
Chapter 3. Advanced File and Directory Processing, and the Registry
File systems provide more than sequential processing; they must also provide random access, file locking, directory processing, and file attribute management. Starting with random file access, which is required by database, file management, and many other applications, this chapter shows how to access files randomly at any location and shows how to use Windows 64-bit file pointers to access files larger than 4GB.
The next step is to show how to scan directory contents and how to manage and interpret file attributes, such as time stamps, access, and size. Finally, file locking protects files from concurrent modification by more than one process (Chapter 6) or thread (Chapter 7).
The final topic is the Windows registry, a centralized database that contains configuration information for applications and for Windows itself. Registry access functions and program structure are similar to the file and directory management functions, as shown by the final program example, so this short topic is at the chapter’s end rather than in a separate chapter.
The 64-Bit File System
The Windows NTFS supports 64-bit file addresses so that files can, in principle, be as long as 264 bytes. The 232-byte length limit of older 32-bit file systems, such as FAT, constrains file lengths to 4GB (4 × 109 bytes). This limit is a serious constraint for numerous applications, including large database and multimedia systems, so any complete modern OS must support much larger files.
Files larger than 4GB are sometimes called very large or huge files, although huge files have become so common that we’ll simply assume that any file could be huge and program accordingly.
Needless to say, some applications will never need huge files, so, for many programmers, 32-bit file addresses will be adequate. It is, however, a good idea to start working with 64-bit addresses from the beginning of a new development project, given the rapid pace of technical change and disk capacity growth,1 cost improvements, and application requirements.
1 Even inexpensive laptop computers contain 80GB or more of disk capacity, so “huge” files larger than 4GB are possible and sometimes necessary, even on small computers.
Win32, despite the 64-bit file addresses and the support for huge files, is still a 32-bit OS API because of its 32-bit memory addressing. Win32 addressing limitations are not a concern until Chapter 5.
File Pointers
Windows, just like UNIX, the C library, and nearly every other OS, maintains a file pointer with each open file handle, indicating the current byte location in the file. The next WriteFile or ReadFile operation will start transferring data sequentially to or from that location and increment the file pointer by the number of bytes transferred. Opening the file with CreateFile sets the pointer to zero, indicating the start of the file, and the handle’s pointer is advanced with each successive read or write. The crucial operation required for random file access is the ability to set the file pointer to an arbitrary value, using SetFilePointer and SetFilePointerEx.
The first function, SetFilePointer, is obsolete, as the handling of 64-bit file pointers is clumsy. SetFilePointerEx, one of a number of “extended”2 functions, is the correct choice, as it uses 64-bit pointers naturally. Nonetheless, we describe both functions here because SetFilePointer is still common. In the future, if the extended function is supported in NT5 and is actually superior, we mention the nonextended function only in passing.
2 The extended functions have an “Ex” suffix and, as would be expected, provide additional functionality. There is no consistency among the extended functions in terms of the nature of the new features or parameter usage. For example, MoveFileEx (Chapter 2) adds a new flag input parameter, while SetFilePointerEx has a LARGE_INTEGER input and output parameters. The registry functions (end of this chapter) have additional extended functions.
SetFilePointer shows, for the first time, how Windows handles addresses in large files. The techniques are not always pretty, and SetFilePointer is easiest to use with small files.

Return: The low-order DWORD (unsigned) of the new file pointer. The high-order portion of the new file pointer goes to the DWORD indicated by lpDistanceToMoveHigh (if non-NULL). In case of error, the return value is 0xFFFFFFFF.
Parameters
hFile is the handle of an open file with read or write access (or both).
lDistanceToMove is the 32-bit LONG signed distance to move or unsigned file position, depending on the value of dwMoveMethod.
lpDistanceToMoveHigh points to the high-order portion of the move distance. If this value is NULL, the function can operate only on files whose length is limited to 232–2. This parameter is also used to receive the high-order return value of the file pointer.3 The low-order portion is the function’s return value.
3 Windows is not consistent, as can be seen by comparing SetFilePointer with GetCurrentDirectory. In some cases, there are distinct input and output parameters.
dwMoveMethod specifies one of three move modes.
• FILE_BEGIN: Position the file pointer from the start of the file, interpreting DistanceToMove as unsigned.
• FILE_CURRENT: Move the pointer forward or backward from the current position, interpreting DistanceToMove as signed. Positive is forward.
• FILE_END: Position the pointer backward or forward from the end of the file.
You can obtain the file length by specifying a zero-length move from the end of file, although the file pointer is changed as a side effect.
The method of representing 64-bit file positions causes complexities because the function return can represent both a file position and an error code. For example, suppose that the actual position is location 232–1 (that is, 0xFFFFFFFF) and that the call also specifies the high-order move distance. Invoke GetLastError to determine whether the return value is a valid file position or whether the function failed, in which case the return value would not be NO_ERROR. This explains why file lengths are limited to 232–2 when the high-order component is omitted.
Another confusing factor is that the high- and low-order components are separated and treated differently. The low-order address is treated as a call by value and returned by the function, whereas the high-order address is a call by reference and is both input and output. SetFilePointerEx is much easier to use, but, first, we need to describe Windows 64-bit arithmetic.
64-Bit Arithmetic
It is not difficult to perform the 64-bit file pointer arithmetic, and our example programs use the Windows LARGE_INTEGER 64-bit data type, which is a union of a LONGLONG (called QuadPart) and two 32-bit quantities (LowPart, a DWORD, and HighPart, a LONG). LONGLONG supports all the arithmetic operations. There is also a ULONGLONG data type, which is unsigned. The guidelines for using LARGE_INTEGER data are:
• SetFilePointerEx and other functions require LARGE_INTEGER parameters.
• Perform arithmetic on the QuadPart component of a LARGE_INTEGER value.
• Use the LowPart and HighPart components as required; this is illustrated in an upcoming example.
SetFilePointerEx
SetFilePointerEx is straightforward, requiring a LARGE_INTEGER input for the requested position and a LARGE_INTEGER output for the actual position. The return result is a Boolean to indicate success or failure.

lpNewFilePointer can be NULL, in which case, the new file pointer is not returned. dwMoveMethod has the same values as for SetFilePointer.
Specifying File Position with an Overlapped Structure
Windows provides another way to specify the read/write file position. Recall that the final parameter to both ReadFile and WriteFile is the address of an overlapped structure, and this value has always been NULL in the previous examples. Two members of this structure are Offset and OffsetHigh. You can set the appropriate values in an overlapped structure, and the I/O operation can start at the specified location. The file pointer is changed to point past the last byte transferred, but the overlapped structure values do not change. The overlapped structure also has a handle member used for asynchronous overlapped I/O (Chapter 14), hEvent, that must be NULL for now.
Caution: Even though this example uses an overlapped structure, this is not overlapped I/O, which is covered in Chapter 14.
The overlapped structure is especially convenient when updating a file record, as the following code fragment illustrates; otherwise, separate SetFilePointerEx calls would be required before the ReadFile and WriteFile calls. The hEvent field is the last of five fields, as shown in the initialization statement. The LARGE_INTEGER data type represents the file position.

If the file handle was created with the FILE_FLAG_NO_BUFFERING CreateFile flag, then both the file position and the record size (byte count) must be multiples of the disk volume’s sector size. Obtain physical disk information, including sector size, with GetDiskFreeSpace.
Note: You can append to the end of the file without knowing the file length. Just specify 0xFFFFFFFF on both Offset and OffsetHigh before performing the write.
Overlapped structures are used again later in this chapter to specify file lock regions and in Chapter 14 for asynchronous I/O and random file access.
Getting the File Size
Determine a file’s size by positioning 0 bytes from the end and using the file pointer value returned by SetFilePointerEx. Alternatively, you can use a specific function, GetFileSizeEx, for this purpose. GetFileSizeEx, like SetFilePointerEx, returns the 64-bit value as a LARGE_INTEGER.
![]()
Return: The file size is in *lpFileSize. A false return indicates an error; check GetLastError.
GetFileSize (now obsolete) and GetFileSizeEx require that the file have an open handle. It is also possible to obtain the length by name. GetCompressedFileSize returns the size of the compressed file, and FindFirstFile, discussed in the upcoming “File Attributes and Directory Processing” section, gives the exact size of a named file.
Setting the File Size, File Initialization, and Sparse Files
The SetEndOfFileEx function resizes the file using the current value of the file pointer to determine the length. A file can be extended or truncated. With extension, the contents of the extended region are not defined. The file will actually consume the disk space and user space quotas unless the file is a sparse file. Files can also be compressed to consume less space. Exercise 3–1 explores this topic.
SetEndOfFileEx sets the physical end of file beyond the current “logical” end. The file’s tail, which is the portion between the logical and physical ends, contains no valid data. You can shorten the tail by writing data past the logical end.
With sparse files, disk space is consumed only as data is written. A file, directory, or volume can be specified to be sparse by the administrator. Also, the DeviceIoControl function can use the FSCTL_SET_SPARSE flag to specify that an existing file is sparse. Program 3-1 illustrates a situation where a sparse file can be used conveniently. SetFileValidData does not apply to sparse files.
Program 3-1 RecordAccess: Direct File Access




NTFS files and file tails are initialized to zeros for security.
Notice that the SetEndOfFileEx call is not the only way to extend a file. You can also extend a file using many successive write operations, but this will result in more fragmented file allocation; SetEndOfFile allows the OS to allocate larger contiguous disk units.
Example: Random Record Updates
Program 3-1, RecordAccess, maintains a fixed-size file of fixed-size records. The file header contains the number of nonempty records in the file along with the file record capacity. The user can interactively read, write (update), and delete records, which contain time stamps, a text string, and a count to indicate how many times the record has been modified. A simple and realistic extension would be to add a key to the record structure and locate records in the file by applying a hash function to the key value.
The program demonstrates file positioning to a specified record and shows how to perform 64-bit arithmetic using the Windows LARGE_INTEGER data type. One error check is included to illustrate file pointer logic. This design also illustrates file pointers, multiple overlapped structures, and file updating with 64-bit file positions.
The total number of records in the file is specified on the command line; a large number will create a very large or even huge file, as the record size is about 300 bytes. Some simple experiments will quickly show that large files should be sparse; otherwise, the entire file must be allocated and initialized on the disk, which could consume considerable time and disk space. While not shown in the Program 3-1 listing, the program contains optional code to create a sparse file. That code will not function on systems that do not support sparse files, such as Windows XP Home Edition.
The Examples file (on the book’s Web site) provides three related programs: tail.c is another example of random file access; getn.c is a simpler version of RecordAccess that can only read records; and cciMT (included with the programs for Chapter 14 in Examples, although not in the text) also illustrates random file access.
Note: Program 3-1 uses the SYSTEMTIME data type and the GetSystemTime function. While we have not discussed these, the usage is straightforward.
Run 3-1 shows RecordAccess working with a 6GB file (20 million records). There are write, read, update, and delete operations. The DIR command at the end shows the file size. The file is not sparse, and writing record number 19,000,000 required about two minutes on the test machine. During this time period, the Windows Resource Monitor showed high disk utilization.
Run 3-1 RecordAccess: Writing, Reading, and Deleting Records
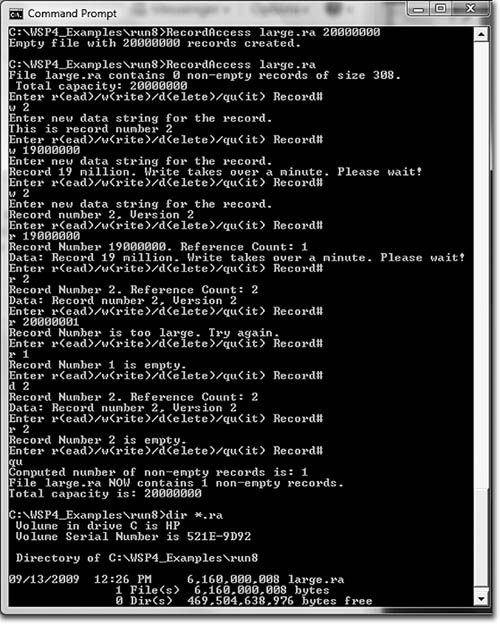
Note: The output messages shown in Program 3-1 were shortened and are not exactly the same as those in the Run 3-1 screenshot.
Caution: If you run this program on your computer, do not create such a large number of records unless you have sufficient free disk space. Initially, it’s safer to use just a few hundred records until you are confident that the program is operating correctly. Furthermore, while Run 3-1 worked well on a desktop system with plentiful memory and disk storage, it hung on a laptop. Laptop operation was successful, however, with a 600MB file (2 million records).
File Attributes and Directory Processing
This section shows how to search a directory for files and other directories that satisfy a specified name pattern and, at the same time, obtain file attributes. Searches require a search handle provided by FindFirstFile. Obtain specific files with FindNextFile, and terminate the search with FindClose. There is also an extended version, FindFirstFileEx, which has more search options, such as allowing for case sensitivity. An exercise suggests exploring the extended function.
![]()
Return: A search handle. INVALID_HANDLE_VALUE indicates failure.
FindFirstFile examines both subdirectory and file names, looking for a name match. The returned HANDLE is for use in subsequent searches. Note that it is not a kernel handle.
Parameters
lpFileName points to a directory or pathname that can contain wildcard characters (? and *). Search for a single specific file by omitting wildcard characters.
lpffd points to a WIN32_FIND_DATA structure (the “WIN32” part of the name is misleading, as this can be used on 64-bit computers) that contains information about the first file or directory to satisfy the search criteria, if any are found.
WIN32_FIND_DATA has the following structure:
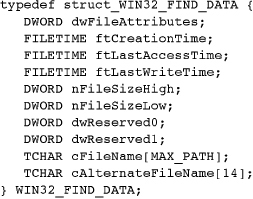
Test dwFileAttributes for the values described with CreateFile along with some additional values, such as FILE_ATTRIBUTE_SPARSE_FILE and FILE_ATTRIBUTE_ENCRYPTED, which CreateFile does not set. The three file times (creation, last access, and last write) are described in an upcoming section. The file size fields, giving the current file length, are self-explanatory. cFileName is not the pathname; it is the file name by itself. cAlternateFileName is the DOS 8.3 (including the period) version of the file name; this information is rarely used and is appropriate only to determine how a file would be named on an old FAT16 file system.
Frequently, the requirement is to scan a directory for files that satisfy a name pattern containing ? and * wildcard characters. To do this, use the search handle obtained from FindFirstFile, which retains information about the search name, and call FindNextFile.
![]()
FindNextFile will return FALSE in case of invalid arguments or if no more matching files are found, in which case GetLastError will return ERROR_NO_MORE_FILES.
When the search is complete, close the search handle. Do not use CloseHandle. Closing a search handle will cause an exception. Instead, use the following:
The function GetFileInformationByHandle obtains the same information for a specific file, specified by an open file handle. It also returns a field, nNumberOfLinks, which indicates the number of hard links set by CreateHardLink; this value is one when the file is first created, is increased by one for each CreateHardLink call targeting the file, and is decreased by one when either a hard link name or the original name is deleted.
The FindNextFile method of wildcard expansion is necessary even in programs executed from the MS-DOS prompt because the DOS shell does not expand wildcards.
Pathnames
You can obtain a file’s full pathname using GetFullPathName. GetShortPathName returns the name in DOS 8.3 format, assuming that the volume supports short names.
NT 5.1 introduced SetFileShortName, which allows you to change the existing short name of a file or directory. This can be convenient because the existing short names are often difficult to interpret.
Other Methods of Obtaining File and Directory Attributes
The FindFirstFile and FindNextFile functions can obtain the following file attribute information: attribute flags, three time stamps, and file size. There are several other related functions, including one to set attributes, and they can deal directly with the open file handle rather than scan a directory or use a file name. Three such functions, GetFileSize, GetFileSizeEx, and SetEndOfFile, were described earlier in this chapter.
Distinct functions are used to obtain the other attributes. For example, to obtain the time stamps of an open file, use the GetFileTime function.

The file times here and in the WIN32_FIND_DATA structure are 64-bit unsigned integers giving elapsed 100-nanosecond units (107 units per second) from a base time (January 1, 1601), expressed as Universal Coordinated Time (UTC).4 There are several convenient functions for dealing with times.
4 Do not, however, expect to get 100-nanosecond precision; precision will vary depending on hardware characteristics.
• FileTimeToSystemTime (not described here; see MSDN or Program 3-2) breaks the file time into individual units ranging from years down to seconds and milliseconds. These units are suitable, for example, when displaying or printing times.
Program 3-2 lsW: File Listing and Directory Traversal




• SystemTimeToFileTime reverses the process, converting time expressed in these individual units to a file time.
• CompareFileTime determines whether one file time is less than (–1), equal to (0), or greater than (+1) another.
• Change the time stamps with SetFileTime; use NULL for times that are not to be changed. NTFS supports all three file times, but the FAT gives an accurate result only for the last access time.
• FileTimeToLocalFileTime and LocalFileTimeToFileTime convert between UTC and the local time.
GetFileType, not described in detail here, distinguishes among disk files, character files (actually, devices such as printers and consoles), and pipes (see Chapter 11). The file, again, is specified with a handle.
The function GetFileAttributes uses the file or directory name, and it returns just the dwFileAttributes information.
The attributes can be tested for appropriate combinations of several mask values. Some attributes, such as the temporary file attribute, are originally set with CreateFile. The attribute values include the following:
• FILE_ATTRIBUTE_DIRECTORY
• FILE_ATTRIBUTE_NORMAL
• FILE_ATTRIBUTE_READONLY
• FILE_ATTRIBUTE_TEMPORARY
Be certain to test the return value for failure (INVALID_FILE_ATTRIBUTES, which is 0xFFFFFFFF) before trying to determine the attributes. This value would make it appear as if all values were set.
The function SetFileAttributes changes these attributes in a named file.
Temporary File Names
The next function creates names for temporary files. The name can be in any specified directory and must be unique.
GetTempFileName gives a unique file name, with the .tmp suffix, in a specified directory and optionally creates the file. This function is used extensively in later examples (Program 6-1, Program 7-1, and elsewhere).

Return: A unique numeric value used to create the file name. This will be uUnique if uUnique is nonzero. On failure, the return value is zero.
Parameters
lpPathName is the directory for the temporary file. “.” is a typical value specifying the current directory. Alternatively, use GetTempPath, a Windows function not described here, to give the name of a directory dedicated to temporary files.
lpPrefixString is the prefix of the temporary name. You can only use 8-bit ASCII characters. uUnique is normally zero so that the function will generate a unique four-digit suffix and will create the file. If this value is nonzero, the file is not created; do that with CreateFile, possibly using FILE_FLAG_DELETE_ON_CLOSE.
lpTempFileName points to the buffer that receives the temporary file name. The buffer’s byte length should be at least the same value as MAX_PATH. The resulting pathname is a concatenation of the path, the prefix, the four-digit hex number, and the .tmp suffix.
Example: Listing File Attributes
It is now time to illustrate the file and directory management functions. Program 3-2, lsW, shows a limited version of the UNIX ls directory listing command, which is similar to the Windows DIR command. lsW can show file modification times and the file size, although this version gives only the low order of the file size.
The program scans the directory for files that satisfy the search pattern. For each file located, the program shows the file name and, if the -l option is specified, the file attributes. This program illustrates many, but not all, Windows directory management functions.
The bulk of Program 3-2 is concerned with directory traversal. Notice that each directory is traversed twice—once to process files and again to process subdirectories—in order to support the -R recursive option.
Program 3-2, as listed here, will properly carry out a command with a relative pathname such as:
lsW -R include*.h
It will not work properly, however, with an absolute pathname such as:
lsW -R C:ProjectslsDebug*.obj
because the program, as listed, depends on setting the directory relative to the current directory. The complete solution (in Examples) analyzes pathnames and will also carry out the second command.
An exercise suggests modifying this program to remove the SetCurrentDirectory calls so as to avoid the risk of program failures leaving you in an unexpected state.
Run 3-2 lsW: Listing Files and Directories

Example: Setting File Times
Program 3-3 implements the UNIX touch command, which changes file access and modifies times to the current value of the system time. Exercise 3–12 enhances touch so that the new file time is a command line option, as with the actual UNIX command.
Program 3-3 touch: Setting File Times

The program uses GetSystemTimeAsFileTime, which is more convenient than calling GetSystemTime (used in Program 3-1) followed by SystemTimeToFileTime. See MSDN for more information, although these functions are straightforward.
Run 3-3 shows touch operation, changing the time of an existing file and creating a new file.
Run 3-3 touch: Changing File Time and Creating New Files

File Processing Strategies
An early decision in any Windows development or porting project is to select whether to perform file processing with the C library or with the Windows functions. This is not an either/or decision because the functions can be mixed (with caution) even when you’re processing the same file.
The C library offers several distinct advantages, including the following.
• The code will be portable to non-Windows systems.
• Convenient line- and character-oriented functions that do not have direct Windows equivalents simplify string processing.
• C library functions are generally higher level and easier to use than Windows functions.
• The line and stream character-oriented functions can easily be changed to generic calls, although the portability advantage will be lost.
Nonetheless, there are some limitations to the C library. Here are some examples.
• The C library cannot manage or traverse directories, and it cannot obtain or set most file attributes.
• The C library uses 32-bit file position in the fseek function, although Windows does provide a proprietary _fseeki64 function. Thus, while it can read huge files sequentially, it is not possible to position arbitrarily in a huge file, as is required, for instance, by Program 3-1.
• Advanced features such as file security, memory-mapped files, file locking, asynchronous I/O, and interprocess communication are not available with the C library. Some of the advanced features provide performance benefits, as shown in Chapter 5 and Appendix C.
Another possibility is to port existing UNIX code using a compatibility library. Microsoft C provides a limited compatibility library with many, but not all, UNIX functions. The Microsoft UNIX library includes I/O functions, but most process management and other functions are omitted. Functions are named with an underscore prefix—for example, _read, _write, _stat, and so on.
Decisions regarding the use and mix of C library, compatibility libraries, and the Windows API should be driven by project requirements. Many of the Windows advantages are shown in the following chapters, and the performance figures in Appendix C are useful when performance is a factor.
File Locking
An important issue in any computer running multiple processes is coordination and synchronization of access to shared objects, such as files.
Windows can lock files, in whole or in part, so that no other process (running program) or thread within the process can access the locked file region. File locks can be read-only (shared) or read-write (exclusive). Most importantly, the locks belong to the process. Any attempt to access part of a file (using ReadFile or WriteFile) in violation of an existing lock will fail because the locks are mandatory at the process level. Any attempt to obtain a conflicting lock will also fail even if the process already owns the lock. File locking is a limited form of synchronization between concurrent processes and threads; synchronization is covered in much more general terms starting in Chapter 8.
The most general function is LockFileEx, and there is a less general function, LockFile.
LockFileEx is a member of the extended I/O class of functions, and the overlapped structure, used earlier to specify file position to ReadFile and WriteFile, is necessary to specify the 64-bit file position and range of the file region to be locked.

LockFileEx locks a byte range in an open file for either shared (multiple readers) or exclusive (one reader-writer) access.
Parameters
hFile is the handle of an open file. The handle must have at least GENERIC_READ.
dwFlags determines the lock mode and whether to wait for the lock to become available.
LOCKFILE_EXCLUSIVE_LOCK, if set, indicates a request for an exclusive, read-write lock. Otherwise, it requests a shared (read-only) lock.
LOCKFILE_FAIL_IMMEDIATELY, if set, specifies that the function should return immediately with FALSE if the lock cannot be acquired. Otherwise, the call blocks until the lock becomes available.
dwReserved must be 0. The two parameters with the length of the byte range are self-explanatory.
lpOverlapped points to an OVERLAPPED data structure containing the start of the byte range. The overlapped structure contains three data members that must be set (the others are ignored); the first two determine the start location for the locked region.
• DWORD Offset (this is the correct name; not OffsetLow).
• DWORD OffsetHigh.
• HANDLE hEvent should be set to 0.
A file lock is removed using a corresponding UnlockFileEx call; all the same parameters are used except dwFlags.

You should consider several factors when using file locks.
• The unlock must use exactly the same range as a preceding lock. It is not possible, for example, to combine two previous lock ranges or unlock a portion of a locked range. An attempt to unlock a region that does not correspond exactly with an existing lock will fail; the function returns FALSE and the system error message indicates that the lock does not exist.
• Locks cannot overlap existing locked regions in a file if a conflict would result.
• It is possible to lock beyond the range of a file’s length. This approach could be useful when a process or thread extends a file.
• Locks are not inherited by a newly created process.
• The lock and unlock calls require that you specify the lock range start and size as separate 32-bit integers. There is no way to specify these values directly with LARGE_INTEGER values as there is with SetFilePointerEx.
Table 3-1 shows the lock logic when all or part of a range already has a lock. This logic applies even if the lock is owned by the same process that is making the new request.

Table 3-2 shows the logic when a process attempts a read or write operation on a file region with one or more locks, owned by a separate process, on all or part of the read-write region. A failed read or write may take the form of a partially completed operation if only a portion of the read or write record is locked.
Table 3-2 Locks and I/O Operation

Read and write operations are normally in the form of ReadFile and WriteFile calls or their extended versions, ReadFileEx and WriteFileEx (Chapter 14). Diagnosing a read or write failure requires calling GetLastError.
Accessing memory mapped to a file is another form of file I/O: see Chapter 5. Lock conflicts are not detected at the time of memory reference; rather, they are detected at the time that the MapViewOfFileEx function is called. This function makes a part of the file available to the process, so the lock must be checked at that time.
The LockFile function is a legacy, limited, special case and is a form of advisory locking. Only exclusive access is available, and LockFile returns immediately. That is, LockFile does not block. Test the return value to determine whether you obtained the lock.
Releasing File Locks
Every successful LockFileEx call must be followed by a single matching call to UnlockFileEx (the same is true for LockFile and UnlockFile). If a program fails to release a lock or holds the lock longer than necessary, other programs may not be able to proceed, or, at the very least, their performance will be negatively impacted. Therefore, programs should be carefully designed and implemented so that locks are released as soon as possible, and logic that might cause the program to skip the unlock should be avoided. Chapter 8 discusses this same issue with regard to mutex and CRITICAL_SECTION locks.
Termination handlers (Chapter 4) are a useful way to ensure that the unlock is performed.
Lock Logic Consequences
Although the file lock logic in Tables 3-1 and 3-2 is natural, it has consequences that may be unexpected and cause unintended program defects. Here are some examples.
• Suppose that process A and process B periodically obtain shared locks on a file, and process C blocks when attempting to gain an exclusive lock on the same file after process A gets its shared lock. Process B may now gain its shared lock even though C is still blocked, and C will remain blocked even after A releases the lock. C will remain blocked until all processes release their shared locks even if they obtained them after C blocked. In this scenario, it is possible that C will be blocked forever even though all the other processes manage their shared locks properly.
• Assume that process A has a shared lock on the file and that process B attempts to read the file without obtaining a shared lock first. The read will still succeed even though the reading process does not own any lock on the file because the read operation does not conflict with the existing shared lock.
• These statements apply both to entire files and to file regions.
• File locking can produce deadlocks in the same way as with mutual exclusion locks (see Chapter 8 for more on deadlocks and their prevention).
• A read or write may be able to complete a portion of its request before encountering a conflicting lock. The read or write will return FALSE, and the byte transfer count will be less than the number requested.
Using File Locks
File locking examples are deferred until Chapter 6, which covers process management. Programs 6-4, 6-5, and 6-6 use locks to ensure that only one process at a time can modify a file.
The Registry
The registry is a centralized, hierarchical database for application and system configuration information. Access to the registry is through registry keys, which are analogous to file system directories. A key can contain other keys or key/value pairs, where the key/value pairs are analogous to directory names and file names. Each value under a key has a name, and for each key/value pair, corresponding data can be accessed and modified.
The user or administrator can view and edit the registry contents through the registry editor, using the REGEDIT command. Alternatively, programs can manage the registry through the registry API functions described in this section.
Note: Registry programming is discussed here due to its similarity to file processing and its importance in some, but not all, applications. The example will be a straightforward modification of the lsW example. This section could, however, be a separate short chapter. Therefore, if you are not concerned with registry programming, skip this section.
The registry contains information such as the following and is stored hierarchically in key/value pairs.
• Windows version number, build number, and registered user. However, programs usually access this information through the Windows API, as we do in Chapter 6 (the version program, available in the Examples).
• Similar information for every properly installed application.
• Information about the computer’s processor type, number of processors, memory, and so on.
• User-specific information, such as the home directory and application preferences.
• Security information such as user account names.
• Installed services (Chapter 13).
• Mappings from file name extensions to executable programs. These mappings are used by the user interface shell when the user clicks on a file icon. For example, the .doc and .docx extensions might be mapped to Microsoft Word.
UNIX systems store similar information in the /etc directory and files in the user’s home directory. The registry centralizes all this information in a uniform way. In addition, the registry can be secured using the security features described in Chapter 15.
The registry management API is described here, but the detailed contents and meaning of the various registry entries are beyond the book’s scope. Nonetheless, Figure 3-1 shows a typical view from the registry editor and gives an idea of the registry structure and contents.
Figure 3-1 The Registry Editor
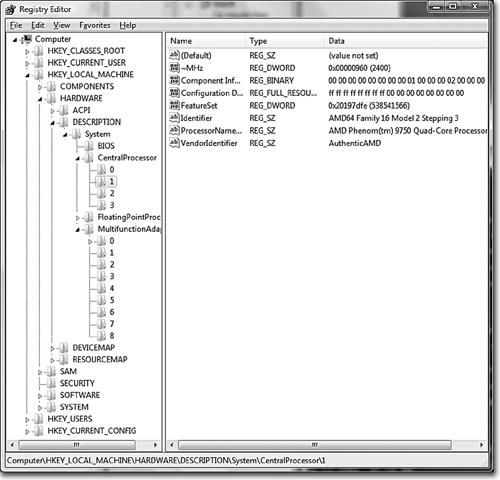
The specific information regarding the host machine’s processor is on the right side. The bottom of the left side shows that numerous keys contain information about the software applications on the host computer. Notice that every key must have a default value, which is listed before any of the other key/value pairs.
Registry implementation, including registry data storage and retrieval, is also beyond the book’s scope; see the reference information at the end of the chapter.
Registry Keys
Figure 3-1 shows the analogy between file system directories and registry keys. Each key can contain other keys or a sequence of values associated with a key. Whereas a file system is accessed through pathnames, the registry is accessed through keys and value names. Several predefined keys serve as entry points into the registry.
1. HKEY_LOCAL_MACHINE stores physical information about the machine, along with information about installed software. Installed software information is generally created in subkeys of the form SOFTWARECompanyNameProductNameVersion.
2. HKEY_USERS defines user configuration information.
3. HKEY_CURRENT_CONFIG contains current settings, such as display resolution and fonts.
4. HKEY_CLASSES_ROOT contains subordinate entries to define mappings from file extensions to classes and to applications used by the shell to access objects with the specified extension. All the keys necessary for Microsoft’s Component Object Model (COM) are also subordinate to this key.
5. HKEY_CURRENT_USER contains user-specific information, including environment variables, printers, and application preferences that apply to the current user.
Registry Management
Registry management functions can query and modify key/value pairs and data and also create new subkeys and key/value pairs. Key handles of type HKEY are used both to specify a key and to obtain new keys.5 Values are typed; there are several types to select from, such as strings, double words, and expandable strings whose parameters can be replaced with environment variables.
5 It would be more convenient and consistent if the HANDLE type were used for registry management. There are several other exceptions to standard Windows practice that are based on Windows history.
Key Management
Key management functions allow you to open named keys, enumerate subkeys of an open key, and create new keys.
RegOpenKeyEx
The first function, RegOpenKeyEx, opens a named subkey. Starting from one of the predefined reserved key handles, you can traverse the registry and obtain a handle to any subordinate key.

The parameters for this first function are explained individually. For later functions, as the conventions become familiar, it is sometimes sufficient to survey them quickly.
hKey identifies a currently open key or one of the predefined reserved key handles. phkResult points to a variable of type HKEY that is to receive the handle to the newly opened key.
lpSubKey is the subkey name you want to open. The subkey name can be a path, such as MicrosoftWindowsNTCurrentVersion. A NULL subkey name causes a new, duplicate key for hKey to be opened.
ulOptions is reserved and must be 0.
samDesired is the access mask describing the security for the new key. Access constants include KEY_ALL_ACCESS, KEY_WRITE, KEY_QUERY_VALUE, and KEY_ENUMERATE_SUBKEYS.
The return is normally ERROR_SUCCESS. Any other result indicates an error. Close an open key handle with RegCloseKey, which takes the handle as its single parameter.
RegEnumKeyEx
RegEnumKeyEx enumerates subkey names of an open registry key, much as FindFirstFile and FindNextFile enumerate directory contents. This function retrieves the key name, class string (rarely used), and time of last modification.

dwIndex should be 0 on the first call and then should be incremented on each subsequent call. The value name and its size, along with the class string and its size, are returned. Note that there are two count parameters, lpcbName (the subkey name) and lpcbClass, which are used for both input and output for buffer size. This behavior is familiar from GetCurrentDirectory (Chapter 2), and we’ll see it again with RegEnumValue. lpClass and lpcbClass are, however, rarely used and should almost always be NULL.
The function returns ERROR_SUCCESS or an error number.
RegCreateKeyEx
You can also create new keys using RegCreateKeyEx. Keys can be given security attributes in the same way as with directories and files (Chapter 15).

The individual parameters are as follows:
• lpSubKey is the name of the new subkey under the open key indicated by the handle hKey.
• lpClass is a user-defined class type for the key. Use NULL, as recommended by MSDN.
• The dwOptions flag is usually 0 (or, equivalently, REG_OPTION_NON_VOLATILE, the default). Another, mutually exclusive value is REG_OPTION_VOLATILE. Nonvolatile registry information is stored in a file and preserved when Windows restarts. Volatile registry keys are kept in memory and will not be restored.
• samDesired is the same as for RegOpenKeyEx.
• lpSecurityAttributes can be NULL or can point to a security attribute. The rights can be selected from the same values as those used with samDesired.
• lpdwDisposition points to a DWORD that indicates whether the key already existed (REG_OPENED_EXISTING_KEY) or was created (REG_CREATED_NEW_KEY).
To delete a key, use RegDeleteKey. The two parameters are an open key handle and a subkey name.
Value and Data Management
These functions allow you to get and set the data corresponding to a value name.
RegEnumValue
RegEnumValue enumerates the value names and corresponding data for a specified open key. Specify an Index, originally 0, which is incremented in subsequent calls. On return, you get the string with the value name as well as its size. You also get the data and its type and size.

The data is returned in the buffer indicated by lpData. The result size can be found from lpcbData.
The data type, pointed to by lpType, has numerous possibilities, including REG_BINARY, REG_DWORD, REG_SZ (a string), and REG_EXPAND_SZ (an expandable string with parameters replaced by environment variables). See MSDN for a list of all the data types.
Test the function’s return result to determine whether you have enumerated all the keys. The result will be ERROR_SUCCESS if you have found a valid key.
RegQueryValueEx is similar except that you specify a value name rather than an index. If you know the value names, you can use this function. If you do not know the names, you can scan with RegEnumValue.
RegSetValueEx
Set the data corresponding to a named value within an open key using RegSetValueEx, supplying the key, value name, data type, and data.

Finally, delete named values using the function RegDeleteValue. There are just two parameters: an open registry key and the value name, just as in the first two RegSetValueEx parameters.
Example: Listing Registry Keys and Contents
Program 3-4, lsReg, is a modification of Program 3-2 (lsW, the file and directory listing program); it processes registry keys and key/value pairs rather than directories and files.
Program 3-4 lsReg: Listing Registry Keys and Contents





Run 3-4 shows lsReg operation, including using the -l option. The -R option also works, but examples require a lot of vertical space and are omitted.
Run 3-4 lsReg: Listing Registry Keys, Values, and Data

Summary
Chapters 2 and 3 described all the important basic functions for dealing with files, directories, and console I/O. Numerous examples show how to use these functions in building typical applications. The registry is managed in much the same way as the file system, as the final example shows.
Later chapters will deal with advanced I/O, such as asynchronous operations and memory mapping.
Looking Ahead
Chapter 4, Exception Handling, simplifies error and exception handling and extends the ReportError function to handle arbitrary exceptions.
Additional Reading
See Jerry Honeycutt’s Microsoft Windows Registry Guide for information on registry programming and registry usage.
Exercises
3–1. Use the GetDiskFreeSpaceEx function to determine how the different Windows versions allocate file space sparsely. For instance, create a new file, set the file pointer to a large value, set the file size, and investigate the free space using GetDiskFreeSpaceEx. The same Windows function can also be used to determine how the disk is configured into sectors and clusters. Determine whether the newly allocated file space is initialized. FreeSpace.c, provided in the Examples file, is the solution. Compare the results for NT5 and NT6. It is also interesting to investigate how to make a file be sparse.
3–2. What happens if you attempt to set a file’s length to a size larger than the disk? Does Windows fail gracefully?
3–3. Modify the tail.c program provided in the Examples file so that it does not use SetFilePointer; use overlapped structures. Also be sure that it works properly with files larger than 4GB.
3–4. Examine the “number of links” field obtained using the function GetFileInformationByHandle. Is its value always 1? Do the link counts appear to count hard links and links from parent directories and subdirectories? Does Windows open the directory as a file to get a handle before using this function? What about the shortcuts supported by the user interface?
3–5. Program 3-2 (lsW) checks for “.” and “..” to detect the names of the current and parent directories. What happens if there are actual files with these names? Can files have these names?
3–6. Does Program 3-2 list local times or UCT? If necessary, modify the program to give the results in local time.
3–7. Enhance Program 3-2 (lsW) so that it also lists the “.” and “..” (current and parent) directories (the complete program is in the Examples file). Also, add options to display the file creation and last access times along with the last write time.
3–8. Further enhance Program 3-2 (lsW) to remove all uses of SetCurrentDirectory. This function is undesirable because an exception or other fault could leave you in an expected working directory.
3–9. Create a file deletion command, rm, by modifying the ProcessItem function in Program 3-2. A solution is in the Examples file.
3–10. Enhance the file copy command, cpW, from Chapter 1 so that it will copy files to a target directory. Further extensions allow for recursive copying (-r option) and for preserving the modification time of the copied files (-p option). Implementing the recursive copy option will require that you create new directories.
3–11. Write an mv command, similar to the UNIX command of the same name, which will move a complete directory. One significant consideration is whether the target is on a different drive from that of the source file or directory. If it is, copy the file(s); otherwise, use MoveFileEx.
3–12. Enhance Program 3-3 (touch) so that the new file time is specified on the command line. The UNIX command allows the time stamp to appear (optionally) after the normal options and before the file names. The format for the time is MMddhhmm[yy], where the uppercase MM is the month and mm is for minutes.
3–13. Program 3-1 (RecordAccess) is written to work with large NTFS file systems. If you have sufficient free disk space, test this program with a huge file (length greater than 4GB, and considerably larger if possible); see Run 3-2. Verify that the 64-bit arithmetic is correct. It is not recommended that you perform this exercise on a network drive without permission from the network administrator. Don’t forget to delete the test file on completion; disk space is cheap, but not so cheap that you want to leave orphaned huge files.
3–14. Write a program that locks a specified file and holds the lock for a long period of time (you may find the Sleep function useful). While the lock is held, try to access the file (use a text file) with an editor. What happens? Is the file properly locked? Alternatively, write a program that will prompt the user to specify a lock on a test file. Two instances of the program can be run in separate windows to verify that file locking works as described. TestLock.c in the Examples file is a solution to this exercise.
3–15. Investigate the Windows file time representation in FILETIME. It uses 64 bits to count the elapsed number of 100-nanosecond units from January 1, 1601. When will the time expire? When will the UNIX file time representation expire?
3–16. Write an interactive utility that will prompt the user for a registry key name and a value name. Display the current value and prompt the user for a new value. The utility could use command prompt cd and dir commands to illustrate the similarities (and differences) between the registry and file systems.
3–17. This chapter, along with most other chapters, describes the most important functions. There are often other functions that may be useful. The MSDN pages for each function provide links to related functions. Examine several, such as FindFirstFileEx, FindFirstFileTransacted, ReplaceFile, SearchPath, and WriteFileGather. Some of these functions are not available in all Windows versions.