
While platform as a service (PaaS) databases such as Azure SQL Database have many upsides, the most common SQL Server deployment method on Azure is in an IaaS virtual machine (VM). The typical reasons for this are that partner software may not support PaaS options, or that you may need to work on older versions of the SQL Server engine. Another common scenario is when an organization chooses to run another SQL Server component, such as SQL Server Integration Services (SSIS), alongside the database engine. Some of the other included features that may be used include PolyBase, which allows data virtualization to other data sources such as MongoDB, Oracle, or Teradata. Also, Machine Learning services allows users to execute R, Python, or Java scripts side by side with SQL Server. While this architecture may not offer the best performance, it does maximize the value of licensing. In this chapter, you will learn about:
- Configuring your VMs to be highly available.
- Monitoring performance over time.
- Optimizing disk layout for SQL Server on Azure VMs
- Benefits of SQL VM resource provider
- Managing your SQL Server estate in Azure.
- Using Azure Active Directory managed identities.
- SQL Server 2019 security features.
Understanding platform availability in Azure
It is important to understand that the Azure infrastructure is built and designed to be highly available, but just like in every computer system, there are failures that can happen. Azure offers you a couple of different ways to build resiliency within your infrastructure. Azure is made up of regions and spread across geographies, as shown in Figure 3.1:

Figure 3.1: Azure regions throughout the world
A geography is a designation that ensures that data residency respects geopolitical boundaries and meets any data sovereignty. A geography is typically defined by the borders of a country (typically Microsoft won't add a region without adding two regions in a given country); however, there are a few exceptions, such as Brazil South, which is a single region within a single country.
Also, Azure will always define regional pairs within its infrastructure. This is an important concept in terms of the overall availability of the platform. Azure paired regions have a few important concepts to take note of:
- If you are using geo-redundant storage, it will be replicated to the paired region (you don't get to choose the target).
- Microsoft performs updates of the infrastructure in a serial fashion across paired regions so that in the event of an update failure, the failure will not cascade.
- Paired regions are at least 500 kilometers/300 miles apart where possible so that they are protected from natural disasters.
- Finally, in the event of a major Azure outage, Microsoft will prioritize the recovery of one region out of every pair.
If you are using IaaS, you do not have to deploy your resource to paired regions for disaster recovery, but it may be in your best interest to do so as it might provide you with the highest levels of availability.
While each region is made up of multiple physical datacenters, the lowest level of granularity you have when you are deploying Azure services is the region. This means that in the event of a physical outage in a datacenter, your application could incur downtime if you do not have a disaster recovery solution in a second region.
Availability Zones
In 2017, Azure introduced Availability Zones, which allow you to split workloads between physical datacenters. When you deploy a VM resource to an Availability Zone, you have the choice of deploying to zone 1, 2, or 3, which can spread your workloads across multiple datacenters in a given region, as shown in Figure 3.2:
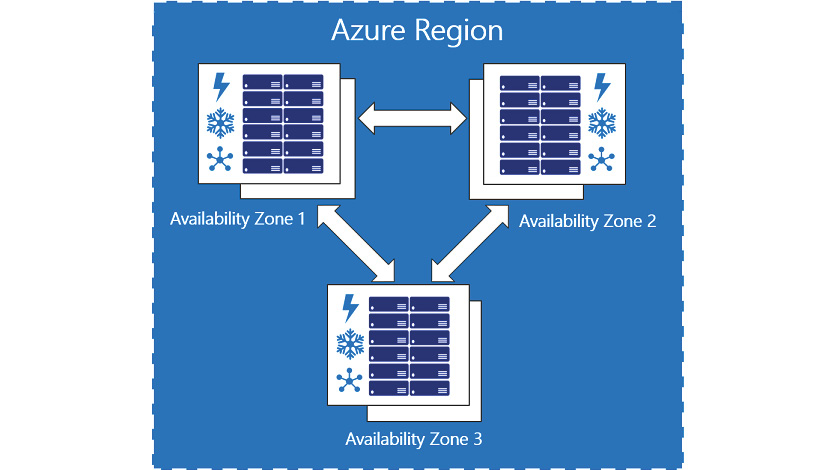
Figure 3.2: Availability Zones
Availability Zones have separate power, network connections, and cooling in order to prevent a single physical failure from taking down your workloads. While Figure 3.2 and the portal will always present you with three logical Availability Zones, in actuality each region that has Availability Zones is divided up into four physical zones—the zones you choose in the portal while ensuring that your workload is placed in different datacenters within the region are not tied to a specific datacenter every time. For example, my deployment to Zone 1 in the East US 2 region may not be in the same datacenter as your deployment to Zone 1 in the same region.
While network latency between datacenters in a region is low, it is important to test that latency before deploying your workloads, as some regions will have higher latency between zones than others. This could affect SQL Server when deploying a technology such as Always On availability groups; you might choose to use synchronous replication if the latency is less than one millisecond for a critical transaction processing application. On the other hand, if the latency is higher, you might risk some data loss with asynchronous replication. It is very important to test the latency between your VMs before deploying your architecture.
Availability sets
In addition to Availability Zones, Azure also has availability sets, which provide availability within a datacenter within a region. A simple way of thinking about this is that if you have three VMs in an availability set, they are all deployed to different racks within the datacenter. In reality, it is more complex than that, with Azure being broken down into update domains, which allow the infrastructure to be updated, and fault domains, which provide isolation to single points of failure in the core infrastructure. This, combined with managed disks, offers 99.95% uptime for multi-VM deployments.
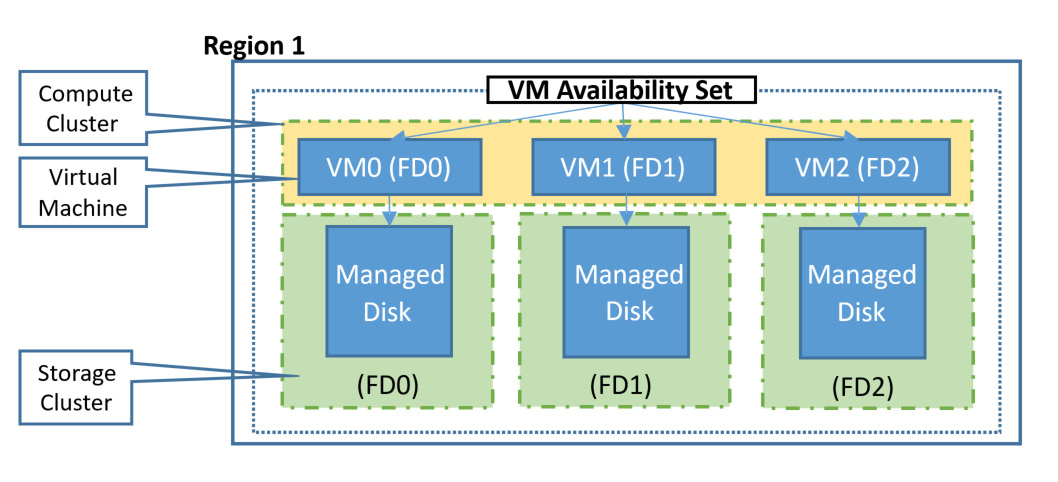
Figure 3.3: Availability set configuration
If you are deploying Always On availability groups or Failover Cluster Instances, you will need to deploy them into an availability set or into an Availability Zone. This is required in order to configure the internal load balancer, which will act as the IP address for the availability group's listener (the virtual IP address that users and applications use to connect directly to the availability group).
While all these solutions provide high availability, none of them protect against regional disasters. One of the benefits of using the public cloud is the ease of putting workloads in multiple regions to protect against natural disasters or regional failure.
Disaster recovery options for SQL Server in Azure
The first step in any good disaster recovery plan is having reliable and redundant backups. SQL Server and Azure work together to make this simple—SQL Server 2012 (specifically Service Pack 1, Cumulative Update 2) onward has supported backing up directly to Azure Blob storage through the BACKUP TO URL syntax. This feature was enhanced in SQL Server 2016 and supports backups larger than 1 TB, and striping the backup to improve performance. Commonly used tools such as the built-in maintenance plans and Ola Hallengen's maintenance scripts support backing up to Azure Blob storage.
Note
While backup to URL is supported in tools, you should note that neither maintenance plans nor Ola Hallengren's scripts support the pruning of older backups. A common workaround for this is to add an SQL Server Agent job step that removes the older backup files upon completion of your backup tasks.
Additionally, you have to use Azure Backup for SQL Server, which builds on top of the Azure Backup service and actively manages your older backups. Azure boosts your availability by providing Geo-Redundant Storage (GRS) accounts, which provide two copies of each backup file stored in a highly available fashion (Azure Storage doesn't use traditional RAID patterns, instead requiring three copies of a file within a region for a write to be considered complete) in two different regions. This replication is asynchronous, which makes it well suited for backups, but not for the storage of SQL Server data files.
Beyond backups
In addition to backups, you should capture your configuration's ARM templates and any SQL Server configuration that exists outside of your databases (cluster configuration, quorum drives) in your source control system. This provides for budget-conscious customers who do not want to have a real-time secondary replica of their database.
Another low-cost (and simplified configuration) option is to use Azure Site Recovery to protect your workloads. Azure Site Recovery replicates your VMs using block-level storage replication from one Azure region to another. There is no need for the target region to be online, which helps reduce the compute costs. Your recovery data is stored in a storage vault in the secondary regions. Azure Site Recovery is priced at $25 USD per instance per month (an instance in this scenario is a VM).
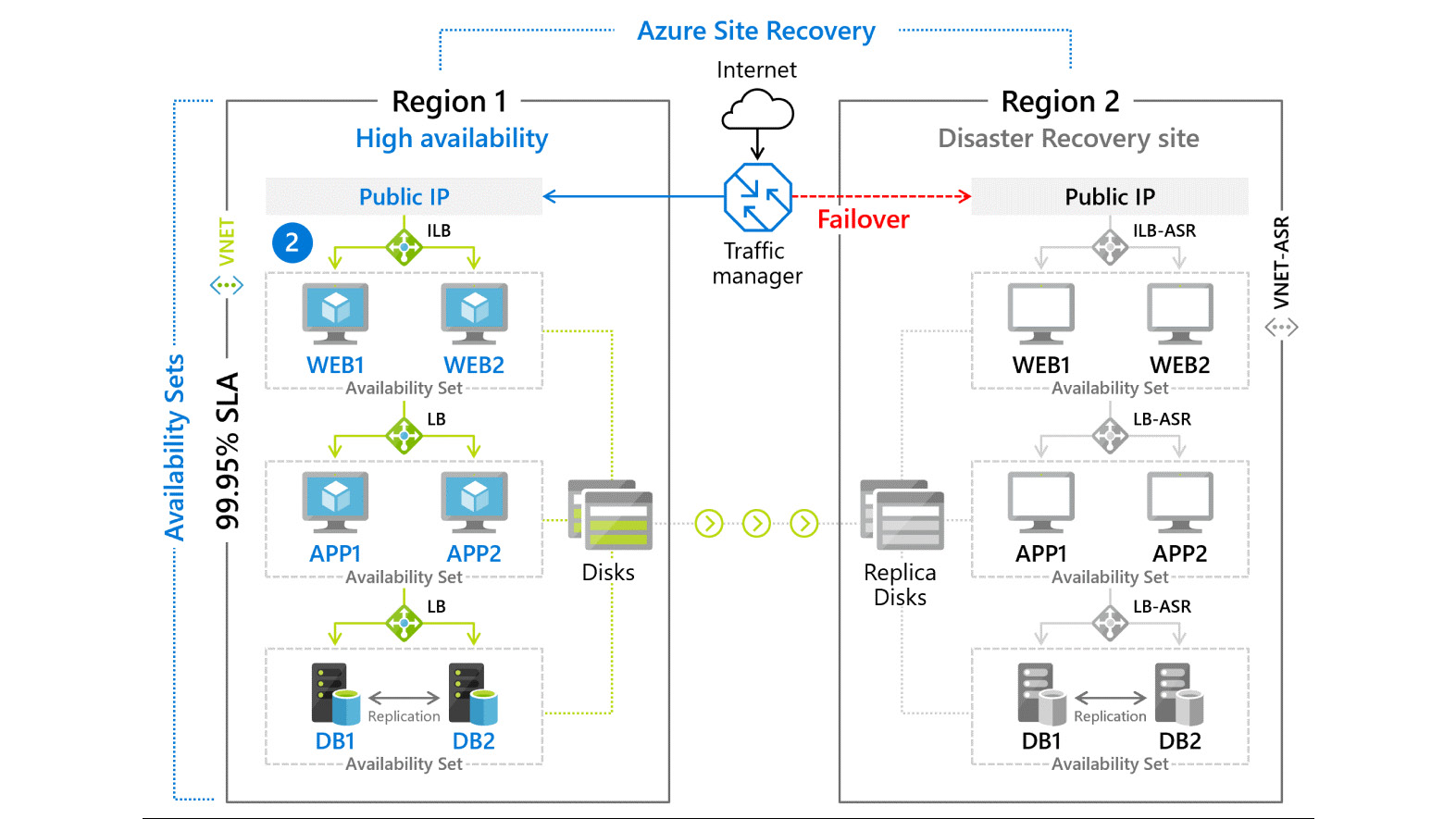
Figure 3.4: Azure Site Recovery Architecture
Azure Site Recovery is not the disaster recovery solution for all workloads—you could potentially lose somewhere between 5 and 60 minutes of data, depending on the failure mechanism. However, it is very cost effective and very simple in terms of setup and management. For high availability and disaster recovery solutions with a lower Recovery Time Objective (RTO) and Recovery Point Objective (RPO), most customers are going to use either Always On availability groups or log shipping techniques.
Always On availability groups
Introduced with SQL Server 2012, Always On availability groups provide both high availability and disaster recovery by allowing synchronous and asynchronous replication between one or more database(s). Additionally, availability groups allow reads to take place on the secondary replicas, allowing you to scale your architectures to put replicas closer to end users or behind a load balancer for general reporting. In SQL Server 2019, you can have up to five synchronous replicas in your availability group (and up to eight total replicas). Synchronous and asynchronous in this context refer to the process of transaction hardening. When an availability group is running in synchronous mode, a transaction is not considered complete on the primary replica until it reaches (and is hardened into) the transaction log of the secondary replica(s). In most configurations, the transaction is considered committed when it reaches the first replica; however, there is an optional required_copies_to_commit setting that provides additional data protection by ensuring the database transaction reaches additional replicas.
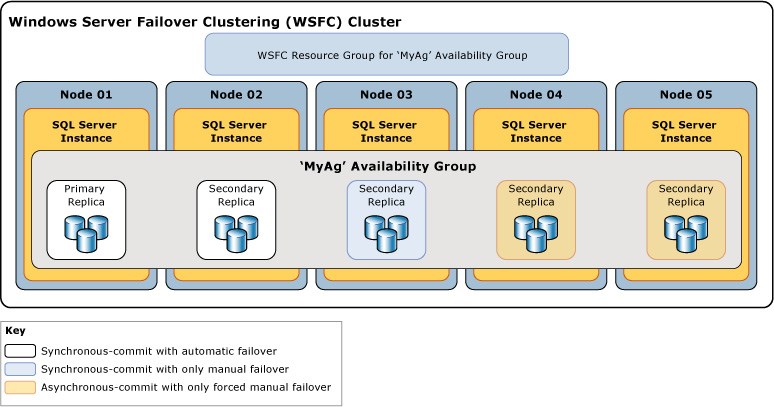
Figure 3.5: Always On availability group architecture
Synchronous replication is typically used when the servers are in the same physical location. In Azure, this would mean that if your VMs are in the same Azure region, synchronous replication would be your choice. The introduction of Availability Zones does add some complexity to this design, as the network latency between zones, while typically low, can differ in different Azure regions. There is no hard-and-fast rule for when to choose synchronous over asynchronous replication, but you should typically consider 10 milliseconds of latency to be the absolute upper limit for synchronous replication. Depending on the nature of your application and its sensitivity to latency (for example, a stock trading application would be extremely latency sensitive, whereas a business intelligence reporting system could tolerate some levels of latency), you may require much lower latency than that.
The other component of synchronous replication is that it is required for automatic failover. SQL Server will not allow you to lose data without accepting the potential data loss, and any asynchronous replication solution will allow you to lose transactions that have committed to the primary database but have yet to reach the transaction log on the secondary database.
While availability groups have typically been deployed in conjunction with Windows Server failover clusters, if you are running SQL Server on Linux it uses Pacemaker as its clustering component. You can learn more about configuring SQL Server with Pacemaker here1. Finally, you can build an availability group with no clustering software; however, this architecture is typically used as a read-scale option, as it does not provide the same levels of automated failover that a clustering solution would.
Differences with availability groups in Azure
In general, configuring SQL Server VMs in Azure is very similar to on-premises VMs or even physical servers. There are a couple of differences, which will both be covered in this chapter—storage and networking. Availability groups use a listener, which is an alias, and an IP address to direct connections into the availability group. The listener will route traffic to the primary replica of the group and, optionally, route read-only traffic to replicas. The listener relies on gratuitous Address Resolution Protocols (ARPs), which can broadcast MAC addresses to IP addresses, which reassigns the IP in the event of failover. Since Azure virtual networks do not support gratuitous ARPs (they do not allow broadcasting for security purposes), you need another mechanism to assign a "floating" IP address.
Note
Azure provides a number of ways to deploy VMs. You have the option to use PowerShell, the Azure portal, the Azure command-line interface (CLI), or ARM templates. You can quickly get started with an availability group by using the quickstart templates2.
In Azure, this floating IP addressed is managed by the internal load balancer (ILB), which acts as a front end for your availability group listener (and can also act as a front end for your clustering software). A load balancer has a relationship with your virtual network, and then a back-end pool of targets, which in an availability group scenario are your SQL Server instances. There are some differences in ILBs, depending on whether you are using availability sets or Availability Zones as your protection mechanism. If you are using sets, you can use a Basic load balancer, while Availability Zones require a Standard load balancer. You can find the steps to create a load balancer at this Microsoft documentation3. For SQL Server on Linux, you will not need to run the PowerShell steps to register the listener into the cluster, but you will need to associate the Pacemaker cluster with the IP address of the listener.
The additional complication for availability groups is the disaster recovery architecture that spans Azure Virtual Networks. This configuration is referred to as a multi-subnet availability group, and it is a fairly common on-premises configuration. In Azure, you simply have to create an ILB for each virtual network where you have availability group replicas. There are also some recommended DNS changes for this type of configuration. You can read more about how to configure for multiple subnets here4.
Availability groups for read-scale workloads
One of the key capabilities of Always On availability groups, in addition to offering a high availability/disaster recovery solution for SQL Server, is the provisioning of readable secondary copies of the database. This can be used in conjunction with read-only routing and the load balancing functionality in SQL Server to spread traffic over multiple readable secondary replicas. You can use this functionality to place copies of the database closer to your end users, or to offload the reporting of the primary replica and add secondary copies locally.
SQL Server on Azure VM resource provider
When you deploy an SQL Server VM from Azure Marketplace, as seen in Figure 3.6, part of the installation process is the IaaS Agent Extension.

Figure 3.6: SQL Server VM creation from Azure Marketplace
Extensions are code that is executed on your VM after deployment, typically to perform post-deployment configurations, such as installing anti-virus or installing a Windows feature. The SQL Server IaaS Agent Extension provides four key features that can reduce your administrative overhead:
- SQL Server Automated Backup: This service automates the scheduling of your backups on the VM. The backups are stored in Azure Blob storage.
- SQL Server Automated Patching: This VM setting allows you to configure a patching window in which Windows updates to your VM can take place. Only SQL Server updates that are pushed down through the Windows Update process will be applied. At the time of writing, that is limited to SQL Server GDR updates, which means in order to keep your SQL Server VM fully patched, the DBA needs to install cumulative updates to SQL Server.
- Azure Key Vault Integration: This integration enables you to use Azure Key Vault as a secure storage location for SQL Server certificates, backup encryption keys, and any other secrets, such as service account passwords.
- License Mobility: You can change your license type and edition of SQL Server and switch from pay-as-you-go to pay per usage, Azure Hybrid Benefit (AHUB) to use your own license, or disaster recovery to activate the free disaster recovery replica license.
In addition to these features, the extension allows you to view information about your SQL Server's configuration and storage utilization, as shown in Figure 3.7:

Figure 3.7: SQL VM configuration in the Azure portal
Performance optimized storage configuration
VMs registered with SQL VM resource provider can automate storage configuration according to performance best practices for SQL Server on Azure VMs through the Azure portal or Azure Quickstart Templates when creating an SQL VM. Best practices are detailed below:
- Separating data and log files to different volumes makes a difference on Azure because data and log files have different caching requirements. This feature can be automated when storage is configured through the Azure portal or Azure Quickstart Templates. Hosting data and log files on the same drive is supported only for general-purpose workloads; separate drives are the default configuration for OLTP and DW workloads.
- The performance of TempDB is critical for SQL Server workloads because SQL Server uses TempDB to store intermediate results as part of query execution. The local storage (D: drive) available to Azure VMs has very low response times and is included in the cost of the VM. Hosting TempDB on local storage has significant price/performance advantages if the size and the storage scale limits of the VM are sufficient for the workload. Measure the I/O bandwidth needed to meet the demands of workloads and test to find the required storage capacity for the TempDB. If the local storage capacity on the VM is not enough for the workload's TempDB requirements, consider hosting TempDB on Premium SSD or ultra disks to get very low response times. Performance-optimized storage configuration automates hosting TempDB on the local storage of the VM. SQL VM resource provider automates the re-configuration required after a restart, allaying concerns about failovers and VM restarts. Hosting TempDB on the local disk is the default configuration for OLTP and DW workloads and is supported for general-purpose workloads.
- Azure ultra disks deliver high throughput, high I/O Operations Per Second (IOPS), and consistent low-latency disk storage for Azure VMs. When storage latencies bottleneck, use ultra disks to increase the throughput. Premium disks have great price/performance advantages with read-only caching and a low-end monthly storage cost. If workloads require storage response times at the microsecond level, use ultra disks as they provide consistent sub-millisecond read and write latencies at all IOPS levels (up to 160,000 IOPS). Leverage ultra disks to optimize storage performance for log files or TempDB files (if the local disk on the VM does not have enough capacity). For read-heavy TPC-E type workloads with limited data modifications, increase throughput by hosting data files on ultra disks. Performance-optimized storage configuration supports using ultra disks to host data, log, and TempDB files through the Azure portal. Azure Quickstart Templates can also deploy an SQL VM with a log file on an ultra disk.
- SQL Server images on Azure Marketplace come with a full and a default installation of SQL Server. SQL Server Database Engine-only images work for SQL Server 2016 SP1, SQL Server 2016 SP2, and SQL Server 2017 Enterprise and Standard editions. Those images can be used to create an SQL VM through the Azure portal, PowerShell, or ARM template deployments. Use the free manageability to simplify SQL Server administration and the performance-optimized storage configuration to boost SQL Server performance on Azure VMs by creating a new SQL VM through the Azure portal or by registering with SQL VM resource provider today.
SQL Server performance in Azure VMs
Many customers are concerned about how their critical workloads will perform after migrating to the public cloud. Given the multitude of VM types available within Azure, there is an extremely wide range of performance options. You can build a VM that's as small as 1 CPU and 0.75 GB of RAM all the way to 416 vCPUs and 12 TB of memory. Beyond that, each VM has a specific limit on storage and network bandwidth and the number of IOPS that the VM can perform. It is important when you are planning a migration to monitor your on-premises workloads so that you can make your Azure footprint the right size. This is particularly important for a relational database management system (RDBMS) such as SQL Server, which is I/O and memory intensive and does not offer easy horizontal scale options such as a web or application tier. Typically, if you have to increase the performance of SQL Server, you have two choices: purchase more hardware or optimize your queries.
One complication of the public cloud is the number of CPU cores aligned with the amount of RAM in a given VM. SQL Server is an application that is heavily dependent on RAM for its performance—throughout the database engine, memory is used to prevent calls to disks that are orders of magnitude more expensive. While having additional vCPU cores will not harm performance in an Azure environment, because SQL Server is licensed by the core, it can create a great deal of additional expense. Microsoft has identified this as an issue and offers a number of constrained core VMs for database workloads. You can identify a constrained core VM by its nomenclature—for example, in Standard_M64-16ms, M identifies the VM class, 64 identifies that this VM would typically have 64 vCPUs, and the -16 indicates that the VM is constrained to 16 cores. The full list of constrained core VMs is available here5. The compute costs for these VMs are the same as if they were unconstrained, but you are not responsible for licensing SQL Server for those non-allocated cores.
Azure Storage
While compute sizing is relatively straightforward, building Azure Storage for performance is slightly more complex. Azure VMs should use managed disks for availability and ease of configuration. Azure offers four types of managed disks to meet your performance and budgetary requirements:
- Standard storage
- Standard SSD
- Premium storage
- Ultra disks
Standard storage will not meet the performance requirements of SQL Server data and log files—it is useful for backing up SQL Server databases, along with any typical file storage that does not require low-latency access. Likewise, standard SSD provides similar but more consistent performance than standard storage, and should not be used for workloads as I/O intensive as SQL Server.
This leaves you with premium storage and ultra disks as your options for database storage. Premium storage typically provides single-digit latency and is particularly effective for read workloads, as it can take advantage of read-caching to provide even better performance.
Note
Azure VMs have a local SSD that is mounted on /dev/sdb on Linux, and the D: drive on Windows. This disk is ephemeral, and data on it may be lost during maintenance activities or when you redeploy a VM. It may be used for TempDB in conjunction with SQL Server, but you should note latency because if you are using read-caching for your disks, the read cache will exist on that temporary drive and may cause contention with your TempDB performance.
Premium storage requires more configuration to approach the performance of ultra disks. A common example is where a database has 2 TB of data but requires 30,000 IOPS. To meet the data volume requirement on premium storage, you could simply allocate one P40 disk, which has 2 TB but only offers 7,500 IOPs. To meet the performance requirement, you should consider allocating six P30 disks, which would have a total of 6 TB of storage but meet the IOPS requirement. In order to achieve this amount of IOPS with premium storage, you would stripe your data volumes across the six disks, giving you a volume of 6 TB and meeting the 30,000 IOPS requirement. You can read more about how to configure this on a Linux VM6 and for a Windows VM7 at the respective Microsoft documentation links. You should note that there is no requirement to mirror the disks in an Azure configuration because Azure provides redundancy at the infrastructure level in order to provide data protection. You should also note that each VM type has a specific amount of IOPS and storage bandwidth available to it, and throttling will kick in as the amount of IOPS approaches that threshold. This applies to all storage types, including ultra disks.
Ultra disks simplify this configuration but are more expensive than premium storage. Rather than simply paying for each disk based on volume and IOPS, the ultra disk option charges for each component individually. You choose the volume of the disk, the amount of IOPS, and the amount of bandwidth for the disk, and the cost is the total of each of those components. This simplifies the configuration, as you can create a single disk that meets your capacity and performance requirements. Ultra disks do not provide caching but can provide performance in the sub-millisecond range for some workloads and have the most consistent performance under heavy load of any of the storage options in Azure. The ultra disk option is built using NVMe storage and remote direct memory access (RDMA) to deliver this level of performance.
Disk layout for SQL Server on Azure
When designing a storage architecture for SQL Server, you should first think about the ways SQL Server performs I/O. For example, when you write an insert or update statement, the following activities happen:
- The data page where the write takes place is updated in memory.
- The insert or update is directly written to the transaction log.
- The transaction is marked as complete.
- Eventually, the data page in memory is flushed to disk, either via the SQL Server lazy writer process or via a checkpoint.
As you can see in this example, the most important factor in completing the transaction is how quickly the write to the transaction log takes place. Another scenario is a query that needs a great deal of memory to execute a join operation. SQL Server's behavior is that if the amount of memory it needs is not available, it will spill into TempDB, effectively treating TempDB like a page file. So, just like the transaction log, it is important for TempDB's data files to have extremely low latency to meet performance requirements.
To translate this to Azure Storage, to maximize performance and minimize costs, you might consider provisioning an ultra disk to host your transaction log and TempDB files, and premium storage with read-caching to store your data files. If your latency requirements are lower, you might consider creating two volumes—a premium storage volume with read-caching enabled, and another premium storage volume without caching for transaction logs and TempDB.
Backups
Backups are critical in terms of data availability and, as mentioned earlier, SQL Server supports directly backing up databases into Azure Blob storage. The basics and troubleshooting guide for this process are in this document8, but we should highlight a couple of basics. When backing up to Azure (or in nearly all on-premises scenarios), you should use the WITH COMPRESSION option because it reduces the size of your backups and shortens both the backup and restore time. If the size of your backups exceeds 1 TB, you will need to stripe your backup across multiple files and adjust the MAXTRANSFERSIZE and BLOCKSIZE options, as shown in the following example:
BACKUP DATABASE TestDb
TO URL = 'https://mystorage.blob.core.windows.net/mycontainer/TestDbBackupSetNumber2_0.bak',
URL = 'https://mystorage.blob.core.windows.net/mycontainer/TestDbBackupSetNumber2_1.bak',
URL = 'https://mystorage.blob.core.windows.net/mycontainer/TestDbBackupSetNumber2_2.bak'
WITH COMPRESSION, MAXTRANSFERSIZE = 4194304, BLOCKSIZE = 65536;
In addition to backup to URL, SQL Server supports using Azure Backup, which can automatically manage your database backups across all of your Azure VMs. Azure Backup installs an extension called AzureBackupWindowsWorkload, which manages the backup using a coordinator and an SQL plugin, which is responsible for the actual backup.
Gathering performance information
SQL Server is extremely well-instrumented software and offers you a number of ways to gather performance data. It uses extensive dynamic management views and system catalog views that let you retrospectively gather data on the performance of the database engine. The extended events engine in SQL Server allows you to trace code execution and isolate specific activities. The Query Store, which was introduced in SQL Server 2016 and has been continually improved since, allows you to capture runtime and execution plan information about individual queries to isolate any change in performance caused by volume changes or parameter changes.
Dynamic management views are covered in detail in Chapter 5, Performance.
Query Store
The Query Store feature has a number of benefits in that it acts as a flight data recorder for SQL Server. It does have to be enabled, and this action can be performed either through T-SQL or using SQL Server Management Studio (SSMS) to change the Operation Mode to Read write, as illustrated in Figure 3.8:

Figure 3.8: Query Store configuration
The Query Store is configured in each user database; busy databases or databases that have a lot of dynamic SQL (and therefore unique query strings) can require more storage. Query Store data exists in the primary filegroup for the individual data so that it is persisted across server restarts and availability group failovers.
There are also a number of reports built into SSMS that allow you to look at various perspectives of query performance in the portal. Figure 3.9 shows a view that highlights the overall resource utilization of a given query and its execution plan:

Figure 3.9: Query Store top resource consumers query view
In addition to being able to quickly identify poorly performing queries, or queries that have regressed in performance (a feature that can really help you mitigate any risks with an SQL Server upgrade), the Query Store allows you to force a given execution plan for a specific query. This can be useful when you have data skew and some parameter values for a query produce a poorly performing execution plan. This functionality is also built into the automated tuning feature that was introduced in SQL Server 2017; if a query's performance regresses, the database engine will revert to the last known good execution plan in an attempt to resolve the performance issue.
Azure portal
The Azure portal also provides a number of metrics to set a baseline for your VM workloads. By default, you will see the CPU average, the network bandwidth, the total disk bytes, and the disk operations per second (read and write) in the Overview blade for your VM. Data is available for the last 30 days, which is enough to set a solid baseline of your server's performance over time. This can help you easily find VMs that are over- or under-provisioned and help you track resources consumed.
In addition to this dashboard, you can allow metrics reporting to go beyond the performance counters in the Overview pane, as shown in Figure 3.10. This monitoring infrastructure can also connect to VM metrics, which provides alerting.

Figure 3.10: Azure VM metrics for an SQL Server VM
For example, if you wanted to report when a VM was using over 80% CPU over a period of 5 minutes, you would create a metric rule and then create an action group to be notified. You have a number of options as to what to do with the alert—you can do the standard SMS/email/push notification, or you can connect to a webhook that launches an action. You can also launch an Azure Automation runbook to carry out a remedial action within Azure. An example of where you might do this for SQL Server is to kick off an index report after a period of high CPU utilization.
Additionally, you collect and aggregate log and performance information from your Azure VMs using the Azure Diagnostics extension, which can connect to your Windows and application logs, and aggregate the logs into a number of destinations including Azure Monitor, Event Hubs, Azure Blob storage, and Application Insights. You can learn more about this functionality here9.
Activity Monitor
The Query Store is one performance metric gathering option, but SSMS also has Activity Monitor, which provides an overview of all the activity on the server at any given time. It includes an overview of the processes running on the server, performance metrics, resource waits, and data file I/O. You can also customize columns to display more detailed information to meet your requirements. Below, in Figure 3.11, you can see Activity Monitor in operation:

Figure 3.11 Activity Monitor in SSMS
Extended Events
SQL Server contains Extended Events, which is a lightweight performance monitoring system that can collect as much or as little information as needed to isolate a performance problem. Extended Events is structured into sessions, which are an event or group of events that have a target. The targets available for Extended Events sessions are:
- Event counter.
- Event file.
- Event pairing.
- Event Tracing for Windows.
- Histogram.
- Ring buffer.
- Azure Blob storage (Azure SQL Database only).
The other benefit of Extended Events is that you can use a predicate to limit the amount of data captured by the engine. SQL Server uses Extended Events sessions to monitor the health of Always On availability groups and general system health. You can also trace queries using Extended Events, including capturing actual execution plans. While this functionality can be helpful for gathering information, it should be carefully considered as there is a large amount of performance overhead associated with capturing actual execution plans.
Management Studio includes two Extended Events sessions under a header called xEvent Profiler, which is designed to emulate the functionality in SQL Server's Profiler tool. The xEvent Profiler tool provides a live view of queries streaming into the database server. This functionality is less intrusive and runs with less overhead than the older Profiler tool.

Figure 3.12: Azure xEvent Profiler in SSMS
Extended Events is a very deep topic and covers almost all of the functionality in the database engine. You can learn more about all of the events that are available here10.
Identifying disk performance issues with SQL Server
As mentioned earlier in the chapter, disk performance is critical to database systems, and this can be exaggerated in an Azure environment where latencies may be slightly higher (for deployments other than ultra disk deployments) than in a high-performance on-premises environment. There are a couple of different ways to measure I/O performance on an SQL Server. The first and most common way is to query the sys.dm_io_virtual_file_stats dynamic management view. You can also query sys.dm_os_wait_stats to identify what the server is waiting for. High percentages of pageiolatch_xx waits can be indicative of storage issues. You can also validate the data reported by SQL Server by capturing data from the Linux iostat command to report on the performance of the devices. On Windows Server deployments of SQL Server, you can use the built-in performance monitor (perfmon) capabilities to capture performance data. This post11 on Microsoft Docs offers more detail on how to identify and troubleshoot a performance issue.
Key performance features in SQL Server
In addition to the monitoring and metric capabilities that both SQL Server and Azure provide, SQL Server provides many features that make use of in-memory technology set to deliver world-class performance:
- In-Memory OLTP tables: An in-memory latchless data structure that delivers extremely fast insert performance.
- Hybrid Transactional/Analytical Processing (HTAP): This technique combines filtered non-clustered columnstore indexes with in-memory OLTP tables to deliver fast transaction processing and to concurrently run analytics queries on the same data.
- TempDB: The memory-optimized TempDB metadata feature effectively removes some contention bottlenecks and unlocks a new level of scalability for TempDB-heavy workloads.
These features are typically implemented in conjunction with new application development. You can learn more about these features here12.
Security concepts
Azure offers a number of built-in and optional security features that help you build a more secure environment. There are a number of options, including network security groups, disk encryption, and key management, that help you ensure your security. Azure is the most compliant database for your SQL installations. You can read more about this here13.
Let's examine the specific security features Azure provides:
- Azure Security Center (ASC) is your centralized security management system in Azure that provides advanced threat protection for your hybrid workloads in the cloud. Using ASC, you can configure security policies for your VMs, detect threats to your VMs and SQL databases via real-time alerts, and mitigate them using ASC's recommendations.
- Advanced data security for SQL Server on Azure VMs is another Azure-specific security feature. It integrates with ASC and enables the detection and mitigation of potential database vulnerabilities and threats.
- Key management for encryption is enhanced in Azure using Azure Key Vault (AKV), which enables you to bring your own key and store it in AKV to manage the encryption and decryption of your databases.
- In addition to the above capabilities, SQL Server Azure VMs can use automated patching14 to schedule the installation of important Windows and SQL Server security updates automatically.
Connecting to Azure VMs
It is important to note that, by default, in the Azure portal, new VMs are created with a public IP address. This is something you should not do for any SQL Server with production data, but if you require a public IP address, you should limit the connections to only the IP addresses that should connect to the VM. When creating this VM, you also have the option to open ports such as 1433 to the internet.
Note
Opening an SQL Server to the public internet will result in a number of failed logins from botnets across the world and may impact the performance of the server. It is something that you should pretty much never do.
Fortunately, Azure provides a number of other ways to connect to your VMs. If you have a site-to-site VPN or Express Route connection from your on-premises network into your virtual network, you can connect to your VM just as if it was in your on-premises datacenter. Azure is just an extension of your datacenter and network once you have a VPN connection. Once you have a VPN connection in place, connecting to a VM in Azure is no different than connecting to a server in a different datacenter. Another option is using Azure Bastion, which is a service that allows a secure connection over port 443 from the Azure portal into your VM using a desktop emulator.
Network security groups
Azure Virtual Networks can be split into subnets. These subnets allow you to isolate your network traffic between various application tiers, as shown in Figure 3.13. Network security groups (NSGs) act as firewalls between these subnets. NSGs contain security rules that filter network traffic inbound to and outbound from a virtual network subnet by IP address, port, and protocol. These security rules are applied to resources deployed within the subnet.
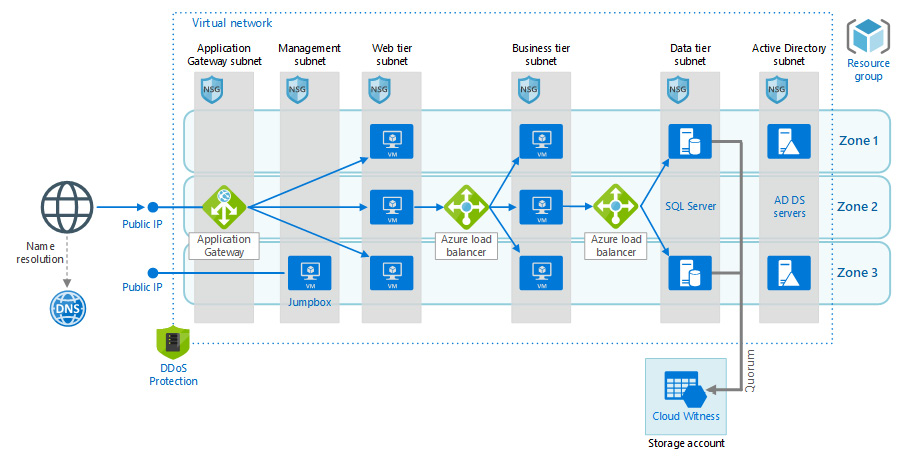
Figure 3.13: Complex Azure network architecture
As we can see in Figure 3.13, there is a single virtual network divided into six subnets. Without going into the full detail of the architecture, there is a public IP address that points to an application gateway, which allows traffic on port 443, and performs SSL termination. The web tier then points to a business subnet, where traffic is directed to a load balancer over the port used by the app server. Finally, the data tier allows traffic only from the business tier into port 1433, and the SQL Server instances have secure access into a storage account for backups and Cloud Witness. While an NSG can be applied on the virtual network, subnet, or even individual virtual NIC, they are most commonly deployed at the subnet level.
Note
Azure Firewall offers some more functionality than NSGs and may be required for some deployments. You can learn more about the differences between the services here15.
In the age of ransomware, proper network segmentation is critical to the security of your data. One of the major benefits of Azure is that you can easily segment your network without any cabling changes.
Azure Security Center
ASC is a service that helps prevent, detect, and respond to threats with increased visibility into and control over the security of resources and hybrid workloads in the cloud and on-premises. It provides integrated security monitoring and policy management across subscriptions, helps detect threats that might go unnoticed, and works with a broad ecosystem of security solutions.
Features include:
- Threat protection: ASC's threat protection includes fusion kill-chain analysis, which automatically correlates alerts based on cyber kill-chain analysis to better understand attack campaigns, providing details on where they started and the impact they had on resources. Other capabilities include the automatic classification of data in Azure SQL, assessments for potential vulnerabilities, and recommendations for how to mitigate them.
- Secure Score: Secure Score is a feature that reviews security recommendations provided by ASC and prioritizes them, targeting the most serious vulnerabilities for investigation first.
- Azure Policy: ASC allows enterprises to define their specific security requirements and configure workloads through Azure Policy. Recommendations will then be based on those policies and can be customized as needed.
- Azure Monitor: Azure Monitor maximizes the availability and performance of applications and services by delivering a comprehensive solution for collecting, analyzing, and acting on telemetry from cloud and on-premises environments. As a security tool, it helps control how data—including sensitive information such as IP addresses or user names—is accessed.
- Security Posture: ASC uses monitoring capabilities to analyze overall security and identify potential vulnerabilities. Information on network configuration is available instantly.
Authentication
SQL Server on both Windows and Linux offer both SQL Server and Windows Authentication (Active Directory). Active Directory authentication allows users to log in using a single sign-on without being prompted for a password. This authentication is provided by using Kerberos based on the connection with the Active Directory domain controllers. In Windows, this feature is provided by joining your server to your Active Directory domain. In Linux, the process is slightly more complicated.
To configure Windows Authentication on SQL Server on Linux, you need at least one domain controller; you have the option of using the realmd and sssd packages on your Linux VM in order to join the VM to your Windows domain. This is the preferred method, but you also have the option to use partner LDAP utilities. You can follow the instructions in this documentation16 to configure your VM for Active Directory authentication.
SQL Server authentication is configured by default on SQL Server on Linux installations. While SQL Server authentication is easier to configure, it has a few disadvantages compared to Windows authentication:
- There is no built-in syncing of logins across servers, and users have to remember additional passwords.
- SQL Server cannot support the Kerberos protocol.
- Windows authentication offers additional security and password policies that SQL Server authentication does not support.
- The encrypted password is passed over the network at the time of authentication, making it another point of vulnerability.
SQL authentication does allow for a wider variety of SQL clients and can be required by some older applications.
SQL Server security
Beyond authentication, SQL Server provides a robust set of permissions and privileges to manage security at each layer—server, database, object, and all the way down to columns. The database engine includes a set of built-in roles and allows logins and users to be defined at the server and database level. Alternatively, users can be scoped to a specific database using contained user functionality. This is typically used for applications that only connect to a single database. You can learn more about the security features of SQL Server here17.
Advanced data security for SQL Server on Azure VMs
Advanced data security for SQL Server on Azure VMs is a new security feature that includes Vulnerability Assessment and Advanced Threat Protection. This feature includes functionality for identifying and mitigating potential database vulnerabilities and detecting anomalous activities that could indicate threats to your database. Some of the tools included to perform these tasks are detailed below:
- Vulnerability Assessment18 is an easy-to-configure service that gives you visibility into your configuration, databases, and data. The tool runs a scan on your database using a knowledge base of best practices and looks for excessive permissions, unprotected sensitive data, and misconfigurations. The assessment products a report that tells you how to remediate the issues that the report finds.
- Advanced Threat Protection19 detects anomalous activities indicating unusual and potentially harmful attempts to access or exploit your SQL Server. It continuously monitors your database for suspicious activities and provides action-oriented security alerts on anomalous database access patterns. These alerts provide the details of any suspicious activity and recommended actions to investigate and mitigate threats.
- Integration with ASC provides benefits such as email notifications for security alerts, with direct links to alert details. You can also explore Vulnerability Assessment reports across all your databases, along with a summary of passing and failing databases, and a summary of failing checks according to risk distribution. Also, you can use ASC to explore and investigate security alerts and get detailed remediation steps and investigation information in each one.
Azure Active Directory
Azure Active Directory is not supported in SQL Server (it is supported for Azure SQL Database and Azure SQL Database managed instances). However, it can play a key role in some VM automation scenarios. You can create a managed service identity for your VM—this is somewhat similar to the concept of a service account in Windows.
The following figure illustrates the Azure managed identity configuration process:

Figure 3.14: Azure managed identity configuration
You can use this identity with a number of Azure services, including Azure Storage and Key Vault, with the identity of the VM. This can allow you to securely execute scripts within your VM using the identity of the VM to authenticate itself.
Azure Key Vault
AKV is a security service that helps with management tasks, key access, and certificate management—all of which are protected by hardware security modules that meet FIPS 140-2 Level 2 requirements. For the sake of simplicity, AKV can be considered as Azure's password manager. Beyond simply being a password manager, AKV enables granular access of secrets by applications, services, and monitoring of its own use.
Where AKV integrates with SQL Server is that you have the option to store your Always Encrypted certificates in a key vault. Additionally, you can store any certificates (for example, transparent data encryption (TDE), backup certificates, or client connection certificates) that are used in your SQL Server environment in a key vault.
SQL Server provides a connector for AKV that allows AKV to serve as an Extensible Key Management solution for storing SQL Server certificates and keys. This provides a critical backup in case any of those certificates are lost, in addition to securing their storage. You can learn more about this process here20.
Transparent data encryption
SQL Server provides different types of encryption. The first and most basic is TDE, which provides encryption at rest for data files. This protects you from an attacker gaining access to the VM's data drive and taking either backups or data files. The following figure illustrates the TDE architecture:

Figure 3.15: TDE architecture
This meets the common requirement of encryption at rest, and also encrypts backups by default. This feature was an Enterprise Edition feature until SQL Server 2019, when it became available in all editions of SQL Server. You can configure TDE at the individual database level, but you should note that when TDE is enabled for a user database, it is enabled on the TempDB system database as well. It is important to ensure the certificates you used when configuring TDE are backed up—without them, you will not be able to restore a database or attach a database.
In addition to these security features, VMs come with their own security, Azure Disk Encryption—a feature that helps protect and safeguard data and meet organization and compliance commitments. So, in the case of TDE customers, they get multiple encryption protections—Azure Disk Encryption and encryption through the SQL Database host.
Always Encrypted
While TDE is designed to meet the requirements of encryption at rest, administrators and users who have access to the database have full access to the unencrypted data, where it can be consumed and potentially exported in a tool such as Excel. Additionally, with any other encryption solution, such as SQL Server's cell-level encryption, database administrators have access to the encryption keys.
Always Encrypted changes this paradigm—the encryption key for the encrypted data is accessed in the client application and never in the database server. The administrators have no access to the encryption key, and therefore no access to the unencrypted values. Having a key management process, such as AKV, enables enhanced separation of duties to prevent this administrator access. In addition to AKV, options include Windows Certificate Store on a client machine, or a hardware security module.
Note
You should never generate the keys for your Always Encrypted columns on the server hosting your database, as anyone with access to the server could potentially gain access to keys in memory.
Always Encrypted is designed to protect sensitive data. It should be applied as an additional layer in tandem with TDE and TLS capabilities and should be used very selectively to protect data such as national ID or U.S. Social Security numbers, or other sensitive fields, and not broadly across all of your tables and columns. You can see more examples of how to use the feature here21.
Since the application client has access to the keys to the VM, if the application executes the following query, the query will be sent to the database server with the SSN value in encrypted ciphertext, where it will be executed against the ciphertext in the Patients table:
SELECT FirstName, LastName FROM Patients WHERE SSN='111-22-3333'
This is shown in Figure 3.13:
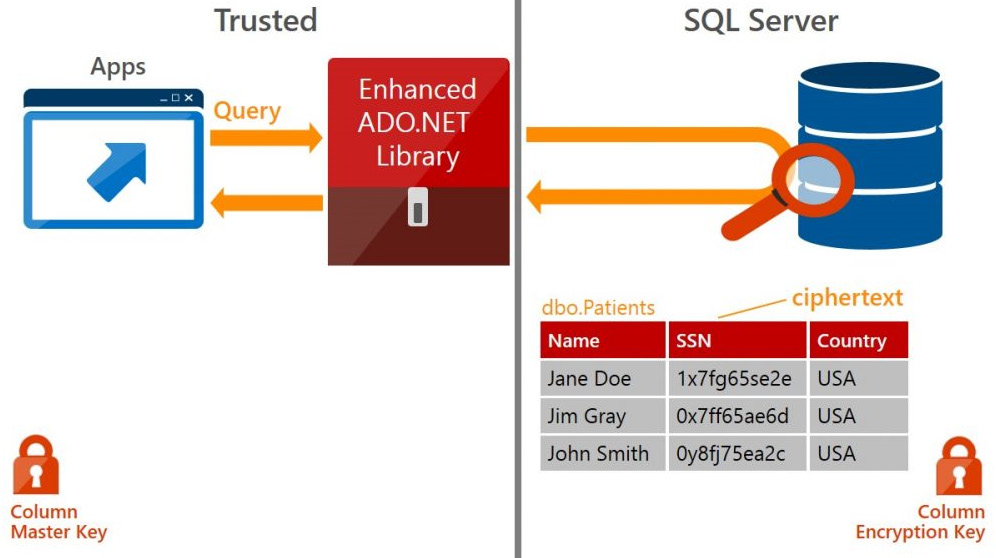
Figure 3.16: Always Encrypted architecture
The Always Encrypted architecture shows that a column master key is created for the application, and a column encryption key is stored in the database. Always Encrypted offers two kinds of encryption, deterministic and randomized. Deterministic encryption means the same value will have the same ciphertext every time—this allows GROUP BY, equality joins, and indexing, among other benefits. While this may be acceptable for many scenarios, columns that have a small set of possible values can be identified by guessing. Randomized encryption should be used where data is not grouped with other data and not where it is used to join tables.
SQL Server 2019 adds even more functionality to the Always Encrypted feature set by adding secure enclaves functionality, which allows the database engine to operate on encrypted data. In earlier versions of Always Encrypted, SQL Server could not perform computations or pattern matching on the data. An enclave is a protected memory region within the SQL Server process that can access encrypted data. The keys are never shown in the engine plaintext during query processing. You can learn more about secure enclaves here22.
Dynamic data masking
While Always Encrypted protects data via encryption, and data is never stored in an unencrypted fashion, dynamic data masking does not touch the underlying data in the database. Dynamic data masking is implemented in the presentation layer, which means it is very easy to implement in an existing application with minimal or no changes to the application code. One interesting use case of dynamic data masking is to randomize the data in sensitive columns, and then export the randomized data to non-production environments (the feature should be considered complementary to other security features, such as Always Encrypted, row-level security, and auditing. Also, note that administrators always have access to the unmasked data). However, it can be a very good feature to limit the amount of data users can see in an application. For example, call center representatives may need to identify customers by the last four digits of an account number.
Dynamic data masking is implemented at the presentation layer, which means it is very easy to implement in an existing application with minimal or no changes to the application code. One interesting use case of dynamic data masking is to randomize the data in sensitive columns, and then export the randomized data to non-production environments.
Azure Disk Encryption
In addition to these security features, VMs come with their own security. In the case of TDE, customers get multiple layers of encryption: Azure Disk Encryption provides encryption at rest for the operating system and data disks associated with the VM, and SQL Server Database also encrypts the data and log files, as well as the backups inside of the operating system. Azure Disk Encryption uses BitLocker on Windows and DM-Crypt on Linux VMs.
You can learn more about Azure Disk Encryption here23.
Auditing
SQL Server provides two types of auditing—server and database auditing. Server audits capture instance-level events, such as backups and restores, database creation and removal, logins, and numerous other options. You can see the full list of server audit events here24. Database-level auditing allows you to track query execution by users and can be configured on specific objects in the schema.
Data Discovery and Classification
One of the recent additions to SQL Server is the Data Discovery and Classification feature. This was first introduced into SSMS using extended properties on database objects. Starting with SQL Server 2019, this functionality is built into the database engine. SQL Server will identify columns (based on names and pattern matching) that could potentially contain sensitive data, which provides an easy way to review and appropriately classify your data. You can then label the columns using tags, which provides visibility in reporting for both compliance and audit purposes. SQL Server 2019 stores this data in a catalog view called sys.sensitvity_classifcations.
Summary
One of the benefits of building an SQL Server VM on Azure is that you can quickly get started learning about the features of SQL Server while configuring a limited amount of infrastructure. Azure makes it possible to simulate complex network architecture with a few lines of code, which allows you to protect your data. SQL Server and Azure also offer a wide variety of performance features that allow you to understand the workloads on your system and troubleshoot problematic queries and workloads. In addition, SQL Server provides best-in-class security features to meet the most stringent encryption needs. In fact, newer security offerings such as Advanced Data Security are only available for SQL Server instances on Azure VMs and not on-premises as yet—an advantage over traditional SQL Server on-premises installation. In the next chapter, you will learn more details about running SQL Server on Linux VMs in Azure.
Chapter links
- https://bit.ly/2X0VExf
- https://bit.ly/2WXwu2G
- https://bit.ly/36rHusa
- https://bit.ly/3c2Z2vX
- https://bit.ly/3cZDIss
- https://bit.ly/2LYy8dW
- https://bit.ly/2WZoLkt
- https://bit.ly/2XsY2Mj
- https://bit.ly/3bZthDZ
- https://bit.ly/3grhUID
- https://bit.ly/3gnwUXA
- https://bit.ly/36tJ9gR
- https://bit.ly/3efwJf7
- https://bit.ly/3c30D4V
- https://bit.ly/3gkJiIc
- https://bit.ly/3griKVN
- https://bit.ly/3ddGxGJ
- https://bit.ly/2X2HdsO
- https://bit.ly/2B2Urxb
- https://bit.ly/3c0L8ub
- https://bit.ly/2XnXMhE
- https://bit.ly/3gnZp7B
- https://bit.ly/2AXajkx
- https://bit.ly/2TCbFYo