
![]()
Stored procedures (SPs) have been a part of T-SQL from the beginning. SPs provide a means for creating server-side subroutines written in T-SQL. This chapter begins with a discussion of what SPs are and why you might want to use them, and it continues with a discussion of SP creation and usage, including examples.
Introducing Stored Procedures
SPs are saved collections of one or more T-SQL statements stored on the server as code units. They are analogous to procedures or subroutines in procedural languages like Visual Basic or C#. And just like procedures in procedural languages, SPs give you the ability to effectively extend the language of SQL Server by letting you add named custom subroutines to your databases.
An SP declaration begins with the CREATE PROCEDURE keywords followed by the name of the SP. Microsoft recommends against naming the SP with the prefix sp_. This prefix is used by SQL Server to name system stored procedures and is not recommended for user SPs in databases other than the master database. The name can specify a schema name and procedure name, or just a procedure name. If you don’t specify a schema name when creating an SP, SQL Server will create it in the default schema for your login. It’s a best practice to always specify the schema name so that your SPs are always created in the proper schema, rather than leaving it up to SQL Server. SQL Server allows you to drop groups of procedures with the same name with a single DROP PROCEDURE statement.
![]() Warning You can also define the stored procedure with the group number option during SP creation. The group number option is deprecated and will be removed from a future version of SQL Server. Don’t use this option in new development, and start planning to update code that uses this option.
Warning You can also define the stored procedure with the group number option during SP creation. The group number option is deprecated and will be removed from a future version of SQL Server. Don’t use this option in new development, and start planning to update code that uses this option.
SPs, like the T-SQL user-defined functions (UDFs) discussed in Chapter 4, can accept and return parameter values from and to the caller. The parameters are specified in a comma-separated list following the procedure name in the CREATE PROCEDURE statement. Unlike UDFs, when you call an SP, you can specify the parameters in any order, and omit them altogether if you assigned a default value at creation time. You can also specify OUTPUT parameters, which return values back from the procedure. All of this makes SP parameters far more flexible than UDF.
Each parameter is declared as a specific type and can also be declared as OUTPUT or with the VARYING keyword (for cursor parameters only). When calling SPs, you have two choices: you can specify parameters by position or by name. If you specify an unnamed parameter list, the values are assigned based on position. If you specify named parameters in the format @parameter = value, they can be in any order. If your parameter specifies a default value in its declaration, you don’t have to pass a value in for that parameter. Unlike UDFs, SPs don’t require the DEFAULT keyword as a placeholder to specify default values. Just leaving a parameter out when you call the SP will apply the default value to that parameter.
Unlike UDFs, which can return results only via the RETURN statement, SPs can communicate with the caller in a variety of ways:
- The RETURN statement of the SP can return an int value to the caller. Unlike UDFs, SPs do not require a RETURN statement. If the RETURN statement is left out of the SP, 0 is returned by default if no errors were raised during execution.
- SPs don’t have the same restrictions on database side effects and determinism as do UDFs. SPs can read, write, delete, and update permanent tables. In this way, the caller and SP can communicate information to one another through the use of permanent tables.
- When a temporary table is created in an SP, that temporary table is available to any SPs called by that SP. There are two types of temporary tables, local and global. The scope of the local temporary table is the current session and the global temporary table is all the sessions. The local temporary table is prefixed with # and the global temporary table is prefixed with ##. Furthermore, the temporary tables are accessible to any SPs subsequently called by those SPs. As an example, if dbo.MyProc1 creates a local temporary table named #Temp and then calls dbo.MyProc2, dbo.MyProc2 will be able to access #Temp as well. If dbo.MyProc2 then calls dbo.MyProc3, dbo.MyProc3 will also have access to the same #Temp temporary table. Global temporary tables are accessible by all users and all connections after they are created. This provides a useful method of passing an entire table of temporary results from one SP to another for further processing.
- Output parameters provide the primary method of retrieving scalar results from an SP. Parameters are specified as output parameters with the OUTPUT keyword.
- To return table-type results from an SP, the SP can return one or more result sets. Result sets are like virtual tables that can be accessed by the caller. Unlike views, updates to these result sets by applications do not change the underlying tables used to generate them. Also, unlike TVFs and inline functions that return a single table only, SPs can return multiple result sets with a single call.
SP RETURN STATEMENTS
Since the SP RETURN statement can’t return tables, character data, decimal numbers, and so on, it is normally used only to return an int status or error code. This is a good convention to follow, since most developers who use your SPs will be expecting it. The normal practice, followed by most of SQL Server’s system SPs, is to return a value of 0 to indicate success and a nonzero value or an error code to indicate an error or a failure.
SQL Server 2012 introduces two new stored procedures and supporting Dynamic Management Views (DMV) to provide new capabilities to help determine metadata associated with code batches or stored procedures. This set of capabilities replaces the SET FMTONLY option, which is being deprecated. Often it is necessary to determine the format of the result set without actually executing the query and there are also scenarios where we have to ensure that the column and parameter metadata from query execution is compatible or identical with the format you specified before executing the query. For example, if you want to generate dynamic screens based on a select statement, you need make sure there are no metadata errors after query execution, so in turn you need to determine if the parameter metadata is compatible pre- and post-query execution.
The new functionality introduces metadata discovery capabilities for result set and parameters using the stored procedures sp_describe_first_result_set and sp_describe_undeclared_parameters and DMV’s dm_exec_describe_first_result_set and dm_exec_describe_first_result_set_for_object.
The stored procedure sp_describe_first_result_set analyzes all possible first result sets and returns the metadata information for the first result set that is executed from the input T-SQL batch. If the stored procedure returns multiple result sets, this procedure will only return the first result set. If SQL Server is unable to determine the metadata for the first query, then an error will be raised.This procedure takes three parameters: @tsql passes the T-SQL batch, @params passes the parameters for the T-SQL batch, and @browse_information_mode determines if additional browse information for each result set is returned.
Alternatively you can use the DMV sys.dm_exec_describe_first_result_set to query against, and this DMV returns the same details as the stored procedure sp_describe_first_result_set. You can use the DMV sys.dm_exec_describe_first_result_set_for_object to analyze objects such as stored procedures or triggers in the database and return the metadata for the first possible result set and the errors associated with them. Let’s say you want to analyze all the objects within the database and use the information for documentation purpose; instead of analyzing the objects one by one, you can use the DMV sys.dm_exec_describe_first_result_set_for_object with query similar to following:
SELECT p.name, p.schema_id, x.* FROM sys.procedures p CROSS APPLY
sys.dm_exec_describe_first_result_set_for_object(p.object_id,0) x
The stored procedure sp_describe_undeclared_parameters analyzes the T-SQL batch and returns the suggestion for the best parameter datatype based on least number of conversions. This feature is very useful when you have complicated calculations or expressions and you are trying to figure out the best datatype for the undeclared parameter value.
Calling Stored Procedures
You can call an SP without the EXECUTE keyword if it is the first statement in a batch. For instance, if you have an SP named MyProc with schema dbo, you can call it like this:
dbo.MyProc;
We recommend you qualify stored procedures with schema names. If a nonqualified stored procedure is called then the database engine looks for the procedure in the following order: in the sys schema, in the caller’s default schema, and then in the dbo schema. On the other hand, you can invoke an SP from anywhere in a batch or from another SP with the EXECUTE statement. Calling it like the following will discard the int return value:
EXECUTE dbo.MyProc;
If you need the return value from the SP, you can use the following variation of EXECUTE to assign the return value to a predefined int variable:
EXECUTE @variable = dbo.MyProc;
Listing 5-1 is a simple SP example with the schema Person that accepts an AdventureWorks employee’s ID and returns the employee’s full name and e-mail address via output parameters.
Listing 5-1. Retrieving an Employee’s Name and E-mail with an SP
CREATE PROCEDURE Person.GetEmployee (@BusinessEntityID int = 199,
@Email_Address nvarchar(50) OUTPUT,
@Full_Name nvarchar(100) OUTPUT)
AS
BEGIN
-- Retrieve email address and full name from HumanResources.Employee table
SELECT @Email_Address = ea.EmailAddress,
@Full_Name = p.FirstName + ' ' + COALESCE(p.MiddleName,'') + ' ' + p.LastName
FROM HumanResources.Employee e
INNER JOIN Person.Person p
ON e.BusinessEntityID = p.BusinessEntityID
INNER JOIN Person.EmailAddress ea
ON p.BusinessEntityID = ea.BusinessEntityID
WHERE e.BusinessEntityID = @BusinessEntityID;
-- Return a code of 1 when no match is found, 0 for success
RETURN (
CASE
WHEN @Email_Address IS NULL THEN 1
ELSE 0
END
);
END;
GO
The SP in the example, Person.GetEmployee, accepts a business entity ID number as an input parameter and returns the corresponding employee’s e-mail address and full name as output parameters. If the business entity ID number passed in is valid, the SP returns 0 as a return value; otherwise 1 is returned. Listing 5-2 shows a sample call to the Person.GetEmployee SP, with results shown in Figure 5-1.
Listing 5-2. Calling the Person.GetEmployee SP
-- Declare variables to hold the result
DECLARE @Email nvarchar(50),@Name nvarchar(100),@Result int;
--Call procedure to get employee information
EXECUTE @Result = Person.GetEmployee 123, @Email OUTPUT, @Name OUTPUT;
Display the results SELECT @Result AS Result, @Email AS Email, @Name AS [Name];

Figure 5-1. Results of the Sample Person.GetEmployee SP Call
The sample SP call retrieves the information for the employee with ID number 123 in variables, and displays the results in a result set via SELECT. Notice that the OUTPUT keyword in the call to the SP is required after the two output parameters.
Let’s discuss another common scenario we come across, which occurs when we need to define or modify the metadata of the stored procedure or dynamic SQL or batch. For example there are cases where the column names need to be redefined to indicate the result set better, or the data type needs to be changed for certain columns.
You can write complex code using table variables or temporary tables or even use openrowset without creating a temporary table, however you will need to enable the Ad Hoc Distributed Queries feature. SQL 2012 introduces a new feature called WITH RESULT SETS to the EXECUTE statement that allows you to modify the data types or column names returned by the stored procedure. One thing to keep in mind when using WITH RESULT SETS is that the column set should match the number of columns in the SP execution. If the data type for the column returned by the query does not match the WITH RESULT SETS option, SQL Server will make an attempt to convert the data returned by the query implicitly and will raise an error if the conversion is not possible.
Listing 5-3 is a slight modification to the SP example that you saw in Listing 5-1. This stored procedure accepts an AdventureWorks employee’s ID and returns the contact’s id, full name, title, last updated date, and the type of contact.
Listing 5-3. Retrieving a Contact’s ID, Name, Title, and DOB with an SP
CREATE PROCEDURE Person.GetContactDetails (@ID int)
AS
BEGIN
SET NOCOUNT ON
-- Retrieve Name and title for a given PersonID
SELECT @ID, p.FirstName + ' ' + COALESCE(p.MiddleName,'') + ' ' + p.LastName, ct.[Name], cast(p.ModifiedDate as varchar(20)), 'Vendor Contact'
FROM [Purchasing].[Vendor] AS v
INNER JOIN [Person].[BusinessEntityContact] bec
ON bec.[BusinessEntityID] = v.[BusinessEntityID]
INNER JOIN [Person].ContactType ct
ON ct.[ContactTypeID] = bec.[ContactTypeID]
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = bec.[PersonID]
WHERE bec.[PersonID] = @ID;
END;
GO
The SP in the example, Person.GetContactDetails, accepts a BusinessEntityID number as an input parameter and returns the corresponding contact’s id, name, title, last updated date, and type of contact in the result set, and there is nothing fancy about any of that. However, when the result set is being returned, the output column names have to be ContactID, ContactName, Title and LastUpdatedBy, and also the data type for the column LastUpdatedBy has to be varchar. Listing 5-4 shows a sample call to Person.GetContactDetails using WITH RESULT SETS. Figure 5-2 shows the resulting output.
Listing 5-4. Calling the Person.GetContactDetails SP
-- Declare variables to hold the result
DECLARE @ContactID int;
SET @ContactID = 1511;
--Call procedure to get consumer information
EXEC dbo.GetContactDetails @ContactID with result sets(
(
ContactID int,--Column Name changed
ContactName varchar(200),--Column Name changed
Title varchar(50),--Column Name changed
LastUpdatedBy varchar(20),--Column Name changed and the data type has been changed from date to varchar
TypeOfContact varchar(20)
))

Figure 5-2. Results of the Sample Person.GetContactDetails SP Call
The feature WITH RESULT SETS can be extended to Multiple Active Result Sets (MARS) as well. MARS Connection is the connection attribute that enables the applications to execute multiple batches in one connection. Let’s extend the stored procedure in Listing 5-5 and see how we can use this feature with MARS.
Listing 5-5. Retrieving a Contact’s ID, Name, Title, and DOB with an SP
ALTER PROCEDURE Person.GetContactDetails
AS
BEGIN
SET NOCOUNT ON
-- Retrieve Name and title for a given PersonID
SELECT p.BusinessEntityID, p.FirstName + ' ' + COALESCE(p.MiddleName,'') + ' ' + p.LastName, ct.[Name], cast(p.ModifiedDate as varchar(20)), 'Vendor Contact'
FROM [Purchasing].[Vendor] AS v
INNER JOIN [Person].[BusinessEntityContact] bec
ON bec.[BusinessEntityID] = v.[BusinessEntityID]
INNER JOIN [Person].ContactType ct
ON ct.[ContactTypeID] = bec.[ContactTypeID]
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = bec.[PersonID];
SELECT p.BusinessEntityID, p.FirstName + ' ' + COALESCE(p.MiddleName,'') + ' ' + p.LastName, ct.[Name], cast(p.ModifiedDate as varchar(20)), p.Suffix, 'Store Contact'
FROM [Sales].[Store] AS s
INNER JOIN [Person].[BusinessEntityContact] bec
ON bec.[BusinessEntityID] = s.[BusinessEntityID]
INNER JOIN [Person].ContactType ct
ON ct.[ContactTypeID] = bec.[ContactTypeID]
INNER JOIN [Person].[Person] p
ON p.[BusinessEntityID] = bec.[PersonID];
END;
GO
Listing 5-6 shows a sample call to Person.GetContactDetails using WITH RESULT SETS. Figure 5-3 shows the output. The order of the rows in the result set may vary in your system.
Listing 5-6. Calling the Modified Person.GetContactDetails SP
--Call procedure to get consumer information
EXEC Person.GetContactDetails with result sets(
--Return Vendor Contact Details
(
ContactID int,--Column Name changed
ContactName varchar(200),--Column Name changed
Title varchar(50),--Column Name changed
LastUpdatedBy varchar(20),--Column Name changed and the data type has been changed from date to varchar
TypeOfContact varchar(20)
),
--Return Store Contact Details
(
ContactID int,--Column Name changed
ContactName varchar(200),--Column Name changed
Title varchar(50),--Column Name changed
LastUpdatedBy varchar(20),--Column Name changed and the data type has been changed from date to varchar
Suffix varchar(5),
TypeOfContact varchar(20)
)
)
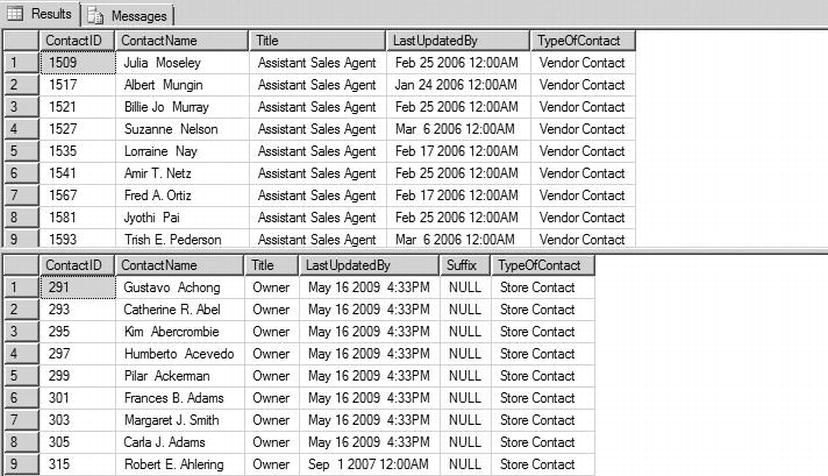
Figure 5-3. Results of the Modified Person.GetContactDetails SP Call
![]() Tip You don’t have to wrap the body of your SP in a BEGIN...END block as we’re doing in these examples, but we personally think it makes the code more readable. It can also help when using the newest version of SSMS or third-party editors that provide collapsible code blocks, as described in Chapter 2.
Tip You don’t have to wrap the body of your SP in a BEGIN...END block as we’re doing in these examples, but we personally think it makes the code more readable. It can also help when using the newest version of SSMS or third-party editors that provide collapsible code blocks, as described in Chapter 2.
As with UDFs, there are additional options you can specify when you create a procedure. The options include the following:
- The ENCRYPTION option obfuscates the SP text and helps prevent unauthorized users from accessing the obfuscated text. This option does for SPs what the UDF ENCRYPTION option does for functions.
- The RECOMPILE option prevents the SQL Server engine from caching the execution plan for the SP, forcing runtime compilation of your SP.
- The EXECUTE AS clause specifies the context that the SP will run under. You can specify CALLER, SELF, OWNER, or a specific username with the EXECUTE AS clause. These options are the same as they are for the UDF EXECUTE AS clause, described in Chapter 4.
Additionally, you can specify FOR REPLICATION to create an SP specifically for replication purposes. An SP created with the FOR REPLICATION option can’t be executed on the replication subscriber. FOR REPLICATION can’t be used with the RECOMPILE option, and this option is not available for contained databases either. A contained database stores all the database and application level objects within the database such as tables, functions, schemas, logins, linked sever details, etc.
T-SQL provides two statements that allow you to modify and delete SPs: the ALTER PROCEDURE and DROP PROCEDURE statements, respectively. ALTER PROCEDURE allows you to modify the code for an SP without first dropping it. The syntax is the same as the CREATE PROCEDURE statement, except that the keywords ALTER PROCEDURE are used in place of CREATE PROCEDURE. ALTER PROCEDURE, like CREATE PROCEDURE, must always be the first statement in a batch. Using the CREATE, DROP and ALTER PROCEDURE statements forces SQL Server to generate a new query plan. The advantage of ALTER over CREATE or DROP is that ALTER preserves the permissions for the object whereas CREATE or DROP resets the permissions.
To delete a procedure from your database, use the DROP PROCEDURE statement. Listing 5-7 shows how to drop the procedure created in Listing 5-1.
Listing 5-7. Dropping the Person.GetEmployee SP
DROP PROCEDURE Person.GetEmployee;
You can specify multiple SPs in a single DROP PROCEDURE statement by putting the SP names in a comma-separated list. Note that you cannot specify the database or server name when dropping an SP, and you must be in the database containing the SP in order to drop it. Additionally, as with other database objects, you can grant or deny EXECUTE permissions on an SP through the GRANT and DENY statements.
Stored Procedures Best Practices
Stored procedures enable you to store batches of Transact-SQL or Managed CLR (Common Language Runtime) code centrally on the server. Stored procedures can be very efficient, and here are some of the best practices that can aid development and avoid common pitfalls that can hurt performance.
- Use the SET NOCOUNT ON statement after the AS keyword, as the first statement in the body of the procedure when you have multiple statements within your stored procedure. This turns off the DONE_IN_PROC messages that SQL Server sends back to the client after each statement in the stored procedure is executed. This also reduces the processing performed by SQL Server and the size of response sent across the network.
- Use schema names when creating or referencing the stored procedure and the database objects within the procedure. This will help SQL Server to find the objects faster and thus reduces compile lock, which will result in less processing time.
- Do not use SP_ or sys** prefixes for naming user-created database objects. They are reserved for Microsoft and have different behaviors.
- Avoid using scalar functions in SELECT statements that return many rows of data. Because the scalar function must be applied to every row, the resulting behavior is like row-based processing and degrades performance.
- Avoid the use of SELECT * and select only the columns you need. This will reduce the processing in the database server as well as network traffic.
- Use parameters when calling stored procedures to increase performance. In your stored procedures explicitly create parameters with type, size, and precision to avoid type conversions.
- Use explicit transactions by using BEGIN/END TRANSACTION and keep transactions as short as possible. The longer the transaction, the more chances you have for locking or blocking and in some cases deadlocking as well. So, keep the transactions short to reduce blocking and locking.
- Use the Transact-SQL TRY...CATCH feature for error handling inside a procedure. TRY...CATCH can encapsulate an entire block of Transact-SQL statements. If you are using TRY...CATCH with loops, place it outside the loop for better performance.This not only creates less performance overhead; it also makes error reporting more accurate with significantly less programming.
- Use NULL or NOT NULL for each column in a temporary table. The ANSI_DFLT_ON and ANSI_DFLT_OFF options control the way the Database Engine assigns the NULL or NOT NULL attributes to columns when these attributes are not specified in a CREATE TABLE or ALTER TABLE statement. If a connection executes a procedure with different settings for these options than the connection that created the procedure, the columns of the table created for the second connection can have different nullability and exhibit different behavior. If NULL or NOT NULL is explicitly stated for each column, the temporary tables are created by using the same nullability for all connections that execute the procedure.
- Use the UNION ALL operator instead of the UNION or OR operators, unless there is a specific need for distinct values. The UNION filters and removes the duplicate records, whereas the UNION ALL operator requires less processing overhead since duplicates are not filtered out of the result set.
WHY STORED PROCEDURES?
Debates have raged through the years over the utility of SQL Server SPs. SPs cache and reuse query execution plans, which provided significant performance improvements in SQL Server 6.5 and 7.0. Although SQL Server 2012 SPs offer the same execution plan caching and reuse, the luster of this benefit has faded somewhat. Query optimization, query caching, and reuse of query execution plans for parameterized queries have been in a state of constant improvement since SQL Server 2000. Query optimization has been improved even more in SQL Server 2012. SPs still offer the performance benefit of not having to send large and complex queries over the network, but the primary benefit of query execution plan caching and reuse is not as enticing as it once was.
So why use SPs? Apart from the performance benefit, which is not as big a factor in these days of highly efficient parameterized queries, SPs offer code modularization and security. Creating code modules helps reduce redundant code, eliminating potential maintenance nightmares caused by duplicate code stored in multiple locations. By using SPs, you can deny users the capability to perform direct queries against tables, but still allow them to use SPs to retrieve the relevant data from those tables. SPs also offer the advantage of centralized administration of portions of your database code. Finally, SPs can return multiple result sets with a single procedure call, such as the sp_help system SP demonstrated here (the results are shown in Figure 5-4):
EXECUTE dbo.sp_help;

Figure 5-4. Results of the dbo.sp_help SP Call
Using SPs, you can effectively build an application programming interface (API) for your database. You can also minimize and almost prevent SQL injection by using stored procedures with input parameters to filter and validate all the inputs. Creation and adherence to such an API can help ensure consistent access across applications and make development easier for front-end and client-side developers who need to access your database. Some third-party applications, such as certain ETL programs and database drivers, also require SPs.
What are the arguments against SPs? One major argument tends to be that they tightly couple your code to the DBMS. A code base that is tightly integrated with SQL Server 2012 will be more difficult to port over to another RDBMS (such as Oracle, DB2, or MySQL) in the future. A loosely coupled application, on the other hand, is much easier to port to different SQL DBMSs.
Portability, in turn, has its own problems. Truly portable code can result in databases and applications that are slow and inefficient. To get true portability out of any RDBMS system, you have to take great care to code everything in plain vanilla SQL, meaning that a lot of the platform-specific performance-enhancing functionality offered by SQL Server is off-limits.
We’re not going to dive too deeply into a discussion of the pluses and minuses of SPs. In the end, the balance between portability and performance needs to be determined by your business needs and corporate IT policies on a per-project basis. Just keep these competing factors in mind when making that decision.
Stored Procedure Example
A common application of SPs is to create a layer of abstraction for various data query, aggregation, and manipulation functionality. The example SP in Listing 5-8 performs the common business reporting task of calculating a running total. The results are shown in Figure 5-5.
Listing 5-8. Procedure to Calculate and Retrieve Running Total for Sales
CREATE PROCEDURE Sales.GetSalesRunningTotal (@Year int)
AS
BEGIN
WITH RunningTotalCTE
AS
(
SELECT soh.SalesOrderNumber,
soh.OrderDate,
soh.TotalDue,
(
SELECT SUM(soh1.TotalDue)
FROM Sales.SalesOrderHeader soh1
WHERE soh1.SalesOrderNumber <= soh.SalesOrderNumber
) AS RunningTotal,
SUM(soh.TotalDue) OVER () AS GrandTotal
FROM Sales.SalesOrderHeader soh
WHERE DATEPART(year, soh.OrderDate) = @Year
GROUP BY soh.SalesOrderNumber,
soh.OrderDate,
soh.TotalDue
)
SELECT rt.SalesOrderNumber,
rt.OrderDate,
rt.TotalDue,
rt.RunningTotal,
(rt.RunningTotal / rt.GrandTotal) * 100 AS PercentTotal
FROM RunningTotalCTE rt
ORDER BY rt.SalesOrderNumber;
RETURN 0;
END;
GO
EXEC Sales.GetSalesRunningTotal @Year = 2005;
GO

Figure 5-5. Partial Results of the Running Total Calculation for Year 2005
The SP in Listing 5-8 accepts a single int parameter indicating the year for which the calculation should be performed:
CREATE PROCEDURE Sales.GetSalesRunningTotal (@Year int)
Inside the SP, we’ve used a CTE to return the relevant data for the year specified, including calculations for the running total via a simple scalar subquery and the grand total via a SUM calculation with an OVER clause:
WITH RunningTotalCTE
AS
(
SELECT soh.SalesOrderNumber,
soh.OrderDate,
soh.TotalDue,
(
SELECT SUM(soh1.TotalDue)
FROM Sales.SalesOrderHeader soh1
WHERE soh1.SalesOrderNumber <= soh.SalesOrderNumber
) AS RunningTotal,
SUM(soh.TotalDue) OVER () AS GrandTotal
FROM Sales.SalesOrderHeader soh
WHERE DATEPART(year, soh.OrderDate) = @Year
GROUP BY soh.SalesOrderNumber,
soh.OrderDate,
soh.TotalDue
)
The result set is returned by the CTE’s outer SELECT query, and the SP finishes up with a RETURN statement that sends a return code of 0 back to the caller:
SELECT rt.SalesOrderNumber,
rt.OrderDate,
rt.TotalDue,
rt.RunningTotal,
(rt.RunningTotal / rt.GrandTotal) * 100 AS PercentTotal FROM RunningTotalCTE rt ORDER BY rt.SalesOrderNumber; RETURN 0;
The running sum, or running total, is a very commonly used business reporting tool. A running sum calculates totals as of certain points in time (usually dollar amounts, and often calculated over days, months, quarters, or years—but not always). In Listing 5-8, the running sum is calculated per order, for each day over the course of a given year.
The running sum generated in the sample gives you a total sales amount as of the date and time when each order is placed. When the first order is placed, the running sum is equal to the amount of that order. When the second order is placed, the running sum is equal to the amount of the first order plus the amount of the second order, and so on. Another closely related and often used calculation is the running average, which represents a calculated point-in-time average as opposed to a point-in-time sum.
As an interesting aside, the ISO SQL standard allows you to use the OVER clause with aggregate functions like SUM and AVG. The ISO SQL standard allows the ORDER BY clause to be used with the aggregate function OVER clause, making for extremely efficient and compact running sum calculations. Unfortunately, SQL Server 2012 does not support this particular option, so you will still have to resort to subqueries and other less efficient methods of performing these calculations for now.
For the next example, assume that AdventureWorks management has decided to add a database-driven feature to its web site. The feature they want is a “recommended products list” that will appear when customers add products to their online shopping carts. Of course, the first step to implementing any solution is to clearly define the requirements. The details of the requirements-gathering process are beyond the scope of this book, so we’ll work under the assumption that the AdventureWorks business analysts have done their due diligence and reported back the following business rules for this particular function:
- The recommended products list should include additional items on orders that contain the product selected by the customer. As an example, if the product selected by the customer is product ID 773 (the silver Mountain-100 44-inch bike), then items previously bought by other customers in conjunction with this bike—like product ID 712 (the AWC logo cap)—should be recommended.
- Products that are in the same category as the product the customer selected should not be recommended. As an example, if a customer has added a bicycle to an order, other bicycles should not be recommended.
- The recommended product list should never contain more than ten items.
- The default product ID should be 776, the black Mountain-100 42-inch bike.
- The recommended products should be listed in descending order of the total quantity that has been ordered. In other words, the best-selling items will be listed in the recommendations list first.
Listing 5-9 shows the SP that implements all of these business rules to return a list of recommended products based on a given product ID.
Listing 5-9. Recommended Product List SP
CREATE PROCEDURE Production.GetProductRecommendations (@ProductID int = 776)
AS
BEGIN
WITH RecommendedProducts
(
ProductID,
ProductSubCategoryID,
TotalQtyOrdered,
TotalDollarsOrdered
)
AS
(
SELECT
od2.ProductID,
p1.ProductSubCategoryID,
SUM(od2.OrderQty) AS TotalQtyOrdered,
SUM(od2.UnitPrice * od2.OrderQty) AS TotalDollarsOrdered
FROM Sales.SalesOrderDetail od1
INNER JOIN Sales.SalesOrderDetail od2
ON od1.SalesOrderID = od2.SalesOrderID
INNER JOIN Production.Product p1
ON od2.ProductID = p1.ProductID
WHERE od1.ProductID = @ProductID
AND od2.ProductID <> @ProductID
GROUP BY
od2.ProductID,
p1.ProductSubcategoryID
)
SELECT TOP(10) ROW_NUMBER() OVER
(
ORDER BY rp.TotalQtyOrdered DESC
) AS Rank,
rp.TotalQtyOrdered,
rp.ProductID,
rp.TotalDollarsOrdered,
p.[Name]
FROM RecommendedProducts rp
INNER JOIN Production.Product p
ON rp.ProductID = p.ProductID
WHERE rp.ProductSubcategoryID <>
(
SELECT ProductSubcategoryID
FROM Production.Product
WHERE ProductID = @ProductID
)
ORDER BY TotalQtyOrdered DESC;
END;
GO
The SP begins with a declaration that accepts a single parameter, @ProductID. The default @ProductID is set to 776, per the AdventureWorks management team’s rules:
CREATE PROCEDURE Production.GetProductRecommendations (@ProductID int = 776)
Next, the CTE that will return the TotalQtyOrdered, ProductID, TotalDollarsOrdered, and ProductSubCategoryID for each product is defined:
WITH RecommendedProducts (
ProductID,
ProductSubCategorylD,
TotalQtyOrdered,
TotalDollarsOrdered )
In the body of the CTE, the Sales.SalesOrderDetail table is joined to itself based on SalesOrderlD. A join to the Production.Product table is also included to get each product’s SubcategorylD. The point of the self-join is to grab the total quantity ordered (OrderQty) and the total dollars ordered (UnitPrice * OrderQty) for each product.
The query is designed to include only orders that contain the product passed in via @ProductID in the WHERE clause, and it also eliminates results for @ProductID itself from the final results. All of the results are grouped by ProductID and ProductSubcategorylD:
(
SELECT
od2.ProductID,
p1.ProductSubCategoryID,
SUM(od2.OrderQty) AS TotalQtyOrdered,
SUM(od2.UnitPrice * od2.OrderQty) AS TotalDollarsOrdered
FROM Sales.SalesOrderDetail od1
INNER JOIN Sales.SalesOrderDetail od2
ON od1.SalesOrderID = od2.SalesOrderID
INNER JOIN Production.Product p1
ON od2.ProductID = p1.ProductID
WHERE od1.ProductID = @ProductID
AND od2.ProductID <> @ProductID
GROUP BY
od2.ProductID,
p1.ProductSubcategoryID
)
The final part of the CTE excludes products that are in the same category as the item passed in by @ProductID. It then limits the results to the top ten and numbers the results from highest to lowest by TotalQtyOrdered. It also joins on the Production.Product table to get each product’s name:
SELECT TOP(lO) ROW_NUMBER() OVER (
ORDER BY rp.TotalOtyOrdered DESC ) AS Rank,
rp.TotalOtyOrdered,
rp.ProductID,
rp.TotalDollarsOrdered,
p.[Name]
FROM RecommendedProducts rp INNER JOIN Production.Product p
ON rp.ProductID = p.ProductID WHERE rp.ProductSubcategorylD <> (
SELECT ProductSubcategorylD FROM Production.Product WHERE ProductID = @ProductID ) ORDER BY TotalOtyOrdered DESC;
Figure 5-6 shows the result set of a recommended product list for people who bought a silver Mountain-100 44-inch bike (ProductID = 773), as shown in Listing 5-10.
Listing 5-10. Getting a Recommended Product List
EXECUTE Production..GetProductRecommendations 773;

Figure 5-6. Recommended Product List for ProductID 773
Implementing this business logic in an SP provides a layer of abstraction that makes it easier to use from front-end applications. Front-end application programmers don’t need to worry about the details of which tables need to be accessed, how they need to be joined, and so on. All your application developers need to know to utilize this logic from the front end is that they need to pass the SP a ProductID number parameter and it will return the relevant information in a well-defined result set.
The same procedure promotes code reuse, and if you have a business logic implemented with complex code in an SP, the code does not have to be written multiple times; instead you can simply call the SP to access the code. Also, if you need to change the business logic, it can be done one time, in one place. Consider what happens if the AdventureWorks management decides to make suggestions based on total dollars worth of a product ordered instead of the total quantity ordered. Simply change the ORDER BY clause from the following:
ORDER BY TotalOtyOrdered DESC;
to the following:
ORDER BY TotalDollarsOrdered DESC;
This simple change in the procedure does the trick. No additional changes to front-end code or logic are required, and no recompilation and redeployment of code to web server farms is required, since the interface to the SP remains the same.
Recursion in Stored Procedures
Like UDFs, SPs can call themselves recursively. There is an SQL Server-imposed limit of 32 levels of recursion. To demonstrate recursion, we’ll solve a very old puzzle.
The Towers of Hanoi puzzle consists of three pegs and a specified number of discs of varying sizes that slide onto the pegs. The puzzle begins with the discs stacked on top of one another, from smallest to largest, all on one peg. The Towers of Hanoi puzzle start position is shown in Figure 5-7.

Figure 5-7. The Towers of Hanoi Puzzle Start Position
The object of the puzzle is to move all of the discs from the first tower to the third tower. The trick is that you can only move one disc at a time, and no larger disc may be stacked on top of a smaller disc at any time. You can temporarily place discs on the middle tower as necessary, and you can stack any smaller disc on top of a larger disc on any tower. The Towers of Hanoi puzzle is often used as an exercise in computer science courses to demonstrate recursion in procedural languages. This makes it a perfect candidate for a T-SQL solution to demonstrate SP recursion.
Our T-SQL implementation of the Towers of Hanoi puzzle will use five discs and display each move as the computer makes it. The complete T-SQL Towers of Hanoi puzzle solution is shown in Listing 5-11.
Listing 5-11. The Towers of Hanoi Puzzle
-- This stored procedure displays all the discs in the appropriate
-- towers.
CREATE PROCEDURE dbo.ShowTowers
AS
BEGIN
-- Each disc is displayed like this "===3===" where the number is the disc
-- and the width of the === signs on either side indicates the width of the
-- disc.
-- These CTEs are designed for displaying the discs in proper order on each
-- tower.
WITH FiveNumbers(Num) -- Recursive CTE generates table with numbers 1...5
AS
(
SELECT 1
UNION ALL
SELECT Num + 1
FROM FiveNumbers
WHERE Num < 5
),
GetTowerA (Disc) -- The discs for Tower A
AS
(
SELECT COALESCE(a.Disc, -1) AS Disc
FROM FiveNumbers f
LEFT JOIN #TowerA a
ON f.Num = a.Disc
),
GetTowerB (Disc) -- The discs for Tower B
AS
(
SELECT COALESCE(b.Disc, -1) AS Disc
FROM FiveNumbers f
LEFT JOIN #TowerB b
ON f.Num = b.Disc
),
GetTowerC (Disc) -- The discs for Tower C
AS
(
SELECT COALESCE(c.Disc, -1) AS Disc
FROM FiveNumbers f
LEFT JOIN #TowerC c
ON f.Num = c.Disc
)
-- This SELECT query generates the text representation for all three towers
-- and all five discs. FULL OUTER JOIN is used to represent the towers in a
-- side-by-side format.
SELECT CASE a.Disc
WHEN 5 THEN ' =====5===== '
WHEN 4 THEN ' ====4==== '
WHEN 3 THEN '===3=== '
WHEN 2 THEN ' ==2== '
WHEN 1 THEN ' =1= '
ELSE ' | '
END AS Tower_A,
CASE b.Disc
WHEN 5 THEN ' =====5===== '
WHEN 4 THEN ' ====4==== '
WHEN 3 THEN ' ===3=== '
WHEN 2 THEN ' ==2== '
WHEN 1 THEN ' =1= '
ELSE ' | '
END AS Tower_B,
CASE c.Disc
WHEN 5 THEN ' =====5===== '
WHEN 4 THEN ' ====4==== '
WHEN 3 THEN ' ===3=== '
WHEN 2 THEN ' ==2== '
WHEN 1 THEN ' =1= '
ELSE ' | '
END AS Tower_C
FROM (
SELECT ROW_NUMBER() OVER(ORDER BY Disc) AS Num,
COALESCE(Disc, -1) AS Disc
FROM GetTowerA
) a
FULL OUTER JOIN (
SELECT ROW_NUMBER() OVER(ORDER BY Disc) AS Num,
COALESCE(Disc, -1) AS Disc
FROM GetTowerB
) b
ON a.Num = b.Num
FULL OUTER JOIN (
SELECT ROW_NUMBER() OVER(ORDER BY Disc) AS Num,
COALESCE(Disc, -1) AS Disc
FROM GetTowerC
) c
ON b.Num = c.Num
ORDER BY a.Num;
END;
GO
-- This SP moves a single disc from the specified source tower to the
-- specified destination tower.
CREATE PROCEDURE dbo.MoveOneDisc (@Source nchar(1),
@Dest nchar(1))
AS
BEGIN
-- @SmallestDisc is the smallest disc on the source tower
DECLARE @SmallestDisc int = 0;
-- IF ... ELSE conditional statement gets the smallest disc from the
-- correct source tower
IF @Source = N'A'
BEGIN
-- This gets the smallest disc from Tower A
SELECT @SmallestDisc = MIN(Disc)
FROM #TowerA;
-- Then delete it from Tower A
DELETE FROM #TowerA
WHERE Disc = @SmallestDisc;
END
ELSE IF @Source = N'B'
BEGIN
-- This gets the smallest disc from Tower B
SELECT @SmallestDisc = MIN(Disc)
FROM #TowerB;
-- Then delete it from Tower B
DELETE FROM #TowerB
WHERE Disc = @SmallestDisc;
END
ELSE IF @Source = N'C'
BEGIN
-- This gets the smallest disc from Tower C
SELECT @SmallestDisc = MIN(Disc)
FROM #TowerC;
-- Then delete it from Tower C
DELETE FROM #TowerC
WHERE Disc = @SmallestDisc;
END
-- Show the disc move performed
SELECT N'Moving Disc (' + CAST(COALESCE(@SmallestDisc, 0) AS nchar(1)) +
N') from Tower ' + @Source + N' to Tower ' + @Dest + ':' AS Description;
-- Perform the move - INSERT the disc from the source tower into the
-- destination tower
IF @Dest = N'A'
INSERT INTO #TowerA (Disc) VALUES (@SmallestDisc);
ELSE IF @Dest = N'B'
INSERT INTO #TowerB (Disc) VALUES (@SmallestDisc);
ELSE IF @Dest = N'C'
INSERT INTO #TowerC (Disc) VALUES (@SmallestDisc);
-- Show the towers
EXECUTE dbo.ShowTowers;
END;
GO
-- This SP moves multiple discs recursively
CREATE PROCEDURE dbo.MoveDiscs (@DiscNum int,
@MoveNum int OUTPUT,
@Source nchar(1) = N'A',
@Dest nchar(1) = N'C',
@Aux nchar(1) = N'B'
)
AS
BEGIN
-- If the number of discs to move is 0, the solution has been found
IF @DiscNum = 0
PRINT N'Done';
ELSE
BEGIN
-- If the number of discs to move is 1, go ahead and move it
IF @DiscNum = 1
BEGIN
-- Increase the move counter by 1
SELECT @MoveNum += 1;
-- And finally move one disc from source to destination
EXEC dbo.MoveOneDisc @Source, @Dest;
END
ELSE
BEGIN
-- Determine number of discs to move from source to auxiliary tower
DECLARE @n int = @DiscNum - 1;
-- Move (@DiscNum - 1) discs from source to auxiliary tower
EXEC dbo.MoveDiscs @n, @MoveNum OUTPUT, @Source, @Aux, @Dest;
-- Move 1 disc from source to final destination tower
EXEC dbo.MoveDiscs 1, @MoveNum OUTPUT, @Source, @Dest, @Aux;
-- Move (@DiscNum - 1) discs from auxiliary to final destination tower
EXEC dbo.MoveDiscs @n, @MoveNum OUTPUT, @Aux, @Dest, @Source;
END;
END;
END;
GO
-- This SP creates the three towers and populates Tower A with 5 discs
CREATE PROCEDURE dbo.SolveTowers
AS
BEGIN
-- SET NOCOUNT ON to eliminate system messages that will clutter up
-- the Message display
SET NOCOUNT ON;
-- Create the three towers: Tower A, Tower B, and Tower C
CREATE TABLE #TowerA (Disc int PRIMARY KEY NOT NULL);
CREATE TABLE #TowerB (Disc int PRIMARY KEY NOT NULL);
CREATE TABLE #TowerC (Disc int PRIMARY KEY NOT NULL);
-- Populate Tower A with all five discs
INSERT INTO #TowerA (Disc)
VALUES (1), (2), (3), (4), (5);
-- Initialize the move number to 0
DECLARE @MoveNum int = 0;
-- Show the initial state of the towers
EXECUTE dbo.ShowTowers;
-- Solve the puzzle. Notice you don't need to specify the parameters
-- with defaults
EXECUTE dbo.MoveDiscs 5, @MoveNum OUTPUT;
-- How many moves did it take?
PRINT N'Solved in ' + CAST (@MoveNum AS nvarchar(10)) + N' moves.';
-- Drop the temp tables to clean up - always a good idea.
DROP TABLE #TowerC;
DROP TABLE #TowerB;
DROP TABLE #TowerA;
-- SET NOCOUNT OFF before we exit
SET NOCOUNT OFF;
END;
GO
To solve the puzzle, just run the following statement:
-- Solve the puzzle
EXECUTE dbo.SolveTowers;
Figure 5-8 is a screenshot of the processing as the discs are moved from tower to tower.
![]() Note The results of Listing 5-11 are best viewed in Results to Text mode. You can put SSMS in Results to Text mode by pressing Ctrl + T while in the Query Editor window. To switch to Results to Grid mode, press Ctrl + D.
Note The results of Listing 5-11 are best viewed in Results to Text mode. You can put SSMS in Results to Text mode by pressing Ctrl + T while in the Query Editor window. To switch to Results to Grid mode, press Ctrl + D.

Figure 5-8. Discs Are Moved from Tower to Tower
The main procedure you call to solve the puzzle is dbo.SolveTowers. This SP creates three temporary tables, named #TowerA, #TowerB, and #TowerC. It then populates #TowerA with five discs and initializes the current move number to 0.
-- Create the three towers: Tower A, Tower B, and Tower C
CREATE TABLE #TowerA (Disc int PRIMARY KEY NOT NULL);
CREATE TABLE #TowerB (Disc int PRIMARY KEY NOT NULL);
CREATE TABLE #TowerC (Disc int PRIMARY KEY NOT NULL);
-- Populate Tower A with all five discs
INSERT INTO #TowerA (Disc)
VALUES (1), (2), (3), (4), (5);
-- Initialize the move number to 0
DECLARE @MoveNum INT = 0;
Since this SP is the entry point for the entire puzzle-solving program, it displays the start position of the towers and calls dbo.MoveDiscs to get the ball rolling:
-- Show the initial state of the towers
EXECUTE dbo.ShowTowers;
-- Solve the puzzle. Notice you don't need to specify the parameters
-- with defaults
EXECUTE dbo.MoveDiscs 5, @MoveNum OUTPUT;
When the puzzle is finally solved, control returns back from dbo.MoveDiscs to dbo. SolveTowers, which displays the number of steps it took to complete the puzzle and performs some cleanup work, like dropping the temporary tables.
-- How many moves did it take?
PRINT N'Solved in ' + CAST (@MoveNum AS nvarchar(10)) + N' moves.';
-- Drop the temp tables to clean up - always a good idea.
DROP TABLE #TowerC;
DROP TABLE #TowerB;
DROP TABLE #TowerA;
-- SET NOCOUNT OFF before we exit
SET NOCOUNT OFF;
![]() Tip When an SP that created temporary tables ends, the temporary tables are automatically dropped. Because temporary tables are created in the tempdb system database, it’s a good idea to get in the habit of explicitly dropping temporary tables. By explicitly dropping temporary tables, you can guarantee that they exist only as long as they are needed, which can help minimize contention in the tempdb database.
Tip When an SP that created temporary tables ends, the temporary tables are automatically dropped. Because temporary tables are created in the tempdb system database, it’s a good idea to get in the habit of explicitly dropping temporary tables. By explicitly dropping temporary tables, you can guarantee that they exist only as long as they are needed, which can help minimize contention in the tempdb database.
The procedure responsible for moving discs from tower to tower recursively is dbo.MoveDiscs. This procedure accepts several parameters, including the number of discs to move (@DiscNum); the number of the current move (@MoveNum); and the names of the source, destination, and auxiliary/intermediate towers. This procedure uses T-SQL procedural IF statements to determine which types of moves are required—single disc moves, recursive multiple-disc moves, or no more moves (when the solution is found). If the solution has been found, the message Done is displayed and control is subsequently passed back to the calling procedure, dbo.SolveTowers.
-- If the number of discs to move is 0, the solution has been found
IF @DiscNum = 0
PRINT N'Done';
ELSE
RETURN 0;
If there is only one disc to move, the move counter is incremented and dbo.MoveOneDisc is called to perform the move:
-- If the number of discs to move is 1, go ahead and move it
IF @DiscNum = 1
BEGIN
-- Increase the move counter by 1
SELECT @MoveNum += 1;
-- And finally move one disc from source to destination
EXEC dbo.MoveOneDisc @Source, @Dest;
END
Finally, if there is more than one disc move required, dbo.MoveDiscs calls itself recursively until there are either one or zero discs left to move:
ELSE
BEGIN
-- Determine number of discs to move from source to auxiliary tower
DECLARE @n INT = @DiscNum - 1;
-- Move (@DiscNum - 1) discs from source to auxiliary tower
EXEC dbo.MoveDiscs @n, @MoveNum OUTPUT, @Source, @Aux, @Dest;
-- Move 1 disc from source to final destination tower
EXEC dbo.MoveDiscs 1, @MoveNum OUTPUT, @Source, @Dest, @Aux;
-- Move (@DiscNum - 1) discs from auxiliary to final destination tower
EXEC dbo.MoveDiscs @n, @MoveNum OUTPUT, @Aux, @Dest, @Source;
END;
The basis of the Towers of Hanoi puzzle is the movement of a single disc at a time from tower to tower, so the most basic procedure, dbo.MoveOneDisc, simply moves a disc from the specified source tower to the specified destination tower. Given a source and destination tower as inputs, this procedure first determines the smallest (or top) disc on the source and moves it to the destination table using simple SELECT queries. The smallest disc is then deleted from the source table.
-- @SmallestDisc is the smallest disc on the source tower
DECLARE @SmallestDisc int = 0;
-- IF ... ELSE conditional statement gets the smallest disc from the
-- correct source tower
IF @Source = N'A'
BEGIN
-- This gets the smallest disc from Tower A
SELECT @SmallestDisc = MIN(Disc)
FROM #TowerA;
-- Then delete it from Tower A
DELETE FROM #TowerA
WHERE Disc = @SmallestDisc;
END
Once the smallest disc of the source table is determined, dbo.MoveOneDisc displays the move it is about to perform, and then performs the INSERT to place the disc in the destination tower. Finally, it calls the dbo.ShowTowers procedure to show the current state of the towers and discs.
-- Show the disc move performed
SELECT N'Moving Disc (' + CAST(COALESCE(@SmallestDisc, 0) AS nchar(1)) + N') from Tower ' + @Source + N' to Tower ' + @Dest + ':' AS Description;
-- Perform the move - INSERT the disc from the source tower into the
-- destination tower
IF @Dest = N'A'
INSERT INTO #TowerA (Disc) VALUES (@SmallestDisc);
ELSE IF @Dest = N'B'
INSERT INTO #TowerB (Disc) VALUES (@SmallestDisc);
ELSE IF @Dest = N'C
INSERT INTO #TowerC (Disc) VALUES (@SmallestDisc);
-- Show the towers
EXECUTE dbo.ShowTowers;
The dbo.ShowTowers procedure doesn’t affect processing; it’s simply included as a convenience to output a reasonable representation of the towers and discs they contain at any given point during processing.
This implementation of a solver for the Towers of Hanoi puzzle demonstrates several aspects of SPs we’ve introduced in this chapter, including the following:
- SPs can call themselves recursively. This is demonstrated with the dbo.MoveDiscs procedure, which calls itself until the puzzle is solved.
- When default values are assigned to parameters in an SP declaration, you do not have to specify values for them when you call the procedure. This concept is demonstrated in the dbo.SolveTowers procedure, which calls the dbo.MoveDiscs procedure.
- The scope of temporary tables created in an SP includes the procedure in which they are created, as well as any SPs it calls, and any SPs they in turn call. This is demonstrated in dbo.SolveTowers, which creates three temporary tables, and then calls other procedures that access those same temporary tables. The procedures called by dbo.SolveTowers and those called by those procedures (and so on) can also access these same temporary tables.
- The dbo.MoveDiscs SP demonstrates output parameters. This procedure uses an output parameter to update the count of the total number of moves performed after each move.
Beginning with SQL Server 2008, developers have the capability of passing table-valued parameters to SPs and UDFs. Prior to SQL Server 2008, the primary methods of passing multiple rows of data to an SP included the following:
- Converting your multiple rows to an intermediate format like comma-delimited or XML. If you use this method, you have to parse out the parameter into a temporary table, table variable, or subquery to extract the rows from the intermediate format. These conversions to and from intermediate format can be costly, especially when large amounts of data are involved.
- Placing rows in a permanent or temporary table and calling the procedure. This method eliminates conversions to and from the intermediate format, but is not without problems of its own. Managing multiple sets of input rows from multiple simultaneous users can introduce a lot of overhead and additional conversion code that must be managed.
- Passing lots and lots of parameters to the SP. SQL Server SPs can accept up to 2,100 parameters. Conceivably, you could pass several rows of data using thousands of parameters and ignore those parameters you don’t need. One big drawback to this method, however, is that it results in complex code that can be extremely difficult to manage.
- Calling procedures multiple times with a single row of data each time. This method is probably the simplest method, resulting in code that is very easy to create and manage. The downside to this method is that querying and manipulating potentially tens of thousands of rows of data or more, one row at a time, can result in a big performance penalty.
A table-valued parameter allows you to pass rows of data to your TSQL statement or SPs and UDFs in tabular format. To create a table-valued parameter you must first create a table type that defines your table structure, as shown in Listing 5-12.
Listing 5-12. Creating a Table Type
CREATE TYPE HumanResources.LastNameTableType
AS TABLE (LastName nvarchar(50) NOT NULL PRIMARY KEY);
GO
The CREATE TYPE statement in Listing 5-12 creates a simple table type that represents a table with a single column named LastName, which also serves as the primary key for the table. To use table-valued parameters, you must declare your SP with parameters of the table type. The SP in Listing 5-13 accepts a single table-valued parameter of the HumanResources.LastNameTableType type from Listing 5-12. It then uses the rows in the table-valued parameter in an inner join to restrict the rows returned by the SP.
Listing 5-13. Simple Procedure Accepting a Table-valued Parameter
CREATE PROCEDURE HumanResources.GetEmployees
(@LastNameTable HumanResources.LastNameTableType READONLY)
AS
BEGIN
SELECT
p.LastName,
p.FirstName,
p.MiddleName,
e.NationalIDNumber,
e.Gender,
e.HireDate
FROM HumanResources.Employee e
INNER JOIN Person.Person p
ON e.BusinessEntityID = p.BusinessEntityID
INNER JOIN @LastNameTable lnt
ON p.LastName = lnt.LastName
ORDER BY
p.LastName,
p.FirstName,
p.MiddleName;
END;
GO
The CREATE PROCEDURE statement in Listing 5-13 declares a single table-valued parameter, @LastNameTable, of the HumanResources.LastNameTableType created in Listing 5-12.
CREATE PROCEDURE HumanResources.GetEmployees
(@LastNameTable HumanResources.LastNameTableType READONLY)
The table-valued parameter is declared READONLY, which is mandatory. Although you can query and join to the rows in a table-valued parameter just like a table variable, you cannot manipulate the rows in table-valued parameters with INSERT, UPDATE, DELETE, or MERGE statements.
The HumanResources.GetEmployees procedure performs a simple query to retrieve the names, national ID number, gender, and hire date for all employees whose last names match any of the last names passed into the SP via the @LastNameTable table-valued parameter. As you can see in Listing 5-13, the SELECT query performs an inner join against the table-valued parameter to restrict the rows returned:
SELECT
p.LastName,
p.FirstName,
p.MiddleName,
e.NationalIDNumber,
e.Gender,
e.HireDate
FROM HumanResources.Employee e
INNER JOIN Person.Person p
ON e.BusinessEntitylD = p.BusinessEntitylD
INNER JOIN @LastNameTable lnt
ON p.LastName = Int.LastName
ORDER BY
p.LastName,
p.FirstName,
p.MiddleName;
To call a procedure with a table-valued parameter, like the HumanResources.GetEmployees SP in Listing 5-13, you need to declare a variable of the same type as the table-valued parameter. Then you populate the variable with rows of data and pass the variable as a parameter to the procedure. Listing 5-14 demonstrates how to call the HumanResources.GetEmployees SP with a table-valued parameter. The results are shown in Figure 5-9.
Listing 5-14. Calling a Procedure with a Table-valued Parameter
DECLARE @LastNameList HumanResources.LastNameTableType;
INSERT INTO @LastNameList
(LastName)
VALUES
(N'Walters'),
(N'Anderson'),
(N'Chen'),
(N'Rettig'),
(N'Lugo'),
(N'Zwilling'),
(N'Johnson'),
EXECUTE HumanResources.GetEmployees @LastNameList;

Figure 5-9. Employees Returned by the SP Call in Listing 5-14
In addition to being read-only, the following additional restrictions apply to table-valued parameters:
- As with table variables, you cannot use a table-valued parameter as the target of an INSERT EXEC or SELECT INTO assignment statement.
- Table-valued parameters are scoped just like other parameters and local variables declared within a procedure or function. They are not visible outside of the procedure in which they are declared.
- SQL Server does not maintain column-level statistics for table-valued parameters, which can affect performance if you are passing large numbers of rows of data via table-valued parameters.
You can also pass table-valued parameters to SPs from ADO.NET clients, which we will discuss in Chapter 15.
In addition to normal SPs, T-SQL provides what are known as temporary SPs. Temporary SPs are created just like any other SPs; the only difference is that the name must begin with a number sign (#) for a local temporary SP and two number signs (##) for a global temporary SP.
While a normal SP remains in the database and schema it was created in until it is explicitly dropped via the DROP PROCEDURE statement, temporary SPs are dropped automatically. A local temporary SP is visible only to the current session and is dropped when the current session ends. A global temporary SP is visible to all connections and is automatically dropped when the last session using it ends.
Normally you won’t use temporary SPs, as they are usually used for specialized solutions, like database drivers. Open Database Connectivity (ODBC) drivers, for instance, make use of temporary SPs to implement SQL Server connectivity functions. Temporary SPs are useful when you want the advantages of using stored procedures such as execution plan reuse and improved error handling with the advantages of ad hoc code. However, temporary stored procedures bring some other effects as well. The temporary stored procedures are often not destroyed until the connection is closed or explicitly dropped. This may cause the procedures to fill up tempdb over time and cause queries to fail. Creating temporary SPs within a transaction may also cause blocking problems since the stored procedure creation causes data page locking in several system tables for the transaction duration.
SQL Server has several features that work behind the scenes to optimize your SP performance. The first time you execute an SP, SQL Server compiles it into a query plan, which it then caches. This compilation process invokes a certain amount of overhead, which can be substantial for procedures that are complex or that are run very often. SQL Server uses a complex caching mechanism to store and reuse query plans on subsequent calls to the same SP, in an effort to minimize the impact of SP compilation overhead. In this section, we’ll talk about managing query plan recompilation and cached query plan reuse.
SQL Server 2012 provides DMVs and dynamic management functions (DMFs) to expose SP query plan usage and caching information that can be useful for performance tuning and general troubleshooting. Listing 5-15 is a procedure that retrieves and displays several relevant SP statistics from a few different DMVs and DMFs.
Listing 5-15. Procedure to Retrieve SP Statistics with DMVs and DMFs
CREATE PROCEDURE dbo.GetProcStats (@order varchar(100) = 'use')
AS
BEGIN
WITH GetQueryStats
(
plan_handle,
total_elapsed_time,
total_logical_reads,
total_logical_writes,
total_physical_reads
)
AS
(
SELECT
qs.plan_handle,
SUM(qs.total_elapsed_time) AS total_elapsed_time,
SUM(qs.total_logical_reads) AS total_logical_reads,
SUM(qs.total_logical_writes) AS total_logical_writes,
SUM(qs.total_physical_reads) AS total_physical_reads
FROM sys.dm_exec_query_stats qs
GROUP BY qs.plan_handle
)
SELECT
DB_NAME(st.dbid) AS database_name,
OBJECT_SCHEMA_NAME(st.objectid, st.dbid) AS schema_name,
OBJECT_NAME(st.objectid, st.dbid) AS proc_name,
SUM(cp.usecounts) AS use_counts,
SUM(cp.size_in_bytes) AS size_in_bytes,
SUM(qs.total_elapsed_time) AS total_elapsed_time,
CAST
(
SUM(qs.total_elapsed_time) AS decimal(38, 4)
) / SUM(cp.usecounts) AS avg_elapsed_time_per_use,
SUM(qs.total_logical_reads) AS total_logical_reads,
CAST
(
SUM(qs.total_logical_reads) AS decimal(38, 4)
) / SUM(cp.usecounts) AS avg_logical_reads_per_use,
SUM(qs.total_logical_writes) AS total_logical_writes,
CAST
(
SUM(qs.total_logical_writes) AS decimal(38, 4)
) / SUM(cp.usecounts) AS avg_logical_writes_per_use,
SUM(qs.total_physical_reads) AS total_physical_reads,
CAST
(
SUM(qs.total_physical_reads) AS decimal(38, 4)
) / SUM(cp.usecounts) AS avg_physical_reads_per_use,
st.text
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
INNER JOIN GetQueryStats qs
ON cp.plan_handle = qs.plan_handle
INNER JOIN sys.procedures p
ON st.objectid = p.object_id
WHERE p.type IN ('P', 'PC')
GROUP BY st.dbid, st.objectid, st.text
ORDER BY
CASE @order
WHEN 'name' THEN OBJECT_NAME(st.objectid)
WHEN 'size' THEN SUM(cp.size_in_bytes)
WHEN 'read' THEN SUM(qs.total_logical_reads)
WHEN 'write' THEN SUM(qs.total_logical_writes)
ELSE SUM(cp.usecounts)
END DESC;
END;
GO
This procedure uses the sys.dm_exec_cached_plans and sys.dm_exec_query_stats DMVs in conjunction with the sys.dmexecsqltext DMF to retrieve relevant SP execution information. The sys.procedures catalog view is used to limit the results to only SPs (type P). Aggregation is required on most of the statistics since the DMVs and DMFs can return multiple rows, each representing individual statements within SPs. The dbo.GetProcStats procedure accepts a single parameter that determines how the result rows are sorted. Setting the @order parameter to size sorts the results in descending order by the sizeinbytes column, while read sorts in descending order by the totallogicalreads column. Other possible values include name and write—all other values sort by the default usecounts column in descending order.
![]() Tip In this SP, we used a few useful system functions: DB_NAME accepts the ID of a database and returns the database name; OBDECT_SCHEMA_NAME accepts the ID of an object and a database ID and returns the name of the schema in which the object resides; and OBJECT_NAME accepts the object ID and returns the name of the object itself. These are handy functions, and you can retrieve the same information via SQL Server’s catalog views.
Tip In this SP, we used a few useful system functions: DB_NAME accepts the ID of a database and returns the database name; OBDECT_SCHEMA_NAME accepts the ID of an object and a database ID and returns the name of the schema in which the object resides; and OBJECT_NAME accepts the object ID and returns the name of the object itself. These are handy functions, and you can retrieve the same information via SQL Server’s catalog views.
Listing 5-16 demonstrates how to call this SP. Sample results are shown in Figure 5-10.
Listing 5-16. Retrieving SP Statistics
EXEC dbo.GetProcStats @order = 'use';
GO

Figure 5-10. Partial Results of Calling the GetProcStats Procedure
SQL Server DMVs and DMFs can be used in this way to answer several questions about your SPs, including the following:
- Which SPs are executed the most?
- Which SPs take the longest to execute?
- Which SPs perform the most logical reads and writes?
The answers to these types of questions can help you quickly locate performance bottlenecks and focus your performance-tuning efforts where they are most needed. We will discuss the performance tuning in detail in Chapter 19, Performance Monitoring and Tuning.
Parameter Sniffing
SQL Server uses a method known as parameter sniffing to further optimize SP calls. During compilation or recompilation of an SP, SQL Server captures the parameters used and passes the values along to the optimizer. The optimizer then generates and caches a query plan optimized for those parameters. This can actually cause problems in some cases—for example, when your SP can return wildly varying numbers of rows based on the parameters passed in. Listing 5-17 shows a simple SP that retrieves all products from the Production.Product table with a Name like the @Prefix parameter passed into the SP.
Listing 5-17. Simple Procedure to Demonstrate Parameter Sniffing
CREATE PROCEDURE Production.GetProductsByName
@Prefix NVARCHAR(100)
AS
BEGIN
SELECT
p.Name,
p.ProductID
FROM Production.Product p
WHERE p.Name LIKE @Prefix;
END;
GO
Calling this SP with the @Prefix parameter set to % results in a query plan optimized to return 504 rows of data with a nonclustered index scan, as shown in Figure 5-11.
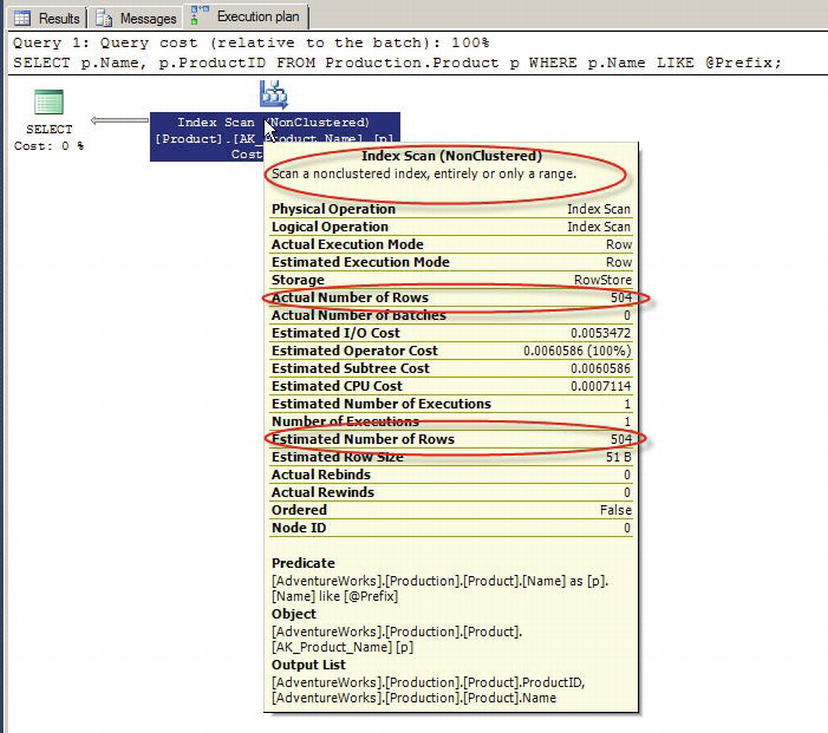
Figure 5-11. Query Plan Optimized to Return 504 Rows
If you run the Production.GetProductsByName procedure a second time with the @Prefix parameter set to M%, the query plan will show that the plan is still optimized to return 504 estimated rows, although only 102 rows are actually returned by the SP. Figure 5-12 shows the query plan for the second procedure call.
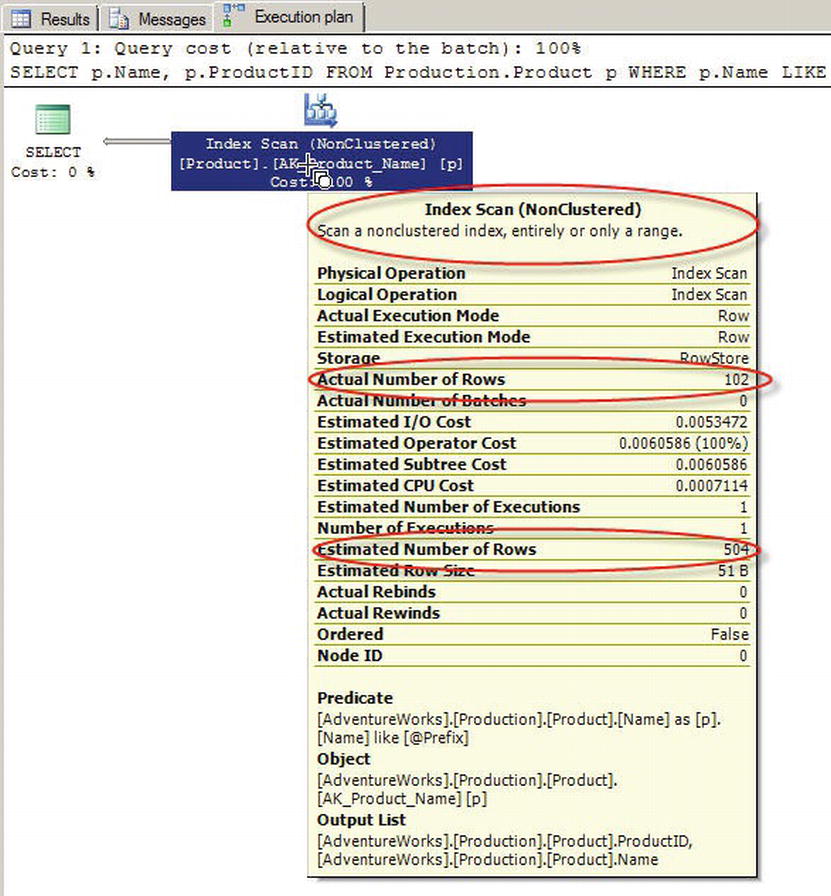
Figure 5-12. Query Plan Optimized for the Wrong Number of Rows
In cases where you expect widely varying numbers of rows to be returned by your SPs, you can override parameter sniffing on a per-procedure basis. Overriding parameter sniffing is simple—just declare a local variable in your SP, assign the parameter value to the variable, and use the variable in place of the parameter in your query. When you override parameter sniffing, SQL Server uses the source table data distribution statistics to estimate the number of rows to return. The theory is that the estimate will be better for a wider variety of possible parameter values. In this case, the estimate will still be considerably off for the extreme case of the 504 rows returned in this example, but it will be much closer and will therefore generate better query plans for other possible parameter values. Listing 5-18 alters the SP in Listing 5-17 to override parameter sniffing. Figure 5-13 shows the results of calling the updated SP with a @Prefix parameter of M%.
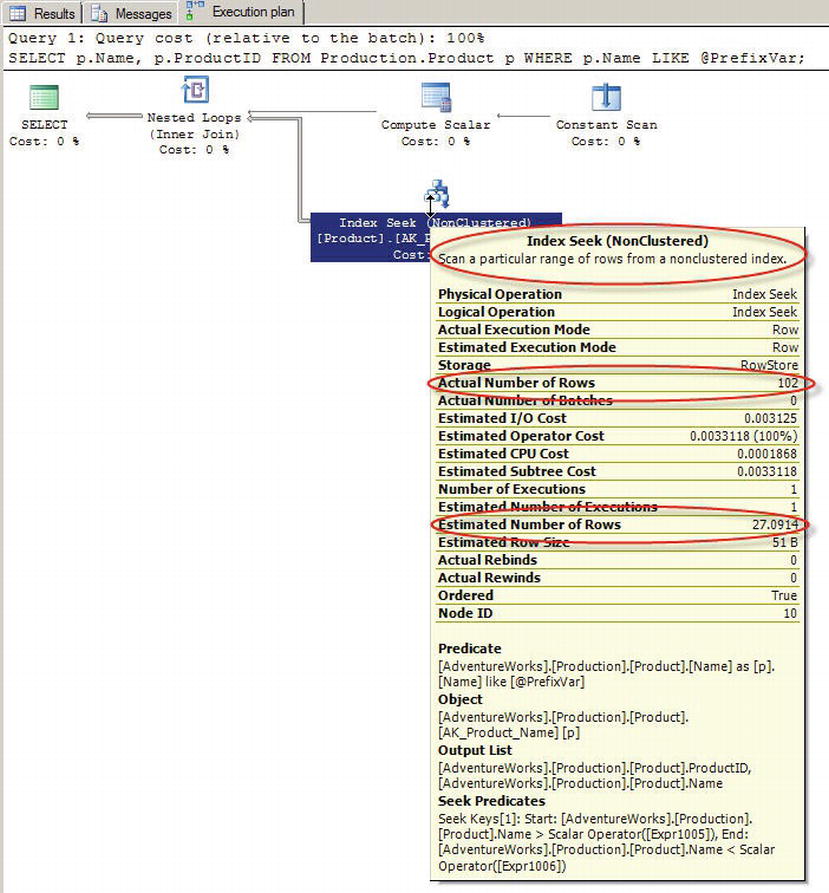
Figure 5-13. Results of the SP with Parameter Sniffing Overridden
Listing 5-18. Overriding Parameter Sniffing in an SP
ALTER PROCEDURE Production.GetProductsByName
@Prefix NVARCHAR(100)
AS
BEGIN
DECLARE @PrefixVar NVARCHAR(100) = @Prefix;
SELECT
p.Name,
p.ProductID
FROM Production.Product p
WHERE p.Name LIKE @PrefixVar;
END;
GO
With parameter sniffing overridden, the query plan for the SP in Listing 5-18 uses the same estimated number of rows, in this case 27.0914, no matter what value you pass in the @Prefix parameter. This results in a query plan that uses a nonclustered index seek—not an index scan—which is a much better query plan for the vast majority of possible parameter values for this particular SP.
As we discussed previously in this chapter, SQL Server optimizes performance by caching compiled query plans while it can. The recompilation of stored procedures is performed on individual statements within stored procedures rather than entire stored procedures to avoid unnecessary recompile consuming CPU resources.
There are several reasons why the stored procedures are recompiled:
- If the object is modified between executions, each statement within the SP that references this object is recompiled.
- If sufficient data has changed in the table that is being referenced by the SP since the original query plan was generated, the SP will recompile the plan.
- Use of temporary table in the SP may cause the SP to be recompiled evey time the procedure is executed.
- If the SP was created with the recompile option, this may cause the SP to be recompiles every time the procedure is executed.
Caching the query plan eliminates the overhead associated with recompiling your query on subsequent runs, but occasionally this feature can cause performance to suffer. When you expect your SP to return widely varying numbers of rows in the result set with each call, the cached query execution plan will only be optimized for the first call. It won’t be optimized for subsequent executions. In cases like this, you may decide to force recompilation with each call. Consider Listing 5-19, which is an SP that returns order header information for a given salesperson.
Listing 5-19. SP to Retrieve Orders by Salesperson
CREATE PROCEDURE Sales.GetSalesBySalesPerson (@SalesPersonId int)
AS
BEGIN
SELECT
soh.SalesOrderID,
soh.OrderDate,
soh.TotalDue
FROM Sales.SalesOrderHeader soh
WHERE soh.SalesPersonID = @SalesPersonId;
END;
GO
There happens to be a nonclustered index on the SalesPersonID column of the Sales.SalesOrderHeader table, which you might expect to be considered by the optimizer. However, when this SP is executed with the EXECUTE statement in Listing 5-20, the optimizer ignores the nonclustered index, and instead performs a clustered index scan, as shown in Figure 5-14.
Listing 5-20. Retrieving Sales for Salesperson 277
EXECUTE Sales.GetSalesBySalesPerson 277;

Figure 5-14. The SP Ignores the Nonclustered Index
The reason the SP ignores the nonclustered index on the SalesPersonID column is because 473 matching rows are returned by the query in the procedure. SQL Server uses a measure called selectivity, the ratio of qualifying rows to the total number of rows in the table, as a factor in determining which index, if any, to use. In Listing 5-20, the parameter value 277 represents low selectivity, meaning that there are a large number of rows returned relative to the number of rows in the table. SQL Server favors indexes for highly selective queries, to the point of completely ignoring indexes when the query has low selectivity.
If you subsequently call the SP with the @SalesPersonId parameter set to 285, which represents a highly selective value (only 16 rows are returned), query plan caching forces the same clustered index scan, even though it’s suboptimal for a highly selective query. Fortunately, SQL Server provides options that allow you to force recompilation at the SP level or the statement level. You can force a recompilation in your SP call by adding the WITH RECOMPILE option to your EXECUTE statement, as shown in Listing 5-21.
Listing 5-21. Executing an SP with Recompilation
EXECUTE Sales.GetSalesBySalesPerson 285 WITH RECOMPILE;
The WITH RECOMPILE option of the EXECUTE statement forces a recompilation of your SP when you execute it. This option is useful if your data has significantly changed since the last SP recompilation or if the parameter value you’re passing to the procedure represents an atypical value. The query plan for this SP call with the highly selective value 285 is shown in Figure 5-15.

Figure 5-15. SP Query Plan Optimized for Highly Selective Parameter Value
You can also use the sp_recompile system SP to force an SP to recompile the next time it is run.
If you expect that the values submitted to your SP will vary a lot, and that the “one execution plan for all parameters” model will cause poor performance, you can specify statement-level recompilation by adding OPTION (RECOMPILE) to your statements. The statement-level recompilation also considers the values of local variables during the recompilation process. Listing 5-22 alters the SP created in Listing 5-20 to add statement-level recompilation to the SELECT query.
Listing 5-22. Adding Statement-Level Recompilation to the SP
ALTER PROCEDURE Sales.GetSalesBySalesPerson (@SalesPersonId int)
AS
BEGIN
SELECT
soh.SalesOrderID,
soh.OrderDate,
soh.TotalDue
FROM Sales.SalesOrderHeader soh
WHERE soh.SalesPersonID = @SalesPersonId
OPTION (RECOMPILE);
END;
GO
As an alternative, you can specify procedure-level recompilation by adding the WITH RECOMPILE option to your CREATE PROCEDURE statement. This option is useful if you don’t want SQL Server to cache the query plan for the SP. With this option in place, SQL Server recompiles the entire SP every time you run it. This can be useful for procedures containing several statements that need to be recompiled often. Keep in mind, however, that this option is less efficient than a statement-level recompile since the entire SP needs to be recompiled. Because it is less efficient than statement-level recompilation, this option should be used with care.
To extend on the Stored Procedure Statistics section, SQL Server 2012 provides details about the last time when the SP or the statements were recompiled with DMVs. This will help you identify the most recompiled stored procedures and allow you to focus on resolving the recompilation issues. Listing 5-23 is a procedure that returns the stored procedures that have been recompiled.
Listing 5-23. SP to Retutn List of Stored Procedures That Have Been Recompiled
CREATE PROCEDURE dbo.GetRecompiledProcs
AS
BEGIN
SELECT
sql_text.text,
stats.sql_handle,
stats.plan_generation_num,
stats.creation_time,
stats.execution_count,
sql_text.dbid,
sql_text.objectid
FROM sys.dm_exec_query_stats stats
Cross apply sys.dm_exec_sql_text(sql_handle) as sql_text
WHERE stats.plan_generation_num > 1
and sql_text.objectid is not null --Filter adhoc queries
ORDER BY stats.plan_generation_num desc
END;
GO
This procedure uses the sys.dm_exec_query_stats DMV with the sys.dm_exec_sql_text DMF to retrieve relevant SP execution information. The query returns only the stored procedures that have been recompiled by filtering the plan_generation_num, and the ad hoc queries are being filered out by removing the object_id with null values.
Listing 5-24 demonstrates how to call this SP, and partial results are shown in Figure 5-16.
Listing 5-24. Retrieving SP Statistics
EXEC dbo.GetRecompiledProcs;
GO

Figure 5-16. Partial Results for Stored Procedure dbo.GetRecompiledProcs
Summary
SPs are powerful tools for SQL Server development. They provide a flexible method of extending the power of SQL Server by allowing you to create custom server-side subroutines. While some of the performance advantages provided by SPs in older releases of SQL Server are not as pronounced in SQL Server 2012, the ability to modularize server-side code, administer your T-SQL code base in a single location, provide additional security, and ease front-end programming development still make SPs powerful development tools in any T-SQL developer’s toolkit.
In this chapter, we introduced key aspects of SP development, including SP creation and management, passing scalar parameters to SPs, and retrieving result sets, output parameters, and return values from SPs. We also demonstrated some advanced topics, including the use of temporary tables to pass tabular data between SPs, writing recursive SPs, and SQL Server 2012’s table-valued parameters.
Finally, we finished the chapter with a discussion of SP optimizations, including SP caching, accessing SP cache statistics through DMVs and DMFs, parameter sniffing, and recompilation options, including statement-level and procedure-level recompilation.
The samples provided in this chapter are designed to demonstrate several aspects of SP functionality in SQL Server 2012. The next chapter introduces further important aspects of T-SQL programming for SQL Server 2012: DML and DDL triggers.
1. [True/False] The SP RETURN statement can return a scalar value of any data type.
2. The recursion level for SPs is 32 levels, as demonstrated by the following code sample, which errors out after reaching the maximum depth of recursion:
CREATE PROCEDURE dbo.FirstProc (@i int)
AS
BEGIN
PRINT @i;
SET @i + = 1;
EXEC dbo.FirstProc @i; END; GO
EXEC dbo.FirstProc 1;
Write a second procedure and modify this one to prove that the recursion limit applies to two SPs that call each other recursively.
3. [Choose one] Table-valued parameters must be declared with which of the following modifiers:
- READWRITE
- WRITEONLY
- RECOMPILE
- READONLY
4. [Choose all that apply] You can use which of the following methods to force SQL Server to recompile an SP:
a. The sp_recompile system SP
- The WITH RECOMPILE option
- The FORCE RECOMPILE option
- The DBCC RECOMPILE_ALL_SPS command