
In this chapter, you will learn the principles behind various distributed computing concepts and how to use Spring in conjunction with some very powerful, open-source–ish third-party products to build solutions leveraging those concepts. There are many different types of distributed computing. In this chapter, we talk about grid computing, which can be defined as an application of many systems in service to a task greater than any single system could usefully handle. Grid computing solves many problems, some more ephemeral than others:
Scalability: The distribution of work enables more requests to be handled. Distribution expands an application's ability to scale, as required, to meet demand. This is the quintessential reason behind clustering and load balancing.
Redundancy: Computers fail. It's built in. The only thing you can guarantee about a hard disk of any make? That it will, at some point or another, fail, and more than likely in your lifetime. Being able to have a computer take over when something else becomes ineffective, or to have a computer's load lessened by adjoining members in a cluster, is a valuable benefit of distribution. Distribution provides built in resilience, if architected carefully.
Parallelization: Distribution enables solutions designed to split problems into more manageable chunks or to expedite processing by bringing more power to bear on the problem. Some problems are inherently, embarrassingly parallelizable. These often reflect real life. Take, for example, a process that's designed to check hotels, car rentals, and airline accommodations and show you the best possible options. All three checks can be done concurrently, as they share no state and have no dependencies on each other. It would be a crime not to parallelize this logic. Some problem domains are not naturally, embarrassingly parallel, so it as at your discretion that you seek to apply parallelization.
The other reasons are more subtle, but very real. Over the course of computing, we've clung to the notion that computers will constantly expand in processing speed with time. This has come to be known as Moore's Law, named for Gordon Moore of Intel. Looking at history, you might remark that we've, in fact, done quite well along that scale. Servers in the early '80s were an order of magnitude slower than computers in the early '90s, and computers at the turn of the millennium were roughly an order of magnitude faster than those in the early '90s. At the time of this writing, in 2009, however, computers are not, strictly speaking, an order of magnitude faster than computers in the late '90s. They've become better parallelized and can better serve software designed to run in parallel. Thus, parallelization isn't just a good idea for big problems; it's a necessity if you want to take full advantage of modern-day processing power.
Additionally, parallelization defeats another trend, as described by Wirth's Law (named for Niklaus Wirth): "Software gets slower faster than hardware gets faster." In the Java landscape, this problem is even more pronounced because of Java's difficulty in addressing large amounts of RAM (anecdotally, 2GB to 4GB is about the most a single JVM can usefully address without pronounced garbage collection pauses). There are garbage collectors in the works that seek to fix some of these issues, but the fact remains that a single computer can have far more RAM than a single JVM could ever utilize. Parallelization is a must. Today, more and more enterprises are deploying entire virtualized operating system stacks on one server simply to isolate Java applications and fully exploit the hardware.
Thus, distribution isn't just a function of resilience or capability; it's a function of common-sense investing.
There are costs to parallelization, as well. There's always going to be some constraint, and very rarely is an entire system uniformly scalable. The cost of coordinating state between nodes, for example, might be too high because the network or hard disks impose latency. Additionally, not all operations are parallelizable. It's important to design systems with this in mind. An example might be the overall processing of a person's uploaded photos (as happens in many web sites today). You might take the moment at which they upload the batch to the moment a process has watermarked them and added them to an online photo album and measure the time during which the whole process is executed serially. Some of these steps are not parallelizable. The one part that is parallelizable—the watermarking—will only lead to a fixed increase, and little can be done beyond that.
You can describe these potential gains. Amdahl's law, also known as Amdahl's argument, is a formula to find the maximum expected improvement to an overall system when only part of the system is improved. It is shown here:
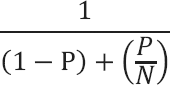
It describes the relationship between a solution's execution time when serially executed and when executed in parallel with the same problem set. Thus, for 90 photos, if we know that it takes a minute for each photo, and that uploading takes 5 minutes, and that posting the resulting photos to the repository takes 5 minutes, the total time is 100 minutes when executed serially. Let's assume we add 9 workers to the watermarking process, for a total of 10 processes that watermark. In the equation, P is the portion of the process that can be parallelized, and N is the factor by which that portion might be parallelized (that is, the number of workers, in this case). For the process described, 90 percent of the process can be parallelized: each photo could be given to a different worker, which means it's parallelizable, which means that 90 percent of the serial execution is parallelizable. If you have 10 nodes working together, the equation is: 1/((1-.9) + (.9 / 10)), or 5.263. So, with 10 workers, the process could be 5 times faster. With 100 workers, the equation yields 9.174, or 9 times faster. It may not make sense to continue adding nodes past a certain point, as you'll achieve progressively smaller gains.
Building an effective distributed solution, then, is an application of cost/benefit analysis. Spring has no direct support for distributed paradigms, per se, because plenty of other solutions do a great job already. Often, these solutions make Spring integration a first priority because it's a de-facto standard. In some cases, these projects have forgone their own configuration format and use Spring itself as the configuration mechanism. If you decide to employ distribution, you'll be glad to know that there are many projects designed to meet the call, whatever it may be.
In this chapter, we discuss a few solutions that are Spring-friendly and ready. A lot of these solutions are possible because of Spring's support for "components," such as its XML schema support and runtime class detection. These technologies often require you to change your frame of mind when building solutions, even if ever so slightly, as compared to solutions built using Java EE, but being able to rely on your Spring skills is powerful. Other times, these solutions may not even be visible, except as configuration. Further still, a lot of these solutions expose themselves as standard interfaces familiar to Java EE developers, or as infrastructure (such as, for example, backing for an HTTP session, or as a cluster-ready message queue) that goes unnoticed and isolated, except at the configuration level, thanks to Spring's dependency injection.
You want to share object state across multiple virtual machines. For example, you'd like to be able to load the names of all the cities in the United States into memory for faster lookup, or load all the products in your company's catalog, or the entire stock market's trading history for the last decade for online calculation and analysis. Any other nodes in the cluster that need access to those objects should be able to get them from the cache and not reload them.
You can use Terracotta to build such a solution. Terracotta (http://www.terracotta.org) is a free, open source clustering solution. The company, Terracotta, has also recently become the corporate sponsor of the Ehcache and Quartz projects. Terracotta works like many other clustered caches, except that, in addition to being a good Hibernate clustered cache, it also works as a mostly unnoticeable engine to enable API-free shared state across a cluster. Terracotta doesn't use serialization of objects (not even highly compact serialization like Swift, Google's Protocol Buffers, Coherence Pofs, or Hazelcast DataSerializables), and instead ferries around deltas of VM memory across the cluster. It provides a VM-level view of other objects, as if they were in the same VM.
Terracotta works as a JVM agent that monitors the object graph of a given JVM instance and ensures replication of object state across a cluster. It does this by referring to a configuration file in which you specify which classes, methods, and fields should be clustered.
It does this for any object in the JVM, not just Hibernate entities or session entries, or objects otherwise updated by some caching API. It's as simple as using a property on an object or updating a shared variable on an object. Instantly, across as many nodes as you want, that updated state is reflected in reads to that property on other instances.
To illustrate, it's best to imagine a threaded application. Imagine a shared integer value in a threaded application. Three threads increment the value of an integer in lockstep, delayed every five seconds. Each thread acquires the lock, increments the integer, and then releases the lock. Other threads see the updated value and print it out. Eventually, as this goes on, the number rises and rises until some condition is met (e.g., you exit the program) to stop it. This is a very effective example of where Java's support for threading is useful, because it guarantees state through concurrent access. Now, imagine perhaps that you have that same integer, and each time a server hits a page, that integer is accessed and incremented. This page is deployed across several nodes, so that hitting the page on each of the nodes causes the integer, and thus the state, to change. Other servers see the new value on refresh, even though the change was last made on another server. The state is visible to all nodes in the cluster, and at the same times as the state would be visible to threads. This is what Terracotta does: it clusters object state. On the whole, your code will remain simple code (perhaps multithreaded in nature) that works across multiple VMs.
Terracotta is different than most clustered caches today because it has no visible API, and because it's far more efficient in conveying the changed state to nodes across the cluster. Most systems use some sort of Java serialization or broadcast mechanism, wherein each other node is given the entire object, or object graph, that's changed, regardless of whether they even they need to be aware of the new state. Terracotta does it differently: it deltas the memory of the object graphs itself and synchronizes other nodes in the cluster as they need a consistent view of the object state. Succinctly, it can do something tantamount to transmitting just one updated variable in an object, and not the entire object.
You want to deploy Terracotta and see what a simple application looks like. This example is a simple client that responds to certain commands that you can give it. After each command, it prompts for another command. It, in turn, uses a service implementation that keeps state. We cluster this state using Terracotta. A client manipulates the CustomerServiceImpl class, shown here, which is an implementation of CustomerService, which implements the following interface:
package com.apress.springrecipes.distributedspring.terracotta.customerconsole.service; import com.apress.springrecipes.distributedspring.terracotta.customerconsole.entity.Customer; import java.util.Date; import java.util.Collection; public interface CustomerService { Customer getCustomerById( String id ) ; Customer createCustomer(String id, String firstName,String lastName, Date birthdate ) ;Customer removeCustomer( String id ) ; Customer updateCustomer( String id, String firstName, String lastName, Datebirthdate ) ; Collection<Customer > getAllCustomers() ; }
As this is meant to be a gentle introduction to Terracotta, I'll forego building a complete Hibernate- and Spring-based solution. The implementation will be in-memory, using nothing but primitives from the JDK.
package com.apress.springrecipes.distributedspring.terracotta.customerconsole.service; import com.apress.springrecipes.distributedspring.terracotta.customerconsole.entity.Customer; import org.apache.commons.collections.CollectionUtils; import org.apache.commons.collections.Predicate;
import java.util.*;
public class CustomerServiceImpl implements CustomerService {
private volatile Set<Customer> customers;
public CustomerServiceImpl() {
customers = Collections.synchronizedSet(new HashSet<Customer>());
}
public Customer updateCustomer(String id, String firstName,
String lastName, Date birthdate) {
Customer customer;
synchronized (customers) {
customer = getCustomerById(id);
customer.setBirthday(birthdate);
customer.setFirstName(firstName);
customer.setLastName(lastName);
removeCustomer(id);
customers.add(customer);
}
return customer;
}
public Collection<Customer> getAllCustomers() {
return (customers);
}
public Customer removeCustomer(String id) {
Customer customerToRemove;
synchronized (customers) {
customerToRemove = getCustomerById(id);
if (null != customerToRemove)
customers.remove(customerToRemove);
}
return customerToRemove;
}
public Customer getCustomerById(final String id) {
return (Customer) CollectionUtils.find(customers, new Predicate() {
public boolean evaluate(Object o) {
Customer customer = (Customer) o;
return customer.getId().equals(id);
}
});
}public Customer createCustomer(String firstName, String lastName, Date birthdate ){
synchronized (customers) {
final Customer newCustomer = new Customer(
firstName, lastName, birthdate);
if (!customers.contains(newCustomer)) {
customers.add(newCustomer);
return newCustomer;
} else {
return (Customer) CollectionUtils.find(
customers, new Predicate() {
public boolean evaluate(Object o) {
Customer customer = (Customer) o;
return customer.equals(newCustomer);
}
});
}
}
}
}The entity, Customer, is a simple POJO with accessors and mutators, and it works equals, hashCode, toString methods.
package com.apress.springrecipes.distributedspring.terracotta.customerconsole.entity;
import org.apache.commons.lang.builder.EqualsBuilder;
import org.apache.commons.lang.builder.HashCodeBuilder;
import org.apache.commons.lang.builder.ReflectionToStringBuilder;
import java.io.Serializable;
import java.util.Date;
import java.util.UUID;
public class Customer implements Serializable {
private String id;
private String firstName, lastName;
private Date birthday;
// ...
// accessor/mutators, id, equals, and hashCode.
// ...
}Note first that nothing we do in that class has any effect on Terracotta. We implement Serializable, ostensibly because the class may very well be serialized in, for example, an HTTP session, not for Terracotta's benefit. The hashCode/equals implementations are good practice because they help our entity play well and comply with the contract of various JDK utilities like the collections implementations.
The client that will allow us to interact with this service class is as follows:
package com.apress.springrecipes.distributedspring.terracotta.customerconsole.view; import com.apress.springrecipes.distributedspring.terracotta.customerconsole.entity.Customer; import com.apress.springrecipes.distributedspring.terracotta.customerconsole.service.CustomerService; import org.apache.commons.lang.StringUtils; import org.apache.commons.lang.SystemUtils; import org.apache.commons.lang.exception.ExceptionUtils; import javax.swing.*; import java.text.DateFormat; import java.text.ParseException; import java.util.Date; public class CustomerConsole { private CustomerService customerService; private void log(String msg) { System.out.println(msg); } private void list() { for (Customer customer : customerService.getAllCustomers()) log(customer.toString()); log(SystemUtils.LINE_SEPARATOR); } private void create(String customerCreationString) { String cmd = StringUtils.defaultString( customerCreationString).trim(); String[] parts = cmd.split(" "); String firstName = parts[1], lastName = parts[2]; Date date = null; try { date = DateFormat.getDateInstance( DateFormat.SHORT).parse(parts[3]); } catch (ParseException e) { log(ExceptionUtils.getFullStackTrace(e)); } customerService.createCustomer( firstName, lastName, date); list(); }
private void delete(String c) {
log("delete:" + c);
String id = StringUtils.defaultString(c).trim().split(" ")[1];
customerService.removeCustomer(id);
list();
}
private void update(String stringToUpdate) {
String[] parts = StringUtils.defaultString(stringToUpdate).trim()
.split(" ");
String idOfCustomerAsPrintedOnConsole = parts[1],
firstName = parts[2],
lastName = parts[3];
Date date = null;
try {
date = DateFormat.getDateInstance(
DateFormat.SHORT).parse(parts[4]);
} catch (ParseException e) {
log(ExceptionUtils.getFullStackTrace(e));
}
customerService.updateCustomer(
idOfCustomerAsPrintedOnConsole,
firstName, lastName, date);
list();
}
public CustomerService getCustomerService() {
return customerService;
}
public void setCustomerService(
CustomerService customerService) {
this.customerService = customerService;
}
enum Commands {
LIST, UPDATE, DELETE, CREATE
}
public void handleNextCommand(String prompt) {
System.out.println(prompt);
String nextLine = JOptionPane.showInputDialog(
null, prompt);
if (StringUtils.isEmpty(nextLine)) {
System.exit(1);
return;
}
log(nextLine);if ((StringUtils.trim(nextLine).toUpperCase())
.startsWith(Commands.UPDATE.name())) {
update(nextLine);
return;
}
if ((StringUtils.trim(nextLine).toUpperCase())
.startsWith(Commands.DELETE.name())) {
delete(nextLine);
return;
}
if ((StringUtils.trim(nextLine).toUpperCase())
.startsWith(Commands.CREATE.name())) {
create(nextLine);
return;
}
if((StringUtils.trim(nextLine).toUpperCase()).startsWith(
Commands.LIST.name())) {
list();
return;
}
System.exit(1);
}
}The client code is simple as well. It's basically a dumb loop waiting for input. The client reacts to commands such as create First Last 12/02/78. You can test it out, without Terracotta, if you like. Simply run the class containing the public static void main(String [] args) method, as you would any other main class. If you're using Maven, you may simply execute the following:
mvn exec:java -Dexec.mainClass=com.apress.springrecipes.distributedspring.terracotta.customerconsole.MainWithSpring
You can imagine how the client would work with Terracotta. The data managed by the CustomerService implementation is shared across a cluster. Changes to the data via an instance of the CustomerConsole on one machine should propagate to other machines instantly, and issuing a call to list() should reflect as much.
Let's dissect deployment. Terracotta has a client/server architecture. The server, in this case, is the one that contains the original working memory. It's what hands out deltas of changed memory to other nodes in the cluster. Other nodes "fault" in that memory as they need it. To deploy a Terracotta application, you first download the distribution. The distribution provides utility scripts, as well as JARs. You may download Terracotta from http://www.terracotta.org.
For Terracotta to work, you need to provide it with a configuration file. This file is an XML file that we'll review shortly. On Unix-like operating systems, you start Terracotta as follows:
$TERRACOTTA_HOME/bin/start-tc-server.sh -f $PATH_TO_TERRACOTTA_CONFIGURATION
If you're on Windows, use the equivalent .bat file instead.
For each virtual machine client that you want to "see" and share that state, start it with a customized bootclasspath parameter when starting Java. The arguments for this vary per operating system, so Terracotta provides a handy script for determining the correct arguments, dso-env.sh. When provided with the host and port of the Terracotta server, it can ensure that all configuration data for each client virtual machine is loaded dynamically from the server. As you might imagine, this greatly eases deployment over a grid of any substantive size! Here's how to use the script on Unix-like operating systems:
$TERRACOTTA_HOME/bin/dso-env.sh $HOST:$PORT
Replace $TERRACOTTA_HOME with the Terracotta's installation directory, and replace $HOST and $PORT with the host and port of the server instance. When run, it will print out the correct arguments, which you then need to feed into each client virtual machine's invocation scripts, for example in the $JAVA_OPTS section for Tomcat or any standard java invocation.
$ dso-env.sh localhost:9510
When executed, this will produce something like the following (naturally, this changes from operating system and environment), which you need to ensure is used in your invocation of the java cjava command:
-Xbootclasspath/p:./../lib/dso-boot/dso-boot-hotspot_linux_160_20.jar -Dtc.install-root=./..
The XML for the Terracotta configuration is verbose but self evident. Terracotta is a 99 percent code-incursion-free solution. Because Terracotta works at such a low level, you don't need to know about it when programming. The only thing of concern may be the introduction of threading issues, which you would not have to deal with in strictly serialized execution. You would, however, have to deal with them if you wrote multithreaded code on your local machine. Think of Terracotta as a layer that lets your thread-safe single VM code work across a cluster. There are no annotations, and no APIs, to direct Terracotta. Instead, Terracotta gets its information from the XML configuration file that you provide it. Our example XML file (tc-customerconsole-w-spring.xml) is as follows:
<?xml version="1.0" encoding="UTF-8"?>
<tc:tc-config xsi:schemaLocation="http://www.terracotta.org/schema/terracotta-5.xsd"
xmlns:tc="http://www.terracotta.org/config" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<servers>
<server host="%i" name="server1">
<dso-port>9510</dso-port>
<jmx-port>9520</jmx-port>
<data>target/terracotta/server/data</data>
<logs>target/terracotta/server/logs</logs>
<statistics>target/terracotta/server/statistics</statistics>
</server>
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<servers>
<server host="%i" name="server1">
<dso-port>9510</dso-port>
<jmx-port>9520</jmx-port>
<data>target/terracotta/server/data</data>
<logs>target/terracotta/server/logs</logs>
<statistics>target/terracotta/server/statistics</statistics>
</server><update-check>
<enabled>true</enabled>
</update-check>
</servers>
<system>
<configuration-model>development</configuration-model>
</system>
<clients>
<logs>target/terracotta/clients/logs/%(tc.nodeName)</logs>
<statistics>target/terracotta/clients/statistics/%(tc.nodeName)</statistics>
</clients>
<application>
<dso>
<instrumented-classes>
<include>
<class-expression>
com.apress.springrecipes.distributedspring.terracotta.
customerconsole.entity.*
</class-expression>
</include>
<include>
<class-expression>
com.apress.springrecipes.distributedspring.terracotta.
customerconsole.service.CustomerServiceImpl
</class-expression>
</include>
</instrumented-classes>
<roots>
<root>
<root-name>customers</root-name>
<field-name>
com.apress.springrecipes.distributedspring.terracotta.
customerconsole.service.CustomerServiceImpl.customers
</field-name>
</root>
</roots>
<locks>
<autolock>
<method-expression>*
com.apress.springrecipes.distributedspring.terracotta.
customerconsole.service.CustomerServiceImpl.*(..)
</method-expression>
</autolock>
</locks>
</dso>
</application>
</tc:tc-config>The servers element tells Terracotta about how to the server behaves: on what port it listens, where logs are, and so forth. The application instance is what's of concern to us. Here, we first spell out which classes are to be clusterable in the instrumented-classes element.
The locks element lets us prescribe what behavior to ensure with regard to concurrent access of fields on classes. The last element, the field-name element, is the most interesting. This instruction tells Terrracotta to ensure that the changes to the customers field in the CustomerServiceImpl class are visible cluster-wide. An element inserted into the collection on one host is visible on other hosts, and this is the crux of our functionality.
At this point, you might be expecting some Spring-specific configuration, but there is none. It just works. Here's a Spring context (called customerconsole-context.xml), as you'd expect.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd">
<bean id="customerService"
class="com.apress.springrecipes.distributedspring.terracotta.
customerconsole.service.CustomerServiceImpl"/>
<bean id="customerConsole"
class="com.apress.springrecipes.distributedspring.terracotta.
customerconsole.view.CustomerConsole">
<property name="customerService" ref="customerService"/>
</bean>
</beans>Let's now look at a client to this Spring bean:
package com.apress.springrecipes.distributedspring.terracotta.customerconsole; import com.apress.springrecipes.distributedspring.terracotta.customerconsole.view.CustomerConsole; import org.springframework.context.ApplicationContext; import org.springframework.context.support.ClassPathXmlApplicationContext; public class MainWithSpring { public static void main(String[] args) { ApplicationContext context = new ClassPathXmlApplicationContext("customerconsole-context.xml"); CustomerConsole customerConsole =(CustomerConsole) context.getBean("customerConsole");
while (true) {
customerConsole.handleNextCommand(
"Welcome to the customer console: your choices are DELETE,
UPDATE, CREATE or LIST");
}
}
}You can run this client as many times as you'd like using the dso-env.sh script previously mentioned (or use the drop-in Terracotta replacement for Java called dso-java.sh, which effectively does what dso-env.sh does, as well as then executing the java command for you). It doesn't matter on how many clients you launch the application; all changes made to the customers collection will be visible cluster wide. For example, you might create a customer and put that person's information in the cache of one node (using a command in the form of "create first last MM/DD/YYYY") and then list the contents of the cache on another (using "list") to verify that there are entries in the cache.
Often, you will use Terracotta behind some other product, which you interface with Spring. Additionally, Terracotta supports a customized integration to cluster your web sessions, and sports specific support for Spring Web Flow and Spring Security. Generally, Terracotta is a good way to bring enterprise-level caching to your application at all tiers. If you need to manipulate something in a cluster directly, there's no need to hesitate. After all, Terracotta doesn't have an API—just configuration. As you've seen in this recipe, creating a useful, clustered Spring bean is very straightforward.
You want to distribute processing over many nodes, perhaps to increase result speed through the use of concurrences, perhaps merely to provide load balance and fault tolerance.
You can use something like GridGain, which was designed to transparently offload processing to a grid. This can be done many ways: one is to use the grid as a load alleviation mechanism, something to absorb the extra work. Another, if possible, is to split the job up in such a way that many nodes can work on it concurrently.
GridGain is an implementation of a processing grid. GridGain differs from data grids like Terracotta or Coherence, although data grids and processing grids are often used together, and in point of fact, GridGain encourages the use of any number of data grids with its processing functionality. There are many data grids, such as Coherence, Terracotta, and Hadoop's HFS, and these are designed to be fault-tolerant, memory-based RAM disks, essentially. These sorts of grids are natural compliments to a processing grid such as GridGain in that they can field massive amounts of data fast enough for a processing grid to keep busy. GridGain allows code to be farmed out to a grid for execution and then the results returned to the client, transparently. You can do this in many ways. The easiest route is to merely annotate the methods you want to be farmed out and then configure some mechanism to detect and act on those annotations, and then you're done!
The other approach is slightly more involved, but it is where solutions such as GridGain and Hadoop really shine: use the map/reduce pattern to partition a job into smaller pieces and then concurrently run those pieces on the grid. Map/reduce is a pattern that was popularized by Google, and it comes from functional programming languages, which often have map() and reduce() functions. The idea is that you somehow partition a job and send those pieces to be processed. Finally, you take the results and join them, and those results are then sent back. Often, you won't have results per se; instead, you'll have sought only to distribute the processing asynchronously.
GridGain packs a lot of power in the few interfaces you're required to ever deal with. Its internal configuration system is Spring, and when you wish to avail yourself of anything besides the absolute minimum configuration options—for example, configuring a certain node with characteristics upon which job routing might be predicated—you do so using Spring. GridGain provides a Spring AOP Aspect for use on beans with the @Gridify annotation for the very simple cases.
To get started, download GridGain from the web site, http://www.gridgain.com. Unzip the distribution, descend into the bin directory, and run gridgain.(bat|sh). If you're running a Unix/Linux instance, you may need to make the scripts executable:
chmod a+x *sh
You need to set up an environment variable, GRIDGAIN_HOME, pointing to the directory in which you installed the distribution for it to function correctly. If you're running Unix, you need to set the variable in your shell environment. Usually, this happens in something like ~/.bashrc or ~/.bash_profile:
export GRIDGAIN_HOME=<YOUR DIRECTORY>
If you are running Windows, you will need to go to System Properties ~TRA Advanced ~TRA Environment Variables and add a new system variable, GRIDGAIN_HOME, pointing to the directory of your installation. Regardless of what operating system you're using, you need to ensure that there are no trailing slashes or backslashes on the variable's path.
Finally, run the script.
./gridgain.sh
If you have more than a few hundred megabytes of RAM, you might run the script several times. Each invocation creates a new node, so that, in essence, you'll have started a grid on your local machine. GridGain uses multicast, so you could put GridGain on several boxes and run numerous instances on each machine, and they'd all join the same grid. If you want to expand your grid to 10 boxes, simply repeat the installation of the GridGain software and set up the environment variable on each. You can partition the grid and characteristics of the nodes if you want, but for now, we'll concern ourselves with the defaults.
Astonishingly, this is all that's required for deployment. Shortly, you'll create executable code (with numerous .jars, no doubt), make changes on your local development machine, and then run the changed job, and the rest of the nodes in the grid will just notice the updated job and participate in running it thanks to its first-rate class-loading magic. This mechanism, peer-to-peer class loading, means that you don't need to do anything to deploy a job besides run the code with the job itself once.
You want to quickly grid-enable a method on a bean using GridGain. You can see doing this, for example, to expose service methods that, in turn, instantiate longer running jobs on the grid. One example might be sending notification e-mails, or image processing, or any process you don't want bogging down a single machine or VM instance or whose results you need quickly.
You can use GridGain's @Gridify annotation along with some Spring AOP configuration to let GridGain know that it can parallelize the execution of the method across the grid.
The first use case you're likely to have is to simply be able to farm out functionality in a bean to other nodes, as a load-balancing precaution, for example. GridGain provides load balancing as well as fault tolerance and routing out of the box, which you get for free by adding this annotation. Let's take a look at a simple service bean with a single method that we want to farm out to the grid. The interface contract looks like the following:
package com.apress.springrecipes.distributedspring.gridgain;
public interface SalutationService {
String saluteSomeoneInForeignLanguage( String recipient);
String[] saluteManyPeopleInRandomForeignLanguage( String[] recipients);
}The only salient requirement here is the saluteSomeoneInForeignLanguage method. Naturally, this is also the method we want to be run on the grid when possible. The implementation looks like this:
package com.apress.springrecipes.distributedspring.gridgain; import java.io.Serializable; import java.util.HashMap; import java.util.Locale; import java.util.Map; import java.util.Set; import org.apache.commons.lang.StringUtils; import org.gridgain.grid.gridify.Gridify; import org.springframework.beans.BeansException; import org.springframework.context.ApplicationContext; import org.springframework.context.ApplicationContextAware;
/**
* Admittedly trivial example of saying 'hello' in a few languages
*
*/
public class SalutationServiceImpl
implements SalutationService, Serializable {
private static final long serialVersionUID = 1L;
private Map<String, String> salutations;
public SalutationServiceImpl() {
salutations = new HashMap<String, String>();
salutations.put(
Locale.FRENCH.getLanguage().toLowerCase(),
"bonjour %s!");
salutations.put(
Locale.ITALIAN.getLanguage().toLowerCase(),
"buongiorno %s!");
salutations.put(
Locale.ENGLISH.getLanguage().toLowerCase(),
"hello %s!");
}
@Gridify
public String saluteSomeoneInForeignLanguage(
String recipient) {
Locale[] locales = new Locale[]{
Locale.FRENCH, Locale.ENGLISH, Locale.ITALIAN};
Locale locale = locales[
(int) Math.floor(
Math.random() * locales.length)];
String language = locale.getLanguage();
Set<String> languages = salutations.keySet();
if (!languages.contains(language))
throw new java.lang.RuntimeException(
String.format(
"this isn't supported! You need to choose " +
"from among the accepted languages: %s",
StringUtils.join(languages.iterator(), ",")));
String salutation = String.format(
salutations.get(language), recipient);
System.out.println(
String.format("returning: %s" ,salutation));
return salutation;
}
@Gridify(taskClass = MultipleSalutationTask.class)
public String[] saluteManyPeopleInRandomForeignLanguage(
String[] recipients) {
return recipients;
}
}There are no telltale signs that this code is Grid-enabled except for the @Gridify annotation. Otherwise, the functionality is self-evident and infinitely testable. We use Spring to ensure that this bean is given a chance to run. The configuration of the Spring file (gridservice.xml, located at the classpath root) side looks like this:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-3.0.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util-3.0.xsd">
<bean id="myGrid" class="org.gridgain.grid.GridSpringBean" scope="singleton">
<property name="configuration">
<bean id="grid.cfg" class="org.gridgain.grid.GridConfigurationAdapter"
scope="singleton">
<property name="topologySpi">
<bean class="org.gridgain.grid.spi.topology.basic.GridBasicTopologySpi">
<property name="localNode" value="false"/>
</bean>
</property>
</bean>
</property>
</bean>
<bean id="interceptor" class="org.gridgain.grid.gridify.aop.spring.
GridifySpringAspect"/>
<bean depends-on="myGrid" id="salutationService" class="org.springframework.aop.
framework.ProxyFactoryBean">
<property name="autodetectInterfaces" value="false"/>
<property name="target">
<bean class="com.apress.springrecipes.distributedspring.gridgain.
SalutationServiceImpl"/>
</property>
<property name="interceptorNames">
<list>
<value>interceptor</value>
</list>
</property>
</bean>
</beans>Here, we use a plain, old-style AOP Proxy in conjunction with the GridGain aspect to proxy our humble service class. I override topologySpi to set localNode to false, which has the effect of stopping jobs from being run on the invoking node—in this case, our service bean's node. The idea is that this node is, locally, the front for application services, and it's inappropriate to run jobs on that virtual machine, which may be handling highly transactional workloads. You might set the value to true if you don't mind a node bearing the load of both handling the services and acting as a grid node. Because you usually set up an instance of the interface Grid to offload work to some other node, this is usually not desirable. We know that invoking that service will cause it to be farmed out. Here's a simple client. The parameter is the only context we have, and it's the only thing you can rely on being present on the node that's run. You can't, if you're running the nodes via the startup script mentioned previously, rely on the Spring beans being wired up. We'll explore this further, but in the meantime, witness our client:
package com.apress.springrecipes.distributedspring.gridgain;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.util.Locale;
public class Main {
public static void main(String[] args)
throws Throwable {
ApplicationContext applicationContext =
new ClassPathXmlApplicationContext("gridservice.xml");
SalutationService salutationServiceImpl =
(SalutationService) applicationContext.getBean("salutationService");
String[] names =("Alan,Arin,Clark,Craig,Drew,Duncan,Gary,Gordon,Fumiko,"+
"Hicham,James,Jordon,Kathy,Ken,Makani,Manuel,Mario, "+
"Mark,Mia,Mike,Nick,Richard,Richelle, "+
"Rod,Ron,Scott,Shaun,Srinivas,Valerie,Venkatesh").split(",");
Locale[] locales = new Locale[]{
Locale.FRENCH, Locale.ENGLISH, Locale.ITALIAN};
for (String name : names) {
System.out.println("Result: " +
salutationServiceImpl.saluteSomeoneInForeignLanguage(name));
}
}
}When you run this, you'll notice—on as many command-line consoles as you've opened by clicking on the startup script—the jobs being handled in a round-robin fashion, each on its own node. If you had 100 names and 10 nodes, you'd notice that each node gets about 10 names listed on the command line, for example.
You want to build a parallelized solution for a problem that's intrinsically better-suited to parallelization or that, for want of resources, needs to be chunked.
Use map/reduce to approach the problem concurrently. As was mentioned earlier, decisions to parallelize shouldn't be taken lightly but with an eye on the ultimate performance expectations and tradeoffs.
Underneath the hood, GridGain works with a GridTask<T>, which specifies how to handle the main unit of work of the interface type GridJob. Sometimes, GridTask splits up and reconciles large jobs. This process is simplified by abstract adapter classes. In this case, we'll use one called GridifyTaskSplitAdapter<T>, which abstracts away most of the minutiae of building a map/reduce–oriented solution. It provides two template methods that we need to override.
In this example, we'll build a modified version of the previous solution that takes an array of String parameters. We intend for all entries in the array to be farmed out to the grid. Let's add the call from the client, which is the Main class we used earlier:
System.out.println("Results:" + StringUtils.join
( salutationServiceImpl.saluteManyPeopleInRandomForeignLanguage(names), ","));We add one method to the original service interface and implementation.
@Gridify( taskClass = MultipleSalutationTask.class )
public String[] saluteManyPeopleInRandomForeignLanguage(String[] recipients) {
return recipients;
}As you can see, the method is simple. The only salient piece is the modified @Gridify annotation, which in this case has a taskClass parameter pointing to a MultipleSalutationTask class.
import java.io.Serializable; import java.util.ArrayList; import java.util.Collection; import java.util.List; import org.gridgain.grid.GridException; import org.gridgain.grid.GridJob; import org.gridgain.grid.GridJobAdapter; import org.gridgain.grid.GridJobResult; import org.gridgain.grid.gridify.GridifyArgument;
import org.gridgain.grid.gridify.GridifyTaskSplitAdapter;
public class MultipleSalutationTask extends GridifyTaskSplitAdapter<String[]> {
private static final long serialVersionUID = 1L;
protected Collection<? extends GridJob> split(int i,
final GridifyArgument gridifyArgument) throws GridException {
Collection<GridJob> jobs = new ArrayList<GridJob>();
Object[] params = gridifyArgument.getMethodParameters();
String[] names = (String[]) params[0];
for (final String n : names)
jobs.add(new GridJobAdapter<String>(n) {
private static final long serialVersionUID = 1L;
public Serializable execute() throws GridException {
SalutationService service =
(SalutationService) gridifyArgument.getTarget();
return service.saluteSomeoneInForeignLanguage(n);
}
});
return jobs;
}
public String[] reduce(List<GridJobResult> gridJobResults)
throws GridException {
Collection<String> res = new ArrayList<String>();
for (GridJobResult result : gridJobResults) {
String data = result.getData();
res.add(data);
}
return res.toArray(new String[res.size()]);
}
}Although this code is pretty straightforward, there is some magic going on that you need to be aware of. When you call the method on the service with the @Gridify annotation pointing to this GridTask implementation, it stops execution of method and loads an instance of this implementation. The parameters, as passed to the method with the annotation, are passed to: split(int i, final GridifyArgument gridifyArgument), which is used to dole out GridJob instances, each one taking as its payload a name from the array. In this code, we create the GridJob instances inline using GridJobAdapter, which is a template class. The work of each GridJob instance is trivial; in this case, we actually just delegate to the first method on the service that we created: saluteSomeoneInForeignLanguage. Note that the invocation of the service in this case does not run the job on the grid again, as we're already on a node. The result is returned to the calling context, which in this case is another virtual machine altogether.
All the results are collected and then passed to the reduce method on the Task class. This method is responsible for doing something with the final results. In this case, the results are simply unwrapped and returned as an array of Strings. Those results are then again sent to the calling context, which in this case is our original method invocation on the service. The results returned from that invocation are the results of all the processing. Thus, if you invoke saluteManyPeopleInRandomForeignLanguage with new String[]{"Steve"}, you're likely to get "Bonjour Steve!" (or something like that), even though it appears you're merely returning the input parameter.
There are several issues to be aware of when deploying applications using GridGain. How do you configure nodes with specific properties that can be used for determining its eligibility for a certain job? How do you inject Spring beans into a node? What is a .gar?
The issues you're likely to confront when using GridGain stem mostly from the fact that what you develop on one node can't always automatically work on another node with no additional configuration. It becomes helpful to think about these deployment issues ahead of time, before you run into a wall in production.
In the previous examples, we deployed simple processing solutions that are deployable using GridGain's peer-to-peer class-loading mechanism. We haven't done anything too complex, however, and as they say, the devil's in the details.
Let's look at the infrastructural components of GridGain in detail. First, let's consider how a node is started up. As you saw before, GridGain lets you start up nodes using the startup script in the bin directory of the distribution. This script invokes a class of interface type GridLoader, of which there are many. The GridLoader's job is to hoist a grid node into existence. It responds to the life cycle events and knows how to work in specific environments. The one that gets started when you use the script that comes with the distribution is the class GridCommandLineLoader. There are others, though, including several for loading a grid instance from within a servlet container or application server instance. A GridLoader instance is responsible for many things, not the least of which is correctly calling GridFactory.start and GridFactory.stop.
GridFactory.start can take as its first parameter a GridConfiguration object or a Spring application context or a path to a Spring application context. This GridConfiguration object is what tells GridGain what is unique about a given node and the grid's topology. By default, it uses $GRIDGAIN_HOME/config/default-spring.xml, which, in turn, does things such as load a Grid object and configure user parameters about a specific node. These parameters may be queried to determine the candidacy of a node to handle a specific job. GridGain, because it is so deeply rooted in Spring, is very flexible and configurable. Different subsystems may be swapped out and replaced. GridGain provides several options via its service provider interfaces (SPIs). In the directory where default-spring.xml is located, there are several other Spring configurations for grids demonstrating integrations with many other technologies. Perhaps you'd like to use JMS as your message exchange platform? There are examples there for three different vendors. Perhaps you'd like to use Mule, or JBoss Cache?
In the previous examples, we deployed instances that were self-contained and had no dependency on any other components. When you do start introducing dependency—and you will, naturally—you'll want to be able to leverage Spring for dependency injection. At this point, you lose some of the elegance of GridGain's peer-to-peer class loading.
You can deploy a.gar archive for which there is an ant task; it will package your .jars and resources and deploy everything to every node's $GRIDGAIN_HOME/work/deployment/file folder. This is far easier than it sounds if you can get away with an NFS mount or something like that to simplify deployment. Additionally, you can tell GridGain to load a resource from an HTTP location, or another remote, URL.
This mechanism has a lot of advantages for production: your extra .jars are visible to the node (which means you won't have to transfer megabytes of libraries over the wire each time you hot redeploy a node instance), and most importantly, the custom beans inside the Spring application context we've been working with will be visible should you need them. When using this method, you can disable peer-to-peer class loading; this, while not significant, represents a gain in startup time.
A GAR archive looks like a standard .jar or .war. It provides several things that are mainly of concern for production. The first is that the libraries are already present, which we discussed. Second, the gridgain.xml file, which is optional, enables you to tell GridGain about which GridTask<T,R> classes are deployed. The structure is as follows:
*class
lib/*jar
META-INF/{gridgain.xml,*}gridgain.xml is a simple Spring application context. An example configuration follows:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util-3.0.xsd">
<description>Gridgain configuration file in gar-file.</description>
<util:list id="tasks">
<value>org.gridgain.examples.gar.GridGarHelloWorldTask</value>
</util:list>
</beans>In this file, we provide a list with ID tasks. This file is consulted to help load any tasks contained in the GAR file. If you don't specify anything, GridGain will simply search for tasks itself.
Instances of the ApplicationContext can be injected into the various GridGain class instances (GridTask<T,R>, GridJob, and so forth) using GridGain's @GridSpringApplicationContextResource annotation. This example shows the Spring application context being injected using the @GridSpringApplicationContextResource annotation. This works like @Autowired or @Resource:
@GridSpringApplicationContextResource
private ApplicationContext applicationContext ;Additionally, you can get components injected directly, using the @GridSpringResource:
@GridSpringResource(resourceName = "customerServiceBean")
private transient CustomerService customerService ;Note the use of transient. These resources aren't copied across the wire, but rather, reinjected on each node's initialization. This is a crucial tool in your tool belt, especially with volatile resources that aren't amenable to being sent over the wire, such as DataSources.
When you start GridGain via the gridgain.sh script, it provides very good defaults. However, sometimes you will want to exercise more control over the process.
When gridgain.sh is run, it consults (of all things!) a Spring application context for its configuration information. This file, located at $GRIDGAIN_HOME/config/default-spring.xml, contains all the information for GridGain to do what it does—communicate with other nodes. Usually, this works well enough. However, there are many things you may want to configure, and because GridGain is Spring-friendly from the core, configuration is very easy. If, instead, you'd like to override the settings in that file, pass in your own application context:
./gridgain.sh my-application-context.xmlIf you want even further control over the process, down to the last shell script, you can bootstrap the GridGain grid nodes yourself. The shell scripts as they ship also, essentially, use the following code to launch the grid from Java. You can as well:
org.gridgain.grid.GridFactory.start( "my-application-context.xml") ;
There are many versions of the start method, but most of them take a Spring application context (either an instance of ApplicationContext, or a String or URL to an XML application context). The application context is where you configure the grid node.
There are many prebuilt implementations for starting a Grid instance however, and you'll rarely need to write your own. The implementations, called grid loaders, provide the necessary integration to start the Grid in many different environments. Summarized in Table 22-1 are some of the common ones.
Table 22.1. Description of the various GridLoader implementations.
Description | |
|---|---|
| This is the default implementation. It is used when you run |
| This is likely the second most useful implementation. It provides a servlet that bootstraps the GridGain instance inside any web container as a servlet. |
| Provides a hook for running a Grid inside of JBoss as JMX MBean. |
| Provides integration with WebLogic's infrastructure for JMX (monitoring), logging, and the WorkManager implementation. |
| This GridGain loader is implemented as a JMX MBean. This, like the WebLogic integration, provides integration with logging, and the WorkManager implementation. |
| Provides integration with Glassfish as a life cycle listener that works on both Glassfish 1 and 2. |
In most of the loaders in Table 22-1 will be some sort of parameter that lets you provide the URL to a Spring XML application context file.
GridGain is imminently configurable. You might, for example, want to use a JMS queue for the communications layer between nodes. You might want to override the discovery mechanism. You might want to make use of any of numerous caching solutions on the market. There are too many permutations to list, but the distribution itself will contain a config/ directory in which you can find numerous example configurations.
One common requirement is sharing one LAN with multiple grids. You could conceivably have five nodes doing one kind of processing and another ten doing another type for a different project, without requiring a separate subnet.
You partition the cluster by setting the gridName property. gridName enables you to start several grids on the same LAN without fear of one grid stealing another grid's jobs.
An example might be as follows:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util-3.0.xsd">
<bean id="grid.cfg" class="org.gridgain.grid.GridConfigurationAdapter"
scope="singleton">
<property name="gridName" value="mygrid-001"/>
<!-- ... other configuration ... -->
</bean>
</beans>The next level of parameterization is user attributes. These parameters are specific to the node on which they're configured. You might imagine using these to partition your grid jobs, or to provide box-specific metadata like a NFS mount, or specify which FireWire or USB device to consult for something. In the following example, we use it to describe to the node on which countries' data it should concern itself with:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util-3.0.xsd">
<bean id="grid.cfg" class="org.gridgain.grid.GridConfigurationAdapter"
scope="singleton">
<property name="userAttributes">
<map>
<entry key="countries">
<util:list>
<value>FR</value>
<value>MX</value>
<value>CA</value><value>BG</value><value>JP</value><value>PH</value></util:list></entry></map> </property> </bean> </beans>
You may access parameters configured in this way using the GridNode interface:
GridNode gridNode = GridFactory.getGrid().getLocalNode();
Serializable attribute = gridNode.getAttribute("countries");In this chapter, you explored the foundations of distributed computing and the use of grids for both processing and storage. You learned how to use Terracotta to synchronize your application's memory over a cluster so that it is highly available and in memory. You learned how to use GridGain to build a processing grid to distribute the load of a large job over smaller, more plentiful nodes. You learned about the basics of the map/reduce pattern, which enables you to build a parallelized solution for better performance, and you learned how to use GridGain's annotation-based approach to easily leverage a bean's methods on a cluster. Last, you learned how clustered GridGain jobs can access beans from a Spring application context.