
9
Understanding Cloud Native Architectures
With this chapter, we are moving on to explore further aspects of Cloud Native in more detail. We will see which concepts are a part of Cloud Native and what is the architecture of Cloud Native, talk about resiliency and autoscaling, and get to know some of the best practices. This chapter covers further requirements of the Cloud Native Architecture domain of the Kubernetes and Cloud Native Associate (KCNA) exam, which makes up a total of 16% of questions.
This chapter has no practical part, so we won’t perform any hands-on exercises, but it is still very important to understand it in order to pass the KCNA exam and advance in the field. We will focus on the following topics:
- Cloud Native architectures
- Resiliency and autoscaling
- Serverless
- Cloud Native best practices
If you’ve skipped the first two chapters of the book and you find some terms discussed here unclear, please go back and read Chapters 1 and 2 to cover the gaps first.
Cloud Native architectures
In the first two chapters, we’ve already covered the definition of Cloud Native. Let’s check it one more time for a quick recap.
Cloud Native
This is an approach to building and running applications on modern, dynamic infrastructures such as clouds. It emphasizes application workloads with high resiliency, scalability, a high degree of automation, ease of management, and observability.
Yet, despite the presence of the word cloud, a Cloud Native application is not strictly required to run in the cloud. It’s an approach that can be followed when building and running applications also on-premises. And yes—you can also build resilient, scalable, highly automated applications on-premises that are Cloud Native, albeit not running in the cloud.
It is important to understand that simply picking a well-known public cloud provider and building on top of its service offerings (whether IaaS, PaaS, SaaS, or FaaS) does not mean your application automatically becomes Cloud Native. For example, if your application requires manual intervention to start then it cannot scale automatically, and it won’t be possible to restart it automatically in case of failure, so it’s not Cloud Native.
Another example: you have a web application consisting of a few microservices, but it is deployed and configured manually without any automation and thus cannot be easily updated. This is not a Cloud Native approach. If you forgot about microservices in the meantime, here is a definition one more time .
Microservices
These are small applications that work together as a part of a larger application or service. Each microservice could be responsible for a single feature of a big application and communicate with other microservices over the network. This is the opposite of monolithic applications, which bundle all functionality and logic in one big deployable piece (tightly coupled).
In practice, to implement a Cloud Native application, you’ll most likely turn to microservices. Microservices are loosely coupled, which makes it possible to scale, develop, and update them independently from each other. Microservices solve many problems but they also add operational overhead as their number grows, and that is why many of the Cloud Native technologies such as Kubernetes and Helm aim to make microservices easy to deploy, manage, and scale.
Again, strictly speaking, you are not required to run microservices managed by Kubernetes to have Cloud Native architecture. But this combination of containerized, small, loosely coupled applications orchestrated by Kubernetes works very well and paves the way toward Cloud Native. It is much, much easier to implement resiliency, autoscaling, controllable rolling updates, and observability with Kubernetes and containers than doing so with many virtual machines (VMs) and homegrown shell scripts. Kubernetes is also infrastructure-agnostic, which makes it very attractive for many environments and use cases. It can run on bare-metal servers, on VMs, in public and private clouds, and could be consumed as a managed service or run in a hybrid environment consisting of cloud resources and on-premises data centers.
Now, before diving deeper into some of the aspects, let’s see at a high level the benefits Cloud Native provides:
- Reduced time to market (TTM) – A high degree of automation and easy updates make it possible to deliver new Cloud Native application features rapidly, which offers a competitive advantage for many businesses.
- Cost efficiency – Cloud Native applications scale based on demand, which means paying only for resources required and eliminating waste.
- Higher reliability – Cloud Native applications can self-heal and automatically recover from failures. This means reduced system downtime, resulting in a better user experience.
- Scalability and flexibility – Microservices can be scaled, developed, and updated individually allowing us to handle various scenarios and provide more flexibility for development teams.
- No vendor lock-in – With the right approach and use of open source technologies, a Cloud Native application could be shifted between different infrastructures or cloud providers with minimum effort.
The list can be continued, but it should be enough to give you an idea of why most modern applications follow Cloud Native approaches and practices. Moving on, we will focus on some of the most important aspects of Cloud Native, such as resiliency and autoscaling.
Resiliency and autoscaling
As funny as it may sound, in order to design and build resilient systems, we need to expect things to fail and break apart. In other words, in order to engineer resilient systems, we need to engineer for failure and provide ways for applications and infrastructure to recover from failures automatically.
Resiliency
This characterizes an application and infrastructure that can automatically recover from failures. The ability to recover without manual intervention is often called self-healing.
We’ve already seen self-healing in action in Chapter 6 when Kubernetes detected that the desired state and the current state were different and quickly spawned additional application replicas. This is possible thanks to the Kubernetes reconciliation loop.
There are, of course, ways to build resilient applications and infrastructure without Kubernetes. For example, the Amazon Web Services (AWS) public cloud offers Autoscaling Groups, which allow you to run a desired number of VMs in a group or increase and decrease the number automatically based on the load. In case of VM failure, it will be detected and reacted upon with the creation of a new VM. In case CPU utilization in the group reaches a certain, pre-defined threshold, new VMs can be provisioned to share the load. And this brings us to another important concept: autoscaling.
Autoscaling
This is an ability to add or reduce computing resources automatically to meet the current demand.
Needless to say, different cloud providers offer many options for configuring autoscaling today. It can be based on various metrics and conditions, where CPU or RAM utilization are just common examples.
Previously, in the times of traditional IT, applications and infrastructure were designed to account for peak system usage, and this resulted in highly underutilized hardware and high running costs. Autoscaling has been a huge improvement, and it became one of the most important features of Cloud Native.
When we talk about autoscaling, it applies to both the application and the infrastructure it runs on, because scaling one without another won’t be sufficient. Let’s consider the following example to explain—you manage multiple microservice applications running in a Kubernetes cluster that under typical load require 10 worker nodes to operate. If additional worker nodes are created and joined into the K8s cluster, there won’t be any pods running on those new nodes until one of the following happens:
- The number of replicas of applications is increased so that new pods are created
- Some of the existing pods exit and get recreated by a controller (such as Deployment, StatefulSet, and so on)
That is because Kubernetes won’t reschedule already running pods when a new node joins the cluster. So, it would be required to increase the number of microservice replicas besides adding new nodes. Why won’t simply adding more replicas be enough? Doing so will eventually max out the CPU/RAM utilization and make Kubernetes nodes unresponsive as the payloads will be fighting for resources.
Scaling in general can also be distinguished into two types, as shown in Figure 9.1:
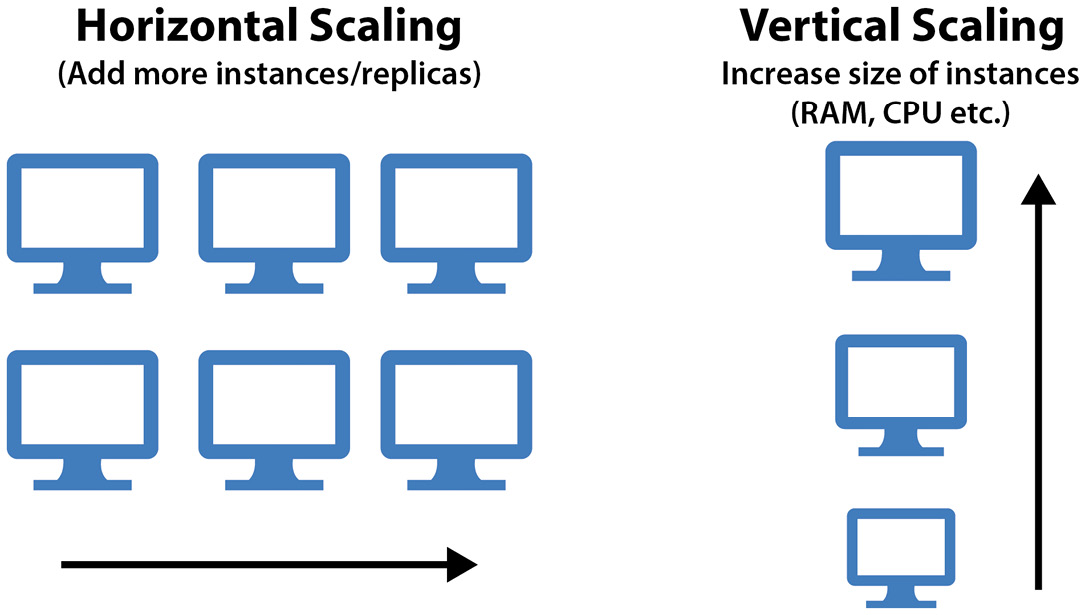
Figure 9.1 – Comparison of horizontal and vertical scaling
Let’s look at this in more detail:
- Horizontal—When we add or reduce the number of instances (VMs or nodes), as in the preceding example. Horizontal scaling is also known as scaling out (adding new VMs) and scaling in (terminating VMs).
- Vertical—When we keep the number of instances the same but change their configuration (such as the number of vCPUs, GB of RAM, size of the disks, and so on). Vertical scaling is also known as scaling up (adding CPU/RAM capacity) and scaling down (reducing CPU/RAM capacity).
To keep it simple, you can memorize horizontal autoscaling as an automatic increase (or decrease) in numbers and vertical autoscaling as an increase (or decrease) in size. Cloud Native microservice architectures commonly apply horizontal autoscaling, whereas old monolithic applications were scaled vertically most of the time. Vertical autoscaling is also more restricting because even the largest flavors of VMs and bare-metal servers available today cannot go beyond certain technological limits. Therefore, scaling horizontally is the preferred way.
From the previous chapters, we already know that we can change the number of Deployment replicas with Kubernetes in just one simple command; however, that is not automatic, but a manual scaling. Apart from that, there are three mechanisms in Kubernetes that allow us to implement automatic scaling:
- Horizontal Pod Autoscaler (HPA)—This updates the workload resource (such as Deployment, StatefulSet) to add more pods when the load goes up and removes pods when the load goes down to match demand. HPA requires configuration of lower and upper bounds of replicas (for example, 3 replicas minimum and 10 maximum).
- Vertical Pod Autoscaler (VPA)—This updates the workload resource requests and limits for containers (CPU, memory, huge page size). It can reduce requests and limits of containers over-requesting resources and scale up requests and limits for under-requesting workloads based on historical usage over time. VPA does not change the number of replicas like HPA does, as shown in Figure 9.2. VPA also optionally allows us to define minimum and maximum request boundaries.
- Cluster Autoscaler—This adjusts the size of the Kubernetes cluster by adding or removing worker nodes when either there are pods that fail to run due to insufficient resources or there are underutilized nodes for an extended period of time and their pods can be placed on other nodes in the cluster. It is recommendable to limit the maximum number of nodes in the cluster to protect against making the cluster too large. Cluster Autoscaler also requires integration with your cloud provider to operate:

Figure 9.2 – Comparison of Kubernetes HPA and VPA
Those mechanisms are especially powerful as they get combined. As you remember, we need to scale both application and the infrastructure where it runs, so using only HPA or only using Cluster Autoscaler won’t be sufficient. In fact, all three mechanisms can be used together, but this is a complex topic that you should not approach without getting enough K8s experience first. For the scope of KCNA, you only need to know what autoscaling is and which autoscaling mechanisms Kubernetes has to offer.
At the end of the day, autoscaling is a crucial part of Cloud Native that is required to strike a balance between workload performance and infrastructure size and costs.
Moving on, we are going to learn more about Serverless—an evolution of computing that gained adoption over the last years.
Serverless
In the very first chapter, we briefly touched on a definition of Serverless—a newer cloud delivery model that appeared around 2010 and is known as Function as a Service or FaaS.
Serverless
This is a computing model where code is written as small functions that are built and run without the need to manage any servers. Those functions are triggered by events (for example, the user clicked a button on the web page, uploaded a file, and so on).
Despite the name, the truth is that Serverless computing still relies on real hardware servers underneath. However, servers running the functions are completely abstracted away from the application development. In this model, the provider handles all operations that are required to run the code: provisioning, scaling, maintenance, security patching, and so on. Since you don’t need to take care of servers ever, the model is called Serverless.
Serverless brings in several advantages besides a lack of routine server operations. The development team can simply upload code to the Serverless platform, and once deployed, the application and infrastructure it runs on will be scaled automatically as needed based on demand.
When a Serverless function idles, most cloud providers won’t charge anything as with no events, there are no executions of the functions and thus no costs are incurred. If there are 10,000 events that trigger 10,000 function executions, then in most cases, their exact execution times will be billed by the provider. This is different from a typical pay-as-you-go VM in the cloud where you pay for all time the VM is running, regardless of the actual CPU/RAM utilization. A sample Serverless architecture is shown in Figure 9.3:

Figure 9.3 – Serverless architecture example
Note
An API Gateway is a part of Serverless that allows us to define endpoints for the REST API of an application and connect those endpoints with corresponding functions implementing the actual logic. API Gateway typically handles user authentication and access control and often provides additional features for observability.
It’s worth mentioning that many popular programming languages (Java, Golang, Python, and Ruby, to name a few) are supported by the cloud providers offering Serverless today, yet not all providers allow the use of our own container images. In fact, most public cloud providers offering Serverless today rely on their own proprietary technology. So, if you develop a Serverless application for AWS Lambda (the Serverless offering of AWS) then migrating it to Google Cloud Functions (the Serverless offering of Google Cloud) will require considerable effort.
Besides fully managed cloud Serverless platforms, there are a few open source alternatives available today that reduce the risk of vendor lock-in. For example, the following Serverless frameworks can be installed on top of Kubernetes with functions code packaged and run as containers:
- OpenFaaS
- CloudEvents
- Knative
- Fn
Knative and CloudEvents are currently curated Cloud Native Computing Foundation (CNCF) projects.
To wrap it up, FaaS can be seen as an evolution of cloud computing models (IaaS, PaaS, and SaaS) that fits well for Cloud Native architectures. While the Serverless market share is still growing, it has become apparent that it will not replace common VMs and managed platform offerings due to limitations that we briefly cover here:
- To persist data, Serverless applications must interact with other stateful components. So, unless you never need to keep the state, you’ll have to involve databases and other storage options.
- In most cases, there is little to no control over runtime configuration. For instance, you won’t be able to change OS or Java Virtual Machine (JVM) parameters when using FaaS offered by a cloud provider.
- Cold start—Initialization of container or infrastructure where the function code will execute takes some time (typically in the range of tens of seconds). If a particular function has not been invoked for a while, the next invocation will suffer from a cold-start delay. The way to go around it is to call the functions periodically to keep them pre-warmed.
- Monitoring, logging, and debugging Serverless applications is often harder. While you don’t need to take care of servers and metrics such as CPU or disk utilization, the ways to debug functions at runtime are limited. You won’t be able to run code line by line as you would do locally in an IDE.
- Risk of vendor lock-in. As already mentioned, FaaS offerings are not standardized, and thus migrating from one provider to another would require significant work.
The list is not exhaustive, but hopefully, it gives you an idea of why you should not necessarily rush your development team to move completely to Serverless. Both cloud provider and open source FaaS offerings have improved a lot in the recent years, so there is a chance that many of the limitations will be resolved in the near future.
Again, we are diving deeper here than required to pass KCNA. You’ll not be questioned about the limitations of Serverless, but you need to understand the concept of the billing model and be able to name a few projects that let you operate your own FaaS on top of Kubernetes.
In the last section of the chapter, we’re going to summarize some key points we’ve learned about Cloud Native.
Cloud Native best practices
As the world is changing fast, users get more and more demanding, and the IT landscape has to change in order to meet expectations. Today, not many people tolerate waiting for a web page to open if it takes 30 seconds and people complain if online banking is not working for a whole hour long.
Cloud Native has signified major improvements in the field by bringing a new approach to building and running applications. Cloud Native applications are designed to expect failures and automatically recover from most of them. A lot of focus is put on making both the application and the infrastructure resilient. This can be achieved in many ways with or without Kubernetes. If using Kubernetes, make sure to run multiple control plane and worker nodes spread across different failure domains such as your cloud provider availability zones (AZs). Always run at least two replicas (pods) of an application using a controller such as Deployment and make sure to spread them across the topology of your cluster. In the case of pod failure, the K8s reconciliation loop will kick in and self-heal the application.
Some companies have taken further steps to improve resiliency by introducing random failures across the infrastructure, allowing them to detect weak spots that need improvement or system redesign. For example, Netflix has become known for its Chaos Monkey tool that randomly terminates VMs and containers in order to incentivize engineers to build highly resilient services.
Next on the list is autoscaling—a crucial element for both performance and cost efficiency. Again, autoscaling must be implemented for both the application and the infrastructure. If running Kubernetes, make sure to set up at least HPA and Cluster Autoscaler. And don’t forget to configure resource requests and limits for all workloads, as it helps K8s to schedule pods in an optimal way.
When it comes to application architecture, apply the principle of loose coupling—develop microservices performing small tasks working together as a part of a larger application. Consider event-driven Serverless architecture if that fits your scenarios. In many cases, Serverless might be more cost-efficient and require almost zero operations.
When it comes to roles, we’ve already learned in Chapter 2 that organizations need to hire the right people for the job. This is not only about hiring DevOps and site reliability engineers to handle infrastructure, but it is also about team collaboration and corporate culture supporting constant change and experimentation. Learnings that come along provide valuable insights and lead to improvements in architecture and system design.
Furthermore, we briefly mentioned before that Cloud Native applications should feature a high degree of automation and ease of management. In Chapter 11, we’ll see in detail how automation helps shipping software faster and more reliably. And in the upcoming Chapter 10, we’ll discuss telemetry and observability.
Summary
In this chapter, we’ve learned about Cloud Native architectures, applications, and their features. Not every application that runs in the cloud automatically becomes Cloud Native. In fact, Cloud Native principles can be successfully applied also on-premises and not just in the cloud. We’ve briefly discussed the benefits of Cloud Native and in-depth about two core features—resiliency and autoscaling. While Cloud Native applications do not strictly require Kubernetes to run them, K8s makes things much easier with its self-healing capabilities and multiple autoscaling mechanisms: HPA, VPA, and Cluster Autoscaler.
Next, we covered Serverless or FaaS—a newer, event-driven computing model that comes with autoscaling and requires almost no operations at all. With Serverless, we are not responsible for any OS, security patching, or server life cycle. Serverless is also billed based on the actual usage calculated by the number of actual function invocations and the time they run. Serverless technologies can be leveraged to implement Cloud Native applications; however, be aware of their limitations.
Finally, we summarized the points about Cloud Native that we’ve learned in this chapter and previously, in Chapter 2. In the upcoming chapter, we will focus on monitoring Cloud Native applications and see how telemetry and observability can be implemented.
Questions
As we conclude, here is a list of questions for you to test your knowledge regarding this chapter’s material. You will find the answers in the Assessments section of the Appendix:
- Which of the following helps to get better resiliency with Kubernetes?
- Resource requests
- Multi-container pods
- Reconciliation loop
- Ingress controller
- Which of the following Kubernetes autoscalers allows us to automatically increase and decrease the number of pods based on the load?
- VPA
- HPA
- RPA
- Cluster Autoscaler
- Which of the following Kubernetes autoscalers adjusts container resource requests and limits based on statistical data?
- VPA
- HPA
- RPA
- Cluster Autoscaler
- Why is it important to downscale the application and infrastructure?
- To reduce the possible attack surface
- To avoid hitting cloud provider limits
- To reduce network traffic
- To reduce costs when computation resources are idling
- What best describes horizontal scaling?
- Adding more CPU to the same service instance
- Adding more replicas/instances of the same service
- Adding more RAM to the same service instance
- To schedule pods to different nodes where other pods already running
- Which scaling approach is preferred for Cloud Native applications?
- Cluster scaling
- Cloud scaling
- Vertical scaling
- Horizontal scaling
- Which of the following projects allow us to operate our own Serverless platform on Kubernetes (pick multiple)?
- KubeVirt
- KEDA
- Knative
- OpenFaaS
- What characterizes Serverless computing (pick multiple)?
- Servers are not needed anymore
- It supports all programming languages
- It is event-based
- The provider takes care of server management
- What is correct about scaling microservices?
- Individual microservices can be scaled in and out
- Only all microservices can be scaled in and out at once
- Microservices do not need to be scaled—only the infrastructure needs to be
- Microservices are best scaled up
- Which application design principle works best with Cloud Native?
- Self-healing
- Tight coupling
- Decoupling
- Loose coupling
- What describes a highly resilient application and infrastructure?
- Ability to automatically shut down in case of issues
- Ability to automatically recover from most failures
- Ability to preserve the state in case of failure
- Ability to perform rolling updates
- What represents the smallest part of a Serverless application?
- Gateway
- Method
- Container
- Function
- Which of the following is a correct statement about Serverless?
- It is only billed for the actual usage
- It is free as no servers are involved
- It is billed at a constant hourly price
- It is billed the same as IaaS services
- Which of the following features do Cloud Native applications have (pick multiple)?
- High scalability
- High efficiency
- High resiliency
- High portability
- What should normally be scaled in order to accommodate the load?
- The application and the infrastructure it runs on
- The load balancer and ingress
- The number of application pods
- The number of Kubernetes worker nodes
- Which resiliency testing tool can be used to randomly introduce failures in the infrastructure?
- Chaos Monster
- Chaos Kube
- Chaos Donkey
- Chaos Monkey
Further reading
To learn more about the topics that were covered in this chapter, take a look at the following resources:
- Autoscaling: https://glossary.cncf.io/auto-scaling/
- Kubernetes HPA walkthrough: https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
- Kubernetes Cluster Autoscaler: https://github.com/kubernetes/autoscaler
- Chaos Monkey: https://github.com/Netflix/chaosmonkey
- OpenFaaS: https://www.openfaas.com/
- Knative: https://knative.dev/docs/