
The inheritance relationship is one of the more important relationships within the object-oriented paradigm. It is best used to capture the a-kind-of relationship between classes, such as ChevyChevelle is a-kind-of Car, Dog is a-kind-of Animal. Its primary purpose is twofold: It acts as a mechanism for expressing commonality between two classes (generalization), and it is used to specify that one class is a special type of another class (specialization). The terms “specialization” and “generalization” are generally considered synonyms of “inheritance.” They are used often during object-oriented design critiques to discuss the process under which inheritance was found, that is, did the designer have the more general class first (specialization) or the more specific class first (generalization)? If an inheritance hierarchy is simply shown to a developer, there is no way that he or she can determine whether specialization or generalization was used to find the inheritance relationships. Many object-oriented designers have found that generalization is the more difficult, and less frequently discovered, form of inheritance.
Generalization usually tends to be more common in version 1 of a system. During the design process, the system architects decide that two or more classes have something in common, namely, data, behavior, or just a common interface. This common information is collected in a more general class from which the two or more classes can inherit. Undiscovered generalization relationships will result in duplicate abstractions and implementations, that is, data, code, and/or public interfaces. Many generalizations are found toward the end of the object-oriented design process. These generalizations can be added late in the process with little or no effect on the other members of the design team.
In contrast, specialization tends to be more common in successive versions of a particular system. As the system adapts to added functionality, some classes will inevitably require special treatment. Inheritance is ideal for implementing these special cases. It is especially useful for adapting standard components for use in application-specific areas. For this reason, inheritance is called the reusability mechanism of the object-oriented paradigm.
It is very important to note that a major stumbling block while learning the object-oriented paradigm is that developers confuse the containment and inheritance relationships in their designs. The information in this chapter is meant to prevent this problem. We will begin with an abstract example of inheritance in order to discuss the vocabulary and semantics of the mechanism. We will then examine many real-world examples of specialization, generalization, and the many misuses of inheritance. Consider the example in Figure 5.1, where class B inherits from class A.
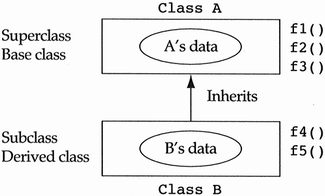
First a little vocabulary. If a class inherits from another class, it is called a subclass. If a class is inherited by another class, it is called a superclass. The inventor of C++, Bjarne Stroustrup, realized that these terms are ambiguous (for reasons we will see in the following discussion). He decided to rename superclass as base class and subclass as derived class. In this example, class A is considered a superclass or base class of class B, and class B is considered a subclass or derived class of class A.
If a class inherits from another class, then the inheriting class should be a special type of the inherited class. In this abstract example, class B is a special type of class A, meaning all B objects are first and foremost A objects. This implies that inheritance is a class-based relationship since all objects of the class must obey the relationship.
The first semantics of the inheritance relationship that one notices is that all derived classes (their objects) get a copy of the base class's data (see Figure 5.2). This does not necessarily imply that methods of the derived class can see the data of their base class; that is a matter for some debate. It implies that a subclass will always have a superset of its superclass's data (a proper superset if the subclass has any data of its own). Many newcomers to the paradigm argue that the terms “superclass” and “subclass” are backwards with regard to the set of data of each class. In fact, the terms “superclass” and “subclass” do not refer to the set of data in each class; they refer to the set of objects under each class. Since all B objects are legal A objects by definition, class A will always have a superset of B's objects (a proper superset if there are any A objects at all). It is this situation that Stroustrup found ambiguous and which led him to create the terms “base class” and “derived class.”

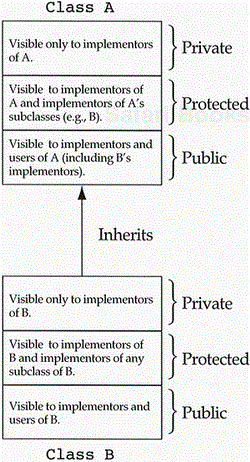
We discussed in Chapter 2 the fact that classes have two access areas, public and private. Within the framework of inheritance, it makes sense to consider a third level of access: protected. All three access areas can contain data as well as function members. The private area of a class is available only to the implementors of the class, that is, those who write methods for the class. The public area of a class is available to all implementors and users of the class. We have argued that no data should be placed in the public section since that would create an undesirable relationship between the users of the class and its implementation. The protected section of the class is something between public and private. It looks like private access to all users of the class except the implementors of derived classes. In our example in Figure 5.3, anything in the protected section of A would be visible to implementors of A (obviously) and implementors of B since B is a derived class of A. It would be invisible to other users of A as well as to the users of B. The main question is, “Should an implementor of B be allowed to see A's data?” Before we answer the question, we need to know a bit more about the semantics of inheritance.
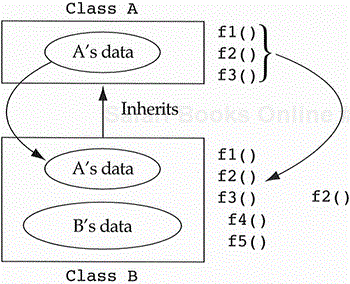
If inheritance only implied getting a copy of the base class data in the derived class, then the relationship would be useless. The containment relationship has the exact same semantics. There would be no difference between “class B inherits from class A” and “class B contains class A.” There must be some other difference that sets inheritance apart from containment. Since classes capture data and behavior, and we have already covered inheritance of data, it must be the behavior that is of interest. When a class inherits from another class, it not only gets a copy of the base class data, it also gets access to the base class functionality. This is what sets the containment and inheritance relationships apart. When a class contains another class, the containing class does not get the functionality of its contained class as part of its public interface. For example, the meal class contains a melon and the melon class has a peel operation that returns a rind. Does this imply that meals have a peel function defined in their public interface? The answer is no! Implementors of meals can send the contained melon the peel message as part of the implementation of a method for the meal class, but meals themselves do not get the operation for free. If the meal class inherited from the melon class, then the meal class would receive the peel function as part of its public interface. This would be necessary since we would be arguing that meals are special kinds of melons. If a class is a special type of another class, then it must behave like the other class.
In our abstract example, objects of class B would be allowed to process the messages f1, f2, and f3 since B objects are special types of A objects. Normally, if a B object were sent the message f1, the system would ask, “Do B objects know how to f1?” If the answer is no, error! Within the presence of inheritance, the system asks the same question, but if the answer is no it then asks, “Does B inherit from someone who does know how to f1?” If the answer is no, it is again an error. If, however, the answer is yes, then the system uses the inherited method to execute the message f1. If inheritance is being used to model a specialization hierarchy—and it should be—then the derived class is not allowed to eliminate any of the functionality of the base class. Otherwise anything could be made a special type of anything else by simply eliminating all behavior of the base class and adding all new behavior to the derived class; for example, a monkey is a special type of banana except it doesn't peel, turn_yellow, or chop; it does jump, squeal, and swing_from_trees though.
The inheritance of functionality and data creates an extremely powerful extensibility mechanism. It allows a designer to create a special type of an existing class which has additional data and function members and to guarantee that the new type is behaviorally compatible with the old type. This implies that I can change each base class object into a new derived class object and guarantee that the system will run exactly as it did before. This fact is easy to prove. Any message being sent to objects of the base class will be inherited from the base class by the new derived objects. These messages access data of the base class only; therefore, we have the same code running on the same data, providing behavioral compatibility (see Figure 5.4).

In many cases, the object-oriented designer uses inheritance to add a specialization relationship that is not behaviorally compatible to the superclass. This implies that the user wishes to override the definition of a base class message with his or her own algorithm. This is allowable within the framework of specialization and is called an overriding method. For specialization, the derived class cannot eliminate messages of the base class but the derived class can change the method that defines them (see Figure 5.5). Most object-oriented languages support the calling of the base class method from the overriding derived method. This is important since many times a designer has added data members to the derived class and wishes to handle their functionality at the derived class level. After handling the new data, the designer delegates up to the base class to let it handle its own data.
Inheritance is transitive in that if class B inherits from class A and class C inherits from class B, then class C inherits (via transitivity) class A (see Figure 5.6). This hierarchy demonstrates that a class can be both a derived class and a base class simultaneously. For example, class B is a base class of class C but a derived class of class A. One should think of inheritance as capturing a categorization hierarchy or taxonomy of the classes involved.

Inheritance should be used only to model a specialization hierarchy.
The containment relationship defines a black-box design where users of a class need not know about the implementation-dependent, internal classes. On the other hand, the inheritance relationship is a white-box design due to the inheritance of functionality. In order to know which messages can be sent to a derived class, I need to see the classes it inherits. If a white-box design is used where a black-box design would work as well, then we have needlessly opened our implementation to users of a class. Specialization cannot be effectively shown with a black-box design. Therefore, the opening of design details is allowable for this type of abstraction. For example, if I told you that I was a special type of XYZ, it would be useless until you understood what an XYZ is and what it does. Base classes are often used to convey high-level category information to readers of the design. In the winter of 1994, I taught a C++/object-oriented design course to a group in Singapore. Someone in the class asked me if I knew what a durian was. I told the attendee that I had no idea. She told me it was a tropical fruit unique to Southeast Asia. I still didn't know exactly what a durian was, but I had a good idea of some of its attributes and expected behaviors.
Derived classes must have knowledge of their base class by definition, but base classes should not know anything about their derived classes.
If base classes have knowledge of their derived classes, then it is implied that if a new derived class is added to a base class, the code of the base class will need modification. This is an undesirable dependency between the abstractions captured in the base and derived classes. We will see a much better solution to these types of dependencies when we discuss the topic of polymorphism later in this chapter.
Getting back to our question on protected data, let us add some real-world names to our classes A and B. Let us say that A is the class fruit, which has, as its data members, a real number called weight and a string called color. In addition, all fruit have a print operation that outputs strings like, “Hi, I'm a .3-pound red fruit.” That is the best the fruit class can do for a good default print function. Assume that class B is an apple that contains the additional data member variety. Should apple objects be able to see their own weight? Another way of asking the question is, “Should the weight data member of the fruit class be in the protected section?”
At first glance, this seems perfectly reasonable. If you do make weight a protected data member, then you are stating that if the weight data member needs to change in the future, you are willing to examine all methods of derived classes as well as the methods of the base class. This is a weakening of data hiding that should be avoided.
All data in a base class should be private; do not use protected data.
Just as I argued against those designers who favored public data, the designers should ask themselves the question, “What am I doing with the protected data, and why doesn't the class that owns the data (namely the base class) do it for me?” When asking the analogous question concerning public data, there is never a good answer. The designer is clearly missing an operation on the class through which he or she wants access to the data. In the case of protected data, there may be a valid answer. Why do I want to make the weight of fruit protected? Because the apple class is overriding the print method of fruit with its own print method. This method prints strings like, “Hi, I'm an apple and I weigh .3 pounds.” In order to define this function at the apple level, I need access to the weight. Why not let the fruit class handle this behavior? Because the fruit class is not supposed to know of any derived class-specific data (Heuristic 5.2). When stuck in these cases, it is best to create a protected access function called get_weight, which simply returns the weight data member. In this case, the methods of apple are dependent only on the protected interface of fruit and not on the implementation of fruit. The protected interface of fruit is much easier to maintain than the implementation. While I railed against public accessor methods in Chapter 3 which often demonstrate a design flaw, there is nothing wrong with defining protected accessor methods. They are allowing derived class implementors access to base class data in an implementation-safe way. The implementors of derived classes have a right to access the data of their base class; however, the users of a class do not have a right to the data of the class they are using.
Beware of the class designer who claims that the weights of fruits have been a real number since time immemorial; therefore we can make the data member protected since we know it will never change. Murphy's 79th law of programming will see us eating fruit on 30 different planets 20 years from now, and the weight data member will no longer be a real number but an object of type planetweight that contains a mass and an acceleration. Our protected access function could easily be updated to accommodate the new implementation, but the direct users of protected data will have to examine each of the methods on their derived classes for possible modifications.
Similarly, watch out for the class designers who claim that they are willing to look at the methods of only three additional classes (apple, banana, and orange) in order to win the right to make weight protected (see Figure 5.7). Twenty years from now, if the fruit class is worth anything, there will be many derived classes hanging off it. These designers will find themselves looking at the kiwi, which inherits from TropicalCitrusFruit, which inherits from CitrusFruit, which inherits from Fruit. Without a doubt, this assumption could become very dangerous, with formidable expense at maintenance time.

Some languages do not support the notion of a protected class access mechanism. These languages are deficient in that they compensate for the missing access protection either by making private access behave as protected, or by forcing the user to put all protected members in the public interface. The first solution opens up the implementations of all base classes to their derived classes, resulting in numerous maintenance headaches. The second solution forces the user to place implementation details in the public interface of the class, thereby forcing the user to violate Heuristic 2.5, which states that class designers should never put in the public interface items that users of the class do not require. In either event, such a language is not expressive enough to capture what we are trying to describe at design time.
What can we say about heuristics on the width and depth of inheritance hierarchies? For containment, we claimed that the width of the hierarchy should be limited to six classes. Is this reasonable for inheritance as well? No. The heuristic exists for containment because the addition of data members to a class increases the complexity of the methods of the class. Adding a new derived type of fruit to our inheritance hierarchy does not increase the complexity of the existing classes, since each derived class is independent of the other, and the base class should be independent of all derived classes (Heuristic 5.2). If there is any heuristic on the width of an inheritance hierarchy, it should be that the wider the hierarchy, the better (assuming the inheritance relationships are valid). A wide hierarchy implies that many classes are taking advantage of the abstraction captured in the base class. Each inheritance link is removing redundant design and implementation effort. However, it is important to note that many of the inheritance pitfalls we will discuss in this chapter manifest themselves as wide inheritance hierarchies.
In theory, inheritance hierarchies should be deep—the deeper, the better.
The motivation behind this heuristic is that by having a deep taxonomy of abstractions, a new derived class can descend the hierarchy, taking on more refined abstractions the deeper it travels. For example, it is better to have a kiwi inherit from TropicalFruitFromThePacificRim, which inherits from TropicalFruit, which inherits from Fruit, than to just have a kiwi inherit from Fruit. The kiwi can capture more and more abstractions as it is categorized by the deeper hierarchy.
In practice, inheritance hierarchies should be no deeper than an average person can keep in his or her short-term memory. A popular value for this depth is six.
Several projects' developers used the “deeper is better” philosophy when designing their object-oriented systems, only to find implementors getting lost in their deep inheritance hierarchies (which, in the case studies, were between 12 and 17 levels in depth). These developers redesigned their systems to take a less refined collection of abstractions with inheritance hierarchies that were only five to seven levels in depth. All projects' developers found these depths to be better. Like the heuristic involving the width of containment hierarchies, the number six is widely regarded as the number of items the average person can keep in short-term memory. Some designers have pointed out that this problem is due to a lack of tools. If a designer has a graphical user interface that allows him or her to point and click on a derived class, resulting in the display of the class with all of its inherited data and interface, then the theoretic heuristic is clearly the more appropriate of the two. Lacking such a tool implies that the pragmatic heuristic is more appropriate.
If you are, or will be, a C++ programmer, there is a note of caution pertaining to inheritance relationships. The C++ language has implemented relationships called private inheritance, protected inheritance, and public inheritance. The public inheritance relationship is synonymous with the definition of inheritance in the object-oriented paradigm. The private and protected inheritance relationships are used to capture the notion of “inheritance for implementation.” The semantics of these relationships are such that the derived class gets a copy of the base class data (with the same access rules of public inheritance); the implementors of the derived class get access to the public section of the base class; but the users of the derived class do not get access to the public section of the base class. In short, private and protected inheritance are the containment relationship. They do not capture the notion of either specialization or categorization. The difference between private and protected inheritance is that protected inheritance allows implementors of grandchildren (derived classes of the derived class) to use the public section of the base class; private inheritance does not.
Since classes can be inherited only once in C++, these relationships are actually a warped form of containment in that the containing class can contain only one object of the specified type. A good heuristic for C++ is to avoid the use of private and protected inheritance, using containment via data members instead. While I can find many C++ programmers who will argue that they know what they are doing and want to use C++'s inheritance relationship to implement containment, they are doing a great disservice to their maintenance people (which is probably them three months later when they cannot remember what they implemented). A serious pitfall in the object-oriented paradigm is confusing the use of containment and inheritance relationships. Using an inheritance syntax to implement containment muddies the waters all the more. In the name of readability, only public inheritance should be used in the C++ language.
The following facts are true, independent of the form of inheritance used (i.e., private, protected, or public inheritance) in the example in Figure 5.8).
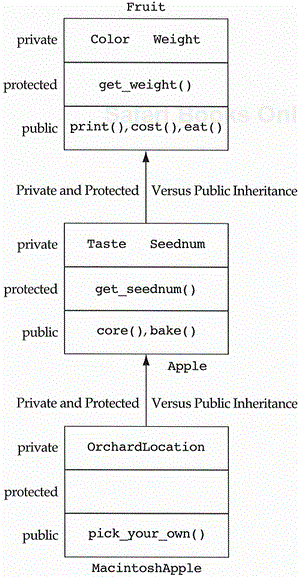
Anything in the private section of a class can be accessed only by implementors of that class, that is, only the implementors of
Fruitcan accessweightandcolorin the private section ofFruit;only the implementors ofApplecan accesstasteandseednumin the private section ofApple;and only the implementors ofMacintoshApplecan access theOrchardLocationin the private section ofMacintoshApple.Anything in the protected section of a class can only be accessed by implementors of that class or a derived class, that is, the
get_weightmethod ofFruitcan be accessed by implementors ofFruit,Apple, orMacintoshApple;theget_seednummethod ofApplecan be accessed by implementors ofAppleorMacintoshApple.Anything in the public section of a class can be accessed by implementors of that class or direct users of that class, that is, the
print,cost, andeatmethods ofFruitare visible to implementors and users ofFruit;thecoreandbakemethods ofAppleare visible to implementors and users ofApple;and thepick_your_ownmethod of theMacintoshAppleis visible to implementors and users ofMacintoshApple.Anything in the public interface of a class can be accessed by implementors of its immediate derived class, that is, the
print,cost, andeatmethods ofFruitare visible to implementors ofApple; thebakeandcoremethods ofAppleare visible to implementors ofMacintoshApple.
The only remaining questions are the following:
Can users of
Appleaccess the public interface ofFruit?Can users of
MacintoshAppleaccess the public interface ofApple?Can implementors of
MacintoshAppleaccess the public interface ofFruit?
If we use public inheritance, whose semantics state that the public interface of the base class appears to be copied into the public interface of the derived class, then the answer to all three questions is yes. If we use protected inheritance, whose semantics state that the public interface of the base class appears to be copied into the protected section of the derived class, then the users of Apple and MacintoshApple cannot access the eat, cost, and print operations since users of a class cannot access the contents of the protected section of a class. However, implementors of MacintoshApple can access the protected section of Apple so they can use the public methods of Fruit. Therefore, the answers to the three key questions are no, no, and yes. Lastly, if we use private inheritance, whose semantics state that the public interface of the base class appears to be copied into the private section of the derived class, then the answer would be no to all three questions since only the implementors of a class can see the private members of a class.
If all of this appears confusing, you are in good company. Private and protected inheritance are simply warped forms of containment and should be avoided. The fact that C++ has implemented these concepts warrants their treatment in this text. All future references to inheritance in this text are synonymous with public inheritance in C++. The reason I balk at creating heuristics telling designers to avoid using private and protected inheritance is that I want the heuristics to be language-independent. Also, both of these constructs have a well-founded theoretic backing (inheritance for implementation). The real problem with their use is understandability on the part of a system architect who is looking at code which uses these constructs. He or she is likely to think about the semantics of specialization when seeing the syntax of private inheritance, when in fact he or she is examining containment.
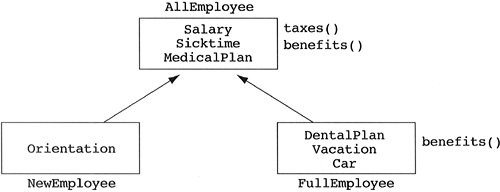
Now that we have seen an abstract model of inheritance, discussed the general semantics of the relationship, and developed some useful heuristics, let us look at some real-world examples of specialization and generalization. Assume we are starting a new company. We might decide that we are all new employees and each new employee gets a salary, sick time, and a medical plan. A couple of methods applicable to new employees is taxes (to compute taxes from salary) and benefits (to handle the sick time and medical plan). Such a class could be diagrammed as shown in Figure 5.9.

Six months go by and our start-up company is doing well because all of the employees work 80-hour weeks. We decide that anyone that has been employed by the company for six months should be considered a full employee with additional benefits over new employees. These benefits include a dental plan, vacation, and company car. Such a class is shown in Figure 5.10.

We notice that the data members of the full employee are the same as the new employee except for the additional benefits. Likewise, as we discuss the taxes and benefits functions for the full employee, we find that the taxes function is identical to the new employee (we assume nontaxable benefits in this example) and the benefits function is the same except for some additional code to handle the dental plan, vacation, and company car. In short, we realize that the full employee is really just a special kind of new employee. Since inheritance is the relationship responsible for modeling specialization, we claim that there is an inheritance relationship between the full and new employee classes with full employee being a derived class of new employee (see Figure 5.11).

All abstract classes must be base classes.
If a class cannot build objects of itself, then that class must be inherited by some derived class that does know how to build objects. If this is not the case, then the functionality of the base class can never be accessed by any object in the system, and therefore the class is irrelevant in the given domain. (There is one degenerate case where an abstract class that is not a base class can exist. We will examine this degenerate case in Chapter 8.)
What about the opposite heuristic—do all base classes have to be abstract? After examining the new and full employee example above, the answer is obviously no. Both the new and full employee classes are concrete classes (i.e. they know how to build objects of themselves) and the new employee is a base class. However, there is a heuristic that captures this desirable design trait.
All base classes should be abstract classes.
This heuristic implies that all the roots of an inheritance tree should be abstract, while only the leaves should be concrete. Why is this a heuristic? Consider our inheritance model for the new and full employees. Our company has been so successful that it takes new employees five months to learn who to see for maintenance, purchase-order signatures, sick time issues, health insurance, etc. The company decides that it is necessary for new employees to have a one-day orientation session to reduce this learning curve. Obviously, full employees already know all of these details, so they do not need an orientation session. In our current design, can we add an orientation to the new employee class without adding it to the full employee class? The answer is no; we cannot add anything to the new employee class without also adding it to the full employee class. This is the danger of inheriting from a concrete class. The fear is that the specialization link between the two classes will not hold up under extension or refinement of the design. How could we have avoided this problem? Instead of claiming that full employees are special types of new employees, we could have claimed that new employees and full employees have something in common. This common information could have been captured in an abstract base class called All Employees, with the new and full employee classes becoming derived classes of this new abstract class (see Figure 5.12).
In order to understand the strength of a heuristic, it is necessary to understand the ramifications of violating it. In this case, the necessary changes to our system were brought about by violating the heuristic. We had to rename all occurrences of NewEmployee to AllEmployee—a global name change. This is the worst that can happen to a designer who violates this heuristic. In fact, if the designer can live with the name of the concrete class as the name of the new abstract class (renaming the concrete class to something different), then he or she may be able to avoid the name change in some languages. For example, name the abstract class NewEmployee and rename what used to be NewEmployee as NewNewEmployee. Typically, and this example is no exception, the name of the concrete base class is too specific to use as the name of the new abstract class.
Given that violations of this heuristic can force a designer to rename classes globally, shouldn't we always turn inheritance from a concrete class into inheritance from an abstract class (using the Employee classes as a model)? The answer would appear to be yes, except that another heuristic gets in our way. Consider the case where we cannot see any change to the base class that we would not want carried into the derived class. As Figure 5.13 shows, the NewEmployee class could still inherit from AllEmployees, but it would be empty—no data and no behavior. All of its attributes would be derived from the abstract base class. This NewEmployee class is an irrelevant class since it adds no meaningful behavior to our system. Therefore, it should be removed, based on Heuristic 3.7.

This is a case where one heuristic tells the designer to go in one direction and another heuristic tells the designer to go in the exact opposite direction. Which direction should we choose? If there is only one place in the design where the choice needs to be made, then it does not matter. One irrelevant class will not ruin a design, nor will one area of the design that may require a global name change. Unfortunately, most designs have many places where this decision needs to be made. I would not want 50 irrelevant classes in my system, nor would I want 50 potential name changes. The typical solution is to attempt to find which of the 50 cases are most likely to change. Add an irrelevant derived class for these. The others are left as inheritance from a concrete class. It is important to realize that finding the classes most likely to change is not an easy task. Imagine a designer in our employee domain standing up in a design critique and stating, “We would never give anything to a new employee that a full employee would not want as well.” The assumption here is that everything a new employee gets is good. The designer has not considered orientation, layoff notices, probationary periods, etc. In languages that allow for type aliasing (e.g., the typedef statement in C and C++), a reasonable solution is to create the inheritance hierarchy with just the full and new employees (no abstract class) and alias the NewEmployee class to the AllEmployee class wherever applicable. This allows for easy global name changes should it ever become necessary.
We consider the preceding example to be specialization because we started with a base class and added a new derived class to our system. Consider the three classes displayed in Figure 5.14. It is obvious that they have some things in common. First, all three contain a weight and a color. This in itself is not enough to constitute an inheritance relationship. If two or more classes share only common data, that is, no common messages, then that common data should be encapsulated in some new class. The two (or more) classes that share the common data can each contain the new class. Since the object-oriented paradigm encapsulates data and behavior in a bidirectional relationship, common data usually implies common behavior. In these cases, an inheritance relationship is required to capture the common abstraction. In our example in Figure 5.14, each of the three classes also has a print and cost function (i.e., common messages). Upon further inspection, we find that the apple and orange classes also have the same implementation for the print function (i.e., common methods). The result is the need to create a common base class called Fruit to capture the common abstractions (see Figure 5.15).

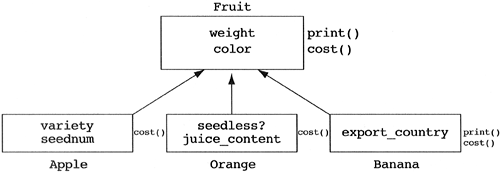
Since we started with derived classes and then found the base class, this is called generalization. While this real-world example makes it look easy to generalize, in practice many of the common abstractions are not found until the late stages of software development. This is not a serious problem since new base classes can be added to the system very late in development with little impact on the system. In this example, even if there were many users of Apple, Orange, and Banana, we could easily add the abstract Fruit class with no effect on these users. The users of these classes are sending messages to apples. They do not care if apple defines the method directly or steals it from a base class. As long as apple prints itself when it is told, the user is happy. Of course, in these situations there is a chance that the implementor of Apple named the method print() but the implementor of Orange named the equivalent method write().
Factor the commonality of data, behavior, and/or interface as high as possible in the inheritance hierarchy.
The point of this heuristic is to allow as many derived classes as possible to take advantage of a common abstraction. A violation of this heuristic implies that a particular abstraction will need to be redesigned and implemented in each of the derived classes, rather than once in the base class [9]. It is important that all derived classes in the hierarchy share the common abstraction, since the abstraction cannot (or should not) be eliminated by a derived class. See Section 5.17 for details of this common pitfall.
The heuristic also allows users of a derived class to decouple themselves from that class in favor of a more general class. For example, rather than depending on the Apple class, a user could depend on some fruit class, which may be an apple.
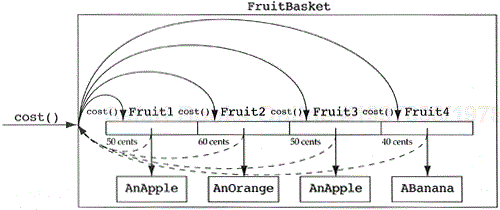
The fruit example, as written, assumes a domain where apples, oranges, and bananas are used separately. They just happen to have a common abstraction (fruit). Let us consider a domain where someone would like to walk up to a fruit, not knowing what type of fruit it happens to be, and tell it to compute its cost. The fruit basket object/class shown in Figure 5.16 is an example where this type of operation might be applicable.

For some of the operations on the fruit basket, it is convenient to think of a fruit basket as a list of fruit. Operations like how_many() do not care what types of fruits have been placed in the fruit basket. Other operations, such as cost, need to know the explicit type of fruit in the fruit basket since apples cost 50 cents, bananas cost 40 cents, and oranges cost 60 cents. In action-oriented programming, this type of construct is usually implemented as a structure-embedded union (in C) or variant record (in Pascal) (see Figure 5.17).

A design that uses variant records to implement the fruit basket inevitably requires explicit case analysis (e.g., a case statement, nested if-then-else statements) to determine which type was stored in the variant record. For example, the cost function for the variant record fruit would look like the following pseudocode:
Function fruit_cost( fruit f)
perform case analysis on the type field of f
case Apple: return 50
case Banana: return 40
case Orange: return 60
End
The problem with explicit case analysis is that if we decide to add a new type of fruit, we need to add a new case to the case statement. When we modify existing code, we risk introducing new bugs into that code. Watch out for the designer who claims that nothing can go wrong since there is only one added case statement. In reality, there is never one added case statement; there are usually many of them sprinkled throughout the code. The probability of forgetting to add the appropriate case to one of them is high [10].
The object-oriented paradigm solves this problem through a mechanism known as polymorphism or dynamic binding. The idea behind polymorphism is that a group of heterogeneous objects (e.g., apples, oranges, bananas) can be made to look homogeneous (e.g., a bunch of fruit), but can then be distinguished based on their own specific type at runtime. If you do not mind believing in magic, then imagine the ability to walk up to any fruit and tell it to give you its cost. You know the object to which you sent the cost message is not a fruit object because there is no such thing as a fruit object (fruit is an abstract class). Therefore, it is an apple, or a banana, or an orange masquerading as a fruit (see Figure 5.18). When the message is sent, the system figures out (magic) which type of fruit you are actually sending the message to and calls the appropriate method, i.e., the cost method of Apple, or the cost method of Banana, or the cost method of Orange.
If you do not like believing in magic, there is an explanation as to how polymorphism is implemented. In the object-oriented community, you may hear people talk about true polymorphism versus polymorphism. The argument here revolves around the implementation of polymorphism. Interpreted languages generally make all message sends polymorphic by definition of the language (e.g., SmallTalk). The typical implementation is for the system to ask the object for its type at the time the message is sent (see Figure 5.19). The object gives the system a string with the name of its type, e.g., “Apple.” The system hashes this string with the string containing the name of the message, e.g., “cost.” This gives the system an index into a hash table where the address of the cost method for the apple class lives. It then jumps to this address, which completes the message send. This is often called true polymorphism.

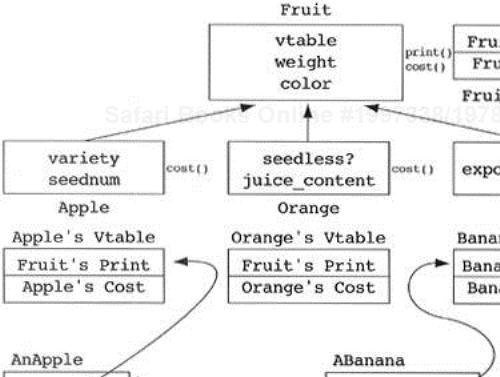
Compiled languages such as C++, which are concerned with higher levels of efficiency, allow the implementors of a class to decide which functions should be polymorphic (or dynamically bound) and which should be monomorphic (or statically bound). These languages typically build jump tables for each class containing poly-morphic functions. As is illustrated in Figure 5.20, a hidden pointer is added to each object, which points at its particular jump table. The address of this jump table maintains the particular type of the base class we are examining, e.g., apple objects point at the apple jump table even if they are being viewed as fruit. At runtime, when a derived class is built, its constructor points the hidden pointer at the appropriate jump table. In order to execute a polymorphic function call, the system need only jump into the jump table with the constant offset defined by the name of the message. No hashing of strings or hash table problems (e.g., collisions) need to be addressed at runtime.
There is another refinement to polymorphism, called pure polymorphism. A pure polymorphic function has no default definition in the base class. Derived classes that inherit a pure polymorphic function are said to be inheriting for interface, that is, they are inheriting messages, not methods. In the fruit example, we state that the print message for the Fruit class has a good default method. The best a fruit can do is print, “Hi, I'm a .3-pound red fruit.” If a derived class does not define its own print function, then it can at least get this default through inheritance. On the other hand, the cost function has no good default. The Fruit class wants to state that all derived classes of Fruit must define a cost method, but it has no clue as to what the algorithm should be. This is the role of pure polymorphism. We say that print for fruit is polymorphic, and cost for fruit is pure polymorphic. In C++, an abstract base class is implemented either as a class that has one or more pure polymorphic functions and/or as a class that has no public constructor.
If two or more classes share only common data (no common behavior), then that common data should be placed in a class that will be contained by each sharing class.
If two or more classes have common data and behavior (i.e., methods), then those classes should each inherit from a common base class that captures those data and methods.
If two or more classes share only a common interface (i.e., messages, not methods), then they should inherit from a common base class only if they will be used polymorphically.
The last heuristic refers to the fact that inheritance for interface does not buy you anything unless the derived objects will be required to perform a runtime type discrimination. If all valves turn on and turn off, but each valve does it differently, then the base class “valve” is not useful unless there exists some place in the application where a generic valve will need to decide which it is at runtime. If water valves are always used in one place, and oil valves are always used in another place, then runtime-type discrimination is unnecessary and the base class “valve” adds no interesting perspectives to the design. Of course, a designer is free to argue that the objects are likely to be polymorphic in the future, thereby justifying the existence of the base class through extensibility concerns.
Explicit case analysis on the type of an object is usually an error. The designer should use polymorphism in most of these cases.
If a designer creates a method that states, “If you are of type1, do this; else if you are of type2, do this; else if are of type3, do this, else if …,” he or she is making a mistake. The better approach is to have all of the types involved in the explicit case analysis inherit from a common class. This common class defines a pure polymorphic function called do_this, and each type can write its own do_this method. Now the method the designer creates need only send the do_this message to the object in question. The polymorphism mechanism can perform the case analysis implicitly, eliminating the need to modify existing code when a new type is added to the system.
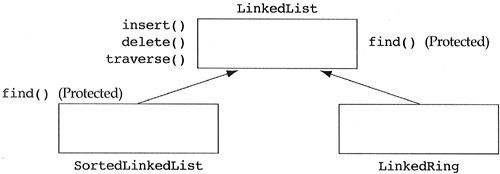
One role of polymorphism is in the creation of reusable, standard components that can be derived into custom components. Beware of the marketing hype that claims that object-oriented designers can take standard components from a reusable library, inherit from them, and produce custom components that optimally reuse the code of the standard component. The following case study is taken from a C++ class library project in which I participated several years ago. In the process of designing a linked list class, I considered the fact that the library was also going to have a sorted linked list class. Early in the design process, I realized that sorted linked lists are special types of linked lists (which are unsorted). I wondered how to get optimal reuse of code from this inheritance relationship, and came up with the design in Figure 5.21.

I then realized that it was not the insert and delete methods that were different—it was where I performed the insertion and deletion that differed. I abstracted out this difference into a polymorphic function called find and made the function protected. The reason for the protected status is that the find method is not an operation for users of the classes, and so it should not be in the public interface, but the derived class (SortedLinkedList) needs to override it. Thus, it cannot be private. The resultant hierarchy, shown in Figure 5.22, produced optimal reusability of the base class code (or at least as optimal as I could imagine). In the actual library, the LinkedList class consisted of 40 pages of code and documentation, whereas the SortedLinkedList class had only 2 pages, most of it documentation.

It is very common to see protected, polymorphic functions being called from monomorphic functions in the base class (in languages that allow implementors a choice between polymorphic and monomorphic functions). Some developers like to call them the “reusability hooks” of a class. Examples of this type of binding can be viewed through examples of a linked list and a sorted linked list inserting a number. The examples assume a compiled language that supports implementor choices between monomorphic and polymorphic functions.
When a linked list wishes to insert a value, the compiler, at compile time, asks the linked list class, “Do you know how to insert into objects of your class?” The answer is yes (see Figure 5.22), so hardwire the function call to
insertfor linked list. This method always takes a reference to a linked list as the implied first argument. However, that reference may be referring to a derived object of linked list (namely a sorted linked list object). At runtime, the insert for linked list method is directly called, and execution continues until the call to thefindmethod. Thefindmessage is polymorphic, so the system must ask the implied first argument, “I know you look like a linked list object, but what are you really?” The object replies, “I'm a linked list!” The system then transfers control to the protectedfindmethod for linked list, which returns the desired result for linked list objects andinsertcontinues.When a sorted linked list wishes to insert a value, the compiler, at compile time, asks the sorted linked list class, “Do you know how to insert into objects of your class?” The answer is no since sorted linked lists do not define an insert method. The compiler then asks, “Do you inherit from someone who does know how to insert?” The answer is yes—the linked list class. The compiler then hardwires the call to
insertfor linked list. At runtime, the insert for linked list method is directly called, and execution continues until the call to thefindmethod. The find message is polymorphic, so the system must ask the implied first argument (which is a reference to a linked list), “I know you look like a linked list object, but what are you really?” The object replies, “Okay! You caught me. I'm a sorted linked list object masquerading as a linked list.” The system then transfers control to the protectedfindmethod for sorted linked list, which returns a result very different from thefindmethod of linked list, andinsertcontinues.
It appeared that the marketing hype was true. I took a standard component (LinkedList) and created a custom component (SortedLinkedList) with optimal code reusability (see Figure 5.23). Given this fact, it would be possible to sell the library as a collection of class definitions (header files) and object code consisting of the compiled class methods. Customizers of my standard components would not need to know the implementation of my base classes in order to customize them. My balloon suddenly burst when I decided to add a linked ring class to my class library. I realized quickly that linked rings are really just special types of linked lists except the tail pointer of the list points back at the head. I was disappointed to find out that I got zero code reusability. When I implemented the methods of linked list, I iterated over the list by using a conditional test that checked to see if the current pointer into the list was nil (or NULL, i.e., zero, for C++ programmers). If it was nil, then I knew I was at the end of the list. By definition, the linked ring abstraction will never see a nil. Even an operation as simple as traverse(), which prints the elements of a list, was unusable. Given a linked list with the values 10, 20, and 30, traverse would print “(10 20 30).” A linked ring of the same value would print “(10 20 30 10 20 30 . . . )” ad infinitum.
Proponents of the marketing hype argue that the problem is mine, not that of inheritance. Their heuristic is that every separate idea within a method of a base class should be encapsulated in a protected, polymorphic function. It is true that if you follow this heuristic you will always get optimal code reusability. You will also go insane if you try to debug or maintain a base class designed in such a manner. The biggest problem is deciding what constitutes a separate idea. Is dynamically allocating a node of a list, perhaps as part of a copy method, a separate idea? It is not, given the classes we have discussed so far. The picture changes when one starts thinking about doubly linked lists, which contain double_nodes instead of nodes. In short, a derived class is what defines separate ideas in the base class methods. Therefore, unless you know about the derived classes, you cannot provide the necessary hooks in the base class methods. This is the bad news. The good news is that optimal reusability can be achieved with some changes to the implementation details of the base class. The important point is that a customizer needs access to the implementation of a base class. The fact that most, if not all, class libraries are sold in source-code format attests to this fact.
In this example we need to abstract out the testing for the end of lists in the base class methods into a protected polymorphic method called at_end(). The at_end method will simply check against NULL for the LinkedList objects and the SortedLinkedList objects (via inheritance; see Figure 5.24). However, the LinkedRing class will override this method with its own at_end method, which will test the current pointer against the head pointer.

The only party affected by the new polymorphic at_end function is the implementors of the LinkedList class. The users are unaffected, and they are the group we worry about most. Many designers point out that as a class gets older, it picks up more and more of these polymorphic hook functions, which makes it easier to get optimal reuse for free. This is entirely true and is called the maturing of the base class. Consider a sorted linked ring class. All of the necessary code is already defined in the existing classes. We simply take the at_end method of LinkedRing and the find method of SortedLinkedList. It is important to note that a new derived class may require more than one polymorphic hook function to get optimal reusability. In our class library, the doubly linked list class required five additional polymorphic hook functions in order to incorporate its abstraction optimally with that of the linked list class. Once we found the necessary abstractions, we had all of the necessary hooks for SortedDoublyLinkedList, DoublyLinkedRing, and SortedDoublyLinkedRing. In any event, these hooks are always implementation details of the base class.
Recall Heuristic 4.13 on the containment relationship. It stated that a contained object should not have knowledge of the class that contains it. We stated that this heuristic is important if a designer wishes to reuse his or her abstractions. If the contained object knows its containing class, then it cannot be reused in a domain that does not have the container and everything else in that container.
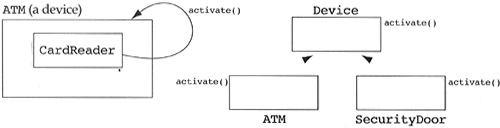
Following this heuristic often becomes a problem when dealing with interrupt driven devices. Consider the problem where ATM contains a CardReader. A use case of this system states that the user puts a card in a CardReader, which activates the ATM. The most intuitive design for such a system might look like the diagram in Figure 5.25. The main problem with this design is that CardReader cannot be reused outside the domain of the ATM. What if we wish to build a new class called SecurityDoor which contains a CardReader? This design would not allow it.

A better solution is to use the inheritance relationship to generalize the ATM to some device (see Figure 5.26). This uses the inheritance relationship to state that an ATM is a special type of device, and it uses the containment relationship to state that CardReaders are contained in some device, not necessarily an ATM. This reduces the constraint from “CardReaders must be used inside an ATM” to “CardReaders must be used inside some device, of which ATM is one of many.” This solution implies that multiple inheritance might be necessary. If the ATM contains two such interrupting devices and wishes to use this generalizing solution, then it will need to inherit from two abstract classes. This inheritance will be easy to live with since the abstract classes will contain only a pure polymorphic interface closely coupled with the contained data object (in this case, the CardReader).
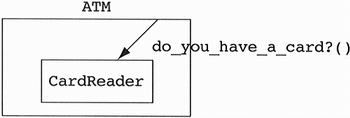
An even better design (from the viewpoint of logical design), which removes all constraints, is to modify the way we look at interrupt-driven systems. In one design course, a participant said, “Everything is a polling system. The difference between polling and interrupt-driven is your point of view. When we poll in hardware, we like to call it interrupt-driven.” With this in mind, let us think of the CardReader as a polled device. Even if it is physically interrupt-driven, we can use the interrupt to change the state of the CardReader object. The ATM can poll for a change in this state. This design allows any object or class to ask the CardReader if it has a card (see Figure 5.27). When it has a card, the client object can react any way it likes. This design offers the needed flexibility when dealing with containment hierarchies. The reader should note that this design might not be practical for physical design reasons, such as efficiency. The fact that an ATM does not do anything while waiting for a card allows us to use the polling solution.
An interesting problem arises due to confusion between attributes versus the need for an inheritance hierarchy. A design philosophy advocated by Weiner, Wilkerson, and Wirfs-Brock [10] includes examining the parts of speech associated with the English description of the system (a requirements specification). They state that nouns are good candidates for classes and objects, verbs are good candidates for operations on these classes and objects, and adjectives tend to signal inheritance. I like their methodology because it gives designers a starting point when they have no idea what their classes/objects, operations, or inheritance should be. I dislike their methodology because it starts designers off with a long list of candidates that must be refined. It puts them on a dangerous path toward the proliferation of classes, one of the more serious problems in the object-oriented paradigm. At this time, let us focus on the adjectives portion of their methodology. I have a requirements specification with the following sentence in it:
In our system, there exist red balls, green balls, and yellow balls.
Which of the designs in Figure 5.28 is a better model of the class Ball?
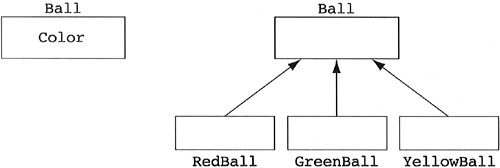
Many designers choose the first model, where there exists one class called Ball, which has color as an attribute. Unfortunately, the requirements specification describes a domain in which red balls bounce twice as high as green balls and yellow balls do not bounce at all. Also, if you eat a red ball you die, a yellow ball makes you sick, and a green ball makes you stronger. Now which design is better?
Another question that demonstrates the same problem can be extracted from the fruit hierarchy described earlier. Why is it considered reasonable to have a variety attribute in the Apple class but not in the Fruit class? There are different types of fruit, and we modeled that abstraction as an inheritance hierarchy. However, there are also different types of apples, and we implemented that abstraction as an attribute. Why is there a difference?
The deciding question is “Does the value of an attribute affect the behavior of the class?” If the answer is yes, then most of the time we want inheritance. If the answer is no, then we want to model the abstraction as an attribute that can take on different values. There are cases where differing values of attributes should not imply inheritance. We will discuss this class of problems a bit later in this chapter.
What would inform a designer that he or she is making a mistake if the error is to model an abstraction as an attribute when it should have been modeled as an inheritance hierarchy? As the designer begins to model methods of his or her class, he or she will notice that some methods are performing explicit case analysis on the values of attributes. This implies that inheritance might be necessary.
What would inform a designer that he or she is making a mistake if the error is to model an abstraction as an inheritance hierarchy when it should have been modeled as an attribute? All meaningful behavior on the derived classes will be the same, so it will migrate to the abstract base class. This implies that all of the derived classes lack meaningful behavior of their own and should be eliminated as irrelevant classes. The first case is much more common. As a design proceeds through many iterations and more information is gathered, it is often the case that attributes end up defining an inheritance hierarchy.
Beware of behaviors defined on derived classes which could be factored into a single behavior of the base class through parameterization via the value of a base class attribute. An example would be a designer who argues that the RedBall, GreenBall, and YellowBall classes need to exist because the print function for RedBall prints “Hi, I'm a red ball!”; the print function for GreenBall prints “Hi, I'm a green ball!”; and the print function for YellowBall prints “Hi, I'm a yellow ball!” The bounce function of ball mentioned earlier might fit into this category. Maybe the Ball class should have an attribute called Bounce-Factor, which would be zero, one, or two.
Let us examine a new inheritance hierarchy that was discovered through application of Heuristic 5.13. While examining a Stack class, a designer realized that the pop method was performing case analysis on the value of the Stack_pointer data member. If it was zero, the stack could not pop, and if it was greater than zero, it had an algorithm for popping. The design was further substantiated when he or she realized that empty stacks know how to push but nonempty stacks know how to both push and pop (see Figure 5.29). That is, the pop method is really an added functionality.
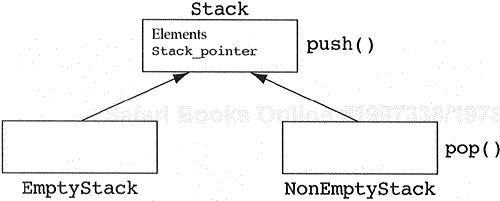
What do you think of this design? Everything seems satisfactory until we think about the life of a stack object. It is created as an empty stack object; someone executes a push operation and the empty stack object is converted to a nonempty stack object. Later, someone executes a pop operation and the nonempty stack object turns back into an empty stack object. The object keeps toggling its type at runtime. In most object-oriented implementations, changing the type of an object at runtime is an expensive operation. It requires constructing an object of the new class using a constructor for the new class which accepts an object of the old class as an argument. The old object must then be destroyed upon return from the constructor.
What has caused this problem? It turns out that explicit case analysis on the value of an attribute is sometimes the implementation of the dynamic semantics of an object (i.e., its states and their transitions). If a designer attempts to capture these dynamic semantics using the static semantics of inheritance, a toggling of types is the result. Whenever an object would have changed its state in the old design, an object of one derived class must be changed to an object of another derived class in the new design. This is highly inefficient and confusing. The modeling of an object's legal states as classes is another cause of proliferation of classes, albeit a trivial one. The designer usually detects this toggling problem at design time, and certainly at implementation time. While the stack class in Figure 5.29 does not look like a serious proliferation problem, consider the state-transition diagram in Figure 2.9 for the class Process (of an operating system). If each state of the Process class is modeled as its own distinct class, then we would be adding five new classes to our system. In addition, many objects would be toggling their types at runtime. In any event, users of a class should not be aware of the mechanics of its states and/or their transitions. These items are implementation details of the class.
Do not model the dynamic semantics of a class through the use of the inheritance relationship. An attempt to model dynamic semantics with a static semantic relationship will lead to a toggling of types at runtime.
How do we implement dynamic semantics? The preferred method is to perform explicit case analysis on the values of the attributes that capture the state information. While explicit case analysis is undesirable, at least this case analysis is used only by implementors of the class. Explicit case analysis on the types of objects is often performed by the users of a class, a much nastier maintenance problem. Also, it is much more likely for applications to get a new type than for a class to get a new state. James Coplien's letter/envelope idiom can be used to provide an interesting polymorphic solution to this problem [11]. I call this solution a dynamic semantic wrapper and display it in Figure 5.30. The idea is to capture the states of a class in an inheritance hierarchy internal to the class. A state field of the class will toggle types, but since the state class does not contain data, type changes are extremely cheap (one-integer assignment in the case of C++).

The problem with this solution is that inheritance hierarchies tend to get a bit unruly in large applications. Having each class with interesting dynamic semantics contain its own inheritance hierarchy adds complexity to the design. Many developers do not feel this added complexity is a good trade-off considering they only get out of explicit case analysis in the hidden implementation of the class. However, as Coplien correctly points out, some classes have very complex state behavior that certainly benefits from the distributive effects of the inheritance solution.
Recall our Dictionary class from Chapter 2's (Section 2.3) discussion on class cohesion and coupling. In that example, we took a dictionary that contained a property list and hash table with the four operations hadd, padd, hfind, and pfind and converted it into two classes called PDictionary and HDictionary, each having “add” and “find” operations. This solution eliminated the weak coupling and non-communicating behavior found in the Dictionary class but required the builder of Dictionary objects to decide which implementation of dictionaries he or she wanted. In some domains, leaving this decision to the users is appropriate. If the builder of a dictionary understands how he or she will use the dictionary, then perhaps he or she should be the one to make the implementation decision. Some may object to my concatenating the name of a data type to the word “dictionary,” but that is just an argument of class naming. If we called them SmallDictionary and LargeDictionary, most objectors would disappear.
(Side note: I am constantly surprised at the amount of time wasted during design critiques when two parties think they are arguing about some important design issue when, in fact, they are arguing only about the name of a class. Some of these discussions are due to the learning curve, and some are intrinsic to design in general. I think I have become faster at catching these cases, but I am amazed at how often I get dragged into such discussions. I am tempted to add this tongue-in-cheek heuristic: “If two parties who know what they are talking about argue for a long period of time during a design critique, flip a coin to resolve the situation.” The argument implies that the two camps are in a design situation where there does not exist a clear trade-off between the two contested designs. The “who know what they are talking about” clause is very important. Sometimes critique arguments go on for a long period of time because neither party knows what they are talking about. I do not mind arguing for six hours over the name of a class as long as I understand that, at the end of the argument, all I stand to win or lose is a class name.)
In many domains it is not appropriate for the users of a class to decide a class's representation. The class implementors are expected to decide the best representation for the class, based on its current state. Whenever the state changes, the class implementors are required to examine the change and determine if the representation still adequately reflects the best solution for the given use of the object. If the representation becomes inappropriate, the implementors are expected to effect the necessary representational changes. In the case of dictionaries, the constraints may state that for dictionaries with less than 100 words, property lists are the best representation; for dictionaries with more than 100 words, hash tables become more appropriate. When a Dictionary object's user adds the 100th word to the object, the Dictionary class automatically changes its representation from a property list to a hash table. If a Dictionary object's word count drops below 100, the Dictionary class will change the representation back to a property list from the hash table. This change of representation is completely hidden from the users of the class (see Figure 5.31).

Consider the inheritance hierarchy shown in Figure 5.32. At first view the inheritance hierarchy looks correct. GeneralMotors, Ford, and Chrysler are all special types of car manufacturers. On second thought, is GeneralMotors really a special type of car manufacturer? Or is it an example of a car manufacturer? This is a classic error and it causes proliferation of classes. The designer of this hierarchy has accidentally turned what should have been objects of a class into derived classes of the class. If you have made this mistake, it will certainly manifest itself as a derived class for which there is only one instance in your system. How many GeneralMotors objects are there? Ford objects? Chrysler objects? The answer for all three classes is one. In this case they should have been objects. Keep in mind that not all derived classes that have only one instance in your system are manifestations of this error, but many will be.
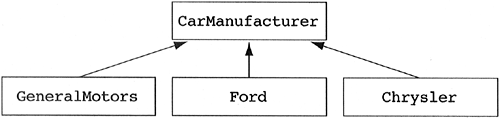
Do not turn objects of a class into derived classes of the class. Be very suspicious of any derived class for which there is only one instance.
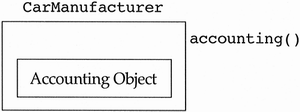
There is a temptation to state that in some domains the three objects of the class CarManufacturer should actually be derived classes due to some domain-specific reason. For example, perhaps GeneralMotors and Ford have very different accounting methods, and we feel this difference in behavior requires a polymorphic method (see Figure 5.33). Even in these cases, the three items in question are still objects. If the accounting methods are different, the developer is required to find some way of abstracting the differences into the data of the CarManufacturer class and to create a generic method that uses this data to manifest the appropriate behavior of each object. It makes no sense to create a derived class for which there can be only one object.
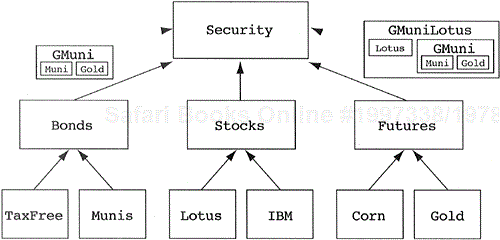
Another category of problem manifests itself through inheritance hierarchies. This problem occurs when a developer thinks that he or she needs to create new classes at runtime. The domain in which this problem presented itself was a case where a development team was designing a trading system for securities. One requirement of the system was to allow securities traders to build deals around a fixed set of securities set by the SEC and other government bodies. They designed the class hierarchy displayed in Figure 5.34 to model these securities.

A second requirement stated that traders want the ability to invent and trade new securities on a moment's notice. For example, a trader may decide to group a gold option with a taxfree municipal bond and call it a new security, say a Gmuni. Even worse, the trader may decide to take his or her new Gmuni security and combine it with Lotus Development Corp. stock and call this new security a GmuniLotus (see Figure 5.35).[*] The possible permutations are endless. This led the developers to assume that they needed an interpreted language to carry out their goals, since compiled languages wouldn't allow them to create classes and inheritance relationships at runtime.
When faced with these situations, a designer needs to reconsider the problem. We should state, “We do not build classes at runtime; we build objects at runtime.” The problem for us to solve is the generalization of the things we consider classes, but are really objects. The resulting generalization will be a new class that captures the abstractions within our problem. In this example, let us consider the Gmuni, GmuniLotus, and a number of other custom-built securities to be objects. What class would capture the abstraction to which these objects belong? In the most general case, these objects belong to a class that is a container of securities. This can be captured in the BasketOfSecurity class shown in Figure 5.36.
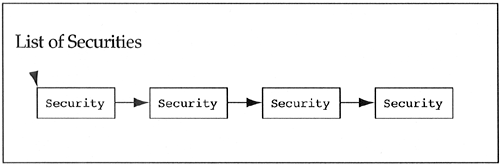
Figure 5.37 illustrates that not only does the BasketOfSecurity class contain a list of securities, but it is itself a security. This is an unusual, but not incorrect, case where a class contains and inherits from the same class. It is unusual only because containers of items are seldom a special type of the items that they contain. Another example of this construct can be seen in graphical user interface classes. A window can be viewed as a container of window items (buttons, sliders, borders, etc.). In addition, a window is a window item because windows can contain windows.

Consider a pure polymorphic function called price(). Each security in the hierarchy must define a price method describing the security's current value. If the price of any BasketOfSecurity is simply the sum of its components, then the method is trivial. We simply loop over the list of securities, summing the price of each. In the active world of securities, this simple scheme is inadequate. The traders of securities build new securities, which amount to hedged bets. By selling gold and buying silver in one security, the trader limits the potential for loss since gold and silver tend to rise and fall together. The trader is hoping the spread between the two increases in his or her favor. Some of these hedging structures can have complex pricing schemes. Beware of class designers who argue that since each BasketOfSecurity knows how to price itself differently, each should be a different class with a polymorphic price method. The items in question are still objects. It is just that the problem of pricing them has gotten tougher to generalize. We need to come up with a pricing formula that is encapsulated in each BasketOfSecurity object (see Figure 5.38). A generic pricing method can then use this encapsulated formula to calculate the price of the new security.

Another case where this problem arose was in a group of developers designing a reporting system for automobile engine test data. The requirements of the system included the ability for end users to describe complex reports such as, “Show me the blah-blah-blah statistics averaged over every tenth point for the first two thousand data points then every fiftieth point for the next fifty thousand data points, etc.” These report descriptions could be extremely complicated. The initial assumption was that each report description represented a class. Again the problem was creating classes at runtime. The solution was to treat every report as an object and then find a good report class that generalized all of them. The data implementation of this class was fairly complex, but the generic methods were surprisingly easy. The main benefit was that only objects were built at runtime, not classes.
Another interesting problem that arises in the construction of inheritance hierarchies occurs when the designer attempts to NOP a base method in the derived class, that is, define an empty method in the derived class. While teaching a C++ course at a telecommunications company, I introduced the following heuristic.
It should be illegal for a derived class to override a base class method with a NOP method, that is, a method that does nothing.
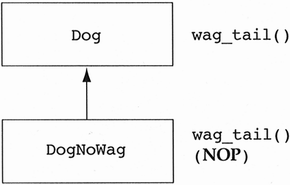
An attendee of the course objected, explaining that their developers did this all of the time. Rather than explaining the actual problem involving classes in their domain combined with a C++ binding for OSF Motif, the objecting person drew a real-world analogy. She stated that they had a situation in which there is an existing class called Dog. The behaviors that all Dogs know how to carry out is bark, chase_cats, and wag_tail. Later in development they discovered a special type of Dog (a derived class) called DogNoWag. This new class was exactly like a Dog except it didn't know how to wag its tail. They claimed that a good solution was to have DogNoWag inherit from Dog and override the wag_tail method with an empty C++ method (i.e., a NOP) (see Figure 5.39).
A number of other students in the class began to shout out supporting statements such as, “What about dogs with paralyzed tails?” “What about dogs with cut-off tails?” “What about dogs with broken tails?” and “What about stupid dogs who haven't learned to wag their tail?” I have encountered this phenomenon with increasing frequency. These questions imply a completely different design problem than the original, although the originators assume they are bolstering the same argument. There are at least two separate arguments being carried out here. I will create three separate arguments from these questions, in order to introduce a third concept.
The first argument is the one raised by the original problem. What is wrong with the design presented in Figure 5.39? The main objection is that the design does not capture a logical relationship. The design implies the following statements:
All dogs know how to wag their tails.
DogNoWagis a special type of dog.DogNoWagdoes not know how to wag its tail.
Obviously, the rules of classic logic are not being obeyed. Either all dogs do not know how to wag their tails or DogNoWag is not a special type of dog. Why should we preserve classic logic? My main argument is that a designer can now use inheritance without restriction. Anything could be considered a specialization of anything else by NOPing all of its base class public interface and adding a new derived public interface.
I have seen this NOPing problem entering many designs since the issue was first raised in this course. I believe the problem is psychological: It has always occurred in designs where a derived class is already present and a base class is being added. For whatever reason, designers tend to consider any new class added to a design as being a derived class of the existing classes. When the new base class is added, it is forced to inherit from something that should be its derived class. The result is to eliminate some of the functionality of the derived (acting as base) class via NOP methods. The correct design is found by flipping the hierarchy upside down, making the base class the derived class and the derived class the base class (see Figure 5.40).

However, in some cases, the DogNoWag class has some message/method that the Dog class does not have. In these cases, neither class is a derived class of the other; they simply have something in common. This common information is captured in an abstract class (e.g., AllDogs), and both classes inherit from the abstract class (see Figure 5.41). This latter solution always eliminates the problem of NOP functions.

A recently published introductory object-oriented text contained an example that argued against this heuristic. The domain was that of the animal kingdom, with a focus on platypuses. The author argued that the real world is more complex than that of simple inheritance. We like to categorize things with exceptions, making statements such as
All mammals have hair, nurse their young with milk, are warm-blooded, and give live birth to their young. Platypuses are special types of mammals that lay eggs instead of giving live birth.
Such a statement maps to the design in Figure 5.42 of mammals and platypuses.

This design is clearly equivalent with the dogs and their tails design: It violates classic logic. Either platypuses are not mammals, or not all mammals give live birth. But what if this is the way human beings like to think of the relationship between mammals and platypuses? Shouldn't we be allowed to model our domains in the way we like to think about them? I will argue against this type of justification. I do not think we can correctly think of a platypus as a special type of mammal unless we are willing to give up the notion that all mammals give live birth. What we really need to state is that mammals and platypuses have a lot in common. That common information needs to be stored in a new base class from which both Platypus and Mammal inherit (see Figure 5.43). This is the same solution we used for the dog example.

What about the stupid dogs, dogs with paralyzed tails, broken tails, cut-off tails? These are not special classes of dogs: They are dogs with bad state. They still have a wag_tail method, which checks the state of the dog, finds that the state is insufficient to manifest behavior, and terminates. This method is not a NOP—it has behavior. If these states were modeled as classes, we would get the same problem we had with the Stack, EmptyStack, and NonEmptyStack classes, namely, toggling types. Stupid dogs will learn to wag their tails and change their type from StupidDog to Dog. Later they might bump their heads into walls and be stupid again, necessitating a change in type (see Figure 5.44). Likewise, paralyzed and broken tails heal, cut-off tails are stitched back on, etc. You would not want to create classes like CarWithDeadBattery, CarWithStolenBattery, CarWithBadStarter, CarWithCrackedBlock, or CarWithWrongEngine. These are simply examples of cars with bad state.

While dogs with their tails cut off can be described as dogs with bad state, they bring up an interesting design point. How do we handle optional components of a class? The tail of a dog is optional, the cocktail sauce on a shrimp cocktail is optional, etc. There are two main proposals for the design of optional components: inheritance and containment by reference. These designs are demonstrated in Figure 5.45 for both of the example domains.

At first glance, some C++ programmers would choose inheritance as a better model because C++ would use a NULL pointer to implement dogs without their optional tail (see Figure 5.46). This would imply that the wag_tail method would need to perform a conditional test on the pointer before sending a message. Since we try to eliminate explicit case analysis, inheritance seems to be a better choice. As any SmallTalk programmer would point out, the problem is not in the design but in the choice of a multiparadigm language. In a pure language, the NULL pointer could be an object that would be sent the necessary message without a conditional test. In addition, the inheritance solution introduces an extra class (i.e., it is more complex). This type of trade-off will take up incredible amounts of time in a design critique. Neither camp can get enough of an advantage to justify one design over another.

While the trade-offs between these two methods are minimal when there is only one optional component, this is not the case when there are two or more optional components. Consider a House class, which has a heating system, a cooling system, a plumbing system, and an electrical system. All four systems are optional components of a house. Using inheritance to model this design, we end up with 17 classes: 16 derived classes and the base class House. The beauty of this design is that every time we add an optional symbol to our House class, the number of derived classes doubles (approximately). Add an optional alarm system, and we end up with 33 classes instead of 17. Add an automatic sprinkler system, and we get 65 classes. This leads to an exponential, and obvious, proliferation of classes (see Figure 5.47).

The solution is to use containment by reference whenever there are two or more optional components (see Figure 5.48). In order to be consistent, most designers will use this choice when there is only one optional component.
All of the problems discussed thus far have a satisfactory solution(s). The following problem occurs often in design but has no satisfactory solution; all known solutions have some major drawback. Consider our previous example of a fruit basket (in Section 5.9) that can contain any number of apples, oranges, and bananas. We discussed the role of polymorphism in this example, and why it was to our advantage to design the fruit basket as containing a mixed list of fruit. It often occurs that this mixed-list design is useful for many operations defined for fruit baskets. However, at some later date we decide that one of the derived classes has a special behavior that the others do not. The designer wishes to iterate over all of the fruit in the list for some operations, but then would like to look only at the objects of a particular derived class. For example, consider the case where apples know how to core themselves, but “core” has no relevant meaning to the other types of fruit. Let us also assume that the designer wishes to iterate over the fruit list, telling just the apples to core themselves. How can this be accomplished? We cannot iterate over all the fruit, telling them to core themselves, since only certain fruit know the meaning of that operation. The two most popular solutions either warp the model of fruit by forcing all fruit to know how to core themselves or force the user of the Fruit hierarchy to perform a large amount of bookkeeping (see Figure 5.49).

It is important to be sure that the problem actually exists before discussing the possible solutions. This problem often occurs due to naming problems of methods. Consider the Fruit hierarchy shown in Figure 5.50.
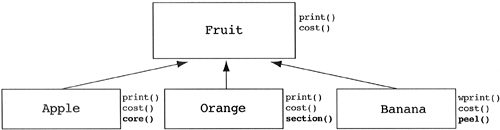
If the designer wants to send the apples the core message, the oranges the section message, and the bananas the peel message, the real problem is found in the naming of the messages. A better solution would be to state that all fruit know how to prepare themselves, but there exists no good default method (i.e., prepare is a pure polymorphic function). The core message of apple, the section message of orange, and the peel message of banana are all renamed to prepare, and the problem is solved (see Figure 5.51).
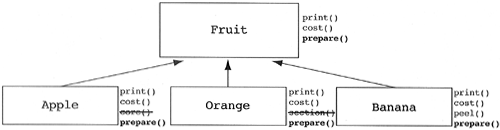
Assuming that the problem really exists, our options are limited. A naive solution is to have each class in the hierarchy maintain a list of messages to which it can respond. At runtime, the developer asks each object for that list of messages. If the appropriate message is in the list, then the developer can send the right message. In this example, the developer would send each fruit object in the fruit basket a “tell me what you can do” message. He or she then checks to see if core is in the list. If it is, the core message can be sent to the object. The maintenance of the “tell me what you can do” method is the Achille's heel of this solution. Implementors will never be able to keep up with changes to the class due to the implicit, accidental complexity introduced by this solution. This solution is sometimes used appropriately in domains where all objects are restricted as to what operations they can perform/add.
A second, and to many designers the best, solution is to define a core method on the fruit class which is defined as a NOP (see Figure 5.52). The designer can now iterate over all of the fruit in the fruit basket, telling each object to core itself. If a fruit does not know how to core itself, it gets a NOP function for free. If it does know how to core itself, it overrides the default NOP function with its own core function.
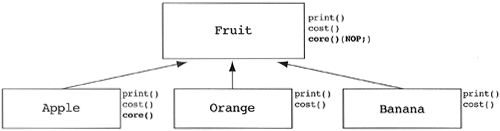
While this solution is easy to implement, it has several problems. First, what if someone adds a pineapple, which also knows how to core itself. The original requirement was to walk through a fruit basket and core all of the apples. In this model, the pineapples would also be cored (unexpectedly). This is certainly an undesirable side effect of our design.
The second and larger problem with this design is that we have warped our model (the fruit hierarchy) to satisfy a warped user of the hierarchy. When the designer of the fruit basket decided to mix all of the fruit in a polymorphic list, he stated that he did not want to know the exact type of fruit at runtime and that he would use polymorphic functions of fruit to distinguish the different behaviors of each fruit type. In the next breath he reneged on this statement and stated that he needed to know which of the mixed fruit were apple objects, a major violation of his original model. By forcing Fruit to know about core, we are warping the polymorphic model for one user: Our base class now has derived class information (a clear violation of Heuristic 5.2). If many designers use this model, it is conceivable that each designer will run into a similar situation. If resolved in this manner, the Fruit class will become hopelessly convoluted with derived class-specific functions all defaulted to NOPs. This design choice is often called the “fat interface” solution.
Another solution is to force the designer of the FruitBasket class to take the responsibility for misusing the fruit abstraction. He or she must maintain a list of apples in addition to the list of mixed fruit in the fruit basket (see Figure 5.53). This maintains the proper abstraction of the Fruit hierarchy and puts the extra effort in the hands of the hierarchy users—those who are responsible for using it in a way for which it was not intended. However, this design is not without its problems. First of all, the bookkeeping job can get very complicated when several lists must be maintained. This can lead to errors of improper objects being added to the wrong lists or objects getting lost in the fruit basket. Second, how does the fruit basket know when the fruit object being added is an apple instead of an orange or a banana? The method add_item is taking a reference to a fruit as an argument, not an apple. One possibility is to create another method on the FruitBasket class called add_apple. The add_item method is responsible for all fruits other than apples. The problem here is that there is nothing to stop a user of a fruit basket from adding an apple via the add_item method, thereby putting the fruit basket in an invalid state with respect to its semantics. The alternative solution is to ask each fruit being added to the fruit basket its type. If its type needs special handling, as apples do in this example, then the fruit basket can handle that processing. Of course, this leads to explicit case analysis on the type of an object, another maintenance headache (and a violation of Heuristic 5.12).

The moral to the story is that there is no optimal solution. All solutions have problems that need to be addressed. I tend to use the latter design where possible only because I do not believe that users of a hierarchy should cause them to be poorly designed. Many people choose the NOP method solution because it is the easiest to implement (no bookkeeping/case analysis), especially when they own the hierarchy and the class that uses it. In this case its a trade-off between warping their code or warping their code, so they choose the warping easiest to implement. Physical design may play a role in selecting the method. Imagine that the fruit basket is stored in a database where retrieval of each piece of fruit is slow. Clearly, the solution of maintaining a separate list of the apples is more appropriate since we do not want to waste the time of extracting a fruit from the database only to find out that it is an orange or a banana.
When building an inheritance hierarchy, try to construct reusable frameworks rather than reusable components.
This heuristic illustrates the difference between system and domain analysis. System analysis attempts to find key abstractions from the particular application you are developing. The result is system-specific classes, which we call components. It is a designer's hope that they will become reusable in other applications. Domain analysis is the process of taking a step back and asking ourselves, “Can we create one design that satisfies the needs of a whole family of applications, of which our system is one member?” If the answer is yes, then the result is often reusable frameworks. In this context, a framework is defined as a class that contains a base class(es) by reference. Consider the design that wishes to place an object-oriented wrapper around the operating system in order to make the transition between hardware platforms easier. Someone performed system analysis and decided which operations an operating system needed in order to satisfy the given application. These became pure polymorphic functions on a base class called OperatingSystem (see Figure 5.54). The derived classes DOS, Unix, and VMS must define each of these methods in order to be useful in the application.
Given this hierarchy, it is possible to port our application to OS/2 by creating a new derived class, OS/2, and implementing the necessary methods in this new operating system. While this is useful, domain analysis would have asked the question, “Can we take the reusable components DOS, VMS, Unix, and now OS/2, and find a reusable framework that models them more fully?” We can generalize these derived classes by realizing that all operating systems consist of a file system, a process system, and a device driver system (see Figure 5.55). Of course, there are different types of file systems, process systems, and device driver systems, each of which requires its own methods. However, we have now captured part of the design of an operating system. With luck we can continue to break down each piece into its generic pieces. Even though we never get any reusable code, we can get a reusable design. Reusable designs are often considered much more useful than reusable code. Do you want to be in a situation where you are told to create an OS/2 class with its 50,000 lines of code? Or would you prefer to be in a situation where you are told to create an OS/2 class with its 50,000 lines of code but it requires the following three pieces, each of which has the following pieces and interfaces, etc.? After creating several object-oriented systems, most developers agree that the production of a good design requires a great amount of effort for each system. Any reduction of that effort is very valuable and can save much more time than a simple reduction in code.
It is important to note that the OperatingSystem class shown in Figure 5.55 allows for an OperatingSystem object to be created from a UnixFS, a DOS_process, and a VMS_devicedriver. This is obviously an unworkable OperatingSystem object. This implies that there exists a semantic constraint between the objects contained in the OperatingSystem class. These semantic constraints are best captured in the class definition when possible. For this reason, many designers will bring back the derived classes DOS, Unix, and VMS for the sole purpose of maintaining the semantic constraints of operating systems. These derived classes usually capture the semantic constraint in their constructors, which build and pass the appropriate pieces of the framework to constructors higher in the hierarchy (see Figure 5.56).
Many case studies demonstrate the benefits of reusable frameworks. In a process control project on which I worked at Draper Laboratories in the mid 1980s, our requirements were to development a system to fold men's suit sleeves with a robot. Instead, our development team took a step back and asked, “What do all process control systems (of which we are aware) require for design and implementation?” We designed a framework for process control architectures based on our answers to that central question. It was on this framework that we built our first representative application, namely, the robotic sleeve-folding system. As it turned out, the textile industry did not prove to be a steady source of funding for automation research and development. However, companies involved with composites manufacturing were in great need of automation. Our framework was used to create a new application, which wrapped kevlar around steel frames to simulate the manufacturing of airplane wings. The new system took less than two days to develop on top of the existing framework. It would have taken considerably longer to build a new system from the beginning, even if some of the existing code was reusable.
In another case study, I taught an object-oriented analysis and design course to a group of employees from The Travelers' Insurance Company. In this course, one-third of the attendees were working on a workmen's compensation insurance claim system, another third on a health insurance claim system, and the last third on an automobile insurance claim system. I argued that this was the perfect class to discuss domain analysis and framework design since clearly they were building three related systems. Several members of the class argued that these related segments of the insurance industry were completely different upon closer inspection. However, after several hours, we were able to produce a considerable collection of abstractions that were common to all three domains. A dissenting member of the class agreed that there were many abstractions in common but stated that upon implementation they differed significantly. She argued that it was not worth the time to create the abstractions if their eventual implementations were going to differ. While there may not be any code in common among the three designs, the fact that the designs overlap is very valuable information. Would you like to build a new system of 500,000 lines of code with nothing but its requirements to guide you? Or would you like to write 500,000 lines of code but know exactly how it is decomposed at the design level? After building systems, any developer will argue that the latter task is much easier than the former.
A third and last case study comes from Salomon Brothers. This company needed to build a collection of applications that dealt with reporting systems for securities trading. Instead of spending two team years building each of a number of systems, an enterprising executive allowed his group the extra time to construct a framework to support all of the applications. The result was that the first application took longer than the expected time, due to the need for framework design and construction. The remaining applications took a small fraction of the expected time, due to a high level of reuse achieved from the framework designed by the first group. This resulted in a substantial net savings in development time and effort as well as increased maintainability of the system. The latter is a result of the large amount of design and code sharing between the applications.
It is important to note that the development and use of a framework requires a front-end investment in time and money. The reward comes in reduced maintenance costs for the systems already developed and in reduced development costs for future systems. This type of cost structure must be supported by the top levels of management for the organization attempting the development of the framework. Unfortunately, there are surprisingly few companies willing to spend the extra time/money today to save significant amounts of both in the future.
- Base class
A class from which another class inherits.
- Derived class
A class that inherits from another class.
- Dynamic binding
A synonym for polymorphism.
- Dynamic semantic wrapper
A construct used to encapsulate the states and transitions of a class in a local inheritance hierarchy.
- Framework
A collection of classes and their relationships which may or may not capture reusable code, but always captures reusable portions of the design of an application family.
- Generalization
A synonym for inheritance, it sometimes implies that the inheritance relationship in question was found by examining existing derived classes in order to find a new base class.
- Inheritance
A class-based, object-oriented relationship that models specialization or a-kind-of relations.
- Monomorphic function
A function whose address is decided at compile time. Also called a statically bound function.
- Overriding method
A method in a derived class which has the same name and argument types as a method in its base class.
- Polymorphic function
A function whose address is decided at runtime. Also called a dynamically bound function.
- Private inheritance
An inheritance mechanism of C++ that allows a derived class to inherit only the data, and not the behavior, of its base class.
- Protected inheritance
An inheritance mechanism of C++ that allows a derived class to inherit only the data, and not the behavior, of its base class. Protected inheritance is distinguished from private inheritance in that protected inheritance allows the descendent implementors (i.e., lower-level derived classes) to see the behavior of the base class; private inheritance does not.
- Public inheritance
An inheritance mechanism of C++ that allows a derived class to inherit the data and behavior of its base class. The semantics of this mechanism are equivalent to the object-oriented paradigm's definition of inheritance.
- Pure polymorphic
function A polymorphic function for which the base class has no meaningful default behavior.
- Specialization
A synonym for inheritance, it sometimes implies that the inheritance relationship in question was found by adding a new derived class to an existing base class.
- Static binding
A synonym for monomorphism.
- Subclass
A class that inherits from another class.
- Superclass
A class from which another class inherits.
- True polymorphism
An implementation of polymorphism focusing on a global hash table of function addresses stored in the environment of the supporting language.
Heuristic 5.1. Inheritance should be used only to model a specialization hierarchy.
Heuristic 5.2. Derived classes must have knowledge of their base class by definition, but base classes should not know anything about their derived classes.
Heuristic 5.3. All data in a base class should be private; do not use protected data.
Heuristic 5.4. In theory, inheritance hierarchies should be deep—the deeper, the better.
Heuristic 5.5. In practice, inheritance hierarchies should be no deeper than an average person can keep in his or her short-term memory. A popular value for this depth is six.
Heuristic 5.6. All abstract classes must be base classes.
Heuristic 5.7. All base classes should be abstract classes.
Heuristic 5.8. Factor the commonality of data, behavior, and/or interface as high as possible in the inheritance hierarchy.
Heuristic 5.9. If two or more classes share only common data (no common behavior), then that common data should be placed in a class that will be contained by each sharing class.
Heuristic 5.10. If two or more classes have common data and behavior (i.e., methods), then those classes should each inherit from a common base class that captures those data and methods.
Heuristic 5.11. If two or more classes share only a common interface (i.e., messages, not methods), then they should inherit from a common base class only if they will be used polymorphically.
Heuristic 5.12. Explicit case analysis on the type of an object is usually an error. The designer should use polymorphism in most of these cases.
Heuristic 5.13. Explicit case analysis on the value of an attribute is often an error. The class should be decomposed into an inheritance hierarchy, where each value of the attribute is transformed into a derived class.
Heuristic 5.14. Do not model the dynamic semantics of a class through the use of the inheritance relationship. An attempt to model dynamic semantics with a static semantic relationship will lead to a toggling of types at runtime.
Heuristic 5.15. Do not turn objects of a class into derived classes of the class. Be very suspicious of any derived class for which there is only one instance.
Heuristic 5.16. If you think you need to create new classes at runtime, take a step back and realize that what you are trying to create are objects. Now generalize these objects into a class.
Heuristic 5.17. It should be illegal for a derived class to override a base class method with a NOP method, that is, a method that does nothing.
Heuristic 5.18. Do not confuse optional containment with the need for inheritance. Modeling optional containment with inheritance will lead to a proliferation of classes.
Heuristic 5.19. When building an inheritance hierarchy, try to construct reusable frameworks rather than reusable components.
[*] Readers that are in the securities industry will find these examples unrealistic for the domain. The securities examples were selected for clarity across a wide audience, and are adequate for discussing the heuristic.