
Chapter 7: Patterns and Idioms
The previous parts of the book were designed to help you learn everything about templates, from the basics to the most advanced features, including the latest concepts and constraints from C++20. Now, it is time for us to put this knowledge to work and learn about various metaprogramming techniques. In this chapter, we will discuss the following topics:
- Dynamic versus static polymorphism
- The Curiously Recurring Template Pattern (CRTP)
- Mixins
- Type erasure
- Tag dispatching
- Expression templates
- Typelists
By the end of the chapter, you will have a good understanding of various multiprogramming techniques that will help you solve a variety of problems.
Let’s start the chapter by discussing the two forms of polymorphism: dynamic and static.
Dynamic versus static polymorphism
When you learn about object-oriented programming, you learn about its fundamental principles, which are abstraction, encapsulation, inheritance, and polymorphism. C++ is a multi-paradigm programming language that supports object-oriented programming too. Although a broader discussion on the principles of object-oriented programming is beyond the scope of this chapter and this book, it is worth discussing at least some aspects related to polymorphism.
So, what is polymorphism? The term is derived from the Greek words for “many forms”. In programming, it’s the ability of objects of different types to be treated as if they were of the same type. The C++ standard actually defines a polymorphic class as follows (see C++20 standard, paragraph 11.7.2, Virtual functions):
It also defines polymorphic objects based on this definition, as follows (see C++20 standard, paragraph 6.7.2, Object model):
However, this actually refers to what is called dynamic polymorphism (or late binding), but there is yet another form of polymorphism, called static polymorphism (or early binding). Dynamic polymorphism occurs at runtime with the help of interfaces and virtual functions, while static polymorphism occurs at compile-time with the help of overloaded functions and templates. This is described in Bjarne Stroustrup’s glossary of terms for the C++ language (see https://www.stroustrup.com/glossary.html):
Let’s look at an example of dynamic polymorphism. The following is a hierarchy of classes representing different units in a game. These units may attack others, so there is a base class with a pure virtual function called attack, and several derived classes implementing specific units that override this virtual function doing different things (of course, for simplicity, here we just print a message to the console). It looks as follows:
struct game_unit
{
virtual void attack() = 0;
};
struct knight : game_unit
{
void attack() override
{ std::cout << "draw sword
"; }
};
struct mage : game_unit
{
void attack() override
{ std::cout << "spell magic curse
"; }
};Based on this hierarchy of classes (which according to the standard are called polymorphic classes), we can write the function fight shown as follows. This takes a sequence of pointers to objects of the base game_unit type and calls the attack member function. Here is its implementation:
void fight(std::vector<game_unit*> const & units)
{
for (auto unit : units)
{
unit->attack();
}
}This function does not need to know the actual type of each object because due to dynamic polymorphism, it can handle them as if they were of the same (base) type. Here is an example of using it:
knight k;
mage m;
fight({&k, &m});But now let’s say you could combine a mage and a knight and create a new unit, a knight mage with special abilities from both these units. C++ enables us to write code as follows:
knight_mage km = k + m; km.attack();
This does not come out of the box, but the language supports overloading operators, and we could do that for any user-defined types. To make the preceding line possible, we need the following:
struct knight_mage : game_unit
{
void attack() override
{ std::cout << "draw magic sword
"; }
};
knight_mage operator+(knight const& k, mage const& m)
{
return knight_mage{};
}Keep in mind these are just some simple snippets without any complex code. But the ability to add a knight and a mage together to create a knight_mage is nothing short of the ability to add two integers together, or a double and an int, or two std::string objects. This happens because there are many overloads of the + operator (both for built-in types and user-defined types) and based on the operands, the compiler is selecting the appropriate overload. Therefore, it can be said there are many forms of this operator. This is true for all the operators that can be overloaded; the + operator is just a typical example since it is ubiquitous. And this is the compile-time version of polymorphism, called static polymorphism.
Operators are not the only functions that can be overloaded. Any function can be overloaded. Although we have seen many examples in the book, let’s take another one:
struct attack { int value; };
struct defense { int value; };
void increment(attack& a) { a.value++; }
void increment(defense& d) { d.value++; }In this snippet, the increment function is overloaded for both the attack and defense types, allowing us to write code as follows:
attack a{ 42 };
defense d{ 50 };
increment(a);
increment(d);We can replace the two overloads of increment with a function template. The changes are minimal, as shown in the next snippet:
template <typename T>
void increment(T& t) { t.value++; }The previous code continues to work, but there is a significant difference: in the former example, we had two overloads, one for attack and one for defense, so you could call the function with objects of these types but nothing else. In the latter, we have a template that defines a family of overloaded functions for any possible type T that has a data member called value whose type supports the post-increment operator. We can define constraints for such a function template, which is something we have seen in the previous two chapters of the book. However, the key takeaway is that overloaded functions and templates are the mechanisms to implement static polymorphism in the C++ language.
Dynamic polymorphism incurs a performance cost because in order to know what functions to call, the compiler needs to build a table of pointers to virtual functions (and also a table of pointers to virtual base classes in case of virtual inheritance). So, there is some level of indirection when calling virtual functions polymorphically. Moreover, the details of virtual functions are not made available to the compiler who cannot optimize them.
When these things can be validated as performance issues, we could raise the question: can we get the benefits of dynamic polymorphism at compile time? The answer is yes and there is one way to achieve this: the Curiously Recurring Template Pattern, which we will discuss next.
The Curiously Recurring Template Pattern
This pattern has a rather curious name: the Curiously Recurring Template Pattern, or CRTP for short. It’s called curious because it is rather odd and unintuitive. The pattern was first described (and its name coined) by James Coplien in a column in the C++ Report in 1995. This pattern is as follows:
- There is a base class template that defines the (static) interface.
- Derived classes are themselves the template argument for the base class template.
- The member functions of the base class call member functions of its type template parameter (which are the derived classes).
Let’s see how the pattern implementation looks in practice. We will transform the previous example with game units into a version using the CRTP. The pattern implementation goes as follows:
template <typename T>
struct game_unit
{
void attack()
{
static_cast<T*>(this)->do_attack();
}
};
struct knight : game_unit<knight>
{
void do_attack()
{ std::cout << "draw sword
"; }
};
struct mage : game_unit<mage>
{
void do_attack()
{ std::cout << "spell magic curse
"; }
};The game_unit class is now a template class but contains the same member function, attack. Internally, this performs an upcast of the this pointer to T* and then invokes a member function called do_attack. The knight and mage classes derive from the game_unit class and pass themselves as the argument for the type template parameter T. Both provide a member function called do_attack.
Notice that the member function in the base class template and the called member function in the derived classes have different names. Otherwise, if they had the same name, the derived class member functions would hide the member from the base since these are no longer virtual functions.
The fight function that takes a collection of game units and calls the attack function needs to change too. It needs to be implemented as a function template, as follows:
template <typename T>
void fight(std::vector<game_unit<T>*> const & units)
{
for (auto unit : units)
{
unit->attack();
}
}Using this function is a little different than before. It goes as follows:
knight k;
mage m;
fight<knight>({ &k });
fight<mage>({ &m });We have moved the runtime polymorphism to compile-time. Therefore, the fight function cannot treat knight and mage objects polymorphically. Instead, we get two different overloads, one that can handle knight objects and one that can handle mage objects. This is static polymorphism.
Although the pattern might not look complicated after all, the question you’re probably asking yourself at this point is: how is this pattern actually useful? There are different problems you can solve using CRT, including the following:
- Limiting the number of times a type can be instantiated
- Adding common functionality and avoiding code duplication
- Implementing the composite design pattern
In the following subsections, we will look at each of these problems and see how to solve them with CRTP.
Limiting the object count with CRTP
Let’s assume that for the game in which we created knights and mages we need some items to be available in a limited number of instances. For instance, there is a special sword type called Excalibur and there should be only one instance of it. On the other hand, there is a book of magic spells but there cannot be more than three instances of it at a time in the game. How do we solve this? Obviously, the sword problem could be solved with the singleton pattern. But what do we do when we need to limit the number to some higher value but still finite? The singleton pattern wouldn’t be of much help (unless we transform it into a “multiton”) but the CRTP would.
First, we start with a base class template. The only thing this class template does is keep a count of how many times it has been instantiated. The counter, which is a static data member, is incremented in the constructor and decremented in the destructor. When that count exceeds a defined limit, an exception is thrown. Here is the implementation:
template <typename T, size_t N>
struct limited_instances
{
static std::atomic<size_t> count;
limited_instances()
{
if (count >= N)
throw std::logic_error{ "Too many instances" };
++count;
}
~limited_instances() { --count; }
};
template <typename T, size_t N>
std::atomic<size_t> limited_instances<T, N>::count = 0;The second part of the template consists of defining the derived classes. For the mentioned problem, they are as follows:
struct excalibur : limited_instances<excalibur, 1>
{};
struct book_of_magic : limited_instances<book_of_magic, 3>
{};We can instantiate excalibur once. The second time we try to do the same (while the first instance is still alive) an exception will be thrown:
excalibur e1;
try
{
excalibur e2;
}
catch (std::exception& e)
{
std::cout << e.what() << '
';
}Similarly, we can instantiate book_of_magic three times and an exception will be thrown the fourth time we attempt to do that:
book_of_magic b1;
book_of_magic b2;
book_of_magic b3;
try
{
book_of_magic b4;
}
catch (std::exception& e)
{
std::cout << e.what() << '
';
}Next, we look at a more common scenario, adding common functionality to types.
Adding functionality with CRTP
Another case when the curiously recurring template pattern can help us is providing common functionalities to derived classes through generic functions in a base class that relies solely on derived class members. Let’s take an example to understand this use case.
Let’s suppose that some of our game units have member functions such as step_forth and step_back that move them one position, forward or backward. These classes would look as follows (at a bare minimum):
struct knight
{
void step_forth();
void step_back();
};
struct mage
{
void step_forth();
void step_back();
};However, it could be a requirement that everything that can move back and forth one step should also be able to advance or retreat an arbitrary number of steps. However, this functionality could be implemented based on the step_forth and step_back functions, which would help avoid having duplicate code in each of these game unit classes. The CRTP implementation for this problem would, therefore, look as follows:
template <typename T>
struct movable_unit
{
void advance(size_t steps)
{
while (steps--)
static_cast<T*>(this)->step_forth();
}
void retreat(size_t steps)
{
while (steps--)
static_cast<T*>(this)->step_back();
}
};
struct knight : movable_unit<knight>
{
void step_forth()
{ std::cout << "knight moves forward
"; }
void step_back()
{ std::cout << "knight moves back
"; }
};
struct mage : movable_unit<mage>
{
void step_forth()
{ std::cout << "mage moves forward
"; }
void step_back()
{ std::cout << "mage moves back
"; }
};We can advance and retreat the units by calling the base class advance and retreat member functions as follows:
knight k; k.advance(3); k.retreat(2); mage m; m.advance(5); m.retreat(3);
You could argue that the same result could be achieved using non-member function templates. For the sake of discussion, such a solution is presented as follows:
struct knight
{
void step_forth()
{ std::cout << "knight moves forward
"; }
void step_back()
{ std::cout << "knight moves back
"; }
};
struct mage
{
void step_forth()
{ std::cout << "mage moves forward
"; }
void step_back()
{ std::cout << "mage moves back
"; }
};
template <typename T>
void advance(T& t, size_t steps)
{
while (steps--) t.step_forth();
}
template <typename T>
void retreat(T& t, size_t steps)
{
while (steps--) t.step_back();
}The client code would need to change but the changes are actually small:
knight k; advance(k, 3); retreat(k, 2); mage m; advance(m, 5); retreat(m, 3);
The choice between these two may depend on the nature of the problem and your preferences. However, the CRTP has the advantage that it is describing well the interface of the derived classes (such as knight and mage in our example). With the non-member functions, you wouldn’t necessarily know about this functionality, which would probably come from a header that you need to include. However, with CRTP, the class interface is well visible to those using it.
For the last scenario we discuss here, let’s see how CRTP helps to implement the composite design pattern.
Implementing the composite design pattern
In their famous book, Design Patterns: Elements of Reusable Object-Oriented Software, the Gang of Four (Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides) describe a structural pattern called composite that enables us to compose objects into larger structures and treat both individual objects and compositions uniformly. This pattern can be used when you want to represent part-whole hierarchies of objects and you want to ignore the differences between individual objects and compositions of individual objects.
To put this pattern into practice, let’s consider the game scenario again. We have heroes that have special abilities and can do different actions, one of which is allying with another hero. That can be easily modeled as follows:
struct hero
{
hero(std::string_view n) : name(n) {}
void ally_with(hero& u)
{
connections.insert(&u);
u.connections.insert(this);
}
private:
std::string name;
std::set<hero*> connections;
friend std::ostream& operator<<(std::ostream& os,
hero const& obj);
};
std::ostream& operator<<(std::ostream& os,
hero const& obj)
{
for (hero* u : obj.connections)
os << obj.name << " --> [" << u->name << "]" << '
';
return os;
}These heroes are represented by the hero class that contains a name, a list of connections to other hero objects, as well as a member function, ally_with, that defines an alliance between two heroes. We can use it as follows:
hero k1("Arthur");
hero k2("Sir Lancelot");
hero k3("Sir Gawain");
k1.ally_with(k2);
k2.ally_with(k3);
std::cout << k1 << '
';
std::cout << k2 << '
';
std::cout << k3 << '
';The output of running this snippet is the following:
Arthur --> [Sir Lancelot]
Sir Lancelot --> [Arthur]
Sir Lancelot --> [Sir Gawain]
Sir Gawain --> [Sir Lancelot]
Everything was simple so far. But the requirement is that heroes could be grouped together to form parties. It should be possible for a hero to ally with a group, and for a group to ally with either a hero or an entire group. Suddenly, there is an explosion of functions that we need to provide:
struct hero_party;
struct hero
{
void ally_with(hero& u);
void ally_with(hero_party& p);
};
struct hero_party : std::vector<hero>
{
void ally_with(hero& u);
void ally_with(hero_party& p);
};This is where the composite design pattern helps us treat heroes and parties uniformly and avoid unnecessary duplications of the code. As usual, there are different ways to implement it, but one way is using the curiously recurring template pattern. The implementation requires a base class that defines the common interface. In our case, this will be a class template with a single member function called ally_with:
template <typename T>
struct base_unit
{
template <typename U>
void ally_with(U& other);
};We will define the hero class as a derived class from base_unit<hero>. This time, the hero class no longer implements ally_with itself. However, it features begin and end methods that are intended to simulate the behavior of a container:
struct hero : base_unit<hero>
{
hero(std::string_view n) : name(n) {}
hero* begin() { return this; }
hero* end() { return this + 1; }
private:
std::string name;
std::set<hero*> connections;
template <typename U>
friend struct base_unit;
template <typename U>
friend std::ostream& operator<<(std::ostream& os,
base_unit<U>& object);
};The class that models a group of heroes is called hero_party and derives from both std::vector<hero> (to define a container of hero objects) and from base_unit<hero_party>. This is why the hero class has begin and end functions to help us perform iterating operations on hero objects, just as we would do with hero_party objects:
struct hero_party : std::vector<hero>,
base_unit<hero_party>
{};We need to implement the ally_with member function of the base class. The code is shown as follows. What it does is iterate through all the sub-objects of the current object and connect them with all the sub-objects of the supplied argument:
template <typename T>
template <typename U>
void base_unit<T>::ally_with(U& other)
{
for (hero& from : *static_cast<T*>(this))
{
for (hero& to : other)
{
from.connections.insert(&to);
to.connections.insert(&from);
}
}
}The hero class declared the base_unit class template a friend so that it could access the connections member. It also declared the operator<< as a friend so that this function could access both the connections and name private members. For more information about templates and friends, see Chapter 4, Advanced Template Concepts. The output stream operator implementation is shown here:
template <typename T>
std::ostream& operator<<(std::ostream& os,
base_unit<T>& object)
{
for (hero& obj : *static_cast<T*>(&object))
{
for (hero* n : obj.connections)
os << obj.name << " --> [" << n->name << "]"
<< '
';
}
return os;
}Having all this defined, we can write code as follows:
hero k1("Arthur");
hero k2("Sir Lancelot");
hero_party p1;
p1.emplace_back("Bors");
hero_party p2;
p2.emplace_back("Cador");
p2.emplace_back("Constantine");
k1.ally_with(k2);
k1.ally_with(p1);
p1.ally_with(k2);
p1.ally_with(p2);
std::cout << k1 << '
';
std::cout << k2 << '
';
std::cout << p1 << '
';
std::cout << p2 << '
';We can see from this that we are able to ally a hero with both another hero and a hero_party, as well as a hero_party with either a hero or another hero_party. That was the proposed goal, and we were able to do it without duplicating the code between hero and hero_party. The output of executing the previous snippet is the following:
Arthur --> [Sir Lancelot]
Arthur --> [Bors]
Sir Lancelot --> [Arthur]
Sir Lancelot --> [Bors]
Bors --> [Arthur]
Bors --> [Sir Lancelot]
Bors --> [Cador]
Bors --> [Constantine]
Cador --> [Bors]
Constantine --> [Bors]
After seeing how the CRTP helps achieve different goals, let’s look at the use of the CRTP in the C++ standard library.
The CRTP in the standard library
The standard library contains a helper type called std::enabled_shared_from_this (in the <memory> header) that enables objects managed by a std::shared_ptr to generate more std::shared_ptr instances in a safe manner. The std::enabled_shared_from_this class is the base class in the CRTP pattern. However, the previous description may sound abstract, so let’s try to understand it with examples.
Let’s suppose we have a class called building and we are creating std::shared_ptr objects in the following manner:
struct building {};
building* b = new building();
std::shared_ptr<building> p1{ b }; // [1]
std::shared_ptr<building> p2{ b }; // [2] badWe have a raw pointer and, on line [1], we instantiate a std::shared_ptr object to manage its lifetime. However, on line [2], we instantiate a second std::shared_ptr object for the same pointer. Unfortunately, the two smart pointers know nothing of each other, so upon getting out of scope, they will both delete the building object allocated on the heap. Deleting an object that was already deleted is undefined behavior and will likely result in a crash of the program.
The std::enable_shared_from_this class helps us create more shared_ptr objects from an existing one in a safe manner. First, we need to implement the CRTP pattern as follows:
struct building : std::enable_shared_from_this<building>
{
};Having this new implementation, we can call the member function shared_from_this to create more std::shared_ptr instances from an object, which all refer to the same instance of the object:
building* b = new building();
std::shared_ptr<building> p1{ b }; // [1]
std::shared_ptr<building> p2{
b->shared_from_this()}; // [2] OKThe interface of the std::enable_shared_from_this is as follows:
template <typename T>
class enable_shared_from_this
{
public:
std::shared_ptr<T> shared_from_this();
std::shared_ptr<T const> shared_from_this() const;
std::weak_ptr<T> weak_from_this() noexcept;
std::weak_ptr<T const> weak_from_this() const noexcept;
enable_shared_from_this<T>& operator=(
const enable_shared_from_this<T> &obj ) noexcept;
};The previous example shows how enable_shared_from_this works but does not help understand when it is appropriate to use it. Therefore, let’s modify the example to show a realistic example.
Let’s consider that the buildings we have can be upgraded. This is a process that takes some time and involves several steps. This task, as well as other tasks in the game, are executed by a designated entity, which we will call executor. In its simplest form, this executor class has a public member function called execute that takes a function object and executes it on a different thread. The following listing is a simple implementation:
struct executor
{
void execute(std::function<void(void)> const& task)
{
threads.push_back(std::thread([task]() {
using namespace std::chrono_literals;
std::this_thread::sleep_for(250ms);
task();
}));
}
~executor()
{
for (auto& t : threads)
t.join();
}
private:
std::vector<std::thread> threads;
};The building class has a pointer to an executor, which is passed from the client. It also has a member function called upgrade that kicks off the execution process. However, the actual upgrade occurs in a different, private, function called do_upgrade. This is called from a lambda expression that is passed to the execute member function of the executor. All these are shown in the following listing:
struct building
{
building() { std::cout << "building created
"; }
~building() { std::cout << "building destroyed
"; }
void upgrade()
{
if (exec)
{
exec->execute([self = this]() {
self->do_upgrade();
});
}
}
void set_executor(executor* e) { exec = e; }
private:
void do_upgrade()
{
std::cout << "upgrading
";
operational = false;
using namespace std::chrono_literals;
std::this_thread::sleep_for(1000ms);
operational = true;
std::cout << "building is functional
";
}
bool operational = false;
executor* exec = nullptr;
};The client code is relatively simple: create an executor, create a building managed by a shared_ptr, set the executor reference, and run the upgrade process:
int main()
{
executor e;
std::shared_ptr<building> b =
std::make_shared<building>();
b->set_executor(&e);
b->upgrade();
std::cout << "main finished
";
}If you run this program, you get the following output:
building created
main finished
building destroyed
upgrading
building is functional
What we can see here is that the building is destroyed before the upgrade process begins. This incurs undefined behavior and, although this program didn’t crash, a real-world program would certainly crash.
The culprit for this behavior is this particular line in the upgrading code:
exec->execute([self = this]() {
self->do_upgrade();
});We are creating a lambda expression that captures the this pointer. The pointer is later used after the object it points to has been destroyed. To avoid this, we would need to create and capture a shared_ptr object. The safe way to do that is with the help of the std::enable_shared_from_this class. There are two changes that need to be done. The first is to actually derive the building class from the std::enable_shared_from_this class:
struct building : std::enable_shared_from_this<building>
{
/* … */
};The second change requires us to call shared_from_this in the lambda capture:
These are two slight changes to our code but the effect is significant. The building object is no longer destroyed before the lambda expression gets executed on a separate thread (because there is now an extra shared pointer that refers to the same object as the shared pointer created in the main function). As a result, we get the output we expected (without any changes to the client code):
building created
main finished
upgrading
building is functional
building destroyed
You could argue that after the main function finishes, we shouldn’t care what happens. Mind that this is just a demo program, and in practice, this happens in some other function and the program continues to run long after that function returns.
With this, we conclude the discussion around the curiously recurring template pattern. Next, we will look at a technique called mixins that is often mixed with the CRTP pattern.
Mixins
Mixins are small classes that are designed to add functionality to other classes. If you read about mixins, you will often find that the curiously recurring template pattern is used to implement mixins in C++. This is an incorrect statement. The CRTP helps achieve a similar goal to mixins, but they are different techniques. The point of mixins is that they are supposed to add functionality to classes without being a base class to them, which is the key to the CRTP pattern. Instead, mixins are supposed to inherit from the classes they add functionality to, which is the CRTP upside down.
Remember the earlier example with knights and mages that could move forth and back with the step_forth and step_back member functions? The knight and mage classes were derived from the movable_unit class template that added the functions advance and retreat, which enabled units to move several steps forth or back. The same example can be implemented using mixins in a reverse order. Here is how:
struct knight
{
void step_forth()
{
std::cout << "knight moves forward
";
}
void step_back()
{
std::cout << "knight moves back
";
}
};
struct mage
{
void step_forth()
{
std::cout << "mage moves forward
";
}
void step_back()
{
std::cout << "mage moves back
";
}
};
template <typename T>
struct movable_unit : T
{
void advance(size_t steps)
{
while (steps--)
T::step_forth();
}
void retreat(size_t steps)
{
while (steps--)
T::step_back();
}
};You will notice that knight and mage are now classes that don’t have any base class. They both provide the step_forth and step_back member functions just as they did before, when we implemented the CRTP pattern. Now, the movable_unit class template is derived from one of these classes and defines the advance and retreat functions, which call step_forth and step_back in a loop. We can use them as follows:
movable_unit<knight> k; k.advance(3); k.retreat(2); movable_unit<mage> m; m.advance(5); m.retreat(3);
This is very similar to what we had with the CRTP pattern, except that now we create instances of movable_unit<knight> and movable_unit<mage> instead of knight and mage. A comparison of the two patterns is shown in the following diagram (with CRTP on the left and mixins on the right):
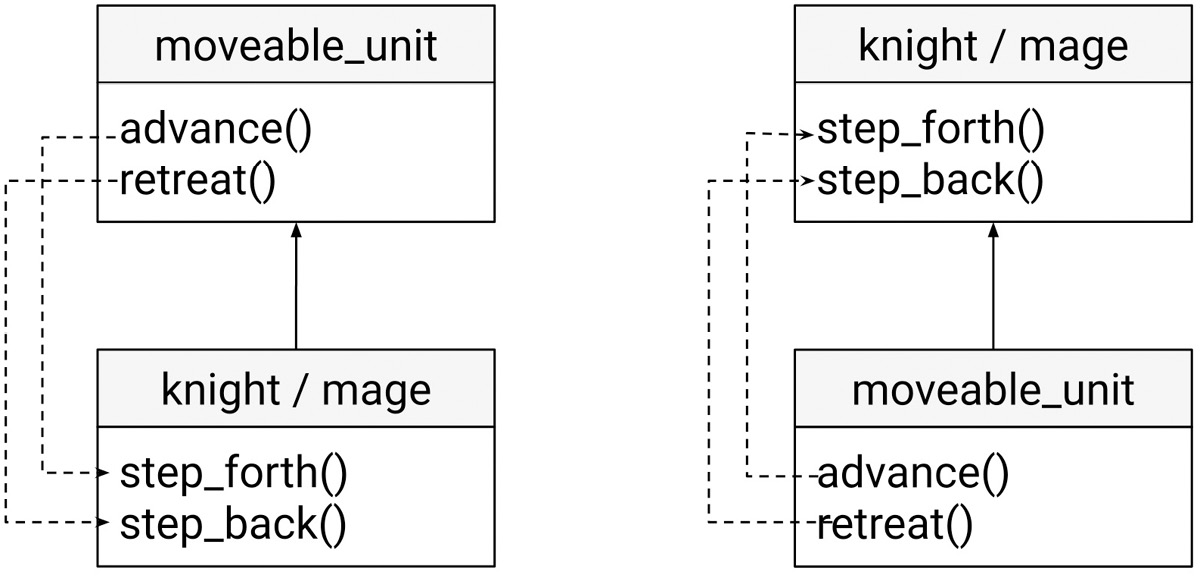
Figure 7.1: Comparison of the CRTP and the mixins patterns
We can combine the static polymorphism achieved with mixins with dynamic polymorphism achieved with interfaces and virtual functions. We’ll demonstrate this with the help of an example concerning game units that fight. We had an earlier example when we discussed the CRTP, where the knight and mage classes had a member function called attack.
Let’s say we want to define multiple attacking styles. For instance, each game unit can use either an aggressive or a moderate attacking style. So that means four combinations: aggressive and moderate knights, and aggressive and moderate mages. On the other hand, both knights and mages could be lone warriors that are comfortable to fight alone, or are team players that always fight in a group with other units.
That means we could have lone aggressive knights and lone moderate knights as well as team player aggressive knights and team player moderate knights. The same applies to mages. As you can see, the number of combinations grows a lot and mixins are a good way to provide this added functionality without expanding the knight and mage classes. Finally, we want to be able to treat all these polymorphically at runtime. Let’s see how we can do this.
First, we can define aggressive and moderate fighting styles. These could be as simple as the following:
struct aggressive_style
{
void fight()
{
std::cout << "attack! attack attack!
";
}
};
struct moderate_style
{
void fight()
{
std::cout << "attack then defend
";
}
};Next, we define mixins as the requirement of being able to fight alone or in a group. These classes are templates and are derived from their template argument:
template <typename T>
struct lone_warrior : T
{
void fight()
{
std::cout << "fighting alone.";
T::fight();
}
};
template <typename T>
struct team_warrior : T
{
void fight()
{
std::cout << "fighting with a team.";
T::fight();
}
};Last, we need to define the knight and mage classes. These themselves will be mixins for the fighting styles. However, to be able to treat them polymorphically at runtime, we derive them from a base game_unit class that contains a pure virtual method called attack that these classes implement:
struct game_unit
{
virtual void attack() = 0;
virtual ~game_unit() = default;
};
template <typename T>
struct knight : T, game_unit
{
void attack()
{
std::cout << "draw sword.";
T::fight();
}
};
template <typename T>
struct mage : T, game_unit
{
void attack()
{
std::cout << "spell magic curse.";
T::fight();
}
};The knight and mage implementation of the attack member function makes use of the T::fight method. You have probably noticed that both the aggresive_style and moderate_style classes on one hand and the lone_warrior and team_warrior mixin classes on the other hand provide such a member function. This means we can do the following combinations:
std::vector<std::unique_ptr<game_unit>> units; units.emplace_back(new knight<aggressive_style>()); units.emplace_back(new knight<moderate_style>()); units.emplace_back(new mage<aggressive_style>()); units.emplace_back(new mage<moderate_style>()); units.emplace_back( new knight<lone_warrior<aggressive_style>>()); units.emplace_back( new knight<lone_warrior<moderate_style>>()); units.emplace_back( new knight<team_warrior<aggressive_style>>()); units.emplace_back( new knight<team_warrior<moderate_style>>()); units.emplace_back( new mage<lone_warrior<aggressive_style>>()); units.emplace_back( new mage<lone_warrior<moderate_style>>()); units.emplace_back( new mage<team_warrior<aggressive_style>>()); units.emplace_back( new mage<team_warrior<moderate_style>>()); for (auto& u : units) u->attack();
In total, there are 12 combinations that we defined here. And this was all possible with only six classes. This shows how mixins help us add functionality while keeping the complexity of the code at a reduced level. If we run the code, we get the following output:
draw sword.attack! attack attack!
draw sword.attack then defend
spell magic curse.attack! attack attack!
spell magic curse.attack then defend
draw sword.fighting alone.attack! attack attack!
draw sword.fighting alone.attack then defend
draw sword.fighting with a team.attack! attack attack!
draw sword.fighting with a team.attack then defend
spell magic curse.fighting alone.attack! attack attack!
spell magic curse.fighting alone.attack then defend
spell magic curse.fighting with a team.attack! attack attack!
spell magic curse.fighting with a team.attack then defend
We have looked here at two patterns, CRTP and mixins, that are both intended to add additional (common) functionality to other classes. However, although they look similar, they have opposite structures and should not be confused with one another. An alternative technique to leverage common functionalities from unrelated types is called type erasure, which we will discuss next.
Type erasure
The term type erasure describes a pattern in which type information is removed, allowing types that are not necessarily related to be treated in a generic way. This is not something specific to the C++ language. This concept exists in other languages with better support than in C++ (such as Python and Java). There are different forms of type erasure such as polymorphism and using void pointers (a legacy of the C language, which is to be avoided), but true type erasure is achieved with templates. Before we discuss this, let’s briefly look at the others.
The most rudimentary form of type erasure is the use of void pointers. This is typical of C and although possible in C++, it is in no way recommended. It is not type-safe and, therefore, error-prone. However, for the sake of the discussion, let’s have a look at such an approach.
Let’s say we again have knight and mage types and they both have an attack function (a behavior), and we want to treat them in a common way to exhibit this behavior. Let’s see the classes first:
struct knight
{
void attack() { std::cout << "draw sword
"; }
};
struct mage
{
void attack() { std::cout << "spell magic curse
"; }
};In a C-like implementation, we could have a function for each of these types, taking a void* to an object of the type, casting it to the expected type of pointer, and then invoking the attack member function:
void fight_knight(void* k)
{
reinterpret_cast<knight*>(k)->attack();
}
void fight_mage(void* m)
{
reinterpret_cast<mage*>(m)->attack();
}These have a similar signature; the only thing that differs is the name. So, we can define a function pointer and then associate an object (or more precisely a pointer to an object) with a pointer to the right function handling it. Here is how:
using fight_fn = void(*)(void*);
void fight(
std::vector<std::pair<void*, fight_fn>> const& units)
{
for (auto& u : units)
{
u.second(u.first);
}
}There is no information about types in this last snippet. All that has been erased using void pointers. The fight function can be invoked as follows:
knight k;
mage m;
std::vector<std::pair<void*, fight_fn>> units {
{&k, &fight_knight},
{&m, &fight_mage},
};
fight(units);From a C++ perspective, this will probably look odd. It should. In this example, I have combined C techniques with C++ classes. Hopefully, we will not see snippets of code like this in production. Things will go wrong by a simple typing error if you pass a mage to the fight_knight function or the other way around. Nevertheless, it’s possible and is a form of type erasure.
An obvious alternative solution in C++ is using polymorphism through inheritance. This is the very first solution we saw at the beginning of this chapter. For convenience, I’ll reproduce it here again:
struct game_unit
{
virtual void attack() = 0;
};
struct knight : game_unit
{
void attack() override
{ std::cout << "draw sword
"; }
};
struct mage : game_unit
{
void attack() override
{ std::cout << "spell magic curse
"; }
};
void fight(std::vector<game_unit*> const & units)
{
for (auto unit : units)
unit->attack();
}The fight function can handle knight and mage objects homogenously. It knows nothing of the actual objects whose addresses were passed to it (within a vector). However, it can be argued that types have not been completely erased. Both knight and mage are game_unit and the fight function handles anything that is a game_unit. For another type to be handled by this function, it needs to derive from the game_unit pure abstract class.
And sometimes that’s not possible. Perhaps we want to treat unrelated types in a similar matter (a process called duck typing) but we are not able to change those types. For instance, we do not own the source code. The solution to this problem is true type erasure with templates.
Before we get to see what this pattern looks like, let’s take it step by step to understand how the pattern developed, starting with the unrelated knight and mage, and the premise that we cannot modify them. However, we can write wrappers around them that would provide a uniform interface to the common functionality (behavior):
struct knight
{
void attack() { std::cout << "draw sword
"; }
};
struct mage
{
void attack() { std::cout << "spell magic curse
"; }
};
struct game_unit
{
virtual void attack() = 0;
virtual ~game_unit() = default;
};
struct knight_unit : game_unit
{
knight_unit(knight& u) : k(u) {}
void attack() override { k.attack(); }
private:
knight& k;
};
struct mage_unit : game_unit
{
mage_unit(mage& u) : m(u) {}
void attack() override { m.attack(); }
private:
mage& m;
};
void fight(std::vector<game_unit*> const & units)
{
for (auto u : units)
u->attack();
}We do not need to call the attack member function in game_unit the same as it was in knight and mage. It can have any name. This choice was purely made on the grounds of mimicking the original behavior name. The fight function takes a collection of pointers to game_unit, therefore being able to handle both knight and mage objects homogenously, as shown next:
knight k;
mage m;
knight_unit ku{ k };
mage_unit mu{ m };
std::vector<game_unit*> v{ &ku, &mu };
fight(v);The trouble with this solution is that there is a lot of duplicate code. The knight_unit and mage_unit classes are mostly the same. And when other classes need to be handled similarly, this duplication increases more. The solution to code duplication is using templates. We replace knight_unit and mage_unit with the following class template:
template <typename T>
struct game_unit_wrapper : public game_unit
{
game_unit_wrapper(T& unit) : t(unit) {}
void attack() override { t.attack(); }
private:
T& t;
};There is only one copy of this class in our source code but the compiler will instantiate multiple specializations based on its usage. Any type information has been erased, with the exception of some type restrictions—the T type must have a member function called attack that takes no arguments. Notice that the fight function didn’t change at all. The client code needs to be slightly changed though:
knight k;
mage m;
game_unit_wrapper ku{ k };
game_unit_wrapper mu{ m };
std::vector<game_unit*> v{ &ku, &mu };
fight(v);This leads us to the form of the type erasure pattern by putting the abstract base class and wrapper class template within another class:
struct game
{
struct game_unit
{
virtual void attack() = 0;
virtual ~game_unit() = default;
};
template <typename T>
struct game_unit_wrapper : public game_unit
{
game_unit_wrapper(T& unit) : t(unit) {}
void attack() override { t.attack(); }
private:
T& t;
};
template <typename T>
void addUnit(T& unit)
{
units.push_back(
std::make_unique<game_unit_wrapper<T>>(unit));
}
void fight()
{
for (auto& u : units)
u->attack();
}
private:
std::vector<std::unique_ptr<game_unit>> units;
};The game class contains a collection of game_unit objects and has a method for adding new wrappers to any game unit (that has an attack member function). It also has a member function, fight, to invoke the common behavior. The client code is, this time, the following:
knight k; mage m; game g; g.addUnit(k); g.addUnit(m); g.fight();
In the type erasure pattern, the abstract base class is called a concept and the wrapper that inherits from it is called a model. If we were to implement the type erasure pattern in the established formal manner it would look as follows:
struct unit
{
template <typename T>
unit(T&& obj) :
unit_(std::make_shared<unit_model<T>>(
std::forward<T>(obj)))
{}
void attack()
{
unit_->attack();
}
struct unit_concept
{
virtual void attack() = 0;
virtual ~unit_concept() = default;
};
template <typename T>
struct unit_model : public unit_concept
{
unit_model(T& unit) : t(unit) {}
void attack() override { t.attack(); }
private:
T& t;
};
private:
std::shared_ptr<unit_concept> unit_;
};
void fight(std::vector<unit>& units)
{
for (auto& u : units)
u.attack();
}In this snippet, game_unit was renamed as unit_concept and game_unit_wrapper was renamed as unit_model. There is no other change to them apart from the name. They are members of a new class called unit that stores a pointer to an object that implements unit_concept; that could be unit_model<knight> or unit_model<mage>. The unit class has a template constructor that enables us to create such model objects from knight and mage objects.
It also has a public member function, attack (again, this can have any name). On the other hand, the fight function handles unit objects and invokes their attack member function. The client code may look as follows:
knight k;
mage m;
std::vector<unit> v{ unit(k), unit(m) };
fight(v);If you’re wondering where this pattern is used in real-world code, there are two examples in the standard library itself:
- std::function: This is a general-purpose polymorphic function wrapper that enables us to store, copy, and invoke anything that is callable, such as functions, lambda expressions, bind expressions, function objects, pointers to member functions, and pointers to data members. Here is an example of using std::function:
class async_bool
{
std::function<bool()> check;
public:
async_bool() = delete;
async_bool(std::function<bool()> checkIt)
: check(checkIt)
{ }
async_bool(bool val)
: check([val]() {return val; })
{ }
operator bool() const { return check(); }
};
async_bool b1{ false };
async_bool b2{ true };
async_bool b3{ []() { std::cout << "Y/N? ";
char c; std::cin >> c;
return c == 'Y' || c == 'y'; } };
if (b1) { std::cout << "b1 is true "; }
if (b2) { std::cout << "b2 is true "; }
if (b3) { std::cout << "b3 is true "; }
- std::any: This is a class that represents a container to any value of a type that is copy-constructible. An example is used in the following snippet:
std::any u;
u = knight{};
if (u.has_value())
std::any_cast<knight>(u).attack();
u = mage{};
if (u.has_value())
std::any_cast<mage>(u).attack();
Type erasure is an idiom that combines inheritance from object-oriented programming with templates to create wrappers that can store any type. In this section, we have seen how the pattern looks and how it works, as well as some real-world implementations of the pattern.
Next in this chapter, we will discuss a technique called tag dispatching.
Tag dispatching
Tag dispatching is a technique that enables us to select one or another function overload at compile time. It is an alternative to std::enable_if and SFINAE and is simple to understand and use. The term tag describes an empty class that has no members (data), or functions (behavior). Such a class is only used to define a parameter (usually the last) of a function to decide whether to select it at compile-time, depending on the supplied arguments. To better understand this, let’s consider an example.
The standard library contains a utility function called std::advance that looks as follows:
Notice that in C++17, this is also constexpr (more about this, shortly). This function increments the given iterator by n elements. However, there are several categories of iterators (input, output, forward, bidirectional, and random access). That means such an operation can be computed differently:
- For input iterators, it could call operator++ a number of n times.
- For bidirectional iterators, it could call either operator++ a number of n times (if n is a positive number) or operator-- a number of n times (if n is a negative number).
- For random-access iterators, it can use the operator+= to increment it directly with n elements.
This implies there can be three different implementations, but it should be possible to select at compile-time which one is the best match for the category of the iterator it is called for. A solution for this is tag dispatching. And the first thing to do is define the tags. As mentioned earlier, tags are empty classes. Therefore, tags that correspond to the five iterator types can be defined as follows:
struct input_iterator_tag {};
struct output_iterator_tag {};
struct forward_iterator_tag : input_iterator_tag {};
struct bidirectional_iterator_tag :
forward_iterator_tag {};
struct random_access_iterator_tag :
bidirectional_iterator_tag {};This is exactly how they are defined in the C++ standard library, in the std namespace. These tags will be used to define an additional parameter for each overload of std::advance, as shown next:
namespace std
{
namespace details
{
template <typename Iter, typename Distance>
void advance(Iter& it, Distance n,
std::random_access_iterator_tag)
{
it += n;
}
template <typename Iter, typename Distance>
void advance(Iter& it, Distance n,
std::bidirectional_iterator_tag)
{
if (n > 0)
{
while (n--) ++it;
}
else
{
while (n++) --it;
}
}
template <typename Iter, typename Distance>
void advance(Iter& it, Distance n,
std::input_iterator_tag)
{
while (n--)
{
++it;
}
}
}
}These overloads are defined in a separate (inner) namespace of the std namespace so that the standard namespace is not polluted with unnecessary definitions. You can see here that each of these overloads has three parameters: a reference to an iterator, a number of elements to increment (or decrement), and a tag.
The last thing to do is provide a definition of an advance function that is intended for direct use. This function does not have a third parameter but calls one of these overloads by determining the category of the iterator it is called with. Its implementation may look as follows:
namespace std
{
template <typename Iter, typename Distance>
void advance(Iter& it, Distance n)
{
details::advance(it, n,
typename std::iterator_traits<Iter>::
iterator_category{});
}
}The std::iterator_traits class seen here defines a sort of interface for iterator types. For this purpose, it contains several member types, one of them being iterator_category. This resolves to one of the iterator tags defined earlier, such as std::input_iterator_tag for input iterators or std::random_access_iterator_tag for random access iterators. Therefore, based on the category of the supplied iterator, it instantiates one of these tag classes, determining the selection at compile-time of the appropriate overloaded implementation from the details namespace. We can invoke the std::advance function as follows:
std::vector<int> v{ 1,2,3,4,5 };
auto sv = std::begin(v);
std::advance(sv, 2);
std::list<int> l{ 1,2,3,4,5 };
auto sl = std::begin(l);
std::advance(sl, 2);The category type of the std::vector’s iterators is random access. On the other hand, the iterator category type for std::list is bidirectional. However, we can use a single function that relies on different optimized implementations by leveraging the technique of tag dispatching.
Alternatives to tag dispatching
Prior to C++17, the only alternative to tag dispatching was SFINAE with enable_if. We have discussed this topic in Chapter 5, Type Traits and Conditional Compilation. This is a rather legacy technique that has better alternatives in modern C++. These alternatives are constexpr if and concepts. Let’s discuss them one at a time.
Using constexpr if
C++11 introduced the concept of constexpr values, which are values known at compile-time but also constexpr functions that are functions that could be evaluated at compile-time (if all inputs are compile-time values). In C++14, C++17, and C++20, many standard library functions or member functions of standard library classes have been changed to be constexpr. One of these is std::advance, whose implementation in C++17 is based on the constexpr if feature, also added in C++17 (which was discussed in Chapter 5, Type Traits and Conditional Compilation).
The following is a possible implementation in C++17:
template<typename It, typename Distance>
constexpr void advance(It& it, Distance n)
{
using category =
typename std::iterator_traits<It>::iterator_category;
static_assert(std::is_base_of_v<std::input_iterator_tag,
category>);
auto dist =
typename std::iterator_traits<It>::difference_type(n);
if constexpr (std::is_base_of_v<
std::random_access_iterator_tag,
category>)
{
it += dist;
}
else
{
while (dist > 0)
{
--dist;
++it;
}
if constexpr (std::is_base_of_v<
std::bidirectional_iterator_tag,
category>)
{
while (dist < 0)
{
++dist;
--it;
}
}
}
}Although this implementation still uses the iterator tags that we saw earlier, they are no longer used to invoke different overloaded functions but to determine the value of some compile-time expressions. The std::is_base_of type trait (through the std::is_base_of_v variable template) is used to determine the type of the iterator category at compile-time.
This implementation has several advantages:
- Has a single implementation of the algorithm (in the std namespace)
- Does not require multiple overloads with implementation details defined in a separate namespace
The client code is unaffected. Therefore, library implementors were able to replace the previous version based on tag dispatching with the new version based on constexpr if, without affecting any line of code calling std::advance.
However, in C++20 there is an even better alternative. Let’s explore it next.
Using concepts
The previous chapter was dedicated to constraints and concepts, introduced in C++20. We have seen not only how these features work but also some of the concepts that the standard library defines in several headers such as <concepts> and <iterator>. Some of these concepts specify that a type is some iterator category. For instance, std::input_iterator specifies that a type is an input iterator. Similarly, the following concepts are also defined: std::output_iterator, std::forward_iterator, std::bidirectional_iterator, std::random_access_iterator, and std::contiguous_iterator (the last one indicating that an iterator is a random-access iterator, referring to elements that are stored contiguously in memory).
The std::input_iterator concept is defined as follows:
template<class I>
concept input_iterator =
std::input_or_output_iterator<I> &&
std::indirectly_readable<I> &&
requires { typename /*ITER_CONCEPT*/<I>; } &&
std::derived_from</*ITER_CONCEPT*/<I>,
std::input_iterator_tag>;Without getting into too many details, it is worth noting that this concept is a set of constraints that verify the following:
- The iterator is dereferenceable (supports *i) and is incrementable (supports ++i and i++).
- The iterator category is derived from std::input_iterator_tag.
This means that the category check is performed within the constraint. Therefore, these concepts are still based on the iterator tags, but the technique is significantly different than tag dispatching. As a result, in C++20, we could have yet another implementation for the std::advance algorithm, as follows:
template <std::random_access_iterator Iter, class Distance>
void advance(Iter& it, Distance n)
{
it += n;
}
template <std::bidirectional_iterator Iter, class Distance>
void advance(Iter& it, Distance n)
{
if (n > 0)
{
while (n--) ++it;
}
else
{
while (n++) --it;
}
}
template <std::input_iterator Iter, class Distance>
void advance(Iter& it, Distance n)
{
while (n--)
{
++it;
}
}There are a couple of things to notice here:
- There are yet again three different overloads of the advanced function.
- These overloads are defined in the std namespace and do not require a separate namespace to hide implementation details.
Although we explicitly wrote several overloads again, this solution is arguably easier to read and understand than the one based on constexpr if because the code is nicely separated into different units (functions), making it easier to follow.
Tag dispatching is an important technique for selecting between overloads at compile-time. It has its trade-offs but also better alternatives if you are using C++17 or C++20. If your compiler supports concepts, you should prefer this alternative for the reasons mentioned earlier.
The next pattern we will look at in this chapter is expression templates.
Expression templates
Expression templates are a metaprogramming technique that enables lazy evaluation of a computation at compile-time. This helps to avoid inefficient operations that occur at runtime. However, this does not come for free, as expression templates require more code and can be cumbersome to read or understand. They are often used in the implementation of linear algebra libraries.
Before seeing how expression templates are implemented, let’s understand what is the problem they solve. For this, let’s suppose we want to do some operations with matrices, for which we implemented the basic operations, addition, subtraction, and multiplication (either of two matrices or of a scalar and a matrix). We can have the following expressions:
auto r1 = m1 + m2; auto r2 = m1 + m2 + m3; auto r3 = m1 * m2 + m3 * m4; auto r4 = m1 + 5 * m2;
In this snippet, m1, m2, m3, and m4 are matrices; similarly, r1, r2, r3, and r4 are matrices that result from performing the operations on the right side. The first operation does not pose any problems: m1 and m2 are added and the result is assigned to r1. However, the second operation is different because there are three matrices that are added. That means m1 and m2 are added first and a temporary is created, which is then added to m3 and the result assigned to r2.
For the third operation, there are two temporaries: one for the result of multiplying m1 and m2 and one for the result of multiplying m3 and m4; these two are then added and the result is assigned to r3. Finally, the last operation is similar to the second, meaning that a temporary object results from the multiplication between the scalar 5 and the matrix m2, and then this temporary is added to m1 and the result assigned to r4.
The more complex the operation, the more temporaries are generated. This can affect performance when the objects are large. Expression templates help to avoid this by modeling the computation as a compile-time expression. The entire mathematical expression (such as m1 + 5 * m2) becomes a single expression template computed when the assignment is evaluated and without the need for any temporary object.
To demonstrate this, we will build some examples using vectors not matrices because these are simpler data structures, and the point of the exercise is not to focus on the representation of data but on the creation of expression templates. In the following listing, you can see a minimal implementation of a vector class that provides several operations:
- Constructing an instance from an initializer list or from a value representing a size (no initializing values)
- Retrieving the number of elements in the vector
- Element access with the subscript operator ([])
The code goes as follows:
template<typename T>
struct vector
{
vector(std::size_t const n) : data_(n) {}
vector(std::initializer_list<T>&& l) : data_(l) {}
std::size_t size() const noexcept
{
return data_.size();
}
T const & operator[](const std::size_t i) const
{
return data_[i];
}
T& operator[](const std::size_t i)
{
return data_[i];
}
private:
std::vector<T> data_;
};This looks very similar to the std::vector standard container, and, in fact, it uses this container internally to hold the data. However, this aspect is irrelevant to the problem we want to solve. Remember we are using a vector and not a matrix because it’s easier to represent in a few lines of code. Having this class, we can define the necessary operations: addition and multiplication, both between two vectors and between a scalar and a vector:
template<typename T, typename U>
auto operator+ (vector<T> const & a, vector<U> const & b)
{
using result_type = decltype(std::declval<T>() +
std::declval<U>());
vector<result_type> result(a.size());
for (std::size_t i = 0; i < a.size(); ++i)
{
result[i] = a[i] + b[i];
}
return result;
}
template<typename T, typename U>
auto operator* (vector<T> const & a, vector<U> const & b)
{
using result_type = decltype(std::declval<T>() +
std::declval<U>());
vector<result_type> result(a.size());
for (std::size_t i = 0; i < a.size(); ++i)
{
result[i] = a[i] * b[i];
}
return result;
}
template<typename T, typename S>
auto operator* (S const& s, vector<T> const& v)
{
using result_type = decltype(std::declval<T>() +
std::declval<S>());
vector<result_type> result(v.size());
for (std::size_t i = 0; i < v.size(); ++i)
{
result[i] = s * v[i];
}
return result;
}These implementations are relatively straightforward and should not pose a problem to understand at this point. Both the + and * operators take two vectors of potentially different types, such as vector<int> and vector<double>, and return a vector holding elements of a result type. This is determined by the result of adding two values of the template types T and U, using std::declval. This has been discussed in Chapter 4, Advanced Template Concepts. A similar implementation is available for multiplying a scalar and a vector. Having these operators available, we can write the following code:
vector<int> v1{ 1,2,3 };
vector<int> v2{ 4,5,6 };
double a{ 1.5 };
vector<double> v3 = v1 + a * v2; // {7.0, 9.5, 12.0}
vector<int> v4 = v1 * v2 + v1 + v2; // {9, 17, 27}As previously explained, this will create one temporary object while computing v3 and two temporaries while computing v4. These are exemplified in the following diagrams. The first shows the first computation, v3 = v1 + a * v2:
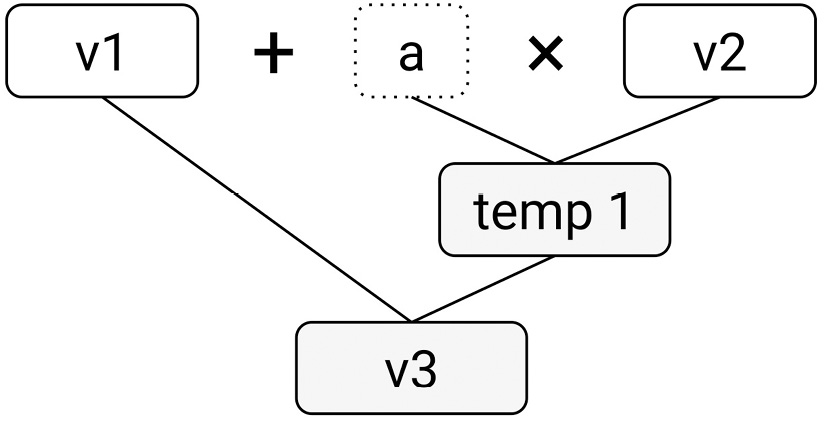
Figure 7.2: A conceptual representation of the first expression
The second diagram, shown next, presents a conceptual representation of the computation of the second expression, v4 = v1 * v2 + v1 + v2:
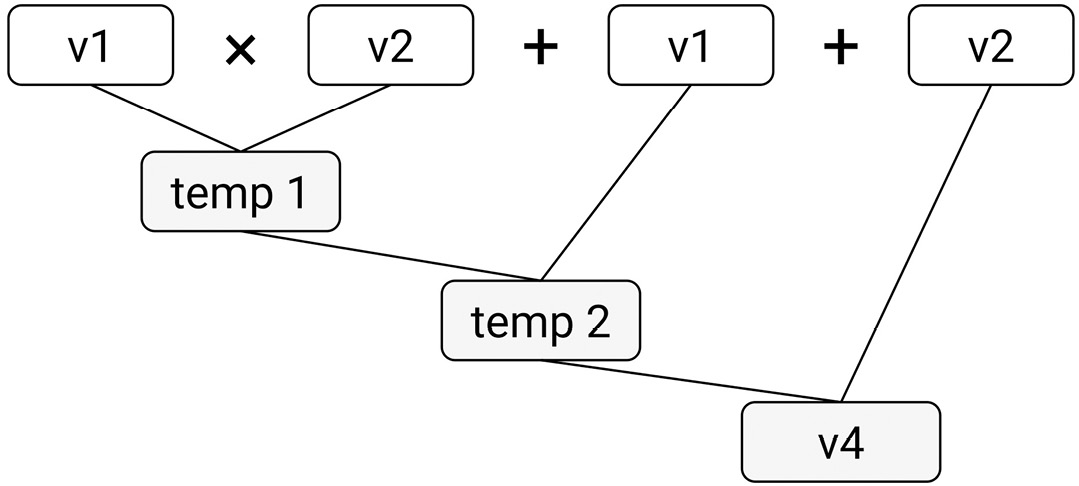
Figure 7.3: A conceptual representation of the second expression
In order to avoid these temporaries, we can rewrite the implementation of the vector class using the expression templates pattern. This requires several changes:
- Defining class templates to represent an expression between two objects (such as the expression of adding or multiplying two vectors).
- Modifying the vector class and parameterize the container for its internal data, which by default would be a std::vector as previously but can also be an expression template.
- Changing the implementation of the overloaded + and * operators.
Let’s see how this is done, starting with the vector implementation. Here is the code:
template<typename T, typename C = std::vector<T>>
struct vector
{
vector() = default;
vector(std::size_t const n) : data_(n) {}
vector(std::initializer_list<T>&& l) : data_(l) {}
vector(C const & other) : data_(other) {}
template<typename U, typename X>
vector(vector<U, X> const& other) : data_(other.size())
{
for (std::size_t i = 0; i < other.size(); ++i)
data_[i] = static_cast<T>(other[i]);
}
template<typename U, typename X>
vector& operator=(vector<U, X> const & other)
{
data_.resize(other.size());
for (std::size_t i = 0; i < other.size(); ++i)
data_[i] = static_cast<T>(other[i]);
return *this;
}
std::size_t size() const noexcept
{
return data_.size();
}
T operator[](const std::size_t i) const
{
return data_[i];
}
T& operator[](const std::size_t i)
{
return data_[i];
}
C& data() noexcept { return data_; }
C const & data() const noexcept { return data_; }
private:
C data_;
};In addition to the operations available in the initial implementation, this time we have also defined the following:
- A default constructor
- A conversion constructor from a container
- A copy constructor from a vector containing elements of a potentially different type
- A copy-assignment operator from a vector containing elements of a potentially different type
- Member function data that provides access to the underlaying container holding the data
An expression template is a simple class template that stores two operands and provides a way to perform the evaluation of the operation. In our case, we need to implement expressions for adding two vectors, multiplying two vectors, and multiplying a scalar and a vector. Let’s look at the implementation of the expression template for adding two vectors:
template<typename L, typename R>
struct vector_add
{
vector_add(L const & a, R const & b) : lhv(a), rhv(b) {}
auto operator[](std::size_t const i) const
{
return lhv[i] + rhv[i];
}
std::size_t size() const noexcept
{
return lhv.size();
}
private:
L const & lhv;
R const & rhv;
};This class stores constant references to two vectors (or, in fact, any type that overloads the subscript operator and provides a size member function). The evaluation of the expression occurs in the overloaded subscript operator but not for the entire vector; only the elements at the indicated index are added.
Notice that this implementation does not handle vectors of different sizes (which you can take as an exercise to change). However, it should be easy to understand the lazy nature of this approach since the addition operation only occurs when invoking the subscript operator.
The multiplication expression templates for the two operations we need are implemented in a similar fashion. The code is shown in the next listing:
template<typename L, typename R>
struct vector_mul
{
vector_mul(L const& a, R const& b) : lhv(a), rhv(b) {}
auto operator[](std::size_t const i) const
{
return lhv[i] * rhv[i];
}
std::size_t size() const noexcept
{
return lhv.size();
}
private:
L const & lhv;
R const & rhv;
};
template<typename S, typename R>
struct vector_scalar_mul
{
vector_scalar_mul(S const& s, R const& b) :
scalar(s), rhv(b)
{}
auto operator[](std::size_t const i) const
{
return scalar * rhv[i];
}
std::size_t size() const noexcept
{
return rhv.size();
}
private:
S const & scalar;
R const & rhv;
};The last part of the change is to modify the definition of the overloaded + and * operators, which is as follows:
template<typename T, typename L, typename U, typename R>
auto operator+(vector<T, L> const & a,
vector<U, R> const & b)
{
using result_type = decltype(std::declval<T>() +
std::declval<U>());
return vector<result_type, vector_add<L, R>>(
vector_add<L, R>(a.data(), b.data()));
}
template<typename T, typename L, typename U, typename R>
auto operator*(vector<T, L> const & a,
vector<U, R> const & b)
{
using result_type = decltype(std::declval<T>() +
std::declval<U>());
return vector<result_type, vector_mul<L, R>>(
vector_mul<L, R>(a.data(), b.data()));
}
template<typename T, typename S, typename E>
auto operator*(S const& a, vector<T, E> const& v)
{
using result_type = decltype(std::declval<T>() +
std::declval<S>());
return vector<result_type, vector_scalar_mul<S, E>>(
vector_scalar_mul<S, E>(a, v.data()));
}Although the code is more complex when implementing this pattern, the client code does not need to change. The snippet showed earlier works without any modifications but in a lazy manner. The evaluation of each element in the result is triggered by the invocation of the subscript operator that occurs in the copy-constructor and copy-assignment operator of the vector class.
If this pattern looks cumbersome to you, there is the alternative of something better: the ranges library.
Using ranges as an alternative to expression templates
One of the major features of C++20 is the ranges library. A range is a generalization of a container - a class that allows you to iterate over its data (elements). A key element of the range library is the views. These are non-owning wrappers of other ranges that transform the underlying range through some operation.
Moreover, they are lazy-evaluated and the time to construct, copy, or destroy them does not depend on the size of the underlying range. The lazy evaluation (the fact that transformations are applied to elements at the moment they are requested, not when the view is created) is a key feature of the library. However, that is exactly what the expression templates are also providing. As a result, many uses of the expression templates can be replaced with ranges. Ranges will be discussed in detail in the next chapter.
The C++ ranges library is based on the range-v3 library created by Eric Niebler. This library is available at https://github.com/ericniebler/range-v3/. Using range-v3, we can write the following code to perform the operation v1 + a * v2:
namespace rv = ranges::views;
std::vector<int> v1{ 1, 2, 3 };
std::vector<int> v2{ 4, 5, 6 };
double a { 1.5 };
auto sv2 = v2 |
rv::transform([&a](int val) {return a * val; });
auto v3 = rv::zip_with(std::plus<>{}, v1, sv2);There is no need for a custom implementation of a vector class; it just works with the std::vector container. There is no need to overload any operator also. The code should be easy to follow, at least if you have some familiarity with the ranges library. First, we create a view that transforms the elements of the v2 vector by multiplying each element with a scalar. Then, a second view is created that applies the plus operator on the elements of the v1 range and the view resulting from the previous operation.
Unfortunately, this code cannot be written in C++20 using the standard library, because the zip_with view has not been included in C++20. However, this view will be available in C++23 under the name zip_view. Therefore, in C++23, we will be able to write this code as follows:
namespace rv = std::ranges::views;
std::vector<int> v1{ 1, 2, 3 };
std::vector<int> v2{ 4, 5, 6 };
double a { 1.5 };
auto sv2 = v2 |
rv::transform([&a](int val) {return a * val; });
auto v3 = rv::zip_wiew(std::plus<>{}, v1, sv2);To conclude the discussion of the expression templates pattern, you should keep in mind the following takeaways: the pattern is designed to provide lazy evaluation for costly operations, and it does so at the expense of having to write more code (that is also arguably more cumbersome) and increased compile-times (since heavy template code will have an impact on that). However, as of C++20, a good alternative to this pattern is represented by the ranges library. We will learn about this new library in Chapter 9, The Ranges Library.
For the next and last section of this chapter, we will look at type lists.
Typelists
A type list (also spelled typelist) is a compile-time construct that enables us to manage a sequence of types. A typelist is somehow similar to a tuple but does not store any data. A typelist only carries type information and is used exclusively at compile-time for implementing different metaprogramming algorithms, type switches, or design patterns such as Abstract Factory or Visitor.
Important Note
Although both the type list and typelist spellings are in use, most of the time you will find the term typelist in C++ books and articles. Therefore, this will be the form we will use in this book.
Typelists were popularized by Andrei Alexandrescu in his book, Modern C++ Design, published a decade before the release of C++11 (and variadic templates). Alexandrescu defined a typelist as follows:
template <class T, class U>
struct Typelist
{
typedef T Head;
typedef U Tail;
};In his implementation, a typelist is composed of a head—which is a type, and a tail—which is another typelist. In order to perform various operations on the typelist (which will be discussed shortly) we also need a type to represent the end of the typelist. This can be a simple, empty type that Alexandrescu defined as follows:
class null_typelist {};Having these two constructs, we can define typelists in the following way:
typedef Typelist<int, Typelist<double, null_typelist>> MyList;
Variadic templates make the implementation of typelists simpler, as shown in the next snippet:
template <typename ... Ts>
struct typelist {};
using MyList = typelist<int, double>;The implementation of operations of typelists (such as accessing a type at a given index, adding or removing types from the list, and so on) differs significantly depending on the selected approach. In this book, we will only consider the variadic template version. The advantage of this approach is simplicity at different levels: the definition of the typelist is shorter, there is no need for a type to represent the end of the list, and defining typelist aliases is also shorter and easier to read.
Today, perhaps many of the problems for which typelists represented the solution can be also solved using variadic templates. However, there are still scenarios where typelists are required. Here is an example: let’s consider a variadic metafunction (a type trait that performs a transformation of types) that does some transformation (such as adding the const qualifier) to the type template arguments. This metafunction defines a member type that represents the input types and one that represents the transformed types. If you try to define it as follows, it will not work:
template <typename ... Ts>
struct transformer
{
using input_types = Ts...;
using output_types = std::add_const_t<Ts>...;
};This code produces compiler errors, because the expansion of the parameter pack is not possible in this context. This is a topic we discussed in Chapter 3, Variadic Templates. The solution to this is to use a typelist, as follows:
template <typename ... Ts>
struct transformer
{
using input_types = typelist<Ts...>;
using output_types = typelist<std::add_const_t<Ts>...>;
};
static_assert(
std::is_same_v<
transformer<int, double>::output_types,
typelist<int const, double const>>);The change is minimal but produces the expected result. Although this is a good example of where typelists are needed, it’s not a typical example of where typelists are used. We will look at such an example next.
Using typelists
It’s worth exploring a more complex example before we look at how to implement operations on typelists. This should give you an understanding of the possible usage of typelists, although you can always search for more online.
Let’s return to the example of the game units. For simplicity, we’ll only consider the following class:
struct game_unit
{
int attack;
int defense;
};A game unit has two data members representing indices (or levels) for attacking and defending. We want to operate changes on these members with the help of some functors. Two such functions are shown in the following listing:
struct upgrade_defense
{
void operator()(game_unit& u)
{
u.defense = static_cast<int>(u.defense * 1.2);
}
};
struct upgrade_attack
{
void operator()(game_unit& u)
{
u.attack += 2;
}
};The first increases the defense index by 20%, while the second increases the attack index by two units. Although this is a small example meant to demonstrate the use case, you can imagine a larger variety of functors like this that could be applied in some well-defined combinations. In our example, however, we want to apply these two functors on a game_unit object. We’d like to have a function as follows:
void upgrade_unit(game_unit& unit)
{
using upgrade_types =
typelist<upgrade_defense, upgrade_attack>;
apply_functors<upgrade_types>{}(unit);
}This upgrade_unit function takes a game_unit object and applies the upgrade_defense and upgrade_attack functors to it. For this, it uses another helper functor called apply_functors. This is a class template that has a single template argument. This template argument is a typelist. A possible implementation for the apply_functors functor is shown next:
template <typename TL>
struct apply_functors
{
private:
template <size_t I>
static void apply(game_unit& unit)
{
using F = at_t<I, TL>;
std::invoke(F{}, unit);
}
template <size_t... I>
static void apply_all(game_unit& unit,
std::index_sequence<I...>)
{
(apply<I>(unit), ...);
}
public:
void operator()(game_unit& unit) const
{
apply_all(unit,
std::make_index_sequence<length_v<TL>>{});
}
};This class template has an overloaded call operator and two private helper functions:
- apply, which applies the functor from the I index of the typelist to a game_unit object.
- apply_all, which applies all the functors in the typelist to a game_unit object by using the apply function in a pack expansion.
We can use the upgrade_unit function as follows:
game_unit u{ 100, 50 };
std::cout << std::format("{},{}
", u.attack, u.defense);
// prints 100,50
upgrade_unit(u);
std::cout << std::format("{},{}
", u.attack, u.defense);
// prints 102,60If you paid attention to the implementation of the apply_functors class template, you will have noticed the use of the at_t alias template and the length_v variable template, which we have not defined yet. We will look at these two and more in the next section.
Implementing operations on typelists
A typelist is a type that only carries valuable information at compile-time. A typelist acts as a container for other types. When you work with typelists, you need to perform various operations, such as counting the types in the list, accessing a type at a given index, adding a type at the beginning or the end of the list, or the reverse operation, removing a type from the beginning or the end of the list, and so on. If you think about it, these are typical operations you’d use with a container such as a vector. Therefore, in this section, we’ll discuss how to implement the following operations:
- size: Determines the size of the list
- front: Retrieves the first type in the list
- back: Retrieves the last type in the list
- at: Retrieves the type at the specified index in the list
- push_back: Adds a new type to the end of the list
- push_front: Adds a new type to the beginning of the list
- pop_back: Removes the type at the end of the list
- pop_front: Removes the type at the beginning of the list
A typelist is a compile-time construct. It is an immutable entity. Therefore, the operations that add or remove a type do not modify a typelist but create a new one. We’ll see that shortly. But first, let’s start with the simplest operation, which is retrieving the size of a typelist.
To avoid naming confusion with the size_t type, we’ll call this operation lenght_t, and not size_t. We can define this as follows:
namespace detail
{
template <typename TL>
struct length;
template <template <typename...> typename TL,
typename... Ts>
struct length<TL<Ts...>>
{
using type =
std::integral_constant<std::size_t, sizeof...(Ts)>;
};
}
template <typename TL>
using length_t = typename detail::length<TL>::type;
template <typename TL>
constexpr std::size_t length_v = length_t<TL>::value;In the detail namespace, we have a class template called length. There is a primary template (without a definition) and a specialization for a typelist. This specialization defines a member type called type that is a std::integral_constant, with a value of the type std::size_t representing the number of arguments in the parameter pack Ts. Furthermore, we have an alias template, length_h, that is an alias for the member called type of the length class template. Finally, we have a variable template called length_v that is initialized from the value of the std::integral_constant member, which is also called value.
We can verify the correctness of this implementation with the help of some static_assert statements, as follows:
static_assert( length_t<typelist<int, double, char>>::value == 3); static_assert(length_v<typelist<int, double, char>> == 3); static_assert(length_v<typelist<int, double>> == 2); static_assert(length_v<typelist<int>> == 1);
The approach used here will be used for defining all the other operations. Let’s look next at accessing the front type in the list. This is shown in the next listing:
struct empty_type {};
namespace detail
{
template <typename TL>
struct front_type;
template <template <typename...> typename TL,
typename T, typename... Ts>
struct front_type<TL<T, Ts...>>
{
using type = T;
};
template <template <typename...> typename TL>
struct front_type<TL<>>
{
using type = empty_type;
};
}
template <typename TL>
using front_t = typename detail::front_type<TL>::type;In the detail namespace, we have a class template called front_type. Again, we declared a primary template but without a definition. However, we have two specializations: one for a typelist that contains at least one type and one for an empty typelist. In the former case, the type member is aliasing the first type in the typelist. In the latter case, there is no type so the type member is aliasing a type called empty_type. This is an empty class whose only role is to act as the return type for operations where no type is to be returned. We can verify the implementation as follows:
static_assert( std::is_same_v<front_t<typelist<>>, empty_type>); static_assert( std::is_same_v<front_t<typelist<int>>, int>); static_assert( std::is_same_v<front_t<typelist<int, double, char>>, int>);
If you expect the implementation of the operation for accessing the back type to be similar, you will not be disappointed. Here is how it looks:
namespace detail
{
template <typename TL>
struct back_type;
template <template <typename...> typename TL,
typename T, typename... Ts>
struct back_type<TL<T, Ts...>>
{
using type = back_type<TL<Ts...>>::type;
};
template <template <typename...> typename TL,
typename T>
struct back_type<TL<T>>
{
using type = T;
};
template <template <typename...> typename TL>
struct back_type<TL<>>
{
using type = empty_type;
};
}
template <typename TL>
using back_t = typename detail::back_type<TL>::type;The only significant difference with this implementation is that there are three specializations of the back_type class template and there is recursion involved. The three specializations are for an empty typelist, a typelist with a single type, and a typelist with two or more types. The last one (which is actually the first in the previous listing) is using template recursion in the definition of its type member. We have seen how this works in Chapter 4, Advanced Template Concepts. To ensure we implemented the operation the right way we can do some validation as follows:
static_assert( std::is_same_v<back_t<typelist<>>, empty_type>); static_assert( std::is_same_v<back_t<typelist<int>>, int>); static_assert( std::is_same_v<back_t<typelist<int, double, char>>, char>);
Apart from accessing the first and last type in a typelist, we are also interested in accessing a type at any given index. However, the implementation of this operation is less trivial. Let’s see it first:
namespace detail
{
template <std::size_t I, std::size_t N, typename TL>
struct at_type;
template <std::size_t I, std::size_t N,
template <typename...> typename TL,
typename T, typename... Ts>
struct at_type<I, N, TL<T, Ts...>>
{
using type =
std::conditional_t<
I == N,
T,
typename at_type<I, N + 1, TL<Ts...>>::type>;
};
template <std::size_t I, std::size_t N>
struct at_type<I, N, typelist<>>
{
using type = empty_type;
};
}
template <std::size_t I, typename TL>
using at_t = typename detail::at_type<I, 0, TL>::type;The at_t alias template has two template arguments: an index and a typelist. The at_t template is an alias for the member type of the at_type class template from the detail namespace. The primary template has three template parameters: an index representing the position of the type to retrieve (I), another index representing the current position in the iteration of the types in the list (N), and a typelist (TL).
There are two specializations of this primary template: one for a typelist that contains at least one type and one for an empty typelist. In the latter case, the member type is aliasing the empty_type type. In the former case, the member type is defined with the help of the std::conditional_t metafunction. This defines its member type as the first type (T) when I == N, or as the second type (typename at_type<I, N + 1, TL<Ts...>>::type) when this condition is false. Here, again, we employ template recursion, incrementing the value of the second index with each iteration. The following static_assert statements validate the implementation:
static_assert( std::is_same_v<at_t<0, typelist<>>, empty_type>); static_assert( std::is_same_v<at_t<0, typelist<int>>, int>); static_assert( std::is_same_v<at_t<0, typelist<int, char>>, int>); static_assert( std::is_same_v<at_t<1, typelist<>>, empty_type>); static_assert( std::is_same_v<at_t<1, typelist<int>>, empty_type>); static_assert( std::is_same_v<at_t<1, typelist<int, char>>, char>); static_assert( std::is_same_v<at_t<2, typelist<>>, empty_type>); static_assert( std::is_same_v<at_t<2, typelist<int>>, empty_type>); static_assert( std::is_same_v<at_t<2, typelist<int, char>>, empty_type>);
The next category of operations to implement is adding a type to the beginning and the end of a typelist. We call these push_back_t and push_front_t and their definitions are as follows:
namespace detail
{
template <typename TL, typename T>
struct push_back_type;
template <template <typename...> typename TL,
typename T, typename... Ts>
struct push_back_type<TL<Ts...>, T>
{
using type = TL<Ts..., T>;
};
template <typename TL, typename T>
struct push_front_type;
template <template <typename...> typename TL,
typename T, typename... Ts>
struct push_front_type<TL<Ts...>, T>
{
using type = TL<T, Ts...>;
};
}
template <typename TL, typename T>
using push_back_t =
typename detail::push_back_type<TL, T>::type;
template <typename TL, typename T>
using push_front_t =
typename detail::push_front_type<TL, T>::type;Based on what we have seen so far with the previous operations, these should be straightforward to understand. The opposite operations, when we remove the first or last type from a typelist, are more complex though. The first one, pop_front_t, looks as follows:
namespace detail
{
template <typename TL>
struct pop_front_type;
template <template <typename...> typename TL,
typename T, typename... Ts>
struct pop_front_type<TL<T, Ts...>>
{
using type = TL<Ts...>;
};
template <template <typename...> typename TL>
struct pop_front_type<TL<>>
{
using type = TL<>;
};
}
template <typename TL>
using pop_front_t =
typename detail::pop_front_type<TL>::type;We have the primary template, pop_front_type, and two specializations: the first for a typelist with at least one type, and the second for an empty typelist. The latter defines the member type as an empty list; the former defines the member type as a typelist with the tail composed from the typelist argument.
The last operation, removing the last type in a typelist, called pop_back_t, is implemented as follows:
namespace detail
{
template <std::ptrdiff_t N, typename R, typename TL>
struct pop_back_type;
template <std::ptrdiff_t N, typename... Ts,
typename U, typename... Us>
struct pop_back_type<N, typelist<Ts...>,
typelist<U, Us...>>
{
using type =
typename pop_back_type<N - 1,
typelist<Ts..., U>,
typelist<Us...>>::type;
};
template <typename... Ts, typename... Us>
struct pop_back_type<0, typelist<Ts...>,
typelist<Us...>>
{
using type = typelist<Ts...>;
};
template <typename... Ts, typename U, typename... Us>
struct pop_back_type<0, typelist<Ts...>,
typelist<U, Us...>>
{
using type = typelist<Ts...>;
};
template <>
struct pop_back_type<-1, typelist<>, typelist<>>
{
using type = typelist<>;
};
}
template <typename TL>
using pop_back_t = typename detail::pop_back_type<
static_cast<std::ptrdiff_t>(length_v<TL>)-1,
typelist<>, TL>::type;For implementing this operation, we need to start with a typelist and recursively construct another typelist, element by element, until we get to the last type in the input typelist, which should be omitted. For this, we use a counter that tells us how many times we iterated the typelist.
This is initiated with the size of the typelist minus one and we need to stop when we reach zero. For this reason, the pop_back_type class template has four specializations, one for the general case when we are at some iteration in the typelist, two for the case when the counter reached zero, and one for the case when the counter reached the value minus one. This is the case when the initial typelist was empty (therefore, length_t<TL> - 1 would evaluate to -1). Here are some asserts that show how to use pop_back_t and validate its correctness:
static_assert(std::is_same_v<pop_back_t<typelist<>>, typelist<>>); static_assert(std::is_same_v<pop_back_t<typelist<double>>, typelist<>>); static_assert( std::is_same_v<pop_back_t<typelist<double, char>>, typelist<double>>); static_assert( std::is_same_v<pop_back_t<typelist<double, char, int>>, typelist<double, char>>);
With these defined, we have provided a series of operations that are necessary for working with typelists. The length_t and at_t operations were used in the example shown earlier with the execution of functors on game_unit objects. Hopefully, this section provided a helpful introduction to typelists and enabled you to understand not only how they are implemented but also how they can be used.
Summary
This chapter was dedicated to learning various metaprogramming techniques. We started by understanding the differences between dynamic and static polymorphism and then looked at the curiously recurring template pattern for implementing the latter.
Mixins was another pattern that has a similar purpose as CRTP—adding functionality to classes, but unlike CRTP, without modifying them. The third technique we learned about was type erasure, which allows similar types that are unrelated to be treated generically. In the second part, we learned about tag dispatching – which allow us to select between overloads at compile time, and expression templates – which enable lazy evaluation of a computation at compile-time to avoid inefficient operations that occur at runtime. Lastly, we explored typelists and learned how they are used and how we can implement operations with them.
In the next chapter, we will look at the core pillars of the standard template library, containers, iterators, and algorithms.
Questions
- What are the typical problems that can be solved by CRTP?
- What are mixins and what is their purpose?
- What is type erasure?
- What is tag dispatching and what are its alternatives?
- What are expression templates and where are they used?
Further reading
- Design Patterns: Elements of Reusable Object-Oriented Software – Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides, p. 163, Addison-Wesley
- Modern C++ Design: Generic Programming and Design Patterns Applied – Andrei Alexandrescu, Addison-Wesley Professional
- Mixin-Based Programming in C++ – Yannis Smaragdakis, Don Batory, https://yanniss.github.io/practical-fmtd.pdf
- Curiously Recurring Template Patterns – James Coplien, http://sites.google.com/a/gertrudandcope.com/info/Publications/InheritedTemplate.pdf
- Mixin Classes: The Yang of the CRTP – Jonathan Boccara, https://www.fluentcpp.com/2017/12/12/mixin-classes-yang-crtp/
- What the Curiously Recurring Template Pattern can bring to your code – Jonathan Boccara, https://www.fluentcpp.com/2017/05/16/what-the-crtp-brings-to-code/
- Combining Static and Dynamic Polymorphism with C++ Mixin classes – Michael Afanasiev, https://michael-afanasiev.github.io/2016/08/03/Combining-Static-and-Dynamic-Polymorphism-with-C++-Template-Mixins.html
- Why C++ is not just an Object-Oriented Programming Language – Bjarne Stroustrup, https://www.stroustrup.com/oopsla.pdf
- enable_shared_from_this - overview, examples, and internals – Hitesh Kumar, https://www.nextptr.com/tutorial/ta1414193955/enable_shared_from_this-overview-examples-and-internals
- Tag dispatch versus concept overloading – Arthur O’Dwyer, https://quuxplusone.github.io/blog/2021/06/07/tag-dispatch-and-concept-overloading/
- C++ Expression Templates: An Introduction to the Principles of Expression Templates – Klaus Kreft and Angelika Langer, http://www.angelikalanger.com/Articles/Cuj/ExpressionTemplates/ExpressionTemplates.htm
- We don’t need no stinking expression templates, https://gieseanw.wordpress.com/2019/10/20/we-dont-need-no-stinking-expression-templates/
- Generic Programming: Typelists and Applications – Andrei Alexandrescu, https://www.drdobbs.com/generic-programmingtypelists-and-applica/184403813
- Of type lists and type switches – Bastian Rieck, https://bastian.rieck.me/blog/posts/2015/type_lists_and_switches/