
Chapter 5. Memory Management, Memory-Mapped Files, and DLLs
Most programs require some form of dynamic memory management. This need arises whenever there is a need to create data structures whose size or number is not known at program build time. Search trees, symbol tables, and linked lists are common examples of dynamic data structures where the program creates new instances at run time.
Windows provides flexible mechanisms for managing a program’s dynamic memory. Windows also provides memory-mapped files to associate a process’s address space directly with a file, allowing the OS to manage all data movement between the file and memory so that the programmer never needs to deal with ReadFile, WriteFile, SetFilePointer, or the other file I/O functions. With memory-mapped files, the program can maintain dynamic data structures conveniently in permanent files, and memory-based algorithms can process file data. What is more, memory mapping can significantly speed up file processing, and it provides a mechanism for memory sharing between processes.
Dynamic link libraries (DLLs) are an essential special case of file mapping and shared memory in which files (primarily read-only code files) are mapped into the process address space for execution.
This chapter describes the Windows memory management and file mapping functions, illustrates their use and performance advantages with several examples, and describes both implicitly and explicitly linked DLLs.
Windows Memory Management Architecture
Win32 (the distinction between Win32 and Win64 is important here) is an API for the Windows 32-bit OS family. The “32-bitness” manifests itself in memory addresses, and pointers (LPCTSTR, LPDWORD, and so on) are 4-byte (32-bit) objects. The Win64 API provides a much larger virtual address space with 8-byte, 64-bit pointers and is a natural evolution of Win32. Nonetheless, use care to ensure that your applications can be targeted at both platforms; the examples have all been tested on both 64-bit and 32-bit systems, and 32-bit and 64-bit executables are available in the Examples file. With the example programs, there are comments about changes that were required to support Win64.
Every Windows process, then, has its own private virtual address space of either 4GB (232 bytes) or 16EB (16 exabytes or 264 bytes1). Win32 makes at least half of this (2–3GB; 3GB must be enabled at boot time) available to a process. The remainder of the virtual address space is allocated to shared data and code, system code, drivers, and so on.
1 Current systems cannot provide the full 264-byte virtual address space. 244 bytes (16 terabytes) is a common processor limit at this time. This limit is certain to increase over time.
The details of these memory allocations, although interesting, are not important here. From the programmer’s perspective, the OS provides a large address space for code, data, and other resources. This chapter concentrates on exploiting Windows memory management without being concerned with OS implementation. Nonetheless, a very short overview follows.
Memory Management Overview
The OS manages all the details of mapping virtual to physical memory and the mechanics of page swapping, demand paging, and the like. This subject is discussed thoroughly in OS texts. Here’s a brief summary.
• The computer has a relatively small amount of physical memory; 1GB is the practical minimum for 32-bit Windows XP, and much larger physical memories are typical.2
2 Memory prices continue to decline, and “typical” memory sizes keep increasing, so it is difficult to define typical memory size. At the time of publication, even the most inexpensive systems contain 2GB, which is sufficient for Windows XP, Vista, and 7. Windows Server systems generally contain much more memory.
• Every process—and there may be several user and system processes—has its own virtual address space, which may be much larger than the physical memory available. For example, the virtual address space of a 4GB process is two times larger than 2GB of physical memory, and there may be many such processes running concurrently.
• The OS maps virtual addresses to physical addresses.
• Most virtual pages will not be in physical memory, so the OS responds to page faults (references to pages not in memory) and loads the data from disk, either from the system swap file or from a normal file. Page faults, while transparent to the programmer, have a significant impact on performance, and programs should be designed to minimize faults. Again, many OS texts treat this important subject, which is beyond the scope of this book.
Figure 5-1 shows the Windows memory management API layered on the Virtual Memory Manager. The Virtual Memory Windows API (VirtualAlloc, VirtualFree, VirtualLock, VirtualUnlock, and so on) deals with whole pages. The Windows Heap API manages memory in user-defined units.
Figure 5-1 Windows Memory Management Architecture

The layout of the virtual memory address space is not shown because it is not directly relevant to the API, and the layout could change in the future. The Microsoft documentation provides this information.
Nonetheless, many programmers want to know more about their environment. To start to explore the memory structure, invoke the following.
The parameter is the address of a PSYSTEM_INFO structure containing information on the system’s page size, allocation granularity, and the application’s physical memory address. You can run the version program in the Examples file to see the results on your computer, and an exercise (with a screenshot) suggests an enhancement.
Heaps
Windows maintains pools of memory in heaps. A process can contain several heaps, and you allocate memory from these heaps.
One heap is often sufficient, but there are good reasons, explained below, for multiple heaps. If a single heap is sufficient, just use the C library memory management functions (malloc, free, calloc, realloc).
Heaps are Windows objects; therefore, they have handles. However, heaps are not kernel objects. The heap handle is necessary when you’re allocating memory. Each process has its own default heap, and the next function obtains its handle.
Notice that NULL is the return value to indicate failure rather than INVALID_HANDLE_VALUE, which is returned by CreateFile.
A program can also create distinct heaps. It is convenient at times to have separate heaps for allocation of separate data structures. The benefits of separate heaps include the following.
• Fairness. If threads allocate memory solely from a unique heap assigned to the thread, then no single thread can obtain more memory than is allocated to its heap. In particular, a memory leak defect, caused by a program neglecting to free data elements that are no longer needed, will affect only one thread of a process.3
3 Chapter 7 introduces threads.
• Multithreaded performance. By giving each thread its own heap, contention between threads is reduced, which can substantially improve performance. See Chapter 9.
• Allocation efficiency. Allocation of fixed-size data elements within a small heap can be more efficient than allocating elements of many different sizes in a single large heap. Fragmentation is also reduced. Furthermore, giving each thread a unique heap for storage used only within the thread simplifies synchronization, resulting in additional efficiencies.
• Deallocation efficiency. An entire heap and all the data structures it contains can be freed with a single function call. This call will also free any leaked memory allocations in the heap.
• Locality of reference efficiency. Maintaining a data structure in a small heap ensures that the elements will be confined to a relatively small number of pages, potentially reducing page faults as the data structure elements are processed.
The value of these advantages varies depending on the application, and many programmers use only the process heap and the C library. Such a choice, however, prevents the program from exploiting the exception generating capability of the Windows memory management functions (described along with the functions). In any case, the next two functions create and destroy heaps.4
4 In general, create objects of type X with the CreateX system call. HeapCreate is an exception to this pattern.
Creating a Heap
Use HeapCreate to create a new heap, specifying the initial heap size.
The initial heap size, which can be zero and is always rounded up to a multiple of the page size, determines how much physical storage (in a paging file) is committed to the heap (that is, the required space is allocated from the heap) initially, rather than on demand as memory is allocated from the heap. As a program exceeds the initial size, additional pages are committed automatically up to the maximum size. Because the paging file is a limited resource, deferring commitment is a good practice unless it is known ahead of time how large the heap will become. dwMaximumSize, if nonzero, determines the heap’s maximum size as it expands dynamically. The process heap will also grow dynamically.

Return: A heap handle, or NULL on failure.
The two size fields are of type SIZE_T rather than DWORD. SIZE_T is defined to be either a 32-bit or 64-bit unsigned integer, depending on compiler flags (_WIN32 and _WIN64). SIZE_T helps to enable source code portability to both Win32 and Win64. SIZE_T variables can span the entire range of a 32- or 64-bit pointers. SSIZE_T is the signed version but is not used here.
flOptions is a combination of three flags.
• HEAP_GENERATE_EXCEPTIONS—With this option, failed allocations generate an exception for SEH processing (see Chapter 4). HeapCreate itself will not cause an exception; rather, functions such as HeapAlloc, which are explained shortly, cause an exception on failure if this flag is set. There is more discussion after the memory management function descriptions.
• HEAP_NO_SERIALIZE—Set this flag under certain circumstances to get a small performance improvement; there is additional discussion after the memory management function descriptions.
• HEAP_CREATE_ENABLE_EXECUTE—This is an out-of-scope advanced feature that allows you to specify that code can be executed from this heap. Normally, if the system has been configured to enforce data execution prevention (DEP), any attempt to execute code in the heap will generate an exception with code STATUS_ACCESS_VIOLATION, partially providing security from code that attempts to exploit buffer overruns.
There are several other important points regarding dwMaximumSize.
• If dwMaximumSize is nonzero, the virtual address space is allocated accordingly, even though it may not be committed in its entirety. This is the maximum size of the heap, which is said to be nongrowable. This option limits a heap’s size, perhaps to gain the fairness advantage cited previously.
• If, on the other hand, dwMaximumSize is 0, then the heap is growable beyond the initial size. The limit is determined by the available virtual address space not currently allocated to other heaps and swap file space.
Note that heaps do not have security attributes because they are not kernel objects; they are memory blocks managed by the heap functions. File mapping objects, described later in the chapter, can be secured (Chapter 15).
To destroy an entire heap, use HeapDestroy. CloseHandle is not appropriate because heaps are not kernel objects.
hHeap should specify a heap generated by HeapCreate. Be careful not to destroy the process’s heap (the one obtained from GetProcessHeap). Destroying a heap frees the virtual memory space and physical storage in the paging file. Naturally, well-designed programs should destroy heaps that are no longer needed.
Destroying a heap is also a quick way to free data structures without traversing them to delete one element at a time, although C++ object instances will not be destroyed inasmuch as their destructors are not called. Heap destruction has three benefits.
1. There is no need to write the data structure traversal code.
2. There is no need to deallocate each individual element.
3. The system does not spend time maintaining the heap since all data structure elements are deallocated with a single call.
Managing Heap Memory
The heap management functions allocate and free memory blocks.
HeapAlloc
Obtain memory blocks from a heap by specifying the heap’s handle, the block size, and several flags.

Return: A pointer to the allocated memory block, or NULL on failure (unless exception generation is specified).
Parameters
hHeap is the heap handle for the heap in which the memory block is to be allocated. This handle should come from either GetProcessHeap or HeapCreate.
dwFlags is a combination of three flags:
• HEAP_GENERATE_EXCEPTIONS and HEAP_NO_SERIALIZE—These flags have the same meaning as for HeapCreate. The first flag is ignored if it was set with the heap’s HeapCreate function and enables exceptions for the specific HeapAlloc call, even if HEAP_GENERATE_EXCEPTIONS was not specified by HeapCreate. The second flag should not be used when allocating within the process heap, and there is more information at the end of this section.
• HEAP_ZERO_MEMORY—This flag specifies that the allocated memory will be initialized to 0; otherwise, the memory contents are not specified.
dwBytes is the size of the block of memory to allocate. For nongrowable heaps, this is limited to 0x7FFF8 (approximately 0.5MB). This block size limit applies even to Win64 and to very large heaps.
The return value from a successful HeapAlloc call is an LPVOID pointer, which is either 32 or 64 bits, depending on the build option.
Note: Once HeapAlloc returns a pointer, use the pointer in the normal way; there is no need to make reference to its heap.
Heap Management Failure
The HeapAlloc has a different failure behavior than other functions we’ve used.
• Function failure causes an exception when using HEAP_GENERATE_EXCEPTIONS. The exception code is either STATUS_NO_MEMORY or STATUS_ACCESS_VIOLATION.
• Without HEAP_GENERATE_EXCEPTIONS, HeapAlloc returns a NULL pointer.
• In either case, you cannot use GetLastError for error information, and hence you cannot use this book’s ReportError function to produce a text error message.
HeapFree
Deallocating memory from a heap is simple.

dwFlags should be 0 or HEAP_NO_SERIALIZE (see the end of the section). lpMem should be a value returned by HeapAlloc or HeapReAlloc (described next), and, of course, hHeap should be the heap from which lpMem was allocated.
A FALSE return value indicates a failure, and you can use GetLastError, which does not work with HeapAlloc. HEAP_GENERATE_EXCEPTIONS does not apply to HeapFree.
HeapReAlloc
Memory blocks can be reallocated to change their size. Allocation failure behavior is the same as with HeapAlloc.

Return: A pointer to the reallocated block. Failure returns NULL or causes an exception.
Parameters
The first parameter, hHeap, is the same heap used with the HeapAlloc call that returned the lpMem value (the third parameter). dwFlags specifies some essential control options.
• HEAP_GENERATE_EXCEPTIONS and HEAP_NO_SERIALIZE—These flags are the same as for HeapAlloc.
• HEAP_ZERO_MEMORY—Only newly allocated memory (when dwBytes is larger than the original block) is initialized. The original block contents are not modified.
• HEAP_REALLOC_IN_PLACE_ONLY—This flag specifies that the block cannot be moved. When you’re increasing a block’s size, the new memory must be allocated at the address immediately after the existing block.
lpMem specifies the existing block in hHeap to be reallocated.
dwBytes is the new block size, which can be larger or smaller than the existing size, but, as with HeapAlloc, it must be less than 0x7FFF8.
It is possible that the returned pointer is the same as lpMem. If, on the other hand, a block is moved (permit this by omitting the HEAP_REALLOC_IN_PLACE_ONLY flag), the returned value might be different. Be careful to update any references to the block. The data in the block is unchanged, regardless of whether or not it is moved; however, some data will be lost if the block size is reduced.
HeapSize
Determine the size of an allocated block by calling HeapSize with the heap handle and block pointer. This function could have been named HeapGetBlockSize because it does not obtain the heap size. The value will be greater than or equal to the size used with HeapAlloc or HeapReAlloc.

Return: The size of the block, or zero on failure.
The only possible dwFlags value is HEAP_NO_SERIALIZE.
The error return value is (SIZE_T)-1. You cannot use GetLastError to find extended error information.
More about the Serialization and Exceptions Flags
The heap management functions use two unique flags, HEAP_NO_SERIALIZE and HEAP_GENERATE_EXCEPTIONS, that need additional explanation.
The HEAP_NO_SERIALIZE Flag
The functions HeapCreate, HeapAlloc, and HeapReAlloc can specify the HEAP_NO_SERIALIZE flag. There can be a small performance gain with this flag because the functions do not provide mutual exclusion to threads accessing the heap. Some simple tests that do nothing except allocate memory blocks measured a performance improvement of about 16 percent. This flag is safe in a few situations, such as the following.
• The program does not use threads (Chapter 7), or, more accurately, the process (Chapter 6) has only a single thread. All examples in this chapter use the flag.
• Each thread has its own heap or set of heaps, and no other thread accesses those heaps.
• The program has its own mutual exclusion mechanism (Chapter 8) to prevent concurrent access to a heap by several threads using HeapAlloc and HeapReAlloc.
The HEAP_GENERATE_EXCEPTIONS Flag
Forcing exceptions when memory allocation fails avoids the need for error tests after each allocation. Furthermore, the exception or termination handler can clean up memory that did get allocated. This technique is used in some examples.
Two exception codes are possible.
1. STATUS_NO_MEMORY indicates that the system could not create a block of the requested size. Causes can include fragmented memory, a nongrowable heap that has reached its limit, or even exhaustion of all memory with growable heaps.
2. STATUS_ACCESS_VIOLATION indicates that the specified heap has been corrupted. For example, a program may have written memory beyond the bounds of an allocated block.
Setting Heap Information
HeapSetInformation allows you to enable the “low-fragmentation” heap (LFH) on NT5 (Windows XP and Server 2003) computers; the LFH is the default on NT6. This is a simple function; see MSDN for an example. The LFH can help program performance when allocating and deallocating small memory blocks with different sizes.
HeapSetInformation also allows you to enable the “terminate on corruption” feature. Windows terminates the process if it detects an error in the heap; such an error could occur, for example, if you wrote past the bounds of an array allocated on the heap.
Use HeapQueryInformation to determine if the LFH is enabled for the heap. You can also determine if the heap supports look-aside lists (see MSDN).
Other Heap Functions
HeapCompact, despite the name, does not compact the heap. However, it does return the size of the largest committed free block in the heap. HeapValidate attempts to detect heap corruption. HeapWalk enumerates the blocks in a heap, and GetProcessHeaps obtains all the heap handles that are valid in a process.
HeapLock and HeapUnlock allow a thread to serialize heap access, as described in Chapter 8.
Some functions, such as GlobalAlloc and LocalAlloc, were used for compatibility with 16-bit systems and for functions inherited from 16-bit Windows. These functions are mentioned first as a reminder that some functions continue to be supported even though they are not always relevant and you should use the heap functions. However, there are cases where MSDN states that you need to use these functions, and memory must be freed with the function corresponding to its allocator. For instance, use LocalFree with FormatMessage (see Program 2-1, ReportError). In general, if a function allocates memory, read MSDN to determine the correct free function, although FormatMessage is the only such function used in this book.
Summary: Heap Management
The normal process for using heaps is straightforward.
1. Get a heap handle with either CreateHeap or GetProcessHeap.
2. Allocate blocks within the heap using HeapAlloc.
3. Optionally, free some or all of the individual blocks with HeapFree.
4. Destroy the heap and close the handle with HeapDestroy.
5. The C run-time library (malloc, free, etc.) are frequently adequate. However, memory allocated with the C library must be freed with the C library. You cannot assume that the C library uses the process heap.
Figure 5-2 and Program 5-1 illustrate this process.
Figure 5-2 Memory Management in Multiple Heaps

Program 5-1 sortBT: Sorting with a Binary Search Tree


Example: Sorting Files with a Binary Search Tree
A search tree is a common dynamic data structure requiring memory management. Search trees are a convenient way to maintain collections of records, and they have the additional advantage of allowing efficient sequential traversal.
Program 5-1 implements a sort (sortBT, a limited version of the UNIX sort command) by creating a binary search tree using two heaps. The keys go into the node heap, which represents the search tree. Each node contains left and right pointers, a key, and a pointer to the data record in the data heap. The complete record, a line of text from the input file, goes into the data heap. Notice that the node heap consists of fixed-size blocks, whereas the data heap contains strings with different lengths. Finally, tree traversal displays the sorted file.
This example arbitrarily uses the first 8 bytes of a string as the key rather than using the complete string. Two other sort implementations in this chapter (Programs 5-4 and 5-5) sort files.
Figure 5-2 shows the sequence of operations for creating heaps and allocating blocks. The program code on the right is pseudocode in that only the essential function calls and arguments are shown. The virtual address space on the left shows the three heaps along with some allocated blocks in each. The figure differs slightly from the program in that the root of the tree is allocated in the process heap in the figure but not in Program 5-1. Finally, the figure is not drawn to scale.
Note: The actual locations of the heaps and the blocks within the heaps depend on the Windows implementation and on the process’s history of previous memory use, including heap expansion beyond the original size. Furthermore, a growable heap may not occupy contiguous address space after it grows beyond the originally committed size. The best programming practice is to make no assumptions; just use the memory management functions as specified.
Program 5-1 illustrates some techniques that simplify the program and would not be possible with the C library alone or with the process heap.
• The node elements are fixed size and go in a heap of their own, whereas the varying-length data element records are in a separate heap.
• The program prepares to sort the next file by destroying the two heaps rather than freeing individual elements.
• Allocation errors are processed as exceptions so that it is not necessary to test for NULL pointers.
An implementation such as Program 5-1 is limited to smaller files when using Windows because the complete file and a copy of the keys must reside in virtual memory. The absolute upper limit of the file length is determined by the available virtual address space (3GB at most for Win32; the practical limit is less). With Win64, you will probably not hit a practical limit.
Program 5-1 calls several tree management functions: FillTree, InsertTree, Scan, and KeyCompare. They are shown in Program 5-2. See Run 5-2, after Program 5-2, for a sortBT run example.
Program 5-2 FillTree: Tree Management Functions


Run 5-2 sortBT: Sorting Small and Large Text Files

This program uses heap exceptions and user-generated exceptions for file open errors. An alternative would be to use ReportError, eliminate use of the HEAP_GENERATE_EXCEPTIONS flag, and test directly for memory allocation errors.
Program 5-2 shows the functions that actually implement the search tree algorithms. FillTree, the first function, allocates memory in the two heaps. KeyCompare, the second function, is used in several other programs in this chapter. Notice that these functions are called by Program 5-1 and use the completion and exception handlers in that program. Thus, a memory allocation error would be handled by the main program, and the program would continue to process the next file.
Run 5-2 shows sortBT sorting small and large text files that were generated with randfile. randfile, introduced in Chapter 1, places 8 random digits in the first 8 bytes of each record to form a sort key. The “x” at the right end of each line is a visual cue and has no other meaning.
The timep utility shows the execution time; see Chapter 6 for the timep implementation.
Note: This search tree implementation is clearly not efficient because the tree may become unbalanced. Implementing a balanced search tree would be worthwhile but would not change the program’s memory management.
Memory-Mapped Files
Dynamic memory in heaps must be physically allocated in a paging file. The OS’s memory management controls page movement between physical memory and the paging file and also maps the process’s virtual address space to the paging file. When the process terminates, the physical space in the file is deallocated.
Windows memory-mapped file functionality can also map virtual memory space directly to normal files. This has several advantages.
• There is no need to perform direct file I/O (reads and writes).
• The data structures created in memory will be saved in the file for later use by the same or other programs. Be careful about pointer usage, as Program 5-5 illustrates.
• Convenient and efficient in-memory algorithms (sorts, search trees, string processing, and so on) can process file data even though the file may be much larger than available physical memory. The performance will still be influenced by paging behavior if the file is large.
• File processing performance is frequently much faster than using the ReadFile() and WriteFile() file access functions.
• There is no need to manage buffers and the file data they contain. The OS does this hard work and does it efficiently with a high degree of reliability.
• Multiple processes (Chapter 6) can share memory by mapping their virtual address spaces to the same file or to the paging file (interprocess memory sharing is the principal reason for mapping to the paging file).
• There is no need to consume paging file space.
The OS itself uses memory mapping to implement DLLs and to load and execute executable (.EXE) files. DLLs are described at the end of this chapter.
Caution: When reading or writing a mapped file, it’s a good idea to use SEH to catch any EXCEPTION_IN_PAGE_ERROR exceptions. The Examples file programs all do this, but the SEH is omitted from the program listings for brevity.
File Mapping Objects
The first step is to create a Windows kernel file mapping object, which has a handle, on an open file and then map all or part of the file to the process’s address space. File mapping objects can be given names so that they are accessible to other processes for shared memory. Also, the mapping object has protection and security attributes and a size.

Return: A file mapping handle, or NULL on failure.
Parameters
hFile is the handle of an open file with protection flags compatible with dwProtect. The value INVALID_HANDLE_VALUE refers to the paging file, and you can use this value for interprocess memory sharing without creating a separate file.
LPSECURITY_ATTRIBUTES allows the mapping object to be secured.
dwProtect specifies the mapped file access with the following flags. Additional flags are allowed for specialized purposes. For example, the SEC_IMAGE flag specifies an executable image; see the MSDN documentation for more information.
• PAGE_READONLY means that the program can only read the pages in the mapped region; it can neither write nor execute them. hFile must have GENERIC_READ access.
• PAGE_READWRITE gives full access to the object if hFile has both GENERIC_READ and GENERIC_WRITE access.
• PAGE_WRITECOPY means that when mapped memory is changed, a private (to the process) copy is written to the paging file and not to the original file. A debugger might use this flag when setting breakpoints in shared code.
dwMaximumSizeHigh and dwMaximumSizeLow specify the size of the mapping object. If they are both 0, the current file size is used; be sure to specify these two size values when using the paging file.
• If the file is expected to grow, use a size equal to the expected file size, and, if necessary, the file size will be set to that size immediately.
• Do not map to a file region beyond this specified size; the mapping object cannot grow.
• An attempt to create a mapping on a zero-length file will fail.
• Unfortunately, you need to specify the mapping size with two 32-bit integers. There is no way to use a single 64-bit integer.
lpMapName names the mapping object, allowing other processes to share the object; the name is case-sensitive. Use NULL if you are not sharing memory.
An error is indicated by a return value of NULL (not INVALID_HANDLE_VALUE).
Opening an Existing File Mapping
You can obtain a file mapping handle for an existing, named mapping by specifying the existing mapping object’s name. The name comes from a previous call to CreateFileMapping. Two processes can share memory by sharing a file mapping. The first process creates the named mapping, and subsequent processes open this mapping with the name. The open will fail if the named object does not exist.

Return: A file mapping handle, or NULL on failure.
dwDesiredAccess is checked against the access to the named object created with CreateFileMapping; see the upcoming MapViewOfFile description for the possible values. lpMapName is the name created by a CreateFileMapping call. Handle inheritance (bInheritHandle) is a subject for Chapter 6.
The CloseHandle function, as expected, destroys mapping handles.
Mapping Objects to Process Address Space
The next step is to map a file into the process’s virtual address space. From the programmer’s perspective, this allocation is similar to HeapAlloc, although it is much coarser, with larger allocation units. A pointer to the allocated block (or file view) is returned; the difference lies in the fact that the allocated block is backed by a user-specified file rather than the paging file. The file mapping object plays the same role played by the heap when HeapAlloc is used.
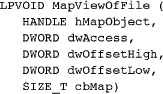
Return: The starting address of the block (file view), or NULL on failure.
Parameters
hMapObject identifies a file mapping object obtained from either CreateFileMapping or OpenFileMapping.
dwAccess must be compatible with the mapping object’s access. The three flag values we’ll use are FILE_MAP_WRITE, FILE_MAP_READ, and FILE_MAP_ALL_ACCESS. (This is the bit-wise “or” of the previous two flags.) See MSDN for the other two flag values, FILE_MAP_COPY and FILE_MAP_EXECUTE.
dwOffsetHigh and dwOffsetLow specify the starting location of the mapped file region. The start address must be a multiple of the allocation granularity (normally 64K; use GetSystemInfo() to get the actual value). Use a zero offset to map from the beginning of the file.
cbMap is the size, in bytes, of the mapped region. Zero indicates the entire file at the time of the MapViewOfFile call.
MapViewOfFileEx is similar except that you can specify the starting memory address in an additional parameter. Windows fails if the process has already mapped the requested space. See MSDN for more explanation.
Closing the Mapping Handle
You can elect to close the mapping handle returned by CreateFileMapping as soon as MapViewOfFile succeeds if you do not need to use the mapping handle again to create other views on the file mapping. Many programmers prefer to do this so as to free resources as soon as possible, and there is the benefit that you do not need to maintain the mapping handle value. However, the example programs and Figure 5-2 do not close the mapping handle until all views are unmapped.
Just as it is necessary to release memory allocated in a heap with HeapFree, it is necessary to release file views.
Figure 5-3 shows the relationship between process address space and a mapped file.
Figure 5-3 A File Mapped into Process Address Space

FlushViewOfFile forces the system to write “dirty” (changed) pages to disk. Normally, a process accessing a file through mapping and another process accessing it through conventional file I/O will not have coherent views of the file. Performing the file I/O without buffering will not help because the mapped memory will not be written to the file immediately.
Therefore, it is not a good idea to access a mapped file with ReadFile and WriteFile; coherency is not ensured. On the other hand, processes that share a file through shared memory will have a coherent view of the file. If one process changes a mapped memory location, the other process will obtain that new value when it accesses the corresponding area of the file in its mapped memory. This mechanism is illustrated in Figure 5-4, and the two views are coherent because both processes’ virtual addresses, although distinct, are in the same physical memory locations. The obvious synchronization issues are addressed in Chapters 8, 9, and 10.5
5 Statements regarding coherency of mapped views do not apply to network files. The files must be local.

File Mapping Limitations
File mapping, as mentioned previously, is a powerful and useful feature. The disparity between Win32’s 64-bit file system and Win32’s 32-bit addressing limits these benefits; Win64 does not have these limitations.
The principal Win32 problem is that if the file is large (greater than 2–3GB in this case), it is not possible to map the entire file into virtual memory space. Furthermore, the entire 3GB will not be available because virtual address space will be allocated for other purposes and available contiguous blocks will be much smaller than the theoretical maximum. Win64 removes this limitation.
When you’re dealing with large files that cannot be mapped to one view in Win32, create code that carefully maps and unmaps file regions as they are needed. This technique can be as complex as managing memory buffers, although it is not necessary to perform the explicit reads and writes.
File mapping has two other notable limitations in both Win32 and Win64.
• An existing file mapping cannot be expanded. You need to know the maximum size when creating the file mapping, and it may be difficult or impossible to determine this size.
• There is no way to allocate memory within a mapped memory region without creating your own memory management functions. It would be convenient if there were a way to specify a file mapping and a pointer returned by MapViewOfFile and obtain a heap handle.
Summary: File Mapping
Here is the standard sequence required by file mapping.
1. Open the file. Be certain that it has at least GENERIC_READ access.
2. If the file is new, set its length either with CreateFileMapping (step 3) or by using SetFilePointerEx followed by SetEndOfFile.
3. Map the file with CreateFileMapping or OpenFileMapping.
4. Create one or more views with MapViewOfFile.
5. Access the file through memory references. If necessary, change the mapped regions with UnmapViewOfFile and MapViewOfFile. Use SEH to protect against EXCEPTION_IN_PAGE_ERROR exceptions.
6. On completion, perform, in order, UnmapViewOfFile, CloseHandle for the mapping handle, and CloseHandle for the file handle.
Example: Sequential File Processing with Mapped Files
cci (Program 2-3) illustrates sequential file processing by encrypting files. This is an ideal application for memory-mapped files because the most natural way to convert the data is to process it one character at a time without being concerned with file I/O. Program 5-3 simply maps the input file and the output file and converts the characters one at a time.
Program 5-3 cci_fMM: File Conversion with Memory Mapping



This example clearly illustrates the trade-off between the file mapping complexity required to initialize the program and the resulting processing simplicity. This complexity may not seem worthwhile given the simplicity of a simple file I/O implementation, but there is a significant performance advantage. Appendix C and the Examples file contain additional performance comparisons and examples; the highlights are summarized here.
• Compared with the best sequential file processing techniques, the performance improvements can be 3:1 or greater.
• You can gain similar advantages with random access; the Examples file contains a memory-mapped version (RecordAccessMM) of Chapter 3’s RecordAccess (Program 3-1) example so that you can compare the performance of two solutions to the same problem. A batch file, RecordAccessTIME.bat, exercises the two programs with large data sets; Appendix C has results on several computers.6
6 Memory management is a good strategy for record access in many, but not all, situations. For example, if records are as large as or larger than the page size, you may not get any benefit and may even decrease performance compared to normal file access.
• The performance advantage can disappear for larger files. In this example, on Win32 systems, as the input file size approaches about one half of the physical memory size, normal sequential scanning is preferable. The mapping performance degrades at this point because the input file fills one half of the memory, and the output file, which is twice as long, fills the other half, forcing parts of the output files to be flushed to disk. Thus, on a 1.5GB RAM computer, mapping performance degenerates for input files longer than about 700MB. Many file processing applications deal with smaller files and can take advantage of file mapping.
• Memory mapping performs well with multithreaded programs (Chapter 7). An additional Examples file project, wcMT, implements a multithreaded “word count” program using memory mapping, and you can compare its performance to the file access version, wc.
• cci_fMM (Program 5-3) will work with files larger than 4GB but only on a Win64 system.
Program 5-3 shows only the function, cci_fMM, without SEH (see the Examples file). The main program is the same as for Program 2-3. Run 5-3 shows the results, comparing the output and timing with cci, which uses normal file access.
Run 5-3 cciMM: File Conversion with Memory-Mapped Files

Example: Sorting a Memory-Mapped File
Another advantage of memory mapping is the ability to use convenient memory-based algorithms to process files. Sorting data in memory, for instance, is much easier than sorting records in a file.
Program 5-4 sorts a file with fixed-length records. This program, called sortFL, is similar to Program 5-1 in that it assumes an 8-byte sort key at the start of the record, but it is restricted to fixed records.
Program 5-4 sortFL: Sorting a File with Memory Mapping


The sorting is performed by the <stdlib.h> C library function qsort. Notice that qsort requires a programmer-defined record comparison function, which is the same as the KeyCompare function in Program 5-2.
This program structure is straightforward. Simply create the file mapping on a temporary copy of the input file, create a single view of the file, and invoke qsort. There is no file I/O. Then the sorted file is sent to standard output using _tprintf, although a null character is appended to the file map.
Exception and error handling are omitted in the listing but are in the Examples solution on the book’s Web site.
Run 5-4 shows the same operations as Run 5-2 for sortBT. sortFL is much faster, requiring about 3 seconds to sort a 1,000,000 record file, rather than over 2 minutes.
Run 5-4 sortFL: Sorting in Memory with File Mapping

This implementation is straightforward, but there is an alternative that does not require mapping. Just allocate memory, read the complete file, sort it in memory, and write it. Such a solution, included in the Examples file, would be as effective as Program 5-4 and is often faster, as shown in Appendix C.
Based Pointers
File maps are convenient, as the preceding examples demonstrate. Suppose, however, that the program creates a data structure with pointers in a mapped file and expects to access that file in the future. Pointers will all be relative to the virtual address returned from MapViewOfFile, and they will be meaningless when mapping the file the next time. The solution is to use based pointers, which are actually offsets relative to another pointer. The Microsoft C syntax, available in Visual C++ and some other systems, is:
type __based (base) declarator
Here are two examples.

Notice that the syntax forces use of the *, a practice that is contrary to Windows convention but which the programmer could easily fix with a typedef.
Example: Using Based Pointers
Previous programs have shown how to sort files in various situations. The object, of course, is to illustrate different ways to manage memory, not to discuss sorting algorithms. Program 5-1 uses a binary search tree that is destroyed after each sort, and Program 5-4 sorts an array of fixed-size records in mapped memory.
Suppose you need to maintain a permanent index file representing the sorted keys of the original file. The apparent solution is to map a file that contains the permanent index in a search tree or sorted key form to memory. Unfortunately, there is a major difficulty with this solution. All pointers in the tree, as stored in the file, are relative to the address returned by MapViewOfFile. The next time the program runs and maps the file, the pointers will be useless.
Program 5-5, together with Program 5-6, solves this problem, which is characteristic of any mapped data structure that uses pointers. The solution uses the __based keyword available with Microsoft C. An alternative is to map the file to an array and use indexing to access records in the mapped files.
Program 5-5 sortMM: Based Pointers in an Index File


Program 5-6 sortMM: Creating the Index File

The program is written as yet another version of the sort command, this time called sortMM. There are enough new features, however, to make it interesting.
• The records are of varying lengths.
• The program uses the first field of each record as a key of 8 characters.
• There are two file mappings. One mapping is for the original file, and the other is for the file containing the sorted keys. The second file is the index file, and each of its records contains a key and a pointer (base address) in the original file. qsort sorts the key file, much as in Program 5-4.
• The index file is saved and can be used later, and there is an option (-I) that bypasses the sort and uses an existing index file. The index file can also be used to perform a fast key file search with a binary search (using, perhaps, the C library bsearch function) on the index file.
• The input file itself is not changed; the index file is the result. sortMM does, however, display the sorted result, or you can use the -n option to suppress printing and then use the -I option with an index file created on a previous run.
Figure 5-5 shows the relationship of the index file to the file to be sorted. Program 5-5, sortMM, is the main program that sets up the file mapping, sorts the index file, and displays the results. It calls a function, CreateIndexFile, shown in Program 5-6.
Figure 5-5 Sorting with a Memory-Mapped Index File

Run 5-6, after the program listings, shows sortMM operation, and the timing can be compared to Run 5-4 for sortFL; sortFL is much faster, as creating the sorted index file requires numerous references to scattered locations in the mapped data file. However, once the index file is created, the -I option allows you to access the sorted data very quickly.
Run 5-6 sortMM: Sorting Using Based Pointers and Mapping

Caution: These two programs make some implicit assumptions, which we’ll review after the program listings and the run screenshot.
Program 5-6 is the CreateIndexFile function, which creates the index file. It scans the input file to find the bound of each varying-length record to set up the structure shown in Figure 5-5.
A Comment about Alignment
sortMM illustrates based pointers in mapped files. The program also allows for different key length and key start positions, which Program 5-5 sets to 8 and 0, respectively. However, the index file has the pointer directly after the key, so these values should be a multiple of the pointer size (4 or 8) to avoid possible alignment exceptions. An exercise asks you to overcome this limitation.
We’re also assuming implicitly that page sizes and MapViewOfFile return values are multiples of pointer, DWORD, and other object sizes.
Dynamic Link Libraries
We have now seen that memory management and file mapping are important and useful techniques in a wide class of programs. The OS itself also uses memory management, and DLLs are the most visible and important use because Windows applications use DLLs extensively. DLLs are also essential to higher-level technologies, such as COM, and many software components are provided as DLLs.
The first step is to consider the different methods of constructing libraries of commonly used functions.
Static and Dynamic Libraries
The most direct way to construct a program is to gather the source code of all the functions, compile them, and link everything into a single executable image. Common functions, such as ReportError, can be put into a library to simplify the build process. This technique was used with all the sample programs presented so far, although there were only a few functions, most of them for error reporting.
This monolithic, single-image model is simple, but it has several disadvantages.
• The executable image may be large, consuming disk space and physical memory at run time and requiring extra effort to manage and deliver to users.
• Each program update requires a rebuild of the complete program even if the changes are small or localized.
• Every program in the computer that uses the functions will have a copy of the functions, possibly different versions, in its executable image. This arrangement increases disk space usage and, perhaps more important, physical memory usage when several such programs are running concurrently.
• Distinct versions of the program, using different techniques, might be required to get the best performance in different environments. For example, the cci_f function is implemented differently in Program 2-3 (cci) and Program 5-3 (cci_fMM). The only method of executing different implementations is to decide which of the two versions to run based on environmental factors.
DLLs solve these and other problems quite neatly.
• Library functions are not linked at build time. Rather, they are linked at program load time (implicit linking) or at run time (explicit linking). As a result, the program image can be much smaller because it does not include the library functions.
• DLLs can be used to create shared libraries. Multiple programs share a single library in the form of a DLL, and only a single copy is loaded into memory. All programs map the DLL code to their process address space, although each process has a distinct copy of the DLL’s global variables. For example, the ReportError function was used by nearly every example program; a single DLL implementation could be shared by all the programs.
• New versions or alternative implementations can be supported simply by supplying a new version of the DLL, and all programs that use the library can use the new version without modification.
• The library will run in the same processes as the calling program.
DLLs, sometimes in limited form, are used in nearly every OS. For example, UNIX uses the term “shared libraries” for the same concept. Windows uses DLLs to implement the OS interfaces, among other things. The entire Windows API is supported by a DLL that invokes the Windows kernel for additional services.
Multiple Windows processes can share DLL code, but the code, when called, runs as part of the calling process and thread. Therefore, the library will be able to use the resources of the calling process, such as file handles, and will use the calling thread’s stack. DLLs should therefore be written to be thread-safe. (See Chapters 8, 9, and 10 for more information on thread safety and DLLs. Programs 12-5 and 12-6 illustrate techniques for creating thread-safe DLLs.) A DLL can also export variables as well as function entry points.
Implicit Linking
Implicit or load-time linking is the easier of the two techniques. The required steps, using Microsoft Visual C++, are as follows.
1. The functions in a new DLL are collected and built as a DLL rather than, for example, a console application.
2. The build process constructs a .LIB library file, which is a stub for the actual code and is linked into the calling program at build time, satisfying the function references. The .LIB file contains code that loads the DLL at program load time. It also contains a stub for each function, where the stub calls the DLL. This file should be placed in a common user library directory specified to the project.
3. The build process also constructs a .DLL file that contains the executable image. This file is typically placed in the same directory as the application that will use it, and the application loads the DLL during its initialization. The alternative search locations are described in the next section.
4. Take care to export the function interfaces in the DLL source, as described next.
Exporting and Importing Interfaces
The most significant change required to put a function into a DLL is to declare it to be exportable (UNIX and some other systems do not require this explicit step). This is achieved either by using a .DEF file or, more simply, with Microsoft C/C++, by using the __declspec (dllexport) storage modifier as follows:
__declspec (dllexport) DWORD MyFunction (...);
The build process will then create a .DLL file and a .LIB file. The .LIB file is the stub library that should be linked with the calling program to satisfy the external references and to create the actual links to the .DLL file at load time.
The calling or client program should declare that the function is to be imported by using the __declspec (dllimport) storage modifier. A standard technique is to write the include file by using a preprocessor variable created by appending the Microsoft Visual C++ project name, in uppercase letters, with _EXPORTS.
One further definition is necessary. If the calling (importing) client program is written in C++, __cplusplus is defined, and it is necessary to specify the C calling convention, using:
extern "C"
For example, if MyFunction is defined as part of a DLL build in project MyLibrary, the header file would contain:

Visual C/C++ automatically defines MYLIBRARY_EXPORTS when invoking the compiler within the MyLibrary DLL project. A client project that uses the DLL does not define MYLIBRARY_EXPORTS, so the function name is imported from the library.
When building the calling program, specify the .LIB file. When executing the calling program, ensure that the .DLL file is available to the calling program; this is frequently done by placing the .DLL file in the same directory as the executable. As mentioned previously, there is a set of DLL search rules that specify the order in which Windows searches for the specified .DLL file as well as for all other DLLs or executables that the specified file requires, stopping with the first instance located. The following default safe DLL search mode order is used for both explicit and implicit linking:
• The directory containing the loaded application.
• The system directory. You can determine this path with GetSystemDirectory; normally its value is C:WINDOWSSYSTEM32.
• The 16-bit Windows system directory. There is no function to obtain this path, and it is obsolete for our purposes.
• The Windows directory (GetWindowsDirectory).
• The current directory.
• Directories specified by the PATH environment variable, in the order in which they occur.
Note that the standard order can be modified, as explained in the “Explicit Linking” section. For some additional detailed information on the search strategy, see MSDN and the SetDllDirectory function. LoadLibraryEx, described in the next section, also alters the search strategy.
You can also export and import variables as well as function entry points, although the examples do not illustrate this capability.
Explicit Linking
Explicit or run-time linking requires the program to request specifically that a DLL be loaded or freed. Next, the program obtains the address of the required entry point and uses that address as the pointer in the function call. The function is not declared in the calling program; rather, you declare a variable as a pointer to a function. Therefore, there is no need for a library at link time. The three required functions are LoadLibrary (or LoadLibraryEx), GetProcAddress, and FreeLibrary. Note: The function definitions show their 16-bit legacy through far pointers and different handle types.
The two functions to load a library are LoadLibrary and LoadLibraryEx.

In both cases, the returned handle (HMODULE rather than HANDLE; you may see the equivalent macro, HINSTANCE) will be NULL on failure. The .DLL suffix is not required on the file name. .EXE files can also be loaded with the LoadLibrary functions. Pathnames must use backslashes (); forward slashes (/) will not work. The name is the one in the .DEF module definition file (see MSDN for details).
Note: If you are using C++ and __dllexport, the decorated name is exported, and the decorated name is required for GetProcAddress. Our examples avoid this difficult problem by using C.
Since DLLs are shared, the system maintains a reference count to each DLL (incremented by the two load functions) so that the actual file does not need to be remapped. Even if the DLL file is found, LoadLibrary will fail if the DLL is implicitly linked to other DLLs that cannot be located.
LoadLibraryEx is similar to LoadLibrary but has several flags that are useful for specifying alternative search paths and loading the library as a data file. The hFile parameter is reserved for future use. dwFlags can specify alternate behavior with one of three values.
1. LOAD_WITH_ALTERED_SEARCH_PATH overrides the previously described standard search order, changing just the first step of the search strategy. The pathname specified as part of lpLibFileName is used rather than the directory from which the application was loaded.
2. LOAD_LIBRARY_AS_DATAFILE allows the file to be data only, and there is no preparation for execution, such as calling DllMain (see the “DLL Entry Point” section later in the chapter).
3. DONT_RESOLVE_DLL_REFERENCE means that DllMain is not called for process and thread initialization, and additional modules referenced within the DLL are not loaded.
When you’re finished with a DLL instance, possibly to load a different version of the DLL, free the library handle, thereby freeing the resources, including virtual address space, allocated to the library. The DLL will, however, remain loaded if the reference count indicates that other processes are still using it.
After loading a library and before freeing it, you can obtain the address of any entry point using GetProcAddress.
![]()
hModule is an instance produced by LoadLibrary or GetModuleHandle (see the next paragraph). lpProcName, which cannot be Unicode, is the entry point name. The return result is NULL in case of failure. FARPROC, like “long pointer,” is an anachronism.
You can obtain the file name associated with an hModule handle using GetModuleFileName. Conversely, given a file name (either a .DLL or .EXE file), GetModuleHandle will return the handle, if any, associated with this file if the current process has loaded it.
The next example shows how to use the entry point address to invoke a function.
Example: Explicitly Linking a File Conversion Function
Program 2-3 is an encryption conversion program that calls the function cci_f (Program 2-5) to process the file using file I/O. Program 5-3 (cciMM) is an alternative function that uses memory mapping to perform exactly the same operation. The circumstances under which cciMM is faster were described earlier. Furthermore, if you are running on a 32-bit computer, you will not be able to map files larger than about 1.5GB.
Program 5-7 reimplements the calling program so that it can decide which implementation to load at run time. It then loads the DLL and obtains the address of the cci_f entry point and calls the function. There is only one entry point in this case, but it would be equally easy to locate multiple entry points. The main program is as before, except that the DLL to use is a command line parameter. Exercise 5–10 suggests that the DLL should be determined on the basis of system and file characteristics. Also notice how the FARPROC address is cast to the appropriate function type using the required, but complex, C syntax. The cast even includes __cdecl, the linkage type, which is also used by the DLL function. Therefore, there are no assumptions about the build settings for the calling program (“client”) and called function (“server”).
Program 5-7 cciEL: File Conversion with Explicit Linking

Building the cci_f DLLs
This program was tested with the two file conversion functions, which must be built as DLLs with different names but identical entry points. There is only one entry point in this case. The only significant change in the source code is the addition of a storage modifier, __declspec (dllexport), to export the function.
Run 5-7 shows the results, which are comparable to Run 5-3.
Run 5-7 cciEL: Explicit Linking to a DLL

The DLL Entry Point
Optionally, you can specify an entry point for every DLL you create, and this entry point is normally invoked automatically every time a process attaches or detaches the DLL. LoadLibraryEx, however, allows you to prevent entry point execution. For implicitly linked (load-time) DLLs, process attachment and detachment occur when the process starts and terminates. In the case of explicitly linked DLLs, LoadLibrary, LoadLibraryEx, and FreeLibrary cause the attachment and detachment calls.
The entry point is also invoked when new threads (Chapter 7) are created or terminated by the process.
The DLL entry point, DllMain, is introduced here but will not be fully exploited until Chapter 12 (Program 12-5), where it provides a convenient way for threads to manage resources and so-called Thread Local Storage (TLS) in a thread-safe DLL.

The hDll value corresponds to the instance obtained from LoadLibrary. lpReserved, if NULL, indicates that the process attachment was caused by LoadLibrary; otherwise, it was caused by implicit load-time linking. Likewise, FreeLibrary gives a NULL value for process detachment.
Reason will have one of four values: DLL_PROCESS_ATTACH, DLL_THREAD_ATTACH, DLL_THREAD_DETACH, and DLL_PROCESS_DETACH. DLL entry point functions are normally written as switch statements and return TRUE to indicate correct operation.
The system serializes calls to DllMain so that only one thread at a time can execute it (Chapter 7 introduces threads). This serialization is essential because DllMain must perform initializations that must complete without interruption. As a consequence, however, there should not be any blocking calls, such as I/O or wait functions (see Chapter 8), within the entry point, because they would prevent other threads from entering. Furthermore, you cannot call other DLLs from DllMain (there are a few exceptions, such as InitializeCriticalSection).
LoadLibrary and LoadLibraryEx, in particular, should never be called from a DLL entry point, as that would create additional DLL entry point calls.
An advanced function, DisableThreadLibraryCalls, will disable thread attach/detach calls for a specified DLL instance. As a result, Windows does not need to load the DLL’s initialization or termination code every time a thread is created or terminates. This can be useful if the DLL is only used by some of the threads.
DLL Version Management
A common problem with DLLs concerns difficulties that occur as a library is upgraded with new symbols and features are added. A major DLL advantage is that multiple applications can share a single implementation. This power, however, leads to compatibility complications, such as the following.
• A new version may change behavior or interfaces, causing problems to existing applications that have not been updated.
• Applications that depend on new DLL functionality sometimes link with older DLL versions.
DLL version compatibility problems, popularly referred to as “DLL hell,” can be irreconcilable if only one version of the DLL is to be maintained in a single directory. However, it is not necessarily simple to provide distinct version-specific directories for different versions. There are several solutions.
• Use the DLL version number as part of the .DLL and .LIB file names, usually as a suffix. For example, Utility_4_0.DLL and Utility_4_0.LIB are used in the Examples projects to correspond with the book edition number. By using either explicit or implicit linking, applications can then determine their version requirements and access files with distinct names. This solution is commonly used with UNIX applications.
• Microsoft introduced the concept of side-by-side DLLs or assemblies and components. This solution requires adding a manifest, written in XML, to the application so as to define the DLL requirements. This topic is beyond the book’s scope, but additional information can be found on the MSDN Web site.
• The .NET Framework provides additional support for side-by-side execution.
The first approach, including the version number as part of the file name, is used in the Examples file, as mentioned in the first bullet.
To provide additional support so that applications can determine additional DLL information beyond just the version number, DllGetVersion is a user-provided callback function; many Microsoft DLLs support this callback function as a standard method to obtain version information dynamically. The function operates as follows:

• Information about the DLL is returned in the DLLVERSIONINFO structure, which contains DWORD fields for cbSize (the structure size), dwMajorVersion, dwMinorVersion, dwBuildNumber, and dwPlatformID.
• The last field, dwPlatformID, can be set to DLLVER_PLATFORM_NT if the DLL cannot run on Windows 9x (this should no longer be an issue!) or to DLLVER_PLATFORM_WINDOWS if there are no restrictions.
• The cbSize field should be set to sizeof(DLLVERSIONINFO). The normal return value is NOERROR.
• Utility_4_0 implements DllGetVersion.
Summary
Windows memory management includes the following features.
• Logic can be simplified by allowing the Windows heap management and exception handlers to detect and process allocation errors.
• Multiple independent heaps provide several advantages over allocation from a single heap, but there is a cost of extra complexity to assure that blocks are freed, or resized, from the correct heap.
• Memory-mapped files, also available with UNIX but not with the C library, allow files to be processed in memory, as illustrated by several examples. File mapping is independent of heap management, and it can simplify many programming tasks. Appendix C shows the performance advantage of using memory-mapped files.
• DLLs are an essential special case of mapped files, and DLLs can be loaded either explicitly or implicitly. DLLs used by numerous applications should provide version information.
Looking Ahead
This completes coverage of what can be achieved within a single process. The next step is to learn how to manage concurrent processing, first with processes (Chapter 6) and then with threads (Chapter 7). Subsequent chapters show how to synchronize and communicate between concurrent processing activities.
Additional Reading
Memory Mapping, Virtual Memory, and Page Faults
Russinovich, Solomon, and Ionescu (Windows Internals: Including Windows Server 2008 and Windows Vista, Fifth Edition) describe the important concepts, and most OS texts provide good in-depth discussion.
Data Structures and Algorithms
Search trees and sort algorithms are explained in numerous texts, including Cormen, Leiserson, Rivest, and Stein’s Introduction to Algorithms.
Using Explicit Linking
DLLs and explicit linking are fundamental to the operation of COM, which is widely used in Windows software development. Chapter 1 of Don Box’s Essential COM shows the importance of LoadLibrary and GetProcAddress.
Exercises
5–1. Design and carry out experiments to evaluate the performance gains from the HEAP_NO_SERIALIZE flag with HeapCreate and HeapAlloc. How are the gains affected by the heap size and by the block size? Are there differences under different Windows versions? The Examples file contains a program, HeapNoSr.c, to help you get started on this exercise and the next one.
5–2. Modify the test in the preceding exercise to determine whether malloc generates exceptions or returns a null pointer when there is no memory. Is this the correct behavior? Also compare malloc performance with the results from the preceding exercise.
5–3. Windows versions differ significantly in terms of the overhead memory in a heap. Design and carry out an experiment to measure how many fixed-size blocks each system will give in a single heap. Using SEH to detect when all blocks have been allocated makes the program easier. A test program, clear.c, in the Examples file will show this behavior.
5–4. Modify sortFL (Program 5-4) to create sortHP, which allocates a memory buffer large enough to hold the file, and read the file into that buffer. There is no memory mapping. Compare the performance of the two programs.
5–5. Compare random file access performance using conventional file access (Chapter 3’s RecordAccess) and memory mapping (RecordAccessMM).
5–6. Program 5-5 exploits the __based pointers that are specific to Microsoft C. If you have a compiler that does not support this feature (or simply for the exercise), reimplement Program 5-5 with a macro, arrays, or some other mechanism to generate the based pointer values.
5–7. Write a search program that will find a record with a specified key in a file that has been indexed by Program 5-5. The C library bsearch function would be convenient here.
5–8. Enhance sortMM (Programs 5-5 and 5-6) to remove all implicit alignment assumptions in the index file. See the comments after the program listings.
5–9. Implement the tail program from Chapter 3 with memory mapping.
5–10. Modify Program 5-7 so that the decision as to which DLL to use is based on the file size and system configuration. The .LIB file is not necessary, so figure out how to suppress .LIB file generation. Use GetVolumeInformation to determine the file system type. Create additional DLLs for the conversion function, each version using a different file processing technique, and extend the calling program to decide when to use each version.
5–11. Put the ReportError, PrintStrings, PrintMsg, and ConsolePrompt utility functions into a DLL and rebuild some of the earlier programs. Do the same with Options and GetArgs, the command line option and argument processing functions. It is important that both the utility DLL and the calling program also use the C library in DLL form. Within Visual Studio, for instance, you can select “Use Run-Time Library (Multithreaded DLL)” in the project settings. Note that DLLs must, in general, be multithreaded because they will be used by threads from several processes. See the Utilities_4_0 project in the Examples file for a solution.
5–12. Build project Version (in the Examples file), which uses version.c. Run the program on as many different Windows versions as you can access. What are the major and minor version numbers for those systems, and what other information is available? The following screenshot, Exercise Run 5-12, shows the result on a Vista computer with four processors. The “Max appl addr” value is wrong, as this is a 64-bit system. Can you fix this defect?
Exercise Run 5-12 version: System Version and Other Information
