
The idea of this chapter is to illustrate a typical web analytics solution, a problem that is often solved using a Hadoop batch job. Unlike a Hadoop implementation, a Storm-based solution will show results that are refreshed in real time.
Our example has three main components (see Figure 6-1):
A Node.js web application, to test the system
A Redis server, to persist the data
A Storm topology, for real-time distributed data processing

Tip
If you want to go through this chapter while playing with the example, you should first read Appendix C.
We have mocked up a simple e-commerce website with three pages: a home page, a product page, and a product statistics page. This application is implemented using the Express Framework and Socket.io Framework to push updates to the browser. The idea of the application is to let you play with the cluster and see the results, but it’s not the focus of this book, so we won’t go into any more detail than a description of the pages it has.
- The Home Page
This page provides links to all the products available on the platform to ease navigation between them. It lists all the items and reads them from the Redis Server. The URL for this page is http://localhost:3000/. (See Figure 6-2.)

- The Product Page
The Product Page shows information related to a specific product, such as price, title, and category. The URL for this page is http://localhost:3000/product/:id. (See Figure 6-3.)

- The Product Stats Page
This page shows the information computed by the Storm cluster, which is collected as users navigate the website. It can be summarized as follows: users that viewed this Product looked at Products in those Categories n times. The URL for this page is http://localhost:3000/product/:id/stats. (See Figure 6-4.)

After starting the Redis server, start the web application by running the following command on the project’s path:
node webapp/app.js
The web application will automatically populate Redis with some sample products for you to play with.
The goal of the Storm topology in this system is to update the product stats in real time while users navigate the website. The Product Stats Page is shows a list of categories with an associated counter, showing the number of users that visited other products in the same category. This helps sellers to understand their customers’ needs. The topology receives a navigation log and updates the product stats as shown in the Figure 6-5.
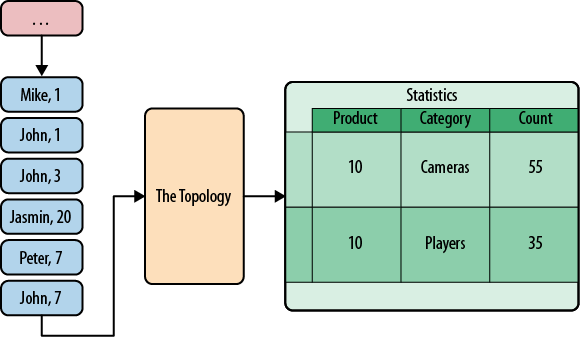
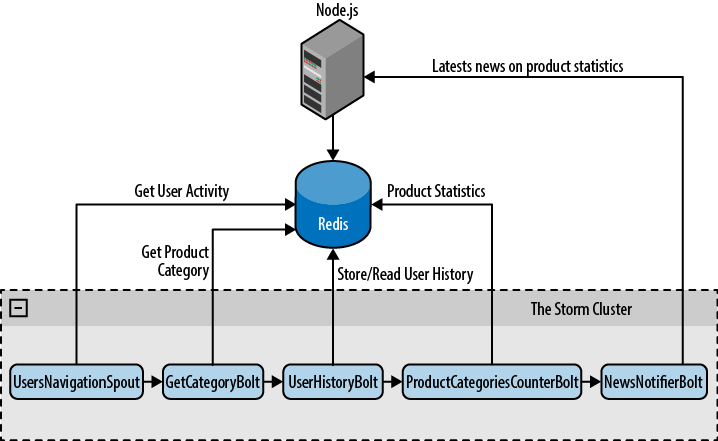
Our Storm Topology has five components: one spout to feed it and four bolts to get the job done.
- UsersNavigationSpout
Reads from the users navigation queue and feeds the topology
- GetCategoryBolt
Reads the product information from the Redis Server and adds its category to the stream
- UserHistoryBolt
Reads the products previously navigated by the user and emits Product:Category pairs to update the counters in the next step
- ProductCategoriesCounterBolt
Keeps track of the number of times that users viewed a product of a specific category
- NewsNotifierBolt
Tells the web application to update the user interface immediately
Here’s how the topology is created (see Figure 6-6):
packagestorm.analytics;...publicclassTopologyStarter{publicstaticvoidmain(String[]args){Logger.getRootLogger().removeAllAppenders();TopologyBuilderbuilder=newTopologyBuilder();builder.setSpout("read-feed",newUsersNavigationSpout(),3);builder.setBolt("get-categ",newGetCategoryBolt(),3).shuffleGrouping("read-feed");builder.setBolt("user-history",newUserHistoryBolt(),5).fieldsGrouping("get-categ",newFields("user"));builder.setBolt("product-categ-counter",newProductCategoriesCounterBolt(),5).fieldsGrouping("user-history",newFields("product"));builder.setBolt("news-notifier",newNewsNotifierBolt(),5).shuffleGrouping("product-categ-counter");Configconf=newConfig();conf.setDebug(true);conf.put("redis-host",REDIS_HOST);conf.put("redis-port",REDIS_PORT);conf.put("webserver",WEBSERVER);LocalClustercluster=newLocalCluster();cluster.submitTopology("analytics",conf,builder.createTopology());}}
The UsersNavigationSpout is in
charge of feeding the topology with navigation entries. Each navigation
entry is a reference to a product page viewed by one user. They are
stored in the Redis Server by the web application. We’ll go into more
detail on that in a moment.
To read entries from the Redis server, you’ll be using https://github.com/xetorthio/jedis, a blazingly small and simple Redis client for Java.
Note
Only the relevant part of the code is shown in the following code block.
packagestorm.analytics;publicclassUsersNavigationSpoutextendsBaseRichSpout{Jedisjedis;...@OverridepublicvoidnextTuple(){Stringcontent=jedis.rpop("navigation");if(content==null||"nil".equals(content)){try{Thread.sleep(300);}catch(InterruptedExceptione){}}else{JSONObjectobj=(JSONObject)JSONValue.parse(content);Stringuser=obj.get("user").toString();Stringproduct=obj.get("product").toString();Stringtype=obj.get("type").toString();HashMap<String,String>map=newHashMap<String,String>();map.put("product",product);NavigationEntryentry=newNavigationEntry(user,type,map);collector.emit(newValues(user,entry));}}@OverridepublicvoiddeclareOutputFields(OutputFieldsDeclarerdeclarer){declarer.declare(newFields("user","otherdata"));}}
First the spout calls jedis.rpop("navigation")
to remove and return the right-most element in the “navigation” list on
the Redis server. If the list is already empty, sleep for 0.3 seconds so
as not to block the server with a busy wait loop. If an entry is found,
parse the content (the content is JSON) and map it to a NavigationEntry object, which is just a POJO
containing the entry information:
The user that was navigating.
The type of page that the user browsed.
Additional page information that depends on the type. The “PRODUCT” page type has an entry for the product ID being browsed.
The spout emits a tuple containing this information by calling
collector.emit(new Values(user, entry)). The content
of this tuple is the input to the next bolt in the topology: The
GetCategoryBolt.
This is a very simple bolt. Its sole responsibility is to deserialize the content of the tuple emitted by the previous spout. If the entry is about a product page, then it loads the product information from the Redis server by using the ProductsReader helper class. Then, for each tuple in the input, it emits a new tuple with further product specific information:
The user
The product
The category of the product
packagestorm.analytics;publicclassGetCategoryBoltextendsBaseBasicBolt{privateProductsReaderreader;...@Overridepublicvoidexecute(Tupleinput,BasicOutputCollectorcollector){NavigationEntryentry=(NavigationEntry)input.getValue(1);if("PRODUCT".equals(entry.getPageType())){try{Stringproduct=(String)entry.getOtherData().get("product");// Call the items API to get item informationProductitm=reader.readItem(product);if(itm==null)return;Stringcateg=itm.getCategory();collector.emit(newValues(entry.getUserId(),product,categ));}catch(Exceptionex){System.err.println("Error processing PRODUCT tuple"+ex);ex.printStackTrace();}}}...}
As mentioned earlier, use the ProductsReader helper class to read the product specific information.
packagestorm.analytics.utilities;...publicclassProductsReader{...publicProductreadItem(Stringid)throwsException{Stringcontent=jedis.get(id);if(content==null||("nil".equals(content)))returnnull;Objectobj=JSONValue.parse(content);JSONObjectproduct=(JSONObject)obj;Producti=newProduct((Long)product.get("id"),(String)product.get("title"),(Long)product.get("price"),(String)product.get("category"));returni;}...}
The UserHistoryBolt is the core of the application. It’s responsible for keeping track of the products navigated by each user and determining the result pairs that should be incremented.
You’ll use the Redis server to store product history by user, and
you’ll also keep a local copy for performance reasons. You hid the data
access details in the methods
getUserNavigationHistory(user)
and
addProductToHistory(user,prodKey)
for read and write access, respectively.
packagestorm.analytics;...publicclassUserHistoryBoltextendsBaseRichBolt{@Overridepublicvoidexecute(Tupleinput){Stringuser=input.getString(0);Stringprod1=input.getString(1);Stringcat1=input.getString(2);// Product key will have category information embedded.StringprodKey=prod1+":"+cat1;Set<String>productsNavigated=getUserNavigationHistory(user);// If the user previously navigated this item -> ignore itif(!productsNavigated.contains(prodKey)){// Otherwise update related itemsfor(Stringother:productsNavigated){String[]ot=other.split(":");Stringprod2=ot[0];Stringcat2=ot[1];collector.emit(newValues(prod1,cat2));collector.emit(newValues(prod2,cat1));}addProductToHistory(user,prodKey);}}}
Note that the desired output of this bolt is to emit the products whose categories relations should be incremented.
Take a look at the source code. The bolt keeps a set of the products navigated by each user. Note that the set contains product:category pairs rather than just products. That’s because you’ll need the category information in future calls and it will perform better if you don’t need to get them from the database each time. This is possible because the products have only one category, and it won’t change during the product’s lifetime.
After reading the set of the user’s previously navigated products
(with their categories), check if the current product has been visited
previously. If so, the entry is ignored. If this is the first time the
user has visited this product, iterate through the user’s history and
emit a tuple for the product being navigated and the categories of all
the products in the history with collector.emit(new
Values(prod1, cat2)), and a second tuple for the other
products and the category of the product being navigated with
collector.emit(new Values(prod2, cat1)). Finally, add
the product and its category to the set.
For example, assume that the user John has the following navigation history:
| User | # | Category |
|---|---|---|
John | 0 | Players |
John | 2 | Players |
John | 17 | TVs |
John | 21 | Mounts |
And the following navigation entry needs to be processed:
| User | # | Category |
|---|---|---|
John | 8 | Phones |
The user hasn’t yet looked at product 8, so you need to process it.
Therefore the emited tuples will be:
| # | Category |
|---|---|
8 | Players |
8 | Players |
8 | TVs |
8 | Mounts |
0 | Phones |
2 | Phones |
17 | Phones |
21 | Phones |
Note that the relation between the products on the left and the categories on the right should be incremented in one unit.
Now, let’s explore the persistence used by the Bolt.
publicclassUserHistoryBoltextendsBaseRichBolt{...privateSet<String>getUserNavigationHistory(Stringuser){Set<String>userHistory=usersNavigatedItems.get(user);if(userHistory==null){userHistory=jedis.smembers(buildKey(user));if(userHistory==null)userHistory=newHashSet<String>();usersNavigatedItems.put(user,userHistory);}returnuserHistory;}privatevoidaddProductToHistory(Stringuser,Stringproduct){Set<String>userHistory=getUserNavigationHistory(user);userHistory.add(product);jedis.sadd(buildKey(user),product);}...}
The getUserNavigationHistory method returns the
set of products that the user has visited. First, attempt to get the
user’s history from local memory with
usersNavigatedItems.get(user),
but if it’s not there, read from the Redis server using
jedis.smembers(buildKey(user)) and add the entry to
the memory structure usersNavigatedItems.
When the user navigates to a new product, call
addProductToHistory to update both the memory
structure with userHistory.add(product) and the Redis
server structure with
jedis.sadd(buildKey(user),
product).
Note that as long as the bolt keeps information in memory by user, it’s very important that when you parallelize it you use fieldsGrouping by user in the first degree, otherwise different copies of the user history will get out of synch.
The ProductCategoriesCounterBolt class is in charge of keeping track of all the product-category relationships. It receives the product-category pairs emitted by the UsersHistoryBolt and updates the counters.
The information about the number of occurrences of each pair is stored on the Redis server. A local cache for reads and a write buffer are used for performance reasons. The information is sent to Redis in a background thread.
This bolt also emits a tuple with the updated counter for the input pair to feed the next bolt in the topology, the NewsNotifierBolt, which is in charge of broadcasting the news to the final users for real-time updates.
publicclassProductCategoriesCounterBoltextendsBaseRichBolt{...@Overridepublicvoidexecute(Tupleinput){Stringproduct=input.getString(0);Stringcateg=input.getString(1);inttotal=count(product,categ);collector.emit(newValues(product,categ,total));}...privateintcount(Stringproduct,Stringcateg){intcount=getProductCategoryCount(categ,product);count++;storeProductCategoryCount(categ,product,count);returncount;}...}
Persistence in this bolt is hidden in the
getProductCategoryCount and
storeProductCategoryCount methods. Let’s take a look
inside them:
packagestorm.analytics;...publicclassProductCategoriesCounterBoltextendsBaseRichBolt{// ITEM:CATEGORY -> COUNTHashMap<String,Integer>counter=newHashMap<String,Integer>();// ITEM:CATEGORY -> COUNTHashMap<String,Integer>pendingToSave=newHashMap<String,Integer>();...publicintgetProductCategoryCount(Stringcateg,Stringproduct){Integercount=counter.get(buildLocalKey(categ,product));if(count==null){StringsCount=jedis.hget(buildRedisKey(product),categ);if(sCount==null||"nil".equals(sCount)){count=0;}else{count=Integer.valueOf(sCount);}}returncount;}...privatevoidstoreProductCategoryCount(Stringcateg,Stringproduct,intcount){Stringkey=buildLocalKey(categ,product);counter.put(key,count);synchronized(pendingToSave){pendingToSave.put(key,count);}}...}
The getProductCategoryCount method first looks
in memory cache counter. If the information is not available there, it
gets it from the Redis server.
The storeProductCategoryCount method updates
the counter cache and the pendingToSave buffer. The buffer is persisted
by the following background thread:
packagestorm.analytics;publicclassProductCategoriesCounterBoltextendsBaseRichBolt{...privatevoidstartDownloaderThread(){TimerTaskt=newTimerTask(){@Overridepublicvoidrun(){HashMap<String,Integer>pendings;synchronized(pendingToSave){pendings=pendingToSave;pendingToSave=newHashMap<String,Integer>();}for(Stringkey:pendings.keySet()){String[]keys=key.split(":");Stringproduct=keys[0];Stringcateg=keys[1];Integercount=pendings.get(key);jedis.hset(buildRedisKey(product),categ,count.toString());}}};timer=newTimer("Item categories downloader");timer.scheduleAtFixedRate(t,downloadTime,downloadTime);}...}
The download thread locks pendingToSave, and creates a new empty buffer for the other threads to use while it sends the old one to Redis. This code block runs each downloadTime milliseconds and is configurable through the download-time topology configuration parameter. The longer the download-time is, the fewer writes to Redis are performed because consecutive adds to a pair are written just once.
Keep in mind that again, as in the previous bolt, it is extremely important to apply the correct fields grouping when assigning sources to this bolt, in this case grouping by product. That’s because it stores in-memory copies of the information by product, and if several copies of the cache and the buffer exist there will be inconsistencies.
The NewsNotifierBolt is in charge of notifying the web application of changes in the statistics, in order for users to be able to view changes in real time. The notification is made by HTTP POST using Apache HttpClient, to the URL configured in the web server parameter of the topology configuration. The POST body is encoded in JSON.
This bolt is removed from the topology when testing.
packagestorm.analytics;...publicclassNewsNotifierBoltextendsBaseRichBolt{...@Overridepublicvoidexecute(Tupleinput){Stringproduct=input.getString(0);Stringcateg=input.getString(1);intvisits=input.getInteger(2);Stringcontent="{ "product": ""+product+"", "categ":""+categ+"", "visits":"+visits+" }";HttpPostpost=newHttpPost(webserver);try{post.setEntity(newStringEntity(content));HttpResponseresponse=client.execute(post);org.apache.http.util.EntityUtils.consume(response.getEntity());}catch(Exceptione){e.printStackTrace();reconnect();}}...}
Redis is an advanced in-memory Key Value Store with support for persistence (see http://redis.io). Use it to store the following information:
The product information, used to serve the website.
The User Navigation Queue, used to feed the Storm Topology.
The Storm Topology Intermediate Data, used by the Topology to recover from failures.
The Storm Topology Results, used to store the desired results.
The Redis Server stores the products using the product ID for the key and a JSON object containing all the product information as the value.
> redis-cli
redis 127.0.0.1:6379> get 15
"{"title":"Kids smartphone cover","category":"Covers","price":30,"id":15}"The user navigation queue is stored in a Redis list named navigation and organized as a first-in-first-out (FIFO) queue. The server adds an entry to the left side of the list each time a user visits a product page, indicating which user viewed which product. The storm cluster constantly removes elements from the right side of the list to process the information.
redis 127.0.0.1:6379> llen navigation
(integer) 5
redis 127.0.0.1:6379> lrange navigation 0 4
1) "{"user":"59c34159-0ecb-4ef3-a56b-99150346f8d5","product":"1","type":"PRODUCT"}"
2) "{"user":"59c34159-0ecb-4ef3-a56b-99150346f8d5","product":"1","type":"PRODUCT"}"
3) "{"user":"59c34159-0ecb-4ef3-a56b-99150346f8d5","product":"2","type":"PRODUCT"}"
4) "{"user":"59c34159-0ecb-4ef3-a56b-99150346f8d5","product":"3","type":"PRODUCT"}"
5) "{"user":"59c34159-0ecb-4ef3-a56b-99150346f8d5","product":"5","type":"PRODUCT"}"The cluster needs to store the history of each user separately. In order to do so, it saves a set in the Redis server with all the products and their categories that were navigated by each user.
redis 127.0.0.1:6379> smembers history:59c34159-0ecb-4ef3-a56b-99150346f8d5 1) "1:Players" 2) "5:Cameras" 3) "2:Players" 4) "3:Cameras"
In order to test the topology, use the provided LocalCluster and a local Redis server (see Figure 6-7). You’ll populate the products database on init and mock the insertion of navigation logs in the Redis server. Our assertions will be performed by reading the topology outputs to the Redis server. Tests are written in Java and Groovy.
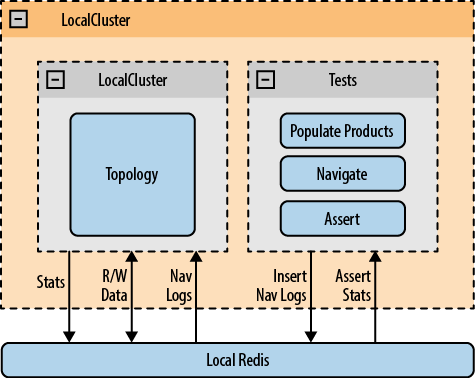
Initialization consists of three steps:
Start the LocalCluster and submit the Topology. Initialization is implemented in the AbstractAnalyticsTest, which is extended by all tests. A static flag called topologyStarted is used to avoid initializing more than once when multiple AbstractAnalyticsTest subclasses are instantiated.
Note that the sleep is there to allow the LocalCluster to start correctly before attempting to retrieve results from it.
publicabstractclassAbstractAnalyticsTestextendsAssert{defjedisstatictopologyStarted=falsestaticsync=newObject()privatevoidreconnect(){jedis=newJedis(TopologyStarter.REDIS_HOST,TopologyStarter.REDIS_PORT)}@BeforepublicvoidstartTopology(){synchronized(sync){reconnect()if(!topologyStarted){jedis.flushAll()populateProducts()TopologyStarter.testing=trueTopologyStarter.main(null)topologyStarted=truesleep1000}}}...publicvoidpopulateProducts(){deftestProducts=[[id:0,title:"Dvd player with surround sound system",category:"Players",price:100],[id:1,title:"Full HD Bluray and DVD player",category:"Players",price:130],[id:2,title:"Media player with USB 2.0 input",category:"Players",price:70],...[id:21,title:"TV Wall mount bracket 50-55 Inches",category:"Mounts",price:80]]testProducts.each(){product->defval="{ "title": "${product.title}" , "category": "${product.category}","+" "price": ${product.price}, "id": ${product.id} }"printlnvaljedis.set(product.id.toString(),val.toString())}}...}
Implement a method called navigate in the AbstractAnalyticsTest class. In order for the different tests to have a way to emulate the behavior of a user navigating the website, this step inserts navigation entries in the Redis server navigation queue.
publicabstractclassAbstractAnalyticsTestextendsAssert{...publicvoidnavigate(user,product){Stringnav="{"user": "${user}", "product": "${product}", "type": "PRODUCT"}".toString()println"Pushing navigation: ${nav}"jedis.lpush('navigation',nav)}...}
Provide a method called getProductCategoryStats in the AbstractAnalyticsTest that reads a specific relation from the Redis server. Different tests will also need to assert against the statistics results in order to check if the topology is behaving as expected.
publicabstractclassAbstractAnalyticsTestextendsAssert{...publicintgetProductCategoryStats(Stringproduct,Stringcateg){Stringcount=jedis.hget("prodcnt:${product}",categ)if(count==null||"nil".equals(count))return0returnInteger.valueOf(count)}...}
In the next snippet, you’ll emulate a few product navigations of
user “1”, then check the results. Note that you wait two seconds before
asserting to be sure that the results have been stored to Redis.
(Remember that the ProductCategoriesCounterBolt has an in-memory
copy of the counters and sends them to Redis in the background.)
packagefunctionalclassStatsTestextendsAbstractAnalyticsTest{@TestpublicvoidtestNoDuplication(){navigate("1","0")// Playersnavigate("1","1")// Playersnavigate("1","2")// Playersnavigate("1","3")// CamerasThread.sleep(2000)// Give two seconds for the system to process the data.assertEquals1,getProductCategoryStats("0","Cameras")assertEquals1,getProductCategoryStats("1","Cameras")assertEquals1,getProductCategoryStats("2","Cameras")assertEquals2,getProductCategoryStats("0","Players")assertEquals3,getProductCategoryStats("3","Players")}}
The architecture of this solution has been simplified to fit into a single chapter of the book. For that reason, you avoided some complexity that would be necessary for this solution to scale and have high availability. There are a couple of major issues with this approach.
The Redis server in this architecture is not only a single point of failure but also a bottleneck. You’ll be able to receive only as much traffic as the Redis server can handle. The Redis layer can be scaled by using sharding, and its availability can be improved by using a Master/Slave configuration, which would require changes to the sources of both the topology and the web application.
Another weakness is that the web application does not scale
proportionately by adding servers in a round robin fashion. This is
because it needs to be notified when some product statistic changes and to
notify all interested browsers. This “notification to browser” bridge is
implemented using Socket.io, but it requires that the listener and the
notifier be hosted on the same web server. This is achievable only if you
shard the GET /product/:id/stats
traffic and the POST /news traffic,
both with same criteria, ensuring that requests referencing the same
product will end up on the same server.