
2
Core Architectural Concepts: Data Life Cycle
This Book Comes with Free Online Content
With this book, you get unlimited access to web-based CTA exam prep tools like flashcards and exam tips.
Figure 2.1 – CTA online resources dashboard
To unlock the content, you’ll need to create an account using your unique sign-up code provided with this book. Refer to the Instructions for Unlocking the Online Content section in the Preface on how to do that.
Accessing the Online Content
If you’ve already created your account using those instructions, visit packt.link/ctabookwebsite or scan the following QR code to quickly open the website.

Figure 2.2 – QR Code to access CTA online resources
Once there, click the Login link in the top-right corner of the page to access the content using your credentials.
As you learned in the previous chapter, the expectations are high for a Salesforce CTA. The architect is expected to have a deep understanding of the platform’s features and capabilities. In addition to a deep understanding of particular architectural concepts, the architect is also expected to have a breadth of knowledge across many architectural domains. Data is one of the key architectural domains that architects need to master. Data is all around you in your daily life, and every day, you discover new potential for it. From sales to services, marketing, business intelligence, and artificial intelligence, data is at the heart of today’s modern systems.
In this chapter, you are going to cover the following main topics:
- Differences between classic RDBMS and Salesforce
- Understanding data governance
- Understanding data security
- Data regulatory compliance
- Exploring data categories
- The nature of data warehouses and data lakes
- Choosing the right document management system
- Understanding data architecture concepts
- Designing and documenting your data model
- Using database relationships
Differences Between Classic RDBMS and Salesforce
People have used databases in their day-to-day activities for centuries. Although they have only been given the name “databases” recently, they have been developed for years with more and more use cases invented for them. Most modern applications utilize a database of some sort. Theoretically, a database is simply a collection of related data. The software system that manages this data is called a database management system (DBMS). The DBMS is also responsible for controlling access to the database.
Databases have evolved over the years from simple file-based systems to sophisticated cloud-based relational database management systems and in-memory databases.
Understanding the problems of file-based systems could help you avoid challenges that could occur in modern database systems. File-based systems were designed for a specific set of use cases. This was primarily driven by an attempt to digitalize the activities that are usually done. Take the manual filing system as an example. Enterprises and some libraries used to have an organized way to store the different files and books they owned. A typical arrangement would see these assets stored in labeled cabinets. The cabinets themselves might have locks to control who could open them and who could not, and an entire set of cabinets could be kept in secured rooms or areas to ensure the right security measures were taken. The simplest way to find a document in this arrangement would be to go through all the documents one by one until you found what you were after.
Eventually, indexing systems were used to help locate a specific file more quickly. In other words, you could have divisions in the filing system or a summarized index sheet that pointed to the location of each stored document.
This system works as long as only a small number of items are stored, or if all you want to do is simply store and retrieve items. You can probably imagine the complexity of retrieving cross-reference data or trying to get any intelligence out of the gathered data.
Relational databases became very popular at the end of the last century. They dominated the enterprise landscape and are still relevant today. The data in RDBs is split across multiple related tables, where each row of these tables has a unique identifier called a primary key. Related tables can be linked by referencing those primary keys with foreign keys. Eventually, the concept of an alternate key or secondary key was introduced. Like the primary key, a secondary key contains a unique identifier for each row. However, for one reason or another, it has not been chosen as the primary key for the table.
In the Salesforce world, each object has a unique ID field that represents a primary key. Lookup and master-detail relationship fields act as foreign keys for the child object. Unique external keys are a good example of alternate keys.
Data is normally accessed using a structured query language (such as SQL or SOQL in Salesforce). The speed of retrieving this data is impacted by several factors, such as the underlying infrastructure, the way data is identified and indexed, and the amount of data that can be stored and retrieved while the data is unindexed.
Relational databases transactions are defined by the following four characteristics (you can remember these with the acronym ACID):
- Atomic: A transaction must be treated as an atomic unit. All its tasks and operations must succeed; otherwise, the entire transaction is rolled back. A database must never be in a state where a transaction is partially completed.
- Consistent: If the data was in a constant state before a particular transaction, then it should stay so once that transaction has been executed. The state of the database should stay consistent throughout the transaction. In other words, the transaction should not have a negative effect on the data in the database.
- Isolated: Transactions are separate, so there should be no dependencies between them and no shared data. This is particularly true when there is more than one transaction being executed simultaneously in parallel. No transaction will impact the existence of the other transactions.
- Durable: Data should be held in a persistent fashion, even if the system fails to restart. When a transaction updates data in a database and commits it, the database is expected to hold the modified data. In case of a system failure, before the data is written to disk, it should be updated once the system is back in action.
Relational databases are ideal for complex operations and data analysis tasks. They are designed to value consistency over availability and provide a rigid structure that the data must fit into.
In the 1990s, when the internet took off, a new challenge arose since web applications started to produce data that was not necessarily structured or organized and was sometimes difficult to fit into such a rigid structure. With this came the rise of non-relational databases, which are now known as not only SQL or NoSQL databases.
Non-relational databases share the following three qualities (you can remember these with the acronym BASE):
- Basically available: The system should be available, even in the event of failure (including network failure).
- Soft state: The state of the data in the system may change because of the eventual consistency activities.
- Eventual consistency: Consistency is not guaranteed, but at some point, the data will end up in a consistent state. Here, you can see the principle of delayed consistency in comparison to the immediate consistency of ACID.
Non-relational databases are highly scalable, though this comes at a cost. Data consistency is not guaranteed at every point in time, which means that different users might see different versions of the same data at the same time – even though the data would eventually end up in a consistent state. Non-relational databases – quite the opposite of relational databases – value availability over consistency.
While designing your Salesforce solution, you might find that you are presented with a challenge that requires a highly available and scalable database system. Heroku supports some of the most popular NoSQL databases as add-ons, such as MongoDB and CouchDB.
The following use cases will help you understand more about the usage of NoSQL:
- Frequently written but rarely read statistical data
- Big data (such as stats across many countries for many years)
- Binary assets (such as PDF or MP3 files), where the need would be to provide storage in a data store that can be served directly to the user’s browser
- Transient/temporary data
- High-availability apps, where downtime is critical
- High-scalability apps, where there is a need to handle a very high number of transactions
The Salesforce Platform is not designed for use cases where you need to receive and ingest tons of incoming data. Think of an IoT scenario where there is normally a need for a highly available and scalable platform to receive, ingest, and aggregate the data before processing it or transferring it to another platform that would handle the processing. This is a use case where a platform such as Heroku can add a lot of value to your solution, especially since it has a built-in connector to the Salesforce Platform via Heroku Connect. During the review board, avoid mistakes that would end up overstretching one of your solution components, such as driving IoT inbound communications into Salesforce directly.
Salesforce is slightly different from regular RDBMS. As an experienced Salesforce Architect, you are already aware that it is a multi-tenant database where the data of different tenants is separated using OrgIDs. However, you need to know about some of the concepts that could be considered suboptimal in standard RDBMS design but are fine in the Salesforce world, such as the following:
- Self-relationships are fine in Salesforce. Actually, they might give you the ability to utilize some out-of-the-box capabilities that will simply not work if you model the data using two objects.
- In a regular database, it is normally not acceptable to have a table with 500 different columns. However, this is acceptable in Salesforce for some use cases, particularly if you are creating a denormalized aggregation object.
- In regular databases, you rarely notice a direct relationship from a child record to a grandparent record. While in Salesforce, this is not something out of the ordinary. Such relationships could be established simply because they impact the way data is presented to the end user (for example, when establishing a lookup relation, related records will simply be displayed automatically on the page layout of the grandparent record, without the need for you to write custom code to roll these records up from the parent record to the grandparent).
- Salesforce fields are type-aware. In addition to their role as data containers, similar to a normal database field, they also provide built-in data type validations. You will not be able to set a number on a checkbox field, and this is not something you can turn off.
- Salesforce has its own structured data query language known as Salesforce Object Query Language (SOQL), which exchanges the flexibility of SQL for some built-in functionalities that will significantly speed up the development of most use cases.
- Data storage is an important topic that you need to keep in mind while designing your Salesforce data model. Storage space itself is one thing, as it is not very cheap compared to other platforms. But most importantly, you should keep an eye on the size of your Salesforce object to ensure the performance of certain functionalities, such as reporting, does not deteriorate with the rapid increase of object size. You will dive deeper into this topic in Chapter 7, Designing a Scalable Salesforce Data Architecture.
- Salesforce comes with a very solid data access control model. This allows you to control not only the access of objects and fields to a particular user but records as well. All of this can be done by using point-and-click features rather than writing code.
However, these functionalities normally create some supporting data behind the scenes in order to drive visibility requirements. You need to understand how they work and anticipate what kind of challenges you might come across while using each different sharing approach. You will also cover this in Chapter 6, Formulating a Secure Architecture in Salesforce.
Now that you understand the main differences between classic RDBMS and Salesforce, move on and explore a common topic between the two, which is also key to the success of any enterprise’s data strategy—data governance.
Understanding Data Governance
Data governance, in an enterprise context, is a data management concept that aims to ensure a high level of data quality throughout the complete life cycle of the data.
The data governance concept can be extended to several focus areas. Enterprises typically focus on topics such as data usability, availability, security, and integrity. This includes any required processes that need to be followed during the different stages of the data life cycle, such as data stewardship, which ensures that the quality of the data is always up to a high standard, and other activities that ensure the data is accessible and available for all consuming applications and entities.
Data governance aims to do the following:
- Increase consistency and confidence in data-driven decisions. This, in turn, enables better decision-making capabilities across the enterprise.
- Break down data silos.
- Ensure that the right data is used for the right purposes. This is done to block potential misuse and to reduce the risk of creating data errors within the systems.
- Decrease the risk associated with regulatory requirements, avoiding fines.
- Continuously monitor and improve data security, as well as define and verify requirements for data distribution policies.
- Enable data monetization.
- Increase information quality by defining accountabilities.
- Enable modern, customer-centric user journeys based on high-quality, trusted data.
- Minimize the need for rework due to a technical department being created by poorly governed activities.
Data governance bodies usually create and maintain the following artifacts:
- Data mapping and classification: This helps with documenting the enterprise’s data assets, and related data flows. Datasets can be classified based on specific criteria, such as containing personal information or confidential data. This, in turn, influences how data governance policies are applied to each dataset.
- Business glossary: This contains definitions of the business terms used in an enterprise. A good example is the definition of what constitutes an active customer.
- Data catalog: These are normally created by collecting metadata from across systems. They are then used to create an inventory of available data assets. Governance policies and information about topics such as automation mechanisms can also be built into catalogs.
A well-designed data governance program typically includes a combination of data stewards and a team that acts as a governing body. They work together to create the required standards and policies for governing the data, as well as implementing and executing the planned activities and procedures. This is mainly carried out by the data stewards.
A data steward is a role within the enterprise and is responsible for maintaining and using the organization’s data governance processes to ensure the availability and quality of both the data and metadata. The data steward also has the responsibility to utilize policies, guidelines, and processes to administer the organization’s data in compliance with given policy and/or regulatory obligations. The data steward and the data custodian may share some responsibilities.
A data custodian is a role within the enterprise and is responsible for transporting and storing data, rather than topics such as what data is going into the system and why. Data stewards are normally responsible for what is stored in datasets, while data custodians cover the technical details, such as environment and database structure. Data custodians are sometimes referred to as database administrators or extract transform load (ETL) developers.
Now that you understand the activities that are covered by the data governing body, as well as data stewards and custodians, move on to have a look at one of the key topics they need to cover in their data strategy—data security.
Understanding Data Security
Data security is one of the greatest concerns for enterprises today, especially with the ever-increasing amount and value of collected data. It is all about protecting digital data from the actions of unauthorized users (such as data leaks or breaches) or from destructive forces. As part of that, there are a few concepts that you need to become familiar with, including encryption, backup and restore, data masking, and data erasure. You will get to know each of them in the next sections.
Data Encryption
Data encryption can be applied at multiple levels and stages of the data life cycle. This includes when the data is stored at its final data store (encryption at rest) and while data is in motion, moving from one system to another (encryption in transit).
Encryption in transit is typically achieved by encrypting the message before it is transmitted and decrypted at the destination. This process intends to protect data while being transferred against attackers who could intercept the transmission or what are sometimes referred to as man-in-the-middle attacks. This is normally achieved by utilizing a secure channel such as HTTPS, although higher levels of security can be applied. You will do a deep dive into this topic in Chapter 3, Core Architectural Concepts: Integration and Cryptography, to better understand how encryption algorithms work and how they are used to exchange data in a secure manner.
Encryption at rest is all about storing the data that has been encrypted. This makes it impossible to read and display the decrypted version of it without having access to a specific encryption key. Some applications or platforms provide this out of the box. This is a protection mechanism against attackers who can gain access to the database or to the physical disk where the data is stored.
Salesforce Shield provides an encryption solution for encrypting data at rest. This is applicable to the filesystem, the database, and the search index files. If you are planning to use Salesforce shield as part of your solution, you need to highlight that clearly in your landscape architecture.
Data Restoration
Backup and restore solutions are used to ensure data is available in a safe location/source in case there is a need to restore or recover it. In most industries, it is essential to keep a backup of any operational data. And most importantly, you must have a clear restoration strategy. Data restoration is typically more challenging than backing it up as it comes with additional challenges, such as restoring partial data, reference data, and parent-child records and relationships.
Note
Salesforce announced that effective July 31, 2020, data recovery as a paid feature would be deprecated and no longer available as a service. However, based on customers’ feedback, Salesforce decided to reinstate its data recovery service. Then, during Autumn 2021, Salesforce announced a new built-in platform with a native backup and restore capability.
Due to this, it is important to create a comprehensive data backup and restore strategy as part of your data governance strategy. There are several tools that can be used to back up and restore data from and to the Salesforce Platform, including Salesforce’s Backup and Restore, in addition to some AppExchange products. A custom-made solution through implementing ETL tools is also possible, despite the additional build cost associated with it. As an architect, you are expected to be able to walk your stakeholders through the various options that are available, as well as the potential pros and cons.
Note
During the review board, you are expected to come up with the best possible solution technically. Cost should not be a consideration unless clearly mentioned in the scenario. Buy versus build decisions always tend to pick the buy option due to its quick return on investment.
Data Masking
Data masking (also known as data obfuscation) of structured data is the process of covering the original data with modified content. This is mainly done to protect data that is classified as personally identifiable information (PII) or sensitive commercial or personal data. An example is masking national identity numbers to display only the last four digits while replacing all other digits with a static character, such as a wildcard. Data is normally obfuscated to protect it from users, such as internal agents, external customers, or even developers (who normally need real production-like data to test specific use cases or fix a particle bug) to be compliant with regulatory requirements.
There are two common techniques for data obfuscation, namely pseudonymization, and anonymization. Here is a brief description of the two:
- Anonymization: This works by changing and scrambling the contents of fields so they become useless. For example, a contact named Rachel Greene could become hA73Hns#d$. An email address such as [email protected] could become an unreadable value such as JA7ehK23.
- Pseudonymization: This converts a field into readable values unrelated to the original value. For example, a contact named Rachel Greene could become Mark Bates. An email address such as [email protected] could become [email protected].
Which technique amongst these two you should choose depends on the degree of risk associated with the masked data and how the data will be processed. Pseudonymous data still allows some sort of reidentification (even if it is remote or indirect), while anonymous data cannot be reidentified. A common way to anonymize data is by scrambling data, a process that can sometimes be reversible; for example, “London” could become “ndooln.” This masking technique allows a part of the data to be hidden with a static or random character. On the other hand, data blurring uses an approximation of data values to make it impossible to identify a person or to make the data’s meaning obsolete.
Data Erasure
Data erasure (also referred to as data clearing, data destruction, or data wiping) is a software-based activity where specific data is overwritten with other values to destroy electronic data and make it unrecoverable. This is different from data deletion, even though they sound the same.
Data deletion can leave data in a recoverable format (for example, by simply removing the reference to it from an index table while still maintaining it on the storage disk). Data erasure, on the other hand, is permanent and particularly important for highly sensitive data. It is important to understand the difference between these terms so that you can suggest the best strategy to your stakeholders while also taking into consideration the limited control they have over how the data is ultimately stored in Salesforce.
It is worth mentioning that encrypted data can be destroyed/erased permanently by simply destroying the encryption keys.
Another key topic the data governing body needs to cover is data regulatory compliance. With the increased amount of gathered customer and business data, it has become essential to introduce rules that govern the use of that data. As an architect, you must be aware of these regulations to design a fully compliant solution. You will likely need to work with subject matter experts to ensure your solution fulfills all regulatory requirements, but you should still be able to cover a good amount of that by yourself. You also need to be able to explain how your solution is compliant with these regulations to your stakeholders.
Data Regulatory Compliance
There are several data regulations in place based on industry standards and government regulations. These have been created to mitigate the risk of unauthorized access to corporate, personal, or government data. Some of the regulations that you may come across more frequently these days while designing a Salesforce solution include the following:
- General Data Protection Regulation (GDPR)
- United Kingdom version of GDPR (UK-GDPR)
- Health Insurance Portability and Accountability Act (HIPAA)
- California Consumer Privacy Act (CCPA)
- Fair and Accurate Credit Transactions Act of 2003 (FACTA)
- Act on the Protection of Personal Information (APPI)
- Gramm-Leach Bliley (GLB)
- Payment Card Industry Data Security Standard (PCI DSS)
Failure to comply with these regulations can result in hefty fines and public damage to the enterprise’s reputation, in addition to civil and criminal liability. The details of these regulations are not covered in this book, but you are encouraged to seek additional knowledge online and from other books. You will come across requirements that must be resolved, along with considerations regarding some of the previously mentioned regulations, in the chapters to come.
PCI DSS, also known as PCI compliance, is an information security standard that’s applicable to all companies involved in activities related to credit card information, such as accepting, processing, storing, or transmitting credit card information from credit card providers. Salesforce billing became PCI level 1 compliant in 2012 and has retained its compliance every year since.
You maintain compliance with PCI by never storing any credit card information in Salesforce at all payment method collection stages (before, during, and after). The payment card’s information should only be transmitted to the payment processors via a token and never stored within Salesforce. Each of these tokens is unique per customer, payment card, merchant, and payment processor. Once the token has been submitted, the payment processor can link it to the actual personal account number stored.
Using tokens, Salesforce can store a representation of the customer’s payment card without storing the actual details of the card itself. If the token falls into the wrong hands, it is useless because it only works when it is being used by the original merchant and payment processor.
The information that can be stored in Salesforce while still maintaining PCI compliance includes data such as the following:
- Name on card
- Last four digits of the credit card number
- Card type
- Token
- Expiration month and year
It is important to understand how online payment mechanisms work and how to select the right one for your solution. Suggesting a non-PCI-compliant solution during the review board could open the door to many other discussions that you do not want to have. When you suggest a suboptimal solution, the judges will try to understand the rationale behind your suggestion. Failing to show enough knowledge and understanding of regulations and compliance could lead to exam failure.
For online payments, you need to know that there are generally two main ways to integrate with a payment gateway. You can either create a checkout page that is hosted on your own website (for example, Salesforce communities) or utilize a checkout page that is provided and hosted by your payment gateway.
In terms of the externally hosted checkout approach, your checkout page is hosted on a different website provided by the payment provider. When the customer clicks on the checkout button on your website, they are redirected to the payment page, which is hosted on a different domain name. The order information and cart total amount will normally be shown on the payment page. The customer will enter their card details on this page and then hit the submit button. Notice that the card details are entered on the external payment website only; your pages and forms are never used to capture such details. Once the payment is successful, the customer is redirected to a landing page on your website. A confirmation or transaction code will also be passed back to your website.
The hosted checkout approach has the following advantages:
- Enhanced security: Every additional party involved in a payment transaction increases the risks associated with data breaches. You should aim to have as few data transfers as you can. Also, since the payment details are collected by the payment provider/processor, your website is not considered a part of the transaction, so the overall security level of this approach is high.
- Less liability: You reduce your liability as a merchant because you are not collecting any sensitive information. All of that is done by the payment provider.
- Peace of mind for the customer: Customers might find it more assuring to provide their payment details to a website/domain they already trust, such as PayPal. This is particularly true for smaller merchants or for newer brands.
- Flexibility in payment methods: Normally, hosted checkout pages provide the user with the choice to choose from multiple payment methods. This page will continue to be updated as the payment provider includes more and more payment methods. You do not need to worry about that or change anything in your code.
- Simplified setup: This method is the easiest to set up and maintain.
- Limited customization: Although the payment page is hosted on another website, many of the payment providers allow a limited level of customization, such as setting a logo, header and footer, and color scheme.
Regarding the onsite checkout approach, the customer provides their payment details on a page hosted on their own website (for example, Salesforce communities). You have full control over the look and feel of this page, but you are also responsible for the implementation of every required functionality, validation, and security measure.
The onsite checkout approach has the following advantages:
- Totally seamless: This is probably the most important advantage of this approach. The customer is not redirected anywhere; the entire payment process feels like part of the journey and experience that you are providing to your customer.
- One-click purchasing: This is similar to what major merchants such as Amazon do. You are collecting the customer’s payment details so that you can attach them to their account. This opens the door to introducing one-click functionality.
- Customization: You can make the payment collection page in any way you like. It can be completely styled to meet your website’s look and feel. This goes beyond UI styling as you can, for example, collect additional details as part of the checkout process.
If you are taking payments via a hosted page, it is much easier to fill in and submit the required forms to stay PCI-compliant. This also makes the maintenance process simpler. If there is no clear need to go with an onsite checkout approach, then it is always safer to suggest an externally hosted page approach.
Now that you have covered some of the key topics you need to know about regarding data regulations, move on to understand the different data categories that are available.
Exploring Data Categories
Reference data and master data are two common data categories that an architect would typically come across in most projects. In addition to these, in this section, you will also discover the characteristics of transactional data, reporting data, metadata, big data, and unstructured data. Having a deeper understanding of these different data categories will help you craft your overall data strategy, including data governance. This will also help you speak the same language your data architects prefer to use. Have a look at each of them closely.
Transactional Data
Transactional data is generated by regular business transactions. It describes business events. Normally, it is the most frequently changing data in the enterprise. Transactional data events could include the following:
- Products sold to customers
- Collected payments
- Created quotes
- Items shipped to customers
Transactional data is normally generated and managed by operational systems, such as CRM, ERM, and HR applications.
Master Data and Master Data Management
Enterprises normally provide key business information that supports daily transactions. Such data normally describes customers, products, locations, and so on.
Such data is called master data, and it is commonly referred to as parties (employees, customers, suppliers, and so on), places (sites, regions, and so on), and things (products, assets, vehicles, and so on).
The usual business operations normally author/create and use master data as part of the normal course of business processes. However, operational applications are usually designed for an application-specific use case for the master data. This could result in a misalignment with the overall enterprise requirement of high-quality, commonly used master data. This would result in the following:
- Master data being low quality
- Duplicated and scattered data
- Lack of truly managed data
Master data management (MDM) is a concept widely used to describe the discipline where IT and business work together to ensure the accuracy and uniformity of the enterprise master data using specific tools and technologies. Maintaining a single version of the truth is one of the highest-priority topics on the agenda of most organizations.
A master data management tool is used to detect and remove duplicates, mass maintain data, and incorporate rules to prevent incorrect data from being entered.
There are different MDM implementation styles, such as the registry, consolidation, and coexistence styles. These styles are the foundation that MDM tools are based on. The business type, its data management strategy, and its situation will largely impact which style is selected.
The main difference between these implementation styles is in the way they deal with data, as well as the role of the MDM tool itself (it is a hub that controls the data or synchronizes data with other data stores). Here are three common ones in use:
- Registry style: This style spots duplicates in various connected systems by running a match, cleansing algorithms, and assigning unique global identifiers to matched records. This helps identify the related records and build a comprehensive 360 degree view of the given data asset across the systems.
In this approach, data is not sent back to the source systems. Changes to master data will continue to take place in source systems. The MDM tool assumes that the source systems can manage their own data quality. When a 360-degree view of a particular data asset is required (for example, the customer needs it), the MDM tool uses each reference system to build the 360-degree views in real time using the unique global identifier. There is normally a need for a continuous process to ensure the unique global identifier is still valid for a given dataset.
- Consolidation style: In this style, the data is normally gathered from multiple sources and consolidated in a hub to create a single version of the truth. This is sometimes referred to as the golden record, which is stored centrally in the hub and eventually used for reporting or as a reference. Any updates that are made to the golden record are then pushed and applied to the original sources. The consolidation style normally follows these steps:
- Identify identical or similar records for a given object. This can use an exact match or a fuzzy match algorithm.
- Determine records that will be automatically consolidated.
- Determine records that will require review by the data steward before they can be consolidated.
During these processes, the tool might use configured field weights. Fields with higher weights are normally considered more important factors when it comes to determining the attributes that would eventually form the golden record.
- Coexistence style: This style is similar to the consolidation style in the sense that it creates a golden record. However, the master data changes can take place either in the MDM hub or in the data source systems. This approach is normally more expensive to apply than the consolidation style due to the complexity of syncing data both ways.
It is also good to understand how the matching logic normally works. There are two main matching mechanisms:
- Fuzzy matching: This is the more commonly used mechanism but is slower to execute due to the effort required to identify the match. Fuzzy matching uses a probabilistic determination based on possible variations in data patterns, such as transpositions, omissions, truncation, misspellings, and phonetic variations.
- Exact matching: This mechanism is faster because it compares the fields on the records with their identical matches from target records.
As a Salesforce Architect, you need to understand the capabilities and limitations of the out-of-the-box tools available in the platform, in addition to the capabilities that are delivered by key MDM players in the market—particularly those that have direct integration with Salesforce via an AppExchange application.
In your review board presentation, as well as in real life, you are expected to guide your stakeholders and explain the different options they have. You should be able to suggest a name for a suitable tool. It is not enough to mention that you need to use an MDM tool as you need to be more specific and provide a suggested product name. This is applicable to all third-party products you may suggest. You may also be asked to explain how these MDM tools will be used to solve a particular challenge. You need to understand the MDM implementation style that is being adopted by your proposed tool.
Reference Data
Think of data such as order status (created, approved, delivered, and so on) or a list of country names with their ISO code. You can also think of a business account type such as silver, gold, platinum, and so on. Both are examples of reference data.
Reference data is typically static or slowly changing data that is used to categorize or classify other data. Reference datasets are sometimes referred to as lookup data. Some of this reference data can be universal (such as the countries with ISO codes, as mentioned earlier), while others might be domain-specific or enterprise-specific.
Reference data is different from master data. They both provide context to business processes and transactions. However, reference data is mostly concerned with categorization and classification, while master data is mainly related to business entities (for example, customers).
Reporting Data
Data organized in a specific way to facilitate reporting and business intelligence is referred to as reporting data. Data used for operational reporting either in an aggregated or non-aggregated fashion belongs in this category.
Reporting data is created by combining master data, reference data, and transactional data.
Metadata
Metadata has a very cool definition; it is known as the data that describes other data. eXtensible Markup Language (XML) is a commonly used metadata format.
A simple example is the properties of a computer file, that is, its size, type, author, and creation date. Salesforce utilizes metadata heavily since most of its features can be described using well-structured metadata. Custom objects, workflows, report structures, validation rules, page layouts, and many more features can all be extracted from the Salesforce Platform as metadata. This enables automated merge and deployment processes, something that you will cover in the chapters to come.
Big Data
Big data refers to datasets that are too massive to be handled by traditional databases or data processing applications; that is, datasets containing hundreds of millions (even billions) of rows. Big data became popular in the past decade, especially with the decreased cost of data storage and increased processing capacity.
Businesses are increasingly understanding the importance of their data and the significant benefits they can gain from it. They do not want to throw away their data and want to make use of it for many purposes, including AI-driven decisions and personalized customer-centric services and journeys. It is worth mentioning that there have been some critics of the big data approach. Some describe it as simply dumping the data somewhere in the hope that it will prove to be useful someday. However, it is also clear that when big data is used in the right way, it can prove to be a differentiator for a particular business. The future seems promising for big data, which is a key ingredient for machine learning algorithms.
As an architect, you should be able to guide the client through combining the technologies required to manage a massive quantity and variety of data (likely in a non-relational database) versus relational data (to handle complex business logic).
Unstructured Data
Unstructured data became more popular due to the internet boom. This data does not have a predefined structure and therefore cannot be fit into structured RDBMSs. In most cases, this type of data is presented as text data; for example, a PDF file where text mining would help with extracting structure and relevant data from this unstructured document.
The rise of big data and unstructured data takes us straight to our next topic—data warehousing and data lakes.
The Nature of Data Warehouses and Data Lakes
Data warehouse (DW or DWH) is a central repository of current and historical data that has been integrated from one or more disparate sources. The DWH (also referred to as an enterprise data warehouse (EDW)) is a system that is used for data analysis and reporting. It is usually considered the core of an enterprise business intelligence strategy.
Data stored in a DWH comes from multiple systems, including operational systems (such as CRM systems). The data may need to undergo a set of data cleansing activities before it can be uploaded into the DWH to ensure data quality.
Some DWH tools have built-in extract, transform, and load (ETL) capabilities, while others rely on external third-party tools (you will cover ETL tools and other integration middleware in Chapter 3, Core Architectural Concepts: Integration and Cryptography). This ETL capability will ensure that the ingested data has a specific quality and structure. Data might be staged in a specific staging area before it is loaded into the DWH. You need to become familiar with the names of some popular data warehousing solutions, such as Amazon Redshift, which is a fully managed, cloud-based data warehouse.
A data lake is a system or repository of data that is stored in an unstructured way. Data is held in its rawest form; it is not processed, modified, or analyzed. Data lakes accept and store all kinds of data from all sources. Structured, semi-structured, processed, and transformed data can also be stored in data lakes (such as XML data or data coming from databases). The data that is gathered will be used for reporting, visualization, business intelligence, machine learning, and advanced analytics. You need to become familiar with the names of some popular data lake solutions, such as AWS Lake Formation.
You also need to know which solution you should propose and the reason. If you need to offer a platform that can provide historical trending reports, deep data analysis capabilities, and the ability to report on a massive amount of data, then a DWH is more suitable for your use case. Keep in mind that data that has been extracted from Salesforce is mostly in a structured format (files are an exception).
In many review board scenarios, you will come across the need to archive the platform data. You will discover the options that are available in Chapter 7, Designing a Scalable Salesforce Data Architecture, but at the moment, all you need to know is that one of these options is a DWH.
Data lakes could be the right solution if you need to store structured and unstructured data in one place to facilitate tasks such as machine learning or advanced analytics.
Another common requirement in today’s enterprise solutions is document management systems. You will learn more about these in the next section.
Choosing the Right Document Management System
Electronic documents are everywhere nowadays in enterprises. An electronic document can simply be thought of as a form of electronic media content that can be used either in its electronic form or as printed output. This does not include system files or computer applications. A document management system (DMS) is a computer application that is used to store, track, and manage electronic documents throughout their life cycles. This includes activities related to these documents, such as versioning and workflows.
Document management overlaps with content management, even though they were originally different in nature. They are often seen combined today as enterprise content management (ECM) systems, mainly because many of today’s electronic documents that are available for a particular enterprise are not necessarily generated by the enterprise itself.
Document management systems today differ in terms of complexity, features, and scope; from simple standalone applications to enterprise-scale systems that can serve massive audiences. Some of the key capabilities available in today’s ECM systems are as follows:
- Security and access management, in a granular format
- Version control
- Comprehensive audit trails
- Ability to check-in and check-out the documents, with locks incorporated
As a Salesforce Architect, it is important to understand the capabilities of document management systems and enterprise content management. You must also understand what additional tools are needed to incorporate a full-fledged DMS into your architecture.
Salesforce comes with built-in features that can deliver some DMS capabilities. It is important to understand the capabilities and limitations of each (including availability since some features may retire with time). These features are as follows:
- Files: This allows users to upload and store electronic documents. Files can be stored privately or shared with others using chatter. Files are stored on the platform and are considered as replacements for the old attachments feature, particularly on lightning experience.
- Salesforce CRM content: This allows users to create, duplicate, and develop enterprise documents. A good example is a presentation or a flyer. It also allows you to share this content with other internal or external users, such as customers or partners.
- Salesforce knowledge: This is more like an enterprise knowledge base. It allows users to create and curate knowledge articles and publish them using a controlled workflow. It also allows internal and external users (through communities) to search these knowledge articles and use them in multiple ways (for instance, attach them to a case). Knowledge articles can be organized into libraries, which makes them easier to maintain and share.
- Documents: These are mostly used to store static files in folders without needing them to be attached to records. This is particularly useful when you need to refer to a static resource (such as a logo) on a Visualforce page, for example.
Most enterprises will already have a DMS of some sort; for example, enterprise-wide applications such as Microsoft SharePoint, Box, Google Drive, One Drive, and others. You will most likely need to integrate with these systems to access and manage external documents within the Salesforce UI rather than create things from scratch.
To do that, you can use another out-of-the-box tool in Salesforce called files connect. It is important to get some hands-on experience with files connect to get a better understanding of how it works. And, since it has its own limitations, it is also important to become familiar with some of the other alternatives available on AppExchange. You are not expected to know the names and capabilities of all the tools under the sun but just make yourself familiar with some of them and understand exactly what they are capable of.
As an architect, you will come across several DMS requirements and challenges. You will also definitely come across business requirements that require your skills and experience to design a solid data architecture. Moving on to the next section, you will learn more about key data architecture concepts.
Understanding Data Architecture Concepts
Previously, you understood the importance of data, as well as the importance of data architecture for the enterprise. The data architect—whom you, as a Salesforce Architect, need to work closely with or, in smaller projects, act as one—needs to tackle the data architecture in a similar fashion to normal building architecture. And to a good extent, similar principles should be followed in software architecture.
First, it is imperative to understand the business processes and create a conceptual and logical blueprint. Then, you need to know the underlying technology to build a detailed design and implementation. To understand these better, take a closer look at the three stages/levels of data architecture design—the conceptual, logical, and physical levels.
Conceptual-Level Data Architecture Design
The data architect, at the conceptual-level stage, needs to gain a deep understanding of business knowledge, business processes, and operations. This includes knowledge related to data flows, business rules, and the way data is used or expected to be used in the enterprise. This could be extended to areas such as financial, product, marketing, and industry-specific knowledge domains (such as manufacturing, insurance, and so on). The data architect can then build a blueprint by designing data entities that represent each of the enterprise’s business domains.
The architect will also define the various taxonomies and data flow behind each business process. The data blueprint is crucial for building a robust and successful data architecture. On many occasions, this activity is done at the project level rather than the enterprise-wide level. And it is usually included as part of the business analyst’s activities. Typically, the following areas need to be covered:
- The key data entities and elements (accounts, products, orders, and so on)
- Data entity relationships, including details such as data integrity requirements and business rules
- The output data expected by the end customers
- Required security policies
- The data that will be gathered, transformed, and used to generate the output data
- Ownership of the defined data entities and how will they be gathered and distributed
Logical-Level Data Architecture Design
This data architecture design is sometimes also referred to as data modeling. At this stage, the architect will start considering the type of technology being dealt with and define the data formats to use. The logical data model connects business requirements to the technology and database’s structure. The data architect should consider the standards, capabilities, best practices, and limitations of each of the underlying systems or databases. Data flows must be defined clearly at this stage. Typically, the following areas need to be covered:
- Data integrity requirements and naming conventions: Naming conventions should be defined and consistently used for each database involved. The data integrity requirements between the operational data and the reference data should be considered and enforced—especially if the data needs to reside in multiple underlying systems (at the conceptual level, all of these data entities should, ideally, belong to the same conceptual entity).
- Data archiving and retention policies: Data cannot be piled up on top of other data indefinitely. Failing to address data archiving and retention policies at an early stage normally has an impact on the project’s overall cost, poor system performance (particularly during data updates or data queries), and potential data inconsistencies. The data architect should work with stakeholders to define the data archiving and retention strategy based on business operations and legal or compliance requirements.
- Privacy and security information: While the conceptual design is more concerned with defining which data element is considered sensitive, the logical design dives into more details to ensure that confidential information is protected, and that data is visible only to the right audience. The data architect also needs to work on the strategy related to data replication and how to protect the replicated data both during the transition and at rest.
- Data flows and pipelines: At this stage, details about how data flows between the different systems and databases should be clearly articulated. These flows should be consistent with the flows defined at the conceptual level and should reflect details such as the required data transformations while in the pipeline, as well as the frequency of the data ingestions.
Physical-Level Data Architecture Design
This data architecture design is also known as the internal level. This is the lowest level of data design. At this stage, the architect is concerned with the actual technical aspects of the underlying system or database. It can even go as far as defining how the data is stored in the storage devices (such as within the specific folder structure).
As a Salesforce Architect, you are likely going to be involved in the conceptual design and, more likely, expected to be involved in the logical design. Your involvement in the physical design is not going to be as intensive and mostly be in an advisory context.
In Chapter 1, Starting Your Journey as a CTA, you covered the importance of creating a data model diagram during the review board exam. This is likely to be based on the logical mode (you will see several examples throughout this book). In real life, a logical model diagram is also required during the design phase of your project, while a physical model diagram is a must-have during the implementation phase.
You are expected to document (or lead the activity of documenting) the full Salesforce physical data model of your solution. This includes providing a full description of each standard and custom object used, how it is used (even for standard objects, it is not enough to mention that you are using the account object; for example, you must clearly explain how it is used), and the source of data in each integrated field, with a clear description of all involved data flows.
Next, you will understand more about the principles behind designing and properly documenting a data model.
Designing and Documenting Your Data Model
The importance of your data model’s design cannot be emphasized enough. It might get overlooked in many cases in the Salesforce world due to the fact that Salesforce comes with a pre-built data model, in addition to great flexibility for creating and changing custom fields and objects.
However, the proper data model design could be the difference between a smart, flexible, and scalable solution (that delivers valuable real-time insight that justifies all efforts required to enter the data) and a poorly designed database with tons of dumped data (that gives an overall feeling that data entry is an overhead).
Your data model is the foundation of your solution. Several solution aspects depend on your data models, such as the data sharing and visibility strategy and your ability to identify large data volume (LDV) objects.
You can read through the solution by understanding its data model. Your solution will be as strong as its foundation. You need to get your data model design right, and to do so, you need to understand key concepts in data modeling. This starts with normalization versus denormalization, going through three of the standard normal forms for database design, and finally, understanding the common relationship types between database tables and how that is reflected in Salesforce.
Normalization Versus Denormalization
Normalization is the process of arranging data in a database efficiently based on its relationships. This approach aims to remove data redundancy as it wastes disk space, slows down queries, and costs more processing time to execute create, read, update, and delete (CRUD) operations. Moreover, redundant data might also increase data inconsistency. For example, when the same data persists in multiple places and gets updated in one of them, you need to ensure that the change gets reflected in all other occurrences; otherwise, you may risk having data inconsistencies. Normalization should aim to get rid of data redundancy, but not at the cost of losing data integrity.
Normalization is based on the concept of what is known as normal forms. The dataset must meet specific criteria in order to be considered in one of these normal forms. There are three main normal forms (1NF, 2NF, and 3NF), all of which you will cover shortly, and others such as BCNF, 4NF, 5NF, and so on, which you are not going to cover in this book for brevity.
Denormalization can be considered the opposite of the normalization process. In a denormalized dataset, you intentionally use redundant information. This is done for several purposes but mostly to improve performance while executing queries and performing analytics. There is an associated overhead, of course, in keeping all the redundant data consistent and aligned.
The denormalization process reduces the number of tables (though it consumes more storage) and simplifies complicated table joins, which effectively enhances the performance while querying data that resides in multiple tables. The concept adopted by denormalization is that by placing all the data in one place, you could simplify the search process as it only needs to be executed on one table.
While designing your data model, you may come across use cases that could be better solved using a normalized set of tables. In other cases, denormalization could be the answer. You would understand the difference better with reference to these user stories.
The focus of this user story is on analytics/reports. Considering the standard reporting capabilities in Salesforce, it makes sense to store the account and account address details in two separate tables. This will also enable us to link the shipment records to the right address straight away, as well as build the desired report with minimal effort, even though Salesforce is doing additional processes behind the scenes to query data from multiple tables.
The following figure represents the proposed data model and an example of the data that is stored:

Figure 2.3 – Data model in a normalized form example
Now, explore the second user story.
The focus here is on the user experience while entering or viewing the data. In this case, it makes sense to use a denormalized dataset. These denormalized fields can easily be added to list views and page layouts. They can also be edited using fewer clicks.
You will come across more complicated scenarios where you could utilize a denormalized dataset to reduce data storage throughout this book. Although theoretically, a denormalized dataset consumes more storage data, in Salesforce, the data storage for the records of most objects is roughly 2 KB (with a few exceptions, such as person accounts and articles). This is true regardless of the number of fields in it, as well as if these fields are filled in or not (some field types are exceptions, such as rich text fields). As mentioned earlier in this book, there are some concepts of data modeling that may look different in Salesforce.
The following figure represents the proposed data model and an example of the data that is stored:

Figure 2.4 – Example of a data model in a denormalized form
The differences between normalized versus denormalized datasets can be summarized as follows:
- The normalization process relies on splitting data into multiple tables. The aim is to reduce data redundancy and increase consistency and data integrity. On the other hand, denormalization relies on combining data to speed up the retrieval processes. In Salesforce, it could also be used to reduce data storage and reduce the size of large data volume (LDV) objects. Despite that, this is not a common benefit in other databases.
- Normalization is usually used in online transaction processing (OLTP) systems, where the speed of insert, delete, and update operations is the key. On the other hand, denormalization is used with online analytical processing (OLAP), where the query’s speed and analytics are key.
- Data integrity is hard to maintain in denormalized datasets, unlike normalized datasets.
- Denormalization increases data redundancy.
- The denormalization process reduces the number of tables and potential join statements, as compared to normalization, which increases both of these.
- Typically, denormalized datasets take more disk storage. As mentioned earlier, this is not necessarily true in Salesforce.
The standard Salesforce data model is in normalized form by default. To further understand the normalization process, you need to understand the three main different types of normal forms.
Normal Forms
As you explored earlier, normalization is all about arranging data in a database efficiently based on its relationships. There are three common forms of data normalization. Explore each of these next.
First Normal Form
A database is considered in the first normal form if it meets the following conditions:
- Contains atomic values only: Atomic values are values that cannot be divided. For example, in the following figure, the value of the Phone Number column can be divided into three different phone numbers. Therefore, it is not in the first normal form (not 1NF):

Figure 2.5 – Table 1, which does not meet the first normal form (1NF)
- No repeating groups: This means that the table does not contain two or more fields/columns that represent multiple values for the same data entity. For example, in the following figure, you can see that the Phone Number 1, Phone Number 2, and Phone Number 3 fields represent multiple values for the same data entity, which is the phone number. Therefore, this table is not in 1NF:

Figure 2.6 – Table 2, which does not meet the first normal form (1NF)
To bring the table shown in Figure 2.5 into the 1NF, you must split the table into the following two tables:
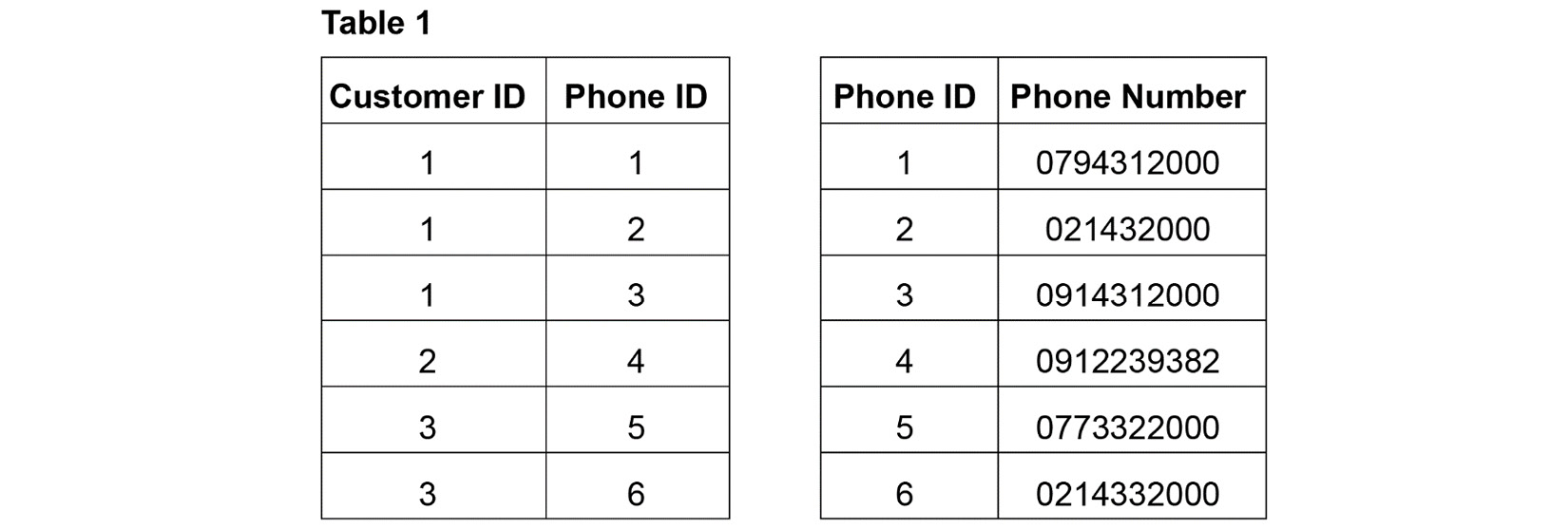
Figure 2.7 – Table 1 from Figure 2.5 modified to meet the first normal form (1NF)
Second Normal Form
A database is considered in the second normal form if it meets the following conditions:
- It is in 1NF.
- Non-key attributes function is based on the primary key. This is particularly applicable to cases where you have a composite key. (In Salesforce, the ID field is always the primary ID. There is no use for composite keys, which means that this condition is always met.) For example, the following table is not in 2NF because Address City is dependent on a subset of the composite key (which is Site ID). This can be clearly seen in the second and fourth rows. Therefore, this table is not in 2NF:

Figure 2.8 – A table that does not meet the second normal form (2NF)
To bring the table into 2NF, you must split the table into the following two tables:
![This shows a table modified to meet the second normal form [2NF]. The table in Fig. 2.5 is split into two tables. One lists ‘Customer ID’ and ‘Site ID’. The other lists ‘Site ID’ and ‘Address City’.](https://imgdetail.ebookreading.net/2023/10/9781803239439/9781803239439__9781803239439__files__image__B18391_02_09.jpg)
Figure 2.9 – The table from Figure 2.8 modified to meet the second normal form (2NF)
Third Normal Form
A database is considered in the third normal form if it meets the following conditions:
- It is in 2NF.
- Non-key attributes are not transitively dependent on the primary key. Take the following table as an example. The ID field is the primary key. The table is in 1NF and 2NF. The Name, Partner Number, and Bank Code fields are functionally dependent on the ID field. However, the Bank Name field is dependent on the Bank Code field. Therefore, this table is not in 3NF:
![This shows a table that does not meet the third normal form [3NF]. The table lists ‘ID’, ‘Name’, ‘Partner Number’, ‘Bank Code’ and ‘Bank Name’.](https://imgdetail.ebookreading.net/2023/10/9781803239439/9781803239439__9781803239439__files__image__B18391_02_10.jpg)
Figure 2.10 – A table that does not meet the third normal form (3NF)
To bring this table into 3NF, you must split the table into the following two tables:
![This table is modified to meet the third normal form [3NF]. The table in Fig 2.8 is split into two tables. One lists ‘ID’, ‘Name’, ‘Partner Number’ and ‘Bank Code’. The other lists ‘Bank Code’ and ‘Bank Name’.](https://imgdetail.ebookreading.net/2023/10/9781803239439/9781803239439__9781803239439__files__image__B18391_02_11.jpg)
Figure 2.11 – The table from Figure 2.10 modified to meet the third normal form (3NF)
Now that you have covered the three normalization normal forms, you will explore the types of relationships that can be created between the different database tables.
Using Database Relationships
One of the goals of the normalization process is to remove data redundancy. To do that, you must divide tables into multiple related subject-based tables. There are three main types of relationships—one-to-one, one-to-many, and many-to-many. Take a look at these in more detail:
- One-to-one relationship: In this type of relationship, each record in the first table has one–and only one–linked record from the second table. And similarly, each record from the second table can have one–and only one–matching record from the first table. In this relationship, one of the tables is effectively considered an extension of the other. In many cases, the additional attributes will simply end up being added to one of the tables. That is why this relationship is not very common. However, it still has its valid cases, including splitting the data for security reasons.
In Salesforce, this is particularly useful considering the rich sharing model available. You can implement one-to-one relationships in many ways, with the most common being to create a lookup relationship from each object to the other, with an automation script (trigger, workflow, process builder, and others) to ensure both lookup fields are always populated with the right values and each object is linked to its counterpart:

Figure 2.12 – One-to-one relationship
- One-to-many relationship: This common type of relationship occurs when a record in one table (sometimes referred to as a parent) is associated with multiple records of another table (sometimes referred to as a child). There are plenty of examples of this, including a customer placing multiple orders, an account with multiple addresses, and an order with multiple order line items.
To have this relationship, you would need to use what are known as primary keys and foreign keys. In the child table, the primary ID would be the unique identifier for each record in that table, while the foreign key would refer to the unique identifier of the parent’s primary key. This type of relationship can be created in Salesforce using lookup fields or master-detail fields. This book assumes you already know the differences between the two. You will also cover some particular differences that you need to remember in later chapters:
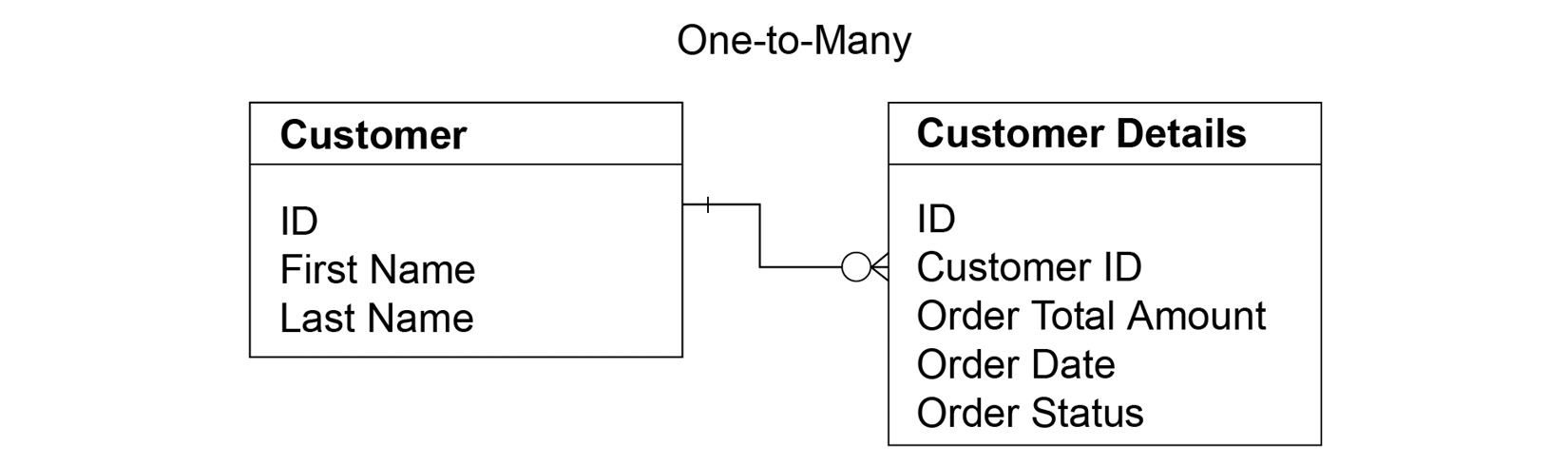
Figure 2.13 – One-to-many relationship
- Many-to-many relationship: This type of relationship occurs when multiple records from the first table can be associated with multiple records from the second table. This is also a common type of relationship that you come across every day. Think of the students and courses example, where each student can attend multiple courses, and each course can have multiple students attending it.
To create a many-to-many relationship between two tables, you need to create a third table, often called a bridge table or a junction table. This many-to-many relationship would effectively be broken into two one-to-many relationships. The junction table’s records would hold the value of two foreign keys, each pointing to a record from the two main tables.
Junction objects can be created in Salesforce by creating a custom object with two master-detail fields, or with two lookup fields (in this case, it is more often referred to as a bridge rather than a junction). Both approaches are valid and have their most suitable use cases.
You can even create a junction object using a mix of master-detail fields and a lookup field. This is assuming you put all the validation and business rules required in place to ensure they are always populated with the right values. You will come across examples of and use cases for Salesforce junction objects in later chapters:

Figure 2.14 – Many-to-many relationship
Keep in mind that the cardinality of these relationships can take different forms. For example, a one-to-many relationship might be better represented as one-to-zero-or-many if there are occurrences where the first table will have zero related records from the second table, as illustrated in the students and courses example earlier.
The following diagram illustrates a list of other relationships’ cardinalities. The one-and-only-one relationship could be a bit confusing. It is used when the relationship between two records from two different tables cannot be modified—for example, a user and a login ID. Once a login ID is associated with a user, it cannot be assigned to any other user after that. And it can be associated with one user only. This differs from the ownership relationship between a user and a mobile phone, for example, where the relationship itself might get updated in the future if the phone were to be sold to another owner:

Figure 2.15 – Table relationship cardinalities
Summary
In this chapter, you learned some historical information about database design, as well as how a proper design can be crucial to the overall Salesforce solution. You also learned about some key concepts, such as reference data, reporting data, and big data, in addition to general information about document management systems.
You then covered various data modeling principles and activities, including the process of normalizing and denormalizing data. You also explored other common architectural knowledge areas, such as normal forms, database relationships, and cardinality.
All this knowledge will be required when you are designing your secure and scalable Salesforce solution. In the next chapter, you will acquire another set of essential common architectural skills. This time, you will focus on the ever-growing and always-interesting integration domain.
Chapter Review Flashcards
Before you proceed to the next chapter, it is recommended that you go through the flashcards from this chapter first. These flashcards condense all the chapter concepts into smaller and easily manageable chunks that will help you with quick review and retention. By engaging with these flashcards, you will strengthen your understanding of key topics, identify areas that require further study, and build your confidence before moving on to new concepts.
The following image shows an example of the flashcards interface.
Figure 2.16 – CTA flashcards
To access the end-of-chapter flashcards from this chapter, follow these steps:
- Open your web browser and go to https://packt.link/ctach2. You will see the following screen:

Figure 2.17 – Chapter summary and login
You can also scan the following QR code to access the website:

Figure 2.18 – QR code to access Chapter 2 flashcards
- Log in to your account using your credentials. If you haven’t activated your account yet, refer to Instructions for Unlocking the Online Content in the Preface for detailed instructions.
After a successful login, you will see the following screen:

Figure 2.19 – Chapter summary and end-of-chapter flashcards
- Click Start on a flashcards stack to begin your review.