
When I originally set out to write a text on object-oriented design heuristics, I intended to devote a chapter on applying the heuristics to an actual design problem. As I got into the project, I realized that looking at actual applications could be a complete text on its own. However, my reviewers were almost unanimous in arguing for a complete example that moves away from meals, alarm clocks, fruit baskets, etc. Although I will argue that the heuristics are independent of domain and we should therefore select simple real-world domains for our exploration of them, it is very useful to see a full design of a computer science domain. Having come full circle in my thoughts on demonstrating the usefulness of heuristics in an actual design problem, I offer you the automatic teller machine problem as an exercise in designing an application. Although this example has been designed in several texts before this one, we will examine it from a very different and more interesting perspective. The published solutions include numerous heuristics violations, that, as I will show, detract from some beneficial facet of the resulting application. By examining both the ATM and the bank side of the software application, we can illustrate a useful design technique when systems span multiple address spaces (i.e., distributed systems) known as “design through proxies” [23].
Consider the following requirement specification for our design problem.
An automated teller machine (ATM) is a machine through which bank customers can perform a number of the most common financial transactions. The machine consists of a card reader, a display screen, a cash dispenser slot, a deposit slot, a keypad, and a receipt printer (see Figure 11.1).
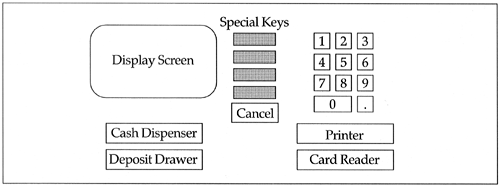
When the machine is idle, a greeting message is displayed. The keys and deposit slot will remain inactive until a bank card has been entered. When a bank card is inserted, the card reader attempts to read it. If the card cannot be read, the user is informed that the card is unreadable, and then the card is ejected.
If the card is readable, the card reader reads the account and PIN (personal identification number) numbers off the card and the user is asked to enter his or her PIN. The user is given feedback (in the form of asterisks, but not the specific digits entered) as to the number of digits entered at the numeric keypad. The PIN entered by the user is compared to the PIN on the ATM card. If the PIN is entered correctly, the user is shown the main menu (described below). Otherwise, the user is given up to two additional chances to enter the PIN correctly. Failure to do so on the third try causes the machine to keep the bank card. The user can retrieve the card only by dealing directly with an authorized bank employee.
The main menu contains a list of the transactions that can be performed. These transactions are as follows:
Deposit funds to an account (required info.: checking/savings, amount);
Withdraw funds from an account (required info.: checking/savings, amount);
Transfer funds from one account to another (required info.: checking/savings, amount, other account number, other checking/savings);
Query the balance of any account (required info.: checking/savings).
The user can select a transaction and specify all relevant information. When a transaction has been completed, the system returns to the main menu.
At any time after reaching the main menu and before finishing a transaction (including before selecting a transaction), the user may press the Cancel key. The transaction being specified (if there is one) is cancelled, the user's card is returned, the receipt of all transactions is printed, and the machine once again becomes idle.
If a deposit transaction is selected, the user is asked to specify the account to which the funds are to be deposited to enter the amount of the deposit, and to insert a deposit envelope.
If a withdrawal transaction is selected, the user is asked to specify the account from which funds are to be withdrawn and the amount of the withdrawal. If the account contains sufficient funds, the funds are given to the user through the cash dispenser.
If a transfer of funds is selected, the user is asked to specify the account to which the funds are to be deposited, whether it is to checking or savings, and the amount of the transfer. If sufficient funds exist, the transfer is made.
If a balance inquiry is selected, the user is asked to specify the account whose balance is requested. The balance is not displayed on screen but is printed on the receipt.
All transactions are carried out cooperatively between the ATM and the bank. The bank holds all of the account information and must be consulted over the network at the appropriate time during the transaction. The bank is also responsible for updating the account information based on the transactions processed.
Two separate systems are being designed here. One is an application that runs on the ATM side of the system. The other application runs on the bank side of the system. We will assume we are building both.
In keeping with my promise in the Preface of this book not to create yet another design methodology, I will examine two competing views of object-oriented analysis and design and show that neither one, in its entirety, is optimal. The first view is defined by a camp of designers who feel that object-oriented analysis should be a data-driven process wherein the developer examines the requirements of the system, looking for associations, natural aggregations, and inheritance. The behavior (i.e., uses relationships) of the system is not assigned until design time. The idea is to produce a full object model without getting involved with assigning behavior. The Rumbaugh method [12] is the most popular of the data-driven models.
The second view is almost the opposite of data driven modeling. This view states that object-oriented analysis should focus on the behavior of the system. The designer is looking for classes and their uses relationships at analysis time. During design, some of these uses relationships are refined to containment relationships, and designers are expected to examine the system for inheritance. Booch, Jacobson, and Weiner/Wilkerson/Wirfs-Brock [7, 3, 4, 9] are three of the better-known behavior-driven methodologies.
The problem with data-driven methodologies is that I do not believe a designer can find a complete object model without talking about behavior.
Question: “Why is A associated with B?”
Answer: “Because A needs B to do ….”
In systems with interesting behavior, many of the associations are due to behavioral needs. When this is the case, the designer is actually finding uses relationships, not just associations (a weaker relationship). A company with which I have worked in the past ran into this situation in designing a very large system. Some of the design groups became frustrated at trying to develop a full object model without talking about behavior. The result was a deliverable (the object model) that did not reflect the process undertaken to discover the information in that deliverable. When designers need to throw away information to fit what they have produced into a deliverable, then it is time to throw away the deliverable in favor of something that more accurately captures the process they are pursuing.
In some management information system (MIS) domains, the data-driven approach can work very well. This is due to the fact that there is no interesting behavior in these MIS applications. These applications are often grinding up an object model and spitting it out in a variety of forms. This is not to trivialize MIS applications. Many projects in this area are very complex; it is just that their behavior is trivial. All of the interest is in the static object model and possibly the user interface. As an example, consider a security reporting system for a brokerage house. All of the interesting design decisions revolve around the modeling of the data that captures the trading of securities and the graphic user interface to support that model. What is actually done with this data? It is printed in numerous reports, each of which uses the same model to generate information in a particular form for some government agency. The model itself has no interesting behavior between its classes. For systems like the ATM domain where the classes in the model have lots of interesting behavior between them, the data-driven approach cannot hope to give a complete object model without discussing the behavior of the system.
The behavior-driven methods share a different but equal problem. In large systems, where there will be many classes, a designer must take advantage of natural aggregations in the analysis model. If these natural aggregations are not considered, then every class in the system ends up at the top level of the design. This creates a very complex collaborations graph (the classes at the top level of design and their uses relationships). Attempts to find containment relationships by examining this graph will prove difficult. This problem is not visible in small systems where there may be only 15 or 20 classes, but attempts to apply this methodology to a system with 200 classes will demonstrate this weakness. The 200 classes may end up organized into 15 containment hierarchies. This is the level at which I want to examine the design, 15 classes rather than 200 classes. Of course, the data-driven model suffers from the fact that only natural aggregations can be found at analysis time. Most systems also use containment to distribute system intelligence within a containment hierarchy. This use of containment cannot be discovered without using the behavior of the system as a guide. The discovery of natural aggregations as well as manufactured containment for system intelligence distribution will be illustrated in the design of the ATM system.
Since I have argued against both data-driven and behavioral-driven design, what is a designer to do when creating a system from a requirement specification? I recommend a hybrid between the two. I always start with a data-driven modeling technique and then progress to a behavioral-driven design method. This allows me to simplify my design using natural aggregations and gives me the flexibility of discussing the behavior of the system at analysis time. It is my belief that starting with data-driven modeling will never hurt, so long as a designer realizes that it may not be possible to produce a full object model in many systems without discussing behavior.
We begin by collecting all of the class candidates in our system. We are basically looking for nouns in the requirement specification. We will ignore the fact that the ATM (and its pieces) and the Bank (and its pieces) are in completely different address spaces on two different processors. We can ignore this fact during analysis time due to a design technique of using proxies, which we will explore when we start discussing the communication between items in the ATM application and items in the Bank application. Likewise, we ignore how objects are stored in our domain. The fact that accounts are in some central database within the bank is irrelevant. A good trick is to think of everything as living in memory. Later, in low-level design, we worry about the actual storage. We can get away with this trick because when an object of one class sends a message to an object of another class, that object will reside in memory. We can always “fake” this by hiding the actual access of the object within its class.
Given these assumptions, we can come up with the object model in Figure 11.2 by examining nouns in the domain and exploiting natural aggregations in the system. Natural aggregations result when tangible items are physically contained in another item; for example, ATMs contain card readers, banks contain accounts.
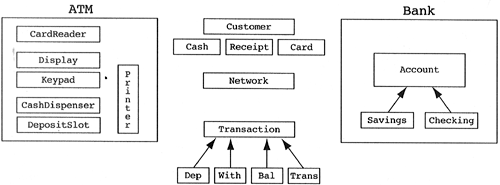
This first object model has captured the natural aggregations inherent in ATMs and Banks. Notice the lack of associations in this model. I argue that most of the associations in this system cannot be captured without examining the behavior of the system. Why are ATMs associated with Banks? They need a bank to process transactions. Why are Transactions associated with Accounts? They need accounts to process themselves. The association exists only to satisfy some behavioral aspect of the system, that is, a uses relationship. This is in contrast to a system that lacks interesting behavior. Why are assignments associated with grades in an automated grading system? Because they just are; it is defined in the requirement specification.
One could argue that the inheritance relationships require behavior as well. After all, do the Transaction and Account classes have derived classes or are they concrete classes? The answer depends on whether or not the derived classes have interesting differences in behavior. If Savings and Checking accounts behave differently, then their design in our object model makes sense. If they do not behave differently, then Savings and Checking will end up irrelevant classes since all of their behavior will factor up to the Account class. There are two schools of thought on this subject. Data-driven analysis states that inheritance should be added up front and then eliminated during design time if the derived classes end up being irrelevant classes. Behavior-driven analysis states that inheritance is added at design time, only when commonality is found between two existing classes. Either view can be useful. We arbitrarily choose the first principle in this example, that is, we add inheritance wherever it is suspected and eliminate it at design time if necessary. (See Section 5.12 for a full discussion on the migration of either design choice to a correct design.)
The first problem that many new designers face is one of understandability. Who starts everything in a decentralized system? In a centralized system, the flow of control is obvious. In a decentralized system, it is more hidden. In a decentralized system, the flow of control is started by something outside of the system. This something is either the main function of a C++ application, the SmallTalk environment, the CLOS environment, or more popularly, the constructor of a large containing class that wraps the entire system. The latter solution is often more useful because if the current system is to be reused as a component of a new larger system, it is a simple matter of adding operations to the large containing class. In the other solutions, some reengineering will have to be enacted in order to capture the desired information. Such a containing class is considered to be just outside the domain of the object-oriented model. In this example, we might define a class called FinancialSystem to wrap the entire object model. The constructor of this class builds Bank and ATM objects and wires them together with referential attributes. This is not the god class problem we spoke of earlier in this text, since the class is outside the system and is used only to build the top-level objects in our domain.
Now, let us examine as a first-use case the withdrawal of money from an ATM. Someone puts a card in the card reader, which detects that a card has been inserted and that it is a valid bank card and not an appropriately sized piece of plastic. Once this has been done, who sends a message to whom and what is the message? This is an important question to keep in mind. Invariably, designers will say, “Now we have to verify a PIN number.” That is too vague. By forcing specific questions at specific places in design, a designer must justify exactly what he or she is doing. A common first choice at this stage of design is to have the card reader send a message to the display screen asking the display to put up an Enter PIN: prompt (see Figure 11.3). This is inevitably followed by a message from the card reader to the keypad to get a key or PIN number, etc.

This design violates Heuristic 4.14, which states that “objects that share lexical scope should not have uses relationships between them.” Why not? We can examine our lexical scope pattern from Chapter 10 to answer that question. First, card readers have nothing to do with display screens except when in the domain of an ATM. We have now rendered the card reader unreusable in domains that do not possess a display screen. If I want to build a security door that also has a card reader, then I need to put a display screen in my security door. Second, and more important, I have added complexity to my design without motivation. The ATM already contains a card reader and display screen; therefore, it has implied uses relationships to them. The containing class can always accomplish any interaction between its pieces with the existing uses relationships. The added relationship is not required. In this example, the ATM should clearly handle the coordination between its pieces. We will see the reason a number of designers fall into this trap a little later in this design discussion.
It is important to note the relationship between heuristics and design patterns here. It is easy to determine when a heuristic is being violated. It is also easy to remember the heuristics since they are rarely more than two sentences of information. Patterns, on the other hand, can be quite long. I do not believe that designers will know intuitively when to select a particular pattern or how to combine them in interesting ways during the design process. Heuristics can provide the glue to help pull this information together.
Having gone this far in the design of the ATM system, a designer is tempted to state, “The card reader should inform the ATM that it has a card, then the ATM can send a message to its display screen to display a prompt” (see Figure 11.4).
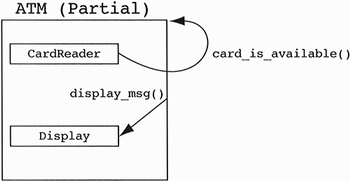
The problem with this design is that the card reader is now aware of its container, a violation of a design heuristic whose intention is to make the contained class more reusable (Heuristic 4.13). We do not want card readers to be dependent on ATMs. Again, a solution around this problem can be found in the patterns from Chapter 10. Ideally, we can change the interrupt-driven nature of our design to a polling architecture. Why not let the ATM poll the card reader, asking it if it has a card? If the ATM has nothing else to do, then it can simply block on the card reader. If the ATM has other task, such as monitoring the bank for any interesting information it might be sending asynchronously, then the ATM should run the polling loop. Note that this last point is simply arguing where the polling should be performed, in the ATM or in the card reader.
There may be designs where an interrupt architecture cannot be turned into a polled architecture for physical design reasons, namely, time efficiency. In this case, we should at least make the card reader aware of a more general architecture, say a SecureDevice class. The ATM then inherits from the SecureDevice class, which has no data and a pure polymorphic card_available() method. The old restriction was that card readers could not be reused outside the domain of ATM. The new restriction is that card readers cannot be reused outside the domain of some SecureDevice. Since SecureDevice has no data and only a pure polymorphic method, it is an easy class from which to inherit. Yes, this solution can lead to multiple inheritance in some designs. Proponents of the technique of using callback functions to solve this problem can convince themselves that the proposed inheritance solution is a more strongly typed and less flexible solution than theirs. The callback function solution states that when a card reader is built, it is given the address of a function to call when a card becomes available. In the proposed inheritance solution, we restrict the address of the callback (polymorphic) function to a base class method pointer, which increases robustness.
Our ATM asks the card reader if it has a card, and eventually the answer is yes. The ATM then asks its display screen to put up the prompt for getting a PIN number. Now what happens? The naive designer will state that the ATM sends a get_pin() message to its keypad object. At first glance this sounds useful; however, the specification stated that after every key is pressed, an asterisk appears on the display screen. This may have looked trivial when first reading the specification, but it creates a complex issue in the design. The ATM is now forced to get a single key from the keypad, then tell its display to put up an asterisk, then get the second key pressed, put up an asterisk, ad nauseam. Many designers argue that the ATM is far too important an entity to be dealing with such picky issues. They wish to distribute the intelligence of the ATM to its pieces. Unfortunately, in order to distribute the intelligence of the system to the pieces of the ATM, it appears that the keypad will have to talk to the display screen (or vice versa). Designers often find themselves with this dilemma. A containing class (e.g., ATM) wants to distribute its intelligence to its pieces, but that intelligence is distributed over several of its objects. There is an interesting solution to this problem. What the designer needs is a new containing class, which sits between the original containing class and the pieces in question. Consider the role of the super keypad created in Figure 11.5.

The ATM can now simply tell its SuperKeypad object to fetch it a PIN number. It is oblivious to the details. In a large design project, this form of containment is useful for hiding the complexity of our model. We can go on with design, stating, that “The ATM gets a PIN number from the SuperKeypad and then it ….” How does the SuperKeypad get the PIN number? That is someone else's problem.
It is important to note that we had to place a display_msg() operation on the SuperKeypad because the ATM needs to put up its greeting message when first created and after every session with a customer. This operation simply passes through to the display_msg() operation on the display object. This constitutes noncommunicating behavior on the part of the SuperKeypad, that is, behavior that uses a proper subset of the data members of SuperKeypad. The noncommunicating behavior acts as a counterforce in creating these third-party containing classes. Too much noncommunicating behavior suggests that the cohesiveness of the class is low, implying that the class needs to be dissolved into its two pieces. For example, if the public interface of the SuperKeypad class consisted solely of display_msg(), enable(), disable(), and get_key(), then it is a useless abstraction with very low cohesion in its data. It is operations like get_pin() that increase the cohesion of the class and make it a worthwhile addition to our system.
Containing classes of this type cannot be found by data-driven analysts. They can be found only by examining the behavior of the classes in a given system. Examining classes that have more than six data members is a good, mindless method for finding good candidates for this type of problem. This heuristic is useless for showing a designer where in these classes an intermediate containing class might be useful. For this second step, we need to discuss the behavior of the class with respect to its use cases.
The next step in our design revolves around verifying the PIN number given to us by the customer with the PIN on the card. Several popular and equivalent designs address this problem. Some designers state that the ATM should get a PIN number from the card reader (which gets it off of the card), get the PIN from the Super-Keypad, and compare them. Others state that the ATM should get a PIN number from the card reader, give it to the SuperKeypad, and let the SuperKeypad verify the user. These designers then argue whether the ATM or SuperKeypad should perform the looping of three chances before ordering the card confiscated. Still others argue that the ATM should get a PIN number from the SuperKeypad and give it to the card reader who then verifies the number. All of these solutions are valid. The arguments all revolve around the question of how the intelligence should be distributed. Since there is no quantitative metric for measuring complexity (and never will be), this issue is left for debate on qualitative, and therefore subjective, grounds. It is usually desirable to distribute the system intelligence away from a containing class, leaving it with just the coordination activities. However, it often happens that one of the pieces, such as the SuperKeypad, starts picking up too much behavior with respect to the containing class. We can then argue that we want some of the work pushed back onto the containing class. The debate of these three solutions can go on for quite some time during a design critique, with no party getting an upper edge on the other.
I have seen designers create a PIN_Validator object whose purpose is to get the two PIN numbers and verify them. The argument is that policy information is no longer encapsulated in a class like ATM or SuperKeypad, making them more reusable outside the domain. I claim that such controller classes consist only of behavior (often only one piece of behavior) and are the artificial separation of data and behavior. They violate the heuristic of keeping data and behavior in one place, as well as turning an operation into a class. What do PIN_Validator objects do? They validate PIN numbers. This is an operation, not an object abstraction. In addition, if we exploit controller classes, it is true that our other classes are more reusable outside the domain. But why? Because they are typically brain-dead chunks of data with a public interface of accessor methods. This is not object-oriented design; it is simply hiding our data structures behind a wall of gets and sets in one place and putting the behavior of that data elsewhere.
An interesting side issue to this design problem is the realization that the card reader must now know how to get PIN numbers. Is this something card readers do, in general? Of course not. A card reader, in general, reads the information off the back of a magnetically encoded card. We have just made our card reader less reusable by giving it knowledge of the ATM domain. We could put this policy of parsing information outside of the card reader, but this leaves the ATM as the candidate for implementing this parsing. The ATM argues that it is doing too much to warrant it handling the parsing. What is a designer to do about this problem? This is very similar to the problem we had with the ATM and its display screen and keypad. However, in this example, only one piece of the containing class is involved. We can use a wrapper around a physical card reader (the general, reusable component). The wrapper translates the general functionality of the physical card reader into the more ATM-specific requirements (see Figure 11.6). The physical card reader is reusable, and the card reader is domain-specific with the purpose of distributing system intelligence away from the ATM. The result is that everyone is happy!
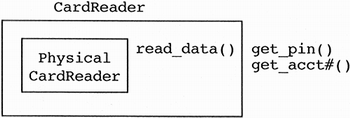
This solution applies to numerous side arguments that erupt in critiquing this example. Should a display screen have a display_msg() operation, or should it have operations like display_pinprompt(), display_mainmenu(), etc.? Should a keypad have a get_key() operation or operations like get_digit(), get_transactionnumber(), etc.?
We now know that we have a verified PIN number on the back of a bank card. What is next? In general, ATMs would like to get a transaction object so that the bank can process it. How can an ATM get a transaction? A classic error is to have the ATM worry about putting up menus, enabling the keypad, getting a special key number, and mapping it to a specific transaction. This would add lots of noncommunicating behavior to the SuperKeypad class. Since the Super-Keypad class has everything it needs to build a transaction (except maybe an account and PIN number), why not let it build the transaction for the ATM? The ATM could get the account and PIN number from the card reader and give them to the SuperKeypad, asking the SuperKeypad to get a transaction.
The SuperKeypad is then faced with the task of getting a transaction. It puts the main menu on the screen (assume the main menu labels key #1 as deposit, key #2 as withdraw, key #3 as balance, and key #4 as transfer), reads a key from the keypad, finds out that special key #2 was pressed, and then what? It is here that many designers assume they have made a mistake. In order to map the key to a transaction object, they are faced with an explicit case analysis. Several heuristics state/imply that explicit case analysis is a bad thing, since it implies that an addition to the system will result in changes to the existing code. This problem is common; whenever an object-oriented model bumps up against a nonobject-oriented system, explicit case analysis is often the result. Our design is not warped—our interface is! If we had an object-oriented interface, we would push a button and the desired constructor would run. Adding a new transaction would imply adding a new button with no change to the existing code. Some designers might argue that this is cheating since someone, somewhere is asking, “Did the user touch the screen between these X/Y-coordinates, or those X/Y-coordinates, etc.?” The important point is that the case analysis is pushed outside of our domain. If this sounds like a cheat, then polymorphism is a cheat. Someone, somewhere must be performing case analysis. Talk of jump tables and pointers to functions does not change the fact that it is case analysis. The only relevant question is, “Do you, the developer, need to perform the case analysis in your domain?” If the answer is no, then you can add new items to your system without modifying the existing code. (For a related discussion, see the object-oriented network section in Chapter 9, Section 9.2.)
There are two main solutions to consider in this mapping. Either we let the SuperKeypad collect the information for the transaction as part of its case statement and then build the appropriate transaction object with this information, or we immediately build the appropriate transaction object and let it polymorphically initialize itself. The disadvantage of the first design is that we are doing a large amount of work in each instance of the case statement. It is considered beneficial to minimize this work so that when a developer needs to add a new case, he or she will be modifying a minimal amount of existing code. The disadvantage of the second solution becomes obvious if we ask how a derived class knows how to collect information for filling in its data members. The derived classes of the transaction class will require a display screen and keypad to collect their information (or at least a SuperKeypad). This creates at least one more uses relationship in our system, adding complexity. The developer must now decide if the amount of work being performed in the case statement warrants a new uses relationship. This is very subjective given that there are no quantitative metrics for measuring complexity. My gut instinct in this example is to collect the information and then build the objects. The complexity of collecting information does not warrant a new uses relationship between Transaction and SuperKeypad. This must be decided on a case-by-case basis, and because of its subjective facet, it causes numerous, endless arguments during design critiques. Either solution to this problem results in a fully initialized transaction object (in this case, a Withdraw object) being returned to the ATM.
At this point in the uses case, the ATM needs to send a message to the Bank object, asking it to process a transaction (passing the Withdraw transaction object as an explicit argument). It is here that the developer realizes that the ATM object lives in one address space (the ATM application) but the Bank lives in a different address space (the Bank application). I argued earlier that the ATM and Bank objects can be viewed as being in the same address space. This is due to a technique that employs proxies for the ATM and the Bank objects in each other's address spaces. The ATM cannot send a direct message to a Bank, so it sends a message to a Bank proxy that lives in the ATM's address space (see Figure 11.7). This proxy packs up the request and transaction object and ships it across the network to an ATM proxy that lives in the Bank's address space. The ATM proxy unpacks the request, reconstitutes the transaction object, and sends the process message to the real Bank object. The real ATM and Bank are completely unaware that they are really talking to proxies. This allows a designer to ignore the distributed facet of a distributed application during high-level design, leaving the gory details to low-level design proxy classes. The high-level of our design simply shows an ATM object sending a process message to a Bank object, when in reality our system is significantly more complex.
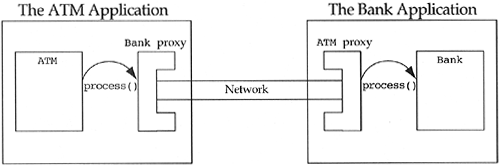
Several different designs come to mind when a developer must decide how to process transactions. Often, the first design to come to mind is to ask the transaction for an account number, use the account number to find the account from the account list object, and then tell the account to process the transaction. The problem here is that the account does not know how to process a transaction. The processing is dependent on the type of the transaction (in this case, withdraw). This implies the need to process the transaction object polymorphically, which brings us to our second design. The bank asks the transaction for its account number, uses the account number to find the account object from within the account list object, then sends the transaction object the process method (polymorphically), passing the account object as an explicit argument. This works great for withdraw, balance query, and deposit. Transfer presents an interesting problem in that it requires two account objects, a source account and a target account. Since the Bank is unaware of which transaction it has, determining the number of accounts that a transaction requires must be performed in a transaction-independent manner. One solution is for the transaction to give a list of account numbers when the Bank requests the account number from the transaction object. The Bank then hands this list to the AccountList object, which retrieves a list of account objects rather than just one. This list can then be handed to the transaction by the Bank when it sends the process method. A better alternative is to have the Bank simply tell its transaction object to process itself, handing it the whole list of accounts. In this way, the particular process method, which runs for a given transaction type, can be responsible for determining the selection of account object(s). It also allows us to keep related data and behavior closer together by eliminating the removal of the account number from the transaction object. Some designers may worry about efficiency at this point, arguing that sending one account object is cheaper than sending thousands. I would argue that we should corrupt the logical design for physical design concerns. In fact, physical design in this case will argue that the accounts are in a database. All we are sending to the process method is a database handle, a pointer. We save nothing by letting the Bank retrieve the account object(s). This fact helps justify heuristics that warn users not to worry too much about physical design issues, most notably efficiency, during logical design.
The actual processing of a transaction with respect to an account is fairly straightforward. Each transaction will check account information to ensure the viability of the transaction, update any information that can be updated (e.g., withdraw), and record any necessary audit trails that may be needed later (e.g., deposit). The transaction process method then returns good or bad to the Bank, which in turn returns this information to the ATM object. Recall that the actual sequence of events includes a return to an ATM proxy, which packages and ships the return value to a Bank proxy using a network. The Bank proxy then unpackages the return value and returns to the actual ATM object. As far as Bank and ATM are concerned, the proxies are the actual objects. The distributed processing has been buried in the implementation details.
The question now is, “What does an ATM do if the transaction is valid?” The problem here is that the ATM has the ability to do anything any transaction could want, but it does not know which transaction it has. The transaction knows (via a polymorphic call) what it needs to do but does not have the objects needed to do it. What do we do? The solution is for the ATM to tell a transaction to post-process itself (polymorphically), passing itself as an explicit argument to the method. The polymorphic call allows the flow control to figure out which transaction it has and what needs to be done; the ATM parameter allows the post-process method the ability to accomplish its goals. In this case, these goals involve dispensing cash to a customer. (It is helpful to note that each transaction also has a preprocess method; for example, deposits take an envelope using the deposit slot object, withdrawals check to be sure the cash dispenser has enough cash, etc.)
This solution bothers a lot of designers because we have a circular uses relationship. The ATM uses Transaction, and now Transaction uses ATM. While I feel uncomfortable with such a construct, it is the cost of eliminating explicit case analysis in the methods of the ATM. It is helpful to note that we are adding a new uses relationship between the Transaction and ATM classes, but this is no more of a concern than the addition of any other uses relationship. Avoid the temptation to say that we only need to pass the cash dispenser to the post-process method of the withdraw class. Keep in mind that the ATM does not know which transaction it has; if it were a balance query, it would require a printer, not a cash dispenser. I have seen solutions where the designer passes a number of ATM pieces to the polymorphic call, letting the actual method determine which of the pieces it will use. This solution is appropriate when we can guarantee that all of the transaction types use a proper subset of the ATM's pieces. If we want to be general and extensible, then we should pass the whole ATM to the method.
This often leads new designers to argue that the ATM now has a method in its public interface which will allow a user to dispense cash without any checking. Keep in mind that “allow a user” refers to a software developer, not an end user of the ATM machine. We are not arguing for a large red button on an ATM machine that, when pressed, mindlessly dispenses cash. This type of argument comes up very frequently when designers confuse software objects with the physical world. I have had attendees of courses worry about the fact that some BankSafe class has an open method. They ask, “How do I prevent a bank teller object from sending the safe object the open method, but allow the bank president object to send that method?” They feel a bit silly when I tell them to not code such a message send from within any method on the teller class. These are software objects; they cannot do things you do not code.
An interesting, related point to the confusion between users of classes and end users of systems came up in a course I was lecturing at a large telecommunications company. Should object-oriented languages support a feature by which a class can limit the access to certain parts of its public interface to a given list of classes? That is, should a BankSafe class be allowed to state that anyone can execute its close method, but only BankPresident, BankVicePresident, IRSOfficer, and Police objects can execute its open method? My initial reaction was to answer no. I argued that this would hinder software reuse in that I would need to modify the class definition if I decided that I wanted to send a restricted message to a class. I further argued that such restrictions were application semantic constraints that should be handled by the application designer. However, the company with which I was dealing was building a large application (millions of lines of code) consisting of an object-oriented framework and many applications to be built on top of it. They argued that within the classes of the framework were many operations in the public interface that were to be used exclusively by the other classes within the framework, not the applications. Other parts of the public interfaces of the framework classes were to be used by both the framework classes and the application writers. Due to the size of the development effort (hundreds of developers on two continents and in three countries), they argued that to convey the necessary aplication-level semantic constraints without language-level support was impossibly complex. Application developers were bound to make mistakes in their use of operations. I agree with this assessment. The trade-off is between communicating application-level semantic constraints versus ease of software reusability. They could have solved the problem by creating an object-oriented API (application interface) that mirrored the classes in the framework. For each class X in the framework, the API would have an APP_X that looked exactly like X except it would have a reduced interface. Each method in APP_X would simply delegate to the exact same method in X. The problem here is keeping each X and APP_X pair in sync with each other, another trade-off to play against the other two solutions.
There are a number of loose ends to tie up in this design. Looking back on our first object model, we see a number of classes we have not examined. The first, and most interesting, is the Network class. We put it in our object model because it is clearly an interesting noun in our requirement specification. If we consider it a key abstraction, then we will use it when we decide to process a Transaction object, recognizing that the Network is an agent between the ATM object and the Bank object. In this scenario, we end up with the ATM object getting a transaction for the Super-Keypad, sending the Network object a process method with the Transaction object as an explicit argument. The Network object would then send the Bank a process method, again passing the Transaction object as an explicit argument. The Bank would process the Transaction as previously discussed, returning good or bad to the Network object. The Network object would then return this return value of good or bad to the ATM object. Most designers will quickly realize that the network is a useless agent between the ATM and Bank and that it should be eliminated in favor of a direct uses relationship. Later in design, when we discuss the ATM and Bank proxies, we realize that they are heavily dependent on the physical network. Not wanting these proxy classes to be tightly coupled with a particular network, we create a wrapper class called Network to isolate the physical network from the proxies that use it. This Network class is completely different from the first network we proposed. The first network was a candidate for a key abstraction, which we threw out of the system because it was a useless agent. The second network is an implementation class, which is of no interest to logical designers. We should consider implementation classes only during physical design.
Another implementation class is one that will wrap the particular storage of account objects, most likely some database. At high-level design, we consider the account object to live in some AccountList object in memory. In reality, the AccountList is really querying some database to get the necessary information to build an Account object in memory. Since we do not want our model dependent on the physical storage of accounts, we hide this information in some Database object. It is the Database object that contains all implementation-dependent information and translations.
A case study attesting to this type of architecture can be found in the insurance industry. In one application with which I had some contact, a group of designers were creating an insurance claim system on an IBM-compatible 486 machine. The actual claim records were stored in a relational database on a mainframe computer. In the first pass of design, the methods of the classes that made up the object-oriented model on the 486 side of the application were riddled with function calls to collect information on the IBM mainframe side of the application (e.g., network connects, SQL query calls). I asked a couple of the designers what they would do if I told them that the claim records would no longer be stored on a mainframe but would live on the local drive of the 486 machine. They quickly realized that a full system rewrite would be the result. Every class in their domain would be affected by this change. The solution was to create a database class with which the classes in the model could send a message to fetch a claim (given a claim number) and through some magic a claim object would be returned. The magic in their case was to run a network to a mainframe database and collect the necessary information to build a Claim object. If, at some later date, the database was to be stored on a local disk drive of the 486, the development team had a central location for any necessary changes. Their object-oriented model remained oblivious to the physical design change. The physical location of the records became the concern of one class, not the entire model.
What about the Customer class? It is true that the end user is providing external stimuli to the ATM domain, but the ATM domain never uses the customer class. This is the hallmark of a class outside the system. The BankCard and Receipt classes are also considered outside the system. They exist as tangible entities but do not provide useful service to the domain model. The Cash class could also be considered outside the system, but it is slightly different than the other three in that the amount of cash must be kept as a value within the cash dispenser. Cash is a good example of a class that has been reduced to an attribute of some other class, in this case the CashDispenser.
What about Savings and Checking account? Should these two entities be derived classes of Account or is the type of account simply an attribute of the Account class? The answer to this question is, “In this domain, do checking and savings accounts behave differently?” The answer, in this example, appears to be no; therefore Checking and Savings are simply values of a descriptive attribute of the Account class. Let us add a use case to the ATM domain that does distinguish the two types of accounts. Let us state that checking accounts bounce but savings accounts do not. That is, it is possible to send a Checking account object a bounce method, passing the number of days as an explicit argument to the method. This method returns the total amount of money in bounced checks the account has suffered during that time period. The FDIC would like to send the bank a bounce method with a number of days to find out how much money in bounced checks the bank has suffered. How do we implement such a method? The first attempt is to state that the Bank runs down its list of accounts, sending each account the bounce method. The problem here is that the Savings accounts in the list do not know what you mean. In fact, accounts in general do not know how to bounce. What can we do? We need to recognize that this is the “core the apple” problem we discussed in Chapter 5. In that example, we had a FruitBasket (the bank) that contained a list of different Fruit objects (the accounts). Apples (the checking account) had an extra method called core (bounce). The question in that example was, “How do we core the apples?” The solution in the Fruit domain was either to keep the Apples in a separate list within the FruitBasket (requiring case analysis on the type of an object) or to add a core method to the Fruit class, which does nothing by default (requiring the placement of derived class information in the base class). In our example, our choice is to keep a separate list of the Checking accounts within the Bank object or to place a Bounce method, which returns zero dollars on the Account class. We might be tempted by the latter solution because it is easier to implement, but when we consider physical design, we see that accessing an Account object is expensive (since the accounts are stored on a disk). This physical design information will argue that the first solution of keeping a separate list of checking accounts is much faster and often more preferable. For example, there may be 2 million accounts but only 800,000 are checking accounts. Why retrieve 2 million accounts when all we need to look at is 800,000? This example shows the interest in patterns and heuristics. Once you realize which problem you have via a heuristics violation, its related patterns offer you the necessary solutions for free.
And last, but not least, how do we handle the Cancel key? If we isolate Cancel to the period in which we collect information, then the SuperKeypad object can detect that the keystroke was the pressing of the Cancel button and will return Cancel to the ATM object, which in turn performs any necessary clean-up. If we wish to cancel after a transaction has been sent to the Bank, then things get a bit more complex. The ATM cannot block on the Bank proxy when it sends the process method. It simply returns and continues to poll the SuperKeypad for a Cancel return value and the Bank proxy for a done return value. If the SuperKeypad returns Cancel to any of the ATM's queries, then the ATM must inform the Bank proxy that the end user has cancelled the transaction. The Bank will then be notified via its proxy and perform any necessary rollback of the transaction. In all cases, the Cancel option does not add much complexity to the design or its implementation.
It is my hope that this discussion has provided some insight into the mechanics of using design heuristics and patterns in the object-oriented analysis and design process. The reader should carefully note the way in which design heuristics allow a designer to reference a group of design patterns, one of which can be used to resolve the conflict implied by the violated heuristic. In addition, this discussion provides a good example of developing a distributed object-oriented design without considering the distributed qualities until after the logical design is complete. Early concerns with process distribution often force a development team to get bogged down in the details of a system. The judicious use of proxies allows the system architects to position all of their efforts at the top level of design, allowing the postponement of the system details. This postponement can dramatically simplify the design process of a distributed object-oriented system.