
"Sometimes the questions are complicated and the answers are simple." | ||
| --Dr. Seuss (Theodor Seuss Geisel) | ||
"The loftier the building, the deeper must the foundation be laid." | ||
| --Thomas à Kempis | ||
The foundation of any system is the data structure definition. In NAV, the building blocks of this foundation are the Tables and the individual data fields that the tables contain. Once the functional analysis and process definition has been completed, any new design work must begin with the data structure. For NAV, that means the tables and their contents.
A NAV table includes much more than just the data fields and keys. A NAV table definition also includes data validation rules, processing rules, business rules, and logic to ensure referential integrity. The rules are in the form of properties and C/AL code.
In this chapter, we will learn about the structure and creation of tables. Details about fields, the components of tables, will be covered in the following chapter. Our topics in this chapter include:
- An overview of tables, including Properties, Triggers, Keys, SumIndexFields, and Field Groups
- Enhancing our scenario application by creating and modifying tables
- Types of tables; that is, Fully Modifiable, Content Modifiable, and Read-Only tables
There is a distinction between the table (data definition and data container) and the data (the contents of a table). The table definition describes the identification information, data structure, validation rules, storage, and retrieval of the data which is stored in the table (container). The definition is defined by the design and can only be changed by a developer. The data is the variable content that originates from user activities. The place where we can see the data explicitly referenced independently of the table as a definition of structure is in the Permissions setup data. In the next image, the data is formally referred to as Table Data:
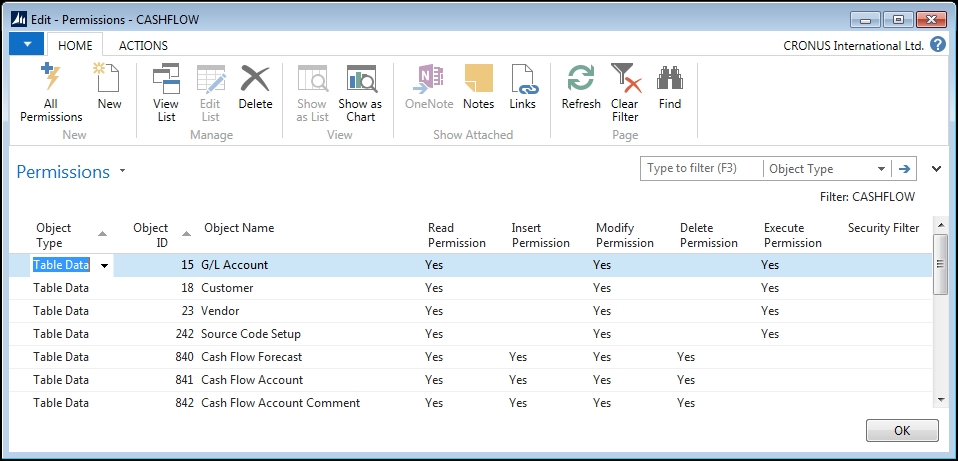
The table is not the data: it is the definition of data contained in the table (stored in the database as metadata). Even so, we commonly refer to both the data and the table as if they were one and the same. That is what we will do in this book.
All permanent data must be stored in a table. All tables are defined by the developer working in the development environment. As much as possible, critical system design components should be embedded in the tables. Each table should include the code that controls what happens when records are added, changed, or deleted, as well as how data is validated when records are added or changed. That includes functions to maintain the aspects of referential integrity that are not automatically handled.
The table object should also include the functions commonly used to manipulate the table and its data, whether for database maintenance or in support of business logic. In those cases where the business logic is either a modification applied to a standard (out-of-the-box) table or that same logic is also used elsewhere in the system, the code should be resident in a function library code unit and called from the table. Table structure as an architectural pattern is being developed and will be published in the Patterns wiki.
The table designer in C/SIDE provides tools for the definition of the data structure within the tables. We will explore these capabilities through examples and analysis of the structure of table objects. We find the approach of embedding control and business logic within the table object has a number of advantages:
A table is made up of Fields, Properties, Triggers (some of which may contain C/AL code), and Keys. Fields also have Properties and Triggers. Keys also have Properties.
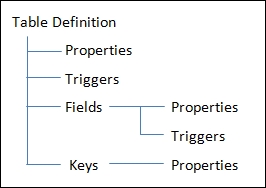
A table definition which takes full advantage of these capabilities reduces the effort required to construct other parts of the application. Good table design can significantly enhance the application's processing speed, efficiency, and flexibility.
A table can have:
- Up to 500 fields
- A defined record size of up to 8,000 bytes (with each field sized at its maximum)
- Up to 40 different keys
There are standardized naming conventions defined for NAV which we should follow. Names for tables and other objects should be as descriptive as possible, while keeping to a reasonable length. This makes our work more self-documenting.
Table names should always be singular. A table containing data about customers should not be named Customers, but Customer. The table we created for our WDTU Radio Station NAV enhancement was named Radio Show, even though it will contain data for all WDTU's radio shows.
In general, we should always name a table such that it is easy to identify the relationship between the table and the data it contains. For example, two tables containing the transactions on which a document page is based should normally be referred to as a Header table (for the main portion of the page) and a Line table (for the line detail portion of the page). As an example, the tables underlying a Sales Order page are the Sales Header and the Sales Line tables. The Sales Header table contains all the data that occurs only once for a Sales Order, while the Sales Line table contains all the lines for the order.
Note
Additional information on table naming can be found in the old, but still useful, Terminology Handbook for C/SIDE and C/AL Programming Guide, which can be found on the Microsoft MSDN site at http://social.msdn.microsoft.com/Search/en-US?query=Terminology%20Handbook%20for%20C%2FSIDE&ac=8 and http://social.msdn.microsoft.com/Search/enUS?query=C%2FAL%20Programming%20Guide%20&ac=8. These older documents may be obsolete in some areas. So of course, we should always refer first to the Developer and IT Pro Help included in NAV that is accessible from the Development Environment. The NAV 2015 Help is also on MSDN at http://msdn.microsoft.com/en-us/library/hh173988(v=nav.80).aspx. Much additional information can be found in the recently released C/AL Coding Guidelines at https://community.dynamics.com/nav/w/designpatterns/156.cal-coding-guidelines, including a How do I video.
There are no hard and fast rules for table numbering, except that we must only use the table object numbers that we are licensed to use. If all we have is the basic Table Designer rights, we are generally allowed to create tables numbered from 50000 to 50009 (unless our license was defined differently from the typical one). If we need more table objects, we can purchase licensing for table objects numbered up to 99999. Independent Software Vendors (ISVs) can purchase access to tables in other number ranges to use for their add-on products.
When creating several related tables, ideally, we should assign them related numbers in sequential order. We should let common sense be our guide to assigning table numbers. It requires considerable effort to renumber tables containing data.
The first step in studying the internal construction of a table is to open it in Design mode. This is done as follows:
- Open the Development Environment window.
- Click on the Table button in the left column of buttons.
- Highlight the table to work on (in this case, Table 18 Customer).
- Click on the Design button at the bottom-right of the screen.
We now have the Customer table open in the Table Designer in Design mode. In Chapter 1, An Introduction to NAV 2015, we reviewed the function of the icons across the top of the Table Designer, but they are labeled in the following screenshot as a memory aid:
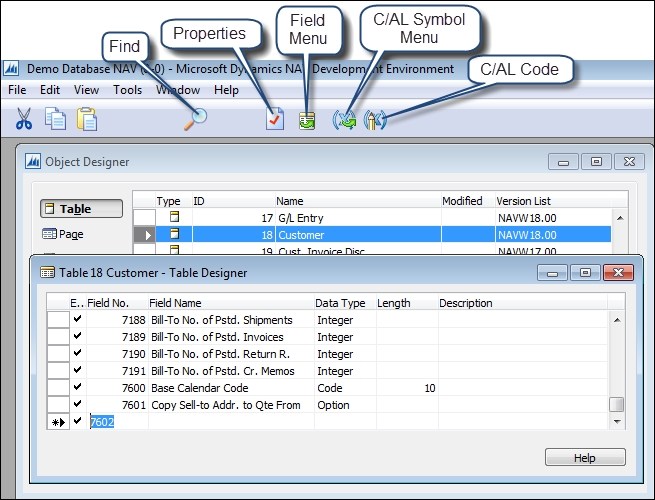
We can access the properties of a table while viewing the table in Design mode. Place the cursor on an empty field line (for example, the line below all the fields as shown in the preceding screenshot), and click on the Properties icon or press Shift + F4 or use View | Properties. If we access properties while focus is on a field line, we will see the properties of that field (not the table).
This will take us to the Table - Properties display. The following screenshot is the Table - Properties display for the Customer table in the demonstration Cronus database:

The table properties are as follows:
- ID: This is the object number of the table.
- Name: This is used for internal identification of the table object and acts as the default caption when data from this table is displayed.
- Caption: This contains the caption defined for the currently selected language. The default language for NAV is US English (ENU).
- CaptionML: This defines the MultiLanguage caption for the table. For an extended discussion on the language capabilities of NAV, refer to the section MultiLanguage Development in the online Developer and IT Pro Help.
- Description: This property is for optional documentation usage.
- DataPerCompany: This lets us define whether or not the data in this table is segregated by company (the default), or whether it is common (shared) across all companies in the database. The generated names of tables within SQL Server (not within NAV) are affected by this choice.
- Permissions: This allows us to grant users of this table different levels of access (r=read, i=insert, m=modify, and d=delete) to the table data in other table objects.
- LookupPageID: This allows us to define which Page is the default for looking up data in this table.
- DrillDownPageID: This allows us to define which Page is the default for drilling down into the supporting detail for the data that is summarized in this table.
- DataCaptionFields: This allows us to define specific fields whose contents will be displayed as part of the caption. For the Customer table, the No. and the Name will be displayed in the title bar at the top of a page showing a customer record.
- PasteIsValid: This property (Paste Is Valid) is not active in NAV 2015.
- LinkedObject: This lets us link the table to a SQL Server object. This feature allows the connection, for data access or maintenance, to a non-NAV system or an independent NAV system. For example, a LinkedObject could be an independently hosted and maintained special purpose database, and thus offload that processing from the main NAV system. When this property is set to Yes, then LinkedInTransactionProperty becomes available. LinkedInTransactionProperty should be set to No for any linkage to a SQL Server object outside the current database. The object being linked to must have a SQL Server table or view definition that is compatible with the Microsoft Dynamics NAV table definition.
As developers, we most frequently deal with the ID, Name, LookupPageID, DrillDownPageID, Caption, CaptionML (for languages other than American English), DataCaption, and Permissions properties. We rarely deal with the others.
To display the triggers with the table open in Table Designer, click on the C/AL Code icon or F9 or View | C/AL Code. The first (top) table trigger is the Documentation trigger. This trigger is somewhat misleadingly named as it only serves as a location for needed documentation. No C/AL code in a Documentation trigger is executed. There are no syntax or format rules here, but we should follow a standard format of some type.
Every change to an object should be briefly documented in the Documentation trigger. The use of a standard format for such entries makes it easier to create them as well as to understand them two years later. For example:
CD.02 – 2015-03-16 Change to track when new customer added - Added field 50012 "Start Date"
The Documentation trigger has the same appearance as the four other triggers in a table definition, shown in the following screenshot, each of which can contain the C/AL code:

The code contained in a trigger is executed prior to the event represented by the trigger. In other words, the code in the OnInsert() trigger is executed before the record is inserted into the table. This allows the developer a final opportunity to perform validations and to enforce data consistency such as referential integrity. We can even abort the intended action if data inconsistencies or conflicts are found.
These triggers are automatically invoked when record processing occurs as the result of User action. But when table data is changed by C/AL code or by a data import, the C/AL code or import process determines whether or not the code in the applicable trigger is executed, as follows:
- OnInsert(): This is executed when a new record is to be inserted in to the table through the User Interface. (In general, new records are added when the last field of the primary key is completed and focus leaves that field. See the
DelayedInsertproperty in Chapter 4, Pages - the Interactive Interface for an exception). - OnModify(): This is executed when a record is rewritten after the contents of any field other than a primary key field have been changed. The change is determined by comparing
xRec(the image of the record prior to being changed) toRec(the current record copy). During our development work, if we need to see what the "before" value of a record or field is, we can reference the contents ofxRecand compare that to the equivalent portion ofRec. These variables (RecandxRec) are System-Defined Variables. - OnDelete(): This is executed before a record is to be deleted from the table.
- OnRename(): This is executed when some portion of the primary key of the record is about to be changed. Changing any part of the primary key is a Rename action. This maintains a level of referential integrity. Unlike some systems, NAV allows the primary key of any master record to be changed, and automatically maintains all the affected foreign key references from other records.
There is an internal inconsistency in the handling of data integrity by NAV. On one hand, the OnRename() trigger automatically maintains one level of referential integrity when any part of the primary key is changed (that is, the record is "renamed"). This happens in a "black box" process, an internal process that we cannot see or touch.
However, if we delete a record, NAV doesn't automatically do anything to maintain referential integrity. For example, child records could be orphaned by a deletion, left without any parent record. Or if there are references in other records back to the deleted record, they could be left with no target. In this latest version of NAV, code has been added to the OnDelete() trigger of many (perhaps all) tables to handle this aspect of referential integrity. As developers, we are responsible for ensuring this part of referential integrity in our customizations.
When we write the C/AL code in one object that updates data in another (table) object, we can control whether or not the applicable table update trigger fires (executes). For example, if we were adding a record to our Radio Show table and used the following C/AL code, the OnInsert() trigger would fire:
"RadioShow".INSERT(TRUE);
However, if we use either of the following C/AL code options instead, the OnInsert() trigger would not fire and none of the logic inside the trigger would be executed:
"RadioShow".INSERT(FALSE);
or,
"RadioShow".INSERT;
It's always a good habit to write code explicitly so there is no doubt what the intended action is; in other words, use the explicit true or false.
The automatic "black box" logic enforcing primary key uniqueness will happen whether or not the OnInsert() trigger is fired.
Table keys are used to identify records, and to speed up filtering and sorting. Having too few keys may result in painfully slow inquiries and reports. However, each key incurs a processing cost because the index containing the key must be updated every time information in a key field changes. Key cost is measured primarily in terms of increased index maintenance processing. There is also additional cost in terms of disk storage space (usually not significant) and additional backup/recovery time (sometimes very important).
When a system is optimized for processing speed, it is critical to analyze the SQL Server indexes that are active because that is where the updating and retrieval time are determined. The determination of the proper number and design of keys and indexes for a table requires a thorough understanding of the types and frequencies of inquiries, reports, and other processing for that table.
Every NAV table must have at least one key—the primary key. The primary key is always the first key in the key list. By default, the primary key is made up of the first field defined in the table. In many of the Reference tables, there is only one field in the primary key and the only key is the primary key. An example is the Payment Terms table. Highlight Table 3 Payment Terms, then click on the Design button to see the Keys window, and click on View | Keys:

The primary key must have a unique value in each table record. We can change the primary key to be any field, or any combination of fields up to 16 fields totaling up to 900 bytes, but the uniqueness requirement must be met. It will automatically be enforced by NAV because NAV will not allow us to add a record in to a table with a duplicate primary key.
When we examine the primary keys in the supplied tables, we see that many of them consist only of or terminate in a Line No., an Entry No., or another data field whose contents make the key unique. For example, the G/L Entry table in the following screenshot uses just the Entry No. as the primary key. It is a NAV standard that the Entry No. fields contain a value that is unique for each record.

The primary key of the Sales Line table shown in the following screenshot is made up of several fields, with the Line No. of each record as the terminating primary key field. In NAV, the Line No. fields are assigned a unique number within the associated document. Line No. combined with the preceding fields in the primary key (usually including fields, such as Document Type and Document No, which relate to the parent Header record) makes each primary key entry unique. The logic supporting the assignment of the Line No. values is done within explicit C/AL code. It is not an automatic feature. The No. Series pattern documentation can be found at https://community.dynamics.com/nav/w/designpatterns/74.no-series.aspx.
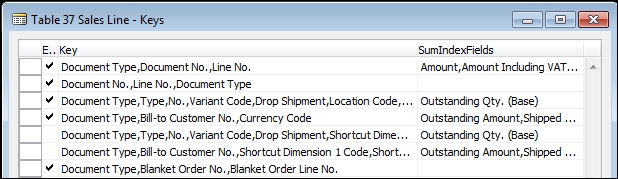
All keys except the primary key are secondary keys. There is no required uniqueness constraint on secondary keys. There is no requirement to have any secondary keys. If we want a secondary key not to have duplicate values, our C/AL code must check for duplication before completing the new entry.
The maximum number of fields that can be used in any one key is 16 with a maximum total length of 900 bytes. At the same time, the total number of different fields that can be used in all the keys combined cannot exceed 16. If the primary key includes three fields (as in the preceding screenshot), then the secondary keys can use up to 13 other fields (16 minus 3) in various combinations, plus any or all of the fields in the primary key. If the primary key has 16 fields, then the secondary keys can only consist of different groupings and sequences of those 16 fields. The first release of the NAV 2015 C/AL compiler allows up to 20 fields in a key, but the last 4 fields are ignored by SQL Server. Behind the scenes, each secondary key has the primary key appended to the backend. A maximum of 40 keys is allowed per table.
A number of SQL Server-specific key-related parameters have been added to NAV. These key properties can be accessed by highlighting a key in the Keys form, then clicking on the Properties icon or pressing Shift + F4. We can also display these properties in the Keys screen by accessing View | Show Column and selecting the columns we want displayed. The following screenshot shows both the Show Column choice form and the resulting Keys form with all the available columns displayed:
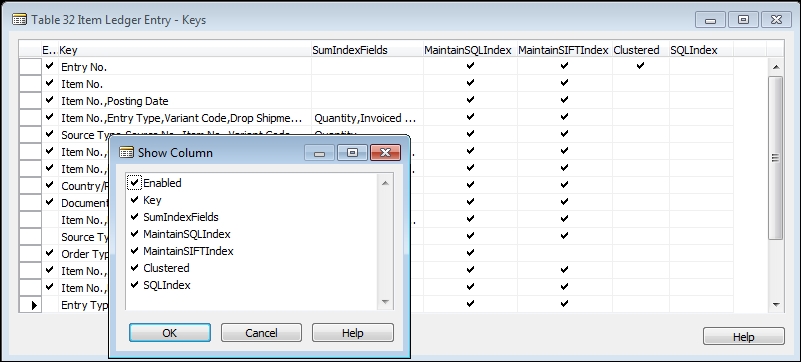
Since the beginning of NAV (formerly Navision), one of its unique capabilities has been the SumIndexField Technology (SIFT) feature These fields serve as the basis for FlowFields (automatically accumulating totals) and are unique to NAV. This feature allows NAV to provide almost instantaneous responses to user inquiries for summed data, calculated on the fly at runtime, related to the SumIndexFields. The cost is primarily that of the time required to maintain the SIFT indexes when a table is updated.
NAV 2015 maintains SIFT totals using SQL Server Indexed Views. An indexed view is a view that has been preprocessed and stored. NAV 2015 creates one indexed view for each enabled SIFT key. SIFT keys are enabled and disabled through the MaintainSIFTIndex property. SQL Server maintains the contents of the view when any changes are made to the base table, unless the MaintainSIFTIndex property is set to No.
SumIndexFields are accumulated sums of individual fields (columns) in tables. When the totals are automatically precalculated, they are easy to use and provide very high-speed access for inquiries. If users need to know the total of the Amount values in a Ledger table, the Amount field can be attached as a SumIndexField to the appropriate keys. In another table such as Customer, FlowFields can be defined as display fields take the advantage of the SumIndexFields property. This gives the users a very rapid response for calculating a total Balance amount inquiry based on detailed Ledger Amounts tied to those keys. We will discuss the various data field types and FlowFields in more detail in a later chapter.
In a typical ERP system, many thousands, millions, or even hundreds of millions of records might have to be processed to give such results, taking considerable time. In NAV, only a few records need to be accessed to provide the requested results. The processing is fast and the programming is greatly simplified.
SQL Server SIFT values are maintained through the use of SQL Indexed Views. By use of the Key property MaintainSIFTIndex, we can control whether or not the SIFT index is maintained dynamically (faster response) or only created when needed (less ongoing system performance load). The C/AL code is the same whether the SIFT is maintained dynamically or not. In NAV 2015, SIFT indexes can be built by SQL Server on-the-fly, but at the cost of having the full SIFT construction happen at one time rather than incrementally as records are added to the table. To define permanent SIFT indexes or not is a design choice that must be made carefully.
Too many Keys or SIFT fields can negatively affect system performance for two reasons. The first, which we already discussed, is the index maintenance processing load. The second is the table locking interference that can occur when multiple threads are requesting update access to a set of records that update SIFT values.
Conversely, the lack of necessary Keys or SIFT definitions can also cause performance problems. Having unnecessary data fields in a SIFT key creates many extra entries, affecting performance. Integer fields usually create an especially large number of unique SIFT index values and the Option fields create a relatively small number of index values.
The best design for a SIFT index has the fields which will be used most frequently in queries positioned on the left-hand side of the index in order of descending frequency of use. In a nutshell, we should be careful in our design of Keys and SIFT fields. While a system is in production, applicable SQL Server statistics should be monitored regularly and appropriate maintenance actions taken. NAV 2015 automatically maintains a count for all SIFT indexes, thus speeding up all COUNT and AVERAGE FlowField calculations.
The MaintainSQLIndex and MaintainSIFTIndex properties shown in the previous image allow the developer and/or system administrator to determine whether or not a particular key or SIFT field will be continuously maintained or will be recreated only when needed. Indexes that are not maintained, minimize record update time but require longer processing time to dynamically create the indexes when they are used. This level of control is useful for managing indexes that are only needed occasionally. For example, a Key or SIFT index that is used only for monthly reports can be disabled and no index maintenance processing be done on a day-to-day basis. If the month end need is for a single report, the particular index will be recreated automatically when the report is run. If the month end need is for a number of reports, the system administrator might enable the index, process the reports, then disable the index again.
When a user starts to enter data in a field where the choices are constrained to existing data (for example, an Item No., a Salesperson Code, a Unit of Measure code, a Customer No., and so on), good design dictates that the system will help the user by displaying the universe of acceptable choices. Put simply, a lookup list of choices should be displayed.
In the Role Tailored Client, the lookup display (a drop-down control) is generated dynamically when its display is requested by the user's effort to enter data in a field that references a table through the TableRelation property (which will be discussed in more detail in the next chapter). The format of the drop-down is a basic list. The fields that are included in that list and their left-to-right display sequence are either defined by default, or by an entry in the Field Groups table.
The Field Groups table is part of the NAV table definition much like the list of Keys. In fact, the Field Groups table is accessed very similarly to the Keys, via View | Field Groups.
If we look at Field
Groups for Table 27 - Item, we see the drop-down information defined in Field Group, which must be named DropDown (without a hyphen):
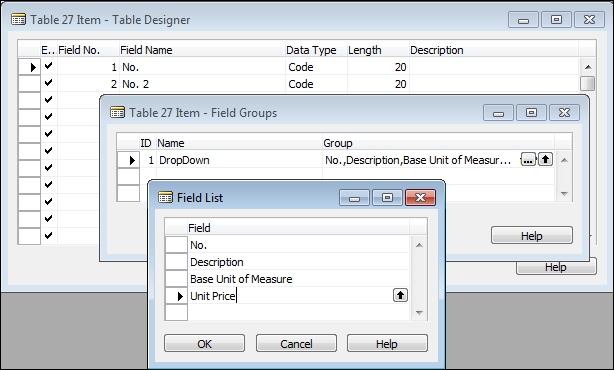
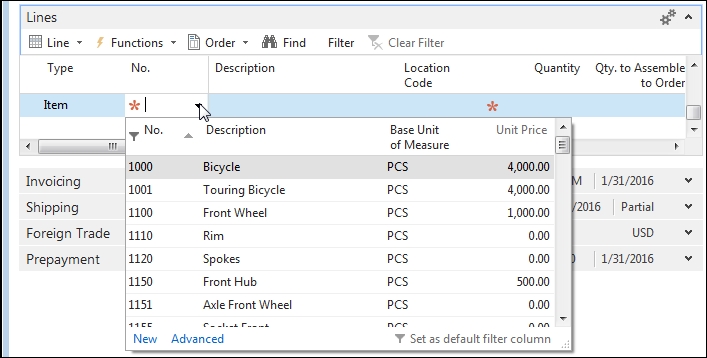
The drop-down display created by this particular Field Group is shown in the following screenshot of the Sales Order page, contains fields in the same order of appearance as in the Field Group definition.
If no Field Group is defined for a table, the system defaults to using the primary key plus the Description field (or Name field).
Since Field Groups can be modified, they provide another opportunity for tailoring the user interface. As we saw in the preceding screenshot, the standard structure for the fields in a Field Group is to have the primary key appear first. The user can choose any of the displayed fields to be the default filter column, the defacto lookup field.
As a system option, the drop-down control provides a find-as-you-type capability, where the set of displayed choices filters and redisplays dynamically as the user types, character by character. The filter applies to the default filter column. Whatever field is used for the lookup, the referential field defined in the page determines what data field contents are copied into the target table. In the preceding image example, the reference table/field is the Sales Line table/field "No." and the target table/field is the Item table/field "No.".
As developers, we can change the order of appearance of the fields in the drop-down display. We can also add or delete fields by changing the contents of the Field Group. For example, we could add a capability to our page that provides an "alternate search" capability (where if the match for an Item No. isn't found in the No. field, the system will look for a match based on another field). In NAV 2015, fields in a field group no longer must be in a key.
Consider this situation: the customer has a system design where the Item No. contains a hard to remember, sequentially assigned code to uniquely identify each item. But the Search Description field contains a product description that is relatively easy for the users to remember. When the user types, the find-as-you-type feature helps them to focus and find the specific Item No. to be entered for the order. In order to support this, we simply need to add the Search Description field to the Field Group for the Item table as the first field in the sequence. The following screenshot shows that change in the Item Field Group table:
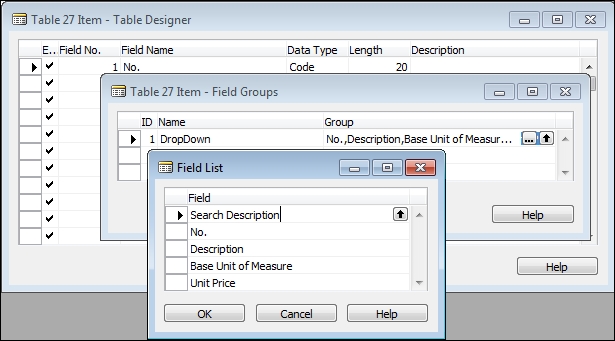
The effect of this change can be seen in the following screenshot which shows the revised drop-down control. The user has begun entry in the No. field, but the lookup has focused on the newly added
Search Description field. Find-as-you-type has filtered the displayed items down to just those that match the data string entered so far (user has entered st; Field Group has filtered to items with Search Description starting with st).

The result of our change allows the user to lookup the items by their Search Description, rather than by the harder to remember Item No. Obviously, any field in the Item table could have been used, including our custom fields.