
With Storm, you can guarantee message processing by using an ack and fail strategy, as mentioned earlier in the book. But what happens if tuples are replayed? How do you make sure you won’t overcount?
Transactional Topologies is a new feature, included in Storm 0.7.0, that enables messaging semantics to ensure you replay tuples in a secure way and process them only once. Without support for transactional topologies, you wouldn’t be able to count in a fully accurate, scalable, and fault-tolerant way.
Note
Transactional Topologies are an abstraction built on top of standard Storm spouts and bolts.
In a transactional topology, Storm uses a mix of parallel and sequential tuple processing. The spout generates batches of tuples that are processed by the bolts in parallel. Some of those bolts are known as committers, and they commit processed batches in a strictly ordered fashion. This means that if you have two batches with five tuples each, both tuples will be processed in parallel by the bolts, but the committer bolts won’t commit the second tuple until the first tuple is committed successfully.
Note
When dealing with transactional topologies, it is important to be able to replay batch of tuples from the source, and sometimes even several times. So make sure your source of data—the one that your spout will be connected to—has the ability to do that.
This can be described as two different steps, or phases:
- The processing phase
A fully parallel phase, many batches are executed at the same time.
- The commit phase
A strongly ordered phase, batch two is not committed until batch one has committed successfully.
Call both of these phases a Storm Transaction.
Tip
Storm uses Zookeeper to store transaction metadata. By default the one used for the topology, will be used to store the metadata. You can change this by overriding the configuration key transactional.zookeeper.servers and transactional.zookeeper.port.
To see how transactions work, you’ll create a Twitter analytics tool. You’ll be reading tweets stored in a Redis database, process them through a few bolts, and store—in another Redis database—the list of all hashtags and their frequency among the tweets, the list of all users and amount of tweets they appear in, and a list of users with their hashtags and frequency.
The topology you’ll build for this tool is described in Figure 8-1.
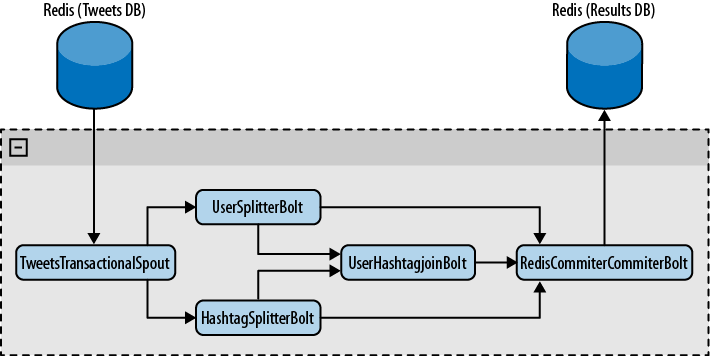
As you can see, TweetsTransactionalSpout is the spout that will
be connecting to your tweets database and will be emitting batches of
tuples across the topology. Two different bolts, UserSplitterBolt and HashtagSplitterBolt, will receive tuples from
the spout. UserSplitterBolt will parse
the tweet and look for users—words preceded by @—and
will emit these words in a custom stream called
users. The HashatagSplitterBolt will also parse the tweet,
looking for words preceded by #, and will emit these
words in a custom stream called hashtags. A third
bolt, the UserHashtagJoinBolt, will
receive both streams and count how many times a hashtag has appeared in a
tweet where a user was named. In order to count and emit the result, this
bolt will be a BaseBatchBolt (more on
that later).
Finally, a last bolt, called RedisCommitterBolt, will receive the three
streams—the ones generated by UserSplitterBolt, HashtagSplitterBolt, and UserHashtagJoinBolt. It will count everything
and once finished processing the batch of tuples, it will send everything
to Redis, in one transaction. This bolt is a special kind of bolt known as
a committer bolt, explained later in this
chapter.
In order to build this topology, use TransactionalTopologyBuilder, like the following
code block:
TransactionalTopologyBuilderbuilder=newTransactionalTopologyBuilder("test","spout",newTweetsTransactionalSpout());builder.setBolt("users-splitter",newUserSplitterBolt(),4).shuffleGrouping("spout");builder.setBolt("hashtag-splitter",newHashtagSplitterBolt(),4).shuffleGrouping("spout");builder.setBolt("user-hashtag-merger",newUserHashtagJoinBolt(),4).fieldsGrouping("users-splitter","users",newFields("tweet_id")).fieldsGrouping("hashtag-splitter","hashtags",newFields("tweet_id"));builder.setBolt("redis-committer",newRedisCommiterCommiterBolt()).globalGrouping("users-splitter","users").globalGrouping("hashtag-splitter","hashtags").globalGrouping("user-hashtag-merger");
Let’s see how you can implement the spout in a transactional topology.
The spout in a transactional topology is completely different from a standard spout.
publicclassTweetsTransactionalSpoutextendsBaseTransactionalSpout<TransactionMetadata>{
As you can see in the class definition, TweetsTransactionalSpout extends BaseTransactionalSpout with a generic type.
The type you set there is something known as the transaction
metadata. It will be used later to emit batches of tuples
from the source.
In this example, TransactionMetadata is defined as:
publicclassTransactionMetadataimplementsSerializable{privatestaticfinallongserialVersionUID=1L;longfrom;intquantity;publicTransactionMetadata(longfrom,intquantity){this.from=from;this.quantity=quantity;}}
Here you’ll store from and
quantity, which will tell you exactly
how to generate the batch of tuples.
To finish the implementation of the spout, you need to implement the following three methods:
@OverridepublicITransactionalSpout.Coordinator<TransactionMetadata>getCoordinator(Mapconf,TopologyContextcontext){returnnewTweetsTransactionalSpoutCoordinator();}@Overridepublicbacktype.storm.transactional.ITransactionalSpout.Emitter<TransactionMetadata>getEmitter(Mapconf,TopologyContextcontext){returnnewTweetsTransactionalSpoutEmitter();}@OverridepublicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){declarer.declare(newFields("txid","tweet_id","tweet"));}
In the getCoordinator method,
you tell Storm which class will coordinate the generation of batches of
tuples. With getEmitter, you tell
Storm which class will be responsible for reading batches of tuples from
the source and emitting them to a stream in the topology. And finally,
as you did before, you need to declare which fields are emitted.
To make the example easier, we’ve decided to encapsulate all operations with Redis in one single class.
publicclassRQ{publicstaticfinalStringNEXT_READ="NEXT_READ";publicstaticfinalStringNEXT_WRITE="NEXT_WRITE";Jedisjedis;publicRQ(){jedis=newJedis("localhost");}publiclonggetAvailableToRead(longcurrent){returngetNextWrite()-current;}publiclonggetNextRead(){StringsNextRead=jedis.get(NEXT_READ);if(sNextRead==null)return1;returnLong.valueOf(sNextRead);}publiclonggetNextWrite(){returnLong.valueOf(jedis.get(NEXT_WRITE));}publicvoidclose(){jedis.disconnect();}publicvoidsetNextRead(longnextRead){jedis.set(NEXT_READ,""+nextRead);}publicList<String>getMessages(longfrom,intquantity){String[]keys=newString[quantity];for(inti=0;i<quantity;i++)keys[i]=""+(i+from);returnjedis.mget(keys);}}
Read carefully the implementation of each method, and make sure you understand what they do.
Let’s see the implementation of the coordinator of this example.
publicstaticclassTweetsTransactionalSpoutCoordinatorimplementsITransactionalSpout.Coordinator<TransactionMetadata>{TransactionMetadatalastTransactionMetadata;RQrq=newRQ();longnextRead=0;publicTweetsTransactionalSpoutCoordinator(){nextRead=rq.getNextRead();}@OverridepublicTransactionMetadatainitializeTransaction(BigIntegertxid,TransactionMetadataprevMetadata){longquantity=rq.getAvailableToRead(nextRead);quantity=quantity>MAX_TRANSACTION_SIZE?MAX_TRANSACTION_SIZE:quantity;TransactionMetadataret=newTransactionMetadata(nextRead,(int)quantity);nextRead+=quantity;returnret;}@OverridepublicbooleanisReady(){returnrq.getAvailableToRead(nextRead)>0;}@Overridepublicvoidclose(){rq.close();}}
It is important to mention that among the entire topology there will be only one coordinator instance. When the coordinator is instantiated, it retrieves from Redis a sequence that tells the coordinator which is the next tweet to read. The first time, this value will be 1, which means that the next tweet to read is the first one.
The first method that will be called is isReady. It will always be called before
initializeTransaction, to make sure
the source is ready to be read from. You should return true or false accordingly. In this example, retrieve
the amount of tweets and compare them with how many tweets you read.
The difference between them is the amount to available tweets to read.
If it is greater than 0, it means you have tweets to read.
Finally, the initializeTransaction is executed. As you
can see, you get txid and prevMetadata as parameters. The first one is
a unique transaction ID generated by Storm, which identifies the batch
of tuples to be generated. prevMetadata is the metadata generated by
the coordinator of the previous transaction.
In this example, first make sure how many tweets are available
to read. And once you have sorted that out, create a new TransactionMetadata, indicating which is the
first tweet to read from, and which
is the quantity of tweets to
read.
As soon as you return the metadata, Storm stores it with the
txid in zookeeper. This guarantees
that if something goes wrong, Storm will be able to replay this with
the emitter to resend the batch.
The final step when creating a transactional spout is implementing the emitter.
Let’s start with the following implementation:
publicstaticclassTweetsTransactionalSpoutEmitterimplementsITransactionalSpout.Emitter<TransactionMetadata>{RQrq=newRQ();publicTweetsTransactionalSpoutEmitter(){}@OverridepublicvoidemitBatch(TransactionAttempttx,TransactionMetadatacoordinatorMeta,BatchOutputCollectorcollector){rq.setNextRead(coordinatorMeta.from+coordinatorMeta.quantity);List<String>messages=rq.getMessages(coordinatorMeta.from,coordinatorMeta.quantity);longtweetId=coordinatorMeta.from;for(Stringmessage:messages){collector.emit(newValues(tx,""+tweetId,message));tweetId++;}}@OverridepublicvoidcleanupBefore(BigIntegertxid){}@Overridepublicvoidclose(){rq.close();}}
Emitters are the one who will read the source and send tuples to
a stream. It is very important for the emitters to always be able to
send the same batch of tuples for the same transaction
id and transaction metadata. This way,
if something goes wrong during the processing of a batch, Storm will
be able to repeat the same transaction id and
transaction metadata with the emitter and make
sure the batch of tuples are repeated. Storm will increase the
attempt id in the TransactionAttempt. This way you know that
the batch is repeated.
The important method here is emitBatch. In this method, use the metadata,
given as a parameter, to get tweets from Redis. Also increase the
sequence in Redis that keeps track of how many tweets you’ve read so
far. And of course, emit the tweets to the topology.
First let’s see the standard bolts of this topology:
publicclassUserSplitterBoltimplementsIBasicBolt{privatestaticfinallongserialVersionUID=1L;@OverridepublicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){declarer.declareStream("users",newFields("txid","tweet_id","user"));}@OverridepublicMap<String,Object>getComponentConfiguration(){returnnull;}@Overridepublicvoidprepare(MapstormConf,TopologyContextcontext){}@Overridepublicvoidexecute(Tupleinput,BasicOutputCollectorcollector){Stringtweet=input.getStringByField("tweet");StringtweetId=input.getStringByField("tweet_id");StringTokenizerstrTok=newStringTokenizer(tweet," ");TransactionAttempttx=(TransactionAttempt)input.getValueByField("txid");HashSet<String>users=newHashSet<String>();while(strTok.hasMoreTokens()){Stringuser=strTok.nextToken();// Ensure this is an actual user, and that it's not repeated in the tweetif(user.startsWith("@")&&!users.contains(user)){collector.emit("users",newValues(tx,tweetId,user));users.add(user);}}}@Overridepublicvoidcleanup(){}}
As mentioned earlier in this chapter, UserSplitterBolt receives tuples, parses the
text of the tweet, and emits words preceded by @,
or the Twitter users. HashtagSplitterBolt works in a very similar
way.
publicclassHashtagSplitterBoltimplementsIBasicBolt{privatestaticfinallongserialVersionUID=1L;@OverridepublicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){declarer.declareStream("hashtags",newFields("txid","tweet_id","hashtag"));}@OverridepublicMap<String,Object>getComponentConfiguration(){returnnull;}@Overridepublicvoidprepare(MapstormConf,TopologyContextcontext){}@Overridepublicvoidexecute(Tupleinput,BasicOutputCollectorcollector){Stringtweet=input.getStringByField("tweet");StringtweetId=input.getStringByField("tweet_id");StringTokenizerstrTok=newStringTokenizer(tweet," ");TransactionAttempttx=(TransactionAttempt)input.getValueByField("txid");HashSet<String>words=newHashSet<String>();while(strTok.hasMoreTokens()){Stringword=strTok.nextToken();if(word.startsWith("#")&&!words.contains(word)){collector.emit("hashtags",newValues(tx,tweetId,word));words.add(word);}}}@Overridepublicvoidcleanup(){}}
Now let’s see what happens in UserHashtagJoinBolt. The first important thing
to notice is that it is a BaseBatchBolt. This means that the execute method will operate on the received
tuples but won’t be emitting any new tuple. Eventually, when the batch
is finished, Storm will call the finishBatch method.
publicvoidexecute(Tupletuple){Stringsource=tuple.getSourceStreamId();StringtweetId=tuple.getStringByField("tweet_id");if("hashtags".equals(source)){Stringhashtag=tuple.getStringByField("hashtag");add(tweetHashtags,tweetId,hashtag);}elseif("users".equals(source)){Stringuser=tuple.getStringByField("user");add(userTweets,user,tweetId);}}
Since you need to associate all the hashtags of a tweet with the
users mentioned in that tweet and count how many times they appeared,
you need to join the two streams of the previous bolts. Do that for the
entire batch, and once it finishes, the finishBatch method is called.
@OverridepublicvoidfinishBatch(){for(Stringuser:userTweets.keySet()){Set<String>tweets=getUserTweets(user);HashMap<String,Integer>hashtagsCounter=newHashMap<String,Integer>();for(Stringtweet:tweets){Set<String>hashtags=getTweetHashtags(tweet);if(hashtags!=null){for(Stringhashtag:hashtags){Integercount=hashtagsCounter.get(hashtag);if(count==null)count=0;count++;hashtagsCounter.put(hashtag,count);}}}for(Stringhashtag:hashtagsCounter.keySet()){intcount=hashtagsCounter.get(hashtag);collector.emit(newValues(id,user,hashtag,count));}}}
In this method, generate and emit a tuple for each user-hashtag, and the amount of times it occurred.
You can see the complete implementation in the downloadable code available on GitHub.
As you’ve learned, batches of tuples are sent by the coordinator and emitters across the topology. Those batched of tuples are processed in parallel without any specific order.
The coordinator bolts are special batch bolts
that implement ICommitter or have
been set with setCommiterBolt in the
TransactionalTopologyBuilder. The
main difference with regular batch bolts is that the finishBatch method of committer bolts executes
when the batch is ready to be committed. This happens when all previous
transactions have been committed successfully. Additionally, finishBatch method is executed sequentially.
So if the batch with transaction ID 1 and the batch with transaction ID
2 are being processed in parallel in the topology, the finishBatch method of the committer bolt that
is processing the batch with transaction ID 2 will get executed only
when the finishBatch of batch with
transaction ID 1 has finished without any errors.
The implementation of this class follows:
publicclassRedisCommiterCommiterBoltextendsBaseTransactionalBoltimplementsICommitter{publicstaticfinalStringLAST_COMMITED_TRANSACTION_FIELD="LAST_COMMIT";TransactionAttemptid;BatchOutputCollectorcollector;Jedisjedis;@Overridepublicvoidprepare(Mapconf,TopologyContextcontext,BatchOutputCollectorcollector,TransactionAttemptid){this.id=id;this.collector=collector;this.jedis=newJedis("localhost");}HashMap<String,Long>hashtags=newHashMap<String,Long>();HashMap<String,Long>users=newHashMap<String,Long>();HashMap<String,Long>usersHashtags=newHashMap<String,Long>();privatevoidcount(HashMap<String,Long>map,Stringkey,intcount){Longvalue=map.get(key);if(value==null)value=(long)0;value+=count;map.put(key,value);}@Overridepublicvoidexecute(Tupletuple){Stringorigin=tuple.getSourceComponent();if("users-splitter".equals(origin)){Stringuser=tuple.getStringByField("user");count(users,user,1);}elseif("hashtag-splitter".equals(origin)){Stringhashtag=tuple.getStringByField("hashtag");count(hashtags,hashtag,1);}elseif("user-hashtag-merger".equals(origin)){Stringhashtag=tuple.getStringByField("hashtag");Stringuser=tuple.getStringByField("user");Stringkey=user+":"+hashtag;Integercount=tuple.getIntegerByField("count");count(usersHashtags,key,count);}}@OverridepublicvoidfinishBatch(){StringlastCommitedTransaction=jedis.get(LAST_COMMITED_TRANSACTION_FIELD);StringcurrentTransaction=""+id.getTransactionId();if(currentTransaction.equals(lastCommitedTransaction))return;Transactionmulti=jedis.multi();multi.set(LAST_COMMITED_TRANSACTION_FIELD,currentTransaction);Set<String>keys=hashtags.keySet();for(Stringhashtag:keys){Longcount=hashtags.get(hashtag);multi.hincrBy("hashtags",hashtag,count);}keys=users.keySet();for(Stringuser:keys){Longcount=users.get(user);multi.hincrBy("users",user,count);}keys=usersHashtags.keySet();for(Stringkey:keys){Longcount=usersHashtags.get(key);multi.hincrBy("users_hashtags",key,count);}multi.exec();}@OverridepublicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){}}
This is all very straightforward, but there is a very important
detail in the finishBatch
method.
...multi.set(LAST_COMMITED_TRANSACTION_FIELD,currentTransaction);...
Here you are storing in your database the last transaction ID committed. Why should you do that? Remember that if a transaction fails, Storm will be replaying it as many times as necessary. If you don’t make sure that you already processed the transaction, you could overcount and the whole idea of a transactional topology would be useless. So remember: store the last transaction ID committed and check against it before committing.
It is very common for a spout to read batches of tuples from a set
of partitions. Continuing the example, you could have several Redis
databases and the tweets could be split across those Redis databases. By
implementing IPartitionedTransactionalSpout, Storm offers
some facilities to manage the state for every partition and guarantee the
ability to replay.
Let’s see how to modify your previous TweetsTransactionalSpout so it can handle
partitions.
First, extend BasePartitionedTransactionalSpout, which
implements IPartitionedTransactionalSpout.
publicclassTweetsPartitionedTransactionalSpoutextendsBasePartitionedTransactionalSpout<TransactionMetadata>{...}
Tell Storm, which is your coordinator.
publicstaticclassTweetsPartitionedTransactionalCoordinatorimplementsCoordinator{@OverridepublicintnumPartitions(){return4;}@OverridepublicbooleanisReady(){returntrue;}@Overridepublicvoidclose(){}}
In this case, the coordinator is very simple. In the numPartitions method, tell Storm how many
partitions you have. And also notice that you don’t return any metadata.
In an IPartitionedTransactionalSpout,
the metadata is managed by the emitter directly.
Let’s see how the emitter is implemented.
publicstaticclassTweetsPartitionedTransactionalEmitterimplementsEmitter<TransactionMetadata>{PartitionedRQrq=newPartitionedRQ();@OverridepublicTransactionMetadataemitPartitionBatchNew(TransactionAttempttx,BatchOutputCollectorcollector,intpartition,TransactionMetadatalastPartitionMeta){longnextRead;if(lastPartitionMeta==null)nextRead=rq.getNextRead(partition);else{nextRead=lastPartitionMeta.from+lastPartitionMeta.quantity;rq.setNextRead(partition,nextRead);// Move the cursor}longquantity=rq.getAvailableToRead(partition,nextRead);quantity=quantity>MAX_TRANSACTION_SIZE?MAX_TRANSACTION_SIZE:quantity;TransactionMetadatametadata=newTransactionMetadata(nextRead,(int)quantity);emitPartitionBatch(tx,collector,partition,metadata);returnmetadata;}@OverridepublicvoidemitPartitionBatch(TransactionAttempttx,BatchOutputCollectorcollector,intpartition,TransactionMetadatapartitionMeta){if(partitionMeta.quantity<=0)return;List<String>messages=rq.getMessages(partition,partitionMeta.from,partitionMeta.quantity);longtweetId=partitionMeta.from;for(Stringmsg:messages){collector.emit(newValues(tx,""+tweetId,msg));tweetId++;}}@Overridepublicvoidclose(){}}
There are two important methods here, emitPartitionBatchNew and emitPartitionBatch. In emitPartitionBatch, you receive from Storm the
partition parameter, which tells you
which partition you should retrieve the batch of tuples from. In this
method, decide which tweets to retrieve, generate the corresponding
metadata, call emitPartitionBatch, and
return the metadata, which will be stored immediately in Zookeeper.
Storm will send the same transaction ID for every partition, as the
transaction exists across all the partitions. Read from the partition the
tweets in the emitPartitionBatch
method, and emit the tuples of the batch to the topology. If the batch
fails, Storm will call emitPartitionBatch with the stored metadata to
replay the batch.
Tip
You can check the code at ch08-transactional topologies on GitHub.
So far, you might have assumed that it’s always possible to replay a batch of tuples for the same transaction ID. But that might not be feasible in some scenarios. What happens then?
It turns out that you can still achieve exactly once semantics, but it requires some more development effort as you will need to keep previous state in case the transaction is replayed by Storm. Since you can get different tuples for the same transaction ID, when emitting in different moments in time, you’ll need to reset to that previous state and go from there.
For example, if you are counting total received tweets, you have
currently counted five and in the last transaction, with ID 321, you count
eight more. You would keep those three values—previousCount=5, currentCount=13, and lastTransactionId=321. In case transaction ID
321 is emitted again and since you get different tuples, you count four
more instead of eight, the committer will detect that is the same
transaction ID, it would reset to the previousCount of five, and will add those new
four and update currentCount to
nine.
Also, every transaction that is being processed in parallel will be cancelled when a previous transaction in cancelled. This is to ensure that you don’t miss anything in the middle.
Your spout should implement IOpaquePartitionedTransactionalSpout and as you
can see, the coordinator and emitters are very simple.
publicstaticclassTweetsOpaquePartitionedTransactionalSpoutCoordinatorimplementsIOpaquePartitionedTransactionalSpout.Coordinator{@OverridepublicbooleanisReady(){returntrue;}}
publicstaticclassTweetsOpaquePartitionedTransactionalSpoutEmitterimplementsIOpaquePartitionedTransactionalSpout.Emitter<TransactionMetadata>{PartitionedRQrq=newPartitionedRQ();@OverridepublicTransactionMetadataemitPartitionBatch(TransactionAttempttx,BatchOutputCollectorcollector,intpartition,TransactionMetadatalastPartitionMeta){longnextRead;if(lastPartitionMeta==null)nextRead=rq.getNextRead(partition);else{nextRead=lastPartitionMeta.from+lastPartitionMeta.quantity;rq.setNextRead(partition,nextRead);// Move the cursor}longquantity=rq.getAvailableToRead(partition,nextRead);quantity=quantity>MAX_TRANSACTION_SIZE?MAX_TRANSACTION_SIZE:quantity;TransactionMetadatametadata=newTransactionMetadata(nextRead,(int)quantity);emitMessages(tx,collector,partition,metadata);returnmetadata;}privatevoidemitMessages(TransactionAttempttx,BatchOutputCollectorcollector,intpartition,TransactionMetadatapartitionMeta){if(partitionMeta.quantity<=0)return;List<String>messages=rq.getMessages(partition,partitionMeta.from,partitionMeta.quantity);longtweetId=partitionMeta.from;for(Stringmsg:messages){collector.emit(newValues(tx,""+tweetId,msg));tweetId++;}}@OverridepublicintnumPartitions(){return4;}@Overridepublicvoidclose(){}}
The most interesting method is emitPartitionBatch, which receives the previous
committed metadata. You should use that information to generate a batch of
tuples. This batch won’t be necessarily the same, as was said earlier, you
might not be able to reproduce the same batch. The rest of the job is
handled by the committer bolts, which use the previous state.