In order to better illustrate the process, let's consider the following dataset, indicating whether a second shoulder dislocation has occurred after the first (recurrence):
|
Age |
Operated |
Sex |
Recurrence |
|
15 |
y |
m |
y |
|
45 |
n |
f |
n |
|
30 |
y |
m |
y |
|
18 |
n |
m |
n |
|
52 |
n |
f |
y |
In order to build a Random Forest tree, we must first decide the number of features that will be considered in each split. As we have three features, we will use the square root of 3, which is approximately 1.7. Usually, we use the floor of this number (we round it down to the closest integer), but as we want to illustrate the process, we will use two features in order to better demonstrate it. For the first tree, we generate a bootstrap sample. The second row is an instance that was chosen twice from the original dataset:
|
Age |
Operated |
Sex |
Recurrence |
|
15 |
y |
m |
y |
|
15 |
y |
m |
y |
|
30 |
y |
m |
y |
|
18 |
n |
m |
n |
|
52 |
n |
f |
y |
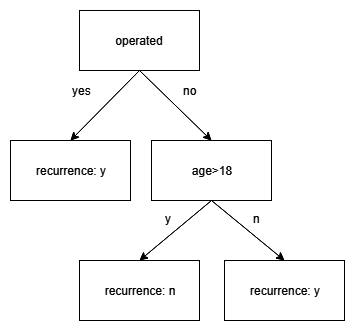
Next, we create the root node. First, we randomly select two features to consider. We choose operated and sex. The best split is given for operated, as we get a leaf with 100% accuracy and one node with 50% accuracy. The resulting tree is depicted as follows:

Next, we again select two features at random and the one that offers the best split. We now choose operated and age. As both misclassified instances were not operated, the best split is offered through the age feature.
Thus, the final tree is a tree with three leaves, where if someone is operated they have a recurrence, while if they are not operated and are over the age of 18 they do not:
Note that medical research indicates that young males have the highest chance for shoulder dislocation recurrence. The dataset here is a toy example that does not reflect reality.