
When most people use the term “object-oriented design,” they are typically referring to logical object-oriented design. There are actually two facets to object-oriented design: logical design and physical design. Logical design involves everything discussed thus far, including the discovery of classes, their protocols, their uses relationships, their containment relationships, and their inheritance relationships. In short, anything that relates to the key abstractions and mechanisms of an application can be categorized as logical design. Physical design involves the techniques used to map these abstract constructs onto given software and hardware platforms. Any implementation details based on target language(s), tools, networks and their protocols, databases, or hardware would be included in physical design. The main heuristic to keep in mind while examining physical design is that physical design should not corrupt the logical design.
A classic example can be found in the world of information management. Many software development teams in this domain are faced with management-directed mandates stating that a given relational database must be used for a particular system. (With good reason! Many MIS-domain companies have spent millions of dollars on this software and cannot justify an additional, equivalent expense to purchase object-oriented database software.) The fear is that these teams will analyze the mandated database and realize it is capable only of capturing the abstractions of data records and their associations. They then extrapolate this realization to state that their object-oriented design need not examine inheritance relationships since they are not directly modeled in the entity-relationship paradigm. The correct method of examining this problem states that logical design should ignore the shortcomings of the relational model (an implementation detail) but instead specify what they need from their database object. The needs can be implemented later in a layer of software sitting on top of the required relational database. The layer of software separating an object-oriented domain from an underlying, nonobject-oriented subsystem is often called a wrapper. We will discuss software wrappers in more detail later in this chapter.
The reader should not assume that the above discussion is an argument that a software developer should ignore physical design until logical design is complete. Many logical design decisions hinge on physical design information. These are not corruptions of a logical design in favor of physical design; they are simply logical design decisions based on physical design constraints. As an example, in my object-oriented analysis and design course, I used an example scenario from an object-oriented analysis and design book which discussed withdrawing $100 from an ATM. The scenario went roughly like this:
A user inserts an ATM card into a card reader.
The ATM detects that its card reader has a card and reads the account number off the card.
The ATM asks for a PIN number on its display screen.
The user enters her PIN number through the ATM's keypad.
The ATM then sends the account and PIN number to the bank, which verifies the user's identification.
The ATM then asks what the user wants to do.
The user uses the keypad to state that she wants to withdraw $100 from her checking account.
The ATM asks the bank to process the transaction.
The bank states that the transaction is valid.
The ATM gives the user $100 from her checking account.
I successfully used this scenario in six or seven classes that each consisted of 15 or 20 people. Everyone was perfectly happy with this scenario. The next class that I taught had an individual who worked for a large New York bank. He immediately objected to the scenario, saying that no ATM in the world worked this way. What was his objection? It turns out that each time we want to use the network (i.e., the ATM wants to talk to the bank, or vice versa), it costs us 50 cents. No ATM is going to spend 50 cents just to ask a bank if the account and PIN number are correct. The person stated that the ATM would check locally if the account and PIN number matched (stating that the account and PIN were electronically encoded on the back of the card). The ATM checked only to see if the person using the card knew what was electronically encoded on the back of the card. What if I created my own card with an account and PIN number; would the ATM let me in? Of course it would, but what danger would that cause? When a transaction is built and sent to the bank for processing, the account and PIN number are sent along as well. The bank can then verify everything with only one network access. In fact, most of today's systems do not even bother with local verification. They assume you are the owner of a card until you try to process a transaction. Travelers quickly learn this when they are in a distant city and they try to use a bank card that is not on the network of the ATM. You are allowed to get all the way through transaction creation. It is only when you try to process the transaction that the ATM spits out your card and informs you that you are not on the given network.
This is a case where logical design does not care which mechanism you choose, but physical design states that if you use a particular mechanism, your software system saves several tens of millions of dollars per year. In effect, physical design considerations force the developer to make a particular logical design choice. We see this in the real world very often. When AT&T first introduced the notion of debit cards for local pay telephones, I wondered why they were going through all of the trouble. After all, didn't they already have telephone access cards? Of course, the first answer that comes to mind is that AT&T gets your money before you make the call, saving the cost of billing (a logical design decision) and allowing them an interest-free loan. Even if these advantages are factored out via discounts, there is still an advantage to AT&T. The debit cards are local, whereas access cards require a network connection to verify the calling card. This physical design information states that debit cards are cheaper to process than calling cards. We can often think of physical design information as the data we need to add a cost factor to each method in a class. With logical design information alone, all messages are considered to be the same value.
Object-oriented designers should not allow physical design criteria to corrupt their logical designs. However, physical design criteria are often used in the decision-making process at logical design time.
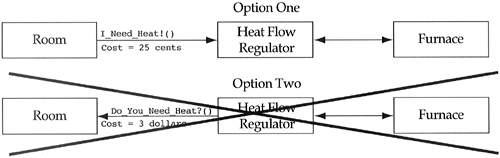
Consider the home heating system problem we have discussed previously. In design courses in which it is used, a frequent argument revolves around whether rooms demand heat from the heat flow regulator or if the heat flow regulator should ask rooms if they need heat. Figure 9.1 depicts these two options.

This particular logical design argument will go on forever. Given logical design information alone, the two designs are equivalent. A good tongue-in-cheek heuristic is if, during a logical design critique, two parties who know what they are talking about argue for a long length of time, it is a safe bet that the argument is irrelevant and a decision should be made with the flip of a coin. The key phrase here is “know what they are talking about.” I have seen many longwinded arguments in a design critique that were very important but could not be resolved because both parties lacked the necessary background to make a proper design decision. One need not look far to see these irrelevant arguments occurring. Most ANSI committees are plagued by long delays between the time they have a reasonable standard and when it is accepted. The reason is difficulty in getting everyone to agree on the small details. The large issues have large trade-offs, which are quickly decided.
How should our home heating system design be resolved? Often, physical design will state that one method is more expensive than the other. This information will coerce the logical design to accept the cheapest solution (see Figure 9.2). In the event that physical design criteria do not offer a solution, I generally add the method to the class which is the least complex. If they offer the same approximate complexity, then I flip a coin.
If this book were to be used as a text in an “Introduction to Software Development” course, then this chapter would be much larger than it is. As it turns out, many of the traditional physical design criteria used in action-oriented design are still applicable to object-oriented physical design. This chapter also happens to involve the same problems and the same solutions. Consider the fact that C programmers have always worried (or should have worried) about the fact that integers on different machines are different sizes. For example, on an IBM PC running DOS, integers are two bytes, but on a Sun workstation they are four bytes. This is a physical design issue that will carry over into the object-oriented paradigm; for example, C++ programmers have the same worries. The fact of the matter is that the solutions are the same and are not impacted by the object-oriented paradigm. This text will assume that the reader has some experience with software development and has faced the mundane problems. We will focus on those areas of physical design unique to the object-oriented paradigm, or at least those that have unique solutions under the object-oriented paradigm. These unique areas include the use of wrappers to isolate nonobject-oriented subsystems from object-oriented applications; persistence in an object-oriented system (i.e., object-oriented database management systems); memory management, including the copying and assigning of objects; minimal public interfaces for all classes in an object-oriented system; concurrency in an object-oriented system; and the mapping of object-oriented designs onto nonobject-oriented languages.
The notion of a software wrapper is not new, but like so many other concepts in the object-oriented paradigm, its name is new. In the past we referred to the notion of software layering. Consider the seven famous layers in a network architecture (e.g., the connection layer, the transport layer, the physical layer). They serve as a mechanism for separating levels of concern in networks, with each layer having control of a particular level of detail. If this architecture were defined today, I am sure it would be called the seven wrappers of a network architecture. Wrappers are simply layers of software written in an object-oriented fashion. There are many examples of the need for such a construct.
The first occasion when I become acquainted with the need for wrappers was at a software developers conference back in the mid-1980s. The conference featured a panel on the reusability of software. Each panelist was a representative of a particular programming language (C++, SmallTalk, Lisp/Flavors, and Eiffel) discussing patterns of reuse among the users of their language. After the panelists had delivered their position papers and a number of language-based questions had been answered, a gentleman approached the microphone and made the following statement (which I found to be one of the more enlightening):
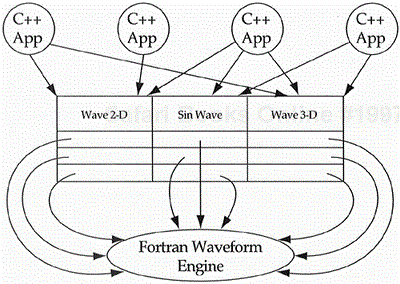
Each of you, in turn, has told me how to reuse C++ if I'm a C++ programmer, SmallTalk if I'm a SmallTalk programmer, Lisp/Flavors if I'm a Lisp/Flavors programmer, Eiffel if I'm an Eiffel programmer. Well, I'm someone who wants to be a C++ programmer but I happen to have a million lines of Fortran IV code which performs calculations on waveforms. How do I reuse my million lines of horrible, unmaintainable, nonextendible, working Fortran IV code in a C++ application? Don't ask me to rewrite the Fortran code, because no one understands how it works and the author left the company 15 years ago.
It was the first time I had considered the problem. Based on the panel's response, it was the first time for a lot of people. This brought up the subject of reusing nonobject-oriented code in an object-oriented application via a wrapper. The idea was to create a collection of classes that modeled the Fortran code in an object-oriented manner. The methods of these classes are function calls into the Fortran library. Of course, the new problem was to find this collection of classes. One technique of finding classes from a collection of existing functions is to examine the arguments passed into each function. Each record type argument is a good candidate for a class, since the corresponding function will end up a method with that record type passed as an implied first argument. Of course, Fortran IV does not even have the notion of record, so it was necessary to look for patterns of arguments being passed to a collection of functions within the library. For example, three integers followed by six real numbers followed by a character string might imply the numeric description of a waveform. Once the classes are found, they can be easily implemented through calls to the Fortran library (see Figure 9.3). If, at a later date, the company decides to rewrite the Fortran waveform engine in C++, the applications will be completely isolated from the Fortran. Object-oriented applications get to talk to the same object-oriented waveform engine. They are users of the engine and could care less how that engine is implemented.
Another example of the need for a wrapper brings me back to my early days of corporate education. Back in 1985/1986, I gave design and C++ courses to four different companies involved with telecommunications networks. Companies involved with telecommunications were among the first to jump into object-oriented programming. This was due to the fact that there exist national standards for telecommunications devices. They are documented in publications with statements like, “If you want to build a T-1 network, then it must have the following abstract behavior, but you are free to implement it as you wish.” The objects in the domain of telecommunications were obvious; however, the architecture of the systems that used them were not so obvious. All four companies ran into the same interesting problem. How do we tell an object called Fido of the class Dog to move from machine M1 to machine M2 over a network? (See Figure 9.4.) In addition, we expect to be moving many objects of different classes from machine to machine.

Discussing this task was trivial during logical design. We simply send Fido the Dog the move message along with the machine object to which it is to move itself, e.g., Fido.move(M2). Unfortunately, along comes physical design with the question, “What does a method like move look like?” This raises the interesting question of how we go about moving objects over networks. This network doesn't know about dogs, cats, tables, chairs, and T-1 objects. What do networks know about? At the lowest level they work with bits, then come bytes, and if we are lucky, packets of bytes. This brought up the need for an encoder, which turned a Dog (and any other object wishing to move from machine to machine) into a collection of packets, and a decoder, to decode the packets on the other machine (see Figure 9.5).

The problem with this solution is evident when we look at the internals of the decoder. It must check some field of the first packet to determine what object the packet stream is representing. Based on the value of this field, it will create the appropriate object. The companies involved with this design realized they were performing explicit case analysis on the type of an object, a violation of an important heuristic. They assumed their design was flawed and searched in vain for a better solution. Their design is not flawed in this example; the network is simply not object-oriented. Whenever an object-oriented application interfaces to a nonobject-oriented subsystem, explicit case analysis is often the result. In this example, an object-oriented application is using a nonobject-oriented network. This network along with an encoder and a decoder can be viewed as an object-oriented network to the objects in the problem domain. Some will argue that the explicit case analysis still exists since only our view (i.e., partitioning) of the system has changed. However, the same argument can be made for polymorphism. Someone must perform an analysis on the exact type of the object. If users of the system need to perform the analysis, it is considered explicit case analysis; if the system performs the analysis, then it is considered implicit case analysis. At the time in question, there existed no object-oriented networks. Each of these companies was left to build its own object-oriented wrapper (i.e., encoder/decoder), which was difficult to maintain due to its explicit case analysis. In addition, the case analysis is dependent on the data types allowed across the network. The eventual solution is to build generic object-oriented networks that require only a description of the data in order to pass that data across the network in an object-oriented fashion.
An architecture for such a network has been proposed by the Object Management Group, and is known as CORBA (Common Object Request Broker Architecture) [13]. It addresses not only the problem of object-oriented networks but the need for objects to send remote messages to objects that live on other machines. Of course, we need not stop there. Why not let C++ objects send remote messages to SmallTalk objects which live on another machine? This creates truly seamless, distributed systems.
Another example of the explicit case analysis problem with respect to object-oriented systems interfacing with nonobject-oriented subsystems can be found in our previously explored fruit basket example. Consider an application that allows users interactively to build a custom fruit basket object by first prompting them for the number of fruit desired, followed by a prompt for each of the fruit as to type and other fields. In a menu-driven system, the application will have to perform explicit case analysis on the type of the fruit. This explicit case analysis is necessary due to the user interface's not being object-oriented. In a graphical user interface environment, we could envision a different icon for each type of fruit. The user would simply click a mouse over the appropriate icon in order to build that type of fruit object. One can argue that case analysis is still required. The code within the graphical user interface will check if the mouse was clicked between certain x and y coordinates. However, this case analysis is implicit since the user of the system is not performing it. It is all a matter of perception; where do the “system” and “outside the system” begin and end?
In all of the preceding examples, we wanted to be sure that nonobject-oriented subsystems were placed in an object-oriented wrapper to ensure the consistent modeling of our object-oriented domain. One special type of wrapper is the database wrapper. Software developers quickly realized that relational databases were not sufficiently expressive to capture the detailed constructs of the object-oriented paradigm. While relational databases are able to capture data structures and their associations, they are inept at describing the bidirectional relationship between data and behavior, uses relationships, containment relationships, and inheritance. Many companies produced or acquired object-oriented database management systems with the goal that these subsystems would map more uniformly to the object-oriented problem model. These databases take a description of the logical design of the system and, from it, derive all the necessary information for mapping the logical design to flat files, with a possible intermediate mapping to a sophisticated database engine. An object-oriented database can be thought of as a wrapper for a relational database. The only task they eliminate from the object-oriented developer's job is the mapping of object-oriented constructs to something a relational database can understand. While this mapping is straightforward, it is an example of accidental complexity that should be eliminated. Much information is lost in the mapping to something less expressive, and there is always the chance of error when it is performed by a human.
Many information-management companies (banks, insurance companies, mailing-list brokers, etc.) have invested millions of dollars in relational database software. Is it worth the money to move to an object-oriented database system? Most of these companies insist that it is not, and I tend to agree with them. Why spend large sums of money on database software that is not as well tested as some of the large relational databases that are available? It is often cheaper for a company to build its own object-oriented wrapper for its relational database, taking advantage of the in-house experience and software.
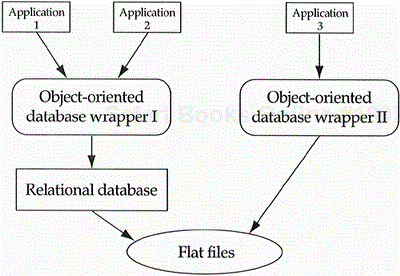
Object-oriented databases are often used by developers building a system in which the database is an auxiliary subsystem not related to the main thrust of the system. For example, one company with which I worked was building a 3-D modeling tool. The tool would allow its users to save the 3-D model they designed. The obvious choice for designing this ability was to use an object-oriented database that could directly map the users' objects onto the flat files of the disk (see Figure 9.6). There is nothing wrong with an information-management application using an object-oriented database. It is just that these companies often have invested huge amounts of money in relational database software, and it should not go to waste. Most of this argument will disappear as soon as the large relational database vendors begin offering object-oriented extensions to their products. This is the general trend, with several third-party vendors already offering object-oriented database wrappers portable to a number of commercial relational databases.
There is a trend within information-management companies to reduce the use of mainframe computers to large data-storage devices with high-bandwidth networks. These data-storage devices are then attached to a collection of PCs or Unix workstations. The workstations or PCs handle all of the user interface work, collecting and displaying information interactively. The mainframe acts as a high-speed retrieval and processing center. Eventually, most of these companies will question why they are spending 10 million dollars on a mainframe when they can get the same use from 1 million dollars of specialized file server hardware. Companies with this architectural mixture of PCs and mainframes are often faced with an object-oriented PC application talking to an database living on the mainframe.
I dealt with an insurance company that was developing a worker's compensation claim system that had this particular problem. The first pass produced a logical design where many methods of the problem domain classes talked directly to the mainframe. I argued that the problem domain classes should not know anything about mainframes and their databases. All they know is that if they throw a claim number over a brick wall, a claim object will come back over the wall (see Figure 9.7). Where does it come from? Who cares! Maybe it is a brain-dead database on a mainframe, maybe it is from a local optical drive (because 15-gigabyte drives will be available for 8 dollars in 1998), or maybe a squirrel pulled it out of its nest. The point is that we do not want our object-oriented domain polluted with nonobject-oriented details. We build a wrapper (the brick wall) and then use that wrapper. Buy an object-oriented database, and you are paying someone else to write the wrapper.

The discussion of object-oriented database management systems brings up the whole subject of persistence. Persistence means that objects can live after the power has been turned off. It is important to note that object-oriented databases and/or object-oriented wrappers for relational databases are only the most common form of one type of persistence, called persistence in time. Traditionally, this has meant storage to a static medium, which for most people implies a database. There is an alternative method for saving objects to a static medium besides using a centralized database (object-oriented or not). Each object can have local knowledge concerning how it should be saved to a disk. This is common in systems with relatively few persistent classes. This book was not stored in an object-oriented database. Each object making up the book—items such as chapters, paragraphs, sentences, words, frames, floating headers, floating footers, graphical objects drawn within frames, etc.—was told to store itself. Many people like to call this form of persistence local persistence (in time). If a class has an output operation that produces a description of the object in a form that can be parsed and used to build the equivalent object (via some input operation), then the class has local persistence. The important distinction is in whether the storage algorithm is decentralized across all of the persistent classes or centralized in some subsystem (e.g., a database) that knows how to store objects of a class based on a description of that class.
There is a relatively new concept referred to as persistence in space. Persistence in space states that objects do not live after the power is turned off by saving themselves to static medium. Instead, they detect the power turning off and scurry across the network to a “safe” machine where they execute what they need or stay idle until their host machine's power returns, at which time they scurry back to the host. While this sounds a bit silly to some people, its uses go beyond the realm of writing distributed game programs. Many telecommunications companies are examining this form of persistence with the intent of applying its principles to routing algorithms. Routing algorithms are often very complex, unruly, and most interesting; they are centralized. The feeling is that decentralizing the routing algorithm will make them simpler. One can imagine a telephone packet finding a trunk line going down (or busy) and rerouting itself to a free trunk line. At this time, most of the work done in this field is in the research phase, with little practical application. It is expected to bring good results in decentralizing object-oriented applications across networked collections of machines.
Another interesting physical design area is that of memory management. There are two categories of languages when viewed from the method used to handle dynamic memory. There are those languages, like Lisp and SmallTalk, that support garbage collection. These systems periodically walk through memory, checking which used memory is no longer referenced by the resident applications. These pieces of memory are swept up for reuse on the environment's heap. The advantage of garbage collection is that application programmers do not have to worry about the allocation and deallocation of dynamic memory. The system does all the work for them. The disadvantage is that garbage collection reduces efficiency. Some systems arbitrarily suspend execution and perform their garbage collection for several seconds to several minutes, not the ideal for real-time systems. Others use some form of incremental garbage collection wherein the execution time slows down uniformly over the execution of an application without uncomfortable suspensions of execution. There is an added performance penalty in that access to an object is often indirect. Actual object addresses cannot be given to the user since the object may be physically moved during garbage collection.
The other language category includes nongarbage-collecting languages like C++. User programmers are given actual physical addresses of objects on the heap. For this reason, these languages cannot offer garbage collection since they cannot update all user-copied values of the physical addresses when garbage collecting. Any garbage-collection algorithms must be implemented by individual application programmers and usually employ the notion of memory handles to store the physical addresses in a memory location and give the address of that location to the users. This provides an extra level of indirection so that the garbage-collection algorithm is free to change the physical addresses so long as the indirect memory locations do not relocate. The advantage of these languages is the increased performance. The disadvantage is the increased chance of memory leakage and/or heap corruption in an application. Memory leakage occurs when a software developer allocates memory and forgets to free it. Users of C++ are especially prone to this error because C++ offers several default operations that cause memory leakage when not explicitly defined under certain, very common, conditions. The gory details of memory leakage in C++ are beyond the scope of a text on object-oriented design. However, due to its prevalence and the large numbers of C++ programmers, in Appendix B I have provided a paper that discusses these details. It is highly recommended that C++ programmers read the paper to familiarize themselves with the eight places that memory leakage occurs in C++ applications.
In 1989 I constructed a commercial C++ class library along with two other developers. We first discussed the classes we would include in the library and came up with the usual assortment of data structures, mathematical entities, collection classes, and primitive data type mimics. Since we were shipping source code, we wanted our code to look consistent to the users of the library. This started us on the subject of coding standards and guidelines. One of the topics we explored was the construction of a minimal public interface that all classes in the library would implement [14]. We discussed the types of operations we wanted, as well as their signatures and abstract behavior. I believe that a minimal public interface should be established if classes are to be reused. The minimal public interface gives users of a collection of reusable classes a basis for understanding the collection's architecture. Users come to expect a minimal functionality from anything they use in the collection.
All classes that have data members should have a constructor (initialization) message that initializes that data. In addition, the class should be defined in such a way that it is not possible for users of the class to create objects in an invalid state, namely, a state for which one or more methods of the class are unprepared. Some languages provide better support for this constraint than others. Languages that have automatic calls to constructors (e.g., C++) are particularly useful in guaranteeing that the user building an object of the class has passed through one of the constructors of that class.
In general, only classes that need to clean up a portion of their object require a destructor or cleanup function. However, often a class that does not require this cleanup is extended in a way that does require cleanup. For this reason, it is common to add empty destructors for extensibility.
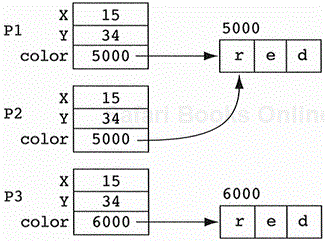
The notion of all classes knowing how to make a copy of their objects seems reasonable. There is a bit of a problem in languages that distinguish containment by value and containment by reference (e.g., C++). In these languages, what do we mean by “copying”? Consider the Point objects shown in Figure 9.8. They have an example of containment by reference (the color field). Is P2 a copy of P1? Is P3 a copy of P1? What's the relationship between P2 and P3?
Before answering any of our questions, we need to consider the fact that containment by reference implies two different types of copying. These are called deep copy and shallow copy. A deep copy of an object is a copy of the entire structure, not just copies of pointers. The original object and its deep copy do not share any memory space. A shallow copy of an object is a copy of the first-level data members. If one of the data members is a pointer, then only the pointer value is copied, not the structure associated with it. The original object and its shallow copy share memory space.
Many real-world examples illustrate this distinction. If you go into a restaurant and tell the waiter/waitress that you want the meal that the person at the next table is eating, you are implying that you want a deep copy of that meal. A shallow copy of the meal would have the waiter/waitress put your fork in the other person's plate and walk away. In this application, a shallow copy of the meal is not adequate. On the other hand, if you are flying on a plane, you would hope that all of the air traffic controllers have a shallow copy of the air traffic map. It would not do any good for each air traffic controller to have a deep copy. Such a situation would imply that if air traffic controller X adds a new plane to the airport's air space, air traffic controllers Y and Z will not see it. This application clearly calls for shallow copying of the airport's air space.
In this example, P2 is a shallow copy of P1 because it shares the memory for the color string. P3 is a deep copy of P1 because it has its own memory for the color string. Technically speaking, P3 is a deep copy of P2 in that they are structurally equivalent but do not share memory. It is important to note that it is not possible to tell whether P1 is a shallow copy of P2 or P2 is a shallow copy of P1. That information is lost in this implementation of shallow copy. Some implementations add flags to the objects in order to determine the original from its shallow copies. Others use a technique called reference counting to make the difference between the two meaningless. We will explore the reference-counting technique later in this chapter.
If each class understands how to copy its objects, then it must understand what it means to assign one of its objects to another of its objects. The only question is whether to use shallow or deep copy. We chose deep copy since it is the least likely to cause side effects to its implementations. In many languages, shallow copies are easiest to implement with some level of side effect. Users of the class should not be aware of whether or not it uses containment by reference in its implementation.
Given the differences between shallow and deep copying of objects, what does it mean for an object to be equal to another object? Since there exist two methods of copying objects, there must also exist two methods to test equality. We call these equal and same. The equal method tests for structural equivalence, while the same method tests for memory sharing. In our example, all three point objects are equal to one another since structurally they are equivalent. Only P1 and P2 are the same since they share data. P3 is not the same with either P1 or P2.
All classes should have a method that knows how to print out its objects in some format; many choose ASCII text. The need for this operation goes back to action-oriented programming, where many developers had set and get operations for each of their data structures. These are useful for debugging applications that use the class in question or for a minimal form of persistence (along with a parse method).
All classes should have a parse method that knows how to initialize an object based on the output of the corresponding print method. Given a print method and a parse method that share output/input, the class can be said to have a form of minimal persistence. A user can tell an object of the class to print itself to a file and, at a later date, use the parse function to recreate that object from the description stored in the file. This is very useful for testing and debugging the use of a class in an application.
Brad Cox [15] published an analogy between hardware reuse and software reuse. Hardware used to cost the earth until we decided to build everything from a set of standard, well-defined components. Now software costs the earth. In order to make software development cheap, we need to define an equivalent set of standard, well-defined components from which all of our software can be built. There are many problems with this analogy, including the fact that the economic models of hardware and software development are different. Hardware costs are all paid for during the development phase. The cost of manufacturing is insignificant compared to the up-front investment. In the case of software, the cost of development is often a small percentage of the cost of the software over its lifetime. Maintenance and extensibility are often the expenses parts of the software lifecycle. In fact, cheap development costs often imply more expensive maintenance in the future, because designers did not take the time to install extensibility hooks into their software.
Having said this, we still borrowed a little of this analogy after reasoning that hardware failure does not imply searching the smallest details to detect the problem. If you were to turn on your PC and it failed, you would not immediately start worrying that you had lost your all-important data on the hard drive. Nor would you drag out an oscilloscope and start checking individual chips until you found a defective one. The PC provides board-level diagnostics to at least attempt to pinpoint the area of the PC causing the problem. We feel that each class should have an equivalent, component-level test mechanism, which we named self-test. The self-test method is a class-specific method (as opposed to all others in the interface, which are object methods) that builds several objects of the class and exercises the public interface, checking for correct results. Some developers pointed out that if the constructor of the class is flawed, we really cannot test much of the class's public interface. We agree. However, if you turn on your PC and nothing happens, you cannot really test much of the PC either. Having that little knowledge does give you much useful information. You do not worry about your hard disk failing, or memory failing. You know to verify that the PC is plugged in, its switch is on, power is being supplied to the wall socket, etc. Likewise, if our self-test method fails outright, we know to check the constructor for problems. Like the PC analogy, there may or may not be many additional problems with the object in question.
This method proved invaluable in the porting of our library from one compiler/platform to another. It was reassuring to have information like, “33 of our 40 classes passed their self-test, but seven need further examination for portability problems.” Of course, the self-test function is only as good as the person who wrote it. Like all good testing procedures, it should be written by someone other than the developer of the class. If the developer thought to test something, then he or she probably did not make that mistake in the development of that class.
Several recent publications have been critical of minimal public interfaces, describing them as misguided efforts [16,17]. The authors of this material demonstrate classes whose semantics seem to break under each of the items listed in this minimal interface. I will avoid this particular argument and refuse to get too religious about the above interface. I invite the reader to check the provided reference, and he or she can be the final judge. I will leave you with the thought that many of the users of the class library that motivated the minimal interface found it useful as a learning hook into the library. Having used one class, they knew something about all of the other classes. The fact that there exist exceptions to the support of such an interface doesn't bother me or, presumably, other users of minimal interfaces.
If we further consider our problems of copying objects whose classes possess containment by reference (i.e., shallow versus deep copying), we will find that we have a problem with shallow copying in languages that force us to perform our own memory management. How do we know when the object contained by reference can be destroyed safely? One method is to mark all shallow copies via a flag (see Figure 9.9) and develop a user-based constraint that states that shallow copies cannot live longer than the original. In this way, the original object is the only object that destroys the memory. The disadvantage is that it relies on a user to maintain the constraint. Programming by convention is a great source of errors.

A safer alternative to using a flag in the objects that share memory is to use a technique called reference or use counting. The idea of reference counting is to encapsulate the shared memory together with an integer counter. When a shallow copy of the object is created, it simply increments the reference counter. When an object is destroyed, it decrements the reference counter. If the counter goes to zero, then the object knows no one else is sharing the memory and so it can be freed (see Figure 9.10).

Let us consider the implementation of our air traffic control problem. How can our air traffic controllers share the same air traffic control memory? If all air traffic controllers in the world were looking at the same memory, then we would want to implement air traffic control memory as a class-specific piece of data. In that way, all air traffic controllers could share the object via the class. In the real world, let us assume that air traffic controllers in San Francisco are not interested in air traffic patterns over Madrid. However, all air traffic controllers in San Francisco are interested in sharing the same air traffic memory with their colleagues. Likewise, air traffic controllers in Madrid are interested in sharing their same memory. This is a case where groups of objects of the same class wish to share memory, but not all objects of that class want the same shared memory (see Figure 9.11). The best solution in these situations is to use reference counting. Each air traffic controller accesses some air traffic control memory object that is shared with other air traffic controllers, but not all air traffic controllers share the same one.
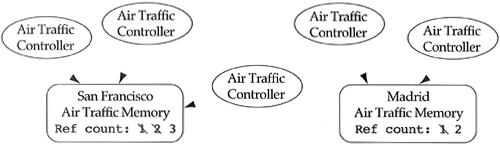
Shallow copying, and therefore reference counting, is used whenever it is necessary for the system requirements (e.g., the air traffic control problem), or to save space and time. The space savings comes from eliminating the need to keep multiple copies of the data. The time savings comes from the reduced need to copy data. It is important to note that if a shallow copy or the original object changes the state of the shared data, then all objects involved in the sharing see the update. In the air traffic control problem, this is exactly what we want. In some domains, this cannot be tolerated, and deep copying, or broadcasting, is required.
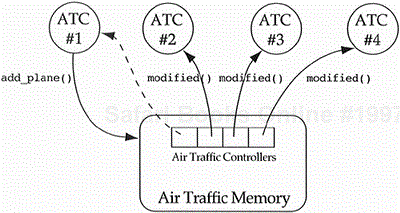
The technique of broadcasting is used when an object is shared by a group of objects through containment by reference relationships with the constraint that state changes to the shared object must be reported to the entire group of objects. In the case of air traffic control, we might argue that one controller's changes to the air traffic control memory should be reported to all the other controllers. The air traffic memory is the best object for broadcasting this message (see Figure 9.12). Of course, this implies that the air traffic memory (a contained object) knows about air traffic controllers (the containing objects), a violation of Heuristic 4.13. We can reduce the impact of this violation by stating that air traffic memory knows about a list of “things” that look at it but does not know the type of these things. The reuse restriction is changed from “anyone wishing to reuse air traffic memory objects must be air traffic controller objects (or their subclass)” to “anyone wishing to reuse air traffic memory objects must inherit from the thing class and implement the state_modified() message.”
At a conference on parallel programming in the mid-1980s, a prominent researcher in the field stated that human beings will never be able to write parallel programs due to their complexity. The human brain, the researcher continued, can barely comprehend the complexity of sequential programming of large systems. Parallelism is out of the question. Of course, this made all of the parallel hardware people upset, since they were at the conference selling the opposite argument of the researcher. Developers then started thinking about parallelism in the real world. When I teach a course, I have no trouble understanding that there are 20 heartbeats running in parallel, a caterer taking away breakfast, a viewgraph projector turned on, several PCs in the room actively running game programs while those interacting with the game are listening to me (in parallel), the occasional car driving on the street below, and, if in New York, a window washer sitting on a small piece of wood some 400 feet above the street. All of these objects are executing methods in parallel, yet I have no problem understanding the complexity. Why not?
A number of researchers have discussed this question in workshops and published it in texts and research articles. Is the fact that the concurrency is locked inside of objects the key to understanding? Is it better to have the concurrency mechanisms outside, but surrounding the objects? Can we apply the notion of concurrent object-oriented programming to our common parallel programming problems and get better solutions? These are the types of questions being addressed today. There are two excellent texts on concurrent object-oriented programming [18,19].
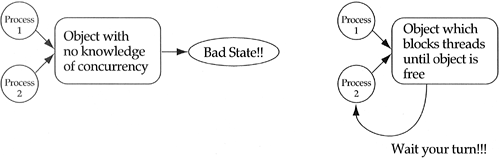
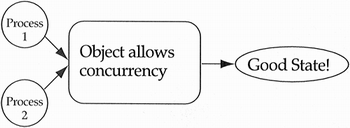
I will not discuss concurrent object-oriented programming in any great detail in this text. I will say that concurrent object-oriented programming is hard—but only because concurrent programming is hard, not because the object-oriented paradigm adds any complexity to the problem. There is some vocabulary worth knowing. When studying concurrent object-oriented programming, you will invariably hear people discuss the notion of passive objects versus active objects. Passive objects belong to classes that fall into one of two categories (see Figure 9.13). The first category consists of classes that have not considered concurrency at all, in which case the semantics of the class are not guaranteed under multiple threads of control. The second category consists of classes that have considered multiple threads of control and have solved the problem through blocking. That is, when two or more threads of control want access to an object, the first thread gets control and the others wait on a queue. Some standard concurrency mechanism is used to control the queue, for example, semaphore, monitor, or guard. Active objects belong to classes that guarantee their semantics in the presence of multiple threads of control without the need for blocking (see Figure 9.14). Be careful when reading research articles on concurrent object-oriented programming. Many alternative definitions and uses for the terms “passive” and “active” exist.
The final topic of interest in the area of physical design is how to go about implementing an object-oriented design in a nonobject-oriented language. This topic was of much greater interest in the late 1980s, when C++ was a moving target. At that time, many C programmers decided that they wanted to take advantage of object-oriented design but did not trust C++ for implementation. Many of them turned to object-oriented programming in C. Today C++ is fairly well defined with an ANSI committee adding on some final features. With this infrastructure in place, this topic becomes less interesting, although I have found a large number of developers who learn a lot about object-oriented programming by examining the implementation of its constructs using nonobject-oriented structures. I will summarize these details by examining each of the object-oriented constructs and how one might implement them in a nonobject-oriented language.
Most nonobject-oriented languages do not support the idea of two functions having the same name as long as their argument types differ (Prolog is one exception). The basic approach to handling this problem is to concatenate the name of the data type to the function name. This is how object-oriented languages implement overloaded functions. Either they mangle the name at compile time (e.g., C++), or they hash the name of the argument with the name of the function in order to find the address of the overloaded function (e.g., SmallTalk).
A standard method of implementing the notion of class in a nonobject-oriented language is to encapsulate a data structure with its associated functions. This can be done by using a function module (if your language supports modules, e.g., Ada83, Modula-2) or in a file (e.g., C).
There is no way to establish data hiding in languages that do not support it except by convention, that is, programmers promise not to access particular data members of a record and/or functions associated with that data. There is an exception in the C programming language. The C language allows its users to define pointers to a data structure without ever defining the data structure itself. However, there are major restrictions on the use of that pointer. The user of the pointer cannot perform any pointer arithmetic or any dereference operation. The only thing he or she can do with the pointer is to pass it to functions. In this way, developers can define a structure (record) called Dog and place it in a file along with all of the functions that work with Dogs. One of these functions is a get_Dog() operation, which returns a pointer to a Dog. This file is compiled separately and given as object code to users of Dogs. Users of Dogs define a pointer to a Dog but are not allowed access to the internal details. They call get_Dog() to get one of these objects and proceed to pass it along to any function defined on Dog. They get to use Dog objects but never get to see any implementation details of the Dog.
Inheritance is a difficult construct to fake. The implementation “trick” is exactly that used for implementing multiple inheritance in a single-inheritance language. The subclass (data structure) contains the superclass as its first data member. The user must then create a delegation function on the containing class for each function associated with the contained superclass. Like our multiple inheritance solution, this introduces accidental complexity in that we cannot just add a method to a superclass and have all of the subclasses inherit it. We must examine every class (data structure) that contains a modified class to determine if the modified class is really contained or if it is faking inheritance. If it is faking inheritance, then a delegation function must be added to the containing class. Many of the benefits of inheritance are lost in its implementation in a nonobject-oriented language.
Polymorphism is clearly the most difficult to implement in a nonobject-oriented language, with all solutions creating maintenance problems larger than the one we originally tried to avoid—explicit case analysis. The traditional approach to getting around polymorphism is to use pointers to functions (in languages that support them, e.g., C) to do something that used to be called generic programming. The idea is to bind the actual address to the function call at runtime by changing the value of a function pointer. Alternatives include performing the binding of a function call by forcing the user to call some function, perhaps named bind, which takes two string arguments: the type of the object making the call and the name of the function call. These two strings are hashed together to form an index, which, when used on a global hash table, returns the appropriate address of the desired function. For example, bind(''Dog'', ''wag_tail'') would hash to 142 (using some hash function which I neglect to provide). When index 142 is retrieved from a global hash table, the address of Dog's wag_tail() function is returned and executed. This is similar to SmallTalk's implementation of polymorphism.
An alternative is to build, and unfortunately maintain, jump tables for every class that wants a polymorphic function(s). When an object is built, it gets a hidden pointer to the appropriate jump table. Users then execute the appropriate function by providing its index in the jump table. Since the user does not know at whose jump table a given object is pointing, the binding is considered dynamic. This is similar to the method C++ employs for implementing polymorphism.
It is important to note that in both cases, the bookkeeping normally done by a programming language is required by the programmer. This often produces more maintenance problems than the original explicit case analysis that the programmer set out to avoid.
- Active object
An object whose semantics are guaranteed under multiple threads of control.
- Broadcasting
The act of an object sending messages to a collection of objects that contain it.
- CORBA
An architecture that discusses the distribution of object-oriented systems across differing architectures. The acronym stands for Common Object Request Broker Architecture. This architecture is being developed by the Object Management Group (OMG).
- Deep copy
The copying of an object in which the entire structure of the object is copied, not just its pointers and references.
- Local persistence (in time)
The act of saving an object to a static medium where each class has knowledge of how to store and retrieve the object.
- Logical object-oriented design
The area of object-oriented design dealing with finding classes, their protocols, and their relationships to one another (i.e., inheritance, containment, uses, and association).
- OMG
The Object Management Group, a consortium of companies dedicated to standardizing distributed, persistent, object-oriented systems across a broad range of development platforms. The designers of CORBA.
- Passive objects
Objects that belong to a class that either has not considered the possibility of multiple threads of control, or has considered the problem and solved it by blocking (i.e., allowing only one thread of control into the object at a time, forcing all other threads to wait).
- Persistence
The quality of an object which allows it to live after the power has been turned off.
- Persistence in space
The implementation of persistence where objects detect that a machine is powering down and scurry across the network to a safe machine where they can continue processing until their home machine is available.
- Persistence in time
The implementation of persistence where objects are stored to some static medium from which they can be reloaded in the future. It usually implies a database.
- Physical object-oriented design
The facet of object-oriented design dealing with hardware and software platforms and their impact on a logical object-oriented design.
- Reference counting
A technique for developing safe shallow copies wherein the data to be shared is encapsulated with an integer counter that maintains the number of containing objects sharing the data.
- Shallow copy
The copying of an object where only its addresses and references are copied. The original object and its copy share the objects representation.
- Wrapper
A layer of software that hides some detail or subsystem of an application from the other subsystem(s).
Heuristic 9.1. Object-oriented designers should not allow physical design criteria to corrupt their logical designs. However, physical design criteria are often used in the decision-making process at logical design time.
Heuristic 9.2. Do not change the state of an object without going through its public interface.