
CHAPTER 17
Managing Identities and Access
This chapter presents the following:
• Authorization mechanisms
• Implementing authentication systems
• Managing the identity and access provisioning life cycle
• Controlling physical and logical access
Locks keep out only the honest.
Identification and authentication of users and systems, which was the focus of the previous chapter, is only half of the access control battle. You may be able to establish that you are truly dealing with Ahmed, but what assets should he be allowed to access? It really depends on the sensitivity of the asset, Ahmed’s role, and any applicable rules on how these assets are supposed be used. Access control can also depend on any number of other attributes of the user, the asset, and the relationship between the two. Finally, access control can be based on risk.
Once you decide what access control model is best for your organization, you still have to implement the right authentication and authorization mechanism. There are many choices, but in this chapter we’ll focus on the technologies that you are likeliest to encounter in the real world (and on the CISSP exam). We’ll talk about how to manage the user access life cycle, which is where a lot of organizations get in trouble by not changing authorizations as situations change. After we cover all these essentials, we’ll see how it all fits together in the context of controlling access to physical and logical assets. Let’s start by looking at authorization mechanisms.
Authorization Mechanisms
Authorization is the process of ensuring authenticated users have access to the resources they are authorized to use and don’t have access to any other resources. This is preceded by authentication, of course, but unlike that process, which tends to be a one-time activity, authorization controls every interaction of every user with every resource. It is an ongoing, all-seeing, access control mechanism.
An access control mechanism dictates how subjects access objects. It uses access control technologies and security mechanisms to enforce the rules and objectives of an access control model. As discussed in this section, there are six main types of access control models: discretionary, mandatory, role-based, rule-based, attribute-based, and risk-based. Each model type uses different methods to control how subjects access objects, and each has its own merits and limitations. The business and security goals of an organization, along with its culture and habits of conducting business, help prescribe what access control model it should use. Some organizations use one model exclusively, whereas others combine models to provide the necessary level of protection.
Regardless of which model or combination of models your organization uses, your security team needs a mechanism that consistently enforces the model and its rules. The reference monitor is an abstract machine that mediates all access subjects have to objects, both to ensure that the subjects have the necessary access rights and to protect the objects from unauthorized access and destructive modification. It is an access control concept, not an actual physical component, which is why it is normally referred to as the “reference monitor concept” or an “abstract machine.” However the reference monitor is implemented, it must possess the following three properties to be effective:
• Always invoked To access an object, you have to go through the monitor first.
• Tamper-resistant It must ensure a threat actor cannot disable or modify it.
• Verifiable It must be capable of being thoroughly analyzed and tested to ensure that it works correctly all the time.
Let’s explore the different approaches to implement and manage authorization mechanisms. The following sections explain the six different models and where they should be implemented.
Discretionary Access Control
If a user creates a file, he is the owner of that file. An identifier for this user is placed in the file header and/or in an access control matrix within the operating system. Ownership might also be granted to a specific individual. For example, a manager for a certain department might be made the owner of the files and resources within her department. A system that uses discretionary access control (DAC) enables the owner of the resource to specify which subjects can access specific resources. This model is called discretionary because the control of access is based on the discretion of the owner. Many times department managers or business unit managers are the owners of the data within their specific department. Being the owner, they can specify who should have access and who should not.
In a DAC model, access is restricted based on the authorization granted to the users. This means users are allowed to specify what type of access can occur to the objects they own. If an organization is using a DAC model, the network administrator can allow resource owners to control who has access to their files. The most common implementation of DAC is through access control lists (ACLs), which are dictated and set by the owners and enforced by the operating system.
Most of the operating systems you may be used to dealing with (e.g., Windows, Linux, and macOS systems and most flavors of Unix) are based on DAC models. When you look at the properties of a file or directory and see the choices that allow you to control which users can have access to this resource and to what degree, you are witnessing an instance of ACLs enforcing a DAC model.
DAC can be applied to both the directory tree structure and the files it contains. The Microsoft Windows world has access permissions of No Access, Read (r), Write (w), Execute (x), Delete (d), Change (c), and Full Control. The Read attribute lets you read the file but not make changes. The Change attribute allows you to read, write, execute, and delete the file but does not let you change the ACLs or the owner of the files. Obviously, the attribute of Full Control lets you make any changes to the file and its permissions and ownership.
Access Control Lists
Access control lists (ACLs) are lists of subjects that are authorized to access a specific object, and they define what level of authorization is granted. Authorization can be specific to an individual, group, or role. ACLs are used in several operating systems, applications, and router configurations.
ACLs map values from the access control matrix to the object. Whereas a capability corresponds to a row in the access control matrix, the ACL corresponds to a column of the matrix. The ACL for a notional File1 object is shown in Table 17-1.

Table 17-1 The ACL for a Notional File1 Object
Challenges When Using DAC
While DAC systems provide a lot of flexibility to the user and less administration for IT, it is also the Achilles’ heel of operating systems. Malware can install itself and work under the security context of the user. For example, if a user opens an attachment that is infected with a virus, the code can install itself in the background without the user’s being aware of this activity. This code basically inherits all the rights and permissions that the user has and can carry out all the activities the user can on the system. It can send copies of itself out to all the contacts listed in the user’s e-mail client, install a back door, attack other systems, delete files on the hard drive, and more. The user is actually giving rights to the virus to carry out its dirty deeds, because the user has discretionary rights and is considered the owner of many objects on the system. This is particularly problematic in environments where users are assigned local administrator or root accounts, because once malware is installed, it can do anything on a system.
While we may want to give users some freedom to indicate who can access the files that they create and other resources on their systems that they are configured to be “owners” of, we really don’t want them dictating all access decisions in environments with assets that need to be protected. We just don’t trust them that much, and we shouldn’t if you think back to the zero-trust principle. In most environments, user profiles are created and loaded on user workstations that indicate the level of control the user does and does not have. As a security administrator you might configure user profiles so that users cannot change the system’s time, alter system configuration files, access a command prompt, or install unapproved applications. This type of access control is referred to as nondiscretionary, meaning that access decisions are not made at the discretion of the user. Nondiscretionary access controls are put into place by an authoritative entity (usually a security administrator) with the goal of protecting the organization’s most critical assets.
Mandatory Access Control
In a mandatory access control (MAC) model, users do not have the discretion of determining who can access objects as in a DAC model. For security purposes, an operating system that is based on a MAC model greatly reduces the amount of rights, permissions, and functionality that a user has. In most systems based on the MAC model, a user cannot install software, change file permissions, add new users, and so on. The system can be used by the user for very focused and specific purposes, and that is it. These systems are usually very specialized and are in place to protect highly classified data. Most people have never interacted directly with a MAC-based system because they are mainly used by government-oriented agencies that maintain top-secret information.
However, MAC is used behind the scenes in some environments you may have encountered at some point. For example, the optional Linux kernel security module called AppArmor allows system administrators to implement MAC for certain kernel resources. There is also a version of Linux called SELinux, developed by the NSA, that implements a flexible MAC model for enhanced security.
The MAC model is based on a security label system. Users are given a security clearance (secret, top secret, confidential, and so on), and data is classified in the same way. The clearance and classification data is stored in the security labels, which are bound to the specific subjects and objects. When the system makes a decision about fulfilling a request to access an object, it is based on the clearance of the subject, the classification of the object, and the security policy of the system. This means that even if a user has the right clearance to read a file, specific policies (e.g., requiring “need to know”) could still prevent access to it. The rules for how subjects access objects are made by the organization’s security policy, configured by the security administrator, enforced by the operating system, and supported by security technologies.
 NOTE
NOTE
Traditional MAC systems are based upon multilevel security policies, which outline how data at different classification levels is to be protected. Multilevel security (MLS) systems allow data at different classification levels to be accessed and interacted with by users with different clearance levels simultaneously.
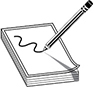
When the MAC model is being used, every subject and object must have a security label, also called a sensitivity label. This label contains the object’s security classification and any categories that may apply to it. The classification indicates the sensitivity level, and the categories enforce need-to-know rules. Figure 17-1 illustrates the use of security labels.
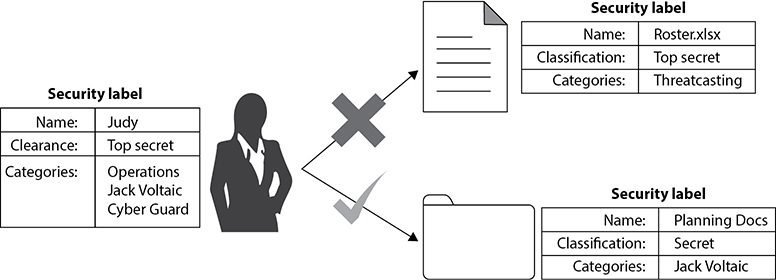
Figure 17-1 A security label is made up of a classification and categories.
The classifications follow a hierarchical structure, with one level being more trusted than another. However, the categories do not follow a hierarchical scheme, because they represent compartments of information within a system. The categories can correspond to departments (intelligence, operations, procurement), project codenames (Titan, Jack Voltaic, Threatcasting), or management levels, among others. In a military environment, the classifications could be top secret, secret, confidential, and unclassified. Each classification is more trusted than the one below it. A commercial organization might use confidential, proprietary, corporate, and sensitive. The definition of the classification is up to the organization and should make sense for the environment in which it is used.
The categories portion of the label enforces need-to-know rules. Just because someone has a top secret clearance does not mean she now has access to all top secret information. She must also have a need to know. As shown in Figure 17-1, Judy is cleared top secret and has the codename Jack Voltaic as one of her categories. She can, therefore, access the folder with the planning documents for Jack Voltaic because her clearance is at least that of the object, and all the categories listed in the object match her own. Conversely, she cannot access the roster spreadsheet because, although her clearance is sufficient, she does not have a need to know that information. We know this last bit because whoever assigned the categories to Judy did not include Threatcasting among them.
 EXAM TIP
EXAM TIP
In MAC implementations, the system makes access decisions by comparing the subject’s clearance and need-to-know level to the object’s security label. In DAC implementations, the system compares the subject’s identity to the ACL on the resource.
Software and hardware guards allow the exchange of data between trusted (high assurance) and less trusted (low assurance) systems and environments. For instance, if you were working on a MAC system (working in the dedicated security mode of secret) and you needed it to communicate to a MAC database (working in multilevel security mode, which goes up to top secret), the two systems would provide different levels of protection. If a system with lower assurance can directly communicate with a system of high assurance, then security vulnerabilities and compromises could be introduced.
A software guard is really just a front-end product that allows interconnectivity between systems working at different security levels. Different types of guards can be used to carry out filtering, processing requests, data blocking, and data sanitization. A hardware guard is a system with two network interface cards (NICs) connecting the two systems that need to communicate with one another. Guards can be used to connect different MAC systems working in different security modes, and they can be used to connect different networks working at different security levels. In many cases, the less trusted system can send messages to the more trusted system and can only receive acknowledgments back. This is common when e-mail messages need to go from less trusted systems to more trusted classified systems.
 TIP
TIP
The terms “security labels” and “sensitivity labels” can be used interchangeably.
Because MAC systems enforce strict access control, they also provide a wide range of security, particularly dealing with malware. Malware is the bane of DAC systems. Viruses, worms, and rootkits can be installed and run as applications on DAC systems. Since users that work within a MAC system cannot install software, the operating system does not allow any type of software, including malware, to be installed while the user is logged in. But while MAC systems might seem to be an answer to all our security prayers, they have very limited user functionality, require a lot of administrative overhead, are very expensive, and are not user friendly. DAC systems are general-purpose computers, while MAC systems serve a very specific purpose.
EXAM TIP
Unlike DAC systems, MAC systems are considered nondiscretionary because users cannot make access decisions based on their own discretion (choice).
Role-Based Access Control
A role-based access control (RBAC) model uses a centrally administrated set of controls to determine how subjects and objects interact. The access control levels are based on the necessary operations and tasks a user needs to carry out to fulfill her responsibilities within an organization. This type of model lets access to resources be based on the role the user holds within the organization. The more traditional access control administration is based on just the DAC model, where access control is specified at the object level with ACLs. This approach is more complex because the administrator must translate an organizational authorization policy into permission when configuring ACLs. As the number of objects and users grows within an environment, users are bound to be granted unnecessary access to some objects, thus violating the least-privilege rule and increasing the risk to the organization. The RBAC approach simplifies access control administration by allowing permissions to be managed in terms of user job roles.
In an RBAC model, a role is defined in terms of the operations and tasks the role will carry out, whereas a DAC model outlines which subjects can access what objects based upon the individual user identity. Let’s say we need a research and development analyst role. We develop this role not only to allow an individual to have access to all product and testing data but also, and more importantly, to outline the tasks and operations that the role can carry out on this data. When the analyst role makes a request to access the new testing results on the file server, in the background the operating system reviews the role’s access levels before allowing this operation to take place.
NOTE
Introducing roles also introduces the difference between rights being assigned explicitly and implicitly. If rights and permissions are assigned explicitly, they are assigned directly to a specific individual. If they are assigned implicitly, they are assigned to a role or group and the user inherits those attributes.
An RBAC model is the best system for an organization that has high employee turnover. If John, who is mapped to the Contractor role, leaves the organization, then Chrissy, his replacement, can be easily mapped to this role. That way, the administrator does not need to continually change the ACLs on the individual objects. He only needs to create a role (Contractor), assign permissions to this role, and map the new user to this role. Optionally, he can define roles that inherit access from other roles higher up in a hierarchy. These features are covered by two components of RBAC: core and hierarchical.
Core RBAC
There is a core component that is integrated into every RBAC implementation because it is the foundation of the model. Users, roles, permissions, operations, and sessions are defined and mapped according to the security policy. The core RBAC
• Has a many-to-many relationship among individual users and privileges
• Uses a session as a mapping between a user and a subset of assigned roles
• Accommodates traditional but robust group-based access control
Many users can belong to many groups with various privileges outlined for each group. When the user logs in (this is a session), the various roles and groups this user has been assigned are available to the user at one time. If you are a member of the Accounting role, RD group, and Administrative role, when you log on, all of the permissions assigned to these various groups are available to you.
This model provides robust options because it can include other components when making access decisions, instead of just basing the decision on a credential set. The RBAC system can be configured to also include time of day, location of role, day of the week, and so on. This means other information, not just the user ID and credential, is used for access decisions.
Hierarchical RBAC
This component allows the administrator to set up an organizational RBAC model that maps to the organizational structures and functional delineations required in a specific environment. This is very useful since organizations are already set up in a personnel hierarchical structure. In most cases, the higher you are in the chain of command, the more access you most likely have. Hierarchical RBAC has the following features:
• Uses role relations in defining user membership and privilege inheritance. For example, the Nurse role can access a certain set of files, and the Lab Technician role can access another set of files. The Doctor role inherits the permissions and access rights of these two roles and has more elevated rights already assigned to the Doctor role. So hierarchical RBAC is an accumulation of rights and permissions of other roles.
• Reflects organizational structures and functional delineations.
• Supports two types of hierarchies:
• Limited hierarchies Only one level of hierarchy is allowed (Role 1 inherits from Role 2 and no other role)
• General hierarchies Allows for many levels of hierarchies (Role 1 inherits Role 2’s and Role 3’s permissions)
Hierarchies are a natural means of structuring roles to reflect an organization’s lines of authority and responsibility. Role hierarchies define an inheritance relation among roles. Different separations of duties are provided through RBAC:
• Static separation of duty (SSD) relations Deters fraud by constraining the combination of privileges (e.g., the user cannot be a member of both the Cashier and Accounts Receivable roles).
• Dynamic separation of duty (DSD) relations Deters fraud by constraining the combination of privileges that can be activated in any session (e.g., the user cannot be in both the Cashier and Cashier Supervisor roles at the same time, but the user can be a member of both). This one warrants a bit more explanation. Suppose José is a member of both the Cashier and Cashier Supervisor roles. If he logs in as a Cashier, the Supervisor role is unavailable to him during that session. If he logs in as Cashier Supervisor, the Cashier role is unavailable to him during that session.
• Role-based access control can be managed in the following ways:
• Non-RBAC Users are mapped directly to applications and no roles are used.
• Limited RBAC Users are mapped to multiple roles and mapped directly to other types of applications that do not have role-based access functionality.
• Hybrid RBAC Users are mapped to multiapplication roles with only selected rights assigned to those roles.
• Full RBAC Users are mapped to enterprise roles.
Rule-Based Access Control
Rule-based access control uses specific rules that indicate what can and cannot happen between a subject and an object. This access control model is built on top of traditional RBAC and is thus commonly called RB-RBAC to disambiguate the otherwise overloaded RBAC acronym. It is based on the simple concept of “if this, then that” (IFTTT) programming rules, which can be used to provide finer-grained access control to resources. Before a subject can access an object in a certain circumstance, the subject must meet a set of predefined rules. This can be simple and straightforward, as in, “If the subject’s ID matches the unique ID value in the provided digital certificate, then the subject can gain access.” Or there could be a set of complex rules that must be met before a subject can access an object. For example, “If the subject is accessing the object on a weekday between 8 A.M. and 5 P.M., and if the subject is accessing the object while physically in the office, and if the subject is in the procurement role, then the subject can access the object.”
Rule-based access allows a developer to define specific and detailed situations in which a subject can or cannot access an object and what that subject can do once access is granted. Traditionally, rule-based access control has been used in MAC systems as an enforcement mechanism of the complex rules of access that MAC systems provide. Today, rule-based access is used in other types of systems and applications as well. Many routers and firewalls use rules to determine which types of packets are allowed into a network and which are rejected. Rule-based access control is a type of compulsory control, because the administrator sets the rules and the users cannot modify these controls.
Attribute-Based Access Control
Attribute-based access control (ABAC) uses attributes of any part of a system to define allowable access. These attributes can belong to subjects, objects, actions, or contexts. Here are some possible attributes we could use to describe our ABAC policies:
• Subjects Clearance, position title, department, years with the organization, training certification on a specific platform, member of a project team, location
• Objects Classification, files pertaining to a particular project, human resources (HR) records, location, security system component
• Actions Review, approve, comment, archive, configure, restart
• Context Time of day, project status (open/closed), fiscal year, ongoing audit
As you can see, ABAC provides the most granularity of any of the access control models. It would be possible, for example, to define and enforce a policy that allows only directors to comment on (but not edit) files pertaining to a project that is currently being audited. This specificity is a two-edged sword, since it can lead to an excessive number of policies that could interact with each other in ways that are difficult to predict.
Risk-Based Access Control
The access control models we’ve discussed so far all require that we decide exactly what is and is not allowed ahead of time. Whether these decisions involve users, security labels, roles, rules, or attributes, we codify them in our systems and, barring the occasional update, the policies are pretty static. But what if we were to make access control decisions dynamically based on the conditions surrounding the subjects’ requests?
Risk-based access control (in case the term RBAC wasn’t already ambiguous) estimates the risk associated with a particular request in real time and, if it doesn’t exceed a given threshold, grants the subject access to the requested resource. It is an attempt to more closely align risk management and access control while striving to share objects as freely as possible. For example, suppose David works for a technology manufacturer that is about to release a super-secret new product that will revolutionize the world. If the details of this product are leaked before the announcement, it will negatively impact revenues and the return on investment of the marketing campaigns. Obviously, the product’s specification sheet will be very sensitive until the announcement. Should David be granted access it?
Risk-based access control would look at it from the perspective of risk, which is the likelihood of an event multiplied by its impact. Suppose that the event about which we are concerned is a leak of the product details ahead of the official announcement. The impact is straightforward, so the real question is how likely it is that David’s request will lead to a leak. That depends on several factors, such as his role (is he involved in the rollout?), trustworthiness (is he suspected of leaking anything before?), context (what is he doing that requires access to the specification sheet?), and possibly many others. The system would gather the necessary information, estimate the risk, compare it to the maximum tolerable threshold, and then make a decision.
Figure 17-2 illustrates the main components of risk-based access control. The risk factors are generally divided into categories like user context, resource sensitivity, action severity, and risk history. We’ve already touched on the first three of these in our example, but we also may want to learn from previous decisions. What is the risk history of similar requests? If the organization doesn’t have a culture of secrecy and has experienced leaks in the past, that drives risk way up. If a particular subject has a history of making bad decisions, that likewise points toward denying access. Regardless of how the decision is arrived at, there is an element of monitoring the user activities to add to this history so we can improve the accuracy of our risk estimates over time.

Figure 17-2 Components of a risk-based access control model
Implementing Authentication and Authorization Systems
Now that you know the theory and principles behind authorization mechanisms, let’s turn our attention to how they are integrated with the authentication systems discussed in Chapter 16. Together, authentication and authorization are at the heart of cybersecurity. The following sections give you some technical details on the most common technologies with which you should be familiar. First, however, we have to talk a bit about markup languages, which, as you’ll see shortly, play an important role in authentication and authorization.
Access Control and Markup Languages
If you can remember when Hypertext Markup Language (HTML) was all we had to make a static web page, you might be considered “old” in terms of the technology world; HTML came out in the early 1990s. HTML evolved from Standard Generalized Markup Language (SGML), which evolved from the Generalized Markup Language (GML). We still use HTML, so it is certainly not dead and gone; the industry has just improved upon the markup languages available for use to meet today’s needs.
A markup language is a way to structure text and data sets, and it dictates how these will be viewed and used. When you adjust margins and other formatting capabilities in a word processor, you are marking up the text in the word processor’s markup language. If you develop a web page, you are using some type of markup language. You can control how it looks and some of the actual functionality the page provides. The use of a standard markup language also allows for interoperability. If you develop a web page and follow basic markup language standards, the page will basically look and act the same no matter what web server is serving up the web page or what browser the viewer is using to interact with it.
As the Internet grew in size and the World Wide Web (WWW) expanded in functionality, and as more users and organizations came to depend upon websites and web-based communication, the basic and elementary functions provided by HTML were not enough. And instead of every website having its own proprietary markup language to meet its specific functionality requirements, the industry had to have a way for functionality needs to be met and still provide interoperability for all web server and web browser interaction. This is the reason that Extensible Markup Language (XML) was developed. XML is a universal and foundational standard that provides a structure for other independent markup languages to be built from and still allow for interoperability. Markup languages with various functionalities were built from XML, and while each language provides its own individual functionality, if they all follow the core rules of XML, then they are interoperable and can be used across different web-based applications and platforms.
As an analogy, let’s look at the English language. Samir is a biology scientist, Trudy is an accountant, and Val is a network administrator. They all speak English, so they have a common set of communication rules, which allow them to talk with each other, but each has their own “spin-off” language that builds upon and uses the English language as its core. Samir uses words like “mitochondrial amino acid genetic strains” and “DNA polymerase.” Trudy uses words such as “accrual accounting” and “acquisition indigestion.” Val uses terms such as “multiprotocol label switching” and “subkey creation.” Each profession has its own “language” to meet its own needs, but each is based off the same core language—English. In the world of the WWW, various websites need to provide different types of functionality through the use of their own language types but still need a way to communicate with each other and their users in a consistent manner, which is why they are based upon the same core language structure (XML). There are hundreds of markup languages based upon XML, but we are going to focus on the ones that are used for identity management and access control purposes.
The Service Provisioning Markup Language (SPML) allows for the exchange of provisioning data between applications, which could reside in one organization or many; allows for the automation of user management (account creation, amendments, revocation) and access entitlement configuration related to electronically published services across multiple provisioning systems; and allows for the integration and interoperation of service provisioning requests across various platforms.
When an organization hires a new employee, that employee usually needs access to a wide range of systems, servers, and applications. Setting up new accounts on every system, properly configuring access rights, and then maintaining those accounts throughout their lifetimes is time-consuming, laborious, and error-prone. What if the organization has 20,000 employees and thousands of network resources that each employee needs various access rights to? This opens the door for confusion, mistakes, vulnerabilities, and a lack of standardization.
SPML allows for all these accounts to be set up and managed simultaneously across the various systems and applications. SPML is made up of three main entities: the Requesting Authority (RA), which is the entity that is making the request to set up a new account or make changes to an existing account; the Provisioning Service Provider (PSP), which is the software that responds to the account requests; and the Provisioning Service Target (PST), which is the entity that carries out the provisioning activities on the requested system.
So when a new employee is hired, there is a request to set up the necessary user accounts and access privileges on several different systems and applications across the enterprise. This request originates in a piece of software carrying out the functionality of the RA. The RA creates SPML messages, which provide the requirements of the new account, and sends them to a piece of software that is carrying out the functionality of the PSP. This piece of software reviews the requests and compares them to the organization’s approved account creation criteria. If these requests are allowed, the PSP sends new SPML messages to the end systems (PST) that the user actually needs to access. Software on the PST sets up the requested accounts and configures the necessary access rights. If this same employee is fired three months later, the same process is followed and all necessary user accounts are deleted. This allows for consistent account management in complex environments. These steps are illustrated in Figure 17-3.

Figure 17-3 SPML provisioning steps
When there is a need to allow a user to log in one time and gain access to different and separate web-based applications, the actual authentication data has to be shared between the systems maintaining those web applications securely and in a standardized manner. This is the role that the Security Assertion Markup Language (SAML) plays. It is an XML standard that allows the exchange of authentication and authorization data to be shared between security domains. Suppose your organization, Acme Corp., uses Gmail as its corporate e-mail platform. You would want to ensure that you maintain control over user access credentials so that you could enforce password policies and, for example, prevent access to the e-mail account of an employee who just got fired. You could set up a relationship with Google that would allow you to do just this using SAML. Whenever one of your organization’s users attempted to access their corporate Gmail account, Gmail would redirect their request to Acme’s single sign-on (SSO) service, which would authenticate the user and relay (through the user) a SAML response. Figure 17-4 depicts this process, though its multiple steps are largely transparent to the user.
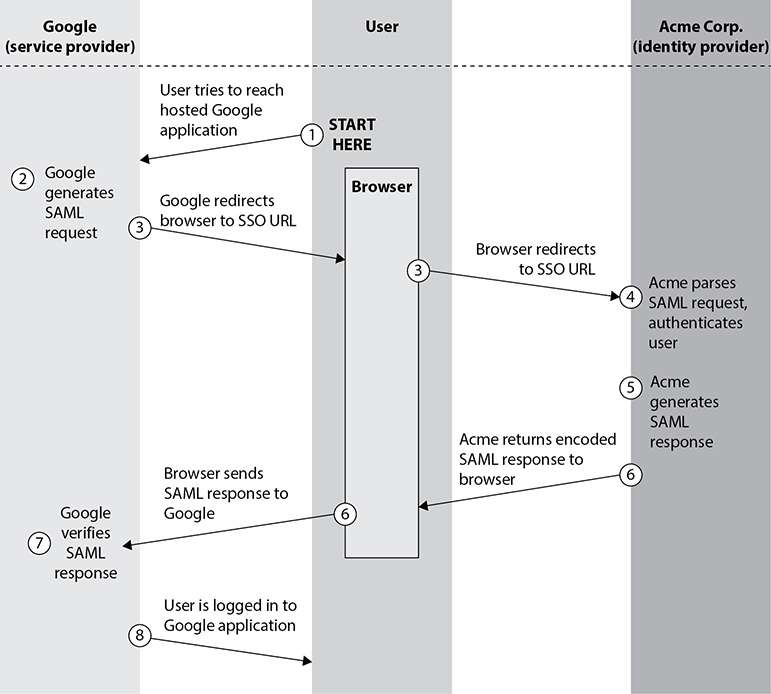
Figure 17-4 SAML authentication
SAML provides the authentication pieces to federated identity management systems to allow business-to-business (B2B) and business-to-consumer (B2C) transactions. In our previous example, the user is considered the principal, Acme Corporation is the identity provider, and Gmail is the service provider.
This is not the only way that the SAML language can be used. The digital world has evolved to being able to provide extensive services and functionality to users through web-based machine-to-machine communication standards. As we discussed in Chapter 13, web services is a collection of technologies and standards that allow services (weather updates, stock tickers, e-mail, customer resource management, etc.) to be provided on distributed systems and be “served up” in one place.
Transmission of SAML data can take place over different protocol types, but a common one is Simple Object Access Protocol (SOAP). As you may recall from Chapter 13, SOAP is a specification that outlines how information pertaining to web services is exchanged in a structured manner. It provides the basic messaging framework, which allows users to request a service and, in exchange, the service is made available to that user. Let’s say you need to interact with your company’s CRM system, which is hosted and maintained by the vendor—for example, Salesforce.com. You would log into your company’s portal and double-click a link for Salesforce. Your company’s portal would take this request and your authentication data and package it up in an SAML format and encapsulate that data into a SOAP message. This message would be transmitted over an HTTP connection to the Salesforce vendor site, and once you were authenticated, you would be provided with a screen that shows you the company’s customer database. The SAML, SOAP, and HTTP relationship is illustrated in Figure 17-5.
Figure 17-5 SAML material embedded within an HTTP message
The use of web services in this manner also allows for organizations to provide service-oriented architecture (SOA) environments. An SOA is a way to provide independent services residing on different systems in different business domains in one consistent manner. For example, if your organization has a web portal that allows you to access the organization’s CRM, an employee directory, and a help-desk ticketing application, this is most likely being provided through an SOA. The CRM system may be within the marketing department, the employee directory may be within the HR department, and the ticketing system may be within the IT department, but you can interact with all of them through one interface. SAML is a way to send your authentication information to each system, and SOAP allows this type of information to be presented and processed in a unified manner.
The last XML-based standard we will look at is Extensible Access Control Markup Language (XACML). XACML is used to express security policies and access rights to assets provided through web services and other enterprise applications. SAML is just a way to send around your authentication information, as in a password, key, or digital certificate, in a standard format. SAML does not tell the receiving system how to interpret and use this authentication data. Two systems have to be configured to use the same type of authentication data. If you log into System A and provide a password and try to access System B, which only uses digital certificates for authentication purposes, your password is not going to give you access to System B’s service. So both systems have to be configured to use passwords. But just because your password is sent to System B does not mean you have complete access to all of System B’s functionality. System B has access policies that dictate the operations that specific subjects can carry out on its resources. The access policies can be developed in the XACML format and enforced by System B’s software.
XACML is both an access control policy language and a processing model that allows for policies to be interpreted and enforced in a standard manner. When your password is sent to System B, there is a rules engine on that system that interprets and enforces the XACML access control policies. If the access control policies are created in the XACML format, they can be installed on both System A and System B to allow for consistent security to be enforced and managed.
XACML uses a Subject element (requesting entity), a Resource element (requested entity), and an Action element (types of access). So if you request access to your company’s CRM, you are the Subject, the CRM application is the Resource, and your access parameters are outlined in the Action element.
NOTE
Who develops and keeps track of all of these standardized languages? The Organization for the Advancement of Structured Information Standards (OASIS). This organization develops and maintains the standards for how various aspects of web-based communication are built and maintained.
Web services, SOA environments, and the implementation of these different XML-based markup languages vary in nature because they allow for extensive flexibility. Because so much of the world’s communication takes place through web-based processes, it is increasingly important for security professionals to understand these issues and technologies.
OAuth
OAuth is an open standard for authorization (not authentication) to third parties. The general idea is that this lets you authorize a website to use something that you control at a different website. For instance, if you have a LinkedIn account, the system might ask you to let it have access to your Google contacts in order to find your friends who already have accounts in LinkedIn. If you agree, you next see a pop-up from Google asking whether you want to authorize LinkedIn to manage your contacts. If you agree to this, LinkedIn gains access to all your contacts until you rescind this authorization. With OAuth a user allows a website to access a third party. The latest version of OAuth, which is version 2.0, is defined in Request for Comments (RFC) 6749. It defines four roles as described here:
• Client A process that requests access to a protected resource. It is worth noting that this term describes the relationship of an entity with a resource provider in a client/server architecture. This means the “client” could actually be a web service (e.g., LinkedIn) that makes requests from another web service (e.g., Google).
• Resource server The server that controls the resource that the client is trying to access.
• Authorization server The system that keeps track of which clients are allowed to use which resources and issues access tokens to those clients.
• Resource owner Whoever owns a protected resource and is able to grant permissions for others to use it. These permissions are usually granted through a consent dialog box. The resource owner is typically an end user, but could be an application or service.
Figure 17-6 shows a resource owner granting an OAuth client access to protected resources in a resource server. This could be a user who wants to tweet directly from a LinkedIn page, for example. The resource owner sends a request to the client, which is redirected to an authorization server. This server negotiates consent with the resource owner and then redirects an HTTPS-secured message back to the client, including in the message an authorization code. The client next contacts the authorization server directly with the authorization code and receives in return an access token for the protected resource. Thereafter, as long as the token has not expired or the authorization is not rescinded by the resource owner, the client is able to present the token to the resource server and access the resource. Note that it is possible (and indeed fairly common) for the resource server and authorization server to reside on the same computing node.
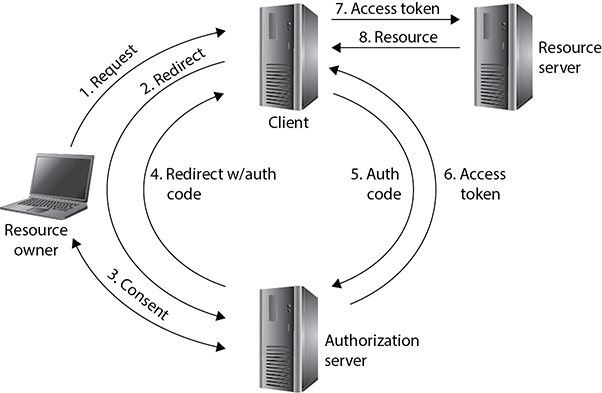
Figure 17-6 OAuth authorization steps
Although OAuth is an authorization framework, it relies on some sort of authentication mechanism to verify the identity of the resource owner whenever permissions are changed on a protected resource. This authentication is outside the scope of the OAuth standard, but can be implicitly used, as described in the following section.
OpenID Connect
OpenID Connect (OIDC) is a simple authentication layer built on top of the OAuth 2.0 protocol. It allows transparent authentication and authorization of client resource requests, as shown in Figure 17-7. Most frequently, OIDC is used to allow a web application (relying party) to not only authenticate an end user using a third-party identity provider (IdP) but also get information about that user from that IdP. When end users attempt to log into the web service, they see a login prompt from the IdP (e.g., Google) and, after correctly authenticating, are asked for consent to share information (e.g., name, e-mail address) with the web service. The information shared can be arbitrary as long as it is configured at the IdP, the relying party explicitly requests it, and the end user consents to it being shared.
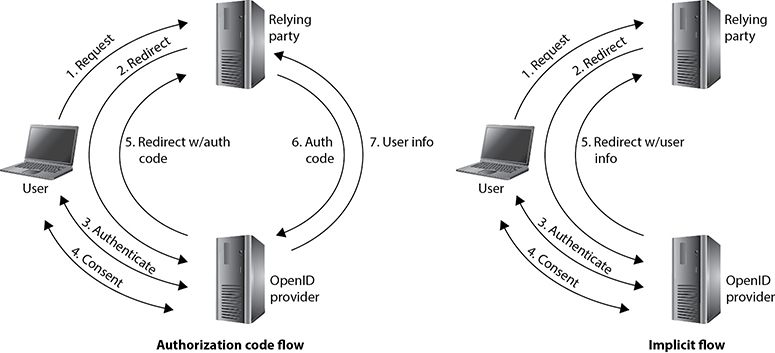
Figure 17-7 Two common OpenID Connect process flows
OIDC supports three flows:
• Authorization code flow The relying party is provided an authorization code (or token) and must use it to directly request the ID token containing user information from the IdP.
• Implicit flow The relying party receives the ID token containing user information with the redirect response from the IdP after user authentication and consent. The token is passed through the user’s browser, potentially exposing it to tampering.
• Hybrid flow Essentially a combination of the previous two flows.
Figure 17-7 illustrates the first two flows, which are the most common ones in use. In the authorization code flow, the user requests a protected resource on the relying party’s server, which triggers a redirect to the OpenID provider for authentication. The OpenID provider authenticates the user and then requests user consent to sharing specific kinds of information (e.g., e-mail, phone, profile, address), which are called scope values. The OpenID provider then redirects the user’s browser back to the relying party and includes an authorization code. The relying party then presents this code to the OpenID provider and requests the user information, which is delivered to it in an ID token.
The implicit flow is similar to the authorization code flow, but the relying party includes the requested scope values in the authentication redirect to the OpenID provider. After the user is authenticated and consents to sharing the information, the OpenID provider includes the ID token with the user’s information in the redirect back to the relying party.
The authorization code flow is preferred because it is more secure. The client app on the relying party obtains the ID token directly from the IdP, which means the user is unable to tamper with it. It also allows the OpenID provider to authenticate the client app that is requesting the user’s information. This flow requires that the client app have a server backend. If the client app is browser-based (e.g., JavaScript) and doesn’t have a server backend, then the implicit flow can be used. It is considered less secure because the ID token with the user information is given to the user’s browser, where it could be compromised or manipulated.
Kerberos
The previous access control technologies were focused on service-oriented architectures and web services. Alas, not every system fits those architectures. We still need authentication and authorization when we log into our work computers and in many other scenarios. Enter Kerberos.
Kerberos is the name of a three-headed dog that guards the entrance to the underworld in Greek mythology. This is a great name for a security technology that provides authentication functionality, with the purpose of protecting an organization’s assets. Kerberos is an authentication protocol and was designed in the mid-1980s as part of MIT’s Project Athena. It works in a client/server model and is based on symmetric key cryptography. The protocol has been used for years in Unix systems and is the default authentication method for Windows operating systems. In addition, Apple macOS, Oracle Solaris, and Red Hat Enterprise Linux all use Kerberos authentication. Commercial products supporting Kerberos are fairly common, so this one might be a keeper.
Kerberos is an example of an SSO system for distributed environments, and it has become a de facto standard for heterogeneous networks. Kerberos incorporates a wide range of security capabilities, which gives organizations much more flexibility and scalability when they need to provide an encompassing security architecture. It has four elements necessary for enterprise access control: scalability, transparency, reliability, and security. However, this open architecture also invites interoperability issues. When vendors have a lot of freedom to customize a protocol, it usually means no two vendors will customize it in the same fashion. This creates interoperability and incompatibility issues.
Kerberos uses symmetric key cryptography and provides end-to-end security. Although it allows the use of passwords for authentication, it was designed specifically to eliminate the need to transmit passwords over the network. Most Kerberos implementations work with shared secret keys.
Main Components in Kerberos
The Key Distribution Center (KDC) is the most important component within a Kerberos environment. The KDC holds all users’ and services’ secret keys. It provides an authentication service, as well as key distribution functionality. The clients and services trust the integrity of the KDC, and this trust is the foundation of Kerberos security.
The KDC provides security services to principals, which can be users, applications, or network services. The KDC must have an account for, and share a secret key with, each principal. For users, a password is transformed into a secret key value. The secret key can be used to send sensitive data back and forth between the principal and the KDC, and is used for user authentication purposes.
A ticket is generated by the ticket granting service (TGS) on the KDC and given to a principal when that principal, let’s say a user, needs to authenticate to another principal, let’s say a print server. The ticket enables one principal to authenticate to another principal. If Emily needs to use the print server, she must prove to the print server she is who she claims to be and that she is authorized to use the printing service. So Emily requests a ticket from the TGS. The TGS gives Emily the ticket, and in turn, Emily passes this ticket on to the print server. If the print server approves this ticket, Emily is allowed to use the print service.
A KDC provides security services for a set of principals. This set is called a realm in Kerberos. The KDC is the trusted authentication server for all users, applications, and services within a realm. One KDC can be responsible for one realm or several realms. Realms enable an administrator to logically group resources and users.
So far, we know that principals (users, applications, and services) require the KDC’s services to authenticate to each other; that the KDC has a database filled with information about every principal within its realm; that the KDC holds and delivers cryptographic keys and tickets; and that tickets are used for principals to authenticate to each other. So how does this process work?
The Kerberos Authentication Process
The user and the KDC share a secret key, while the service and the KDC share a different secret key. The user and the requested service do not share a symmetric key in the beginning. The user trusts the KDC because they share a secret key. They can encrypt and decrypt data they pass between each other, and thus have a protected communication path. Once the user authenticates to the service, they, too, will share a symmetric key (session key) that is used for authentication purposes.
Here are the exact steps:
1. Emily comes in to work and enters her username and password into her workstation at 8:00 A.M. The Kerberos software on Emily’s computer sends the username to the authentication service (AS) on the KDC, which in turn sends Emily a ticket granting ticket (TGT) that is encrypted with the TGS’s secret key.
2. If Emily has entered her correct password, the TGT is decrypted and Emily gains access to her local workstation desktop.
3. When Emily needs to send a print job to the print server, her system sends the TGT to the TGS, which runs on the KDC, and a request to access the print server. (The TGT allows Emily to prove she has been authenticated and allows her to request access to the print server.)
4. The TGS creates and sends a second ticket to Emily, which she will use to authenticate to the print server. This second ticket contains two instances of the same session key, one encrypted with Emily’s secret key and the other encrypted with the print server’s secret key. The second ticket also contains an authenticator, which contains identification information on Emily, her system’s IP address, sequence number, and a timestamp.
5. Emily’s system receives the second ticket, decrypts and extracts the embedded session key, adds a second authenticator set of identification information to the ticket, and sends the ticket on to the print server.
6. The print server receives the ticket, decrypts and extracts the session key, and decrypts and extracts the two authenticators in the ticket. If the print server can decrypt and extract the session key, it knows the KDC created the ticket, because only the KDC has the secret key used to encrypt the session key. If the authenticator information that the KDC and the user put into the ticket matches, then the print server knows it received the ticket from the correct principal.
7. Once this is completed, it means Emily has been properly authenticated to the print server and the server prints her document.
This is an extremely simplistic overview of what is going on in any Kerberos exchange, but it gives you an idea of the dance taking place behind the scenes whenever you interact with any network service in an environment that uses Kerberos. Figure 17-8 provides a simplistic view of this process.

Figure 17-8 The user must receive a ticket from the KDC before being able to use the requested resource.
The authentication service is the part of the KDC that authenticates a principal, and the TGS is the part of the KDC that makes the tickets and hands them out to the principals. TGTs are used so the user does not have to enter his password each time he needs to communicate with another principal. After the user enters his password, it is temporarily stored on his system, and any time the user needs to communicate with another principal, he just reuses the TGT.
EXAM TIP
Be sure you understand that a session key is different from a secret key. A secret key is shared between the KDC and a principal and is static in nature. A session key is shared between two principals and is generated when needed and is destroyed after the session is completed.
If a Kerberos implementation is configured to use an authenticator, the user sends to the print server her identification information and a timestamp and sequence number encrypted with the session key they share. The print server decrypts this information and compares it with the identification data the KDC sent to it about this requesting user. If the data is the same, the print server allows the user to send print jobs. The timestamp is used to help fight against replay attacks. The print server compares the sent timestamp with its own internal time, which helps determine if the ticket has been sniffed and copied by an attacker and then submitted at a later time in hopes of impersonating the legitimate user and gaining unauthorized access. The print server checks the sequence number to make sure that this ticket has not been submitted previously. This is another countermeasure to protect against replay attacks.
NOTE
A replay attack is when an attacker captures and resubmits data (commonly a credential) with the goal of gaining unauthorized access to an asset.
The primary reason to use Kerberos is that the principals do not trust each other enough to communicate directly. In our example, the print server will not print anyone’s print job without that entity authenticating itself. So none of the principals trust each other directly; they only trust the KDC. The KDC creates tickets to vouch for the individual principals when they need to communicate. Suppose Rodrigo needs to communicate directly with you, but you do not trust him enough to listen and accept what he is saying. If he first gives you a ticket from something you do trust (KDC), this basically says, “Look, the KDC says I am a trustworthy person. The KDC asked me to give this ticket to you to prove it.” Once that happens, then you will communicate directly with Rodrigo.
The same type of trust model is used in PKI environments. In a PKI environment, users do not trust each other directly, but they all trust the certificate authority (CA). The CA vouches for the individuals’ identities by using digital certificates, the same as the KDC vouches for the individuals’ identities by using tickets.
So why are we talking about Kerberos? Because it is one example of an SSO technology. The user enters a user ID and password one time and one time only. The tickets have time limits on them that administrators can configure. Many times, the lifetime of a TGT is eight to ten hours, so when the user comes in the next day, he has to present his credentials again.
NOTE
Kerberos is an open protocol, meaning that vendors can manipulate it to work properly within their products and environments. The industry has different “flavors” of Kerberos, since various vendors require different functionality.
Weaknesses of Kerberos
The following are some of the potential weaknesses of Kerberos:
• The KDC can be a single point of failure. If the KDC goes down, no one can access needed resources. Redundancy is necessary for the KDC.
• The KDC must be able to handle the number of requests it receives in a timely manner. It must be scalable.
• Secret keys are temporarily stored on the users’ workstations, which means it is possible for an intruder to obtain these cryptographic keys.
• Session keys are decrypted and reside on the users’ workstations, either in a cache or in a key table. Again, an intruder might capture these keys.
• Kerberos is vulnerable to password guessing. The KDC does not know if a dictionary attack is taking place.
• Network traffic is not protected by Kerberos if encryption is not enabled.
• If the keys are too short, they can be vulnerable to brute-force attacks.
• Kerberos needs all client and server clocks to be synchronized.
Kerberos must be transparent (work in the background without the user needing to understand it), scalable (work in large, heterogeneous environments), reliable (use distributed server architecture to ensure there is no single point of failure), and secure (provide authentication and confidentiality).
Remote Access Control Technologies
The following sections present some examples of centralized remote access control technologies. Each of these authentication protocols is referred to as an AAA protocol, which stands for authentication, authorization, and auditing. (Some resources have the last A stand for accounting, but it is the same functionality—just a different name.)
Depending upon the protocol, there are different ways to authenticate a user in this client/server architecture. The traditional authentication protocol is the Challenge Handshake Authentication Protocol (CHAP), but many systems are now using Extensible Authentication Protocol (EAP). We discussed each of these authentication protocols at length in Chapter 15.
RADIUS
Remote Authentication Dial-In User Service (RADIUS) is a network protocol that provides client/server authentication and authorization and audits remote users. A network may have access servers, DSL, ISDN, or a T1 line dedicated for remote users to communicate through. The access server requests the remote user’s logon credentials and passes them back to a RADIUS server, which houses the usernames and password values. The remote user is a client to the access server, and the access server is a client to the RADIUS server.
Most ISPs today use RADIUS to authenticate customers before they are allowed access to the Internet. The access server and customer’s software negotiate through a handshake procedure and agree upon an authentication protocol (CHAP or EAP). The customer provides to the access server a username and password. This communication takes place over a Point-to-Point Protocol (PPP) connection. The access server and RADIUS server communicate over the RADIUS protocol. Once the authentication is completed properly, the customer’s system is given an IP address and connection parameters and is allowed access to the Internet. The access server notifies the RADIUS server when the session starts and stops for billing purposes.
RADIUS was developed by Livingston Enterprises for its network access server product series, but was then published as a set of standards (RFC 2865 and RFC 2866). This means it is an open protocol that any vendor can use and manipulate so that it works within its individual products. Because RADIUS is an open protocol, it can be used in different types of implementations. The format of configurations and user credentials can be held in LDAP servers, various databases, or text files. Figure 17-9 shows some examples of possible RADIUS implementations.

Figure 17-9 Environments can implement different RADIUS infrastructures.
TACACS
Terminal Access Controller Access Control System (TACACS) has a very funny name. Not funny ha-ha, but funny “huh?” TACACS has been through three generations: TACACS, Extended TACACS (XTACACS), and TACACS+. TACACS combines its authentication and authorization processes; XTACACS separates authentication, authorization, and auditing processes; and TACACS+ is XTACACS with extended two-factor user authentication. TACACS uses fixed passwords for authentication, while TACACS+ allows users to employ dynamic (one-time) passwords, which provides more protection. Although TACACS+ is now an open standard, both it and XTACACS started off as Cisco-proprietary protocols that were inspired by, but are not compatible with, TACACS.
NOTE
TACACS+ is really not a new generation of TACACS and XTACACS; it is a distinct protocol that provides similar functionality and shares the same naming scheme. Because it is a totally different protocol, it is not backward-compatible with TACACS or XTACACS.
TACACS+ provides basically the same functionality as RADIUS with a few differences in some of its characteristics. First, TACACS+ uses TCP as its transport protocol, while RADIUS uses UDP. “So what?” you may be thinking. Well, any software that is developed to use UDP as its transport protocol has to be “fatter” with intelligent code that looks out for the items that UDP will not catch. Since UDP is a connectionless protocol, it will not detect or correct transmission errors. So RADIUS must have the necessary code to detect packet corruption, long timeouts, or dropped packets. Since the developers of TACACS+ chose to use TCP, the TACACS+ software does not need to have the extra code to look for and deal with these transmission problems. TCP is a connection-oriented protocol, and that is its job and responsibility.
RADIUS encrypts the user’s password only as it is being transmitted from the RADIUS client to the RADIUS server. Other information, as in the username, accounting, and authorized services, is passed in cleartext. This is an open invitation for attackers to capture session information for replay attacks. Vendors who integrate RADIUS into their products need to understand these weaknesses and integrate other security mechanisms to protect against these types of attacks. TACACS+ encrypts all of this data between the client and server and thus does not have the vulnerabilities inherent in the RADIUS protocol.
The RADIUS protocol combines the authentication and authorization functionality. TACACS+ uses a true AAA architecture, which separates the authentication, authorization, and accounting functionalities. This gives a network administrator more flexibility in how remote users are authenticated. For example, if Tomika is a network administrator and has been assigned the task of setting up remote access for users, she must decide between RADIUS and TACACS+. If the current environment already authenticates all of the local users through a domain controller using Kerberos, then Tomika can configure the remote users to be authenticated in this same manner, as shown in Figure 17-10. Instead of having to maintain a remote access server database of remote user credentials and a database within Active Directory for local users, Tomika can just configure and maintain one database. The separation of authentication, authorization, and accounting functionality provides this capability. TACACS+ also enables the network administrator to define more granular user profiles, which can control the actual commands users can carry out.

Figure 17-10 TACACS+ works in a client/server model.
Remember that RADIUS and TACACS+ are both protocols, and protocols are just agreed-upon ways of communication. When a RADIUS client communicates with a RADIUS server, it does so through the RADIUS protocol, which is really just a set of defined fields that will accept certain values. These fields are referred to as attribute-value pairs (AVPs). As an analogy, suppose Ivan sends you a piece of paper that has several different boxes drawn on it. Each box has a headline associated with it: first name, last name, hair color, shoe size. You fill in these boxes with your values and send it back to Ivan. This is basically how protocols work; the sending system just fills in the boxes (fields) with the necessary information for the receiving system to extract and process.
Since TACACS+ allows for more granular control on what users can and cannot do, TACACS+ has more AVPs, which allows the network administrator to define ACLs, filters, user privileges, and much more. Table 17-2 points out the differences between RADIUS and TACACS+.
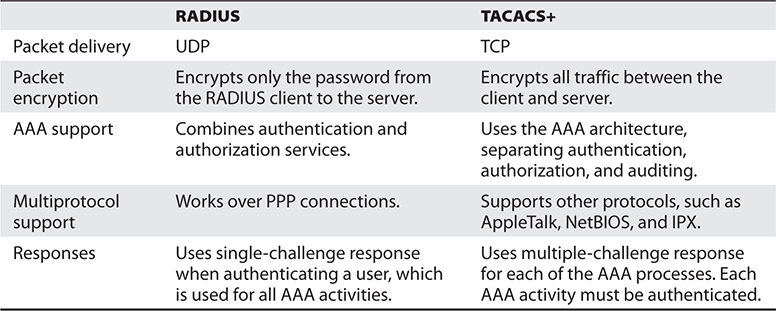
Table 17-2 Specific Differences Between These Two AAA Protocols
So, RADIUS is the appropriate protocol when simplistic username/password authentication can take place and users only need an Accept or Deny for obtaining access, as in ISPs. TACACS+ is the better choice for environments that require more sophisticated authentication steps and tighter control over more complex authorization activities, as in corporate networks.
Diameter
Diameter is a protocol that has been developed to build upon the functionality of RADIUS and overcome many of its limitations. The creators of this protocol decided to call it Diameter as a play on the term RADIUS—as in the diameter is twice the radius.
Diameter is another AAA protocol that provides the same type of functionality as RADIUS and TACACS+ but also provides more flexibility and capabilities to meet the demands of today’s complex and diverse networks. Today, we want our wireless devices and smartphones to be able to authenticate themselves to our networks, and we use roaming protocols, Mobile IP, Ethernet over PPP, Voice over IP (VoIP), and other crazy stuff that the traditional AAA protocols cannot keep up with. So the smart people came up with a new AAA protocol, Diameter, that can deal with these issues and many more.
The Diameter protocol consists of two portions. The first is the base protocol, which provides the secure communication among Diameter entities, feature discovery, and version negotiation. The second is the extensions, which are built on top of the base protocol to allow various technologies to use Diameter for authentication.
Up until the conception of Diameter, the Internet Engineering Task Force (IETF) had individual working groups who defined how VoIP, Fax over IP (FoIP), Mobile IP, and remote authentication protocols work. Defining and implementing them individually in any network can easily result in too much confusion and interoperability. It requires customers to roll out and configure several different policy servers and increases the cost with each new added service. Diameter provides a base protocol, which defines header formats, security options, commands, and AVPs. This base protocol allows for extensions to tie in other services, such as VoIP, FoIP, Mobile IP, wireless, and cell phone authentication. So Diameter can be used as an AAA protocol for all of these different uses.
As an analogy, consider a scenario in which ten people all need to get to the same hospital, which is where they all work. They all have different jobs (doctor, lab technician, nurse, janitor, and so on), but they all need to end up at the same location. So, they can either all take their own cars and their own routes to the hospital, which takes up more hospital parking space and requires the gate guard to authenticate each car, or they can take a bus. The bus is the common element (base protocol) to get the individuals (different services) to the same location (networked environment). Diameter provides the common AAA and security framework that different services can work within.
RADIUS and TACACS+ are client/server protocols, which means the server portion cannot send unsolicited commands to the client portion. The server portion can only speak when spoken to. Diameter is a peer-based protocol that allows either end to initiate communication. This functionality allows the Diameter server to send a message to the access server to request the user to provide another authentication credential if she is attempting to access a secure resource.
Diameter is not directly backward-compatible with RADIUS but provides an upgrade path. Diameter uses TCP and AVPs and provides proxy server support. It has better error detection and correction functionality than RADIUS, as well as better failover properties, and thus provides better network resilience.
Diameter has the functionality and ability to provide the AAA functionality for other protocols and services because it has a large AVP set. RADIUS has 28 (256) AVPs, while Diameter has 232 (a whole bunch). Recall from earlier in the chapter that AVPs are like boxes drawn on a piece of paper that outline how two entities can communicate back and forth. So, having more AVPs allows for more functionality and services to exist and communicate between systems.
Diameter provides the AAA functionality, as listed next.
Authentication:
• CHAP and EAP
• End-to-end protection of authentication information
• Replay attack protection
Authorization:
• Redirects, secure proxies, relays, and brokers
• State reconciliation
• Unsolicited disconnect
• Reauthorization on demand
Accounting:
• Reporting, roaming operations (ROAMOPS) accounting, event monitoring
Managing the Identity and Access Provisioning Life Cycle
Once an organization develops access control policies and determines the appropriate mechanisms, techniques, and technologies, it needs to implement procedures to ensure that identity and access are deliberately and systematically being issued to (and taken away from) users and systems. Many of us have either heard of or experienced the dismay of discovering that the credentials for someone who was fired months or years ago are still active in a domain controller. Some of us have even had to deal with that account having been used long after the individual left.
Identity and access have a life cycle, as illustrated in Figure 17-11. It begins with provisioning of an account, which we’ve already touched on in Chapter 16 in the context of registration and proofing of identities. Identities spend most of their lives being used for access control, which, as discussed in this chapter and the previous one, entails identification, authentication, and authorization of accounts. Changes invariably occur in organizations, and these changes impact identity and access control. For example, an employee gets promoted and her authorizations change. When changes occur, we want to ensure that our access control configurations remain up to date and effective. At some point, we need to ensure that we are in compliance with all applicable policies and regulations, so we also have to periodically review all the identities in the organization and their accesses. If all checks out, we let them continue to be used for access control. Inevitably, however, accounts need to be deprovisioned, which pops them out of the life-cycle model.
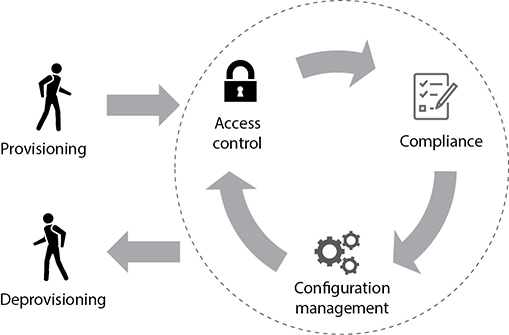
Figure 17-11 The identity and access management life cycle
Provisioning
As introduced in Chapter 5, provisioning is the set of all activities required to provide one or more new information services to a user or group of users (“new” meaning previously not available to that user or group). In terms of identification and access management, this pertains to the creation of user objects or accounts and the assignment of permissions to those accounts. Sometimes, the term provisioning is used to describe the whole life cycle, but our focus in this section is on the first phase only, which is generating the account.
Normally, provisioning happens when a new user or system is added to an organization. For people, this is part of onboarding, which we discussed in Chapter 1. It is important to have an established process for ensuring that digital identities are issued only to the right folks. This usually involves reviews and approvals from HR staff, the individual’s supervisor, and the IT department. The process is crucial for the rest of the life cycle because it answers the important question “Why did we provision this account?” The answer determines whether the account remains active or is deprovisioned at some point in the future. Keep in mind that some accounts are used for long periods of time, and rationales for provisioning accounts that were obvious in the beginning may be forgotten with the passage of time and with staffing changes.
Identity and access provisioning also pertains to system accounts, which are usually associated with services and automated agents and oftentimes require privileged access. A challenge here is that most organizations have a lot of system accounts that are largely invisible on a day-to-day basis. Just as for user identity and access, the trick here is to document what accounts were created, where they were created, and why they were created.
Access Control
We’ve already covered much of what happens in this phase of the life cycle, but it bears highlighting the fact that this is where most of the risk resides. Most security incidents are enabled by compromised authentication (e.g., user passwords are guessed, allowing adversaries to impersonate them) or authorization abuses (e.g., data to which users have legitimate access is used inappropriately or leaked). This is why it is essential to continuously monitor access controls, detect suspicious or malicious events, and generate alerts automatically. One of the most effective ways to do this is through the use of user and entity behavior analytics (UEBA), which we’ll discuss in detail in Chapter 21.
Compliance
Monitoring access and detecting interesting events early is essential to ensure compliance both with internal policies and procedures and with any applicable external regulations. Keep in mind that the intent of these policies and regulations is to ensure information systems security, so being able to attest that we are doing things “by the book” is good all around. It gives us personal peace of mind, protects our systems, and ensures our organizations don’t get hit with hefty fines. Note that rights and permission reviews have been incorporated into many regulatory-induced processes. For example, as part of the Sarbanes-Oxley Act (SOX) regulations (introduced in Chapter 1), managers have to review their employees’ permissions to data on an annual basis.
Compliance can be summed up in three major components:
• Written standards must exist that assign responsibilities to individuals. This could range from acceptable use policies to national laws like SOX.
• There must be a program by which applicable aspects of the security program are compared against the standard. In terms of identity and access management, this program is centered on user and system access reviews.
• Any discrepancies between the standard and reality must be addressed and resolved in a systemic way that ensures the issues are not likely to resurface next month.
We’ve already covered the first part (policies, regulations, and such) in Chapter 3, so let’s look at user and system access reviews (in turn) and resolving discrepancies.
User Access Review
One day, every user account will be deprovisioned because no one works (or lives) forever. It may also be necessary to change permissions (such as when a user changes roles) or temporarily disable accounts (such as when a user goes on an extended leave of absence or is under some sort of adverse administrative action). The list of conditions under which an account is disabled or deprovisioned will vary by organization, but we all need to have such a list. We need a process by which we periodically (or upon certain conditions) check every user account against that list. The purpose of these user access reviews is to ensure we don’t have excessive authorizations or active accounts that are no longer needed.
Ideally, we conduct reviews periodically (say, every six months) for all accounts (or, at least, a sampling of them). A review should also be triggered by certain administrative actions. A best practice is to integrate these reviews into the HR procedures because HR typically is involved in administrative actions anyway. Though it is obvious that user accounts should be disabled or deprovisioned when an employee is terminated, other situations are not as clear-cut, such as the following, and require a deliberate review by the individual’s supervisor and/or the IT department:
• Promotion
• Transfer
• Extended vacation or sabbatical
• Hospitalization
• Long-term disability (with an expected future return)
• Investigation for possible wrongdoing
• Unexpected disappearance
System Account Access Review
As with user access, we should conduct system account access reviews both periodically and when certain conditions are met. Though HR would not be involved in these reviews, the principle is the same: every system account eventually needs to be changed, disabled, or deprovisioned. What makes reviewing systems accounts a bit trickier is that it is easy to forget they exist in the first place. It is not unusual for a service to require multiple accounts with which nobody interacts directly and yet are absolutely critical for the system. What’s worse, sometimes software updates can remove the need for legacy system accounts that are not deprovisioned as part of the updating process and remain in place as a potential vulnerability. A systematic approach to system account access review is your best way to avoid ending up with unneeded, potentially privileged accounts.
Although these two terms are synonymous to most IT and security professionals, the CISSP CBK distinguishes between a system account and a service account. Technically, a system account is created by the operating system for use by a particular process, not by a human. Most OSs have a “system” context in which they run privileged operations. A service account is a system account for a process that runs as a service (i.e., it listens for and responds to requests from other processes).
Resolving Discrepancies
So, you just completed an account access review (user, service, and/or system) and have found some discrepancies. What do you do? A possible approach would be to change, disable, or deprovision the accounts and go on your merry way. This solves the immediate problem but may result in your having to repeat this process after every review if the cause for the discrepancies is systemic. That is why you are much better off treating the discrepancies as symptoms of a problem, not the end problems themselves.
A good approach is to list all the deficiencies and, for each one, answer the four guiding questions listed here. For each, we offer an example answer for illustration purposes.
• What happened? You came across an account used by a service that was removed during a software upgrade months ago. The service is gone, but its account remains.
• Why did it happen? Because your team didn’t fully understand the impact of the software update and didn’t check the state of the system after it was applied.
• What can we infer from it about discrepancies in other places and/or the future? There may be other similarly orphaned service accounts in the environment, so we should audit them all.
• How do we best correct this across the board? We should create a process by which all services are characterized prior to being updated, the effects of the update are determined ahead of time, and any changes to access controls are implemented during the update process. This should all be included in our configuration management program going forward.
The example shouldn’t be surprising, since many of us have come across this (or a very similar) situation. We find an account that is still enabled even though the staff member left the organization a year ago and we rush to fix it without thinking about how this happened in the first place. Fixing a broken process is way more effective than fixing a single discrepancy that was caused by it, and there is no more important process in the identity and access life cycle than configuration management.
Configuration Management
Configuration management is a broad subject that we’ll discuss in detail in Chapter 20. However, with regard to the identity and access management life cycle, it really boils down to having a firm grasp (and control) of all the subjects and objects in our environment and of the manner in which they interrelate. If you think of the identity and access management (IAM) configuration of your systems in this way, you’ll see that there are three drivers of change to your systems’ configurations: users change, objects change, and authorizations change. The first of these (users change) is covered here in the provisioning and deprovisioning sections. We already gave an example of the second (objects change) in our previous example of a system account access review earlier in this chapter. Let’s turn our attention in the sections that follow to what is, perhaps, the thorniest of the three: authorizations change.
Role Definitions
We tend to be very thorough in assigning the right authorizations to our staff members when we onboard them and provision their accounts. Usually, we follow lots of processes and ensure that various forms are signed by the correct people. We tend to not be as thorough, however, when somebody’s role in the organization changes. This could be a promotion, a transfer to a new role, or a merger (or split) of roles. It is just as important to be thorough in these cases to ensure we maintain proper access controls.
A good way to do this is for the HR, IT, security, and business teams to jointly develop a role matrix that specifies who should have access to what and to periodically review and update the matrix as needed. Then, whenever there is a personnel action, the HR team notifies the IT staff of it. IT, in turn, updates the person’s authorizations and everyone is happy.
More commonly, however, staff members are often assigned more and more access rights and permissions over time as their roles change and they move from one department to another. This is commonly referred to as authorization creep. It can be a large risk for an organization because it leads to too many users having too much privileged access to the organization’s assets. In the past, it has usually been easier for network administrators to give more access than less, because then the user would not come back and require more work to be done on her profile. It is also difficult to know the exact access levels different individuals require unless something like a role matrix exists. Enforcing least privilege on user accounts should be an ongoing job, which means it should be part of a formal configuration management process.
Privilege Escalation
If we apply the principle of least privilege effectively, then everyone should be running with minimal access to get their day-to-day tasks done. Even system administrators should have to temporarily elevate their privileges to perform sensitive tasks. In Linux environments, this is normally done using the sudo command, which temporarily changes the authorizations of a user, typically to the root user. The Windows graphical user interface gives you the option to “run as administrator,” which is similar to sudo but not as powerful or flexible. If you want that level of power, you need to drop to the Windows command line and use the runas command.
Privilege escalation, necessary as it might be, should be minimized in any environment. That means you want the least number of folks with admin privileges running around. It also means that you want to put in place policies regarding when and why account privileges should be escalated. Lastly, you want to log any such escalation so the use of newly escalated privileges use can be audited. We get into managing privileged accounts in Chapter 20, but these principles are worth keeping in mind (and repeating a few times).
Managed Service Accounts
Closely related to privilege escalation is the concept of service accounts that need to be accessible to certain administrators. Service accounts can be tricky because they are typically privileged but are not normally used by a human user. It is (sadly) all too common to see administrators install and configure a service, create an account for it to run under, and forget about the account. Passwords for these accounts are frequently exempt from password policy enforcement (e.g., complexity, expiration), so you can have some well-intentioned admins set an easy-to-remember password (because it could be disastrous if they ever forgot it) that never expired on a privileged account that few knew existed in the first place. Not good.
Microsoft Windows includes a feature that helps solve this challenge. Managed service accounts (MSAs) are Active Directory (AD) domain accounts that are used by services and provide automatic password management. MSAs can be used by multiple users and systems without any of them having to know the password. The way MSAs work is that AD creates policy-compliant passwords for these accounts and regularly changes them (every 30 days by default). Systems and users that are authorized to use these accounts need only be authenticated themselves on a domain controller and be included in that MSA’s ACL. Think of it as an extension to SSO where you get to be authenticated as yourself or as any MSA that you are authorized to access.
Deprovisioning
As we already said, sooner or later every account should get deprovisioned. For users, this is usually part of the termination procedures we covered in Chapter 1. For system accounts, this could happen because we got rid of a system or because some configuration change rendered an account unnecessary. Whatever the type of account or the reason for getting rid of it, it is important to document the change so we no longer track that account for reviewing purposes.
A potential challenge with deprovisioning accounts is that it could leave orphaned resources. Suppose that Jonathan is the owner of project files on a shared folder to which no one else has access. If he leaves the company and has his account deprovisioned, that shared folder would be left on the server, but nobody (except administrators) could do anything with it. Apart from being wasteful, this situation could hinder the business if those files were important later on. When deprovisioning an account, therefore, it is important to transfer ownership of its resources to someone else.
Controlling Physical and Logical Access
We’ve focused our discussion so far on logical access control to our information, applications, and systems. The mechanisms we’ve covered can be implemented at various layers of a network and individual systems. Some controls are core components of operating systems or embedded into applications and devices, and some security controls require third-party add-on packages. Although different controls provide different functionality, they should all work together to keep the bad guys out and the good guys in and to provide the necessary quality of protection.
We also need to consider physical access controls to protect the devices on which these assets run as well as the facilities in which they reside. No organization wants people to be able to walk into their buildings arbitrarily, sit down at an employee’s workstation, and be able to access any assets. While the mechanisms we’ve discussed in this chapter are mostly not applicable to physical security, most of the access control models (with the possible exception of risk-based access control) are.
Information Access Control
Controlling access to information assets is particularly tricky. Sure, we can implement the mechanisms described in the preceding sections to ensure only authorized subjects can read, write, or modify information in digital files. However, information can exist in a multitude of other places. Consider a fancy briefing room with a glass wall or doors leading into it. Inside, one of our staff members is giving a presentation on a product we’ll soon be releasing that will turn our company’s fortunes around. The slides are being projected, but the presenter provided hard copies for all attendees so they could take notes on them. Consider all the media on which our sensitive product information can exist:
• Secondary storage The slides exist in a file somewhere in the presenter’s computer or in some network share (though this is probably the easiest medium to secure using the mechanisms discussed in this chapter).
• Screen Anyone walking by the room can see (or take a photo of) the slides being presented.
• Handouts If the attendees don’t protect the hard copies of the slides or dispose of them improperly (say, by dumping them in a trash or recycling bin), the custodial staff (or anyone up for some dumpster diving) could get the information.
• Voices Not only can the presenter’s remarks be overheard by unauthorized individuals but so can conversations that attendees have with each other in the break area.
The point is that our information access controls need to consider the variety of media and contexts in which sensitive information can exist. This is why it is important to consider both logical and physical controls for it. We’ve covered the logical side in depth here (though you may want to review Chapter 6 on data security); for a similar coverage of physical security, we refer you to Chapter 10’s discussion of site and facility controls.
System and Application Access Control
Systems are a lot more closely aligned with the logical controls we described in this chapter, compared to the information assets we just covered. We kind of lumped all software together when we covered access controls. There is, however, a subtlety between systems and applications that bears pointing out, particularly with regard to the CISSP exam. Technically, a system is a type of software that provides services to other software. Web, e-mail, and authentication services are all examples of systems. An application is a type of software that interacts directly with a human user. A web browser, e-mail client, and even the authentication box that pops up to request your credentials are all examples of applications, as are stand-alone products like word processors and spreadsheets.
Access Control to Devices
All information that is stored in electronic media and all software exist within hardware devices. Whether it is the smartphone in your pocket, the laptop on your desk, or the server in the data center (or the cloud), you have to concern yourself with who can physically access them just as much as you worry about who can logically do so. After all, if an attacker can physically touch a device, then he can own it. We make the threat actors’ jobs significantly more difficult by controlling physical access to our devices and assets. We can install and configure physical controls on each computer, such as install locks on the cover so the internal parts cannot be stolen, remove the USB and optical drives to prevent copying of confidential information, and implement a protection device that reduces the electrical emissions to thwart attempts to gather information through airwaves.
Speaking of electrical signals, different types of cabling can be used to carry information throughout a network. As a review of some of the cabling issues from Chapter 14, recall that some cable types have sheaths that protect the data from being affected by the electrical interference of other devices that emit electrical signals. Some types of cable have protection material around each individual wire to ensure there is no crosstalk between the different wires. Choosing the right kind of cable can help protect the devices they connect from accidental or environmental interferences. There is also, of course, the issue of deliberate tapping of these cables. If an adversary cannot get to a device but can tap its network cable, we could have issues unless all traffic is end-to-end encrypted (which it almost never is). Recall that distribution facilities (where one end of these cables terminates) need security controls and that some types of cables (UTP) are easier to tap than others (fiber optic).
Facilities Access Control
We discussed facility security in Chapter 10, but it is worthwhile to review and perhaps extend our conversation around access control. An example of facilities access controls is having a security guard verify individuals’ identities prior to allowing them to enter a facility. How might the guard make that decision? In a classified facility, the guard may check that the clearance of the individual meets or exceeds that of the facility she is trying to enter and that she has a need to be there (perhaps from an access roster). This would be a simplified implementation of a MAC model. If the facility had different floors for different departments, another approach would be to check the person’s department and grant her access to that floor only, which would be a form of RBAC. We could refine that access control by putting some rules around it, such as access is only granted during working hours, unless the person is an executive or a manager. We would then be using an RB-RBAC model.
These examples are simply meant to illustrate that physical access controls, just like their logical counterparts, should be deliberately designed and implemented. To this end, the models we discussed at the beginning of this chapter are very helpful. They can then inform the specific controls we implement. In the sections that follow, we take a closer look at some of the major considerations when thinking of facilities access control.
Perimeter Security
Perimeter security is concerned with controlling physical access to facilities. How it is implemented depends upon the organization and the security requirements of that environment. One environment may require employees to be authorized by a security guard by showing a security badge that contains a picture identification before being allowed to enter a section. Another environment may require no authentication process and let anyone and everyone into different sections. Perimeter security can also encompass closed-circuit TVs that scan the parking lots and waiting areas, fences surrounding a building, the lighting of walkways and parking areas, motion detectors, sensors, alarms, and the location and visual appearance of a building. These are examples of perimeter security mechanisms that provide physical access control by providing protection for individuals, facilities, and the components within facilities.
Work Area Separation
Some environments might dictate that only particular individuals can access certain areas of the facility. For example, research companies might not want office personnel to be able to enter laboratories, so that they can’t disrupt or taint experiments or access test data. Most network administrators allow only network staff in the server rooms and wiring closets to reduce the possibilities of errors or sabotage attempts. In financial institutions, only certain employees can enter the vaults or other restricted areas. These examples of work area separation are physical controls used to support access control and the overall security policy of the company.
Control Zone
An organization’s facility should be split up into zones that are based on the sensitivity of the activity that takes place per zone. The front lobby could be considered a public area, the product development area could be considered top secret, and the executive offices could be considered secret. It does not matter what classifications are used, but it should be understood that some areas are more sensitive than others, which will require different access controls based on the needed protection level. The same is true of the organization’s network. It should be segmented, and access controls should be chosen for each zone based on the criticality of devices and the sensitivity of data being processed.
Chapter Review
This is one of the more important chapters in the book for a variety of reasons. First, access control is central to security. The models and mechanisms discussed in this chapter are security controls you should know really well and be able to implement in your own organization. Also, the CISSP exam has been known to include lots of questions covering the topics discussed in this chapter, particularly the access control models.
We chose to start this chapter with these models because they set the foundations for the discussion. You may think that they are too theoretical to be useful in your daily job, but you might be surprised how often we’ve seen them crop up in the real world. They also inform the mechanisms we discussed in more detail, like OAuth, OpenID Connect, and Kerberos. While these technologies are focused on logical access control, we wrapped up the chapter with a section on how physical and logical controls need to work together to protect our organizations.
Quick Review
• An access control mechanism dictates how subjects access objects.
• The reference monitor is an abstract machine that mediates all access subjects have to objects, both to ensure that the subjects have the necessary access rights and to protect the objects from unauthorized access and destructive modification.
• There are six main access control models: discretionary, mandatory, role-based, rule-based, attribute-based, and risk-based.
• Discretionary access control (DAC) enables data owners to dictate what subjects have access to the files and resources they own.
• Access control lists are bound to objects and indicate what subjects can use them.
• The mandatory access control (MAC) model uses a security label system. Users have clearances, and resources have security labels that contain data classifications. MAC systems compare these two attributes to determine access control capabilities.
• The terms “security labels” and “sensitivity labels” can be used interchangeably.
• Role-based access control (RBAC) is based on the user’s role and responsibilities (tasks) within the company.
• Rule-based RBAC (RB-RBAC) builds on RBAC by adding “if this, then that” (IFTTT) rules that further restrict access.
• Attribute-based access control (ABAC) is based on attributes of any component of the system. It is the most granular of the access control models.
• Risk-based access control estimates the risk associated with a particular request in real time and, if it doesn’t exceed a given threshold, grants the subject access to the requested resource.
• Extensible Markup Language (XML) is a set of rules for encoding documents in machine-readable form to allow for interoperability between various web-based technologies.
• The Service Provisioning Markup Language (SPML) allows for the automation of user management (account creation, amendments, revocation) and access entitlement configuration related to electronically published services across multiple provisioning systems.
• The Security Assertion Markup Language (SAML) allows for the exchange of authentication and authorization data to be shared between security domains.
• Extensible Access Control Markup Language (XACML), which is both a declarative access control policy language implemented in XML and a processing model, describes how to interpret security policies.
• OAuth is an open standard that allows a user to grant authority to some web resource, like a contacts database, to a third party.
• OpenID Connect is an authentication layer built on the OAuth 2.0 protocol that allows transparent authentication and authorization of client resource requests.
• Kerberos is a client/server authentication protocol based on symmetric key cryptography that can provide single sign-on (SSO) for distributed environments.
• The Key Distribution Center (KDC) is the most important component within a Kerberos environment because it holds all users’ and services’ secret keys, provides an authentication service, and securely distributes keys.
• Kerberos users receive a ticket granting ticket (TGT), which allows them to request access to resources through the ticket granting service (TGS), which in turn generates a new ticket with the session keys.
• The following are weaknesses of Kerberos: the KDC is a single point of failure; it is susceptible to password guessing; session and secret keys are locally stored; KDC needs to always be available; and management of secret keys is required.
• Some examples of remote access control technologies are RADIUS, TACACS+, and Diameter.
• The identity and access provisioning life cycle consists of provisioning, access control, compliance, configuration management, and deprovisioning.
• A system account is created by the operating system for use by a particular process, not by a human. A service account is a system account for a process that runs as a service (i.e., it listens for and responds to requests from other processes).
• Authorization creep takes place when a user gains too much access rights and permissions over time.
• Managed service accounts (MSAs) are Active Directory domain accounts that are used by services and provide automatic password management.
Questions
Please remember that these questions are formatted and asked in a certain way for a reason. Keep in mind that the CISSP exam is asking questions at a conceptual level. Questions may not always have the perfect answer, and the candidate is advised against always looking for the perfect answer. Instead, the candidate should look for the best answer in the list.
1. Which access control method is considered user directed?
A. Nondiscretionary
B. Mandatory
C. Identity-based
D. Discretionary
2. Which item is not part of a Kerberos authentication implementation?
A. Message authentication code
B. Ticket granting service
C. Authentication service
D. Users, applications, and services
3. If a company has a high turnover rate, which access control structure is best?
A. Role-based
B. Decentralized
C. Rule-based
D. Discretionary
4. In discretionary access control security, who has delegation authority to grant access to data?
A. User
B. Security officer
C. Security policy
D. Owner
5. Who or what determines if an organization is going to operate under a discretionary, mandatory, or nondiscretionary access control model?
A. Administrator
B. Security policy
C. Culture
D. Security levels
6. Which of the following best describes what role-based access control offers organizations in terms of reducing administrative burdens?
A. It allows entities closer to the resources to make decisions about who can and cannot access resources.
B. It provides a centralized approach for access control, which frees up department managers.
C. User membership in roles can be easily revoked and new ones established as job assignments dictate.
D. It enforces enterprise-wide security policies, standards, and guidelines.
Use the following scenario to answer Questions 7–9. Tanya is working with the company’s internal software development team. Before a user of an application can access files located on the company’s centralized server, the user must present a valid one-time password, which is generated through a challenge/response mechanism. The company needs to tighten access control for these files and reduce the number of users who can access each file. The company is looking to Tanya and her team for solutions to better protect the data that has been classified and deemed critical to the company’s missions. Tanya has also been asked to implement a single sign-on technology for all internal users, but she does not have the budget to implement a public key infrastructure.
7. Which of the following best describes what is currently in place?
A. Capability-based access system
B. Synchronous tokens that generate one-time passwords
C. RADIUS
D. Kerberos
8. Which of the following is one of the easiest and best solutions Tanya can consider for proper data protection?
A. Implementation of mandatory access control
B. Implementation of access control lists
C. Implementation of digital signatures
D. Implementation of multilevel security
9. Which of the following is the best single sign-on technology for this situation?
A. PKI
B. Kerberos
C. RADIUS
D. TACACS+
Use the following scenario to answer Questions 10–12. Harry is overseeing a team that has to integrate various business services provided by different company departments into one web portal for both internal employees and external partners. His company has a diverse and heterogeneous environment with different types of systems providing customer relationship management, inventory control, e-mail, and help-desk ticketing capabilities. His team needs to allow different users access to these different services in a secure manner.
10. Which of the following best describes the type of environment Harry’s team needs to set up?
A. RADIUS
B. Service-oriented architecture
C. Public key infrastructure
D. Web services
11. Which of the following best describes the types of languages and/or protocols that Harry needs to ensure are implemented?
A. Security Assertion Markup Language, Extensible Access Control Markup Language, Service Provisioning Markup Language
B. Service Provisioning Markup Language, Simple Object Access Protocol, Extensible Access Control Markup Language
C. Extensible Access Control Markup Language, Security Assertion Markup Language, Simple Object Access Protocol
D. Service Provisioning Markup Language, Security Association Markup Language
12. The company’s partners need to integrate compatible authentication functionality into their web portals to allow for interoperability across the different company boundaries. Which of the following will deal with this issue?
A. Service Provisioning Markup Language
B. Simple Object Access Protocol
C. Extensible Access Control Markup Language
D. Security Assertion Markup Language
Answers
1. D. The discretionary access control (DAC) model allows users, or data owners, the discretion of letting other users access their resources. DAC is implemented by ACLs, which the data owner can configure.
2. A. Message authentication code (MAC) is a cryptographic function and is not a key component of Kerberos. Kerberos is made up of a Key Distribution Center (KDC), a realm of principals (users, applications, services), an authentication service, tickets, and a ticket granting service.
3. A. A role-based structure is easier on the administrator because she only has to create one role, assign all of the necessary rights and permissions to that role, and plug a user into that role when needed. Otherwise, she would need to assign and extract permissions and rights on all systems as each individual joined the company and left the company.
4. D. Although user might seem to be the correct choice, only the data owner can decide who can access the resources she owns. She may or may not be a user. A user is not necessarily the owner of the resource. Only the actual owner of the resource can dictate what subjects can actually access the resource.
5. B. The security policy sets the tone for the whole security program. It dictates the level of risk that management and the company are willing to accept. This in turn dictates the type of controls and mechanisms to put in place to ensure this level of risk is not exceeded.
6. C. With role-based access control, an administrator does not need to revoke and reassign permissions to individual users as they change jobs. Instead, the administrator assigns permissions and rights to a role, and users are plugged into those roles.
7. A. A capability-based access control system means that the subject (user) has to present something, which outlines what it can access. The item can be a ticket, token, or key. A capability is tied to the subject for access control purposes. A synchronous token is not being used, because the scenario specifically states that a challenge esponse mechanism is being used, which indicates an asynchronous token.
8. B. Systems that provide mandatory access control (MAC) and multilevel security are very specialized, require extensive administration, are expensive, and reduce user functionality. Implementing these types of systems is not the easiest approach out of the list. Since there is no budget for a PKI, digital signatures cannot be used because they require a PKI. In most environments, access control lists (ACLs) are in place and can be modified to provide tighter access control. ACLs are bound to objects and outline what operations specific subjects can carry out on them.
9. B. The scenario specifies that PKI cannot be used, so the first option is not correct. Kerberos is based upon symmetric cryptography; thus, it does not need a PKI. RADIUS and TACACS+ are remote centralized access control protocols.
10. B. A service-oriented architecture (SOA) will allow Harry’s team to create a centralized web portal and offer the various services needed by internal and external entities.
11. C. The most appropriate languages and protocols for the purpose laid out in the scenario are Extensible Access Control Markup Language, Security Assertion Markup Language, and Simple Object Access Protocol. Harry’s group is not necessarily overseeing account provisioning, so the Service Provisioning Markup Language is not necessary, and there is no language called “Security Association Markup Language.”
12. D. Security Assertion Markup Language allows the exchange of authentication and authorization data to be shared between security domains. It is one of the most commonly used approaches to allow for single sign-on capabilities within a web-based environment.