
CHAPTER 17
Complexity Theory
An algorithm's performance is always important when you try to solve a problem. An algorithm won't do you much good if it takes too long or requires too much memory or other resources to actually run on a computer.
Computational complexity theory, or just complexity theory, is the study of the difficulty of computational problems. Rather than focusing on specific algorithms, complexity theory focuses on problems.
For example, the mergesort algorithm described in Chapter 6 can sort a list of N numbers in O(N log N) time. Complexity theory asks what you can learn about the task of sorting in general, not what you can learn about a specific algorithm. It turns out that you can show that any sorting algorithm that sorts by using comparisons must use at least N × log(N) time in the worst case.
Complexity theory is a large and difficult topic, so there's no room here to cover it fully. However, every programmer who studies algorithms should know at least something about complexity theory in general and the two sets P and NP in particular. This chapter introduces complexity theory and describes what these important classes of problems are.
Notation
One of the first topics covered in this book was Big O notation. Chapter 1 described Big O notation somewhat intuitively by saying that it describes how an algorithm's worst-case performance increases as the problem's size increases.
For most purposes, that definition is good enough to be useful, but in complexity theory Big O notation has a more technical definition. If an algorithm's run time is ![]() , then the algorithm has Big O performance of
, then the algorithm has Big O performance of ![]() if
if ![]() for some constant k and for N large enough. In other words, the function
for some constant k and for N large enough. In other words, the function ![]() is an upper bound for the actual run-time function
is an upper bound for the actual run-time function ![]() .
.
Two other notations similar to Big O notations are sometimes useful when discussing algorithmic complexity. Big Omega notation, written ![]() , means that the run-time function is bounded below by the function
, means that the run-time function is bounded below by the function ![]() . For example, as explained a moment ago,
. For example, as explained a moment ago, ![]() is a lower bound for algorithms that sort by using comparisons, so those algorithms are
is a lower bound for algorithms that sort by using comparisons, so those algorithms are ![]() .
.
Big Theta notation, written ![]() , means that the run-time function is bounded both above and below by the function
, means that the run-time function is bounded both above and below by the function ![]() . For example, the mergesort algorithm's run time is bounded above by
. For example, the mergesort algorithm's run time is bounded above by ![]() , and the run time of any algorithm that sorts by using comparisons is bounded below by
, and the run time of any algorithm that sorts by using comparisons is bounded below by ![]() , so mergesort has performance
, so mergesort has performance ![]() .
.
In summary, Big O notation gives an upper bound, Big Omega ![]() gives a lower bound, and Big Theta
gives a lower bound, and Big Theta ![]() gives an upper and lower bound.
gives an upper and lower bound.
Note that some algorithms have different upper and lower bounds. For example, like all algorithms that sort by using comparisons, quicksort has a lower bound of ![]() . In the best and expected cases, quicksort's performance actually is
. In the best and expected cases, quicksort's performance actually is ![]() . In the worst case, however, quicksort's performance is
. In the worst case, however, quicksort's performance is ![]() . The algorithm's lower and upper bounds are different, so no function gives quicksort a Big Theta notation. In practice, however, quicksort is often faster than algorithms such as mergesort that are tightly bounded by
. The algorithm's lower and upper bounds are different, so no function gives quicksort a Big Theta notation. In practice, however, quicksort is often faster than algorithms such as mergesort that are tightly bounded by ![]() , so it is still a popular algorithm.
, so it is still a popular algorithm.
Complexity Classes
Algorithmic problems are sometimes grouped into classes of algorithms that have similar run times (or space requirements) when running on a certain type of hypothetical computer. The two most common kinds of hypothetical computers are deterministic and nondeterministic.
A deterministic computer's actions are completely determined by a finite set of internal states (the program's variables and code) and its input. In other words, if you feed a certain set of inputs into the computer, the results are completely predictable. (More technically, the “computer” used for this definition is a Turing machine that is fairly similar to the deterministic finite automata or DFAs described in Chapter 15.)
In contrast, a nondeterministic computer is allowed to be in multiple states at one time. This is similar to how the NFAs described in Chapter 15 can be in multiple states at once. Because the nondeterministic machine can follow any number of paths through its states to an accepting state, all it really needs to do is use the input on all of the possible states in which it could be and verify that one of the paths of execution works. Essentially (and less precisely), that means it can guess the correct solution and then simply verify that the solution is correct.
Note that a nondeterministic computer doesn't need to prove negative results. If there is a solution, the computer is allowed to guess the solution and verify it. If there is no solution, the computer doesn't need to prove that.
For example, to find the prime factors for an integer, a deterministic computer would need somehow to find the factors, perhaps by trying all possible factors up to the number's square root or by using a sieve of Eratosthenes. (See Chapter 2 for more information on those methods.) This would take a very long time.
In contrast, a nondeterministic computer can guess the factorization and then verify that it is correct by multiplying the factors together to see that the product is the original number. This would take very little time.
After you understand what the terms deterministic and nondeterministic mean in this context, understanding most of the common complexity classes is relatively easy. The following list summarizes the most important deterministic complexity classes:
- DTIME(f(N)) Problems that can be solved in
 time by a deterministic computer. These problems can be solved by some algorithm with run time
time by a deterministic computer. These problems can be solved by some algorithm with run time  for some function
for some function  . For example,
. For example,  includes problems that can be solved in
includes problems that can be solved in  time, such as sorting by using comparisons.
time, such as sorting by using comparisons. - P Problems that can be solved in polynomial time by a deterministic computer. These problems can be solved by some algorithm with run time
 for some power P no matter how large, even
for some power P no matter how large, even  .
. - EXPTIME (or EXP) Problems that can be solved in exponential time by a deterministic computer. These problems can be solved by some algorithm with run time
 for some polynomial function
for some polynomial function  .
.
The following list summarizes the most important nondeterministic complexity classes:
- NTIME(f(N)) Problems that can be solved in
 time by a nondeterministic computer. These problems can be solved by some algorithm with run time
time by a nondeterministic computer. These problems can be solved by some algorithm with run time  for some function
for some function  . For example,
. For example,  includes problems in which an algorithm can guess the answer and verify that it is correct in
includes problems in which an algorithm can guess the answer and verify that it is correct in  time.
time. - NP Problems that can be solved in polynomial time by a nondeterministic computer. For these problems, an algorithm guesses the correct solution and verifies that it works in polynomial time
 for some power P.
for some power P. - NEXPTIME (or NEXP) Problems that can be solved in exponential time by a nondeterministic computer. For these problems, an algorithm guesses the correct solution and verifies that it works in exponential time
 for some polynomial function
for some polynomial function  .
.
Similarly, you can define classes of problems that can be solved with different amounts of available space. These have the rather predictable names DSPACE(f(N)), PSPACE (polynomial space), EXPSPACE (exponential space), NPSPACE (nondeterministic polynomial space), and NEXPSPACE (nondeterministic exponential space).
Some relationships among these classes are known. For example, ![]() . (The
. (The ![]() symbol means “is a subset of,” so this statement means “P is a subset of NP.”) In other words, if a problem is in P, then it is also in NP.
symbol means “is a subset of,” so this statement means “P is a subset of NP.”) In other words, if a problem is in P, then it is also in NP.
To see why this is true, suppose that a problem is in P. Then there is a deterministic algorithm that can find a solution to the problem in polynomial time. In that case, you can use the same algorithm to solve the problem with a nondeterministic computer. If the algorithm works—in other words, if the solution it finds must be correct—that trivially proves the solution is correct, so the nondeterministic algorithm works too.
Some of the other relationships are less obvious. For example, ![]() and
and ![]() .
.
The most profound question in complexity theory is, “Does P equal NP?” Many problems, such as sorting, are known to be in P. Many other problems, such as the knapsack and traveling salesman problems described in Chapter 12, are known to be in NP. The big question is, are the problems in NP also in P?
Lots of people have spent a huge amount of time trying to determine whether these two sets are the same. No one has discovered a polynomial time deterministic algorithm to solve the knapsack or traveling salesman problem, but that doesn't prove that no such algorithm is possible.
One way that you can compare the difficulty of two algorithms is by reducing one to the other, as described in the next section.
Reductions
To reduce one problem to another, you must come up with a way for the solution to the second problem to give you the solution to the first. If you can do that within a certain amount of time, the maximum run time of the two algorithms is the same within the amount of time you spent on the reduction.
For example, you know that prime factoring is in NP and that sorting is in P. Suppose that you could find an algorithm that can reduce factoring into a sorting problem. In other words, if you have a factoring problem, then you can convert it into a sorting problem that leads to a solution to the sorting problem. If you can convert the factoring problem into the sorting problem and then use the solution to the sorting problem in polynomial time, then you can solve factoring problems in polynomial time. (Of course, no one knows how to reduce factoring to sorting. If someone had discovered such a reduction, then factoring wouldn't be as hard as it is.)
Polynomial time reductions are particularly important because they let you reduce many problems in NP to other problems in NP. In fact, there are some problems to which every problem in NP can be reduced. Those problems are called NP-complete.
The first known NP-complete problem was the satisfiability problem (SAT). In this problem, you are given a Boolean expression that includes variables that could be true or false, such as (A AND B) OR (B AND NOT C). The goal is to determine whether there is a way to assign the values true and false to the variables to make the statement true.
The Cook-Levin theorem (or just Cook's theorem) proves that SAT is NP-complete. The details are rather technical (see https://en.wikipedia.org/wiki/Cook-Levin_theorem), but the basic ideas aren't too confusing.
To show that SAT is NP-complete, you need to do two things: show that SAT is in NP, and show that any other problem in NP can be reduced to SAT.
SAT is in NP because you can guess the assignments for the variables and then verify that those assignments make the statement true.
Proving that any other problem in NP can be reduced to SAT is the tricky part. Suppose that a problem is in NP. In that case, you must be able to make a nondeterministic Turing machine with internal states that let it solve the problem. The idea behind the proof is to build a Boolean expression that says the inputs are passed into the Turing machine, the states work correctly, and the machine stops in an accepting state.
The Boolean expression contains three kinds of variables that are named ![]() ,
, ![]() , and
, and ![]() for various values of i, j, k, and q. The following list explains each variable's meaning:
for various values of i, j, k, and q. The following list explains each variable's meaning:
 is true if tape cell i contains symbol j at step k of the computation.
is true if tape cell i contains symbol j at step k of the computation.-
 is true if the machine's read/write head is on tape cell i at step k of the computation.
is true if the machine's read/write head is on tape cell i at step k of the computation.  is true if the machine is in state q at step k of the computation.
is true if the machine is in state q at step k of the computation.
The expression must also include some terms to represent how a Turing machine works. For example, suppose that the tape can hold only 0s and 1s. Then the statement (![]() AND NOT
AND NOT ![]() ) OR (NOT
) OR (NOT ![]() AND
AND ![]() ) means that cell 0 at step 1 of the computation contains either a 0 or a 1 but not both.
) means that cell 0 at step 1 of the computation contains either a 0 or a 1 but not both.
Other parts of the expression ensure that the read/write head is in a single position at each step of the computation, that the machine starts in state 0, that the read/write head starts at tape cell 0, and so on.
The full Boolean expression is equivalent to the original Turing machine for the problem in NP. In other words, if you set the values of the variables ![]() to represent a series of inputs, the truth of the Boolean expression tells you whether the original Turing machine would accept those inputs.
to represent a series of inputs, the truth of the Boolean expression tells you whether the original Turing machine would accept those inputs.
This reduces the original problem to the problem of determining whether the Boolean expression can be satisfied. Because we have reduced the arbitrary problem to SAT, SAT is NP-complete.
Once you have found one problem that is NP-complete, such as SAT, then you can prove that other problems are NP-complete by reducing them to the first problem.
If problem A can be reduced to problem B in polynomial time, then you can write ![]() .
.
The following sections provide examples that reduce one problem to another.
3SAT
The 3SAT problem is to determine whether a Boolean expression in three-term conjunctive normal form can be satisfied. Three-term conjunctive normal form (3CNF) means that the Boolean expression consists of a series of clauses combined with AND NOT, and that each clause combines exactly three variables with OR and NOT. For example, the following statements are all in 3CNF:
- (A OR B OR NOT C) AND (C OR NOT A OR B)
- (A OR C OR C) AND (A OR B OR B)
- (NOT A OR NOT B OR NOT C)
Clearly 3SAT is in NP because, as is the case with SAT, you can guess an assignment of true and false to the variables and then check whether the statement is true.
With some work, you can convert any Boolean expression in polynomial time into an equivalent expression in 3CNF. That means SAT is polynomial-time reducible to 3SAT (![]() ). Because SAT is NP-complete, 3SAT must also be NP-complete.
). Because SAT is NP-complete, 3SAT must also be NP-complete.
Bipartite Matching
A bipartite graph is one in which the nodes are divided into two sets and no link connects two nodes in the same set, as shown in Figure 17.1.

Figure 17.1: In a bipartite graph, the nodes are divided into two sets, and links can only connect nodes in one set to nodes in the other.
In a bipartite graph, a matching is a set of links, no two of which share a common end point.
In the bipartite matching problem, you are given a bipartite graph and a number k. The goal is to determine whether there is a matching that contains at least k links.
The section “Work Assignment” in Chapter 14 explained how you could use a maximal flow problem to perform work assignment. Work assignment is simply a maximal bipartite matching between nodes representing employees and nodes representing jobs, so that algorithm also solves the bipartite matching problem.
To apply work assignment to this problem, add a source node and connect it to all of the nodes in one set. Next, create a sink node and connect all of the nodes in the other set to it. Now the maximal flow algorithm finds a maximal bipartite matching. After you find the matching, compare the maximal flow to the number k to solve the bipartite matching problem.
NP-Hardness
A problem is NP-complete if it is in NP and every other problem in NP is polynomial-time reducible to it. A problem is NP-hard if every other problem in NP is polynomial-time reducible to it. The only difference between NP-complete and NP-hard is that an NP-hard problem might not be in NP.
Note that all NP-complete problems are NP-hard, plus they are in NP.
Being NP-hard in some sense means that the problem is at least as hard as any problem in NP because you can reduce any problem in NP to it.
You can show that a problem is NP-complete by showing that it is polynomial-time reducible to another NP-complete problem. Similarly, you can show that a problem is NP-hard by showing that it is polynomial-time reducible to another NP-hard problem.
Detection, Reporting, and Optimization Problems
Many interesting problems come in three flavors: detection, reporting, and optimization. The detection problem asks you to determine whether a solution of a given quality exists. The reporting problem asks you to find a solution of a given quality. The optimization problem asks you to find the best possible solution.
For example, in the zero sum subset problem, you are given a set of numbers. The goal is to find a subset of those numbers that adds up to 0. There are three associated problems:
- Detection: Is there a subset of the numbers that adds up to 0 to within some k? (In other words, is there a subset with total between −k and
 ?)
?) - Reporting: Find a subset of the numbers that adds up to 0 to within some value k, if such a subset exists.
- Optimization: Find a subset of the numbers with a total as close to 0 as possible.
At first, some of these problems may seem easier than others. For example, the detection problem only asks you to prove that a subset adds up to 0 to within some amount. Because it doesn't make you find subsets like the reporting problem does, you might think that the detection problem is easier. In fact, you can use reductions to show that the three forms of problems have the same difficulty, at least as far as complexity theory is concerned.
To do that, you need to show four reductions.
Figure 17.2 shows the relationships graphically.

Figure 17.2: Detection, reporting, and optimization have the same complexity.
Reductions are transitive, so the first two reductions show that ![]() , and the second two reductions show that
, and the second two reductions show that ![]() .
.
Detection ≤p Reporting
The reduction ![]() is relatively obvious. If you have an algorithm for reporting subsets, then you can use it to detect subsets. For a value k, use the reporting algorithm to find a subset that adds up to 0 to within k. If the algorithm finds one, then the answer to the detection problem is, “Yes, such a subset exists.”
is relatively obvious. If you have an algorithm for reporting subsets, then you can use it to detect subsets. For a value k, use the reporting algorithm to find a subset that adds up to 0 to within k. If the algorithm finds one, then the answer to the detection problem is, “Yes, such a subset exists.”
To look at this in another way, suppose that ReportSum is a reporting algorithm for the subset sum problem. In other words, ReportSum(k) returns a subset with sum between ![]() and k, if such a subset exists. Then DetectSum(k) can simply call ReportSum(k) and return true if ReportSum(k) returns a subset.
and k, if such a subset exists. Then DetectSum(k) can simply call ReportSum(k) and return true if ReportSum(k) returns a subset.
Reporting ≤p Optimization
The reduction ![]() is also fairly obvious. Suppose that you have an algorithm for finding the optimal solution. In other words, the algorithm finds a subset with total as close to 0 as possible. Then you can use that algorithm to solve the reporting problem.
is also fairly obvious. Suppose that you have an algorithm for finding the optimal solution. In other words, the algorithm finds a subset with total as close to 0 as possible. Then you can use that algorithm to solve the reporting problem.
Suppose that you want to find a subset with a total that is within k of 0. First use the optimization algorithm to find the subset with total value that is closest to 0. If that subset's total is within k of 0, return it. If the optimal subset's sum is more than k away from 0, then there is no solution for this reporting problem.
To look at this in another way, suppose OptimizeSum(k) returns a subset with a total as close as possible to 0. Then ReportSum(k) can call OptimizeSum(k) and see if the returned subset's total is less than k. If the total is less than k, ReportSum(k) returns that subset. If the total is greater than k, ReportSum(k) returns nothing to indicate that no such subset exists.
Reporting ≤p Detection
The reduction ![]() is less obvious than the previous reductions. First, use the detection algorithm to see whether a solution is possible. If there is no solution, then the reporting algorithm doesn't need to do anything.
is less obvious than the previous reductions. First, use the detection algorithm to see whether a solution is possible. If there is no solution, then the reporting algorithm doesn't need to do anything.
If a solution is possible, simplify the problem somehow to give an equivalent problem and then use the detection algorithm to see if a solution is still possible. If a solution no longer exists, remove the simplification and try a different one. When you have tried all of the possible simplifications and none of them will work, then whatever is left must be the solution that the reporting algorithm should return.
To look at this in another way, suppose DetectSum(k) returns true if there is a subset with total value between ![]() and k. The following pseudocode shows how to use that algorithm to build a ReportSum algorithm:
and k. The following pseudocode shows how to use that algorithm to build a ReportSum algorithm:
- Use DetectSum(k) on the whole set to see whether a solution is possible. If no solution is possible, then the ReportSum algorithm returns that fact and is done.
- For each value Vi in the set:
- Remove Vi from the set, and call DetectSum(k) for the remaining set to see whether there is still a subset with total value between
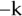 and k.
and k. - If DetectSum(k) returns false, restore Vi to the set, and continue the loop at Step 2.
- If DetectSum(k) returns true, leave Vi out of the set, and continue the loop at Step 2.
- Remove Vi from the set, and call DetectSum(k) for the remaining set to see whether there is still a subset with total value between
When the loop in step 2 finishes, the remaining values in the set form a subset with total value between ![]() and k.
and k.
Optimization ≤p Reporting
The final step in showing that the three kinds of problems have the same complexity is showing that ![]() . Suppose that you have a reporting algorithm Report(k). Then the optimization algorithm can call Report(0), Report(1), Report(2), and so on, until it finds a solution. That solution will be optimal.
. Suppose that you have a reporting algorithm Report(k). Then the optimization algorithm can call Report(0), Report(1), Report(2), and so on, until it finds a solution. That solution will be optimal.
These reductions show ![]() and Optimization
and Optimization ![]() , so the problems all have the same complexity.
, so the problems all have the same complexity.
Approximate Optimization
Even though the detection, reporting, and optimization problems have the same complexity, the optimization problem is slightly different from the other two because you can approximate its solutions. The detection problem asks if a certain solution exists. The answer is either “yes” or “no”—it can't be “approximately yes.” Similarly, the reporting problem asks you to find a particular solution. The result is a solution, not an approximation. For example, the reporting version of the subset sum problem should return a subset. It wouldn't make sense for it to return a subset and say, “Most of these items are members of a subset that works.”
In contrast, an optimization problem must define some sort of criterion that you can use to evaluate solutions so you can tell which one is best. Even if you cannot find an optimal solution or if you cannot prove that a particular solution is optimal, you can still determine that some solutions are better than others.
All of this means that you can often write a program that searches for an optimal solution. Over time, the program can produce better and better solutions. Depending on the problem, you may not be sure that the latest solution is the best possible, but at least you'll have some sort of approximation to the optimal solution.
In contrast, the detection and reporting versions of the problem can continue to search for solutions, but until they find one, they can only produce the result, “Still haven't found a solution.”
NP-Complete Problems
More than 3,000 NP-complete problems have been discovered, so the following list is only a small subset of them. They are listed here to give you an idea of some kinds of problems that are NP-complete.
Remember that NP-complete problems have no known polynomial time solution, so these are all considered very hard problems. Many can only be solved exactly for very small problem sizes.
Because these problems are all NP-complete, there is a way to reduce each of them to every other problem (although that reduction may not be very useful).
- Art gallery problem: Given an arrangement of rooms and hallways in an art gallery, find the minimum number of guards needed to watch the entire gallery.
- Bin packing: Given a set of objects of different sizes or weights and a collection of bins, find a way to pack the objects into the fewest bins possible.
- Bottleneck traveling salesman problem: Find a Hamiltonian path through a weighted network that has the minimum possible largest link weight.
- Chinese postman problem (or route inspection problem): Given a network, find the shortest circuit that visits every link.
- Chromatic number (or vertex coloring, or network coloring): Given a graph, find the smallest number of colors needed to color the graph's nodes. (The graph is not necessarily planar.)
- Clique: Given a graph, find the largest clique in the graph. (See the section “Cliques” in Chapter 14 for more information.)
- Clique cover problem: Given a graph and a number k, find a way to partition the graph into k sets that are all cliques.
- Degree-constrained spanning tree: Given a graph, find a spanning tree with a given maximum degree.
- Dominating set: Given a graph, find the smallest set of nodes S so that every other node is adjacent to one of the nodes in the set S.
- Exact cover problem: Suppose you have a set of numbers X, and a collection of subsets
 where each Si contains some of the numbers in X. An exact cover is a collection of some of the S's such that every value in X is contained in exactly one of those subsets. The exact cover problem is to determine whether an exact cover exists for a particular X and collection of subsets S.
where each Si contains some of the numbers in X. An exact cover is a collection of some of the S's such that every value in X is contained in exactly one of those subsets. The exact cover problem is to determine whether an exact cover exists for a particular X and collection of subsets S. - Feedback vertex set: Given a graph, find the smallest set S of vertices that you can remove to leave the graph free of cycles.
- Graph isomorphism problem: Given two graphs G and H, determine whether they are isomorphic. (The graphs are isomorphic if you can find a mapping from nodes in G to nodes in H such that any pair of vertices u and v are adjacent in G if and only if the corresponding nodes u' and v' are adjacent in H.)
- Hamiltonian completion: Find the minimum number of edges that you need to add to a graph to make it Hamiltonian (in other words, to make it so that it contains a Hamiltonian path).
- Hamiltonian cycle (or Hamiltonian circuit, HAMC): Determine whether there is a path through a graph that visits every node exactly once and then returns to its starting point.
- Hamiltonian path (HAM): Determine whether there is a path through a graph that visits every node exactly once.
- Job shop scheduling: Given N jobs of various sizes and M identical machines, schedule the jobs for the machines to minimize the total time to finish all of the jobs.
- Knapsack: Given a knapsack with a given capacity and a set of objects with weights and values, find the set of objects with the largest possible value that fits in the knapsack.
- Longest path: Given a network, find the longest path that doesn't visit the same node twice.
- Maximum independent set: Given a graph, find the largest set of nodes where no two nodes in the set are connected by a link.
- Maximum leaf spanning tree: Given a graph, find a spanning tree that has the maximum possible number of leaves.
- Minimum degree spanning tree: Given a graph, find a spanning tree with the minimum possible degree.
- Minimum k-cut: Given a graph and a number k, find the minimum weight set of edges that you can remove to divide the graph into k pieces.
- Partitioning: Given a set of integers, find a way to divide the values into two sets with the same total value. (Variations use more than two sets.)
- Satisfiability (SAT): Given a Boolean expression containing variables, find an assignment of true and false to the variables to make the expression true. (See the section “Reductions” in this chapter for more details.)
- Subgraph isomorphism problem: Given two graphs G and H, determine whether G contains a subgraph that is isomorphic to H.
- Subset sum: Given a set of integers, find a subset with a given total value.
- Three-partition problem: Given a set of integers, find a way to divide the set into triples that all have the same total value.
- Three-satisfiability (3SAT): Given a Boolean expression in conjunctive normal form, find an assignment of true and false to the variables to make the expression true. (See the section “3SAT” earlier in this chapter for more details.)
- Traveling salesman problem (TSP): Given a list of cities and the distances between them, find the shortest route that visits all of the cities and returns to the starting city.
- Unbounded knapsack: This is similar to the knapsack problem, except that you can select any item multiple times.
- Vehicle routing: Given a set of customer locations and a fleet of vehicles, find the most efficient routes for the vehicles to visit all of the customer locations. (This problem has many variations. For example, the route might require delivery only or both pickup and delivery, items might need to be delivered in last-picked-up, next-delivered order, vehicles might have limited or varying capacities, and so on.)
- Vertex cover: Given a graph, find a minimal set of vertices so that every link in the graph touches one of the selected vertices.
Summary
This chapter provided a brief introduction to complexity theory. It explained what complexity classes are and described some of the more important ones, including P and NP. You don't necessarily need to know the fine details of every complexity class, but you should certainly understand P and NP.
Later sections in this chapter explained how to use polynomial-time reductions to show that one problem is at least as hard as another. Those sorts of reductions are useful for studying complexity theory, but the concept of reducing one problem to another is also useful more generally for using an existing solution to solve a new problem. This chapter doesn't describe any practical algorithms that you might want to implement on a computer, but the reductions show how you can use an algorithm that solves one problem to solve a different problem.
The problems described in this chapter may also help you realize when you're attempting to solve a very hard problem so that you'll know a perfect solution may be impossible. If you face a programming problem that is another version of the Hamiltonian path, traveling salesman, or knapsack problem, then you know that you can only solve the problem exactly for small problem sizes.
Having read this chapter, you should now understand one of the most profound questions in computer science: does P equal NP? This question has deep philosophical implications. In a sense, it asks, “What is knowable?” I suspect that most students leave their first programming class thinking that every problem is solvable if you work hard enough and give the computer enough time. Even a brief study of NP destroys that notion.
Just as countingsort and bucketsort “cheat” to sort items in less than ![]() time, someone may someday discover a way to “cheat” and solve NP-complete problems in a reasonable amount of time. Maybe quantum computing will get the job done. Unless someone finally shows that
time, someone may someday discover a way to “cheat” and solve NP-complete problems in a reasonable amount of time. Maybe quantum computing will get the job done. Unless someone finally shows that ![]() , or someone builds a new kind of computer that can solve these problems, some problems will remain unsolved.
, or someone builds a new kind of computer that can solve these problems, some problems will remain unsolved.
Chapter 12 discusses methods that you can use to address some of these very hard problems. Branch and bound lets you solve problems that are larger than you could otherwise solve by using a brute-force approach. Heuristics let you find approximate solutions to even larger problems.
Another technique that lets you address larger problems is parallelism. If you can divide the work across multiple CPUs or computers, you may be able to solve problems that would be impractical on a single computer. The next chapter describes some algorithms that are useful when you can use multiple CPUs or computers to solve a problem.
Exercises
You can find the answers to these exercises in Appendix B. Asterisks indicate particularly difficult problems. Problems with two asterisks are exceptionally hard or time-consuming.
- If any algorithm that sorts by using comparisons must use at least
 time in the worst case, how do algorithms such as the countingsort and bucketsort algorithms described in Chapter 6 sort more quickly than that?
time in the worst case, how do algorithms such as the countingsort and bucketsort algorithms described in Chapter 6 sort more quickly than that? - Given a network, the goal of the bipartite detection problem is to determine whether the graph is bipartite. Find a polynomial time reduction of this problem to a map coloring problem. What can you conclude about the complexity class containing bipartite detection?
- Give a network, the goal of the three-cycle problem is to determine whether the graph contains any cycles of length 3. Find a polynomial time reduction of this problem to another problem. What can you conclude about the complexity class containing the three-cycle problem?
- Given a network, the goal of the odd-cycle problem is to determine whether the graph contains any cycles of odd length. Find a polynomial time reduction of this problem to another problem. What can you conclude about the complexity class containing the odd-cycle problem? How does this relate to the three-cycle problem?
- Given a network, the goal of the Hamiltonian path problem (HAM) is to find a path that visits every node exactly once. Show that HAM is in NP.
- Given a network, the goal of the Hamiltonian cycle problem (HAMC) is to find a path that visits every node exactly once and then returns to its starting node. Show that this problem is in NP.
- **Find a polynomial time reduction of HAM to HAMC.
- **Find a polynomial time reduction of HAMC to HAM.
- Given a network and an integer k, the goal off the network coloring problem is to find a way to color the network's nodes using at most k colors such that no two adjacent nodes have the same color. Show that this problem is in NP.
- Given a set of numbers, the goal of the zero-sum subset problem is to determine whether there is a subset of those numbers that adds up to zero. Show that this problem is in NP.
- *Suppose you are given a set of objects with weights Wi and values Vi, and a knapsack that can hold a total weight of W. Then the following list describes three forms of the knapsack problem:
- Detection: For a value k, is there a subset of objects that fits into the knapsack and has a total value of at least k?
- Reporting: For a value k, find a subset of objects that fits into the knapsack and has a total value of at least k, if such a subset exists.
- Optimization: Find a subset that fits in the knapsack and has the largest possible total value.
Find a reduction of the reporting problem to the detection problem.
- *For the problems defined in Exercise 11, find a reduction of the optimization problem to the detection problem.
- **Suppose you are given a set of objects with values Vi. Then the following list describes two forms of the partition problem:
- Detection: Is there a way to divide the objects into two subsets A and B that have the same total value?
- Reporting: Find subsets A and B that divide the objects and that have the same total value.
Find a reduction of the reporting problem to the detection problem.
For more practice with the concepts described in this chapter, write a few programs that solve some of the NP-complete problems described in this chapter. Because those problems are NP-complete, you probably won't be able to find a solution that can solve large problems quickly. However, you should be able to solve small problems with brute force. You may also be able to locate heuristics to find approximate solutions for some problems.