
In this chapter, you’ll see how to pass tuples between the different components of a Storm topology, and how to deploy a topology into a running Storm cluster.
One of the most important things that you need to do when designing
a topology is to define how data is exchanged between components (how
streams are consumed by the bolts). A Stream Grouping
specifies which stream(s) are consumed by each bolt and how the stream will be consumed.
Tip
A node can emit more than one stream of data. A stream grouping allows us to choose which stream to receive.
The stream grouping is set when the topology is defined, as we saw in Chapter 2:
...builder.setBolt("word-normalizer",newWordNormalizer()).shuffleGrouping("word-reader");...
In the preceding code block, a bolt is set on the topology builder, and then a source is set using the shuffle stream grouping. A stream grouping normally takes the source component ID as a parameter, and optionally other parameters as well, depending on the kind of stream grouping.
Tip
There can be more than one source per InputDeclarer, and each source can be grouped
with a different stream grouping.
Shuffle Grouping is the most commonly used grouping. It takes a single parameter (the source component) and sends each tuple emitted by the source to a randomly chosen bolt warranting that each consumer will receive the same number of tuples.
The shuffle grouping is useful for doing atomic operations such as a math operation. However, if the operation can’t be randomically distributed, such as the example in Chapter 2 where you needed to count words, you should consider the use of other grouping.
Fields Grouping allows you to control how tuples are sent to
bolts, based on one or more fields of the tuple. It guarantees that a
given set of values for a combination of fields is always sent to the
same bolt. Coming back to the word count example, if you group the
stream by the word field, the word-normalizer bolt will always send tuples
with a given word to the same instance of the word-counter bolt.
...builder.setBolt("word-counter",newWordCounter(),2).fieldsGrouping("word-normalizer",newFields("word"));...
Tip
All fields set in the fields grouping must exist in the sources’s field declaration.
All Grouping sends a single copy of each tuple to all instances of
the receiving bolt. This kind of grouping is used to send
signals to bolts. For example, if you need to
refresh a cache, you can send a refresh cache
signal to all bolts. In the word-count example, you could use
an all grouping to add the ability to clear the counter cache (see Topologies
Example).
publicvoidexecute(Tupleinput){Stringstr=null;try{if(input.getSourceStreamId().equals("signals")){str=input.getStringByField("action");if("refreshCache".equals(str))counters.clear();}}catch(IllegalArgumentExceptione){//Do nothing}...}
We’ve added an if to check the
stream source. Storm gives us the possibility to declare named streams
(if you don’t send a tuple to a named stream, the stream is "default"); it’s an excellent way to identify
the source of the tuples, such as this case where we want to identify
the signals.
In the topology definition, you’ll add a second stream to the word-counter bolt that sends each tuple from the signals-spout stream to all instances of the bolt.
builder.setBolt("word-counter",newWordCounter(),2).fieldsGrouping("word-normalizer",newFields("word")).allGrouping("signals-spout","signals");
The implementation of signals-spout can be found at the git repository.
You can create your own custom stream grouping by implementing the
backtype.storm.grouping.CustomStreamGrouping
interface. This gives you the power to decide which bolt(s) will receive
each tuple.
Let’s modify the word count example, to group tuples so that all words that start with the same letter will be received by the same bolt.
publicclassModuleGroupingimplementsCustomStreamGrouping,Serializable{intnumTasks=0;@OverridepublicList<Integer>chooseTasks(List<Object>values){List<Integer>boltIds=newArrayList();if(values.size()>0){Stringstr=values.get(0).toString();if(str.isEmpty())boltIds.add(0);elseboltIds.add(str.charAt(0)%numTasks);}returnboltIds;}@Overridepublicvoidprepare(TopologyContextcontext,FieldsoutFields,List<Integer>targetTasks){numTasks=targetTasks.size();}}
You can see a simple implementation of CustomStreamGrouping, where we use the amount
of tasks to take the modulus of the integer value of the first character
of the word, thus selecting which bolt will receive the tuple.
To use this grouping in the example, change the word-normalizer grouping by the
following:
builder.setBolt("word-normalizer",newWordNormalizer()).customGrouping("word-reader",newModuleGrouping());
This is a special grouping where the source decides which
component will receive the tuple. Similarly to the previous example, the
source will decide which bolt receives the tuple based on the first
letter of the word. To use direct grouping, in the WordNormalizer bolt, use the emitDirect method instead of emit.
publicvoidexecute(Tupleinput){...for(Stringword:words){if(!word.isEmpty()){...collector.emitDirect(getWordCountIndex(word),newValues(word));}}// Acknowledge the tuplecollector.ack(input);}publicIntegergetWordCountIndex(Stringword){word=word.trim().toUpperCase();if(word.isEmpty())return0;elsereturnword.charAt(0)%numCounterTasks;}
Work out the number of target tasks in the prepare method:
publicvoidprepare(MapstormConf,TopologyContextcontext,OutputCollectorcollector){this.collector=collector;this.numCounterTasks=context.getComponentTasks("word-counter");}
And in the topology definition, specify that the stream will be grouped directly:
builder.setBolt("word-counter",newWordCounter(),2).directGrouping("word-normalizer");
Global Grouping sends tuples generated by all instances of the source to a single target instance (specifically, the task with lowest ID).
At the time of this writing (Storm version 0.7.1), using this grouping is the same as using Shuffle Grouping. In other words, when using this grouping, it doesn’t matter how streams are grouped.
Until now, you have used a utility called LocalCluster to run the topology on your local
computer. Running the Storm infrastructure on your computer lets you run
and debug different topologies easily. But what about when you want to
submit your topology to a running Storm cluster? One of the interesting
features of Storm is that it’s easy to send your topology to run in a real
cluster. You’ll need to change the LocalCluster to a StormSubmitter and implement the submitTopology method, which is responsible for
sending the topology to the cluster.
You can see the changes in the code below:
//LocalCluster cluster = new LocalCluster();//cluster.submitTopology("Count-Word-Topology-With-Refresh-Cache", conf,builder.createTopology());StormSubmitter.submitTopology("Count-Word-Topology-With-Refresh-Cache",conf,builder.createTopology());//Thread.sleep(1000);//cluster.shutdown();
Tip
When you use a StormSubmitter,
you can’t control the cluster from your code as you could with a
LocalCluster.
Next, package the source into a jar, which is sent when you run the Storm Client command to submit the topology. Because you used Maven, the only thing you need to do is go to the source folder and run the following:
mvn package
Once you have the generated jar, use the storm jar command to submit the topology (you
should know how to install the Storm client into Appendix A). The syntax is storm jar allmycode.jar org.me.MyTopology arg1 arg2
arg3.
In this example, from the topologies source project folder, run:
storm jar target/Topologies-0.0.1-SNAPSHOT.jar countword.TopologyMain src/main/resources/words.txt
With these commands, you have submitted the topology to the cluster.
To stop/kill it, run:
storm kill Count-Word-Topology-With-Refresh-Cache
Note
The topology name must be unique.
Tip
To install the Storm Client, see Appendix A.
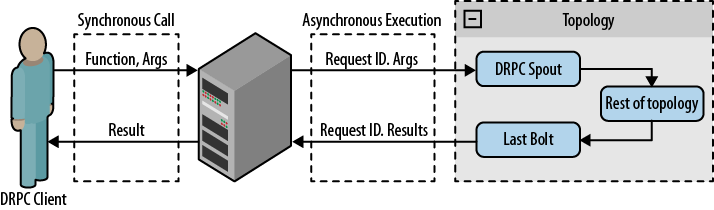
There is a special type of topology known as Distributed Remote Procedure Call (DRPC), that executes Remote Procedure Calls (RPC) using the distributed power of Storm (see Figure 3-1). Storm gives you some tools to enable the use of DRPC. The first is a DRPC server that runs as a connector between the client and the Storm topology, running as a source for the toplogy spouts. It receives a function to execute and its parameters. Then for each piece of data on which the function operates, the server assigns a request ID used through the topology to identify the RPC request. When the topology executes the last bolt, it must emit the RPC request ID and the result, allowing the DRPC server to return the result to the correct client.
Tip
A single DRPC server can execute many functions. Each function is identified by a unique name.
The second tool that Storm provides (used in the example) is the
LinearDRPCTopologyBuilder, an
abstraction to help build DRPC topologies. The topology generated creates
DRPCSpouts—which connect to DRPC
servers and emit data to the rest of the topology—and wraps bolts so that
a result is returned from the last bolt. All bolts added to a LinearDRPCTopologyBuilder are executed in
sequential order.
As an example of this type of topology, you’ll create a process that adds numbers. This is a simple example, but the concept could be extended to perform complex distributed math operations.
The bolt has the following output declarer:
publicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){declarer.declare(newFields("id","result"));}
Because this is the only bolt in the topology, it must emit the RPC ID and the result.
The execute method is responsible
for executing the add operation:
publicvoidexecute(Tupleinput){String[]numbers=input.getString(1).split("\+");Integeradded=0;if(numbers.length<2){thrownewInvalidParameterException("Should be at least 2 numbers");}for(Stringnum:numbers){added+=Integer.parseInt(num);}collector.emit(newValues(input.getValue(0),added));}
Include the added bolt in the topology definition as follows:
publicstaticvoidmain(String[]args){LocalDRPCdrpc=newLocalDRPC();LinearDRPCTopologyBuilderbuilder=newLinearDRPCTopologyBuilder("add");builder.addBolt(newAdderBolt(),2);Configconf=newConfig();conf.setDebug(true);LocalClustercluster=newLocalCluster();cluster.submitTopology("drpc-adder-topology",conf,builder.createLocalTopology(drpc));Stringresult=drpc.execute("add","1+-1");checkResult(result,0);result=drpc.execute("add","1+1+5+10");checkResult(result,17);cluster.shutdown();drpc.shutdown();}
Create a LocalDRPC object that
runs the DRPC server locally. Next, create a topology builder and add the
bolt to the topology. To test the topology, use the execute method on your DRPC object.
Tip
To connect to a remote DRPC server, use the DRPCClient class. The DRPC server exposes a
Thrift API that could be
used from many languages, and it’s the same API if you run DRPC server
in locally or remote.
To submit a topology to a Storm cluster, use the method createRemoteTopology of the builder object
instead of createLocalTopology, which
uses the DRPC configuration from Storm config.