
The coefficient vector  must be estimated using the available training data. Although we could use (non-linear) least squares to fit the logistic regression model, the more general method of maximum likelihood is preferred, since it has better statistical properties. As we have just discussed, the basic intuition behind using maximum likelihood to fit a logistic regression model is to seek estimates for such that the predicted probability
must be estimated using the available training data. Although we could use (non-linear) least squares to fit the logistic regression model, the more general method of maximum likelihood is preferred, since it has better statistical properties. As we have just discussed, the basic intuition behind using maximum likelihood to fit a logistic regression model is to seek estimates for such that the predicted probability  corresponds as closely as possible to the actual outcome. In other words, we try to find
corresponds as closely as possible to the actual outcome. In other words, we try to find  such that these estimates yield a number close to 1 for all cases where the stock price went up, and a number close to 0 otherwise. More formally, we are seeking to maximize the likelihood function:
such that these estimates yield a number close to 1 for all cases where the stock price went up, and a number close to 0 otherwise. More formally, we are seeking to maximize the likelihood function:

It is easier to work with sums than with products, so let's take logs on both sides to get the log-likelihood function and the corresponding definition of the logistic regression coefficients:

Maximizing this equation by setting the derivatives of 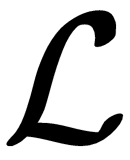 with respect to to zero yields p+1 so-called score equations that are nonlinear in the parameters that can be solved using iterative numerical methods for the concave log-likelihood function.
with respect to to zero yields p+1 so-called score equations that are nonlinear in the parameters that can be solved using iterative numerical methods for the concave log-likelihood function.