
Chapter 8: Ranges and Algorithms
By reaching this point of the book, you have learned everything about the syntax and the mechanism of templates in C++, up to the latest version of the standard, C++20. This has equipped you with the necessary knowledge to write templates from simple forms to complex ones. Templates are the key to writing generic libraries. Even though you might not write such a library yourself, you’d still be using one or more. In fact, the everyday code that you’re writing in C++ uses templates. And the main reason for that is that as a modern C++ developer, you’re using the standard library, which is a library based on templates.
However, the standard library is a collection of many libraries, such as the containers library, iterators library, algorithms library, numeric library, input/output library, filesystem library, regular expressions library, thread support library, utility libraries, and others. Overall, it’s a large library that could make the topic of at least an entire book. However, it is worth exploring some key parts of the library to help you get a better understanding of some of the concepts and types you are or could be using regularly.
Because addressing this topic in a single chapter would lead to a significantly large chapter, we will split the discussion into two parts. In this chapter, we will address the following topics:
- Understanding the design of containers, iterators, and algorithms
- Creating a custom container and iterator
- Writing a custom general-purpose algorithm
By the end of this chapter, you will have a good understanding of the three main pillars of the standard template library, which are containers, iterators, and algorithms.
We will begin this chapter with an overview of what the standard library has to offer in this respect.
Understanding the design of containers, iterators, and algorithms
Containers are types that represent collections of elements. These collections can be implemented based on a variety of data structures, each with different semantics: lists, queues, trees, and so on. The standard library provides three categories of containers:
- Sequence containers: vector, deque, list, array, and forward_list
- Associative containers: set, map, multiset, and multimap
- Unordered associative containers: unordered_set, unordered_map, unordered_multiset, and unordered_multimap
In addition to this, there are also container adaptors that provide a different interface for sequence containers. This category includes the stack, queue, and priority_queue classes. Finally, there is a class called span that represents a non-owning view over a contiguous sequence of objects.
The rationale for these containers to be templates was presented in Chapter 1, Introduction to Templates. You don’t want to write the same implementation again and again for each different type of element that you need to store in a container. Arguably, the most used containers from the standard library are the following:
- vector: This is a variable-size collection of elements stored contiguously in memory. It’s the default container you would choose, provided no special requirements are defined. The internal storage expands or shrinks automatically as needed to accommodate the stored elements. The vector allocates more memory than needed so that the risk of having to expand is low. The expansion is a costly operation because new memory needs to be allocated, the content of the current storage needs to be copied to the new one, and lastly, the previous storage needs to be discarded. Because elements are stored contiguously in memory, they can be randomly accessed by an index in constant time.
- array: This is a fixed-size collection of elements stored contiguously in memory. The size must be a compile-time constant expression. The semantics of the array class is the same as a structure holding a C-style array (T[n]). Just like the vector type, the elements of the array class can be accessed randomly in constant time.
- map: This is a collection that associates a value to a unique key. Keys are sorted with a comparison function and the map class is typically implemented as a red-black tree. The operations to search, insert, or remove elements have logarithmic complexity.
- set: This is a collection of unique keys. The keys are the actual values stored in the container; there are no key-value pairs as in the case of the map class. However, just like in the case of the map class, set is typically implemented as a red-black tree that has logarithmic complexity for searching, inserting, and the removing of elements.
Regardless of their type, the standard containers have a few things in common:
- Several common member types
- An allocator for storage management (with the exception of the std::array class)
- Several common member functions (some of them are missing from one or another container)
- Access to the stored data with the help of iterators
The following member types are defined by all standard containers:
using value_type = /* ... */; using size_type = std::size_t; using difference_type = std::ptrdiff_t; using reference = value_type&; using const_reference = value_type const&; using pointer = /* ... */; using const_pointer = /* ... */; using iterator = /* ... */; using const_iterator = /* ... */;
The actual types these names are aliasing may differ from container to container. For instance, for std::vector, value_type is the template argument T, but for std::map, value_type is the std::pair<const Key, T> type. The purpose of these member types is to help with generic programming.
Except for the std::array class, which represents an array of a size known at compile time, all the other containers allocate memory dynamically. This is controlled with the help of an object called an allocator. Its type is specified as a type template parameter, but all containers default it to std::allocator if none is specified. This standard allocator uses the global new and delete operators for allocating and releasing memory. All constructors of standard containers (including copy and move constructors) have overloads that allow us to specify an allocator.
There are also common member functions defined in the standard containers. Here are some examples:
- size, which returns the number of elements (not present in std::forward_list).
- empty, which checks whether the container is empty.
- clear, which clears the content of the container (not present in std::array, std::stack, std::queue, and std::priority_queue).
- swap, which swaps the content of the container objects.
- begin and end methods, which return iterators to the beginning and end of the container (not present in std::stack, std::queue, and std::priority_queue, although these are not containers but container adaptors).
The last bullet mentions iterators. These are types that abstract the details of accessing elements in a container, providing a uniform way to identify and traverse the elements of containers. This is important because a key part of the standard library is represented by general-purpose algorithms. There are over one hundred such algorithms, ranging from sequence operations (such as count, count_if, find, and for_each) to modifying operations (such as copy, fill, transform, rotate, and reverse) to partitioning and sorting (partition, sort, nth_element, and more) and others. Iterators are key for ensuring they work generically. If each container had different ways to access its elements, writing generic algorithms would be virtually impossible.
Let’s consider the simple operation of copying elements from one container to another. For instance, we have a std::vector object and we want to copy its elements to a std::list object. This could look as follows:
std::vector<int> v {1, 2, 3};
std::list<int> l;
for (std::size_t i = 0; i < v.size(); ++i)
l.push_back(v[i]);What if we want to copy from a std::list to a std::set, or from a std::set to a std::array? Each case would require different kinds of code. However, general-purpose algorithms enable us to do this in a uniform way. The following snippet shows such an example:
std::vector<int> v{ 1, 2, 3 };
// copy vector to vector
std::vector<int> vc(v.size());
std::copy(v.begin(), v.end(), vc.begin());
// copy vector to list
std::list<int> l;
std::copy(v.begin(), v.end(), std::back_inserter(l));
// copy list to set
std::set<int> s;
std::copy(l.begin(), l.end(), std::inserter(s, s.begin()));Here we have a std::vector object and we copy its content to another std::vector, but also to a std::list object. Consequently, the content of the std::list object is then copied to a std::set object. For all cases, the std::copy algorithm is used. This algorithm has several arguments: two iterators that define the beginning and end of the source, and an iterator that defines the beginning of the destination. The algorithm copies one element at a time from the input range to the element pointer by the output iterator and then increments the output iterator. Conceptually, it can be implemented as follows:
template<typename InputIt, class OutputIt>
OutputIt copy(InputIt first, InputIt last,
OutputIt d_first)
{
for (; first != last; (void)++first, (void)++d_first)
{
*d_first = *first;
}
return d_first;
}Important Note
This algorithm was discussed in Chapter 5, Type Traits and Conditional Compilation, when we looked at how its implementation can be optimized with the help of type traits.
Considering the previous example, there are cases when the destination container does not have its content already allocated for the copying to take place. This is the case with copying to the list and to the set. In this case, iterator-like types, std::back_insert_iterator and std:insert_iterator, are used—indirectly through the std::back_inserter and std::inserter helper functions, for inserting elements into a container. The std::back_insert_iterator class uses the push_back function and std::insert_iterator uses the insert function.
There are six iterator categories in C++:
- Input iterator
- Output iterator
- Forward iterator
- Bidirectional iterator
- Random access iterator
- Contiguous iterator
The contiguous iterator category was added in C++17. All operators can be incremented with the prefix or postfix increment operator. The following table shows the additional operations that each category defines:

Table 8.1
With the exception of the output category, each category includes everything about it. That means a forward iterator is an input iterator, a bidirectional iterator is a forward iterator, a random-access iterator is a bidirectional iterator, and, lastly, a contiguous iterator is a random-access iterator. However, iterators in any of the first five categories can also be output iterators at the same time. Such an iterator is called a mutable iterator. Otherwise, they are said to be constant iterators.
The C++20 standard has added support for concepts and a concepts library. This library defines standard concepts for each of these iterator categories. The following table shows the correlation between them:
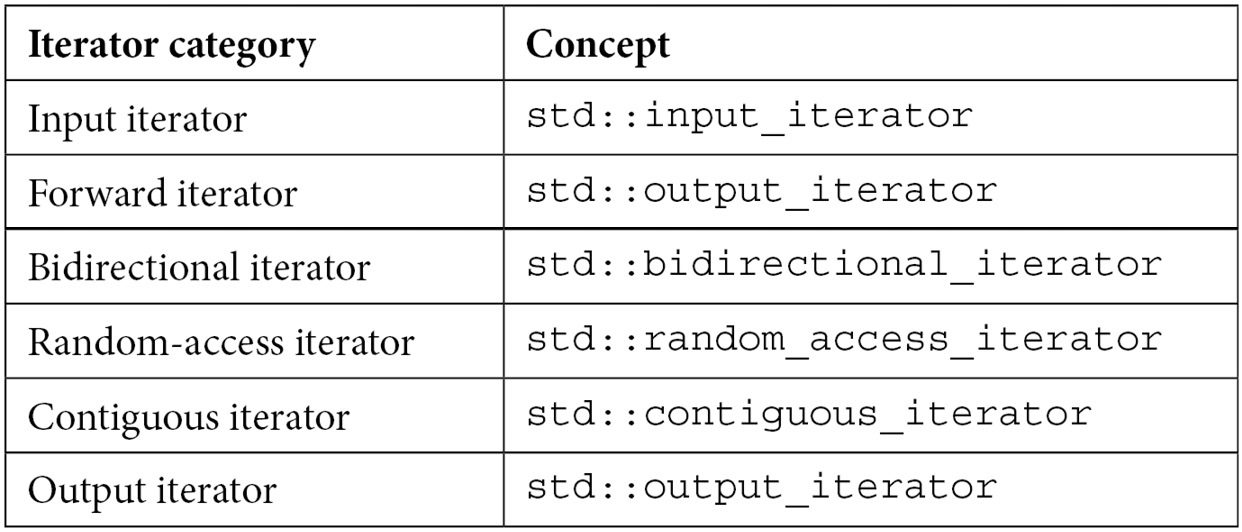
Table 8.2
Important Note
Iterator concepts were briefly discussed in Chapter 6, Concepts and Constraints.
All containers have the following members:
- begin: It returns an iterator to the beginning of the container.
- end: It returns an iterator to the end of the container.
- cbegin: It returns a constant iterator to the beginning of the container.
- cend: It returns a constant iterator to the end of the container.
Some containers also have members that return reverse iterators:
- rbegin: It returns a reverse iterator to the beginning of the reversed container.
- rend: It returns a reverse iterator to the end of the reversed container.
- rcbegin: It returns a constant reverse iterator to the beginning of the reversed container.
- rcend: It returns a constant reverse iterator to the end of the reversed container.
There are two things that must be well understood to be able to work with containers and iterators:
- The end of a container is not the last element of the container but the one past the last.
- Reversed iterators provide access to the elements in reverse order. A reversed iterator to the first element of a container is actually the last element of the non-reversed container.
To better understand these two points, let’s look at the following example:
std::vector<int> v{ 1,2,3,4,5 };
// prints 1 2 3 4 5
std::copy(v.begin(), v.end(),
std::ostream_iterator<int>(std::cout, " "));
// prints 5 4 3 2 1
std::copy(v.rbegin(), v.rend(),
std::ostream_iterator<int>(std::cout, " "));The first call to std::copy prints the elements of the container in their given order. On the other hand, the second call to std::copy prints the elements in their reversed order.
The following diagram illustrates the relationship between iterators and container elements:

Figure 8.1
A sequence of elements (regardless of what kind of data structure they are stored in memory) delimited by two iterators (a begin and an end, which is the one past the last element) is called a range. This term is used extensively in the C++ standard (especially with algorithms) and in literature. It is also the term that gave the name to the ranges library in C++20, which will be discussed in Chapter 9, The Ranges Library.
Apart from the set of the begin/end member functions of the standard containers, there are also stand-alone functions with the same name. Their equivalence is presented in the following table:

Table 8.3
Although these free functions do not bring much benefit when working with standard containers, they help us in writing generic code that can handle both standard containers and C-like arrays, since all these free functions are overloaded for static arrays. Here is an example:
std::vector<int> v{ 1,2,3,4,5 };
std::copy(std::begin(v), std::end(v),
std::ostream_iterator<int>(std::cout, " "));
int a[] = { 1,2,3,4,5 };
std::copy(std::begin(a), std::end(a),
std::ostream_iterator<int>(std::cout, " "));Without these functions, we would have to write std::copy(a, a + 5, …). Perhaps a big benefit of these functions is that they enable us to use arrays with range-based for loops, as follows:
std::vector<int> v{ 1,2,3,4,5 };
for (auto const& e : v)
std::cout << e << ' ';
int a[] = { 1,2,3,4,5 };
for (auto const& e : a)
std::cout << e << ' ';It is not the purpose of this book to teach you how to use each container or the many standard algorithms. However, it should be helpful for you to learn how to create containers, iterators, and algorithms. This is what we will do next.
Creating a custom container and iterator
The best way to understand how containers and iterators work is to experience them first-hand by creating your own. To avoid implementing something that already exists in the standard library, we will consider something different – more precisely, a circular buffer. This is a container that, when full, overwrites existing elements. We can think of different ways such a container could work; therefore, it’s important that we first define the requirements for it. These are as follows:
- The container should have a fixed capacity that is known at compile-time. Therefore, there would be no runtime memory management.
- The capacity is the number of elements the container can store, and the size is the number of elements it actually contains. When the size equals the capacity, we say the container is full.
- When the container is full, adding a new element will overwrite the oldest element in the container.
- Adding new elements is always done at the end; removing existing elements is always done at the beginning (the oldest element in the container).
- There should be random access to the elements of the container, both with the subscript operator and with iterators.
Based on these requirements, we can think of the following implementation details:
- The elements could be stored in an array. For convenience, this could be the std::array class.
- We need two variables, which we call head and tail, to store the index of the first and last elements of the container. This is needed because due to the circular nature of the container, the beginning and the end shift over time.
- A third variable will store the number of elements in the container. This is useful because otherwise, we would not be able to differentiate whether the container is empty or has one element only from the values of the head and tail indexes.
Important Note
The implementation shown here is provided for teaching purposes only and is not intended as a production-ready solution. The experienced reader will find different aspects of the implementation that could be optimized. However, the purpose here is to learn how to write a container and not how to optimize the implementation.
The following diagram shows a visual representation of such a circular buffer, with a capacity of eight elements with different states:

Figure 8.2
What we can see in this diagram is the following:
- Figure A: This is an empty buffer. The capacity is 8, the size is 0, and the head and tail both point to index 0.
- Figure B: This buffer contains one element. The capacity is still 8, the size is 1, and the head and tail both still point to index 0.
- Figure C: This buffer contains two elements. The size is 2, the head contains index 0, and the tail contains index 1.
- Figure D: This buffer is full. The size is 8, which is equal to the capacity, and the head contains index 0 and the tail contains index 7.
- Figure E: This buffer is still full, but an additional element has been added, triggering the overwriting of the oldest element in the buffer. The size is 8, the head contains index 1, and the tail contains index 0.
Now that we have looked at the semantics of the circular buffer, we can start writing the implementation. We will begin with the container class.
Implementing a circular buffer container
The code for the container class would be too long to be put in a single listing, so we’ll break it up into multiple snippets. The first is as follows:
template <typename T, std::size_t N>
requires(N > 0)
class circular_buffer_iterator;
template <typename T, std::size_t N>
requires(N > 0)
class circular_buffer
{
// ...
};There are two things here: the forward declaration of a class template called circular_buffer_iterator, and a class template called circular_buffer. Both have the same template arguments, a type template parameter T, representing the type of the elements, and a non-type template parameter, representing the capacity of the buffer. A constraint is used to ensure that the provided value for capacity is always positive. If you are not using C++20, you can replace the constraint with a static_assert statement or enable_if to enforce the same restriction. The following snippets are all part of the circular_buffer class.
First, we have a series of member type definitions that provide aliases to different types that are relevant to the circular_buffer class template. These will be used in the implementation of the class. They are shown next:
public: using value_type = T; using size_type = std::size_t; using difference_type = std::ptrdiff_t; using reference = value_type&; using const_reference = value_type const&; using pointer = value_type*; using const_pointer = value_type const*; using iterator = circular_buffer_iterator<T, N>; using const_iterator = circular_buffer_iterator<T const, N>;
Second, we have the data members that store the buffer state. The actual elements are stored in a std::array object. The head, tail, and size are all stored in a variable of the size_type data type. These members are all private:
private: std::array<value_type, N> data_; size_type head_ = 0; size_type tail_ = 0; size_type size_ = 0;
Third, we have the member functions that implement the functionality described earlier. All the following members are public. The first to list here are the constructors:
constexpr circular_buffer() = default;
constexpr circular_buffer(value_type const (&values)[N]) :
size_(N), tail_(N-1)
{
std::copy(std::begin(values), std::end(values),
data_.begin());
}
constexpr circular_buffer(const_reference v):
size_(N), tail_(N-1)
{
std::fill(data_.begin(), data_.end(), v);
}There are three constructors defined here (although we can think of additional ones). These are the default constructor (which is also defaulted) that initializes an empty buffer, a constructor from a C-like array of size N, which initializes a full buffer by copying the array elements, and, finally, a constructor that takes a single value and initializes a full buffer by copying that value into each element of the buffer. These constructors allow us to create circular buffers in any of the following ways:
circular_buffer<int, 1> b1; // {}
circular_buffer<int, 3> b2({ 1, 2, 3 }); // {1, 2, 3}
circular_buffer<int, 3> b3(42); // {42, 42, 42}Next, we define several member functions that describe the state of the circular buffer:
constexpr size_type size() const noexcept
{ return size_; }
constexpr size_type capacity() const noexcept
{ return N; }
constexpr bool empty() const noexcept
{ return size_ == 0; }
constexpr bool full() const noexcept
{ return size_ == N; }
constexpr void clear() noexcept
{ size_ = 0; head_ = 0; tail_ = 0; };The size function returns the number of elements in the buffer, the capacity function the number of elements that the buffer can hold, the empty function to check whether the buffer has no elements (the same as size() == 0), and the full function to check whether the buffer is full (the same as size() == N). There is also a function called clear that puts the circular buffer in the empty state. Beware that this function doesn't destroy any element (does not release memory or call destructors) but only resets the values defining the state of the buffer.
We need to access the elements of the buffer; therefore, the following functions are defined for this purpose:
constexpr reference operator[](size_type const pos)
{
return data_[(head_ + pos) % N];
}
constexpr const_reference operator[](size_type const pos) const
{
return data_[(head_ + pos) % N];
}
constexpr reference at(size_type const pos)
{
if (pos < size_)
return data_[(head_ + pos) % N];
throw std::out_of_range("Index is out of range");
}
constexpr const_reference at(size_type const pos) const
{
if (pos < size_)
return data_[(head_ + pos) % N];
throw std::out_of_range("Index is out of range");
}
constexpr reference front()
{
if (size_ > 0) return data_[head_];
throw std::logic_error("Buffer is empty");
}
constexpr const_reference front() const
{
if (size_ > 0) return data_[head_];
throw std::logic_error("Buffer is empty");
}
constexpr reference back()
{
if (size_ > 0) return data_[tail_];
throw std::logic_error("Buffer is empty");
}
constexpr const_reference back() const
{
if (size_ > 0) return data_[tail_];
throw std::logic_error("Buffer is empty");
}Each of these members has a const overload that is called for constant instances of the buffer. The constant member returns a constant reference; the non-const member returns a normal reference. These methods are as follows:
- The subscript operator that returns a reference to the element specified by its index, without checking the value of the index
- The at method that works similarly to the subscript operator, except that it checks that the index is smaller than the size and, if not, throws an exception
- The front method that returns a reference to the first element; if the buffer is empty, it throws an exception
- The back method that returns a reference to the last element; if the buffer is empty, it throws an exception
We have members to access the elements, but we need members for adding and removing elements to/from the buffer. Adding new elements always happens at the end, so we’ll call this push_back. Removing existing elements always happens at the beginning (the oldest element), so we’ll call this pop_front. Let’s look first at the former:
constexpr void push_back(T const& value)
{
if (empty())
{
data_[tail_] = value;
size_++;
}
else if (!full())
{
data_[++tail_] = value;
size_++;
}
else
{
head_ = (head_ + 1) % N;
tail_ = (tail_ + 1) % N;
data_[tail_] = value;
}
}This works based on the defined requirements and the visual representations from Figure 8.2:
- If the buffer is empty, copy the value to the element pointed by the tail_ index and increment the size.
- If the buffer is neither empty nor full, do the same but also increment the value of the tail_ index.
- If the buffer is full, increment both the head_ and the tail_ and then copy the value to the element pointed by the tail_ index.
This function copies the value argument to a buffer element. However, this could be optimized for temporaries or objects that are no longer needed after pushing to the buffer. Therefore, an overload that takes an rvalue reference is provided. This moves the value to the buffer, avoiding an unnecessary copy. This overload is shown in the following snippet:
constexpr void push_back(T&& value)
{
if (empty())
{
data_[tail_] = value;
size_++;
}
else if (!full())
{
data_[++tail_] = std::move(value);
size_++;
}
else
{
head_ = (head_ + 1) % N;
tail_ = (tail_ + 1) % N;
data_[tail_] = std::move(value);
}
}A similar approach is used for implementing the pop_back function to remove elements from the buffer. Here is the implementation:
constexpr T pop_front()
{
if (empty()) throw std::logic_error("Buffer is empty");
size_type index = head_;
head_ = (head_ + 1) % N;
size_--;
return data_[index];
}This function throws an exception if the buffer is empty. Otherwise, it increments the value of the head_ index and returns the value of the element from the previous position of the head_. This is described visually in the following diagram:
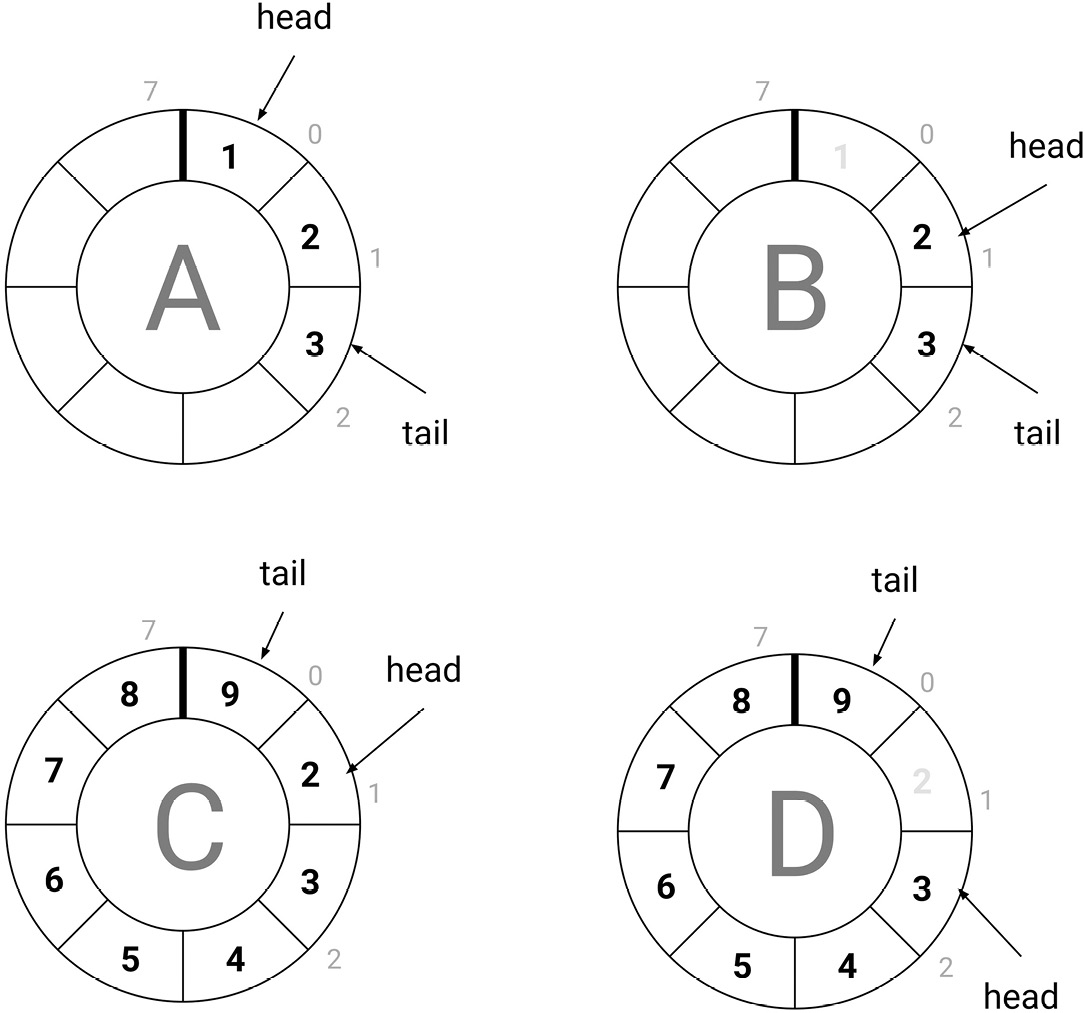
Figure 8.3
What we can see here is the following:
- Figure A: The buffer has 3 elements (1, 2, and 3), head is at index 0, and tail is at index 2.
- Figure B: An element has been removed from the front, which was index 0. Therefore, head is now index 1 and tail is still index 2. The buffer now has two elements.
- Figure C: The buffer has eight elements, which is its maximum capacity, and an element has been overwritten. The head is at index 1 and the tail is at index 0.
- Figure D: An element has been removed from the front, which was index 1. The head is now at index 2 and the tail is still at index 0. The buffer now has seven elements.
An example of using both the push_back and the pop_front member functions is shown in the next snippet:
circular_buffer<int, 4> b({ 1, 2, 3, 4 });
assert(b.size() == 4);
b.push_back(5);
b.push_back(6);
b.pop_front();
assert(b.size() == 3);
assert(b[0] == 4);
assert(b[1] == 5);
assert(b[2] == 6);Finally, we have the member functions begin and end that return iterators to the first and one-past-the-last elements of the buffer. Here is their implementation:
iterator begin()
{
return iterator(*this, 0);
}
iterator end()
{
return iterator(*this, size_);
}
const_iterator begin() const
{
return const_iterator(*this, 0);
}
const_iterator end() const
{
return const_iterator(*this, size_);
}To understand these, we need to see how the iterator class is actually implemented. We will explore this in the next section.
Implementing an iterator type for the circular buffer container
We declared the iterator class template at the beginning of the previous section when we started with the circular_buffer container. However, we need to define its implementation too. Yet, there is one more thing we must do: in order for the iterator class to be able to access the private members of the container it needs to be declared as a friend. This is done as follows:
private: friend circular_buffer_iterator<T, N>;
Let’s look now at the circular_buffer_iterator class, which actually has similarities with the container class. This includes the template parameters, the constraints, and the set of member types (some of them being common to those in circular_buffer). Here is a snippet of the class:
template <typename T, std::size_t N>
requires(N > 0)
class circular_buffer_iterator
{
public:
using self_type = circular_buffer_iterator<T, N>;
using value_type = T;
using reference = value_type&;
using const_reference = value_type const &;
using pointer = value_type*;
using const_pointer = value_type const*;
using iterator_category =
std::random_access_iterator_tag;
using size_type = std::size_t;
using difference_type = std::ptrdiff_t;
public:
/* definitions */
private:
std::reference_wrapper<circular_buffer<T, N>> buffer_;
size_type index_ = 0;
};The circular_buffer_iterator class has a reference to a circular buffer and an index to the element in the buffer that it points to. The reference to circular_buffer<T, N> is wrapped inside a std::reference_wrapper object. The reason for this will be unveiled shortly. Such an iterator can be explicitly created by providing these two arguments. Therefore, the only constructor looks as follows:
explicit circular_buffer_iterator(
circular_buffer<T, N>& buffer,
size_type const index):
buffer_(buffer), index_(index)
{ }If we now look back at the definitions of the begin and end member functions of circular_buffer, we can see that the first argument was *this, and the second was 0 for the begin iterator and size_ for the end iterator. The second value is the offset from the head of the element pointed by the iterator. Therefore, 0 is the first element, and size_ is the one-past-the-last element in the buffer.
We have decided that we need random access to the elements of the buffer; therefore, the iterator category is random-access. The member type iterator_category is an alias for std::random_access_iterator_tag. This implies that we need to provide all the operations supported for such an iterator. In the previous section of this chapter, we discussed the iterator categories and the required operations for each category. We will implement all the required ones next.
We start with the requirements for an input iterator, which are as follows:
self_type& operator++()
{
if(index_ >= buffer_.get().size())
throw std::out_of_range("Iterator cannot be
incremented past the end of the range");
index_++;
return *this;
}
self_type operator++(int)
{
self_type temp = *this;
++*this;
return temp;
}
bool operator==(self_type const& other) const
{
return compatible(other) && index_ == other.index_;
}
bool operator!=(self_type const& other) const
{
return !(*this == other);
}
const_reference operator*() const
{
if (buffer_.get().empty() || !in_bounds())
throw std::logic_error("Cannot dereferentiate the
iterator");
return buffer_.get().data_[
(buffer_.get().head_ + index_) %
buffer_.get().capacity()];
}
const_reference operator->() const
{
if (buffer_.get().empty() || !in_bounds())
throw std::logic_error("Cannot dereferentiate the
iterator");
return buffer_.get().data_[
(buffer_.get().head_ + index_) %
buffer_.get().capacity()];
}We have implemented here incrementing (both pre- and post-fix), checking for equality/inequality, and dereferencing. The * and -> operators throw an exception if the element cannot be dereferenced. The cases when this happens are when the buffer is empty, or the index is not within bounds (between head_ and tail_). We used two helper functions (both private), called compatible and is_bounds. These are shown next:
bool compatible(self_type const& other) const
{
return buffer_.get().data_.data() ==
other.buffer_.get().data_.data();
}
bool in_bounds() const
{
return
!buffer_.get().empty() &&
(buffer_.get().head_ + index_) %
buffer_.get().capacity() <= buffer_.get().tail_;
}A forward iterator is an input iterator that is also an output iterator. The requirements for output iterators will be discussed toward the end of this section. Those for the input iterators we have seen previously. Apart from those, forward iterators can be used in multi-pass algorithms, which is possible because performing an operation on a dereferenceable forward iterator does not make its iterator value non-dereferenceable. That means if a and b are two forward iterators and they are equal, then either they are non-dereferenceable, otherwise, their iterator values, *a and *b, refer to the same object. The opposite is also true, meaning that if *a and *b are equal, then a and b are also equal. This is true for our implementation.
The other requirement for forward iterators is that they are swappable. That means if a and b are two forward iterators, then swap(a, b) should be a valid operation. This leads us back to using a std::reference_wrapper object to hold a reference to a circular_buffer<T, N>. References are not swappable, which would have made circular_buffer_iterator not swappable either. However, std::reference_wrapper is swappable, and that also makes our iterator type swappable. That can be verified with a static_assert statement, such as the following:
static_assert( std::is_swappable_v<circular_buffer_iterator<int, 10>>);
Important Note
An alternative to using std::reference_wrapper is to use a raw pointer to a circular_buffer class, since pointers can be assigned values and are, therefore swappable. It is a matter of style and personal choice which one to use. In this example, I preferred the solution that avoided the raw pointer.
For fulfilling the requirements for the bidirectional iterator category, we need to support decrementing. In the next snippet, you can see the implementation of both pre- and post-fix decrement operators:
self_type& operator--()
{
if(index_ <= 0)
throw std::out_of_range("Iterator cannot be
decremented before the beginning of the range");
index_--;
return *this;
}
self_type operator--(int)
{
self_type temp = *this;
--*this;
return temp;
}Finally, we have the requirements of the random-access iterators. The first requirements to implement are arithmetic (+ and -) and compound (+= and -=) operations. These are shown next:
self_type operator+(difference_type offset) const
{
self_type temp = *this;
return temp += offset;
}
self_type operator-(difference_type offset) const
{
self_type temp = *this;
return temp -= offset;
}
difference_type operator-(self_type const& other) const
{
return index_ - other.index_;
}
self_type& operator +=(difference_type const offset)
{
difference_type next =
(index_ + next) % buffer_.get().capacity();
if (next >= buffer_.get().size())
throw std::out_of_range("Iterator cannot be
incremented past the bounds of the range");
index_ = next;
return *this;
}
self_type& operator -=(difference_type const offset)
{
return *this += -offset;
}Random-access iterators must support inequality comparison with other operations. That means, we need to overload the <, <=, >, and >= operators. However, the <=, >, and >= operators can be implemented based on the < operator. Therefore, their definition can be as follows:
bool operator<(self_type const& other) const
{
return index_ < other.index_;
}
bool operator>(self_type const& other) const
{
return other < *this;
}
bool operator<=(self_type const& other) const
{
return !(other < *this);
}
bool operator>=(self_type const& other) const
{
return !(*this < other);
}Last, but not least, we need to provide access to elements with the subscript operator ([]). A possible implementation is the following:
value_type& operator[](difference_type const offset)
{
return *((*this + offset));
}
value_type const & operator[](difference_type const offset) const
{
return *((*this + offset));
}With this, we have completed the implementation of the iterator type for the circular buffer. If you had trouble following the multitude of code snippets for these two classes, you can find the complete implementation in the GitHub repository for the book. A simple example for using the iterator type is shown next:
circular_buffer<int, 3> b({1, 2, 3});
std::vector<int> v;
for (auto it = b.begin(); it != b.end(); ++it)
{
v.push_back(*it);
}This code can be actually simplified with range-based for loops. In this case, we don’t use iterators directly, but the compiler-generated code does. Therefore, the following snippet is equivalent to the previous one:
circular_buffer<int, 3> b({ 1, 2, 3 });
std::vector<int> v;
for (auto const e : b)
{
v.push_back(e);
}However, the implementation provided here for circular_buffer_iterator does not allow the following piece of code to compile:
circular_buffer<int, 3> b({ 1,2,3 });
*b.begin() = 0;
assert(b.front() == 0);This requires that we are able to write elements through iterators. However, our implementation doesn’t meet the requirements for the output iterator category. This requires that expressions such as *it = v, or *it++ = v are valid. To do so, we need to provide non-const overloads of the * and -> operators that return non-const reference types. This can be done as follows:
reference operator*()
{
if (buffer_.get().empty() || !in_bounds())
throw std::logic_error("Cannot dereferentiate the
iterator");
return buffer_.get().data_[
(buffer_.get().head_ + index_) %
buffer_.get().capacity()];
}
reference operator->()
{
if (buffer_.get().empty() || !in_bounds())
throw std::logic_error("Cannot dereferentiate the
iterator");
return buffer_.get().data_[
(buffer_.get().head_ + index_) %
buffer_.get().capacity()];
}More examples for using the circular_buffer class with and without iterators can be found in the GitHub repository. Next, we will focus our attention on implementing a general-purpose algorithm that works for any range, including the circular_buffer container we defined here.
Writing a custom general-purpose algorithm
In the first section of this chapter, we saw why abstracting access to container elements with iterators is key for building general-purpose algorithms. However, it should be useful for you to practice writing such an algorithm because it can help you better understand the use of iterators. Therefore, in this section, we will write a general-purpose algorithm.
The standard library features many such algorithms. One that is missing is a zipping algorithm. What zipping means is actually interpreted or understood differently by different people. For some, zipping means taking two or more input ranges and creating a new range with the elements from the input ranges intercalated. This is exemplified in the following diagram:
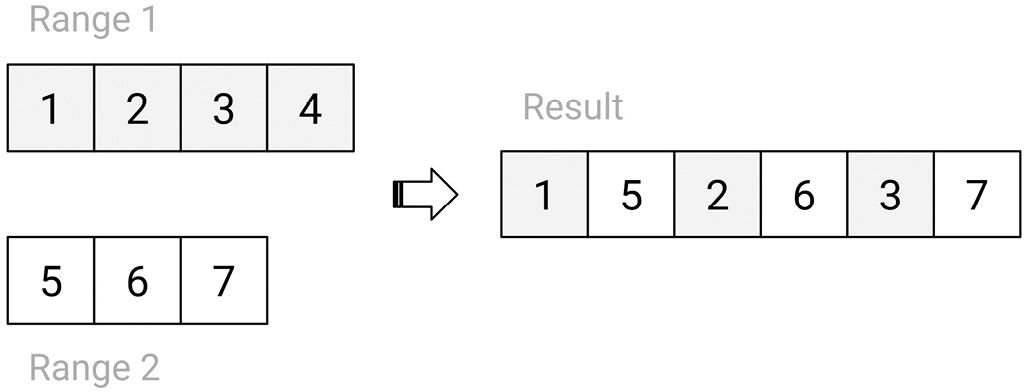
Figure 8.4
For others, zipping means taking two or more input ranges and creating a new range, with elements being tuples formed from the elements of the input ranges. This is shown in the next diagram:
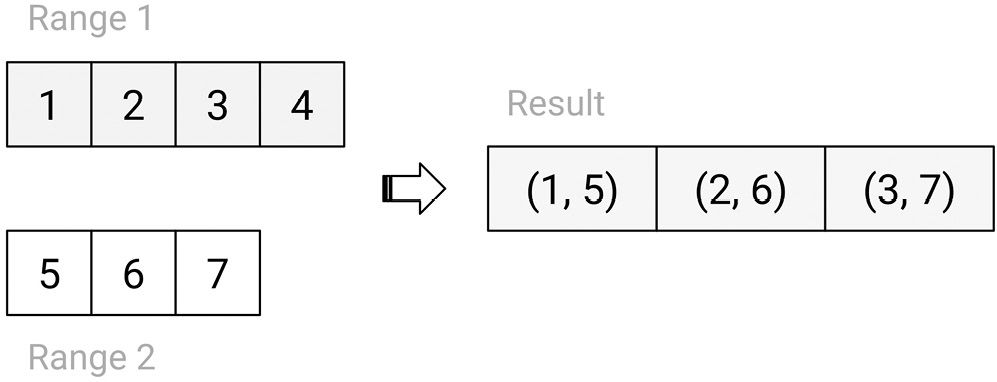
Figure 8.5
In this section, we will implement the first algorithm. In order to avoid confusion, we will call this flatzip. Here are the requirements for it:
- The algorithm takes two input ranges and writes to an output range.
- The algorithm takes iterators as arguments. A pair of first and last input iterators define the bounds of each input range. An output iterator defines the beginning of the output range where the elements will be written to.
- The two input ranges should contain elements of the same type. The output range must have elements of the same type or a type to which the input type is implicitly convertible.
- If the two input ranges are of different sizes, the algorithm stops when the smallest of the two has been processed (as shown in the previous diagrams).
- The return value is the output iterator to the one-past-the-last element that was copied.
A possible implementation for the described algorithm is shown in the following listing:
template <typename InputIt1, typename InputIt2,
typename OutputIt>
OutputIt flatzip(
InputIt1 first1, InputIt1 last1,
InputIt2 first2, InputIt2 last2,
OutputIt dest)
{
auto it1 = first1;
auto it2 = first2;
while (it1 != last1 && it2 != last2)
{
*dest++ = *it1++;
*dest++ = *it2++;
}
return dest;
}As you can see in the snippet, the implementation is quite simple. All we do here is iterate through both input ranges at the same time and copy elements alternately from them to the destination range. The iteration on both input ranges stops when the end of the smallest range is reached. We can use this algorithm as follows:
// one range is empty
std::vector<int> v1 {1,2,3};
std::vector<int> v2;
std::vector<int> v3;
flatzip(v1.begin(), v1.end(), v2.begin(), v2.end(),
std::back_inserter(v3));
assert(v3.empty());
// neither range is empty
std::vector<int> v1 {1, 2, 3};
std::vector<int> v2 {4, 5};
std::vector<int> v3;
flatzip(v1.begin(), v1.end(), v2.begin(), v2.end(),
std::back_inserter(v3));
assert(v3 == std::vector<int>({ 1, 4, 2, 5 }));These examples use std::vector for both the input and output ranges. However, the flatzip algorithm knows nothing about containers. The elements of the container are accessed with the help of iterators. Therefore, as long as the iterators meet the specified requirements, we can use any container. This includes the circular_buffer container we previously wrote since circular_buffer_container meets the requirements for both the input and output iterator categories. This means we can also write the following snippet:
circular_buffer<int, 4> a({1, 2, 3, 4});
circular_buffer<int, 3> b({5, 6, 7});
circular_buffer<int, 8> c(0);
flatzip(a.begin(), a.end(), b.begin(), b.end(), c.begin());
std::vector<int> v;
for (auto e : c)
v.push_back(e);
assert(v == std::vector<int>({ 1, 5, 2, 6, 3, 7, 0, 0 }));We have two input circular buffers: a, which has four elements, and b, which has three elements. The destination circular buffer has a capacity of eight elements, all initialized with zero. After applying the flatzip algorithm, six elements of the destination circular buffer will be written with values from the a and b buffers. The result is that the circular buffer will contain the elements 1, 5, 2, 6, 3, 7, 0, 0.
Summary
This chapter was dedicated to seeing how templates can be used to build general-purpose libraries. Although we couldn’t cover these topics in great detail, we have explored the design of containers, iterators, and algorithms from the C++ standard library. These are the pillars of the standard library. We spent most of the chapter understanding what it takes to write a container similar to the standard ones as well as an iterator class to provide access to its elements. For this purpose, we implemented a class that represents a circular buffer, a data structure of fixed size where elements are overwritten once the container is full. Lastly, we implemented a general-purpose algorithm that zips elements from two ranges. This works for any container including the circular buffer container.
Ranges, as discussed in this chapter, are an abstract concept. However, that changed with C++20, which introduced a more concrete concept of ranges with the new ranges library. This is what we will discuss in the final chapter of this book.
Questions
- What are the sequence containers from the standard library?
- What are the common member functions defined in the standard containers?
- What are iterators and how many categories exist?
- What operations does a random-access iterator support?
- What are range access functions?