the day off because he is sick? Or if mac is too busy? Or if mac gets hit by lightning (a truly exceptional event)?
Ten different people will give ten different answers as to which, if any, of these are errors. The only way to be sure is to refer to the contract with mac. If the contract says that someone (not necessarily mac) will mow the lawn some time after a request is submitted, then none of the situations is an error, because mac or one of his heirs can eventually fulfill the contract. If the contract says the lawn will be mowed on the same day that the request is submitted, then running out of gas might not be an error, but mac's illness and a breakdown requiring overnight repairs are errors.
FAQ 9.09 When should a function throw an exception?
When it can't fulfill its promises.
When a function detects a problem that prevents it from fulfilling its promises, the function should throw an exception. If the function can recover from the problem so that it can still provide its user with the services it promised, then it has handled the problem and should not throw an exception.
Ideally, exceptions are rare in practice (less than 1% of the time). If an event happens much more frequently than this, perhaps it is not an error, and perhaps the exception-handling mechanism isn't the right choice.
In the following example, the gardener throws an exception if he cannot mow the lawn on the same day the user requests the lawn to be mowed. This occurs when the gardener's lawn mower runs out of gas after 5:00 P.M. (when the gas stations close).



FAQ 9.10 What is the best approach for the hierarchy of exception objects?
![]()
A monolithic hierarchy of exception classes works best.
Within the limited realm of exception classes, a singly rooted inheritance tree is superior to a forest of trees. This is an exception (pun intended) to the usual guideline that C++ class hierarchies should be a forest of trees.
One advantage of a monolithic hierarchy for exception classes is in catch-all situations. For example, main() often uses a try block that catches all possible exceptions. This catch-all block logs the uncaught exception and possibly restarts main(). This can be done via ellipses (catch (...)), but a monolithic hierarchy of exception classes allows main()'s catch clause to extract information from the exception object by means of member functions provided by the root class of the exception hierarchy. This allows a more detailed description of the unknown exception to be logged.
For example, suppose all exceptions are derived from the standard exception class called exception:

FAQ 9.11 How should exception classes be named?
Name the error, not the thrower.
The server should throw an exception whose class name describes the error that occurred rather than describing the code that detected the exception. In other words, the type of the exception object should embody the meaning of what went wrong.
For example, if a List class is asked to remove an element and the List is empty, the List should throw an exception such as EmptyContainer rather than an exception such as ListError.
The purpose of this advice is to enhance information hiding. For example, suppose class List is used to build class Queue; the EmptyContainer exception might be meaningful to users of Queue.
However, if List threw a ListError, users of Queue would become aware of the internal implementation details of Queue (that is, it uses a List). Since this could introduce a ripple effect (for example if the Queue found it more efficient to use a vector than to use a List, all the users of Queue might have to update their catch(ListError) blocks), the author of the Queue class would probably want to catch all these ListError exceptions and repackage them as something that doesn't expose the List detail, then throw that more generic object. So either the author of Queue has extra work to do or the users of Queue end up knowing too much about how Queue is implemented. Clearly it would have been easier if List had thrown something generic such as ContainerIsEmpty.
FAQ 9.12 Where do setjmp and longjmp belong in C++?
In your worst enemy's code.
Never use setjmp() and longjmp() in C++. Use try / catch / throw instead. The major problem with longjmp() is that it jumps out of the function without unwinding the stack, so local (auto) objects aren't destructed properly. In contrast, when C++ exceptions are used, local (auto) objects are properly destructed.