
Chapter 18. Arguments
Chapter 17 explored the details behind Python’s scopes—the places where variables are defined and looked up. As we learned, the place where a name is defined in our code determines much of its meaning. This chapter continues the function story by studying the concepts in Python argument passing—the way that objects are sent to functions as inputs. As we’ll see, arguments (a.k.a. parameters) are assigned to names in a function, but they have more to do with object references than with variable scopes. We’ll also find that Python provides extra tools, such as keywords, defaults, and arbitrary argument collectors, that allow for wide flexibility in the way arguments are sent to a function.
Argument-Passing Basics
Earlier in this part of the book, I noted that arguments are passed by assignment. This has a few ramifications that aren’t always obvious to beginners, which I’ll expand on in this section. Here is a rundown of the key points in passing arguments to functions:
Arguments are passed by automatically assigning objects to local variable names. Function arguments—references to (possibly) shared objects sent by the caller—are just another instance of Python assignment at work. Because references are implemented as pointers, all arguments are, in effect, passed by pointer. Objects passed as arguments are never automatically copied.
Assigning to argument names inside a function does not affect the caller. Argument names in the function header become new, local names when the function runs, in the scope of the function. There is no aliasing between function argument names and variable names in the scope of the caller.
Changing a mutable object argument in a function may impact the caller. On the other hand, as arguments are simply assigned to passed-in objects, functions can change passed-in mutable objects in place, and the results may affect the caller. Mutable arguments can be input and output for functions.
For more details on references, see Chapter 6; everything we learned there also applies to function arguments, though the assignment to argument names is automatic and implicit.
Python’s pass-by-assignment scheme isn’t quite the same as C++’s reference parameters option, but it turns out to be very similar to the C language’s argument-passing model in practice:
Immutable arguments are effectively passed “by value.” Objects such as integers and strings are passed by object reference instead of by copying, but because you can’t change immutable objects in-place anyhow, the effect is much like making a copy.
Mutable arguments are effectively passed “by pointer.” Objects such as lists and dictionaries are also passed by object reference, which is similar to the way C passes arrays as pointers—mutable objects can be changed in-place in the function, much like C arrays.
Of course, if you’ve never used C, Python’s argument-passing mode will seem simpler still—it involves just the assignment of objects to names, and it works the same whether the objects are mutable or not.
Arguments and Shared References
To illustrate argument-passing properties at work, consider the following code:
>>>def f(a):# a is assigned to (references) passed object ...a = 99# Changes local variable a only ... >>>b = 88>>>f(b)# a and b both reference same 88 initially >>>print(b)# b is not changed 88
In this example the variable a is assigned the object 88 at the moment the function is called
with f(b), but a lives only within the called function.
Changing a inside the function
has no effect on the place where the function is called; it simply
resets the local variable a to a
completely different object.
That’s what is meant by a lack of name
aliasing—assignment to an argument name inside
a function (e.g., a=99) does not
magically change a variable like b in the scope of the function call.
Argument names may share passed objects initially (they are
essentially pointers to those objects), but only temporarily, when
the function is first called. As soon as an argument name is
reassigned, this relationship ends.
At least, that’s the case for assignment to argument names themselves. When arguments are passed mutable objects like lists and dictionaries, we also need to be aware that in-place changes to such objects may live on after a function exits, and hence impact callers. Here’s an example that demonstrates this behavior:
>>>def changer(a, b):# Arguments assigned references to objects ...a = 2# Changes local name's value only ...b[0] = 'spam'# Changes shared object in-place ... >>>X = 1>>>L = [1, 2]# Caller >>>changer(X, L)# Pass immutable and mutable objects >>>X, L# X is unchanged, L is different! (1, ['spam', 2])
In this code, the changer
function assigns values to argument a itself, and to a component of the object
referenced by argument b. These
two assignments within the function are only slightly different in
syntax but have radically different results:
Because
ais a local variable name in the function’s scope, the first assignment has no effect on the caller—it simply changes the local variableato reference a completely different object, and does not change the binding of the nameXin the caller’s scope. This is the same as in the prior example.Argument
bis a local variable name, too, but it is passed a mutable object (the list thatLreferences in the caller’s scope). As the second assignment is an in-place object change, the result of the assignment tob[0]in the function impacts the value ofLafter the function returns.
Really, the second assignment statement in changer doesn’t change b—it changes part of the object that
b currently references. This
in-place change impacts the caller only because the changed object
outlives the function call. The name L hasn’t changed either—it still references the same,
changed object—but it seems as though L differs after the call because the value
it references has been modified within the function.
Figure 18-1 illustrates the name/object bindings that exist immediately after the function has been called, and before its code has run.
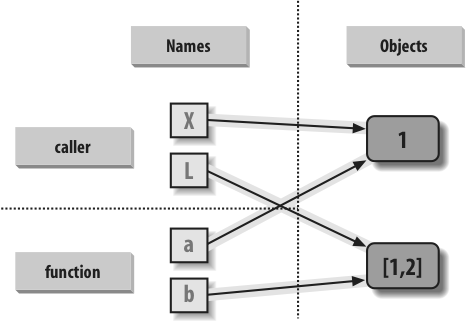
If this example is still confusing, it may help to notice that the effect of the automatic assignments of the passed-in arguments is the same as running a series of simple assignment statements. In terms of the first argument, the assignment has no effect on the caller:
>>>X = 1>>>a = X# They share the same object >>>a = 2# Resets 'a' only, 'X' is still 1 >>>print(X)1
The assignment through the second argument does affect a variable at the call, though, because it is an in-place object change:
>>>L = [1, 2]>>>b = L# They share the same object >>>b[0] = 'spam'# In-place change: 'L' sees the change too >>>print(L)['spam', 2]
If you recall our discussions about shared mutable objects in Chapters 6 and 9, you’ll recognize the phenomenon at work: changing a mutable object in-place can impact other references to that object. Here, the effect is to make one of the arguments work like both an input and an output of the function.
Avoiding Mutable Argument Changes
This behavior of in-place changes to mutable arguments isn’t a bug—it’s simply the way argument passing works in Python. Arguments are passed to functions by reference (a.k.a. pointer) by default because that is what we normally want. It means we can pass large objects around our programs without making multiple copies along the way, and we can easily update these objects as we go. In fact, as we’ll see in Part VI, Python’s class model depends upon changing a passed-in “self” argument in-place, to update object state.
If we don’t want in-place changes within functions to impact objects we pass to them, though, we can simply make explicit copies of mutable objects, as we learned in Chapter 6. For function arguments, we can always copy the list at the point of call:
L = [1, 2]
changer(X, L[:]) # Pass a copy, so our 'L' does not changeWe can also copy within the function itself, if we never want to change passed-in objects, regardless of how the function is called:
def changer(a, b):
b = b[:] # Copy input list so we don't impact caller
a = 2
b[0] = 'spam' # Changes our list copy onlyBoth of these copying schemes don’t stop the function from changing the object—they just prevent those changes from impacting the caller. To really prevent changes, we can always convert to immutable objects to force the issue. Tuples, for example, throw an exception when changes are attempted:
L = [1, 2]
changer(X, tuple(L)) # Pass a tuple, so changes are errorsThis scheme uses the built-in tuple function, which builds a new tuple
out of all the items in a sequence (really, any iterable). It’s also
something of an extreme—because it forces the function to be written
to never change passed-in arguments, this solution might impose more
limitations on the function than it should, and so should generally
be avoided (you never know when changing arguments might come in
handy for other calls in the future). Using this technique will also
make the function lose the ability to call any list-specific methods
on the argument, including methods that do not change the object
in-place.
The main point to remember here is that functions might update mutable objects like lists and dictionaries passed into them. This isn’t necessarily a problem if it’s expected, and often serves useful purposes. Moreover, functions that change passed-in mutable objects in place are probably designed and intended to do so—the change is likely part of a well-defined API that you shouldn’t violate by making copies.
However, you do have to be aware of this property—if objects change out from under you unexpectedly, check whether a called function might be responsible, and make copies when objects are passed if needed.
Simulating Output Parameters
We’ve already discussed the return statement and used it in a few
examples. Here’s another way to use this statement: because return can send back any sort of object,
it can return multiple values by packaging them
in a tuple or other collection type. In fact, although Python
doesn’t support what some languages label “call-by-reference”
argument passing, we can usually simulate it by returning tuples and
assigning the results back to the original argument names in the
caller:
>>>def multiple(x, y):...x = 2# Changes local names only ...y = [3, 4]...return x, y# Return new values in a tuple ... >>>X = 1>>>L = [1, 2]>>>X, L = multiple(X, L)# Assign results to caller's names >>>X, L(2, [3, 4])
It looks like the code is returning two values here, but it’s
really just one—a two-item tuple with the optional surrounding
parentheses omitted. After the call returns, we can use tuple
assignment to unpack the parts of the returned tuple. (If you’ve
forgotten why this works, flip back to Tuples
in Chapter 4, Chapter 9, and Assignment Statements in Chapter 11.) The net
effect of this coding pattern is to simulate the output parameters
of other languages by explicit assignments. X and L
change after the call, but only because the code said so.
Note
Unpacking arguments in Python 2.X: The preceding example unpacks a tuple returned by the function with tuple assignment. In Python 2.6, it’s also possible to automatically unpack tuples in arguments passed to a function. In 2.6, a function defined by this header:
def f((a, (b, c))):
can be called with tuples that match the expected structure:
f((1, (2,
3))) assigns a, b,
and c to 1, 2,
and 3, respectively. Naturally,
the passed tuple can also be an object created before the call
(f(T)). This def syntax is no longer supported in
Python 3.0. Instead, code this function as:
def f(T): (a, (b, c)) = T
to unpack in an explicit assignment statement. This explicit
form works in both 3.0 and 2.6. Argument unpacking is an obscure
and rarely used feature in Python 2.X. Moreover, a function header
in 2.6 supports only the tuple form of sequence assignment; more
general sequence assignments (e.g., def
f((a, [b, c])):) fail on syntax errors in 2.6 as well
and require the explicit assignment form.
Tuple unpacking argument syntax is also disallowed by 3.0 in
lambda function argument lists:
see the sidebar Why You Will Care: List Comprehensions and map for an
example. Somewhat asymmetrically, tuple unpacking assignment is
still automatic in 3.0 for
loops targets, though; see Chapter 13
for examples.
Special Argument-Matching Modes
As we’ve just seen, arguments are always passed by
assignment in Python; names in the def header are assigned to passed-in
objects. On top of this model, though, Python provides additional
tools that alter the way the argument objects in a call are
matched with argument names in the header prior
to assignment. These tools are all optional, but they allow us to
write functions that support more flexible calling patterns, and you
may encounter some libraries that require them.
By default, arguments are matched by position, from left to right, and you must pass exactly as many arguments as there are argument names in the function header. However, you can also specify matching by name, default values, and collectors for extra arguments.
The Basics
Before we go into the syntactic details, I want to stress that these special modes are optional and only have to do with matching objects to names; the underlying passing mechanism after the matching takes place is still assignment. In fact, some of these tools are intended more for people writing libraries than for application developers. But because you may stumble across these modes even if you don’t code them yourself, here’s a synopsis of the available tools:
- Positionals: matched from left to right
The normal case, which we’ve mostly been using so far, is to match passed argument values to argument names in a function header by position, from left to right.
- Keywords: matched by argument name
Alternatively, callers can specify which argument in the function is to receive a value by using the argument’s name in the call, with the
name=valuesyntax.- Defaults: specify values for arguments that aren’t passed
Functions themselves can specify default values for arguments to receive if the call passes too few values, again using the
name=valuesyntax.- Varargs collecting: collect arbitrarily many positional or keyword arguments
Functions can use special arguments preceded with one or two
*characters to collect an arbitrary number of extra arguments (this feature is often referred to as varargs, after the varargs feature in the C language, which also supports variable-length argument lists).- Varargs unpacking: pass arbitrarily many positional or keyword arguments
Callers can also use the
*syntax to unpack argument collections into discrete, separate arguments. This is the inverse of a*in a function header—in the header it means collect arbitrarily many arguments, while in the call it means pass arbitrarily many arguments.- Keyword-only arguments: arguments that must be passed by name
In Python 3.0 (but not 2.6), functions can also specify arguments that must be passed by name with keyword arguments, not by position. Such arguments are typically used to define configuration options in addition to actual arguments.
Matching Syntax
Table 18-1 summarizes the syntax that invokes the special argument-matching modes.
Syntax | Location | Interpretation |
| Caller | Normal argument: matched by position |
| Caller | Keyword argument: matched by name |
| Caller | Pass all objects in sequence as individual positional arguments |
| Caller | Pass all key/value
pairs in |
| Function | Normal argument: matches any passed value by position or name |
| Function | Default argument value, if not passed in the call |
| Function | Matches and collects remaining positional arguments in a tuple |
| Function | Matches and collects remaining keyword arguments in a dictionary |
| Function | Arguments that must be passed by keyword only in calls (3.0) |
These special matching modes break down into function calls and definitions as follows:
In a function call (the first four rows of the table), simple values are matched by position, but using the
name=valueform tells Python to match by name to arguments instead; these are called keyword arguments. Using a*sequenceor**dictin a call allows us to package up arbitrarily many positional or keyword objects in sequences and dictionaries, respectively, and unpack them as separate, individual arguments when they are passed to the function.In a function header (the rest of the table), a simple
nameis matched by position or name depending on how the caller passes it, but thename=valueform specifies a default value. The*nameform collects any extra unmatched positional arguments in a tuple, and the**nameform collects extra keyword arguments in a dictionary. In Python 3.0 and later, any normal or defaulted argument names following a*nameor a bare*are keyword-only arguments and must be passed by keyword in calls.
Of these, keyword arguments and defaults are probably the most commonly used in Python code. We’ve informally used both of these earlier in this book:
We’ve already used keywords to specify options to the 3.0
printfunction, but they are more general—keywords allow us to label any argument with its name, to make calls more informational.We met defaults earlier, too, as a way to pass in values from the enclosing function’s scope, but they are also more general—they allow us to make any argument optional, providing its default value in a function definition.
As we’ll see, the combination of defaults in a function header and keywords in a call further allows us to pick and choose which defaults to override.
In short, special argument-matching modes let you be fairly
liberal about how many arguments must be passed to a function. If a
function specifies defaults, they are used if you pass too
few arguments. If a function uses the * variable argument list forms, you can
pass too many arguments; the * names collect the extra arguments in
data structures for processing in the function.
The Gritty Details
If you choose to use and combine the special argument-matching modes, Python will ask you to follow these ordering rules:
In a function call, arguments must appear in this order: any positional arguments (
value), followed by a combination of any keyword arguments (name=value) and the*sequenceform, followed by the**dictform.In a function header, arguments must appear in this order: any normal arguments (
name), followed by any default arguments (name=value), followed by the*name(or*in 3.0) form if present, followed by anynameorname=valuekeyword-only arguments (in 3.0), followed by the**nameform.
In both the call and header, the **arg form must appear last if present. If
you mix arguments in any other order, you will get a syntax error
because the combinations can be ambiguous. The steps that Python
internally carries out to match arguments before assignment can
roughly be described as follows:
Assign nonkeyword arguments by position.
Assign keyword arguments by matching names.
Assign extra nonkeyword arguments to
*nametuple.Assign extra keyword arguments to
**namedictionary.Assign default values to unassigned arguments in header.
After this, Python checks to make sure each argument is passed just one value; if not, an error is raised. When all matching is complete, Python assigns argument names to the objects passed to them.
The actual matching algorithm Python uses is a bit more complex (it must also account for keyword-only arguments in 3.0, for instance), so we’ll defer to Python’s standard language manual for a more exact description. It’s not required reading, but tracing Python’s matching algorithm may help you to understand some convoluted cases, especially when modes are mixed.
Note
In Python 3.0, argument names in a function header can also
have annotation values, specified as name:value (or name:value=default when defaults are
present). This is simply additional syntax for arguments and does
not augment or change the argument-ordering rules described here.
The function itself can also have an annotation value, given as
def
f()->value. See the discussion of function
annotation in Chapter 19 for more
details.
Keyword and Default Examples
This is all simpler in code than the preceding descriptions may imply. If you don’t use any special matching syntax, Python matches names by position from left to right, like most other languages. For instance, if you define a function that requires three arguments, you must call it with three arguments:
>>> def f(a, b, c): print(a, b, c)
...Here, we pass them by position—a is matched to 1, b is
matched to 2, and so on (this
works the same in Python 3.0 and 2.6, but extra tuple parentheses
are displayed in 2.6 because we’re using 3.0 print calls):
>>> f(1, 2, 3)
1 2 3Keywords
In Python, though, you can be more specific about what goes where when you call a function. Keyword arguments allow us to match by name, instead of by position:
>>> f(c=3, b=2, a=1)
1 2 3The c=3 in this call, for
example, means send 3 to the
argument named c. More
formally, Python matches the name c in the call to the argument named
c in the function definition’s
header, and then passes the value 3 to that argument. The net effect of
this call is the same as that of the prior call, but notice that
the left-to-right order of the arguments no longer matters when
keywords are used because arguments are matched by name, not by
position. It’s even possible to combine positional and keyword
arguments in a single call. In this case, all positionals are
matched first from left to right in the header, before keywords
are matched by name:
>>> f(1, c=3, b=2)
1 2 3When most people see this the first time, they wonder why
one would use such a tool. Keywords typically have two roles in
Python. First, they make your calls a bit more self-documenting
(assuming that you use better argument names than a, b,
and c). For example, a call of
this form:
func(name='Bob', age=40, job='dev')
is much more meaningful than a call with three naked values separated by commas—the keywords serve as labels for the data in the call. The second major use of keywords occurs in conjunction with defaults, which we turn to next.
Defaults
We talked about defaults in brief earlier, when discussing nested function scopes. In short, defaults allow us to make selected function arguments optional; if not passed a value, the argument is assigned its default before the function runs. For example, here is a function that requires one argument and defaults two:
>>> def f(a, b=2, c=3): print(a, b, c)
...When we call this function, we must provide a value for
a, either by position or by
keyword; however, providing values for b and c is optional. If we don’t pass values
to b and c, they default to 2 and 3, respectively:
>>>f(1)1 2 3 >>>f(a=1)1 2 3
If we pass two values, only c gets its default, and with three
values, no defaults are used:
>>>f(1, 4)1 4 3 >>>f(1, 4, 5)1 4 5
Finally, here is how the keyword and default features interact. Because they subvert the normal left-to-right positional mapping, keywords allow us to essentially skip over arguments with defaults:
>>> f(1, c=6)
1 2 6Here, a gets 1 by position, c gets 6 by keyword, and b, in between, defaults to 2.
Be careful not to confuse the special name=value syntax in a function header
and a function call; in the call it means a match-by-name keyword
argument, while in the header it specifies a default for an
optional argument. In both cases, this is not an assignment
statement (despite its appearance); it is special syntax for these
two contexts, which modifies the default argument-matching
mechanics.
Combining keywords and defaults
Here is a slightly larger example that demonstrates
keywords and defaults in action. In the following, the caller must
always pass at least two arguments (to match spam and eggs), but the other two are optional.
If they are omitted, Python assigns toast and ham to the defaults specified in the
header:
def func(spam, eggs, toast=0, ham=0): # First 2 required print((spam, eggs, toast, ham)) func(1, 2) # Output: (1, 2, 0, 0) func(1, ham=1, eggs=0) # Output: (1, 0, 0, 1) func(spam=1, eggs=0) # Output: (1, 0, 0, 0) func(toast=1, eggs=2, spam=3) # Output: (3, 2, 1, 0) func(1, 2, 3, 4) # Output: (1, 2, 3, 4)
Notice again that when keyword arguments are used in the
call, the order in which the arguments are listed doesn’t matter;
Python matches by name, not by position. The caller must supply
values for spam and eggs, but they can be matched by
position or by name. Again, keep in mind that the form name=value means different things in the
call and the def: a keyword in
the call and a default in the header.
Arbitrary Arguments Examples
The last two matching extensions, * and **, are designed to support functions that
take any number of arguments. Both can appear in either the function
definition or a function call, and they have related purposes in the
two locations.
Collecting arguments
The first use, in the function definition, collects unmatched positional arguments into a tuple:
>>> def f(*args): print(args)
...When this function is called, Python collects all the
positional arguments into a new tuple and assigns the variable
args to that tuple. Because it
is a normal tuple object, it can be indexed, stepped through with
a for loop, and so on:
>>>f()() >>>f(1)(1,) >>>f(1, 2, 3, 4)(1, 2, 3, 4)
The ** feature is
similar, but it only works for keyword
arguments—it collects them into a new dictionary, which can then
be processed with normal dictionary tools. In a sense, the
** form allows you to convert
from keywords to dictionaries, which you can then step through
with keys calls, dictionary
iterators, and the like:
>>>def f(**args): print(args)... >>>f(){} >>>f(a=1, b=2){'a': 1, 'b': 2}
Finally, function headers can combine normal arguments, the
*, and the ** to implement wildly flexible call
signatures. For instance, in the following, 1 is passed to a by position, 2 and 3 are collected into the pargs positional tuple, and x and y wind up in the kargs keyword dictionary:
>>>def f(a, *pargs, **kargs): print(a, pargs, kargs)... >>>f(1, 2, 3, x=1, y=2)1 (2, 3) {'y': 2, 'x': 1}
In fact, these features can be combined in even more complex
ways that may seem ambiguous at first glance—an idea we will
revisit later in this chapter. First, though, let’s see what
happens when * and ** are coded in function calls instead
of definitions.
Unpacking arguments
In recent Python releases, we can use the * syntax when we call a function, too.
In this context, its meaning is the inverse of its meaning in the
function definition—it unpacks a collection of arguments, rather
than building a collection of arguments. For example, we can pass
four arguments to a function in a tuple and let Python unpack them
into individual arguments:
>>>def func(a, b, c, d): print(a, b, c, d)... >>>args = (1, 2)>>>args += (3, 4)>>>func(*args)1 2 3 4
Similarly, the ** syntax
in a function call unpacks a dictionary of key/value pairs into
separate keyword arguments:
>>>args = {'a': 1, 'b': 2, 'c': 3}>>>args['d'] = 4>>>func(**args)1 2 3 4
Again, we can combine normal, positional, and keyword arguments in the call in very flexible ways:
>>>func(*(1, 2), **{'d': 4, 'c': 4})1 2 4 4 >>>func(1, *(2, 3), **{'d': 4})1 2 3 4 >>>func(1, c=3, *(2,), **{'d': 4})1 2 3 4 >>>func(1, *(2, 3), d=4)1 2 3 4 >>>func(1, *(2,), c=3, **{'d':4})1 2 3 4
This sort of code is convenient when you cannot predict the
number of arguments that will be passed to a function when you
write your script; you can build up a collection of arguments at
runtime instead and call the function generically this way. Again,
don’t confuse the */** syntax in the function header and the
function call—in the header it collects any number of arguments,
while in the call it unpacks any number of arguments.
Note
As we saw in Chapter 14, the
*pargs form in a call is an
iteration context, so technically it
accepts any iterable object, not just tuples or other sequences
as shown in the examples here. For instance, a file object works
after the *, and unpacks its
lines into individual arguments (e.g., func(*open('fname')).
This generality is supported in both Python 3.0 and 2.6,
but it holds true only for calls—a *pargs in a call allows any iterable,
but the same form in a def
header always bundles extra arguments into a
tuple. This header behavior is similar in
spirit and syntax to the * in
Python 3.0 extended sequence unpacking assignment forms we met
in Chapter 11
(e.g., x, *y = z), though
that feature always creates lists, not tuples.
Applying functions generically
The prior section’s examples may seem obtuse, but they
are used more often than you might expect. Some programs need to
call arbitrary functions in a generic fashion, without knowing
their names or arguments ahead of time. In fact, the real power of
the special “varargs” call syntax is that you don’t need to know
how many arguments a function call requires before you write a
script. For example, you can use if logic to select from a set of
functions and argument lists, and call any of them
generically:
if <test>:
action, args = func1, (1,) # Call func1 with 1 arg in this case
else:
action, args = func2, (1, 2, 3) # Call func2 with 3 args here
...
action(*args) # Dispatch genericallyMore generally, this varargs call syntax is useful any time you cannot predict the arguments list. If your user selects an arbitrary function via a user interface, for instance, you may be unable to hardcode a function call when writing your script. To work around this, simply build up the arguments list with sequence operations, and call it with starred names to unpack the arguments:
>>>args = (2,3)>>>args += (4,)>>>args(2, 3, 4) >>>func(*args)
Because the arguments list is passed in as a tuple here, the program can build it at runtime. This technique also comes in handy for functions that test or time other functions. For instance, in the following code we support any function with any arguments by passing along whatever arguments were sent in:
def tracer(func, *pargs, **kargs): # Accept arbitrary arguments print('calling:', func.__name__) return func(*pargs, **kargs) # Pass along arbitrary arguments def func(a, b, c, d): return a + b + c + d print(tracer(func, 1, 2, c=3, d=4))
When this code is run, arguments are collected by the tracer and then propagated with varargs call syntax:
calling: func 10
We’ll see larger examples of such roles later in this book; see especially the sequence timing example in Chapter 20 and the various decorator tools we will code in Chapter 38.
The defunct apply built-in (Python 2.6)
Prior to Python 3.0, the effect of the *args and **args varargs call syntax could be
achieved with a built-in function named apply. This original technique has been
removed in 3.0 because it is now redundant (3.0 cleans up many
such dusty tools that have been subsumed over the years). It’s
still available in Python 2.6, though, and you may come across it
in older 2.X code.
In short, the following are equivalent prior to Python 3.0:
func(*pargs, **kargs)# Newer call syntax: func(*sequence, **dict)apply(func, pargs, kargs)# Defunct built-in: apply(func, sequence, dict)
For example, consider the following function, which accepts any number of positional or keyword arguments:
>>>def echo(*args, **kwargs): print(args, kwargs)... >>>echo(1, 2, a=3, b=4)(1, 2) {'a': 3, 'b': 4}
In Python 2.6, we can call it
generically with apply, or with
the call syntax that is now required in 3.0:
>>>pargs = (1, 2)>>>kargs = {'a':3, 'b':4}>>>apply(echo, pargs, kargs)(1, 2) {'a': 3, 'b': 4} >>>echo(*pargs, **kargs)(1, 2) {'a': 3, 'b': 4}
The unpacking call syntax form is newer than the apply function, is preferred in general,
and is required in 3.0. Apart from its symmetry with the *pargs and **kargs collector forms in def headers, and the fact that it
requires fewer keystrokes overall, the newer call syntax also
allows us to pass along additional arguments without having to
manually extend argument sequences or dictionaries:
>>> echo(0, c=5, *pargs, **kargs) # Normal, keyword, *sequence, **dictionary
(0, 1, 2) {'a': 3, 'c': 5, 'b': 4}That is, the call syntax form is more
general. Since it’s required in 3.0, you should now
disavow all knowledge of apply (unless, of course, it appears in
2.X code you must use or maintain...).
Python 3.0 Keyword-Only Arguments
Python 3.0 generalizes the ordering rules in function headers to allow us to specify keyword-only arguments—arguments that must be passed by keyword only and will never be filled in by a positional argument. This is useful if we want a function to both process any number of arguments and accept possibly optional configuration options.
Syntactically, keyword-only arguments are coded as named
arguments that appear after *args
in the arguments list. All such arguments must be passed using
keyword syntax in the call. For example, in the following, a may be passed by name or position,
b collects any extra positional
arguments, and c must be passed
by keyword only:
>>>def kwonly(a, *b, c):...print(a, b, c)... >>>kwonly(1, 2, c=3)1 (2,) 3 >>>kwonly(a=1, c=3)1 () 3 >>>kwonly(1, 2, 3)TypeError: kwonly() needs keyword-only argument c
We can also use a *
character by itself in the arguments list to indicate that a
function does not accept a variable-length argument list but still
expects all arguments following the * to be passed as keywords. In the next
function, a may be passed by
position or name again, but b and
c must be keywords, and no extra
positionals are allowed:
>>>def kwonly(a, *, b, c):...print(a, b, c)... >>>kwonly(1, c=3, b=2)1 2 3 >>>kwonly(c=3, b=2, a=1)1 2 3 >>>kwonly(1, 2, 3)TypeError: kwonly() takes exactly 1 positional argument (3 given) >>>kwonly(1)TypeError: kwonly() needs keyword-only argument b
You can still use defaults for keyword-only arguments, even
though they appear after the * in
the function header. In the following code, a may be passed by name or position, and
b and c are optional but must be passed by
keyword if used:
>>>def kwonly(a, *, b='spam', c='ham'):...print(a, b, c)... >>>kwonly(1)1 spam ham >>>kwonly(1, c=3)1 spam 3 >>>kwonly(a=1)1 spam ham >>>kwonly(c=3, b=2, a=1)1 2 3 >>>kwonly(1, 2)TypeError: kwonly() takes exactly 1 positional argument (2 given)
In fact, keyword-only arguments with defaults are optional, but those without defaults effectively become required keywords for the function:
>>>def kwonly(a, *, b, c='spam'):...print(a, b, c)... >>>kwonly(1, b='eggs')1 eggs spam >>>kwonly(1, c='eggs')TypeError: kwonly() needs keyword-only argument b >>>kwonly(1, 2)TypeError: kwonly() takes exactly 1 positional argument (2 given) >>>def kwonly(a, *, b=1, c, d=2):...print(a, b, c, d)... >>>kwonly(3, c=4)3 1 4 2 >>>kwonly(3, c=4, b=5)3 5 4 2 >>>kwonly(3)TypeError: kwonly() needs keyword-only argument c >>>kwonly(1, 2, 3)TypeError: kwonly() takes exactly 1 positional argument (3 given)
Ordering rules
Finally, note that keyword-only arguments must be specified
after a single star, not two—named arguments cannot appear
after the **args arbitrary
keywords form, and a ** can’t
appear by itself in the arguments list. Both attempts generate a
syntax error:
>>>def kwonly(a, **pargs, b, c):SyntaxError: invalid syntax >>>def kwonly(a, **, b, c):SyntaxError: invalid syntax
This means that in a function header,
keyword-only arguments must be coded before the **args arbitrary keywords form and after
the *args arbitrary positional
form, when both are present. Whenever an argument name appears
before *args, it is a possibly
default positional argument, not keyword-only:
>>>def f(a, *b, **d, c=6): print(a, b, c, d)# Keyword-only before **! SyntaxError: invalid syntax >>>def f(a, *b, c=6, **d): print(a, b, c, d)# Collect args in header ... >>>f(1, 2, 3, x=4, y=5)# Default used 1 (2, 3) 6 {'y': 5, 'x': 4} >>>f(1, 2, 3, x=4, y=5, c=7)# Override default 1 (2, 3) 7 {'y': 5, 'x': 4} >>>f(1, 2, 3, c=7, x=4, y=5)# Anywhere in keywords 1 (2, 3) 7 {'y': 5, 'x': 4} >>>def f(a, c=6, *b, **d): print(a, b, c, d)# c is not keyword-only! ... >>> f(1, 2, 3, x=4) 1 (3,) 2 {'x': 4}
In fact, similar ordering rules hold true in function
calls: when keyword-only arguments are
passed, they must appear before a **args form. The keyword-only argument
can be coded either before or after the *args, though, and may be included in
**args:
>>>def f(a, *b, c=6, **d): print(a, b, c, d)# KW-only between * and ** ... >>>f(1, *(2, 3), **dict(x=4, y=5))# Unpack args at call 1 (2, 3) 6 {'y': 5, 'x': 4} >>>f(1, *(2, 3), **dict(x=4, y=5), c=7)# Keywords before **args! SyntaxError: invalid syntax >>>f(1, *(2, 3), c=7, **dict(x=4, y=5))# Override default 1 (2, 3) 7 {'y': 5, 'x': 4} >>>f(1, c=7, *(2, 3), **dict(x=4, y=5))# After or before * 1 (2, 3) 7 {'y': 5, 'x': 4} >>>f(1, *(2, 3), **dict(x=4, y=5, c=7))# Keyword-only in ** 1 (2, 3) 7 {'y': 5, 'x': 4}
Trace through these cases on your own, in conjunction with the general argument-ordering rules described formally earlier. They may appear to be worst cases in the artificial examples here, but they can come up in real practice, especially for people who write libraries and tools for other Python programmers to use.
Why keyword-only arguments?
So why care about keyword-only arguments? In short, they make it easier to allow a function to accept both any number of positional arguments to be processed, and configuration options passed as keywords. While their use is optional, without keyword-only arguments extra work may be required to provide defaults for such options and to verify that no superfluous keywords were passed.
Imagine a function that processes a set of passed-in objects and allows a tracing flag to be passed:
process(X, Y, Z) # use flag's default process(X, Y, notify=True) # override flag default
Without keyword-only arguments we have to use both *args and **args and manually inspect the
keywords, but with keyword-only arguments less code is required.
The following guarantees that no positional argument will be
incorrectly matched against notify and requires that it be a keyword
if passed:
def process(*args, notify=False): ...
Since we’re going to see a more realistic example of this later in this chapter, in Emulating the Python 3.0 print Function, I’ll postpone the rest of this story until then. For an additional example of keyword-only arguments in action, see the iteration options timing case study in Chapter 20. And for additional function definition enhancements in Python 3.0, stay tuned for the discussion of function annotation syntax in Chapter 19.
The min Wakeup Call!
Time for something more realistic. To make this chapter’s concepts more concrete, let’s work through an exercise that demonstrates a practical application of argument-matching tools.
Suppose you want to code a function that is able to compute the
minimum value from an arbitrary set of arguments and an arbitrary set
of object data types. That is, the function should accept zero or more
arguments, as many as you wish to pass. Moreover, the function should
work for all kinds of Python object types: numbers, strings, lists,
lists of dictionaries, files, and even None.
The first requirement provides a natural example of how the
* feature can be put to good use—we
can collect arguments into a tuple and step over each of them in turn
with a simple for loop. The second
part of the problem definition is easy: because every object type
supports comparisons, we don’t have to specialize the function per
type (an application of polymorphism); we can simply compare objects
blindly and let Python worry about what sort of comparison to
perform.
Full Credit
The following file shows three ways to code this operation, at least one of which was suggested by a student in one of my courses:
The first function fetches the first argument (
argsis a tuple) and traverses the rest by slicing off the first (there’s no point in comparing an object to itself, especially if it might be a large structure).The second version lets Python pick off the first and rest of the arguments automatically, and so avoids an index and slice.
The third converts from a tuple to a list with the built-in
listcall and employs the listsortmethod.
The sort method is coded in C, so it can be
quicker than the other approaches at times, but the linear scans of
the first two techniques will make them faster most of the
time.[41] The file mins.py contains the code for all three
solutions:
def min1(*args):
res = args[0]
for arg in args[1:]:
if arg < res:
res = arg
return res
def min2(first, *rest):
for arg in rest:
if arg < first:
first = arg
return first
def min3(*args):
tmp = list(args) # Or, in Python 2.4+: return sorted(args)[0]
tmp.sort()
return tmp[0]
print(min1(3,4,1,2))
print(min2("bb", "aa"))
print(min3([2,2], [1,1], [3,3]))All three solutions produce the same result when the file is run. Try typing a few calls interactively to experiment with these on your own:
% python mins.py
1
aa
[1, 1]Notice that none of these three variants tests for the case where no arguments are passed in. They could, but there’s no point in doing so here—in all three solutions, Python will automatically raise an exception if no arguments are passed in. The first variant raises an exception when we try to fetch item 0, the second when Python detects an argument list mismatch, and the third when we try to return item 0 at the end.
This is exactly what we want to happen—because these functions support any data type, there is no valid sentinel value that we could pass back to designate an error. There are exceptions to this rule (e.g., if you have to run expensive actions before you reach the error), but in general it’s better to assume that arguments will work in your functions’ code and let Python raise errors for you when they do not.
Bonus Points
You can get bonus points here for changing these functions
to compute the maximum, rather than minimum,
values. This one’s easy: the first two versions only require
changing < to >, and the third simply requires that
we return tmp[−1] instead of
tmp[0]. For an extra point, be
sure to set the function name to “max” as well (though this part is
strictly optional).
It’s also possible to generalize a single function to compute
either a minimum or a maximum value, by
evaluating comparison expression strings with a tool like the
eval built-in function (see the
library manual) or passing in an arbitrary comparison function. The
file minmax.py shows how to
implement the latter scheme:
def minmax(test, *args):
res = args[0]
for arg in args[1:]:
if test(arg, res):
res = arg
return res
def lessthan(x, y): return x < y # See also: lambda
def grtrthan(x, y): return x > y
print(minmax(lessthan, 4, 2, 1, 5, 6, 3)) # Self-test code
print(minmax(grtrthan, 4, 2, 1, 5, 6, 3))
% python minmax.py
1
6Functions are another kind of object that can be passed into a
function like this one. To make this a max (or other) function, for example, we
could simply pass in the right sort of test function. This may seem like extra
work, but the main point of generalizing functions this way (instead
of cutting and pasting to change just a single character) is that
we’ll only have one version to change in the future, not two.
The Punch Line...
Of course, all this was just a coding exercise. There’s really
no reason to code min or max functions, because both are built-ins
in Python! We met them briefly in Chapter 5
in conjunction with numeric tools, and again in Chapter 14 when exploring
iteration contexts. The built-in versions work almost exactly like
ours, but they’re coded in C for optimal speed and accept either a
single iterable or multiple arguments. Still, though it’s
superfluous in this context, the general coding pattern we used here
might be useful in other scenarios.
Generalized Set Functions
Let’s look at a more useful example of special
argument-matching modes at work. At the end of Chapter 16, we wrote a function that returned the
intersection of two sequences (it picked out items that appeared in
both). Here is a version that intersects an arbitrary number of
sequences (one or more) by using the varargs matching form *args to collect all the passed-in
arguments. Because the arguments come in as a tuple, we can process
them in a simple for loop. Just for
fun, we’ll code a union function that also accepts an arbitrary
number of arguments to collect items that appear in any of the
operands:
def intersect(*args):
res = []
for x in args[0]: # Scan first sequence
for other in args[1:]: # For all other args
if x not in other: break # Item in each one?
else: # No: break out of loop
res.append(x) # Yes: add items to end
return res
def union(*args):
res = []
for seq in args: # For all args
for x in seq: # For all nodes
if not x in res:
res.append(x) # Add new items to result
return resBecause these are tools worth reusing (and they’re too big to
retype interactively), we’ll store the functions in a module file
called inter2.py (if you’ve
forgotten how modules and imports work, see the introduction in Chapter 3, or stay tuned for in-depth coverage
in Part V). In both functions, the arguments
passed in at the call come in as the args tuple. As in the original intersect, both work on any kind of
sequence. Here, they are processing strings, mixed types, and more
than two sequences:
%python>>>from inter2 import intersect, union>>>s1, s2, s3 = "SPAM", "SCAM", "SLAM">>>intersect(s1, s2), union(s1, s2)# Two operands (['S', 'A', 'M'], ['S', 'P', 'A', 'M', 'C']) >>>intersect([1,2,3], (1,4))# Mixed types [1] >>>intersect(s1, s2, s3)# Three operands ['S', 'A', 'M'] >>>union(s1, s2, s3)['S', 'P', 'A', 'M', 'C', 'L']
Note
I should note that because Python now has a set object type (described in Chapter 5), none of the set-processing examples in this book are strictly required anymore; they are included only as demonstrations of coding techniques. Because it’s constantly improving, Python has an uncanny way of conspiring to make my book examples obsolete over time!
Emulating the Python 3.0 print Function
To round out the chapter, let’s look at one last example of
argument matching at work. The code you’ll see here is intended for use in Python
2.6 or earlier (it works in 3.0, too, but is pointless there): it uses
both the *args arbitrary positional
tuple and the **args arbitrary
keyword-arguments dictionary to simulate most of what the Python 3.0
print function does.
As we learned in Chapter 11, this isn’t
actually required, because 2.6 programmers can always enable the 3.0
print function with an import of
this form:
from __future__ import print_function
To demonstrate argument matching in general, though, the following file, print30.py, does the same job in a small amount of reusable code:
"""
Emulate most of the 3.0 print function for use in 2.X
call signature: print30(*args, sep=' ', end='
', file=None)
"""
import sys
def print30(*args, **kargs):
sep = kargs.get('sep', ' ') # Keyword arg defaults
end = kargs.get('end', '
')
file = kargs.get('file', sys.stdout)
output = ''
first = True
for arg in args:
output += ('' if first else sep) + str(arg)
first = False
file.write(output + end)To test it, import this into another file or the interactive
prompt, and use it like the 3.0 print function. Here is a test script,
testprint30.py
(notice that the function must be called “print30”, because “print” is
a reserved word in 2.6):
from print30 import print30 print30(1, 2, 3) print30(1, 2, 3, sep='') # Suppress separator print30(1, 2, 3, sep='...') print30(1, [2], (3,), sep='...') # Various object types print30(4, 5, 6, sep='', end='') # Suppress newline print30(7, 8, 9) print30() # Add newline (or blank line) import sys print30(1, 2, 3, sep='??', end='. ', file=sys.stderr) # Redirect to file
When run under 2.6, we get the same results as 3.0’s print function:
C:misc> c:python26python testprint30.py
1 2 3
123
1...2...3
1...[2]...(3,)
4567 8 9
1??2??3.Although pointless in 3.0, the results are the same when run there. As usual, the generality of Python’s design allows us to prototype or develop concepts in the Python language itself. In this case, argument-matching tools are as flexible in Python code as they are in Python’s internal implementation.
Using Keyword-Only Arguments
It’s interesting to notice that this example could be coded with Python 3.0 keyword-only arguments, described earlier in this chapter, to automatically validate configuration arguments:
# Use keyword-only args
def print30(*args, sep=' ', end='
', file=sys.stdout):
output = ''
first = True
for arg in args:
output += ('' if first else sep) + str(arg)
first = False
file.write(output + end)This version works the same as the original, and it’s a prime example of how keyword-only arguments come in handy. The original version assumes that all positional arguments are to be printed, and all keywords are for options only. That’s almost sufficient, but any extra keyword arguments are silently ignored. A call like the following, for instance, will generate an exception with the keyword-only form:
>>> print30(99, name='bob')
TypeError: print30() got an unexpected keyword argument 'name'but will silently ignore the name argument in the original version. To
detect superfluous keywords manually, we could use dict.pop() to delete fetched entries, and
check if the dictionary is not empty. Here is an equivalent to the
keyword-only version:
# Use keyword args deletion with defaults
def print30(*args, **kargs):
sep = kargs.pop('sep', ' ')
end = kargs.pop('end', '
')
file = kargs.pop('file', sys.stdout)
if kargs: raise TypeError('extra keywords: %s' % kargs)
output = ''
first = True
for arg in args:
output += ('' if first else sep) + str(arg)
first = False
file.write(output + end)This works as before, but it now catches extraneous keyword arguments, too:
>>> print30(99, name='bob')
TypeError: extra keywords: {'name': 'bob'}This version of the function runs under Python 2.6, but it requires four more lines of code than the keyword-only version. Unfortunately, the extra code is required in this case—the keyword-only version only works on 3.0, which negates most of the reason that I wrote this example in the first place (a 3.0 emulator that only works on 3.0 isn’t incredibly useful!). In programs written to run on 3.0, though, keyword-only arguments can simplify a specific category of functions that accept both arguments and options. For another example of 3.0 keyword-only arguments, be sure to see the upcoming iteration timing case study in Chapter 20.
Chapter Summary
In this chapter, we studied the second of two key concepts related to functions: arguments (how objects are passed into a function). As we learned, arguments are passed into a function by assignment, which means by object reference, which really means by pointer. We also studied some more advanced extensions, including default and keyword arguments, tools for using arbitrarily many arguments, and keyword-only arguments in 3.0. Finally, we saw how mutable arguments can exhibit the same behavior as other shared references to objects—unless the object is explicitly copied when it’s sent in, changing a passed-in mutable in a function can impact the caller.
The next chapter continues our look at functions by exploring
some more advanced function-related ideas: function annotations,
lambdas, and functional tools such
as map and filter. Many of these concepts stem from the
fact that functions are normal objects in Python, and so support some
advanced and very flexible processing modes. Before diving into those
topics, however, take this chapter’s quiz to review the argument ideas
we’ve studied here.
Test Your Knowledge: Quiz
What is the output of the following code, and why?
>>>
def func(a, b=4, c=5):...print(a, b, c)... >>>func(1, 2)What is the output of this code, and why?
>>>
def func(a, b, c=5):...print(a, b, c)... >>>func(1, c=3, b=2)How about this code: what is its output, and why?
>>>
def func(a, *pargs):...print(a, pargs)... >>>func(1, 2, 3)What does this code print, and why?
>>>
def func(a, **kargs):...print(a, kargs)... >>>func(a=1, c=3, b=2)One last time: what is the output of this code, and why?
>>>
def func(a, b, c=3, d=4): print(a, b, c, d)... >>>func(1, *(5,6))Name three or more ways that functions can communicate results to a caller.
Test Your Knowledge: Answers
The output here is
'1 2 5', because1and2are passed toaandbby position, andcis omitted in the call and defaults to5.The output this time is
'1 2 3':1is passed toaby position, andbandcare passed2and3by name (the left-to-right order doesn’t matter when keyword arguments are used like this).This code prints
'1 (2, 3)', because1is passed toaand the*pargscollects the remaining positional arguments into a new tuple object. We can step through the extra positional arguments tuple with any iteration tool (e.g.,for arg in pargs: ...).This time the code prints
'1 {'c': 3, 'b': 2}', because1is passed toaby name and the**kargscollects the remaining keyword arguments into a dictionary. We could step through the extra keyword arguments dictionary by key with any iteration tool (e.g.,for key in kargs: ...).The output here is
'1 5 6 4':1matchesaby position,5and6matchbandcby*namepositionals (6overridesc’s default), andddefaults to4because it was not passed a value.Functions can send back results with
returnstatements, by changing passed-in mutable arguments, and by setting global variables. Globals are generally frowned upon (except for very special cases, like multithreaded programs) because they can make code more difficult to understand and use.returnstatements are usually best, but changing mutables is fine, if expected. Functions may also communicate with system devices such as files and sockets, but these are beyond our scope here.
[41] Actually, this is fairly complicated. The Python sort routine is coded in C and uses a
highly optimized algorithm that attempts to take advantage of
partial ordering in the items to be sorted. It’s named “timsort”
after Tim Peters, its creator, and in its documentation it
claims to have “supernatural performance” at times (pretty good,
for a sort!). Still, sorting is an inherently exponential
operation (it must chop up the sequence and put it back together
many times), and the other versions simply perform one linear
left-to-right scan. The net effect is that sorting is quicker if
the arguments are partially ordered, but is likely to be slower
otherwise. Even so, Python performance can change over time, and
the fact that sorting is implemented in the C language can help
greatly; for an exact analysis, you should time the alternatives
with the time or timeit modules we’ll meet in Chapter 20.