
15
Extending Kubernetes
In this chapter, we will dig deep into the guts of Kubernetes. We will start with the Kubernetes API and learn how to work with Kubernetes programmatically via direct access to the API, the controller-runtime Go library, and automating kubectl. Then, we’ll look into extending the Kubernetes API with custom resources. The last part is all about the various plugins Kubernetes supports. Many aspects of Kubernetes operation are modular and designed for extension. We will examine the API aggregation layer and several types of plugins, such as custom schedulers, authorization, admission control, custom metrics, and volumes. Finally, we’ll look into extending kubectl and adding your own commands.
The covered topics are as follows:
- Working with the Kubernetes API
- Extending the Kubernetes API
- Writing Kubernetes and kubectl plugins
- Writing webhooks
Working with the Kubernetes API
The Kubernetes API is comprehensive and encompasses the entire functionality of Kubernetes. As you may expect, it is huge. But it is designed very well using best practices, and it is consistent. If you understand the basic principles, you can discover everything you need to know. We covered the Kubernetes API itself in Chapter 1, Understanding Kubernetes Architecture. If you need a refresher, go and take a look. In this section, we’re going to dive deeper and learn how to access and work with the Kubernetes API. But, first let’s look at OpenAPI, which is the formal foundation that gives structure to the entire Kubernetes API.
Understanding OpenAPI
OpenAPI (formerly Swagger) is an open standard that defines a language- and framework-agnostic way to describe RESTful APIs. It provides a standardized, machine-readable format for describing APIs, including their endpoints, parameters, request and response bodies, authentication, and other metadata.
In the context of Kubernetes, OpenAPI is used to define and document the API surface of a Kubernetes cluster. OpenAPI is used in Kubernetes to provide a standardized way to document and define the API objects that can be used to configure and manage the cluster. The Kubernetes API is based on a declarative model, where users define the desired state of their resources using YAML or JSON manifests. These manifests follow the OpenAPI schema, which defines the structure and properties of each resource. Kubernetes uses the OpenAPI schema to validate manifests, provide auto-completion and documentation in API clients, and generate API reference documentation.
One of the key benefits of using OpenAPI in Kubernetes is that it enables code generation for client libraries. This allows developers to interact with the Kubernetes API using their programming language of choice and generated client libraries, which provide a native and type-safe way to interact with the API.
Additionally, OpenAPI allows tools like kubectl to provide autocompletion and validation for Kubernetes resources.
OpenAPI also enables automated documentation generation for the Kubernetes API. With the OpenAPI schema, Kubernetes can automatically generate API reference documentation, which serves as a comprehensive and up-to-date resource for understanding the Kubernetes API and its capabilities.
Kubernetes has had stable support for OpenAPI v3 since Kubernetes 1.27.
Check out https://www.openapis.org for more details.
In order to work with the Kubernetes API locally, we need to set up a proxy.
Setting up a proxy
To simplify access, you can use kubectl to set up a proxy:
$ k proxy --port 8080
Now, you can access the API server on http://localhost:8080 and it will reach the same Kubernetes API server that kubectl is configured for.
Exploring the Kubernetes API directly
The Kubernetes API is highly discoverable. You can just browse to the URL of the API server at http://localhost:8080 and get a nice JSON document that describes all the available operations under the paths key.
Here is a partial list due to space constraints:
{
"paths": [
"/api",
"/api/v1",
"/apis",
"/apis/",
"/apis/admissionregistration.k8s.io",
"/apis/admissionregistration.k8s.io/v1",
"/apis/apiextensions.k8s.io",
"/livez/poststarthook/storage-object-count-tracker-hook",
"/logs",
"/metrics",
"/openapi/v2",
"/openapi/v3",
"/openapi/v3/",
"/openid/v1/jwks",
"/readyz/shutdown",
"/version"
]
}
You can drill down any one of the paths. For example, to discover the endpoint for the default namespace, I first called the /api endpoint, then discovered /api/v1, which told me there was /api/v1/namespaces, which pointed me to /api/v1/namespaces/default. Here is the response from the /api/v1/namespaces/default endpoint:
{
"kind": "Namespace",
"apiVersion": "v1",
"metadata": {
"name": "default",
"uid": "7e39c279-949a-4fb6-ae47-796bb797082d",
"resourceVersion": "192",
"creationTimestamp": "2022-11-13T04:33:00Z",
"labels": {
"kubernetes.io/metadata.name": "default"
},
"managedFields": [
{
"manager": "kube-apiserver",
"operation": "Update",
"apiVersion": "v1",
"time": "2022-11-13T04:33:00Z",
"fieldsType": "FieldsV1",
"fieldsV1": {
"f:metadata": {
"f:labels": {
".": {},
"f:kubernetes.io/metadata.name": {}
}
}
}
}
]
},
"spec": {
"finalizers": [
"kubernetes"
]
},
"status": {
"phase": "Active"
}
}
You can explore the Kubernetes API from the command line using tools like cURL or even kubectl itself, but sometimes using a GUI application is more convenient.
Using Postman to explore the Kubernetes API
Postman (https://www.getpostman.com) is a very polished application for working with RESTful APIs. If you lean more to the GUI side, you may find it extremely useful.
The following screenshot shows the available endpoints under the batch v1 API group:

Figure 15.1: The available endpoints under the batch v1 API group
Postman has a lot of options, and it organizes the information in a very pleasing way. Give it a try.
Filtering the output with HTTPie and jq
The output from the API can be too verbose sometimes. Often, you’re interested just in one value out of a huge chunk of a JSON response. For example, if you want to get the names of all running services, you can hit the /api/v1/services endpoint. The response, however, includes a lot of additional information that is irrelevant. Here is a very partial subset of the output:
$ http http://localhost:8080/api/v1/services
{
"kind": "ServiceList",
"apiVersion": "v1",
"metadata": {
"resourceVersion": "3237"
},
"items": [
...
{
"metadata": {
"name": "kube-dns",
"namespace": "kube-system",
...
},
"spec": {
...
"selector": {
"k8s-app": "kube-dns"
},
"clusterIP": "10.96.0.10",
"type": "ClusterIP",
"sessionAffinity": "None",
},
"status": {
"loadBalancer": {}
}
}
]
}
The complete output is 193 lines long! Let’s see how to use HTTPie and jq to gain full control over the output and show only the names of the services. I prefer HTTPie(https://httpie.org/) over cURL for interacting with REST APIs on the command line. The jq (https://stedolan.github.io/jq/) command-line JSON processor is great for slicing and dicing JSON.
Examining the full output, you can see that the service name is in the metadata section of each item in the items array. The jq expression that will select just the name is as follows:
.items[].metadata.name
Here is the full command and output on a fresh kind cluster:
$ http http://localhost:8080/api/v1/services | jq '.items[].metadata.name'
"kubernetes"
"kube-dns"
Accessing the Kubernetes API via the Python client
Exploring the API interactively using HTTPie and jq is great, but the real power of APIs comes when you consume and integrate them with other software. The Kubernetes Incubator project provides a full-fledged and very well-documented Python client library. It is available at https://github.com/kubernetes-incubator/client-python.
First, make sure you have Python installed (https://wiki.python.org/moin/BeginnersGuide/Download). Then install the Kubernetes package:
$ pip install kubernetes
To start talking to a Kubernetes cluster, you need to connect to it. Start an interactive Python session:
$ python
Python 3.9.12 (main, Aug 25 2022, 11:03:34)
[Clang 13.1.6 (clang-1316.0.21.2.3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
The Python client can read your kubectl config:
>>> from kubernetes import client, config
>>> config.load_kube_config()
>>> v1 = client.CoreV1Api()
Or it can connect directly to an already running proxy:
>>> from kubernetes import client, config
>>> client.Configuration().host = 'http://localhost:8080'
>>> v1 = client.CoreV1Api()
Note that the client module provides methods to get access to different group versions, such as CoreV1Api.
Dissecting the CoreV1Api group
Let’s dive in and understand the CoreV1Api group. The Python object has 407 public attributes!
>>> attributes = [x for x in dir(v1) if not x.startswith('__')]
>>> len(attributes)
407
We ignore the attributes that start with double underscores because those are special class/instance methods unrelated to Kubernetes.
Let’s pick ten random methods and see what they look like:
>>> import random
>>> from pprint import pprint as pp
>>> pp(random.sample(attributes, 10))
['replace_namespaced_persistent_volume_claim',
'list_config_map_for_all_namespaces_with_http_info',
'connect_get_namespaced_pod_attach_with_http_info',
'create_namespaced_event',
'connect_head_node_proxy_with_path',
'create_namespaced_secret_with_http_info',
'list_namespaced_service_account',
'connect_post_namespaced_pod_portforward_with_http_info',
'create_namespaced_service_account_token',
'create_namespace_with_http_info']
Very interesting. The attributes begin with a verb such as replace, list, or create. Many of them have a notion of a namespace and many have a with_http_info suffix. To understand this better, let’s count how many verbs exist and how many attributes use each verb (where the verb is the first token before the underscore):
>>> from collections import Counter
>>> verbs = [x.split('_')[0] for x in attributes]
>>> pp(dict(Counter(verbs)))
{'api': 1,
'connect': 96,
'create': 38,
'delete': 58,
'get': 2,
'list': 56,
'patch': 50,
'read': 54,
'replace': 52}
We can drill further and look at the interactive help for a specific attribute:
>>> help(v1.create_node)
Help on method create_node in module kubernetes.client.apis.core_v1_api:
create_node(body, **kwargs) method of kubernetes.client.api.core_v1_api.CoreV1Api instance
create_node # noqa: E501
create a Node # noqa: E501
This method makes a synchronous HTTP request by default. To make an
asynchronous HTTP request, please pass async_req=True
>>> thread = api.create_node(body, async_req=True)
>>> result = thread.get()
:param async_req bool: execute request asynchronously
:param V1Node body: (required)
:param str pretty: If 'true', then the output is pretty printed.
:param str dry_run: When present, indicates that modifications should not be persisted. An invalid or unrecognized dryRun directive will result in an error response and no further processing of the request. Valid values are: - All: all dry run stages will be processed
:param str field_manager: fieldManager is a name associated with the actor or entity that is making these changes. The value must be less than or 128 characters long, and only contain printable characters, as defined by https://golang.org/pkg/unicode/#IsPrint.
:param str field_validation: fieldValidation instructs the server on how to handle objects in the request (POST/PUT/PATCH) containing unknown or duplicate fields, provided that the `ServerSideFieldValidation` feature gate is also enabled. Valid values are: - Ignore: This will ignore any unknown fields that are silently dropped from the object, and will ignore all but the last duplicate field that the decoder encounters. This is the default behavior prior to v1.23 and is the default behavior when the `ServerSideFieldValidation` feature gate is disabled. - Warn: This will send a warning via the standard warning response header for each unknown field that is dropped from the object, and for each duplicate field that is encountered. The request will still succeed if there are no other errors, and will only persist the last of any duplicate fields. This is the default when the `ServerSideFieldValidation` feature gate is enabled. - Strict: This will fail the request with a BadRequest error if any unknown fields would be dropped from the object, or if any duplicate fields are present. The error returned from the server will contain all unknown and duplicate fields encountered.
:param _preload_content: if False, the urllib3.HTTPResponse object will
be returned without reading/decoding response
data. Default is True.
:param _request_timeout: timeout setting for this request. If one
number provided, it will be total request
timeout. It can also be a pair (tuple) of
(connection, read) timeouts.
:return: V1Node
If the method is called
returns the request thread.
We see that the API is vast, which makes sense because it represents the entire Kubernetes API. We also learned how to discover groups of related methods and how to get detailed information on specific methods.
You can poke around yourself and learn more about the API. Let’s look at some common operations, such as listing, creating, and watching objects.
Listing objects
You can list different kinds of objects. The method names start with list_. Here is an example listing all namespaces:
>>> for ns in v1.list_namespace().items:
... print(ns.metadata.name)
...
default
kube-node-lease
kube-public
kube-system
local-path-storage
Creating objects
To create an object, you need to pass a body parameter to the create method. The body must be a Python dictionary that is equivalent to a YAML configuration manifest you would use with kubectl. The easiest way to do it is to actually use a YAML manifest and then use the Python YAML module (not part of the standard library and must be installed separately) to read the YAML file and load it into a dictionary. For example, to create an nginx-deployment with 3 replicas, we can use this YAML manifest (nginx-deployment.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
To install the yaml Python module, type this command:
$ pip install yaml
Then the following Python program (create_nginx_deployment.py) will create the deployment:
from os import path
import yaml
from kubernetes import client, config
def main():
# Configs can be set in Configuration class directly or using
# helper utility. If no argument provided, the config will be
# loaded from default location.
config.load_kube_config()
with open(path.join(path.dirname(__file__),
'nginx-deployment.yaml')) as f:
dep = yaml.safe_load(f)
k8s = client.AppsV1Api()
dep = k8s.create_namespaced_deployment(body=dep,
namespace="default")
print(f"Deployment created. status='{dep.status}'")
if __name__ == '__main__':
main()
Let’s run it and check the deployment was actually created using kubectl:
$ python create_nginx_deployment.py
Deployment created. status='{'available_replicas': None,
'collision_count': None,
'conditions': None,
'observed_generation': None,
'ready_replicas': None,
'replicas': None,
'unavailable_replicas': None,
'updated_replicas': None}'
$ k get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 56s
Watching objects
Watching objects is an advanced capability. It is implemented using a separate watch module. Here is an example of watching 10 namespace events and printing them to the screen (watch_demo.py):
from kubernetes import client, config, watch
# Configs can be set in Configuration class directly or using helper utility
config.load_kube_config()
v1 = client.CoreV1Api()
count = 10
w = watch.Watch()
for event in w.stream(v1.list_namespace, _request_timeout=60):
print(f"Event: {event['type']} {event['object'].metadata.name}")
count -= 1
if count == 0:
w.stop()
print('Done.')
Here is the output:
$ python watch_demo.py
Event: ADDED kube-node-lease
Event: ADDED default
Event: ADDED local-path-storage
Event: ADDED kube-system
Event: ADDED kube-public
Note that only 5 events were printed (one for each namespace) and the program continues to watch for more events.
Let’s create and delete some namespaces in a separate terminal window, so the program can end:
$ k create ns ns-1
namespace/ns-1 created
$ k delete ns ns-1
namespace "ns-1" deleted
$ k create ns ns-2
namespace/ns-2 created
The final output is:
$ python watch_demo.py
Event: ADDED default
Event: ADDED local-path-storage
Event: ADDED kube-system
Event: ADDED kube-public
Event: ADDED kube-node-lease
Event: ADDED ns-1
Event: MODIFIED ns-1
Event: MODIFIED ns-1
Event: DELETED ns-1
Event: ADDED ns-2
Done.
You can of course react to events and perform a useful action when an event happens (e.g., automatically deploy a workload in each new namespace).
Creating a pod via the Kubernetes API
The API can be used for creating, updating, and deleting resources too. Unlike working with kubectl, the API requires specifying the manifests in JSON and not YAML syntax (although every JSON document is also valid YAML). Here is a JSON pod definition (nginx-pod.json):
{
"kind": "Pod",
"apiVersion": "v1",
"metadata":{
"name": "nginx",
"namespace": "default",
"labels": {
"name": "nginx"
}
},
"spec": {
"containers": [{
"name": "nginx",
"image": "nginx",
"ports": [{"containerPort": 80}]
}]
}
}
The following command will create the pod via the API:
$ http POST http://localhost:8080/api/v1/namespaces/default/pods @nginx-pod.json
To verify it worked, let’s extract the name and status of the current pods. The endpoint is /api/v1/namespaces/default/pods.
The jq expression is items[].metadata.name,.items[].status.phase.
Here is the full command and output:
$ FILTER='.items[].metadata.name,.items[].status.phase'
$ http http://localhost:8080/api/v1/namespaces/default/pods | jq $FILTER
"nginx"
"Running"
Controlling Kubernetes using Go and controller-runtime
Python is cool and easy to work with, but for production-level tools, controllers, and operators, I prefer to use Go, and in particular the controller-runtime project. The controller-runtime is the standard Go client to use to access the Kubernetes API.
Using controller-runtime via go-k8s
The controller-runtime project is a set of Go libraries that can fully query and manipulate Kubernetes in a very efficient manner (e.g., advanced caching to avoid overwhelming the API server).
Working directly with controller-runtime is not easy. There are many interlocking pieces and different ways to accomplish things.
See https://pkg.go.dev/sigs.k8s.io/controller-runtime.
I created a little open-source project called go-k8s that encapsulates some of the complexity and helps with using a subset of the controller-runtime functionality with less hassle.
Check it out here: https://github.com/the-gigi/go-k8s/tree/main/pkg/client.
Note that the go-k8s project has other libraries, but we will focus on the client library.
The go-k8s client package supports two types of clients: Clientset and DynamicClient. The Clientset client supports working with well-known kinds, but explicitly specifying the API version, kind, and operation as method names. For example, listing all pods using Clientset looks like this:
podList, err := clientset.CoreV1().Pods("ns-1").List(context.Background(), metav1.ListOptions{})
It returns a pod list and an error. The error is nil if everything is OK. The pod list is of struct type PodList, which is defined here: https://github.com/kubernetes/kubernetes/blob/master/pkg/apis/core/types.go#L2514.
Conveniently, you can find all the Kubernetes API types in the same file. The API is very nested, for example, a PodList, as you may expect, is a list of Pod objects. Each Pod object has TypeMeta, ObjectMeta, PodSpec, and PodStatus:
type Pod struct {
metav1.TypeMeta
metav1.ObjectMeta
Spec PodSpec
Status PodStatus
}
In practice, this means that when you make a call through the Clientset, you get back a strongly typed nested object that is very easy to work with. For example, if we want to check if a pod has a label called app and its value, we can do it in one line:
app, ok := pods[0].ObjectMeta.Labels["app"]
If the label doesn’t exist, ok will be false. If it does exist, then its value will be available in the app variable.
Now, let’s look at DynamicClient. Here, you get the ultimate flexibility and the ability to work with well-known types as well as custom types. In particular, if you want to create arbitrary resources, the dynamic client can operate in a generic way on any Kubernetes type.
However, with the dynamic client, you always get back a generic object of type Unstructured, defined here: https://github.com/kubernetes/apimachinery/blob/master/pkg/apis/meta/v1/unstructured/unstructured.go#L41.
It is really a very thin wrapper around the generic Golang type map[string]interface{}. It has a single field called Object of type map[string]interface{}. This means that the object you get back is a map of field names to arbitrary other objects (represented as interface{}). To drill down the hierarchy, we have to perform typecasting, which means taking an interface{} value and casting it explicitly to its actual type. Here is a simple example:
var i interface{} = 5
x, ok := i.(int)
Now, x is a variable of type int with a value of 5 that can be used as an integer. The original i variable can’t be used as an integer because its type is the generic interface{} even if it contains an integer value.
In the case of the objects returned from the dynamic client, we have to keep typecasting an interface{} to a map[string]interface{} until we get to the field we are interested in. To get to the app label of our pod, we need to follow this path:
pod := pods[0].Object
metadata := pod["metadata"].(map[string]interface{})
labels := metadata["labels"].(map[string]interface{})
app, ok := labels["app"].(string)
This is extremely tiresome and error-prone. Luckily, there is a better way. The Kubernetes apimachinery/runtime package provides a conversion function that can take an unstructured object and convert it into a known type:
pod := pods[0].Object
var p corev1.Pod
err = runtime.DefaultUnstructuredConverter.FromUnstructured(pod, &p)
if err != nil {
return err
}
app, ok = p.ObjectMeta.Labels["app"]
The controller-runtime is very powerful, but it can be tedious to deal with all the types. One way to “cheat” is to use kubectl, which actually uses the controller-runtime under the covers. This is especially easy using Python and its dynamic typing.
Invoking kubectl programmatically from Python and Go
If you don’t want to deal with the REST API directly or client libraries, you have another option. Kubectl is used mostly as an interactive command-line tool, but nothing is stopping you from automating it and invoking it through scripts and programs. There are some benefits to using kubectl as your Kubernetes API client:
- Easy to find examples for any usage
- Easy to experiment on the command line to find the right combination of commands and arguments
- kubectl supports output in JSON or YAML for quick parsing
- Authentication is built in via kubectl configuration
Using Python subprocess to run kubectl
Let’s use Python first, so you can compare using the official Python client to rolling your own. Python has a module called subprocess that can run external processes such as kubectl and capture the output.
Here is a Python 3 example running kubectl on its own and displaying the beginning of the usage output:
>>> import subprocess
>>> out = subprocess.check_output('kubectl').decode('utf-8')
>>> print(out[:276])
Kubectl controls the Kubernetes cluster manager.
Find more information at https://kubernetes.io/docs/reference/kubectl/overview/.
The check_output() function captures the output as a bytes array, which needs to be decoded into utf-8 to be displayed properly. We can generalize it a little bit and create a convenience function called k() in the k.py file. It accepts any number of arguments it feeds to kubectl, and then decodes the output and returns it:
from subprocess import check_output
def k(*args):
out = check_output(['kubectl'] + list(args))
return out.decode('utf-8')
Let’s use it to list all the running pods in the default namespace:
>>> from k import k
>>> print(k('get', 'po'))
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 4h48m
nginx-deployment-679f9c75b-c79mv 1/1 Running 0 132m
nginx-deployment-679f9c75b-cnmvk 1/1 Running 0 132m
nginx-deployment-679f9c75b-gzfgk 1/1 Running 0 132m
This is nice for display, but kubectl already does that. The real power comes when you use the structured output options with the -o flag. Then the result can be converted automatically into a Python object. Here is a modified version of the k() function that accepts a Boolean use_json keyword argument (defaults to False), and if True, adds -o json and then parses the JSON output to a Python object (dictionary):
from subprocess import check_output
import json
def k(*args, use_json=False):
cmd = ['kubectl'] + list(args)
if use_json:
cmd += ['-o', 'json']
out = check_output(cmd).decode('utf-8')
if use_json:
out = json.loads(out)
return out
That returns a full-fledged API object, which can be navigated and drilled down just like when accessing the REST API directly or using the official Python client:
result = k('get', 'po', use_json=True)
>>> for r in result['items']:
... print(r['metadata']['name'])
...
nginx-deployment-679f9c75b-c79mv
nginx-deployment-679f9c75b-cnmvk
nginx-deployment-679f9c75b-gzfgk
Let’s see how to delete the deployment and wait until all the pods are gone. The kubectl delete command doesn’t accept the -o json option (although it has -o name), so let’s leave out use_json:
>>> k('delete', 'deployment', 'nginx-deployment')
while len(k('get', 'po', use_json=True)['items']) > 0:
print('.')
print('Done.')
.
.
.
.
Done.
Python is great, but what if you prefer Go for automating kubectl? No worries, I have just the package for you. The kugo package provides a simple Go API to automate kubectl. You can find the code here: https://github.com/the-gigi/kugo.
It provides 3 functions: Run(), Get(), and Exec().
The Run() function is your Swiss Army knife. It can run any kubectl command as is. Here is an example:
cmd := fmt.Sprintf("create deployment test-deployment --image nginx --replicas 3 -n ns-1")
_, err := kugo.Run(cmd)
This is super convenient because you can interactively compose the exact command and parameters you need using kubectl and then, once you’ve figured out everything, you can literally take the same command and pass it to kuge.Run() in your Go program.
The Get() function is a smart wrapper around kubectl get. It accepts a GetRequest parameter and provides several amenities: it supports field selectors, fetching by label, and different output types. Here is an example of fetching all namespaces by name using a custom kube config file and custom kube context:
output, err := kugo.Get(kugo.GetRequest{
BaseRequest: kugo.BaseRequest{
KubeConfigFile: c.kubeConfigFile,
KubeContext: c.GetKubeContext(),
},
Kind: "ns",
Output: "name",
})
Finally, the Exec() function is a wrapper around kubectl exec and lets you execute commands on a running pod/container. It accepts an ExecRequest that looks like this:
type GetRequest struct {
BaseRequest
Kind string
FieldSelectors []string
Label string
Output string
}
Let’s look at the code of the Exec() function. It is pretty straightforward. It does basic validation that required fields like Command and Target were provided and then it builds a kubectl argument list starting with the exec command and finally calls the Run() function:
// Exec executes a command in a pod
//
// The target pod can specified by name or an arbitrary pod
// from a deployment or service.
//
// If the pod has multiple containers you can choose which
// container to run the command in
func Exec(r ExecRequest) (result string, err error) {
if r.Command == "" {
err = errors.New("Must specify Command field")
return
}
if r.Target == "" {
err = errors.New("Must specify Target field")
return
}
args := []string{"exec", r.Target}
if r.Container != "" {
args = append(args, "-c", r.Container)
}
args = handleCommonArgs(args, r.BaseRequest)
args = append(args, "--", r.Command)
return Run(args...)
}
Now, that we have accessed Kubernetes programmatically via its REST API, client libraries, and by controlling kubectl, it’s time to learn how to extend Kubernetes.
Extending the Kubernetes API
Kubernetes is an extremely flexible platform. It was designed from the get-go for extensibility and as it evolved, more parts of Kubernetes were opened up, exposed through robust interfaces, and could be replaced by alternative implementations. I would venture to say that the exponential adoption of Kubernetes across the board by start-ups, large companies, infrastructure providers, and cloud providers is a direct result of Kubernetes providing a lot of capabilities out of the box, but allowing easy integration with other actors. In this section, we will cover many of the available extension points, such as:
- User-defined types (custom resources)
- API access extensions
- Infrastructure extensions
- Operators
- Scheduler extensions
Let’s understand the various ways you can extend Kubernetes.
Understanding Kubernetes extension points and patterns
Kubernetes is made of multiple components: the API server, etcd state store, controller manager, kube-proxy, kubelet, and container runtime. You can deeply extend and customize each and every one of these components, as well as adding your own custom components that watch and react to events, handle new requests, and modify everything about incoming requests.
The following diagram shows some of the available extension points and how they are connected to various Kubernetes components:

Figure 15.2: Available extension points
Let’s see how to extend Kubernetes with plugins.
Extending Kubernetes with plugins
Kubernetes defines several interfaces that allow it to interact with a wide variety of plugins from infrastructure providers. We discussed some of these interfaces and plugins in detail in previous chapters. We will just list them here for completeness:
- Container networking interface (CNI) – the CNI supports a large number of networking solutions for connecting nodes and containers
- Container storage interface (CSI) – the CSI supports a large number of storage options for Kubernetes
- Device plugins – allows nodes to discover new node resources beyond CPU and memory (e.g., a GPU)
Extending Kubernetes with the cloud controller manager
Kubernetes needs to be deployed eventually on some nodes and use some storage and networking resources. Initially, Kubernetes supported only Google Cloud Platform and AWS. Other cloud providers had to customize multiple Kubernetes core components (Kubelet, the Kubernetes controller manager, and the Kubernetes API server) in order to integrate with Kubernetes. The Kubernetes developers identified it as a problem for adoption and created the cloud controller manager (CCM). The CCM cleanly defines the interaction between Kubernetes and the infrastructure layer it is deployed on. Now, cloud providers just provide an implementation of the CCM tailored to their infrastructure, and they can utilize upstream Kubernetes without costly and error-prone modification to the Kubernetes code. All the Kubernetes components interact with the CCM via the predefined interfaces and Kubernetes is blissfully unaware of which cloud (or no cloud) it is running on.
The following diagram demonstrates the interaction between Kubernetes and a cloud provider via the CCM:

Figure 15.3: Interaction between Kubernetes and a cloud provider via the CCM
If you want to learn more about the CCM, check out this concise article I wrote a few years ago: https://medium.com/@the.gigi/kubernetes-and-cloud-providers-b7a6227d3198.
Extending Kubernetes with webhooks
Plugins run in the cluster, but in some cases, a better extensibility pattern is to delegate some functions to an out-of-cluster service. This is very common in the area of access control where companies and organizations may already have a centralized solution for identity and access control. In those cases, the webhook extensibility pattern is useful. The idea is that you can configure Kubernetes with an endpoint (webhook). Kubernetes will call the endpoint where you can implement your own custom functionality and Kubernetes will take action based on the response. We saw this pattern when we discussed authentication, authorization, and dynamic admission control in Chapter 4, Securing Kubernetes.
Kubernetes defines the expected payloads for each webhook. The webhook implementation must adhere to them in order to successfully interact with Kubernetes.
Extending Kubernetes with controllers and operators
The controller pattern is where you write a program that can run inside the cluster or outside the cluster, watch for events, and respond to them. The conceptual model for a controller is to reconcile the current state of the cluster (the parts the controller is interested in) with the desired state. A common practice for controllers is to read the Spec of an object, take some actions, and update its Status. A lot of the core logic of Kubernetes is implemented by a large set of controllers managed by the controller manager, but there is nothing stopping us from deploying our own controllers to the cluster or running controllers that access the API server remotely.
The operator pattern is another flavor of the controller pattern. Think of an operator as a controller that also has its own set of custom resources, which represents an application it manages. The goal of operators is to manage the lifecycle of an application that is deployed in the cluster or some out-of-cluster infrastructure. Check out https://operatorhub.io for examples of existing operators.
If you plan to build your own controllers, I recommend starting with Kubebuilder (https://github.com/kubernetes-sigs/kubebuilder). It is an open project maintained by the Kubernetes API Machinery SIG and has support for defining multiple custom APIs using CRDs, and scaffolds out the controller code to watch these resources. You will implement your controller in Go.
However, there are multiple other frameworks for writing controllers and operators with different approaches and using other programming languages:
- The Operator Framework
- Kopf
- kube-rs
- KubeOps
- KUDO
- Metacontroller
Check them out before you make your decision.
Extending Kubernetes scheduling
Kubernetes’ primary job, in one sentence, is to schedule pods on nodes. Scheduling is at the heart of what Kubernetes does, and it does it very well. The Kubernetes scheduler can be configured in very advanced ways (daemon sets, taints, tolerations, etc.). But still, the Kubernetes developers recognize that there may be extraordinary circumstances where you may want to control the core scheduling algorithm. It is possible to replace the core Kubernetes scheduler with your own scheduler or run another scheduler side by side with the built-in scheduler to control the scheduling of a subset of the pods. We will see how to do that later in the chapter.
Extending Kubernetes with custom container runtimes
Kubernetes originally supported only Docker as a container runtime. The Docker support was embedded into the core Kubernetes codebase. Later, dedicated support for rkt was added. The Kubernetes developers saw the light and introduced the container runtime interface (CRI), a gRPC interface that enables any container runtime that implements it to communicate with the kubelet. Eventually, the hard-coded support for Docker and rkt was phased out and now the kubelet talks to the container runtime only through the CRI:

Figure 15.4: Kubelet talking to the container runtime through the CRI
Since the introduction of the CRI, the number of container runtimes that work with Kubernetes has exploded.
We’ve covered multiple ways to extend different aspects of Kubernetes. Let’s turn our attention to the major concept of custom resources, which allow you to extend the Kubernetes API itself.
Introducing custom resources
One of the primary ways to extend Kubernetes is to define new types of resources called custom resources. What can you do with custom resources? Plenty. You can use them to manage, through the Kubernetes API, resources that live outside the Kubernetes cluster but that your pods communicate with. By adding those external resources as custom resources, you get a full picture of your system, and you benefit from many Kubernetes API features such as:
- Custom CRUD REST endpoints
- Versioning
- Watches
- Automatic integration with generic Kubernetes tooling
Other use cases for custom resources are metadata for custom controllers and automation programs.
Let’s dive in and see what custom resources are all about.
In order to play nice with the Kubernetes API server, custom resources must conform to some basic requirements. Similar to built-in API objects, they must have the following fields:
apiVersion:apiextensions.k8s.io/v1metadata: Standard Kubernetes object metadatakind:CustomResourceDefinitionspec: Describes how the resource appears in the API and toolsstatus: Indicates the current status of the CRD
The spec has an internal structure that includes fields like group, names, scope, validation, and version. The status includes the fields acceptedNames and Conditions. In the next section, I’ll show you an example that clarifies the meaning of these fields.
Developing custom resource definitions
You develop your custom resources using custom resource definitions, AKA CRDs. The intention is for CRDs to integrate smoothly with Kubernetes, its API, and tooling. That means you need to provide a lot of information. Here is an example for a custom resource called Candy:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# name must match the spec fields below, and be in the form: <plural>.<group>
name: candies.awesome.corp.com
spec:
# group name to use for REST API: /apis/<group>/<version>
group: awesome.corp.com
# version name to use for REST API: /apis/<group>/<version>
versions:
- name: v1
# Each version can be enabled/disabled by Served flag.
served: true
# One and only one version must be marked as the storage version.
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
flavor:
type: string
# either Namespaced or Cluster
scope: Namespaced
names:
# plural name to be used in the URL: /apis/<group>/<version>/<plural>
plural: candies
# singular name to be used as an alias on the CLI and for display
singular: candy
# kind is normally the CamelCased singular type. Your resource manifests use this.
kind: Candy
# shortNames allow shorter string to match your resource on the CLI
shortNames:
- cn
The Candy CRD has several interesting parts. The metadata has a fully qualified name, which should be unique since CRDs are cluster-scoped. The spec has a versions section, which can contain multiple versions with a schema for each version that specifies the field of the custom resource. The schema follows the OpenAPI v3 specification (https://github.com/OAI/OpenAPI-Specification/blob/master/versions/3.0.0.md#schemaObject). The scope field could be either Namespaced or Cluster. If the scope is Namespaced, then the custom resources you create from the CRD will exist only in the namespace they were created in, whereas cluster-scoped custom resources are available in any namespace. Finally, the names section refers to the names of the custom resource (not the name of the CRD from the metadata section). The names section has plural, singular, kind, and shortNames options.
Let’s create the CRD:
$ k create -f candy-crd.yaml
customresourcedefinition.apiextensions.k8s.io/candies.awesome.corp.com created
Note, that the metadata name is returned. It is common to use a plural name. Now, let’s verify we can access it:
$ k get crd
NAME CREATED AT
candies.awesome.corp.com 2022-11-24T22:56:27Z
There is also an API endpoint for managing this new resource:
/apis/awesome.corp.com/v1/namespaces/<namespace>/candies/
Integrating custom resources
Once the CustomResourceDefinition object has been created, you can create custom resources of that resource kind – Candy in this case (candy becomes CamelCase Candy). Custom resources must respect the schema of the CRD. In the following example, the flavor field is set on the Candy object with the name chocolate. The apiVersion field is derived from the CRD spec group and versions fields:
apiVersion: awesome.corp.com/v1
kind: Candy
metadata:
name: chocolate
spec:
flavor: sweeeeeeet
Let’s create it:
$ k create -f chocolate.yaml
candy.awesome.corp.com/chocolate created
Note that the spec must contain the flavor field from the schema.
At this point, kubectl can operate on Candy objects just like it works on built-in objects. Resource names are case-insensitive when using kubectl:
$ k get candies
NAME AGE
chocolate 34s
We can also view the raw JSON data using the standard -o json flag. Let’s use the short name cn this time:
$ k get cn -o json
{
"apiVersion": "v1",
"items": [
{
"apiVersion": "awesome.corp.com/v1",
"kind": "Candy",
"metadata": {
"creationTimestamp": "2022-11-24T23:11:01Z",
"generation": 1,
"name": "chocolate",
"namespace": "default",
"resourceVersion": "750357",
"uid": "49f68d80-e9c0-4c20-a87d-0597a60c4ed8"
},
"spec": {
"flavor": "sweeeeeeet"
}
}
],
"kind": "List",
"metadata": {
"resourceVersion": ""
}
}
Dealing with unknown fields
The schema in the spec was introduced with the apiextensions.k8s.io/v1 version of CRDs that became stable in Kubernetes 1.17. With apiextensions.k8s.io/v1beta, a schema wasn’t required so arbitrary fields were the way to go. If you just try to change the version of your CRD from v1beta to v1, you’re in for a rude awakening. Kubernetes will let you update the CRD, but when you try to create a custom resource later with unknown fields, it will fail.
You must define a schema for all your CRDs. If you must deal with custom resources that may have additional unknown fields, you can turn validation off, but the additional fields will be stripped off.
Here is a Candy resource that has an extra field, texture, not specified in the schema:
apiVersion: awesome.corp.com/v1
kind: Candy
metadata:
name: gummy-bear
spec:
flavor: delicious
texture: rubbery
If we try to create it with validation, it will fail:
$ k create -f gummy-bear.yaml
Error from server (BadRequest): error when creating "gummy-bear.yaml": Candy in version "v1" cannot be handled as a Candy: strict decoding error: unknown field "spec.texture"
But, if we turn validation off, then all is well, except that only the flavor field will be present and the texture field will not:
$ k create -f gummy-bear.yaml --validate=false
candy.awesome.corp.com/gummy-bear created
$ k get cn gummy-bear -o yaml
apiVersion: awesome.corp.com/v1
kind: Candy
metadata:
creationTimestamp: "2022-11-24T23:13:33Z"
generation: 1
name: gummy-bear
namespace: default
resourceVersion: "750534"
uid: d77d9bdc-5a53-4f8e-8468-c29e2d46f919
spec:
flavor: delicious
Sometimes, it can be useful to keep unknown fields. CRDs can support unknown fields by adding a special field to the schema.
Let’s delete the current Candy CRD and replace it with a CRD that supports unknown fields:
$ k delete -f candy-crd.yaml
customresourcedefinition.apiextensions.k8s.io "candies.awesome.corp.com" deleted
$ k create -f candy-with-unknown-fields-crd.yaml
customresourcedefinition.apiextensions.k8s.io/candies.awesome.corp.com created
The new CRD has the x-kubernetes-preserve-unknown-fields field set to true in the spec property:
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
x-kubernetes-preserve-unknown-fields: true
properties:
flavor:
type: string
Let’s create our gummy bear again WITH validation and check that the unknown texture field is present:
$ k create -f gummy-bear.yaml
candy.awesome.corp.com/gummy-bear created
$ k get cn gummy-bear -o yaml
apiVersion: awesome.corp.com/v1
kind: Candy
metadata:
creationTimestamp: "2022-11-24T23:38:01Z"
generation: 1
name: gummy-bear
namespace: default
resourceVersion: "752234"
uid: 6863f767-5dc0-43f7-91f3-1c734931b979
spec:
flavor: delicious
texture: rubbery
Finalizing custom resources
Custom resources support finalizers just like standard API objects. A finalizer is a mechanism where objects are not deleted immediately but have to wait for special controllers that run in the background and watch for deletion requests. The controller may perform any necessary cleanup options and then remove its finalizer from the target object. There may be multiple finalizers on an object. Kubernetes will wait until all finalizers have been removed and only then delete the object. The finalizers in the metadata are just arbitrary strings that their corresponding controller can identify. Kubernetes doesn’t know what they mean.
It just waits patiently for all the finalizers to be removed before deleting the object. Here is an example with a Candy object that has two finalizers: eat-me and drink-me:
apiVersion: awesome.corp.com/v1
kind: Candy
metadata:
name: chocolate
finalizers:
- eat-me
- drink-me
spec:
flavor: sweeeeeeet
Adding custom printer columns
By default, when you list custom resources with kubectl, you get only the name and the age of the resource:
$ k get cn
NAME AGE
chocolate 11h
gummy-bear 16m
But the CRD schema allows you to add your own columns. Let’s add the flavor and the age as printable columns to our Candy objects:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: candies.awesome.corp.com
spec:
group: awesome.corp.com
versions:
- name: v1
...
additionalPrinterColumns:
- name: Flavor
type: string
description: The flavor of the candy
jsonPath: .spec.flavor
- name: Age
type: date
jsonPath: .metadata.creationTimestamp
...
Then we can apply it, add our candies again, and list them:
$ k apply -f candy-with-flavor-crd.yaml
customresourcedefinition.apiextensions.k8s.io/candies.awesome.corp.com configured
$ k get cn
NAME FLAVOR AGE
chocolate sweeeeeeet 13m
gummy-bear delicious 18m
Understanding API server aggregation
CRDs are great when all you need is some CRUD operations on your own types. You can just piggyback on the Kubernetes API server, which will store your objects and provide API support and integration with tooling like kubectl. If you need more power, you can run controllers that watch for your custom resources and perform some operations when they are created, updated, or deleted. The Kubebuilder (https://github.com/kubernetes-sigs/kubebuilder) project is a great framework for building Kubernetes APIs on top of CRDs with your own controllers.
But CRDs have limitations. If you need more advanced features and customization, you can use API server aggregation and write your own API server, which the Kubernetes API server will delegate to. Your API server will use the same API machinery as the Kubernetes API server itself. Some advanced capabilities are available only through the aggregation layer:
- Make your API server adopt different storage APIs rather than etcd
- Extend long-running subresources/endpoints like WebSocket for your own resources
- Integrate your API server with any other external systems
- Control the storage of your objects (custom resources are always stored in etcd)
- Custom operations beyond CRUD (e.g., exec or scale)
- Use protocol buffer payloads
Writing an extension API server is a non-trivial effort. If you decide you need all that power, there are a couple of good starting points. You can look at the sample API server for inspiration (https://github.com/kubernetes/sample-apiserver). You may want to check out the apiserver-builder-alpha project (https://github.com/kubernetes-sigs/apiserver-builder-alpha). It takes care of a lot of the necessary boilerplate code. The API builder provides the following capabilities:
- Bootstrap complete type definitions, controllers, and tests as well as documentation
- An extension control plane you can run on a local cluster or on an actual remote cluster
- Your generated controllers will be able to watch and update API objects
- Add resources (including sub-resources)
- Default values you can override if needed
There is also a walkthrough here: https://kubernetes.io/docs/tasks/extend-kubernetes/setup-extension-api-server/.
Building Kubernetes-like control planes
What if you want to use the Kubernetes model to manage other things and not just pods? It turns out that this is a very desirable capability. There is a project with a lot of momentum that provides it: https://github.com/kcp-dev/kcp.
kcp also ventures into multi-cluster management.
What does kcp bring to the table?
- It is a control plane for multiple conceptual clusters called workspaces
- It enables external API service providers to integrate with the central control plane using multi-tenant operators
- Users can consume APIs easily in their workspaces
- Scheduling workloads flexibly to physical clusters
- Move workloads transparently between compatible physical clusters
- Users can deploy their workloads while taking advantage of capabilities such as geographic replication and cross-cloud replication.
We have covered different ways to extend Kubernetes by adding controllers and aggregated API servers. Let’s take a look at another mode of extending Kubernetes, by writing plugins.
Writing Kubernetes plugins
In this section, we will dive into the guts of Kubernetes and learn how to take advantage of its famous flexibility and extensibility. We will learn about different aspects that can be customized via plugins and how to implement such plugins and integrate them with Kubernetes.
Writing a custom scheduler
Kubernetes is all about orchestrating containerized workloads. The most fundamental responsibility is to schedule pods to run on cluster nodes. Before we can write our own scheduler, we need to understand how scheduling works in Kubernetes
Understanding the design of the Kubernetes scheduler
The Kubernetes scheduler has a very simple role – when a new pod needs to be created, assign it to a target node. That’s it. The Kubelet on the target node will take it from there and instruct the container runtime on the node to run the pod’s containers.
The Kubernetes scheduler implements the Controller pattern:
- Watch for pending pods
- Select the proper node for the pod
- Update the node’s spec by setting the
nodeNamefield
The only complicated part is selecting the target node. This process involves multiple steps split into two cycles:
- The scheduling cycle
- The binding cycle
While scheduling cycles are executed sequentially, binding cycles can be executed in parallel. If the target pod is considered unschedulable or an internal error occurs, the cycle will be terminated, and the pod will be placed back in the queue to be retried at a later time.
The scheduler is implemented using an extensible scheduler framework. The framework defines multiple extension points that you can plug into to affect the scheduling process. The following diagram shows the overall process and the extension points:
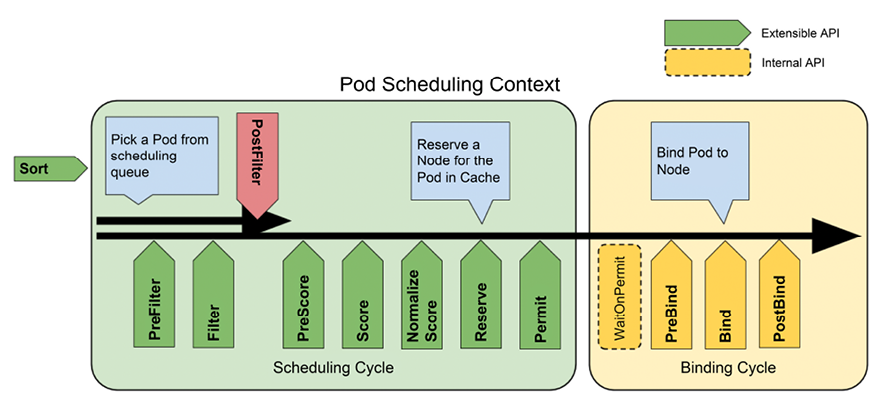
Figure 15.5: The workflow of the Kubernetes scheduler
The scheduler takes a tremendous amount of information and configuration into account. Filtering removes nodes that don’t satisfy one of the hard constraints from the candidate list. Ranking nodes assigns a score to each of the remaining nodes and chooses the best node.
Here are the factors the scheduler evaluates when filtering nodes:
- Verify that the ports requested by the pod are available on the node, ensuring the required network connectivity.
- Ensure that the pod is scheduled on a node whose hostname matches the specified node preference.
- Validate the availability of requested resources (CPU and memory) on the node to meet the pod’s requirements.
- Match the node’s labels with the pod’s node selector or node affinity to ensure proper scheduling.
- Confirm that the node supports the requested volume types, considering any failure zone restrictions for storage.
- Evaluate the node’s capacity to accommodate the pod’s volume requests, accounting for existing mounted volumes.
- Ensure the node’s health by checking for indicators such as memory pressure or PID pressure.
- Evaluate the pod’s tolerations to determine compatibility with the node’s taints, enabling or restricting scheduling accordingly.
Once the nodes have been filtered, the scheduler will score the modes based on the following policies (which you can configure):
- Distribute pods across hosts while considering pods belonging to the same Service, StatefulSet, or ReplicaSet.
- Give priority to inter-pod affinity, which means favoring pods that have an affinity or preference for running on the same node.
- Apply the “Least requested” priority, which favors nodes with fewer requested resources. This policy aims to distribute pods across all nodes in the cluster.
- Apply the “Most requested” priority, which favors nodes with the highest requested resources. This policy tends to pack pods into a smaller set of nodes.
- Use the “Requested to capacity ratio” priority, which calculates a priority based on the ratio of requested resources to the node’s capacity. It uses a default resource scoring function shape.
- Prioritize nodes with balanced resource allocation, favoring nodes with balanced resource usage.
- Utilize the “Node prefer avoid pods” priority, which prioritizes nodes based on the node annotation
scheduler.alpha.kubernetes.io/preferAvoidPods. This annotation is used to indicate that two different pods should not run on the same node. - Apply node affinity priority, giving preference to nodes based on the node affinity scheduling preferences specified in
PreferredDuringSchedulingIgnoredDuringExecution. - Consider taint toleration priority, preparing a priority list for all nodes based on the number of intolerable taints on each node. This policy adjusts a node’s rank, taking taints into account.
- Give priority to nodes that already have the container images required by the pod using the “Image locality” priority.
- Prioritize spreading pods backing a service across different nodes with the “Service spreading” priority.
- Apply pod anti-affinity, which means avoiding running pods on nodes that already have similar pods based on anti-affinity rules.
- Use the “Equal priority map,” where all nodes have the same weight and there are no favorites or biases.
Check out https://kubernetes.io/docs/concepts/scheduling-eviction/scheduling-framework/ for more details.
As you can see, the default scheduler is very sophisticated and can be configured in a very fine-grained way to accommodate most of your needs. But, under some circumstances, it might not be the best choice.
In particular, in large clusters with many nodes (hundreds or thousands), every time a pod is scheduled, all the nodes need to go through this rigorous and heavyweight procedure of filtering and scoring. Now, consider a situation where you need to schedule a large number of pods at once (e.g., training machine learning models). This can put a lot of pressure on your cluster and lead to performance issues.
Kubernetes can make the filtering and scoring process more lightweight by allowing you to filter and score only some of the pods, but still, you may want better control.
Fortunately, Kubernetes allows you to influence the scheduling process in several ways. Those ways include:
- Direct scheduling of pods to nodes
- Replacing the scheduler with your own scheduler
- Extending the scheduler with additional filters
- Adding another scheduler that runs side by side with the default scheduler
Let’s review various methods you can use to influence pod scheduling.
Scheduling pods manually
Guess what? We can just tell Kubernetes where to place our pod when we create the pod. All it takes is to specify a node name in the pod’s spec and the scheduler will ignore it. If you think about the loosely coupled nature of the controller pattern, it all makes sense. The scheduler is watching for pending pods that DON’T have a node name assigned yet. If you are passing the node name yourself, then the Kubelet on the target node, which watches for pending pods that DO have a node name, will just go ahead and make sure to create a new pod.
Let’s look at the nodes of our k3d cluster:
$ k get no
NAME STATUS ROLES AGE VERSION
k3d-k3s-default-agent-1 Ready <none> 155d v1.23.6+k3s1
k3d-k3s-default-server-0 Ready control-plane,master 155d v1.23.6+k3s1
k3d-k3s-default-agent-0 Ready <none> 155d v1.23.6+k3s1```
Here is a pod with a pre-defined node name, k3d-k3s-default-agent-1:
apiVersion: v1
kind: Pod
metadata:
name: some-pod-manual-scheduling
spec:
containers:
- name: some-container
image: registry.k8s.io/pause:3.8
nodeName: k3d-k3s-default-agent-1
schedulerName: no-such-scheduler
Let’s create the pod and see that it was indeed scheduled to the k3d-k3s-default-agent-1 node as requested:
$ k create -f some-pod-manual-scheduling.yaml
pod/some-pod-manual-scheduling created
$ k get po some-pod-manual-scheduling -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
some-pod-manual-scheduling 1/1 Running 0 26s 10.42.2.213 k3d-k3s-default-agent-1 <none> <none>
Direct scheduling is also useful for troubleshooting when you want to schedule a temporary pod to a tainted node without mucking around with adding tolerations.
Let’s create our own custom scheduler now.
Preparing our own scheduler
Our scheduler will be super simple. It will just schedule all pending pods that request to be scheduled by the custom-scheduler to the node k3d-k3s-default-agent-0. Here is a Python implementation that uses the kubernetes client package:
from kubernetes import client, config, watch
def schedule_pod(cli, name):
target = client.V1ObjectReference()
target.kind = 'Node'
target.apiVersion = 'v1'
target.name = 'k3d-k3s-default-agent-0'
meta = client.V1ObjectMeta()
meta.name = name
body = client.V1Binding(metadata=meta, target=target)
return cli.create_namespaced_binding('default', body)
def main():
config.load_kube_config()
cli = client.CoreV1Api()
w = watch.Watch()
for event in w.stream(cli.list_namespaced_pod, 'default'):
o = event['object']
if o.status.phase != 'Pending' or o.spec.scheduler_name != 'custom-scheduler':
continue
schedule_pod(cli, o.metadata.name)
if __name__ == '__main__':
main()
If you want to run a custom scheduler long term, then you should deploy it into the cluster just like any other workload as a deployment. But, if you just want to play around with it, or you’re still developing your custom scheduler logic, you can run it locally as long as it has the correct credentials to access the cluster and has permissions to watch for pending pods and update their node name.
Note that I strongly recommend building production custom schedulers on top of the scheduling framework (https://kubernetes.io/docs/concepts/scheduling-eviction/scheduling-framework/).
Assigning pods to the custom scheduler
OK. We have a custom scheduler that we can run alongside the default scheduler. But how does Kubernetes choose which scheduler to use to schedule a pod when there are multiple schedulers?
The answer is that Kubernetes doesn’t care. The pod can specify which scheduler it wants to schedule it. The default scheduler will schedule any pod that doesn’t specify the schedule or that specifies explicitly default-scheduler. Other custom schedulers should be responsible and only schedule pods that request them. If multiple schedulers try to schedule the same pod, we will probably end up with multiple copies or naming conflicts.
For example, our simple custom scheduler is looking for pending pods that specify a scheduler name of custom-scheduler. All other pods will be ignored by it:
if o.status.phase != 'Pending' or o.spec.scheduler_name != 'custom-scheduler':
continue
Here is a pod spec that specifies custom-scheduler:
apiVersion: v1
kind: Pod
metadata:
name: some-pod-with-custom-scheduler
spec:
containers:
- name: some-container
image: registry.k8s.io/pause:3.8
schedulerName: custom-scheduler
What happens if our custom scheduler is not running and we try to create this pod?
$ k create -f some-pod-with-custom-scheduler.yaml
pod/some-pod-with-custom-scheduler created
$ k get po
NAME READY STATUS RESTARTS AGE
some-pod-manual-scheduling 1/1 Running 0 9m33s
some-pod-with-custom-scheduler 0/1 Pending 0 14s
The pod is created just fine (meaning the Kubernetes API server stored it in etcd), but it is pending, which means it wasn’t scheduled yet. Since it specified an explicit scheduler, the default scheduler ignores it.
But, if we run our scheduler… it will immediately get scheduled:
python custom_scheduler.py
Waiting for pending pods...
Scheduling pod: some-pod-with-custom-scheduler
Now, we can see that the pod was assigned to a node, and it is in a running state:
$ k get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
some-pod-manual-scheduling 1/1 Running 0 4h5m 10.42.2.213 k3d-k3s-default-agent-1 <none> <none>
some-pod-with-custom-scheduler 1/1 Running 0 87s 10.42.0.125 k3d-k3s-default-agent-0 <none> <none>
That was a deep dive into scheduling and custom schedulers. Let’s check out kubectl plugins.
Writing kubectl plugins
Kubectl is the workhorse of the aspiring Kubernetes developer and admin. There are now very good visual tools like k9s (https://github.com/derailed/k9s), octant (https://github.com/vmware-tanzu/octant), and Lens Desktop (https://k8slens.dev). But, for many engineers, kubectl is the most complete way to work interactively with your cluster, as well to participate in automation workflows.
Kubectl encompasses an impressive list of capabilities, but you will often need to string together multiple commands or a long chain of parameters to accomplish some tasks. You may also want to run some additional tools installed in your cluster.
You can package such functionality as scripts or containers, or any other way, but then you’ll run into the issue of where to place them, how to discover them, and how to manage them. Kubectl plugins give you a one-stop shop for those extended capabilities. For example, recently I needed to periodically list and move around files on an SFTP server managed by a containerized application running on a Kubernetes cluster. I quickly wrote a few kubectl plugins that took advantage of my KUBECONFIG credentials to get access to secrets in the cluster that contained the credentials to access the SFTP server and then implemented a lot of application-specific logic for accessing and managing those SFTP directories and files.
Understanding kubectl plugins
Until Kubernetes 1.12, kubectl plugins required a dedicated YAML file where you specified various metadata and other files that implemented the functionality. In Kubernetes 1.12, kubectl started using the Git extension model where any executable on your path with the prefix kubectl- is treated as a plugin.
Kubectl provides the kubectl plugins list command to list all your current plugins. This model was very successful with Git and it is extremely simple now to add your own kubectl plugins.
If you add an executable called kubectl-foo, then you can run it via kubectl foo. You can have nested commands too. Add kubectl-foo-bar to your path and run it via kubectl foo bar. If you want to use dashes in your commands, then in your executable, use underscores. For example, the executable kubectl-do_stuff can be run using kubectl do-stuff.
The executable itself can be implemented in any language, have its own command-line arguments and flags, and display its own usage and help information.
Managing kubectl plugins with Krew
The lightweight plugin model is great for writing your own plugins, but what if you want to share your plugins with the community? Krew (https://github.com/kubernetes-sigs/krew) is a package manager for kubectl plugins that lets you discover, install, and manage curated plugins.
You can install Krew with Brew on Mac or follow the installation instructions for other platforms. Krew is itself a kubectl plugin as its executable is kubectl-krew. This means you can either run it directly with kubectl-krew or through kubectl kubectl krew. If you have a k alias for kubectl, you would probably prefer the latter:
$ k krew
krew is the kubectl plugin manager.
You can invoke krew through kubectl: "kubectl krew [command]..."
Usage:
kubectl krew [command]
Available Commands:
completion generate the autocompletion script for the specified shell
help Help about any command
index Manage custom plugin indexes
info Show information about an available plugin
install Install kubectl plugins
list List installed kubectl plugins
search Discover kubectl plugins
uninstall Uninstall plugins
update Update the local copy of the plugin index
upgrade Upgrade installed plugins to newer versions
version Show krew version and diagnostics
Flags:
-h, --help help for krew
-v, --v Level number for the log level verbosity
Use "kubectl krew [command] --help" for more information about a command.
Note that the krew list command shows only Krew-managed plugins and not all kubectl plugins. It doesn’t even show itself.
I recommend that you check out the available plugins. Some of them are very useful, and they may inspire you to write your own plugins. Let’s see how easy it is to write our own plugin.
Creating your own kubectl plugin
Kubectl plugins can range from super simple to very complicated. I work a lot these days with AKS node pools created using the Cluster API and CAPZ (the Cluster API provider for Azure). I’m often interested in viewing all the node pools on a specific cloud provider. All the node pools are defined as custom resources in a namespace called cluster-registry. The following kubectl command lists all the node pools:
$ k get -n cluster-registry azuremanagedmachinepools.infrastructure.cluster.x-k8s.io
aks-centralus-cluster-001-nodepool001 116d
aks-centralus-cluster-001-nodepool002 116d
aks-centralus-cluster-002-nodepool001 139d
aks-centralus-cluster-002-nodepool002 139d
aks-centralus-cluster-002-nodepool003 139d
...
This is not a lot of information. I’m interested in information like the SKU (VM type and size) of each node pool, its Kubernetes version, and the number of nodes in each node pool. The following kubectl command can provide this information:
$ k get -n cluster-registry azuremanagedmachinepools.infrastructure.cluster.x-k8s.io -o custom-columns=NAME:.metadata.name,SKU:.spec.sku,VERSION:.status.version,NODES:.status.replicas
NAME SKU VERSION NODES
aks-centralus-cluster-001-nodepool001 Standard_D4s_v4 1.23.8 10
aks-centralus-cluster-001-nodepool002 Standard_D8s_v4 1.23.8 20
aks-centralus-cluster-002-nodepool001 Standard_D16s_v4 1.23.8 30
aks-centralus-cluster-002-nodepool002 Standard_D8ads_v5 1.23.8 40
aks-centralus-cluster-002-nodepool003 Standard_D8ads_v5 1.23.8 50
However, this is a lot to type. I simply put this command in a file called kubectl-npa-get and stored it in /usr/local/bin. Now, I can invoke it just by calling k npa get. I could define a little alias or shell function, but a kubectl plugin is more appropriate as it is a central place for all kubectl-related enhancements. It enforces a uniform convention and it is discoverable via kubectl list plugins.
This was an example of an almost trivial kubectl plugin. Let’s look at a more complicated example – deleting namespaces. It turns out that reliably deleting namespaces in Kubernetes is far from trivial. Under certain conditions, a namespace can be stuck forever in a terminating state after you try to delete it. I created a little Go program to reliably delete namespaces. You can check it out here: https://github.com/the-gigi/k8s-namespace-deleter.
This is a perfect use case for a kubectl plugin. The instructions in the README recommend building the executable and then saving it in your path as kubectl-ns-delete. Now, when you want to delete a namespace, you can just use k ns delete <namespace> to invoke k8s-namespace-deleter and reliably get rid of your namespace.
If you want to develop plugins and share them on Krew, there is a more rigorous process there. I highly recommend developing the plugin in Go and taking advantage of projects like cli-runtime (https://github.com/kubernetes/cli-runtime/) and krew-plugin-template (https://github.com/replicatedhq/krew-plugin-template).
Kubectl plugins are awesome, but there are some gotchas you should be aware of. I ran into some of these issues when working with kubectl plugins.
Don’t forget your shebangs!
If you don’t specify a shebang for your shell-based executables, you will get an obscure error message:
$ k npa get
Error: exec format error
Naming your plugin
Choosing a name for your plugin is not easy. Luckily, there are some good guidelines: https://krew.sigs.k8s.io/docs/developer-guide/develop/naming-guide.
Those naming guidelines are not just for Krew plugins, but make sense for any kubectl plugin.
Overriding existing kubectl commands
I originally named the plugin kubectl-get-npa. In theory, kubectl should try to match the longest plugin name to resolve ambiguities. But, apparently, it doesn’t work with built-in commands like kubectl get. This is the error I got:
$ k get npa
error: the server doesn't have a resource type "npa"
Renaming the plugin to kubectl-npa-get solved the problem.
Flat namespace for Krew plugins
The space of kubectl plugins is flat. If you choose a generic plugin name like kubectl-login, you’ll have a lot of problems. Even if you qualify it with something like kubectl-gcp-login, you might conflict with some other plugin. This is a scalability problem. I think the solution should involve a strong naming scheme for plugins like DNS and the ability to define short names and aliases for convenience.
We have covered kubectl plugins, how to write them, and how to use them. Let’s take a look at extending access control with webhooks.
Employing access control webhooks
Kubernetes provides several ways for you to customize access control. In Kubernetes, access control can be denoted with triple-A: Authentication, Authorization, and Admission control. In early versions, access control happened through plugins that required Go programming, installing them into your cluster, registration, and other invasive procedures. Now, Kubernetes lets you customize authentication, authorization, and admission control via web hooks. Here is the access control workflow:
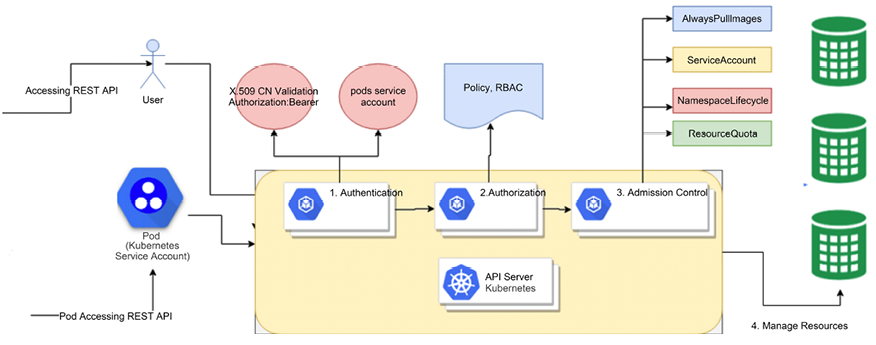
Figure 15.6: Access control workflow
Using an authentication webhook
Kubernetes lets you extend the authentication process by injecting a webhook for bearer tokens. It requires two pieces of information: how to access the remote authentication service and the duration of the authentication decision (it defaults to two minutes).
To provide this information and enable authentication webhooks, start the API server with the following command-line arguments:
- --authentication-token-webhook-config-file=<authentication config file>
- --authentication-token-webhook-cache-ttl (how long to cache auth decisions, default to 2 minutes)
The configuration file uses the kubeconfig file format. Here is an example:
# Kubernetes API version
apiVersion: v1
# kind of the API object
kind: Config
# clusters refers to the remote service.
clusters:
- name: name-of-remote-authn-service
cluster:
certificate-authority: /path/to/ca.pem # CA for verifying the remote service.
server: https://authn.example.com/authenticate # URL of remote service to query. Must use 'https'.
# users refers to the API server's webhook configuration.
users:
- name: name-of-api-server
user:
client-certificate: /path/to/cert.pem # cert for the webhook plugin to use
client-key: /path/to/key.pem # key matching the cert
# kubeconfig files require a context. Provide one for the API server.
current-context: webhook
contexts:
- context:
cluster: name-of-remote-authn-service
user: name-of-api-sever
name: webhook
Note that a client certificate and key must be provided to Kubernetes for mutual authentication against the remote authentication service.
The cache TTL is useful because often users will make multiple consecutive requests to Kubernetes. Having the authentication decision cached can save a lot of round trips to the remote authentication service.
When an API HTTP request comes in, Kubernetes extracts the bearer token from its headers and posts a TokenReview JSON request to the remote authentication service via the webhook:
{
"apiVersion": "authentication.k8s.io/v1",
"kind": "TokenReview",
"spec": {
"token": "<bearer token from original request headers>"
}
}
The remote authentication service will respond with a decision. The status authentication will either be true or false. Here is an example of a successful authentication:
{
"apiVersion": "authentication.k8s.io/v1",
"kind": "TokenReview",
"status": {
"authenticated": true,
"user": {
"username": "[email protected]",
"uid": "42",
"groups": [
"developers",
],
"extra": {
"extrafield1": [
"extravalue1",
"extravalue2"
]
}
}
}
}
A rejected response is much more concise:
{
"apiVersion": "authentication.k8s.io/v1",
"kind": "TokenReview",
"status": {
"authenticated": false
}
}
Using an authorization webhook
The authorization webhook is very similar to the authentication webhook. It requires just a configuration file, which is in the same format as the authentication webhook configuration file. There is no authorization caching because, unlike authentication, the same user may make lots of requests to different API endpoints with different parameters, and authorization decisions may be different, so caching is not a viable option.
You configure the webhook by passing the following command-line argument to the API server:
--authorization-webhook-config-file=<configuration filename>
When a request passes authentication, Kubernetes will send a SubjectAccessReview JSON object to the remote authorization service. It will contain the requesting user (and any user groups it belongs to) and other attributes such as the requested API group, namespace, resource, and verb:
{
"apiVersion": "authorization.k8s.io/v1",
"kind": "SubjectAccessReview",
"spec": {
"resourceAttributes": {
"namespace": "awesome-namespace",
"verb": "get",
"group": "awesome.example.org",
"resource": "pods"
},
"user": "[email protected]",
"group": [
"group1",
"group2"
]
}
}
The request will either be allowed:
{
"apiVersion": "authorization.k8s.io/v1",
"kind": "SubjectAccessReview",
"status": {
"allowed": true
}
}
Or denied with a reason:
{
"apiVersion": "authorization.k8s.io/v1beta1",
"kind": "SubjectAccessReview",
"status": {
"allowed": false,
"reason": "user does not have read access to the namespace"
}
}
A user may be authorized to access a resource, but not some non-resource attributes, such as /api, /apis, /metrics, /resetMetrics, /logs, /debug, /healthz, /swagger-ui/, /swaggerapi/, /ui, and /version.
Here is how to request access to the logs:
{
"apiVersion": "authorization.k8s.io/v1",
"kind": "SubjectAccessReview",
"spec": {
"nonResourceAttributes": {
"path": "/logs",
"verb": "get"
},
"user": "[email protected]",
"group": [
"group1",
"group2"
]
}
}
We can check, using kubectl, if we are authorized to perform an operation using the can-i command. For example, let’s see if we can create deployments:
$ k auth can-i create deployments
yes
We can also check if other users or service accounts are authorized to do something. The default service account is NOT allowed to create deployments:
$ k auth can-i create deployments --as default
no
Using an admission control webhook
Dynamic admission control supports webhooks too. It has been generally available since Kubernetes 1.16. Depending on your Kubernetes version, you may need to enable the MutatingAdmissionWebhook and ValidatingAdmissionWebhook admission controllers using --enable-admission-plugins=Mutating,ValidatingAdmissionWebhook flags to kube-apiserver.
There are several other admission controllers that the Kubernetes developers recommend running (the order matters):
--admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota
In Kubernetes 1.25, these plugins are enabled by default.
Configuring a webhook admission controller on the fly
Authentication and authorization webhooks must be configured when you start the API server. Admission control webhooks can be configured dynamically by creating MutatingWebhookConfiguration or ValidatingWebhookConfiguration API objects. Here is an example:
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
...
webhooks:
- name: admission-webhook.example.com
rules:
- operations: ["CREATE", "UPDATE"]
apiGroups: ["apps"]
apiVersions: ["v1", "v1beta1"]
resources: ["deployments", "replicasets"]
scope: "Namespaced"
...
An admission server accesses AdmissionReview requests such as:
{
"apiVersion": "admission.k8s.io/v1",
"kind": "AdmissionReview",
"request": {
"uid": "705ab4f5-6393-11e8-b7cc-42010a800002",
"kind": {"group":"autoscaling","version":"v1","kind":"Scale"},
"resource": {"group":"apps","version":"v1","resource":"deployments"},
"subResource": "scale",
"requestKind": {"group":"autoscaling","version":"v1","kind":"Scale"},
"requestResource": {"group":"apps","version":"v1","resource":"deployments"},
"requestSubResource": "scale",
"name": "cool-deployment",
"namespace": "cool-namespace",
"operation": "UPDATE",
"userInfo": {
"username": "admin",
"uid": "014fbff9a07c",
"groups": ["system:authenticated","my-admin-group"],
"extra": {
"some-key":["some-value1", "some-value2"]
}
},
"object": {"apiVersion":"autoscaling/v1","kind":"Scale",...},
"oldObject": {"apiVersion":"autoscaling/v1","kind":"Scale",...},
"options": {"apiVersion":"meta.k8s.io/v1","kind":"UpdateOptions",...},
"dryRun": false
}
}
If the request is admitted, the response will be:
{
"apiVersion": "admission.k8s.io/v1",
"kind": "AdmissionReview",
"response": {
"uid": "<value from request.uid>",
"allowed": true
}
}
If the request is not admitted, then allowed will be False. The admission server may provide a status section too with an HTTP status code and message:
{
"apiVersion": "admission.k8s.io/v1",
"kind": "AdmissionReview",
"response": {
"uid": "<value from request.uid>",
"allowed": false,
"status": {
"code": 403,
"message": "You cannot do this because I say so!!!!"
}
}
}
That concludes our discussion of dynamic admission control. Let’s look at some more extension points.
Additional extension points
There are some additional extension points that don’t fit into the categories we have discussed so far.
Providing custom metrics for horizontal pod autoscaling
Prior to Kubernetes 1.6, custom metrics were implemented as a Heapster model. In Kubernetes 1.6, new custom metrics APIs landed and matured gradually. As of Kubernetes 1.9, they are enabled by default. As you may recall, Keda (https://keda.sh) is a project that focuses on custom metrics for autoscaling. However, if for some reason Keda doesn’t meet your needs, you can implement your own custom metrics. Custom metrics rely on API aggregation. The recommended path is to start with the custom metrics API server boilerplate, available here: https://github.com/kubernetes-sigs/custom-metrics-apiserver.
Then, you can implement the CustomMetricsProvider interface:
type CustomMetricsProvider interface {
// GetRootScopedMetricByName fetches a particular metric for a particular root-scoped object.
GetRootScopedMetricByName(groupResource schema.GroupResource, name string, metricName string) (*custom_metrics.MetricValue, error)
// GetRootScopedMetricByName fetches a particular metric for a set of root-scoped objects
// matching the given label selector.
GetRootScopedMetricBySelector(groupResource schema.GroupResource, selector labels.Selector, metricName string) (*custom_metrics.MetricValueList, error)
// GetNamespacedMetricByName fetches a particular metric for a particular namespaced object.
GetNamespacedMetricByName(groupResource schema.GroupResource, namespace string, name string, metricName string) (*custom_metrics.MetricValue, error)
// GetNamespacedMetricByName fetches a particular metric for a set of namespaced objects
// matching the given label selector.
GetNamespacedMetricBySelector(groupResource schema.GroupResource, namespace string, selector labels.Selector, metricName string) (*custom_metrics.MetricValueList, error)
// ListAllMetrics provides a list of all available metrics at
// the current time. Note that this is not allowed to return
// an error, so it is recommended that implementors cache and
// periodically update this list, instead of querying every time.
ListAllMetrics() []CustomMetricInfo
}
Extending Kubernetes with custom storage
Volume plugins are yet another type of plugin. Prior to Kubernetes 1.8, you had to write a kubelet plugin, which required registration with Kubernetes and linking with the kubelet. Kubernetes 1.8 introduced the FlexVolume, which is much more versatile. Kubernetes 1.9 took it to the next level with the CSI, which we covered in Chapter 6, Managing Storage. At this point, if you need to write storage plugins, the CSI is the way to go. Since the CSI uses the gRPC protocol, the CSI plugin must implement the following gRPC interface:
service Controller {
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
rpc DeleteVolume (DeleteVolumeRequest)
returns (DeleteVolumeResponse) {}
rpc ControllerPublishVolume (ControllerPublishVolumeRequest)
returns (ControllerPublishVolumeResponse) {}
rpc ControllerUnpublishVolume (ControllerUnpublishVolumeRequest)
returns (ControllerUnpublishVolumeResponse) {}
rpc ValidateVolumeCapabilities (ValidateVolumeCapabilitiesRequest)
returns (ValidateVolumeCapabilitiesResponse) {}
rpc ListVolumes (ListVolumesRequest)
returns (ListVolumesResponse) {}
rpc GetCapacity (GetCapacityRequest)
returns (GetCapacityResponse) {}
rpc ControllerGetCapabilities (ControllerGetCapabilitiesRequest)
returns (ControllerGetCapabilitiesResponse) {}
}
This is not a trivial undertaking and typically only storage solution providers should implement CSI plugins.
The additional extension points of custom metrics and custom storage solutions demonstrate the commitment of Kubernetes to being truly extensible and allowing its users to customize almost every aspect of its operation.
Summary
In this chapter, we covered three major topics: working with the Kubernetes API, extending the Kubernetes API, and writing Kubernetes plugins. The Kubernetes API supports the OpenAPI spec and is a great example of REST API design that follows all current best practices. It is very consistent, well organized, and well documented. Yet it is a big API and not easy to understand. You can access the API directly via REST over HTTP, using client libraries including the official Python client, and even by invoking kubectl programmatically.
Extending the Kubernetes API may involve defining your own custom resources, writing controllers/operators, and optionally extending the API server itself via API aggregation.
Plugins and webhooks are a foundation of Kubernetes design. Kubernetes was always meant to be extended by users to accommodate any needs. We looked at various plugins, such as custom schedulers, kubectl plugins, and access control webhooks. It is very cool that Kubernetes provides such a seamless experience for writing, registering, and integrating all those plugins.
We also looked at custom metrics and even how to extend Kubernetes with custom storage options.
At this point, you should be well aware of all the major mechanisms to extend, customize, and control Kubernetes via API access, custom resources, controllers, operators, and custom plugins. You are in a great position to take advantage of these capabilities to augment the existing functionality of Kubernetes and adapt it to your needs and your systems.
In the next chapter, we will look at governing Kubernetes via policy engines. This will continue the theme of extending Kubernetes as policy engines are dynamic admission controllers on steroids. We will cover what governance is all about, review existing policy engines, and dive deep into Kyverno, which is the best policy engine for Kubernetes in my opinion.