
![]()
CLR Integration Programming
One of the most prominent enhancements to SQL Server 2005 was the introduction of the integrated SQL Common Language Runtime, that was named SQL CLR at that time. What is now called CLR integration is an SQL Server-specific version of the .NET Common Language Runtime, which allows you to run .NET managed code in the database. CLR integration programming is a broad subject that could easily fill an entire book, and in fact it does—Pro SQL Server 2005 Assemblies, by Robin Dewson and Julian Skinner (Apress, 2005), is an excellent resource for in-depth coverage of CLR integration programming. In this chapter, we’ll discuss the methods used to extend SQL Server functionality in the past, and explain the basics of the CLR integration programming model in SQL Server 2012.
The Old Way
In versions of SQL Server prior to the 2005 release, developers could extend SQL Server functionality by writing extended stored procedures (XPs). Writing high-quality XPs required a strong knowledge of the Open Data Services (ODS) library and the poorly documented C-style Extended Stored Procedure API. Anyone who attempted the old style of XP programming can tell you it was a complex undertaking, in which a single misstep could easily result in memory leaks and corruption of the SQL Server process space. Additionally, the threading model used by XPs required SQL Server to rely on the operating system to control threading within the XP. This could lead to many issues, such as unresponsiveness of XP code.
![]() Caution XPs have been deprecated since SQL Server 2005. Use CLR integration instead of XPs for SQL Server 2012 development.
Caution XPs have been deprecated since SQL Server 2005. Use CLR integration instead of XPs for SQL Server 2012 development.
Earlier SQL Server releases also allowed you to create OLE Automation server objects via the spOACreate SP. Creating OLE Automation servers can be complex and awkward as well. OLE Automation servers created with spOACreate can result in memory leaks and in some instances corruption of the SQL Server process space.
Another option in previous versions of SQL Server was to code all business logic exclusively in physically separate business objects. While this method is preferred by many developers and administrators, it can result in extra network traffic and a less robust security model than can be achieved through tight integration with the SQL Server security model.
The CLR Integration Way
The CLR integration programming model provides several advantages over older methods of extending SQL Server functionality via XPs, OLE Automation, or external business objects. These advantages include the following:
- A managed code base that runs on the CLR integration .NET Framework is managed by the SQL Server Operating System (SQL OS). This means that SQL Server can properly manage threading, memory usage, and other resources accessed via CLR integration code.
- Tight integration of the CLR into SQL Server means that SQL Server can provide a robust security model for running code, and maintain stricter control over database objects and external resources accessed by CLR code.
- CLR integration is more thoroughly documented in more places than the Extended Stored Procedure API ever was (or presumably ever will be).
- CLR integration does not tie you to the C language-based Extended Stored Procedure API. In theory, the .NET programming model does not tie you to any one specific language (although you cannot use dynamic languages like IronPython in CLR integration).
- CLR integration allows access to the familiar .NET namespaces, data types, and managed objects, easing development.
- CLR integration introduces SQL Server-specific namespaces that allow direct access to the underlying SQL Server databases and resources, which can be used to limit or reduce network traffic generated by using external business objects.
There’s a misperception expressed by some that CLR integration is a replacement for T-SQL altogether. CLR integration is not a replacement for T-SQL, but rather a supplement that works hand in hand with T-SQL to make SQL Server 2012 more powerful than ever. So when should you use CLR code in your database? There are no hard and fast rules concerning this, but here are some general guidelines:
- Existing custom XPs on older versions of SQL Server are excellent candidates for conversion to SQL Server CLR integration assemblies—that is, if the functionality provided isn’t already part of SQL Server 2012 T-SQL (e.g., encryption).
- Code that accesses external server resources, such as calls to xpcmdshell, are also excellent candidates for conversion to more secure and robust CLR assemblies.
- T-SQL code that performs lots of complex calculations and string manipulations can make strong candidates for conversion to CLR integration assemblies.
- Highly procedural code with lots of processing steps might be considered for conversion.
- External business objects that pull a lot of data across the wire and perform a lot of processing on that data might be considered for conversion. You might first consider these business objects for conversion to T-SQL SPs, especially if they don’t perform a lot of processing on the data in question.
On the flip side, here are some general guidelines for items that should not be converted to CLR integration assemblies:
- External business objects that pull relatively little data across the wire, or that pull a lot of data across the wire but perform little processing on that data, are good candidates for conversion to T-SQL SPs instead of CLR assemblies.
- T-SQL code and SPs that do not perform many complex calculations or string manipulations generally won’t benefit from conversion to CLR assemblies.
- T-SQL can be expected to always be faster than CLR integration for set-based operations on data stored in the database.
- You might not be able to integrate CLR assemblies into databases that are hosted on an ISP’s (Internet Service Provider’s) server, if the ISP didn’t allow CLR integration at the database server level. This is mainly for security reasons and because there can be less control of the code within an assembly.
- CLR integration is not supported on the SQL Azure platform.
As with T-SQL SPs, the decision on whether and to what extent CLR integration will be used in your databases depends on your needs, including organizational policies and procedures. The recommendations we have presented here are guidelines of instances that can make good business cases for conversion of existing code and creation of new code.
CLR Integration Assemblies
CLR integration exposes .NET managed code to SQL Server via assemblies. An assembly is a compiled .NET managed code library that can be registered with SQL Server using the CREATE ASSEMBLY statement. Publicly accessible members of classes within the assemblies are then referenced in the appropriate CREATE statements, which we will describe later in this chapter. Creating a CLR integration assembly requires:
- Designing and programminxg .NET classes that publicly expose the appropriate members.
- Compiling the .NET classes into managed code DLL manifest files containing the assembly.
- Registering the assemblies with SQL Server via the CREATE ASSEMBLY statement.
- Registering the appropriate assembly members via the appropriate CREATE FUNCTION, CREATE PROCEDURE, CREATE TYPE, CREATE TRIGGER, or CREATE AGGREGATE statements.
CLR integration provides additional SQL Server-specific namespaces, classes, and attributes to facilitate development of assemblies. Visual Studio 2010 and Visual Studio 11 (in beta at the time of this writing) also include an SQL Server project type that assists in quickly creating assemblies. Also, to maximize your SQL Server development possibilities with Visual Studio, install the SQL Server Data Tools (SSDT) from the Microsoft Data Developer Center website (http://msdn.microsoft.com/en-us/data/tools.aspx) which provide an integrated environment for database developers inside Visual Studio by allowing you to create and manage database objects and data and to execute T-SQL queries directly.
Perform the following steps to create a new assembly using Visual Studio 2010:
- Select File
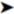 New Project from the menu.
New Project from the menu. - Go to Database SQL Server in the Installed Templates list and select either Visual Basic CLR Database Project or Visual C# CLR Database Project, as shown in Figure 14-1. Make sure you target the .NET Framework 4 as it is the version of the SQL Server 2012 CLR Integration.
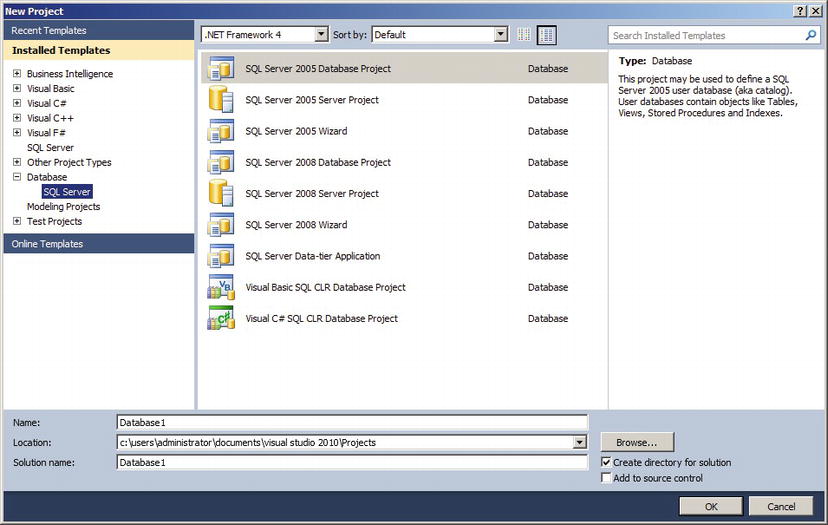
Figure 14-1. Visual Studio 2010 New Project Dialog Box
- You will be prompted with a dialog to select a database connection for the project, as shown in Figure 14-2. You may be prompted to turn on CLR integration debugging for the connection. This is required if you want to test your assemblies in debug mode, which involves remote debugging handled by remote debugging components on the SQL Server communicating with the Visual Studio host. You might need to take extra steps to configure your firewall for it to work. Refer to Set Up Remote Debugging in the Visual Studio online help (http://msdn.microsoft.com/en-us/library/bt727f1t.aspx).
Figure 14-2. The Add Database Reference Dialog Box
- Next, highlight the project name in the Solution Explorer and right-click. Then choose a type of CLR integration item to add to the solution (User-Defined Function, Stored Procedure, etc.), as shown in Figure 14-3.

Figure 14-3. Adding a New CLR Integration Class to Your Project
- Visual Studio will show you an “Add New Item” dialog box in which you can change the name of the item, and then automatically generate a template for the item you select in the language of your choice, complete with the appropriate Imports statements in VB.NET or using in C#.
In addition to the standard .NET namespaces and classes, CLR integration implements some SQL Server-specific namespaces and classes to simplify interfacing your code with SQL Server. Some of the most commonly used namespaces include the following:
- The System namespace, which includes the base .NET data types and the Object base class from which all .NET classes inherit.
- The System.Data namespace, which contains the DataSet class and other classes for ADO.NET data management.
- The System.Data.SqlClient namespace, which contains the SQL Server-specific ADO.NET data provider.
- The System.Data.SqlTypes namespace, which contains SQL Server data types. This is important because (unlike the standard .NET data types) these types can be set to SQL NULL and are defined to conform to the same operator rules, behaviors, precision, and scale as their SQL Server type counterparts.
- The Microsoft.SqlServer.Server namespace, which contains the SqlContext and SqlPipe classes that allow assemblies to communicate with SQL Server.
Once the assembly is created and compiled, it is registered with SQL Server via the CREATE ASSEMBLY statement. Listing 14-1 demonstrates a CREATE ASSEMBLY statement that registers a CLR integration assembly with SQL Server from an external DLL file. The DLL file used in the example is not supplied in precompiled form in the sample downloads for this book, but you can compile it yourself from the code we will introduce in Listing 14-2. Source code is included in the sample downloads available on the Apress web site. As CLR integration is not enabled by default, we also need to enable it at the server level. Here, we do it using the sp_configure system stored procedure prior to running the CREATE ASSEMBLY statement. CREATE ASSEMBLY would succeed even if CLR integration is disabled; an error would be raised by SQL Server only when a CLR integration code module would be called by a user later on. The RECONFIGURE statement applies the configuration change immediately.
Listing 14-1. Registering a CLR Integration Assembly with SQL Server
EXEC sp_configure 'CLR Enabled';
RECONFIGURE;
CREATE ASSEMBLY ApressExamples
AUTHORIZATION dbo
FROM N'C:MyApplicationApress.Examples.DLL'
WITH PERMISSION_SET = SAFE;
GO
The CREATE ASSEMBLY statement in the example specifies an assembly name of EmailUDF. This name must be a valid SQL Server identifier, and it must be unique within the database. You will use this assembly name when referencing the assembly in other statements.
The AUTHORIZATION clause specifies the owner of the assembly, in this case dbo. If you leave out the AUTHORIZATION clause, it defaults to the current user.
The FROM clause in this example specifies the full path to the external DLL file. Alternatively, you can specify a varbinary value instead of character file name. If you use a varbinary value, SQL Server uses it, as it is a long binary string representing the compiled assembly code, and no external file needs to be specified.
Finally, the WITH PERMISSION_SET clause grants a set of Code Access Security (CAS) permissions to the assembly. Valid permission sets include the following:
- The SAFE permission set is the most restrictive, preventing the assembly from accessing system resources outside of SQL Server. SAFE is the default.
- EXTERNAL_ACCESS allows assemblies to access some external resources, such as files, network, the registry, and environment variables.
- UNSAFE permission allows assemblies unlimited access to external resources, including the ability to execute unmanaged code.
After the assembly is installed, you can use variations of the T-SQL database object creation statements (e.g., CREATE FUNCTION, CREATE PROCEDURE) to access the methods exposed by the assembly classes. We will demonstrate these statements individually in the following sections.
CLR integration UDFs that return scalar values are similar to standard .NET functions. The primary differences with standard .NET functions are that the SqlFunction attribute must be applied to the main function of CLR integration functions if you are using Visual Studio to deploy your function or if you need to set additional attribute values like IsDeterministic and DataAccess. Listing 14-2 demonstrates a scalar UDF that accepts an input string value and a regular expression pattern and returns a bit value indicating a match (1) or no match (0). The UDF is named EmailMatch() and is declared as a method of the UDFExample class, inside the Apress.Example namespace that we will use for all our examples in this chapter.
Listing 14-2. Regular Expression Match UDF
using System.Data.SqlTypes;
using System.Text.RegularExpressions;
namespace Apress.Examples
{
public static class UDFExample
{
private static readonly Regex email_pattern = new Regex
(
// Everything before the @ sign (the "local part")
"^[a-z0-9!#$%&'*+/=?^_'{|} ∼ −] + (?:\.[a-z0-9!#$%&'*+/=?^_'{|} ∼ −]+)*" +
// Subdomains after the @ sign
"@(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.) + " +
// Top-level domains
"(?:[a-z]{2}|com|org|net|gov|mil|biz|info|mobi|name|aero|jobs|museum)\b$"
);
[Microsoft.SqlServer.Server.SqlFunction
(
IsDeterministic = true
)]
public static SqlBoolean EmailMatch(SqlString input)
{
SqlBoolean result = new SqlBoolean();
if (input.IsNull)
result = SqlBoolean.Null;
else
result = (email_pattern.IsMatch(input.Value.ToLower()) == true)
? SqlBoolean.True : SqlBoolean.False;
return result;
}
}
}
The first part of the listing specifies the required namespaces to import. This UDF uses the System.Data.SqlTypes and System.Text.RegularExpressions namespaces.
using System.Data.SqlTypes;
using System.Text.RegularExpressions;
The UDFExample class and the EmailMatch function it exposes are both declared static. CLR integration functions need to be declared as static. A static function is shared between all instances of the class. Here, the class itself is also static, so it cannot be instantiated; this allows the class to be loaded faster and its memory to be shared between SQL Server sessions. The function is decorated with the Microsoft.SqlServer.Server.SqlFunction attribute with the IsDeterministic property set to true to indicate the function is a deterministic CLR integration method. The function body is relatively simple. It accepts an SqlString input string value. If the input string is NULL, the function returns NULL; otherwise the function uses the .NET Regex.IsMatch function to perform a regular expression match. If the result is a match, the function returns a bit value of 1; otherwise it returns 0.
public static class UDFExample
{
private static readonly Regex email_pattern = new Regex
(
// Everything before the @ sign (the "local part")
"^[a-z0-9!#$%&'*+/=?^_'{|} ∼ −] + (?:\.[a-z0-9!#$%&'*+/=?^_'{|} ∼ −]+)*" +
// Subdomains after the @ sign
"@(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.) + " +
// Top-level domains
"(?:[a-z]{2}|com|org|net|gov|mil|biz|info|mobi|name|aero|jobs|museum)\b$"
);
[Microsoft.SqlServer.Server.SqlFunction
(
IsDeterministic = true
)]
public static SqlBoolean EmailMatch(SqlString input)
{
SqlBoolean result = new SqlBoolean();
if (input.IsNull)
result = SqlBoolean.Null;
else
result = (email_pattern.IsMatch(input.Value.ToLower()) == true)
? SqlBoolean.True : SqlBoolean.False;
return result;
}
}
The regular expression pattern used in Listing 14-2 was created by Jan Goyvaerts of Regular-Expressions.info (www.regular-expressions.info). Jan’s regular expression validates e-mail addresses according to RFC 2822, the standard for e-mail address formats. While not perfect, Jan estimates that this regular expression matches over 99 percent of “e-mail addresses in actual use today.” Performing this type of e-mail address validation using only T-SQL statements would be cumbersome, complex, and inefficient.
![]() Tip It’s considered good practice to use the SQL Server data types for parameters and return values to CLR Integration methods (SqlString, SqlBoolean, SqlInt32, etc.). Standard .NET data types have no concept of SQL NULL and will error out if NULL is passed in as a parameter, calculated within the function, or returned from the function.
Tip It’s considered good practice to use the SQL Server data types for parameters and return values to CLR Integration methods (SqlString, SqlBoolean, SqlInt32, etc.). Standard .NET data types have no concept of SQL NULL and will error out if NULL is passed in as a parameter, calculated within the function, or returned from the function.
After the assembly is installed via the CREATE ASSEMBLY statement we wrote in Listing 14-1, the function is created with the CREATE FUNCTION statement using the EXTERNAL NAME clause, as shown in Listing 14-3.
Listing 14-3. Creating CLR UDF from Assembly Method
CREATE FUNCTION dbo.EmailMatch (@input nvarchar(4000))
RETURNS bit
WITH EXECUTE AS CALLER
AS
EXTERNAL NAME ApressExamples.[Apress.Examples.UDFExample].EmailMatch
GO
After this, the CLR function can be called like any other T-SQL UDF, as shown in Listing 14-4. The results are shown in Figure 14-4.
Listing 14-4. Validating E-mail Addresses with Regular Expressions
SELECT
'[email protected]' AS Email,
dbo.EmailMatch (N'[email protected]') AS Valid
UNION
SELECT
'123@456789',
dbo.EmailMatch('123@456789')
UNION
SELECT '[email protected]',
dbo.EmailMatch('[email protected]'),
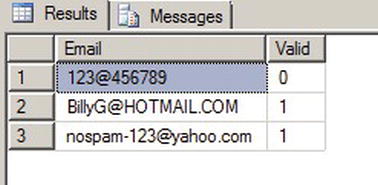
Figure 14-4. Results of E-mail Address Validation with Regular Expressions
![]() Tip Normally you can automate the process of compiling your assembly, registering it with SQL Server, and installing the CLR Integration UDF with Visual Studio’s Build
Tip Normally you can automate the process of compiling your assembly, registering it with SQL Server, and installing the CLR Integration UDF with Visual Studio’s Build ![]() Deploy option. You can also test the CLR Integration UDF with the Visual Studio Debug
Deploy option. You can also test the CLR Integration UDF with the Visual Studio Debug ![]() Start Debugging option. With Visual Studio 2010 this does not work, as it does not recognize SQL Server 2012, wich was released after Visual Studio. In Visual Studio 11, available in beta at the time of this writing, you should be able to deploy the assembly with Visual Studio. This is just a detail; it is straightforward to copy the assembly on the server and register it manually with CREATE ASSEMBLY as shown in Listing 14-1.
Start Debugging option. With Visual Studio 2010 this does not work, as it does not recognize SQL Server 2012, wich was released after Visual Studio. In Visual Studio 11, available in beta at the time of this writing, you should be able to deploy the assembly with Visual Studio. This is just a detail; it is straightforward to copy the assembly on the server and register it manually with CREATE ASSEMBLY as shown in Listing 14-1.
As we mentioned previously, CLR UDFs also allow tabular results to be returned to the caller. This example demonstrates another situation in which CLR integration can be a useful supplement to T-SQL functionality—accessing external resources such as the file system, network resources, or even the Internet. Listing 14-5 uses a CLR function to retrieve the Yahoo Top News Stories RSS feed and return the results as a table. Table-valued CLR UDFs are a little more complex than scalar functions. The following code could be added to the sqme Visual Studio project that we created for the first CLR function example. Here we create another class named YahooRSS.
Listing 14-5. Retrieving Yahoo RSS Feed Top News Stories
using System;
using System.Collections;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
using System.Xml;
namespace Apress.Examples {
public partial class YahooRSS {
[Microsoft.SqlServer.Server.SqlFunction (
IsDeterministic = false,
DataAccess = DataAccessKind.None,
TableDefinition = "title nvarchar(256),"
+ "link nvarchar(256), "
+ "pubdate datetime, "
+ "description nvarchar(max)",
FillRowMethodName = "GetRow" )
]
public static IEnumerable GetYahooNews() {
XmlTextReader xmlsource =
new XmlTextReader("http://rss.news.yahoo.com/rss/topstories");
XmlDocument newsxml = new XmlDocument();
newsxml.Load(xmlsource);
xmlsource.Close();
return newsxml.SelectNodes("//rss/channel/item");
}
private static void GetRow (
Object o,
out SqlString title,
out SqlString link,
out SqlDateTime pubdate,
out SqlString description )
{
XmlElement element = (XmlElement)o;
title = element.SelectSingleNode("./title").InnerText;
link = element.SelectSingleNode("./link").InnerText;
pubdate = DateTime.Parse(element.SelectSingleNode("./pubDate").InnerText);
description = element.SelectSingleNode("./description").InnerText;
}
}
}
Before we step through the source listing, we need to address security since this function accesses the Internet. Because the function needs to access an external resource, it requires EXTERNAL_ACCESS permissions. In order to deploy a non-SAFE assembly, one of two sets of conditions must be met:
- The database must be marked TRUSTWORTHY and the user installing the assembly must have EXTERNAL ACCESS ASSEMBLY or UNSAFE ASSEMBLY permission; or
- The assembly must be signed with an asymmetric key or certificate associated with a login that has proper permissions.
To meet the first set of requirements:
- Execute the ALTER DATABASE AdventureWorks SET TRUSTWORTHY ON; statement.
- In Visual Studio, select Project Properties Database and change the permission level to EXTERNAL_ACCESS.
- If you manually import the assembly into SQL Server, specify the EXTERNAL_ACCESS permission set when issuing the CREATE ASSEMBLY statement as shown in Listing 14-6.
Listing 14-6. CREATE ASSEMBLY with EXTERNAL_ACCESS Permission Set
CREATE ASSEMBLY ApressExample
AUTHORIZATION dbo
FROM N'C:MyApplicationApress.Example.DLL'
WITH PERMISSION_SET = EXTERNAL_ACCESS;
As mentioned previously, signing assemblies is beyond the scope of this book. Additional information on signing assemblies can be found in this MSDN Data Access Technologies blog entry: http://blogs.msdn.com/b/dataaccesstechnologies/archive/2011/10/29/deploying-sql-clr-assembly-using-asymmetric-key.aspx.
The code listing begins with the using statements. This function requires the addition of the System.Xml namespace in order to parse the RSS feed, and the System.Collections namespace to allow the collection to be searched amongst other functionality specific to collections.
using System;
using System.Collections;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
using System.Xml;
The primary public function again requires that the SqlFunction attribute be declared. This time there are several additional attributes that need to be declared with it:
[Microsoft.SqlServer.Server.SqlFunction (
IsDeterministic = false,
DataAccess = DataAccessKind.None,
TableDefinition = "title nvarchar(256),"
+ "link nvarchar(256), "
+ "pubdate datetime, "
+ "description nvarchar(max)",
FillRowMethodName = "GetRow" )
]
public static IEnumerable GetYahooNews()
{
XmlTextReader xmlsource =
new XmlTextReader("http://rss.news.yahoo.com/rss/topstories");
XmlDocument newsxml = new XmlDocument();
newsxml.Load(xmlsource);
xmlsource.Close();
return newsxml.SelectNodes("//rss/channel/item");
}
We specifically set the IsDeterministic attribute to false this time to indicate that the contents of an RSS feed can change between calls, making this UDF nondeterministic. Since the function does not read data from system tables using the in-process data provider, the DataAccess attribute is set to DataAccessKind.None. This CLR TVF also sets the additional TableDefinition attribute defining the structure of the result set for Visual Studio. It also needs the FillRowMethodName attribute to designate the fill-row method. The fill-row method is a user method that converts each element of an IEnumerable object into an SQL Server result set row.
The public function is declared to return an IEnumerable result. This particular function opens an XmlTextReader that retrieves the Yahoo Top News Stories RSS feed and stores it in an XmlDocument. The function then uses the SelectNodes method to retrieve news story summaries from the RSS feed. The SelectNodes method, used to return results from the function, generates an XmlNodeList. The XmlNodeList class implements the IEnumerable interface. This is important since the fill-row method is fired once for each object returned by the IEnumerable collection returned (in this case the XmlNodeList).
The GetRow method is declared as a C# void function, which means that no value will be returned by the function; the method communicates with SQL Server via its out parameters. The first parameter is an Object passed by value—in this case an XmlElement. The remaining parameters correspond to the columns of the result set. The GetRow method casts the first parameter to an XmlElement (the parameter cannot be directly an XmlElement because the fill-row method signature must have an Object as first parameter). It then uses the SelectSingleNode method and InnerText property to retrieve the proper text from individual child nodes of the XmlElement, assigning each to the proper columns of the result set along the way.
private static void GetRow (
Object o,
out SqlString title,
out SqlString link,
out SqlDateTime pubdate,
out SqlString description )
{
XmlElement element = (XmlElement)o;
title = element.SelectSingleNode("./title").InnerText;
link = element.SelectSingleNode("./link").InnerText;
pubdate = DateTime.Parse(element.SelectSingleNode("./pubDate").InnerText);
description = element.SelectSingleNode("./description").InnerText;
}
The CLR TVF can be called with a SELECT query, as shown in Listing 14-7. The results are shown in Figure 14-5.
Listing 14-7. Querying a CLR Integration TVF
CREATE FUNCTION dbo.GetYahooNews()
RETURNS TABLE(title nvarchar(256), link nvarchar(256), pubdate datetime, description nvarchar(max))
AS EXTERNAL NAME ApressExamples.[Apress.Examples.YahooRSS].GetYahooNews
GO
SELECT
title,
link,
pubdate,
description
FROM dbo.GetYahooNews();
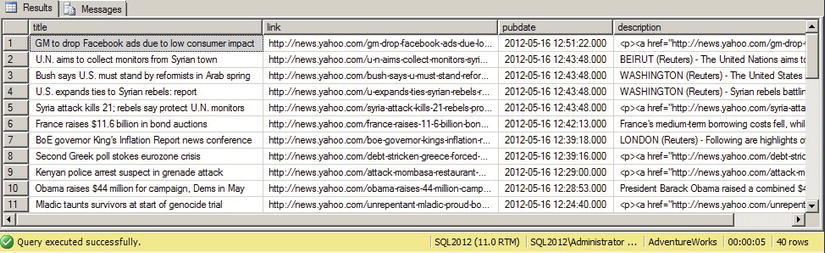
Figure 14-5. Retrieving the Yahoo RSS Feed with the GetYahooNews() Function
CLR integration SPs provide an alternative to extend SQL Server functionality when T-SQL SPs just won’t do. Of course, like other CLR integration functionality, there is a certain amount of overhead involved with CLR SPs, and you can expect them to be less efficient than comparable T-SQL code for set-based operations. On the other hand, if you need to access .NET functionality or external resources, or if you have code that is computationally intensive, CLR integration SPs can provide an excellent alternative to straight T-SQL code.
Listing 14-8 shows how to use CLR integration to retrieve operating system environment variables and return them as a recordset via an SP. In the Apress.Examples namespace, we create a SampleProc class.
Listing 14-8. Retrieving Environment Variables with a CLR Stored Procedure
using System;
using System.Collections;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
namespace Apress.Examples
{
public partial class SampleProc
{
[Microsoft.SqlServer.Server.SqlProcedure()]
public static void GetEnvironmentVars()
{
try
{
SortedList environment_list = new SortedList();
foreach (DictionaryEntry de in Environment.GetEnvironmentVariables())
{
environment_list[de.Key] = de.Value;
}
SqlDataRecord record = new SqlDataRecord (
new SqlMetaData("VarName", SqlDbType.NVarChar, 1024),
new SqlMetaData("VarValue", SqlDbType.NVarChar, 4000)
);
SqlContext.Pipe.SendResultsStart(record);
foreach (DictionaryEntry de in environment_list)
{
record.SetValue(0, de.Key);
record.SetValue(1, de.Value);
SqlContext.Pipe.SendResultsRow(record);
}
SqlContext.Pipe.SendResultsEnd();
}
catch (Exception ex)
{
SqlContext.Pipe.Send(ex.Message);
}
}
}
};
As with the previous CLR integration examples, appropriate namespaces are imported at the top:
using System;
using System.Collections;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
The GetEnvironmentVars() method is declared as a public void function. The SqlProcedure() attribute is applied to the function in this code to indicate to Visual Studio that this is a CLR SP. The body of the SP is wrapped in a try . . . catch block to capture any .NET exceptions, which are returned to SQL Server. If an exception occurs in the .NET code, it’s sent back to SQL Server via the SqlContext.Pipe.Send method.
public partial class SampleProc
{
[Microsoft.SqlServer.Server.SqlProcedure()]
public static void GetEnvironmentVars()
{
try
{
...
}
catch (Exception ex)
{
SqlContext.Pipe.Send(ex.Message);
}
}
}
};
THROWING READABLE EXCEPTIONS
When you need to raise an exception in a CLR SP, you have two options. For code readability reasons, I’ve chosen the simpler option of just allowing exceptions to bubble up through the call stack. This results in .NET Framework exceptions being returned to SQL Server. The .NET Framework exceptions return a lot of extra information, like call stack data, however.
If you want to raise a nice, simple SQL Server-style error without all the extra .NET Framework exception information, you can use a method introduced in the book Pro SQL Server 2005, by Thomas Rizzo et al. (Apress, 2005). This second method involves using the ExecuteAndSend() method of the SqlContext.Pipe to execute a T-SQL RAISERROR statement. This method is shown in the following C# code snippet:
try {
SqlContext.Pipe.ExecuteAndSend("RAISERROR ('This is a T-SQL Error', 16, 1);");
}
catch
{
// do nothing
}
The ExecuteAndSend() method call executes the RAISERROR statement on the current context connection. The try...catch block surrounding the call prevents the .NET exception generated by the RAISERROR to be handled by .NET and reported as a new error. Keep this method in mind if you want to raise SQL Server-style errors instead of returning the verbose .NET Framework exception information to SQL Server.
As the procedure begins, all of the environment variable names and their values are copied from the .NET Hashtable returned by the Environment.GetEnvironmentVariables() functions to a .NET SortedList. In this procedure, we chose to use the SortedList to ensure that the results are returned in order by key. I added the SortedList just for display purposes, but it’s not required. Greater efficiency can be gained by iterating the HashTable directly without a SortedList.
SortedList environment_list = new SortedList();
foreach (DictionaryEntry de in Environment.GetEnvironmentVariables())
{
environment_list[de.Key] = de.Value;
}
The procedure uses the SqlContext.Pipe to return results to SQL Server as a result set. The first step to using the SqlContext.Pipe to send results back is to set up an SqlRecord with the structure that you wish the result set to take. For this example, the result set consists of two nvarchar columns: VarName, which contains the environment variable names; and VarValue, which contains their corresponding values.
SqlDataRecord record = new SqlDataRecord (
new SqlMetaData("VarName", SqlDbType.NVarChar, 1024),
new SqlMetaData("VarValue", SqlDbType.NVarChar, 4000)
);
Next, the function calls the SendResultsStart() method with the SqlDataRecord to initialize the result set:
SqlContext.Pipe.SendResultsStart(record);
Then it’s a simple matter of looping through the SortedList of environment variable key/value pairs and sending them to the server via the SendResultsRow() method:
foreach (DictionaryEntry de in environment_list) {
record.SetValue(0, de.Key);
record.SetValue(1, de.Value);
SqlContext.Pipe.SendResultsRow(record);
}
The SetValue() method is called for each column of the SqlRecord to properly set the results, and then SendResultsRow() is called for each row. After all results have been sent to the client, the SendResultsEnd() method of the SqlContext.Pipe is called to complete the result set and return the SqlContext.Pipe to its initial state.
SqlContext.Pipe.SendResultsEnd();
The GetEnvironmentVars CLR SP can be called using the T-SQL EXEC statement, shown in Listing 14-9. The results are shown in Figure 14-6.
Listing 14-9. Executing the GetEnvironmentVars CLR Procedure
CREATE PROCEDURE dbo.GetEnvironmentVars
AS EXTERNAL NAME ApressExamples.[Apress.Examples.SampleProc].GetEnvironmentVars;
GO
EXEC dbo.GetEnvironmentVars;

Figure 14-6. Retrieving Environment Variables with CLR
User-defined aggregates (UDAs) are an exciting addition to SQL Server’s functionality. UDAs are similar to the built-in SQL aggregate functions (SUM, AVG, etc.) in that they can act on entire sets of data at once, as opposed to one item at a time. An SQL CLR UDA has access to .NET functionality and can operate on numeric, character, date/time, or even user-defined data types. A basic UDA has four required methods:
- The UDA calls its Init() method when the SQL Server engine prepares to aggregate. The code in this method can reset member variables to their start state, initialize buffers, and perform other initialization functions.
- The Accumulate() method is called as each row is processed, allowing you to aggregate the data passed in. The Accumulate() method might increment a counter, add a row’s value to a running total, or possibly perform other more complex processing on a row’s data.
- The Merge() method is invoked when SQL Server decides to use parallel processing to complete an aggregate. If the query engine decides to use parallel processing, it will create multiple instances of your UDA and call the Merge() method to join the results into a single aggregation.
- The Terminate() method is the final method of the UDA. It is called after all rows have been processed and any aggregates created in parallel have been merged. The Terminate() method returns the final result of the aggregation to the query engine.
![]() Tip In SQL Server 2005, there was a serialization limit of 8,000 bytes for an instance of a SQL CLR UDA, making certain tasks harder to perform using a UDA. For instance, creating an array, hash table, or other structure to hold intermediate results during an aggregation (like aggregates that calculate statistical mode or median) could cause a UDA to very quickly run up against the 8,000-byte limit and throw an exception for large datasets. SQL Server 2008 and 2012 do not have this limitation.
Tip In SQL Server 2005, there was a serialization limit of 8,000 bytes for an instance of a SQL CLR UDA, making certain tasks harder to perform using a UDA. For instance, creating an array, hash table, or other structure to hold intermediate results during an aggregation (like aggregates that calculate statistical mode or median) could cause a UDA to very quickly run up against the 8,000-byte limit and throw an exception for large datasets. SQL Server 2008 and 2012 do not have this limitation.
Creating a Simple UDA
The sample UDA in Listing 14-10 determines the statistical range for a set of numbers. The statistical range for a given set of numbers is the difference between the minimum and maximum values for the set. The UDA determines the minimum and maximum values of the set of numbers passed in and returns the difference.
Listing 14-10. Sample Statistical Range UDA
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
namespace Apress.Examples {
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate(Format.Native)]
public struct Range
{
SqlDouble min, max;
public void Init() {
min = SqlDouble.Null;
max = SqlDouble.Null;
}
public void Accumulate(SqlDouble value)
{
if (!value.IsNull) {
if (min.IsNull || value < min)
{
min = value;
}
if (max.IsNull || value > max)
{
max = value;
}
}
}
public void Merge(Range group)
{
if (min.IsNull || (!group.min.IsNull && group.min < min))
{
min = group.min;
}
if (max.IsNull || (!group.max.IsNull && group.max > max))
{
max = group.max;
}
}
public SqlDouble Terminate() {
SqlDouble result = SqlDouble.Null;
if (!min.IsNull && !max.IsNull)
{
result = max - min;
}
return result;
}
}
}
This UDA begins, like the previous CLR integration assemblies, by importing the proper namespaces:
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
Next, the code declares the struct that represents the UDA. The attributes Serializable and SqlUserDefinedAggregate are applied to the struct. We used the Format.Native serialization format for this UDA. Because this is a simple UDA, Format.Native will provide the best performance and will be the easiest to implement. More complex UDAs that use reference types require Format.UserDefined serialization and must implement the IBinarySerialize interface.
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate(Format.Native)]
public struct Range
{
}
The struct declares two member variables, min and max, which will hold the minimum and maximum values encountered during the aggregation process:
SqlDouble min, max;
The mandatory Init() method in the aggregate body initializes the min and max member variables to SqlDouble.Null:
public void Init() {
min = SqlDouble.Null;
max = SqlDouble.Null;
}
The Accumulate() method accepts a SqlDouble parameter. This method first checks that the value is not NULL (NULL is ignored during aggregation). Then it checks to see if the value passed in is less than the min variable (or if min is NULL), and if so, assigns the parameter value to min. The method also checks max and updates it if the parameter value is greater than max (or if max is NULL). In this way, the min and max values are determined on the fly as the query engine feeds values into the Accumulate() method.
public void Accumulate(SqlDouble value)
{
if (!value.IsNull) {
if (min.IsNull || value < min)
{
min = value;
}
if (max.IsNull || value > max)
{
max = value;
}
}
}
The Merge() method merges a Range structure that was created in parallel with the current structure. The method accepts a Range structure and compares its min and max variables to those of the current Range structure. It then adjusts the current structure’s min and max variables based on the Range structure passed into the method, effectively merging the two results.
public void Merge(Range group)
{
if (min.IsNull || (!group.min.IsNull && group.min < min))
{
min = group.min;
}
if (max.IsNull || (!group.max.IsNull && group.max > max))
{
max = group.max;
}
}
The final method of the UDA is the Terminate() function, which returns an SqlDouble result. This function checks for min or max results that are NULL. The UDA returns NULL if either min or max is NULL. If neither min nor max is NULL, the result is the difference between the max and min values.
public SqlDouble Terminate() {
SqlDouble result = SqlDouble.Null;
if (!min.IsNull && !max.IsNull)
{
result = max - min;
}
return result;
}
![]() Note The Terminate() method must return the same data type that the Accumulate() method accepts. If these data types do not match, an error will occur. Also, as mentioned previously, it is best practice to use the SQL Server-specific data types, since the standard .NET types will choke on NULL.
Note The Terminate() method must return the same data type that the Accumulate() method accepts. If these data types do not match, an error will occur. Also, as mentioned previously, it is best practice to use the SQL Server-specific data types, since the standard .NET types will choke on NULL.
Listing 14-11 is a simple test of this UDA. The test determines the statistical range of unit prices that customers have paid for AdventureWorks products. Information like this, on a per-product or per-model basis, can be paired with additional information to help the AdventureWorks sales teams set optimal price points for their products. The results are shown in Figure 14-7.
Listing 14-11. Retrieving Statistical Ranges with UDA
CREATE AGGREGATE Range (@value float) RETURNS float
EXTERNAL NAME ApressExamples.[Apress.Examples.Range];
GO
SELECT
ProductID,
dbo.Range(UnitPrice) AS UnitPriceRange
FROM Sales.SalesOrderDetail
WHERE UnitPrice > 0
GROUP BY ProductID;
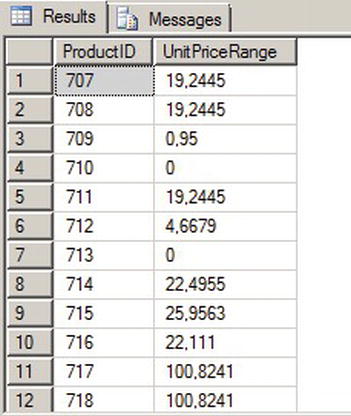
Figure 14-7. Results of the Range Aggregate Applied to Unit Prices
![]() Caution This UDA is an example. It will be faster to use regular T-SQL aggregation functions for this type of calculation, especially if you have a large number of rows to process.
Caution This UDA is an example. It will be faster to use regular T-SQL aggregation functions for this type of calculation, especially if you have a large number of rows to process.
Creating an Advanced UDA
You can create more advanced CLR aggregates that use reference data types and user-defined serialization. When creating a UDA that uses reference (nonvalue) data types such as ArrayLists, SortedLists, and Objects, CLR integration imposes the additional restriction that you cannot mark the UDA for Format.Native serialization. Instead these aggregates have to be marked for Format.UserDefined serialization, which means that the UDA must implement the IBinarySerialize interface, including both the Read and Write methods. Basically, you have to tell SQL Server how to serialize your data when using reference types. There is a performance impact associated with Format.UserDefined serialization as opposed to Format.Native.
Listing 14-12 is a UDA that calculates the statistical median of a set of numbers. The statistical median is the middle number of an ordered group of numbers. If there is an even number of numbers in the set, the statistical median is the average (mean) of the middle two numbers in the set.
Listing 14-12. UDA to Calculate Statistical Median
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.SqlTypes;
using System.Runtime.InteropServices;
using Microsoft.SqlServer.Server;
namespace Apress.Examples {
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate (
Format.UserDefined,
IsNullIfEmpty = true,
MaxByteSize = −1 )]
#160; [StructLayout(LayoutKind.Sequential)]
public struct Median : IBinarySerialize
{
List<double> temp; // List of numbers
public void Init()
{
// Create new list of double numbers
this.temp = new List<double> ();
}
public void Accumulate(SqlDouble number)
{
if (!number.IsNull) // Skip over NULLs
{
this.temp.Add(number.Value); // If number is not NULL, add it to list
}
}
public void Merge(Median group)
{
// Merge two sets of numbers
this.temp.InsertRange(this.temp.Count, group.temp);
}
public SqlDouble Terminate() {
SqlDouble result = SqlDouble.Null; // Default result to NULL
this.temp.Sort(); // Sort list of numbers
int first, second; // Indexes to middle two numbers
if (this.temp.Count % 2 == 1)
{
// If there is an odd number of values get the middle number twice
first = this.temp.Count / 2;
second = first;
}
else
{
// If there is an even number of values get the middle two numbers
first = this.temp.Count / 2-1;
second = first + 1;
}
if (this.temp.Count > 0) // If there are numbers, calculate median
{
// Calculate median as average of middle number(s)
result = (SqlDouble)( this.temp[first] + this.temp[second] ) / 2.0;
}
return result;
}
#region IBinarySerialize Members
// Custom serialization read method
public void Read(System.IO.BinaryReader r)
{
// Create a new list of double values
this.temp = new List<double> ();
// Get the number of values that were serialized
int j = r.ReadInt32();
// Loop and add each serialized value to the list
for (int i = 0; i < j; i++)
{
this.temp.Add(r.ReadDouble());
}
}
// Custom serialization write method
public void Write(System.IO.BinaryWriter w)
{
// Write the number of values in the list
w.Write(this.temp.Count);
// Write out each value in the list
foreach (double d in this.temp)
{
w.Write(d);
}
}
#endregion
}
}
This UDA begins, like the other CLR integration examples, with namespace imports. We’ve added the System.Collections.Generic namespace this time so we can use the .NET List<T> strongly typed list.
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.SqlTypes;
using System.Runtime.InteropServices;
using Microsoft.SqlServer.Server;
The Median structure in the example is declared with the Serializable attribute to indicate that it can be serialized, and the StructLayout attribute with the LayoutKind.Sequential property to force the structure to be serialized in sequential fashion for a UDA that has a Format different from Native. The SqlUserDefinedAggregate attribute declares three properties, as follows:
- The Format.UserDefined property indicates that the UDA will implement serialization methods through the IBinarySerialize interface. This is required since the List<T> reference type is being used in the UDA.
- The IsNullIfEmpty property is set to true, indicating that NULL will be returned if no rows are passed to the UDA.
- The MaxByteSize property is set to −1 so that the UDA can be serialized if it is greater than 8,000 bytes. (The 8,000-byte serialization limit was a strict limit in SQL Server 2005 that prevented serialization of large objects, like large ArrayList objects, in the UDA.)
Because Format.UserDefined was specified on the Median structure, it must implement the IBinarySerialize interface. Inside the body of the struct, we’ve defined a List<double> named temp that will hold an intermediate temporary list of numbers passed into the UDA.
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedAggregate (
Format.UserDefined,
IsNullIfEmpty = true,
MaxByteSize = −1 )]
[StructLayout(LayoutKind.Sequential)]
public struct Median : IBinarySerialize
{
List<double> temp; // List of numbers
...
}
The Read() and Write() methods of the IBinarySerialize interface are used to deserialize and serialize the list, respectively:
#region IBinarySerialize Members
// Custom serialization read method
public void Read(System.IO.BinaryReader r)
{
// Create a new list of double values
this.temp = new List<double>();
// Get the number of values that were serialized
int j = r.ReadInt32();
// Loop and add each serialized value to the list
for (int i = 0; i < j; i++)
{
this.temp.Add(r.ReadDouble());
}
}
// Custom serialization write method
public void Write(System.IO.BinaryWriter w)
{
// Write the number of values in the list
w.Write(this.temp.Count);
// Write out each value in the list
foreach (double d in this.temp)
{
w.Write(d);
}
}
#endregion
The Init method of the UDA initializes the temp list by creating a new List<double> instance:
public void Init() {
// Create new list of double numbers
this.temp = new List<double>();
}
The Accumulate() method accepts a SqlDouble number and adds all non-NULL values to the temp list. Although you can include NULLs in your aggregate results, keep in mind that T-SQL developers are used to the NULL handling of built-in aggregate functions like SUM and AVG. In particular, developers are used to their aggregate functions discarding NULL. This is the main reason we eliminate NULL in this UDA.
public void Accumulate(SqlDouble number)
{
if (!number.IsNull) // Skip over NULLs
{
this.temp.Add(number.Value); // If number is not NULL, add it to list
}
}
The Merge() method in the example merges two lists of numbers if SQL Server decides to calculate the aggregate in parallel. If so, the server will pass a list of numbers into the Merge() method. This list of numbers must then be appended to the current list. For efficiency, we use the InsertRange() method of List<T> to combine the lists.
public void Merge(Median group)
{
// Merge two sets of numbers
this.temp.InsertRange(this.temp.Count, group.temp);
}
The Terminate() method of the UDA sorts the list of values and then determines the indexes of the middle numbers. If there is an odd number of values in the list, there is only a single middle number; if there is an even number of values in the list, the median is the average of the middle two numbers. If the list contains no values (which can occur if every value passed to the aggregate is NULL), the result is NULL; otherwise the Terminate() method calculates and returns the median.
public SqlDouble Terminate() {
SqlDouble result = SqlDouble.Null; // Default result to NULL
this.temp.Sort(); // Sort list of numbers
int first, second; // Indexes to middle two numbers
if (this.temp.Count % 2 == 1)
{
// If there is an odd number of values get the middle number twice
first = this.temp.Count / 2;
second = first;
}
else
{
// If there is an even number of values get the middle two numbers
first = this.temp.Count / 2–1;
second = first + 1;
}
if (this.temp.Count > 0) // If there are numbers, calculate median
{
// Calculate median as average of middle number(s)
result = (SqlDouble)( this.temp[first] + this.temp[second] ) / 2.0;
}
return result;
}
Listing 14-13 demonstrates the use of this UDA to calculate the median UnitPrice from the Sales.SalesOrderDetail table on a per-product basis. The results are shown in Figure 14-8.
Listing 14-13. Calculating Median Unit Price with a UDA
CREATE AGGREGATE dbo.Median (@value float) RETURNS float
EXTERNAL NAME ApressExamples.[Apress.Examples.Median];
GO
SELECT
ProductID,
dbo.Median(UnitPrice) AS MedianUnitPrice
FROM Sales.SalesOrderDetail
GROUP BY ProductID;

Figure 14-8. Median Unit Price for Each Product
CLR Integration User-Defined Types
SQL Server 2000 had built-in support for user-defined data types, but they were limited in scope and functionality. The old-style user-defined data types had the following restrictions and capabilities:
- They had to be derived from built-in data types.
- Their format and/or range could only be restricted through T-SQL rules.
- They could be assigned a default value.
- They could be declared as NULL or NOT NULL.
SQL Server 2012 provides support for old-style user-defined data types and rules, presumably for backward compatibility with existing applications. The AdventureWorks database contains examples of old-style user-defined data types, like the dbo.Phone data type, which is an alias for the varchar(25) data type.
![]() Caution Rules (CHECK constraints that can be applied to user-defined data types) have been deprecated since SQL Server 2005 and will be removed from a future version. T-SQL user-defined data types are now often referred to as alias types.
Caution Rules (CHECK constraints that can be applied to user-defined data types) have been deprecated since SQL Server 2005 and will be removed from a future version. T-SQL user-defined data types are now often referred to as alias types.
SQL Server 2012 supports a far more flexible solution to your custom data type needs in the form of CLR user-defined types. CLR integration user-defined types allow you to access the power of the .NET Framework to meet your custom data type needs. Common examples of CLR UDTs include mathematical concepts like points, vectors, complex numbers, and other types not built into the SQL Server type system. In fact, CLR UDTs are so powerful that Microsoft has begun including some as standard in SQL Server. These CLR UDTs include the spatial data types geography and geometry, and the hierarchyid data type.
CLR UDTs are useful for implementing data types that require special handling and that implement their own special methods and functions. Complex numbers, which are a superset of real numbers, are one example. Complex numbers are represented with a “real” part and an “imaginary” part in the format “a + bi,” where a is a real number representing the real part of the value, b is a real number representing the imaginary part, and the literal letter i after the imaginary part stands for the imaginary number i, which is the square root of −1. Complex numbers are often used in math, science, and engineering to solve difficult abstract problems. Some examples of complex numbers include 101.9 + 3.7i, 98 + 12i, -19i, and 12 + 0i (which can also be represented as 12). Because their format is different from real numbers and calculations with them require special functionality, complex numbers are a good candidate for CLR. The example in Listing 14-14 implements a complex number CLR UDT.
![]() Note To keep the example simple, only a partial implementation is reproduced here. The sample download file includes the full version of this CLR UDT that includes basic operators as well as additional documentation and implementations of many more mathematical operators and trigonometric functions.
Note To keep the example simple, only a partial implementation is reproduced here. The sample download file includes the full version of this CLR UDT that includes basic operators as well as additional documentation and implementations of many more mathematical operators and trigonometric functions.
Listing 14-14. Complex Numbers UDT
using System;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
using System.Text.RegularExpressions;
namespace Apress.Examples
{
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedType
(
Format.Native,
IsByteOrdered = true
)]
public struct Complex : INullable
{
#region "Complex Number UDT Fields/Components"
private bool m_Null;
public Double real;
public Double imaginary;
#endregion
#region "Complex Number Parsing, Constructor, and Methods/Properties"
private static readonly Regex rx = new Regex(
"^(?<Imaginary>[+−]?([0–9] + |[0–9]*\.[0–9]+))[i|I]$|" +
"^(?<Real>[+−]?([0–9] + |[0–9]*\.[0–9]+))$|" +
"^(?<Real>[+−]?([0–9] + |[0–9]*\.[0–9]+))" +
"(?<Imaginary>[+−]?([0–9] + |[0–9]*\.[0–9]+))[i|I]$");
public static Complex Parse(SqlString s)
{
Complex u = new Complex();
if (s.IsNull)
u = Null;
else
{
MatchCollection m = rx.Matches(s.Value);
if (m.Count == 0)
throw (new FormatException("Invalid Complex Number Format."));
String real_str = m[0].Groups["Real"].Value;
String imaginary_str = m[0].Groups["Imaginary"].Value;
if (real_str == "" && imaginary_str == "")
throw (new FormatException("Invalid Complex Number Format."));
if (real_str == "")
u.real = 0.0;
else
u.real = Convert.ToDouble(real_str);
if (imaginary_str == "")
u.imaginary = 0.0;
else
u.imaginary = Convert.ToDouble(imaginary_str);
}
return u;
}
public override String ToString()
{
String sign = "";
if (this.imaginary >= 0.0)
sign = " + ";
return this.real.ToString() + sign + this.imaginary.ToString() + "i";
}
public bool IsNull
{
get
{
return m_Null;
}
}
public static Complex Null
{
get
{
Complex h = new Complex();
h.m_Null = true;
return h;
}
}
public Complex(Double r, Double i)
{
this.real = r;
this.imaginary = i;
this.m_Null = false;
}
#endregion
#region "Complex Number Basic Operators"
// Complex number addition
public static Complex operator + (Complex n1, Complex n2)
{
Complex u;
if (n1.IsNull || n2.IsNull)
u = Null;
else
u = new Complex(n1.real + n2.real, n1.imaginary + n2.imaginary);
return u;
}
#endregion
#region "Exposed Mathematical Basic Operator Methods"
// Add complex number n2 to n1
public static Complex CAdd(Complex n1, Complex n2)
{
return n1 + n2;
}
// Subtract complex number n2 from n1
public static Complex Sub(Complex n1, Complex n2)
{
return n1 - n2;
}
#endregion
// other complex operations are available in the source code
}
}
The code begins with the required namespace imports and the namespace declaration for the sample:
using System;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
using System.Text.RegularExpressions;
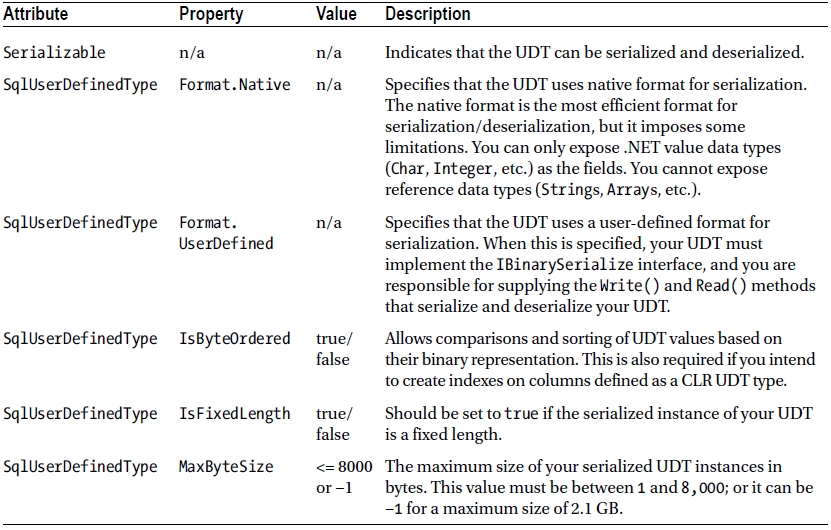
Next is the declaration of the structure that represents an instance of the UDT. The Serializable, Format.Native, and IsByteOrdered = true attributes and attribute properties are all set on the UDT. In addition, all CLR UDTs must implement the INullable interface. INullable requires that the IsNull and Null properties be defined. The CLR UDT attributes are detailed in Table 14-1.
Table 14-1. Common CLR UDT Attributes
[Serializable]
[Microsoft.SqlServer.Server.SqlUserDefinedType
(
Format.Native,
IsByteOrdered = true
)]
public struct Complex : INullable
{
...
}
Table 14-1 shows a few of the common attributes that are used in CLR integration UDT definitions.
The public and private fields are declared inside the body of the Complex structure. The real and imaginary public fields represent the real and imaginary parts of the complex number, respectively. The m_Null field is a bool value that is set to true if the current instance of the complex type is NULL, and is set to false otherwise.
#region "Complex Number UDT Fields/Components"
private bool m_Null;
public Double real;
public Double imaginary;
#endregion
The first method declared in the UDT is the Parse method (required by all UDTs), which takes a string value from SQL Server and parses it into a complex number. The Parse method uses a .NET regular expression to simplify parsing a bit.
private static readonly Regex rx = new Regex(
"^(?<Imaginary>[+−]?([0–9] + |[0–9]*\.[0–9]+))[i|I]$|" +
"^(?<Real>[+−]?([0–9] + |[0–9]*\.[0–9]+))$|" +
"^(?<Real>[+−]?([0–9] + |[0–9]*\.[0–9]+))" +
"(?<Imaginary>[+−]?([0–9] + |[0–9]*\.[0–9]+))[i|I]$");
public static Complex Parse(SqlString s)
{
Complex u = new Complex();
if (s.IsNull)
u = Null;
else
{
MatchCollection m = rx.Matches(s.Value);
if (m.Count == 0)
throw (new FormatException("Invalid Complex Number Format."));
String real_str = m[0].Groups["Real"].Value;
String imaginary_str = m[0].Groups["Imaginary"].Value;
if (real_str == "" && imaginary_str == "")
throw (new FormatException("Invalid Complex Number Format."));
if (real_str == "")
u.real = 0.0;
else
u.real = Convert.ToDouble(real_str);
if (imaginary_str == "")
u.imaginary = 0.0;
else
u.imaginary = Convert.ToDouble(imaginary_str);
}
return u;
}
The regular expression (a.k.a. regex) uses named groups to parse the input string into Real and/or Imaginary named groups. If the regex is successful, at least one (if not both) of these named groups will be populated. If unsuccessful, both named groups will be empty and an exception of type FormatException will be thrown. If at least one of the named groups is properly set, the string representations are converted to Double type and assigned to the appropriate UDT fields. Table 14-2 shows some sample input strings and the values assigned to the UDT fields when they are parsed.
Table 14-2. Complex Number Parsing Samples

The ToString() method is required for all UDTs as well. This method converts the internal UDT data to its string representation. In the case of complex numbers, ToString() needs to perform the following steps:
- Convert the real part to a string.
- Append a plus sign (+) if the imaginary part is 0 or positive.
- Append the imaginary part.
- Append the letter i to indicate that it does in fact represent a complex number.
Notice that if the imaginary part is negative, no sign is appended between the real and imaginary parts, since the sign is already included in the imaginary part:
public override String ToString()
{
String sign = "";
if (this.imaginary >= 0.0)
sign = " + ";
return this.real.ToString() + sign + this.imaginary.ToString() + "i";
}
The IsNull and Null properties are both required by all UDTs. IsNull is a bool property that indicates whether a UDT instance is NULL or not. The Null property returns a NULL instance of the UDT type. One thing you need to be aware of any time you invoke a UDT (or any CLR integration object) from T-SQL is SQL NULL. For purposes of the Complex UDT, we take a cue from T-SQL and return a NULL result any time a NULL is passed in as a parameter to any UDT method. So a Complex value plus NULL returns NULL, as does a Complex value divided by NULL, and so on. You will notice a lot of code in the complete Complex UDT listing that is specifically designed to deal with NULL.
public bool IsNull
{
get
{
return m_Null;
}
}
public static Complex Null
{
get
{
Complex h = new Complex();
h.m_Null = true;
return h;
}
}
This particular UDT includes a constructor function that accepts two Double type values and creates a UDT instance from them:
public Complex(Double r, Double i)
{
this.real = r;
this.imaginary = i;
this.m_Null = false;
}
![]() Tip For a UDT designed as a.NET structure, a constructor method is not required. In fact, a default constructor (that takes no parameters) is not even allowed. To keep later code simple, we added a constructor method to this example.
Tip For a UDT designed as a.NET structure, a constructor method is not required. In fact, a default constructor (that takes no parameters) is not even allowed. To keep later code simple, we added a constructor method to this example.
In the next region, we defined a few useful complex number constants and exposed them as static properties of the Complex UDT:
#region "Useful Complex Number Constants"
// The property "i" is the Complex number 0 + 1i. Defined here because
// it is useful in some calculations
public static Complex i
{
get
{
return new Complex(0, 1);
}
}
...
#endregion
To keep this listing short but highlight the important points, the sample UDT shows only the addition operator for complex numbers. The UDT overrides the + operator. Redefining operators makes it easier to write and debug additional UDT methods. These overridden .NET math operators are not available to T-SQL code, so the standard T-SQL math operators will not work on the UDT.
// Complex number addition
public static Complex operator + (Complex n1, Complex n2)
{
Complex u;
if (n1.IsNull || n2.IsNull)
u = Null;
else
u = new Complex(n1.real + n2.real, n1.imaginary + n2.imaginary);
return u;
}
Performing mathematical operations on UDT values from T-SQL must be done via explicitly exposed methods of the UDT. These methods in the Complex UDT are CAdd and Div, for complex number addition and division, respectively. Note that we chose CAdd (which stands for “complex number add”) as a method name to avoid conflicts with the T-SQL reserved word ADD. We won’t go too deeply into the inner workings of complex numbers, but we chose to implement the basic operators in this listing because some (like complex number addition) are straightforward operations, while others (like division) are a bit more complicated. The math operator methods are declared as static, so they can be invoked on the UDT data type itself from SQL Server instead of on an instance of the UDT.
#region "Exposed Mathematical Basic Operator Methods"
// Add complex number n2 to n1
public static Complex CAdd(Complex n1, Complex n2)
{
return n1 + n2;
}
// Subtract complex number n2 from n1
public static Complex Sub(Complex n1, Complex n2)
{
return n1 - n2;
}
#endregion
![]() Note Static methods of a UDT (declared with the static keyword in C# or the Shared keyword in Visual Basic) are invoked from SQL Server using a format like this:
Note Static methods of a UDT (declared with the static keyword in C# or the Shared keyword in Visual Basic) are invoked from SQL Server using a format like this:
Complex::CAdd(@nl, @n2)
Nonshared, or instance methods of a UDT are invoked from SQL Server using a format similar to this:
@>nl.CAdd(@n2)
The style of method you use (shared or instance) is a determination you’ll need to make on a case-by-case basis.
Listing 14-15 demonstrates how the Complex UDT can be used, and the results are shown in Figure 14-9.
Listing 14-15. Complex Number UDT Demonstration
CREATE TYPE dbo.Complex
EXTERNAL NAME ApressExamples.[Apress.Examples.Complex];
GO
DECLARE @c complex = ' + 100-10i',
@d complex = '5i';
SELECT 'ADD: ' + @c.ToString() + ' , ' + @d.ToString() AS Op,
complex::CAdd(@c, @d).ToString() AS Result
UNION
SELECT 'DIV: ' + @c.ToString() + ' , ' + @d.ToString(),
complex::Div(@c, @d).ToString()
UNION
SELECT 'SUB: ' + @c.ToString() + ' , ' + @d.ToString(),
complex::Sub(@c, @d).ToString()
UNION
SELECT 'MULT: ' + @c.ToString() + ' , ' + @d.ToString(),
complex::Mult(@c, @d).ToString()
UNION
SELECT 'PI: ',
complex::Pi.ToString();
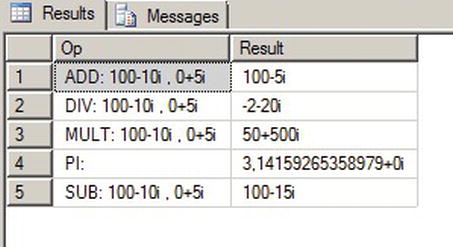
Figure 14-9. Performing Operations with the Complex UDT
In addition to the basic operations, the Complex class can be easily extended to support several more advanced complex number operators and functions. The code sample download file contains a full listing of an expanded Complex UDT, including all the basic math operators, as well as logarithmic and exponential functions (Log(), Power(), etc.) and trigonometric and hyperbolic functions (Sin(), Cos(), Tanh(), etc.) for complex numbers.
Finally, you can also create .NET triggers. This is logical; after all, triggers are just a specialized type of stored procedures. There are few examples of really interesting .NET triggers. Most of what you want to do in a trigger can be done with regular T-SQL code. When SQL Server 2005 was released, we saw an example of a .NET trigger on a location table that calls a web service to find the coordinates of a city and adds them to a coordinates column. This could at first sound like a cool idea, but if you remember that a trigger is fired inside the scope of the DML statement’s transaction, you can guess that the latency added to every insert and update on the table might be a problem. Usually, we try to keep the trigger impact as light as possible. Listing 14-16 presents an example of a .NET trigger based on our previous regular expression UDF. It tests an e-mail inserted or modified on the AdventureWorks Person.EmailAddress table, and rolls back the transaction if it does not match the pattern of a correct e-mail address. Let’s see it in action.
Listing 14-16. Trigger to Validate an E-mail Address
using System;
using System.Data;
using System.Data.SqlClient;
using Microsoft.SqlServer.Server;
using System.Text.RegularExpressions;
using System.Transactions;
namespace Apress.Examples
{
public partial class Triggers
{
private static readonly Regex email_pattern = new Regex
(
// Everything before the @ sign (the "local part")
"^[a-z0-9!#$%&'*+/=?^_'{|} ∼ −] + (?:\.[a-z0-9!#$%&'*+/=?^_'{|} ∼ −]+)*" +
// Subdomains after the @ sign
"@(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.) + " +
// Top-level domains
"(?:[a-z]{2}|com|org|net|gov|mil|biz|info|mobi|name|aero|jobs|museum)\b$"
);
[Microsoft.SqlServer.Server.SqlTrigger(
Name = "EmailAddressTrigger",
Target = "[Person].[EmailAddress]",
Event = "FOR INSERT, UPDATE")]
public static void EmailAddressTrigger()
{
SqlTriggerContext tContext = SqlContext.TriggerContext;
// Retrieve the connection that the trigger is using.
using (SqlConnection cn
= new SqlConnection(@"context connection=true"))
{
SqlCommand cmd;
SqlDataReader r;
cn.Open();
cmd = new SqlCommand(@"SELECT EmailAddress FROM INSERTED", cn);
r = cmd.ExecuteReader();
try
{
while (r.Read())
{
if (!email_pattern.IsMatch(r.GetString(0).ToLower()))
Transaction.Current.Rollback();
}
}
catch (SqlException ex)
{
// Catch the expected exception.
}
finally
{
r.Close();
cn.Close();
}
}
}
}
}
As we now are used to, we first declare our .NET namespaces. To manage the transaction, we have to declare the System.Transactions namespace. In your Visual Studio project, it might not be recognized. You need to right-click on the project in the Solution Explorer and select “add reference.” Then, go to the SQL Server tab, and check “System.Transactions for framework 4.0.0.0.”
Then, like in our previous UDF, we declare the Regex object. The trigger body follows. In the function’s decoration, we name the trigger, and we declare for which target table it is intended. We also specify at what events it will fire.
[Microsoft.SqlServer.Server.SqlTrigger(
Name = "EmailAddressTrigger",
Target = "[Person].[EmailAddress]",
Event = "FOR INSERT, UPDATE")]
public static void EmailAddressTrigger()
{ ...
Then, we declare an instance of the SqlTriggerContext class. This class exposes a few properties that give information about the trigger’s context, like what columns are updated, what the action is that fired the trigger, and in case of a DDL trigger, it also gives access to the EventData XML structure containing all the execution details.
SqlTriggerContext tContext = SqlContext.TriggerContext;
The next line opens the so-called context connection to SQL Server. There is only one way to access the content of a table: with a T-SQL SELECT statement. Even a .NET code executed inside SQL Server cannot escape from this rule. To be able to retrieve the e-mails that have been inserted or updated, we need to open a connection to SQL Server and query the inserted virtual table. For that, we use a special type of connection available inside CLR integration named the context connection, which is designed to be faster than a regular network or local connection. Then we use a data reader to retrieve the e-mails in the EmailAddress column. We loop through the results and apply the regular expression pattern to each address. If it doesn’t match, we roll back the transaction by using the Transaction.Current.Rollback() method. We need to protect the rollback by a try ... catch block, because it will throw an ambiguous exception, stating that “Transaction is not allowed to roll back inside a user defined routine, trigger or aggregate because the transaction is not started in that CLR level.” This can be safely ignored. Another error will be raised even if the try ... catch block is there, and it must be dealt with at the T-SQL level. We will see that in our example later on.
using (SqlConnection cn
= new SqlConnection(@"context connection = true"))
{
SqlCommand cmd;
SqlDataReader r;
cn.Open();
cmd = new SqlCommand(@"SELECT EmailAddress FROM INSERTED", cn);
r = cmd.ExecuteReader();
try
{
while (r.Read())
{
if (!email_pattern.IsMatch(r.GetString(0).ToLower()))
Transaction.Current.Rollback();
}
}
catch (SqlException ex)
{
// Catch the expected exception.
}
finally
{
r.Close();
cn.Close();
}
}
}
}
Now that the trigger is written, let’s try it out. When the assembly is compiled and added to the AdventureWorks database using CREATE ASSEMBLY, we can add the trigger to the Person.EmailAddress table, as shown in Listing 14-17.
Listing 14-17. Creation of the CLR Trigger to Validate an E-mail Address
CREATE TRIGGER atr_Person_EmailAddress_ValidateEmail
ON Person.EmailAddress
AFTER INSERT, UPDATE
AS EXTERNAL NAME ApressExamples.[Apress.Examples.Triggers].EmailAddressTrigger;
We now try to update a line to an obviously invalid e-mail address in Listing 14-18. The result is shown in Figure 14-10.
Listing 14-18. Setting an Invalid E-mail Address
UPDATE Person.EmailAddress
SET EmailAddress = 'pro%sql@apress@com'
WHERE EmailAddress = '[email protected]';

Figure 14-10. Result of the Trigger’s Action
As you can see, the trigger worked and rolled back the UPDATE attempt, but the error message generated for the CLR code is not very user-friendly. We need to catch the exception in our T-SQL statement. A modified UPDATE dealing with that is shown in Listing 14-19.
Listing 14-19. UPDATE Statement Modified to Handle the Error
BEGIN TRY
UPDATE Person.EmailAddress
SET EmailAddress = 'pro%sql@apress@com'
WHERE EmailAddress = '[email protected]';
END TRY
BEGIN CATCH
IF ERROR_NUMBER() = 3991
RAISERROR('invalid email address', 16, 10)
END CATCH
This CLR trigger is an example, and it might not be the best solution to our e-mail checking needs, for two reasons: firstly because we need to handle the CLR error in our calling code, which forces us to enclose every statement modifying the EmailAddress inside a try ... catch block, and secondly because of performance considerations. Our CLR code loops through a DataReader and checks it line per line. A set-oriented T-SQL trigger like the one shown in Listing 14-20 will certainly be faster, especially if there are many rows affected by the INSERT or UPDATE statement.
Listing 14-20. T-SQL Trigger to Validate an E-mail Address
CREATE TRIGGER atr_Person_EmailAddress_ValidateEmail
ON Person.EmailAddress
AFTER INSERT, UPDATE
AS BEGIN
IF @@ROWCOUNT = 0 RETURN
IF EXISTS (SELECT * FROM inserted WHERE dbo.EmailMatch(EmailAddress) = 0)
BEGIN
RAISERROR('an email is invalid', 16, 10)
ROLLBACK TRANSACTION
END
END;
Summary
SQL Server 2005 introduced SQL CLR integration, allowing you to create UDFs, UDAs, SPs, UDTs, and triggers in managed .NET code. SQL Server 2008 improved on CLR integration by allowing UDTs and UDAs to have a maximum size of 2.1 GB, which is still the case in SQL Server 2012.
In this chapter, we talked about CLR integration usage considerations, and scenarios when CLR integration code might be considered a good alternative to strict T-SQL. We also discussed assemblies and security, including the SAFE, EXTERNAL_ACCESS, and UNSAFE permission sets that can be applied on a per-assembly basis.
Finally, we provided several examples of CLR integration code that cover a wide range of possible uses, including the following:
- CLR integration can be invaluable when access to external resources is required from the server.
- CLR integration can be useful when non-table specific aggregations are required.
- CLR integration simplifies complex data validations that would be complex and difficult to perform in T-SQL.
- CLR integration allows you to supplement SQL Server’s data typing system with your own specialized data types that define their own built-in methods and properties.
This chapter has served as an introduction to CLR integration programming. For in-depth CLR integration programming information, I highly recommend Pro SQL Server 2005 Assemblies, by Robin Dewson and Julian Skinner (Apress, 2005). Though written for SQL Server 2005, much of the information it contains is still relevant to SQL Server 2012. In the next chapter, we will introduce client-side .NET connectivity to SQL Server 2012.
EXERCISES
1. [Choose all that apply] SQL Server 2012 provides support for which of the following CLR integration objects:
- UDFs
- UDAs
- UDTs
- SPs
- Triggers
- User-defined catalogs
2. [True/False] SQL Server 2012 limits CLR integration UDAs and UDTs to a maximum size of 8000 bytes.
3. [Choose one] SAFE permissions allow your CLR integration code to
a. Write to the file system
- Access network resources
- Read the computer’s registry
- Execute managed .NET code
- All of the above
4. [True/False] CLR integration UDAs and UDTs must be defined with the Serializable attribute.
5. [Fill in the blank] A CLR integration UDA that is declared as Format.UserDefined must implement the _________ interface.
6. [Choose all that apply] A CLR integration UDA must implement which of the following methods?
a. Init
- Aggregate
- Terminate
- Merge
- Accumulate