
One of Linux’s keys to success is its ability to coexist comfortably with other systems. You can transparently mount disks or partitions that host file formats used by Windows, other Unix systems, or even systems with tiny market shares like the Amiga. Linux manages to support multiple disk types in the same way other Unix variants do, through a concept called the Virtual Filesystem.
The idea behind the Virtual Filesystem is to put a wide range of information in the kernel to represent many different types of filesystems; there is a field or function to support each operation provided by any real filesystem supported by Linux. For each read, write, or other function called, the kernel substitutes the actual function that supports a native Linux filesystem, the NT filesystem, or whatever other filesystem the file is on.
This chapter discusses the aims, structure, and implementation of Linux’s Virtual Filesystem. It focuses on three of the five standard Unix file types—namely, regular files, directories, and symbolic links. Device files are covered in Chapter 13, while pipes are discussed in Chapter 19. To show how a real filesystem works, Chapter 17 covers the Second Extended Filesystem that appears on nearly all Linux systems.
The Virtual Filesystem (also known as Virtual Filesystem Switch or VFS) is a kernel software layer that handles all system calls related to a standard Unix filesystem. Its main strength is providing a common interface to several kinds of filesystems.
For instance, let’s assume that a user issues the shell command:
$ cp /floppy/TEST /tmp/test
where /floppy is the mount point of an MS-DOS diskette and /tmp is a normal Second Extended Filesystem (Ext2) directory. As shown in Figure 12-1(a), the VFS is an abstraction layer between the application program and the filesystem implementations. Therefore, the cp program is not required to know the filesystem types of /floppy/TEST and /tmp/test. Instead, cp interacts with the VFS by means of generic system calls known to anyone who has done Unix programming (see Section 1.5.6); the code executed by cp is shown in Figure 12-1(b).

Filesystems supported by the VFS may be grouped into three main classes:
- Disk-based filesystems
These manage the memory space available in a local disk partition. Some of the well-known disk-based filesystems supported by the VFS are:
Filesystems for Linux such as the widely used Second Extended Filesystem (Ext2), the recent Third Extended Filesystem (Ext3), and the Reiser Filesystems (ReiserFS)[81]
Filesystems for Unix variants such as SYSV filesystem (System V, Coherent, XENIX), UFS (BSD, Solaris, Next), MINIX filesystem, and VERITAS VxFS (SCO UnixWare)
Microsoft filesystems such as MS-DOS, VFAT (Windows 95 and later releases), and NTFS (Windows NT)
ISO9660 CD-ROM filesystem (formerly High Sierra Filesystem) and Universal Disk Format (UDF) DVD filesystem
Other proprietary filesystems such as IBM’s OS/2 (HPFS), Apple’s Macintosh (HFS), Amiga’s Fast Filesystem (AFFS), and Acorn Disk Filing System (ADFS)
Additional journaling file systems originating in systems other than Linux such as IBM’s JFS and SGI’s XFS.
- Network filesystems
These allow easy access to files included in filesystems belonging to other networked computers. Some well-known network filesystems supported by the VFS are NFS, Coda, AFS (Andrew filesystem), SMB (Server Message Block, used in Microsoft Windows and IBM OS/2 LAN Manager to share files and printers), and NCP (Novell’s NetWare Core Protocol).
- Special filesystems (also called virtual filesystems)
These do not manage disk space, either locally or remotely. The
/procfilesystem is a typical example of a special filesystem (see the later section Section 12.3.1).
In this book, we describe in detail the Ext2 and Ext3 filesystems only (see Chapter 17); the other filesystems are not covered for lack of space.
As mentioned in Section 1.5, Unix
directories build a tree whose root is the /
directory. The root directory is contained in the root filesystem
, which in Linux, is usually of type
Ext2. All other filesystems can be
“mounted” on subdirectories of the
root filesystem.[82]
A disk-based filesystem is usually stored in a hardware block device
like a hard disk, a floppy, or a CD-ROM. A useful feature of
Linux’s VFS allows it to handle virtual block devices
like /dev/loop0,
which may be used to mount filesystems stored in regular files. As a
possible application, a user may protect his own private filesystem
by storing an encrypted version of it in a regular file.
The first Virtual Filesystem was included in Sun Microsystems’s SunOS in 1986. Since then, most Unix filesystems include a VFS. Linux’s VFS, however, supports the widest range of filesystems.
The key idea behind the VFS consists of introducing a common file model capable of representing all supported filesystems. This model strictly mirrors the file model provided by the traditional Unix filesystem. This is not surprising, since Linux wants to run its native filesystem with minimum overhead. However, each specific filesystem implementation must translate its physical organization into the VFS’s common file model.
For instance, in the common file model, each directory is regarded as a file, which contains a list of files and other directories. However, several non-Unix disk-based filesystems use a File Allocation Table (FAT), which stores the position of each file in the directory tree. In these filesystems, directories are not files. To stick to the VFS’s common file model, the Linux implementations of such FAT-based filesystems must be able to construct on the fly, when needed, the files corresponding to the directories. Such files exist only as objects in kernel memory.
More essentially, the Linux kernel cannot hardcode a particular
function to handle an operation such as read( ) or
ioctl( ). Instead, it must use a pointer for each
operation; the pointer is made to point to the proper function for
the particular filesystem being accessed.
Let’s illustrate this concept by showing how the
read( ) shown in Figure 12-1 would be translated
by the kernel into a call specific to the MS-DOS filesystem. The
application’s call to read( )
makes the kernel invoke the corresponding sys_read( ) service routine, just like any other system call. The
file is represented by a file data structure in
kernel memory, as we shall see later in this chapter. This data
structure contains a field called f_op that
contains pointers to functions specific to MS-DOS files, including a
function that reads a file. sys_read( ) finds the
pointer to this function and invokes it. Thus, the
application’s read( ) is turned
into the rather indirect call:
file->f_op->read(...);
Similarly, the write( ) operation triggers the
execution of a proper Ext2 write function associated with the output
file. In short, the kernel is responsible for assigning the right set
of pointers to the file variable associated with
each open file, and then for invoking the call specific to each
filesystem that the f_op field points to.
One can think of the common file model as object-oriented, where an object is a software construct that defines both a data structure and the methods that operate on it. For reasons of efficiency, Linux is not coded in an object-oriented language like C++. Objects are therefore implemented as data structures with some fields pointing to functions that correspond to the object’s methods.
The common file model consists of the following object types:
- The superblock object
Stores information concerning a mounted filesystem. For disk-based filesystems, this object usually corresponds to a filesystem control block stored on disk.
- The inode object
Stores general information about a specific file. For disk-based filesystems, this object usually corresponds to a file control block stored on disk. Each inode object is associated with an inode number , which uniquely identifies the file within the filesystem.
- The file object
Stores information about the interaction between an open file and a process. This information exists only in kernel memory during the period when each process accesses a file.
- The dentry object
Stores information about the linking of a directory entry with the corresponding file. Each disk-based filesystem stores this information in its own particular way on disk.
Figure 12-2 illustrates with a simple example how processes interact with files. Three different processes have opened the same file, two of them using the same hard link. In this case, each of the three processes uses its own file object, while only two dentry objects are required—one for each hard link. Both dentry objects refer to the same inode object, which identifies the superblock object and, together with the latter, the common disk file.
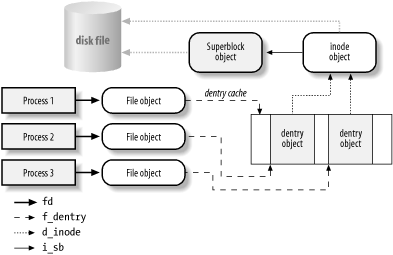
Besides providing a common interface to all filesystem implementations, the VFS has another important role related to system performance. The most recently used dentry objects are contained in a disk cache named the dentry cache , which speeds up the translation from a file pathname to the inode of the last pathname component.
Generally speaking, a disk cache is a software mechanism that allows the kernel to keep in RAM some information that is normally stored on a disk, so that further accesses to that data can be quickly satisfied without a slow access to the disk itself.[83] Beside the dentry cache, Linux uses other disk caches, like the buffer cache and the page cache, which are described in forthcoming chapters.
Table 12-1 illustrates the VFS system calls that refer to
filesystems, regular files, directories, and symbolic links. A few
other system calls handled by the VFS, such as ioperm( ), ioctl( ), pipe( ),
and mknod( ), refer to device files and pipes.
These are discussed in later chapters. A last group of system calls
handled by the VFS, such as socket( ),
connect( ), bind( ), and
protocols( ), refer to sockets and are used to
implement networking; some of them are discussed in Chapter 18. Some of the kernel service routines that
correspond to the system calls listed in Table 12-1
are discussed either in this chapter or in Chapter 17.
Table 12-1. Some system calls handled by the VFS
|
System call name |
Description |
|---|---|
|
|
Mount/unmount filesystems |
|
|
Get filesystem information |
|
|
Get filesystem statistics |
|
|
Change root directory |
|
|
Manipulate current directory |
|
|
Create and destroy directories |
|
|
Manipulate directory entries |
|
|
Manipulate soft links |
|
|
Modify file owner |
|
|
Modify file attributes |
|
|
Read file status |
|
|
Open and close files |
|
|
Manipulate file descriptors |
|
|
Asynchronous I/O notification |
|
|
Change file size |
|
|
Change file pointer |
|
|
Carry out file I/O operations |
|
|
Seek file and access it |
|
|
Handle file memory mapping |
|
|
Synchronize file data |
|
|
Manipulate file lock |
We said earlier that the VFS is a layer between application programs
and specific filesystems. However, in some cases, a file operation
can be performed by the VFS itself, without invoking a lower-level
procedure. For instance, when a process closes an open file, the file
on disk doesn’t usually need to be touched, and
hence the VFS simply releases the corresponding file object.
Similarly, when the lseek( ) system call modifies
a file pointer, which is an attribute related to the interaction
between an opened file and a process, the VFS needs to modify only
the corresponding file object without accessing the file on disk and
therefore does not have to invoke a specific filesystem procedure. In
some sense, the VFS could be considered a
“generic” filesystem that relies,
when necessary, on specific ones.
[81] Although these filesystems owe their birth to Linux, they have been ported to several other operating systems.
[82] When a filesystem is mounted on a directory, the contents of the directory in the parent filesystem are no longer accessible, since any pathname, including the mount point, will refer to the mounted filesystem. However, the original directory’s content shows up again when the filesystem is unmounted. This somewhat surprising feature of Unix filesystems is used by system administrators to hide files; they simply mount a filesystem on the directory containing the files to be hidden.
[83] Notice how a disk cache differs from a hardware cache or a memory cache, neither of which has anything to do with disks or other devices. A hardware cache is a fast static RAM that speeds up requests directed to the slower dynamic RAM (see Section 2.4.7). A memory cache is a software mechanism introduced to bypass the Kernel Memory Allocator (see Section 7.2.1).