
pLSA is equivalent to non-negative matrix factorization using a Kullback-Leibler Divergence objective (see references on GitHub https://github.com/PacktPublishing/Hands-On-Machine-Learning-for-Algorithmic-Trading). Hence, we can use the sklearn.decomposition.NM class to implement this model, following the LSA example.
Using the same train-test split of the DTM produced by the TfidfVectorizer, we fit pLSA as follows:
nmf = NMF(n_components=n_components,
random_state=42,
solver='mu',
beta_loss='kullback-leibler',
max_iter=1000)
nmf.fit(train_dtm)
We get a measure of the reconstruction error, which is a substitute for the explained variance measure from before:
nmf.reconstruction_err_
316.2609400385988
Due to its probabilistic nature, pLSA produces only positive topic weights that result in more straightforward topic-category relationships for the test and training sets:
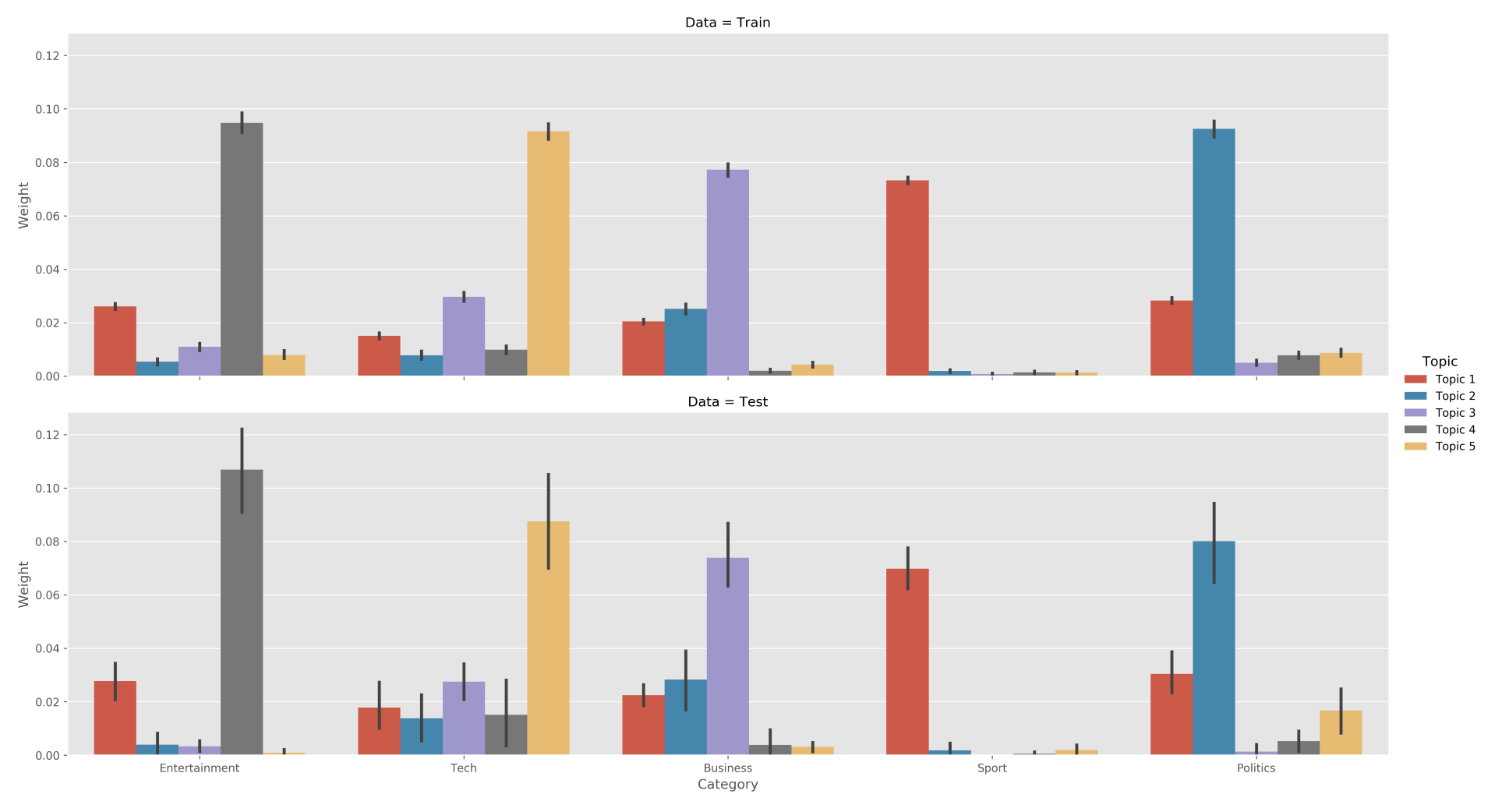
We can also see that the word lists that describe each topic begin to make more sense; for example, the Entertainment category is most directly associated with Topic 4, which includes the words film, start, and so on:
