
C/AL syntax is relatively simple and straightforward. The basic structure of most C/AL statements is essentially similar to what we learned with other programming languages. C/AL is modeled on Pascal and tends to use many of the same special characters and syntax practices.
Assignment is represented with a colon followed by an equal sign, the combination being treated as a single symbol. The evaluated value of the expression, to the right of the assignment symbol, is assigned to the variable on the left-side.
"Phone No." := '312-555-1212';
All statements are terminated with a semi-colon. Multiple statements can be placed on a single program line, but that makes the code hard for others to read.
Fully qualified data fields are prefaced with the name of the record variable of which they are a part (see the preceding code line as an example where the record variable is named ClientRec). The same structure applies to fully qualified function references; the function name is prefaced with the name of the object in which they are defined.
Single quotes are used to surround string literals (see the phone number string in the preceding code line).
Double quotes are used to surround an identifier (for example, a variable or a function name) that contains any character other than numerals or upper and lower case letters. For example, the Phone No. field name in the preceding code line is constructed as "Phone No." because it contains a space and a period. Other examples would be "Post Code"(contains a space), "E-Mail" (contains a dash), and "No." (contains a period).
Parentheses are used much the same as in other languages, to indicate sets of expressions to be interpreted according to their parenthetical groupings. The expressions are interpreted in sequence - first the innermost parenthetical group, then the next level, and so forth. The expression (A / (B + (C * (D + E)))) would be evaluated as follows:
- Summing D + E into Result1
- Multiplying Result1 times C yielding Result2
- Adding Result2 to B yielding Result3
- Dividing A by Result3
Brackets [ ] are used to indicate the presence of subscripts for indexing of array variables. A text string can be treated as an array of characters and we can use subscripts with the string name to access individual character positions within the string (but not beyond the terminating character of the string). For example, Address[1] represents the leftmost character in the Address text variable contents.
Brackets are also used for IN (In range) expressions, such as
Boolean := SearchValue IN[SearchTarget]
In this case, SearchValue and SearchTarget are text variables.
Statements can be continued on multiple lines without any special punctuation, though we can't split a variable or literal across two lines. Since the C/AL code editor limits lines to 132 characters long, this capability is often used. The following example shows two instances that are interpreted exactly in the same manner by the compiler:
ClientRec."Phone No." := '312' + '-' + '555' + '-' + '1212'; ClientRec."Phone No." := '312' + '-' + '555' + '-' + '1212';
Expressions in C/AL are made up of four elements: constants, variables, operators, and functions. We could include a fifth element, expressions, because an expression may include a subordinate expression within it. As we become more experienced in coding C/AL, we find that the capability of nesting expressions can be both a blessing and a curse, depending on the specific use and "readability" of the result.
We can create complex statements that will conditionally perform important control actions and operate in much the same way as a person would think about the task. We can also create complex statements that are very difficult for a person to understand. These are tough to debug and sometimes almost impossible to deal with in a modification.
One of our responsibilities is to learn to tell the difference so we can write code that makes sense in operation, and is also easy to read and understand.
According to NAV Developer and IT Pro Help, a C/AL Expression is a group of characters (data values, variables, arrays, operators, and functions) that can be evaluated with the result having an associated data type. Following are two code statements that accomplish the same result in slightly different ways. They each assign a literal string to a text data field. In the first one, the right side is a literal data value. In the second, the right side of the := assignment symbol is an expression.
ClientRec."Phone No." := '312-555-1212'; ClientRec."Phone No." := '312' + '-' + '555' + '-' + '1212';
Now we'll review the C/AL operators grouped by category. Depending on the data types we are using with a particular operator, we may need to know the type conversion rules defining the allowed combinations of operator and data types for an expression. The NAV Developer and IT Pro Help provides good information on type conversion rules. Search for the phrase Type Conversion.
Before we review the operators that can be categorized, let's discuss some operators that don't fit well in any of the categories. These include the following:
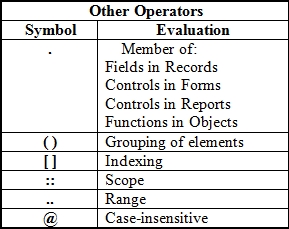
Following are the explanations regarding the uses of this set of symbols:
- The symbol represented by a single dot or period doesn't have a given name in the NAV documentation, so we'll call it the Member symbol or Dot operator (as it is referred to in the MSDN Visual Basic Developer documentation). It indicates that a field is a member of a table (
TableName.FieldName), or that a control is a member of a page (PageName.ControlName) or report (ReportName.ControlName), or that a function is a member of an object (Objectname.FunctionName). - Parentheses ( ) and Brackets [ ] could be considered operators based on the effect their use has on the results of an expression. We discussed their use in the context of parenthetical grouping and indexing using brackets, as well as with the
INfunction, earlier. Parentheses are also used to enclose the parameters in a function call:Objectname.FunctionName(Param1,Param2,Param3);
- The Scope operator is a two character sequence consisting of two colons in a row "::" . The Scope operator is used to allow the C/AL code to refer to a specific Option value using the text descriptive value rather than the integer value that is actually stored in the database. For example, in our C/AL database Radio Show table, we have an Option field defined that is called Frequency with Option string values of (blank), Hourly, Daily, Weekly, and Monthly. Those values would be stored as integers 0, 1, 2, 3 or 4, but we can use the strings to refer to them in code, which makes our code more self-documenting. The Scope operator allows us to refer to
Frequency::Hourly(rather than 1) andFrequency::Monthly(rather than 4). These constructs are translated by the compiler to 1 and 4, respectively. If we want to type fewer characters when entering code, we could enter just enough of the Option string value to be unique, letting the compiler automatically fill in the rest when we next save, compile, close, and reopen the object. In similar fashion, we can refer to objects in the format[Object Type::"Object Name"]to be translated to the object number. For example:PAGE.RUN(PAGE::"Bin List"); is equivalent to PAGE.RUN(7303);
- The Range operator is a two character sequence
.., that is two dots in a row. This operator is very widely used in NAV, not only in the C/AL code (includingCASEstatements andINexpressions), but also in filters entered by the users. The English lower case alphabet can be represented by the rangea..z; the set of single digit numbers by the range-9..9(that is, minus 9 dot dot 9); and all the entries starting with the letter "a" (lower case) bya..a*. Don't underestimate the power of the range operator. For more information on filtering syntax, refer to the NAV Developer and IT Pro Help section Entering Criteria in Filters.
The Arithmetic operators include the following:

As we can see in the Data Types column, these operators can be used on various data types. Numeric includes Integer, Decimal, Boolean, and Character data types. Text and Code are both String data.
Following are sample statements using DIV and MOD, where BigNumber is an integer containing 200:
DIVIntegerValue := BigNumber DIV 60;
The contents of DIVIntegerValue after executing the preceding statement would be 3.
MODIntegerValue := BigNumber MOD 60;
The contents of MODIntegerValue after executing the preceding statement would be 20.
The syntax for these DIV and MOD statements is:
IntegerQuotient := IntegerDividend DIV IntegerDivisor; IntegerModulus := IntegerDividend MOD IntegerDivisor;
Boolean operators only operate on expressions that can be evaluated as Boolean. They are as follows:

The result of an expression based on a Boolean operator will also be Boolean.
The Relational operators are listed in the next screenshot. Each of these is used in an expression of the format:
Expression RelationalOperator Expression
For example: (Variable1 + 97) > ((Variable2 * 14.5) / 57.332)

We will spend a little extra time on the IN operator, because this can be very handy and is not documented elsewhere. The term Valueset in the
Evaluation column for IN refers to a list of defined values. It would be reasonable to define a Valueset as a container of a defined set of individual values, expressions, or other Valuesets. Some examples of IN as used in the standard NAV product code are as follows:
GLEntry."Posting Date" IN [0D,WORKDATE]
Description[I+2] IN ['0'..'9']
"Gen. Posting Type" IN ["Gen. Posting Type"::Purchase,
"Gen. Posting Type"::Sale]
SearchString IN ['','=><']
No[i] IN ['5'..'9']
"FA Posting Date" IN [01010001D..12312008D]Here is another example of what IN used in an expression might look like:
TestString IN ['a'..'d','j','q','l'..'p'];
If the value of
TestString were a or m, then this expression would evaluate to TRUE. If the value of TestString were z, then this expression would evaluate to FALSE. Note that the Data Type of the search value must be the same as the Data Type of the Valueset.
When expressions are evaluated by the C/AL compiler, the parsing routines use a predefined precedence hierarchy to determine what operators to evaluate first, what to evaluate second, and so forth. That precedence hierarchy is provided in the NAV Developer and IT Pro Help section C/AL Operators – Operator Hierarchy, but for convenience, the information is repeated here, in the following table:

For complex expressions, we should always freely use parentheses to make sure the expressions are evaluated the way we intend.
It's time to learn some more of the standard functions provided by C/SIDE. We will focus on some frequently used functions: MESSAGE, ERROR, CONFIRM, and STRMENU.
There is a group of functions in C/AL called
Dialog functions. The purpose of these functions is to allow for communications (that is, dialog) between the system and the user. In addition, the Dialog functions can be useful for quick and simple testing / debugging. In order to make it easier for us to proceed with our next level of C/AL development work, we're going to take time now to learn about those four dialog functions. None of these functions will operate if the C/AL code is running on the NAV Application Server as it has no GUI available. To handle such situation in previous versions of NAV, the Dialog function statements had to be conditioned with the GUIALLOWED function to check whether or not the code is running in a GUI allowed environment. If the code was being used in a Web Service or NAS, it would not be GUIALLOWED. However in NAV 2015, NAS and Web Services simply ignore the Dialogue functions.
In each of these functions, data values can be inserted through use of a substitution string. The substitution string is the % (percent sign) character followed by the number 1 through 10, located within a message text string. That could look like the following (assuming the local currency was defined as USD):
MESSAGE('A message + a data element to display = %1', "OrderAmount");If the OrderAmount value was $100.53, the output from the preceding would be:
A message + a data element to display = $100.53
We can have up to ten substitution strings in one dialog function. The use of substitution strings and their associated display values is optional. We can use any one of the Dialog functions to display a completely predefined text message with nothing variable. Use of a Text Constant (accessed through View | C/AL Globals in the Text Constants tab) for the message is recommended as it makes maintenance and multilanguage enabling easier.
The MESSAGE
function is easy to use for the display of transient data and can be placed almost anywhere in our C/AL code. All it requires of the user is acknowledgement that the message has been read. The disadvantage of messages is that they are not displayed until either the object completes its run or pauses for some other external action. Plus, if we inadvertently create a situation that generates hundreds or thousands of messages, there is no graceful way to terminate their display once they begin displaying.
It's common to use MESSAGE as the elementary trace tool. We can program the display of messages to occur only under particular circumstances and use them to view either the flow of processing (by outputting simple identifyng codes from different points in our logic) or to view the contents of particular data elements through multiple processing cycles.
MESSAGE has the following syntax: MESSAGE (String [, Value1] , ...]), where there are as many ValueX entries as there are %X substitution strings (up to ten).
Here is a sample debugging message:
MESSAGE('Loop %1, Item No. %2',LoopCounter,"Item No.");The display would look similar to the following image (when the counter was 14 and the Item No. was BX0925):

When an ERROR function is invoked, the execution of the current process terminates, the message is immediately displayed, and the database returns to the status it had following the last (implicit or explicit) COMMIT function as though the process calling the ERROR function had not run at all.
Note
We can use the ERROR function in combination with the MESSAGE function to assist in repetitive testing. The MESSAGE functions can be placed in code to show what is happening with an ERROR function placed just prior to where the process would normally complete. Because the ERROR function rolls back all database changes, this technique allows us to run through multiple tests against the same data without any time-consuming backup and restoration of our test data. The enhanced Testing functionality built into NAV 2015 can accomplish the same things in a much more sophisticated fashion, but sometimes there's room for a temporary, simple approach.
An ERROR function call is formatted almost exactly like a MESSAGE call. ERROR has the syntax ERROR (String [, Value1] ,...]) where there are as many ValueX entries as there are %X substitution strings (up to ten). If the preceding MESSAGE was an ERROR function instead, the code line would be:
ERROR('Loop %1, Item No. %2',LoopCounter,"Item No.");The display would look as shown in the following screenshot:

The big X in a bold red circle tells us that this is an ERROR message, but some users might not immediately realize that. We can increase the ease of ERROR message recognition by including the word ERROR in our message, as seen in the following screenshot:

Even in the best of circumstances, it is difficult for a system to communicate clearly with the users. Sometimes our tools, in their effort to be flexible, make it too easy for developers to take the easy way out and communicate poorly or not at all. For example, an ERROR statement of the form ERROR(' ' ) will terminate the run and roll back all data processing without even displaying any message at all. An important part of our job as developers is to ensure that our systems communicate clearly and completely.
The third dialog function is the CONFIRM function. A CONFIRM function call causes processing to stop until the user responds to the dialog. In CONFIRM, we would include a question in our text because the function provides Yes and No button options. The application logic can then be conditioned on the user's response.
Note
We can also use CONFIRM as a simple debugging tool to control the path the processing will take. Display the status of data or processing flow and then allow the operator to make a choice (Yes or No) that will influence what happens next. Execution of a CONFIRM function will also cause any pending MESSAGE outputs to be displayed before the CONFIRM function displays. Combined with MESSAGE and ERROR, creative use of CONFIRM can add to our elementary debugging/diagnostic toolkit.
CONFIRM has the following syntax:
BooleanValue := CONFIRM(String [, Default] [, Value1] ,...)
When we do not specify a value for Default, the system will choose FALSE (which displays as No). We should almost always choose that option as a Default that will do no damage if accepted inadvertently by an inattentive user. The Default choice is FALSE, which is often the safest choice (but TRUE may be specified by the programmer). There are as many ValueX entries as there are %X substitution strings (up to ten).
If we just code OK := CONFIRM(String), the Default choice will be False. Note that True and False appear onscreen as the active language equivalent of Yes and No (a feature that is consistent throughout NAV for C/AL Boolean values displayed from NAV code but not for RDLC report controls displayed by the report viewer see NAV Developer and IT Pro Helps How to: Change the Printed Values of Boolean Variables).
A CONFIRM function call with similar content as the preceding examples might look as shown in the following for the code and the display:
Answer := CONFIRM('Loop %1, Item No. %2OK to continue?',TRUE,LoopCounter,"Item No.");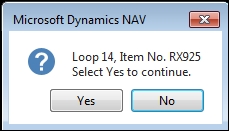
In typical usage, the CONFIRM function is part of, or is referred to, by a conditional statement that uses the Boolean value returned by the CONFIRM function.
An additional feature for on-screen dialogs is the use of the backslash () which forces a new line in the displayed message. This works throughout NAV screen display functions. Following are examples in Text Constants Text063 and Text064 in Table 36 – Sales Header:

To display a backslash on-screen, we must put two of them in our message text string, \.
The fourth dialog function is the STRMENU function. A STRMENU function call also causes processing to pause while the user responds to the dialog. The advantage of the STRMENU function is the ability to provide several choices, rather than just two (Yes or No). A common use is to provide an option menu in response to the user pressing a command button.
STRMENU has the following syntax:
IntegerValue := STRMENU(StringVariable of Options separated by commas [, OptionDefault][, Instruction])
Here IntegerValue will contain the user's selection and OptionDefault is an integer representing which option will be selected by default when the menu displays. If we do not provide an OptionDefault, the first option listed will be used as the default. Instruction is a text string which will display above the list of options. If the user responds Cancel or presses the Esc key, the value returned by the function is 0.
Use of the STRMENU function eliminates the need to use a Page object when asking the user to select from a limited set of options. The STRMENU can also be utilized from within a report or Codeunit when calling a Page would restrict processing choices.
If we phrase our instruction as a question rather than simply an explanation, then we can use STRMENU as a multiple choice inquiry to the user.
Here is an example of STRMENU with the instruction phrased as a question:
OptionNo := STRMENU('Blue,Plaid,Yellow,Hot Pink,Orange,Unknown',6,
'Which of these is not like the others?'),
Setting the default to 6 caused the sixth option (Unknown) to be the active selection when the menu is displayed.
Now we will review some of the functions that we commonly use in Record processing.
The syntax for
SETCURRENTKEY is:
[BooleanValue :=] Record.SETCURRENTKEY(FieldName1,[FieldName2], ... )
The BooleanValue is optional. If we do not specify it and no matching key is found, a runtime error will occur.
Because NAV 2015 is based on the SQL Server database, SETCURRENTKEY simply determines the order in which the data will be presented for processing. The actual choice of the index to be used for the query is made by the SQL Server Query Analyzer. For this reason, it is very important that the data and resources available to the SQL Server Query Analyzer are well maintained. This includes maintaining the statistics that are used by the Query Analyzer, as well as making sure that efficient index options have been defined. Even though SQL Server picks the actual index, the developer's choice of the appropriate SETCURRENTKEY parameter can have a major affect on performance.
The indexes that are defined in SQL Server do not have to be the same as those defined in the C/AL table definition (for example, we can add additional indixes in SQL Server and not in C/AL, we can disable indixes in SQL Server but leave the matching keys enabled in C/AL, and so on). Any maintenance of the SQL Server indixes should be done through the NAV Table Designer using the NAV keys and properties, not directly in SQL Server. Even though the system may operate without problem, any mismatch between the application system and the underlying database system makes maintenance and upgrades more difficult and error prone. NAV defined keys are no longer required to support SIFT indexes because SQL Server can dynamically create the required indixes. However, depending on dynamic indixes for larger data sets can lead to bad performance. Good design is still our responsibility as developers.
The SETRANGE function provides the ability to set a simple range filter on a field. SETRANGE syntax is as follows:
Record.SETRANGE(FieldName [,From-Value] [,To-Value]);
Prior to applying its range filter, the SETRANGE function removes any filters that were previously set for the defined field (filtering functions are defined in more detail in the next Chapter). If SETRANGE is executed with only one value, that one value will act as both the From and To values. If SETRANGE is executed without any From or To values, it will clear the filters on the field. This is a common use of SETRANGE. Some examples of the SETRANGE function in code are as follows:
- Clear the filters on Item.No.:
Item.SETRANGE("No."); - Filter to get only Items with a No. from 1300 through 1400:
Item.SETRANGE("No.",'1300','1400'), - Or with the variable values from
LowValthroughHiVal:Item.SETRANGE("No.",LowVal,HiVal);
In order to be effective in a Query, SETRANGE must be called before the OPEN, SAVEASXML, and SAVEASCSV functions.
SETFILTER is similar to, but much more flexible than, the SETRANGE function because it supports the application of any of the supported NAV filter functions to table fields. SETFILTER syntax is as follows:
Record.SETFILTER(FieldName, FilterExpression [Value],...);
The FilterExpression consists of a string (Text or Code) in standard NAV filter format including any of the operators < > * & | = in any legal combination. Replacement fields (%1, %2, …, %9) are used to represent the Values that will be inserted into FilterExpression by the compiler to create an operating filter formatted as though it were entered from the keyboard. Just as with SETRANGE, prior to applying its filter, the SETFILTER function clears any filters that were previously set for the defined field.
- Filter to get only
Itemswith aNo.from1300through1400:Item.SETFILTER("No.",'%1..%2','1300','1400'), - Or with any of the variable values of
LowVal,MedVal, orHiVal:Item.SETFILTER"No.",'%1|%2|%3',LowVal,MedVal,HiVal);
In order to be effective in a Query, SETFILTER must be called before the OPEN, SAVEASXML, and SAVEASCSV functions.
The GET function is the basic data retrieval function in C/AL. GET retrieves a single record, based on the Primary Key only. It has the following syntax:
[BooleanValue :=] Record.GET ( [KeyFieldValue1] [,KeyFieldValue2] ,...)
The parameter for the GET
function is the Primary Key value (or all the values, if the Primary Key consists of more than one field).
Assigning the GET function result to a BooleanValue is optional. If the GET function is not successful (no record found) and the statement is not part of an IF statement, the process will terminate with a runtime error. Typically, therefore, the GET function is encased in an IF statement structured as shown in the following:
IF Customer.GET(NewCustNo) THEN ...
The FIND family of functions is the general purpose data retrieval function in C/AL. It is much more flexible than GET, therefore more widely used. GET has the advantage of being faster as it operates only on an unfiltered direct access via the Primary Key, looking for a single uniquely keyed entry. There are two forms of FIND in C/AL, one a remnant from a previous database structure and the other designed specifically to work efficiently with SQL Server. Both are supported and we will find both in the standard code.
The older version of the FIND function has the following syntax:
[BooleanValue :=] RecordName.FIND ( [Which] ).
The newer SQL Server specific members of the FIND family have slightly different syntax, as we shall see shortly.
Just as with the GET function, assigning the FIND function result to a Boolean value is optional. But in almost all the cases, FIND is embedded in a condition that controls subsequent processing appropriately. Either way, it is important to structure our code to handle the instance where FIND is not successful.
Following are several important ways in which FIND differs from GET:
FINDoperates under the limits of whatever filters are applied on the subject field.FINDpresents the data in the sequence of the key which is currently selected by default or by C/AL code.- When
FINDis used, the index used for the data reading is controlled by the SQL Server Query Analyzer. - Different variations of the
FINDfunction are designed specifically for use in different situations. This allows coding to be optimized for better SQL Server performance. All theFINDfunctions are described further in the Help section C/AL Database Functions and Performance on SQL Server.
Following are the various forms of FIND:
FIND('-'): Finds the first record in a table that satisfies the defined filter and current key.FINDFIRST: Finds the first record in a table that satisfies the defined filter and defined key choice. Conceptually equivalent toFIND(' -') for a single record read but better for SQL Server when a filter or range is applied.FIND('+'): Finds the last record in a table that satisfies the defined filter and defined key choice. Often not an efficient option for SQL Server bcause it causes SQL Server to read a set of records when many times only a single record is needed. The exception is when a table is to be processed in reverse order. Then it is appropriate to useFIND(' +' )with SQL Server.FINDLAST: Finds the last record in a table that satisfies the defined filter and current key. Conceptually equivalent toFIND(' +' )but often much better for SQL Server as it reads a single record, not a set of records.FINDSET: The efficient way to read a set of records from SQL Server for sequential processing within a specified filter and range.FINDSETallows defining the standard size of the read record cache as a setup parameter, but normally defaults to reading 50 records (table rows) for the first server call. The syntax includes two optional parameters:FINDSET([ForUpdate][, UpdateKey]);
The first parameter controls whether or not the read is in preparation for an update and the second parameter is
TRUEwhen the first parameter isTRUEand the update is of key fields.FINDSETclears any FlowFields in the record read.
Let's review the options of the FIND function using the following syntax:
[BooleanValue :=] RecordName.FIND ( [Which] )
The [Which] parameter allows the specification of which record is searched for relative to the defined key values. The defined key values are the set of values currently in the fields of the active key in the memory-resident record of table RecordName.
The following table lists the Which parameter options and prerequisites
![FIND ([Which]) options and the SQL Server alternates](http://imgdetail.ebookreading.net/business/10/9781784394202/9781784394202__programming-microsoft-dynamicstm__9781784394202__graphics__4202_06_52.jpg)
The following table lists the FIND options that are specific to SQL Server:
![FIND ([Which]) options and the SQL Server alternates](http://imgdetail.ebookreading.net/business/10/9781784394202/9781784394202__programming-microsoft-dynamicstm__9781784394202__graphics__4202_06_53.jpg)
For all FIND options, the results always respect applied filters.
The FIND('-') function is sometimes used as the first step of reading a set of data, such as reading all the sales invoices for a single customer. In such a case, the NEXT function is used to trigger all subsequent data reads after the sequence is initiated with a FIND('-'). Generally FINDSET should be used rather than FIND(' -' ), however FINDSET only works for reading forward, not in reverse. Or use FINDFIRST if only the first record in the specified range is of interest.
One form of the typical C/SIDE database read loop is as follows:
IF MyData.FIND('-') THEN
REPEAT
Processing logic here
UNTIL MyData.NEXT = 0;The same processing logic using the FINDSET function is as follows:
IF MyData.FINDSET THEN REPEAT Processing logic here UNTIL MyData.NEXT = 0;
We will discuss the REPEAT–UNTIL control structure in more detail in the next chapter. Essentially, it does what it says: "repeat the following logic until the defined condition is true". For the FIND–NEXT read loop, the NEXT function provides both the definition of how the read loop will advance through the table and when the loop is to exit.
When DataTable.NEXT = 0, it means there are no more records to be read. We have reached the end of the available data, based on the filters and other conditions that apply to our reading process.
The specific syntax of the NEXT function is DataTable.NEXT(Step). DataTable is the name of the table being read. Step defines the number of records NAV will move forward (or backward) per read. The default Step is 1, meaning NAV moves ahead one record at a time, reading every record. A Step of 0 works the same as a Step of 1. If the Step is set to 2, NAV will move ahead two records at a time and the process will only be presented with every other record.
Step can also be negative, in which case NAV moves backwards through the table. This would allow us to do a FIND('+') for the end of the table, then a NEXT(-1) to read backwards through the data. This is very useful if, for example, we need to read a table sorted ascending by date and want to access the most recent entries first.
Conditional statements are the heart of process flow structure and control.
In C/AL, there are instances where the syntax only allows for use of a single statement. But a design may require the execution of several (or many) code statements.
C/AL provides at least two ways to address this need. One method is to have the single statement call a function that contains multiple statements.
However, inline coding is often more efficient to run and to understand. So C/AL provides a syntax structure to define a Compound Statement or Block of code. A compound statement containing any number of statements can be used in place of a single code statement.
A compound statement is enclosed by the reserved words BEGIN and END. The compound statement structure looks like this:
BEGIN <Statement 1>; <Statement 2>; .. <Statement n>; END
The C/AL code contained within a BEGIN – END block should be indented two characters, as shown in the preceding code, to make it obvious that it is a block of code.
IF is the basic conditional statement of most programming languages. It operates in C/AL similarly to how it works in other languages. The basic structure is: IF a conditional expression is true, THEN execute Statement-1 ELSE (if condition not true) execute Statement-2. The ELSE portion is optional. The syntax is:
IF <Condition> THEN <Statement-1> [ ELSE <Statement-2> ]
Note that the statements within the IF do not have terminating semicolons unless they are contained in a BEGIN – END framework. IF statements can be nested so that conditionals are dependent on the evaluation of other conditionals. Obviously, one needs to be careful with such constructs, because it is easy to end up with convoluted code structures that are difficult to debug and difficult for the developer following us to understand. In the next chapter, we will review the CASE statement which can make some complicated conditionals much easier to format and to understand.
As we work with the NAV C/AL code, we will see that often <Condition> is really an expression built around a standard C/AL function. This approach is frequently used when the standard syntax for the function is "Boolean value, function expression". Some examples are as follows:
IF Customer.FIND('+') THEN... ELSE...IF CONFIRM(' OK to update?' ,TRUE) THEN... ELSE...IF TempData.INSERT THEN... ELSE...IF Customer.CALCFIELDS(Balance,Balance(LCY)) THEN...
Since we have just discussed the BEGIN–END compound statements and IF conditional statements, which also are compound (that is, containing multiple expressions), this seems a good time to discuss indenting code.
In C/AL, the standard practice for indenting subordinate, contained, or continued lines is relatively simple. Always indent such lines by two characters except where there are left and right parentheses to be aligned.
In the following examples, the parentheses are not required in all the instances, but they don't cause any problems and can make the code easier to read:
IF (A <> B) THEN
A := A + Count1
ELSE
B := B + Count2;
Or:
IF (A <> B) THEN
A := A + Count1;
Or:
IF (A <> B)THEN
BEGIN
A := A + Count1;
B := A + Count2;
IF (C > (A * B)) THEN
C := A * B;
END
ELSE
B := B + Count2;