
Chapter 10: Exporting, Batching, Bulking, and Loading
Manipulating large amounts of data requires serious skills (know-how and programming skills) in exporting, batching, bulking, and loading data. Each of these areas requires a significant amount of code and a lot of time to be implemented and tested against real datasets. Fortunately, jOOQ provides comprehensive APIs that cover all these operations and expose them in a fluent style, while hiding the implementation details. In this context, our agenda includes the following:
- Exporting data in text, JSON, XML, CSV, charts, and INSERT statements
- Batching INSERT, UPDATE, DELETE, MERGE, and Record
- Bulking queries
- Loading JSON, CSV, arrays, and Record
Let's get started!
Technical requirements
The code for this chapter can be found on GitHub at https://github.com/PacktPublishing/jOOQ-Masterclass/tree/master/Chapter10.
Exporting data
Exporting (or formatting) data is achievable via the org.jooq.Formattable API. jOOQ exposes a suite of format() and formatFoo() methods that can be used to format Result and Cursor (remember fetchLazy() from Chapter 8, Fetching and Mapping) as text, JSON, XML, CSV, XML, charts, and INSERT statements. As you can see in the documentation, all these methods come in different flavors capable of exporting data into a string or a file via the Java OutputStream or Writer APIs.
Exporting as text
I'm sure that you have already seen in your console output something similar to the following:
Figure 10.1 – Tabular text data
This textual tabular representation can be achieved via the format() method. A flavor of this method takes an integer argument representing the maximum number of records to include in the formatted result (by default, jOOQ logs just the first five records of the result formatted via jOOQ's text export, but we can easily format and log all the fetch records as result.format(result.size()). But, if you need a fine-tuning of this output, then jOOQ has a dedicated immutable class named TXTFormat with a lot of intuitive options available in the documentation. Using this class in conjunction with exporting the resulting text into a file named result.txt via format(Writer writer, TXTFormat format) can be done as shown in the following example:
try (BufferedWriter bw = Files.newBufferedWriter(
Paths.get("result.txt"), StandardCharsets.UTF_8, StandardOpenOption.CREATE_NEW, StandardOpenOption.WRITE)) {ctx.select(PRODUCTLINE.PRODUCT_LINE, PRODUCT.PRODUCT_ID,
PRODUCT.PRODUCT_NAME)
.from(PRODUCTLINE)
.join(PRODUCT).onKey()
.fetch()
.format(bw, new TXTFormat().maxRows(25).minColWidth(20));
} catch (IOException ex) { // handle exception }You can see this example in the bundled code, Format (available for MySQL and PostgreSQL), next to other examples.
Exporting JSON
Exporting Result/Cursor as JSON can be done via formatJSON() and its overloads. Without arguments, formatJSON() produces a JSON containing two main arrays: an array named "fields", representing a header (as you'll see later, this can be useful for importing the JSON into the database), and an array named "records", which wraps the fetched data. Here is such an output:
{"fields": [
{"schema": "public", "table": "productline", "name": "product_line", "type": "VARCHAR"},
{"schema": "public", "table": "product", "name": "product_id", "type": "BIGINT"},
{"schema": "public", "table": "product", "name": "product_name", "type": "VARCHAR"}
],
"records": [
["Vintage Cars", 80, "1936 Mercedes Benz 500k Roadster"],
["Vintage Cars", 29, "1932 Model A Ford J-Coupe"],
...
]
}
So, this JSON can be obtained via the formatJSON() method without arguments, or via formatJSON(JSONFormat.DEFAULT_FOR_RESULTS). If we want to render only the "records" array and avoid rendering the header represented by the "fields" array, then we can rely on formatJSON(JSONFormat.DEFAULT_FOR_RECORDS). This produces something as shown here (as you'll see later, this can also be imported back into the database):
[
["Vintage Cars", 80, "1936 Mercedes Benz 500k Roadster"],
["Vintage Cars", 29, "1932 Model A Ford J-Coupe"],
...
]
DEFAULT_FOR_RESULTS and DEFAULT_FOR_RECORDS are two statics of the immutable org.jooq.JSONFormat used to fine-tune JSON imports/exports. When these statics are not enough, we can instantiate JSONFormat and fluently append a suite of intuitive options such as the ones from this example (check all the available options in the jOOQ documentation):
JSONFormat jsonFormat = new JSONFormat()
.indent(4) // defaults to 2
.header(false) // default to true
.newline("
") // "
" is default.recordFormat(
JSONFormat.RecordFormat.OBJECT); // defaults to ARRAY
Further, let's use jsonFormat in the context of exporting a JSON into a file via formatJSON(Writer writer, JSONFormat format):
try ( BufferedWriter bw = Files.newBufferedWriter(
Paths.get("resultObject.json"), StandardCharsets.UTF_8, StandardOpenOption.CREATE_NEW, StandardOpenOption.WRITE)) {ctx.select(PRODUCTLINE.PRODUCT_LINE, PRODUCT.PRODUCT_ID,
PRODUCT.PRODUCT_NAME)
.from(PRODUCTLINE)
.join(PRODUCT).onKey()
.fetch()
.formatJSON(bw, jsonFormat);
} catch (IOException ex) { // handle exception }The resulting JSON looks like this (also importable into the database):
[
{"product_line": "Vintage Cars",
"product_id": 80,
"product_name": "1936 Mercedes Benz 500k Roadster"
},
…
]
If we fetch a single Record (so, not Result/Cursor, via fetchAny(), for instance), then formatJSON() will return an array containing only the data, as in this sample of fetching Record3<String, Long, String>:
["Classic Cars",2,"1952 Alpine Renault 1300"]
But, if we explicitly mention JSONFormat.RecordFormat.OBJECT, then this becomes the following:
{"product_line":"Classic Cars","product_id":2,"product_name":"1952 Alpine Renault 1300"}
You can check out this example in the bundled code, Format (available for MySQL and PostgreSQL), next to other examples including formatting a UDT, an array type, and an embeddable type as JSON.
Export XML
Exporting Result/Cursor as XML can be done via formatXML() and its overloads. Without arguments, formatXML() produces an XML containing two main elements: an element named <fields/>, representing a header, and an element named <records/>, which wraps the fetched data. Here is such an output:
<result xmlns="http:...">
<fields>
<field schema="public" table="productline"
name="product_line" type="VARCHAR"/>
<field schema="public" table="product"
name="product_id" type="BIGINT"/>
<field schema="public" table="product"
name="product_name" type="VARCHAR"/>
</fields>
<records>
<record xmlns="http:...">
<value field="product_line">Vintage Cars</value>
<value field="product_id">80</value>
<value field="product_name">1936 Mercedes Benz ...</value>
</record>
...
</records>
</result>
The jOOQ code that produced this output is as follows:
ctx.select(PRODUCTLINE.PRODUCT_LINE,
PRODUCT.PRODUCT_ID, PRODUCT.PRODUCT_NAME)
.from(PRODUCTLINE)
.join(PRODUCT).onKey()
.fetch()
.formatXML();
So, this XML can be obtained via the formatXML() method without arguments or via formatXML(XMLFormat.DEFAULT_FOR_RESULTS). If we want to keep only the <records/> element and avoid rendering the <fields/> element, then use formatJXML(XMLFormat.DEFAULT_FOR_RECORDS). This is an output sample:
<result>
<record>
<value field="product_line">Vintage Cars</value>
<value field="product_id">80</value>
<value field="product_name">1936 Mercedes Benz ...</value>
</record>
...
</result>
DEFAULT_FOR_RESULTS and DEFAULT_FOR_RECORDS are two statics of the immutable org.jooq.XMLFormat, used to fine-tune XML imports/exports. Besides these, we can instantiate XMLFormat and fluently append a suite of intuitive options. For instance, the previous snippets of XML are rendered based on the default record format, XMLFormat.RecordFormat.VALUE_ELEMENTS_WITH_FIELD_ATTRIBUTE; notice the <value/> element and the field attribute. But, using XMLFormat, we can go for two other options: VALUE_ELEMENTS and COLUMN_NAME_ELEMENTS. The former formats the records using just the <value/> element as follows:
<record xmlns="http:...">
<value>Vintage Cars</value>
<value>29</value>
<value>1932 Model A Ford J-Coupe</value>
</record>
COLUMN_NAME_ELEMENTS uses the column names as elements. Let's use this setting next to header(false) to format the MANAGER.MANAGER_EVALUATION UDT (available in the PostgreSQL schema):
ctx.select(MANAGER.MANAGER_ID, MANAGER.MANAGER_EVALUATION)
.from(MANAGER)
.fetch()
.formatXML(new XMLFormat()
.header(false)
.recordFormat(XMLFormat.RecordFormat.COLUMN_NAME_ELEMENTS))
The resulting XML looks like this:
<record xmlns="http...">
<manager_id>1</manager_id>
<manager_evaluation>
<record xmlns="http...">
<communication_ability>67</communication_ability>
<ethics>34</ethics>
<performance>33</performance>
<employee_input>66</employee_input>
</record>
</manager_evaluation>
</record>
If we fetch a single Record (so, no Result/Cursor via fetchAny(), for instance) then formatXML() will return an XML containing only the data, as in this sample of fetching Record3<String, Long, String>:
<record>
<value field="product_line">Classic Cars</value>
<value field="product_id">2</value>
<value field="product_name">1952 Alpine Renault 1300</value>
</record>
Of course, you can alter this default output via XMLFormat. For instance, let's consider that we have this record:
<Record3<String, Long, String> oneResult = …;
And, let's apply RecordFormat.COLUMN_NAME_ELEMENTS:
String xml = oneResult.formatXML(new XMLFormat().recordFormat(
XMLFormat.RecordFormat.COLUMN_NAME_ELEMENTS));
The rendered XML is as follows:
<record xmlns="http://...">
<product_line>Classic Cars</product_line>
<product_id>2</product_id>
<product_name>1952 Alpine Renault 1300</product_name>
</record>
Consider this example next to others (including exporting XML into a file) in the bundled code, Format (available for MySQL and PostgreSQL).
Exporting HTML
Exporting Result/Cursor as HTML can be done via formatHTML() and its overloads. By default, jOOQ attempts to wrap the fetched data in a simple HTML table, therefore, expect to see tags such as <table/>, <th/>, and <td/> in the resultant HTML. For instance, formatting the MANAGER.MANAGER_EVALUATION UDT (available in the PostgreSQL schema) can be done as follows:
ctx.select(MANAGER.MANAGER_NAME, MANAGER.MANAGER_EVALUATION)
.from(MANAGER)
.fetch()
.formatHTML();
The resultant HTML looks like this:
<table>
<thead>
<tr>
<th>manager_name</th>
<th>manager_evaluation</th>
</tr>
</thead>
<tbody>
<tr>
<td>Joana Nimar</td>
<td>(67, 34, 33, 66)</td>
</tr>
...
Notice that the value of MANAGER_EVALUATION, (67, 34, 33, 66), is wrapped in a <td/> tag. But, maybe you'd like to obtain something like this:
<h1>Joana Nimar</h1>
<table>
<thead>
<tr>
<th>communication_ability</th>
<th>ethics</th>
<th>performance</th>
<th>employee_input</th>
</tr>
</thead>
<tbody>
<tr>
<td>67</td>
<td>34</td>
<td>33</td>
<td>66</td>
</tr>
</tbody>
</table>
We can obtain this HTML by decorating our query as follows:
ctx.select(MANAGER.MANAGER_NAME, MANAGER.MANAGER_EVALUATION)
.from(MANAGER)
.fetch()
.stream()
.map(e -> "<h1>".concat(e.value1().concat("</h1>")).concat(e.value2().formatHTML()))
.collect(joining("<br />"))Check out more examples in the bundled code, Format (available for MySQL and PostgreSQL).
Exporting CSV
Exporting Result/Cursor as CSV can be done via formatCSV() and its overloads. By default, jOOQ renders a CSV file as the one here:
city,country,dep_id,dep_name
Bucharest,"","",""
Campina,Romania,3,Accounting
Campina,Romania,14,IT
…
Among the handy overloads, we have formatCSV(boolean header, char delimiter, String nullString). Via this method, we can specify whether the CSV header should be rendered (by default, true), the record's delimiter (by default, a comma), and a string for representing NULL values (by default, ""). Next to this method, we also have a suite of combinations of these arguments such as formatCSV(char delimiter, String nullString), formatCSV(char delimiter), and formatCSV(boolean header, char delimiter). Here is an example that renders the header (default) and uses TAB as a delimiter and "N/A" for representing NULL values:
ctx.select(OFFICE.CITY, OFFICE.COUNTRY,
DEPARTMENT.DEPARTMENT_ID.as("dep_id"), DEPARTMENT.NAME.as("dep_name")).from(OFFICE).leftJoin(DEPARTMENT).onKey().fetch()
.formatCSV(' ', "N/A");The resulting CSV looks like this:
City country dep_id dep_name
Bucharest N/A N/A N/A
Campina Romania 3 Accounting
…
Hamburg Germany N/A N/A
London UK N/A N/A
NYC USA 4 Finance
...
Paris France 2 Sales
Whenever we need more options, we can rely on the immutable CSVFormat. Here is an example of using CSVFormat and exporting the result in a file:
try (BufferedWriter bw = Files.newBufferedWriter(
Paths.get("result.csv"), StandardCharsets.UTF_8, StandardOpenOption.CREATE_NEW, StandardOpenOption.WRITE)) {ctx.select(OFFICE.CITY, OFFICE.COUNTRY,
DEPARTMENT.DEPARTMENT_ID, DEPARTMENT.NAME)
.from(OFFICE).leftJoin(DEPARTMENT).onKey()
.fetch()
.formatCSV(bw, new CSVFormat()
.delimiter("|").nullString("{null}"));} catch (IOException ex) { // handle exception }The complete code next to other examples is available in the bundled code, Format (available for MySQL and PostgreSQL).
Exporting a chart
Exporting Result/Cursor as a chart may result in something as observed in this figure:

Figure 10.2 – jOOQ chart sample
This is an area chart containing three graphs: a, b, and c. Graph a represents PRODUCT.BUY_PRICE, graph b represents PRODUCT.MSRP, and graph c represents avg(ORDERDETAIL.PRICE_EACH). While this chart can be displayed on the console, it can be exported to a file as shown here:
try (BufferedWriter bw = Files.newBufferedWriter(
Paths.get("result2Chart.txt"), StandardCharsets.UTF_8, StandardOpenOption.CREATE_NEW, StandardOpenOption.WRITE)) {ctx.select(PRODUCT.PRODUCT_ID, PRODUCT.BUY_PRICE,
field("avg_price"), PRODUCT.MSRP).from(PRODUCT, lateral(select(
avg(ORDERDETAIL.PRICE_EACH).as("avg_price")) .from(ORDERDETAIL)
.where(PRODUCT.PRODUCT_ID.eq(ORDERDETAIL.PRODUCT_ID))))
.limit(5).fetch()
.formatChart(bw, cf);
} catch (IOException ex) { // handle exception }Obviously, the chart is obtained via the formatChart() method. More precisely, in this example, via formatChart(Writer writer, ChartFormat format). The ChartFormat class is immutable and contains a suite of options for customizing the chart. While you can check all of them in the jOOQ documentation, here is the cf used in this example:
DecimalFormat decimalFormat = new DecimalFormat("#.#");ChartFormat cf = new ChartFormat()
.showLegends(true, true) // show legends
.display(ChartFormat.Display.DEFAULT) // or,
// HUNDRED_PERCENT_STACKED
.categoryAsText(true) // category as text
.type(ChartFormat.Type.AREA) // area chart type
.shades('a', 'b', 'c') // shades of PRODUCT.BUY_PRICE, // PRODUCT.MSRP,
// avg(ORDERDETAIL.PRICE_EACH)
.values(1, 2, 3) // value source column numbers
.numericFormat(decimalFormat);// numeric format
The complete code next to other examples is available in the bundled code in the application named Format (available for MySQL and PostgreSQL).
Exporting INSERT statements
jOOQ can export Result/Cursor as INSERT statements via the formatInsert() method and its overloads. By default, if the first record is TableRecord, then formatInsert() uses the first record's TableRecord.getTable() method to generate INSERT statements into this table, otherwise, it generates INSERT statements into UNKNOWN_TABLE. In both cases, jOOQ calls the Result.fields() method to determine the column names.
Here is an example that exports the generated INSERT statements into a file on disk. The INSERT statements are generated into a database table named product_stats specified via formatInsert(Writer writer, Table<?> table, Field<?>… fields):
try (BufferedWriter bw = Files.newBufferedWriter(
Paths.get("resultInserts.txt"), StandardCharsets.UTF_8, StandardOpenOption.CREATE_NEW, StandardOpenOption.WRITE)) {ctx.select(PRODUCT.PRODUCT_ID, PRODUCT.BUY_PRICE,
field("avg_price"), PRODUCT.MSRP).from(PRODUCT, lateral(select(
avg(ORDERDETAIL.PRICE_EACH).as("avg_price")) .from(ORDERDETAIL)
.where(PRODUCT.PRODUCT_ID.eq(ORDERDETAIL
.PRODUCT_ID))))
.limit(5)
.fetch()
.formatInsert(bw, table("product_stats"));} catch (IOException ex) { // handle exception }A generated INSERT statement looks like the following:
INSERT INTO product_stats VALUES (29, 108.06, 114.23, 127.13);
The complete code next to other examples, including exporting INSERT statements for UDT, JSON, array, and embeddable types, is available in the bundled code, Format (available for MySQL and PostgreSQL). Next, let's talk about batching.
Batching
Batching can be the perfect solution for avoiding performance penalties caused by a significant number of separate database/network round trips representing inserts, deletes, updates, merges, and so on. For instance, without batching, having 1,000 inserts requires 1,000 separate round trips, while employing batching with a batch size of 30 will result in 34 separate round trips. The more inserts (statements) we have, the more helpful batching is.
Batching via DSLContext.batch()
The DSLContext class exposes a suite of batch() methods that allow us to execute a set of queries in batch mode. So, we have the following batch() methods:
BatchBindStep batch(String sql)
BatchBindStep batch(Query query)
Batch batch(String... queries)
Batch batch(Query... queries)
Batch batch(Queries queries)
Batch batch(Collection<? extends Query> queries)
Batch batch(String sql, Object[]... bindings)
Batch batch(Query query, Object[]... bindings)
Behind the scenes, jOOQ implements these methods via JDBC's addBatch(). Each query is accumulated in the batch via addBatch(), and in the end, it calls the JDBC executeBatch() method to send the batch to the database.
For instance, let's assume that we need to batch a set of INSERT statements into the SALE table. If you have a Hibernate (JPA) background, then you know that this kind of batch will not work because the SALE table has an auto-incremented primary key, and Hibernate will automatically disable/prevent insert batching. But, jOOQ doesn't have such issues, so batching a set of inserts into a table having an auto-incremented primary key can be done via batch(Query... queries), as follows:
int[] result = ctx.batch(
ctx.insertInto(SALE, SALE.FISCAL_YEAR, SALE.EMPLOYEE_NUMBER,
SALE.SALE_, SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH)
.values(2005, 1370L, 1282.64, 1, 0.0),
ctx.insertInto(SALE, SALE.FISCAL_YEAR, SALE.EMPLOYEE_NUMBER,
SALE.SALE_, SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH)
.values(2004, 1370L, 3938.24, 1, 0.0),
...
).execute();
The returned array contains the number of affected rows per INSERT statement (in this case, [1, 1, 1, …]). While executing several queries without bind values can be done as you just saw, jOOQ allows us to execute one query several times with bind values as follows:
int[] result = ctx.batch(
ctx.insertInto(SALE, SALE.FISCAL_YEAR,SALE.EMPLOYEE_NUMBER,
SALE.SALE_, SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH)
.values((Integer) null, null, null, null, null))
.bind(2005, 1370L, 1282.64, 1, 0.0)
.bind(2004, 1370L, 3938.24, 1, 0.0)
...
.execute();
Notice that you will have to provide dummy bind values for the original query, and this is commonly achieved via null values, as in this example. jOOQ generates a single query (PreparedStatement) with placeholders (?) and will loop the bind values to populate the batch. Whenever you see that int[] contains a negative value (for instance, -2) it means that the affected row count value couldn't be determined by JDBC.
In most cases, JDBC prepared statements are better, so, whenever possible, jOOQ relies on PreparedStatement (www.jooq.org/doc/latest/manual/sql-execution/statement-type/). But, we can easily switch to static statements (java.sql.Statement) via setStatementType() or withStatementType() as in the following example (you can also apply this globally via @Bean):
int[] result = ctx.configuration().derive(new
Settings().withStatementType(StatementType.STATIC_STATEMENT))
.dsl().batch(
ctx.insertInto(SALE, SALE.FISCAL_YEAR,
SALE.EMPLOYEE_NUMBER, SALE.SALE_, SALE.FISCAL_MONTH,
SALE.REVENUE_GROWTH)
.values((Integer) null, null, null, null, null))
.bind(2005, 1370L, 1282.64, 1, 0.0)
.bind(2004, 1370L, 3938.24, 1, 0.0)
...
.execute();
This time, the bind values will be automatically inlined into a static batch query. This is the same as the first examples from this section, which use batch(Query... queries).
Obviously, using binding values is also useful for inserting (updating, deleting, and so on) a collection of objects. For instance, consider the following list of SimpleSale (POJO):
List<SimpleSale> sales = List.of(
new SimpleSale(2005, 1370L, 1282.64, 1, 0.0),
new SimpleSale(2004, 1370L, 3938.24, 1, 0.0),
new SimpleSale(2004, 1370L, 4676.14, 1, 0.0));
First, we define the proper BatchBindStep containing one INSERT (it could be UPDATE, DELETE, and so on, as well):
BatchBindStep batch = ctx.batch(ctx.insertInto(SALE,
SALE.FISCAL_YEAR, SALE.EMPLOYEE_NUMBER, SALE.SALE_,
SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH)
.values((Integer) null, null, null, null, null));
Second, we bind the values and execute the batch:
sales.forEach(s -> batch.bind(s.getFiscalYear(),
s.getEmployeeNumber(), s.getSale(),
s.getFiscalMonth(),s.getRevenueGrowth()));
batch.execute();
You can find these examples in the bundled code, BatchInserts, next to examples for batching updates, BatchUpdates, and deletes, BatchDeletes, as well. But, we can also combine all these kinds of statements in a single batch() method, as follows:
int[] result = ctx.batch(
ctx.insertInto(SALE, SALE.FISCAL_YEAR,SALE.EMPLOYEE_NUMBER,
SALE.SALE_, SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH)
.values(2005, 1370L, 1282.64, 1, 0.0),
ctx.insertInto(SALE, SALE.FISCAL_YEAR, SALE.EMPLOYEE_NUMBER,
SALE.SALE_, SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH)
.values(2004, 1370L, 3938.24, 1, 0.0),
...
ctx.update(EMPLOYEE).set(EMPLOYEE.SALARY,
EMPLOYEE.SALARY.plus(1_000))
.where(EMPLOYEE.SALARY.between(100_000, 120_000)),
ctx.update(EMPLOYEE).set(EMPLOYEE.SALARY,
EMPLOYEE.SALARY.plus(5_000))
.where(EMPLOYEE.SALARY.between(65_000, 80_000)),
...
ctx.deleteFrom(BANK_TRANSACTION)
.where(BANK_TRANSACTION.TRANSACTION_ID.eq(1)),
ctx.deleteFrom(BANK_TRANSACTION)
.where(BANK_TRANSACTION.TRANSACTION_ID.eq(2)),
...
).execute();
While using batch() methods, jOOQ will always preserve your order of statements and will send all these statements in a single batch (round trip) to the database. This example is available in an application named CombineBatchStatements.
During the batch preparation, the statements are accumulated in memory, so you have to pay attention to avoid memory issues such as OOMs. You can easily emulate a batch size by calling the jOOQ batch in a for loop that limits the number of statements to a certain value. You can execute all batches in a single transaction (in case of an issue, roll back all batches) or execute each batch in a separate transaction (in case of an issue, roll back only the last batch). You can see these approaches in the bundled code, EmulateBatchSize.
While a synchronous batch ends up with an execute() call, an asynchronous batch ends up with an executeAsync() call. For example, consider the application named AsyncBatch. Next, let's talk about batching records.
Batching records
Batching records is another story. The jOOQ API for batching records relies on a set of dedicated methods per statement type as follows:
- INSERT: batchInsert() follows TableRecord.insert() semantics
- UPDATE: batchUpdate() follows UpdatableRecord.update() semantics
- DELETE: batchDelete() follows UpdatableRecord.delete() semantics
- MERGE: batchMerge() follows UpdatableRecord.merge() semantics
- INSERT/UPDATE: batchStore() follows UpdatableRecord.store() semantics
Next, we'll cover each of these statements but before that, let's point out an important aspect. By default, all these methods create batch operations for executing a certain type of query with bind values. jOOQ preserves the order of the records as long as the records generate the same SQL with bind variables, otherwise, the order is changed to group together the records that share the same SQL with bind variables. So, in the best-case scenario, when all records generate the same SQL with bind variables, there will be a single batch operation, while in the worst-case scenario, the number of records will be equal to the number of batch operations. In short, the number of batch operations that will be executed is equal to the number of distinct rendered SQL statements.
If we switch from the default PreparedStatement to a static Statement (StatementType.STATIC_STATEMENT), then the record values are inlined. This time, there will be just one batch operation and the order of records is preserved exactly. Obviously, this is preferable when the order of records must be preserved and/or the batch is very large, and rearranging the records can be time-consuming and results in a significant number of batch operations.
Batch records insert, update, and delete
Let's consider the following set of Record:
SaleRecord sr1 = new SaleRecord(…, 2005, 1223.23, 1370L, …);
SaleRecord sr2 = new SaleRecord(…, 2004, 5483.33, 1166L, …);
SaleRecord sr3 = new SaleRecord(…, 2005, 9022.21, 1370L, …);
Inserting these records in batch can be done as follows:
int[] result = ctx.batchInsert(sr3, sr1, sr2).execute();
In this case, these records are inserted in a single batch operation since the generated SQL with bind variables is the same for sr1 to sr3. Moreover, the batch preserves the order of records as given (sr3, sr1, and sr2). If we want to update, and respectively to delete these records, then we replace batchInsert() with batchUpdate(), and, respectively, batchDelete(). You can also have these records in a collection and pass that collection to batchInsert(), as in this example:
List<SaleRecord> sales = List.of(sr3, sr1, sr2);
int[] result = ctx.batchInsert(sales).execute();
Next, let's consider a mix of records:
SaleRecord sr1 = new SaleRecord(…);
SaleRecord sr2 = new SaleRecord(…);
BankTransactionRecord bt1 = new BankTransactionRecord(…);
SaleRecord sr3 = new SaleRecord(…);
SaleRecord sr4 = new SaleRecord(…);
BankTransactionRecord bt2 = new BankTransactionRecord(…);
Calling batchInsert(bt1, sr1, sr2, bt2, sr4, sr3) is executed in two batch operations, one for SaleRecord and one for BankTransactionRecord. jOOQ will group SaleRecord (sr1, sr2, sr3, and sr4) in one batch operation and BankTransactionRecord (bt1 and bt2) in another batch operation, so the order of records in not preserved (or, is partially preserved) since (bt1, sr1, sr2, bt2, sr4, and sr3) may become ((bt1 and bt2), (sr1, sr2, sr4, and sr3)).
Finally, let's consider these records:
SaleRecord sr1 = new SaleRecord();
sr1.setFiscalYear(2005);
sr1.setSale(1223.23);
sr1.setEmployeeNumber(1370L);
sr1.setTre"d("UP");sr1.setFiscalMonth(1);
sr1.setRevenueGrowth(0.0);
SaleRecord sr2 = new SaleRecord();
sr2.setFiscalYear(2005);
sr2.setSale(9022.21);
sr2.setFiscalMonth(1);
sr2.setRevenueGrowth(0.0);
SaleRecord sr3 = new SaleRecord();
sr3.setFiscalYear(2003);
sr3.setSale(8002.22);
sr3.setEmployeeNumber(1504L);
sr3.setFiscalMonth(1);
sr3.setRevenueGrowth(0.0);
If we execute batchInsert(sr3, sr2, sr1), then there will be three batch operations, since sr1, sr2, and sr3 produce three SQLs that will different bind variables. The order of records is preserved as sr3, sr2, and sr1. The same flow applies for batchUpdate() and batchDelete().
Any of these examples can take advantage of JDBC static statements by simply adding the STATIC_STATEMENT setting as follows:
int[] result = ctx.configuration().derive(new Settings()
.withStatementType(StatementType.STATIC_STATEMENT))
.dsl().batchInsert/Update/…(…).execute();
You can practice these examples in BatchInserts, BatchUpdates, and BatchDeletes.
Batch merge
As you already know from the bullet list from the Batching records section, batchMerge() is useful for executing batches of MERGE statements. Mainly, batchMerge() conforms to the UpdatableRecord.merge() semantics covered in Chapter 9, CRUD, Transactions, and Locking.
In other words, batchMerge() renders the synthetic INSERT ... ON DUPLICATE KEY UPDATE statement emulated depending on dialect; in MySQL, via INSERT ... ON DUPLICATE KEY UPDATE, in PostgreSQL, via INSERT ... ON CONFLICT, and in SQL Server and Oracle, via MERGE INTO. Practically, batchMerge() renders an INSERT ... ON DUPLICATE KEY UPDATE statement independent of the fact that the record has been previously fetched from the database or is created now. The number of distinct rendered SQL statements gives us the number of batches. So, by default (which means default settings, default changed flags, and no optimistic locking), jOOQ renders a query that delegates to the database the decision between insert and update based on the primary key uniqueness. Let's consider the following records:
SaleRecord sr1 = new SaleRecord(1L, 2005, 1223.23, ...);
SaleRecord sr2 = new SaleRecord(2L, 2004, 543.33, ...);
SaleRecord sr3 = new SaleRecord(9999L, 2003, 8002.22, ...);
We execute a merge in batch as shown here:
int[] result = ctx.batchMerge(sr1, sr2, sr3).execute();
For instance, in PostgreSQL, the render SQL is as follows:
INSERT INTO "public"."sale" ("sale_id", "fiscal_year", ..., "trend")
VALUES (?, ?, ..., ?) ON CONFLICT ("sale_id") DOUPDATE SET "sale_id" = ?,
"fiscal_year" = ?, ..., "trend" = ?
WHERE "public"."sale"."sale_id" = ?
Because sr1 (having primary key 1) and sr2 (having primary key 2) already exist in the SALE table, the database will decide to update them, while sr3 (having primary key 9999) will be inserted, since it doesn't exist in the database. There will be just one batch since the generated SQL with bind variables is the same for all SaleRecord. The order of records is preserved. More examples are available in BatchMerges.
Batch store
batchStore() is useful for executing INSERT or UPDATE statements in the batch. Mainly, batchStore() conforms to UpdatableRecord.store(), which was covered in the previous chapter. So, unlike batchMerge(), which delegates the decision of choosing between update or insert to the database, batchStore() allows jOOQ to decide whether INSERT or UPDATE should be rendered by analyzing the state of the primary key's value.
For instance, let's rely on defaults (which means default settings, default changed flags, and no optimistic locking), the following two records are used for executing in a batch store:
SaleRecord sr1 = new SaleRecord(9999L,
2005, 1223.23, 1370L, ...);
SaleRecord sr2 = ctx.selectFrom(SALE)
.where(SALE.SALE_ID.eq(1L)).fetchOne();
sr2.setFiscalYear(2006);
int[] result = ctx.batchStore(sr1, sr2).execute();
Since sr1 is a brand-new SaleRecord, it will result in INSERT. On the other hand, sr2 was fetched from the database and it was updated, so it will result in UPDATE. Obviously, the generated SQL statements are not the same, therefore, there will be two batch operations and the order will be preserved as sr1 and sr2.
Here is another example that updates SaleRecord and adds a few more:
Result<SaleRecord> sales = ctx.selectFrom(SALE).fetch();
// update all sales
sales.forEach(sale -> { sale.setTrend("UP"); });// add more new sales
sales.add(new SaleRecord(...));
sales.add(new SaleRecord(...));
...
int[] result = ctx.batchStore(sales)
.execute();
We have two batch operations: a batch that contains all updates needed to update the fetched SaleRecord and a batch that contains all inserts needed to insert the new SaleRecord.
In the bundled code, you can find more examples that couldn't be listed here because they are large, so take your time to practice examples from BatchStores. This was the last topic of this section. Next, let's talk about the batched connection API.
Batched connection
Besides the batching capabilities covered so far, jOOQ also comes with an API named org.jooq.tools.jdbc.BatchedConnection. Its main purpose is to buffer already existing jOOQ/JDBC statements and execute them in batches without requiring us to change the SQL strings or the order of execution. We can use BatchedConnection explicitly or indirectly via DSLContext.batched(BatchedRunnable runnable) or DSLContext.batchedResult(BatchedCallable<T> callable). The difference between them consists of the fact that the former returns void and the latter returns T.
For instance, let's assume that we have a method (service) that produces a lot of INSERT and UPDATE statements:
void insertsAndUpdates(Configuration c) {DSLContext ctxLocal = c.dsl();
ctxLocal.insertInto(…).execute();
…
ctxLocal.update(…).execute();
…
}
To improve the performance of this method, we can simply add batch-collecting code via DSLContext.batched(), as here:
public void batchedInsertsAndUpdates() {ctx.batched(this::insertsAndUpdates);
}
Of course, if INSERT statements are produced by an inserts(Configuration c) method and UPDATE statements by another method, updates(Configuration c), then both of them should be collected:
public void batchedInsertsAndUpdates() { ctx.batched((Configuration c) -> {inserts(c);
updates(c);
});
}
Moreover, this API can be used for batching jOOQ records as well. Here is a sample:
ctx.batched(c -> {Result<SaleRecord> records = c.dsl().selectFrom(SALE)
.limit(5).fetch();
records.forEach(record -> { record.setTrend("CONSTANT");...
record.store();
});
});
List<SaleRecord> sales = List.of(
new SaleRecord(...), new SaleRecord(...), ...
);
ctx.batched(c -> { for (SaleRecord sale : sales) {c.dsl().insertInto(SALE)
.set(sale)
.onDuplicateKeyUpdate()
.set(SALE.SALE_, sale.getSale())
.execute();
}
}); // batching is happening here
Notice that jOOQ will preserve exactly your order of statements and this order may affect the number of batch operations. Read carefully the following note, since it is very important to have it in your mind while working with this API.
Important Note
jOOQ automatically creates a new batch every time it detects that:
- The SQL string changes (even whitespace is considered a change).
- A query produces results (for instance, SELECT); such queries are not part of the batch.
- A static statement occurs after a prepared statement (or vice versa).
- A JDBC interaction is invoked (transaction committed, connection closed, and so on).
- The batch size threshold is reached.
As an important limitation, notice that the affected row count value will be reported always by the JDBC PreparedStatement.executeUpdate() as 0.
Notice that the last bullet from the previous note refers to a batch size threshold. Well, this API can take advantage of Settings.batchSize(), which sets the maximum batch statement size as here:
@Bean
public Settings jooqSettings() {return new Settings().withBatchSize(30);
}
Moreover, if we rely on BatchedConnection explicitly, then we can wrap the JDBC connection and specify the batch size as an argument via the BatchedConnection(Connection delegate, int batchSize) constructor as follows (here, the batch size is set to 2; consider reading the comments):
try ( BatchedConnection conn = new BatchedConnection(
DriverManager.getConnection(
"jdbc:mysql://localhost:3306/classicmodels",
"root", "root"), 2)) {try ( PreparedStatement stmt = conn.prepareStatement(
"insert into `classicmodels`.`sale` (`fiscal_year`,
`employee_number`, `sale`, `fiscal_month`,
`revenue_growth`) " + "values (?, ?, ?, ?, ?);")) {// the next 2 statements will become the first batch
stmt.setInt(1, 2004);
stmt.setLong(2, 1166L);
stmt.setDouble(3, 543.33);
stmt.setInt(4, 1);
stmt.setDouble(5, 0.0);
stmt.executeUpdate();
stmt.setInt(1, 2005);
stmt.setLong(2, 1370L);
stmt.setDouble(3, 9022.20);
stmt.setInt(4, 1);
stmt.setDouble(5, 0.0);
stmt.executeUpdate();
// reached batch limit so this is the second batch
stmt.setInt(1, 2003);
stmt.setLong(2, 1166L);
stmt.setDouble(3, 3213.0);
stmt.setInt(4, 1);
stmt.setDouble(5, 0.0);
stmt.executeUpdate();
}
// since the following SQL string is different,
// next statements represents the third batch
try ( PreparedStatement stmt = conn.prepareStatement(
"insert into `classicmodels`.`sale` (`fiscal_year`,
`employee_number`, `sale`, `fiscal_month`,
`revenue_growth`,`trend`) "
+ "values (?, ?, ?, ?, ?, ?);")) {stmt.setInt(1, 2004);
stmt.setLong(2, 1166L);
stmt.setDouble(3, 4541.35);
stmt.setInt(4, 1);
stmt.setDouble(5, 0.0);
stmt.setString(6, "UP");
stmt.executeUpdate();
stmt.setInt(1, 2005);
stmt.setLong(2, 1370L);
stmt.setDouble(3, 1282.64);
stmt.setInt(4, 1);
stmt.setDouble(5, 0.0);
stmt.setString(6, "DOWN");
stmt.executeUpdate();
}
} catch (SQLException ex) { … } Moreover, BatchedConnection implements java.sql.Connection, so you can use the entire arsenal of Connection methods, including methods for shaping the behavior of transactions. More examples are available in Batched.
Next, let's tackle two special cases encountered in PostgreSQL and SQL Server.
Batching and fetching sequences in PostgreSQL/Oracle
As you know, PostgreSQL/Oracle can rely on sequences for providing primary keys (and other unique values). For instance, our PostgreSQL employee table uses the following sequence for producing sequence values for employee_number:
CREATE TABLE "employee" (
"employee_number" BIGINT NOT NULL,
...
CONSTRAINT "employee_pk" PRIMARY KEY ("employee_number"),...
);
CREATE SEQUENCE "employee_seq" START 100000 INCREMENT 10
MINVALUE 100000 MAXVALUE 10000000
OWNED BY "employee"."employee_number";
But, in the context of batching, fetching the employee primary keys from the application requires a database round trip (SELECT) for each primary key. Obviously, it is a performance penalty to have a batch of n INSERT statements and execute n round trips (SELECT statements) just to fetch their primary keys. Fortunately, jOOQ leverages at least two solutions. One of them is to inline sequence references in SQL statements (the EMPLOYEE_SEQ.nextval() call):
int[] result = ctx.batch(
ctx.insertInto(EMPLOYEE, EMPLOYEE.EMPLOYEE_NUMBER,
EMPLOYEE.LAST_NAME, ...)
.values(EMPLOYEE_SEQ.nextval(), val("Lionel"), ...),ctx.insertInto(EMPLOYEE, EMPLOYEE.EMPLOYEE_NUMBER,
EMPLOYEE.LAST_NAME...)
.values(EMPLOYEE_SEQ.nextval(), val("Ion"), ...),...
).execute();
Another approach is to pre-fetch a number of n primary keys via SELECT:
var ids = ctx.fetch(EMPLOYEE_SEQ.nextvals(n));
Then, use these primary keys in batch (notice the ids.get(n).value1() call):
int[] result = ctx.batch(
ctx.insertInto(EMPLOYEE, EMPLOYEE.EMPLOYEE_NUMBER,
EMPLOYEE.LAST_NAME, ...)
.values(ids.get(0).value1(), "Lionel", ...),
ctx.insertInto(EMPLOYEE, EMPLOYEE.EMPLOYEE_NUMBER,
EMPLOYEE.LAST_NAME, ...)
.values(ids.get(1).value1(), "Ion", ...),
...
).execute();
Both of these examples rely on the public static final EMPLOYEE_SEQ field or, more precisely, on jooq.generated.Sequences.EMPLOYEE_SEQ. Mainly, the jOOQ Code Generator will generate a sequence object per database sequence and each such object has access to methods such as nextval(), currval(), nextvals(int n), and others, which will be covered in Chapter 11, jOOQ Keys.
Of course, if you rely on an auto-generated sequence from (BIG)SERIAL or on a sequence associated as default (for example, in the sale table, we have a sequence associated to sale_id as DEFAULT NEXTVAL ('sale_seq')), then the simplest way to batch is to omit the primary key field in statements, and the database will do the rest. The previous examples, along with many more, are available in BatchInserts for PostgreSQL.
SQL Server IDENTITY columns and explicit values
Inserting explicit values for the SQL Server IDENTITY columns results in the error Cannot insert explicit value for identity column in table 'table_name' when IDENTITY_INSERT is set to OFF. Bypassing this error can be done by setting IDENTITY_INSERT to ON before INSERT. In the context of batching, this can be done as shown here:
int[] result = ctx.batch(
ctx.query("SET IDENTITY_INSERT [sale] ON"),ctx.insertInto(SALE, SALE.SALE_ID, SALE.FISCAL_YEAR, …)
.values(1L, 2005, …),
ctx.insertInto(SALE, SALE.SALE_ID, SALE.FISCAL_YEAR, …)
.values(2L, 2004, …),
...
ctx.query("SET IDENTITY_INSERT [sale] OFF")).execute();
You can find this example in BatchInserts for SQL Server. Next, let's talk about bulking.
Bulking
Writing bulk queries in jOOQ is just a matter of using the jOOQ DSL API. For instance, a bulk insert SQL looks like this:
INSERT IGNORE INTO `classicmodels`.`order` (
`order_date`, `required_date`, `shipped_date`,
`status`, `comments`, `customer_number`, `amount`)
VALUES (?, ?, ?, ?, ?, ?, ?), (?, ?, ?, ?, ?, ?, ?),
(?, ?, ?, ?, ?, ?, ?)
This can be expressed in jOOQ by chaining the values() call:
ctx.insertInto(ORDER)
.columns(ORDER.ORDER_DATE, ORDER.REQUIRED_DATE,
ORDER.SHIPPED_DATE, ORDER.STATUS,
ORDER.COMMENTS,ORDER.CUSTOMER_NUMBER,
ORDER.AMOUNT)
.values(LocalDate.of(2004,10,22), LocalDate.of(2004,10,23),
LocalDate.of(2004,10,23", "Shipped",
"New order inserted...", 363L, BigDecimal.valueOf(322.59))
.values(LocalDate.of(2003,12,2), LocalDate.of(2003,1,3),
LocalDate.of(2003,2,26), "Resolved",
"Important order ...", 128L, BigDecimal.valueOf(455.33))
...
.onDuplicateKeyIgnore() // onDuplicateKeyUpdate().set(...)
.execute()
Or, you can use a bulk update SQL as follows:
update `classicmodels`.`sale`
set
`classicmodels`.`sale`.`sale` = case when
`classicmodels`.`sale`.`employee_number` = ? then (
`classicmodels`.`sale`.`sale` + ?
) when `classicmodels`.`sale`.`employee_number` = ? then (
`classicmodels`.`sale`.`sale` + ?
) when `classicmodels`.`sale`.`employee_number` = ? then (
`classicmodels`.`sale`.`sale` + ?
) end
where
`classicmodels`.`sale`.`employee_number` in (?, ?, ?)
It can be expressed in jOOQ as follows:
ctx.update(SALE).set(SALE.SALE_,
case_()
.when(SALE.EMPLOYEE_NUMBER.eq(1370L), SALE.SALE_.plus(100))
.when(SALE.EMPLOYEE_NUMBER.eq(1504L), SALE.SALE_.plus(500))
.when(SALE.EMPLOYEE_NUMBER.eq(1166L), SALE.SALE_.plus(1000)))
.where(SALE.EMPLOYEE_NUMBER.in(1370L, 1504L, 1166L))
.execute();
More examples are available in Bulk for MySQL. Next, let's talk about the Loader API, which has built-in bulk support.
Loading (the Loader API)
Whenever we need to load (import) our database tables with data coming from different sources (CSV, JSON, and so on), we can rely on the jOOQ Loader API (org.jooq.Loader). This is a fluent API that allows us to smoothly tackle the most important challenges, such as handling duplicate keys, bulking, batching, committing, and error handling.
The Loader API syntax
Typically, we have a file containing the data to be imported in a common format such as CSV or JSON, and we customize the Loader API general syntax to fit our needs:
ctx.loadInto(TARGET_TABLE)
.[options]
.[source and source to target mapping]
.[listeners]
.[execution and error handling]
While TARGET_TABLE is obviously the table in which the data should be imported, let's see what options we have.
Options
We can mainly distinguish between three types of options that can be used for customizing the import process: options for handling duplicate keys, throttling options, and options for handling failures (errors). The following diagram highlights each category of options and the valid paths that can be used for chaining these options fluently:
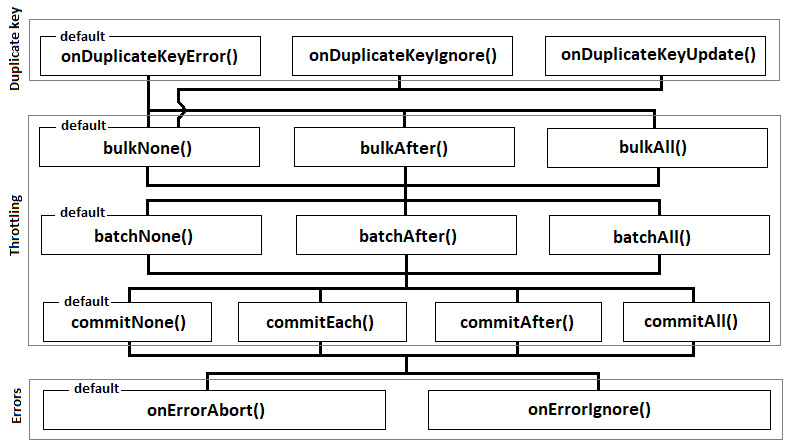
Figure 10.3 – The Loader API options
Let's explore each of these categories, starting with the one for tackling duplicate keys.
Duplicate keys options
A duplicate key occurs when a unique key exists in the table and we attempt to import a record having the same key. By unique key, jOOQ means any unique key, not only primary keys.
So, handling duplicate keys can be done via onDuplicateKeyError(), which is the default, or via onDuplicateKeyIgnore() or onDuplicateKeyUpdate(). The default behavior throws an exception if there are any duplicate keys.
By explicitly using onDuplicateKeyIgnore(), we instruct jOOQ to skip any duplicate key without throwing an exception (this is the synthetic ON DUPLICATE KEY IGNORE clause, which can be emulated by jOOQ depending on dialect). We can instruct jOOQ to execute UPDATE instead of INSERT via onDuplicateKeyUpdate() (this is the synthetic ON DUPLICATE KEY UPDATE clause, which can be emulated by jOOQ depending on dialect).
Throttling options
There are three throttling options that can be used to fine-tune the import. These options refer to bulking, batching, and committing. jOOQ allows us to explicitly use any combination of these options or to rely on the following defaults: no bulking, batching, and committing.
Bulking can be set via bulkNone() (which is the default and means that no bulking will be used), bulkAfter(int rows) (which allows us to specify how many rows will be inserted in one bulk via a multi-row INSERT (insert into ... (...) values (?, ?, ?,...), (?, ?, ?,...), (?, ?, ?,...), ...), and bulkAll() (which attempts to create one bulk from the entire source of data).
As you can see from Figure 10.3, bulkNone() is the only one that can be chained after all options used for handling duplicate values. The bulkAfter() and bulkAll() methods can be chained only after onDuplicateKeyError(). Moreover, bulkNone(), bulkAfter(), and bulkAll() are mutually exclusive.
Batching can be avoided via the default batchNone(), or it can be explicitly set via batchAfter(int bulk) or batchAll(). Explicitly specifying the number of bulk statements that should be sent to the server as a single JDBC batch statement can be accomplished via batchAfter(int bulk). On the other hand, sending a single batch containing all bulks can be done via batchAll(). If bulking is not used (bulkNone()) then it is as if each row represents a bulk, so, for instance, batchAfter(3) means to create batches of three rows each.
As you can see from Figure 10.3, batchNone(), batchAfter(), and batchAll() are mutually exclusive.
Finally, committing data to the database can be controlled via four dedicated methods. By default, commitNone() leaves committing and rolling back operations up to client code (for instance, via commitNone(), we can allow Spring Boot to handle commit and rollback). But, if we want to commit after a certain number of batches, then we have to use commitAfter(int batches) or the handy commitEach() method, which is equivalent to commitAfter(1). And, if we decide to commit all batches at once, then we need commitAll(). If batching is not used (relying on batchNone()), then it is as if each batch is a bulk, (for instance, commitAfter(3) means to commit after every three bulks). If bulking is not used either (relying on bulkNone()), then it is as if each bulk is a row (for instance, commitAfter(3) means to commit after every three rows).
As you can see from Figure 10.3, commitNone(), commitAfter(), commitEach(), and commitAll() are mutually exclusive.
Error options
Attempting to manipulate (import) large amounts of data is a process quite prone to errors. While some of the errors are fatal and should stop the importing process, others can be safely ignored or postponed to be resolved after import. In the case of fatal errors, the Loader API relies on a method named onErrorAbort(). If an error occurs, then the Loader API stops the import process. On the other hand, we have onErrorIgnore(), which instructs the Loader API to skip any insert that caused an error and try to execute the next one.
Special cases
While finding the optimal combination of these options is a matter of benchmarking, there are several things that you should know, as follows:
- If there are no unique keys in our table then onDuplicateKeyUpdate() acts exactly as onDuplicateKeyIgnore().
- If bulkAll() + commitEach() or bulkAll() + commitAfter() is used, then jOOQ forces the usage of commitAll().
- If batchAll() + commitEach() or batchAll() + commitAfter() is used, then jOOQ forces the usage of commitAll().
Next, let's quickly cover the supported sources of data.
Importing data sources
Providing the source of data can be accomplished via dedicated methods that are specific to the supported different data types. For instance, if the data source is a CSV file, then we rely on the loadCSV() method; if it is a JSON file, then we rely on the loadJSON() method; and if it is an XML file, then we rely on loadXML(). Moreover, we can import arrays via loadArrays() and jOOQ Records via loadRecords().
The loadCSV(), loadJSON(), and loadXML() methods come in 10+ flavors that allow us to load data from String, File, InputStream, and Reader. On the other hand, loadArrays() and loadRecords() allow us to load data from an array, Iterable, Iterator, or Stream.
Listeners
The Loader API comes with import listeners to be chained for keeping track of import progress. We mainly have onRowStart(LoaderRowListener listener) and onRowEnd(LoaderRowListener listener). The former specifies a listener to be invoked before processing the current row, while the latter specifies a listener to be invoked after processing the current row. LoaderRowListener is a functional interface.
Execution and error handling
After the Loader API is executed, we have access to meaningful feedback that is available through the returned org.jooq.Loader. For instance, we can find out the number of executed bulks/batches via the executed() method, the number of processed rows via the processed() method, the number of stored rows (INSERT/UPDATE) via the stored() method, the number of ignored rows (caused by errors or duplicate keys) via the ignored() method, and the potential errors via the errors() method as List<LoaderError>. As you'll see in the next section of examples, LoaderError contains details about the errors (if any).
Examples of using the Loader API
Finally, after all this theory, it is time to see some examples of loading CSV, JSON, Record, and arrays. All these examples are executed and dissected in the context of Spring Boot @Transactional. Feel free to practice them under the jOOQ transactional context by simply removing @Transactional and wrapping the code as follows:
ctx.transaction(configuration -> {// Loader API code
configuration.dsl()…
});
So, let's start by loading some CSV.
Loading CSV
Loading CSV is accomplished via the loadCSV() method. Let's start with a simple example based on the following typical CSV file (in.csv):
sale_id,fiscal_year,sale,employee_number,…,trend
1,2003,5282.64,1370,0,…,UP
2,2004,1938.24,1370,0,…,UP
3,2004,1676.14,1370,0,…,DOWN
…
Obviously, this data should be imported in the sale table, so TARGET_TABLE (Table<R>) that should be passed to loadInto() is SALE. Pointing jOOQ to this file is accomplished via the loadCSV() method as follows:
ctx.loadInto(SALE)
.loadCSV(Paths.get("data", "csv", "in.csv").toFile(), StandardCharsets.UTF_8)
.fieldsCorresponding()
.execute();
This code relies on the default options. Notice the call of the fieldsCorresponding() method. This method signals to jOOQ that all input fields having a corresponding field in SALE (with the same name) should be loaded. Practically, in this case, all fields from the CSV file have a correspondent in the SALE table, so all of them will be imported.
But, obviously, this is not always the case. Maybe we want to load only a subset of scattered fields. In such cases, simply pass dummy nulls for the field indexes (positions) that shouldn't be loaded (this is an index/position-based field mapping). This time, let's collect the number of processed rows as well via processed():
int processed = ctx.loadInto(SALE)
.loadCSV(Paths.get("data", "csv", "in.csv").toFile(), StandardCharsets.UTF_8)
.fields(null, SALE.FISCAL_YEAR, SALE.SALE_,
null, null, null, null, SALE.FISCAL_MONTH,
SALE.REVENUE_GROWTH,SALE.TREND)
.execute()
.processed();
This code loads from CSV only SALE.FISCAL_YEAR, SALE.SALE_, SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH, and SALE.TREND. Notice that we've used the fields() method instead of fieldsCorresponding(), since fields() allows us to keep only the desired fields and skip the rest. A sample of the resultant INSERT (in MySQL dialect) looks like this:
INSERT INTO `classicmodels`.`sale` (`fiscal_year`, `sale`,
`fiscal_month`, `revenue_growth`, `trend`)
VALUES (2005, 5243.1, 1, 0.0, 'DOWN')
While this CSV file is a typical one (first line header, data separated by a comma, and so on), sometimes we have to deal with CSV files that are quite customized, such as the following one:
1|2003|5282.64|1370|0|{null}|{null}|1|0.0|*UP*2|2004|1938.24|1370|0|{null}|{null}|1|0.0|*UP*3|2004|1676.14|1370|0|{null}|{null}|1|0.0|*DOWN*…
This CSV file contains the same data as the previous one expect that there is no header line, the data separator is |, the quote mark is *, and the null values are represented as {null}. Loading this CSV file into SALE requires the following code:
List<LoaderError> errors = ctx.loadInto(SALE)
.loadCSV(Paths.get("data", "csv", "in.csv").toFile(), StandardCharsets.UTF_8)
.fields(SALE.SALE_ID, SALE.FISCAL_YEAR, SALE.SALE_,
SALE.EMPLOYEE_NUMBER, SALE.HOT, SALE.RATE, SALE.VAT,
SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH, SALE.TREND)
.ignoreRows(0)
.separator('|').nullString("{null}").quote('*') .execute()
.errors();
First of all, since there is no header, we rely on fields() to explicitly specify the list of fields (SALE_ID is mapped to index 1 in CSV, FISCAL_YEAR to index 2, and so on). Next, we call ignoreRows(0); by default, jOOQ skips the first line, which is considered the header of the CSV file, but since there is no header in this case, we have to instruct jOOQ to take into account the first line as a line containing data. Obviously, this method is useful for skipping n rows as well. Taking it a step further, we call separator(), nullString(), and quote() to override the defaults. Finally, we call errors() and collect potential errors in List<LoaderError>. This is an optional step and is not related to this particular example. In the bundled code (LoadCSV for MySQL), you can see how to loop this list and extract valuable information about what happened during the loading process. Moreover, you'll see more examples of loading CSV files. Next, let's explore more examples for loading a JSON file.
Loading JSON
Loading JSON is done via the loadJSON() method. Let's start with a JSON file:
{"fields": [
{"schema": "classicmodels",
"table": "sale",
"name": "sale_id",
"type": "BIGINT"
},
...
],
"records": [
[1, 2003, 5282.64, 1370, 0, null, null, 1, 0.0, "UP"],
[2, 2004, 1938.24, 1370, 0, null, null, 1, 0.0, "UP"],
...
]
}
This JSON file was previously exported via formatJSON(). Notice the "fields" header, which is useful for loading this file into the SALE table via the mapping provided by the fieldsCorresponding() method. Without a header, the fieldsCorresponding() method cannot produce the expected results since the input fields are missing. But, if we rely on the fields() method, then we can list the desired fields (all or a subset of them) and count on index-based mapping without worrying about the presence or absence of the "fields" header. Moreover, this time, let's add an onRowEnd() listener as well:
ctx.loadInto(SALE)
.loadJSON(Paths.get("data", "json", "in.json").toFile(), StandardCharsets.UTF_8)
.fields(null, SALE.FISCAL_YEAR, SALE.SALE_, null, null,
null, null, SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH,
SALE.TREND)
.onRowEnd(ll -> { System.out.println("Processed row: " + Arrays.toString(ll.row()));
System.out.format("Executed: %d, ignored: %d, processed: %d, stored: %d ", ll.executed(), ll.ignored(),
ll.processed(), ll.stored());
})
.execute();
After each row is processed you'll see an output in the log as shown here:
Processed row: [28, 2005, 5243.1, 1504, …, DOWN]
Executed: 28, ignored: 0, processed: 28, stored: 28
But, let's look at a JSON file without the "fields" header, as follows:
[
{"fiscal_month": 1,
"revenue_growth": 0.0,
"hot": 0,
"vat": null,
"rate": null,
"sale": 5282.64013671875,
"trend": "UP",
"sale_id": 1,
"fiscal_year": 2003,
"employee_number": 1370
},
{…
},
…
This kind of JSON can be loaded via fieldsCorresponding() or via fields(). Since the field names are available as JSON keys, the fieldsCorresponding() method maps them correctly. Using fields() should be done by keeping in mind the order of keys in this JSON. So, "fiscal_month" is on index 1, "revenue_growth" on index 2, and so on. Here is an example that loads only "fiscal_month", "revenue_growth", "sale", "fiscal_year", and "employee_number":
int processed = ctx.loadInto(SALE)
.loadJSON(Paths.get("data", "json", "in.json").toFile(), StandardCharsets.UTF_8)
.fields(SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH,
null, null, null, SALE.SALE_, null, null,
SALE.FISCAL_YEAR, SALE.EMPLOYEE_NUMBER)
.execute()
.processed();
But, sometimes, the missing data is in JSON itself, as here:
[
{"sale_id": 1,
"fiscal_year": 2003,
"sale": 5282.64
"fiscal_month": 1,
"revenue_growth": 0.0
},
…
Here is another example:
[
[
1,
2003,
5282.64,
1,
0.0
],
…
This time, in both cases, we must rely on fields(), as here:
ctx.loadInto(SALE)
.loadJSON(Paths.get("data", "json", "in.json").toFile(), StandardCharsets.UTF_8)
.fields(SALE.SALE_ID, SALE.FISCAL_YEAR, SALE.SALE_,
SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH)
.execute();
Next, let's assume that we have a JSON file that should be imported into the database using batches of size 2 (rows), so we need batchAfter(2). The commit (as in all the previous examples) will be accomplished by Spring Boot via @Transactional:
@Transactional
public void loadJSON () {int executed = ctx.loadInto(SALE)
.batchAfter(2)// each *batch* has 2 rows
.commitNone() // this is default, so it can be omitted
.loadJSON(Paths.get("data", "json", "in.json").toFile(), StandardCharsets.UTF_8)
.fieldsCorresponding()
.execute()
.executed();
}
Since commitNone() is the default behavior, it could be omitted. Essentially, commitNone() allows @Transactional to handle the commit/rollback actions. By default, @Transactional commits the transaction at the end of the annotated method. If something goes wrong, the entire payload (all batches) is rolled back. But, if you remove @Transactional, then auto-commit =true goes into action. This commits after each batch (so, after every two rows). If something goes wrong, then there is no rollback action, but the loading process is aborted immediately since we rely on the default settings, onDuplicateKeyError() and onErrorAbort(). If we remove @Transactional and set auto-commit to false (spring.datasource.hikari.auto-commit=false), then nothing commits.
This example returns the number of executed batches via executed(). For instance, if there are 36 rows processed with batchAfter(2), then executed() returns 18.
Next, let's consider a JSON file that contains duplicate keys. Every time a duplicate key is found, the Loader API should skip it, and, in the end, it should report the number of ignored rows. Moreover, the Loader API should commit after each batch of three rows:
int ignored = ctx.loadInto(SALE)
.onDuplicateKeyIgnore()
.batchAfter(3) // each *batch* has 3 rows
.commitEach() // commit each batch
.loadJSON(Paths.get("data", "json", "in.json").toFile(), StandardCharsets.UTF_8)
.fieldsCorresponding()
.execute()
.ignored();
If you want to execute UPDATE instead of ignoring duplicate keys, just replace onDuplicateKeyIgnore() with onDuplicateKeyUpdate().
Finally, let's import a JSON using bulkAfter(2), batchAfter(3), and commitAfter(3). In other words, each bulk has two rows, and each batch has three bulks. Therefore, six rows commit after three batches, that is nine bulks, so after 18 rows, you get the following:
int inserted = ctx.loadInto(SALE)
.bulkAfter(2) // each *bulk* has 2 rows
.batchAfter(3) // each *batch* has 3 *bulks*, so 6 rows
.commitAfter(3) // commit after 3 *batches*, so after 9
// *bulks*, so after 18 rows
.loadJSON(Paths.get("data", "json", "in.json").toFile(), StandardCharsets.UTF_8)
.fieldsCorresponding()
.execute()
.stored();
If something goes wrong, the last uncommitted batch is rolled back without affecting the already committed batches. More examples are available in the bundled code, LoadJSON, for MySQL.
Loading records
Loading jOOQ Record via the Loader API is a straightforward process accomplished via the loadRecords() method. Let's consider the following set of records:
Result<SaleRecord> result1 = …;
Result<Record3<Integer, Double, String>> result2 = …;
Record3<Integer, Double, String>[] result3 = …;
SaleRecord r1 = new SaleRecord(1L, …);
SaleRecord r2 = new SaleRecord(2L, …);
SaleRecord r3 = new SaleRecord(3L, …);
Loading them can be done as follows:
ctx.loadInto(SALE)
.loadRecords(result1)
.fields(null, SALE.FISCAL_YEAR, SALE.SALE_,
SALE.EMPLOYEE_NUMBER, SALE.HOT, SALE.RATE, SALE.VAT,
SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH, SALE.TREND)
.execute();
ctx.loadInto(SALE).loadRecords(result2/result3)
.fieldsCorresponding()
.execute();
ctx.loadInto(SALE).loadRecords(r1, r2, r3)
.fieldsCorresponding()
.execute();
Let's look at loading the following map of Record:
Map<CustomerRecord, CustomerdetailRecord> result = …;
So, CustomerRecord should be loaded in CUSTOMER, and CustomerdetailRecord should be loaded in CUSTOMERDETAIL. For this, we can use Map.keySet() and Map.values() as follows:
ctx.loadInto(CUSTOMER)
.onDuplicateKeyIgnore()
.loadRecords(result.keySet())
.fieldsCorresponding()
.execute();
ctx.loadInto(CUSTOMERDETAIL)
.onDuplicateKeyIgnore()
.loadRecords(result.values())
.fieldsCorresponding()
.execute();
More examples are available in the bundled code, LoadRecords, for MySQL.
Loading arrays
Loading arrays is accomplished via the loadArrays() method. Let's consider the following array containing data that should be loaded into the SALE table:
Object[][] result = ctx.selectFrom(…).fetchArrays();
Loading this array can be done as follows:
ctx.loadInto(SALE)
.loadArrays(Arrays.stream(result)) // Arrays.asList(result)
.fields(null, SALE.FISCAL_YEAR, SALE.SALE_,
SALE.EMPLOYEE_NUMBER, SALE.HOT, SALE.RATE, SALE.VAT,
SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH, SALE.TREND)
.execute();
Here is another example that relies on loadArrays(Object[]... os):
int executed = ctx.loadInto(SALE)
.onDuplicateKeyIgnore()
.batchAfter(2)
.commitEach()
.loadArrays(
new Object[]{1, 2005, 582.64, 1370, 0,… , "UP"}, new Object[]{2, 2005, 138.24, 1370, 0,… , "DOWN"}, new Object[]{3, 2005, 176.14, 1370, 0,… , "DOWN"}).fields(SALE.SALE_ID, SALE.FISCAL_YEAR, SALE.SALE_,
SALE.EMPLOYEE_NUMBER, SALE.HOT, SALE.RATE,
SALE.VAT, SALE.FISCAL_MONTH, SALE.REVENUE_GROWTH,
SALE.TREND)
.execute()
.ignored();
You can check out these examples next to others not listed here in the bundled code, LoadArrays, for MySQL. It is time to summarize this chapter.
Summary
In this chapter, we've covered four important topics: exporting, batching, bulking, and loading. As you saw, jOOQ comes with dedicated APIs for accomplishing each of these tasks that require a lot of complex code under the hood. Frequently, jOOQ simplifies the complexity (as usual) and allows us to focus on what we have to do and less on how we do it. For instance, it is amazing to see that it takes seconds to write a snippet of code for loading a CSV or a JSON file into the database while having fluent and smooth support for error handling control, diagnosis output, bulking, batching, and committing control.
In the next chapter, we will cover the jOOQ keys.