
Chapter 5. Storing data—the persistence layer
This chapter covers
- Using Anorm
- Using Squeryl
- Caching data
The persistence layer is a crucial part of the architecture for most Play applications; unless you’re writing a trivial web application, you’ll need to store and retrieve data at some point. This chapter explains how to build a persistence layer for your application.
There are different kinds of database paradigms in active use, today. In this chapter we’ll focus on SQL databases. Figure 5.1 shows the persistence layer’s relationship to the rest of the framework.
Figure 5.1. An overview of Play’s persistence layer
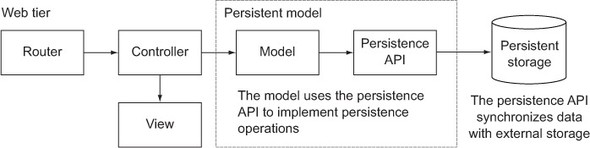
If we manage to create our own persistence layer without leaking any of the web application concepts into it, we’ll have a self-contained model that will be easier to maintain, and a standalone API that could potentially be used in another application that uses the same model.
In this chapter we’ll teach you how to use Anorm, which comes out of the box with Play and Squeryl.
5.1. Talking to a database
In order to talk to the database, you’ll have to create SQL at some point. A modern object-relation mapper (ORM) like Hibernate or the Java Persistence API (JPA) provides its own query language (HQL and JPQL, respectively), which is then translated into the target database’s SQL dialect.
5.1.1. What are Anorm and Squeryl?
Anorm and Squeryl are at opposite ends of the SQL-generation/translation spectrum. Squeryl generates SQL by providing a Scala domain-specific language (DSL) that’s similar to actual SQL. Anorm doesn’t generate any SQL, and instead relies on the developer to write SQL. In case you’re used to ORMs like Hibernate or JPA, we should probably repeat that Anorm doesn’t define a new query language but uses actual SQL.
Both approaches have their benefits and disadvantages. These are the most important benefits of each:
- Anorm allows you to write any SQL that you can come up with, even using proprietary extensions of the particular database that you’re using.
- Squeryl’s DSL allows the compiler to check that your queries are correct, which meshes well with Play’s emphasis on type safety.
5.1.2. Saving model objects in a database
Most web applications will store data at some point. Whether that data is a shopping basket, user profiles, or blog entries doesn’t matter much. What does matter is that your application should be able to receive—or generate—the data in question, store it in a persistent manner, and show it to the user when requested.
In the following sections, we’ll explain how to define your model—for both Anorm and Squeryl—and create an API to be used from your controllers.
We’ll be going back to our paperclip warehouse example to explain how to create a persistence layer, with both Anorm and Squeryl. We’ll explain how to create classes for our paperclips, stock levels, and warehouses; how to retrieve them from the database; and how to save the changes to them.
5.1.3. Configuring your database
Play comes with support for an H2 in-memory database out of the box, but there’s no database configured by default. In order to configure a database, you need to uncomment two lines in conf/application.conf or add them if you’ve been following along from the start and removed them earlier.
db.default.driver=org.h2.Driver db.default.url="jdbc:h2:mem:play"
An in-memory database is fine for development and testing but doesn’t cut it for most production environments. In order to configure another database, you need to get the right kind of JDBC library first. You can specify a dependency in project/Build.scala (assuming you used play new to create our Play project). Just add a line for PostgreSQL in the appDependenciesSeq. Since Play 2.1, JDBC and Anorm are modules and are no longer enabled by default. You have to uncomment jdbc if you want Play to handle your database connections for you. If you want to use Anorm, you can go ahead and uncomment anorm also.
val appDependencies = Seq( jdbc, anorm, "postgresql" % "postgresql" % "9.1-901.jdbc4" )
Now you can configure your database in application.conf.
db.default.user=user db.default.password=qwerty db.default.url="jdbc:postgresql://localhost:5432/paperclips" db.default.driver=org.postgresql.Driver
5.2. Creating the schema
Anorm can’t create your schema for you because it doesn’t know anything about your model. Squeryl can create your schema for you, but it’s unable to update it. This means you’ll have to write the SQL commands to create (and later update) your schema yourself.
Play does offer some help in the form of evolutions. To use evolutions, you write an SQL script for each revision of your database; Play will then automatically detect that a database needs to be upgraded and will do so after asking for your permission.
Evolutions scripts should be placed in the conf/evolutions/default directory and be named 1.sql for the first revision, 2.sql for the second, and so on. Apart from statements to upgrade a schema, the scripts should also contain statements to revert the changes and downgrade a schema to a previous version. This is used when you want to revert a release.
Listing 5.1 shows what our script looks like.
Listing 5.1. Schema creation

Next time you run your application, Play will ask if you want to have your script applied to the configured database.
Just click the red button labeled “Apply this script now!” (shown in figure 5.2) and you’re set.
Figure 5.2. Applying your script to the default database

5.3. Using Anorm
Anorm lets you write SQL queries and provides an API to parse result sets. What we’re talking about here is actual unaltered SQL code in strings. The idea behind this is that you should be able to use the full power of your chosen database’s SQL dialect. Because there are so many SQL dialects, and most (if not all) of them provide at least one unique feature, it’s impossible for ORMs to map all those features onto a higher-level language—such as HQL.
With Anorm, you can write your own queries and map them to your model or create any kind of collection of data retrieved from your database. When you retrieve data with Anorm, there are three ways to process the results: the Stream API, pattern matching, and parser combinators. We’ll show you how to use all three methods, but since they all eventually yield the same results, we suggest that you choose the method you like best.
First we have to show you how to create your model.
5.3.1. Defining your model
Anorm relies on you to build queries, so it doesn’t need to know anything about your model. Therefore, your model is simply a bunch of classes that represent the entities that you want to use in your application and store in the database, as shown in listing 5.2. These entities are the same as in chapter 2.
Listing 5.2. The model
case class Product( id: Long, ean: Long, name: String, description: String) case class Warehouse(id: Long, name: String) case class StockItem( id: Long, productId: Long, warehouseId: Long, quantity: Long)
That’s it; that’s our model. No Anorm-related annotations or imports are necessary for this step. Like we said, Anorm doesn’t know about your model. The only thing Anorm wants to know is how to map result sets to the collections of objects that you’re going to use in your application. There are several ways you can do that with Anorm.
Before we can do anything else with our database, we need to create our schema; section 5.2 taught us how to use evolutions to do this.
Now let’s take a look at the stream API.
5.3.2. Using Anorm’s stream API
Before we can get any results, we have to create a query. With Anorm, you call anorm.SQL with your query as a String parameter:
import anorm.SQL
import anorm.SqlQuery
val sql: SqlQuery = SQL("select * from products order by name asc")
We’re making the sql property part of the Product companion object. The entity’s companion object is a convenient place to keep any data access functionality related to the entity, turning the companion object into a DAO (Data Access Object).
Now that we have our query, we can call its apply method. The apply method has an implicit parameter block that takes a java.sql.Connection, which Play provides in the form of DB.withConnection. Because apply returns a Stream[SqlRow], we can use the map method to transform the results into entity objects. In listing 5.3 you can see our first DAO method.
Listing 5.3. Convert the query results to entities

The row variable in the function body passed to map is an SqlRow, which has an apply method that retrieves the requested field by name. The type parameter is there to make sure the results are cast to the right Scala type. Our getAll method uses a standard map operation (in Scala, anyway) to convert a collection of database results into instances of our Product class.
Let’s now see how to do this with pattern matching.
5.3.3. Pattern matching results
An alternative to the stream API is to use pattern matching to handle query results. The pattern-matching version of the previous method is similar. Take a look at listing 5.4.
Listing 5.4. Use a pattern to convert query results

Instead of calling map, we’re calling collect with a partial function. This partial function specifies that for each row that matches its pattern—a Row containing two Some instances with Long instances and two Some instances with String instances—we want to create a Product with the values from the Row. Anorm wraps each value that comes from a nullable column in a Some so that nulls can be represented with None.
We’ve said before that the query’s apply method returns a standard Scala Stream; we’ve used this Stream in both of the last two examples. Both map and collect are part of the standard Scala collections API, and Streams are simply lists that haven’t computed—or in this case retrieved—their contents yet. This is why we had to convert them to Lists with toList to actually retrieve the contents.
We’ve been writing pretty standard Scala code. Anorm has only had to provide us with a way to create a Stream[SqlRow] from a query string, as well as a class (SqlRow) and an extractor (Row) to do some fancy stuff. But that’s not all; Anorm provides parser combinators as well.
5.3.4. Parsing results
You can also parse results with parser combinators,[1] a functional programming technique for building parsers by combining other parsers, which can then be used in other parsers, and so on. Anorm supports this concept by providing field, row, and result set parsers. You can build your own parsers with the parsers that are provided.
Building a single-record parser
We’ll need to retrieve (and therefore parse) our entities many times, so it’s a good idea to build parsers for each of our entities. Let’s build a parser for a Product record, as shown in listing 5.5.
Listing 5.5. Parse a product

long and str are parsers that expect to find a field with the right type and name. These are combined with ~ to form a complete row. The part after map is where we specify what we want to turn this pattern into; we convert a sequence of four fields into a Product.
We’re not quite done: from our method’s return type, you can see we’ve made a RowParser, but Anorm needs a ResultSetParser. OK, let’s make one:
import anorm.ResultSetParser
val productsParser: ResultSetParser[List[Product]] = {
productParser *
}
Yes, it’s that simple; by combining our original parser with *, we’ve built a ResultSetParser. The * parses zero or more rows of whatever parser is in front of it.
In order to use our new parser, we can pass it to our query’s as method:
def getAllWithParser: List[Product] = DB.withConnection {
implicit connection =>
sql.as(productsParser)
}
By giving Anorm the right kind of parser, we can produce a list of Products from our query.
So far we’ve been converting result sets into instances of our model class, but you can use any of the techniques described here to generate anything you like. For example, you could write a query that returns a tuple of each product’s name and EAN code, or a query that returns each product along with all of its stock items. Let’s do that with parser combinators.
Building a multirecord parser
You may recall from our example model that each product in our catalog is associated with zero or more stock items, which each record the quantity that’s available in a particular warehouse. To fetch stock item data, we’ll use SQL to query the products and stock_items database tables.
Because we’re going to be parsing a product’s StockItems, we’ll need another parser. We’ll put this parser in StockItem’s companion object:
val stockItemParser: RowParser[StockItem] = {
import anorm.SqlParser._
import anorm.~
long("id") ~ long("product_id") ~
long("warehouse_id") ~ long("quantity") map {
case id ~ productId ~ warehouseId ~ quantity =>
StockItem(id, productId, warehouseId, quantity)
}
}
We’re not doing anything new here: it looks just like our Product parser.
In order to get our products and stock items results, we’ll have to write a join query, which will give us rows of stock items with their corresponding products, thereby repeating the products. This isn’t exactly what we want, but we can deal with that later. For now, let’s build a parser that can parse the combination of a product and stock item:
def productStockItemParser: RowParser[(Product, StockItem)] = {
import anorm.SqlParser._
import anorm.~
productParser ~ StockItem.stockItemParser map (flatten)
}
As before, we’re combining parsers to make new parsers—they don’t call them parser combinators for nothing. This looks mostly like stuff we’ve done before, but there’s something new. flatten (in map (flatten)) turns the given ~[Product, StockItem] into a standard tuple.
You can see what the final result looks like in listing 5.6.
Listing 5.6. Products with stock items

The call to groupBy groups the list’s elements by the first part of the tuple (_._1), using that as the key for the resulting map. The value for each key is a list of all its corresponding elements. This leaves us with a Map[Product, List[(Product, StockItem)]], which is why we map over the values and, for each value, we map over each list to produce a Map[Product, List[StockItem]].
Now that you’ve seen three ways to get data out of the database, let’s look at how we can put some data in.
5.3.5. Inserting, updating, and deleting data
To insert data, we simply create an insert statement and call executeUpdate on it. The following example also shows how to supply named parameters.
Listing 5.7. Inserting records

Executing an insert statement is much like running a query: you create a string with the statement and get Anorm to execute it. As you can guess, update and delete statements are the same: see listing 5.8.
Listing 5.8. Update and delete

In the previous sections, we’ve looked at how to use Anorm to retrieve, insert, update, and delete from the database. We’ve also seen different methods for parsing query results. Let’s take a look at how Squeryl does things differently.
5.4. Using Squeryl
Squeryl is a Scala library for mapping an object model to an RDBMS. Squeryl’s author defines it as “A Scala ORM and DSL for talking with databases with minimum verbosity and maximum type safety” (http://squeryl.org/). This means that Squeryl is an ORM that gives you a feature that other ORMs don’t: a type-safe query language. You can write queries in a language that the Scala compiler understands, and you’ll find out whether there are errors in your queries at compile time.
For instance, if you remove a field from one of your model classes, all Squeryl queries that specifically use that field will no longer compile. Contrast this with other ORMs (or Anorm—Anorm is not an ORM) that rely on the database to tell you that there are errors in your query, and don’t complain until the queries are actually run. Many times you don’t discover little oversights until your users tell you about them.
The following sections will teach you how to create your model and map it to a relational database, store and retrieve records, and handle transactions.
5.4.1. Plugging Squeryl in
Before you can use Squeryl to perform queries, you’ll have to add Squeryl as a dependency to your project and initialize Squeryl.
To add a dependency for Squeryl to our project, we’ll add another line to appDependencies in project/Build.scala:
val appDependencies = Seq( jdbc, "org.squeryl" %% "squeryl" % "0.9.5-6" )
The next step is to tell Squeryl how to get a connection to the database. To achieve this, we define a Global object that extends GlobalSettings, whose onStart method will be called by Play on startup. In this onStart method, we can initialize a SessionFactory, which Squeryl will use to create sessions as needed. A Squeryl session is just an SQL connection so that it can talk to a database and an implementation of a Squeryl database adapter that knows how to generate SQL for that specific database. In listing 5.9 we show how to do this.
Listing 5.9. Initialize Squeryl

We’re using an H2 database in this example, but most mainstream databases will work. We give Squeryl’s SessionFactory a function that creates a session that’s wrapped in a Some. Every time Squeryl needs a new session, it’ll call our function. This function does nothing more than call Session.create with a java.sql.Connection and an org .squeryl.adapters.H2Adapter, which is an H2 implementation of DatabaseAdapter.
The call to DB.getConnection looks weird because we’re supplying the method with a one-parameter list after an empty parameter list. This is because DB.getConnection is intended to be used in an environment where an Application is available as an implicit, and you can call it without the second parameter list. This isn’t the case here; it’s being supplied as a lowly method parameter. If we wanted, we could make it available as an implicit by assigning app to a new implicit val:
implicit val implicitApp = app DB.getConnection()
We only recommend this if the implicit Application is going to be used several more times.
There, we’ve set up Play to make Squeryl available in our code. Now we can define a model.
5.4.2. Defining your model
In order for Squeryl to work with our data, we need to tell it how the data is structured. This will enable Squeryl to store and retrieve our data in a database and even tell us whether our queries are correct at compile time.
When it comes to defining a model, Squeryl gives you a certain amount of freedom; you can use normal classes or case classes, and mutable or immutable fields (val versus var). We’ll be using the same logical data model as in the Anorm section, with minor changes to accommodate Squeryl. We’ll explain how to define our data model and support code in the following code samples. All the samples live in the models package; we put them in the same file, but you can split them up if you like.
First, we define three classes that represent records in each of the three tables. We’ll be using case classes in this example because that gives us several benefits, with minimal boilerplate. The immutability of our model classes is especially useful. Because you can’t change an instance of a case class—you can only instantiate a modified copy with the instance’s copy method—one thread can never change another thread’s view on the model by changing fields in entities that they might be sharing. Our model is shown in listing 5.10.
Listing 5.10. The model
import org.squeryl.KeyedEntity case class Product( id: Long, ean: Long, name: String, description: String) extends KeyedEntity[Long] case class Warehouse( id: Long, name: String) extends KeyedEntity[Long] case class StockItem( id: Long, product: Long, location: Long, quantity: Long) extends KeyedEntity[Long]
The only thing that’s different from vanilla case classes here is that we’re extending KeyedEntity. This tells Squeryl that it can use the id for updates and deletes.
Immutability and threads
Let’s explain in more detail why you might want to use an immutable model. In simple applications, you won’t have to worry about your model being mutable because you won’t be passing entities between threads, but if you start caching database results or passing entities to long-running jobs, you might get into a situation where multiple threads are using and updating the same objects. This can lead to all sorts of race conditions, due to one thread updating an object while another thread is reading it.
You can avoid this by making sure that you can’t actually change the objects you’re passing around; in other words, make them immutable. When an object is immutable, you can only change it by making a copy. This ensures that other threads that have a reference to the same object won’t be affected by the changes.
There’s another case to be made for using immutable objects, which is to protect yourself from errors in your code. This helps in the same way we use the type system to protect ourselves from, for instance, passing the wrong kind of parameters to our methods. When we only pass immutable parameters, buggy methods can never cause problems for the calling code by unexpectedly updating the parameters.
Next we’ll define our schema.
Defining the schema
The schema is where we tell Squeryl which tables our database will contain. org.squeryl.Schema contains some utility methods and will allow us to group our entity classes in such a way that Squeryl can make sense of them. We do this by creating a Database object that extends Schema and contains three Table fields that map to our entity classes. We’ll use these Table fields later in our queries.
Listing 5.11 shows what our Database object looks like.
Listing 5.11. Define the schema

The table method returns a table for the class specified as the type parameter, and the optional string parameter defines the table’s name in the database. That’s it; we’ve defined three classes to contain records, and we’ve told Squeryl which tables we want it to create and how to map them to our model. What we’ve built is illustrated in figure 5.3.
Figure 5.3. The relationship between the schema and the model classes

In the previous listing, we added a bunch of type annotations to make it clear what all the properties are—the same reason we’ve added them to several other listings. But this looks verbose to most experienced Scala developers, and in this example it starts to be too much. Here’s a more idiomatic version of the same code.
Listing 5.12. Idiomatic schema
import org.squeryl.Schema
import org.squeryl.PrimitiveTypeMode._
object Database extends Schema {
val productsTable = table[Product]("products")
val stockItemsTable = table[StockItem]("stock_items")
val warehousesTable = table[Warehouse]("warehouses")
on(productsTable) { p => declare {
p.id is(autoIncremented)
}}
on(stockItemsTable) { s => declare {
s.id is(autoIncremented)
}}
on(warehousesTable) { w => declare {
w.id is(autoIncremented)
}}
}
Before we can do anything else, we’ll have to make sure our schema is created. Squeryl does define a create method that creates the schema when called from the Database object. But since this can’t update a schema, it’s better to use the evolutions method that we discussed in section 5.2.
Now that we have a database, we can define our data access objects for performing queries.
5.4.3. Extracting data—queries
At some point, you’ll want to get data out of your database to show to the user. In order to write your Squeryl queries, you’ll use Squeryl’s DSL.
Writing Squeryl queries
Let’s see what a minimal query looks like:
import org.squeryl.PrimitiveTypeMode._
import org.squeryl.Table
import org.squeryl.Query
import collection.Iterable
object Product {
import Database.{productsTable, stockItemsTable}
def allQ: Query[Product] = from(productsTable) {
product => select(product)
}
We import the products table from Database for convenience. from takes a table as its first parameter, and the second parameter is a function that takes an item and calls, at least, select. select determines what the returned list will contain.
Let’s see what this looks like in figure 5.4.
Figure 5.4. What a simple query looks like

Instead of returning a model object, we can also return a field from the product by calling select(product.name), for instance. This will return—when the query is actually called—a list of all the name fields in the products table.
As a next step we’re going to sort our results:
def allQ = from(productsTable) {
product => select(product) orderBy(product.name desc)
}
In Squeryl, we order by using an order by clause, just like in SQL; figure 5.5 shows what it looks like.
Figure 5.5. Squeryl’s order by clause

Note that we’ve only defined the query; we haven’t run it or accessed the database in any way. So how do we get our results?
Accessing a query’s results
If you look up the source code for Query (the return type of our query methods), you’ll see that it also extends Iterable. This might suggest that you can just loop over the query or otherwise extract its contents to get at the results. Well... yes, but not yet. Our Iterable doesn’t actually contain the results yet, but it will retrieve them for you as soon as you try to access its content (by looping over it, for example). Without a database connection available, this will fail with an exception, but we can provide our query with a connection by wrapping our code in a transaction.
In Squeryl lingo, a transaction is just a database context: a collection of a database connection and a database transaction (something you can commit or roll back) and any other bookkeeping that Squeryl needs to keep track of. This will provide our query with a context to run in, which makes the right kind of variables available for it to be able to talk to our database.
Knowing that, we can define a method to get our result set:
def findAll: Iterable[Product] = inTransaction {
allQ.toList
}
That’s right; all we have to do to get our records is call the toList method. toList loops over collection items and puts each of them in a newly created list. This may not seem like much—after all, we’re just turning one kind of collection into another kind of collection with the same contents. But we’ve done something crucial here: we’ve made Squeryl retrieve our records and turn our lazy Iterable into a collection that actually contains our results and can be used outside of a transaction.
The crucial bit in this section is that, although your query behaves like an Iterable, you can’t access any results outside of a transaction. You either do everything you have to do inside one of the transaction blocks or, like in the example, you call toList on the query (also inside a transaction) and then use that list outside of a transaction.
Building queries from queries
We told you that from takes a table as a parameter. We lied; it takes a Queryable. A Table is a Queryable, but so is a Query. This makes it possible to combine queries to create new queries, like creating multiple queries that filter on different fields all based on the same base query. This is useful because you can apply the don’t repeat yourself principle to queries.
The query in listing 5.13 shows one example of this.
Listing 5.13. A nested query

Instead of passing a table parameter to from, we’ve given it a query (productsInWarehouse). By doing this, we’ve defined one way to filter products on whether they’re present in a specific warehouse, and we’ve reused the same filter in another query. We can now use the productsInWarehouse query as the basis for all queries that need to filter in the same way. If we decide, at some point, that the filter needs to change in some way, we only have to do it in one place.
If you’re an experienced Scala developer, you’ll already have started thinking about using this feature to implement automatic filtering capabilities. You could, for instance, add an implicit parameter list to all your queries and use that to filter all queries based on the current user.
By using queries as building blocks for other queries, we can achieve a higher level of reuse and reduce the likelihood of bugs.
Now that we know how to get data out of the database, how do we put it in?
5.4.4. Saving records
We can be brief on saving records: you call the table’s insert or update method.
def insert(product: Product): Product = inTransaction {
productsTable.insert(product)
}
def update(product: Product) {
inTransaction { productsTable.update(product) }
}
Again, we’re wrapping our code in a transaction. That’s it; that’s how you store data in Squeryl.
There’s something strange going on, though. If you’re using immutable classes—which vanilla case classes are—you might be worried when you discover that Squeryl updates your object’s supposedly immutable id field when you insert the object. That means that if you execute the following code,
val myImmutableObject = Product(0, 5010255079763l, "plastic coated blue", "standard paperclip, coated with blue plastic") Database.productsTable.insert(myImmutableObject) println(myImmutableObject)
the output will unexpectedly be something like: Product(13, 5010255079763, "plastic coated blue", "standard paperclip, coated with blue plastic"). This can lead to bad situations if the rest of your code expects an instance of one of your model classes to never change. In order to protect yourself from this sort of stuff, we recommend you change the insert methods we showed you earlier into this:
def insert(product: Product): Product = inTransaction {
val defensiveCopy = product.copy
productsTable.insert(defensiveCopy)
}
This version of insert gives Squeryl’s insert a throw-away copy of our instance for Squeryl to do with it as it pleases—this is one of the nice features a case class gives you: a copy method. This way we don’t have to change our assumptions about the (im)mutability of our model classes.
Now there’s just one more thing to explain: transactions. We’re almost there.
5.4.5. Handling transactions
In order to ensure your database’s data integrity, you’ll want to use transactions. Databases that provide transactions guarantee that all write operations in the same transaction will either succeed together or fail together. For example, this protects you from having a Product without its StockItem in your database when you were trying to insert both. Figure 5.6 illustrates the problem.
Figure 5.6. The problem that transactions solve
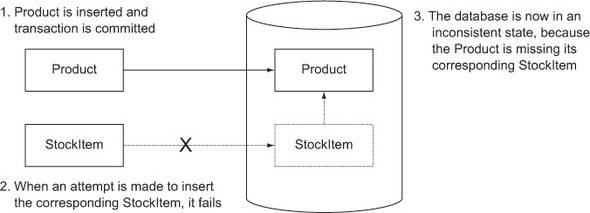
Squeryl provides two methods for working with transactions: transaction and inTransaction. Both of these make sure that the code block they wrap is in a transaction. The difference is that transaction always makes its own transaction and inTransaction only makes a transaction (and eventually commits) if it’s not already in a transaction. This means that because our DAO methods wrap everything in an inTransaction, they themselves can be wrapped in a transaction and succeed or fail together and never separately.
Let’s say our warehouse receives a shipment of a product that’s not yet known. We can insert the new Product and the new StockItem and be sure that both will be in the database if the outer transaction succeeds, or neither if it fails. To illustrate, we’ll put two utility methods in our controller (listing 5.14): one good and one not so good.
Listing 5.14. Using transactions

In addNewProductGood we’re wrapping two inTransaction blocks in one transaction block, effectively creating just one transaction.
In contrast, because addNewProductBad doesn’t wrap the calls to the insert methods, each of them will create their own transaction. If something goes wrong with the second transaction, but not with the first, we’d end up in a situation where the Product is in the database, but the not the StockItem. This isn’t what we want.
We illustrate this difference in figure 5.7.
Figure 5.7. Using transactions to protect data integrity

The diagram shows that addNewProductBad relies on the calls to inTransaction in each of the insert methods and therefore fails to create a single transaction around both of the inserts, which could lead to inconsistent data in the database. The call to transaction in addNewProductGood creates a single transaction and ensures that either both records are inserted or neither are.
Now that you know all about transactions, let’s take a look at what kind of support Squeryl has for relationships between entities.
5.4.6. Entity relations
There are two flavors of entity relations in Squeryl. One works somewhat like traditional ORMs, in the sense that it allows you to traverse the object tree, and one is... different. Let’s start with the approach that’s different, which Squeryl calls stateless relations.
Stateless relations
Squeryl’s stateless relations don’t allow you to traverse the object tree like traditional ORMs do. Instead they give you ready-made queries that you can call toList on, or use in other queries’ from clauses.
Before we go any further, let’s redefine our model to use stateless relations. The result is shown in listing 5.15.
Listing 5.15. Stateless relations version of our model


Once we’ve defined our relationships, each entity has a ready-made query to get its related entities. Now you can simply get a product’s related stock items,
def getStockItems(product: Product) =
inTransaction {
product.stockItems.toList
}
or define a new query that filters the stock items further:
def getLargeStockQ(product: Product, quantity: Long) =
from(product.stockItems) ( s =>
where(s.quantity gt quantity)
select(s)
)
Obviously, you need to be able to add stock items to products and warehouses. You could set the foreign keys in each stock item by hand, which is simple enough, but Squeryl offers some help here. OneToMany has the methods assign and associate, both of which assign the key of the “one” end to the foreign key field of the “many” end. Assigning a stock item to a product and warehouse is simple:
product.stockItems.assign(stockItem)
warehouse.stockItems.assign(stockItem)
transaction { Database.stockItemsTable.insert(stockItem) }
The difference between assign and associate is that associate also saves the stock item; this becomes the following:
transaction {
product.stockItems.associate(stockItem)
warehouse.stockItems.associate(stockItem)
}
Note that because Squeryl uses the entity’s key to determine whether it needs to do an insert or an update, this will only work with entity classes that extend KeyedEntity.
Stateful relations
Instead of providing queries, Squeryl’s stateful relations provide collections of related entities that you can access directly. To use them, you only need to change the call to left to leftStateful and similarly right to rightStateful:
lazy val stockItems = Database.productToStockItems.leftStateful(this)
Because a stateful relation gets the list of related entities during initialization, you should always make it lazy. Otherwise you’ll have problems instantiating entities outside of a transaction. This also means that you need to be in a transaction the first time you try to access the list of related entities.
StatefulOneToMany has an associate method that does the same thing as its non-stateful counterpart, but it doesn’t have an assign method. Apart from that, there’s a refresh method that refreshes the list from the database. Because a StatefulOneToMany is a wrapper for a OneToMany, you can access relation to get the latter’s features.
5.5. Caching data
Certain applications have usage patterns where the same information is retrieved and sent to the users many times. When your application hits a certain threshold of concurrent usage, the load caused by continuously hitting your database with queries for the same information will degrade your application’s performance. Like the cache in your computer’s processor, this kind of cache can return data more quickly than where the data normally resides. This gives us several benefits, the most important of which are that heavily used data is retrieved more quickly, and that the system will perform better because it can use its resources for other things.
Any database worth its salt will cache results for queries it encounters often. But you’re still dealing with the overhead of talking to the database, and there are usually more queries hitting the database, which may push these results out of the cache or invalidate them eagerly. In order to mitigate these performance issues, we can use an application cache.
An application cache can be more useful than a database cache, because it knows what it’s doing with the data and can make informed decisions about when to invalidate what. Play’s Cache API is rather straightforward: to put something in the cache, you call Cache.set(), and to retrieve it, Cache.getAs().
It’s possible that your application’s usage pattern is such that an insert is usually followed by several requests for the inserted entity. In that case, your insert action might look like this:
def insert(product: Product) {
val insertedProduct = Product.insert(product)
Cache.set("product-" + product.id, product)
}
Here’s the corresponding show action:
def show(productId: Long) {
Cache.getAs[Product]("product-" + productId) match {
case Some(product) => Ok(product)
case None => Ok(Product.findById(productId))
}
}
There’s more about using Play’s Cache API in section 10.1.3.
5.6. Summary
Play has flexible support for database storage. Anorm allows you to use any SQL that your database supports, without limits. It also lets you map any result set that you can produce with a query onto entity classes or any kind of data structure you can think of by leveraging standard Scala collections APIs and parser combinators. Play makes it easy to plug in other libraries, which allows you to use other libraries, like Squeryl. Squeryl allows you to write type-safe queries that are checked at compile time against your model.
Evolutions are an easy-to-use tool for upgrading the schema in your development and production databases when necessary. You just create scripts with the appropriate commands. The cache allows you to increase your application’s performance by making it easy to store data in memory for quick retrieval later.
This chapter explained how to move data between your database and application; chapter 6 will teach you how to use view templates to build the user interface and present this data to your users.