
In Chapter 1, I discussed some general concepts about physical and logical n-tier architecture, including a 5-layer model for describing systems logically. In this chapter, I take that 5-layer logical model and expand it into a framework design. Specifically, this chapter will map the logical layers against the technologies illustrated in Figure 2-1.
The CSLA .NET framework itself will focus on the Business Logic and Data Access layers. This is primarily due to the fact that there are already powerful technologies for building Windows, web (browser-based and XML-based services), and mobile interface layers. Also, there are already powerful data-storage options available, including SQL Server, Oracle, DB2, XML documents, and so forth.
Recognizing that these preexisting technologies are ideal for building the Presentation and UI layers, as well as for handling data storage, allows business developers to focus on the parts of the application that have the least technological support, where the highest return on investment occurs through reuse. Analyzing, designing, implementing, testing, and maintaining business logic is incredibly expensive. The more reuse achieved, the lower long-term application costs become. The easier it is to maintain and modify this logic, the lower costs will be over time.

Note
This is not to say that additional frameworks for UI creation or simplification of data access are bad ideas. On the contrary, such frameworks can be very complementary to the ideas presented in this book; and the combination of several frameworks can help lower costs even further.
When I set out to create the architecture and framework discussed in this book, I started with the following set of high-level guidelines:
The task of creating object-oriented applications in a distributed .NET environment should be simplified.
The interface developer (Windows, web service, or workflow) should never see or be aware of SQL, ADO.NET, or other raw data concepts but should instead rely on a purely object-oriented model of the problem domain.
Business object developers should be able to use "natural" coding techniques to create their classes—that is, they should employ everyday coding using fields, properties, and methods. Little or no extra knowledge should be required.
The business classes should provide total encapsulation of business logic, including validation, manipulation, calculation, and authorization. Everything pertaining to an entity in the problem domain should be found within a single class.
It should be possible to achieve clean separation between the business logic code and the data access code.
It should be relatively easy to create code generators, or templates for existing code generation tools, to assist in the creation of business classes.
An n-layer logical architecture that can be easily reconfigured to run on one to four physical tiers should be provided.
Complex features in .NET should be used, but they should be largely hidden and automated (WCF, serialization, security, deployment, etc.).
The concepts present in the framework from its inception should carry forward, including validation, authorization, n-level undo, and object-state tracking (
IsNew, IsDirty, IsDeleted).
In this chapter, I focus on the design of a framework that allows business developers to make use of object-oriented design and programming with these guidelines in mind. After walking through the design of the framework, Chapters 6 through 16 dive in and implement the framework itself, focusing first on the parts that support UI development and then on the providing of scalable data access and object-relational mapping for the objects. Before I get into the design of the framework, however, let's discuss some of the specific goals I am attempting to achieve.
When creating object-oriented applications, the ideal situation is that any nonbusiness objects already exist. This includes UI controls, data access objects, and so forth. In that case, all developers need to do is focus on creating, debugging, and testing the business objects themselves, thereby ensuring that each one encapsulates the data and business logic needed to make the application work.
As rich as the .NET Framework is, however, it doesn't provide all the nonbusiness objects needed in order to create most applications. All the basic tools are there but there's a fair amount of work to be done before you can just sit down and write business logic. There's a set of higher-level functions and capabilities that are often needed but aren't provided by .NET right out of the box.
These include the following:
Validation and maintaining a list of broken business rules
Standard implementation of business and validation rules
Tracking whether an object's data has changed (is it "dirty"?)
Integrated authorization rules at the object and property levels
Strongly typed collections of child objects (parent-child relationships)
N-level undo capability
A simple and abstract model for the UI developer
Full support for data binding in WPF, Windows Forms, and Web Forms
Saving objects to a database and getting them back again
Custom authentication
Other miscellaneous features
In all of these cases, the .NET Framework provides all the pieces of the puzzle, but they must be put together to match your specialized requirements. What you don't want to do, however, is to have to put them together for every business object or application. The goal is to put them together once so that all these extra features are automatically available to all the business objects and applications.
Moreover, because the goal is to enable the implementation of object-oriented business systems, the core object-oriented concepts must also be preserved:
Abstraction
Encapsulation
Polymorphism
Inheritance
The result is a framework consisting of a number of classes. The design of these classes is discussed in this chapter and their implementation is discussed in Chapters 6 through 16.
Tip
The Diagrams folder in the Csla project in the code download includes FullCsla.cd, which shows all the framework classes in a single diagram. You can also get a PDF document showing that diagram at www.lhotka.net/cslanet/download.aspx.
Before getting into the details of the framework's design, let's discuss the desired set of features in more detail.
A lot of business logic involves the enforcement of validation rules. The fact that a given piece of data is required is a validation rule. The fact that one date must be later than another date is a validation rule. Some validation rules involve calculations and others are merely toggles. You can think about validation rules as being either broken or not. And when one or more rules are broken the object is invalid.
A similar concept is the idea of business rules that might alter the state of the object. The fact that a given piece of text data must be all uppercase is a business rule. The calculation of one property value based on other property values is a business rule. Most business rules involve some level of calculation.
Because all validation rules ultimately return a Boolean value, it is possible to abstract the concept of validation rules to a large degree. Every rule is implemented as a bit of code. Some of the code might be trivial, such as comparing the length of a string and returning false if the value is zero. Other code might be more complex, involving validation of the data against a lookup table or through a numeric algorithm. Either way, a validation rule can be expressed as a method that returns a Boolean result.
Business rules typically alter the state of the object and usually don't enforce validation at the same time. Still, every business rule is implemented as a bit of code, and that code might be trivial or very complex.
The .NET Framework provides the delegate concept, making it possible to formally define a method signature for a type of method. A delegate defines a reference type (an object) that represents a method. Essentially, delegates turn methods into objects, allowing you to write code that treats the method like an object; and of course they also allow you to invoke the method.
I use this capability in the framework to formally define a method signature for all validation and business rules. This allows the framework to maintain a list of validation rules for each object, enabling relatively simple application of those rules as appropriate. With that done, every object can easily maintain a list of the rules that are broken at any point in time and has a standardized way of implementing business rules.
Note
There are commercial business rule engines and other business rule products that strive to take the business rules out of the software and keep them in some external location. Some of these are powerful and valuable. For most business applications, however, the business rules are typically coded directly into the software. When using object-oriented design, this means coding them into the objects.
A fair number of validation rules are of the toggle variety: required fields, fields that must be a certain length (no longer than, no shorter than), fields that must be greater than or less than other fields, and so forth. The common theme is that validation rules, when broken, immediately make the object invalid. In short, an object is valid if no rules are broken but is invalid if any rules are broken.
Rather than trying to implement a custom scheme in each business object in order to keep track of which rules are broken and whether the object is or isn't valid at any given point, this behavior can be abstracted. Obviously, the rules themselves are often coded into an application, but the tracking of which rules are broken and whether the object is valid can be handled by the framework.
Tip
Defining a validation rule as a method means you can create libraries of reusable rules for your application. The framework in this book includes a small library with some of the most common validation rules so you can use them in applications without having to write them.
The result is a standardized mechanism by which the developer can check all business objects for validity. The UI developer should also be able to retrieve a list of currently broken rules to display to the user (or for any other purpose).
Additionally, this provides the underlying data required to implement the System.ComponentModel.IDataErrorInfo interface defined by the .NET Framework. This interface is used by the data binding infrastructure in WPF and Windows Forms to automate the display of validation errors to the user.
Some validation rules may interact with the database or could be very complex in other ways. In these cases, you may want to allow the user to move on to editing other data while a validation rule is running in the background. To this end, you can choose to implement a validation rule (though not a business rule) to run asynchronously on a background thread.
The reason this only works with validation rules is that an async rule method won't have access to the real business object. For thread safety reasons, it is provided with a copy of the property values to be validated so it can do its work. Since a business rule manipulates the business object's data, I don't allow them to be implemented as an async operation.
Another concept is that an object should keep track of whether its state data has been changed. This is important for the performance and efficiency of data updates. Typically, data should only be updated into the database if the data has actually changed. It's a waste of effort to update the database with values it already has. Although the UI developer could keep track of whether any values have changed, it's simpler to have the object take care of this detail and it allows the object to better encapsulate its behaviors.
This can be implemented in a number of ways, ranging from keeping the previous values of all fields (allowing comparisons to see if they've changed) to saying that any change to a value (even "changing" it to its original value) will result in the object being marked as having changed.
Rather than having the framework dictate one cost over the other, it will simply provide a generic mechanism by which the business logic can tell the framework whether each object has been changed. This scheme supports both extremes of implementation, allowing you to make a decision based on the requirements of a specific application.
Applications also need to be able to authorize the user to perform (or not perform) certain operations or view (or not view) certain data. Such authorization is typically handled by associating users with roles and then indicating which roles are allowed or disallowed for specific behaviors.
Note
Authorization is just another type of business logic. The decisions about what a user can and can't do or can and can't see within the application are business decisions. Although the framework will work with the .NET Framework classes that support authentication, it's up to the business objects to implement the rules themselves.
Later, I discuss authentication and how the framework supports both integrated Windows and AD authentication and custom authentication. Either way, the result of authentication is that the application has access to the list of roles (or groups) to which the user belongs. This information can be used by the application to authorize the user as defined by the business.
While authorization can be implemented manually within the application's business code, the business framework can help formalize the process in some cases. Specifically, objects must use the user's role information to restrict what properties the user can view and edit. There are also common behaviors at the object level—such as loading, deleting, and saving an object—that are subject to authorization.
As with validation rules, authorization rules can be distilled to a set of fairly simple yes/no answers. Either a user can or can't read a given property. Either a user can or can't delete the object's data. The business framework includes code to help a business object developer easily restrict which object properties a user can or can't read or edit and what operations the user can perform on the object itself. In Chapter 12, you'll also see a common pattern that can be implemented by all business objects to control whether an object can be retrieved, deleted, or saved.
Not only does this business object need access to this authorization information but the UI does as well. Ideally, a good UI will change its display based on how the current user is allowed to interact with an object. To support this concept, the business framework will help the business objects expose the authorization rules such that they are accessible to the UI layer without duplicating the authorization rules themselves.
The .NET Framework includes the System.Collections.Generic namespace, which contains a number of powerful collection objects, including List<T>, Dictionary<TKey, TValue>, and others. There's also System.ComponentModel.BindingList<T>, which provides collection behaviors and full support for data binding, and the less capable System.ComponentModel.ObservableCollection<T>, which provides support only for WPF data binding.
A Short Primer on Generics
Generic types are a feature introduced in .NET 2.0. A generic type is a template that defines a set of behaviors but the specific data type is specified when the type is used rather than when it is created. Perhaps an example will help.
Consider the ArrayList collection type. It provides powerful list behaviors but it stores all its items as type object. While you can wrap an ArrayList with a strongly typed class or create your own collection type in many different ways, the items in the list are always stored in memory as type object.
The new List<T> collection type has the same behaviors as ArrayList but it is strongly typed—all the way to its core. The type of the indexer, enumerator, Remove(), and other methods are all defined by the generic type parameter, T. Even better, the items in the list are stored in memory as type T, not type object.
So what is T? It is the type provided when the List<T> is created:
List<int> myList = new List<int>();
In this case, T is int, meaning that myList is a strongly typed list of int values. The public properties and methods of myList are all of type int, and the values it contains are stored internally as int values.
Not only do generic types offer type safety due to their strongly typed nature, but they typically offer substantial performance benefits because they avoid storing values as type object.
Strongly Typed Collections of Child Objects
Sadly, the basic functionality provided by even the generic collection classes isn't enough to integrate fully with the rest of the framework. The business framework supports a set of relatively advanced features such as validation and n-level undo capabilities. Supporting these features requires that collections of child objects interact with the parent object and the objects contained in the collection in ways not implemented by the basic collection and list classes provided by .NET.
For example, a collection of child objects needs to be able to indicate if any of the objects it contains have been changed. Although the business object developer could easily write code to loop through the child objects to discover whether any are marked as dirty, it makes a lot more sense to put this functionality into the framework's collection object. That way the feature is simply available for use. The same is true with validity: if any child object is invalid, the collection should be able to report that it's invalid. If all child objects are valid, the collection should report itself as being valid.
As with the business objects themselves, the goal of the business framework is to make the creation of a strongly typed collection as close to normal .NET programming as possible, while allowing the framework to provide extra capabilities common to all business objects. What I'm defining here are two sets of behaviors: one for business objects (parent and/or child) and one for collections of business objects. Though business objects will be the more complex of the two, collection objects will also include some very interesting functionality.
Many Windows applications provide users with an interface that includes OK and Cancel buttons (or some variation on that theme). When the user clicks an OK button, the expectation is that any work the user has done will be saved. Likewise, when the user clicks a Cancel button, he expects that any changes he's made will be reversed or undone.
Simple applications can often deliver this functionality by saving the data to a database when users click OK and discarding the data when they click Cancel. For slightly more complex applications, the application must be able to undo any editing on a single object when the user presses the Esc key. (This is the case for a row of data being edited in a DataGridView: if the user presses Esc, the row of data should restore its original values.)
When applications become much more complex, however, these approaches won't work. Instead of simply undoing the changes to a single row of data in real time, you may need to be able to undo the changes to a row of data at some later stage.
Note
It is important to realize that the n-level undo capability implemented in the framework is optional and is designed to incur no overhead if it is not used.
Consider the case of an Invoice object that contains a collection of LineItem objects. The Invoice itself contains data that the user can edit plus data that's derived from the collection. The TotalAmount property of an Invoice, for instance, is calculated by summing up the individual Amount properties of its LineItem objects. Figure 2-2 illustrates this arrangement.

The UI may allow the user to edit the LineItem objects and then press Enter to accept the changes to the item or Esc to undo them. However, even if the user chooses to accept changes to some LineItem objects, she can still choose to cancel the changes on the Invoice itself. Of course, the only way to reset the Invoice object to its original state is to restore the states of the LineItem objects as well, including any changes to specific LineItem objects that might have been "accepted" earlier.
As if this isn't enough, many applications have more complex hierarchies of objects and subobjects (which I'll call child objects). Perhaps the individual LineItem objects each has a collection of Component objects beneath it. Each Component object represents one of the components sold to the customer that makes up the specific line item, as shown in Figure 2-3.

Now things get even more complicated. If the user edits a Component object, the changes ultimately impact the state of the Invoice object itself. Of course, changing a Component also changes the state of the LineItem object that owns the Component.
The user might accept changes to a Component but cancel the changes to its parent LineItem object, thereby forcing an undo operation to reverse accepted changes to the Component. Or in an even more complex scenario, the user may accept the changes to a Component and its parent LineItem only to cancel the Invoice. This would force an undo operation that reverses all those changes to the child objects.
Implementing an undo mechanism to support such n-level scenarios isn't trivial. The application must implement code to take a snapshot of the state of each object before it's edited so that changes can be reversed later on. The application might even need to take more than one snapshot of an object's state at different points in the editing process so that the object can revert to the appropriate point, based on when the user chooses to accept or cancel any edits.
Note
This multilevel undo capability flows from the user's expectations. Consider a typical word processor, where the user can undo multiple times to restore the content to ever earlier states.
And the collection objects are every bit as complex as the business objects themselves. The application must handle the simple case in which a user edits an existing LineItem, but it must also handle the case in which a user adds a new LineItem and then cancels changes to the parent or grandparent, resulting in the new LineItem being discarded. Equally, it must handle the case in which the user deletes a LineItem and then cancels changes to the parent or grandparent, thereby causing that deleted object to be restored to the collection as though nothing had ever happened.
Things get even more complex if you consider that the framework keeps a list of broken validation rules for each object. If the user changes an object's data so that the object becomes invalid but then cancels the changes, the original state of the object must be restored. The reverse is true as well: an object may start out invalid (perhaps because a required field is blank), so the user must edit data until it becomes valid. If the user later cancels the object (or its parent, grandparent, etc.), the object must become invalid once again because it will be restored to its original invalid state.
Fortunately, this is easily handled by treating the broken rules and validity of each object as part of that object's state. When an undo operation occurs, not only is the object's core state restored but so is the list of broken rules associated with that state. The object and its rules are restored together.
N-level undo is a perfect example of complex code that shouldn't be written into every business object. Instead, this functionality should be written once, so that all business objects support the concept and behave the way we want them to. This functionality will be incorporated directly into the business object framework—but at the same time, the framework must be sensitive to the different environments in which the objects will be used. Although n-level undo is of high importance when building sophisticated Windows user experiences, it's virtually useless in a typical web environment.
In web-based applications, users typically don't have a Cancel button. They either accept the changes or navigate away to another task, allowing the application to simply discard the changed object. In this regard, the web environment is much simpler, so if n-level undo isn't useful to the web UI developer, it shouldn't incur any overhead if it isn't used. The framework design takes into account that some UI types will use the concept while others will simply ignore it.
At this point, I've discussed some of the business object features that the framework will support. One of the key reasons for providing these features is to make the business object support Windows and web-style user experiences with minimal work on the part of the UI developer. In fact, this should be an overarching goal when you're designing business objects for a system. The UI developer should be able to rely on the objects to provide business logic, data, and related services in a consistent manner.
Beyond all the features already covered is the issue of creating new objects, retrieving existing data, and updating objects in some data store. I discuss the process of object persistence later in the chapter, but first this topic should be considered from the UI developer's perspective. Should the UI developer be aware of any application servers? Should he be aware of any database servers? Or should he simply interact with a set of abstract objects? There are three broad models to choose from:
UI-in-charge
Object-in-charge
Class-in-charge
To a greater or lesser degree, all three of these options hide information about how objects are created and saved and allow us to exploit the native capabilities of .NET. In the end, I settle on the option that hides the most information (keeping development as simple as possible) and best allows you to exploit the features of .NET.
Note
Inevitably, the result will be a compromise. As with many architectural decisions, there are good arguments to be made for each option. In your environment, you may find that a different decision would work better. Keep in mind though that this particular decision is fairly central to the overall architecture of the framework, so choosing another option will likely result in dramatic changes throughout the framework.
To make this as clear as possible, the following discussion assumes the use of a physical n-tier configuration, whereby the client or web server is interacting with a separate application server, which in turn interacts with the database. Although not all applications will run in such configurations, it is much easier to discuss object creation, retrieval, and updating in this context.
UI in Charge
One common approach to creating, retrieving, and updating objects is to put the UI in charge of the process. This means that it's the UI developer's responsibility to write code that will contact the application server in order to retrieve or update objects.
In this scheme, when a new object is required, the UI will contact the application server and ask it for a new object. The application server can then instantiate a new object, populate it with default values, and return it to the UI code. The code might be something like this:
Customer result = null;
var factory =
new ChannelFactory<BusinessService.IBusinessService>("BusinessService");
try
{
var proxy = factory.CreateChannel();
using (proxy as IDisposable)
{
result = proxy.CreateNewCustomer();
}
}
finally
{
factory.Close();
}Here the object of type IBusinessService is anchored, so it always runs on the application server. The Customer object is mobile, so although it's created on the server, it's returned to the UI by value.
Note
This code example uses Windows Communication Foundation to contact an application server and have it instantiate an object on the server. In Chapter 15, you'll see how CSLA .NET abstracts this code into a much simpler form, effectively wrapping and hiding the complexity of WCF.
This may seem like a lot of work just to create a new, empty object, but it's the retrieval of default values that makes it necessary. If the application has objects that don't need default values, or if you're willing to hard-code the defaults, you can avoid some of the work by having the UI simply create the object on the client workstation. However, many business applications have configurable default values for objects that must be loaded from the database; and that means the application server must load them.
Retrieving an existing object follows the same basic procedure. The UI passes criteria to the application server, which uses the criteria to create a new object and load it with the appropriate data from the database. The populated object is then returned to the UI for use. The UI code might be something like this:
Customer result = null;
var factory =
new ChannelFactory<BusinessService.IBusinessService>("BusinessService");
try
{
var proxy = factory.CreateChannel();
using (proxy as IDisposable)
{
result = proxy.GetCustomer(criteria);
}
}
finally
{
factory.Close();
}Updating an object happens when the UI calls the application server and passes the object to the server. The server can then take the data from the object and store it in the database. Because the update process may result in changes to the object's state, the newly saved and updated object is then returned to the UI. The UI code might be something like this:
Customer result = null;
var factory =
new ChannelFactory<BusinessService.IBusinessService>("BusinessService");
try
{
var proxy = factory.CreateChannel();
using (proxy as IDisposable)
{
result = proxy.UpdateCustomer(customer);
}
}
finally
{
factory.Close();
}Overall, this model is straightforward—the application server must simply expose a set of services that can be called from the UI to create, retrieve, update, and delete objects. Each object can simply contain its business logic without the object developer having to worry about application servers or other details.
The drawback to this scheme is that the UI code must know about and interact with the application server. If the application server is moved, or some objects come from a different server, the UI code must be changed. Moreover, if a Windows UI is created to use the objects and then later a web UI is created that uses those same objects, you'll end up with duplicated code. Both types of UI will need to include the code in order to find and interact with the application server.
The whole thing is complicated further if you consider that the physical configuration of the application should be flexible. It should be possible to switch from using an application server to running the data access code on the client just by changing a configuration file. If there's code scattered throughout the UI that contacts the server any time an object is used, there will be a lot of places where developers might introduce a bug that prevents simple configuration file switching.
Object in Charge
Another option is to move the knowledge of the application server into the objects themselves. The UI can just interact with the objects, allowing them to load defaults, retrieve data, or update themselves. In this model, simply using the new keyword creates a new object:
Customer cust = new Customer();
Within the object's constructor, you would then write the code to contact the application server and retrieve default values. It might be something like this:
public Customer()
{
var factory =
new ChannelFactory<BusinessService.IBusinessService>("BusinessService");
try
{
var proxy = factory.CreateChannel();
using (proxy as IDisposable)
{
var tmp = proxy.GetNewCustomerDefaults();
_field1 = tmp.Field1Default;
_field2 = tmp.Field2Default;
// load all fields with defaults here
}
}
finally
{
factory.Close();
}
}Notice that the previous code does not take advantage of the built-in support for passing an object by value across the network. In fact, this technique forces the creation of some other class that contains the default values returned from the server.
Given that both the UI-in-charge and class-in-charge techniques avoid all this extra coding, let's just abort the discussion of this option and move on.
Class-in-Charge (Factory Pattern)
The UI-in-charge approach uses .NET's ability to pass objects by value but requires the UI developer to know about and interact with the application server. The object-in-charge approach enables a very simple set of UI code but makes the object code prohibitively complex by making it virtually impossible to pass the objects by value.
The class-in-charge option provides a good compromise by providing reasonably simple UI code that's unaware of application servers while also allowing the use of .NET's ability to pass objects by value, thus reducing the amount of "plumbing" code needed in each object. Hiding more information from the UI helps create a more abstract and loosely coupled implementation, thus providing better flexibility.
Note
The class-in-charge approach is a variation on the Factory design pattern, in which a "factory" method is responsible for creating and managing an object. In many cases, these factory methods are static methods that may be placed directly into a business class—hence the class-in-charge moniker.[1]
In this model, I make use of the concept of static factory methods on a class. A static method can be called directly without requiring an instance of the class to be created first. For instance, suppose that a Customer class contains the following code:
[Serializable()]
public class Customer
{
public static Customer NewCustomer()
{
var factory =
new ChannelFactory<BusinessService.IBusinessService>("BusinessService");
try
{
var proxy = factory.CreateChannel();
using (proxy as IDisposable)
{
return = proxy.CreateNewCustomer ();
}
}
finally
{
factory.Close();
}
}
}The UI code could use this method without first creating a Customer object, as follows:
Customer cust = Customer.NewCustomer();
A common example of this tactic within the .NET Framework itself is the Guid class, whereby a static method is used to create new Guid values, as follows:
Guid myGuid = Guid.NewGuid();
This accomplishes the goal of making the UI code reasonably simple; but what about the static method and passing objects by value? Well, the NewCustomer() method contacts the application server and asks it to create a new Customer object with default values. The object is created on the server and then returned back to the NewCustomer() code, which is running on the client. Now that the object has been passed back to the client by value, the method simply returns it to the UI for use.
Likewise, you can create a static method in the class in order to load an object with data from the data store as shown:
public static Customer GetCustomer(string criteria)
{
var factory =
new ChannelFactory<BusinessService.IBusinessService>("BusinessService");
try
{
var proxy = factory.CreateChannel();
using (proxy as IDisposable)
{
return = proxy.GetCustomer (criteria);
}
}
finally
{
factory.Close();
}
}Again, the code contacts the application server, providing it with the criteria necessary to load the object's data and create a fully populated object. That object is then returned by value to the GetCustomer() method running on the client and then back to the UI code.
As before, the UI code remains simple:
Customer cust = Customer.GetCustomer(myCriteria);
The class-in-charge model requires that you write static factory methods in each class but keeps the UI code simple and straightforward. It also takes full advantage of .NET's ability to pass objects across the network by value, thereby minimizing the plumbing code in each object. Overall, it provides the best solution, which is used (and refined further) in the chapters ahead.
For more than a decade, Microsoft has included some kind of data binding capability in its development tools. Data binding allows developers to create forms and populate them with data with almost no custom code. The controls on a form are "bound" to specific fields from a data source (such as an entity object, a DataSet, or a business object).
Data binding is provided in WPF, Windows Forms, and Web Forms. The primary benefits or drivers for using data binding in .NET development include the following:
Data binding offers good performance, control, and flexibility.
Data binding can be used to link controls to properties of business objects.
Data binding can dramatically reduce the amount of code in the UI.
Data binding is sometimes faster than manual coding, especially when loading data into list boxes, grids, or other complex controls.
Of these, the biggest single benefit is the dramatic reduction in the amount of UI code that must be written and maintained. Combined with the performance, control, and flexibility of .NET data binding, the reduction in code makes it a very attractive technology for UI development.
In WPF, Windows Forms, and Web Forms, data binding is read-write, meaning that an element of a data source can be bound to an editable control so that changes to the value in the control will be updated back into the data source as well.
Data binding in .NET is very powerful. It offers good performance with a high degree of control for the developer. Given the coding savings gained by using data binding, it's definitely a technology that needs to be supported in the business object framework.
Enabling the Objects for Data Binding
Although data binding can be used to bind against any object or any collection of homogeneous objects, there are some things that object developers can do to make data binding work better. Implementing these "extra" features enables data binding to do more work for you and provide a superior experience. The .NET DataSet object, for instance, implements these extra features in order to provide full data binding support to WPF, Windows Forms, and Web Forms developers.
The IEditableObject Interface
All editable business objects should implement the interface called System.ComponentModel.IEditableObject. This interface is designed to support a simple, one-level undo capability and is used by simple forms-based data binding and complex grid-based data binding alike.
In the forms-based model, IEditableObject allows the data binding infrastructure to notify the business object before the user edits it so that the object can take a snapshot of its values. Later, the application can tell the object whether to apply or cancel those changes based on the user's actions. In the grid-based model, each of the objects is displayed in a row within the grid. In this case, the interface allows the data binding infrastructure to notify the object when its row is being edited and then whether to accept or undo the changes based on the user's actions. Typically, grids perform an undo operation if the user presses the Esc key, and an accept operation if the user presses Enter or moves off that row in the grid by any other means.
The INotifyPropertyChanged Interface
Editable business objects need to raise events to notify data binding any time their data values change. Changes that are caused directly by the user editing a field in a bound control are supported automatically—however, if the object updates a property value through code, rather than by direct user editing, the object needs to notify the data binding infrastructure that a refresh of the display is required.
The .NET Framework defines System.ComponentModel.INotifyPropertyChanged, which should be implemented by any bindable object. This interface defines the PropertyChanged event that data binding can handle to detect changes to data in the object.
The INotifyPropertyChanging Interface
In .NET 3.5, Microsoft introduced the System.ComponentModel.INotifyPropertyChanging interface so business objects can indicate when a property is about to be changed. Strictly speaking, this interface is optional and isn't (currently) used by data binding. For completeness, however, it is recommended that this interface be used when implementing INotifyPropertyChanged.
The INotifyPropertyChanging interface defines the PropertyChanging event that is raised before a property value is changed, as a complement to the PropertyChanged event that is raised after a property value has changed.
The IBindingList Interface
All business collections should implement the interface called System.ComponentModel.IBindingList. The simplest way to do this is to have the collection classes inherit from System.ComponentModel.BindingList<T>. This generic class implements all the collection interfaces required to support data binding:
IBindingListIListICollectionIEnumerableICancelAddNewIRaiseItemChangedEvents
As you can see, being able to inherit from BindingList<T> is very valuable. Otherwise, the business framework would need to manually implement all these interfaces.
This interface is used in grid-based binding, in which it allows the control that's displaying the contents of the collection to be notified by the collection any time an item is added, removed, or edited so that the display can be updated. Without this interface, there's no way for the data binding infrastructure to notify the grid that the underlying data has changed, so the user won't see changes as they happen.
Along this line, when a child object within a collection changes, the collection should notify the UI of the change. This implies that every collection object will listen for events from its child objects (via INotifyPropertyChanged) and in response to such an event will raise its own event indicating that the collection has changed.
The INotifyCollectionChanged Interface
In .NET 3.0, Microsoft introduced a new option for building lists for data binding. This new option only works with WPF and Silverlight and is not supported by Windows Forms or Web Forms. The System.ComponentModel.INotifyCollectionChanged interface defines a CollectionChanged event that is raised by any list implementing the interface. The simplest way to do this is to have the collection classes inherit from System.ComponentModel.ObservableCollection<T>. This generic class implements the interface and related behaviors.
When implementing a list or a collection you must choose to use either IBindingList or INotifyCollectionChanged. If you implement both, data binding in WPF will become confused, as it honors both interfaces and will always get duplicate events for any change to the list.
You should only choose to implement INotifyCollectionChanged or use ObservableCollection<T> if you are absolutely certain your application will only need to support WPF or Silverlight and never Windows Forms.
Because CSLA .NET supports Windows Forms and Web Forms along with WPF, the list and collection types defined in the framework implement IBindingList by subclassing BindingList<T>.
Events and Serialization
The events that are raised by business collections and business objects are all valuable. Events support the data binding infrastructure and enable utilization of its full potential. Unfortunately, there's a conflict between the idea of objects raising events and the use of .NET serialization via the Serializable attribute.
When an object is marked as Serializable, the .NET Framework is told that it can pass the object across the network by value. As part of this process, the object will be automatically converted into a byte stream by the .NET runtime. It also means that any other objects referenced by the object will be serialized into the same byte stream, unless the field representing it is marked with the NonSerialized attribute. What may not be immediately obvious is that events create an object reference behind the scenes.
When an object declares and raises an event, that event is delivered to any object that has a handler for the event. WPF forms and Windows Forms often handle events from objects, as illustrated in Figure 2-4.

How does the event get delivered to the handling object? It turns out that behind every event is a delegate—a strongly typed reference that points back to the handling object. This means that any object that raises events can end up with bidirectional references between the object and the other object/entity that is handling those events, as shown in Figure 2-5.

Even though this back reference isn't visible to developers, it's completely visible to the .NET serialization infrastructure. When serializing an object, the serialization mechanism will trace this reference and attempt to serialize any objects (including forms) that are handling the events. Obviously, this is rarely desirable. In fact, if the handling object is a form, this will fail outright with a runtime error because forms aren't serializable.
Note
If any nonserializable object handles events that are raised by a serializable object, you'll be unable to serialize the object because the .NET runtime serialization process will error out.
Solving this means marking the events as NonSerialized. It turns out that this requires a bit of special syntax when dealing with events. Specifically, a more explicit block structure must be used to declare the event. This approach allows manual declaration of the delegate field so it is possible to mark that field as NonSerialized. The BindingList<T> class already declares its event in this manner, so this issue only pertains to the implementation of INotifyPropertyChanged and INotifyPropertyChanging (or any custom events you choose to declare in your business classes).
The IDataErrorInfo Interface
Earlier I discussed the need for objects to implement business rules and expose information about broken rules to the UI. The System.ComponentModel.IDataErrorInfo interface is designed to allow data binding to request information about broken validation rules from a data source.
We will already have the tools needed to easily implement IDataErrorInfo, given that the object framework already helps the objects manage a list of all currently broken validation rules. This interface defines two methods. The first allows data binding to request a text description of errors at the object level, while the second provides a text description of errors at the property level.
By implementing this interface, the objects will automatically support the feedback mechanisms built into the Windows Forms DataGridView and ErrorProvider controls.
One of the biggest challenges facing a business developer building an object-oriented system is that a good object model is almost never the same as a good relational data model. Because most data is stored in relational databases using a relational model, we're faced with the significant problem of translating that data into an object model for processing and then changing it back to a relational model later on to persist the data from the objects back into the data store.
Note
The framework in this book doesn't require a relational model, but since that is the most common data storage technology, I focus on it quite a bit. You should remember that the concepts and code shown in this chapter can be used against XML files, object databases, or almost any other data store you are likely to use.
Relational vs. Object Modeling
Before going any further, let's make sure we're in agreement that object models aren't the same as relational models. Relational models are primarily concerned with the efficient storage of data, so that replication is minimized. Relational modeling is governed by the rules of normalization, and almost all databases are designed to meet at least the third normal form. In this form, it's quite likely that the data for any given business concept or entity is split between multiple tables in the database in order to avoid any duplication of data.
Object models, on the other hand, are primarily concerned with modeling behavior, not data. It's not the data that defines the object but the role the object plays within your business domain. Every object should have one clear responsibility and a limited number of behaviors focused on fulfilling that responsibility.
Tip
I recommend the book Object Thinking by David West (DV-Microsoft Professional, 2004) for some good insight into behavioral object modeling and design. Though my ideas differ somewhat from those in Object Thinking, I use many of the concepts and language from that book in my own object-oriented design work and in this book.
For instance, a CustomerEdit object may be responsible for adding and editing customer data. A CustomerInfo object in the same application may be responsible for providing read-only access to customer data. Both objects will use the same data from the same database and table, but they provide different behaviors.
Similarly, an InvoiceEdit object may be responsible for adding and editing invoice data. But invoices include some customer data. A naïve solution is to have the InvoiceEdit object make use of the aforementioned CustomerEdit object. That CustomerEdit object should only be used in the case where the application is adding or editing customer data—something that isn't occurring while working with invoices. Instead, the InvoiceEdit object should directly interact with the customer data it needs to do its job.
Through these two examples, it should be clear that sometimes multiple objects will use the same relational data. In other cases, a single object will use relational data from different data entities. In the end, the same customer data is being used by three different objects. The point, though, is that each one of these objects has a clearly defined responsibility that defines the object's behavior. Data is merely a resource the object needs to implement that behavior.
Behavioral Object-Oriented Design
It is a common trap to think that data in objects needs to be normalized like it is in a database. A better way to think about objects is to say that behavior should be normalized. The goal of object-oriented design is to avoid replication of behavior, not data.
At this point, most people are struggling. Most developers have spent years programming their brains to think relationally, and this view of object-oriented design flies directly in the face of that conditioning. Yet the key to the successful application of object-oriented design is to divorce object thinking from relational or data thinking.
Perhaps the most common objection at this point is this: if two objects (e.g., CustomerEdit and InvoiceEdit) both use the same data (e.g., the customer's name), how do you make sure that consistent business rules are applied to that data? And this is a good question.
The answer is that the behavior must be normalized. Business rules are merely a form of behavior. The business rule specifying that the customer name value is required, for instance, is just a behavior associated with that particular value.
Earlier in the chapter I discuss the idea that a validation rule can be reduced to a method defined by a delegate. A delegate is just an object that points to a method, so it is quite possible to view the delegate itself as the rule. Following this train of thought, every rule then becomes an object.
Behavioral object-oriented design relies heavily on the concept of collaboration. Collaboration is the idea that an object should collaborate with other objects to do its work. If an object starts to become complex, you can break the problem into smaller, more digestible parts by moving some of the sub-behaviors into other objects that collaborate with the original object to accomplish the overall goal.
In the case of a required customer name value, there's a Rule object that defines that behavior. Both the CustomerEdit and InvoiceEdit objects can collaborate with that Rule object to ensure that the rule is consistently applied. As you can see in Figure 2-6, the actual rule is only implemented once but is used as appropriate—effectively normalizing that behavior.
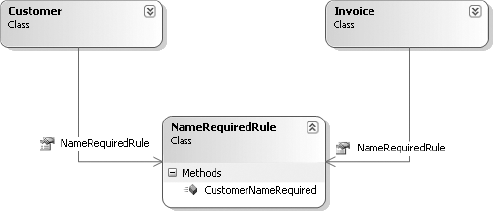
It could be argued that the CustomerName concept should become an object of its own and that this object would implement the behaviors common to the field. While this sounds good in an idealistic sense, it has serious performance and complexity drawbacks when implemented on development platforms such as .NET. Creating a custom object for every field in your application can rapidly become overwhelming, and such an approach makes the use of technologies such as data binding very complex.
My approach of normalizing the rules themselves provides a workable compromise: providing a high level of code reuse while still offering good performance and allowing the application to take advantage of all the features of the .NET platform.
In fact, the idea that a string value is required is so pervasive that it can be normalized to a general StringRequired rule that can be used by any object with a required property anywhere in an application. In Chapter 11, I implement a CommonRules class containing several common validation rules of this nature.
Object-Relational Mapping
If object models aren't the same as relational models (or some other data models that we might be using), some mechanism is needed by which data can be translated from the Data Storage and Management layer up into the object-oriented Business layer.
Note
This mismatch between object models and relational models is a well-known issue within the object-oriented community. It is commonly referred to as the impedance mismatch problem, and one of the best discussions of it can be found in David Taylor's book, Object-Oriented Technology: A Manager's Guide (Addison-Wesley, 1991).
Several object-relational mapping (ORM) products from various vendors, including Microsoft, exist for the .NET platform. In truth, however, most ORM tools have difficulty working against object models defined using behavioral object-oriented design. Unfortunately, most of the ORM tools tend to create "superpowered" DataSet equivalents, rather than true behavioral business objects. In other words, they create a data-centric representation of the business data and wrap it with business logic.
The differences between such a data-centric object model and what I am proposing in this book are subtle but important. Responsibility-driven object modeling creates objects that are focused on the object's behavior, not on the data it contains. The fact that objects contain data is merely a side effect of implementing behavior; the data is not the identity of the object. Most ORM tools, by contrast, create objects based around the data, with the behavior being a side effect of the data in the object.
Beyond the philosophical differences, the wide variety of mappings that you might need and the potential for business logic driving variations in the mapping from object to object make it virtually impossible to create a generic ORM product that can meet everyone's needs.
Consider the CustomerEdit object example discussed earlier. While the customer data may come from one database, it is totally realistic to consider that some data may come from SQL Server while other data comes through screen scraping a mainframe screen. It's also quite possible that the business logic will dictate that some of the data is updated in some cases but not in others. Issues such as these are virtually impossible to solve in a generic sense, and so solutions almost always revolve around custom code. The most a typical ORM tool can do is provide support for simple cases, in which objects are updated to and from standard, supported, relational data stores. At most, they provide hooks by which you can customize their behavior. Rather than trying to build a generic ORM product as part of this book, I'll aim for a much more attainable goal.
The framework in this book defines a standard set of four methods for creating, retrieving, updating, and deleting objects. Business developers will implement these four methods to work with the underlying data management tier by using the ADO.NET Entity Framework, LINQ to SQL, raw ADO.NET, the XML support in .NET, XML services, or any other technology required to accomplish the task. In fact, if you have an ORM (or some other generic data access) product, you'll often be able to invoke that tool from these four methods just as easily as using ADO.NET directly.
Note
The approach taken in this book and the associated framework is very conducive to code generation. Many people use code generators to automate the process of building common data access logic for their objects, thus achieving high levels of productivity while retaining the ability to create a behavioral object-oriented model.
The point is that the framework will simplify object persistence so that all developers need to do is implement these four methods in order to retrieve or update data. This places no restrictions on the object's ability to work with data and provides a standardized persistence and mapping mechanism for all objects.
Preserving Encapsulation
As I noted at the beginning of the chapter, one of my key goals is to design this framework to provide powerful features while following the key object-oriented concepts, including encapsulation. Encapsulation is the idea that all of the logic and data pertaining to a given business entity is held within the object that represents that entity. Of course, there are various ways in which one can interpret the idea of encapsulation—nothing is ever simple.
One approach is to encapsulate business data and logic in the business object and then encapsulate data access and ORM behavior in some other object: a persistence object. This provides a nice separation between the business logic and data access and encapsulates both types of behavior, as shown in Figure 2-7.

Although there are certainly some advantages to this approach, there are drawbacks, too. The most notable of these is that it can be challenging to efficiently get the data from the persistence object into or out of the business object. For the persistence object to load data into the business object, it must be able to bypass business and validation processing in the business object and somehow load raw data into it directly. If the persistence object tries to load data into the object using the object's public properties, you'll run into a series of issues:
The data already in the database is presumed valid, so a lot of processing time is wasted unnecessarily revalidating data. This can lead to a serious performance problem when loading a large group of objects.
There's no way to load read-only property values. Objects often have read-only properties for things such as the primary key of the data, and such data obviously must be loaded into the object, but it can't be loaded via the normal interface (if that interface is properly designed).
Sometimes properties are interdependent due to business rules, which means that some properties must be loaded before others or errors will result. The persistence object would need to know about all these conditions so that it could load the right properties first. The result is that the persistence object would become very complex, and changes to the business object could easily break the persistence object.
On the other hand, having the persistence object load raw data into the business object breaks encapsulation in a big way because one object ends up directly tampering with the internal fields of another. This could be implemented using reflection or by designing the business object to expose its private fields for manipulation. But the former is slow and the latter is just plain bad object design: it allows the UI developer (or any other code) to manipulate these fields, too. That's just asking for the abuse of the objects, which will invariably lead to code that's impossible to maintain.
What's needed is a workable compromise, where the actual data access code is in one object while the code to load the business object's fields is in the business object itself. This can be accomplished by creating a separate data access layer (DAL) assembly that is invoked by the business object. The DAL defines an interface the business object can use to retrieve and store information, as shown in Figure 2-8.

This is a nice compromise because it allows the business object to completely manage its own fields and yet keeps the code that communicates with the database cleanly separated into its own location.
There are several ways to implement such a DAL, including the use of raw ADO.NET and the use of LINQ to SQL. The raw ADO.NET approach has the benefit of providing optimal performance. In this case the DAL simply returns a DataReader to the business object and the object can load its fields directly from the data stream.
Creating the DAL using LINQ to SQL or the ADO.NET Entity Framework provides a higher level of abstraction and simplifies the DAL code. However, this approach is slower, because the data must pass through a set of data transfer objects (DTOs) or entity objects as it flows to and from the business object.
Note
In many CSLA .NET applications, the data access code is directly embedded within the business object. While this arguably blurs the boundary between layers, it often provides the best performance and the simplest code.
The examples in this book use a formal data access layer created using LINQ to SQL, but the same architecture supports creation of a DAL that uses raw ADO.NET or many other data access technologies.
Supporting Physical N-Tier Models
The question that remains then is how to support physical n-tier models if the UI-oriented and data-oriented behaviors reside in one object.
UI-oriented behaviors almost always involve a lot of properties and methods, with a very fine-grained interface with which the UI can interact in order to set, retrieve, and manipulate the values of an object. Almost by definition, this type of object must run in the same process as the UI code itself, either on the Windows client machine with WPF or Windows Forms or on the web server with Web Forms.
Conversely, data-oriented behaviors typically involve very few methods: create, fetch, update, delete. They must run on a machine where they can establish a physical connection to the data store. Sometimes this is the client workstation or web server, but often it means running on a physically separate application server.
This point of apparent conflict is where the concept of mobile objects enters the picture. It's possible to pass a business object from an application server to the client machine, work with the object, and then pass the object back to the application server so that it can store its data in the database. To do this, there needs to be some black-box component running as a service on the application server with which the client can interact. This black-box component does little more than accept the object from the client and then call methods on the object to retrieve or update data as required. But the object itself does all the real work. Figure 2-9 illustrates this concept, showing how the same physical business object can be passed from application server to client, and vice versa, via a generic router object that's running on the application server.
In Chapter 1, I discussed anchored and mobile objects. In this model, the business object is mobile, meaning that it can be passed around the network by value. The router object is anchored, meaning that it will always run on the machine where it's created.
In the framework, I'll refer to this router object as a data portal. It will act as a portal for all data access for all the objects. The objects will interact with this portal in order to retrieve default values (create), fetch data (read), update or insert data (update), and remove data (delete). This means that the data portal will provide a standardized mechanism by which objects can perform all create, read, update, delete (CRUD) operations.
The end result will be that each business class will include a factory method that the UI can call in order to load an object based on data from the database, as follows:
public static Customer GetCustomer(string customerId)
{
return DataPortal.Fetch<Customer>(
new SingleCriteria<Customer, string>(customerId));
}
Notice how the data portal concept abstracts the use of WCF, and so this code is far simpler than the WCF code used earlier in the chapter.
The actual data access code will be contained within each of the business objects. The data portal will simply provide an anchored object on a machine with access to the database server and will invoke the appropriate CRUD methods on the business objects themselves. This means that the business object will also implement a method that will be called by the data portal to actually load the data. That method will look something like this:
private void DataPortal_Fetch(SingleCriteria<Customer, string> criteria)
{
// Code to load the object's fields with data goes here
}The UI won't know (or need to know) how any of this works, so in order to create a Customer object, the UI will simply write code along these lines:
var cust = Customer.GetCustomer("ABC");The framework, and specifically the data portal, will take care of all the rest of the work, including figuring out whether the data access code should run on the client workstation or on an application server.
Using the data portal means that all the logic remains encapsulated within the business objects, while physical n-tier configurations are easily supported. Better still, by implementing the data portal correctly, you can switch between having the data access code running on the client machine and placing it on a separate application server just by changing a configuration file setting. The ability to change between 2- and 3-tier physical configurations with no changes to code is a powerful and valuable feature.
Application security is often a challenging issue. Applications need to be able to authenticate the user, which means that they need to verify the user's identity. The result of authentication is not only that the application knows the identity of the user but that the application has access to the user's role membership and possibly other information about the user. Collectively, I refer to this as the user's profile data. This profile data can be used by the application for various purposes, most notably authorization.
CSLA .NET directly supports integrated security. This means that you can use objects within the framework to determine the user's Windows identity and any domain or Active Directory (AD) groups to which they belong. In some organizations, this is enough; all the users of the organization's applications are in AD, and by having users log in to a workstation or a website using integrated security, the applications can determine the user's identity and roles (groups).
In other organizations, applications are used by at least some users who are not part of the organization's NT domain or AD. They may not even be members of the organization in question. This is very often the case with web and mobile applications, but it's surprisingly common with Windows applications as well. In these cases, you can't rely on Windows integrated security for authentication and authorization.
To complicate matters further, the ideal security model would provide user profile and role information not only to server-side code but also to the code on the client. Rather than allowing the user to attempt to perform operations that will generate errors due to security at some later time, the UI should gray out the options, or not display them at all. This requires that the developer has consistent access to the user's identity and profile at all layers of the application, including the UI, Business, and Data Access layers.
Remember that the layers of an application may be deployed across multiple physical tiers. Due to this fact, there must be a way of transferring the user's identity information across tier boundaries. This is often called impersonation.
Implementing impersonation isn't too hard when using Windows integrated security, but it's often problematic when relying on roles that are managed in a custom SQL Server database, an LDAP store, or any other location outside of AD.
The CSLA .NET framework will provide support for both Windows integrated security and custom authentication, in which you define how the user's credentials are validated and the user's profile data and roles are loaded. This custom security is a model that you can adapt to use any existing security tables or services that already exist in your organization. The framework will rely on Windows to handle impersonation when using Windows integrated or AD security and will handle impersonation itself when using custom authentication.
So far, I have focused on the major goals for the framework. Having covered the guiding principles, let's move on to discuss the design of the framework so it can meet these goals. In the rest of this chapter, I walk through the various classes that will combine to create the framework. After covering the design, in Chapters 6 through 16 I dive into the implementation of the framework code.
A comprehensive framework can be a large and complex entity. There are usually many classes that go into the construction of a framework, even though the end users of the framework—the business developers—only use a few of those classes directly. The framework discussed here and implemented in Chapters 6 through 16 accomplishes the goals I've just discussed, along with enabling the basic creation of object-oriented n-tier business applications. For any given application or organization, this framework will likely be modified and enhanced to meet specific requirements. This means that the framework will grow as you use and adapt it to your environment.
The CSLA .NET framework contains a lot of classes and types, which can be overwhelming if taken as a whole. Fortunately, it can be broken down into smaller units of functionality to better understand how each part works. Specifically, the framework can be divided into the following functional groups:
Business object creation
N-level undo functionality
Data binding support
Validation and business rules
A data portal enabling various physical configurations
Transactional and nontransactional data access
Authentication and authorization
Helper types and classes
For each functional group, I'll focus on a subset of the overall class diagram, breaking it down into more digestible pieces.
First, it's important to recognize that the key classes in the framework are those that business developers will use as they create business objects but that these are a small subset of what's available. In fact, many of the framework classes are never used directly by business developers. Figure 2-10 shows only those classes the business developer will typically use.

Obviously, the business developer may periodically interact with other classes as well, but these are the ones that will be at the center of most activity. Classes or methods that the business developer shouldn't have access to will be scoped to prevent accidental use.
Table 2-1 summarizes each class and its intended purpose.
Table 2.1. Business Framework Base Classes
Class | Purpose |
|---|---|
| Inherit from this class to create a single editable business object such as |
| Inherit from this class to create an editable collection of business objects such as |
| Inherit from this class to implement a collection of business objects, where changes to each object are committed automatically as the user moves from object to object (typically in a data bound grid control). |
| Inherit from this class to implement a command that should run on the application server, such as implementation of a |
| Inherit from this class to create a single read-only business object such as |
| Inherit from this class to create a read-only collection of objects such as |
| Inherit from this class to create a read-only collection of key/value pairs (typically for populating drop-down list controls) such as |
These base classes support a set of object stereotypes. A stereotype is a broad grouping of objects with similar behaviors or roles. The supported stereotypes are listed in Table 2-2.
Table 2.2. Supported Object Stereotypes
Let's discuss each stereotype in a bit more detail.
Editable Root
The BusinessBase class is the base from which all editable (read-write) business objects will be created. In other words, to create a business object, inherit from BusinessBase, as shown here:
[Serializable]
public class CustomerEdit : BusinessBase<CustomerEdit>
{
}When creating a subclass, the business developer must provide the specific type of new business object as a type parameter to BusinessBase<T>. This allows the generic BusinessBase type to expose strongly typed methods corresponding to the specific business object type.
Behind the scenes, BusinessBase<T> inherits from Csla.Core.BusinessBase, which implements the majority of the framework functionality to support editable objects. The primary reason for pulling the functionality out of the generic class into a normal class is to enable polymorphism. Polymorphism is what allows you to treat all subclasses of a type as though they were an instance of the base class. For example, all Windows Forms—Form1, Form2, and so forth—can be treated as type Form. You can write code like this:
Form form = new Form2(); form.Show();
This is polymorphic behavior, in which the variable form is of type Form but references an object of type Form2. The same code would work with Form1 because both inherit from the base type Form.
It turns out that generic types are not polymorphic like normal types.
Another reason for inheriting from a non-generic base class is to make it simpler to customize the framework. If needed, you can create alternative editable base classes starting with the functionality in Core.BusinessBase.
Csla.Core.BusinessBase and the classes from which it inherits provide all the functionality discussed earlier in this chapter, including n-level undo, tracking of broken rules, "dirty" tracking, object persistence, and so forth. It supports the creation of root objects (top-level) and child objects. Root objects are objects that can be retrieved directly from and updated or deleted within the database. Child objects can only be retrieved or updated in the context of their parent object.
Note
Throughout this book, it is assumed that you are building business applications, in which case almost all objects are ultimately stored in the database at one time or another. Even if an object isn't persisted to a database, you can still use BusinessBase to gain access to the n-level undo and business, validation, and authorization rules and change tracking features built into the framework.
For example, an InvoiceEdit is typically a root object, though the LineItem objects contained by an InvoiceEdit object are child objects. It makes perfect sense to retrieve or update an InvoiceEdit, but it makes no sense to create, retrieve, or update a LineItem without having an associated InvoiceEdit.
The BusinessBase class provides default implementations of the data access methods that exist on all root business objects.
Note
The default implementations are a holdover from a very early version of the framework. They still exist to preserve backward compatibility to support users who have been using CSLA .NET for many years and over many versions.
These methods will be called by the data portal mechanism. These default implementations all raise an error if they're called. The intention is that the business objects can opt to override these methods if they need to support, create, fetch, insert, update, or delete operations. The names of these methods are as follows:
DataPortal_Create()DataPortal_Fetch()DataPortal_Insert()DataPortal_Update()DataPortal_DeleteSelf()DataPortal_Delete()
Though virtual implementations of these methods are in the base class, developers will typically implement strongly typed versions of DataPortal_Create(), DataPortal_Fetch(), and DataPortal_Delete(), as they all accept a criteria object as a parameter. The virtual methods declare this parameter as type object, of course; but a business object will typically want to use the actual data type of the criteria object itself. This is discussed in more detail in Chapters 15 and 18.
The data portal also supports three other (optional) methods for pre- and post-processing and exception handling. The names of these methods are as follows:
DataPortal_OnDataPortalInvoke()DataPortal_OnDataPortalInvokeComplete()DataPortal_OnDataPortalException()
Editable root objects are very common in most business applications.
Editable Child
Editable child objects are always contained within another object and they cannot be directly retrieved or stored in the database. Ultimately there's always a single editable root object that is retrieved or stored.
BusinessBase includes a method that can be called to indicate that the object is a child object: MarkAsChild(). Normally this method is invoked automatically by CSLA .NET as the object instance is created by the data portal. This means that a child object might look like this:
[Serializable]
public class Child : BusinessBase<Child>
{
}Notice that there's no different from the previous root object. If for some reason you do not use the data portal (discussed later in the "Data Portal" section) to create instances of your objects, you may need to call MarkAsChild() manually in the object's constructor:
[Serializable]
public class Child : BusinessBase<Child>
{
private Child()
{
MarkAsChild();
}
}The data access methods for a child object are different from those of a root object. The names of these methods are as follows:
Child_Create()Child_Fetch()Child_Insert()Child_Update()Child_DeleteSelf()
The BusinessBase class does not provide virtual implementations of these methods; they must be explicitly declared by the author of the child class. These methods are called by the data portal to notify each child object when it should perform its data persistence operations.
BusinessBase provides a great deal of functionality to the business objects, whether root or child. Chapter 6 covers the implementation of BusinessBase itself, and Chapters 17 and 18 show how to create business objects using BusinessBase.
Editable Root List
The BusinessListBase class is the base from which all editable collections of business objects are created. Given an InvoiceEdit object with a collection of LineItem objects, BusinessListBase is the base for creating that collection:
[Serializable]
public class LineItems : BusinessListBase<LineItems, LineItem>
{
}When creating a subclass, the business developer must provide the specific types of his new business collection, and the child objects the collection contains, as type parameters to BusinessListBase<T,C>. This allows the generic type to expose strongly typed methods corresponding to the specific business collection type and the type of the child objects.
The result is that the business collection automatically has a strongly typed indexer, along with strongly typed Add() and Remove() methods. The process is the same as if the object had inherited from System.ComponentModel.BindingList<T>, except that this collection will include all the functionality required to support n-level undo, object persistence, and the other business object features.
Note
BusinessListBase inherits from System.ComponentModel.BindingList<T>, so it starts with all the core functionality of a data-bindable .NET collection.
The BusinessListBase class also defines the data access methods discussed previously in the section on BusinessBase. This allows retrieval of a collection of objects directly (rather than a single object at a time), if that's what is required by the application design. Typically only the following methods are implemented in a list:
DataPortal_Create()DataPortal_Fetch()
There is a DataPortal_Update() method, but BusinessListBase provides a default implementation that is usually sufficient to save all objects contained in the list.
Editable Child List
The BusinessListBase class also defines the MarkAsChild() method discussed in the previous "Editable Child" section. This is typically called automatically when an instance of the class is created by the data portal and indicates that the list is a child of some other object.
When creating a child list, the developer will typically implement the following data access methods:
Child_Create()Child_Fetch()
There is a Child_Update() method but BusinessListBase provides a default implementation that is usually sufficient to save all objects contained in the list.
Dynamic Root List
The EditableRootListBase class is the base from which collections of editable root business objects can be created. This stereotype and base class exist to support a very specific scenario where the list is data bound to a Windows Forms grid control, allowing the user to do in-place editing of the data in the grid.
In that data bound grid scenario, when using a dynamic root list, all changes to data on a row in the grid are committed as soon as the user moves off that row. If the user deletes a row, the object is immediately deleted. If the user edits a value and moves up or down to another row, that change is immediately saved.
This is fundamentally different from an editable root list, where the user's changes to items in the list aren't committed to the database until the UI saves the entire list.
Given a CategoryList object with a collection of CategoryEdit objects, EditableRootListBase will be the base for creating that collection:
[Serializable]
public class CategoryList : EditableRootListBase<CategoryEdit>
{
}When creating a subclass, the business developer must provide the specific type of the objects the collection contains. The contained objects should be editable root objects, with one variation. Rather than implementing DataPortal_Fetch(), they will typically implement Child_Fetch() so they can be loaded into memory by the containing collection.
Like BusinessListBase, EditableRootListBase inherits from BindingList<T> and so supports all the rich data binding behaviors provided by .NET.
A dynamic root list will usually implement only one data access method: DataPortal_Fetch(). Again, this stereotype and base class exist to serve a very specific function; but when dynamic in-place editing of data in a Windows Forms grid is required, this is a very useful approach.
Command
Most applications consist not only of interactive forms or pages (which require editable objects and collections) but also of non-interactive processes. In a one- or two-tier physical model, these processes run on the client workstation or web server, of course. But in a three-tier model, they should run on the application server to have optimal access to the database server or other back-end resources.
Common examples of non-interactive processes include tasks as simple as checking to see if a specific customer or product exists and as complex as performing all the back-end processing required to ship and order or post an invoice.
The CommandBase class provides a clear starting point for implementing these types of behaviors. A command object is created on the client and initialized with the data it needs to do its work on the server. It is then executed on the server through the data portal. Unlike other objects, however, command objects implement a special execute method:
DataPortal_Execute()
The optional pre-, post-, and exception data portal methods can also be implemented if desired. But the DataPortal_Execute() method is the important one, since that is where the business developer writes the code to implement the non-interactive back-end processing.
I make use of CommandBase in Chapter 17 when implementing the sample application objects.
Read-Only Root and Child
Sometimes applications don't want to expose an editable object. Many applications have objects that are read-only or display-only. Read-only objects need to support object persistence only for retrieving data, not for updating data. Also, they don't need to support any of the n-level undo or other editing-type behaviors because they're created with read-only properties.
For editable objects, there's BusinessBase, which has a property that can be set to indicate whether it's a parent or child object. The same base supports both types of objects, allowing dynamic switching between parent and child at runtime.
Making an object read-only or read-write is a bigger decision because it impacts the interface of the object. A read-only object should only include read-only properties as part of its interface, and that isn't something you can toggle on or off at runtime. You can make objects read-only, and consequently more specialized and with less overhead, by implementing a specific base class.
The ReadOnlyBase class is used to create read-only objects, as follows:
[Serializable]
public class StaticContent : ReadOnlyBase<StaticContent>
{
}Classes shouldn't implement any read-write properties. If this were to happen, it would be entirely up to the code in the object to handle any undo, persistence, or other features for dealing with the changed data. If an object has editable properties, it should subclass from BusinessBase.
Read-only objects include authorization rules so the object can control which users can view each property. Obviously they don't implement business or validation rules because such rules are only invoked when a property changes, and that won't happen with read-only properties.
ReadOnly Root and Child List
Not only do applications sometimes need read-only business objects, they also commonly require immutable collections of objects. The ReadOnlyListBase class lets you create strongly typed collections of objects, whereby the object and collection are both read-only:
[Serializable]
public class StaticList : ReadOnlyListBase<StaticList, ChildType>
{
}As with ReadOnlyBase, this object supports only the retrieval of data. It has no provision for updating data or handling changes to its data. While the child objects in such a collection may inherit from ReadOnlyBase, they don't have to. More commonly, the child objects in a read-only collection are just simple .NET objects that merely expose read-only properties.
Name/Value List
The NameValueListBase class is designed specifically to support the idea of lookup tables or lists of read-only key/value data such as categories, customer types, product types, and so forth. The goal of this class is to simplify the process of retrieving such data and displaying it in common controls such as drop-down lists, combo boxes, and other list controls. The following shows the beginnings of a custom name/value list:
[Serializable]
public class CodeList : NameValueListBase<int, string>
{
}While the business developer does need to create a specific class for each type of name/value data, inheriting from this base class largely trivializes the process.
There are a couple similar types in the System.Collections.Specialized namespace: NameObjectCollectionBase and NameValueCollection. These types don't automatically integrate with the rest of the CSLA .NET framework for tasks such as object persistence and don't fully support data binding.
The implementation of n-level undo functionality is quite complex and involves heavy use of reflection. Fortunately, you can use inheritance to place the implementation in a base class so that no business object needs to worry about the undo code. In fact, to keep things cleaner, this code is in its own base class, separate from any other business object behaviors, as shown in Figure 2-11.
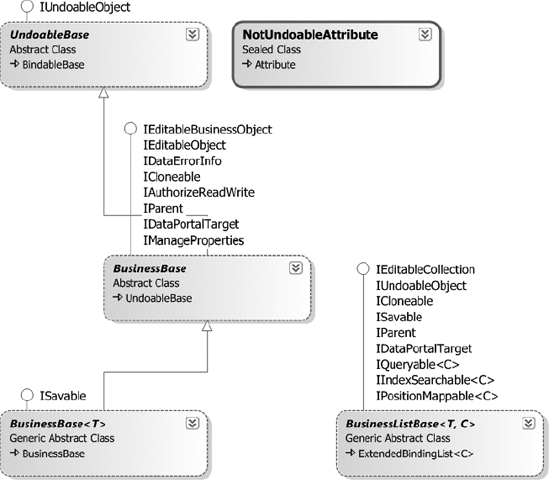
At first glance, it might appear that you could use .NET serialization to implement undo functionality: what easier way to take a snapshot of an object's state than to serialize it into a byte stream? Unfortunately, this isn't as easy as it might sound, at least when it comes to restoring the object's state.
Taking a snapshot of a Serializable object is easy and can be done with code similar to this:
[Serializable]
public class Customer
{
public byte[] Snapshot()
{
using (var buffer = new MemoryStream())
{
var formatter = new BinaryFormatter();
formatter.Serialize(buffer, this);
buffer.Position = 0;
return buffer.ToArray();
}
}
}This converts the object into a byte stream, returning that byte stream as an array of type byte. That part is easy—it's the restoration that's tricky. Suppose that the user now wants to undo the changes, requiring that the byte stream be restored back into the object. The code that deserializes a byte stream looks like this:
[Serializable]
public class Customer
{
public Customer Deserialize(byte[] state)
{
using (var buffer = new MemoryStream(state))
{
var formatter = new BinaryFormatter();
return (Customer) formatter.Deserialize(buffer);
}
}
}Notice that this function returns a new customer object. It doesn't restore the existing object's state; it creates a new object. Somehow, you would have to tell any and all code that has a reference to the existing object to use this new object. In some cases, that might be easy to do, but it isn't always trivial. In complex applications, it's hard to guarantee that other code elsewhere in the application doesn't have a reference to the original object; and if you don't somehow get that code to update its reference to this new object, it will continue to use the old one.
What's needed is some way to restore the object's state in place, so that all references to the current object remain valid but the object's state is restored. This is the purpose of the UndoableBase class.
UndoableBase
The BusinessBase class inherits from UndoableBase and thereby gains n-level undo capabilities. Because all business objects inherit from BusinessBase, they too gain n-level undo. Ultimately, the n-level undo capabilities are exposed to the business object and to UI developers via three methods:
BeginEdit()tells the object to take a snapshot of its current state, in preparation for being edited. Each timeBeginEdit()is called, a new snapshot is taken, allowing the state of the object to be trapped at various points during its life. The snapshot will be kept in memory so the data can be easily restored to the object ifCancelEdit()is called.CancelEdit()tells the object to restore the object to the most recent snapshot. This effectively performs an undo operation, reversing one level of changes. IfCancelEdit()is called the same number of times asBeginEdit(), the object will be restored to its original state.ApplyEdit()tells the object to discard the most recent snapshot, leaving the object's current state untouched. It accepts the most recent changes to the object. IfApplyEdit()is called the same number of times asBeginEdit(), all the snapshots will be discarded, essentially making any changes to the object's state permanent.
Sequences of BeginEdit(), CancelEdit(), and ApplyEdit() calls can be combined to respond to the user's actions within a complex Windows Forms UI. Alternatively, you can totally ignore these methods, taking no snapshots of the object's state. In such a case, the object will incur no overhead from n-level undo, but it also won't have the ability to undo changes. This is common in web applications in which the user has no option to cancel changes. Instead, the user simply navigates away to perform some other action or view some other data.
The Csla.Core.ISupportUndo interface exists to allow UI developers and framework authors to polymorphically invoke these three methods on any object that supports the concept. The BusinessBase and BusinessListBase classes already implement this interface.
Supporting Child Objects
As it traces through a business object to take a snapshot of the object's state, UndoableBase may encounter child objects. For n-level undo to work for complex objects as well as simple objects, any snapshot of object state must extend down through all child objects as well as the parent object.
I discussed this earlier with the InvoiceEdit and LineItem example. When BeginEdit() is called on an InvoiceEdit, it must also take snapshots of the states of all its LineItem objects because they're technically part of the state of the InvoiceEdit object itself. To do this while preserving encapsulation, each individual object takes a snapshot of its own state so that no object data is ever made available outside the object, thus preserving encapsulation for each object.
However, to complicate matters, a BeginEdit() call on a parent object does not cascade to its child objects when BeginEdit() is called through the IEditableObject interface. This is because data binding, which uses IEditableObject, gets confused if that happens and the child objects will end up out of sync with the parent, resulting in very hard to debug issues with data bound interfaces.
In that case, UndoableBase simply calls a method on the child object to cascade the BeginEdit(), CancelEdit(), or ApplyEdit() call to that object. It is then up to the individual child object to take a snapshot of its own data. In other words, each object is responsible for managing its own state, including taking a snapshot and potentially restoring itself to that snapshot later.
UndoableBase implements Core.IUndoableObject, which simplifies the code in the class. This interface defines the methods required by UndoableBase during the undo process.
A child object could also be a collection derived from BusinessListBase. Notice that BusinessListBase implements the Core.IEditableCollection interface, which inherits from the Core.IUndoableObject interface.
The final concept to discuss regarding n-level undo is the idea that some data might not be subject to being in a snapshot. Taking a snapshot of an object's data takes time and consumes memory; there's no reason to take a snapshot if the object includes read-only values. Because the values can't be changed, there's no benefit in restoring them to the same value in the course of an undo operation.
To accommodate this scenario, the framework includes a custom attribute named NotUndoableAttribute, which you can apply to fields within your business classes, as follows:
[NotUndoable]
private string _readonlyData;The code in UndoableBase simply ignores any fields marked with this attribute as the snapshot is created or restored, so the field will always retain its value regardless of any calls to BeginEdit(), CancelEdit(), or ApplyEdit() on the object.
You should be aware that the n-level undo implementation doesn't handle circular references, so if you have a field that references another object in a way that would cause a circular reference, you must mark the field as NotUndoable to break the circle.
As I discuss earlier in the chapter, the .NET data binding infrastructure directly supports the concept of data binding to objects and collections. However, an object can provide more complete behaviors by implementing a few interfaces in the framework base classes. Table 2-3 lists the interfaces and their purposes.
Table 2.3. .NET Data Binding Interfaces
Interface | Purpose |
|---|---|
| Defines data binding behaviors for collections, including change notification, sorting, and filtering (implemented by |
| Defines data binding behaviors for collections to allow data binding to cancel addition of a new child object (implemented by |
| Indicates that a collection object will raise a |
| Defines a |
| Defines single-level undo behavior for a business object, allowing the object to behave properly with in-place editing in a |
| Defines an event allowing an object to notify data binding when a property has been changed |
| Defines an event allowing an object to notify listeners when a property is about to be changed |
| Defines properties used by the |
The IBindingList interface is a well-defined interface that (among other things) raises a single event to indicate that the contents of a collection have changed. Fortunately, there's the System.ComponentModel.BindingList<T> base class that already implements this interface, so virtually no effort is required to gain these benefits.
As mentioned earlier, INotifyCollectionChanged and the corresponding ObservableCollection<T> class are WPF-only replacements for IBindingList and BindingList<T>. You should only implement one or the other solution, and CSLA .NET uses BindingList<T> to gain support for Windows Forms as well as WPF.
The System.ComponentModel.INotifyPropertyChanged and INotifyPropertyChanging interface members are a bit more complex. These interfaces define events that a business object should raise any time a property value is changing or changed. As discussed earlier, in a serializable object, events must be declared using a more explicit syntax than normal so the delegate references can be marked as NonSerialized.
The BindableBase class exists to encapsulate this event declaration and related functionality. This acts as the ultimate base class for BusinessBase<T>, while BindingList<T> is the base class for BusinessListBase<T,C>, as shown in Figure 2-12.

Combined with implementing System.ComponentModel.IEditableObject and System.ComponentModel.IDataErrorInfo in BusinessBase, the objects can fully support data binding in WPF, Windows Forms, and Web Forms.
The CSLA .NET list base classes don't support sorting of a collection through IBindingList. They do provide support for LINQ, however, which means you can use LINQ to CSLA queries to sort or filter the items in any CSLA list.
Note
CSLA .NET does include SortedBindingList and FilteredBindingList classes that provide sorted and filtered views against any collection derived from IList<T> (which in turn means any BindingList<T>). These solutions are obsolete with LINQ but remain in the framework for backward compatibility.
ExtendedBindingList Class
The list base classes inherit from ExtendedBindingList<T>, which is a specialized subclass of BindingList<T> that adds a couple important features "missing" from the standard .NET base class.
Most notably, it adds the RemovingItem event, which notifies a business object author that a child object is being removed, including providing a reference to the child object. The standard ListChanged event is useful, but it is raised after the child has been removed, and so there's no way to get a reference to the removed child.
This class also implements a ChildChanged event. Unlike the PropertyChanged or ListChanged events, the ChildChanged event bubbles up through all parent objects to the root object. This means the UI developer can handle the ChildChanged event on any editable root object to be notified when any child object has been changed.
The ExtendedBindingList class also adds an AddRange() method, which makes it easier for a business developer to add multiple items to a collection. This feature is particularly useful when using LINQ to SQL or LINQ to Entities to initialize a collection with data from the data store.
Finally, the class implements the IsSelfBusy and IsBusy properties and related functionality required to support the asynchronous object persistence behaviors discussed in Chapter 15. The IsBusy property returns true while any asynchronous operation is in progress for this object or objects contained in the collection. The IsSelfBusy property returns true while any asynchronous operation is in progress for this object (but not the child objects it contains).
While BindingList<T> does nearly everything required to support data binding, the ExtendedBindingList<T> adds some important features that improve the usability of all CSLA .NET collection base classes.
Recall that one of the framework's goals is to simplify and standardize the creation of business and validation rules. It also automates the tracking of broken validation rules. An important side benefit of this is that the UI developer will have read-only access to the list of broken rules, which means that the descriptions of the broken rules can be displayed to the user in order to explain what's making the object invalid.
The support for tracking broken business rules is available to all editable business objects, so it's implemented at the BusinessBase level in the framework. To provide this functionality, each business object has an associated collection of broken business rules. Additionally, a rule is defined as a method that returns a Boolean value indicating whether the business requirement is met. In the case that the result is false (the rule is broken), a rule also returns a text description of the problem for display to the user.
To automate this process, each business object has an associated list of rule methods for each property in the object.
Figure 2-13 illustrates all the framework classes required to implement both the management of rule methods and maintenance of the list of broken rule descriptions.

A business object taps into this functionality through methods exposed on BusinessBase. The end result is that a business property is always coded in a consistent manner. In the following example, the highlighted line of code triggers the validation rules behavior:
private static PropertyInfo<string> NameProperty =
RegisterProperty<string>(new PropertyInfo<string>(typeof(Customer), "Name"));
public string Name
{
get { return GetProperty<string>(NameProperty); }
set { SetProperty<string>(NameProperty, value); }
}Behind the scenes, the SetProperty() method calls a ValidationRules.CheckRules() method to trigger all rules associated with this property. You can call that method directly if you need to force rules to be checked at other times during the object's life cycle.
You'll see more complete use of the validation rules functionality in Chapter 17, during the implementation of the sample application.
There are three types of functionality displayed in Figure 2-13. The ValidationRules, RuleHandler, RuleArgs, and ValidationException classes manage the rule methods associated with the properties of an object. The BrokenRulesCollection and BrokenRule classes maintain a list of currently broken validation rules for an object. Finally, the CommonRules class implements a set of commonly used validation rules, such as StringRequired.
Managing Rule Methods
Business rules are defined by a specific method signature as declared in the RuleHandler delegate:
public delegate bool RuleHandler(object target, RuleArgs e);
There are also two generic variations on this signature:
public delegate bool RuleHandler<T>(T target, RuleArgs e); public delegate bool RuleHandler<T, R>(T target, R e);
Each business object contains an instance of the ValidationRules object, which in turn maintains a list of rules for each property in the business object. Within ValidationRules there is an optimized data structure that is used to efficiently store and access a list of rules for each property. This allows the business object to request that validation rules for a specific property be executed, or that all rules for all properties be executed.
Each rule method returns a Boolean value to indicate whether the rule is satisfied. If a rule is broken, it returns false. A RuleArgs object is passed to each rule method. This object includes a Description property that the rule can set to describe the nature of a broken rule.
As ValidationRules executes each rule method, it watches for a response. When it gets a negative response, it adds an item to the BrokenRulesCollection for the business object. On the other hand, a positive response causes removal of any corresponding item in BrokenRulesCollection.
Finally, there's the ValidationException class. A ValidationException is not thrown when a rule is broken, since the broken rule is already recorded in BrokenRulesCollection. Instead, ValidationException is thrown by BusinessBase itself in the case that there's an attempt to save the object to the database when it's in an invalid state.
Maintaining a List of Broken Rules
The ValidationRules object maintains a list of rule methods associated with an object. It also executes those methods to check the rules, either for a specific property or for all properties. The end result of that process is that descriptions for broken rules are recorded into the BrokenRulesCollection associated with the business object.
The BrokenRulesCollection is a list of BrokenRule objects. Each BrokenRule object represents a validation rule that is currently broken by the data in the business object. These BrokenRule objects are added and removed from the collection by ValidationRules as part of its normal processing.
The BusinessBase class uses its BrokenRulesCollection to implement an IsValid property. IsValid returns true only if BrokenRulesCollection contains no items. If it does contain items, the object is in an invalid state.
The primary point of interest with the BusinessRulesCollection is that it is designed to not only maintain a list of current broken rules but also to provide read-only access to the UI. This is the reason for implementing a specialized collection object that can change its own data but is seen by the UI as being read-only. On top of that, the base class implements support for data binding so that the UI can display a list of broken rule descriptions to the user by simply binding the collection to a list or grid control.
Additionally, the implementation of IDataErrorInfo makes use of the BrokenRulesCollection to return error text for the object or for individual properties. Supporting this interface allows WPF data binding and the Windows Forms DataGridView and ErrorProvider controls to automatically display validation error text to the user.
Implementing Common Rules
If you consider the validation rules applied to most properties, there's a set of common behaviors that occur time and time again. For example, there's the idea that a string value is required, or that a string has a maximum length.
Rather than requiring every business application to implement these same behaviors over and over again, you can have them be supplied by the framework. As you'll see in Chapter 11, the implementation makes use of reflection—so there's a performance cost. If you find in your particular application that performance cost to be too high, you can always do what you would have done anyway—that is, write the rule implementation directly into the application. In most cases, however, the benefit of code reuse will outweigh the small performance cost incurred by reflection.
Supporting object persistence—the ability to store and retrieve an object from a database—can be quite complex. This is covered earlier in the chapter during the discussion about basic persistence and the concept of ORM.
As you'll see in Chapter 18, data access logic is encapsulated within the formal data access layer assembly, which is invoked by the business objects. This data access assembly must be deployed to the physical tier that will execute the data access code.
At the same time, however, you don't want to be in a position in which a change to your physical architecture requires every business object in the system to be altered. The ability to easily switch between having the data access code run on the client machine and having it run on an application server is the goal, with that change driven by a configuration file setting.
On top of this, when using an application server, not every business object in the application should be directly exposed by the server. This would be a maintenance and configuration nightmare because it would require updating configuration information on all client machines any time a business object is added or changed.
Note
This is a lesson learned from years of experience with DCOM and MTS/COM+. Exposing large numbers of components, classes, and methods from a server almost always results in a tightly coupled and fragile relationship between clients and the server.
Instead, it would be ideal if there were one consistent entry point to the application server so that every client could simply be configured to know about that single entry point and never have to worry about it again. This is exactly what the data portal concept provides, as shown in Figure 2-14.
The data portal provides a single point of entry and configuration for the server. It manages communication with the business objects while they're on the server running their data access code. Additionally, the data portal concept provides the following other key benefits:
Centralized security when calling the application server
A consistent object-persistence mechanism (all objects persist the same way)
Abstraction of the network transport between client and server (enabling support for WCF, remoting, web services, Enterprise Services, and custom protocols)
One point of control to toggle between running the data access code locally or on a remote application server

The data portal functionality is designed in several parts, as shown in Table 2-4.
Table 2.4. Parts of the Data Portal Concept
Area | Functionality |
|---|---|
Client-side | Functions as the primary entry point to the data portal infrastructure, for use by code in business objects |
Implements the channel adapter pattern to abstract the underlying network protocol from the application | |
Message objects | Transfers data to and from the server, including security information, application context, the business object's data, the results of the call, or any server-side exception data |
Server-side host classes | Exposes single points of entry for different server hosts, such as WCF, remoting, |
Server-side data portal | Implements transactional and nontransactional data access behaviors, delegating all actual data access to appropriate business objects |
Server-side child data portal | Implements data access behaviors for objects that are contained within other objects |
Object factory | Provides an alternate model for the data portal, where the data portal creates and invokes a factory object instead of interacting directly with the business object |
Let's discuss each area of functionality in turn.
Client-Side DataPortal
The client-side DataPortal is implemented as a static class, which means that any public methods it exposes become available to business object code without the need to create a DataPortal object. The methods it provides are Create(), Fetch(), Update(), Delete(), and Execute(). Business objects and collections use these methods to retrieve and update data, or in the case of a CommandBase-derived object, to execute server code on the server.
The client-side DataPortal has a great deal of responsibility, however, since it contains the code to read and act on the client's configuration settings. These settings control whether the "server-side" data portal components will actually run on the server or locally on the client. It also looks at the business object itself, since a RunLocal attribute can be used to force persistence code to run on the client, even if the configuration says to run it on the server.
Either way, the client-side DataPortal always delegates the call to the server-side data portal, which handles the actual object-persistence behaviors. However, if the client configuration indicates that the server-side data portal really will run on a server, the configuration will also specify which network transport should be used. It is the client-side DataPortal that reads that configuration and loads the appropriate client-side proxy object. That proxy object is then responsible for handling the network communication.
As an object is implemented, its code will use the client-side DataPortal to retrieve and update the object's information. An automatic result is that the code in the business object won't need to know about network transports or whether the application is deployed into a 1-, 2-, or n-tier physical environment. The business object code always looks something like this:
public static Customer GetCustomer(string id)
{
return DataPortal.Fetch<Customer>(new SingleCriteria<Customer, string>(id));
}An even more important outcome is that any UI code using these business objects will look something like this:
var cust = Customer.GetCustomer(myId);
Neither of these code snippets changes, regardless of whether you've configured the server-side data portal to run locally or on a remote server via WCF, remoting, web services, or Enterprise Services. All that changes is the application's configuration file.
Client-Side Proxies
While it is the client-side DataPortal that reads the client configuration to determine the appropriate network transport, the client-side proxy classes actually take care of the details of each network technology. There is a different proxy class for each technology: WCF, remoting, web services, and Enterprise Services.
The design also allows for a business application to provide its own proxy class to use other protocols. This means you can write your own TCP sockets protocol if you are so inclined.
The WCF proxy can use any synchronous channel supported by WCF. The data portal requires synchronous communication between client and server but otherwise doesn't care which WCF channel is actually used (HTTP, TCP, etc.). Additionally, you can configure WCF using any of its normal options, such as encryption.
The remoting and web services proxies use the HTTP protocol for communication across the network. This makes both of them firewall and Internet friendly. The Enterprise Services proxy uses DCOM for communication across the network. This is often faster than HTTP but harder to configure for firewalls or the Internet. Both HTTP and DCOM can be configured to encrypt data on the wire and so provide quite high levels of security if needed.
Every client-side proxy has a corresponding server-side host class. This is because each transport protocol requires that both ends of the network connection use the same technology.
The client-side DataPortal simply creates an instance of the appropriate client-side proxy and then delegates the request (Create, Fetch, Update, Delete, or Execute) to the proxy object. The proxy object is responsible for establishing a network connection to the server-side host object and delegating the call across the network.
The proxy must also pass other message data, such as security and application context, to the server. Similarly, the proxy must receive data back from the server, including the results of the operation, application context information, and any exception data from the server.
To this last point, if an exception occurs on the server, the full exception details are returned to the client. This includes the nature of the exception, any inner exceptions, and the stack trace related to the exception. This exception information will often be used on the client to rethrow the exception, giving the illusion that the exception flows naturally from the code on the server back to the code on the client.
Message Objects
When the client-side DataPortal calls the server-side data portal, several types of information are passed from client to server. Obviously, the data method call (Create, Update, Insert, etc.) itself is transferred from client to server. But other information is also included, as follows:
Client-side context data (such as the client machine's culture setting)
Application-wide context data (as defined by the application)
The user's principal and identity security objects (if using custom authentication)
Client-side context data is passed one way, from the client to the server. This information may include items such as the client workstation's culture setting, thus allowing the server-side code to also use that context when servicing requests for that user. This can be important for localization of an application when a server may be used by workstations in different nations.
Application-wide context data is passed both from client to server and from server back to client. You may use this context data to pass arbitrary application-specific data between client and server on each data portal operation. This can be useful for debugging, as it allows you to build up a trace log of the call as it goes from client to server and back again.
CSLA .NET also includes the concept of local context, which is not passed from client to server or server to client. Local context exists on the client and the server, but each has its own separate context.
If the application is using custom authentication, the custom principal and identity objects representing the user are passed from client to server. This means the code on the server will run under the same security context as the client. If you are using Windows integrated or AD security, you must configure your network transport technology (WCF, remoting, etc.) to handle the impersonation.
When the server-side data portal has completed its work, the results are returned to the client. Other information is also included, as follows:
Application-wide context data (as defined by the application)
Details about any server-side exception that may have occurred
Again, the application-wide context data is passed from client to server and from server to client. If an exception occurs on the server, the details about that exception are returned to the client. This is important for debugging, as it means you get the full details about any issues on the server. It is also important at runtime, since it allows you to write exception handling code on the client to gracefully handle server-side exceptions—including data-oriented exceptions such as duplicate key or concurrency exceptions.
The preceding information is passed to and from the server on each data portal operation. Keeping in mind that the data portal supports several verbs, it is important to understand what information is passed to and from the server to support each verb. This is listed in Table 2-5.
Table 2.5. Data Passed to and from the Server for Data Portal Operations
Verb | To Server | From Server |
|---|---|---|
| Type of object to create and (optional) criteria about new object | New object loaded with default values |
| Type of object to retrieve and criteria for desired object | Object loaded with data |
| Object to be updated | Object after update (possibly containing changed data) |
| Type of object to delete and criteria for object to be deleted | Nothing |
| Object to be executed (must derive from | Object after execution (possibly containing changed data) |
Notice that the Create, Fetch, and Delete operations all use criteria information about the object to be created, retrieved, or removed. A criteria object contains any data you need to describe your particular business object. A criteria object can be created one of three ways:
By using the
SingleCriteriaclass provided by CSLA .NETBy creating a nested class within your business class
By creating a class that inherits from
CriteriaBase
The SingleCriteria class is a generic type that passes a single criteria value to the server. You specify the type of the value and the value itself. Since most objects are identified by a single unique value, this class can be used to create, fetch, and delete most objects.
If your object has more complex criteria, perhaps a compound key in the database or a set of filter values, you'll need to create your own custom criteria class, either as a nested class or by subclassing CriteriaBase.
When a criteria class is nested within a business class, the .NET type system can be used to easily determine the type of class in which the criteria is nested. The CriteriaBase class, on the other hand, directly includes a property you must set, indicating the type of the business object.
In either case, your custom criteria class should include properties containing any specific information you need in order to identify the specific object to be created, retrieved, or removed.
Server-Side Host Objects
I've already discussed the client-side proxy objects and how each one has a corresponding server-side host object. In Chapter 15, I show how the WCF host object is created. You can look at the CSLA .NET code to see how the other three host objects work for remoting, web services, and Enterprise Services. It is also possible to add new host objects without altering the core framework, providing broad extensibility. Any new host object would need a corresponding client-side proxy, of course.
Server-side host objects are responsible for two things: first, they must accept inbound requests over the appropriate network protocol from the client, and those requests must be passed along to the server-side data portal components; second, the host object is responsible for running inside the appropriate server-side host technology.
Microsoft provides server-side host technologies for hosting application server code: Windows Activation Service (WAS), Internet Information Services (IIS), and Enterprise Services.
It is also possible to write your own Windows service that could act as a host technology, but I strongly recommend against such an approach. By the time you write the host and add in security, configuration, and management support, you'll have recreated most or all of WAS, IIS, or Enterprise Services. Worse, you'll have opened yourself up for unforeseen security and stability issues.
The WCF host object is designed to run within the WAS or IIS hosts. This way, it can take advantage of the management, stability, and security features inherent in those server hosting technologies. Both WAS and IIS provide a robust process model and thread management and so supply very high levels of scalability.
Server-Side Data Portal
At its core, the server-side data portal components provide an implementation of the message router design pattern. The server-side data portal accepts requests from the client and routes those requests to an appropriate handler—either a business object or a factory object.
Note
I say "server-side," but keep in mind that the server-side data portal components may run on either the client workstation or on a remote server. Refer to the "Client-Side DataPortal" section of this chapter regarding how this selection is made. The data portal is implemented to minimize overhead as much as possible when configured to run locally or remotely, so it is appropriate for use in either scenario.
For Create, Fetch, and Delete operations, the server-side data portal requires type information about your business object. For update and execute operations, the business object itself is passed to the server-side data portal.
But the server-side data portal is more than a simple message router. It also provides optional access to the transactional technologies available within .NET, namely the new System.Transactions namespace and Enterprise Services (MTS/COM+).
The business framework defines a custom attribute named TransactionalAttribute that can be applied to methods within business objects. Specifically, you can apply it to any of the data access methods that your business object might implement to create, fetch, update, or delete data, or to execute server-side code. This allows you to use one of three models for transactions, as listed in Table 2-6.
Table 2.6. Transaction Options Supported by Data Portal
Option | Description | Transactional Attribute |
|---|---|---|
| You are responsible for implement-ing your own transactions using ADO.NET, stored procedures, etc. | None or |
| Your data access code will run within a COM+ distributed transactional context, providing distributed transactional support. |
|
| Your data access code will run within a |
|
So in the business object there may be an update method (overriding the one in BusinessBase) marked to be transactional:
[Transactional(TransactionalTypes.TransactionScope)]
protected override void DataPortal_Update()
{
// Data update code goes here
}At the same time, the object might have a fetch method in the same class that's not transactional:
private void DataPortal_Fetch(Criteria criteria)
{
// Data retrieval code goes here
}Or if you are using an object factory (discussed in the next section), the Transactional attribute would be applied to the Update() method in the factory class:
public class MyFactory : Csla.Server.ObjectFactory
{
[Transactional(TransactionalTypes.TransactionScope)]
public object Update()
{
// Data update code goes here
}
}This facility means that you can control transactional behavior at the method level rather than at the class level. This is a powerful feature because it means that you can do your data retrieval outside of a transaction to get optimal performance and still do updates within the context of a transaction to ensure data integrity.
The server-side data portal examines the appropriate method on the business object before it routes the call to the business object itself. If the method is marked with [Transactional(TransactionalTypes.TransactionScope)], the call is routed to a TransactionalDataPortal object that is configured to run within a System.Transactions.TransactionScope. A TransactionScope is powerful because it provides a lightweight transactional wrapper in the case that you are updating a single database; but it automatically upgrades to a distributed transaction if you are updating multiple databases. In short, you get the benefits of COM+ distributed transactions if you need them, but you don't pay the performance penalty if you don't need them.
If the method is marked as [Transactional(TransactionalTypes.EnterpriseServices)], the call is routed to a ServicedDataPortal object that is configured to require a COM+ distributed transaction. The ServicedDataPortal then calls the SimpleDataPortal, which delegates the call to your business object, but only after it is running within a distributed transaction. Either way, your code is transactionally protected.
If the method doesn't have the attribute, or is marked as [Transactional(TransactionalTypes.Manual)], the call is routed directly to the SimpleDataPortal, as illustrated in Figure 2-15.

Object Factory Model
By default, the server-side data portal components route calls to methods of an instance of the business object itself. In other words, the business object becomes responsible for initializing itself with new data, loading itself with existing data, and inserting, updating, or deleting its data.
That approach is very simple and efficient but may not offer the best separation between business and data access logic. The ObjectFactory attribute and ObjectFactory base class provide an alternative, where the data portal creates an instance of an object factory class and interacts with that factory object, instead of the business object.
In the default model, the data portal does a lot of work on behalf of the business developer. It creates instances of the business object, manages the object's state values, and generally shepherds the object through the data persistence process.
In the object factory model, the data portal leaves all those details to the factory object, which is created by the business developer. The result is that the business developer has a lot of flexibility but assumes a lot more responsibility. If the business developer doesn't properly manage the business object's state, other areas of CSLA .NET (such as data binding or n-level undo) may not function correctly.
I discuss the details around object factories in Chapters 4 and 5 and the underlying implementation in Chapter 15.
Data Portal Behaviors
Now that you have a grasp of the areas of functionality required to implement the data portal concept, let's discuss the specific data behaviors the data portal will support. The behaviors were listed earlier in Table 2-5.
Create
The create operation is intended to allow the business objects to load themselves with values that must come from the database. Business objects don't need to support or use this capability, but if they do need to initialize default values, this is the mechanism to use.
There are many types of applications for which this is important. For instance, order entry applications typically have extensive defaulting of values based on the customer. Inventory management applications often have many default values for specific parts, based on the product family to which the part belongs. Medical records also often have defaults based on the patient and physician involved.
When the Create() method of the DataPortal is invoked, it's passed a criteria object. As I've explained, the data portal will either use reflection against the criteria object or will rely on the type information in CriteriaBase to determine the type of business object to be created. Using that information, the data portal uses reflection to create an instance of the business object itself. However, this is a bit tricky because all business objects have private or protected constructors to prevent direct creation by code in the UI:
[Serializable]
public class Employee : BusinessBase<Employee>
{
private Employee()
{ /* prevent direct creation */ }
}Business objects will expose static factory methods to allow the UI code to create or retrieve objects. Those factory methods will invoke the client-side DataPortal. (I discuss this "class-in-charge" concept earlier in the chapter.) As an example, an Employee class may have a static factory method, such as the following:
public static Employee NewEmployee()
{
return DataPortal.Create<Employee>();
}Notice that no Employee object is created on the client here. Instead, the factory method asks the client-side DataPortal for the Employee object. The client-side DataPortal passes the call to the server-side data portal. If the data portal is configured to run remotely, the business object is created on the server; otherwise, the business object is created locally on the client.
Even though the business class has only a private constructor, the server-side data portal uses reflection to create an instance of the class. The alternative is to make the constructor public, in which case the UI developer will need to learn and remember that they must use the static factory methods to create the object. Making the constructor private provides a clear and direct reminder that the UI developer must use the static factory method, thus reducing the complexity of the interface for the UI developer. Keep in mind that not implementing the default constructor won't work either, because in that case, the compiler provides a public default constructor on your behalf.
Once the server-side data portal has created the business object, it calls the business object's DataPortal_Create() method, optionally passing a criteria object as a parameter. At this point, code inside the business object is executing, so the business object can do any initialization that's appropriate for a new object. Typically, this will involve going to the database to retrieve any configurable default values.
When the business object is done loading its defaults, the server-side data portal returns the fully created business object back to the client-side DataPortal. If the two are running on the same machine, this is a simple object reference; but if they're configured to run on separate machines, the business object is serialized across the network to the client (i.e., it's passed by value), so the client machine ends up with a local copy of the business object.
The UML sequence diagram in Figure 2-16 illustrates this process.

You can see how the UI interacts with the business object class (the static factory method), which then creates a criteria object and passes it to the client-side DataPortal. The client-side DataPortal then delegates the call to the server-side data portal (which may be running locally or remotely, depending on configuration). The server-side data portal then creates an instance of the business object itself and calls the business object's DataPortal_Create() method so it can populate itself with default values. The resulting business object is then ultimately returned to the UI.
Alternatively, the DataPortal_Create() method could request the default data values from a persistence object in another assembly, thus providing a clearer separation between the Business Logic and Data Access layers.
In a physical n-tier configuration, remember that the criteria object starts out on the client machine and is passed by value to the application server. The business object itself is created on the application server where it's populated with default values. It's then passed back to the client machine by value. This architecture truly takes advantage of the mobile object concept.
Fetch
Retrieving a preexisting object is very similar to the creation process just discussed. Again, a criteria object is used to provide the data that the object will use to find its information in the database. The criteria class is nested within the business object class and/or inherits from CriteriaBase, so the server-side data portal code can determine the type of business object desired and then use reflection to create an instance of the class.
The UML sequence diagram in Figure 2-17 illustrates all of this.
The UI interacts with the factory method, which in turn creates a criteria object and passes it to the client-side DataPortal code. The client-side DataPortal determines whether the server-side data portal should run locally or remotely and then delegates the call to the server-side data portal components.
The server-side data portal uses reflection to determine the assembly and type name for the business class and creates the business object itself. After that, it calls the business object's DataPortal_Fetch() method, passing the criteria object as a parameter. Once the business object has populated itself from the database, the server-side data portal returns the fully populated business object to the UI.
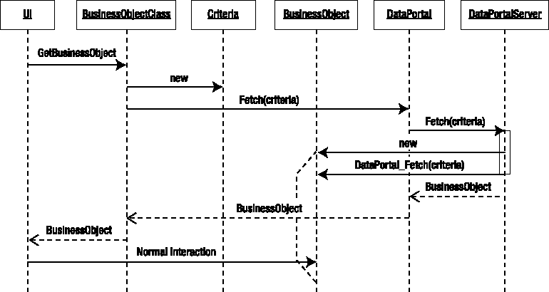
Alternatively, the DataPortal_Fetch() method could delegate the fetch request to a persistence object from another assembly, thus providing a clearer separation between the Business Logic and Data Access layers.
As with the create process, in an n-tier physical configuration, the criteria object and business object move by value across the network as required. You don't have to do anything special beyond marking the classes as Serializable; the .NET runtime handles all the details on your behalf.
You may also choose to use the DataContract and DataMember attributes instead of Serializable, but only if you exclusively use WCF for serialization. I discuss this in Chapter 6 but generally recommend using Serializable as the simplest option.
Update
The update process is a bit different from the previous operations. In this case, the UI already has a business object with which the user has been interacting, and this object needs to save its data into the database. To achieve this, all editable business objects have Save() and BeginSave() methods (as part of the BusinessBase class from which all business objects inherit). The save methods call the DataPortal to do the update, passing the business object itself, this, as a parameter.
The Save() method is synchronous, while the BeginSave() method is asynchronous and reports that it is completed by raising an event. This event is automatically raised on the UI thread in WPF and Windows Forms. In Web Forms or other technologies you'll need to provide your own thread synchronization if you use BeginSave().
The thing to remember when doing updates is that the object's data will likely change as a result of the update process. Any changed data must be placed back into the object.
There are two common scenarios illustrating how data changes during an update. The first is when the database assigns the primary key value for a new object. That new key value needs to be put into the object and returned to the client. The second scenario is when a time stamp is used to implement optimistic first-write-wins concurrency. In this case, every time the object's data is inserted or updated, the time stamp value must be refreshed in the object with the new value from the database. Again, the updated object must be returned to the client. This means that the update process is bidirectional. It isn't just a matter of sending the data to the server to be stored but also a matter of returning the object from the server after the update has completed so that the UI has a current, valid version of the object.
Due to the way .NET passes objects by value, it may introduce a bit of a wrinkle into the overall process. When passing the object to be saved over to the server, .NET makes a copy of the object from the client onto the server, which is exactly what is desired. However, after the update is complete, the object must be returned to the client. When an object is returned from the server to the client, a new copy of the object is made on the client, which isn't really the desired behavior.
Figure 2-18 illustrates the initial part of the update process.

The UI has a reference to the business object and calls its Save() method. This causes the business object to ask the data portal to save the object. The result is that a copy of the business object is made on the server, where it can save itself to the database. So far, this is pretty straightforward.
The business object has a Save() method, but the data portal infrastructure has methods named Update(). Although this is a bit inconsistent, remember that the business object is being called by UI developers; and I've found that it's more intuitive for the typical UI developer to call Save() than Update(), especially since the Save() call can trigger an Insert, Update, or even Delete operation. However, once this part is done, the updated business object is returned to the client and the UI must update its references to use the newly updated object instead, as shown in Figure 2-19.
This is fine, too—but it's important to keep in mind that you can't continue to use the old business object; you must update all object references to use the newly updated object. Figure 2-20 is a UML sequence diagram that shows the overall update process.
You can see that the UI calls the Save() or BeginSave() method on the business object, which results in a call to the client-side DataPortal's Update() method, passing the business object as a parameter. As usual, the client-side DataPortal determines whether the server-side data portal is running locally or remotely and then delegates the call to the server-side data portal. The server-side data portal then simply calls the DataPortal_Update() method on the business object so that the object can save its data into the database. DataPortal_Insert() would be called if the object is a new object; DataPortal_DeleteSelf() would be called if the object is marked for deletion.
These methods may implement the code to insert, update, or delete the object directly within the business class, or they may delegate the call to a persistence object in another assembly.
At this point, two versions of the business object exist: the original version on the client and the newly updated version on the application server. However, the best way to view this is to think of the original object as being obsolete and invalid at this point. Only the newly updated version of the object is valid.


Once the update is done, the new version of the business object is returned to the UI. The UI can then continue to interact with the new business object as needed.
Note
The UI must update any references from the old business object to the newly updated business object as soon as the new object is returned from the data portal.
In a physical n-tier configuration, the business object is automatically passed by value to the server and the updated version is returned by value to the client. If the server-side data portal is running locally, however, the object is cloned and the clone is updated and returned to the calling code. This is necessary because it is possible for the update process to fail halfway through. If your business object contains other business objects, some might have been changed during the update process, while others are unchanged. The database transaction will ensure that the database is in a consistent state, but your object model can be left in an inconsistent state. By saving a clone, if the update fails, the UI is left referencing the original unchanged object, which is still in a consistent state.
Delete
The final operation, and probably the simplest, is to delete an object from the database. The framework actually supports two approaches to deleting objects.
The first approach is called deferred deletion. In this model, the object is retrieved from the database and is marked for deletion by calling a Delete() method on the business object. Then the Save() or BeginSave() method is called to cause the object to update itself to the database (thus actually doing the Delete operation). In this case, the data is deleted by the DataPortal_DeleteSelf() method.
The second approach, called immediate deletion, consists of simply passing criteria data to the server, where the object is deleted immediately within the DataPortal_Delete() method. This second approach provides superior performance because you don't need to load the object's data and return it to the client. Instead, you simply pass the criteria fields to the server, where the object deletes its data.
The framework supports both models, providing you with the flexibility to allow either or both in your object models, as you see fit.
Deferred deletion follows the same process as the update process I just discussed, so let's explore immediate deletion. In this case, a criteria object is created to describe the object to be deleted and the data portal is invoked to do the deletion. Figure 2-21 is a UML diagram that illustrates the process.

Because the data has been deleted at this point, you have nothing to return to the UI, so the overall process remains pretty straightforward. As usual, the client-side DataPortal delegates the call to the server-side data portal. The server-side data portal creates an instance of the business object and invokes its DataPortal_Delete() method, providing the criteria object as a parameter.
The business logic to do the deletion itself is encapsulated within the business object, along with all the other business logic relating to the object. Alternatively, the business object could delegate the deletion request to a persistence object in another assembly.
As discussed earlier in the chapter, many environments include users who aren't part of a Windows domain or AD. In such a case, relying on Windows integrated security for the application is problematic at best, and you're left to implement your own security scheme. Fortunately, the .NET Framework includes several security concepts, along with the ability to customize them to implement your own security as needed.
The following discussion applies to you only in the case that Windows integrated security doesn't work for your environment. In such a case, you'll typically maintain a list of users and their roles in a database, or perhaps in an LDAP server. The custom authentication concepts discussed here will help you integrate the application with that preexisting security database.
Custom Principal and Identity Objects
The .NET Framework includes a couple of built-in principal and identity objects that support Windows integrated security or generic security. You can also create your own principal and identity objects by creating classes that implement the IPrincipal and IIdentity interfaces from the System.Security.Principal namespace.
Implementations of principal and identity objects will be specific to your environment and security requirements. However, CSLA .NET includes a BusinessPrincipalBase class to streamline the process.
When you create a custom principal object, it must inherit from BusinessPrincipalBase. Code in the data portal ensures that only a WindowsPrincipal or BusinessPrincipalBase object is passed between client and server, depending on the application's configuration.
In many cases, your custom principal object will require very little code. The base class already implements the IPrincipal interface, and it is quite likely that you'll only need to implement the IsInRole() method to fit your needs.
However, you will need to implement a custom identity object that implements IIdentity. Typically, this object will populate itself with user profile information and a list of user roles from a database. Essentially, this is just a read-only business object, and so you'll typically inherit from ReadOnlyBase. Such an object might be declared like this:
[Serializable]
public class CustomIdentity : ReadOnlyBase<CustomIdentity>, IIdentity
{
// implement here
}You'll also need to implement a Login method that the UI code can call to initiate the process of authenticating the user's credentials (username and password) and loading data into the custom identity object. This is often best implemented as a static factory method on the custom principal class. In many cases, this factory method will look something like this:
public static void Login(string username, string password)
{
CustomIdentity identity = CustomIdentity.GetIdentity(username, password);
if (identity.IsAuthenticated)
{
IPrincipal principal = new CustomPrincipal(identity);
Csla.ApplicationContext.User = principal;
}
}The GetIdentity method is a normal factory method in CustomIdentity that just calls the data portal to load the object with data from the database. A corresponding Logout method may look like this:
public static void Logout()
{
CustomIdentity identity = CustomIdentity.UnauthenticatedIdentity();
IPrincipal principal = new CustomPrincipal(identity);
Csla.ApplicationContext.User = principal;
}The UnauthenticatedIdentity() method is actually a variation on the factory concept, but in this case, it probably doesn't use the data portal. Instead, it merely needs to create an instance of CustomIdentity, in which IsAuthenticated returns false.
Virtually all applications rely on some form of authorization. At the very least, there is typically control over which users have access to the application at all. But more commonly, applications need to restrict which users can view or edit specific bits of data at either the object or property level. This is often accomplished by assigning users to roles and then specifying which roles are allowed to view or edit various data.
To help control whether the current user can view or edit individual properties, the business framework allows the business developer to specify the roles that are allowed or denied the ability to view or edit each property. Typically, these role definitions are set up as the object is created, and they may be hard-coded into the object or loaded from a database, as you choose.
With the list of allowed and denied roles established, the framework is able to implement authentication in the GetProperty() and SetProperty() helper methods. Behind the scenes there are CanReadProperty() and CanWriteProperty() methods that are called to do the actual authentication. Rather than using the GetProperty() and SetProperty() helper methods, you could choose to make explicit calls to the authentication and validation subsystems in CSLA .NET. The result would be a property that looks like this:
private string _name = string.Empty;
public string Name
{
get
{
CanReadProperty("Name", true);
return _name;
}set
{
CanWriteProperty("Name", true);
if (string.IsNullOrEmpty(value)) value = string.Empty;
if (_name != value)
{
_name = value;
PropertyHasChanged("Name");
}
}
}Obviously the helper methods discussed earlier in the chapter result in a lot less code and are the preferred approach for coding properties.
The CanReadProperty() and CanWriteProperty() methods check the current user's roles against the list of roles allowed and denied read and write access to this particular property. If the authorization rules are violated, a security exception is thrown; otherwise, the user is allowed to read or write the property.
The CanReadProperty() and CanWriteProperty() methods are public in scope. This is important because it allows code in the UI layer to ask the object about the user's permissions to read and write each property. The UI can use this information to alter its display to give the user visual cues as appropriate. In Chapter 19, you'll see how this capability can be exploited by a custom WPF control to eliminate most authorization code in a typical application. While the story isn't quite as compelling in Web Forms, Chapter 20 demonstrates how to leverage this capability in a similar manner.
Most business applications require a set of common behaviors not covered by the concepts discussed thus far. These behaviors are a grab bag of capabilities that can be used to simplify common tasks that would otherwise be complex. These include the items listed in Table 2-7.
Table 2.7. Helper Types and Classes
Type or Class | Description |
|---|---|
| Enables easy reuse of an open database connection, making the use of |
| Enables easy reuse of a LINQ to SQL data context, making the use of |
| Wraps any |
| Maps data from an |
| Implements a |
Let's discuss each of these in turn.
ConnectionManager
The TransactionScope class from System.Transactions is typically the preferred technology for implementing data update transactions because it results in simpler code and good performance. Unfortunately, TransactionScope automatically invokes the Distributed Transaction Coordinator (DTC) if your code opens more than one database connection and that results in a substantial performance penalty (often around 15 percent). If you avoid opening multiple database connections, TransactionScope uses a lightweight transaction scheme that is just as safe but is much faster.
The result is that you should reuse one open database connection across all your objects when using a TransactionScope object for transactional support. This means you must write code to open the connection object and then make it available to all objects that will be interacting with the database within the transaction. That can unnecessarily complicate what should be simple data access code.
The Csla.Data.ConnectionManager class is intended to simplify this process by managing and automatically reusing a single database connection object. The result is that all data access code that uses a database connection object has the following structure:
using (var ctx = ConnectionManager<SqlConnection>.GetManager("DatabaseName"))
{
// ctx.Connection is now an open connection to the database
// save your data here
// call any child objects to save themselves here
}If the connection isn't already open, a connection object is created and opened. If the connection is already open it is reused. When the last nested using block completes, the connection object is automatically disposed of.
ContextManager
When using LINQ to SQL, your code won't typically interact with the underlying database connection object directly. To share an open database connection you must really share the LINQ data context object. Csla.Data.ContextManager is intended to simplify this process by managing and automatically reusing a single data context object. The result is that all data access code that uses a data context object has the following structure:
using (var ctx = ContextManager<SqlConnection>.GetManager("DatabaseName"))
{
// ctx.Context is now an open data context object
// save your data here
// call any child objects to save themselves here
}If the connection isn't already open, a connection object is created and opened. If the data context is already open, it is reused. When the last using block completes, the data context object is automatically disposed of.
SafeDataReader
Most of the time, the difference between a null value and an empty value (such as an empty string or a zero) is not important in regard to applications, though it is in databases. When retrieving data from a database, an application needs to handle the occurrence of unexpected null values with code such as the following:
if(dr.IsDBNull(idx))
myValue = string.Empty;
else
myValue = dr.GetString(idx);Clearly, doing this over and over again throughout the application can get very tiresome. One solution is to fix the database so that it doesn't allow nulls when they provide no value, but this is often impractical for various reasons.
Note
Here's one of my pet peeves: allowing nulls in a column in which you care about the difference between a value that was never entered and the empty value ("", or 0, or whatever) is fine. Allowing nulls in a column where you don't care about the difference merely complicates your code for no good purpose, thereby decreasing developer productivity and increasing maintenance costs.
As a more general solution, CSLA .NET includes a utility class that uses SqlDataReader (or any IDataReader implementation) in such a way that you never have to worry about null values again. Unfortunately, the SqlDataReader class isn't inheritable; it can't be subclassed directly. Instead, it is wrapped using containment and delegation. The result is that your data access code works the same as always, except that you never need to write checks for null values. If a null value shows up, SafeDataReader will automatically convert it to an appropriate empty value.
Obviously, if you do care about the difference between a null and an empty value, you can just use a regular SqlDataReader to retrieve the data. Starting in .NET 2.0, you can use the Nullable<T> generic type that helps manage null database values. This new type is very valuable when you do care about null values: when business rules dictate that an "empty" value such as 0 is different from null.
DataMapper
In Chapter 20, you will see how to implement an ASP.NET Web Forms UI on top of business objects. This chapter makes use of the data binding capabilities introduced in Web Forms 2.0. In this technology, the Insert and Update operations provide the data from the form in IDictionary objects (name/value pairs). The values in these name/value pairs must be loaded into corresponding properties in the business object. You end up writing code much like this:
cust.Name = e.Values["Name"].ToString(); cust.Address1 = e.Values["Address1"].ToString(); cust.City = e.Values["City"].ToString();
Similarly, in Chapter 21, you'll see how to implement a WCF service interface on top of business objects. When data is sent or received through a web service, it goes through a proxy object, an object with properties containing the data but no other logic or code. Since the goal is to get the data into or out of a business object, this means copying the data from one object's properties to the other. You end up writing code much like this:
cust.Name = message.Name; cust.Address1 = message.Address1; cust.City = message.City;
In both cases, this is repetitive, boring code to write. One alternative, though it does incur a performance hit, is to use reflection to automate the copy process. This is the purpose of the DataMapper class: to automate the copying of data to reduce all those lines of code to one simple line. It is up to you whether to use DataMapper in your applications.
SmartDate
Dates are a perennial development problem. Of course, there's the DateTime data type, which provides powerful support for manipulating dates, but it has no concept of an "empty" date. The trouble is that many applications allow the user to leave date fields empty, so you need to deal with the concept of an empty date within the application.
On top of this, date formatting is problematic—rather, formatting an ordinary date value is easy, but again you're faced with the special case whereby an "empty" date must be represented by an empty string value for display purposes. In fact, for the purposes of data binding, you often want any date properties on the objects to be of type string so that the user has full access to the various data formats as well as the ability to enter a blank date into the field.
Dates are also a challenge when it comes to the database; the date data types in the database don't recognize an empty date any more than .NET does. To resolve this, date columns in a database typically do allow null values, so a null can indicate an empty date.
Note
Technically, this is a misuse of the null value, which is intended to differentiate between a value that was never entered and one that's empty. Unfortunately, you're typically left with no choice because there's no way to put an empty date value into a date data type.
You may be able to use DateTime? (Nullable<DateTime>) as a workable data type for your date values. But even that isn't always perfect because DateTime? doesn't offer specialized formatting and parsing capabilities for working with dates, nor does it really acknowledge an empty date; it isn't possible to compare actual dates with empty dates, yet that is often a business requirement.
The SmartDate type is an attempt to resolve this issue. Repeating the problem with SqlDataReader, the DateTime data type isn't inheritable, so SmartDate can't just subclass DateTime to create a more powerful data type. Instead, it uses containment and delegation to create a new type that provides the capabilities of the DateTime data type while also supporting the concept of an empty date.
This isn't as easy at it might at first appear, as you'll see when the SmartDate class is implemented in Chapter 16. Much of the complexity flows from the fact that applications often need to compare an empty date to a real date, but an empty date might be considered very small or very large. You'll see an example of both cases in the sample application in Chapter 17.
The SmartDate class is designed to support these concepts and to integrate with the SafeDataReader so that it can properly interpret a null database value as an empty date.
Additionally, SmartDate is a robust data type, supporting numerous operator overloads, casting, and type conversion. Better still, it works with both DateTime and the new DateTimeOffset type.
At this point, I've walked through many of the classes that make up CSLA .NET. Given that there are quite a few classes and types required to implement the framework, there's a need to organize them into a set of namespaces for easier discovery and use. Namespaces allow you to group classes together in meaningful ways so that you can program against them more easily. Additionally, namespaces allow different classes to have the same name as long as they're in different namespaces. From a business perspective, you might use a scheme such as the following:
MyCompany.MyApplication.FunctionalArea.Class
A convention like this immediately indicates that the class belongs to a specific functional area within an application and organization. It also means that the application could have multiple classes with the same names:
MyCompany.MyApplication.Sales.Product MyCompany.MyApplication.Manufacturing.Product
It's quite likely that the concept of a "product" in sales is different from that in manufacturing, and this approach allows reuse of class names to make each part of the application as clear and self-documenting as possible. The same is true when you're building a framework. Classes should be grouped in meaningful ways so that they're comprehensible to the end developer. Additionally, use of the framework can be simplified for the end developer by putting little-used or obscure classes in separate namespaces. This way, the business developer doesn't typically see them via IntelliSense.
Consider the UndoableBase class, which isn't intended for use by a business developer; it exists for use within the framework only. Ideally, when business developers are working with the framework, they won't see UndoableBase via IntelliSense unless they go looking for it by specifically navigating to a specialized namespace. The framework has some namespaces that are to be used by end developers and others that are intended for internal use.
All the namespaces in CSLA .NET are prefixed with Csla. Table 2-8 lists the namespaces used in the CSLA .NET framework.
Table 2.8. Namespaces Used in the CSLA .NET Framework
Namespace | Description |
|---|---|
| Contains the types most commonly used by business developers |
Contains the types that provide core functionality for the framework; not intended for use by business developers | |
Contains the optional types used to support data access operations; often used by business developers, web UI developers, and web service developers | |
Contains the types that support the client-side | |
Contains types that implement the LINQ to CSLA functionality; not intended for use by business developers | |
Contains code generated by Visual Studio for the | |
Contains types that abstract and enhance the use of reflection; not intended for use by business developers | |
Contains the types supporting authorization; used when creating a custom principal object | |
Contains code to abstract the use of the .NET | |
Contains the types supporting the server-side data portal behaviors; not intended for use by business developers | |
Contains the types supporting server-side data portal hosts; used when creating a custom data portal host | |
Contains the types supporting validation and business rules; often used when creating rule methods | |
Contains the | |
Contains the supporting types for the | |
Contains the web services data portal host; not intended for use by business developers | |
Contains controls to assist with Windows Forms data binding; used by Windows UI developers | |
| Contains types to assist with the use of Windows Workflow Foundation (WF); used by workflow developers |
| Contains controls to assist with WPF data binding; used by WPF UI developers |
The primary base classes intended for use by business developers go into the Csla namespace itself. They are named as follows:
Csla.BusinessBase<T>Csla.BusinessListBase<T,C>Csla.ReadOnlyBase<T>Csla.ReadOnlyListBase<T,C>Csla.NameValueListBase<K,V>Csla.CommandBase
The rest of the classes and types in the framework are organized into the remaining namespaces based on their purpose. You'll see how they all fit and are implemented in Chapters 6 through 16.
The end result is that a typical business developer can simply use the Csla namespace as follows:
using Csla;
All they'll see are the classes intended for use during business development. All the other classes and concepts within the framework are located in other namespaces and therefore won't appear in IntelliSense by default, unless the developer specifically imports those namespaces.
When using custom authentication, you'll likely import the Csla.Security namespace. But if you're not using that feature, you can ignore those classes and they won't clutter up the development experience. Similarly, Csla.Data and Csla.Validation may be used in some cases, as you'll see in Chapters 17 and 18. If the types they contain are useful, they can be brought into a class with a using statement; otherwise, they are safely out of the way.
This chapter examines some of the key design goals for the CSLA .NET business framework, including the following:
Validation and maintaining a list of broken business rules
Standard implementation of business and validation rules
Tracking whether an object's data has changed (is it "dirty"?)
Integrated authorization rules at the object and property levels
Strongly typed collections of child objects (parent-child relationships)
N-level undo capability
A simple and abstract model for the UI developer
Full support for data binding in WPF, Windows Forms, and Web Forms
Saving objects to a database and getting them back again
Custom authentication
Other miscellaneous features
You've also walked through the design of the framework itself, providing a high-level glimpse into the purpose and rationale behind each of the classes that make it up. With each class, I discuss how it relates back to the key goals to provide the features and capabilities of the framework.
The chapter closes by defining the namespaces that contain the framework classes. This way they're organized so that they're easily understood and used.
Chapter 3 covers some important object-oriented design concepts. Though you can use the ideas in this book in many ways, Chapter 3 describes the thought process I use and the one I'm trying to support by creating the CSLA .NET framework.
Then Chapters 4 and 5 provide details on how a business developer can use CSLA .NET to build business classes based on the stereotypes in Table 2-2.
Chapters 6 through 16 detail the implementation of the concepts discussed in this chapter. If you are interested in the thought process and key implementation techniques used to build the framework, these chapters are for you.
Then Chapters 17 to 21 walk through the design and implementation of a sample application using object-oriented concepts and the CSLA .NET framework. These chapters, combined with Chapters 3 through 5, explore how the framework functions and how it meets the goals set forth in this chapter.
[1] Design Patterns: Elements of Reusable Object-Oriented Software (Addison-Wesley, 1995) by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides