
7
Designing a Scalable Salesforce Data Architecture
In this chapter, you will continue looking at other Salesforce-specific knowledge areas a CTA must master. The data domain is the third out of the seven. You will understand the needed knowledge and then complete a hands-on exercise using a mini hypothetical scenario for each domain.
The data domain is broad, with a lot of interdependencies. It impacts several other domains and vice versa and can be considered the central part of any Salesforce solution. It involves understanding the fundamental principles of designing your data model, which is the core of any software solution. Arguably, the key to the success of several world-class applications is their well-designed data model.
A successful data architect should also be able to spot potential challenges in a data model, based on logic and experience, and propose a practical mitigation strategy. These challenges could have direct implications on the solution’s performance or scalability if left unmitigated.
Structuring the data in the right way will allow you to deliver value from the data you have gathered. As a Salesforce data architect, you need to guide your project’s stakeholders through the different tools and techniques to achieve that. You should also advise them on the best approaches to managing the data and migrating it to the target platform.
You already covered some general data architectural concepts in Chapter 2, Core Architectural Concepts: Data Life Cycle. In this chapter, you will be diving deeper into more Salesforce-specific topics and architectural principles. The following are the main topics to be covered:
- Understanding what you should be able to do as a Salesforce data architect
- Introducing the data architecture domain mini hypothetical scenario—Packt Online Wizz (POW)
- Learning about data architecture considerations and impact, and building your solution and presentation
Understanding What You Should Be Able to Do as a Salesforce Data Architect
A data architect is an experienced technology professional responsible for designing and describing a solution’s overall data modeling concepts and determining policies, procedures, and considerations for data collection, organization, and migration. The data architect is the principal for designing a scalable, performant, and optimized data model that considers the impact of large data volume (LDV) objects. It is worth mentioning that LDV challenges are not only specific to the Salesforce Platform, although a Salesforce data architect should probably be more conscious of them.
Note
According to Salesforce’s online documentation, the CTA candidate should meet a specific set of objectives, all of which can be found at the following link: https://packt.link/3Q0IV.
Have a closer look at each of these objectives.
Describing Platform Considerations, Their Impact, and Optimization Methods while Working with Large Data Volume Objects
Having LDV objects in your Salesforce implementation can lead to several performance considerations, such as slower queries, slower record creations, and record locks. A CTA should be aware of such challenges and anticipate the potential risk of an identified LDV on the overall solution. The CTA should accordingly prepare a mitigation strategy to address these risks and challenges.
First, you need to be able to identify an LDV. A simple mathematical method can be used to identify LDVs, where an object must meet at least one of the following conditions:
- Has more than 5 million records
- Has a growth rate that would lead to creating 5 million new records per year
In addition, some other indicators can point to an LDV use case, such as the following:
- Having an org with thousands of active users who can access the system concurrently
- The object has lookup/parent objects with related/child objects that have more than 10,000 records
- Having an org that uses over 100 GB of storage space
The preceding criteria could be a bit conservative. Salesforce could perform well with double that number of records. However, it is recommended to follow a safer approach and use the previously mentioned figures to identify LDV objects.
Impact of LDVs
LDVs have a wide impact on multiple features, including the following:
- Slow down CRUD record operations
- Slow down the standard search functionality
- Slow down SOQL and SOSL queries
- Slow down list views
- Slow down reports and dashboards
- Impact the data integration interfaces
- Increase the time required for record-sharing calculations and recalculations
- Impact the performance of the Salesforce APIs
- Higher chances of hitting the governor limits
- Slow down the Full Copy sandboxes refresh process
- Consume your org data storage
- Increase the chances of encountering record lock errors
It is worth mentioning that not all the transactions on the Salesforce org will get impacted by LDVs. The preceding implications are limited to the LDV objects and their related objects. In other words, reports involving non-LDV objects will not be impacted because you have some LDVs on your instance. On the other hand, the existence of some LDVs might impact the overall performance of the instance in some specific cases, such as recalculating the sharing records.
There is hardly any full CTA review board scenario that does not contain at least one LDV-related requirement. In real life, it pretty much depends on the type and size of the project, as well as the business you are working with.
Mitigating the LDV Objects’ Impact
When you identify an LDV object, you are expected to come up with a crisp and sharp mitigation strategy. This is not a mixture of potential solutions, but a clearly recommended and justified approach, similar to all the other requirements in the CTA review board. The following list and diagram will help summarize the different tools and techniques that you can use to create an LDV mitigation strategy:
LDV mitigation techniques:
- Skinny tables
- Indexes
- Divisions
- Data archiving
- Off-platform data storage
LDV mitigation tools:
- Data consumption analysis
- Query Optimizer
- Bulk API
- Batch Apex
- Deferred sharing
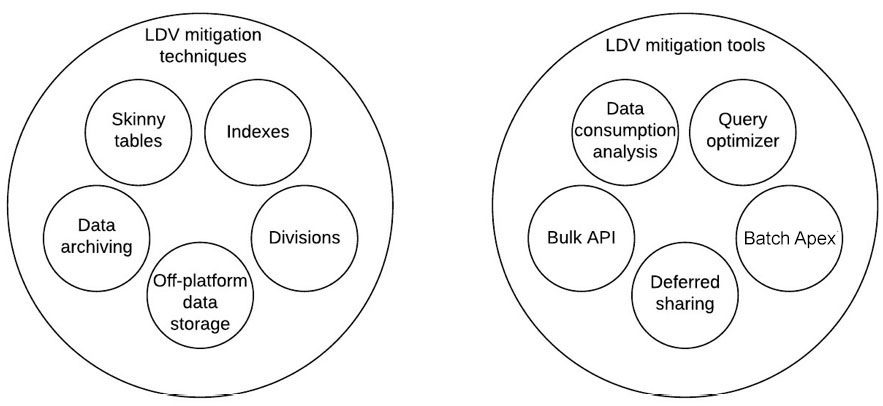
Figure 7.1 – LDV mitigation techniques and tools
Now, let’s briefly go through each of these techniques and tools.
Skinny Tables
You can enable Salesforce skinny tables on your Salesforce org by contacting Salesforce support. A skinny table is a special type of read-only custom object that contains a subset of fields from a standard or custom Salesforce object. Skinny tables can significantly boost the speed of Salesforce reports, list views, and SOQL queries that utilize them. Skinny tables can be created only on the Account, Contact, Opportunity, Lead, and Case objects and Custom Objects.
Behind the scenes, Salesforce stores its standard and custom objects using two separate tables and joins them on the fly whenever a user queries that object. One of these tables is used for standard fields, while the other is used for custom fields. Skinny tables combine both types of fields in one table. This removes the need for joining the two tables and, thus, makes skinny tables ideal for reporting. However, due to its nature, it cannot contain fields from more than one Salesforce object, and it cannot have more than 100 fields.
Salesforce will automatically switch between original tables and skinny tables when appropriate; this is not something you have control over.
The following diagram explains the anatomy of skinny tables:
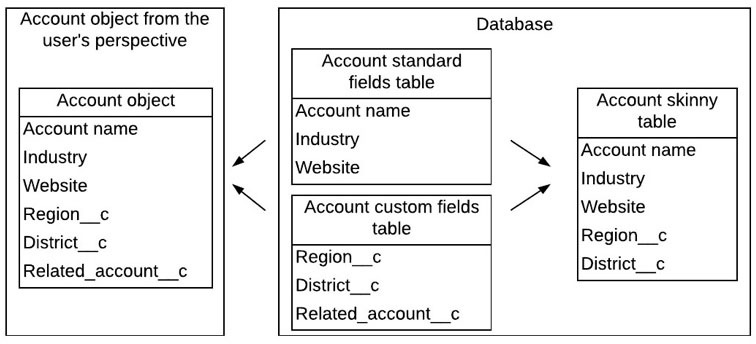
Figure 7.2 – The anatomy of skinny tables
Note
You can learn more about skinny tables at the following link: https://packt.link/nKZKd.
Make sure you fully understand the limitations and use cases of skinny tables.
It is worth mentioning that skinny tables do not contain soft-deleted records. Soft-deleted records are simply flagged as deleted but not completely removed from the platform yet and can be accessed and restored via the Salesforce Recycle Bin. Hard-deleting records of a specific object can reduce the LDV impact on that object, mainly when there is a massive set of soft-deleted records.
Standard and Custom Indexes
Just like any database, you can run performant queries if you use indexes in your query criteria. Just like any other databases, primary keys (the object’s ID field in Salesforce), foreign keys (the lookup and master/detail relationships in Salesforce), and alternate keys (unique external keys in Salesforce) are indexed by default.
Note
In addition, there is a set of standard indexed fields such as RecordTypeId, Division, CreatedDate, Systemmodstamp(LastModifiedDate), Name, and Email (for contacts and leads). You can find more details at the following link: https://packt.link/esgWV.
You can also request enabling custom indexes on some other fields. The queries that utilize indexed fields will perform much better as long as the query is returning a specific percentage of records out of the full dataset. Poor LDV query performance can still occur despite using indexed fields. In many cases, this is due to a misunderstanding of how the Salesforce Query Optimizer works. Make sure you fully understand the special cases where a query will not utilize the index. More details can be found at the previous link.
Divisions
Divisions act like normal database partitions. They let you segment your Salesforce instance’s data into multiple logical partitions. This effectively turns one massive dataset into a subset of smaller datasets, which makes searches, list views, and reports more performant. Divisions are not meant for security as they do not restrict access to data.
Divisions are typically done by geography. Once enabled, they impact several features in Salesforce, such as reports and list views.
Note
You can find out more details about divisions at the following link: https://packt.link/tkU62.
Off-Platform Data Storage
One of the most effective and efficient mechanisms to handle LDVs is to analyze and re-consider whether a specific dataset needs to be stored on-platform (which is the term used to describe storing data on the Salesforce Core Cloud, or what was previously known as Force.com) or off-platform and retrieved on the fly when needed.
There are several mechanisms for fetching data on the fly from external data sources/applications and displaying it in Salesforce, including APIs and mashups.
Data can be stored on a cloud-based or on-premises-hosted platform. One of the platforms commonly used for this is Heroku. Heroku comes with an out-of-the-box connector to the Salesforce Core Cloud called Heroku Connect. This can be used to sync data between the two platforms without consuming any of the Salesforce org’s governance limits.
Other platforms include AWS, Microsoft Azure, Google Cloud, and Rackspace. Storing some data off-platform could take place as part of a data design decision or as part of a data archiving strategy, which will be explained in the next section.
Data Archiving
Archiving is a very effective strategy used to handle LDVs. It relies on identifying data that does not necessarily need to be kept on-platform and can be moved to off-platform storage. Sometimes, you can even expose back the archived data using tools such as APIs or mashups. Salesforce also provides a tool that is compatible with the OData standard called Salesforce Connect. It allows you to expose external data tables as Salesforce External Objects. External Objects are similar to custom objects but with specific limitations and considerations.
Note
You can find out more details about External Objects at the following link: https://packt.link/zF5TQ.
Now, have a closer look at an example of using an off-platform data storage/archiving mitigation strategy. Assume that you have a Salesforce org with heavy use of the standard case object. Usually, more than 10 million cases are created every month. This qualifies the case object as an LDV. List views, reports, as well as other CRUD-related operations would all experience performance challenges accordingly. One way to mitigate the LDV impact would be to offload the data into another data storage platform (such as a PostgreSQL database on Heroku, but for this example, you can pick Azure Data Lake). The data offloading process involves the following steps:
- Cases closed for more than a month are copied from Salesforce to Azure on a regular basis (an ETL batch job could do the trick). Copied data is then purged from Salesforce (and the Recycle Bin is emptied). This ensures that the case object remains slim. However, accessing the off-loaded/archived data is going to be a bit challenging and time-consuming for the users.
- To enhance the user experience, you can develop a custom Lightning component (or Visualforce page) that invokes APIs developed on top of Azure to retrieve the stored data. Then embed that component into the standard case page layout. However, this means you need to develop a custom Lightning component and probably a set of customized APIs to retrieve the data from Azure in a flexible way, which is both time- and resource-consuming.
- To speed things up, you can use an adapter (such as the one offered by CData.com) to expose the data stored in Azure as OData and then utilize Salesforce Connect to consume it. This will generate an External Object for the archived case object in the target Salesforce org. It could be named something such as Case__x. External Objects are easy to link with other Salesforce objects and can be easily added to page layouts with few clicks, thus saving time and enabling a faster functionality release.
Note
You can read more about the OData standard at the following link: https://packt.link/tU4YW.
To develop a solid archiving strategy, you need to get answers to the following key questions:
- How much data/records must be kept on-platform?
- What is the data retention period for the archived object?
- What other systems are involved in this strategy? Which system would the data flow to?
- Which objects will be archived, and how will that impact child/related objects?
You can archive the data into an off-platform storage container, such as Heroku, or use Salesforce Big Objects. Big Objects are designed to store billions of records on-platform. But as with any other technology, it has its strong and weak spots. The following summarized table can help you determine the right technology to use:
|
Salesforce Big Objects |
Off-platform storage | |
|
Benefits |
Store and manage billions of records Relatively low-cost data storage On-platform storage, no need for additional technologies Fewer platforms to maintain, as it is part of the Salesforce Core Cloud |
Store and manage billions of records Data storage cost is usually low You can select a target archiving platform that supports both data archiving and reporting Several options to choose from, including self-hosted solutions More suitable for larger organizations, particularly when a central data warehouse is used Assuming the platform supports OData, the archived data could be exposed back to Salesforce using Salesforce Connect |
|
Considerations |
No out-of-the-box UI; need to develop a Visualforce page or Lightning component No out-of-the-box reporting capability No out-of-the-box search capability Need to develop custom code to insert data into Big Objects No record-level access control capability |
Third-party middleware tool is likely required to archive and migrate the data periodically from Salesforce to the external system Data will be distributed on multiple data sources; building a report that combines all data sources might require an additional tool Additional platform to maintain Could potentially lead to additional efforts for compliance due diligence Record-level access control capability requires developing or purchasing specific modules |
Table 7.1 – Comparison between Salesforce Big Objects and off-platform storage
You might need to consider several other aspects, depending on the use case, such as the fact that off-platform storage could consume some of your API limits unless you are archiving to Heroku via Heroku Connect.
Now let’s find out some more details on some of the tools that can support crafting an LDV mitigation strategy.
LDV Mitigation Tools
These are a select set of tools that can support you in crafting your LDV mitigation strategy. Understanding how and when to use these tools is essential if you wish to develop the right end-to-end solution.
Deferred Sharing Calculations
You learned in Chapter 6, Formulating a Secure Architecture in Salesforce, that Salesforce generates a shared record in several use cases to grant record access permissions to a particular user or group. Calculating and creating these shared records is time-consuming, especially when you are dealing with a massive number of records.
Deferred sharing calculation is a permission that lets an administrator suspend the sharing calculations, then resume them later to avoid disrupting or impacting any critical business processes.
Deferring the processing of sharing rules can come in handy when you are loading a massive number of records. You can stop calculating sharing records until you have finished loading the new data or completed a multi-step change of sharing mechanisms across the org.
Note
You can find out more about this feature at the following link: http://packt.link/TPeWw.
Query Optimizer
Query Optimizer is a transparent tool that works behind the scenes. It evaluates queries (SOQL and SOSL) and routes the queries to the right indexes. As Salesforce is a multi-tenant platform, it needs to track its own statistical information to find the best way to retrieve the data. The statistics-gathering process takes place nightly, with no user interference required.
Bulk API
The Bulk API is designed to provide a quick and efficient mechanism for loading or retrieving a vast amount of data into/from a Salesforce org.
The Bulk API functionality is available if it is enabled on your Salesforce org. It is enabled by default for performance, unlimited, enterprise, and developer orgs.
You can write a custom application that utilizes the Bulk API or buy readymade products that do. Most modern ETL tools that come with built-in Salesforce connectors support the Bulk API. Some are even built to automatically switch to the Bulk API when they detect that you are about to load a huge amount of data.
Note
You can find out more about the Bulk API at the following link: https://packt.link/7RX2x.
Batch Apex
Batch Apex can be used to develop complex, long-running processes that deal with a huge number of records and therefore require more relaxed governor rules.
Batch Apex operates in batches, handling one batch of a pre-determined size/number of records at a time. It does this until the entire record set it is operating on is complete.
You can use Batch Apex to build a data archiving solution that runs at a scheduled time (for example, every week). The code could look for records older than a pre-defined age and archive them in a pre-defined mechanism (for example, move them to an aggregated denormalized table).
You need to remember that this is still an on-platform functionality that adheres to governor limits. It is just that the governor limits are a bit more relaxed for Batch Apex. You should continue to consider using a third-party tool (such as an ETL) to do such data archiving activities.
Note
You can find out more about Batch Apex at the following link: https://packt.link/8ysjA.
Data Consumption Analysis
One of the techniques that could be very handy to determine the right LDV mitigation strategy is to understand how the data storage is consumed, find out whether there are orphan records being created due to poor data governance rules, and analyze the impact the existing data model has on the number of generated/used records.
Note
You can find more details about an instance’s data usage using the data usage tool. Find more details at the following link: https://packt.link/J64p6.
Explaining Data Modeling Concepts and Their Impact on the Database’s Design
Standard Salesforce objects are normalized. They store data efficiently in tables with relationships that minimize redundancy and ensure data integrity.
You can create custom objects that are normalized or denormalized. Due to the nature of Salesforce objects, you can use patterns that are considered sub-optimal in typical database systems, such as defining objects with a huge number of fields.
Records in Salesforce consume around 2 KB of data storage, regardless of the number of fields/columns (with few exceptions). Creating a denormalized object to store aggregated data is one of the LDV mitigation strategies you can use. It is considered a special case of data archiving.
Note
For more details about normalized and denormalized datasets, review Chapter 2, Core Architectural Concepts: Data Life Cycle.
In addition to that, you need to become familiar with data skew. Salesforce utilizes a relational database under the hood where there is a crucial need to maintain data integrity across different objects. Salesforce uses temporary locks to ensure data integrity while updating records and does so in a timely manner, so you will not usually encounter any issues. However, the locks could persist for longer than usual while updating a huge number of records. This can lead to transaction failure.
To avoid such incidents, you need to design your data model in a way that avoids/mitigates the non-uniform distribution of data in your dataset, which is referred to as data skew.
There are three types of data skew to consider while designing your data model, as well as when uploading data into that data model:
- Account data skew
- Lookup skew
- Ownership skew
You will briefly cover the different types of Salesforce data skews in the next section.
Account Data Skew
This is related to specific standard Salesforce objects, such as account and opportunity. These objects have a special type of data relationship between them, allowing access to both parent and child records when the organization-wide default (OWD) of the account is private.
Account data skew happens when there is a huge number of child records associated with the same parent account record. Under these conditions, you could run into a record lock when you update many child records (for example, opportunity records) linked to the same account in parallel (for example, via the Bulk API). Salesforce, in this case, locks the opportunities that are being updated, as well as their parent account, to ensure data integrity. These locks are held for a very short period of time. Nevertheless, because the parallel update processes are all trying to lock the same account, there is a high chance that the update will fail due to the inability to lock an already locked record.
Lookup Skew
Linking a large number of records to a single parent/lookup record (applicable to standard or custom objects) creates what is known as a lookup skew.
For example, you could have millions of records of a custom object associated with a single account record via a lookup relationship. Every time a record of that custom object is created and linked to an account record, Salesforce locks the target account record until the inserted record is committed to the database to ensure data integrity.
Again, this takes a very short amount of time under normal circumstances, which means you are highly unlikely to experience any issues. However, the time required to execute custom code, sharing records’ calculations, and other workflows on an LDV object could slow down the save operation and therefore increase the chance of hitting a lock exception (basically, attempting to lock an already locked record), which will cause the operation to fail. It is worth mentioning that record lock does not occur if the lookup relationship is configured to clear the value of the field when the lookup record is deleted.
Lookup skews are hard to spot. Reviewing the data model to understand the object relationships and then comparing it with the data usage patterns and the record volume in each object is a good approach to start with.
You typically focus more on objects with a vast number of records and those with a high number of concurrent insert and update operations.
Ownership Skew
Ownership skew happens when the same user owns several records of the same object type. All records must have an owner in Salesforce, and sometimes, a business process might park records or assign them by default to a single specific user. However, this could have an impact on performance due to the activities required to calculate the sharing records. Salesforce uses Share Records of Share Objects to control access and visibility when sharing a private object. For example, records of the object AccountShare are used to grant access to records from the Account object (if the OWD of the Account object is set to private). These sharing records can be created in multiple ways, including Apex-managed sharing.
Ownership changes are considered expensive transactions in Salesforce. Every time a record owner is updated, the system removes all sharing records that belong to the previous owner and parent users in the role hierarchy. In addition, the system removes sharing records associated with other users, which are created by sharing rules or other sharing mechanisms, such as manual sharing.
You can minimize the risk of ownership skew by distributing record ownership to multiple users or by ensuring the assigned owner does not have a role and, therefore, does not belong to the role hierarchy. You can also ensure that the assigned owner belongs to a role at the top of the hierarchy.
Determining the Data Migration Approach, Tools, and Strategy
Data migration is a typical exercise for Salesforce projects. While it is an extensive topic, you are expected to explain your data migration strategy’s high-level details during the CTA review board. You will go into far more detail in real life and include many other factors in your decision-making.
Key Topics to Consider in Your Data Migration Strategy
During the review board, you need to keep an eye on crucial topics such as the following:
- The record count is crucial, that is, how many objects you are going to migrate and the number of records in each object.
- Depending on the migrated dataset’s size, you need to come up with a rough migration plan that avoids business disruption. For example, you can propose doing the full migration in a 4-hour blackout period at the weekend.
- The number and type of involved systems and the mechanism of extracting the data from them. You might need to assume that the data will be provided in a specific format and based on a shared template to limit the risk from your end.
- You need to determine which data migration approach works best for you. The two key approaches are the big bang and ongoing accumulative approaches.
- You can derive other approaches from the key approaches, such as a local big bang executed sequentially across different regions/business units, an ongoing migration approach where more than one live system is maintained and the delta of the data is migrated regularly, and so on.
- You need to consider the different governor limits that could be impacted, such as the daily inbound API calls limit.
- Triggers and workflows execute specific logic based on specific criteria. They also take time and CPU power and consume governor limits while executing, which could be a risk when loading a massive amount of data. As a best practice, you are advised to turn them off or provide a mechanism to bypass them during the data load.
- Use the Bulk API if possible. This could be a simple switch if you are using a modern ETL tool.
- Use the Deferred sharing calculation feature described earlier in the LDV Mitigation Tools section. Then, activate sharing rule calculation once you have finished loading the data.
- When loading child records, try to group them by their parent ID.
Moreover, you need to propose the right tool based on your assumptions, experience, and logic.
Data Backup and Restore
Salesforce announced that effective July 31, 2020, data recovery, as a paid feature, would be deprecated and no longer available as a service. However, based on customers’ feedback, Salesforce decided to reinstate its data recovery service. In Autumn 2021, Salesforce announced a new built-in platform-native backup and restore capability.
Be prepared to explain how your solution will fulfill data backup and restore requirements (if specified in the scenario).
You can review Chapter 2, Core Architectural Concepts: Data Life Cycle, to find out more about the different approaches and tools to achieve this.
Introducing the Data Architecture Domain Mini Hypothetical Scenario—Packt Online Wizz
The following mini scenario describes a challenge with a particular client. The scenario has been tuned to focus on challenges related to data architecture specifically. However, this domain is tightly related to the security domain—sharing and visibility in particular. Therefore, you will still notice a considerable amount of sharing and visibility requirements. There will be other scenarios in later chapters that also have dependencies on the data architecture domain.
You will go through the scenario and create a solution step by step. To get the most out of this scenario, it is recommended to read each paragraph, try to solve the situation yourself, then come back to this chapter, go through the suggested solution, compare it with yours, and take notes.
Remember that the solutions listed here are not necessarily the only possible solutions. Alternate solutions are acceptable as long as they are technically correct and logically justified.
Scenario
Packt Online Wizz (POW) is an online shopping portal where traders offer different items to consumers. POW is currently dealing with over 100,000 different traders. POW currently estimates that they have over 2 million unique products for sale, organized into 150 different categories. According to their current website traffic, more than 5 million visitors visit their website every day. They place around 150,000 orders every day. Each order contains an average of five items.
Current Situation
The current website allows consumers to place their orders anonymously or as registered users. They currently have 3 million registered users. The website also supports all major online payment methods, such as PayPal and credit cards. POW shares the following information:
- Once an order has been placed, it can be fulfilled via either POW or the traders themselves, depending on the preferences provided by the traders for each of their products. Orders are usually fulfilled in no more than two weeks.
- POW stores the bank account details of all its traders. Once the item is shipped to the consumer (either by POW or the traders), POW automatically calculates its commission, deducts it from the collected payment amount, and deposits the remainder into the trader’s bank account.
POW has a global support center containing 2,000 support agents and 100 managers operating 24/7 across phone and email channels. POW shares the following information:
- The support center handles roughly 20,000 cases per day.
- Each support manager leads a team of 20 support agents. Cases are available for all support teams.
POW has a global ERP system to handle billing, inventory management, and order returns. They use a bespoke application as an item master and run their custom website on AWS. They utilize MuleSoft as an integration middleware between all systems.
Requirements
POW has shared the following requirements:
- The company would like to provide a convenient self-service experience to its consumers, allowing them to raise support tickets and inquiries.
- POW would also like to expose a rich set of searchable FAQs to their consumers to help deflect as many cases from their call center as possible.
- Registered consumers should be able to view their purchase history for up to four years.
- Registered consumers should be able to review an item they have purchased. These reviews should be publicly available to both registered and non-registered website visitors.
- The support agents should have a 360-degree view of the consumer who raised a specific case. This should include the customer’s order history from the past four years, other cases that were raised in the past four years, order returns, and any product reviews from the customer.
- The support agents should be able to see the overall consumer value indicator, which shows the value of this consumer across their entire history of engagement with POW. This indicator should take into consideration several factors, such as purchased products, monthly spending amount, purchase quantities, and the customer’s social media influence factor. The social media influence factor is a value POW gathers and updates daily from three different providers.
- Traders should be able to view their customers’ purchase history for up to four years.
- Traders should be able to log in to the POW trader’s portal to view their current pending orders. They should also receive an email notification once a new order is placed. All emails should be sent to a specified corporate email address.
- Traders should be able to raise support tickets for themselves to resolve issues related to payments and inventory-related queries.
- POW’s top management should be able to run reports and dashboards to track the performance trends of items across different categories. The dashboards should include information such as the number of items sold, returns, and the total weekly value of sold items in a particular period.
- Historically, POW used a custom-developed solution to manage consumers’ complaints. POW is looking to decommission this system and replace it with a new solution. The current system contains more than 200 million records, including some that are still undergoing processing.
POW is concerned about the system’s overall performance and would like to get clear recommendations from you, as an architect, about designing the solution to ensure it has the best possible performance.
Learning about Data Architecture Considerations and Impact, and Building your Solution and Presentation
Give yourself time to quickly skim through the scenario, understand the big picture, and develop some initial thoughts about the solution. Once you have done this, you are ready to go through it again, section by section, and incrementally build the solution.
Understanding the Current Situation
The first paragraph contains some general information about POW’s business model. It also contains some interesting figures, such as 5 million daily visitors and 150,000 orders per day, with an average of five items in each order. Take some notes about these figures. In some scenarios, there are figures that are not necessarily going to impact the solution from a technical perspective. However, they could be mixed up with other figures, which you should be careful writing about.
For example, at first glance, you will notice the huge number of daily visitors, which could impact the governor limits in many ways. It is still unclear which governor limit is at risk at this stage but make note of this number and move on. After all, it might simply be a figure impacting an off-platform, third-party solution.
The number of daily orders is also massive. Keep that on your radar too. Start scribbling your data model diagram. You do not know yet whether any of these objects would end up in Salesforce, but nevertheless, having that diagram will help you make the right decisions once you go further into the scenario. What you know so far is that you are likely going to use the following objects: account, contact, product, order, and order line item.
The first and second paragraphs are also helpful in building an early understanding of the system landscape. So far, you know that there is a website being used to list, display, and capture orders. There must be an order fulfillment system, a shipment system, and an invoicing system. You do not know exactly which of these functionalities will be fulfilled by Salesforce and which will not, but capture these requirements and add the assumed systems to your initial landscape architecture diagram.
Once an order has been placed, it can be fulfilled either via POW or the traders themselves, depending on the preferences provided by the traders for each of their products.
You can see a clear description of one of the business processes. The business process diagram is not as essential as the other diagrams for the review board, Still, it is handy to help you tie back your solution to a business process, which, in turn, will help you present the solution in an engaging manner. The business process diagram is a must-have in real-life projects as it can significantly improve the quality of the client requirements you have gathered. Start creating your draft business process diagram. The next paragraph completes this picture:
POW stores the bank account details of all its traders. Once the item is shipped to the consumer (either by POW or the traders), POW automatically calculates its commission, deducts it from the collected payment amount, and deposits the remainder into the trader’s bank account.
You know more about the process now. You do not know which system is going to be used for order fulfillment yet but create the business process diagram to the best of your knowledge and expectations at this stage.
There is potentially a need for one more object that will hold the trader’s payment details and the calculated commissions. There is also a need for an application to complete the bank deposit. You are still not sure whether that is going to be an on- or off-platform solution but add it to the landscape diagram anyway and update that later. After updating your diagrams, you may have the following business process diagram:

Figure 7.3 – Ordering business process diagram (first draft)
Your data model may look as follows:

Figure 7.4 – Data model (first draft)
Your system landscape diagram may look as follows:

Figure 7.5 – Landscape architecture (first draft)
Now, move on to the next paragraph:
POW has a global support center containing 2,000 support agents and 100 managers operating 24/7 across phone and email channels.
You can now add more actors to your notes or your draft actors and licenses diagram. The scenario does not mention any detail about the call center infrastructure and how it is integrated with Salesforce. You can assume that the client is using Service Cloud Voice and Email-to-Case to handle the email support channel.
POW has a global ERP system to handle billing, inventory management, and order returns.
Adding the ERP system, the item master, and MuleSoft to the landscape will help you complete the landscape architecture. You still have not gone through the entire set of requirements, but at this stage, you can take another look at some of the early assumptions. The commission calculating module can be closely related to the invoicing process. Also, the process of depositing funds into the trader’s bank account is likely going to end up with the ERP system. Now, update the landscape architecture accordingly and take some notes about the number of raised cases. They might indicate that the case is going to be an LDV object.
Your updated landscape architecture may look as follows:

Figure 7.6 – Landscape architecture (second draft)
This concludes the first part of the scenario, which is mostly describing the as-is situation. Now, move on to the next part of the scenario, which describes POW’s requirements.
Diving into the Shared Requirements
POW shares a set of requirements. You will go through each of them, craft a proposed solution, and update your diagrams accordingly. Start with the first requirement:
The company would like to provide a convenient self-service experience to its consumers, allowing them to raise support tickets and inquiries.
The consumers are currently placing their orders using the public website, and you know from the scenario that the website allows the consumers to register themselves and log in to some sort of portal.
Using the capabilities of Salesforce Service Cloud, it makes sense to propose that cases should be raised and managed to fulfill this requirement. However, a question that might come to your mind is, should you recommend using Salesforce communities or simply build a custom-developed solution on top of the existing portal, then integrate it with Salesforce Service Cloud?
After all, the portal already exists. You can simply develop the functionality of creating, viewing, and updating cases in it, and then integrate that with Service Cloud using an integration user, right? The answer is no. This is another build-or-buy decision. The buy option gives a better return on investment in most cases. In this one, though, it is easy to justify why.
To build a secure portal, you will need to build an entire user access control capability on top of the existing portal to ensure that the users cannot access cases that they should not. The integration user will likely have access to all the cases. A fully custom user access control module is not easy to develop, test, or maintain.
Moreover, utilizing an integration user in that fashion could breach Salesforce’s terms and conditions and could lead to a major data leak if the portal is compromised.
All these reasons are good enough to justify using Salesforce communities instead. They come with a solid user access control module, in addition to configurable pages. Some clients prefer to use their own fully customized pages instead. In that case, they could end up utilizing the Salesforce community licenses but not the pages. This is technically an acceptable approach.
POW has not shared a requirement indicating that they want the capability of raising support tickets embedded within their current portal. You can propose introducing an additional entirely new portal based on Salesforce communities. Then, you have the two portals linked via SSO so that the users would not need to log in twice.
Your proposed solution could be as follows:
Update your actors and licenses diagram, your landscape architecture diagram, and your integration interfaces accordingly. Now, look at the next requirement:
POW would also like to expose a rich set of searchable FAQs to their consumers to help deflect as many cases from their call center as possible.
Salesforce Knowledge is a powerful tool you can use to build an internal or external knowledge base. Community users can be configured to have read access to specific article types using profiles and permission sets. Note that the org must have at least one Salesforce Knowledge license to enable and set up Salesforce Knowledge. Your proposed solution could be as follows:
Update your landscape architecture and move to the next requirement, which is as follows:
Registered consumers should be able to view their purchase history for up to four years.
According to the scenario, there are 150,000 daily orders, with an average of five items in each. This means there are nearly 4.5 million orders every month and 22.5 million order line items. In four years, those numbers will become massive, at around 216 million orders and more than a billion order line items. These two tables are categorized as LDV objects on two fronts, that is, the monthly data growth and the total number of records per year.
You are also still unclear on the system that will be used for order fulfillment. Considering the amount of data, you could propose an off-platform solution, such as using a custom Heroku solution, an extension to the ERP, or a completely new system.
However, according to the scenario, orders are usually fulfilled in no more than two weeks. This means you can use an on-platform order fulfillment solution to handle open orders and use an archiving mechanism to move fulfilled orders off the platform. The number of open orders stored on-platform at any given time would not result in creating an LDV object.
There are several order management solutions on AppExchange. Salesforce also has its own solution called Salesforce Order Management, which was introduced back in 2019. The scenario itself does not dive into the details of how the orders will be fulfilled, which means that even if you do not fully know how Salesforce Order Management works, you can still propose and assume its capabilities are good enough for POW.
Delivering this functionality using an on-platform solution will allow you to cover other upcoming requirements. Therefore, it is recommended to skim through the scenario at least once before you start the solution. This will help you build an early idea about some key parts of the potential solution.
You can still propose an off-platform solution, but you need to ensure that it can still fulfill all of POW’s requirements.
Note
Be careful of shifting more duties than you should to off-platform applications. This could indicate you do not fully understand the platform’s value and capabilities, nor the benefits of building your solution on top of a flexible platform such as Force.com, which offers native integration with other CRM functionalities.
In short, when proposing an off-platform solution, make sure it adds value and solves a problem that cannot be optimally fulfilled using on-platform capabilities.
For this requirement, you can choose a solution such as the following:
Again, remember that this is one suggested solution; it is not the only possible solution. What you need to deliver is a solution that works, fulfills all requirements, and is technically correct. You also need to justify your solution and explain the rationale behind selecting it. You will need to defend your solution during the Q&A section. This would not be difficult if you are confident in your logic. While explaining such topics, keep an eye on the timer. The preceding statement should be covered in no more than 180 seconds.
Now, update your diagrams, including your data model (so that it includes the External Objects), and move on to the next requirement, which starts with the following line:
Registered consumers should be able to review an item they have purchased.
These reviews should be publicly available to both registered and non-registered website visitors. You have nearly 2 million products. You do not have a clear idea of the average number of reviews, so you can make some assumptions. You also do not have additional requirements for the product review capability, apart from the fact that it should be publicly available for registered and unregistered customers.
Typically, product reviews allow other users to rate the review, and probably even respond to it. However, POW has not requested such a feature. You are free to make your own assumptions here.
The next question in line is whether there is an out-of-the-box feature that fulfills this requirement, or do you need to consider a custom solution? And what kind of assumptions do you need to make to avoid having an LDV object?
Your proposed solution could be as follows:
Can you think of other potential solutions? You could have created an external reviews object and used it with an unlimited number of reviews. But then, you would need to introduce several more objects to hold data such as likes, comments, and attachments. Again, it is a decision between using an out-of-the-box functionality knowing its limitations or developing a customized functionality that could require significantly more time and effort but has more capabilities. In this case, you used the former.
Update your data model diagram. The Chatter module contains several objects, and you are not expected to know all of them. You can simply just add the FeedItem object to your data model.
Now, move on to the next requirement, which starts with the following line:
The support agents should have a 360-degree view of the consumer who raised a specific case.
The requirement here is related to four different data entities, delivered by several systems. Orders are managed in Salesforce, then archived to Heroku once they are fulfilled. Cases are managed in Salesforce as well, but with 20,000 new cases daily, you have the potential for an LDV object here. This grows to nearly 600,000 records every month, which would lead to roughly 7.2 million new cases annually.
In four years, that number will be nearly 28.8 million records. This is not very high, but it is still high enough to consider the object an LDV. The use case is not as strong and obvious as it was with the Order object, but this is still an object that you need to include in your LDV strategy.
Luckily, you already have Heroku in the landscape, and you are already utilizing an ETL tool to archive orders and order line items. You can easily extend that to include the case object. You can also archive orders, order line items, and cases using Big Objects. At this stage, there is no clear requirement that indicates which option would be best between these two. Archiving the data into Heroku allows you to expose it to a customer-facing mobile app via Heroku Connect. This is not something that POW requested, though.
Order returns are handled by the ERP. You have multiple ways to access these records from Salesforce. The scenario did not mention any details about the ERP system, so you must make some realistic assumptions. You know that MuleSoft is used to connect the ERP to other POW systems. It is fair to assume that MuleSoft has access to this data, and it can expose a REST service on top of it that allows any authenticated party, including Salesforce, to access this data. You can even assume that MuleSoft would expose this REST interface in the OData standard format. This allows you to use Salesforce Connect to display the data in Salesforce without developing any custom modules, such as Lightning components.
Finally, the product reviews are stored as Chatter posts, and you can develop a Lightning component that displays all review posts created by a specific user. Now, put all the different elements of this solution together:
The support agents should be able to see the overall consumer value indicator, which shows the value of this consumer across the entire history of engagement with POW.
The questions you should ask yourself are as follows:
- Where will the data for this report be coming from?
- Is there an out-of-the-box feature that can be used to build such a report, considering the amount of data included?
- How can you utilize the data coming from the three social media influence sources?
Such a requirement should point you directly to the need for a business intelligence (BI) tool. Most of this data resides outside the Salesforce Core Cloud, and the volume of the data should easily tell you this is not something you can achieve with standard Salesforce reports. Building a custom module is too expensive and would not deliver the needed flexibility. This should be an easy buy decision.
There are plenty of BI tools available on the market with built-in connectors to Salesforce, Heroku, and other data sources. Salesforce CRM Analytics is one of them, and it is a Salesforce product that provides attractive dashboards that can be easily embedded in the Salesforce Core Cloud. There could be many other factors to consider in real life when it comes to selecting the right tool for this job, but for this scenario, Salesforce CRM Analytics sounds like a good solution.
Your solution could be as follows:
Update your actors and licenses and landscape architecture diagrams, and then move on to the next requirement, which starts as follows:
Traders should be able to view their customers’ purchase history for up to four years.
This one should be straightforward, considering you have that data available in External Objects.
Your solution could be as follows:
Traders should be able to log in to the POW trader’s portal to view their current pending orders.
Be careful with such requirements as they might include other minor requirements in them. For example, the main requirement here is to explain how the trader will get access to the right records, but you also have an embedded requirement that requests sending an email notification upon creating an order. Your solution could be as follows:
Avoid missing easy points by overlooking easy-to-configure features such as email alerts. Now, update your diagrams, and move on to the next requirement, which starts as follows:
Traders should be able to raise support tickets for themselves to resolve issues related to payments and inventory-related queries.
This one should be straightforward; your solution could be as follows:
Now move on to the next requirement, which starts with the following line:
POW’s top management should be able to run reports and dashboards to track the performance trends of items across different categories.
This is another requirement that should point you straight to proposing a BI tool. You have already proposed one. Your solution could be as follows:
Update your diagrams and move to the next requirement, which starts with the following line:
Historically, POW used a custom-developed solution to manage consumers’ complaints.
This is a data migration requirement related to one system that is going to be retired. Therefore, there is no need to maintain parallel running systems. This could be a big bang approach, if not for the huge amount of data that needs to be migrated. Your proposed solution could be as follows:
That was the last shared POW requirement. Now, update all the diagrams and see what they look like. The ordering business process flow diagram should look as follows:

Figure 7.7 – Ordering business process diagram (final)
The landscape architecture diagram should look as follows:

Figure 7.8 – Landscape architecture (final)
The list of integration interfaces should be as follows:
![The figure shows the final integration interfaces. This lists the interface codes [Mig-001 and SSO-001] under Source/Destination, Integration Layer, Integration Pattern, Description, Security, and Authentication.](https://imgdetail.ebookreading.net/2023/10/9781803239439/9781803239439__9781803239439__files__image__B18391_07_09.jpg)
Figure 7.9 – Integration interfaces (final)
The actors and licenses diagram should look as follows:

Figure 7.10 – Actors and licenses (final)
Finally, the data model diagram should look as follows:
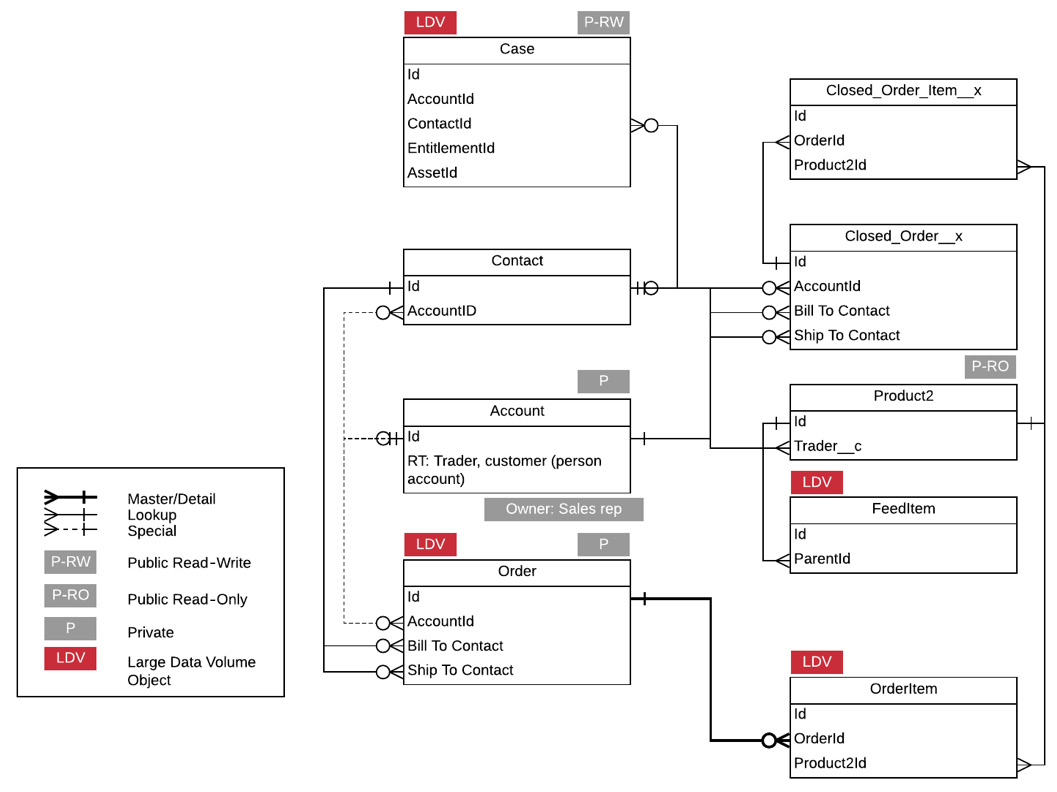
Figure 7.11 – Data model (final)
That concludes this scenario. Remember that your diagrams are tools to help you make the end-to-end solution crisp and clear. They are not the targets themselves, but tools that can help you design and document a better solution. They add a lot of value to your presentation.
Summary
In this chapter, you have dived into the details of the Salesforce data architecture domain. You learned what a CTA must cover and the extent of detail. You then discovered some interesting principles that a Salesforce data architect needs to master and had an under-the-hood look at the causes, impact, and mitigation strategies for LDV objects.
You then tackled a mini hypothetical scenario that focused on data architecture, and you solutioned it and created some engaging presentation pitches. You identified several LDV objects and prepared a comprehensive mitigation strategy based on the business’s nature and shared requirements.
If you are now part of a Salesforce implementation project, or you are administrating a running instance, you can practice the process of identifying LDVs. Start by analyzing the data model diagram (or create it if you still do not have one!) and use the tools and techniques you covered in this chapter to identify LDVs. Do your calculations and share your observations, concerns, and the proposed solution with your stakeholders. Remember to make your solution crisp and clear; it must cover the topic from end to end, and it must logically explain why it is the right solution from your perspective.
You also covered several other topics in the mini scenario, including selecting the right reporting tool and explaining how to get the data into it. You then created a comprehensive data migration strategy based on the shared requirements, ensuring data integrity and minimizing disruption to daily operations.
In the next chapter, you will learn about the fourth domain you need to master: solution architecture.