
This is the final chapter covering the implementation of the CSLA .NET framework. The framework is based on the concepts in Chapter 1 and the design in Chapter 2. Chapters 6 through 15 walked through the implementation of the major features of the framework, including the base classes, validation, authorization, LINQ to CSLA, data binding, and the concept of mobile objects and support for object persistence.
This chapter concludes the implementation of the framework by discussing several classes that are useful when building business applications. The following topic areas will be addressed:
Date handling
Data access
Executing workflows
There are many views on what makes good UI design. One common view holds that the user should be free to enter arbitrary text and it is up to the application to try and make sense of the entry. Nowhere is this truer than with date values, and the SmartDate type is designed to simplify how a business developer uses dates and exposes them to the UI.
When it comes to data access, the .NET Framework provides powerful support through many technologies, including LINQ to SQL, the ADO.NET Entity Framework, and raw ADO.NET itself. Even with all these options, dealing with data remains somewhat complex.
It is quite common to use TransactionScope to manage transactions, but to avoid the overhead of the DTC, you must ensure that only one database connection is opened during the entire transaction. The ConnectionManager, ObjectContextManager, and ContextManager classes help make that easy to implement in your data access code.
Another common issue when using raw ADO.NET is that database columns often store null values, but the application requires simpler, empty values (e.g., an empty string instead of a null). The SafeDataReader eliminates null values from the data, transforming them into appropriate empty values instead.
Yet another issue when dealing with data, especially in Web Forms and XML services, is that data must be copied from business objects into and out of other types of objects. This is especially true when building web services because data coming into a web service is contained in a proxy object, and that data must be moved into or out of your business objects. The DataMapper class helps streamline this process, reducing the amount of code you must write and maintain.
You can use business objects with workflows. Workflows consist of activities, and each activity is a stand-alone piece of functionality that can be implemented using business objects. That doesn't require any extra support from CSLA .NET. But business objects, especially using the command object stereotype, can be used to execute workflows and CSLA .NET includes the WorkflowManager class to simplify that process.
As you can see, this chapter is a collection of topics that don't fit neatly into the categories covered in the chapters thus far. But the elements discussed here are often some of the most widely used parts of the CSLA .NET framework.
One common view of good UI design holds that the user should be free to enter arbitrary text and it is up to the application to make sense of the entry. Nowhere is this truer than with date values, and the SmartDate type is designed to simplify how a business developer uses dates and exposes them to the UI.
Examples of free-form date entry are easy to find. Just look at widely used applications such as Microsoft Money or Intuit's Quicken. In these applications, users are free to enter dates in whatever format is easiest for them. Additionally, various shortcuts are supported; for example, the plus character (+) means tomorrow, while the minus (-) means yesterday.
Most users find this approach more appealing than being forced to enter a date in a strict format through a masked edit control or having to always use the mouse for a graphical calendar control. Of course, being able to additionally support a calendar control is a great UI design choice.
Date handling is also quite challenging because the standard DateTime data type doesn't have any comprehension of an "empty" or "blank" date. Many applications have date values that may be empty for a time and are filled in later. Consider a sales order in which the shipment date is unknown when the order is entered. That date should remain blank or empty until an actual date is known. Without the concept of an empty date, an application will require the user to enter an invalid "placeholder" date until the real date is known; and that's just poor application design.
Tip
In the early 1990s, I worked at a company where all "far-future" dates were entered as 12/31/99. Guess how much trouble the company had around Y2K, when all of its never-to-be-delivered orders started coming due.
It is true that the Nullable<T> type can be applied to a DateTime value like this: Nullable<DateTime>. This allows a date to be "empty" in a limited sense. Unfortunately, that isn't enough for many applications because an actual date value can't be meaningfully compared to a null value. Is the null value greater than or less than a given date? With Nullable<T>, the answer is an exception, which is not a very useful answer.
Additionally, data binding doesn't deal well with null values, so exposing a null value from a business object's property often complicates the UI code.
The Csla.SmartDate type is designed to augment the standard .NET DateTime type to make it easier to work with date values. In particular, it provides the following key features:
Automatic translation between
stringandDateTimetypesTranslation of shortcut values to valid dates
Understanding of the concept of an "empty" date
Meaningful comparison between a date and an empty date
Creating your own primitive data type turns out to be very complex, and all the details are outside the scope of this book. When you create a primitive data type you must provide operator overloads and type converters, support formatting, and implement other .NET concepts. The SmartDate type is even more complex because it is designed to be as similar as possible to the preexisting DateTime data type.
The DateTime data type is marked sealed, meaning that a new type can't inherit from it to create a different data type. However, it is possible to use containment and delegation to "wrap" a DateTime value with extra functionality. That's exactly how the SmartDate type is implemented. Like DateTime itself, SmartDate is a value type:
[Serializable][System.ComponentModel.TypeConverter(typeof(Csla.Core.TypeConverters.SmartDateConverter))]public struct SmartDate : Csla.Core.ISmartField,IComparable, IConvertible, IFormattable, Csla.Serialization.Mobile.IMobileObject{private DateTime _date;private bool _initialized;private EmptyValue _emptyValue;private string _format;private static string _defaultFormat;
The type has an associated TypeConverter so it can be converted to and from string, DateTime, DateTime?, and DateTimeOffset values. It also implements IConvertible and a set of implicit and explicit operator overloads to enable various type conversion and casting behaviors.
The IComparable interface allows SmartDate values to have meaningful comparisons to values of type SmartDate, DateTime, DateTime?, DateTimeOffset, and string. The IFormattable interface allows SmartDate values to be formatted using an IFormatProvider and is implemented to achieve similar functionality to DateTime. All these interfaces and type conversion concepts are standard parts of .NET and are things that any primitive type should implement.
The ISmartField interface is unique to CSLA .NET. It exists to allow other people to author similar primitive types, such that CSLA .NET uses them properly. The CSLA .NET community has created types such as SmartInt, SmartBool, and so forth, and this interface is designed to allow those types to integrate smoothly into CSLA .NET.
Note
The IMobileObject interface is for compatibility with CSLA .NET for Silverlight. CSLA .NET for Silverlight is outside the scope of this book, but this interface allows SmartDate values to properly serialize to and from Silverlight clients when using CSLA .NET for Silverlight.
The most important field is the _date field, which is the underlying DateTime value of the SmartDate. Remember that in the end, SmartDate is just a wrapper around a DateTime value.
Supporting empty date values is more complex than it might appear. An empty date still has meaning and, in fact, it is possible to compare a regular date to an empty date and get a valid result.
Consider a sales order example. If the shipment date of a sales order is unknown, the date will be empty. But effectively, that empty date is infinitely far in the future. Were you to compare that empty shipment date to any other date, the shipment date would be the larger of the two. Conversely, there are cases in which an empty date should be considered to be smaller than the smallest possible date.
This concept is important, as it allows for meaningful comparisons between dates and empty dates. Such comparisons make implementation of validation rules and other business logic far simpler. You can, for instance, loop through a set of Order objects to find all the objects with a shipment date before today, without the need to worry about empty dates:
foreach (Order order in OrderList) if (order.ShipmentDate <= DateTime.Today)
Assuming ShipmentDate is a SmartDate, it will work great, and any empty dates will be considered to be larger than any actual date value.
The _emptyValue field keeps track of whether the SmartDate instance should consider an empty date to be the smallest or largest possible date value. If it is EmptyValue.MaxDate, an empty date is considered to be the largest possible value, while EmptyValue.MinDate indicates the reverse.
The _format field stores a .NET format string that provides the default format for converting a DateTime value into a string representation.
The _defaultFormat is a static field that provides a default value for _format if it hasn't been explicitly set on an instance of SmartDate.
The _initialized field keeps track of whether the SmartDate has been initialized. Remember that SmartDate is a struct not an object. This severely restricts how the type's fields can be initialized.
As with any struct, SmartDate can be created with or without calling a constructor. This means a business object could declare SmartDate fields using any of the following:
private SmartDate _date1;
private SmartDate _date2 = new SmartDate(EmptyValue.MinDate);
private SmartDate _date3 = new SmartDate(DateTime.Today);
private SmartDate _date4 = new SmartDate(DateTime.Today, EmptyValue.MaxDate);
private SmartDate _date5 = new SmartDate("1/1/2008", EmptyValue.MaxDate);
private SmartDate _date6 = new SmartDate("",EmptyValue.MaxDate);In the first two cases, the SmartDate starts out being empty, with empty meaning that it has a value smaller than any other date.
The _date3 value starts out containing the current date. If it is set to an empty value later, that empty value will correspond to a value smaller than any other date.
The next two values are initialized to either the current date or a fixed date based on a string value. In both cases, if the SmartDate is set to an empty value later, that empty value will correspond to a value larger than any other date.
Finally, _date6 is initialized to an empty date value, where that value is larger than any other date.
Handling this initialization is a bit tricky because the C# compiler requires that all instance fields in a struct be assigned a value in any constructor before any properties or methods can be called. Yet the _date5 and _date6 fields in particular require that a method be called to parse the string value into a date value. Due to this compiler limitation, each constructor sets all instance fields to values (sometimes dummy values) and then calls properties or methods as needed.
An additional complication is that a struct can't have a default constructor. Yet even in the previous case of _date1, some initialization is required. This is the purpose of the _initialized instance field. It, of course, defaults to a value of false so can be used in the properties of the struct to determine whether the struct has been initialized. As you'll see, this allows SmartDate to initialize itself the first time a property is called, assuming it hasn't been initialized previously.
All the constructors follow the same basic flow. Here's one of them:
public SmartDate(string value, EmptyValue emptyValue){_emptyValue = emptyValue;_format = null;_initialized = true;_date = DateTime.MinValue;this.Text = value;}
Notice that all the instance fields are assigned values. Even the _date field is assigned a value, though as you'll see, the Text property immediately changes that value based on the value parameter passed into the constructor. This includes translation of an empty string value into the appropriate empty date value.
SmartDate already has a field to control whether an empty date represents the largest or smallest possible date. This field is exposed as a property so that other code can determine how dates are handled:
public bool EmptyIsMin{get { return (_emptyValue == EmptyValue.MinDate); }}
SmartDate also implements an IsEmpty property so that code can ask if the SmartDate object represents an empty date:
public bool IsEmpty{get{if (_emptyValue == EmptyValue.MinDate)return this.Date.Equals(DateTime.MinValue);elsereturn this.Date.Equals(DateTime.MaxValue);}}
Notice the use of the _emptyValue field to determine whether an empty date is to be considered the largest or smallest possible date for comparison purposes. If it is the smallest date, it is empty if the date value equals DateTime.MinValue; if it is the largest date, it is empty if the value equals DateTime.MaxValue.
Given this understanding of empty dates, it is possible to create a couple of functions to convert dates to text (or text to dates) intelligently. For consistency with other .NET types, SmartDate also includes a Parse() method to convert a string into a SmartDate. These are static methods so that they can be used even without creating an instance of SmartDate. Using these methods, a developer can write business logic such as this:
DateTime userDate = SmartDate.StringToDate(userDateString);
Table 16-1 shows the results of this function based on various user text inputs.
Table 16.1. Results of the StringToDate Method Based on Various Inputs
User Text Input | EmptyValue | Result of StringToDate |
|---|---|---|
|
|
|
|
|
|
Any text that can be parsed as a date | Ignored | A date value |
StringToDate() converts a string value containing a date into a DateTime value. It knows that an empty string should be converted to either the smallest or the largest date, based on an optional parameter.
It also handles translation of shortcut values to valid date values. The characters ., +, and -, correspond to today, tomorrow, and yesterday, respectively. Additionally, the values t, today, tom, tomorrow, y, and yesterday work in a similar manner. These text values are defined in the project's Resource.resx file and are subject to localization for other languages.
Given a string of nonzero length, StringToDate() attempts to parse it directly to a DateTime field. If that fails, the various shortcut values are checked. If that fails as well, an exception is thrown to indicate that the string value can't be parsed into a date.
SmartDate also implements the Parse() and TryParse() methods, which provide a more standard API for translating a text value into a non-text type. These methods simply delegate the calls to the StringToDate() method.
SmartDate can translate dates the other way as well, such as converting a DateTime field into a string and retaining the concept of an empty date. Again, an optional parameter controls whether an empty date represents the smallest or the largest possible date. Another parameter controls the format of the date as it's converted to a string. Table 16-2 illustrates the results for various inputs.
Table 16.2. Results of the DateToString Method Based on Various Inputs
User Date Input | EmptyValue | Result of DateToString |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
Any other valid date | Ignored | String representing the date value |
The DateToString() method functions as a mirror to the StringToDate() method. This means it is possible to start with an empty string, convert it to a DateTime, and then convert that DateTime back into an empty string.
This method uses a format string, which defines how the DateTime value is to be formatted as a string. This is used to create a complete .NET format string such as {0:d}.
Next, let's implement functions in SmartDate that support both text and DateTime access to the underlying DateTime value. When business code needs to expose a date value to the UI, it will often prefer to expose it as a string. (Exposing it as a DateTime precludes the possibility of the user entering a blank value for an empty date; and while that's great if the date is required, it isn't good for optional date values.)
Exposing a date as text requires the ability to format the date properly. To make this manageable, the _format field is used to control the format used for outputting a date. The default value for _format is d for the short date format. SmartDate includes a FormatString property so that the business developer can alter this format value to override the default.
There's also a SetDefaultFormatString() method, which is static. This can be used to provide an application-wide change to the default format string, though the FormatString property can still override the default on a per-instance basis.
Given the FormatString property, the Text property can use the StringToDate() and DateToString() methods to translate between text and date values. This property can be used to retrieve or set values using string representations of dates, where an empty string is appropriately handled:
public string Text{get { return DateToString(this.Date, FormatString, _emptyValue); }set { this.Date = StringToDate(value, _emptyValue); }}
This property is used in the constructors as well, meaning that the same rules for dealing with an empty date apply during object initialization as when setting its value via the Text property.
There's one other text-oriented method to implement: ToString(). All objects in .NET have a ToString() method, which ideally returns a useful text representation of the object's contents. In this case, it should return the formatted date value:
public override string ToString(){return this.Text;}
Since the Text property already converts the SmartDate value to a string, this is easy to implement.
It should be possible to treat a SmartDate like a regular DateTime—as much as possible, anyway. Since it's not possible for it to inherit from DateTime, there's no way for it to be treated just like a regular DateTime. The best approximation is to implement a Date property that returns the internal value:
public DateTime Date{get{if (!_initialized){_date = DateTime.MinValue;_initialized = true;}return _date;}set{_date = value;_initialized = true;}}
Notice the use of the _initialized field to determine whether the SmartDate has been initialized. If the SmartDate instance is declared without explicitly calling one of the constructors, it will not be initialized; so the _date field needs to be set before it can be returned. It is set to DateTime.MinValue because that is the empty date when _emptyValue is MinDate (which it is by default).
SmartDate also implements numerous conversion methods and operator overloads as well as the same set of date manipulation functions to add and subtract values as DateTime. The end result is that you can use a SmartDate instead of a DateTime value in almost any scenario, unless the consuming code directly expects a DateTime type.
The final bit of code in SmartDate exists to help simplify data access. This is done by implementing a method that allows a SmartDate value to be converted to a format suitable for writing to the database. Though SmartDate already has methods to convert a date to text and text to a date, it doesn't have any good way of getting a date formatted properly to write to a database. Specifically, it needs a way to either write a valid date or write a null value if the date is empty.
In ADO.NET, a null value is usually expressed as DBNull.Value, so it is possible to implement a method that returns either a valid DateTime object or DBNull.Value:
public object DBValue{get{if (this.IsEmpty)return DBNull.Value;elsereturn this.Date;}}
Since SmartDate already implements an IsEmpty() property, the code here is pretty straight-forward. If the value is empty, DBNull.Value is returned, which can be used to put a null value into a database via ADO.NET. Otherwise, a valid date value is returned.
At this point, you've seen the implementation of the core SmartDate functionality. While using SmartDate is certainly optional, it does offer business developers an easy way to handle dates that must be represented as text and to support the concept of an empty date. Later, the section on the SafeDataReader discusses some data access functionality to make it easy to save and restore a SmartDate from a database.
This same approach can be used to make other data types "smart" if you so desire. Even with the Nullable<T> support from the .NET Framework, dealing with empty values often requires extra coding, which is often most efficiently placed in a framework class such as SmartDate.
Almost all applications employ some data access. Obviously, the CSLA .NET framework puts heavy emphasis on enabling data access through the data portal, as described in Chapter 15. Beyond the basic requirement to create, read, update, and delete data, however, there are other needs.
One of the most common issues occurs when using the TransactionScope object from the System.Transactions namespace to provide transactional behaviors. While TransactionScope is very powerful, it has one big limitation in that it uses the DTC to manage any transaction where the code opens more than one database connection. If you are only working with a single database, it doesn't make sense to pay the performance cost of the DTC, and yet it can be difficult to ensure your code always reuses the same database connection.
Note
There are other things that can trigger the use of the DTC when using TransactionScope. These include using a database other than SQL Server 2005 or 2008 or interacting with other resource managers (e.g., MSMQ). CSLA .NET doesn't help address these issues.
The ConnectionManager class helps you write consistent data access code, which automatically reuses the same database connection. Similarly, the ObjectContextManager and ContextManager classes do the same thing for ADO.NET Entity Framework and LINQ to SQL code, respectively.
During the process of reading data from a database, many application developers find themselves writing repetitive code to eliminate null database values. SafeDataReader is a wrapper around any ADO.NET DataReader object that automatically eliminates any null values that might come from the database.
When creating many web applications using either Web Forms or Web Services, data must be copied into and out of business objects. In the case of Web Forms data binding, data comes from the page in a dictionary of name/value pairs, which must be copied into the business object's properties. With Web Services, the data sent or received over the network often travels through simple DTOs. The properties of those DTOs must be copied into or out of a business object within the web service. The DataMapper class contains methods to simplify these tasks.
The TransactionScope object is a convenient and powerful way to manage transactions in .NET. It offers the performance of ADO.NET transactions with the coding simplicity of Enterprise Services. All you need to do is wrap your data access code in a using block:
using (var tr = new TransactionScope())
{
// open database and do data access here
tr.Commit();
}You get the same behavior with the data portal by using the Transactional attribute on your data access method, as discussed in Chapter 15. The catch is that you can't open more than one database connection within that using block or TransactionScope will enlist the DTC to manage the transaction. That typically causes a 15 percent performance cost, which doesn't make sense if all you are doing is opening multiple connections to the same database with the same connection string. And that is quite common, especially when updating an object graph into the database. In many cases, the simplest way to write your data access code is to put the insert, update, and delete calls in a method for each business object so your code inserts a sales order, then each line item. And to keep things simple, each object opens its own connection to the database.
Of course, each object doesn't really open its own connection to the database because database connection pooling automatically causes reuse of the same connection. So this technique is simple and performs well and is very attractive—until you use TransactionScope.
So what's needed is some way by which the data access methods can appear to open a new connection each time but in reality use the same already open connection. This is the purpose behind the types listed in Table 16-3, which are found in the Csla.Data namespace.
Table 16.3. Connection Manager Types
Type | Description |
|---|---|
| Opens and manages an ADO.NET |
| Opens and manages an ADO.NET Entity Framework object context |
| Opens and manages a LINQ to SQL data context |
All three of these classes use a similar technique and are used in data access code in a similar manner. If you are using TransactionScope and the ConnectionManager, for example, your root business object's data access method would look like this:
[Transactional(TransactionTypes.TransactionScope)]
private void DataPortal_Insert()
{
using (var ctx = ConnectionManager<SqlConnection>.GetManager("MyDb"))
{
// insert object's data here using ctx.Connection
// ...
FieldManager.UpdateChildren(this);
}
}In this example, I'm letting the data portal put the code into a TransactionScope by using the Transactional attribute. The ConnectionManager creates and opens a SqlConnection object, using MyDb as the key to look up the connection string from the application's connectionStrings section in the config file.
All code inside the using block can use ctx.Connection to access the open connection object. When the using block exits, the connection is automatically closed.
Notice the UpdateChildren() call though. This causes all child objects contained by this object to be updated. Each child object needs to insert its own data, too. It is important to realize that UpdateChildren() is called inside the using block so the connection is open.
A child's data access method would look like this:
private void Child_Insert(object parent)
{
using (var ctx = ConnectionManager<SqlConnection>.GetManager("MyDb"))
{
// insert object's data here using ctx.Connection
}
}The child code also uses the ConnectionManager. This time, however, ConnectionManager determines that there's already an open connection for MyDb and so it simply returns that already open connection. It also increases a reference count so it knows that it is nested within two using blocks. That way when this using block exists, it does not close the connection. Instead it just decrements the reference count. Only when the reference count reaches zero does the connection get closed.
The ObjectContextManager and ContextManager classes work in exactly the same way, except they manage ObjectContext and DataContext objects respectively. Of course each of those object types contains an open database connection, and the real goal is to reuse that already open database connection.
ConnectionManager
Because all three classes are so similar, I'll walk through ConnectionManager in detail and only briefly discuss the implementation of the other two.
The ConnectionManager class contains a database connection, which is a disposable object. This means that ConnectionManager must also be disposable, so it implements the IDisposable interface:
public class ConnectionManager<C> :IDisposable where C : IDbConnection, new()
ConnectionManager can decrement the reference count each time Dispose() is called and can close the connection when the reference count reaches zero. I discuss this later in this section.
Notice that this is a generic type. And moreover, the type parameter, C, is constrained to only accept types that implement IDbConnection and that have a public default constructor. This works fine with most connection types such as SqlConnection and is a requirement of the factory method that must create and open the connection:
public static ConnectionManager<C> GetManager(string database, bool isDatabaseName){if (isDatabaseName){var conn =ConfigurationManager.ConnectionStrings[database].ConnectionString;if (string.IsNullOrEmpty(conn))throw new ConfigurationErrorsException(String.Format(Resources.DatabaseNameNotFound, database));database = conn;}lock (_lock){ConnectionManager<C> mgr = null;if (ApplicationContext.LocalContext.Contains("__db:" + database)){mgr = (ConnectionManager<C>)(ApplicationContext.LocalContext["__db:" + database]);}else{mgr = new ConnectionManager<C>(database);ApplicationContext.LocalContext["__db:" + database] = mgr;}mgr.AddRef();return mgr;}}
The first part of this method determines whether the database parameter is the connection string or the name of the database. By default it is the name of the database, and the code uses the .NET ConfigurationManager to retrieve a connection string from the application's config file.
Once the code has a connection string, it can create and open the database connection. It does this within a lock statement because this is a static method. By convention, static methods in .NET should be implemented in a thread-safe manner, and this lock statement ensures that only one thread at a time can attempt to create an open connection.
The first thing the code does is attempt to retrieve any existing ConnectionManager from a cache. I am using thread local storage for the cache because TLS is a globally available location for storing per-thread data:
if (ApplicationContext.LocalContext.Contains("__db:" + database))
{
mgr = (ConnectionManager<C>)(
ApplicationContext.LocalContext["__db:" + database]);Not all database connection objects are thread-safe, so ConnectionManager manages its connection objects on a per-thread basis to avoid accidentally providing a connection object from one thread to some other thread.
Notice that the database name is used as a key value to store and retrieve the ConnectionManager object. This allows the ConnectionManager to have many open connections at once, each for a different database.
If a preexisting ConnectionManager is in TLS, it is retrieved. If there isn't one in TLS, a new one is created and put into TLS:
else
{
mgr = new ConnectionManager<C>(database);
ApplicationContext.LocalContext["__db:" + database] = mgr;The ConnectionManager has a constructor that creates and opens the connection object:
private ConnectionManager(string connectionString){_connectionString = connectionString;// open connection_connection = new C();_connection.ConnectionString = connectionString;_connection.Open();}
Here's where the constraints on C become important. The new constraint ensures that it is possible to create a new C(), and the IDbConnection constraint ensures the object has a ConnectionString property and an Open() method.
Back in the static method, either an existing object is retrieved from TLS or a new one is created. Either way, its AddRef() method is called to increment its reference count (because it is now inside a using block) and the CommandManager instance is returned to the caller.
In the Dispose() method, the reference count is decremented:
public void Dispose(){DeRef();}
And in the DeRef() method, when the reference count reaches zero, the connection is closed:
private void DeRef(){lock (_lock){_refCount -= 1;if (_refCount == 0){_connection.Dispose();ApplicationContext.LocalContext.Remove("__db:" + _connectionString);}}}
That is also the trigger for removing the CommandManager instance from TLS.
You should now understand how calling the GetManager() method creates or retrieves the manager object and the underlying connection, while incrementing the reference count. And how the Dispose() method decrements the reference count and cleans everything up when the count reaches zero.
The ObjectContextManager and ContextManager work in exactly the same way, but with different types of connection objects.
ObjectContextManager
The ObjectContextManager class manages an ADO.NET Entity Framework ObjectContext object in the same way CommandManager manages ADO.NET connection objects. Here's the class definition:
public class ObjectContextManager<C> :IDisposable where C : ObjectContext
The constraint on the generic type parameter, C, is that it must be an ObjectContext type. The new constraint can't be used because ObjectContext doesn't have a default public constructor.
In the constructor of ObjectContextManager, the code does create an instance of the ObjectContext object by using Activator.CreateInstance():
private ObjectContextManager(string connectionString){_connectionString = connectionString;_context = (C)(Activator.CreateInstance(typeof(C), connectionString));}
There's a small amount of fragility here in that the code expects that the constructor will accept a single string parameter that contains the database connection. But this is pretty low-risk because if Microsoft changes that API, it would break virtually all code that uses the Entity Framework in any application.
Other than these differences, the ObjectContextManager works just like ConnectionManager, using reference counting to determine when it can close the context.
ContextManager
The ContextManager class manages a LINQ to SQL DataContext object in the same way CommandManager manages ADO.NET connection objects. Here's the class definition:
public class ContextManager<C> :IDisposable where C : DataContext
The constraint on the generic type parameter, C, is that it must be a DataContext type. The new constraint can't be used because DataContext doesn't have a default public constructor.
In the constructor of ContextManager, the code does create an instance of the DataContext object by using Activator.CreateInstance():
private ContextManager(string connectionString){_connectionString = connectionString;_context = (C)(Activator.CreateInstance(typeof(C), connectionString));}
This is also a bit fragile because, like ObjectContextManager, the code expects that the constructor will accept a single string parameter that contains the database connection. There's a similar low risk because if Microsoft changes that API it would break almost everything that uses LINQ to SQL.
Apart from those differences, the ContextManager works just like ConnectionManager, counting references to determine when it can close the context.
There are only three reasons null values should be allowed in database columns. The first is to support foreign key relationships between tables. Ideally, in this case, your key values aren't real data values but are actual keys, so you can use null values to indicate that no data exists for a given foreign key relationship.
The second is when the business rules dictate that the application cares about the difference between a value that was never entered and a value that is zero (or an empty string). In other words, the end user actually cares about the difference between "" and null or between 0 and null. There are applications where this matters—where the business rules revolve around whether a field ever had a value (even an empty one) or never had a value at all.
The third reason for using a null value is when a data type doesn't intrinsically support the concept of an empty field. The most common example is the SQL DateTime data type, which has no way to represent an empty date value; it always contains a valid date. In such a case, null values in the database column are used specifically to indicate an empty date.
Of course, these last two reasons are mutually exclusive. When using null values to differentiate between an empty field and one that never had a value, you need to come up with some other scheme to indicate an empty DateTime field. The solution to this problem is outside the scope of this book—but thankfully the problem itself is quite rare.
The reality is that very few applications ever care about the difference between an empty value and one that was never entered, so the first scenario seldom applies. If it does apply to your application, dealing with null values at the database level isn't an issue because you'll use nullable types from the database all the way through to the UI. In this case, you can ignore SafeDataReader entirely, as it has no value for your application.
But for most applications, the only reason for using null values is the second scenario, and this one is quite common. Any application that uses date values, and for which an empty date is a valid entry, will likely use null to represent an empty date.
Unfortunately, a whole lot of poorly designed databases allow null values in columns where neither scenario applies, and we developers have to deal with them. These are databases that contain null values even if the application makes no distinction between a 0 and a null.
Writing defensive code to guard against tables in which null values are erroneously allowed can quickly bloat data access code and make it hard to read. To avoid this, the SafeDataReader class takes care of these details automatically by eliminating null values and converting them into a set of default values.
As a rule, DataReader objects are sealed, meaning that you can't simply subclass an existing DataReader class (such as SqlDataReader) and extend it. However, like the SmartDate class with DateTime, it is quite possible to encapsulate or "wrap" a DataReader object.
To ensure that SafeDataReader can wrap any DataReader object, it relies on the root IDataReader interface from the System.Data namespace that's implemented by all DataReader objects. Also, since SafeDataReader is to be a DataReader object, it must implement that interface as well:
public class SafeDataReader : IDataReader{private IDataReader _dataReader;protected IDataReader DataReader{get { return _dataReader; }}public SafeDataReader(IDataReader dataReader){_dataReader = dataReader;}}
The class defines a field to store a reference to the real DataReader that it is encapsulating. That field is exposed as a protected property as well, allowing for subclasses of SafeDataReader in the future.
There's also a constructor that accepts the IDataReader object to be encapsulated as a parameter.
This means that ADO.NET code in a business object's DataPortal_Fetch() method might appear as follows:
var dr = new SafeDataReader(cm.ExecuteReader());
The ExecuteReader() method returns an object that implements IDataReader (such as SqlDataReader) that is used to initialize the SafeDataReader object. The rest of the code in the data access method can use the SafeDataReader object just like a regular DataReader object because it implements IDataReader. The benefit, though, is that the business object's data access code never has to worry about getting a null value from the database.
The implementation of IDataReader is a lengthy business—it contains a lot of methods—so I'm not going to go through all of it here. Instead I'll cover a few methods to illustrate how the overall class is implemented.
GetString
There are two overloads for each method that returns column data, one that takes an ordinal column position and the other that takes the string name of the property. This second overload is a convenience but makes the code in a business object much more readable. All the methods that return column data are "null protected" with code like this:
public string GetString(string name){return GetString(_dataReader.GetOrdinal(name));}public virtual string GetString(int i){if( _dataReader.IsDBNull(i))return string.Empty;elsereturn _dataReader.GetString(i);}
If the value in the database is null, the method returns some more palatable value—typically, whatever passes for "empty" for the specific data type. If the value isn't null, it simply returns the value from the underlying DataReader object.
For string values, the empty value is string.Empty; for numeric types, it is 0; and for Boolean types, it is false. You can look at the full code for SafeDataReader to see all the translations.
Notice that the GetString() method that actually does the translation of values is marked as virtual. This allows you to override the behavior of any of these methods by creating a subclass of SafeDataReader.
The GetOrdinal() method translates the column name into an ordinal (numeric) value, which can be used to actually retrieve the value from the underlying IDataReader object. GetOrdinal() looks like this:
public int GetOrdinal(string name){return _dataReader.GetOrdinal(name);}
Every data type supported by IDataReader (and there are a lot of them) has a pair of methods that reads the data from the underlying IDataReader object, replacing null values with empty default values as appropriate.
GetDateTime and GetSmartDate
Most types have empty values that are obvious, but DateTime is problematic as it has no empty value. The minimum date value is arbitrarily used as the empty value. This isn't perfect, but it does avoid returning a null value or throwing an exception.
A better solution may be to use the SmartDate type instead of DateTime. To simplify retrieval of a date value from the database into a SmartDate, SafeDataReader implements two variations of a GetSmartDate() method:
public Csla.SmartDate GetSmartDate(string name){return GetSmartDate(_dataReader.GetOrdinal(name), true);}public virtual Csla.SmartDate GetSmartDate(int i){return GetSmartDate(i, true);}public Csla.SmartDate GetSmartDate(string name, bool minIsEmpty){return GetSmartDate(_dataReader.GetOrdinal(name), minIsEmpty);}public virtual Csla.SmartDate GetSmartDate(int i, bool minIsEmpty){if (_dataReader.IsDBNull(i))return new Csla.SmartDate(minIsEmpty);elsereturn new Csla.SmartDate(_dataReader.GetDateTime(i), minIsEmpty);}
Data access code in a business object can choose either to accept the minimum date value as being equivalent to empty or to retrieve a SmartDate that understands the concept of an empty date:
SmartDate myDate = dr.GetSmartDate(0);
or
SmartDate myDate = dr.GetSmartDate(0, false);
GetBoolean
Likewise, there is no empty value for the bool type. GetBoolean() arbitrarily returns a false value in this case.
Other Methods
The IDataReader interface also includes a number of methods that don't return column values, such as the Read() method:
public bool Read(){return _dataReader.Read();}
In these cases, it simply delegates the method call down to the underlying DataReader object for it to handle. Any return values are passed back to the calling code, so the fact that SafeDataReader is involved is entirely transparent.
The SafeDataReader class can be used to simplify data access code dramatically, any time an object is working with tables in which null values are allowed in columns where the application doesn't care about the difference between an empty and a null value. If your application does care about the use of null values, you can simply use the regular DataReader objects instead.
When Web Forms data binding needs to insert or update data, it provides the data elements to the ASP.NET data source control in the form of a dictionary object of name/value pairs. The CslaDataSource control discussed in Chapter 10 simply provides this dictionary object to the UI code as an event argument.
This means that in a typical Web Forms application that uses the CslaDataSource, the UI code must copy the values from the dictionary to the business object's properties. The name is the name of the property to be updated and the value is the value to be placed into the property of the business object. Copying the values isn't hard—the code looks something like this:
cust.FirstName = e.Values["FirstName"].ToString(); cust.LastName = e.Values["LastName"].ToString(); cust.City = e.Values["City"].ToString();
Unfortunately, this is tedious code to write and debug; and if your object has a lot of properties, this can add up to a lot of lines of code. An alternative is to use reflection to automate the process of copying the values.
Tip
If you feel that reflection is too slow for this purpose, you can continue to write all the mapping code by hand. Keep in mind, however, that data binding uses reflection extensively anyway, so this little bit of additional reflection is not likely to cause any serious performance issues.
A similar problem exists when building web services. Business objects should not be returned directly as a result of a web service, as that would break encapsulation. In such a case, your business object interface would become part of the web service interface, preventing you from ever adding or changing properties on the object without running the risk of breaking any clients of the web service.
Instead, data should be copied from the business object into a DTO, which is then returned to the web service client. Conversely, data from the client often comes into the web service in the form of a DTO. These DTOs are often created based on WSDL or an XSD defining the contract for the data being passed over the web service. The end result is that the code in a web service has to map property values from business objects to and from DTOs. That code often looks like this:
cust.FirstName = dto.FirstName; cust.LastName = dto.LastName; cust.City = dto.City;
Again, this isn't hard code to write but it's tedious and could add up to many lines.
The DataMapper class uses reflection to help automate these data mapping operations, from either a collection implementing IDictionary or an object with public properties.
In both cases, it is possible or even likely that some properties can't be mapped. Business objects often have read-only properties, and obviously it isn't possible to set those values. Yet the IDictionary or DTO may have a value for that property. It is up to the business developer to deal on a case-by-case basis with properties that can't be automatically mapped.
The DataMapper class will accept a list of property names to be ignored. Properties matching those names simply won't be mapped during the process. Additionally, DataMapper will accept a Boolean flag that can be used to suppress exceptions during the mapping process. This can be used simply to ignore any failures.
An alternative is to provide DataMapper with a DataMap object that explicitly describes the source and target properties for the mapping.
Setting Values
The core of the DataMapper class is the SetValue() method. This method is ultimately responsible for putting a value into a specified property of a target object:
public static void SetValue(object target, MemberInfo memberInfo, object value){if (value != null){object oldValue;Type pType;if (memberInfo.MemberType == MemberTypes.Property){PropertyInfo pInfo = (PropertyInfo)memberInfo;pType = pInfo.PropertyType;oldValue = pInfo.GetValue(target, null);}else{FieldInfo fInfo = (FieldInfo)memberInfo;pType = fInfo.FieldType;oldValue = fInfo.GetValue(target);}Type vType =Utilities.GetPropertyType(value.GetType());value = Utilities.CoerceValue(pType, vType, oldValue, value);}if (memberInfo.MemberType == MemberTypes.Property)((PropertyInfo)memberInfo).SetValue(target, value, null);else((FieldInfo)memberInfo).SetValue(target, value);}
A MemberInfo object is passed in as a parameter. This is a reflection object that can describe a property or a field of the target object that is to receive the new value.
The type of the property or field is retrieved using reflection. But it is important to realize that this type may be imprecise thanks to generics and the Nullable<T> concept. So the specific type of the property's return value is retrieved using a GetPropertyType() helper method in the Utilities class. That helper method exists to deal with the possibility that the property could return a value of type Nullable<T>. If that happens, the real underlying data type (behind the Nullable<T> type) must be returned. Here's the GetPropertyType() method from the Utilities class:
public static Type GetPropertyType(Type propertyType){Type type = propertyType;if (type.IsGenericType &&(type.GetGenericTypeDefinition() == typeof(Nullable<>)))return Nullable.GetUnderlyingType(type);return type;}
If Nullable<T> isn't involved, the original type passed as a parameter is simply returned. But if Nullable<T> is involved, the underlying type is returned instead:
return Nullable.GetUnderlyingType(type);
This ensures that the actual data type of the property is used rather than Nullable<T>.
Back in the SetValue() method, the PropertyInfo object has a SetValue() method that sets the value of the property, but it requires that the new value have the same data type as the property itself. The CoerceValue() method from the Utilities class is used to coerce the new value to the required type:
value = Utilities.CoerceValue(pType, vType, oldValue, value);
The CoerceValue() method uses a number of techniques in an attempt to coerce a value to the new type:
If the value is already the right type, do nothing.
If the target type is
Nullable<T>, try to convert toT.If the target type is an
enum, try to parse the value.If the target type is a
SmartDate, try to cast the value.If the target type is a primitive type or
decimaland the value is an emptystring, set the value to0.If nothing has worked yet, call
Convert.ChangeType()to convert the type.If
ChangeType()fails, see if there's aTypeConverterfor the target type and if so use theTypeConverter.If nothing has worked yet, throw an exception.
The CoerceValue() method is used in numerous places in CSLA .NET, and it is public so a business developer can use it as well.
Back in the SetValue() method, the value has been coerced to the correct type so it can be used to set the property or field value:
if (memberInfo.MemberType == MemberTypes.Property)
((PropertyInfo)memberInfo).SetValue(target, value, null);
else
((FieldInfo)memberInfo).SetValue(target, value);The end result is that the specified property or field is set to the new value.
Mapping from IDictionary
A collection that implements IDictionary is effectively a name/value list. The DataMapper.Map() method assumes that the names in the list correspond directly to the names of properties on the business object to be loaded with data. It simply loops through all the keys in the dictionary, attempting to set the value of each entry into the target object.
While looping through the key values in the dictionary, the ignoreList is checked on each entry. If the key from the dictionary is in the ignore list, that value is ignored.
Otherwise, the SetValue() method is called to assign the new value to the specified property of the target object.
Note
A DataMap cannot be used when mapping from an IDictionary to an object. This feature is designed specifically to support Web Forms data binding, and in that model the names of the UI elements and the object properties must match.
If an exception occurs while a property is being set, it is caught. If suppressExceptions is true, the exception is ignored; otherwise, it is wrapped in an ArgumentException. The reason for wrapping it in a new exception object is so the property name can be included in the message returned to the calling code. That bit of information is invaluable when using the Map() method.
Mapping from an Object
Mapping from one object to another is done in a similar manner. The primary exception is that the list of source property names doesn't come from the keys in a dictionary but rather the list must be retrieved from the source object.
Note
The Map() method can be used to map to or from a business object.
The GetSourceProperties() method retrieves the list of properties from the source object:
private static PropertyInfo[] GetSourceProperties(Type sourceType){List<PropertyInfo> result = new List<PropertyInfo>();PropertyDescriptorCollection props =TypeDescriptor.GetProperties(sourceType);foreach (PropertyDescriptor item in props)if (item.IsBrowsable)result.Add(sourceType.GetProperty(item.Name));return result.ToArray();}
This method filters out methods that are marked as [Browsable(false)]. This is useful when the source object is a CSLA .NET-style business object, as the IsDirty, IsNew, and similar properties from BusinessBase are automatically filtered out. The result is that GetSourceProperties() returns a list of properties that are subject to data binding.
First, reflection is invoked by calling the GetProperties() method to retrieve a collection of PropertyDescriptor objects. These are similar to the more commonly used PropertyInfo objects, but they are designed to help support data binding. This means they include an IsBrowsable property that can be used to filter out those properties that aren't browsable.
A PropertyInfo object is added to the result list for all browsable properties and then that result list is converted to an array and returned to the calling code.
The calling code is an overload of the Map() method that accepts two objects rather than an IDictionary and an object:
public static void Map(object source, object target,bool suppressExceptions,params string[] ignoreList){List<string> ignore = new List<string>(ignoreList);PropertyInfo[] sourceProperties =GetSourceProperties(source.GetType());foreach (PropertyInfo sourceProperty in sourceProperties){string propertyName = sourceProperty.Name;if (!ignore.Contains(propertyName)){try{SetValue(target, propertyName,sourceProperty.GetValue(source, null));}catch (Exception ex){if (!suppressExceptions)throw new ArgumentException(String.Format("{0} ({1})",Resources.PropertyCopyFailed, propertyName), ex);}}}}
The source object's properties are retrieved into an array of PropertyInfo objects:
PropertyInfo[] sourceProperties =
GetSourceProperties(source.GetType());Then the method loops through each element in that array, checking each one against the list of properties to be ignored. If the property isn't in the ignore list, the SetValue() method is called to set the property on the target object. The GetValue() method on the PropertyInfo object is used to retrieve the value from the source object:
SetValue(
target, propertyName,
sourceProperty.GetValue(source, null));Exceptions are handled (or ignored) just like they are when copying from an IDictionary.
While the DataMapper functionality may not be useful in all cases, it is useful in many cases and can dramatically reduce the amount of tedious data-copying code a business developer needs to write to use data binding in Web Forms or to implement XML services.
Mapping from an Object with a DataMap
You can also create a DataMap to describe the mapping of properties or fields from one object to another. This DataMap can be passed to the DataMapper object's Map() method, and in that case the DataMap is used to determine the source and target properties or fields.
A DataMap is created using code like this:
var map = new DataMap(typeof(CustomerData), typeof(CustomerEdit));
map.AddPropertyMapping("Name", "ShortName");The DataMap constructor requires that the types of the source and target objects be provided. This is required because it does use reflection behind the scenes to get PropertyInfo or FieldInfo objects for each property or field you specify. Table 16-4 lists the methods used to load a DataMap with mappings.
Table 16.4. Methods on DataMap
Method | Description |
|---|---|
| Sets up a mapping from one property to another property |
| Sets up a mapping from one field to another field (even if the fields are non- |
| Sets up a mapping from a field to a property |
| Sets up a mapping from a property to a field |
These methods give you the flexibility to map most values from one object to another in a very flexible manner.
Warning
Reflection against public members is much faster than against non-public members. If you set up a DataMap that copies to or from non-public properties or fields, you should do careful performance testing to ensure you are comfortable with the results.
The Map() method works the same as described earlier except that it uses the information in the DataMap object to determine the source and target properties or fields. Because you are specifying the map explicitly, no ignoreList parameter is used.
At this point you've seen the major classes in the Csla.Data namespace. Most applications use at least some of these types in their data access code.
WF has been a pillar of the .NET Framework since version 3.0. WF is a basic workflow engine, but it also comes with a designer that integrates into Visual Studio.
It is important to realize that workflow, in general, is a procedural programming model. You might think that there's little need for object-oriented concepts in the workflow world because procedural programming and object-oriented programming are quite different. But that isn't entirely the case.
Certainly, the workflow itself is procedural: workflows are basically animated flowcharts after all. But an object-oriented application can invoke a workflow, and workflow activities can be constructed using objects behind the scenes.
A workflow activity is by definition a self-contained unit of functionality with defined inputs and outputs. This is also the basic definition of a use case. As a result, you can view a workflow activity as a use case. This is exciting because creating workflow activities using object-oriented design concepts is as close as most of us will ever get to doing pure object design without all the complexities of user interaction and so forth.
Figure 16-1 illustrates at a high level one architectural view of using both objects and workflows.
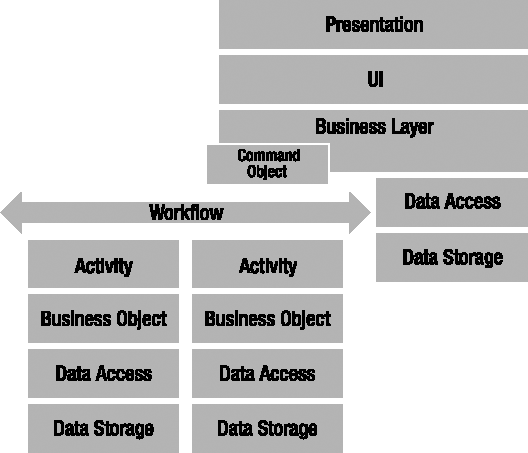
At the top of the diagram is your normal application, with its presentation, UI, business data access, and data storage layers. In this case, however, the business layer invokes a workflow through a command object. The workflow itself (in the lower left of the diagram) executes a series of activities. Each activity is implemented using business objects, which in turn invoke data access and data storage layers.
The important thing to keep in mind with Figure 16-1 is the level of encapsulation involved. To the application's business layer, the workflow is a black box that performs some useful operation. To the workflow, each activity is a black box and performs a specific task. Each activity relies on business objects to implement its task, and the activity should view these objects as black boxes.
Maintaining this level of encapsulation is important, as it provides maximum flexibility and reuse. It allows you to change the workflow without having an impact (directly at least) on the calling application. It allows you to change the implementation of an activity without having an impact (directly) on the workflow or the calling application. Finally, it allows you to change the implementation of the business objects used by an activity without having an impact on the activity, the workflow, or the calling application.
Pragmatically, most applications have two general types of functionality. There's the part that interacts with the user, displaying and collecting data. Then there's the part that performs non-interactive back-end processing, typically once the user is done entering his data.
Generally speaking, workflow can be very useful in implementing that non-interactive back-end processing. You can use WF to run a workflow on a background thread, and sometimes it is easier to visualize complex processing using the flowchart-style designer than directly through code.
Executing a workflow from a business object is not much different from executing a workflow in any other context. If you add a workflow console application in Visual Studio, the code will include the basic template for executing your workflow. Any time you execute a workflow, you'll follow this basic pattern:
Create a thread synchronization object.
Create a workflow runtime instance.
Set up some event handlers (at least for
CompletedandTerminated) where youSet()the synchronization object.Create the workflow instance.
Start the workflow instance.
Wait on the thread synchronization object until it is
Set()by one of the event handlers.
However, there is one important difference when using business objects both to start the workflow and to build workflow activities. To use business objects when creating workflow activities, the workflow project references the business layer. To execute a workflow, you need access to a Type object for that workflow, which implies that the business layer would have a reference to the workflow project. This sort of circular reference between assemblies is not allowed by .NET.
If you look back at Figure 16-1, the workflow is architecturally treated as just another interface to the business layer. And that's a good way to think about the workflow. That means that having the workflow reference the assembly containing the business objects is a good thing, so I don't recommend changing that.
To avoid a circular reference, the business layer must not reference the workflow assembly. You can avoid the circular reference by dynamically loading the workflow type. This is done with code like this:
Type workflowType = Type.GetType("Namespace.WorkflowClass, Assembly");
WorkflowInstance instance =
workflowRuntime.CreateWorkflow(workflowType);The Namespace.WorkflowClass part of the text is the fully qualified type name of the workflow class, including namespace. The Assembly part of the text is the name of the assembly containing the workflow class. Notice how the CreateWorkflow() method then accepts the Type object. This allows the workflow runtime to properly create an instance of the workflow, without this code needing a reference to the assembly that contains the workflow.
CSLA .NET provides a WorkflowManager class in the Csla.Workflow namespace to help abstract the process of executing a workflow. The primary purpose of this class is to help manage the use of thread synchronization, while maintaining the flexibility provided by the workflow runtime model.
Table 16-5 lists the methods provided by the WorkflowManager object.
Several of these methods allow you to execute a workflow or to resume a suspended workflow. In both cases, control won't return to your code until the workflow is completed, terminated, or suspended.
Other methods allow you to start execution of a workflow on a background thread or to resume execution of a workflow on a background thread. Your thread remains active and can be used to perform other tasks while the workflow is running.
Table 16.5. Methods Provided by WorkflowManager
Method | Description |
|---|---|
| Synchronously executes a workflow, blocking the calling thread until the workflow stops |
| Asynchronously starts executing a workflow; the calling thread is not blocked but must call |
| Synchronously waits for the workflow to stop; returns immediately if the workflow has already stopped; this method can optionally dispose the WF runtime instance |
| Synchronously resumes execution of a workflow, blocking the calling thread until the workflow stops |
| Asynchronously resumes execution of a workflow; the calling thread is not blocked but must call |
| Synchronously initializes the WF runtime, allowing the calling code to manipulate the runtime before calling one of the methods to execute or resume a workflow |
| Synchronously disposes the workflow runtime |
Synchronous Execution of a Workflow
In its simplest usage, the WorkflowManager can execute a workflow, by Type or type name, in two lines of code:
WorkflowManager mgr = new WorkflowManager();
mgr.ExecuteWorkflow("PTWorkflow.ProjectWorkflow, PTWorkflow");In this case, the ExecuteWorkflow() method creates a Type object for the workflow based on the assembly qualified name of the workflow, such as PTWorkflow.ProjectWorkflow, PTWorkflow. Alternatively, you can just pass a Type object as a parameter rather than the type name:
WorkflowManager mgr = new WorkflowManager(); mgr.ExecuteWorkflow(typeof(ProjectWorkflow));
Either way, this synchronously executes the workflow. When ExecuteWorkflow() returns, the workflow is complete or terminated and the workflow runtime is disposed.
You can examine mgr.Status to determine the final state of the workflow. The possible values are listed in Table 16-6.
Table 16.6. WorkflowManager Status Property Values
Status | Description |
|---|---|
| The workflow is being initialized and has not yet started executing. |
| The workflow is being executed. |
| The workflow completed properly. |
| The workflow was abnormally terminated. Use the |
| The workflow was suspended. |
| The workflow is idled. |
| The workflow was aborted. |
For simple workflows, you can expect Completed or Terminated results once the ExecuteWorkflow() method has returned.
Dealing with Idled or Suspended Workflows
More complex workflows might use a persistence service to store an idled or suspended workflow to a database so it can be resumed later. That complicates the code slightly because you need to associate a persistence service with the workflow runtime and be more detailed in checking the status of the workflow when ExecuteWorkflow() returns.
This code shows the basic structure required to execute a workflow that might be idled or suspended and that will be persisted to a database in both those cases:
Csla.Workflow.WorkflowManager mgr = new Csla.Workflow.WorkflowManager();
mgr.InitializeRuntime();
// associate your persistence service with mgr.RuntimeInstance here
mgr.ExecuteWorkflow("WorkflowApp.Workflow1, WorkflowApp", false);
if (mgr.Status == Csla.Workflow.WorkflowStatus.Suspended)
{
Guid instanceId = mgr.WorkflowInstance.InstanceId;
mgr.WorkflowInstance.Unload();
// store instanceId so you can resume the workflow later
}
mgr.DisposeRuntime();If you expect your workflow might become idled or suspended and you want to store that workflow instance in a database to resume later, you need to provide a persistence service to the workflow runtime.
Associating a Persistence Service with the Runtime
By explicitly calling InitializeRuntime(), the previous code creates and initializes the workflow runtime, allowing you to then associate a persistence service (or other services) with that runtime. This is done with code similar to the following:
Csla.Workflow.WorkflowManager mgr = new Csla.Workflow.WorkflowManager();
mgr.InitializeRuntime();
string connectionString =
@"Data Source=ineroth;Initial Catalog=WorkflowPersistenceStore;
Persist Security Info=True;User ID=test;Password=test";
bool unloadOnIdle = true;
TimeSpan instanceOwnershipDuration = TimeSpan.MaxValue;
TimeSpan loadingInterval = new TimeSpan(0, 2, 0);// Add the SqlWorkflowPersistenceService to the runtime engine.
SqlWorkflowPersistenceService persistService =
new SqlWorkflowPersistenceService(
connectionString, unloadOnIdle,
instanceOwnershipDuration, loadingInterval);
mgr.RuntimeInstance.AddService(persistService);This code creates and configures an instance of SqlWorkflowPersistenceService, a built-in persistence service provided with WF. This persistence service stores the serialized workflow state in the SQL Server database specified by the connection string. Before using that database, you need to run a prebuilt SQL script to set up the required tables and do some other administrative tasks. This MSDN article describes the required steps: http://msdn2.microsoft.com/en-US/library/aa349366.aspx.
The unloadOnIdle parameter also specifies that an Idled workflow should be automatically persisted.
Notice the last line of code:
mgr.RuntimeInstance.AddService(persistService);
This line of code adds the service to the workflow runtime instance being used by the WorkflowManager.
Unloading a Suspended Workflow
Returning to the original code that executes the workflow, notice that ExecuteWorkflow() is called with an extra parameter of false. This parameter indicates that the workflow runtime should not be disposed before ExecuteWorkflow() returns. This is important because if the workflow is suspended, you need to use the runtime to persist the workflow by calling the workflow's Unload() method:
if (mgr.Status == Csla.Workflow.WorkflowStatus.Suspended)
{
Guid instanceId = mgr.WorkflowInstance.InstanceId;
mgr.WorkflowInstance.Unload();
// store instanceId so you can resume the workflow later
}Once this is done, the DisposeRuntime() method of the WorkflowManager is called to dispose the workflow runtime.
Make special note of the comment in the previous code. If you unload a workflow, you need the workflow's InstanceId value, a Guid, to reload and resume the workflow later. Without this value the workflow can't be reloaded.
Loading and Resuming a Workflow
The following code reloads and resumes the workflow, assuming the instanceId field contains a valid workflow ID:
Csla.Workflow.WorkflowManager mgr = new Csla.Workflow.WorkflowManager();
mgr.InitializeRuntime();
// associate your persistence service with mgr.RuntimeInstance here
mgr.ResumeWorkflow(instanceId);The ResumeWorkflow() method uses the instanceId value to load the workflow instance from the persistence service and then resumes the workflow execution.
At this point, you should understand how to execute, unload, and resume a workflow that could become idle or suspended as it runs.
Resuming a Suspended Workflow Without Unloading
You don't have to unload a suspended workflow. You could keep the workflow instance in memory and simply resume it. This is often valuable if the workflow requires that the application or user do something immediately to allow the workflow to continue.
The following code shows how to resume a suspended workflow without unloading it:
Csla.Workflow.WorkflowManager mgr = new Csla.Workflow.WorkflowManager();
mgr.ExecuteWorkflow("WorkflowApp.Workflow1, WorkflowApp", false);
if (mgr.Status == Csla.Workflow.WorkflowStatus.Suspended)
{
// perform any actions required before resuming the workflow
mgr.ResumeWorkflow(false);
}
mgr.DisposeRuntime();Notice that no persistence service is required because the workflow is never unloaded. However, the ExecuteWorkflow() method is still called such that the workflow runtime is not disposed when it completes. The Status property is then checked, and if the workflow is suspended, the application needs to do any work that is required before the workflow is resumed. This is represented by the first highlighted line of code.
The second highlighted line of code shows how to resume the current workflow. Since the workflow wasn't unloaded, it is still in memory, just suspended. The ResumeWorkflow() method call resumes the workflow and allows it to run to completion.
Executing a Workflow from a Business Object
You can use the WorkflowManager class to simplify execution of a workflow from within a business object or you can directly invoke the WF objects yourself. Either way, a workflow is typically executed from one of the DataPortal_XYZ methods in a business object or the data access method in a factory object.
Execution of a workflow should fit naturally into your object model. Remember that the UI layer always interacts with your business objects, never with the database or any other services directly. If your application makes use of a workflow to perform some back-end processing, that processing should be represented somehow within your object model.
In many cases, this situation means that the workflow will be represented by a command object, which is a subclass of CommandBase. For example, you could execute a workflow from a ProjectCloser object. From the UI perspective, this object is clearly responsible for closing a project, and the fact that it uses a workflow to do the work is an implementation detail:
[Serializable]
public class ProjectCloser : CommandBase
{
public static void CloseProject(Guid id)
{
ProjectCloser cmd = new ProjectCloser(id);
cmd = DataPortal.Execute<ProjectCloser>(cmd);
}private Guid _projectId;
private ProjectCloser()
{ /* require use of factory methods */ }
private ProjectCloser(Guid projectId)
{
_projectId = projectId;
}
protected override void DataPortal_Execute()
{
Dictionary<string, object> parameters = new Dictionary<string, object>();
parameters.Add("ProjectId", _projectId);
WorkflowManager mgr = new WorkflowManager();
mgr.ExecuteWorkflow(
"PTWorkflow.ProjectWorkflow, PTWorkflow", parameters);
if (mgr.Status == WorkflowStatus.Terminated)
throw mgr.Error;
}
}The code in DataPortal_Execute() is highlighted, as this is the code that executes the workflow.
Notice the use of a Dictionary to pass in name/value parameters to the workflow. The parameter sets the ProjectId dependency property of the workflow. The assumption is that the workflow will have defined one or more dependency properties, such as ProjectId, that accept inbound parameter values.
It is also important to note that ExecuteWorkflow() is called using the type name of the workflow. This avoids any circular reference that might be caused if activities within the workflow make use of the same business assembly that contains the ProjectCloser class.
When ExecuteWorkflow() completes, the Status property is checked to see whether the workflow terminated abnormally. The exception from the workflow is then thrown, indicating to the original caller of the object that the command failed.
With ProjectCloser implemented this way, any code using the business layer can close a project like this:
ProjectCloser.CloseProject(projectId);
The calling code doesn't need to be concerned with workflows, threading, or any of the details. Everything is abstracted behind the business object.
Better yet, ProjectCloser is a standard CSLA .NET business object, which means that its call to DataPortal.Execute() uses the data portal. If the application is configured properly, it means that the workflow would run on the application server, or if the application is configured to use a local data portal, the workflow would run on the client machine.
The WorkflowManager is a useful tool when mixing business objects and workflows in the same application. But it can be useful in any scenario where workflows are used because it abstracts away many of the more complex aspects involved in executing a workflow.
This chapter concludes creation of the CSLA .NET framework. Over the past several chapters, you have learned how CSLA .NET delivers a wide variety of functionality to support the development of business objects. This chapter combined a range of capabilities, including the following:
Date handling
Data access
Executing WF workflows
The remainder of the book focuses on how to use this framework to create business objects, a data access layer, and a variety of UIs for those objects, including WPF, Web Forms, and XML services.