
Regression problems aim to predict a continuous variable. The root-mean-square error (RMSE) is the most popular loss function and error metric, not least because it is differentiable. The loss is symmetric, but larger errors weigh more in the calculation. Using the square root has the advantage of measuring the error in the units of the target variable. The same metric in combination with the RMSE log of the error (RMSLE) is appropriate when the target is subject to exponential growth because of its asymmetric penalty that weights negative errors less than positive errors. You can also log-transform the target first and then use the RMSE, as we do in the example later in this section.
The mean absolute errors (MAE) and median absolute errors (MedAE) are symmetric but do not weigh larger errors more. The MedAE is robust to outliers.
The explained variance score computes the proportion of the target variance that the model accounts for and varies between 0 and 1. The R2 score or coefficient of determination yields the same outcome the mean of the residuals is 0, but can differ otherwise. In particular, it can be negative when calculated on out-of-sample data (or for a linear regression without intercept).
The following table defines the formulas used for calculation and the corresponding sklearn function that can be imported from the metrics module. The scoring parameter is used in combination with automated train-test functions (such as cross_val_score and GridSearchCV) that we will introduce later in this section, and which are illustrated in the accompanying notebook:
|
Name |
Formula |
sklearn |
Scoring parameter |
|
Mean squared error |
|
mean_squared_error |
neg_mean_squared_error |
|
Mean squared log error |
|
mean_squared_log_error |
neg_mean_squared_log_error |
|
Mean absolute error |
|
mean_absolute_error |
neg_mean_absolute_error |
|
Median absolute error |
|
median_absolute_error |
neg_median_absolute_error |
|
Explained variance |
|
explained_variance_score |
explained_variance |
|
R2 score |
|
r2_score |
r2 |

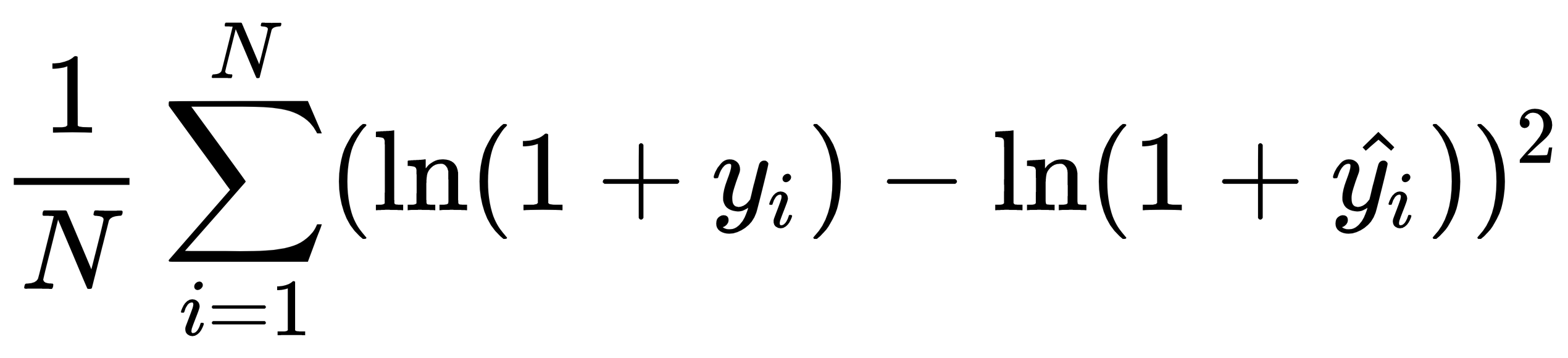

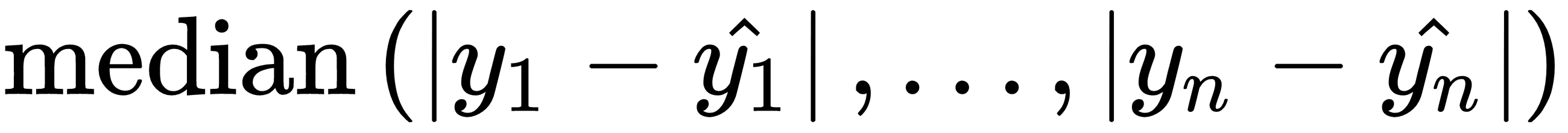
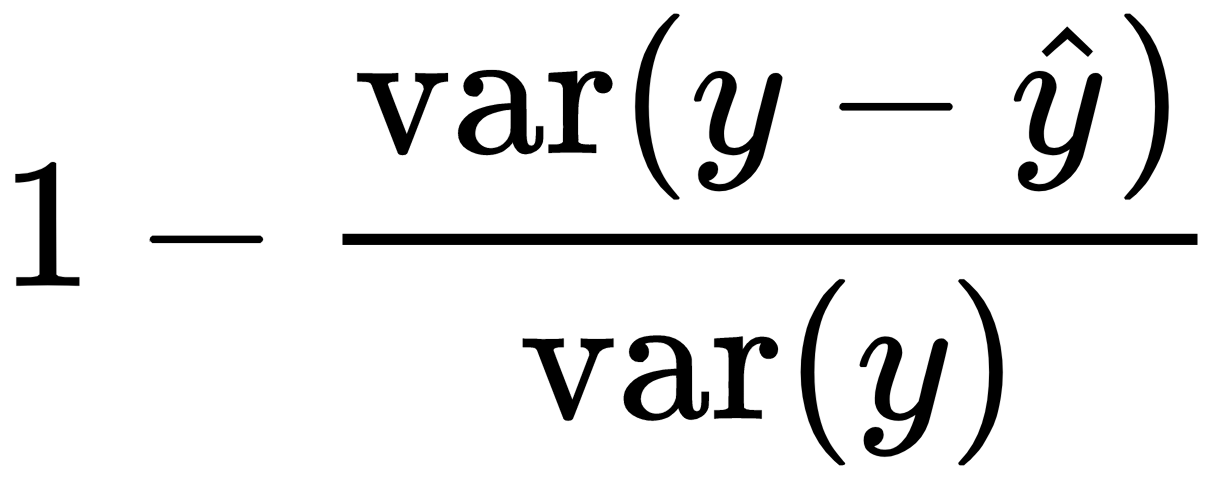
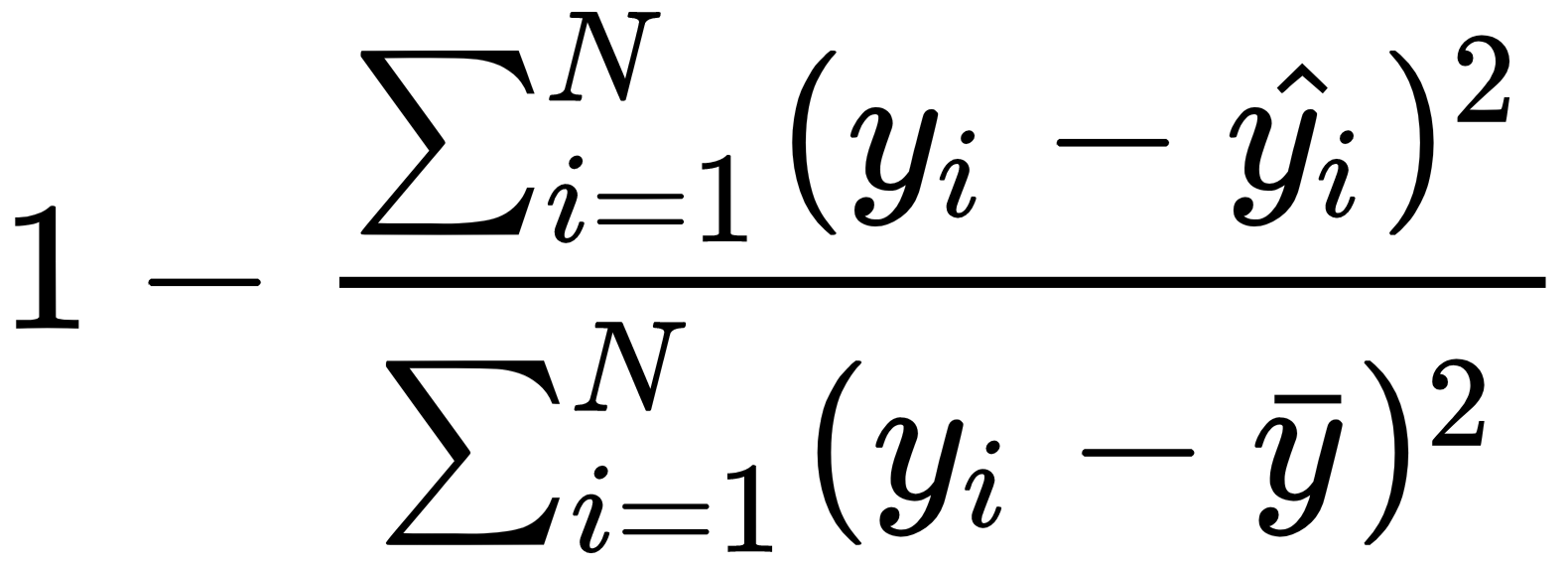
The following screenshot shows the various error metrics for the house price regression demonstrated in the notebook:

The sklearn function also supports multilabel evaluation—that is, assigning multiple outcome values to a single observation; see the documentation referenced on GitHub for more details (https://github.com/PacktPublishing/Hands-On-Machine-Learning-for-Algorithmic-Trading/tree/master/Chapter06).